
Abstract
The existing approaches of multicriteria decision-making (MCDM) process might yield unreliable and questionable results. The notable challenges of MCDM approaches are rank reversal paradox and uncertainty. The prime inspiration for researchers is the MCDM for hesitant fuzzy sets (HFSs). In some scenarios, the decision-makers could not choose one from numerous values while expressing their preferences. HFS which is the extension of fuzzy sets (FS) is found to be helpful in solving such decision-making (DM) problems. The DM process is revolutionized with the commencement of powerful and efficient tools of data representation for expressing vagueness and uncertainty in data sets as FSs (both generalized and hesitant ones). This paper copes with one such novel approach that involves entropy-based attribute weighting, followed by an evaluation of approximate sets in the fuzzy rough framework. Correlation of the input alternatives in respect of evaluation criteria and the output class is evaluated. With the fuzzy technique for ordered preference by similarity to ideal solutions (FTOPSIS), the generated correlation matrix is utilized for calculating the degree of closeness (\( \delta \)) of the output classes to the input alternatives. This paper made a novel contribution of performance indicator centered on FTOPSIS for the hesitant fuzzy rough domain. The proposed method’s efficiency is established through comprehensive and systematic experimentation on datasets utilized by researchers globally. The proposed algorithms prove its ability to handle datasets that involve human-like hesitant thinking in the MCDM system by contrasting with the existing ones.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
For decades, MCDM has remained as an inexorable topic of research. Optimum selection of alternatives considerably affects the DM of picking a suitable one from a provided set of conflicting criteria. The uncertainty and vagueness involved with the human DM process could be effectually modeled by FS theory. MCDM embraces attributes, decision methods, selection criteria, and even subjective estimation of experts [1]. Improvisation in classical FSs [2] was done for handling the uncertainties and vagueness. Extended versions of FSs embrace fuzzy rough sets (FRS) [3] which could handle the indiscernible datasets effectually in a fuzzy framework. Researchers made countless attempts for incorporating real-life complex scenarios that involve uncertainty into the datasets and solve it utilizing FTOPSIS [4–7]. It has now been meticulously adopted in several use cases on account of its simplicity, comprehensive mathematical concept along with computational efficiency. The extension of the classical TOPSIS approach in regard of fuzzy logic, namely FTOPSIS, has also been effectively implemented in disparate applications like Networks, Supply Chain Management, Defense Industry, Construction, Healthcare, etc., FTOPSIS was employed in countless practical use cases, starting from choosing a suitable supplier for manufacturing through assessment of service quality and ending at selection and ranking of the renewable energy (RE) sources, confirming that is widely implemented in innumerable practical issues. Additionally, the energy policies’ selection and ranking of the RE sources are the eminent challenges tackled by FTOPSIS. Hence, there TOPSIS studies are becoming popular regarding the problems, which consider sustainable development, environment, and RE sources. Decision-makers present variable opinions for the alternatives, which brings uncertainty. HFS has an imperative role in modeling such uncertainty. This difference in opinions could be due to inadequate information or their different backgrounds. Researchers have widely explored HFSs in respect of the aggregation operators (AOs), various information measures as well as their application on DM [8]. Expert assessment of the attributes is done utilizing probable membership values that the attribute could possibly take. HFSs were proffered by [9] and were intensively utilized by researchers in respect of AOs for DM [10–12]. An outline of trends and tools associated with HFSs was studied by [13]. A fusion of the Rough Sets (RS) model and HFSs was explored by [14] by rendering an axiomatic and constructive mathematical framework. Probabilistic and Pawlak’s models were propounded by [15]. Enhanced concept associated to approximate precision and roughness for hesitant fuzzy compatible rough space was examined by [16]. Dual HFSs and associated AOs were studied by [17]. Attribute reduction was intensively examined by [18]. The utilization of decision-theoretic RSs for the purpose of resolving DM problems in HFSs was carried out by [19]. However, it might be difficult or expensive to develop criteria set, wherein all criteria are independent in certain situations. In some real-life scenarios, on account of the higher uncertainty of the situation and the restricted cognition of human thinking, it is hard for decision-makers to make a choice in selecting merely one alternative as of a candidate alternative set or evaluation arguments set to show their preference. They might highly hesitate amongst several alternatives or evaluation arguments. In these similar scenarios, it is reasonable to formulate a new DM rule or build a tool that permits decision-makers to express their judgments or preferences on several objects with individual degrees of hesitation. Consequently, it is requisite to comprehensively study the HFSs with inter-active criteria and construct an MCDM approach by considering the interaction amongst criteria. This paper has brought about a pioneering work in the FRSs field as it bridges the gap from RSs to HFSs for attribute reduction. It can elevate the DM efficiency and lessen the decision pressure, because, here, the decision-makers are permitted to express their preference in form of entropy centered weighted attribute selection.
