
Abstract
We propose a new technique for handling multiple attribute group decision making (MAGDM) problems in interval-valued hesitant fuzzy (IVHF) environments with imperfect weight information. Firstly, the quadratic programming model is given to acquire the weights of decision makers by utilizing maximum group consensus between individual and group IVHF decision matrices. Then, the maximum deviation method is employed to build an optimum model, where the best weights for attributes are obtained. Subsequently, an IVHF–TOPSIS approach is developed to obtain a solution that simultaneously has the smallest distance from the IVHF-positive ideal solution (IVHFPIS) and the largest distance from the IVHF-negative ideal solution (IVHFNIS). Ultimately, the novel method is verified with an investment example.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
For any element, when confirming its membership degree of a set, it is difficult to have some possible numerical values (Torra and Narukawa 2009) rather than error amplitude (Atanassov 1986; Atanassov and Gargov 1989; Zadeh 1975) or a certain possibility distribution on the possible values (Dubois and Prade 1980). To address this issue, Torra and Narukawa (2009) extended fuzzy sets (Zadeh 1965) and introduced hesitant fuzzy sets (HFS) where, for any element, its membership degree is simultaneously represented by several numerical values in [0, 1]. Consequently, hesitant fuzzy sets as an efficient tool for dealing with uncertainty have attracted increasing attention (Farhadinia 2013; Peng et al. 2013; Qian et al. 2013; Rodríguez et al. 2012, 2013; Wei 2012; Xia and Xu 2011; Xia et al. 2013; Xu and Xia 2011a, b; Zhang 2013; Zhang and Wei 2013; Zhu et al. 2012; Zhu and Xu 2013).
Recently, Chen et al. (2013a, b) defined the interval-valued hesitant fuzzy set (IVHFS) and investigated several IVHF operators for aggregating IVHF information. Based on these operators, some new IVHF-aggregation operators and MAGDM methods (Chen et al. 2013b; Wei and Zhao 2013; Wei et al. 2013; Zhang and Wu 2014) have also been developed for dealing with the MAGDM problems within the context of IVHFSs. However, these existing interval-valued hesitant fuzzy MAGDM methods have some inherent limitations: (1) when using these methods, the weight information for decision makers and attributes is given ahead of time, which, unavoidably, is more or less subjective and inadequate. (2) These existing methods usually carry out some aggregation operations on interval-valued hesitant fuzzy arguments. Accordingly, the dimensionality of the aggregated IVHF elements may increase. In particular, if the dimensions of the input IVHF elements are a little large, the dimensionality of the fused IVHF elements will be very large, which not only increases computation burden but also results in more original information loss. (3) In many MAGDM problems with IVHF information, the weight information for decision makers and attributes is imperfectly known or entirely unknown.
To make up the above drawbacks, this study develops a new technique for MAGDM under IVHF environments with incomplete weight information. The motivations mainly come from three aspects: (1) how to avoid the information loss of the original information and reduce the computation complexity deserves to be addressed in the developed method. (2) To avoid subjective randomness, DMs’ weights should not be given in advance or assumed to be the same for GDM problems. (3) How to address the situation that the weight information for decision makers and attributes is imperfectly known or entirely unknown is a challenging task.
This novel method can be divided into three parts: first, by using the maximizing group consensus method, we establish a quadratic programming model to objectively obtain the most desirable weight vector of decision makers. Second, according to the maximum deviation method, a new model is built to objectively obtain the optimum weight vector of attributes. Finally, motivated by the classical TOPSIS, we develop an extended TOPSIS to determine the best alternative(s), which includes two stages. The first stage is named IVHF–TOPSIS, which can be used to compute the individual relative closeness coefficient for every alternative to the individual IVHFPIS. The second stage is the standard TOPSIS, which is used to determine the group relative-closeness coefficient for every alternative to group positive ideal solution (GPIS) and choose the most desirable alternative that has the maximum group relative-closeness coefficient.
The paper is arranged as follows: some preliminaries regarding HFS and IVHFS are introduced in Sect. 2; A new approach for handling the IVHF-MAGDM problem with imperfect weight information is developed in Sect. 3; An investment example to show the validity and practicality of our method is given in Sect. 4; Some conclusions are presented in Sect. 5.
2 Preliminaries
Torra (2010) presented the concept of HFS as follows:
Definition 2.1
(Torra 2010) Let us assume \(X\) is a reference set. An HFS \(A\) on \(X\) is a function \({h_A}\left( x \right)\) that returns a subinterval in \(\left[ {0,1} \right]\) when applied to \(X\).
The HFS is characterized by
where \({h_A}\left( x \right)\) consists of some values in \(\left[ {0,1} \right]\) and is simply called a hesitant fuzzy element (HFE) in Xia and Xu (2011), expressed as \(h={h_A}\left( x \right)\).
Let \({l_h}\) represent the number of values in \(h\). For simplicity, we arrange the values in \(h\) in descending order, that is, \(h=\left\{ {\left. {{h^{\sigma \left( i \right)}}} \right|i=1,2, \ldots ,{l_h}} \right\}\); here, we denote \({h^{\sigma \left( i \right)}}\) as the ith largest value in \(h\).
Torra (2010) gave the following laws for any three HFEs, \(h\), \({h_1}\) and \({h_2}\):
-
1.
\({h^c}=\bigcup\nolimits_{{\gamma \in h}} {\left\{ {1 - \gamma } \right\}}\);
-
2.
\({h_1} \cup {h_2}=\bigcup\nolimits_{{{\gamma _1} \in {h_1},{\gamma _2} \in {h_2}}} {\left\{ {{\gamma _1} \vee {\gamma _2}} \right\}}\);
-
3.
\({h_1} \cap {h_2}=\bigcup\nolimits_{{{\gamma _1} \in {h_1},{\gamma _2} \in {h_2}}} {\left\{ {{\gamma _1} \wedge {\gamma _2}} \right\}}\).
Actually, in many MAGDM problems, experts may have difficulties in assigning crisp numbers as their preference values, but the values can be indicated by a subinterval of [0,1]. Thus, Chen et al. (2013a, b) proposed the concept of IVHFS, which will be briefly reviewed here.
Assume that \(D\left( {\left[ {0,1} \right]} \right)\) includes all closed subintervals of \(\left[ {0,1} \right]\), that is,
Definition 2.2
(Xu and Da 2002) Let \(a=\left[ {{a^L},{a^U}} \right],b=\left[ {{b^L},{b^U}} \right] \in D\left( {\left[ {0,1} \right]} \right)\). Then,
-
1.
