
Abstract
So far, many methods have been proposed to classify items based on ABC analysis, but the results of these methods have had relatively low compliance with the principles of ABC. More precisely, collective value and sometimes the number of items belonging to each category in the methods provided do not meet the basic requirements of ABC called Pareto’s principle. In this study, a number of hybrid methodologies including Shannon’s entropy, TOPSIS (the technique for order preference by similarity to ideal solution) and goal programming are respectively used for determining the weight of criteria which are effective in the inventory items classification, calculations of each item value and its classification based on Pareto’s principle. To this end, the value of each item as well as classification of inventory items is calculated based on Pareto’s principle. The performance of the proposed method is evaluated through (1) statistical analysis, (2) checking the percentage of similarity with other methods and (3) comparison with another method in terms of the number and value allocated to each class. The results confirm the capability of the listed method.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Firms and factories in the world, no matter how small they are, may keep an amount of goods as inventory in storage [1]. The number and variety of goods increase with increased demand and corporate activity. These items are generally divided into three categories: raw materials, semi-manufactured products, and finished goods. Inventories are usually kept with many goals such as flexibility in production, scheduling, and reducing costs including the cost of shortages and storage [2].
For organizations that keep thousands of items of inventory, paying equal attention to all items is irrational. Managers need classification to better control these items. ABC analysis is a widely used and the most comprehensive classification technique of inventory [3]. The main purpose of ABC analysis is to focus on tight control of class A items, less control of class B items, and very low control of class C items [4]. Conventional ABC analysis follows the 80/20 law of Pareto [5]. According to this law, class A is the mostly valued class by having 60–80% of the total value with 10–20% of inventory; class C with the value between 5 and 15% while having 50–60% of inventory has the least significance among the classes. From 20 to 25% of items belonging to class B, values close to 30% can be achieved [6].
In traditional classification, items are classified based on annual dollar usage. However, in addition to the value of annual consumption, there are other measures important in inventory management. Among these, lead-time, obsolescence, and availability can be pointed out [6,7,8]. As the number of criteria increases, so does the need to use multi-criteria decision-making (MCDM) methods to classify items [9]. So far, many studies with different methods and criteria have been carried out for ABC analysis. All previous studies conducted on ABC analysis have focused their attention on two issues, namely using different qualitative and quantitative criteria as well as increasing accuracy in calculating the value of each item. The base of these studies is calculating the value of each item according to different parameters and the final classification based on the resulting value.
In addition to these two issues, determining the number and value of each class of the classification is of the requirements of ABC analysis. In most research conducted in this field, items related to each class are determined qualitatively. This means that after the score is calculated for each item, according to various criteria, the decision makers, based on experience, determine the percentage of items related to each class and rank them. This kind of classification ignores the limitation of the number of items and the total value in Pareto’s principle. This means that in final classifications, one of the two mentioned criteria usually becomes the base and classification is performed on that basis. With this purpose, in this study, it is attempted to offer a model by combining MCDM methods so that, in addition to calculating the value of each item with different qualitative and quantitative criteria, it has the ability to satisfy Pareto’s law limitations.
The reminder parts of this paper are organized based on the description below. In Sect. 2, the literature is reviewed. In Sect. 3, the methods used in this study are described and the mathematical model which classifies inventory items is presented. In Sect. 4, using the information of some studies, the proposed model is run and evaluated, and finally in Sect. 5, the conclusion and future research are presented.
2 Literature review
For the first time, Flores and Whybark [6, 10], using the joint criteria matrix, raised the issue of the multi-attribute inventory classification. The suggested method is appropriate when two criteria are considered for classification. Flores et al. [11] propounded an approach that merged the clustering method with operations constraints. Partovi and Hopton [12] as well as Gajpal et al. [13] presented the analytical hierarchy process (AHP) method to address ABC inventory analysis. Considering different qualitative and quantitative parameters and not requiring plenty of measurements are the advantages of this methodology. Ramanathan [3] proposed a weighted linear optimization model to classify inventory items. In this research, a weighted additive function was used to obtain the score of the performance of inventory items. Ng [7] proposed a linear optimization model for the multiple criteria inventory classification (MCIC). The proposed model converts all the criteria of inventory items into a scalar score. Bhattacharya et al. [14] used TOPSIS to classify inventory items in a company in India. They determined the effectiveness of the proposed method by the analysis of variance (ANOVA) technique. Zhou and Fan [15] proposed the R-model for classification of inventory items. This model that is the improved version of Ramanathan’s model uses two sets of weights for each item.