The forthcoming section handles preliminaries of hesitant FRSs, as well as RSs, and is followed by methodology and experimentation. A detailed explanation of proposed work and its implementation on two disparate cases of hesitant fuzzy data sets are done in subsequent sections.
Preliminaries
Here, the basic RS and FRS concepts are expounded in detail.
Definition 1
[20] Consider information system ‘I’, universes of discourse ‘X’, non-empty finite set ‘A’, and attribute value ‘\( Y_{a} \)’ where I = (X, A). \( {\text{for}}\;{\text{every}}\;a:X \to Y_{a} \;{\text{for}}\;{\text{every}}\;a \in \, A \). And, ‘A’ that is a decision system could be defined as \( A = (C \cup \, D) \), where C and D are a set of conditional and decision attributes, respectively. The core notion in RS theory exists in finding the lower approximations (LA) as well as upper approximations (UA) centered on IND (P)-equivalence relation, where
Definition 2
[20] If \( (x,y) \in {\text{IND}}(P) \), then (x, y) is indiscernible by ‘P’ attribute. Consider an equivalence class generated as of IND (P) as \( [x]_{P} \). Here, the LA is \( \underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{P} X \) and UA is \( \bar{P}X \), and both are evaluated as
The tuples \( \underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{P} X \) and \( \bar{P}X \) are termed an RS:
Definition 3
[20, 21] The considered positive region comprises all objects which could be positively classified to the classes of U/Q. The determination of dependence between the attributes is proffered by Eq. (3).
By determining the change in the dependence, while a feature is added or removed, significance of the feature is evaluated by [20, 22].
The issue of crisp LA and UA adversely influences the classification accuracy and is effectually handled by FRS explained in [3, 23, 24].
Definition 4
The definitions of Membership functions for fuzzy LA and fuzzy UA are proffered as Eq. (4)
where \( F_{i} \)—fuzzy equivalence classes belonging to U/P.
A fuzzy positive area is then evaluated using extension principle as:
Likewise, a new Fuzzy dependence function could be evaluated as:
RS theory as introduced by Pawlak regards the information subspaces in the sort of LA, UA, and boundary region, whereas the FRSs approximate the same subspaces as overlapping regions having certain membership values [25]. The FRSs’ concept was extended by Zhang et al. [26] and Chen et al. [27] for the cases embracing DM uncertainty. Hesitant FRSs have been utilized effectually in the literary works for handling hesitant DM.
Hesitant fuzzy sets: basic concepts
Definition 5
Consider X as a reference set and, here, the HFSs A on the X set defined in respect of function \( h_{A} (x) \). While it is employed to X, it returns a sub set A as \( A = \{ \langle x,h_{A} (x)\rangle |x \in X\} \), where \( h_{A} (x) \) could be called hesitant fuzzy elements (HFE) [10, 28] and it indicates the set of possible membership degrees of \( x \in X \) element to A.
Definition 6
For a given HFE (h), the lower bound as well as upper bound as per [29] are,
Definition 7
The score function of the HFSs \( s(h_{A} (x)) \) as per [29] is:
However, the normalized score function could be proffered as:
Definition 8
If X, Y are the ‘2’ non-empty finite universes and as well R signifies “X to Y” hesitant fuzzy relationship, then (X, Y, R) is called Hesitant fuzzy rough approximations (HFRA) space. For any \( P \in {\text{HF}}(Y) \), the LA and UA are indicated by \( \underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{R} (P) \) and \( \bar{R}(P) \) respectively [26],
where
where
Definition 9
As X stands as a finite universe of discourse, Torra et al. [9] offered the succeeding operations on hesitant FRSs. For any \( P,Q \in {\text{HF}}(X) \), then for all \( x \in X \):
-
1.
The union of HFSs A and B is
$$ h_{P \cup Q} (x) = h_{P} (x) \vee h_{Q} (x) = \bigcup\limits_{{\xi_{1} \in h_{P} (x),\xi_{2} \in h_{Q} (x)}} {\hbox{max} (\xi_{1} ,\xi_{2} )} . $$(13) -
2.
The intersection of HFSs A and B is
$$ h_{P \cap Q} (x) = h_{P} (x) \wedge h_{Q} (x) = \bigcup\limits_{{\xi_{1} \in h_{P} (x),\xi_{2} \in h_{Q} (x)}} {\hbox{min} (\xi_{1} ,\xi_{2} )} $$(14) -
3.
