
Abstract
A simple technique for prediction of suspended sediment concentration (SSC) or total suspended matter in the Himalayan Bhagirathi river is presented. Artificial neural network models have been developed using short time period data of discharge (Q) and SSC during the high activity monsoon period of June to October 2004, when variations are maximum. Two modeling approaches have been employed, a daily approach and a three hourly approach. Although the time period considered is the same in both the approaches, the modeling performance is marginally better in the three hourly approaches where there is a sixfold increase in the data set. The Levenberg–Marquardt optimization algorithm has been improved with NARX [nonlinear autoregressive with exogenous input] architecture and high values of coefficient of determination have been obtained [0.89–0.97]. This study shows that short duration time series data can be used for successfully predicting geo-hydrological variables in the highly complex Himalayan river scenario.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The Q–SSC relationship in the Bhagirathi river of the Himalaya is highly complex and nonlinear involving interplay of several socio-geo-hydrological parameters varying in space and time. The Q and sediment load variations observed in the river affect downstream habitation, engineering structures and landuse, necessitating modeling and prediction in the Bhagirathi river basin. The river drains through a great range of relief and climate, active tectonic zones and easily erodible rocks of the Himalaya. Its hydrology is immensely affected by the monsoons when large variations in Q and sediment load are observed in a relatively short time span [June to October]. The physical weathering rate [PWR ~ 907 tons/km2/year] of the river is much higher than the global average PWR of 156 tons/km2/year despite its relatively small catchment [~ 7.8 × 103 km2] because of predominantly silicate lithology undergoing intense physical breakdown under high gradient, (Chakrapani and Saini 2009). Landslides and breach floods (Hewitt 1998) are frequent along the river which further contribute to surges in sediment load in the river. In addition to the above, haphazard developmental activities in the Bhagirathi valley, like construction of dams and highways also impact sediment load variations in the river basin. Therefore, it becomes pertinent to model SSC in the Bhagirathi river. Understanding the SSC–Q relationship in the Himalayan scenario with the ANN technique can be quite interesting and challenging. Here, the rivers carry large sediments load draining through a great range of relief and climate, active tectonic zones and easily erodible rocks (Hasnain and Thayyen 1999). In the past, ANN has been generally been applied in modeling geo-hydrological variables using continuous time series data of long durations. Many studies in the recent times have indicated the potential advantage of artificial neural networks (ANN) in sediment modeling (Abrahart and White 2001; Cigizoglu and Kisi 2006; Nagy et al. 2002; Isazadeh et al. 2017). ANN is a data-driven, self-adaptive flexible mathematical structure with an inter-connected assembly of simple processing units known as artificial neurons which are arranged in an architecture inspired by the human brain (ASCE 2000a, b). The working of ANN and its internal structure has been very frequently argued in the literature and detail like Hassoun 1995; Hertz et al. 1991 may be referred for the same. In the areas of hydrology and water resources, the application of ANNs is comprehensively reviewed and provided by the Maier and Dandy (2000) and ASCE (2000a, b). In the last 2 decades, ANN has been most commonly applied for modeling rainfall-runoff processes (Minns and Hall 1996; Smith and Eli 1995, 2002; Shamseldin 1997; Zhang and Govindaraju 2003; Tokar and Johnson 1999; Rajaee et al. 2010; Kisi et al. 2008; Khan et al. 2016a, 2019a, 2019b). Advances in the field of suspended sediment modeling have also been made by several workers (Rai and Mathur 2008; Sinnakaudan et al. 2006; Boukhrissa et al. 2013).
However, still the most common learning method used for supervised learning with feedforward neural networks (FNNs) is back propagation (BP) algorithm. The BP algorithm calculates the gradient of the network’s error with respect to the network’s modifiable weights. However, the BP algorithm may result in a movement toward the local minimum. To overcome the local minimum problems, many methods have been proposed. A widely used one is to train a neural network more than once, starting with a random set of weights (Park et al. 1993; Iyer and Rhinehart 1999). An advantage of this approach lies in the simplicity of using and applying to other learning algorithms. Nevertheless, this approach requires more time to train the networks.
