
Abstract
We consider the topology of simplicial complexes with vertices the points of a random point process and faces determined by distance relationships between the vertices. In particular, we study the Betti numbers of these complexes as the number of vertices becomes large, obtaining limit theorems for means, strong laws, concentration inequalities and central limit theorems. As opposed to most prior papers treating random complexes, the limit with which we work is in the so-called ‘thermodynamic’ regime (which includes the percolation threshold) in which the complexes become very large and complicated, with complex homology characterised by diverging Betti numbers. The proofs combine probabilistic arguments from the theory of stabilizing functionals of point processes and topological arguments exploiting the properties of Mayer–Vietoris exact sequences. The Mayer–Vietoris arguments are crucial, since homology in general, and Betti numbers in particular, are global rather than local phenomena, and most standard probabilistic arguments are based on the additivity of functionals arising as a consequence of locality.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
This paper is concerned with structures created by taking (many) random points and building the structure based on neighbourhood relations between the points. Perhaps the simplest way to describe this is to let \(\Phi = \{x_1,x_2,\dots \}\) be a finite or countable, locally finite, subset of points in \({\mathbb {R}}^d\), for some \(d>1\), and to consider the set
where \(0<r<\infty \), and \(B_x(r)\) denotes the d-dimensional ball of radius r centred at \(x \in {\mathbb {R}}^d\).
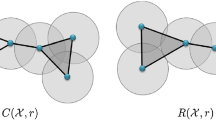
When the points of \(\Phi \) are those of a stationary Poisson process on \({\mathbb {R}}^d\), this union is a special case of a ‘Boolean model’, and its integral geometric properties—such as volume, surface area, Minkowski functionals—have been studied in the setting of stochastic geometry since the earliest days of that subject. Our interest, however, lies in the homological structure of \(\mathcal{C}_B(\Phi ,r)\), in particular, as expressed through its Betti numbers. Thus our approach will be via the tools of algebraic topology, and, to facilitate this, we shall generally work not with \(\mathcal{C}_B(\Phi ,r)\) but with a homotopically equivalent abstract simplicial complex with a natural combinatorial structure. This will be the Čech complex with radius r built over the point set \(\Phi \), denoted by \({{\mathcal {C}}}(\Phi ,r)\), and defined below in Sect. 2.1.
The first, and perhaps most natural topological question to ask about these sets is how connected are they. This is more a graph theoretic question than a topological one, and has been well studied in this setting, with [31] being the standard text in the area. There are various ‘regimes’ in which it is natural to study these questions, depending on the radius r. If r is small, then the balls in (1.1) will only rarely overlap, and so the topology of both \(\mathcal{C}_B(\Phi ,r)\) and \({{\mathcal {C}}}(\Phi ,r)\) will be mainly that of many isolated points. This is known as the ‘dust regime’. However, as r grows, the balls will tend to overlap, and so a large, complex structure will form, leading to the notion of ‘continuum percolation’, for which the standard references are [16, 25]. The percolation transition occurs within what is known as the ‘thermodynamic’, regime (described in more detail in Sect. 2.2), and is typically the hardest to analyse. The third and final regime arises as r continues to grow, and (loosely speaking) \(\mathcal{C}_B(\Phi ,r)\) merges into a single large set with no empty subsets and so no interesting topology.
Motivated mainly by issues in topological data analysis (e.g. [27, 28]) there has been considerable recent interest in the topological properties of \(\mathcal{C}_B(\Phi ,r)\) and \({{\mathcal {C}}}(\Phi ,r)\) that go beyond mere connectivity or the volumetric measures provided by integral geometry. These studies were initiated by Matthew Kahle in [19], in a paper which studied the growth of the expected Betti numbers of these sets when the underlying point process \(\Phi \) was either a Poisson process or a random sample from a distribution satisfying mild regularity properties. Shortly afterwards, more sophisticated distributional results were proven in [21]. An extension to more general stationary point processes \(\Phi \) on \({\mathbb {R}}^d\) can be found in [42], while, in the Poisson and binomial settings, [3] looks at these problems from the point of view of the Morse theory of the distance function. Recently [5] has established important—from the point of view of applications—extensions to the results of [3, 19, 21] in which the underlying point process lies on a manifold of lower dimension than an ambient Euclidean space in which the balls of (1.1) are defined. See also the recent survey [4].
However, virtually all of the results described in the previous paragraph (with the notable exception of some growth results for expected Betti numbers in [19] and numbers of critical points in [3]) deal with the topology of the dust regime. What is new in the current paper is a focus on the thermodynamic regime, and new results that go beyond the earlier ones about expectations. Moreover, because of the long range dependencies in the thermodynamic regime, proofs here involve considerably more topological arguments than is the case for the dust regime.
Our main results are summarised in the following subsection, after which we shall give some more details about the current literature. Then, in Sect. 2, we shall recall some basic notions from topology and from the theory of point processes. The new results begin in Sect. 3, where we shall treat the setting of general stationary point processes, while the Poisson and binomial settings will be treated in Sect. 4. The paper concludes with some appendices containing variations of some known tools, adapted to our needs.
1.1 Summary of results
Throughout the paper we shall assume that all our point processes are defined over \({\mathbb {R}}^d\) for \(d \ge 2\). Denoting Betti numbers of a set \(A \subset {\mathbb {R}}^d\) by \(\beta _k(A)\), \(k=1,\dots ,d-1\), we are interested in \(\beta _k(\mathcal{C}_B(\Phi ,r))\) for point processes \(\Phi \subset {\mathbb {R}}^d\). Since the Betti numbers for \(k\ge d\) are identically zero, these values of k are uninteresting. On the other hand, \(\beta _0(A)\) gives the number of connected components of A. While this is clearly interesting and important in our setting, it has already been studied in detail from the point of view of random graph theory, as described above. Indeed, (sometimes stronger) versions of virtually all our results for the higher Betti numbers already exist for \(\beta _0\) (cf. [1, 31]), and so this case will appear only peripherally in what follows.
Here is a summary of our results, grouped according to the underlying point processes involved. Formal definitions of technical terms are postponed to later sections.
-
1.
General stationary point processes: For a stationary point process \(\Phi \) and \(r \in (0,\infty )\), we study the asymptotics of \(\beta _k(\mathcal{C}_B(\Phi \cap W_l,r))\) as \(l \rightarrow \infty \) and where \(W_l = [-\frac{l}{2},\frac{l}{2})^d\). We show convergence of expectations (Lemma 3.3) and, assuming ergodicity, we prove strong laws (Theorem 3.5) for all the Betti numbers and a concentration inequality for \(\beta _0\) (Theorem 3.6) in the special case of determinantal point processes.
-
2.
Stationary Poisson point processes: Retain the same notation as above, but take \(\Phi = {\mathcal {P}}\), a stationary Poisson point process on \({\mathbb {R}}^d\). In this setting we prove a central limit theorem (Theorem 4.7) for the Betti numbers of \(\mathcal{C}_B({\mathcal {P}}\cap W_l, r)\) and \({{\mathcal {C}}}({\mathcal {P}}\cap W_l,r)\), for any \(r\in (0,\infty )\), as \(l\rightarrow \infty \). We also treat the case in which l points are chosen uniformly in \(W_l\) and obtain a similar result, although in this case we can only prove the central limit theorem for \(r \notin I_d\), where the interval \(I_d\) will be defined in Sect. 4.2. Informally, \(I_d\) is the interval of radii where both \(\mathcal{C}_B({\mathcal {P}},r)\) and its complement have unbounded components a.s. We only remark here that \(I_2 = \emptyset \) and \(I_d\) is a non-degenerate interval for \(d \ge 3\).
-
3.
Inhomogeneous Poisson and binomial point processes: Now, consider either the Poisson point process \({\mathcal {P}}_n\) with non-constant intensity function nf, for a ‘nice’, compactly supported, density f, or the binomial process of n iid random variables with probability density f. In this case the basic set-up requires a slight modification, and so we consider asymptotics for \(\beta _k(\mathcal{C}_B({\mathcal {P}}_n,r_n))\) as \(n \rightarrow \infty \) and \(nr_n^d \rightarrow r \in (0,\infty )\). We derive an upper bound for variances and a weak law (Lemma 4.2). In the Poisson case, we also derive a variance lower bound for the top homology. For the corresponding binomial case we prove a concentration inequality (Theorem 4.5) and use this to prove a strong law for both cases (Theorem 4.6).
A few words on our proofs: In the case of stationary point processes, we shall use the nearly-additive properties of Betti numbers along with sub-additive theory arguments [39, 43]. In the Poisson and binomial cases, the proofs center around an analysis of the so-called add-one cost function,
where O is the origin in \({\mathbb {R}}^d\). While simple combinatorial topology bounds with martingale techniques suffice for strong laws, weak laws, and concentration inequalities, a more careful analysis via the Mayer–Vietoris sequence is required for the central limit theorems.
Our central limit theorems rely on similar results for stabilizing Poisson functionals (cf. [33]), which in turn were based upon martingale central limit theory. As for variance bounds, while upper bounds can be derived via Poincaré or Efron–Stein inequalities, the more involved lower bounds exploit the recent bounds developed in [23] using chaos expansions of Poisson functionals.
One of the difficulties in analyzing Betti numbers that will become obvious in the proof of the central limit theorem is their global nature. Most known examples of stochastic geometric functionals satisfy both the notions of stabilization (cf. [33]) known as ‘weak’ and ‘strong’ stabilization. However, we shall prove that higher Betti numbers satisfy weak stabilization but satisfy strong stabilization only for certain radii regimes. We are unable to prove strong stabilization of higher Betti numbers for all radii regimes because of the global dependence of Betti numbers on the underlying point process.
1.2 Some history
To put our results into perspective, and to provide some motivation, here is a little history.
As already mentioned, recent interest in random geometric complexes was stimulated by their connections to topological data analysis and, more broadly, applied topology. There are a number of accessible surveys on this subject (e.g. [6, 9, 12, 15, 45]), all of which share a common theme of studying topological invariants of simplicial complexes built on point sets. At the time of writing, another excellent review [7] by Carlsson appeared, which is longer than the earlier ones, more up to date, and which also contains a gentle introduction the topological concepts needed in the current paper. Throughout this literature, Betti numbers, apart from being a simple topological invariant, appear as the first step to understanding persistent homology, undoubtedly the single most important tool to emerge from current research in applied topology.