Tsai and Yeh [16] suggested the particle swarm optimization (PSO) algorithm for the inventory classification. They considered three objectives including minimizing costs, maximizing inventory turnover ratios and maximizing inventory correlation for classification of inventory items. Chu et al. [17] proposed a new inventory control approach called the ABC-fuzzy classification (ABC-FC). The strengths of this approach are the ability to handle variables with either nominal or non-nominal attribute and its easy application. Rezaie [18], to improve the model provided by Ramanathan [3], developed a model that is able to rank items with an optimal score of 1 using a cross-efficiency technique. Hadi-Vancheh [19] conducted a study to extend the Ng-model [7] for classifying inventory items. The extended model, that is a nonlinear programming, determined the most favorable weights within the feasible region for each item. Hadi-Vancheh and Mohamadghasemi [1] in their study proposed the fuzzy analytical hierarchy process (FAHP) and data envelopment analysis (DEA) to calculate weights of criteria and scores of items, respectively. Inventory items in this study were classified under four criteria including annual dollar usage, limitation of warehouse space, average lot cost and lead time. Xiao et al. [20] presented an algorithm which classifies inventors into three classes using the lost profit of item/itemset. Chen [9] proposed an alternative approach to MCIC. He first compared all real items with two virtual items, i.e. the positive ideal item (PII) and negative ideal item (NII), and then calculated an overall performance index for classification of inventory items using relative closeness (RC) index derived from TOPSIS.
Torabi et al. [21] presented a DEA-like model for the ABC inventory classification. The proposed model can consider both quantitative and qualitative criteria. Annual dollar usage, average unit cost, critical factor and lead time are the four criteria used in this research. Kabir and Akhtar Hasin [22] proposed an FAHP approach which determines the weight of criteria in MCIC problems. To accredit the proposed model, 351 raw materials of the switch gear section of Energypac engineering limited (EEL), a large power engineering company in Bangladesh, were classified in their study. Kiris [23] applied the fuzzy analytical network process (FANP) and simple additive weighting (SAW) for the MCIC problem. They categorized inventory items based on 16 criteria categorized into five categories including price, criticality, storage ability, procurement process, and maintenance. Kabir and Akhtar Hasin [24] proposed a hybrid model including FAHP and ANN for classification of inventory items. Unit price, annual demand, criticality, last use date and durability are the criteria used in their study. Lolli et al. [25] introduced a new hybrid MCIC method for the inventory classification based on AHP and the K-means algorithm. Annual dollar usage, critical factor and replenishment lead time are the three factors used in their study. Soyla and Akyol [26] used a classification scheme based on a linear utility function to classify inventory items. For this purpose, a linear programming (LP) was presented with the objective of minimizing average classification errors over the reference set. Park et al. [27] used the cross-evaluation-based weighted linear optimization (CL-WLO) model for classification of inventory items. They classified 47 items based on three criteria including average unit cost, annual dollar usage, and lead time.
Hatefi and Torabi [28] applied a novel methodology which used the concept of the common weight linear optimization model for solving the MCIC problem. The proposed method reduced the number of required LP models for the ABC inventory items classification problem. Kaabi and Jabeur [29] used two TOPSIS models with two different distance metrics (first order and second order metrics) and a combination of the weights of subjective–objective criteria for the inventory classification. They used the variable neighborhood search (VNS) and AHP to calculate the weights of the two types of criteria. Kartal et al. [30] applied three MCDM methods (SAW, AHP and Visekriterijumsko Kompromisno Rangiranje (VIKOR) integrated with machine learning for solving the MCIC problem. Douissa and Jabeur [31] used Elimination and Choice Expressing Reality III (ELECTRE III), as well as entropy and continuous variable neighborhood search (CVNS) techniques for classification of inventory items. Accordingly, the ELECTRE III method was used to compute the global score of each item, CVNS estimated the ELECTRE III parameters and the entropy method was applied to calculate the criteria weights. Kaabi and Alsulimani [32] suggested a hybrid multi objective genetic algorithm TOPSIS (MOGA-TOPSIS) approach for the inventory classification. Through the proposed approach, first, a set of feasible optimal solutions was generated and then, using TOPSIS, an optimal solution was selected. Hadi-vencheh et al. [33] proposed a hybrid model including TOPSIS and Gaussian interval type-2 fuzzy sets (GIT2FSs) for the ABC inventory classification. They used two linear programs to determine the weights of criteria in this research. Rauf et al. [34] applied the TOPSIS method for solving the MCIC problem. Four criteria including average unit cost, average annual usage, critical factor and lead time were used in this research for classification of inventory items.