\(a=b \Leftrightarrow \left[ {{a^L},{a^U}} \right]=\left[ {{b^L},{b^U}} \right] \Leftrightarrow {a^L}={b^L}{\kern 1pt} {\kern 1pt} {\kern 1pt} {\text{and}}{\kern 1pt} {\kern 1pt} {\kern 1pt} {a^U}={b^U}\);
-
2.
\(a+b=\left[ {{a^L},{a^U}} \right]+\left[ {{b^L},{b^U}} \right]=\left[ {{a^L}+{b^L},{a^U}+{b^U}} \right]\);
-
3.
\(\lambda a=\lambda \left[ {{a^L},{a^U}} \right]=\left[ {\lambda {a^L},\lambda {a^U}} \right]\);
-
4.
The complement of \(a\) is denoted by \({a^c}={\left[ {{a^L},{a^U}} \right]^c}=\left[ {1 - {a^U},1 - {a^L}} \right]\).
For intervals \(a=\left[ {{a^L},{a^U}} \right]\) and \(b=\left[ {{b^L},{b^U}} \right]\), Xu and Da (2002) developed a comparison law as follows:
Definition 2.3
(Xu and Da 2002) Let \(\tilde {a}=\left[ {{a^L},{a^U}} \right],\tilde {b}=\left[ {{b^L},{b^U}} \right] \in D\left( {\left[ {0,1} \right]} \right)\), and \({l_{\tilde {a}}}={a^U} - {a^L}\), \({l_{\tilde {b}}}={b^U} - {b^L}\). Then, the possibility degree of \(\tilde {a} \geq \tilde {b}\) is described as:
To rank \({\tilde {a}_i}=\left[ {a_{i}^{L},a_{i}^{U}} \right] \in D\left( {\left[ {0,1} \right]} \right)\) (\(i=1,2, \dots ,n\)), a complementary matrix was introduced as:
where \({p_{ij}}=p\left( {{{\tilde {a}}_i} \geq {{\tilde {a}}_j}} \right)\), \({p_{ij}} \geq 0\), \({p_{ij}}+{p_{ji}}=1\), \({p_{ii}}=\frac{1}{2}\), \(i,j=1,2, \cdots ,n\).
Let \({p_i}=\sum\limits_{{j=1}}^{n} {{p_{ij}}}\), \(i=1,2, \dots ,n\). Then, we can sort the \({a_i}=\left[ {a_{i}^{L},a_{i}^{U}} \right]\) (\(i=1,2, \dots ,n\)) in descending order according to the size of\({p_i}\).
Definition 2.4
(Chen et al. 2013a, b) Supposing \(X\) is a fixed set. An IVHFS \(\tilde {A}\) on \(X\) is a function \(\tilde {A}:X \to D\left( {\left[ {0,1} \right]} \right)\) and is expressed as:
For simplicity, \(\widetilde {h}={\tilde {h}_{\tilde {A}}}\left( x \right)\) is named the interval-valued hesitant fuzzy element (IVHFE). If \(\tilde {\gamma } \in \widetilde {h}\), then \(\tilde {\gamma }=\left[ {{{\tilde {\gamma }}^L},{{\tilde {\gamma }}^U}} \right]\), where \({\tilde {\gamma }^L}=\inf \tilde {\gamma }\) and \({\tilde {\gamma }^U}=\sup \tilde {\gamma }\) denote the lower and upper limits of \(\tilde {\gamma }\), respectively. If \({\tilde {\gamma }^L}={\tilde {\gamma }^U}\) for all \(\tilde {\gamma } \in \widetilde {h}\), then the IVHFE is just the HFE.
Denote \({l_{\tilde {h}}}\) as the number of intervals in \(\tilde {h}\). For simplicity, we rank the values in \(\tilde {h}\) in descending order, that is, \(\tilde {h}=\left\{ {\left. {{{\tilde {h}}^{\sigma \left( j \right)}}} \right|j=1,2, \dots ,{l_{\tilde {h}}}} \right\}\). Here, we denote \({\tilde {h}^{\sigma \left( j \right)}}\) as the jth largest interval in \(\tilde {h}\).
Definition 2.5
(Chen et al. 2013a, b) Suppose that \(\widetilde {h}\), \({\tilde {h}_1}\) and \({\tilde {h}_2}\) are IVHFEs; we define several operations on them:
-
1.
\({\widetilde {h}^c}=\left\{ {\left. {\left[ {1 - {{\tilde {\gamma }}^U},1 - {{\tilde {\gamma }}^L}} \right]} \right|\tilde {\gamma } \in \widetilde {h}} \right\};\)
-
2.
\({\tilde {h}_1} \cup {\tilde {h}_2}=\left\{ {\left. {\left[ {\tilde {\gamma }_{1}^{L} \vee \tilde {\gamma }_{2}^{L},\tilde {\gamma }_{1}^{U} \vee \tilde {\gamma }_{2}^{U}} \right]} \right|{{\tilde {\gamma }}_1} \in {{\tilde {h}}_1},{{\tilde {\gamma }}_2} \in {{\tilde {h}}_2}} \right\};\)
-
3.
\({\tilde {h}_1} \cap {\tilde {h}_2}=\left\{ {\left. {\left[ {\tilde {\gamma }_{1}^{L} \wedge \tilde {\gamma }_{2}^{L},\tilde {\gamma }_{1}^{U} \wedge \tilde {\gamma }_{2}^{U}} \right]} \right|{{\tilde {\gamma }}_1} \in {{\tilde {h}}_1},{{\tilde {\gamma }}_2} \in {{\tilde {h}}_2}} \right\};\)
-
4.
\({\widetilde {h}^\lambda }=\left\{ {\left. {\left[ {{{\left( {{{\tilde {\gamma }}^L}} \right)}^\lambda },{{\left( {{{\tilde {\gamma }}^U}} \right)}^\lambda }} \right]} \right|\tilde {\gamma } \in \widetilde {h}} \right\},\) \(\lambda>0;\)
-
5.
\(\lambda \widetilde {h}{\text{=}}\left\{ {\left. {\left[ {1 - {{\left( {1 - {{\tilde {\gamma }}^L}} \right)}^\lambda },1 - {{\left( {1 - {{\tilde {\gamma }}^U}} \right)}^\lambda }} \right]} \right|\tilde {\gamma } \in \widetilde {h}} \right\},\) \(\lambda>0;\)
-
6.