The complement of A is
$$ h_{{P^{c} }} (x) = \sim h_{P} (x) = \bigcup\limits_{{\xi \in h_{P} (x)}} {\{ 1 - \xi \} } . $$(15)
Definition 10
For HFSs A and B on \( X = \{ x_{1} ,x_{2} \ldots x_{3} \} \), their weights are provided as weight vector \( w = \{ w_{1} ,w_{2} \ldots w_{n} \}^{\text{T}} \) with \( w_{i} \ge 1 \) and \( \sum\nolimits_{i = 1}^{n} {w_{i} = 1} \). The proposed correlation grounded on entropy-centric ordered weighted approach for HFRS is proffered as:
where \( \delta_{m} (A,B) \) satisfies the below properties
Proof
-
1.
It is highly straight forward.
-
2.
The inequality \( \delta_{m} (A,B) \) > 0 is obvious and to prove \( \delta_{m} (A,B) \le 1 \):
$$ \begin{aligned} \kappa_{\text{HFRS}} (A,B) & = \sum\limits_{i = 1}^{n} {w_{mi} \left( {\frac{1}{{l_{i} }}\left( {\sum\limits_{j = 1}^{{l_{i} }} {h_{A\sigma (j)}^{'} (x_{i} )*h_{B\sigma (j)}^{'} (x_{i} )} } \right)} \right)} \\ & = w_{m1} \left( {\frac{1}{{l_{1} }}\left( {\sum\limits_{j = 1}^{{l_{i} }} {h_{A\sigma (j)}^{'} (x_{i} )*h_{B\sigma (j)}^{'} (x_{i} )} } \right)} \right) + w_{m2} \left( {\frac{1}{{l_{2} }}\left( {\sum\limits_{j = 1}^{{l_{i} }} {h_{A\sigma (j)}^{'} (x_{i} )*h_{B\sigma (j)}^{'} (x_{i} )} } \right)} \right) \\ & \quad \cdots w_{mn} \left( {\frac{1}{{l_{n} }}\left( {\sum\limits_{j = 1}^{{l_{i} }} {h_{A\sigma (j)}^{'} (x_{i} )*h_{B\sigma (j)}^{'} (x_{i} )} } \right)} \right) \\ \end{aligned} $$(18)$$ = w_{m1} \sum\limits_{j = 1}^{{l_{1} }} {\frac{{h_{A\sigma (j)}^{'} (x_{i} )}}{{\sqrt {l_{1} } }}} *\frac{{h_{B\sigma (j)}^{'} (x_{i} )}}{{\sqrt {l_{1} } }} + w_{m2} \sum\limits_{j = 1}^{{l_{1} }} {\frac{{h_{A\sigma (j)}^{'} (x_{i} )}}{{\sqrt {l_{2} } }}} *\frac{{h_{B\sigma (j)}^{'} (x_{i} )}}{{\sqrt {l_{2} } }} + \cdots + w_{mn} \sum\limits_{j = 1}^{{l_{1} }} {\frac{{h_{A\sigma (j)}^{'} (x_{i} )}}{{\sqrt {l_{n} } }}} *\frac{{h_{B\sigma (j)}^{'} (x_{i} )}}{{\sqrt {l_{n} } }}. $$(19)
By utilizing Cauchy’s Schwarz inequality, the above equation becomes:
Therefore:
When A = B, then:
Definition 11
[30] Information entropy H(X) of knowledge X proffers the uncertainty measure about knowledge X and is evaluated as
Methodology
Here, a detailed and systematic description on the proposed mathematical design for DM in HFR framework is proffered. The novelty exists in rendering weighted entropy centered optimum attribute selection method for assessing correlation of the input alternatives with the output class in HFR domain. Entropy weight approach gauges value dispersion in DM and is the common weighting methodology. If the degree of dispersion is greater, then its degree of differentiations will be greater, and can derive more information. Moreover, the maximal weight must be provided to the index and vice versa. This entropy weighting approach always gives reliable and effective results. As per [9], the DM uncertainty could be best expounded with the employment of HFSs. The relevant attributes could be specified for further processing utilizing entropy centered evaluation of weights for the attributes. MCDM in HFS was extensively studied by [10, 16]. Nevertheless, the performance indicators employed by Zhang et al. [29] render ambiguous outcomes on the dataset utilized in this work. Hence, these performance indicators are re-framed in the proposed model. As the fifth parameter, the FTOPSIS centered performance indicator is utilized to assess the alternatives appropriately. A detailed clarification of the approach is proffered below:
-
1.