The main controlling factors for sediment load (which is the product of discharge and sediment concentration) are relief, tectonic disturbances, lithology and rainfall (Chakrapani 2005; Khan et al. 2016a; Khan and Chakrapani 2016b; Panwar et al. 2016). Himalaya, in general, is prone to violent crustal movements responsible for high erosion rates (Valdiya 1998). The steep channel gradients result in higher hydraulic efficiency, higher stream energy per unit area and greater competence (Kale 2003). Tectonics are active in the area owing to the presence of deep seated weak zones and high seismicity (Seismic zone IV). Landslides caused due to high magnitude rainfall events not only add a tremendous amount of sediment to the river, but also block the river with debris resulting in massive floods when they fail. The river drains through easily erodible lithologies like quartzites, dolomitic limestones and metabasic formations. Rainfall in the monsoon season leads to huge water flows, which account for a considerable amount of the annual water flow and subsequently high sediment discharges. Also, the summer months experience more supraglacial melting, which increases discharge and competence of the river resulting in greater sediment transport. The contribution of humans to erratic changes in sediment discharge can be seen in the form of haphazard developmental activities like unplanned construction, mountain-toe cutting for road construction, mining activities and deforestation. All these factors account for the temporal and spatial changes in concentration of sediment in the Ramganga river basin.
The primary focus of the present study is to create ANN model(s) with the potential to forecast SSC of Bhagirathi river at Maneri, up to a high level of precision. The study gained vital significant in the backdrop of the recent avalanche of cloud burst occurred in 2013 in the Uttarakhand region of the Himalayas in which sediment and debris are mainly responsible for changing of river routes, thus leading to loss of flora and fauna. This has been achieved by understanding the underlying hydrological processes, controlling factors of sediment load variations, statistical analysis of time series data followed by model development, training and evaluation.
Study area
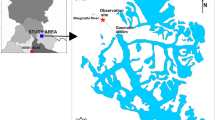
The Bhagirathi river originates at an altitude of 3892 m above sea level (asl) at the snout of Gangotri glacier (Goumukh) in the higher Himalayas. It flows for around 225 km draining through easily erodible lithologies like quartzites, dolomitic limestones and metabasic formations (Valdiya 1998; Bickle et al. 2003) across the Himalayas before its confluence with the Alaknanda river at Devprayag to form river Ganga. The upstream length of Bhagirathi river at Maneri (Fig. 1) is around 75 km. The study area has high relief, with deeply incised valleys and steep slopes of the order of 50.0 m to 3.0 m per km in the upper reaches (AHEC Report 2011).

Map showing location of study area in the Bhagirathi river basin; digital elevation model showing relief
Its annual Q and SSC are 4.91 × 1012 l/year and 1.24 × 103 mg/L, respectively (Yadav and Chakrapani 2011). Bhagirathi river transports, on an average, 81% of its annual sediment load in (July and August) monsoon season. Also the summer months experience more supraglacial melting which increases Q and competence of the river resulting in greater sediment transport.
Methodology
Hydrological time series data has been used to carry out ANN modeling at Maneri. High frequency (daily and three hourly) time series data for Q and SSC from Maneri during the high activity monsoon period of June to October of the year 2004 has been used for modeling [Data source-Uttaranchal Jal Vidhyut Nigam Limited (UJVNL)]. To understand the internal data structure and variations, the trends in the data have been studied (Fig. 2). Descriptive statistics presents a quick look into the performance of a substantial data set in terms of symmetry, shape and dispersion (Table 1).

Line graph for variation in daily Q (m3/s) and SSC (ppm) from June–October 2004 at Maneri. (Inset) Scatter plot showing relationship between Q (m3/s) and SSC (ppm) in the Bhagirathi river at Maneri
It is observed that onefold increase in Q leads to two–threefold increase in SSC. Q data shows a maximum value of 45,011 km3/s in the month of August and minimum value of 4432 km3/s during late October. SSC values vary from a high of 3329 mg/L in August to a low of 35 mg/L in late October. The scatter plot (Fig. 2, inset) between Q and SSC shows a high degree of association between them.
