
Abstract
In this expository article, we survey the rapidly emerging area of random geometric simplicial complexes. Random geometric complexes may be viewed as higher-dimensional generalizations of random geometric graphs, where vertices are generated by a random point process, and edges are placed based on proximity. Extending the notion of connected components and cycles in graphs, the main object of study has been the homology of these complexes. We review the results known to date about the probabilistic behavior of the homology (and related structures) generated by these random complexes.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Perhaps the most studied model of random graphs is the Erdős–Rényi model G(n, p), where every edge appears independently with probability p. Textbooks overviewing this subject include those by Bollobás (2001) and Janson et al. (2000). Simplicial complex analogues of G(n, p) and their topological properties have been the subject of a lot of activity in recent years. See for example Babson et al. (2011); Kahle (2014a); Linial and Meshulam (2006); Meshulam and Wallach (2009) and the references in the survey article Kahle (2014b).
For certain applications, however, and especially for modeling real-world networks such as social networks, the edge-independent model G(n, p) is not considered to be particularly realistic. For example, we might expect in a social network that if we know that X is friends with Y and Z, then it becomes much more likely than it would be otherwise that Y is friends with Z.
Many other models of random graphs have been studied in recent years, and one family of models that has received a lot of attention is the random geometric graphs—see Penrose’s monograph (2003) for an overview. The random geometric graph G(n, r) is made by choosing n points independently and identically distributed (i.i.d.), according to a probability measure on Euclidean space \(\mathbb {R}^d\) (or any other metric space), and these points correspond to the vertices of the graph. Two vertices x and y are connected by an edge if and only if the distance between x and y satisfies \(d(x,y) \le r\). Since one is usually interested in asymptotic properties as \(n \rightarrow \infty \), we usually think of the threshold distance r as a function of n.
This is a very general setup, and many variations on this basic model have been studied. The most closely related model to the n points i.i.d. model is a geometric graph on a Poisson point process with expected number of points n. A Poisson point process replaces the independence of points with spatial independence. There is a lot of technology available for transferring theorems between these two models. See, for example, Section 1.7 of Penrose (2003). One might also consider more general point processes than Poisson. For example, Yogeshwaran and Adler (2015) studied random geometric graphs and complexes over more general stationary point processes. This family includes certain attractive and repulsive point processes, as well as stationary determinantal processes. In addition, we can consider random geometric graphs in metric measure spaces, such as Riemannian manifolds equipped with probability measures. The topological and geometric properties of such graphs (and their higher-dimensional analogues) were recently studied in Bobrowski and Mukherjee (2014); Bobrowski and Oliveira (2017).
There are several natural ways of extending a geometric graph to a simplicial complex, in particular the Čech complex and the Vietoris–Rips complex, whose definitions we review in Sect. 2. Our interest in the topology of random geometric complexes will be mainly confined to their homology. Briefly, if X is a topological space, its degree k-homology, denoted by \(H_k(X)\) is a vector space (assuming field coefficients). The vector space \(H_0(X)\) contains information about the connected components in X, and its dimension is the number of components. For \(k>0\), \(H_k(X)\) contains information about k-dimensional ‘cycles‘ or ‘holes’ (see more details in Sect. 2). The Betti numbers of X are defined as \(\beta _k(X) = \dim H_k(X)\).
One motivation for studying the topological features of random geometric complexes comes from topological data analysis (TDA). In TDA one builds a simplicial complex (or filtered simplicial complex) on data, and infers qualitative features of the data from homology (or persistent homology) of the point cloud. Studying the topology of random geometric complexes is related to developing probabilistic null hypotheses for topological statistics. We discuss this further in Sect. 9. The seminal work by Niyogi-Smale-Weinberger (2008, 2011) introduced a probabilistic analysis to homology recovery algorithms. This was further extended in Balakrishnan et al. (2012); Bobrowski and Mukherjee (2014); Bobrowski et al. (2017); Fasy et al. (2014). For surveys of persistent homology in topological data analysis, see Carlsson (2009) and Ghrist (2008).
Studying the limiting behavior of random geometric complexes, the first observation we make is that there exist three main regimes in which the limiting properties of the complexes are significantly different. The term that controls the limiting behavior is \(\Lambda = nr^d\), which can be thought of as the average number of points in a ball of radius r (up to a constant).
The subcritical (sometimes called ‘sparse’ or ‘dust’) regime, is when \(\Lambda \rightarrow 0\). In this regime the geometric complex is highly disconnected, and this is where homology first appears.
The critical regime (sometimes called ‘the thermodynamic regime’) is when \(\Lambda = \lambda \in (0,\infty )\). Here, the dimension of homology reaches its peak linear growth, and this is also where percolation occurs (the formation of a ‘giant’ component) — see the discussion in Sect. 3.2.
Finally, in the supercritical regime we have \(\Lambda \rightarrow \infty \). In this regime it is known that the number of components slowly decays, until we reach the connectivity threshold. An analogous process occurs for higher homology — cycles get filled, until eventually every k-cycle is a boundary and homology \(H_k\) vanishes. But in contrast, for higher homology \(k \ge 1\) there is another phase transition where homology \(H_k\) first appears.
We note that the connectivity (or \(H_0\)) properties of random geometric graphs were extensively studied in the past, see Penrose (2003) for a comprehensive review. Thus, in this survey we will mainly focus on more recent results related to higher degrees of homology (\(H_k,\ k\ge 1\)).
The rest of this survey is structured as follows. In Sect. 2 we present the concepts and notation that will be used later. Section 3 quickly reviews classical results about the connectivity of random geometric graphs for completeness. Section 4 presents a summary of the main results known to date about the limiting behavior of the homology of random geometric complexes. In Sect. 5 we review an alternative approach to study the homology of random Čech complexes using Morse theory for the distance function. Sections 6 and 7 review two extensions to the results in Sect. 4—one for compact manifolds and the other for stationary point processes. Section 8 discusses the case where the distribution underlying the point process has an unbounded support, from an extreme value analysis perspective. In Sect. 9 we discuss work in progress that studies the persistent homology generated by random geometric complexes. Finally, in Sect. 10 we present a list of open problems and future work in this area.
2 Preliminaries
In this section we wish to briefly introduce the concepts and notation that will be used throughout this survey.
2.1 Homology
We wish to introduce the concept of homology here in an intuitive rather than a rigorous way. For a comprehensive introduction to homology, see Hatcher (2002) and Munkres (1984). Let X be a topological space. The homology of X is a set of abelian groups \(\left\{ H_k(X)\right\} _{k=0}^\infty \), which are topological invariants of X.
In this paper we consider homology with coefficients in a field \(\mathbb {F}\), in this case \(H_k(X)\) is actually a vector space. The zeroth homology \(H_0(X)\) is generated by elements that represent connected components of X. For example, if X has three connected components, then \(H_0(X) \cong \mathbb {F} \oplus \mathbb {F} \oplus \mathbb {F}\) (here \(\cong \) denotes group isomorphism), and each of the three generators corresponds to a different connected component of X. For \(k\ge 1\), the k-th homology \(H_k(X)\) is generated by elements representing k-dimensional “holes” or “cycles” in X. An intuitive way to think about a k-dimensional hole is as the result of taking the boundary of a \((k+1)\)-dimensional body. For example, if X is a circle then \(H_1(X) \cong \mathbb {F}\), if X is a 2-dimensional sphere then \(H_2(X) \cong \mathbb {F}\), and in general if X is a n-dimensional sphere, then
For another example, consider the 2-dimensional torus \(\mathbb {T}\). The torus has a single connected component so \(H_0({\mathbb {T}}) \cong \mathbb {F}\), and a single 2-dimensional hole (the void inside the surface) implying that \(H_2({\mathbb {T}}) \cong \mathbb {F}\). As for 1-cycles (or closed loops) the torus has two linearly independent loops, and so \(H_1({\mathbb {T}}) \cong \mathbb {F}\oplus \mathbb {F}\).
The dimension of the k-th homology group is called the k-th Betti number, denoted by \(\beta _k(X) := \dim (H_k(X))\).
2.2 Geometric complexes
The geometric complexes we will be studying are the Čech and the Vietoris-Rips complexes, defined as follows. We will use \(B_r(x)\) to denote the ball of radius r around a point x.
Definition 2.1
[Čech complex] Let \(\mathcal {X}= \left\{ x_1,x_2,\ldots ,x_n\right\} \) be a collection of points in \(\mathbb {R}^d\), and let \(r>0\). The Čech complex \(\mathcal {C}_r(\mathcal {X})\) is constructed as follows:
-
1.
The 0-simplices (vertices) are the points in \(\mathcal {X}\).
-
2.
A k-simplex \([x_{i_0},\ldots ,x_{i_k}]\) is in \(\mathcal {C}_r(\mathcal {X})\) if \(\bigcap _{j=0}^{k} {B_{r/2}(x_{i_j})} \ne \emptyset \).
Definition 2.2
Let \(\mathcal {X}= \left\{ x_1,x_2,\ldots ,x_n\right\} \) be a collection of points in \(\mathbb {R}^d\), and let \(r>0\). The Vietoris–Rips complex \(\mathcal {R}_r(\mathcal {X})\) is constructed as follows:
-
1.
The 0-simplices (vertices) are the points in \(\mathcal {X}\).
-
2.
A k-simplex \([x_{i_0},\ldots ,x_{i_k}]\) is in \(\mathcal {R}_r(\mathcal {X})\) if \(\left\| x_{i_j} - x_{i_l}\right\| \le r\) for all \(0\le j,l \le k\).
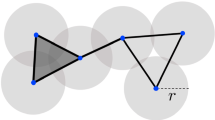
Figure 1 shows an example for the Čech and Rips complexes constructed from the same set of points and the same radius r, and highlights the difference between them. As mentioned above, our interest in these complexes will be mostly focused on their homology which is introduced in the next section.

On the left - the Čech complex \(\mathcal {C}_r(\mathcal {X})\), on the right - the Rips complex \(R(\mathcal {X},r)\) with the same set of vertices and the same radius. We see that the three left-most balls do not have a common intersection and therefore do not generate a 2-dimensional face in the Čech complex. However, since all the pairwise intersections occur, the Rips complex does include the corresponding face
Associated with the Čech complex \(\mathcal {C}_r(\mathcal {X})\) is the union of balls used to generate it (in the underlying metric space), which we define as
The spaces \(\mathcal {C}_r(\mathcal {X})\) and \(B_{r/2}(\mathcal {X})\) are of a completely different nature. Nevertheless, the following lemma claims that they are very similar in the topological sense. This lemma is a special case of a more general topological statement originated in Borsuk (1948) and commonly referred to as the ‘Nerve Lemma’.