Consider an attribute set of {\( {\text{A}}_{1} , {\text{A}}_{2} , {\text{A}}_{3} \ldots {\text{A}}_{n} \)} for an HFS in \( X = \{ x_{1} ,x_{2} ,x_{3} \ldots x_{n} \} \). The hesitant fuzzy decision matrix (HFDM) is
$$ D = \left[ {\begin{array}{*{20}c} {h_{11} } & {h_{12} } & \ldots & {h_{1n} } \\ {h_{21} } & {h_{21} } & \ldots & \ldots \\ . & \ldots & \ldots & \ldots \\ {h_{m1} } & \ldots & \ldots & {h_{mn} } \\ \end{array} } \right]. $$(25)Also consider \( R(x_{i} ,y_{j} ) \) as the relational matrix which shows the fuzzy relation from \( X \to Y \) where input is \( x{}_{i}(x_{i} \in X) \) and output is \( y_{j} (y \in Y) \)
-
2.
This step finds \( S_{n} \) which is the normalized score matrix (NSM), where S indicates a score matrix as per Definition 3
-
3.
As provided in Definition 8, the entropy-based determination of weights of attributes is
$$ E_{j} = - \frac{1}{\ln m}\sum\limits_{i = 1}^{m} {\bar{s}_{ij} } \ln \bar{s}_{ij} \;{\text{where}}\; \, j = 1 \ldots n, $$(26)where \( \bar{s}_{ij} \) signifies the NSM. Attribute weights are given is
$$ w_{mj} = \frac{{1 - E_{j} }}{{\sum\nolimits_{j = 1}^{n} {(1 - E_{j} )} }}. $$(27) -
4.
Calculation of correlation coefficient for every alternative \( A_{i} \) and the output \( y_{j} \) is given in step 7.
-
5.
Calculation of LA and UA spaces in respect of (X, Y, R) is symbolized as \( \underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{R} (P) \) and \( \bar{R}(P) \) which are the ‘2’ approximate hesitant FRS.
-
6.
Computation of the performance indices (\( {\text{PI}}_{i} \)) [29] is detailed below:
$$ {\text{PI}}_{1} = \mathop {\hbox{max} }\limits_{{y_{i} \in Y}} \{ s(h_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{R} (P)}} (y_{i} ))\} $$(28)$$ {\text{PI}}_{2} = \mathop {\hbox{max} }\limits_{{y_{i} \in Y}} \{ s(h_{{\bar{R}(P)}} (y_{i} ))\} $$(29)$$ {\text{PI}}_{3} = \hbox{max} (s(h_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{R} (P)}} (y_{i} )),s(h_{{\bar{R}(P)}} (y_{i} ))) $$(30)$$ {\text{PI}}_{4} = \mathop {\hbox{max} }\limits_{{y_{i} \in Y}} \{ \delta_{m} (P,R(x,y)\} . $$(31)The applied decision rules are:
-
1.
If \( {\text{PI}}_{1} \cap {\text{PI}}_{2} \cap {\text{PI}}_{3} \cap {\text{PI}}_{4} \ne \emptyset \), and then, the optimal output will be \( y_{k} \) where k = \( {\text{PI}}_{1} \cap {\text{PI}}_{2} \cap {\text{PI}}_{3} \cap {\text{PI}}_{4} \).
-
2.
If \( {\text{PI}}_{1} \cap {\text{PI}}_{2} \cap {\text{PI}}_{3} \cap {\text{PI}}_{4} = \emptyset \), then optimal output would be \( y_{k} \) where k = \( {\text{PI}}_{1} \cap {\text{PI}}_{2} \cap {\text{PI}}_{3} . \),
-
3.
If \( {\text{PI}}_{1} \cap {\text{PI}}_{2} \cap {\text{PI}}_{3} = \emptyset \), then optimal output will be \( y_{k} \) where k = \( {\text{PI}}_{i} \cap {\text{PI}}_{j} \), \( i \ne j{\kern 1pt} {\text{ and }}{\kern 1pt} i,j = 2,3,4 \)
-
4.
The decision for optimal output shall be provided by \( {\text{PI}}_{1} \) when 1 and 2 are false
-
1.
-
7.
This work proposed the application of FTOPSIS to evaluate the degree of closeness (\( \delta \)) as performance indicator (\( {\text{PI}}_{5} \)). A novel integration of FTOPSIS with the FRS centered MCDM renders an accurate and robust optimal DM system. The proposed performance indicator (\( {\text{PI}}_{5} \)) could be computed as follows:
-
(a)
Consider the correlation matrix between \( A_{i} \) and \( y_{j} . \)
-
(b)
Evaluate normalized correlation score matrix \( r_{ij} \)
$$ r_{ij} = \frac{{x_{ij} }}{{\sqrt {\sum\nolimits_{i = 1}^{n} {x_{ij}^{2} } } }}. $$(32) -
(c)
Multiply each column with the weights decided by the experts to evaluate the weighted decision matrix \( v_{ij} \)
$$ v_{ij} = w_{ij} r_{ij} . $$(33) -
(d)
The maximum value of each column vector is determined and is the ideal positive solution \( v_{j}^{*} \). Also, the ideal negative solution \( v_{j}^{ - } \) is determined.