\({\tilde {h}_1} \oplus {\tilde {h}_2}{\text{=}}\left\{ {\left. {\left[ {\tilde {\gamma }_{1}^{L}+\tilde {\gamma }_{2}^{L} - \tilde {\gamma }_{1}^{L}\tilde {\gamma }_{2}^{L},\tilde {\gamma }_{1}^{U}+\tilde {\gamma }_{2}^{U} - \tilde {\gamma }_{1}^{U}\tilde {\gamma }_{2}^{U}} \right]} \right|{{\tilde {\gamma }}_1} \in {{\tilde {h}}_1},{{\tilde {\gamma }}_2} \in {{\tilde {h}}_2}} \right\};\)
-
7.
\({\tilde {h}_1} \otimes {\tilde {h}_2}{\text{=}}\left\{ {\left. {\left[ {\tilde {\gamma }_{1}^{L}\tilde {\gamma }_{2}^{L},\tilde {\gamma }_{1}^{U}\tilde {\gamma }_{2}^{U}} \right]} \right|{{\tilde {\gamma }}_1} \in {{\tilde {h}}_1},{{\tilde {\gamma }}_2} \in {{\tilde {h}}_2}} \right\}.\)
Generally, the number of intervals in different IVHFEs is not the same. Then, we assume that \(l=\hbox{max} \left\{ {{l_{{{\tilde {h}}_1}}},{l_{{{\tilde {h}}_2}}}} \right\}\), where \({l_{{{\tilde {h}}_1}}}\) and \({l_{{{\tilde {h}}_2}}}\) indicate the number of intervals in IVHFEs \({\tilde {h}_1}\) and \({\tilde {h}_2}\), respectively. For the sake of a more exact operation between \({\tilde {h}_1}\) and \({\tilde {h}_2}\), the following approach proposed in Xu and Zhang (2013) can be used to generalize the shorter IVHFE until their lengths are equal to each other.
Definition 2.6
(Xu and Zhang 2013) Let \(\tilde {h}\) be an IVHFE and \({\tilde {h}^+}\), \({\tilde {h}^ - }\) be the largest and smallest intervals in \(\tilde {h}\), respectively. The interval \(\bar {\tilde {h}}=\eta {\tilde {h}^+}+\left( {1 - \eta } \right){\tilde {h}^ - }\) is said to be an extension value, in which \(\eta \in [0,1]\) indicates the controlling parameter given by the DM based on her/his risk appetite.
Chen et al. (2013a) developed an IVHF Hamming distance between two IVHFEs \({\tilde {h}_1}\) and \({\tilde {h}_2}\) as:
where \(l=\hbox{max} \left\{ {{l_{{{\tilde {h}}_1}}},{l_{{{\tilde {h}}_2}}}} \right\}\), and \(\tilde {h}_{1}^{{\sigma \left( i \right)}}\) and \(\tilde {h}_{2}^{{\sigma \left( i \right)}}\) are the ith largest intervals in \({\tilde {h}_1}\) and \({\tilde {h}_2}\), respectively.
3 A novel method for MAGDM with IVHF information
3.1 Problem description
A MAGDM problem with IVHF information is presented as follows: Suppose \(X=\left\{ {{x_1},{x_2}, \ldots ,{x_m}} \right\}\) is a collection of \(m\) alternatives; \(C=\left\{ {{c_1},{c_2}, \ldots ,{c_n}} \right\}\) is a collection of \(n\) attributes that has the weight information \(w={\left( {{w_1},{w_2}, \ldots ,{w_n}} \right)^T}\), satisfying \({w_j} \in \left[ {0,1} \right]\), \(j=1,2, \ldots ,n\), and \(\sum\nolimits_{{j=1}}^{n} {{w_j}=1.}\) Let \(D=\left\{ {{d_1},{d_2}, \ldots ,{d_p}} \right\}\) represent \(p\) DMs with weight information \(\omega ={\left( {{\omega _1},{\omega _2}, \ldots ,{\omega _p}} \right)^T}\), satisfying \({\omega _k} \in \left[ {0,1} \right]\), \(k=1,2, \dots ,p\), and \(\sum\nolimits_{{k=1}}^{p} {{\omega _k}=1} .\) In addition, let \({\tilde {A}^{\left( k \right)}}={\left( {\tilde {a}_{{ij}}^{{\left( k \right)}}} \right)_{m \times n}}\) be an IVHF decision matrix, where \(\tilde {a}_{{ij}}^{{\left( k \right)}}=\left\{ {\left. {{{\left( {\tilde {a}_{{ij}}^{{\left( k \right)}}} \right)}^{\sigma \left( t \right)}}} \right|t=1,2, \dots ,{l_{\tilde {a}_{{ij}}^{{\left( k \right)}}}}} \right\}\) is composed of the interval values of \({x_i} \in X\) on \({c_j} \in C\), provided by the DM \({d_k} \in D\).
Generally, there exist benefit and cost attributes in an MAGDM problem. For each \(k=1,2, \ldots ,p\), we will obtain the normalized decision matrix \({\tilde {B}^{\left( k \right)}}={\left( {\tilde {b}_{{ij}}^{{\left( k \right)}}} \right)_{m \times n}}\) from the original decision matrices \({\tilde {A}^{\left( k \right)}}={\left( {\tilde {a}_{{ij}}^{{\left( k \right)}}} \right)_{m \times n}}\) by using the following transformation formula:
In most cases, the total elements for different IVHFEs \(\tilde {b}_{{ij}}^{{\left( k \right)}}\) of \({\tilde {B}^{\left( k \right)}}\) (\(k=1,2, \dots ,p\)) are not the same. Assume that
By the use of the regulations mentioned in Xu and Zhang (2013), the normalized decision matrices \({\tilde {B}^{\left( k \right)}}={\left( {\tilde {b}_{{ij}}^{{\left( k \right)}}} \right)_{m \times n}}\) can be replaced by the corresponding decision matrices \({\tilde {H}^{\left( k \right)}}={\left( {\tilde {h}_{{ij}}^{{\left( k \right)}}} \right)_{m \times n}}\) (\(k=1,2, \dots ,p\)), such that \({l_{\tilde {h}_{{ij}}^{{\left( k \right)}}}}=l\), \(\forall\)\(i=1,2, \dots ,m\), \(j=1,2, \dots ,n\), and \(k=1,2, \dots ,p\).
Remark 3.1
Netrusophic theory is also an effective tool to handle uncertainty associated with ambiguity in a manner analogous to human thought, and has been applied into GDM problems successfully (Abdel-Basset et al. 2017; Mohamed et al. 2017). While, Netrusophic set is differentiated by truth-membership function, indeterminacy-membership function and falsity-membership function, which is different from hesitant fuzzy set. Hence, the literature (Abdel-Basset et al. 2017; Mohamed et al. 2017) cannot handle the GDM problems in the interval-valued hesitant fuzzy environments.