Although the study of random geometric complexes seems to have originated in [19], it is worth noting that Betti numbers of a random complex model were already investigated in [24], where a higher-dimensional version of the Erdös–Renyi random graph model was constructed. The recent paper [20] gives a useful survey of what is known about the topology of these models, which are rather different to those in the current paper.
As we already noted above, the Boolean model (1.1) has long been studied in stochastic geometry, mainly through its volumetric measures. However, one of these measures is the Euler characteristic, \(\chi \), which is also one of the basic homotopy invariants of topology, and is given by an alternating sum of Betti numbers. Results for Euler characteristics which are related to ours for the individual Betti numbers can be found, for example, in [35], which establishes ergodic theorems for \(\chi (\mathcal{C}_B(\Phi ,r))\) when the underlying point process \(\Phi \) is itself ergodic. More recently, a slew of results have been established for \(\chi (\mathcal{C}_B({\mathcal {P}},r))\) (i.e. the Poisson case) in the preprint [18]. The arguments in this paper replace more classic integral geometric arguments, and are based on new results in the Malliavin–Stein approach to limit theory (cf. [29] and esp. [36]). To some extent we shall also exploit these methods in the current paper, although they are not as well suited to the study of Betti numbers as they are to the Euler characteristic, due to the non-additivity of the former.
An alternative approach to the Euler characteristic of a simplicial complex is via an alternating sum of the numbers of faces of different dimensions. This fact has been used to good effect in [10], which derives exact expressions for moments of face counts, and a central limit theorem and concentration inequality for the Euler characteristic and \(\beta _0\) when the underlying space is a torus. (Working on a torus rather avoids otherwise problematic boundary issues which complicate moment calculations.) Some additional results on phase transitions in face counts for a wide variety of underlying stationary point processes can be found in [42, Section 3].
1.3 Beyond the Čech complex
Although this paper concentrates on the Čech complex as the basic topological object determined by a point process, this is but one of the many geometric complexes that could have been chosen. There are various other natural choices including the Vietoris-Rips, alpha, witness, cubical, and discrete Morse complexes (cf. [14, Section 7], [44, Section 3]) that are also of interest. In particular, the alpha complex is homotopy equivalent to the Čech complex [44, Section 3.2], as is an appropriate discrete Morse complex [14, Theorem 2.5]. This immediately implies that all the limit theorems for Betti numbers in this paper also hold for these complexes.
Moreover, since our main topological tools—Lemmas 2.2 and 2.3—can be shown to hold for all the complexes listed above, most of our arguments should easily extend to obtain similar theorems for these cases as well.
2 Preliminaries
This section introduces a handful of basic concepts and definitions from algebraic topology and the theory of point processes. The aim is not to make the paper self-contained, which would be impossible, but to allow readers from these two areas to have at least the vocabulary for reading our results. We refer readers to the standard texts such as [17, 26] for more details on the topology we need, while [35, 40] covers the point process material.
2.1 Topological preliminaries
An abstract simplicial complex, or simply complex, \({{\mathcal {K}}}\) is a finite collection of finite sets such that \(\sigma _1 \in {{\mathcal {K}}}\) and \(\sigma _2 \subset \sigma _1\) implies \(\sigma _2 \in {{\mathcal {K}}}\). The sets in \({{\mathcal {K}}}\) are called faces or simplices and the dimension \(\text {dim}(\sigma )\) of any simplex \(\sigma \in {{\mathcal {K}}}\) is the cardinality of \(\sigma \) minus 1. If \(\sigma \in {{\mathcal {K}}}\) has dimension k, we say that \(\sigma \) is a k-simplex of \({{\mathcal {K}}}\). The k-skeleton of \({{\mathcal {K}}}\), denoted by \({{\mathcal {K}}}^k\), is the complex formed by all faces of \({{\mathcal {K}}}\) with dimension at most k.
Note that a singleton containing a simplex of dimension greater than zero is not necessarily a simplicial complex. (This is as opposed to their usual concrete representations as subsets of Euclidean space, in which a closed simplex physically contains all its lower dimensional faces.) When we want to study the complex generated by a simplex \(\sigma \), we shall refer to it as the full simplex \(\sigma \), or, equivalently, \(\sigma ^k\), its k-skeleton, where \(k =\) dim\((\sigma )\).
A map \(g:\, {{\mathcal {K}}}^0 \rightarrow {{\mathcal {L}}}^0\) between two complexes \({{\mathcal {K}}}\) and \({{\mathcal {L}}}\) is said to be a simplicial map if, for any \(m \ge 0\), \(\{g(v_1),\ldots ,g(v_m)\}\in \mathcal L\) whenever \(\{v_1,\ldots ,v_m\}\in \mathcal K\).
Given a point set in \({\mathbb {R}}^d\) (or generally, in a metric space) there are various ways to define a simplicial complex that captures some of the geometry and topology related to the set. We shall be concerned with a specific construction—the so-called Čech complex.
Definition 2.1
Let \({{\mathcal {X}}}=\{x_i\}_{i=1}^n\subset {\mathbb {R}}^d\) be a finite set of points. For any \(r>0\), the Čech complex of radius r is the abstract simplicial complex
where \(B_x(r)\) denotes the ball of radius r centered at x.
For future reference, note that by the nerve theorem (cf. [2, Theorem 10.7]) the Čech complex built over a finite set of points is homotopic to the Boolean model (1.1) constructed over the same set.
The Čech complexes that we shall treat will be generated by random point sets, and we shall be interested in their homology groups \(H_k\), with coefficients from a field \({\mathbb {F}}\), which will be anonymous but fixed throughout the paper. A common choice is to take \({\mathbb {F}}={\mathbb {Z}}_2\), which is computationally convenient, but this will not be necessary here.
A few words are in place for the reader unfamiliar with homology theory. On the heuristic level, the homology groups of a space are meant to capture the topological structure of cycles or ‘holes’ in it. Of course, such concepts are best understood in a geometric setting, e.g. when the space is a subset in \({\mathbb {R}}^{d}\), or an abstract complex generated by a triangulation of such a subset. Nevertheless, high dimensional cycles can be defined combinatorially, much like 1-dimensional ones are defined for graphs. Besides simply defining the cycles, one wishes to be able to ignore trivial cycles or ones that are equivalent to others. As concrete examples, the boundary of a full disc should not be regarded as a ‘hole’ and the two cycles forming the boundary of a hollow cylinder are to be thought of as representatives of the same ‘hole’ (where, to obtain an abstract complex, one should consider triangulations of these objects, or alternatively work with singular homology). The way the theory deals with these two issues is by defining \(H_{k}\) as the quotient of a group \(Z_{k}\) representing cycles by another group \(B_{k}\) representing boundaries. Then, trivial cycles are exactly those in the class of 0 and equivalent ones belong to the same class. The groups \(Z_{k}\) and \(B_{k}\) are subgroups of the free group generated by (oriented) simplices; i.e. their elements are formal sums of simplices with coefficients taken from some field. In general, the coefficients are from an Abelian group but we shall work with field coefficients. Having made the choice of working with field coefficients, all groups in our case are vector spaces. The dimension of \(H_{k}\), denoted by \(\beta _k\), is called the k-th Betti number and has a special meaning: it is the maximal number of non-equivalent cycles of dimension k. It is important to note that, for \(k=0\), \(\beta _0\) is the maximal number of vertices which (pairwise) cannot be connected by a sequence of 1-simplices; that is, \(\beta _0\) is the number of connected components of the space. Throughout the paper, we shall concentrate on the (random) Betti numbers \(\beta _k\), \(0\le k\le d-1\), of Čech complexes.
Our two main topological tools are collected in the following two lemmas. The first is needed for obtaining various moment bounds on Betti numbers of random simplicial complexes, and the second will replace the role that additivity of functionals usually plays in most probabilistic limit theorems. Because the arguments underlying these lemmas are important for what follows, and will be unfamiliar to most probabilistic readers, we shall prove them both. However both contain results that are well known to topologists.
Lemma 2.2
Let \({{\mathcal {K}}},{{\mathcal {K}}}_1\) be two finite simplicial complexes such that \({{\mathcal {K}}}\subset {{\mathcal {K}}}_1\) (i.e., every simplex in \({{\mathcal {K}}}\) is also a simplex in \({{\mathcal {K}}}_1).\) Then, for every \(k \ge 1,\) we have that
Proof
We start with the simple case when \({{\mathcal {K}}}_1 = {{\mathcal {K}}}\bigcup \{\sigma \}\) where \(\sigma \) is a j-simplex for some \(j \ge 0\). Note that since both \({{\mathcal {K}}}\) and \({{\mathcal {K}}}_1\) are simplicial complexes it follows that all the proper subsets of \(\sigma \) must already be present in \({{\mathcal {K}}}\). Thus we immediately have that
Thus the lemma is proven for the case \({{\mathcal {K}}}_1 = {{\mathcal {K}}}\bigcup \{\sigma \}\). For arbitrary complexes \({{\mathcal {K}}}\subset {{\mathcal {K}}}_1\), enumerate the simplices in \({{\mathcal {K}}}_1{\setminus }{{\mathcal {K}}}\) such that lower dimensional simplices are added before the higher dimensional ones and repeatedly apply the above argument along with the triangle inequality. \(\square \)
With a little more work, one can go further than the previous lemma and derive an explicit equality for differences of Betti numbers. This is again a classical result in algebraic topology which is derived using the Mayer–Vietoris sequence (see [11, Corollary 2.2]). However we shall state it here as it is important for our proof of the central limit theorem.
A little notation is needed before we state the lemma. A sequence of Abelian groups \(G_1,\ldots ,G_l\) and homomorphisms \(\eta _i: G_i \rightarrow G_{i+1}\), \(i=1,\ldots ,l-1\) is said to be exact if \(\mathrm{im}\,\eta _i = \mathrm{ker}\, \eta _{i+1}\) for all \(i = 1,\ldots ,l-1\). If \(l = 5\) and \(G_1\) and \(G_5\) are trivial, then the sequence is called short exact.