Model development
Neural network (NN) tool in MATLAB (R2013a) have been used to develop the models to estimate the process of hydrologic flow at Maneri. Six ANN models [T1–T6] have been developed using daily water Q–SSC data pertaining to high activity monsoon period of June–October, 2004, when maximum variations in Q and SSSC are reported. These models have been compared with six corresponding models [T1a–T6a] using high frequency three hourly data of the same variables in the same time period. Although the time period remains the same in both the approaches, data volume is nearly sixfold increases in the case of three hourly data. A comparative analysis of the modeling response of short duration-daily data and high frequency, three hourly data has been attempted. Levenberg–Marquardt back propagation algorithm was employed using a pure linear function and a nonlinear log-sigmoidal transfer function in the output layer and hidden layer, respectively. The normalization of the data is important so that the range of input for each variable should lie in between, (0 and 1). The procedure of normalization was carried out after collecting the data of each variable viz, SSC and Q by using the following equation: Xnorm = (Xi − Xmin)/(Xmax − Xmin) where Xnorm is the normalized value of the observed variable Xi, Xmin is the minimum value of the variable; and Xmax is the maximum value of the variable (Rajurkara et al. 2004). A series parallel NARX [nonlinear autoregressive with exogenous input] architecture has been used to improvised the feedforward backpropagation algorithm, wherein the error between the actual and computed value as SSC outputs were fed back into the inputs during training improving the network response. SSC (ppm) at the present time-step, S(t), was the output in all the models while the inputs were a combination of present Q (m3/s) and/or one, two antecedent time step Qs [i.e., Q(t), Q(t − 1), Q(t − 2)] and/or present, one, two antecedent time step SSCs (ppm) (i.e. S(t − 1), S(t − 2). The details of model architecture are given in Table 2. The data, in all the models, were divided into training (70% of whole data set) and evaluation (30% of whole data) subsets. Data training was carried out, and the models were configured from time to time by changing training parameters such as no. of inputs, no. of hidden layer neurons, learning rate, momentum, no. of epochs, etc. The evaluation data subset was not employed during training and was kept as a separate subset of the whole data to be used for later model evaluation.
Results and discussion
Regression plots were drawn between targets (observed) and output (ANN predicted) values for training and testing data subsets for all the models. The goodness of fit were evaluated on the basis of R [correlation coefficient], R2 [coefficient of determination] and MSE [mean square error] values. The R value was obtained by performing linear regression between the ANN-predicted values and the targets. ANN performance is considered good when R and R2 values are closer to one and MSE values are nearer to 0. The regression plots obtained during testing of data for models in both the approaches (T–T6 and T1a–T6a) are shown in Fig. 3. The performance is best for model T6 (R2 = 0.970) [Table 3]. Overall, the range of coefficient of determination is 0.891–0.970 which indicates that the overall performance of the models is good, and the SSC values have been closely predicted.

Regression plots for twelve ANN models (T1/1a to T6/6a) during testing of data at Maneri. The relationship between observed (target) and model calculated (output) values of SSC can be seen in the ordinate label
It can be seen that as an average, that the three hourly approach models tend to perform relatively better than the corresponding daily approach models [Avg. R2 in daily approach = 0.93; Avg. R2 in three hourly approach = 0.94]. It is also observed that the use of previous SSC values as network inputs enhances model performance. The response of all the models was seen with the assistance of plots where the observed (target) estimations of SSC were plotted with the model ascertained (output) values against time. The errors got in the process were likewise plotted against time. The training and evaluation response plots of best performing models for Maneri, T6 (daily approach) and T4a (three hourly approach) are shown in Fig. 4. The overall trend of SSC is well captured by the models, but there are two important characteristics of the observed (target) and ANN predicted (output) SSC values which can be seen in the performance plots. Initially, when the size of values is littler, the fluctuation or variation in it is likewise low. This can be seen amid the before and later part of the curve. Furthermore, when the size is more noteworthy, the variation is additionally bigger. This compares to the center part of the curve. The execution plots demonstrate that the network error, i.e., contrast among observed and ANN predicted SSC is normally larger when values of observed SSC are higher, around the time of July and August when Q and SSC and extremely high in the Bhagirathi river. Errors in the period before and after that are smaller and so are the observed values of SSC. This time corresponds to the onset (June) and waning (September–October), respectively, of monsoons in the study area. Also interesting to note is, there is a general under-prediction during the high SSC period of July–August (observed values are mostly higher than predicted ones, as can be seen in the performance plots) and there is a general over-prediction in the low SSC period of June, September and October (observed values are lesser than predicted values). Nevertheless, despite the high variation during the peak monsoon period, ANN has been able to closely predict the SSC values.