-
(e)
Evaluate the Euclidean distance (ED) from \( v_{j}^{*} \) to each alternative as,
$$ D^{ + } (x_{j} ) = \sqrt {\sum\limits_{j = 1}^{n} {(v_{j}^{*} - v_{ij} )^{2} } } . $$(34) -
(f)
Compute the ED between \( v_{j}^{ - } \) and each alternative as,
$$ D^{ - } (x_{j} ) = \sqrt {\sum\limits_{j = 1}^{n} {(v_{j}^{ - } - v_{ij} )^{2} } } . $$(35) -
(g)
The \( \delta \) renders a rational solution to the problem of ascertaining optimum attributes for a specific dataset. Find \( \delta \) for every alternative as:
$$ \delta (x_{j} ) = \frac{{D^{ - } (x_{j} )}}{{D^{ - } (x_{j} ) + D^{ + } (x_{j} )}}. $$(36)
-
(a)
This work proposes \( \delta \) as the \( {\text{PI}}_{5} \), an additional performance indicator in fuzzy rough approach. The decision rules are also enhanced accordingly to have rules which assist in choosing input samples having maximal correlation with the class and \( \delta \) regarding the output parameters. The rules are re-framed as:
-
1.
If \( {\text{PI}}_{1} \cap {\text{PI}}_{2} \cap {\text{PI}}_{3} \cap {\text{PI}}_{4} \cap {\text{PI}}_{5} \ne \emptyset \), then optimal output will be \( y_{k} \) where k = \( {\text{PI}}_{1} \cap {\text{PI}}_{2} \cap {\text{PI}}_{3} \cap {\text{PI}}_{4} \cap {\text{PI}}_{5} . \)
-
2.
If \( {\text{PI}}_{1} \cap {\text{PI}}_{2} \cap {\text{PI}}_{3} \cap {\text{PI}}_{4} \cap {\text{PI}}_{5} = \emptyset \), then optimal output would be \( y_{k} \) where k = \( ({\text{PI}}_{1} \cap {\text{PI}}_{2} \cap {\text{PI}}_{3} ) \cup ({\text{PI}}_{4} \cup {\text{PI}}_{5} ). \)
-
3.
If \( {\text{PI}}_{1} \cap {\text{PI}}_{2} \cap {\text{PI}}_{3} = \emptyset \), then optimal output will be \( y_{k} \) with k = \( ({\text{PI}}_{1} \cap {\text{PI}}_{2} ) \cup ({\text{PI}}_{4} \cup {\text{PI}}_{5} ). \)
-
4.
If \( {\text{PI}}_{1} \cap {\text{PI}}_{2} = \emptyset \), then optimal output would be \( y_{k} \); here, k = \( ({\text{PI}}_{4} \cup {\text{PI}}_{5} ). \)
-
5.
If \( ({\text{PI}}_{4} \cup {\text{PI}}_{5} ) = \emptyset \), then optimal output will be \( {\text{PI}}_{5} . \)
Experimentation and implementation
Experimentation is made on two datasets. A medical diagnosis dataset which is utilized by [6, 31, 32] is proffered as Table 1. Medical diagnosis dataset has patients \( A = \{ A_{1} ,A_{2} ,A_{3} ,A_{4} \} \) who show the symptoms are evinced as \( x = \{ x_{1} ,x_{2} ,x_{3} ,x_{4} ,x_{5} \} \) where \( x_{1} \) indicates “temperature”,\( x_{2} \) stands for “headache”,\( x_{3} \) stands for “stomach pain”,\( x_{4} \) stands for “cough”, and \( x_{5} \) stands for “chest pain”. The probable diseases are evinced as \( Y = \{ y_{1} ,y_{2} ,y_{3} ,y_{4} \} \) where \( y_{1} \) stands for “Viral fever”,\( y_{2} \) stands for “Malaria”,\( y_{3} \) stands for “Typhoid”, and \( y_{4} \) stands for “Chest problem”. Table 2 indicates the values that are possible as per the expert information. Grounded on the steps described in methodology, correlation matrix is proffered as Fig. 1 and is calculated. It is followed by the evaluation of LA and UA sets. The proposed performance indicator (\( {\text{PI}}_{5} \)) is evaluated utilizing the FTOPSIS technique as elucidated in Step 7. Finally, the rules stated in the proposed work are applied for diagnosis of the disease. Table 3 evinces the calculations for ideal positive and negative solutions, and \( \delta \). Performance indicator \( {\text{PI}}_{5} \) provides \( \delta \) between the input samples and the outputs. Hence, for the medical diagnosis problem,\( y_{1} \) exhibits greater \( \delta \) to the input samples, i.e., patients. This result is completely consistent with the outcomes acquired utilizing the performance indicators proposed by [16]

Correlation matrix between the input alternative (patients) and the outputs (diseases)