Lemma 2.3
(The Nerve Lemma, Borsuk (1948)) Let \(\mathcal {C}_r(\mathcal {X})\) and \(B_{r/2}(\mathcal {X})\) as defined above. If for every \(x_{i_1},\ldots ,x_{i_k}\) the intersection \(B_{r/2}(x_{i_1})\cap \cdots \cap B_{r/2}(x_{i_k})\) is either empty or contractible (homotopy equivalent to a point), then \(\mathcal {C}_r(\mathcal {X})\simeq B_{r/2}(\mathcal {X})\), and in particular,
This lemma is highly useful in the study of the random Čech complex, since it allows us to translate questions about the random complex into questions about coverage properties, and enables the use of Morse theory (see Sect. 5). One immediate consequence of the Nerve Lemma is that if \(\mathcal {X}\subset \mathbb {R}^d\) then \(H_k(\mathcal {C}_r(\mathcal {X})) = 0\) for all \(k\ge d\).
2.3 Point processes
Most of the results on random geometric complexes focus on two very similar point processes. In both cases we start with a probability density function \(f:\mathbb {R}^d\rightarrow \mathbb {R}\), which we always assume to be measurable and bounded.
-
The binomial process \(\mathcal {X}_n = \{X_1,X_2,\ldots , X_n\}\) is a set of \(\mathrm {i.i.d.}\) (independent and identically distributed) random variables in \(\mathbb {R}^d\) generated by the density function f.
-
The Poisson process \(\mathcal {P}_n\) is a spatial Poisson process in \(\mathbb {R}^d\) with intensity function \(\mu = nf\). The distribution of \(\mathcal {P}_n\) satisfies the following properties:
-
1.
For every compact set \(A\subset \mathbb {R}^d\) we have \(\left| {\mathcal {P}_n \cap A}\right| \sim \mathrm {Poisson}\;({\mu (A))}\), where \(\mu (A) = \int _A \mu (x) dx.\)
-
2.
For every two disjoint sets \(A,B \subset \mathbb {R}^d\), we have that \(\left| {\mathcal {P}_n\cap A}\right| \) and \(\left| {\mathcal {P}_n \cap B}\right| \) are independent.
This process is also a special case of a ‘Boolean model’.
-
1.
Note \(\left| {\mathcal {P}_n}\right| \sim \mathrm {Poisson}\;({n})\), so that \(\mathbb {E}\left\{ {\left| {\mathcal {P}_n}\right| }\right\} = n\). In addition, given that \(\left| {\mathcal {P}_n}\right| = M\), the process \(\mathcal {P}_n\) consists of M \(\mathrm {i.i.d.}\) points distributed according to the density function f. In other words, the two processes \(\mathcal {X}_n\) and \(\mathcal {P}_n\) are very similar. We will state most of the results in terms of the binomial process \(\mathcal {X}_n\), and unless otherwise stated, the same results apply to the Poisson process \(\mathcal {P}_n\).
In the following we will use the notation \(\mathcal {C}_r(n) := \mathcal {C}_r(\mathcal {X}_n)\), and \(\mathcal {R}_r(n) := \mathcal {R}_r(\mathcal {X}_n)\) to state the results about the Čech and Vietoris–Rips complexes generated by the binomial process. Consequently, \(\beta _k(n)\) will represent the k-th Betti number for either \(\mathcal {C}_r(n)\) or \(\mathcal {R}_r(n)\) (which will be clear from the context). Figure 2 illustrates the Betti numbers of a random Čech complex, for a fixed \(n=10,000\). In most cases we will be interested in the limiting behavior of these complexes as \(n\rightarrow \infty \) and simultaneously \(r = r(n) \rightarrow 0\).

The Betti numbers of a random Čech complex as a function of the radius r. Here we generated \(n=10,\!000\) points uniformly in \([0,1]^4\). The Betti numbers were calculated using the GUDHI library (The GUDHI Project 2015)
2.4 Convergence of sequences of random variables
Probability theory uses a number of different notions of convergence. Below we define the ones used in this survey.
Let \(X_1,X_2,\ldots \) be a sequence of real valued random variables, with the cumulative distribution function of \(X_n\) given by
and let X be a random variable with a cumulative distribution function F.
Definition 2.4
\(X_n\) converges in distribution, or in law to X, denoted by \({X_n} {\xrightarrow {\mathcal {L}}} X\), if
for every \(x\in \mathbb {R}\) at which F(x) is continuous.
This type of convergence is also sometimes referred to as ‘weak convergence’.
Definition 2.5
\(X_n\) converges in \(L^p\) to X, denoted by \({X_n} {\xrightarrow {L^p}} X\), if
We will mostly use the case \(p=2\).
Definition 2.6
\(X_n\) converges to X almost surely, denoted by \({X_n} {\xrightarrow {a.s.}} X\), if
Finally, we have the following probabilistic definition related to limiting events rather than random variables.
Definition 2.7
Let \(A_n\) be a sequence of events, perhaps on a sequence of probability spaces. We say that \(A_n\) occurs asymptotically almost surely (a.a.s.) if
2.5 Some notation
Throughout this paper, we use the Landau big-O and related notations. All of these notations are understood as the number of vertices \(n \rightarrow \infty \). In particular, we write
-
\(a_n = O(b_n)\) if there exists a constant C and \(n_0 >0\) such that \(a_n \le C b_n\) for every \(n> n_0\);
-
\(a_n = \Omega (b_n)\) if there exists a constant \(C>0\) and \(n_0 >0\) such that \(a_n \ge C b_n\) for every \(n> n_0\);
-
\(a_n = \Theta (b_n)\) if both \(a_n = O(b_n)\) and \(a_n = \Omega (b_n)\). We will also denote that by \(a_n \sim b_n\);
-
\(a_n = o(b_n)\) if \(\lim _{n\rightarrow \infty } \left| {a_n / b_n}\right| = 0\). We will also denote that by \(a_n \ll b_n\);
-
\(a_n = \omega (b_n)\) if \(\lim _{n\rightarrow \infty } \left| {a_n / b_n}\right| = \infty \). We will also denote that by \(a_n \gg b_n\).
In addition to the above, we use \(a_n \approx b_n\) to denote that \(\lim _{n\rightarrow \infty } a_n/b_n = 1\).
Finally, for any set \(A\subset \mathbb {R}^d\) we use \(\left| {A}\right| \) to denote the d-dimensional volume of the set.
3 Connectivity
The zeroth homology \(H_0\) is generated by the connected components, and its rank \(\beta _0\) is the number of components. Note that the connectivity properties of any simplicial complex depend only on its one-dimensional skeleton, namely the underlying graph. In the Čech and Vietoris–Rips complexes \(\mathcal {C}_r(n)\) and \(\mathcal {R}_r(n)\) the underlying graph is the random geometric graph G(n, r) described above, and therefore the results related to connectivity are the same for both complexes. As we mentioned in the introduction, the main purpose of this survey is to review recent results related to homology in degree \(k\ge 1\). However, for completeness, we wish to include a brief review of the key properties related to the connected components. Connectivity in graphs is tightly related to the average degree. Note that in the G(n, r) the degree of a vertex is the number of points lying in a ball of radius r around that vertex. Therefore, for both the binomial and the Poisson processes, the expected degree is proportional to the term
As mentioned above, the limiting behavior splits into three main regimes, depending on the limit of the term \(\Lambda \). We will correspondingly split the discussion on the limiting results.
3.1 The subcritical regime
The subcritical regime (also known as the ‘sparse’ or ‘dust’ regime) is when \(\Lambda \rightarrow 0\). In this regime, the graph G(n, r) is very sparse, and mostly disconnected. Therefore, the study of connectivity did not draw much attention in the past. See Bobrowski and Mukherjee (2014) for a proof of the following.
Theorem 3.1
If \(\Lambda \rightarrow 0\) then
This statement can be sharpened to a central limit theorem, and a law of large numbers can be proved for deviation from the mean. In fact, as we see in the next section, a central limit theorem and law of large numbers continue, even into the critical regime.
3.2 The critical regime
The critical regime (also known as the ‘thermodynamic limit’) is when \(\Lambda = \lambda \in (0,\infty )\). In this regime \(\beta _0(n) \approx c n \) for some constant \(c<1\) (depending on \(\lambda \)), so the number of components is still \(\Theta (n)\), but is significantly lower than in the subcritical regime. The following law of large numbers is proved in section 13.7 of Penrose (2003).
Theorem 3.2
(Penrose 2003) If \(\Lambda = \lambda \in (0,\infty )\), then:
where
where \({G}(\{x_1,x_2,\ldots , x_k\},1)\) is a geometric graph on a fixed set of vertices, and
The infinite sum in (3) comes from the fact that we need to count the number of components consisting of any possible number of vertices. The limiting expression provided by the theorem is highly intricate, and at this point impossible to evaluate analytically. Nonetheless, as we will discuss later, this theorem provides the only formula available to date for the limit of the Betti numbers in the critical regime.
In addition to a law of large numbers, there is also a central limit theorem available.
Theorem 3.3
(Penrose 2003) If \(\Lambda = \lambda \in (0,\infty )\) then there exists \(\sigma >0\) such that
A more geometric view of connectivity is studied in percolation theory. Penrose considered the case where f is a uniform probability density on a d-dimensional unit cube, and \(\Lambda = \lambda \). A remarkable fact is that there exists a constant \(\lambda _c >0\) such that if \(\lambda < \lambda _c\) then a.a.s. every connected component is of order \(O( \log n)\), and if \(\lambda > \lambda _c\) then a.a.s. there is a unique “giant” component on \(\Theta (n)\) vertices. This sudden change in behavior over a very small shift of parameter is sometimes called a sharp phase transition.
In Chapters 9 and 10 of Penrose (2003), Penrose relates percolation on random geometric graphs to more classical continuum percolation theory. In continuum percolation, also called the Gilbert disk model, see Gilbert (1961), one considers a random geometric graph on a unit-intensity uniform Poisson process on \(\mathbb {R}^d\), and then there is a threshold radius \(r_c > 0\) such that for \(r > r_c\) the random geometric graph has an infinite connected component, and for \(r< r_c\) every component is finite size. For a deeper study of continuum percolation, see Meester and Roy’s book (1996). For an introduction and overview of the subject, see Chapter 8 of Bollobas–Riordan (2006) or Section 12.10 of Grimmett (1999).