Response plots of the best performing models T6 (daily approach) and T-4a (three hourly approach) showing a close match between observed and model calculated values of SSC (ppm) during training at Maneri. The variation in error through time can also be seen
Conclusion
ANN modeling using daily Q against SSC and three hourly Qs against SSC at Maneri on Bhagirathi river is analyzed using NN. The total time period considered in both the approaches remains the same i.e., the monsoon period of June to October when occurrence of high Q related floods is maximum. In the present study, the inputs increase from model T1/1a to T6/6a and a clear increasing trend of coefficient of determination with this increase is observed except T3. It can be said that using a larger data set, even if representing a short duration, leads to a relative improvement in model performance. In general, it is a rather difficult proposition to generalize any criteria of determining the optimum network architecture in ANNs. ANN modeling is largely area and problem dependent, and hence, no two study areas can be modeled with similar ANN architectures.
It has been successfully established that ANN can model and predict SSC in the highly nonlinear Bhagirathi river system of the Himalaya. In the study, a systematic, step-by-step approach has been used for modeling wherein the pre-modeling understanding of the study area and data analysis has been stressed upon. The models have been trained, and tested using an improvised Levenberg–Marquardt backpropagation algorithm [NARX] to predict values of SSC. The coefficient of determination values obtained are extremely high (0.89–0.97) which implies that predicted output values are very close to the target values. Overall, the average performance is better in the three hourly approach which could be due to an almost sixfold increase in data numbers. The advantage of using ANN is that every step of the modeling process can be configured and improved based upon model performance. This increases flexibility and also the understanding of the procedure which is otherwise rather complex to comprehend. This study shows that short duration geo-hydrological time series data can also be predicted by ANN modeling with substantial accuracy. Prediction would not just help in filling gaps in hydrological data but will also enable continuous monitoring of SSC which is difficult in the Himalayan Rivers where floods and other such eventualities commonly occur.
References
Abrahart RJ, White SM (2001) Modeling sediment transfer in Malawi: comparing backpropagation neural network solutions against a multiple linear regression benchmark using small data sets. Phys Chem Earth B 26(1):19–24
Alternate Hydro Energy Center Report (2011) Assessment of cumulative impact of hydropower projects in Bhagirathi and Alaknanda Basins
ASCE Task Committee on Application of the Artificial Neural Networks in Hydrology (2000a) Artificial neural networks in hydrology I: preliminary concepts. J Hydraul Eng ASCE 5(2):115–123
ASCE Task Committee on Application of The Artificial Neural Networks in Hydrology (2000b) Artificial neural networks in hydrology II: hydrologic applications. J Hydraul Eng ASCE 5(2):124–137
Bickle JM, Bunbury J, Chapman JH, Harris BWN, Fairchild JI, Ahmad T (2003) Fluxes of Sr into the headwaters of the Ganges. Geochim Cosmochim Acta 67(14):2567–2584
Boukhrissa ZA, Khanchoul K, Le Bissonnais Y, Tourki M (2013) Prediction of sediment load by sediment rating curve and neural network (ANN) in El Kebir catchment, Algeria. J Earth Syst Sci 122(5):1303–1312
Chakrapani GJ (2005) Major and trace element geochemistry in upper Ganga river in the Himalayas. India. Environ Geol 48(2):189–201
Chakrapani GJ, Saini RK (2009) Temporal and spatial variations in water discharge and sediment load in the Alaknanda and Bhagirathi rivers in Himalaya, India. J Asian Earth Sci 35:545–553
Cigizoglu HK, Kisi O (2006) Methods to improve the neural network performance in suspended sediment estimation. J Hydrol 317(3–4):221–238
Hasnain SI, Thayyen RJ (1999) Discharge and suspended sediment concentration of meltwaters, draining from the Dokriani glacier_Bamak, Garhwal Himalaya. India. J Hydrol 218(3–4):191–198
Hassoun MH (1995) Fundamentals of artificial neural networks. The MIT Press, Cambridge
Hertz J, Krogh A, Palmer RD (1991) Introduction to the theory of neural computation. Addison-Wesley, Boston
