
Abstract
This paper takes into account the estimation of the unknown model parameters and the reliability characteristics for a generalized Fréchet distribution under progressive type-II censored sample. Maximum likelihood estimates are obtained. We calculate asymptotic confidence intervals and also compare in terms of their coverage probabilities for the unknown parameters, and the reliability and hazard rate functions. Further, Bayes estimates are derived with respect to various balanced type symmetric as well as asymmetric loss functions. Note that it is impossible to get the estimates in closed-form. So, we adopt importance sampling method in computing the Bayes estimates. Furthermore, we consider one-sample and two-sample prediction problems under Bayesian framework. In this case, the appropriate predictive intervals are proposed. Monte Carlo simulations are performed to observe the performance of various estimates. Moreover, results from simulation studies indicating the performance of the proposed methods are included. Finally, a real dataset is considered and analyzed for the illustration of the inferential procedures studied in this paper.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The Fréchet distribution was introduced by a French mathematician Maurice Fréchet in 1927. Since then, various extreme value events (skewed data) have been modeled by this distribution. For several applications of Fréchet distribution, we refer to Kotz and Nadarajah (2000). Note that the Fréchet distribution is a particular case of the generalized extreme value distribution. It is dubbed as type-II extreme value distribution (or inverse Weibull distribution) in the literature. Sometimes, it is required to expand families of distributions by introducing new parameter(s) for better description of the data. A way to achieve this goal is by taking power of the cumulative distribution function (CDF), or its difference from 1. That is, \(G^{\alpha }\), which is known as Lehmann type-I distribution, or \(1-(1-G)^{\alpha }\), known as Lemann type-II distribution, where G is the baseline distribution. Nadarajah and Kotz (2003) introduced exponentiated Fréchet distribution with CDF
Here, \(\sigma\) is known as the scale parameter, \(\lambda\) and \(\alpha\) are the shape parameters. The CDF given in (1.1) was constructed by taking the form \(1-(1-G)^{\alpha }\). Note that when \(\alpha =1\), the generalized Fréchet distribution reduces to the usual Fréchet distribution. Inverse generalized exponential distribution is obtained for \(\lambda =1\) (see Abouammoh and Alshingiti 2009). This distribution is right skewed with unique mode. Henceforth, we denote \(X\sim GF(\alpha ,\lambda ,\sigma )\) if X has the distribution function given by (1.1). The probability density function (PDF) of \(GF(\alpha ,\lambda ,\sigma )\) distribution is given by
It can be observed that thicker tails are associated with small values of \(\alpha\) when other parameters are fixed. Further, more peaked distributions are obtained by larger values of \(\lambda\). The tail thickness of the distribution is determined by the product \(\alpha \lambda\). Thus, the generalized Fréchet distribution with CDF (1.1) is much more flexible than the usual Fréchet distribution. For example, in actuarial related studies, usually, a large loss generates a long-right tail distribution. In such cases, generalized Fréchet distribution is useful for modeling them (see Panjer 2006; Gündüz and Genç 2016).
Nadarajah and Kotz (2003) discussed maximum likelihood estimation for this distribution. Abd-Elfattah and Omima (2009) considered the problem of estimating parameters of a generalized Fréchet distribution based on the complete sample when \(\lambda\) is known. They obtained maximum likelihood estimates (MLEs) for \(\sigma\) and \(\alpha\). Mubarak (2011a) studied the problem of estimation of Fréchet distribution based on the record values and obtained various estimates for the unknown parameters. Mubarak (2011b) considered Fréchet distribution associated with scale, shape and location parameters and obtained MLEs based on progressive type-II censored data with binomial removals. Soliman et al. (2014) proposed various estimates of the unknown parameters for lifetime performance index of a two parameter exponentiated Fréchet distribution on the progressive first-failure-censored observations. Soliman et al. (2015) derived maximum likelihood and Bayes estimates for the parameters and some lifetime parameters (reliability and hazard rate functions) of a two parameter exponentiated Fréchet model based on the progressive type-II censored data. They computed approximate Bayes estimates using balanced squared and balanced linex loss functions.
In many practical situations, the Bayesian prediction problem plays a very important role under known prior information in statistics. It can manipulate the past data to acquire future observation for the same population. The main concern relating to the informative sample is the prediction of Bayes for unknown observable that is predicting the future sample from the current sample. It is useful for a real-life practical field such as bio-medical treatments, industrial experiments, and economic data, etc. For some more references in recent years where the problem prediction of censored or future observation based on Bayesian framework under progressive type-II censoring, we refer to Kayal et al. (2017), Singh et al. (2017), Dey et al. (2018) and Bdair et al. (2019). To the best of our knowledge, nobody has considered estimation and prediction for a generalized Fréchet distribution with CDF given in (1.1) based on the progressive type-II censored sample. In this paper, we study this problem. Below, we provide brief description on the progressive type-II censored sample.
The data are often censored in reliability and life testing experiments. The most popular censoring schemes are type-I and type-II. However, for these schemes, the main drawback is that we can not remove live items while an experiment is going on. As mentioned above, in this paper, we consider a generalization of the type-II censoring scheme, where the live items can be removed during the experiment. This is known as the progressive type-II censoring scheme. Under this scheme, we assume that n items are placed on a life testing experiment and \(m(<n)\) are completely observed until failure. When the first failure occurs at random time \(X_{1:m:n}\), \(R_1\) randomly chosen items are removed from \(n-1\) surviving items. At the second failure time \(X_{2:m:n}\), \(R_2\) items are removed randomly from \(n-R_1-2\) remaining items. We continue this process till the mth failure. Denote \(X_{m:m:n}\) as the mth failure time. The set of observed lifetimes \(X_{1:m:n},X_{2:m:n},\ldots ,X_{m:m:n}\) is known as the progressive type-II censored sample with scheme \((R_1,R_2,\ldots ,R_m)\). Note that when \(R_1=R_2=\cdots =R_{m-1}=0\) and \(R_{m}=n-m\), the progressive type-II censored scheme reduces to the type-II censoring scheme, and when \(R_1=R_2=\cdots =R_m=0\), it becomes complete sampling scheme. For relevant detail on this sampling scheme, we refer to Balakrishnan and Aggarwala (2000), Balakrishnan (2007) and Balakrishnan and Cramer (2014).