3.3 The supercritical regime
The supercritical regime is when \(\Lambda \rightarrow \infty \). As we will see soon, if the radius is large enough (yet still satisfying \(r\rightarrow 0\)) then it can be shown that the graph G(n, r) becomes connected (caveat, this statement depends on the underlying distribution). This phase is sometimes referred to as the ‘connected regime’. As the radius increases, starting at the critical regime where \(\beta _0(n) = \Theta (n)\) and ending at the connected regime where \(\beta _0(n) = \Theta (1)\), the number of components in G(n, r) should exhibit some kind of a decay within the supercritical regime. To this date only partial information is available about this decay process, and we will present it later. We start by describing the connected regime.
In the case of a uniform distribution on the d-dimensional unit box \([0,1]^d\), Penrose gives a sharp result for the connectivity threshold. See Penrose (2003), Chapter 13.
Theorem 3.4
(Penrose 2003) Let \(c \in \mathbb {R}\) be fixed, and set
where \(\omega _d\) is the volume of the unit ball in \(\mathbb {R}^d\). Then
as \(n \rightarrow \infty \).
In other words, the threshold radius for connectivity is \(r = \left( \frac{2^{d-1}}{d\omega _d}\cdot \frac{\log n}{n}\right) ^{1/d}\) (or \(\Lambda = (2^{d-1}/d\omega _d) \log n\)). It is interesting to contrast Theorem 3.4 with the analogous statement for a standard multivariate normal distribution \(\mathcal {N}(0,\mathbf{{I}}_{d\times d})\) in \(\mathbb {R}^d\), a case which Penrose also studies. Here r must be significantly larger, roughly \(1 / \sqrt{ \log n}\), in order to ensure connectivity.
Theorem 3.5
(Penrose 2003) Let \(X_i \sim \mathcal {N}(0,\mathbf{{I}}_{d\times d})\) and \(c \in \mathbb {R}\) be fixed. If
then
as \(n \rightarrow \infty \).
In both cases, letting \(c \rightarrow \pm \infty \) gives the correct width of the critical window. The critical window is the range of functions r such that the probability of connectedness approaches a constant strictly between 0 and 1.
Why does the threshold distance \(r=r(n)\) have to be so much larger in the Gaussian case? The support of the Gaussian distribution is unbounded, and there are outlier points at distance roughly \(\sqrt{2 \log n}\). The radius must be large enough just to connect these points to the rest of the graph.
The contrast of Theorems 3.4 and 3.5 suggests that whatever we hope to prove about the topology of random geometric complexes will necessarily depend on the underlying distribution. On the other hand, certain theorems in geometric probability are fairly general and do not depend on the underlying distribution so drastically.
For example, if we ask what is the threshold for G(n, r) to contain a given subgraph, or what is the expected number of occurrences of a given subgraph in the sparse regime, then in some sense the answer does not depend too much on the underlying density function. The following is proved in Chapter 3 of Penrose (2003).
Theorem 3.6
(Penrose 2003) Let \(\Gamma \) be a finite connected graph on k vertices, and let \(N_\Gamma \) count the number of subgraphs isomorphic to \(\Gamma \) in G(n, r). Then
as \(n \rightarrow \infty \).
Note that Theorem 3.6 applies equally well to uniform distribution on \([0,1]^d\) and to Gaussian distributions; there is no assumption that the underlying measure has compact support. It is only the implied constant in the limit that depends on the measure. This constant may be written out explicitly as an integral -
where \(f^k(x) = (f(x))^k\), and \(h_\Gamma (x_1,\ldots , x_k) = 1\) if \({G}(\{x_1,\ldots , x_k\}, 1) \cong \Gamma \) and 0 otherwise.
As a rule of thumb, one might expect that global properties such as connectivity depend very delicately on the underlying probability measure. Local properties, such as subgraph counts or behavior in the subcritical regime, do not depend so much on the underlying measure.
To conclude this section, we mention a recent result about the supercritical regime preceding connectivity. As mentioned above, there is a huge gap remaining between the critical regime where \(\beta _0(n) = \Theta (n)\) and the connectivity point where \(\beta _0(n) = \Theta (1)\). Recent work by Ganesan studies the decay in the number of components within the supercritical regime, in the case \(d=2\). The assumption is that the underlying probability measure on \([0,1]^2\) is supported on a measurable density function f, and that f is bounded above and below. The following is Theorem 1 in Ganesan (2013).
Theorem 3.7
(Ganesan 2013) There exist \(a,b,c >0\), such that if \(a \log n\le \Lambda \le b \log n\), then a.a.s.
where the constants a and b depend only on the density function f.
We will see an analogue of this theorem for higher Betti numbers of the random Čech and Vietoris–Rips complexes in the following section.
4 Homology and Betti Numbers
Recall that the k-th Betti number \(\beta _k\) is the dimension of k-th homology, i.e.
As mentioned in the introduction, the homology groups \(H_k\) (\(k\ge 1\)) basically describe cycles (or holes) of different dimensions, and thus the Betti numbers represent the number of cycles.
Betti numbers of random geometric complexes were first studied by Robins in (2006). Robins studies “alpha shapes” on random point sets (see Edelsbrunner et al. (1983)), which are topologically equivalent to Čech complexes but more convenient from the point of view of computation. The underlying distributions are uniform on a d-dimensional cube, but to avoid boundary effects periodic, boundary conditions are imposed. Robins computes the expected Betti numbers over a large number of experiments. Furthermore, she explains the shapes of these curves in the “small radius–low intensity” regime, writing formulas in the \(d=2\) and \(d=3\) cases.
The study of the limiting Betti numbers was revisited and significantly extended later in a series of papers by various authors, see for example - Bobrowski and Adler (2014); Bobrowski and Mukherjee (2014); Kahle (2011); Kahle and Meckes (2013); Yogeshwaran and Adler (2015) and Yogeshwaran et al. (2017). In contrast to connectivity which corresponds to the zeroth homology \({H}_0\), the higher homology of random geometric complexes \(H_k(\mathcal {C}_r(n))\), \(k \ge 1\) is not monotone with respect to r. Each homology group passes through two main phase transitions, one where it appears and one where it disappears.
For the random Čech complex, the phase transition where \(H_k\) occurs when \(\Lambda \sim n^{-\frac{1}{k+1}}\) (or \(r \sim n^{-\frac{k+2}{d(k +1)} }\)). This radius is within the subcritical regime (\(\Lambda \rightarrow 0\)). In this regime the complex is sparse and highly disconnected which allows very precise Betti number computations — in particular we will see that \(\beta _k(n) \sim n \Lambda ^{k+1}\), and therefore \(\beta _k(n) = o(n).\)
The phase transition where the k-th homology vanishes depends on the underlying probability distribution, but if f has a compact support then we will see that it occurs at \(\Lambda = \Theta (\log n)\) (or \(r = \Theta ((\log n / n)^{1/d})\)), which is within the supercritical regime. This radius is similar to the connectivity threshold we saw in Section 3.3, though the constants are different. The exact vanishing radius for each of the homology groups \(H_k\) has not been discovered yet, but it is known that it is controlled by a second order (\(\log \log n\)) term that depends on k. We will discuss this in Sect. 6.
In the critical regime the analysis of the Betti numbers \(\beta _k(n)\), \(k\ge 1\), is significantly more complicated than the analysis of \(\beta _0(n)\). In this case we will see that \(\beta _k(n) = \Theta (n)\), however the limiting constants are unknown to date.
We now review the results known to date about the topology of random geometric complexes for each of the regimes.
4.1 The subcritical regime
The work in Kahle (2011) and Kahle and Meckes (2013) provides a detailed study for the Betti numbers in the subcritical regime. Since a random geometric complex in this regime is so sparse, the vast majority of k-cycles are generated by “small” sphere-like shapes, with the minimum number of vertices possible. For the Čech complex, the minimum number of vertices to form an k-cycle is \(k+2\) (for example, to create a 1-cycle, or a loop, we need at least 3 vertices). These sphere-like formations are local features, so by the rule of thumb above, we might expect a theorem that holds across a wide class of measures.
A key ingredient in the results is the following indicator function
testing whether a minimal set forms an k-cycle or not. The following theorem provides the limit for the expected Betti numbers.
Theorem 4.1
(Kahle 2011) Let \(\Lambda \rightarrow 0\), \(k\ge 1\) and \(d\ge 2\). Then
as \(n \rightarrow \infty \), where
Theorem 4.1 states that \(\mathbb {E}\left\{ {\beta _k(n)}\right\} \sim n\Lambda ^{k+1}\). Note that within the subcritical regime the limit of the term \(n\Lambda ^{k+1}\) can be either zero, a finite number, or infinity (for different choices of r). Combining with the second moment method (see for example Chapter 4 of Alon and Spencer (2008)), this is the threshold radius for the phase transition where homology first appears.
Theorem 4.2
(Kahle 2011) Let \(d \ge 2\) and \(1 \le k \le d-1\) be fixed. Suppose that \(\Lambda \rightarrow 0\).
-
1.
If
$$\begin{aligned} \Lambda \ll {n^ {-\frac{1}{k +1} }}, \end{aligned}$$then a.a.s. \(H_k( \mathcal {C}_r(n)) = 0\), and
-
2.
if
$$\begin{aligned} \Lambda \gg {n^{ -\frac{1}{k +1}}} \end{aligned}$$then a.a.s. \(H_k( \mathcal {C}_r(n)) \ne 0\).
Thus, the threshold where the k-th homology first appears is \(\Lambda = \Theta (n^{-\frac{1}{k+1}})\), or \(r = \Theta (n^{ -\frac{k+2}{d(k +1)}})\).
The parallel result for Vietoris–Rips complexes is also given in Kahle (2011).
Theorem 4.3
(Kahle 2011) Let \(d \ge 2\) and \(k \ge 1\) be fixed. Suppose that \(\Lambda \rightarrow 0\).
-
1.
If
$$\begin{aligned} \Lambda \ll {n^ {-\frac{1}{2k +1} }}, \end{aligned}$$then a.a.s. \(H_k( \mathcal {R}_r(n)) = 0\), and
-
2.
if
$$\begin{aligned} \Lambda \gg {n^{ -\frac{1}{2k +1}}} \end{aligned}$$then a.a.s. \(H_k( \mathcal {R}_r(n)) \ne 0\).
The difference in exponents stems from the fact that in the Vietoris–Rips complex case, the smallest possible vertex support for a nontrivial cycle in \(H_k\) is on \(2k+2\) vertices (rather than \(k+2\) in the Čech complex), a triangulated sphere combinatorially isomorphic to the boundary of the \((k+1)\)-dimensional cross polytope. Another difference is that while in the Čech complex the homology degree is bounded by \(d-1\) (a consequence of the Nerve Lemma), for the Vietoris–Rips complex it is unbounded, and we can have cycles of every possible dimension.