Hewitt K (1998) Catastrophic landslides and their effects on the upper Indus streams, Karakoram Himalaya, northern Pakistan. Geomorphology 26:47–80
Isazadeh M, Biazar SM, Ashrafzadeh A (2017) Support vector machines and feed-forward neural networks for spatial modeling of groundwater qualitative parameters. Environ Earth Sci 76(17):610
Iyer MS, Rhinehart RR (1999) A method to determine the required number of neural network training repetitions. IEEE Trans Neural Netw 10:427–432
Kale VS (2003) Geomorphic effects of monsoon floods on Indian rivers. In: Flood problem and management in south asia Springer, Dordrecht pp 65–84
Khan MYA, Hasan F, Panwar S, Chakrapani GJ (2016a) Neural network model for discharge and water-level prediction for Ramganga River catchment of Ganga Basin, India. Hydrol Sci J 61(11):2084–2095
Khan MYA, Chakrapani GJ (2016b) Particle size characteristics of Ramganga catchment area of Ganga River. In: Geostatistical and geospatial approachesfor the characterization of natural resources in the environment Springer, Cham, pp 307–312
Khan MYA, Hasan F, Tian F (2019a) Estimation of suspended sediment load using three neural network algorithms in Ramganga River catchment of Ganga Basin, India. Sustain Water Resour Manag 5:1115–1131
Khan MYA, Tian F, Hasan F, Chakrapani GJ (2019b) Artificial neural network simulation for prediction of suspended sediment concentration in the River Ramganga, Ganges Basin, India. Int J Sediment Res 34(2):95–107
Kisi O, Yuksel I, Dogan E (2008) Modelling daily suspended sediment of rivers in Turkey using several data-driven techniques/Modélisation de la charge journalière en matières en suspension dans des rivièresturques à l’aide de plusieurs techniques empiriques. Hydrol Sci J 53(6):1270–1285
Maier HR, Dandy GC (2000) Neural networks for the prediction and forecasting of water resources variables: a review of modelling issues and application. Environ Model Softw 15:101–124
Minns AW, Hall MJ (1996) Artificial neural networks as rainfall runoff models. Hydrol Sci J 41(3):399–417
Nagy HM, Watanabe K, Hirano M (2002) Prediction of sediment load concentration in rivers using artificial neural network model. J Hydraul Eng 128(6):588–595
Panwar S, Khan MYA, Chakrapani GJ (2016) Grain size characteristics and provenance determination of sediment and dissolved load of Alaknanda River, Garhwal Himalaya. India. Environ Earth Sci 75(2):91
Park YR, Murray TJ, Chung C (1993) Predicting sun spots using a layered perceptron neural network. IEEE Trans Neural Netw 7:501–505
Rai RK, Mathur BS (2008) Event-based sediment yield modeling using artificial neural network. Water Resour Manag 22:423–441
Rajaee T, Nourani V, Zounemat-Kermani M, Kisi O (2010) River suspended sediment load prediction: application of ANN and wavelet conjunction model. J Hydrol Eng 16(8):613–627
Rajurkara MP, Kothyari UC, Chaube UC (2004) Modeling of the daily rainfall-runoff relationship with artificial neural network. J Hydrol 285:96–113
Shamseldin AY (1997) Application of a neural network technique to rainfall runoff modeling. J Hydrol 199:272–294
Sinnakaudan SK, Ghani AA, Ahmad MSS, Zakaria NA (2006) Multiple linear regression model for total bed material load prediction. J Hydraul Eng ASCE 132(5):521
Smith J, Eli RN (1995) Neural network models of rainfall runoff process. J Water Resour Plan Manag ASCE 121(6):499–508
Tokar AS, Johnson PA (1999) Rainfall-runoff modeling using artificial neural networks. J Hydrol Eng ASCE 4(3):232–239
Valdiya KS (1998) Dynamics of Himalaya. Universities Press, Hyderabad
Yadav SK, Chakrapani GJ (2011) Geochemistry, dissolved elemental flux rates, and dissolution kinetics of lithologies of Alaknanda and Bhagirathi rivers in Himalayas, India. Environ Earth Sci 62:593–610
Zhang B, Govindaraju R (2003) Geomorphology-based artificial neural networks (GANNs) for estimation of direct runoff over watersheds. J Hydrol 273:18–34
Acknowledgements
The authors gratefully acknowledge the comments of the reviewers and the editor, which enormously improved the presentation of the final manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Singh, N., Khan, M.Y.A. ANN modeling of the complex discharge-sediment concentration relationship in Bhagirathi river basin of the Himalaya. Sustain. Water Resour. Manag. 6, 36 (2020). https://doi.org/10.1007/s40899-020-00396-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40899-020-00396-6