The objective of this paper is to obtain point and interval estimates of the model parameters and the lifetime parameters (reliability and hazard rate functions) of a \(GF(\alpha ,\lambda ,\sigma )\) distribution based on the progressive type-II censored sample. The reliability and hazard rate functions at time \(t>0\) are given by
and
respectively, where \(\alpha ,\lambda ,\sigma >0\). In particular, we obtain MLEs of \(\alpha ,\lambda ,\sigma ,r(t;\alpha ,\lambda ,\sigma )\) and \(h(t;\alpha ,\lambda ,\sigma )\). For convenience, denote \(r(t)\equiv r(t;\alpha ,\lambda ,\sigma )\) and \(h(t)\equiv h(t;\alpha ,\lambda ,\sigma )\). We also derive Bayes estimates with respect to various balanced loss functions. We obtain confidence intervals using normal and log-normal approximations of the MLEs. Note that various authors have considered estimation of parameters and their functions based on progressive type-II censored sample for different lifetime distributions. Few of these are Ahmed (2014, 2015), Dey and Dey (2014), Rastogi and Tripathi (2014a, b), Singh et al. (2015), Dey et al. (2016, 2017), Seo and Kang (2016), Lee and Cho (2017), Chaudhary and Tomer (2018), Kumar et al. (2018) and Maiti and Kayal (2019).
The paper is arranged as follows. In Sect. 2, we obtain MLEs of the unknown parameters, and the reliability and hazard rate functions. The asymptotic confidence intervals are calculated in Sect. 3. In Sect. 4, we compute Bayes estimates with respect to various balanced loss functions such as balanced squared error, balanced linex and balanced entropy loss functions. Note that it is difficult to obtain the Bayes estimates in closed form. In Sect. 5, importance sampling method is employed to obtain approximate Bayes estimates. Section 6 is devoted for Bayesian prediction. A simulation study is carried out in Sect. 7 to compare the estimates based on their average values and mean squared errors. Further, real life dataset is considered and analyzed for illustrating all the inferential methods developed in Sect. 8. Concluding remarks are added in Sect. 9.
2 Maximum likelihood estimation
In this section, we derive MLEs for the model parameters \(\alpha ,\lambda ,\sigma\), reliability function r(t) and hazard rate function h(t) of a \(GF(\alpha ,\lambda ,\sigma )\) distribution based on the progressive type-II censored data. Denote \(\varvec{X}=(X_{1:m:n},X_{2:m:n},\ldots ,X_{m:m:n})\) the progressive type-II censored sample of size m from a sample of size n drawn from \(GF(\alpha ,\lambda ,\sigma )\) distribution with CDF and PDF given in (1.1) and (1.2), respectively. For convenience, henceforth, we denote \(X_i=X_{i:m:n},\,i=1,2,\ldots ,m.\) The likelihood function is given by
where \(x_{i}=x_{i:m:n}\), \(\vartheta (\lambda ,\sigma ;x_{i})=1-\exp \{-\left( \sigma /x_{i}\right) ^{\lambda }\}\), \(\varvec{x}=(x_1,x_2,\ldots ,x_m)\) and \(C =n(n-R_1-1)(n-R_1-R_2-2)\ldots (n-\sum _{i=1}^{m-1}(R_i+1))\). On differentiating the log-likelihood function \((\ln L(.)=\ell (.))\) with respect to the parameters partially, and then equating to zero, we obtain the normal equations as
and
where \(\xi (\lambda ,\sigma ;x_{i})=\exp \{-\left( \sigma /x_{i}\right) ^{\lambda }\}/ (1-\exp \{-\left( \sigma /x_{i}\right) ^{\lambda }\})\). The solutions of this system of non-linear equations give the MLEs of \(\alpha ,\lambda\) and \(\sigma\). It is easy to notice that the closed-form expressions of the MLEs of \(\alpha ,\lambda\) and \(\sigma\) do not exist. We need to adopt numerical iterative technique in order to get approximate solutions for \(\alpha ,\lambda\) and \(\sigma\). In this purpose, we employ Newton–Raphson iteration method. Denote the MLEs of \(\alpha ,\lambda\) and \(\sigma\) by \({\hat{\alpha }},{\hat{\lambda }}\) and \({\hat{\sigma }}\), respectively. Further, using invariant property, the MLEs of r(t) and h(t) at \(t=t_0\) are respectively obtained as
3 Interval estimation
In this section, we compute approximate confidence intervals for three parameters \(\alpha ,\lambda ,\sigma\), and two lifetime parameters r(t) and h(t). To evaluate asymptotic confidence intervals, the usual large sample approximation is used. Here, the maximum likelihood estimators can be treated as approximately multivariate normal. We use two approaches: (i) normal approximation (NA) of the MLE and (ii) normal approximation of the log-transformed (NL) MLE. To obtain the asymptotic confidence intervals of \(\alpha ,\lambda ,\sigma\), it is required to compute observed Fisher information matrix \((\hat{\mathcal {I}})\) of the MLEs. Denote \(\ell =\ln L\). Then,
where the second order partial derivatives are given in Eqs. (10.1)–(10.5). Further, to obtain the asymptotic variance covariance matrix \(({\hat{M}})\) for the MLEs of \(\alpha ,\lambda\) and \(\sigma\), we need to compute the inverse of \(\hat{\mathcal {I}}\), which is given by
that is, \(\tau _{ij}\) is the (i, j)th element of \({\hat{M}}\); \(i,j=1,2,3\).
3.1 Confidence intervals for \(\alpha ,\lambda\) and \(\sigma\)
In this section, we present confidence intervals for the unknown model parameters based on NA and NL methods. First, consider NA method.
3.1.1 Normal approximation of the MLE
In this subsection, we derive confidence intervals of the parameters \(\alpha ,\lambda\) and \(\sigma\) using asymptotic normality property of the MLEs. From large-sample theory of the MLEs, the sampling distribution of \(({\hat{\alpha }},{\hat{\lambda }},{\hat{\sigma }})\) can be approximately distributed as \(N((\alpha ,\lambda ,\sigma ),{\hat{M}})\). Thus, \(100(1-\gamma )\%\) approximate confidence intervals for \(\alpha ,\lambda\) and \(\sigma\) are obtained as
respectively, where \(Z_{\gamma /2}\) is the upper \((\gamma /2)\)th percentile of the standard normal distribution.