Kahle and Meckes studied limiting distributions of Betti numbers in the subcritical regime in (2013). When \(\Lambda = \Theta ( n^{-\frac{1}{k+1}})\) (or \(r = \Theta (n^{ -\frac{k+2}{d(k+1)}})\)), the following is a refinement of Theorem 4.2, and shows that at the threshold where the homology \(H_k\) first appears, there is a regime in which the Betti number \(\beta _k(n)\) converges in law to a Poisson distribution.
Theorem 4.4
(Kahle and Meckes 2013) Let \(1 \le k \le d-1\) and \(\mu > 0\) be fixed, and suppose that \(n\Lambda ^{k+1} \rightarrow \mu \). Then
as \(n \rightarrow \infty \), where \(c_k\) is defined in Theorem 4.1.
When r is above the threshold, the number of cycles goes to infinity, and with the proper normalization it obeys a central limit theorem. Let \(\mathcal {N}(0,1)\) denote a normal distribution with mean 0 and variance 1.
Theorem 4.5
(Kahle and Meckes 2013, 2015) Let \(1 \le k \le d-1\) and suppose that \(\Lambda \rightarrow 0\) and
Then
as \(n \rightarrow \infty \).
Again, because we are in the subcritical regime, these results hold for a wide variety of measures—whenever the underlying probability measure has a measurable density function which is bounded above. They hold even without compact support, for example for a multivariate normal distribution. In Kahle and Meckes (2013) Theorems 4.4 and 4.5 are accompanied by formulas for expectation and variance of the Betti numbers. Parallel limit theorems are also proved for Vietoris–Rips complexes.
4.2 The critical regime
The study of the Betti numbers becomes significantly more complicated in the critical regime. In the subcritical regime, since the random geometric complex is very sparse and disconnected, the vast majority of k-cycles are vertex-minimal—spanning \(k+2\) vertices for the Čech complex, \(2k+2\) for the Rips. In the critical regime a giant connected component emerges—see the discussion in Sect. 3.2 on percolation theory—and this significantly complicates the analysis.
To date, there has been some partial progress in studying these cases. For example, we have the following result for expectation.
Theorem 4.6
(Kahle 2011) Suppose that \(d \ge 2\) and \(0 \le k \le d-1\) are fixed, and \(\Lambda = \lambda \in (0,\infty )\). Then for the Čech complex \(\mathcal {C}_r(n)\) we have
A parallel theorem in Kahle (2011) gives the same result for the Vietoris–Rips complex \(\mathcal {R}_r(n)\), but in this case one does not require the assumption that \(k \le d-1\); in the critical regime, \(\beta _k\) is growing linearly for every \(k \ge 0\).
The last theorem provides us with the expected order of magnitude of the Betti numbers, but the actual constants have not yet been discovered. Nevertheless, recent work by Yogeshwaran et al. (2017) gives laws of large numbers and central limit theorems for Betti numbers of random Čech complexes in the thermodynamic limit. We state here a few of these results relevant for the Čech complex \(\mathcal {C}_r(n)\). The following law of large numbers is Theorem 4.6 in Yogeshwaran et al. (2017).
Theorem 4.7
(Yogeshwaran et al. 2017) If \(\Lambda = \lambda \in (0,\infty )\), then for each \(1\le k \le d-1\) we have almost surely that
The version of the central limit theorem proved in Yogeshwaran et al. (2017) is for an underlying uniform distribution, and for simplicity assumes that it is supported on the unit cube in \(\mathbb {R}^d\). In this case, they define \(I_d(\mathcal {P})\) as an interval in \(\mathbb {R}\) whose endpoints are the percolation radii for \(\mathcal {C}_r(n)\) and \(\mathbb {R}^d\backslash \mathcal {C}_r(n)\).
Theorem 4.8
(Yogeshwaran et al. 2017) Let \(1\le k\le d-1\) and \(\Lambda = \lambda \in (0,\infty )\) such that \(\lambda \not \in I_d(\mathcal {P})\). Then there exists a finite \(\sigma ^2>0\) such that
It is mentioned in Yogeshwaran et al. (2017) that it is not clear whether the restriction to \(\lambda \not \in I_d(\mathcal {P})\) is required or just a technical artifact of the proof. For the Poisson process \(\mathcal {P}_n\) similar theorems are proved for all \(\lambda > 0\).
4.3 The supercritical regime
In the supercritical regime the correct order of magnitude of the Betti numbers is still not known, but there are bounds. In particular, we have the following for the random Vietoris–Rips complex, which is Theorem 5.1 in Kahle (2011).
Theorem 4.9
(Kahle 2011) Let \(\mathcal {R}_r(n)\) be the random Vietoris–Rips complex, generated by a uniform distribution on a unit-volume convex body in \(\mathbb {R}^d\). Then,
for some constant \(c_d > 0\). Here \(c_d\) depends on the dimension d but not on k.
In particular, if \(\Lambda \rightarrow \infty \) (the supercritical regime) then \(\mathbb {E}\left\{ {\beta _k(n)}\right\} = o(n)\). Theorem 4.9 can be compared to Theorem 3.7 which bounds the number of connected components. As an immediate corollary of Theorem 4.9 we have the following.
Corollary 4.10
If \(\Lambda \ge c \log n\) then a.a.s. \(H_k( \mathcal {R}_r(n)) = 0\). Here c is any constant such that \(c > 1 / c_d\), where \(c_d\) is defined in Theorem 4.9.
The proof of Theorem 4.9 uses discrete Morse theory to collapse the Vietoris–Rips complex onto a homotopy equivalent CW complex with far fewer faces. Combining Theorem 4.3 with Corollary 4.10 gives the following global picture for vanishing and non-vanishing homology of the random Vietoris–Rips complex.
Theorem 4.11
(Kahle 2011) Let \(d \ge 2\) be fixed, and suppose that the underlying distribution is uniform on a convex body. Then there exist a, b such that
-
1.
If
$$\begin{aligned} \Lambda \ll n^ {-\frac{1}{2k +1}}, \end{aligned}$$then a.a.s. \(H_k( \mathcal {R}_r(n)) = 0\),
-
2.
if
$$\begin{aligned} n^{-\frac{1}{2k +1}} \ll \Lambda \le a \log n, \end{aligned}$$then a.a.s. \(H_k( \mathcal {R}_r(n)) \ne 0\),
-
3.
and if
$$\begin{aligned} \Lambda \ge b \log n \end{aligned}$$then a.a.s. \(H_k( \mathcal {R}_r(n)) =0\).
For the Čech complex similar bounds are studied in Bobrowski and Oliveira (2017); Bobrowski and Weinberger (2017), using Morse theory for the distance function (discussed in Sect. 5). The idea there is to look for critical points of the distance function, that are responsible for changes in the k-th homology. We note that the following bounds were proven for closed manifolds (compact and without a boundary), while a similar proof can be repeated for the compact and convex case. We shall discuss these bounds in detail in Sect. 6.
Theorem 4.12
Let \(\mathcal {C}_r(n)\) be the random Čech complex, generated by a uniform distribution on a unit-volume convex body in \(\mathbb {R}^d\). If \(\Lambda \rightarrow \infty \), then there exist \(a_k,b_k >0\) and \(c_{d,1},c_{d,2} > 0\) such that
Combining Theorems 4.2 and 4.12, we have the following statement for the Čech complex.
Theorem 4.13
(Kahle 2011) Let \(d \ge 2\) and \(1 \le k \le d-1\) be fixed, and suppose that the underlying distribution is uniform on a convex body. Then there exist A, B such that
-
1.
If
$$\begin{aligned} \Lambda \ll n^ {-\frac{1}{k +1}}, \end{aligned}$$then a.a.s. \(H_k( \mathcal {C}_r(n)) = 0\),
-
2.
if
$$\begin{aligned} n^ {-\frac{1}{k +1}} \ll \Lambda \le A \log n, \end{aligned}$$then a.a.s. \(H_k( \mathcal {C}_r(n)) \ne 0\),
-
3.
and if
$$\begin{aligned} \Lambda \ge B \log n \end{aligned}$$then a.a.s. \(H_k( \mathcal {C}_r(n)) =0\).
Theorems 4.11 and 4.13 show that the vanishing threshold radius for higher homology has the same order of magnitude as the connectivity threshold that we saw in Theorem 3.4, i.e. it occurs when the average degree is \(\Lambda \sim \log n\). Note that this is also when the union of balls \(B_{r/2}(\mathcal {P}_n)\) is known to completely cover the support of the distribution, in which case it can be shown that \(H_k(B_{r/2}(\mathcal {P}_n)) = 0\). The proof in Kahle (2011) uses this fact together with the Nerve Lemma 2.3 to prove part 3 of the Theorem.
In Sect. 6 we discuss a more refined picture of this transition. We will also see in Sect. 6 that these results can be generalized — for example, to any compact manifold, and for any probability distribution with a density function that is bounded away from zero.
5 Morse theory for the distance function
In Bobrowski and Adler (2014) and Bobrowski and Weinberger (2017), a different approach was taken to study the homology of Čech complexes which focuses on distance functions. For a finite set of points \(\mathcal {P}\subset \mathbb {R}^d\) we can define the distance function as follows
Our interest in this function stems in the following straightforward observation about the sub-level sets of the distance function:
In other words, the sub-level sets of the distance function are exactly the union of balls used to generate a Čech complex. Moreover, from the Nerve Lemma 2.3 we know that these sets have the same homology as the corresponding Čech complex. Morse theory links the study of critical points of functions with the changes to the homology of their sub-level sets. Thus, we conclude that studying the critical points of \(d_{\mathcal {P}}\) might assist us in studying the homology of the Čech complex. In this section we explore the limiting behavior of the critical points for the random distance function and its consequence to the study of random Čech complexes.
5.1 Critical points of the distance function
The classical definition of critical points in calculus is as follows. Let \(f:\mathbb {R}^d\rightarrow \mathbb {R}\) be a \(C^2\) function. A point \(c\in \mathbb {R}\) is called a critical point of f if \(\nabla f (c) =0\), and the real number f(c) is called a critical value of f. A critical point c is called non-degenerate if the Hessian matrix \(H_f(c)\) is non-singular. In that case, the Morse index of f at c, denoted by \(\mu (c)\) is the number of negative eigenvalues of \(H_f(c)\). A \(C^2\) function f is a Morse function if all its critical points are non-degenerate, and its critical values are distinct.