3.2 A quadratic programming model for the weights of decision makers
First, for each \(k=1,2, \dots ,p,\) the individual decision matrices
can be aggregated into the group decision matrix
where
Then, the issue of how to confirm the weights of the decision makers can be discussed in two cases as follows:
-
(1)
If for all \(k=1,2, \dots ,p, {\tilde {H}^{\left( k \right)}}\) are equal to each other, that is, \({\tilde {H}^{\left( k \right)}}=\tilde {H}\), then it is rational to assign the decision makers \({d_k}\) the same weight \(\frac{1}{p}\).
-
(2)
If not all \({\tilde {H}^{\left( k \right)}}\) (\(k=1,2, \dots ,p\)) are equal, that is, there exist at least two matrices \({\tilde {H}^{\left( {{k_1}} \right)}}\) and \({\tilde {H}^{\left( {{k_2}} \right)}}\) (\({k_1},{k_2} \in \left\{ {1,2, \dots ,p} \right\}\)) such that \({\tilde {H}^{\left( {{k_1}} \right)}} \ne {\tilde {H}^{\left( {{k_2}} \right)}}\), then we introduce the deviation variables
for all \(i=1,2, \dots ,m\), \(j=1,2, \dots ,n\), \(k=1,2, \dots ,p\). Then, the square deviations among all \({\tilde {H}^{\left( k \right)}}\) (\(k \in \{ 1,2, \dots ,p\}\)) and \(\tilde {H}\) are given by
It is obvious that \(e\left( \omega \right)\) is the function with decision makers’ weight vector \(\omega ={\left( {{\omega _1},{\omega _2}, \dots ,{\omega _p}} \right)^T}\). Let \(G={\left( {{g_{{q_1}{q_2}}}} \right)_{p \times p}}\) be a matrix, where
Thus, Eq. (8) can be rewritten as
Therefore, from the standpoint of maximum group consensus, one can utilize the following model to obtain the weights of decision makers in the GDM environments:
Suppose that \(E={\left( {1,1, \dots ,1} \right)^T}\), one can have
In case we do not consider the condition of \(\omega \geq 0\) temporally, model (M-2) can become
Theorem 3.1
Suppose\({\tilde {H}^{\left( k \right)}}={\left( {\tilde {h}_{{ij}}^{{\left( k \right)}}} \right)_{m \times n}}\) (\(k=1,2, \dots ,p\)) are\(p\)IVHF decision matrices and\(\tilde {H}={\left( {{{\tilde {h}}_{ij}}} \right)_{m \times n}}\)is the group IVHF decision matrix derived from Eq. (6). If not all of\({\tilde {H}^{\left( k \right)}}\) (\(k=1,2, \dots ,p\)) are the same, then (M-3) has the optimum solution:
Proof
Because not all of \({\tilde {H}^{\left( k \right)}}\) (\(k=1,2, \dots ,p\)) are equal, there exists at least one matrix \({\tilde {H}^{\left( {{k_0}} \right)}}\) (\({k_0} \in \left\{ {1,2, \dots ,p} \right\}\)) such that \({\tilde {H}^{\left( {{k_0}} \right)}} \ne \tilde {H}\). Thus, there exists \({i_0} \in \left\{ {1,2, \dots ,m} \right\}\), \({j_0} \in \left\{ {1,2, \dots ,n} \right\}\), and \({t_0} \in \left\{ {1,2, \dots ,l} \right\}\), satisfying \({\left( {\tilde {h}_{{{i_0}{j_0}}}^{{\left( {{k_0}} \right)}}} \right)^{\sigma \left( {{t_0}} \right)}} \ne \tilde {h}_{{{i_0}{j_0}}}^{{\sigma \left( {{t_0}} \right)}}\), i.e., \({\left( {{{\left( {\tilde {h}_{{{i_0}{j_0}}}^{{\left( {{k_0}} \right)}}} \right)}^{\sigma \left( {{t_0}} \right)}}} \right)^L} \ne {\left( {\tilde {h}_{{{i_0}{j_0}}}^{{\sigma \left( {{t_0}} \right)}}} \right)^L}\) or \({\left( {{{\left( {\tilde {h}_{{{i_0}{j_0}}}^{{\left( {{k_0}} \right)}}} \right)}^{\sigma \left( {{t_0}} \right)}}} \right)^U} \ne {\left( {\tilde {h}_{{{i_0}{j_0}}}^{{\sigma \left( {{t_0}} \right)}}} \right)^U}\). Therefore, we have
Thus,
Obviously, according to Eq. (9), we have
Therefore, \(G={\left( {{g_{{q_1}{q_2}}}} \right)_{p \times p}}\) is a symmetry matrix. According to Eqs. (10) and (12), we have
Because\(\omega \ne 0\) stands for the weight vector of experts, so \(G={\left( {{g_{{q_1}{q_2}}}} \right)_{p \times p}}\) is a definite and nonsingular matrix. Then, we can derive the most desirable solution of (M-3) by the following procedures:
The Lagrange function is given by
in which \(\lambda\) represents the Lagrange multiplier.
Second, we acquire the equations as below:
Solving Eq. (14) yields the optimal solution as
Because \(\frac{{{\partial ^2}L\left( {\omega ,\lambda } \right)}}{{\partial {\omega ^2}}}=2G\) is a definite matrix, \(e\left( \omega \right)={\omega ^T}G\omega\) is a strictly convex function. Consequently, \({\omega ^ * }=\frac{{{G^{ - 1}}E}}{{{E^T}{G^{ - 1}}E}}\) is the unique optimum solution of (M-3). The theorem is verified. □
If \({\omega ^ * }=\frac{{{G^{ - 1}}E}}{{{E^T}{G^{ - 1}}E}} \geq 0\), then it is the only optimum solution of (M-3) too; or else we utilize the LINGO software package to handle model (M-3).
3.3 Determining the optimal weights of attributes based on the maximizing deviation method
Assume that \(\Delta\) is a collection of the given weight information (Kim and Ahn 1999; Kim et al. 1999; Park 2004; Park and Kim 1997), where \(\Delta\) is established as having the following forms for \(i \ne j\):
Form 1.
A weak ranking \(\left\{ {{w_i} \geq {w_j}} \right\};\)
Form 2.
A strict ranking \(\left\{ {{w_i} - {w_j} \geq {\alpha _i}} \right\}\left( {{\alpha _i}>0} \right);\)
Form 3.