3.1.2 Normal approximation of the log-transformed MLE
Since the parameters \(\alpha ,\lambda\) and \(\sigma\) are positive valued, it is also possible to use logarithmic transformation to compute approximate confidence intervals for these parameters. We refer to Meeker and Escobar (1998) in this direction. They pointed out that the confidence interval obtained using NL method has better coverage probability than that obtained using NA method as in Sect. 3.1.1. The \(100(1-\gamma )\%\) normal approximate confidence intervals for log-transformed MLE are respectively
where \(\tau _{11}\ln {\hat{\alpha }}=var(\ln {\hat{\alpha }})\), \(\tau _{22}\ln {\hat{\lambda }}=var(\ln {\hat{\lambda }})\) and \(\tau _{33}\ln {\hat{\sigma }}=var(\ln {\hat{\sigma }})\). Thus, based on NL method, \(100(1-\gamma )\%\) confidence intervals for \(\alpha\), \(\lambda\) and \(\sigma\) are obtained as
respectively.
3.2 Confidence intervals for r(t) and h(t)
In the previous subsection, we obtain confidence intervals for \(\alpha ,\lambda\) and \(\sigma\). Here, we compute confidence intervals for the reliability characteristics r(t) and h(t) given in (1.3) and (1.4), respectively.
3.2.1 Normal approximation of the MLE
Using this approach, to obtain the approximate confidence intervals for r(t) and h(t), it is required to evaluate their variances. This can be obtained from the inverted observed Fisher information matrix. Here, we use delta method. One may refer to Greene (2000) for detail on delta method. Denote \(A^t\) as the transpose of A. Let
where the first order partial derivatives are given in (10.6)–(10.9). Now, from delta method, the estimates of the variances of \({\hat{r}}\) and \({\hat{h}}\) can be obtained approximately as
respectively, where the partial derivatives are computed at \(({\hat{\alpha }},{\hat{\lambda }},{\hat{\sigma }})\). Again, from the general asymptotic theory of the MLE, the sampling distribution of
can be approximated by a standard normal distribution. Hence, \(100(1-\gamma )\%\) approximate confidence intervals of r and h respectively are
3.2.2 Normal approximation of the log-transformed MLE
In this subsection, we obtain confidence intervals for r(t) and h(t) using NL method. Note that the computation is similar to that discussed in Sect. 3.1.2, and thus the details are omitted. The approximate \(100(1-\gamma )\%\) confidence intervals for the reliability and hazard rate functions are obtained respectively as,
4 Bayesian estimation
This section concerns Bayesian point estimates for three unknown parameters \(\alpha\), \(\lambda\) and \(\sigma\), the reliability and hazard rate functions r(t) and h(t) of the \(GF(\alpha ,\lambda ,\sigma )\) distribution. One of the motivations of taking balanced loss functions is due to its usefulness in decision making. In statistical decision theory, usually, the loss functions focus on the precision of estimation. But, another important criterion in this direction is “goodness of fit”. Zellner (1994) first introduced a balanced loss function (BLF) for the estimation of an unknown parameter \(\theta\) based on random vector \(\varvec{Y}=(Y_1,Y_2, \ldots , Y_n)\) as
where \(0\le \omega \le 1\). Note that this loss function was studied in the context of the general linear model to reflect both goodness of fit and precision of estimation. In the statistical inference, loss functions often reflect any of these two criteria, but not both. As an example, least square estimation reflects goodness of fit consideration. The linex loss function involves a sole emphasis on the precision of estimation. later, Jozani et al. (2006) proposed an extended class of balanced type loss functions of the form
where \(\eta (\theta ,\delta )\) is an arbitrary loss function, \({\hat{\delta }}\) is a priori target estimate of \(\theta\) which can be obtained from the criterion of maximum likelihood, \(\delta\) is an estimate of \(\theta\) and \(\omega \in [0,1]\) is weight. The loss function given by (4.2) has been used by various authors. In the direction, we refer to Farsipour and Asgharzadeh (2004), Asgharzadeh and Farsipour (2008), Ahmadi et al. (2009), Jozani et al. (2012) and Barot and Patel (2017). Note that this loss function was used by Zellner (1986, 1988) to develop minimum expected loss estimates for the coefficients of structural econometric models. It is also remarked that for many years, the balanced loss functions have been the subject of many theoretical and applied studies. For example, Rodrigues and Zellner (1994) used this loss function on the estimation of time to failure, Wolfe and Godsill (2003) applied the BLF on spectral amplitude estimation in audio signal analysis. Further, one may argue that the loss function given by (4.2) provides a potentially useful tool for decision making because of the flexibility of the choices of \(\omega\) and \({\hat{\delta }}\). The BLF (4.2) is well suited to assist in setting credibility insurance premiums with the target choice \({\hat{\delta }}\) relating to a collective estimate of risk and with many instances where a squared error loss is not necessarily an appropriate choice (see Gómez-Déniz 2008). Various authors used a symmetric loss function due to its symmetrical nature in several estimation problems. It provides equal weight to over-estimation as well as to under-estimation. However, there are many situations, where the loss function is not of symmetrical nature. In such situations, an asymmetric loss function would be a better choice than a symmetric loss function. In this paper, we consider both balanced symmetric loss function and balanced asymmetric loss function for better insight in the Bayesian estimation and prediction problems. Especially, we consider balanced squared error loss (BSEL), balanced linex loss (BLL) and balanced entropy loss (BEL) functions, which are respectively given as
The Bayes estimates of the unknown parameter \(\theta\) with respect to the BSEL, BLL and BEL functions given in (4.3)–(4.5) are respectively given by (see Jozani et al. 2012; Barot and Patel 2017)
When \(\omega =1\), the above estimators reduce to the MLE. To derive Bayes estimates, it is required to assign prior distributions to describe the uncertainty of all the unknown parameters of the model. Here, we assume that the model parameters \(\alpha ,\lambda\) and \(\sigma\) have independent gamma distributions with PDFs
respectively, where the hyper-parameters \(a_{i},b_{i},\,i=1,2,3\) are known. The joint prior distribution of \(\alpha\), \(\lambda\) and \(\sigma\) is given by
After some simplification, the posterior distribution of \(\alpha\), \(\lambda\) and \(\sigma\) given \(\varvec{X}=\varvec{x}\) is
where
and
Now, we compute Bayes estimates of the model parameters \(\alpha ,\lambda ,\sigma\) and lifetime parameters r(t), h(t) with respect to the BSEL, BLL and BEL functions. From (4.6), (4.7) and (4.8), the Bayes estimates for \(\varvec{\theta }=(\alpha ,\lambda ,\sigma , r, h)\) are respectively obtained as
and
where \(0\le \omega \le 1\) and \(\hat{\varvec{\theta }}\) is the MLE for \(\varvec{\theta }\). Further, \(\hat{\varvec{\theta }}_{s}\), \(\hat{\varvec{\theta }}_{l}\) and \(\hat{\varvec{\theta }}_{e}\) in (4.15), (4.16) and (4.17) are the Bayes estimates of \(\varvec{\theta }\) with respect to the squared error loss function \(\eta (\varvec{\theta },\delta )=(\delta -\varvec{\theta })^2\), linex loss function \(\eta (\varvec{\theta },\delta )=\exp \{p(\delta -\varvec{\theta })\}-p(\delta -\varvec{\theta })-1\), \(p\ne 0\) and generalized entropy loss function \(\eta (\varvec{\theta },\delta )=(\delta /\varvec{\theta })^{q}-q \ln (\delta /\varvec{\theta })-1,\,q\ne 0\). For the sake of brevity, we omit the complete form of the Bayes estimators of \(\alpha ,\lambda ,\sigma , r(t)\) and h(t) with respect to these loss functions.