Lemma 2.3
(Mayer–Vietoris Sequence) Let \({{\mathcal {K}}}_1\) and \({{\mathcal {K}}}_2\) be two finite simplicial complexes and \({{\mathcal {L}}}= {{\mathcal {K}}}_1 \cap {{\mathcal {K}}}_2\) (i.e., \({{\mathcal {L}}}\) is the complex formed from all the simplices in both \({{\mathcal {K}}}_1\) and \({{\mathcal {K}}}_2).\) Then the following are true :
-
1.
The following is an exact sequence, and, furthermore, the homomorphisms \(\lambda _k\) are induced by inclusions :
$$\begin{aligned}&\cdots \rightarrow H_k({{\mathcal {L}}}) \mathop {\rightarrow }\limits ^{\lambda _k} H_k({{\mathcal {K}}}_1)\oplus H_k({{\mathcal {K}}}_2) \rightarrow H_k({{\mathcal {K}}}_1 \cup {{\mathcal {K}}}_2)\\&\qquad \rightarrow H_{k-1}({{\mathcal {L}}}) \mathop {\rightarrow }\limits ^{\lambda _{k-1}} H_{k-1}({{\mathcal {K}}}_1)\oplus H_{k-1}({{\mathcal {K}}}_2)\rightarrow \cdots \end{aligned}$$ -
2.
Furthermore,
$$\begin{aligned} \beta _k\left( {{\mathcal {K}}}_1 \bigcup {{\mathcal {K}}}_2\right) =\beta _k({{\mathcal {K}}}_1) + \beta _k({{\mathcal {K}}}_2)+ \beta (N_k) +\beta (N_{k-1})-\beta _k({{\mathcal {L}}}), \end{aligned}$$where \(\beta (G)\) denotes the rank of a vector space G and \(N_j = \mathrm{ker}\, \lambda _j\).
Proof
The first part of the lemma is just a simplicial version of the classical Mayer–Vietoris theorem (cf. [26, Theorem 25.1]). The second part follows from the first part, as follows: Suppose we have the exact sequence
Then we also have the short exact sequence
where the quotient space \(\mathrm{coker}\, \eta _1 = G_2 / \mathrm{im}\, \eta _1\) is the cokernel of \(\eta _1\). From the exactness of the sequence we have that
Now applying this to the Mayer–Vietoris sequence with \(G_1 = H_k({{\mathcal {L}}})\), etc, we have
which completes the proof. \(\square \)
2.2 Point process preliminaries
A point process \(\Phi \) is formally defined to be a random, locally-finite (Radon), counting measure on \({\mathbb {R}}^d\). More formally, let \({\mathcal {B}}_{b}\) be the \(\sigma \)-ring of bounded, Borel subsets of \({\mathbb {R}}^d\) and let \({\mathbb {M}}\) be the corresponding space of non-negative Radon counting measures. The Borel \(\sigma \)-algebra \(\mathcal M\) is generated by the mappings \(\mu \rightarrow \mu (B)\) for all \(B\in {\mathcal {B}}_{b}\). A point process \(\Phi \) is a random element in \(({\mathbb {M}}, \mathcal M)\), i.e. a measurable map from a probability space \((\Omega ,\mathcal F,{\mathbb {P}})\) to \(({\mathbb {M}},\mathcal M)\). The distribution of \(\Phi \) is the measure \({\mathbb {P}}\Phi ^{-1}\) on \(({\mathbb {M}},\mathcal M)\).
We shall typically identify \(\Phi \) with the positions \(\{x_1,x_2,\dots \}\) of its atoms, and so for Borel \(B\subset {\mathbb {R}}^d\), we shall allow ourselves to write
where \(\#\) denotes cardinality and \(\delta _x\) the single atom measure with mass one at x. The intensity measure of \(\Phi \) is the non-random measure defined by \(\mu (B)={\mathbb {E}}\left\{ \Phi (B)\right\} \), and, when \(\mu \) is absolutely continuous with respect to Lebesgue measure, the corresponding density is called the intensity of \(\Phi \). A point process is called simple if its points (i.e., \(x_i\)’s) are a.s. distinct. In this article, we shall consider only simple point processes.
For a measure \(\phi \in {\mathbb {M}}\), let \(\phi _{(x)}\) be the translate measure given by \(\phi _{(x)}(B) = \phi (B-x)\) for \(x \in {\mathbb {R}}^d\) and \(B\in {\mathcal {B}}_{b}\). A point process is said to be stationary if the distribution of \(\Phi _{(x)}\) is invariant under such translation, i.e. \({\mathbb {P}}\Phi ^{-1}_{(x)} = {\mathbb {P}}\Phi ^{-1}\) for all \(x \in {\mathbb {R}}^d\). For a stationary point process in \({\mathbb {R}}^d\), \(\mu (B) = \lambda |B|\) for all \(B\in {\mathcal {B}}_b\), where |B| denotes the Lebesgue measure of B, and the constant of proportionality \(\lambda \) is called the intensity of the point process.
Of particular importance to us are the Poisson and Binomial point processes. These processes are characterized through their relation to one of the most fundamental notions of probability theory—statistical independence. A Poisson process \({\mathcal {P}}\) is the simple point process uniquely determined by its intensity measure \(\mu \) and the following property: for any collection of disjoint measurable sets \(\{A_i\}\), \(\{{\mathcal {P}}(A_i)\}\) are independent random variables. An equivalent, direct definition is given by the finite dimensional distributions,
where \(P_i\) are Poisson variables with parameter \(\mu (A_i)\) and, again, \(A_i\) are assumed to be disjoint. A Binomial point process \({{\mathcal {X}}}_n\) is a process formed by n i.i.d points \(X_1,\ldots ,X_n\). It is worth mentioning that conditioning a Poisson process to have exactly n points yields a Binomial process; and conversely, mixing a Binomial process by taking n to be a Poisson variable produces a Poisson process.
For all of the point processes we consider, we shall be interested in behavior in the so-called thermodynamic limit. That is, while letting the number of points n increase to infinity, we choose the radii \(r_n\) so that the average degree of a point (in the random 1-skeleton) converges to a constant. (Note, however, that this average depends on the location of the point for inhomogeneous processes.) As was described in Sect. 1.1, this is done either by scaling the space and taking r to be n-independent for stationary processes, or by fixing the space, increasing the intensity and decreasing \(r_n\) for inhomogeneous processes.
We conclude the section with some more definitions. For Borel \(A \subset {\mathbb {R}}^d\), we write \(\Phi _A\) for both the restricted random measure given by \(\Phi _A(B):=\Phi (A\cap B)\) (when treating \(\Phi \) itself as a measure) and the point set \(\Phi \cap A\) (when treating \(\Phi \) as a point set). To save space, we shall write \(\Phi _l\) for \(\Phi _{W_l}\), where \(W_l\) is the ‘window’ \([-l/2,l/2)^d\), for all \(l \ge 0\).
For a set of measures \( \Theta \in \mathcal {M}\), let the translate family be \(\Theta _x := \{\phi _{(x)} :\, \phi \in \Theta \}\). A point process \(\Phi \) is said to be ergodic if
for all \(\Theta \in {\mathcal {M}}\) for which
for all \(x \in {\mathbb {R}}^d\).
Finally, we say that \(\Phi \) has all moments if, for all bounded Borel \(B \subset {\mathbb {R}}^d\), we have
3 Limit theorems for stationary point processes
This section is concerned with the Čech complex \(\mathcal{C}(\Phi _l ,r)\), where \(\Phi \) is a stationary point process on \({\mathbb {R}}^d\) with unit intensity and, as above, \(\Phi _l\) is the restriction of \(\Phi \) to the window \(W_l=[-l/2,l/2)^d\). The radius r is arbitrary but fixed.
It is natural to expect that, as a consequence of stationarity, letting \(l\rightarrow \infty \), \(l^{-d}{\mathbb {E}}\left\{ \beta _k(\mathcal{C}(\Phi _l ,r))\right\} \) will converge to a limit. Furthermore, if we also assume ergodicity for \(\Phi \), one expects convergence of \(l^{-d} \beta _k(\mathcal{C}(\Phi _l ,r))\) to a random limit. All this would be rather standard fare, and rather easy to prove from general limit theorems, if it were only true that Betti numbers were additive functionals on simplicial complexes, or, alternatively, the Betti numbers of Čech complexes were additive functionals of the underlying point processes. Although this is not the case, Betti numbers are ‘nearly additive’, and a correct quantification of this near additivity is what will be required for our proofs.
As hinted before Lemma 2.2, the additivity properties of Betti numbers are related to simplicial counts \(S_j ({{\mathcal {X}}},r)\), which, for \(j\ge 0\), denotes the number of j-simplices in \(\mathcal{C}({{\mathcal {X}}},r)\), and \(S_j({{\mathcal {X}}},r;A)\), which denotes the number of j-simplices with at least one vertex in A.
Our first results are therefore limit theorems for these quantities.
Lemma 3.1
Let \(\Phi \) be a unit intensity stationary point process on \({\mathbb {R}}^d,\) possessing all moments. Then, for each \(j\ge 0,\) there exists a constant \(c_j:= c({{\mathcal {L}}}_{\Phi },j,d,r)\) such that
Proof
We have the following trivial upper bound for simplicial counts:
Due to the stationarity of \(\Phi \) along with the assumption that it has all moments, we have that the measure
is translation invariant and finite on compact sets. Thus \(\mu _0(A) = c_j |A|\) for some \(c_j\in (0,\infty )\), and we are done. \(\square \)
Lemma 3.2
Let \(\Phi \) be a unit intensity, ergodic, point process on \({\mathbb {R}}^d\) possessing all moments. Then, for each \(j\ge 0,\) there exists a constant, \(\widehat{S}_j:=\widehat{S} ({{\mathcal {L}}}_{\Phi },j,d,r),\) such that, with probability one,
Proof
Define the function
Recalling that by \(\Phi -z\) we mean the points of \(\Phi \) moved by \(-z\), it is easy to check that
Since \(\Phi \) has all moments, we have that
and so are in position to apply the multivariate ergodic theorem (e.g. [25, Proposition 2.2]) to each of the sums in (3.1). This implies the existence of a constant \(\widehat{S}_j({{\mathcal {L}}}_{\Phi },r) \in [0,\infty )\) such that, with probability one,
This gives the ergodic theorem for \(S_j(\Phi _l,r)\). The result for \(S_j(\Phi ,r;W_l)\) follows from this and the bounds
\(\square \)
3.1 Strong law for Betti numbers
In this section we shall start with a convergence result for the expectation of \(\beta _k(\mathcal{C}(\Phi _l,r))\) when \(\Phi \) is a quite general stationary point process, and then proceed to a strong law. We treat these results separately, since convergence of expectations can be obtained under weaker conditions than the strong law. In addition, seeing the proof for expectations first should make the proof of strong law easier to follow.