A ranking of differences \(\left\{ {{w_i} - {w_j} \geq {w_k} - {w_l}} \right\},\quad {\text{for}}\quad j \ne k \ne l;\)
Form 4.
A ranking with multiples \(\left\{ {{w_i} \geq {\alpha _i}{w_j}} \right\}\left( {0 \leq {\alpha _i} \leq 1} \right);\)
Form 5.
An interval form \(\left\{ {{\alpha _i} \leq {w_i} \leq {\alpha _i}+{\varepsilon _i}} \right\}\left( {0 \leq {\alpha _i} \leq {\alpha _i}+{\varepsilon _i} \leq 1} \right).\)
In what follows, motivated by considering the maximum deviation method proposed by Wang (1997), we build a model to obtain the most desirable weights of attributes. For each \({c_j} \in C\), the deviation of \({x_i} \in X\) from any other alternatives regarding the expert \({d_k} \in D\) is defined by:
\(i=1,2, \dots ,m\), \(j=1,2, \dots ,n\), \(k=1,2, \dots ,p\). Let
Further, let
From the above discussion, a model is built to obtain the best weight vector \(w\) by maximizing \(D\left( w \right)\):
To obtain the solution of (M-4), we construct a Lagrange function as below:
where \(\lambda\) represents the Lagrange multiplier.
Moreover, we have
It follows from Eq. (19) that
Substituting Eq. (21) into Eq. (20) yields
Then, we have
Upon normalizing \({w_j}\) (\(j=1,2, \dots ,n\)), we obtain
which is the most desirable weighting vector of attributes.
Furthermore, the constrained optimization model below is built to address the situation in which the information for the weight vector is partially known:
3.4 Extended TOPIS approach for the MAGDM with IVHF information
This subsection will extend the classical TOPIS, originally introduced in Hwang and Yoon (1981), to a MAGDM problem under IVHF environments.
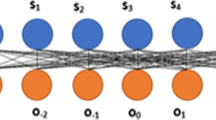
The flowchart of the extended TOPIS method is shown in Fig. 1. The extended method includes the following steps:

The flowchart of the developed method
Step 1. The experts \({d_k} \in D\) furnish the IVHF decision matrices \({\tilde {A}^{\left( k \right)}}={\left( {\tilde {a}_{{ij}}^{{\left( k \right)}}} \right)_{m \times n}}\), which are transformed into normalized decision matrices \({\tilde {H}^{\left( k \right)}}={\left( {\tilde {h}_{{ij}}^{{\left( k \right)}}} \right)_{m \times n}}\) via Eq. (5), for \(k=1,2, \dots ,p\).
Step 2. In cases where we are unaware of the weighting information of experts, we can acquire the weights of experts through Eq. (11).
Step 3. In cases where we are entirely unaware of the weighting information of attributes, we can acquire the attribute weights through Eq. (24); in cases where we are partially aware of the weighting information of attributes, we can derive the attribute weights by solving model (M-5).
Step 4. Determine the IVHFPIS \(\tilde {h}_{+}^{{\left( k \right)}}=\left\{ {\tilde {h}_{{+1}}^{{\left( k \right)}},\tilde {h}_{{+2}}^{{\left( k \right)}}, \dots ,\tilde {h}_{{+n}}^{{\left( k \right)}}} \right\}\) and the IVHFNIS \(\tilde {h}_{ - }^{{\left( k \right)}}=\left\{ {\tilde {h}_{{ - 1}}^{{\left( k \right)}},\tilde {h}_{{ - 2}}^{{\left( k \right)}}, \dots ,\tilde {h}_{{ - n}}^{{\left( k \right)}}} \right\}\) for each decision maker \({d_k}\) by the following equations:
Step 5. Compute \(d_{{+i}}^{{\left( k \right)}}\) for each alternative \({x_i}\) from the IVHFPIS \(h_{+}^{{\left( k \right)}}\) regarding the decision maker \({d_k}\) as:
In a similar way, compute \(d_{{ - i}}^{{\left( k \right)}}\) for each alternative \({x_i}\) from the IVHFNIS \(h_{ - }^{{\left( k \right)}}\) with respect to the decision maker \({d_k}\) as:
Step 6. Compute the RCC of each alternative \({x_i}\) to the IVHFPIS \(h_{+}^{{\left( k \right)}}\) regarding the decision maker \({d_k}\) as:
After calculating the \(C_{i}^{{\left( k \right)}}\) for every decision maker \({d_k}\) (\(k=1,2, \dots ,p\)), we then construct the relative-closeness coefficient matrix as below:
Steps 4–6 extend the standard TOPSIS to IVHF environments. Therefore, it can be called the IVHF–TOPSIS.
Step 7. Utilize the following formulas to confirm the group positive and negative ideal solutions, respectively, and obtain the GPIS \(\tilde {h}_{+}^{G}\) and GNIS \(\tilde {h}_{ - }^{G}\):
Step 8. For any alternative \({x_i}\) from the GPIS \(\tilde {h}_{+}^{G}\) and the GNIS \(\tilde {h}_{ - }^{G}\), compute the separation measures \(d_{{+i}}^{G}\) and \(d_{{ - i}}^{G}\), respectively, as follows:
Step 9. For any alternative \({x_i}\) to GPIS \(d_{{+i}}^{G}\), compute the group relative-closeness coefficient (GRCC) \(C_{i}^{G}\) as below:
Step 10. Based on the GRCCs \(C_{i}^{G},\) we array all alternatives\({x_i}\), \(i=1,2, \dots ,m\), and obtain the most desirable alternative. When the value of \(C_{i}^{G}\) is larger, the alternative \({x_i}\) and the group negative ideal object \(d_{{ - i}}^{G}\) are more different, while the alternative \({x_i}\) and the group positive ideal object \(d_{{+i}}^{G}\) are more similar. Thus, the alternative(s) with the largest GRCC can be selected as the optimum one(s).
4 Illustrative examples
The section will first give an investment example to demonstrate the proposed method. Then, a comparative discussion with other methods will be made to show the superiority of the developed method.
4.1 An investment problem in an IVHF environment
Example 4.1
Consider an investment problem adapted from (Herrera and Herrera-Viedma 2000; Xu 2006), which is composed of five alternatives, four attributes and three decision makers (DMs). The five alternatives are specified as follows: a truck industry (\({x_1}\)), a drug company (\({x_2}\)), a refrigerator company (\({x_3}\)), an arms company (\({x_4}\)) and a television company (\({x_5}\)). The four attributes include the investment risk (\({c_1}\)), the investment return (\({c_2}\)), the social–political impact (\({c_3}\)) and the investment environment (\({c_4}\)). Assume that three experts \({d_k}\) (\(k=1,2,3\)) furnish the IVHF decision matrices \({\tilde {A}^{\left( k \right)}}={\left( {\tilde {a}_{{ij}}^{{\left( k \right)}}} \right)_{m \times n}}\) (\(k=1,2,3\)), shown in Tables 1, 2 and 3.