Note that the distance function \(d_{\mathcal {P}}\) defined in (4) is not everywhere differentiable, therefore the definition above does not apply. However, following Gershkovich and Rubinstein (1997), one can still define a notion of non-degenerate critical points for the distance function, as well as their Morse index. Extending Morse theory to functions that are non-smooth has been developed for a variety of applications Baryshnikov et al. (2014); Bryzgalova (1978); Gershkovich and Rubinstein (1997); Matov (1982). The class of functions studied in these papers have been the minima (or maxima) of a functional and called ‘min-type’ functions.
We wish to avoid the exact definitions of critical points for the distance function and their indexes and introduce them in a more intuitive way. For the full rigorous definitions and statements see Bobrowski and Adler (2014). Figure 3 presents the values of \(d_{\mathcal {P}}\) and the critical points for a set \(\mathcal {P}\) consisting of three points (the blue circles) in \(\mathbb {R}^2\). Obviously, the minima (index 0 critical points) of \(d_{\mathcal {P}}\) are the points in the set \(\mathcal {P}\) where \(d_{\mathcal {P}} = 0\). The yellow circle in the middle would be a maximum (index 2) and the green circles are saddle points (index 1). Note that each of the saddle points lies on the segment connecting two sample (blue) points, whereas the maximum lies inside the 2-simplex spanned by all the three sample points. This is the typical behavior of the critical points of the distance function, and in general we claim that the existence and location of every critical point of index k of \(d_{\mathcal {P}}\) is determined by the configuration of a subset \(\mathcal {S}\subset \mathcal {P}\) with \(\left| {\mathcal {S}}\right| = k+1\).

Critical points for the distance function in \(\mathbb {R}^2\)
5.2 Morse theory
The study of homology is strongly connected to the study of critical points of real valued functions. The link between them is called Morse theory, and we shall describe it here briefly. For a deeper introduction, we refer the reader to Milnor (1963).
The main idea of Morse theory is as follows. Suppose that M is a closed manifold (a compact manifold without boundary), and let \(f:M\rightarrow \mathbb {R}\) be a Morse function. Denote
(sublevel sets of f). If there are no critical values in (a, b], then \(M_a\) and \(M_b\) are homotopy equivalent and in particular have isomorphic homology. Next, suppose that c is a critical point of f with Morse index i, and let \(v=f(c)\) be the critical value at c. Then the homology of \(M_{\rho }\) changes at v in the following way. For a small enough \(\epsilon \) we have that the homology of \(M_{v+\epsilon }\) is obtained from the homology of \(M_{v-\epsilon }\) by either adding a generator to \(H_k\) (increasing \(\beta _k\) by one) or terminating a generator of \(H_{k-1}\) (decreasing \(\beta _{k-1}\) by one). In other words, as we pass a critical value, either a new k-dimensional cycle is formed, or an existing \((k-1)\)-dimensional cycle is bounded or filled.
While classical Morse theory deals with smooth (or \(C^2\)) Morse functions on compact manifolds Milnor (1963), it has been extended to many more general situations, and the extension to “min-type” functions presented in Gershkovich and Rubinstein (1997) enables one to apply similar concepts to the distance function \(d_{\mathcal {P}}\) as well.
Let \(\mathcal {X}_n\) be the binomial process we had before. For \(0\le k\le d\), we define \(C_k(r)\) to be the number of critical points of index k of the distance function \(d_{\mathcal {X}_n}\), for which the critical value is less then or equal to r. According to Morse theory (and the Nerve Lemma 2.3), the critical points accounted for by \(C_{k}(r)\) are the ones generating the homology of \(\mathcal {C}_r(n)\).
Similarly to the study in Sect. 4, we can study the limiting behavior of the random values \(C_k(r)\) as \(n\rightarrow \infty \) and \(r\rightarrow 0\). This was studied in Bobrowski and Adler (2014). This limiting behavior is in some ways very similar to what we observed for the Betti numbers \(\beta _k(n)\). However, as opposed to homology which involves global behavior, the nature of critical points is much more local. This enables us to compute precise limits for \(C_k(r)\) even in the critical and supercritical regimes, where the analysis of the Betti numbers at this point has yet to be completed. We present here the limiting results for the expected values of \(C_k(r)\).
Theorem 5.1
(Bobrowski and Adler 2014) For \(1\le k \le d\) we have,
-
1.
If \(\Lambda \rightarrow 0\) then
$$\begin{aligned} \mathbb {E}\left\{ {C_k(r)}\right\} \approx \tilde{c}_k n \Lambda ^k; \end{aligned}$$ -
2.
If \(\Lambda = \lambda \in (0,\infty ]\) then
$$\begin{aligned} \mathbb {E}\left\{ {C_k(r)}\right\} \approx \gamma _k(\lambda )\cdot n; \end{aligned}$$
The values \(\tilde{c}_k\) and \(\gamma _k(\lambda )\) are presented in Bobrowski and Adler (2014), and they depend on the density function f, d and \(\lambda \) via integration, similarly to the constants \(c_k\) in Theorem 4.1.
In the subcritical regime, one can observe that the expected value of \(C_k(r)\) is similar to the limit of \(\beta _k(n)\) and differs mostly by the index k. This is due to the fact that a critical point of index k is generated by a subset of \(k+1\) vertices (see discussion above) whereas an k-cycle in the subcritical regime is generated by a subset of \(k+2\) vertices. Not surprisingly, the distribution of \(C_k(r)\) has limit theorems very similar to the ones presented in Sect. 4 for the Betti numbers (see Bobrowski and Adler (2014)).
In the critical regime we have \(C_k(r) = \Theta (n)\) for all \(0\le k \le d\), which, with Morse theory in mind, perfectly agrees with Theorem 4.7 stating that \(\beta _{k}(n) = \Theta (n)\) as well. As opposed to the Betti numbers, studying the critical points yields precise limits for the expectation as well as a central limit theorem (cf. Bobrowski and Adler (2014)). This will enable us later to get a very interesting conclusion regarding the Euler characteristic of \(\mathcal {C}_r(n)\).
In the supercritical regime, we still have the exact limits for the number of critical points. However, in this case, it will not reveal much information about \(\mathcal {C}_r(n)\), since most of the critical points accounted for by \(C_k(r)\) were formed in the critical regime (note that \(C_k(r)\) is a monotone function of r), and the number of critical points actually being formed in the supercritical regime is actually o(n). Nevertheless, in some cases (see Sect. 6), it is possible to study the behavior of critical points within the supercritical regime in a finer resolution and use that to draw conclusions about the vanishing of the different degrees of homology.
5.3 The Euler characteristic
The Euler characteristic of a simplicial complex \(\mathcal {S}\) has a number of equivalent definitions, and a number of important applications. One of the definitions, via Betti numbers, is
Thus, one can think of the Euler characteristic as an integer “summary” of the set of Betti numbers of the complex. In the case of the random Čech complex \(\mathcal {C}_r(n)\) we have
However, using Morse theory for the distance function, \(\chi _r(n)\) can also be computed in the following way
The limiting behavior of the critical points presented in Sect. 5.2, thus leads us to the following conclusion.
Corollary 5.2
(Bobrowski and Adler 2014) Let \(\chi _r(n)\) be the Euler characteristic of \(\mathcal {C}_r(n)\), and let \(\Lambda = \lambda \in (0,\infty )\). Then
where \(\gamma _k(\lambda )\) are increasing functions of \(\lambda \) and are defined in Bobrowski and Adler (2014).
Note that (6) cannot be proven using only the existing results on Betti numbers, since the values of the limiting mean in the critical regime are not available. This demonstrates one of the advantages of studying the homology of the Čech complex via the distance function. An alternative way to compute the Euler characteristic is
where \(\Delta _k(r)\) is the number of k-simplexes in \(\mathcal {C}_r(n)\). In Decreusefond et al. (2014) the Euler characteristic was studied this way for a uniform distribution on a d-dimensional torus. Computing the mean value (and also the variance) of \(\Delta _k(r)\) is possible, however there are going to be infinitely many summands in this formula, which will make it highly complicated. Thus, counting critical points is still advantageous.
Figure 4 presents the limiting expected Euler characteristic (divided by n) as a function of \(\lambda \) for a uniform distribution on the unit cube in \(\mathbb {R}^3\). In this case the functions \(\gamma _k\) (\(k=1,2,3\)) were computed explicitly in Bobrowski and Mukherjee (2014) and are given by
In Fig. 4 we observe the curve starts at positive values, turns negative and then becomes positive once and for all. Note that in \(\mathbb {R}^3\) the formula (5) implies that \(\mathcal {X}= \beta _0-\beta _1+\beta _2\). This, together with the shapes of the Betti number curves in Fig. 2 suggests the conjecture that each of the different Betti numbers becomes dominant in a slightly different regime. A similar phenomenon is known to occur for certain random abstract simplicial complexes, see Kahle (2014a), but it is still not known whether and to what extent such a phenomenon exist in random geometric complexes.

The limiting Euler characteristic curve for a uniform distribution on the unit cube in \(\mathbb {R}^3\)
6 Extending to manifolds
In Sects. 3–5 the distributions studied are supported on d-dimensional subsets of \(\mathbb {R}^d\). The work in Bobrowski and Mukherjee (2014) studied the same type of problems for the case where the distributions are supported on a closed m-dimensional manifold embedded in \(\mathbb {R}^d\) (\(m<d\)). In Bobrowski and Weinberger (2017) the flat torus was studied as a special case of a Riemannian manifold, and this was extended later to compact (smooth) Riemannian manifolds in Bobrowski and Oliveira (2017). In this section we will limit the discussion to the Čech complex, although some of the results (in particular the behavior in the subcritical and critical regimes) could be similarly generalized.
6.1 Closed manifolds embedded in \(\mathbb {R}^d\)
The exact setup studied was as follows. Let \(M\subset \mathbb {R}^d\) be a m-dimensional smooth closed manifold (compact and without a boundary). Let \(f:M\rightarrow \mathbb {R}\) be a probability density function on M. Let \(\mathcal {X}_n = \{X_1,\ldots , X_n\}\) be a set of \(\mathrm {i.i.d.}\) points generated by f, and let \(\mathcal {C}_r(n)\) be the Čech complex generated by these points (using d-dimensional balls). The results in this case turn out to be very similar to the ones we described earlier, even though the proofs require different analysis tools. In the following we briefly review the results in Bobrowski and Mukherjee (2014) and highlight the main difference from the results in \(\mathbb {R}^d\).