From [42, Theorem 4.2] we know that
The following lemma strengthens this result.
Lemma 3.3
Let \(\Phi \) be a unit intensity stationary point process possessing all moments. Then, for each \(0\le k\le d-1,\) there exists a constant \(\widehat{\beta }_k:= \widehat{\beta }_k({{\mathcal {L}}}_{\Phi },r) \in [0,\infty )\) such that
Remark 3.4
The lemma is interesting only in the case when \(\widehat{\beta }_k > 0\), and this does not always hold. However, it can be guaranteed for negatively associated point processes (including Poisson processes, simple perturbed lattices and determinantal point processes) under some simple conditions on void probabilities, cf. [42, Theorem 3.3].
Proof of Lemma 3.3
Set
and define
Fix \(t > 0\). Let \(Q_{it}, i = 1,\ldots ,m^d\) be an enumeration of \(\{tz_i + W_t \subset W_{mt}:\, z_i \in {\mathbb {Z}}^d\}\). Note that the \(Q_{it}, i = 1,\ldots ,m^d\) form a partition \(W_{mt}\).
Define the complex
and note that it is a subcomplex of \(\mathcal{C}(\Phi _{mt},r)\). Since the union here is of disjoint complexes,
Note that the vertices of any simplex in \(\mathcal{C}(\Phi _{mt},r) {\setminus } {{\mathcal {K}}}(r,t)\) must lie in the set \(\bigcup _{i=1}^{m^d} (\partial Q_{it})^{(2r)}\), where for any set \(A\subset {\mathbb {R}}^d\), \(A^{(r)}\) is the set of points in \({\mathbb {R}}^d\) with distance at most r from A. Hence, by Lemma 2.2,
Thus, since for \(c:=c(d,r)\) large enough, for any \(t\ge 1\),
it follows from Lemma 3.1 that
By the stationarity of \(\Phi \), taking expectations over (3.3) and applying (3.4) we obtain that, for any \(t\ge 1\),
Now fix \(\varepsilon >0\). By (3.2), we can find an arbitrarily large \(t_0 \ge 1\) such that \(\frac{\psi (t_0)}{t_0^d} \ge \widehat{\beta }_k - \frac{\varepsilon }{2}\) and \(\frac{c}{t_0} \le \frac{\varepsilon }{2}\). Hence, from the above we have that, for all \(m \ge 1\),
Now take \(l > 0\), and let m be the unique integer \(m=m(l)\) such that \(mt_0 \le l < (m+1)t_0\). Again, applying Lemma 2.2 yields
Since \(\Vert W_l{\setminus } W_{mt_0}\Vert \le d(l-mt_0)l^{d-1}\), as before, using Lemma 3.1, it is easy to verify that
Since \(m \rightarrow \infty \) as \(l \rightarrow \infty \), it follows that \(\liminf _{l \rightarrow \infty } \frac{\psi (l)}{l^d} \ge \widehat{\beta }_k - \varepsilon .\) This and (3.2) complete the proof.\(\square \)
Theorem 3.5
Let \(\Phi \) be a unit intensity ergodic point process possessing all moments. Then, for \(0\le k\le d-1,\) and \(\widehat{\beta }_k\) as in Lemma 3.3,
Proof
As in the previous proof, fix \(t > 0\) and let \(Q_{it}, i = 1,\ldots ,m^d\) be the partition of \(W_{mt}\) to translations of \(W_t\). Further, for each real \(l>0\), let \(m=m(l,t)\) be the unique integer for which \(mt \le l < (m+1)t\).
The proof contains two steps. Firstly, we shall establish a strong law for \(\beta _k(\mathcal{C}(\Phi _{W_{mt}},r))\) in m, and then show that the error term in (3.5) vanishes asymptotically. Many of our arguments will rely on the multi-parameter ergodic theorem (e.g. [25, Proposition 2.2]).
Let \(e_i, i=1,\ldots ,d\), be the d unit vectors in \({\mathbb {R}}^d\), and \(T_i=T_i(t)\) the measure preserving transformation defined by a shift of \(te_i\). Then, setting \(Y = \beta _k(\mathcal{C}(\Phi _{W_t},r))\), and noting that \({\mathbb {E}}\left\{ Y\right\} \le {\mathbb {E}}\left\{ \Phi (W_t)^{k+1}\right\} < \infty \), it follows immediately from the multi-parameter ergodic theorem that
as \(m\rightarrow \infty \).
Applying the multiparameter ergodic theorem again, but now with
we obtain
where \(\widehat{S}_t \le ct^{d-1}\). This bound follows by applying Lemma 3.1 to obtain
for some \(c:= c({{\mathcal {L}}}_{\Phi },j,d,r)\).
Note that, for \(j=k,k+1\),
It follows immediately from (3.6)–(3.9) that, with probability one,
Now, given \(\varepsilon > 0\), by Lemma 3.3, we can choose \(t_0\) large enough so that, with probability one,
Now consider the error terms in (3.5). For \(j = k,k+1\), we have that
By Lemma 3.2, we know that there exist \(\widehat{S}_j(\Phi ,r) \in [0,\infty )\), \(j = k,k+1\), such that, with probability one,
Hence, with probability one,
Substituting this in (3.5) gives that, with probability one,
so that
and the proof is complete. \(\square \)
The following concentration inequality is an easy consequence of the general concentration inequality of [30].
Theorem 3.6
Let \(\Phi \) be a unit intensity stationary determinantal point process. Then for all \(l \ge 1,\) \(\varepsilon > 0,\) and \(a \in (\frac{1}{2},1],\) we have that
where \(K_d\) is the maximum number of disjoint unit balls that can be packed into \(B_O(2)\).
Proof
Firstly, note that \(\beta _0\), viewed as a function on finite point sets is \(K_d\)-Lipschitz; viz. for any finite point set \({{\mathcal {X}}}\subset {\mathbb {R}}^d\) and \(x \in {\mathbb {R}}^d\),
This follows from the fact that, on the one hand, adding a point x to \({{\mathcal {X}}}\) can add no more than one connected component to \(\mathcal{C}({{\mathcal {X}}},r)\). On the other hand, the largest decrease in the number of disjoint components in \(\mathcal{C}({{\mathcal {X}}},r)\) is bounded by the number of disjoint r-balls in \(B_x(2r)\). By scale invariance, the latter number depends only on the dimension d and not on r, and is denoted by \(K_d\).
The remainder of the proof is a simple application of [30, Theorem 3.5] (see also [30, Example 6.4]). \(\square \)
4 Poisson and binomial point processes
Since there is already an extensive literature on \(\beta _0(\mathcal{C}({{\mathcal {X}}},r))\) for Poisson and binomial point processes, albeit in the language of connectedness of random graphs (e.g. [31]), in this section we shall restrict ourselves only to \(\beta _k\) for \( 1\le k\le d-1\).
The models we shall treat start with a Lebesgue-almost everywhere continuous probability density f on \({\mathbb {R}}^d\), with a compact, convex support that (for notational convenience) includes the origin, and such that
The models are \({\mathcal {P}}_n\), the Poisson point process on \({\mathbb {R}}^d\) with intensity nf, and the binomial point process \({{\mathcal {X}}}_n=\{X_1,\ldots ,X_n\}\), where the \(X_i\) are i.i.d. random vectors with density f. From [19], we know that for both \({\mathcal {P}}_n\) and \({{\mathcal {X}}}_n\) the thermodynamic regime corresponds to the case \(nr_n^d \rightarrow r \in (0,\infty )\), so that for such a radius regime we have that
In proving limit results for Betti numbers in these cases, much will depend on moment estimates for the add-one cost function. The add-one cost function for a real-valued functional F defined over finite point sets \({{\mathcal {X}}}\) is defined by
Our basic estimate follows. For notational convenience, we write
where \(\{r_n\}_{n \ge 1}\) is a sequence of radii to be determined.
Lemma 4.1
Let \(1\le k \le d-1\). For the Poisson point process \({\mathcal {P}}_n\) and binomial point process \({{\mathcal {X}}}_n,\) with \(nr_n^d \rightarrow r \in (0,\infty ),\) we have that
is finite.
Proof
The lemma is a consequence of the following simple bounds from Lemma 2.2.
and, similarly,
Set \(r_*= \sup _{n \ge 1}\omega _dnr_n^d < \infty \), where \(\omega _d\) is the volume of a d-dimensional unit ball. Let \(\mathrm{Poi}(\lambda )\) and \(\mathrm{Bin}(n,p)\) denote the Poisson random variable with mean \(\lambda \) and the binomial random variable with parameters n, p respectively. Then, we obtain that
The lemma now follows from the boundedness of moments of Poisson and binomial random variables with constant means. \(\square \)
4.1 Strong laws
We begin with a lemma giving variance inequalities, which, en passant, establish weak laws for Betti numbers.
Lemma 4.2
For the Poisson point process \({\mathcal {P}}_n\) and binomial point process \({{\mathcal {X}}}_n,\) with \(nr_n^d \rightarrow r \in (0,\infty ),\) and each \(1\le k \le d-1,\) there exists a positive constant \(c_1\) such that for all \(n \ge 1,\)
Thus, as \(n \rightarrow \infty ,\)
and
Proof
Note firstly that the two weak laws (4.5) follow immediately from the upper bounds in (4.4) and Chebyshev’s inequality.
Thus it remains to prove (4.4). The Poisson case is the easiest, since by Poincaré’s inequality (e.g. [22, equation (1.8)]), the Cauchy-Schwartz inequality and Lemma 4.1,
where \(\Delta _k<\infty \) is given by (4.3).