However, the below example clearly emphasizes the necessity of the proposed performance indicator i.e.\( {\text{PI}}_{5} \) as \( {\text{PI}}_{1} \) to \( {\text{PI}}_{4} \) performance indicators produced ambiguous results. Consider the following HFS in \( X = \{ x_{1} ,x_{2} ,x_{3} ,x_{4} ,x_{5} \} \) which indicates the decision given by the risk evaluation committee. Let \( A = \{ A_{1} ,A_{2} \ldots A_{10} \} \) be the ten firms to be evaluated on the basis of criteria { \( x_{1} \):managers’ work experience, \( x_{2} \):profitability, \( x_{3} \):operating capacity, \( x_{4} \): ability of paying debt, and \( x_{5} \): market competition}. The outcome is also provided as imprecise membership values as evaluated by the risk evaluation committee in the form of FS which is a special form of hesitant set [1]. The corresponding HFDM is proffered as Table 4. \( Y = \{ y_{1} ,y_{2} ,y_{3} \} \) where \( y_{1} \): corporate stability index, \( y_{2} \): survival index and \( y_{3} \):long-term economical growth. Let the correlation between the criteria \( x_{i} \) and Y is provided by the risk evaluation committee as indicated in Tables 4 and 5.
The algorithm commences with the evaluation of score matrix for Table 6 as expounded in Definition 7. The evaluated score matrix is proffered in Table 6.
The NSM given in Table 7 facilitates the evaluation of entropy and weights (as in Definition 8) to have optimal attributes.
The NSM given in Table 8 facilitates the evaluation of entropy and weights (as in Definition 8) for the computation of optimal attributes:
The weight vector wj symbolizes the significance of the attributes. Therefore, further steps involve the computation of the weighted decision matrix proffered as Table 9 which is attained by multiplying the elements of Table 8 with their respective column weights given by \( w_{j} \). Table 9 is same as Table 1, but the only difference is that the length of all sequences is made the same by extending the higher membership value for a specific sequence as stated by [1]. This updation in the HFDM is needed for the evaluation of the correlation matrix.
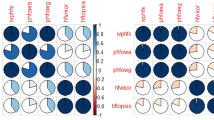
Table 9 is then utilized to evaluate the correlation coefficient \( \kappa_{\text{HFRS}} (A_{i} ,y_{i} ) \) utilizing Definition 10. This further enables the calculation of \( \delta_{m} (A_{i} ,y_{i} ) \) as evinced in Fig. 2

Correlation between input samples and output space
Figure 2 signifies the correlation of the ten firms \( A_{i} \) which were to be evaluated centered on the criteria {\( x_{1} \):managers’ work experience, \( x_{2} \):profitability, \( x_{3} \):operating capacity, \( x_{4} \): ability of paying debt, and \( x_{5} \):market competition with \( Y = \{ y_{1} ,y_{2} ,y_{3} \} \), where {\( y_{1} \): corporate stability index, \( y_{2} \): survival index as well as \( y_{3} \): long-term economical growth. The output \( y_{1} \) has a maximal degree of correlation (0.213) to the input samples \( A_{8} \), while the output \( y_{2} \) has 0.205 (higher) to the input samples \( A_{5} \), and the output \( y_{3} \) has 0.219 (higher) to the input samples \( A_{1} \;{\text{and}}\;A_{7} \). As given in the methodology, the upper HFRA and lower HFRA are evaluated utilizing Definition 8. The outcomes are proffered as Tables 10 and 11
For calculating the performance indices, the equivalent score matrices of LA and UA hesitant FRSs are needed. These sets are evaluated and even tabulated as Table 12 and 13.
Calculation for \( {\text{PI}}_{5} \) grounded on FTOPSIS approach is then carried out. The correlation matrix which is the input matrix for FTOPSIS is evaluated. Figure 2 details those correlation matrices between input samples and output samples. The weights for \( y_{i} \) for the further calculations are presumed to be 1 as all the outputs \( y_{i} \) are equally significant. Figure 3 indicates the ideal positive solution and ideal negative solution as expounded in step 7. This follows the ED calculation which is evinced in Tables 14 and 15. Finally, Fig. 4 indicates \( \delta \) calculation.