The first thing to note is that here, the average degree behaves like \(\Lambda = nr^m\) (m being the intrinsic dimension of the manifold). In the subcritical regime, the results for both the Betti numbers \(\beta _k(n)\) and the number of critical points \(C_k(r)\) are almost identical to those presented in Sects. 4.1 and 5.2. The main difference is that the ambient dimension d is replaced by the intrinsic dimension m, and the limiting constants are a bit different. For example, we have that
where
These differences stem from the fact that in the subcritical regime the Betti numbers computation is very ‘local’, and locally, a m-dimensional manifold looks very similar to \(\mathbb {R}^m\). In the critical regime we also have very similar statements to the Euclidean setup.
The main difference in studying manifolds shows up when we study the vanishing of the homology. When studying compact and convex bodies, Theorem 4.13 states that homology completely vanishes when \(\Lambda \sim \log n\) (or \(r \sim \left( \frac{\log n}{n}\right) ^{1/d}\)). Sampling from a manifold, by the Nerve Lemma, we expect that upon coverage the homology of the complex \(\mathcal {C}_r(n)\) will not vanish but rather become equal to the homology of M. This result is stated in the following theorem.
Theorem 6.1
(Bobrowski and Mukherjee 2014) Suppose that \(f_{\min } = \inf _{x\in M} f(x) >0\), and let \(\epsilon > 0\) be fixed. If
then \(H_k(\mathcal {C}_r(n))\cong H_k(M)\) for all \(0\le k \le m\) a.a.s. and if
then \(H_k(\mathcal {C}_r(n))\not \cong H_k(M)\) for all \(1\le k \le m\) a.a.s. where \(\omega _m\) is the volume of the m-dimensional unit ball.
We note that while the second part of this theorem did not appear explicitly in Bobrowski and Mukherjee (2014), it is a direct consequence of the calculations done there in addition to the Morse theoretical arguments made in Bobrowski and Weinberger (2017) (discussed later). Also note that the vanishing radius for \(H_k\) (\(k\ge 1\)) is twice the radius of connectivity in the same setup (an analogous result of Theorem 3.4 was proved for the flat torus in Penrose (2003), and can be extended to any compact embedded or Riemannian manifold using the techniques in Bobrowski and Mukherjee (2014); Bobrowski and Oliveira (2017)). This phenomenon has a non formal, yet convincing, explanation. In Penrose (2003) (Theorem 13.17) it is shown that at the edge of connectivity the graph G(n, r) consists roughly of a giant component and some isolated vertices. For a vertex to be isolated, a ball of radius r around it has to be vacant (i.e. with no other points in \(\mathcal {X}_n\) inside it). To get all the higher homology groups correctly, we need to guarantee that the balls of radius r / 2 (the ones used to construct the Čech complex) cover the support. Now, the support is covered if and only if there is no vacant ball of radius r / 2. Thus, it seems harder to reach coverage than connectivity, and the vacancy radii involved have the same ratio as the thresholds we presented.
The statement in Theorem 6.1 has an important consequence to problems in manifold learning, since it shows that by studying Čech complexes we can recover the homology of an unknown manifold M from a finite (yet probably large) number of random samples. The analysis of this type of “topological manifold learning” was established by the seminal work in Niyogi et al. (2008) and (2011), and Theorem 6.1 can be viewed as an asymptotic and extended version of the main results there. Considering asymptotic behavior has the advantage of covering a more general class of distributions and using fewer assumptions.
Theorem 6.1 shows that for large enough radii, the Betti numbers computed \(\beta _k(n)\) converge to the Betti numbers of the manifold \(\beta _k(M)\). Denoting the error by
Theorem 6.1 can be viewed as describing the vanishing of the ‘noisy homology’ (so that \(\hat{\beta }_k(n) \rightarrow 0\)).
6.2 Riemannian manifolds and homological connectivity
The work in Bobrowski and Oliveira (2017) and Bobrowski and Weinberger (2017) studied a similar case to the previous one, only that now the random point process is generated on a d-dimensional Riemmanian manifold (M, g). The main difference in this setup, is that now the balls used to create the geometric complexes, are d-dimensional intrinsic balls on the manifold (i.e. using the Riemannian rather than the Euclidean metric). As before, most of the statements we had for random geometric complexes in Euclidean spaces, can be extended to the Riemannian setting. In this section we focus on one particular aspect that has been further studied in the case of compact Riemannian manifolds. In the following we will limit ourself to uniform distributions on manifolds with a unit volume (in which case \(f \equiv 1\)).
By ‘homological connectivity’ we refer to the phenomenon described above where the k-th homology of the Čech complex becomes isomorphic to that of the underlying manifold (i.e. \(H_k(\mathcal {C}_r(n))\cong H_k(M)\)). We note that this term was coined by Linial and Meshulam in (2006). The result in Theorem 6.1 (which could be extended to compact Reiamannian manifolds) states that for all \(k\ge 1\) homological connectivity for \(H_k\) occurs around \(\Lambda = (2^d/\omega _d) \log n\). Note, however, that this result does not differentiate between the different homology groups. Since our previous study shows that cycles in different dimensions are formed by different type of structures, and occur at different radii, we also expect to observe differences in the homological connectivity thresholds for different dimensions k.
The work in Bobrowski and Weinberger (2017) revisited the study of critical points for the distance function for the case when M is the flat torus (i.e. \(\mathbb {T}^d = \mathbb {R}^d / \mathbb {Z}^d\) which can be viewed as the unit box \([0,1]^d\) with the metric \(\rho (x,y) = \min _{\Delta \in \mathbb {Z}^d} \left\| x-y+\Delta \right\| \)). By providing more details estimates to the number of critical points, the following statement was proved.
Proposition 6.2
(Bobrowski and Weinberger 2017) Let \(1\le k \le d-1\). If \(\Lambda \rightarrow \infty \), then there exist \(a_k,b_k >0\) such that
To get the upper bound, we denote by \(\hat{C}_k(r)\) the number of critical points whose critical value is bigger than r. Then \(\beta _k(n) \le \beta _k(M) +\hat{C}_{k+1}(r)\) since by Morse theory all the cycles in \(H_k(\mathcal {C}_r(n))\) that do not belong to \(H_k(M)\) are to be terminated by some critical point of index \(k+1\). For the lower bound, we look for critical points of index k with a special local behavior that guarantees to generate a new k-cycle (See Bobrowski and Weinberger (2017) for details). The last inequality then leads to the following result.
Theorem 6.3
Let \(1\le k \le d-1\) and suppose that \(w(n)\rightarrow \infty \) as \(n\rightarrow \infty \). Then,
Note that: (a) This statement is about isomorphism of the homology groups, which is stronger than just the equality of the Betti numbers; (b) There is a gap in this description of the phase transition, as the two thresholds differ a \(\log \log n\) factor. In Bobrowski and Oliveira (2017) these results were extended from the flat torus to any compact smooth d-dimensional Riemannian manifold. However, it is not clear how this result generalizes to spaces that have boundaries (as the ones in Sect. 4.3).
Finally, we note that we believe the following conjecture to be the most accurate description of the phase transition for homological connectivity.
Conjecture 6.4
Let (M, g) be a smooth d-dimensional compact Riemannian manifold. Let \(1\le k \le d-1\) and suppose that \(w(n)\rightarrow \infty \) as \(n\rightarrow \infty \). Then,
The reason why this conjecture should be true is that the same phase transition can be shown to describe the vanishing of isolated k-faces (k-simplexes that do not have any \((k+1)\)-coface). In all other random simplicial complexes studied in the past it was shown that these isolated faces generate the last cycles that prevent homology from converging. Proving this conjectures, however, remains as future work.
7 Stationary point processes
The results we presented so far in this survey describe the behavior of geometric complexes constructed from either the binomial process \(\mathcal {X}_n\) or the Poisson process \(\mathcal {P}_n\). Both models exhibit a strong level of independence which plays a significant role in the proofs. For the binomial process \(\mathcal {X}_n\) the number of points is fixed, while the locations of the points are independent. For the Poisson process \(\mathcal {P}_n\) the amount of points in different regions are independent, and given the number of points in a region their locations are independent.
Recent work by Yogeshwaran and Adler (2015) extends some of the results presented in this survey to a more general class of spatial point processes allowing certain attractive and repulsive point processes, as well as stationary determinantal processes. In this section we wish to briefly review their results.
A general point process in \(\mathbb {R}^d\) can be thought of as a random measure \(\Phi (\cdot ) = \sum _i \delta _{X_i}(\cdot )\) where \(\delta _x\) is the Dirac delta measure concentrated at x. In that case, for every subset \(A\subset \mathbb {R}^d\), \(\Phi (A)\) is a random variable counting the number of points lying inside A. The distribution of a random point process \(\Phi \) can be characterized by its factorial moment measure functions \(\alpha ^{(m)}\) defined as follows -
where \(B_1,\ldots , B_m\) are disjoint Borel subsets of \(\mathbb {R}^d\). A stationary point process is such that the functions \(\alpha ^{(m)}\) are translation invariant. For example, for the homogeneous Poisson process with constant rate \(\mu \), we have that
which depends only on the volumes of the sets and therefore invariant to translations. Note that if \(\Phi \) is a stationary point process, and \(\mathcal {C}_r(\Phi )\) is the corresponding Čech complex, then depending on r either \(\mathbb {E}\left\{ {\beta _k(\mathcal {C}_r(\Phi ))}\right\} = 0\) or \(\mathbb {E}\left\{ {\beta _k(\mathcal {C}_r(\Phi ))}\right\} = \infty \) (since the process is supported in an infinite domain). Therefore, it does not make sense to try to analyze \(\beta _k(\mathcal {C}_r(\Phi ))\). Instead, we can define
and try to study
Note that if \(\Phi \) is a homogeneous Poisson process with rate \(\mu =1\), and \(\mathcal {P}_n\) is the Poisson process we used previously supported on the unit cube, then \(\mathcal {C}_r(\Phi _n)\) is a scaled version of \(\mathcal {C}_{n^{-1/d}r}(\mathcal {P}_n)\), and so \(\beta _k^\Phi (n) = \beta _k(n)\). Therefore, we can view the results in Yogeshwaran and Adler (2015) as an extension of the models described earlier in this survey. Similarly to the study of the binomial and the Poisson processes we described before, the limiting behavior of \(\beta _k^\Phi (n)\) splits into three main regimes. Due to the different scaling, the term controlling the limiting behavior is r rather than \(\Lambda \).