5 Importance sampling method
We propose to use the importance sampling technique. In the section, we consider another approximation technique, the importance sampling method to obtain the Bayes estimates for the parameters, reliability and hazard functions. We rewrite the joint posterior distribution of \(\alpha\), \(\lambda\) and \(\sigma\) is given by (4.12) as
where
Now, the importance sampling technique has following steps for sample generation process.
-
Step-1
Generate \(\lambda\) from \(G_\lambda \left( m+a_2, b+\sum _{i=1}^m \ln x_i\right)\) (i.e. a Gamma distribution with shape parameter \((m+a_2)\) and rate parameter \((b+\sum _{i=1}^m \ln x_i)\)).
-
Step-2
For a given \(\lambda\) in Step 1, generate \(\sigma\) from \(G_{\sigma |\lambda } (m\lambda +a_3, b_3)\) (i.e. a Gamma distribution with shape parameter \((m\lambda +a_3)\) and rate parameter \(b_3\)).
-
Step-3
For a given \(\lambda\) in Step 1 and \(\sigma\) in Step 2, generate \(\alpha\) from \(G_{\alpha |\lambda ,\sigma }\left( m+a_1, b_1-\sum _{i=1}^m (1+R_i)\ln \vartheta (\lambda ,\sigma ;x_i)\right)\) (i.e. a Gamma distribution with shape parameter \((m+a_1)\) and rate parameter \((b_1-\sum _{i=1}^m (1+R_i)\ln \vartheta (\lambda ,\sigma ;x_i))\)).
-
Step-4
We repeat 1000 times to obtain \((\alpha _1, \lambda _1, \sigma _1)\), \((\alpha _2,\lambda _2, \sigma _2)\), ..., \((\alpha _{1000}, \lambda _{1000}, \sigma _{1000})\).
The Bayes estimates of a parametric function \(g(\alpha , \lambda , \sigma )\) under linex and entropy loss functions are given by, respectively
and
We compute the Bayes estimates of \(\alpha , \lambda , \sigma , r(t)\) and h(t) after substituting \(\alpha , \lambda , \sigma , r(t)\) and h(t) in place of \(g(\alpha , \lambda , \sigma )\), respectively in Eqs. (5.2) and (5.3) under linex and entropy loss functions. When \(q=-1\), (5.3) reduces to the Bayes estimate with respect to squared error loss function. The details of this method have been omitted to maintain brevity. The respective Bayes estimates with respect to the BLL and BEL can be obtained after replacing the desisted Bayes estimates in (4.15)–(4.17). For some recent references in this direction, we may refer to Sultan et al. (2014), Kundu and Raqab (2015) and Chacko and Asha (2018).
6 Bayesian prediction
In the previous section, we obtain the Bayesian estimation for unknown parameters, reliability and hazard functions. Here, we discuss Bayesian prediction for the future observations based on progressive type-II censoring sample from GF distribution and also compute the corresponding prediction intervals. For various applications of prediction problem, we refer to the recent articles Singh and Tripathi (2015), Asgharzadeh et al. (2015) and Kayal et al. (2017). In this section, we have used two different prediction methods (one-sample and two-sample) for computing prediction estimates and prediction intervals of progressive censoring observations.
6.1 One-sample prediction
Suppose we have observed n number of total life testing units on experiments. Let an informative observed progressive censored sample \(y_i=(y_{i1}, y_{i2}, \ldots , y_{iR_i})\) represents ith failure times at censored \(x_i\). We wish to predict future observations \(y=(y_{ic}; i=1,2,\ldots ,m; c=1,2,\ldots ,R_i)\). Let \(\varvec{x}=(x_1,x_2,\ldots ,x_m)\) be the progressive type-II censored sample with censoring scheme \(R=(R_1,R_2,\ldots ,R_m)\) from a distribution whose CDF and PDF are respectively given by (1.1) and (1.2). We wish to predict future observation \(y=(y_{ic}; i=1,2,\ldots ,m; c=1,2,\ldots ,R_i)\) based on observed samples \((x_1,x_2,\ldots ,x_m)\). The conditional density and distribution functions of y given \(\varvec{x}\) can be written as
and
Notice that the posterior predictive density and distribution functions under the prior \(\pi (\alpha , \lambda , \sigma )\) are respectively given by
and
The Bayesian predictive estimate of y under linex and entropy functions are given by
and
where
and
Note that the above integrals cannot be determined analytically. Thus, one needs to use numerical technique in order to compute the predictive estimates. In this purpose, we use importance sampling methods as mentioned in Sect. 5. Equations (6.5) and (6.6) can be evaluated using importance sampling method as
and
6.1.1 Bayesian prediction interval
The associated predictive survival function \(S_1(y|\varvec{x}, \alpha , \beta )\) is obtained as
The associated posterior distribution function under the prior distribution \(\pi (\alpha , \lambda , \sigma )\) is given by
Equation (6.11) can be evaluated using importance sampling method under squared error loss function as
We obtain two sided \(100(1-\gamma )\%\) equal-tail symmetric predictive interval (L, U), where the lower bound L and the upper bound U can be computed by solving the following non-linear equations
One may refer to Singh and Tripathi (2015) for the algorithm to obtain L and U.