Ideal positive and negative solutions

Degree of closeness between input and output samples
Figure 4 evinces \( \delta \) of the ‘Y’ output in respect of the input samples. The output \( y_{1} \) has higher \( \delta \) (0.58) to the input samples \( A{}_{i} \) which means that the ten firms could provide a better corporate stability as contrasted to long-term economical growth and survival index. That means the output of the survival index (\( y_{2} \)) as well as long-term economical growth (\( y_{3} \)) gives \( \delta \) of 0.44 and 0.51 to the input samples which are lower on considering the output \( y_{1} \). Tables 10, 11, 12, 13, 14, and 15 finally help in \( (PI_{i} ) \) calculation of as proffered in Table 16
Table 16 implies that the entire alternatives cannot be estimated utilizing an algorithm that is recommended in [16]. Column 6 has a letter I written for alternatives \( A_{3} ,A_{4} ,A_{9} \) and \( A_{10} \).Those alternatives have \( {\text{PI}}_{2} \) carrying two values. Zhang et al.’s algorithm [29] does not render a solution for these cases. Nevertheless, the proposed algorithm incorporated an additional performance indicator \( {\text{PI}}_{5} \) that is centered on FTOPSIS, and this is capable of having a solution to the aforesaid ambiguity. The \( \delta \) betwixt the input alternatives and output aids the fuzzy rough centered MCDM in making a suitable decision. Therefore, the proposed work exclusively renders correlations betwixt the input alternatives and the output in line with the evaluation criterion. It is concluded as of the aforesaid outcomes that the proposed DM can be properly employed to resolve the manifold and DM issues with completely unidentified attribute weights. The proposed work renders a helpful means for managing multicriteria fuzzy DM issues within attribute weights. An appropriate entropy weighting methodology derives the attribute weights as per alternative, and it picks the best alternative as per them.
Conclusion
The proposed work methodically modeled the MCDM for hesitant FRSs. An additional performance parameter “FTOPSIS centered \( \delta \)” is also proposed here to resolve ambiguous cases effectively. And, this is confirmed via implementations on multiple datasets. Correlation matrix which shows the correlation of input alternatives with the output class grounded on a certain set of criteria eventually assists in computing the proposed FTOPSIS centered performance index. Entropy-centric weighing of the attribute aids in selecting the relevant as well as non-redundant attributes. Grounded on the volume of information, this entropy approach finds the index’s weight for the attributes, which is the objective fixed weight methodology. The disorder degrees of the attributes and their utility in the system information are ascertained by Entropy. Finally, the evaluations of upper HFRA and lower approximate HFRA further facilitate the selection of optimum attributes. Thus, a generic approach which is hybrid entropy-centric optimal attribute selector, i.e., RSs and HFSs, shall effectually assist the researchers in vagueness and uncertain DM problems without an ambiguity. Utilizing this proposed entropy weight centric approach, the weights of the attributes are found and the appropriate attributes are selected which eradicates the disturbances (caused by man) and makes outcomes as per facts. The entropy weight together with FTOPSIS method is clear, simple, and reasonable when contrasted to fuzzy synthetic assessment and other evaluation approaches. Nevertheless, the entropy weighting approach merely regards the numerical discrimination degrees of the attribute index and disregards rank discrimination. These shortcomings signify that the entropy approach could not exactly reflect the significance of the index weight, thus causing distorted DM results. This problem can well be tackled in future.
In addition, knowledge reduction is the notable content for the research of RS theory. Therefore, in the future, the proposed algorithm can be extended grounded on interval-valued FRSs and type 2 FSs for knowledge reduction under complete information systems.