The sparse (or the subcritical) regime is when \(r\rightarrow 0\). In this case, Yogeshwaran and Adler (2015) shows that there exists a sequence of functions \(f^{(k)}\) such that either \(f^{(k)}\equiv 1\) or \(\lim _{r\rightarrow 0}f^{(k)}(r) = 0\) (depending on the distribution of \(\Phi \)), and then
where the exact limiting constant is given by a formula similar in spirit to \(c_k\) in Theorem 4.1. The results in Yogeshwaran and Adler (2015) also provide equivalent limits for the distribution as in Theorems 4.4, 4.5.
The critical (thermodynamic) regime is when \(r = \lambda \in (0,\infty )\). In this case, Yogeshwaran and Adler (2015) show that \(\mathbb {E}\left\{ {\beta _k^\Phi (n)}\right\} = \Theta (n)\) and provide a limit for the Euler characteristic similarly to Corollary 5.2.
Finally, in the supercritical regime (\(r\rightarrow \infty \)) Yogeshwaran and Adler (2015) discuss the connectivity regime, which is when \(r^d = \Theta (\log n)\). Similarly to Theorem 4.13 they show that there exists a constant c such that if \(r \ge c\left( \frac{1}{\log n}\right) ^{1/d}\) then \(\mathcal {C}_r(\Phi _n)\) is a.a.s contractible.
In addition to the Betti numbers of the Čech complex, they also provide equivalent results for the Vietoris-Rips complexes \(\mathcal {R}_r(\Phi _n)\) and for the critical point counts \(c_k\) for the distance function \(d_{\Phi _n}\). In Yogeshwaran et al. (2017) these theorems are extended in some cases, to laws of large numbers and central limit theorems.
8 Extreme value analysis of random geometric complexes
The results in the supercritical regime (\(\Lambda \rightarrow \infty \)) that we presented so far, assumed that the point process is generated by a distribution with a bounded support (see e.g. Theorems 3.4, 4.9, 4.12). As the result in Theorem 3.5 suggests, the limiting behavior can be significantly different once we generate the point process by a distribution with an unbounded support (e.g. the Gaussian distribution). The work in Adler et al. (2014) and Owada and Adler (2015) studied the distribution of the Betti numbers in these cases.
The general setup in Adler et al. (2014) and Owada and Adler (2015) is the following. Let \(f:\mathbb {R}^d\rightarrow \mathbb {R}\) be a probability density function whose support is \(\mathbb {R}^d\), and let \(\mathcal {C}_r(n)\) defined as before. The results in these paper show that as \(n\rightarrow \infty \) and \(r\rightarrow 0\), even when \(\Lambda \gg \log n\), many cycles can still show up far away from the origin. Moreover, it can be shown that homology has a very organized spatial structure. Loosely speaking, we can split \(\mathbb {R}^d\) into a sequence of annuli, such that inside each annulus we can find connected components that generate homology in different degrees. More concretely, there is a sequence of radii \(R_{0,n}> R_{1,n}> R_{2,n}> \cdots >R_{d,n}\) (depending on r and f). Considering the Čech complex generated by all vertices in the annulus \((R_{k,n}, R_{k-1,n})\), its k-th Betti number is finite, while for \(i>k\) we have \(\beta _i = 0\) and for \(i < k\) we have \(\beta _i \rightarrow \infty \). In addition, there is a smaller radius \(R_{c,n} < R_{d,n}\) such that the Čech complex generated by the vertices inside \(B_{R_{c,n}}(0)\) is contractible, and thus contains no nontrivial homology. This region is referred to as ‘the core’. This phenomenon is described in Fig. 5.

The work in Owada and Adler (2015) studies this phenomena in detail, discussing the differences between light and heavy-tailed distributions, and proving that there is a limiting Poisson law that describes the spatial distribution of cycles appearing in each annulus.
9 Persistent homology
Persistent homology is one of the most heavily used tools in applied topology, or TDA (cf. Carlsson 2009; Ghrist 2008). However, very little is known about its probabilistic properties. Briefly, the persistent homology of a Čech or a Rips complex tracks the evolution of the homology of the complex as the radius r changes from zero to infinity. In this section we will review some recent work related to the persistent homology of random geometric complexes (Bobrowski et al. 2015; Duy et al. 2016).
Loosely speaking, the k-th persistent homology \({{\mathrm{PH}}}_k\) contains a list of all the k-dimensional nontrivial cycles that are created (and later terminated) in a geometric complex as r is increased from 0 to \(\infty \). For every cycle \(\gamma \in {{\mathrm{PH}}}_k\), we can assign a pair of values \((\gamma _{{{\mathrm{birth}}}}, \gamma _{{{\mathrm{death}}}})\) that represent the radii at which \(\gamma \) appear and vanish (born and dies), respectively. A popular way to visualize the information provided by persistent homology is called the persistence diagram. Here, for every cycle \(\gamma \in {{\mathrm{PH}}}_k\) we place a single point in the plane, where the x and y axes correspond to the birth and death times, respectively. Figure 6 shows the persistence diagram of \(H_1\) for a random Čech filtration.

The persistence diagram of a random Čech filtration. The point process (on the left) is generated on an annulus in \(\mathbb {R}^2\). The \(H_1\) persistence diagram (on the right) describes the birth and death times (radii) of all the 1-cycles that appear in this filtration. Notice that most of the points in the persistence diagram are close to the diagonal (where death=birth), and one might consider these cycles as “noise”. There is one point that stands out in the diagram, which corresponds to the hole of the annulus. The persistent homology was computed using the GUDHI library (The GUDHI Project 2015)
9.1 Limit theorems for persistence diagrams
Denote by \(\xi _k\) the persistence diagram for \({{\mathrm{PH}}}_k\). Clearly, \(\xi _k \subset \Delta \), where \(\Delta := \{ (x,y) : 0 \le x< y < \infty \}\), since death always occurs after birth (see Fig. 6).
In Duy et al. (2016), the Čech and the Rips complex were considered, taken over stationary point processes \(\Phi \) (as discussed in Sect. 7). In this case, taking \(\xi _{k,n}\) to be the k-th persistence diagram of \(\Phi _n\), then \(\xi _{k,n}\) is a random point process, or random Radon measure, in \(\mathbb {R}^2\). One of the main theorems in Duy et al. (2016) states that as \(n\rightarrow \infty \) this measure has a nonrandom limit \(\nu _k\). In particular,
Theorem 9.1
(Duy et al. 2016) If \(\Phi \) is a stationary point process in \(\mathbb {R}^d\) with finite moments, then there exists a unique Radon measure \(\nu _k\) on \(\Delta \) such that
where the convergence is in terms of the vague convergence of measures on \(\Delta \). If, in addition, \(\Phi \) is ergodic, then almost surely
Under some additional conditions on \(\Phi \) they show that the support of the limiting measure \(\nu _k\) is the subspace \(R_k\subset \Delta \) of all (birth, death) pairs realizable by the corresponding filtration (which can be Čech, Rips, and others). For example, for the Čech filtration
In addition to the convergence of the entire measure, they study the variables \(\beta _k^{r,s}\) counting cycles with \(\gamma _{{{\mathrm{birth}}}} \le r\) and \(\gamma _{{{\mathrm{death}}}} \ge s\). Using similar techniques to the ones in Yogeshwaran et al. (2017) they prove a law of large numbers and a central limit theorem.
9.2 Maximal cycles in persistent homology
In this section we review the result in Bobrowski et al. (2015), related to extremal cycles. Traditionally, the persistence (or significance) of a cycle \(\gamma \) is measured by the difference \(\gamma _{death}-\gamma _{birth}\). In this work, persistence was measured by the ratio \(\pi (\gamma ) := \gamma _{death}/\gamma _{birth}\). There are a number of reasons to measure the persistence of a cycle multiplicatively.
-
This persistence measure is scale invariant, i.e. the persistence of cycles for n points chosen uniformly in a cube \([0,1]^d\) will have the same distribution as for n points chosen uniformly in a cube \([0, \lambda ]^d\) for any \(\lambda > 0\).
-
In a random geometric setting, one issue with measuring persistence by \(\gamma _{death}-\gamma _{birth}\) is that both terms are tending to zero as the number of vertices goes to infinity, and \(\gamma _{birth} \ll \gamma _{death}\). For the prominent cycles, \(\gamma _{birth}\rightarrow 0\) much faster than \(\gamma _{death}\), and therefore if we measure persistence as \(\gamma _{death} - \gamma _{birth}\), then \(\gamma _{birth}\) will just be a small error term and it will be hard to differentiate between the birth and death times. The multiplicative way of measuring persistence is more informative.
-
Both Čech complexes \(\mathcal {C}_r(n)\) and Vietoris–Rips complexes \(\mathcal {R}_r(n)\) are central to the theory of persistent homology, and it is important to be able to compare them. The standard way of relating them is via the inclusion maps
$$\begin{aligned} \cdots \hookrightarrow \mathcal {C}_r(n) \hookrightarrow \mathcal {R}_r(n) \hookrightarrow \mathcal {C}_{\sqrt{2}r}(n) \hookrightarrow \mathcal {R}_{\sqrt{2}r}(n) \hookrightarrow \cdots \end{aligned}$$(In general \(\mathcal {C}_r(n) \hookrightarrow \mathcal {R}_r(n) \hookrightarrow \mathcal {C}_{\alpha r}(n)\) for Čech and Vietoris–Rips complexes in Euclidean space \(\mathbb {R}^d\), as long as \(\alpha \ge \sqrt{ 2d / (d+1)}\), as shown in Theorem 2.5 of de Silva and Ghrist (2007). So one may relate persistent homology between the two types of complexes. Because this relationship is naturally multiplicative in r, our results are stated in a way that holds for both types of complexes.
The result in Bobrowski et al. (2015) was proven for a homogeneous Poisson process on the unit cube \([0,1]^d\). However, similar results should hold for any measurable density function f on any d-dimensional compact and convex body, provided that f is bounded from below and above.
Theorem 9.2
Let \(\mathcal {P}_n\) be a unit-intensity Poisson process on the unit cube \([0,1]^d\). Let \({{\mathrm{PH}}}_k(n)\) be the k-th dimensional persistent homology of either the Čech or the Rips filtration generated by \(\mathcal {P}_n\). Define,
i.e. \(\Pi _k(n)\) is the maximal persistence of all k-cycles. Then a.a.s. we have that
The implied constants in the asymptotic notation \(\Theta \) only depend on the underlying probability distribution.