For the binomial case, we need the Efron–Stein inequality (cf. [13] and for the case of random vectors [38, (2.1)]), which states that for a symmetric function \(F:\, ({\mathbb {R}}^d)^n \rightarrow {\mathbb {R}}\),
where \({{\mathcal {X}}}_n\) and \({{\mathcal {X}}}_{n+1}\) are coupled so that \({{\mathcal {X}}}_{n+1} = {{\mathcal {X}}}_{n}\cup \{X_{n+1}\}\). Applying this inequality, we have
where in the second inequality we have used Lemma 4.1. This completes the proof.
\(\square \)
Thanks to the recent bound of [23, Theorem 5.2] (see Lemma 5.1), we can also give a lower bound for the Poisson point process in the case of \(k = d-1\).
Lemma 4.3
For the Poisson point process \({\mathcal {P}}_n\) with \(nr_n^d \rightarrow r \in (0,\infty ),\) let \(n_0\) be such that there is a set \(A \subset \mathrm{{supp}}(f)\) with \(A \oplus B_O(3r_n) \subset \mathrm{{supp}}(f)\) and \(|A| > 0\) for all \(n \ge n_0\). Then, there exists a positive constant \(c_2\) such that, for all \(n \ge n_0\) as above,
Remark 4.4
Note that from the universal coefficient theorem [26, Theorem 45.8] and Alexander duality [37, Theorem 16], we have thatFootnote 1
Thus
\(\beta _0({\mathbb {R}}^d {\setminus } \mathcal{C}_B({\mathcal {P}}_n,r))\) is nothing but the number of components of the vacant region of the Boolean model, which is easier to analyse and this will play a crucial role in our proof.
Proof
The proof will be based on Lemma 5.1 and the duality argument of Remark 4.4. The finiteness of moments required by this lemma is guaranteed by Lemma 4.1. Choose \(n \ge n_0\) for \(n_0\) as defined in the statement of the lemma and also the set A guaranteed by this assumption. Let \(x \in A\). So we now have to show that, for each \(1 \le k\le d-1\), there exists an m (depending on k and d only) and a finite set of points \(\{z_1,\ldots ,z_m\} \in B_O(2r_n)\) such that for some constants \(c, c_* \in (0,1)\) and for all \((y_1,\ldots ,y_m) \in \prod _{i=1}^mB_{x+z_i}(c_*r_n)\),
and
with probability one. Though not explicitly mentioned, it is to be understood that the above choices of \(m,z_i,c,c_*\) are not dependent on \(x \in A\). The above two inequalities imply that
so that condition (5.1) required in Lemma 5.1 is satisfied for the add-one cost function with the constant c above, and the lower bound to the variance given there holds. Though, in this proof we require the construction only for \(k = d-1\), we have stated one of the inequalities for all k as this will be important to the variance lower bound argument in Theorem 4.7.
Moreover, it is easy to check that, given our choice of \(\{z_1,\ldots ,z_m\}\) and \(c_*r_n\) (in place of r in Lemma 5.1), the bound in (5.2) can be further bounded from below by \(c_2 n\) for some \(c_2>0\) (depending only on f, A, k, r and d). This will prove the lemma.
Thus, all that remains is to find an m and construct \(z_1,\ldots ,z_m\) satisfying the above conditions.
Fix \(k \in \{1,\ldots ,d-1\}\). Let \(S^k\) denote the unit k-dimensional sphere, and embed it via the usual inclusion in the unit sphere in \({\mathbb {R}}^d\). For \(\varepsilon < \frac{1}{4}\) let \(S_\varepsilon ^k=\{x\in {\mathbb {R}}^d:\, \min _{y\in S^k} \Vert x-y\Vert \le \varepsilon \}\) denote the \(\varepsilon \)-thickening of \(S^k\).
Now choose m large enough (but depending only on k and d only) such that there exist points \(v_1,\ldots ,v_{m}\) in \({\mathbb {R}}^d\) so that
and, for all \(0\le j\le d-1\),
(Recall that \( \beta _j(S^k)=0\) for \(j\ne 0,k\), while \(\beta _0(S^k) = \beta _k(S^k) =1\).)
Now, if needed choose m larger such that there is a \(c_* > 0\) for which all \((y_1,\ldots ,y_m) \in \prod _{i=1}^mB_{c_*}(v_i)\) satisfy (4.9) and (4.10). Note that by scaling we have, for all \(\{y_1,\ldots ,y_m\} \in \prod _{i=1}^mB_{r_nv_i}(c_*r_n) \),
while \(\beta _k(\mathcal{C}(\{y_1,\ldots ,y_m\},r_n)) = 1\).
Setting \(z_i = r_nv_i\) for \(i = 1,\ldots , m\), we have that \(z_i \in B_O(2r_n)\) as required as well as \(c_*\) chosen as above ensures the size requirements we need. So, what remains is to show that (4.7) and (4.8) hold for \(\{y_1,\ldots ,y_m\}\in B_{n,m} := \prod _{i=1}^mB_{x+z_i}(c_*r_n)\).
On the other hand, the structure of \(B_{n,m}\) implies that, for \(\{y_1,\ldots ,y_m\}\in B_{n,m}\),
Furthermore, it is immediate from Poisson void probabilities that
where \(r_*:= \sup _{n \ge 1}n\omega _dr_n^d\). These two facts together imply that (4.7) holds with \(c = e^{-r_*f^*} > 0\).
We now turn to the second of these inequalities (which is only for \(k = d-1\)), for which we need the nerve theorem [2, Theorem 10.7] along with duality argument (Remark 4.4). The nerve theorem allows us to prove the inequality for \(\beta _{d-1}(\mathcal{C}_B({\mathcal {P}}_n,r_n))\) instead of \(\beta _{d-1}({{\mathcal {C}}}({\mathcal {P}}_n,r_n))\), and the duality argument further reduces our task to proving
with probability one.
Set \(V_n := {\mathbb {R}}^d {\setminus } \mathcal{C}_B({\mathcal {P}}_n \cup \{y_1,\ldots ,y_m\},r_n)\). Since \(x \oplus r_nS_{r_n\varepsilon }^{d-1} \subset \bigcup _{i =1}^{m}B_{y_i}(r_n)\), we have that \(V_n\) is the disjoint union of \(V_n \cap B_x(r_n)\) and \(V_n \cap B_x(r_n)^c\). Thus,
So,
where in the second equality, we have used the fact
This proves (4.11) and hence we have (4.8), which was all that was required to complete the proof. \(\square \)
Our next main result is a concentration inequality for \(\beta _k (\mathcal{C}({{\mathcal {X}}}_n,r_n)\).
Theorem 4.5
Let \(1\le k \le d-1,\) \({{\mathcal {X}}}_n\) be a binomial point process, and assume that \(nr_n^d \rightarrow r\in (0,\infty )\). Then, for any \(a > \frac{1}{2}\) and \(\varepsilon > 0,\) for n large enough,
where \(\gamma = {(2a-1)}/{4k}\) and \({C} > 0\) is a constant depending only on a, r, k, d and the density f.
The proof, close to that of [31, Theorem 3.17], is based on a concentration inequality for martingale differences.
Proof
Fix \(n \in {\mathbb {N}}\). Let \(Q_{n,i}\) be a partition of \({\mathbb {R}}^d\) into cubes of side length \(r_n\). Define the set \({\mathbb {A}}_n\) as follows:
For large enough n, since \({{\mathcal {X}}}_n(Q_{n,i})\) is stochastically dominated by a \(\mathrm{Bin}(n,f^*r_n^d)\) random variable, elementary bounds (e.g. [31, Lemma 1.1]), yield that
for some constant \({c_1}\). Since the above bound is dependent only on the mean of the binomial random variable and r, the constants d and r are suppressed. Recall that the points of \({{\mathcal {X}}}_n\) are denoted by \(X_1,\dots ,X_n\), and let \({{\mathcal {F}}}_i = \sigma (X_1,\ldots ,X_i)\) be the sequence of \(\sigma \)-fields they generate, with \({{\mathcal {F}}}_0\) denoting the trivial \(\sigma \)-field. (The actual ordering of the \(X_j\) will not be important.) We can define the finite martingale
for \(0=1,\dots ,n\), along with the corresponding martingale differences
\(i=1,\dots ,n\), and \(D^{(n)}_0 =0\). Writing
and setting \({{\mathcal {X}}}^{i}_n = {{\mathcal {X}}}_{n+1}{\setminus } \{X_i\}\), we have that \(D_{i}^{(n)}\) can be represented as
Let \(A_{i,n}:= \{ {{\mathcal {X}}}_n \in {\mathbb {A}}_n , {{\mathcal {X}}}^i_n \in {\mathbb {A}}_n \}\). Then, recalling that \(S_j({{\mathcal {X}}},r;A)\) denotes the number of j-simplices with at least one vertex in A, and appealing again to Lemma 2.2, we have that, conditioned on the event \(A_{i,n}\), for n large enough,
In all cases, we have the universal bound \(|\beta _k(\mathcal{C}({{\mathcal {X}}}_n,r_n)) - \beta _k(\mathcal{C}({{\mathcal {X}}}^i_n,r_n))| \le n^k\), and so,
Defining \(B_{i,n}:= \{ {\mathbb {P}}\{A^c_{i,n}\mid {{\mathcal {F}}}_i\} \le n^{-k} \}\), Markov’s inequality implies
Thus, since \(|D_{i}^{(n)}|\mathbf {1}_{B_{i,n}} \le {c}_3(rn^{\gamma })^k\), using [8, Lemma 1], we have that for any \(b_1,b_2 > 0\),
Choosing \(b_1 = \varepsilon n^a\) and \(b_2 = {c}_3(rn^{\gamma })^k\), we have
for large enough n and a constant \({c} > 0\) which depends only on a, r, k, d. The last inequality above follows from the fact that \(\gamma < a - \frac{1}{2}\) and hence, for large enough n, \(\exp (-n^{\gamma })\) is the dominating term in the penultimate expression. \(\square \)
We now finally have the ingredients needed to lift the weak laws of Lemma 4.2 to the promised strong convergence.
Theorem 4.6
For the Poisson point process \({\mathcal {P}}_n\) and binomial point process \({{\mathcal {X}}}_n,\) with \(nr_n^d \rightarrow r \in (0,\infty ),\) and each \(1\le k \le d-1,\) we have, with probability one,
and
Proof
By choosing \(a = 1\) in Theorem 4.5 and summing over n, we have, for all \(\varepsilon > 0\),
The Borel–Cantelli lemma immediately implies the strong law for \(\beta _k(\mathcal{C}({{\mathcal {X}}}_n,r_n))\).