To apply our method to seek the optimal alternative, two situations are considered as follows:
Situation 1
We are entirely unaware of the weights information for attributes.
Step 1. Since all attributes \({c_j}\) (\(j=1,2,3,4\)) are benefit types, it is unnecessary to normalize \({\tilde {A}^{\left( k \right)}}={\left( {\tilde {a}_{{ij}}^{{\left( k \right)}}} \right)_{5 \times 4}}\) (\(k=1,2,3\)). Under the assumption that all three DMs \({d_k}\) (\(k=1,2,3\)) are pessimists, \({\tilde {A}^{\left( k \right)}}={\left( {\tilde {a}_{{ij}}^{{\left( k \right)}}} \right)_{m \times n}}\) is normalized and becomes\({\tilde {H}^{\left( k \right)}}={\left( {\tilde {h}_{{ij}}^{{\left( k \right)}}} \right)_{m \times n}}\), \(k=1,2,3\) (refer to Tables 4, 5, 6).
Step 2
Calculating the weights of decision makers through Eq. (11) yields
Step 3. By Eq. (24), attribute weights are generated as follows:
Step 4. Using Eqs. (25) and (26), we identify the IVHFPIS \(\tilde {h}_{+}^{{\left( k \right)}}\) and the IVHFNIS \(\tilde {h}_{ - }^{{\left( k \right)}}\) for each decision maker \({d_k}\), respectively, \(k=1,2,3\).
Step 5
Use Eqs. (27) and (28) to compute \(d_{{+i}}^{{\left( k \right)}}\) and \(d_{{ - i}}^{{\left( k \right)}}\) for each alternative \({x_i}\) for the decision maker \({d_k}\):
\(d_{{+1}}^{{\left( 1 \right)}}={\text{0.1923,}}\quad d_{{ - 1}}^{{\left( 1 \right)}}={\text{0.2206,}}\quad d_{{+2}}^{{\left( 1 \right)}}={\text{0.2388}},\quad d_{{ - 2}}^{{\left( 1 \right)}}={\text{0.1741,}}\quad d_{{+3}}^{{\left( 1 \right)}}={\text{0.1525}},\quad d_{{ - 3}}^{{\left( 1 \right)}}={\text{0.2603}},\quad d_{{+4}}^{{\left( 1 \right)}}={\text{0.1449,}}\quad d_{{ - 4}}^{{\left( 1 \right)}}={\text{0.2679}},\quad d_{{+5}}^{{\left( 1 \right)}}={\text{0.2105}},\quad d_{{ - 5}}^{{\left( 1 \right)}}={\text{0.2023}},\)\(d_{{+1}}^{{\left( 2 \right)}}={\text{0.1902,}}\quad d_{{ - 1}}^{{\left( 2 \right)}}={\text{0.2162}},\quad d_{{+2}}^{{\left( 2 \right)}}={\text{0.2100}},\quad d_{{ - 2}}^{{\left( 2 \right)}}={\text{0.1965}},\quad d_{{+3}}^{{\left( 2 \right)}}={\text{0.2612}},\quad d_{{ - 3}}^{{\left( 2 \right)}}={\text{0.1453}},\quad d_{{+4}}^{{\left( 2 \right)}}={\text{0.2709}},\quad d_{{ - 4}}^{{\left( 2 \right)}}={\text{0.1355}},\quad d_{{+5}}^{{\left( 2 \right)}}={\text{0.2001}},\quad d_{{ - 5}}^{{\left( 2 \right)}}={\text{0.2063}},\)\(d_{{+1}}^{{\left( 3 \right)}}={\text{0.2118}},\quad d_{{ - 1}}^{{\left( 3 \right)}}={\text{0.2162}},\quad d_{{+2}}^{{\left( 3 \right)}}={\text{0.2051}},\quad d_{{ - 2}}^{{\left( 3 \right)}}={\text{0.1965}},\quad d_{{+3}}^{{\left( 3 \right)}}={\text{0.2050}},\quad d_{{ - 3}}^{{\left( 3 \right)}}={\text{0.1453}},\quad d_{{+4}}^{{\left( 3 \right)}}={\text{0.2432}},\quad d_{{ - 4}}^{{\left( 3 \right)}}={\text{0.1355}},\quad d_{{+5}}^{{\left( 3 \right)}}={\text{0.1159}},\quad d_{{ - 5}}^{{\left( 3 \right)}}={\text{0.2063}}.\)Step 6: Use Eq. (29) to compute the RCC \(C_{i}^{{\left( k \right)}}\) of each alternative \({x_i}\)regarding the IVHFPIS \(\tilde {h}_{+}^{{\left( k \right)}}\) of the decision maker \({d_k}\) as
Then, we construct the relative-closeness coefficient matrix as:
Step 7. Use Eqs. (31) and (32) to get the GPIS and GNIS, respectively, as:
Step 8. Use Eqs. (33) and (34) to compute \(d_{{+i}}^{G}\) and \(d_{{ - i}}^{G}\) of the alternative \({x_i}\) regarding the GPIS \(\tilde {h}_{+}^{G}\) and the GNIS \(\tilde {h}_{ - }^{G}\), respectively, as follows:
Step 9. Use Eq. (35) to compute the GRCC \(C_{i}^{G}\) of each alternative \({x_i}\) to GPIS \(d_{{+i}}^{G}\) as:
Step 10
As per the GRCC \(C_{i}^{G}\), all alternatives \({x_i}\) (\(i=1,2,3,4,5\)) are ranked as \({x_5} \succ {x_1} \succ {x_3} \succ {x_2} \succ {x_4}\), therefore, \({x_5}\) is chosen as the best alternative.
Situation 2
The information for the weighting vector of attributes is partially known and given as below:
Step 1′
Same as Step 1.
Step 2′
Same as Step 2.
Step 3′
A model is built through (M-5):
Solving this equation yields the weights of attributes as \(w={\left( {{\text{0.2000,0.2500,0.3000,0.4000}}} \right)^T}\).
Step 4′
See Step 4.