In general, the conducted studies can be categorized into two groups: MCDM and multi objective decision making (MODM). MCDM methods such as AHP, ANP, TOPSIS, and ELECTRE III were used for (1) increasing the accuracy of classification in compared to the previous methods, (2) considering various quantitative and qualitative criteria, (3) considering the trade-off between criteria, and (4) considering linguistic variables in the weighting process of criteria. By reviewing studies on MODM, we can point out that they were used to (1) increase the accuracy of previous models, (2) optimize the number of items and (3) minimize the error values in each item by using combination methods and paying attention to the impact of items on each other.
As the literature review reveals, simultaneously considering the value and number of items in the problem of classifying inventory items is a main issue which has been neglected in previous studies. In this study, for the first time, a hybrid methodology is presented which solves the MCIC problem so that the maintained issue, Pareto’s principle, is covered as much as possible.
3 Methods used in the study
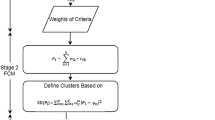
The present study is conducted to provide an appropriate model for ABC analysis. Components of the proposed model are shown in Fig. 1. The first step in the proposed model is to determine criteria related to ABC analysis. The important criteria are determined according to the decision-making environment and decision makers’ ideas. The second step is to determine the weight of each criterion. In the proposed model, the weight of each criterion is determined by Shannon’s entropy.

Methods used in this study
The third step is to determine the value of each item according to various quantitative and qualitative criteria. In this step, using TOPSIS, all items are evaluated and ranked. After the value of each item is determined, items require to be classified. Classification should be based on Pareto’s law and taking into account both the number and value of the criteria. The need to have a minimum deviation of the quantity of each criterion on each floor leads to the use of goal programming for this purpose. Thus, in the fourth step, items are classified using goal programming in three classes of A, B and C. The proposed goal-programming model is presented below.
3.1 Shannon’s entropy
In MCDM problems, knowing the relative weight of the existing criteria is a major step forward in the process of problem solving. Among the methods available, Shannon’s entropy is one of the most popular methods for calculating the weight of criteria [35]. Entropy in the social sciences, physics, and information theory is a concept used to measure uncertainties. As the entropy of information becomes more, its value will be less and vice versa. Entropy is also used in decision-making in the same sense. Thus, as a criterion has more uncertainty (or less entropy), it has more weight and importance. Therefore, by calculating the uncertainty in criteria, one can determine the weight of criteria. Among the properties of Shannon’s entropy is its flexibility in acceptance or non-acceptance of sometimes contradictory comments made by decision makers. Steps necessary to calculate the weight of each criterion using the entropy technique are given below [36, 37].
3.1.1 Step one: normalization
One multi-attribute problem can be fully defined in form of a matrix. Suppose that there are m items and n evaluation criteria. The decision matrix (D) is an m × n matrix whose xij element represents the value of the j-th criteria for the i-th item
To normalize the elements of the matrix, Eq. 2 is used
3.1.2 Step two: determining the value of entropy for each criterion
After normalizing the decision matrix, the value of entropy (ej) for each criterion is obtained by Eq. 3
In the above equation, K is equal to:
3.1.3 Step three: calculating the amount of deviation for each criterion
By determination of entropy for each criterion, the criterion deviation of j-th (dj) can be achieved from Eq. 5:
3.1.4 Step four: calculating the weight of each criterion
The weight of the j-th criterion (wj) is obtained from Eq. 6
The number obtained from the above equations is a parameter that describes the degree of importance of each criterion. As is clear, higher amount of criterion entropy causes the criterion to have much less importance. If a decision-maker considers a special weight (λj) beforehand based on experience or based on the existing methods such as AHP for the j-th criterion, then, the new weight wj′ is calculated as follows
3.2 TOPSIS
TOPSIS is a widely used method in multi-attribute decision-making that ranks m alternatives according to n criteria. Hwang presented TOPSIS for the first time. In this method, alternatives are assessed based on proximity to positive and negative ideal points and then an alternative with maximum proximity to the positive ideal point and maximum distance from the negative ideal point is selected [38]. Among the advantages of using this method are simplicity and producing solution compatible with prioritization (ability to yield an indisputable preference order) [39]. Steps required to prioritize alternatives by TOPSIS are given below.