6.2 Two-sample prediction
In this section, we evaluate Bayesian two-sample prediction estimation from future observation based on progressive type-II censoring sample. Two-sample prediction is general version of one-sample prediction. Let \(\varvec{x}=(x_1,x_2,\ldots ,x_m)\) be a progressive censoring sample. Suppose, two-sample prediction is use to predict the jth failure time from a failure sample of size M. A two-sample prediction problem involves the prediction and associated inference about the failure sample \(\varvec{z}=(z_1,z_2,\ldots ,z_M)\). The condition predictive density function of \(z_j\) can be written as
The two-sample posterior predictive density function is given by
The Bayesian predictive estimate of \(z_j\) under linex and entropy loss functions using importance sampling method are obtained as
and
where
and
The predictive survival function is given by
where
which can be approximated using importance sampling method. To obtain the two-sided \(100(1-\gamma )\%\) equal-tail symmetric prediction interval \((L_1,U_1)\) for \(z_j\), we can solve the following non-linear equations
7 Numerical comparisons
In this section, we perform a Monte Carlo simulation study to compare the estimates developed in the previous sections. We obtain their average values and the mean squared error values using statistical software R. Based on the algorithm proposed by Balakrishnan and Sandhu (1995), we replicated 1000 progressive type-II censored samples of size m from a sample of size n drawn from a generalized Fréchet distribution with CDF given by (1.1). Note that \(n=30,40\); \(m=20,25,30,40\) and \(\omega =0,0.3,1\) are considered for the purpose of the numerical study. The true value of \((\alpha , \lambda , \sigma )\) is taken as (0.75, 3.5, 0.25). For three distinct values of \(\omega =0,0.3,1\), the Bayes estimates with respect to the BSEL, BLL and BEL functions are calculated. The values of p and q are considered as \(p=-0.5, 0.005, 1.0\) and \(q=-0.25, -0.05, 0.5\), respectively. All the Bayes estimates are evaluated with respect to the noninformative prior distributions with \(a_1=a_2=a_3=0\) and \(b_1=b_2=b_3=1\). We compute mean squared error (MSE) using the formula
Here, \(\theta _1=\alpha ,\theta _2=\lambda , \theta _3=\sigma , \theta _4=r(t)\), \(\theta _5=h(t)\) and \(M'=1000\). We consider the following censoring schemes (CS)
-
CS-I: \((R_1,R_2,\ldots ,R_m)=(n-m, 0^*(m-1))\)
-
CS-II: \((R_1,R_2,\ldots ,R_m)=(0^*\frac{m}{2}, (n-m), 0^*(\frac{m}{2}-1))\) if m is even, \((R_1,R_2,\ldots ,R_m)=(0^*\frac{m-1}{2}, (n-m), 0^*\frac{m-1}{2})\) if m is odd
-
CS-III: \((R_1,R_2,\ldots ,R_m)=(0^*(m-1),n-m)\)
-
CS-IV: \((R_1,R_2,\ldots ,R_m)=(0^*m)\) if \(m=n\),
where for example \((0^*3,2)\) denotes the censoring scheme (0, 0, 0, 2). The average values and MSE values of the MLEs and the Bayes estimates of \(\alpha ,\lambda ,\sigma ,r(t)\) and h(t) are tabulated in Tables 1 and 2, respectively. Note that the third columns of all the tables are for the MLEs (when \(\omega =1\)), fifth is for the Bayes estimates under BSEL function, sixth, seventh and eighth columns are for the Bayes estimates under BLL function, and ninth, tenth and eleventh columns are for the Bayes estimates with respect to BEL function. Further, each value of \(\omega\) (here \(\omega =0,0.3\)) corresponds to four rows. First and second rows respectively represent average values and the MSE values of the Bayes estimates obtained via importance sampling method. The following points are observed from the tabulated values.
-
(i)
Table 1 presents the simulated values of the average values and the MSE values of the MLEs and the Bayes estimates for \(\alpha\), \(\lambda\) and \(\sigma\) for various choices of n and m. The values are presented under four different sampling schemes described above. In general, in terms of the average values and MSE values, the proposed Bayes estimates perform better than the MLEs. However, among all the Bayes estimates, estimates obtained with respect to the BEL function are superior to others. When considering BLL function, \(p=1\) seems to be a reasonable choice among the other choices. For the case of BEL function, \(q=0.5\) is the best choice among the other choices considered in Table 1. It is noticed that when p is small, the average and MSE values of the Bayes estimates with respect to the BLL and BSEL functions are quiet close, as expected. Moreover, we notice that the MSE decreases when n and m increase.
-
(ii)
Similar to Table 1, we present estimated average values and the MSE values of the reliability function r(t) and hazard rate function h(t) based on various sampling schemes in Table 2. Note that for \((\alpha , \lambda , \sigma )=(0.75, 3.5, 0.25)\), r(t) = 0.156858 and \(h(t)=5.021398\) for \(t=0.5\). Similar pattern of the estimates developed for r(t) and h(t) is observed.
-
(iii)
We have tabulated 90% and 95% asymptotic confidence intervals and coverage probabilities for the parameters \(\alpha ,\lambda\) and \(\sigma\) in Table 3. Six rows are presented corresponding to each sampling scheme. First, third and fifth rows are for the confidence intervals of \(\alpha ,\lambda\) and \(\sigma\), respectively. Second, fourth and sixth rows are for the coverage probabilities of \(\alpha ,\lambda\) and \(\sigma\), respectively. These intervals and coverage probabilities are calculated using NA and NL methods for various choices of n, m and sampling schemes. In general, with the effective increase in sample size, the average lengths of confidence intervals and coverage probabilities tend to decrease. It is also observed that the average lengths of confidence intervals and coverage probabilities obtained by NL method are larger than the corresponding lengths by NA method. Among the coverage probabilities, estimates obtained via NL method perform better than NA method. The coverage probabilities lie below the nominal level of 0.90 and 0.95.