References
Garg H, Arora R (2018) Dual hesitant fuzzy soft aggregation operators and their application in decision-making. Cogn Comput 10(5):769–789
Zadeh LA (1979) Fuzzy sets and information granularity. Adv Fuzzy Set Theory Appl 11:3–18
Dubois D, Prade H (1990) Rough fuzzy sets and fuzzy rough sets. Int J Gen Syst 17(2–3):191–209
Wang Y-J, Lee H-S (2007) Generalizing topsis for fuzzy multiple-criteria group decision-making. Comput Math Appl 53(11):1762–1772
Büyüközkan G, Ҫifҫi G (2012) A novel hybrid MCDM approach based on fuzzy DEMATEL, fuzzy ANP and fuzzy TOPSIS to evaluate green suppliers. Expert Syst Appl 39(3):3000–3011
Wang T-C, Lee H-D (2009) Developing a fuzzy TOPSIS approach based on subjective weights and objective weights. Expert Syst Appl 36(5):8980–8985
Ashtiani B, Haghighirad F, Makui A, Montazer G (2009) Extension of fuzzy TOPSIS method based on interval-valued fuzzy sets. Appl Soft Comput 9(2):457–461
Junhua H, Yang Y, Zhang X, Chen X (2018) Similarity and entropy measures for hesitant fuzzy sets. Int Trans Oper Res 25(3):857–886
Torra V (2010) Hesitant fuzzy sets. Int J Intell Syst 25(6):529–539
Chen N, Xu Z, Xia M (2013) Correlation coefficients of hesitant fuzzy sets and their applications to clustering analysis. Appl Math Model 37(4):2197–2211
Xu Z, Xia M (2011) Distance and similarity measures for hesitant fuzzy sets. Inf Sci 181(11):2128–2138
Farhadinia B (2014) Correlation for dual hesitant fuzzy sets and dual interval-valued hesitant fuzzy sets. Int J Intell Syst 29(2):184–205
Rodríguez RM, Martínez L, Torra V, Xu ZS, Herrera F (2014) Hesitant fuzzy sets: state of the art and future directions. Int J Intell Syst 29(6):495–524
Yang X, Song X, Qi Y, Yang J (2014) Constructive and axiomatic approaches to hesitant fuzzy rough set. Soft Comput 18(6):1067–1077
Herbert JP, Yao JT (2009) Criteria for choosing a rough set model. Comput Math Appl 57(6):908–918
Zhang H, He Y (2018) Hesitant fuzzy compatible rough set and its application in hesitant fuzzy soft set based decision making. J Intell Fuzzy Syst 35(1):995–1006
Lu M, Wei G-W (2016) Models for multiple attribute decision making with dual hesitant fuzzy uncertain linguistic information. Int J Knowl Based Intell Eng Syst 20(4):217–227
Yao Y, Zhao Y (2008) Attribute reduction in decision-theoretic rough set models. Inf Sci 178(17):3356–3373
Liang D, Liu D (2015) A novel risk decision making based on decision-theoretic rough sets under hesitant fuzzy information. IEEE Trans Fuzzy Syst 23(2):237–247
Pawlak Z (1982) Rough sets. Int J Comput Inform Sci 11(5):341–356
Jensen R, Shen Q (2001) October). A rough set-aided system for sorting WWW bookmarks. In: Asia-Pacific conference on web intelligence. Springer, Berlin, Heidelberg, pp 95–105
Jensen R, Shen Q (2004) Semantics-preserving dimensionality reduction: rough and fuzzy-rough-based approaches. IEEE Trans Knowl Data Eng 16(12):1457–1471
Jensen R, Shen Q (2004) Fuzzy-rough attribute reduction with application to web categorization. Fuzzy Sets Syst 141(3):469–485
Dubois D, Prade H (1992) Putting rough sets and fuzzy sets together. Intelligent decision support. Springer, Dordrecht, pp 203–232
Pawlak Z (1991) Imprecise categories, approximations and rough sets. Rough sets. Springer, Dordrecht, pp 9–32
Zhang C, Li D, Yan Y (2015) A dual hesitant fuzzy multigranulation rough set over two-universe model for medical diagnoses. Comput Math Methods Med 2015:292710. https://doi.org/10.1155/2015/292710
Chen D, Zhang L, Zhao S, Qinghua H, Zhu P (2011) A novel algorithm for finding reducts with fuzzy rough sets. IEEE Trans Fuzzy Syst 20(2):385–389
Chen S-W, Chen H-C, Chan H-L (2006) A real-time qrs detection method based on moving-averaging incorporating with wavelet denoising. Comput Methods Programs Biomed 82(3):187–195
Zhang H, Shu L, Liao S (2017) Hesitant fuzzy rough set over two universes and its application in decision making. Soft Comput 21(7):1803–1816
Shannon CE (1948) A mathematical theory of communication. Bell Syst Tech J 27(3):379–423
Arora R, Garg H (2018) A robust correlation coefficient measure of dual hesitant fuzzy soft sets and their application in decisionmaking. Eng Appl Artif Intell 72:80–92
Song Y, Hu J (2017) Vector similarity measures of hesitant fuzzy linguistic term sets and their applications. PLoS One 12(12):e0189579
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dikshit-Ratnaparkhi, A., Bormane, D. & Ghongade, R. A novel entropy-based weighted attribute selection in enhanced multicriteria decision-making using fuzzy TOPSIS model for hesitant fuzzy rough environment. Complex Intell. Syst. 7, 1785–1796 (2021). https://doi.org/10.1007/s40747-020-00187-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-020-00187-8