Turning to the Poisson case, we shall use the standard coupling of \({\mathcal {P}}_n\) to \({{\mathcal {X}}}_n\) to complete the proof of the theorem. Let \(N_n\) be a Poisson random variable with mean n. Then, by choosing \({\mathcal {P}}_n = \{X_1,\ldots ,X_{N_n}\}\), we have coupled it with \({{\mathcal {X}}}_n = \{X_1,\ldots ,X_n\}\), \(n\ge 1\). By Lemma 2.2, we have that
Now note that,
with a similar inequality holding for \(S_{k+1}()\). From [32, Theorem 2.2] and the remarks following that result, we have that there exists a constant \(\widehat{S}_k(f) \in (0,\infty )\) such that, with probability one,
A similar limit law holds true for \(S_{k+1}\), and so we have that, with probability one,
Thus,
and the strong law for \(\beta _k(\mathcal{C}({\mathcal {P}}_n,r_n)\) follows. \(\square \)
4.2 Central limit theorem
We have finally come to main result of this section: central limit theorems for Betti numbers.
We start with some definitions from percolation theory for the Boolean model on Poisson processes [25] needed for the proof of the Poisson central limit theorem. Recall firstly that we say that a subset A of \({\mathbb {R}}^d\) percolates if it contains an unbounded connected component of A.
Now let \({\mathcal {P}}\) be a stationary Poisson point process on \({\mathbb {R}}^d\) with unit intensity. (Unit intensity is for notational convenience only. The arguments of this section will work for any constant intensity.) We define the critical (percolation) radii for \({\mathcal {P}}\) as follows:
and,
By Kolmogorov’s zero-one law, it is easy to see that the both of the probabilities inside the infimum and supremum here are either 0 or 1. The first critical radius is called the critical radius for percolation of the occupied component and the second is the critical radius for percolation of the vacant component.
We define the interval of co-existence, \(I_d({\mathcal {P}})\), for which unbounded components of both the Boolean model and its complement co-exist, as follows:
From [25, Theorem 4.4 and Theorem 4.5], we know that \(I_2({\mathcal {P}})= \emptyset \) and from [34, Theorem 1] we know that \(I_d({\mathcal {P}}) \ne \emptyset \) for \(d \ge 3\). In high dimensions, it is known that \(r_c \notin I_d({\mathcal {P}})\) (cf. [41]).
We now need a little additional notation. Let \(\{B_n\}_{n \ge 1}\) be a sequence of bounded Borel subsets in \({\mathbb {R}}^d\) satisfying the following four conditions:
-
(A)
\(|B_n| = {n}\), for all \(n \ge 1\).
-
(B)
\(\bigcup _{n \ge 1}\bigcap _{m \ge n} B_m = {\mathbb {R}}^d\).
-
(C)
\( {|(\partial B_n)^{(r)}|}/{n} \rightarrow 0\), for all \(r > 0\).
-
(D)
There exists a constant \(b_1\) such that diam\((B_n) \le b_1n^{b_1}\), where diam(B) is the diameter of B.
In a moment we shall state and prove a central limit theorem for the sequences of the form \(\beta _k(\mathcal{C}({\mathcal {P}}\cap B_n,r))\), when the \(B_n\) are as above. Setting up the central limit theorem for the binomial case requires a little more notation.
In particular, we write \({{\mathcal {U}}}_n\) to denote the point process obtained by choosing n points uniformly in \(B_n\), and call this the extended binomial point process. This is a natural binomial counterpart to the Poisson point process \({\mathcal {P}}\cap B_n\).
We finally have all that we need to formulate the main central limit theorem.
Theorem 4.7
Let \(\{B_n\}\) be a sequence of sets in \({\mathbb {R}}^d\) satisfying conditions (A)–(D) above, and let \({\mathcal {P}}\) and \({{\mathcal {U}}}_n, \ n \ge 1,\) respectively, be the unit intensity Poisson process and the extended binomial point process described above. Take \(k \in \{1,\ldots ,d-1\}\) and \(r \in (0,\infty )\). Then there exists a constant \(\sigma ^2 > 0\) such that, as \(n \rightarrow \infty ,\)
and
Furthermore, for \(r \notin I_d({\mathcal {P}}),\) there exists a \(\tau ^2\) with \(0 < \tau ^2 \le \sigma ^2\) such that
and
The constants \(\sigma ^2\) and \(\tau ^2\) are independent of the sequence \(\{B_n\}\).
Remark 4.8
The condition \(r \notin I_d({\mathcal {P}})\), needed for the binomial central limit theorem, is rather irritating, and we are not sure if it is necessary or an artefact of the proof. It is definitely not needed for the case \(k=d-1\). To see this, note that from the duality argument of Remark 4.4, we have that
However, \({\mathbb {R}}^d {\setminus } \mathcal{C}({\mathcal {P}}\cap B_n,r)\) is nothing but the vacant component of the Boolean model, and central limit theorems for \(\beta _0({\mathbb {R}}^d {\setminus } \mathcal{C}({{\mathcal {X}}}\cap B_n,r))\) for both Poisson and binomial point processes are given in [33, p 1040] for all \(r \in (0,\infty )\). By the above duality arguments, this proves both the central limit theorems of Theorem 4.7, when \(k=d-1\), and without the requirement that \(r \notin I_d({\mathcal {P}})\).
Proof
Since the theorem is somewhat of an omnibus collection of results, the proof is rather long. Thus we shall break it up into signposted segments.
I. Poisson central limit theorem: Since \(\beta _k(\mathcal{C}(\,\cdot \, ,r))\) is a translation invariant functional over finite subsets of \({\mathbb {R}}^d\), we need only check that Conditions 3 and 4 in Theorem 5.2, along with the weak stabilization of (5.4), hold in order to prove the convergence of variances and the asymptotic normality in the Poisson case. The strict positivity of \(\sigma ^2\) will follow from that of \(\tau ^2\), to be proven below.
We treat each of the three necessary conditions separately.
(i) Weak stabilization: Firstly, we shall show that there exist a.s. finite random variables \(D_{\beta _k}(\infty ),\) and R such that, for all \(\rho > R\),
where \(\beta _k^r({{\mathcal {X}}})\mathop {=}\limits ^{\Delta }\beta _k(\mathcal{C}({{\mathcal {X}}},r))\) for any finite point-set \({{\mathcal {X}}}\). Then, we shall complete the proof of weak stabilization by showing the above for any \({\mathfrak {B}}\)-valued sequence of sets \(A_n\) tending to \({\mathbb {R}}^d\). (See the paragraphs preceding Theorem 5.2 for the definition of \({\mathfrak {B}}\).)
For any \(\rho >2r\), define the simplicial complexes
and note that \({{\mathcal {K}}}_{\rho }={{\mathcal {K}}}_{\rho }'\cup {{\mathcal {K}}}''\) and that, as implied by the notation, \({{\mathcal {L}}}\) and \({{\mathcal {K}}}''\) do not depend on \(\rho \).
From the second part of Lemma 2.3, we have that
where \(N_k^{\rho }\) is the kernel of the induced homomorphism
Hence, all that remains is to show that \(\beta (N_j^{\rho })\), \(j=k,k-1\), remain unchanged as \(\rho \) increases beyond some random variable R. Since these variables are integer valued, it suffices to show that they are increasing and bounded to prove (4.12). We shall do this for \(\beta (N_k^{\rho })\). The same proof also works for \(\beta (N_{k-1}^{\rho })\).
The boundedness is immediate, since
All that remains to show is that \(\beta (N_k^{\rho })\) is increasing. Let \(\rho _1,\rho _2\) be such that \(2r < \rho _1 \le \rho _2\). We need to show that \(\beta (N_k^{\rho _1}) \le \beta (N_k^{\rho _2})\).
Since \({{\mathcal {L}}}\subset {{\mathcal {K}}}_{\rho _1} \subset {{\mathcal {K}}}_{\rho _2}\), we have the corresponding simplicial maps defined by the respective inclusions (see Sect. 2.1) and hence the following homomorphisms:
Also, by the functoriality of homology, \(\lambda _k^{\rho _2} = \eta \circ \lambda _k^{\rho _1}\). Since \(\mathrm{ker}\, \eta \subset \mathrm{ker}\, \eta ' \circ \eta \) for any two homomorphisms \(\eta ,\eta '\), we have that
This proves that \(\beta (N_k^{\rho })\) is increasing in \(\rho \), as, similarly, is \(\beta (N_{k-1}^{\rho })\). Combining the convergence of \(\beta (N_j^{\rho })\), \(j=k,k-1\), with (4.13) gives (4.12).
Now, let \(A_n\) be a \({\mathfrak {B}}\)-valued sequence of sets tending to \({\mathbb {R}}^d\). To complete the proof of weak stabilization, we need to show that there exists an integer valued random variable N such that for all \(n > N\),
where, as before, \(\beta _k^r({{\mathcal {X}}})\mathop {=}\limits ^{\Delta }\beta _k(\mathcal{C}({{\mathcal {X}}},r))\) for any finite point-set \({{\mathcal {X}}}\). Firstly, choose R as in (4.12) and WLOG assume \(R>2r\). In particular, this implies that \(\beta (N_j^{\rho })\) remains constant for \(\rho > R\) for \(j = k-1,k\). Since \({\mathcal {P}}\cap B_O(R + 1)\) is a.s. finite and \(\bigcup _{n \ge 1}\bigcap _{m \ge n}A_m = {\mathbb {R}}^d\), there exists an a.s. finite random variable \(N^*\) such that
Hence, \(\{0\} \cup {\mathcal {P}}\cap B_O(R + 1) \subset A_n\) for all \(n > N^*\). Let \(n > N^*\), and note that since \(A_n\in {\mathfrak {B}}\), diam\((A_n)<\infty \) and so we can choose \(R_n<\infty \) such that \(A_n \subset B_O(R_n)\). Define the simplicial complexes
where, again, \({{\mathcal {L}}}\) and \({{\mathcal {K}}}''\) do not depend of n. Now applying the second part of Lemma 2.3, since \({{\mathcal {K}}}_n = {{\mathcal {K}}}_n' \cup {{\mathcal {K}}}''\),we have that
where \(M_j^{n},j=k,k-1\), is the kernel of the induced homomorphism
Again, to prove (4.15), all we need to show is that \(\beta (M_j^n)\), \(j=k,k-1\), remain constant for any \(n > N^*\).