Step 5′
Use Eqs. (27) and (28) to calculate \(d_{{+i}}^{{\left( k \right)}}\) and \(d_{{ - i}}^{{\left( k \right)}}\) of the alternative \({x_i}\) regarding the decision maker \({d_k}\):
Step 6′
Use Eq. (29) to compute the RCC \(C_{i}^{{\left( k \right)}}\) of each alternative \({x_i}\) relating to the IVHFPIS \(\tilde {h}_{+}^{{\left( k \right)}}\) of the decision maker \({d_k}\) as
Then, we construct the relative-closeness coefficient matrix as:
Step 7′. Utilize Eqs. (31) and (32) to identify the GPIS and GNIS, respectively, as:
Step 8′. Utilize Eqs. (33) and (34) to compute \(d_{{+i}}^{G}\) and \(d_{{ - i}}^{G}\) of the alternative \({x_i}\) relating to the GPIS \(\tilde {h}_{+}^{G}\) and the GNIS \(\tilde {h}_{ - }^{G}\), respectively, as follows:
Step 9′. Use Eq. (35) to compute the GRCC \(C_{i}^{G}\) of each alternative \({x_i}\) with respect to GPIS \(d_{{+i}}^{G}\) as:
Step 10′
Rank all alternatives \({x_i}\) via the GRCC \(C_{i}^{G}\), \(i=1,2,3,4,5\). Clearly, \({x_1} \succ {x_5} \succ {x_2} \succ {x_4} \succ {x_3}\), and \({x_1}\) is determined to be the best alternative.
4.2 Comparison analysis with other IVHF-MADM methods
This subsection will compare the new method with other IVHF-MADM methods and demonstrate the merits of our method.
4.2.1 Comparison with the IVHF-MADM methods based on TOPSIS
Recently, a new approach was developed to solve an MADM problem with IVHF information in Xu and Zhang (2013). Compared with the method, our method has the following advantages: the method proposed in Xu and Zhang (2013) focuses on only the MADM problems, while our method gives a novel procedure to handle a MAGDM problem in the IVHF surroundings. First, in our method, a quadratic programming model is constructed to obtain the weight vector of experts, which is not considered in the method in Xu and Zhang (2013). Second, although Xu and Zhang (2013) established a model to obtain the weight vector of attributes, this model determined the attribute weights from only an individual IVHF decision matrix, and it cannot confirm the importance weights of attributes in group decision making environments. Our method can obtain the optimal weights of attributes from all of the individual IVHF decision matrices. Finally, TOPSIS methods in Xu and Zhang (2013) only included one stage, while the extended TOPSIS proposed by our method includes two stages: The first stage is called the IVHF-TOPSIS, which can be used to calculate the individual RCC of each alternative to the individual IVHFPIS. The second stage is the standard TOPSIS, which is used to calculate the GRCC of each alternative to GPIS and choose the most desirable one with the maximum group relative-closeness coefficient.
4.2.2 Comparison with the IVHF-MADM methods based on aggregation operators
Recently, many aggregation operators were studied to accommodate IVHF arguments (Wei and Zhao 2013; Wei et al. 2013; Zhang and Wu 2014), including the IVHFWA, IVHFWG, GIVHFWA, GIVHFWG, IVHFOWA, IVHFOWG, GIVHFOWA, GIVHFOWG, IVHFHA, IVHFHG, GIVHFHA, GIVHFHG, HIVFEWA, HIVFEOWA, I-HIVFEOWA, HIVFEWG, HIVFEOWG, I-HIVFEOWG, A-IVHFWA, and A-IVHFWG operators, based on which some IVHF-MADM methods (Wei and Zhao 2013; Wei et al. 2013; Zhang and Wu 2014) have also been proposed to handle a MADM problem in the context of IVHFSs. It is noted that the aforesaid operators and approaches have some inherent weaknesses, which are displayed as follows:
(1) The existing operators and approaches perform an aggregation on the IVHF arguments. Accordingly, the dimension of the fused IVHFE may increase as such an aggregation is performed, which might increase the complexity of calculation and therefore cause information loss. In contrast, our method does not carry out such an aggregation but directly deals with interval-valued hesitant fuzzy arguments. Consequently, it does not increase the dimension of the fused IVHFE and retains as much original preference information as possible.
(2) Our method utilizes the maximizing group consensus and the maximizing deviation methods to obtain the weight vectors of experts and attributes, respectively. In contrast, existing methods in (Wei and Zhao 2013; Wei et al. 2013; Zhang and Wu 2014) assign these weight vectors in advance. Therefore, our method is more objective and reasonable, whereas existing methods in (Wei and Zhao 2013; Wei et al. 2013; Zhang and Wu 2014) are subjective and unreasonable.
5 Conclusions
The paper has proposed a novel method for MAGDM problems with imperfect weight information under IVHF environments, which involves three main findings.
(1) Inspired by the idea that a set of group members should have the largest degree of agreement solution, we have established a quadratic programming model to obtain the most desirable weights of decision makers.
(2) A maximum deviation method was employed to acquire the optimum weights of attributes.
(3) An extended TOPSIS method was proposed to solve a MAGDM problem with IVHF-information. The extended TOPSIS includes two stages: the IVHF–TOPSIS and the standard TOPSIS. The former is used to calculate the RCC of each alternative to the IVHFPIS, while the latter is used to calculate the GRCC of each alternative to GPIS, from which all the alternatives will be ranked and the optimal alternative(s) with the maximum GRCC will be selected.
The validity and practicality of our method have been demonstrated with an investment example, and the merits of the new method have been shown by comparing it with other IVHF-MADM approaches. Comparison analysis shows that the proposed method needs less computational complexity and results in less information losing, which means that the proposed method is much more simplified and effective. In addition, the proposed builds a programming model to determine the weights of the DMs that is based on the maximum consensus analysis. Furthermore, the proposed method can efficiently address the MAGDM problem where the evaluative ratings of alternatives take the form of IVHFE, the weight information of DMs is completely unknown and the weight of attributions are completely unknown or partially unknown. However, it is noted that the proposed method requires all IVHFEs in a MAGDM problem offered by the DM to have the same length; otherwise, it needs to add extra interval numbers to those IVHFEs with the shorter length. However, it is unsuitable to add extra interval numbers into IVHFEs because such a procedure changes the original judgments offered by the DMs and produces different IVHFEs with respect to the original ones based on added different interval numbers, and these different IVHFEs do not equal to the original ones. Thus, how to circumvent this drawback is a meaning and challenging task and also is our future research direction. In addition, in the future, we will continue to study the application of the new method and solve other decision making problems in the setting of interval-valued hesitant fuzzy environments. Furthermore, we will extend the new theoretical results to other types of uncertain environments.