-
(iv)
Table 4 represents \(90\%\) and \(95\%\) asymptotic confidence intervals for the reliability and hazard rate functions. Here, each sampling scheme corresponds to four rows. First and second rows present the asymptotic confidence interval and coverage probabilities for the reliability function and the third and fourth rows present the confidence intervals and coverage probabilities for the hazard rate function. Here, we observe similar pattern as discussed in the previous point.
-
(v)
In Tables 5 and 6, we present one-sample and two-sample predictive estimates under Bayesian framework using Monte Carlo simulation. Here, we consider same true values of the parameters and hyper-parameters. In one-sample prediction, the values of c are taken as 1 and 2 at the stage of ith failure. Similarly, in two-sample prediction, the values of j are considered as 1 and 2. Further, we take the sample size \(M=m\).
For computing the predictive estimates with respect to the BLL and BEL loss functions, we assume \(p=-0.5,0.005,1.0\) and \(q=-0.25,-0.05,0.5\), respectively. With respective to BLL and BEL, the predictive estimate values seems to be smaller at \(p=1.0\) and \(q=0.5\), respectively. It is observed that the predictive estimate values increase when the lifetime of higher order units increase under one-and two-sample cases. Also, we notice that the values of predictive estimates tend to decrease with the effective increase in sample size.
-
(vi)
Table 7 provides the \(90\%\) and \(95\%\) prediction intervals for one-sample and two-sample Bayes prediction. We observe that the \(90\%\) produces prediction intervals with shorter average length than \(95\%\). The average lengths of prediction intervals tend to decrease with the increase in effective sample size. The lengths of these intervals increase with c and j increase under one-and two-sample prediction, respectively.
8 Real data analysis
In this section, we consider real dataset to discuss the estimates obtained in this paper. The dataset presented below, represents the number of cycles to failure for 60 electrical appliances in a life test experiment (see Lawless 2011). Note that this dataset has been used by Seo et al. (2017) (see also Sarhan et al. 2012) for the study of robust Bayesian estimation of a two-parameter bathtub-shaped distribution.
0.014 | 0.034 | 0.059 | 0.061 | 0.069 | 0.080 | 0.123 | 0.142 | 0.165 | 0.210 |
0.381 | 0.464 | 0.479 | 0.556 | 0.574 | 0.839 | 0.917 | 0.969 | 0.991 | 1.064 |
1.088 | 1.091 | 1.174 | 1.270 | 1.275 | 1.355 | 1.397 | 1.477 | 1.578 | 1.649 |
1.702 | 1.893 | 1.932 | 2.001 | 2.161 | 2.292 | 2.326 | 2.337 | 2.628 | 2.785 |
2.811 | 2.886 | 2.993 | 3.122 | 3.248 | 3.715 | 3.790 | 3.857 | 3.912 | 4.100 |
4.106 | 4.116 | 4.315 | 4.510 | 4.580 | 5.267 | 5.299 | 5.583 | 6.065 | 9.701 |
We consider fitting of four reliability models such as exponential (Exp), Fréchet (FR), exponentiated exponential (Eexp) and generalized Fréchet (GF) distributions (see Table 8). To estimate the parameters of these distributions, maximum likelihood estimation is used. Now, for the purpose of the test the goodness of fit of the above models, we employ various test statistics such as (i) Kolmogorov–Smirnov statistic (K–S statistic), (ii) the negative log-likelihood criterion, (iii) Akaikes-information criterion (AIC), (iv) the associated second-order information criterion (AICc) and (v) Bayesian information criterion (BIC).
From the computed values presented in Table 8, it is noticed that the generalized Fréchet distribution fits the given dataset reasonably well since it has the smallest values of the statistics among the fitted models. Thus, based on a progressive type-II censored sample with total size \(n=60\) and the failure sample size \(m=50\) (see Table 9) drawn from the given dataset, we calculate the estimates developed above. Here, we have used various sampling schemes discussed in Sect. 7.
Tables 10 and 11 represent the average values of the estimates for \(\alpha ,\lambda , \sigma\) and r(t), h(t), respectively. Third column of these tables represents the MLEs, fifth represents the Bayes estimates under BSEL function (denoted as BS); sixth, seventh and eighth columns represent the Bayes estimates with respect to BLL function (denoted as BL) and the last three columns represent the Bayes estimates with respect to the BEL function (denoted as BE). Further, in Table 10, each censoring scheme has three row values in the third column (MLE) and six row values in the columns corresponding to the Bayes estimates under importance sampling method. First, second and third row values in the third column represent the MLEs of \(\alpha ,\lambda\) and \(\sigma\), respectively. Fifth column onwards, first two row values correspond to the Bayes estimates for \(\alpha\), next two row values represent the Bayes estimates for \(\lambda\) and final two row values correspond to that for \(\sigma\). In Table 11, each censoring scheme corresponds to two rows in the third column (MLE), and four rows for the Bayes estimates of r(t) and h(t) functions. Furthermore, each value of \(\omega\) corresponds to two rows. In Tables 12 and 13, we present \(90\%\) and \(95\%\) asymptotic confidence intervals and coverage probabilities of \(\alpha ,\lambda ,\sigma\) and r(t), h(t), respectively. In Table 12, each scheme has six rows. First, third and fifth rows and second, four and six rows are for asymptotic confidence intervals and coverage probabilities of \(\alpha ,\lambda\) and \(\sigma\), respectively. Similarly, in Table 13, each scheme has four rows. First two rows represent confidence interval and coverage probabilities for r(t) and the next two rows represent that for h(t). In Table 14, we obtain one-sample prediction estimates of the lifetime of first two units at ith failure. The two-sample prediction estimates of the lifetime of first two units and size of sample \(M=5\) are tabulated in Table 15. Finally, we represent \(90\%\) and \(95\%\) prediction intervals of one-and two-sample prediction cases (Table 16).