Persistent homology is becoming a very popular and powerful data analysis tool. Studying this type of extremal behavior for persistent homology can be later used to provide a statistical analysis to persistent homology. For example, suppose that the data are sampled from a distribution supported on a manifold M with non trivial homology that we wish to recover. Knowing the distribution of \(\Pi _k\) for convex bodies (where homology is trivial), would enable us to develop statistical tests to differentiate between the signal (real cycles of M) and noise (artifacts of the sampling mechanism) in this type of data analysis problem. Persistent homology in random contexts was studied earlier by Bubenik and Kim in (2007).
10 Open problems/future directions
We close by mentioning several possible directions for future research.
-
Sharper results in the thermodynamic limit. Proving strong results for expectation of Betti numbers in the critical regime remains a challenging problem. The best result so far is that
$$\begin{aligned} \frac{\mathbb {E}[\beta _k(n)] }{n} \rightarrow C, \end{aligned}$$where \(C > 0\) is some constant which depends on the underlying distribution on \(\mathbb {R}^d\) and the degree k, see Yogeshwaran et al. (2017). It would be a breakthrough to write an explicit formula for C and we expect that the results would find applications in TDA.
-
Connections between the various models. Is there a model for random geometric complex which approximates the sub-level sets of the Gaussian random field? See Adler and Taylor (2007) and Adler and Taylor (2011) for introduction and overview of Gaussian random fields and their topological properties.
-
Torsion. All of the results in this survey for homology of random geometric complexes do not depend on the choice of coefficients. In dimensions \(d \ge 4\) and higher, these complexes will likely have torsion in integer homology. What can be said about the limiting distribution of this torsion group?
-
Higher-dimensional percolation theory. All of the random geometric complexes discussed here are analogues of random geometric graphs where the number of vertices n is finite and \(n \rightarrow \infty \). Percolation theory is of a somewhat different flavor—one considers an infinite random graph, by taking a random subgraph of a lattice, and then analyzes large-scale structure such as whether or not an infinite connected component appears. Analogous lattice models with higher-dimensional cells have been studied, for example “plaquette percolation” (Aizenman et al. 1983; Grimmett and Holroyd 2010). So rather than study homology-vanishing thresholds for finite random geometric complexes with size tending to infinity, one might study the appearance of “infinite” cycles in lattice models. So far, this seems to be relatively unexplored.
References
Adler, R.J., Bobrowski, O., Weinberger, S.: Crackle: the homology of noise. Discret. Comput. Geom. 52(4), 680–704 (2014)
Adler, R.J., Taylor, J.E.: Random fields and geometry, Springer Monographs in Mathematics. Springer, New York (2007)
Adler, R.J., Taylor, J.E.: Topological complexity of smooth random functions. In: Lecture Notes in Mathematics, vol. 2019. Springer, Heidelberg (2011)
Aizenman, M., Chayes, J.T., Chayes, L., Fröhlich, J., Russo L.: On a sharp transition from area law to perimeter law in a system of random surfaces. Comm. Math. Phys. 92(1), 19–69 (1983)
Alon, N., Spencer J.H.: The probabilistic method. Wiley-Interscience Series in Discrete Mathematics and Optimization, 3rd ed. Wiley, Hoboken (2008) (with an appendix on the life and work of Paul Erdős).
Babson, E., Hoffman, C., Kahle, M.: The fundamental group of random 2-complexes. J. Amer. Math. Soc. 24(1), 1–28 (2011)
Balakrishnan, S., Rinaldo, A., Sheehy, D., Singh, A., Wasserman, L.A.: Minimax rates for homology inference. AISTATS 9, 206–207 (2012)
Baryshnikov, Y., Bubenik, P., Kahle, M.: Min-type Morse theory for configuration spaces of hard spheres. Int. Math. Res. Not. IMRN 9, 2577–2592 (2014). (MR 3207377)
Bobrowski, O., Adler, R.J.: Distance functions, critical points, and the topology of random Čech complexes. Homol. Homotopy Appl. 16(2), 311–344 (2014). (en)
Bobrowski, O., Kahle, M., Skraba, P.: Maximally persistent cycles in random geometric complexes. Ann. Appl. Prob. 27(4), 2032–2060 (2017)
Bobrowski, O., Mukherjee, S.: The topology of probability distributions on manifolds. Probab. Theory Relat Fields 161(3–4), 651–686 (2014)
Bobrowski, O., Mukherjee, S., Taylor, J.E.: Topological consistency via kernel estimation. Bernoulli 23(1), 288–328 (2017)
Bobrowski, O., Oliveira, G.: Random Čech complexes on riemannian manifolds (2017) arXiv:1704.07204 (arXiv preprint)
Bobrowski, O., Weinberger, S.: On the vanishing of homology in random Čech complexes. Random Struct. Algorithm 51(1), 14–51 (2017)
Bollobás, B.: Random graphs, 2nd edn. Cambridge studies in advanced mathematics, vol. 73. Cambridge University Press, Cambridge (2001)
Bollobás, B., Riordan, O.: Percolation. Cambridge University Press, New York (2006)
Borsuk, K.: On the imbedding of systems of compacta in simplicial complexes. Fund. Math. 35, 217–234 (1948)
Bryzgalova, L.N.: The maximum functions of a family of functions that depend on parameters. Funktsional. Anal. i Prilozhen. 12(1), 66–67 (1978)
Bubenik, P., Kim, P.T.: A statistical approach to persistent homology. Homol. Homotopy Appl. 9(2), 337–362 (2007)
Carlsson, G.: Topology and data. Bull. Amer. Math. Soc. (N.S.) 46(2), 255–308 (2009)
De Silva, V., Ghrist, R.: Coverage in sensor networks via persistent homology. Algebr. Geom. Topol. 7, 339–358 (2007)
Decreusefond, L., Ferraz, E., Randriambololona, H., Vergne, A.: Simplicial homology of random configurations. Adv. Appl. Probab. 46(2), 325–347 (2014)
Duy, T.K., Hiraoka, Y., Shirai, T.: Limit theorems for persistence diagrams (2016) arXiv:1612.08371 [math]
Edelsbrunner, H., Kirkpatrick, D.G., Seidel, R.: On the shape of a set of points in the plane. IEEE Trans. Inform. Theory 29(4), 551–559 (1983)
Fasy, B.T., Lecci, F., Rinaldo, A., Wasserman, L., Balakrishnan, S., Singh, A.: Confidence sets for persistence diagrams. Ann. Stat. 42(6), 2301–2339 (2014)
Ganesan, G.: Size of the giant component in a random geometric graph. Ann. Inst. Henri Poincaré Probab. Stat. 49(4), 1130–1140 (2013)
Gershkovich, V., Rubinstein, H.: Morse theory for Min-type functions. Asian J. Math. 1(4), 696–715 (1997)
Ghrist, R.: Barcodes: the persistent topology of data. Bull. Amer. Math. Soc. (N.S.) 45(1), 61–75 (2008)
Gilbert, E.N.: Random plane networks. J. Soc. Indust. Appl. Math. 9, 533–543 (1961)
Grimmett, G.: Percolation, 2nd ed., Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences], vol. 321. Springer, Berlin (1999)
Grimmett, G.R., Holroyd, A.E.: Plaquettes, spheres, and entanglement. Electron. J. Probab. 15, 1415–1428 (2010)
Hatcher, A.: Algebraic topology. Cambridge University Press, Cambridge (2002)
Janson, S., Łuczak, T., Rucinski, A.: Random graphs. Wiley-Interscience Series in Discrete Mathematics and Optimization. Wiley, New York (2000)
Kahle, M.: Random geometric complexes. Discrete Comput. Geom. 45(3), 553–573 (2011)
Kahle, M.: Sharp vanishing thresholds for cohomology of random flag complexes. Ann. Math. (2) 179(3), 1085–1107 (2014)
Kahle, M.: Topology of random simplicial complexes: a survey. AMS Contemp. Math 620, 201–222 (2014)
Kahle, M., Meckes, E.: Limit theorems for Betti numbers of random simplicial complexes. Homol. Homotopy Appl. 15(1), 343–374 (2013)
Kahle, M., Meckes, E.: Erratum: Limit theorems for betti numbers of random simplicial complexes (2015). arXiv:1501.03759 (arXiv preprint)
Linial, N., Meshulam, R.: Homological connectivity of random 2-complexes. Combinatorica 26(4), 475–487 (2006)
Matov, V.I.: Topological classification of the germs of functions of the maximum and minimax of families of functions in general position. Uspekhi Mat. Nauk 37(4)(226), 167–168 (1982)
Meester, R., Roy R.: Continuum percolation, Cambridge Tracts in Mathematics, vol. 119. Cambridge University Press, Cambridge (1996)
Meshulam, R., Wallach, N.: Homological connectivity of random \(k\)-dimensional complexes. Random Struct. Algorithms 34(3), 408–417 (2009)
Milnor, J.: Morse theory. In: Based on lecture notes by M. Spivak and R. Wells. Annals of Mathematics Studies, no. 51. Princeton University Press, Princeton (1963)
Niyogi, P., Smale, S., Weinberger, S.: Finding the homology of submanifolds with high confidence from random samples. Discrete Comput. Geom. 39(1–3), 419–441 (2008)
Munkres, J.R.: Elements of algebraic topology. Addison-Wesley Publishing Company, Menlo Park (1984)
Niyogi, P., Smale, S., Weinberger, S.: A topological view of unsupervised learning from noisy data. SIAM J. Comput. 40(3), 646–663 (2011)
Owada, T., Adler, R.J.: Limit theorems for point processes under geometric constraints (and topological crackle). Ann. Prob. 45(3), 2004–2055 (2017)
Penrose, M.: Random geometric graphs, Oxford Studies in Probability, vol. 5. Oxford University Press, Oxford (2003)
Robins, V.: Betti number signatures of homogeneous poisson point processes. Phys. Rev. E 74(6), 061107 (2006)
The GUDHI Project: GUDHI user and reference manual. GUDHI Editorial Board (2015)
Yogeshwaran, D., Adler, R.J.: On the topology of random complexes built over stationary point processes. Ann. Appl. Prob. 25(6), 3338–3380 (2015)
Yogeshwaran, D., Subag, E., Adler, R.J.: Random geometric complexes in the thermodynamic regime. Prob. Theory Relat. Fields 167(1–2), 107–142 (2017)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Matthew Kahle gratefully acknowledges support from NSF-DMS #1352386.
Rights and permissions
About this article

Cite this article
Bobrowski, O., Kahle, M. Topology of random geometric complexes: a survey. J Appl. and Comput. Topology 1, 331–364 (2018). https://doi.org/10.1007/s41468-017-0010-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41468-017-0010-0