References
Abdel-Basset M, Mai M, Sangaiah AK (2017) Neutrosophic AHP-Delphi Group decision making model basedon trapezoidal neutrosophic numbers. J Amb Intel Hum Comput 1–17
Atanassov K (1986) Intuitionistic fuzzy sets. Fuzzy Set Syst 20:87–96
Atanassov K, Gargov G (1989) Interval valued intuitionistic fuzzy sets. Fuzzy Set Syst 31:343–349
Chen N, Xu ZS, Xia MM (2013a) Correlation coefficients of hesitant fuzzy sets and their applications to clustering analysis. Appl Math Model 37(4):2197–2211
Chen N, Xu ZS, Xia MM (2013b) Interval-valued hesitant preference relations and their applications to group decision making. Knowl Based Syst 37:528–540
Dubois D, Prade H (1980) Fuzzy sets and systems: theory and applications. Academic Press, New York
Farhadinia B (2013) Information measures for hesitant fuzzy sets and interval-valued hesitant fuzzy sets. Inf Sci 240:129–144
Herrera F, Herrera-Viedma E (2000) Linguistic decision analysis: steps for solving decision problems under linguistic information. Fuzzy Set Syst 115:67–82
Hwang CL, Yoon K (1981) Multiple attribute decision making: methods and applications. Springer, Berlin
Kim SH, Ahn BS (1999) Interactive group decision making procedure under incomplete information. Eur J Oper Res 116:498–507
Kim SH, Choi SH, Kim JK (1999) An interactive procedure for multiple attribute group decision making with incomplete information: range-based approach. Eur J Oper Res 118:139–152
Mohamed AB, Mohamed M, Hussien AN et al (2017) A novel group decision-making model based on triangular neutrosophic numbers. Soft Comput. https://doi.org/10.1007/s00500-017-2758-5
Park KS (2004) Mathematical programming models for charactering dominance and potential optimality when multicriteria alternative values and weights are simultaneously incomplete. IEEE T Syst Man Cycle A 34:601–614
Park KS, Kim SH (1997) Tools for interactive multi-attribute decision making with incompletely identified information. Eur J Oper Res 98:111–123
Peng DH, Gao CY, Gao ZF (2013) Generalized hesitant fuzzy synergetic weighted distance measures and their application to multiple criteria decision-making. Appl Math Model 37:5837–5850
Qian G, Wang H, Feng X (2013) Generalized hesitant fuzzy sets and their application in decision support system. Knowl Based Syst 37:357–365
Rodríguez RM, Martínez L, Herrera F (2012) Hesitant fuzzy linguistic term sets for decision making. IEEE Trans Fuzzy Syst 20(1):109–119
Rodríguez RM, Martínez L, Herrera F (2013) A group decision making model dealing with comparative linguistic expressions based on hesitant fuzzy linguistic term sets. Inf Sci 241:28–42
Torra V (2010) Hesitant fuzzy sets. Int J Intell Syst 25(6):529–539
Torra V, Narukawa Y (2009) On hesitant fuzzy sets and decision. In: The 18th IEEE international conference on fuzzy systems, Jeju Island, Korea, pp 1378–1382
Wang Y (1997) Using the method of maximizing deviation to make decision for multi-indices. J Syst Eng Electr 8(3):21–26
Wei GM (2012) Hesitant fuzzy prioritized operators and their application to multiple attribute decision making. Knowl Based Syst 31:176–182
Wei GM, Zhao XF (2013) Induced hesitant interval-valued fuzzy Einstein aggregation operators and their application to multiple attribute decision making. J Intell Fuzzy Syst 24(4):789–803
Wei GM, Zhao XF, Lin R (2013) Some hesitant interval-valued fuzzy aggregation operators and their applications to multiple attribute decision making. Knowl Based Syst 46:43–53
Xia MM, Xu ZS (2011) Hesitant fuzzy information aggregation in decision making. Int J Approx Reason 52:395–407
Xia MM, Xu ZS, Chen N (2013) Some hesitant fuzzy aggregation operators with their application in group decision making. Group Decis Neg 22(2):259–279
Xu ZS (2006) Induced uncertain linguistic OWA operators applied to group decision making. Inf Fusion 7:231–238
Xu ZS, Da QL (2002) The uncertain OWA operator. Int J Intell Syst 17:569–575
Xu ZS, Xia MM (2011a) Distance and similarity measures for hesitant fuzzy sets. Inf Sci 181:2128–2138
Xu ZS, Xia MM (2011b) On distance and correlation measures of hesitant fuzzy information. Int J Intell Syst 26:(2011) 410–425
Xu ZS, Zhang XL (2013) Hesitant fuzzy multi-attribute decision making based on TOPSIS with incomplete weight information. Knowl Based Syst 52:53–64
Zadeh LA (1965) Fuzzy sets. Inf Control 8:338–353
Zadeh LA (1975) The concept of a linguistic variable and its application to approximate reasoning, Part I. Inf Sci 8:199–249
Zhang ZM (2013) Hesitant fuzzy power aggregation operators and their application to multiple attribute group decision making. Inf Sci 234:150–181
Zhang N, Wei GW (2013) Extension of VIKOR method for decision making problem based on hesitant fuzzy set. Appl Math Model 37:4938–4947
Zhang ZM, Wu C (2014) Some interval-valued hesitant fuzzy aggregation operators based on Archimedean t-norm and t-conorm with their application in multi-criteria decision making. J Intell Fuzzy Syst 27:2737–2748
Zhu B, Xu ZS (2013) Hesitant fuzzy Bonferroni means for multi-criteria decision making. J Oper Res Soc 64:1831–1840
Zhu B, Xu ZS, Xia MM (2012) Hesitant fuzzy geometric Bonferroni means. Inf Sci 205:72–85
Acknowledgements
The authors thank the anonymous referees for their valuable suggestions in improving this paper. This work was supported by the National Natural Science Foundation of China (Nos. 11626079 and 61672205), the Natural Science Foundation of Hebei Province of China (No. F2015402033), the Scientific Research Project of Department of Education of Hebei Province of China (Nos. BJ2017031, QN2018161, and QN2016235), and the Natural Science Foundation of Hebei University (Nos. 799207217073 and 799207217108).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors claim that they have no conflicts of interest.
Human/animal rights statement
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhang, C., Wang, C., Zhang, Z. et al. A novel technique for multiple attribute group decision making in interval-valued hesitant fuzzy environments with incomplete weight information. J Ambient Intell Human Comput 10, 2417–2433 (2019). https://doi.org/10.1007/s12652-018-0912-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-018-0912-2