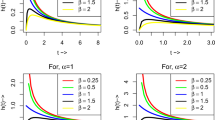
In Fig. 1, we present the histogram of the real dataset and fitted probability density function of four models such as exponential, Fréchet, exponentiated exponential and generalized Fréchet distributions. Here, we show the generalized Fréchet distribution covers the maximum area of the dataset comparing to other distributions. Figure 2a–c present estimated density, reliability and hazard function plots under four censoring schemes. In this case, the unknown model parameters are estimated using maximum likelihood estimation technique. Figure 3a represents the graphs of the estimated probability density functions where the parameters are estimated by maximum likelihood estimation and Bayesian estimation by importance sampling method under BSEL function. Figure 3b depicts the graphs of the density functions where parameters are estimated based on the Bayesian estimation under BLL function for \(p=-0.5,0.005\) and 1. In Fig. 3c, we plot the densities where parameters are estimated based on the Bayesian estimation under BEL function for \(q=-0.25,-0.05\) and 0.5. Similarly, Fig. 4 presents the graphs of the reliability and hazard rate functions for the given dataset. Here, we consider \(\omega =0.3\) while computing Bayes estimates with respect to balanced loss functions for the purpose of plotting the graphs. In Figs. 3 and 4, BS_Im denote for the Bayes estimates with respect to the squared error loss function using importance sampling method. Further, \(p=0.005\)_BL_Im (\(q=-0.05\)_BE_Im) represent Bayes estimates with respect to the BLL (BEL) function when \(p=0.005\) (\(q=-0.05\)).

The histogram of the real dataset and the plots of the probability density functions of the fitted Eexp, FR, Exp, GF models

The plots of the a density, b reliability function and c hazard function based on different censoring schemes

Estimated density plots based on real dataset presented in Sect. 8. a represents the density plots based on the MLE and the Bayes estimates with respect to the balanced squared error loss function, b presents the density plots based on the balanced linex loss function for different values of p, c we provide plots of the density functions using Bayes estimates under balanced entropy loss function for various values of q

Estimated plots of the reliability (a–c) and hazard (d–f) functions based on real dataset
9 Concluding remarks
In this paper, we established various methods for estimating the unknown parameters and reliability characteristics of the exponentiated Fréchet distribution based on progressive type-II censored sample. We applied Newton-Raphson method to compute the maximum likelihood estimates and the asymptotic confidence intervals. Further, Bayes estimates are obtained with respect to three balanced type loss functions. In this purpose, importance sampling method have been introduced. One-sample as well as two-sample Bayesian prediction for the Future observations based on progressive type-II censored sample have been considered. The prediction intervals are also computed. Monte-Carlo simulation is employed to proposed estimates. From the simulation study, it is noticed that the Bayesian estimation is more accurate than the maximum likelihood estimation.
References
Abd-Elfattah A, Omima A (2009) Estimation of the unknown parameters of the generalized Frechet distribution. J Appl Sci Res 5(10):1398–1408
Abouammoh A, Alshingiti AM (2009) Reliability estimation of generalized inverted exponential distribution. J Stat Comput Simul 79(11):1301–1315
Ahmadi J, Jozani MJ, Marchand É, Parsian A (2009) Bayes estimation based on k-record data from a general class of distributions under balanced type loss functions. J Stat Plan Inference 139(3):1180–1189
Ahmed EA (2014) Bayesian estimation based on progressive Type-II censoring from two-parameter bathtub-shaped lifetime model: an markov chain monte carlo approach. J Appl Stat 41(4):752–768
Ahmed EA (2015) Estimation of some lifetime parameters of generalized gompertz distribution under progressively Type-II censored data. Appl Math Model 39(18):5567–5578
Asgharzadeh A, Farsipour NS (2008) Estimation of the exponential mean time to failure under a weighted balanced loss function. Stat Pap 49(1):121–131
Asgharzadeh A, Valiollahi R, Kundu D (2015) Prediction for future failures in weibull distribution under hybrid censoring. J Stat Comput Simul 85(4):824–838
Balakrishnan N (2007) Progressive censoring methodology: an appraisal. Test 16(2):211–259
Balakrishnan N, Aggarwala R (2000) Progressive censoring: theory, methods, and applications. Springer, Berlin
Balakrishnan N, Cramer E (2014) The art of progressive censoring. Springer, Berlin
Balakrishnan N, Sandhu R (1995) A simple simulational algorithm for generating progressive type-II censored samples. Am Stat 49(2):229–230
Barot D, Patel M (2017) Posterior analysis of the compound Rayleigh distribution under balanced loss functions for censored data. Commun Stat Theory Methods 46(3):1317–1336
Bdair O, Awwad RA, Abufoudeh G, Naser M (2019) Estimation and prediction for flexible Weibull distribution based on progressive type II censored data. Commun Math Stat. https://doi.org/10.1007/s40304-018-00173-0
Chacko M, Asha P (2018) Estimation of entropy for generalized exponential distribution based on record values. J Indian Soc Probab Stat 19(1):79–96
Chaudhary S, Tomer SK (2018) Estimation of stress-strength reliability for Maxwell distribution under progressive type-II censoring scheme. Int J Syst Assur Eng Manag 9(5):1107–1119
Dey S, Dey T (2014) On progressively censored generalized inverted exponential distribution. J Appl Stat 41(12):2557–2576
Dey T, Dey S, Kundu D (2016) On progressively Type-II censored two-parameter Rayleigh distribution. Commun Stat Simul Comput 45(2):438–455
Dey S, Sharma VK, Anis M, Yadav B (2017) Assessing lifetime performance index of weibull distributed products using progressive type II right censored samples. Int J Syst Assur Eng Manag 8(2):318–333
Dey S, Nassar M, Maurya RK, Tripathi YM (2018) Estimation and prediction of Marshall–Olkin extended exponential distribution under progressively type-II censored data. J Stat Comput Simul 88(12):2287–2308
Farsipour NS, Asgharzadeh A (2004) Estimation of a normal mean relative to balanced loss functions. Stat Pap 45(2):279–286
Gómez-Déniz E (2008) A generalization of the credibility theory obtained by using the weighted balanced loss function. Insur Math Econ 42(2):850–854