To see this, start by noting that, by the choice of \(n,R,R_n\), we have the following inclusions:
Hence the corresponding simplicial maps give rise to the following induced homomorphisms:
Note that \(\gamma _k^n = \eta _2 \circ \eta _1\). Also, from the choice of \(R, {{\mathcal {K}}}\) and \({{\mathcal {K}}}_n^*\), we have that
where \(N_k^\rho \) for any \(\rho \ge 2r\) was defined after (4.13). Now, by an argument similar to that used to obtain (4.14), we have the following inequality:
Thus, we have that \(\beta (M_k^n) = \beta (N_k^{R+1})\) for \(n > N^*\) with a corresponding result holding for \(\beta (M_{k-1}^n)\). Using this in (4.16) proves (4.15), and so we have shown that \(\beta _k(\mathcal{C}({\mathcal {P}},r))\) is weakly stabilizing on \({\mathcal {P}}\) for all \(r \ge 0\).
(ii) Uniformly bounded moments: Via a calculation similar to that in Lemma 4.1, we obtain that, for \(m \in [{|A|}/{2},{3|A|}/{2}]\),
where the inequalities here are to be read as ‘bounded by a random variable with distribution’. Thus, the uniformly bounded fourth moments for the rightmost binomial random variable implies uniformly bounded fourth moments for the add-one cost function.
(iii) Polynomial boundedness: This follows easily from the relation
From Theorem 5.2 and the remarks below it, the above three items suffice to prove the central limit theorem for the Poisson point processes.
II. Binomial central limit theorem: Given the bounds proven in the previous part of the proof, all that remains to complete the central limit theorem for the binomial case is to prove the strong stabilization of \(D_O\beta _k\) for \(r \notin I_d\).
What we need to show is that there exist a.s. finite random variables \(\widehat{D}_{\beta _k}(\infty ),S\) such that for all finite \({{\mathcal {X}}}\subset B_O(S)^c\),
We shall handle the two case of \(r < r_c\) and \(r > r_c^*\) separately.
Assume that \(r < r_c\), or \(r \le r_c\) if \(r_c \notin I_d\). In this case, since \(\mathcal{C}_B({\mathcal {P}},r)\) does not percolate, there are only finitely many components of \(\mathcal{C}_B({\mathcal {P}},r)\) that intersect \(B_O(r)\) and all of them are a.s. bounded. Let \(C_1,\ldots , C_M\) be an enumeration of the components for some a.s. finite \(M>0\). (We exclude the trivial but possible case of \(M = 0\).) Further, \(C_1,\ldots , C_M\) are a.s. bounded subsets and so \(C = \bigcup _{i=1}^MC_i\) is also a.s. bounded. Thus, in this case we can choose an a.s. finite S such that \(d(x,C) > 3r\) for all \(x \notin B_O(S)\). This implies that for any locally finite \({{\mathcal {X}}}\subset B_O(S)^c\) we have \(C \cap \mathcal{C}_B({{\mathcal {X}}},r) = \emptyset \). Thus, for any finite \({{\mathcal {X}}}\subset [B_O(S)]^c\),
i.e. \(\beta _k\) strongly stabilizes with stabilization radius S and
Now assume that \(r > r_c^*\). Since \({\mathbb {R}}^d {\setminus } \mathcal{C}_B({\mathcal {P}},r)\) has only finitely many components that intersect \(B_O(r)\), duality arguments, as in Remark 4.8, establish strong stabilization for \(\beta _k({\mathcal {P}},r)\).
Consequently, (4.17) and duality establishes strong stabilization of \(\beta _k({{\mathcal {C}}}({\mathbb {P}},r))\) for \(r \notin I_d\), and this completes the proof of the central limit theorem for \(\beta _k(\mathcal{C}({{\mathcal {U}}}_n,r))\).
III. Positivity of \(\tau ^2\): All that remains is to show the strict positivity of \(\tau ^2\). By Theorem 5.2, it suffices to show that \(D_{\beta _k}(\infty )\) is non-degenerate and this we shall do by using similar arguments to those we used to obtain (4.7) and (4.8).
Write \({\mathcal {P}}_n\) for \({\mathcal {P}}\cap B_O(n)\). We showed in (4.12) that \(|(D_O\beta _k)({\mathcal {P}}_n)| \mathop {\rightarrow }\limits ^{a.s. }|D_{\beta _k}(\infty )|\), and we have from Lemma 2.2 that, for n large enough,
Since \({\mathbb {E}}\left\{ {\mathcal {P}}(B_O(2r))^{k+1}\right\} < \infty \), we can use the dominated convergence theorem to obtain that \({\mathbb {E}}\left\{ |(D_O\beta _k)({\mathcal {P}}_n)|\right\} \rightarrow {\mathbb {E}}\left\{ |D_{\beta _k}(\infty )|\right\} \) as \(n \rightarrow \infty \).
Choose m (depending on k, d only) as in the proof of variance lower bound in Lemma 4.2 (see (4.9) and (4.10)) and define the set \(B^*_m\) as there. Setting \(B^*_{r,m}= rB^*_m\), we have that \(|B^*_{m,r}| = |B^*_m|r^{md} > 0\). Thus, for all \(n \ge 5r\),
Thus,
This shows that \({\mathbb {P}}\left\{ D_{\beta _k}(\infty ) \ne 0 \right\} > 0\). Thus, to complete the proof of non-degeneracy of \(D_{\beta _k}(\infty )\), it suffices show that \({\mathbb {P}}\left\{ D_O\beta _{\infty } = 0 \right\} > 0\).
\(\square \)
Notes
The \(\tilde{H}_k\) are the reduced homology groups and it suffices to note that \(\tilde{H}_k \cong H_k\) for \(k \ne 0\) and \(H_0 \cong \tilde{H}_0 \oplus {\mathbb {F}}\).
References
Akcoglu, M.A., Krengel, U.: Ergodic theorems for superadditive processes. J. Reine Angew. Math. 323, 53–67 (1981)
Björner, A.: Topological methods. In: Graham, R., Grötschel, M., Lovász, L. (eds.) Handbook of Combinatorics, vol. 2, pp. 1819–1872. Elsevier, Amsterdam (1995)
Bobrowski, O., Adler, R.J.: Distance functions, critical points, and the topology of random Čech complexes. Homol. Homotopy Appl. 16(2), 311–344 (2014)
Bobrowski, O., Kahle, M.: Topology of random geometric complexes: a survey (2014). arXiv:1409.4734
Bobrowski, O., Mukherjee, S.: The topology of probability distributions on manifolds. Probab. Theory Relat. Fields 161(3–4), 651–686 (2015)
Carlsson, G.: Topology and data. Bull. Am. Math. Soc. (N.S.) 46(2), 255–308 (2009)
Carlsson, G.: Topological pattern recognition for point cloud data. Acta Numer. 23, 289–368 (2014)
Chalker, T.K., Godbole, A.P., Hitczenko, P., Radcliff, J., Ruehr, O.G.: On the size of a random sphere of influence graph. Adv. Appl. Probab. 31(3), 596–609 (1999)
Costa, A.E., Farber, M., Kappeler, T.: Topics of stochastic algebraic topology. In: Proceedings of the Workshop on Geometric and Topological Methods in Computer Science (GETCO). Electronic Notes in Theoretical Computer Science, vol. 283(0), pp. 53–70 (2012)
Decreusefond, L., Ferraz, E., Randriam, H., Vergne, A.: Simplicial homology of random configurations. Adv. Appl. Probab. 46, 1–20 (2014)
Delfinado, C.J.A., Edelsbrunner, H.: An incremental algorithm for Betti numbers of simplicial complexes. In: Proceedings of the Ninth Annual Symposium on Computational Geometry, SCG ’93, New York, NY, USA, pp. 232–239. ACM (1993)
Edelsbrunner, H., Harer, J.L.: Computational Topology, An Introduction. American Mathematical Society, Providence (2010)
Efron, B., Stein, C.: The jackknife estimate of variance. Ann. Stat. 9(3), 586–596 (1981)
Forman, R.: A user’s guide to discrete Morse theory. Sém. Lothar. Comb. 48, (2002)
Ghrist, R.: Barcodes: the persistent topology of data. Bull. Am. Math. Soc. (N.S.) 45(1), 61–75 (2008)
Hall, P.: Introduction to the theory of coverage processes. In: Wiley Series in Probability and Mathematical Statistics: Probability and Mathematical Statistics. Wiley, New York (1988)
Hatcher, A.: Algebraic Topology. Cambridge University Press, Cambridge (2002)
Hug, D., Last, G., Schulte, M.: Second order properties and central limit theorems for geometric functionals of Boolean models. Ann. Appl. Probab. (2013) (to appear). arXiv:1308.6519
Kahle, M.: Random geometric complexes. Discret. Comput. Geom. 45(3), 553–573 (2011)
Kahle, M.: Topology of random simplicial complexes: a survey. In: Tillmann, U., Galatius, S., Sinha, D. (eds.) Algebraic Topology: Applications and New Directions. Contemporary Mathematics, vol. 620, pp. 201–221. American Mathematical Society, Providence (2014)
Kahle, M., Meckes, E.: Limit theorems for Betti numbers of random simplicial complexes. Homol. Homotopy Appl. 15(1), 343–374 (2013)
Last, G., Penrose, M.D.: Poisson process Fock space representation, chaos expansion and covariance inequalities. Probab. Theory Relat. Fields 150(3–4), 663–690 (2011)
Last, G., Peccatti, G., Schulte, M.: Normal approximation on Poisson spaces: Mehler’s formula, second order Poincaré inequality and stabilization. Probab. Theory Relat. Fields 1–57 (2015). doi:10.1007/s00440-015-0643-7
Linial, N., Meshulam, R.: Homological connectivity of random 2-complexes. Combinatorica 26(4), 475–487 (2006)
Meester, R., Roy, R.: Continuum Percolation. Cambridge University Press, Cambridge (1996)
Munkres, J.R.: Elements of Algebraic Topology. Addison-Wesley, Reading (1984)
Niyogi, P., Smale, S., Weinberger, S.: Finding the homology of submanifolds with high confidence from random samples. Discret. Comput. Geom. 39(1–3), 419–441 (2008)
Niyogi, P., Smale, S., Weinberger, S.: A topological view of unsupervised learning from noisy data. SIAM J. Comput. 40(3), 646–663 (2011)