Greene WH (2000) Econometric analysis, 4th edn. Prentice-Hall, New York
Gündüz FF, Genç Aİ (2016) The exponentiated fréchet regression: an alternative model for actuarial modelling purposes. J Stat Comput Simul 86(17):3456–3481
Jozani MJ, Marchand E, Parsian A (2006) Bayes estimation under a general class of balanced loss functions. Rapport de recherche 36. Universit de Sherbrooke, Dpartement de mathmatiques. http://www.usherbrooke.ca/mathematiques/telechargement
Jozani MJ, Marchand É, Parsian A (2012) Bayesian and robust Bayesian analysis under a general class of balanced loss functions. Stat Pap 53(1):51–60
Kayal T, Tripathi YM, Singh DP, Rastogi MK (2017) Estimation and prediction for chen distribution with bathtub shape under progressive censoring. J Stat Comput Simul 87(2):348–366
Kotz S, Nadarajah S (2000) Extreme value distributions: theory and applications. World Scientific, Singapore
Kumar M, Singh SK, Singh U (2018) Bayesian inference for poisson-inverse exponential distribution under progressive type-II censoring with binomial removal. Int J Syst Assur Eng Manag 9(6):1235–1249
Kundu D, Raqab MZ (2015) Estimation of R= P [Y < X] for three-parameter generalized rayleigh distribution. J Stat Comput Simul 85(4):725–739
Lawless JF (2011) Statistical models and methods for lifetime data, vol 362. Wiley, New York
Lee K, Cho Y (2017) Bayesian and maximum likelihood estimations of the inverted exponentiated half logistic distribution under progressive Type II censoring. J Appl Stat 44(5):811–832
Maiti K, Kayal S (2019) Estimation of parameters and reliability characteristics for a generalized rayleigh distribution under progressive type-II censored sample. Commun Stat Simul Comput. https://doi.org/10.1080/03610918.2019.1630431
Meeker WQ, Escobar LA (1998) Statistical methods for reliability data. Wiley, New York
Mubarak M (2011a) Estimation of the Frèchet distribution parameters based on record values. Arab J Sci Eng 36(8):1597–1606
Mubarak M (2011b) Parameter estimation based on the Frechet progressive Type II censored data with binomial removals. Int J Qual Stat Reliab. 2012, Article ID 245910, 5 pages
Nadarajah S, Kotz S (2003) The exponentiated Fréchet distribution. Interstat Electron J. http://interstat.statjournals.net/YEAR/2003/articles/0312001.pdf
Panjer HH (2006) Operational risk: modeling analytics, vol 620. Wiley, New York
Rastogi MK, Tripathi YM (2014a) Estimation for an inverted exponentiated Rayleigh distribution under type II progressive censoring. J Appl Stat 41(11):2375–2405
Rastogi MK, Tripathi YM (2014b) Parameter and reliability estimation for an exponentiated half-logistic distribution under progressive type II censoring. J Stat Comput Simul 84(8):1711–1727
Rodrigues J, Zellner A (1994) Weighted balanced loss function and estimation of the mean time to failure. Commun Stat Theory Methods 23(12):3609–3616
Sarhan AM, Hamilton D, Smith B (2012) Parameter estimation for a two-parameter bathtub-shaped lifetime distribution. Appl Math Model 36(11):5380–5392
Seo J-I, Kang S-B (2016) An objective Bayesian analysis of the two-parameter half-logistic distribution based on progressively type-II censored samples. J Appl Stat 43(12):2172–2190
Seo JI, Kang SB, Kim Y (2017) Robust Bayesian estimation of a bathtub-shaped distribution under progressive Type-II censoring. Commun Stat Simul Comput 46(2):1008–1023
Singh S, Tripathi YM (2015) Bayesian estimation and prediction for a hybrid censored lognormal distribution. IEEE Trans Reliab 65(2):782–795
Singh SK, Singh U, Sharma VK, Kumar M (2015) Estimation for flexible weibull extension under progressive Type-II censoring. J Data Sci 13(1):21–41
Singh DP, Tripathi YM, Rastogi MK, Dabral N (2017) Estimation and prediction for a burr type-III distribution with progressive censoring. Commun Stat Theory Methods 46(19):9591–9613
Soliman AA-E, Ahmed EA-S, Ellah AHA, Farghal A-WA (2014) Assessing the lifetime performance index using exponentiated Frechet distribution with the progressive first-failure-censoring scheme. Am J Theor Appl Stat 3(6):167–176
Soliman AA, Ellah AA, Ahmed EA, Farghal A-WA (2015) Bayesian estimation from exponentiated Frechet model using MCMC approach based on progressive Type-II censoring data. J Stat Appl Probab 4(3):387–403
Sultan K, Alsadat N, Kundu D (2014) Bayesian and maximum likelihood estimations of the inverse Weibull parameters under progressive type-II censoring. J Stat Comput Simul 84(10):2248–2265
Wolfe PJ, Godsill SJ (2003) A perceptually balanced loss function for short-time spectral amplitude estimation. In: 2003 IEEE international conference on acoustics, speech, and signal processing, 2003. Proceedings.(ICASSP’03), vol 5. IEEE, pp V-425
Zellner A (1986) Further results on Bayesian minimum expected loss (MELO) estimates and posterior distributions for structural coefficients. In: Berger JO, Gupta SS (eds) HGB Alexander Foundation. Springer, New York
Zellner A (1988) Bayesian analysis in econometrics. J Econom 37(1):27–50
Zellner A (1994) Bayesian and non-Bayesian estimation using balanced loss functions. In: Statistical decision theory and related topics V. Springer, pp 377–390
Acknowledgements
The authors would like to thank the Editor, Associate Editor and three anonymous reviewers for their valuable comments which have improved the presentation of this paper. One of the author Kousik Maiti thanks the Ministry of Human Resource Development (M.H.R.D.), Government of India for the financial assistantship received to carry out this research work. Suchandan Kayal gratefully acknowledges the partial financial support for this research work under a Grant MTR/2018/000350, SERB, India.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Partial derivatives for Sect. 3
The following partial derivatives are required to compute observed Fisher information matrix \(\hat{\mathcal {I}}\) given in (3.1).
Now, we present the partial derivatives which are needed to compute \(\Phi _{r}^{t}\) and \(\Phi _{h}^{t}\) given in Eq. (3.3).
Rights and permissions
About this article

Cite this article
Maiti, K., Kayal, S. Estimation for the generalized Fréchet distribution under progressive censoring scheme. Int J Syst Assur Eng Manag 10, 1276–1301 (2019). https://doi.org/10.1007/s13198-019-00875-w
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13198-019-00875-w
Keywords
- Progressive type-II censoring
- Maximum likelihood estimation
- Confidence intervals
- Balanced loss functions
- Bayesian estimation
- Importance sampling method
- Bayesian prediction
- Monte Carlo simulation