Nourdin, I., Peccati, G.: Normal approximations with Malliavin calculus. In: Cambridge Tracts in Mathematics, vol. 192. Cambridge University Press, Cambridge (2012). From Stein’s method to universality
Pemantle, R., Peres, Y.: Concentration of Lipschitz functionals of determinantal and other strong Rayleigh measures. Combin. Probab. Comput. 23, 140–160 (2013)
Penrose, M.D.: Random Geometric Graphs. Oxford University Press, New York (2003)
Penrose, M.D.: Laws of large numbers in stochastic geometry with statistical applications. Bernoulli 13(4), 1124–1150 (2007)
Penrose, M.D., Yukich, J.E.: Central limit theorems for some graphs in computational geometry. Ann. Appl. Probab. 11(4), 1005–1041 (2001)
Sarkar, A.: Co-existence of the occupied and vacant phase in Boolean models in three or more dimensions. Adv. Appl. Probab. 29(4), 878–889 (1997)
Schneider, R., Weil, W.: Stochastic and integral geometry. In: Probability and its Applications (New York). Springer, Berlin (2008)
Schulte, M.: Malliavin–Stein method in stochastic geometry. Ph.D. thesis (2013). http://repositorium.uni-osnabrueck.de/handle/urn:nbn:de:gbv:700-2013031910717
Spanier, E.H.: Algebraic Topology. McGraw-Hill Book Co., New York (1966)
Steele, J.M.: An Efron-Stein inequality for nonsymmetric statistics. Ann. Stat. 14(2), 753–758 (1986)
Steele, J.M.: Probability theory and combinatorial optimization. In: CBMS-NSF Regional Conference Series in Applied Mathematics, vol. 69. SIAM, Philadelphia (1997)
Stoyan, D., Kendall, W., Mecke, J.: Stochastic Geometry and its Applications. Wiley, Chichester (1995)
Tanemura, H.: Critical behavior for a continuum percolation model. In: Probability Theory and Mathematical Statistics (Tokyo, 1995), pp. 485–495. World Scientific Publishing, River Edge (1996)
Yogeshwaran, D., Adler, R.J.: On the topology of random complexes built over stationary point processes. Ann. Appl. Probab. 25(6), 3338–3380 (2015)
Yukich, J.E.: Probability theory of classical Euclidean optimization problems. Lecture Notes in Mathematics, vol. 1675. Springer, Berlin, Heidelberg (1998)
Zomorodian, A.: Topological data analysis. In: Advances in Applied and Computational Topology. Proceedings of Symposia in Applied Mathematics, vol. 70, pp. 1–39. American Mathematical Society, Providence (2012)
Zomorodian, A.J.: Topology for computing. Cambridge Monographs on Applied and Computational Mathematics, vol. 16. Cambridge University Press, Cambridge (2009)
Acknowledgments
The work has benefitted from discussions with various people. On the topology side, we are thankful to Antonio Rieser and Primoz Skraba. On the probability side, Joseph Yukich answered many questions about the literature on sub-additive and stabilizing functionals, while Mathias Schulte explained to DY the variance lower bound technique of Lemma 5.1. Thanks are also due to his co-authors Günter Last and Giovanni Peccatti for sharing their results with us in advance of publication.
Author information
Authors and Affiliations
Corresponding author
Additional information
D. Yogeshwaran’s research was supported in part by FP7-ICT-318493-STREP.
Eliran Subag’s research was supported in part by Israel Science Foundation, 853/10.
Robert J. Adler’s research was supported in part by AFOSR FA8655-11-1-3039 and ERC 2012 Advanced Grant 20120216.
Appendices
Appendices
1.1 Appendix 1
The following useful lemma needed for variance lower bounds is essentially a simplification of [23, Theorem 5.2] to our situation.
Lemma 5.1
Let \(n \ge 1\) and \({\mathcal {P}}_n\) be the Poisson point process with density nf, where f satisfies (4.1). Let F be a translation invariant functional on locally finite point sets of \({\mathbb {R}}^d\) such that \({\mathbb {E}}\left\{ F({\mathcal {P}}_n)^2\right\} < \infty \). Assume that there exist \(m \in {\mathbb {N}},\) a set \(A \subset \mathrm{{supp}}(f),\) a finite set of points \(z_1,\ldots , z_{m}\) and \(r > 0\) with \(A \oplus B_{z_i}(r) \subset \mathrm{{supp}}(f)\) for all \(i \in \{1,\ldots ,m\}\) such that for all \(x \in A \) and \((x_1,\ldots ,x_m) \in \prod _{i=1}^mB_{x+z_i}(r),\) we have that
for some positive constant c. Then
Proof
[23, Theorem 5.3] simplifies [23, Theorem 5.2] to the case of stationary Poisson point processes in Euclidean space. However, since we are dealing with Poisson point processes with non-uniform densities, we require a small change in the arguments there and shall describe this in a moment. In any case, the similarity of our lower bound (5.2) to that of [23, Theorem 5.3] is to be expected. In particular, if we set \(f_* = f^* = \lambda \), then (5.2) is exactly the variance lower bound in [23, Theorem 5.3] with t there replaced by \(\lambda n\) here (although the set A and r are different).
Now, more specifically, set
Note that this plays the role of U as defined in [23, Theorem 5.2] and defining g on U as
we have that \(g > c/2\) Lebesgue a.e. on U. Setting \(\nu _n(.)\) to be the intensity measure of the point process \({\mathcal {P}}_n\), we have that
where we recall that |.| stands for the Lebesgue measure on \({\mathbb {R}}^d\). Using these bounds for \(\nu _n(.)\), we firstly obtain that
Secondly, let \(\emptyset \ne J \subset \{1,\ldots ,m+1\}\) and for \(y = (y_1,\ldots ,y_{m+1}) \in {\mathbb {R}}^{d(m+1)}\), let \(y_J\) be the components of y with indices in J. If \(y \in U\), then \(|y_i - y_j| \le 2r\) for all \(1 \le i,j \le m+1\) and so for any \(y_J \in {\mathbb {R}}^{d|J|}\), we have that
Using the above upper and lower bounds in the proof of [23, Theorem 5.3] along with the a.e. lower bound for g on U, (5.2) follows. \(\square \)
1.2 Appendix 2
We use the notation of Sect. 4.2, and consider a sequence \(\{B_n\}\) of subsets of \({\mathbb {R}}^d\) satisfying Conditions (A)–(D) there.
Given such a sequence, let \({\mathfrak {B}}\) (\(={\mathfrak {B}}(\{B_n\})\)) be the collection of all subsets A of \({\mathbb {R}}^d\) such that \(A = B_n + x\) for some \(B_n\) in the sequence and some point \(x \in {\mathbb {R}}^d\).
For a \(A \in {\mathfrak {B}}\), we shall denote by \({{\mathcal {U}}}_{m,A}\) the point process obtained by choosing m points uniformly in A. Then the extended binomial process \({{\mathcal {U}}}_n\) of Sect. 4.2 is equivalent to \({{\mathcal {U}}}_{n,B_n}\) in the current notation.
Theorem 5.2
[33, Theorem 2.1] Let H be a real-valued functional defined for all finite subsets of \({\mathbb {R}}^d\) and satisfying the following four conditions :
-
1.
Translation invariance: \(H({{\mathcal {X}}}+ y) = H({{\mathcal {X}}})\) for all finite subsets \({{\mathcal {X}}}\) and \(y \in {\mathbb {R}}^d\).
-
2.
Strong stabilization: H is called strongly stabilizing if there exist a.s. finite random variables R (called the radius of stabilization for H) and \(D_H(\infty )\) such that, with probability 1,
$$\begin{aligned} (D_OH)\big (({\mathcal {P}}\cap B_O(R)) \cup A\big )= D_H(\infty ) \end{aligned}$$for all finite \(A \subset B_O(R)^c\).
-
3.
Uniformly bounded moments:
$$\begin{aligned} \sup _{A \in {\mathfrak {B}} ; \, 0 \in A} \, \sup _{m \in \left[ {|A|}/{2},{3|A|}/{2}\right] }{\mathbb {E}}\left\{ \left[ (D_OH)({{\mathcal {U}}}_{m,A})\right] ^4\right\} <\infty . \end{aligned}$$ -
4.
Polynomial boundedness: There is a constant \(b_2\) such that, for all finite subsets \({{\mathcal {X}}}\subset {\mathbb {R}}^d,\)
$$\begin{aligned} |H({{\mathcal {X}}})| \le b_2\left[ \mathrm{diam}({{\mathcal {X}}}) +| {{\mathcal {X}}}|\right] ^{b_2}. \end{aligned}$$(5.3)
Then, there exist constants \(\sigma ^2,\tau ^2\) with \(0 \le \tau ^2 \le \sigma ^2,\) such that, as \(n \rightarrow \infty ,\)
and
where \(\Rightarrow \) denotes convergence in distribution. The constants \(\sigma ^2,\tau ^2\) are independent of the choice of \(B_n\). If \(D_H(\infty )\) is non-degenerate, then \(\tau ^2 > 0\) and also \(\sigma ^2 > 0\). Further, if \({\mathbb {E}}\left\{ D_H(\infty )\right\} \ne 0,\) then \(\tau ^2 < \sigma ^2\).
The last statement follows from the remark below [33, Theorem 2.1]. In the Poisson case the strongly stabilizing condition required for the central limit theorem can be replaced by the so-called weak stabilization condition, as in [33, Theorem 3.1]. H is said to be weakly stabilizing if there exists a random variable \(D_{\infty }(H)\) such that
for any \({\mathfrak {B}}\)-valued sequence \(A_n\) growing to \({\mathbb {R}}^d\).
Rights and permissions
About this article

Cite this article
Yogeshwaran, D., Subag, E. & Adler, R.J. Random geometric complexes in the thermodynamic regime. Probab. Theory Relat. Fields 167, 107–142 (2017). https://doi.org/10.1007/s00440-015-0678-9
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00440-015-0678-9