3.2.1 Step one: normalizing the decision matrix
Consider the decision matrix (D) in the previous section. To normalize the elements of this matrix (rij), Eq. 8 is used
In normalizing the decision matrix (D) elements, the normalized matrix R is obtained (see Eq. 9)
3.2.2 Step two: weighting the normalized matrix
In order to enter the importance of criteria in the evaluation process, the predetermined weight of each criterion (wi) using Eq. 10 is multiplied in the elements of the R matrix. The result is the normalized weighted matrix (Y) below
3.2.3 Step three: determining positive and negative ideal solutions
The positive ideal point (\( A_{i}^{ + } ;i = 1,2, \ldots , n \)) \( A^{ + } \) is obtained from the maximum amount of alternatives in each positive criterion (or from the least value in each negative criterion) in the matrix Y. The negative ideal point A− (\( A_{i}^{ - } ;i = 1,2, \ldots , n \)) is obtained from the minimum amount of alternatives in each positive criterion (or from the maximum value in each negative criterion) in the matrix Y. Equations 12 and 13 show how to calculate either of the amount listed
In the above equation, B and C denote the set of positive and negative criteria, respectively.
3.2.4 Step four: obtaining the value of distances
At this stage, distance from each positive and negative ideal point (\( {\text{S}}_{i}^{ - } \) and \( {\text{S}}_{i}^{*} \)) is obtained from Eqs. 14 and 15, respectively
3.2.5 Step five: calculating how near the options are to the ideal solution
This step solves the similarities to an ideal solution by Eq. 16:
3.3 Goal programming
Goal programming is a prominent planning tool for multi-objective decision analysis with features such as achieving several goals simultaneously based on the priority-rating [40]. Charnes and Cooper introduced this programming for the first time. Goal programming attempts to combine the logic of optimization with the requirements of decision-makers to satisfy several goals. This model includes several goals simultaneously and is set based on minimizing deviations from the targets. The main advantage of goal programming is in removing or fading weak human argument during programming and decision-making [41]. The mathematical formula of goal programming is presented below:
where fk (x) is the function of the k-th goal, and gk is the aspiration level of the k-th goal.
For classification of inventory items based on value and quantity, we present a goal programing mode which uses the result of Shannon’s entropy and TOPSIS as parameter. The mathematical model determines the class of each item. All the parameters and decision variables applied in the proposed model are presented in Table 1. The proposed model including explanation is presented as follows:
3.3.1 Objective function
In the proposed model, the objective function (Eq. 18) refers to minimizing deviations from the goals
3.3.2 Constraints
The set of constraints considered in the proposed method is as follows:
3.3.2.1 The total value of items belonging to each class
Constraints 19–21 decrease the deviation of value that belongs to each class. Based on Eqs. 19–21, the ideal value belonging to classes A, B and C is respectively TPA, \( TP_{B} , \) and TPC percent of the total value of inventory items, which is satisfied by minimizing the amount of \( d_{1}^{ - } ,d_{2}^{ - } , d_{3}^{ - } , d_{2}^{ + } , d_{2}^{ + } \,{\text{and}}\,d_{3}^{ + } \) in the objective function
3.3.2.2 The number of items belonging to each class
Constraints 22 and 23 guarantee that the number of items belonging to each class have the minimum deviation from their aspirations, i.e. \( TN_{A} , TN_{B} , \,and\,TN_{C} \) for classes \( A, B,\,and\,C, \) respectively. These concepts are satisfied by minimizing \( d_{4}^{ - } ,d_{5}^{ - } , d_{6}^{ - } , d_{4}^{ + } , d_{5}^{ + } \,{\text{and}}\,d_{6}^{ + } \) in the objective function
3.3.2.3 Classification rules
The value of each item categorized into class A should be greater than or equal to the value of each item in class B; moreover, the value of each item categorized in class C should be less than or equal to each item in class B. Constraints 25–27 satisfy the maintained rules.
Subject to:
4 Numerical analysis
Numerical analysis of the model is performed in two separate parts. The first part is related to the validation of the model in terms of percentage of similarity of the carried out classification compared with other research. To this end, the information of the article by Yu [5] is used. The mentioned study has examined 47 items according to the four criteria including average unit cost, annual dollar usage, critical factor, and lead-time data. Information on the items in any of the listed parameters is provided in Table 2. According to the availability of the criteria, the first step to use the proposed model is to calculate the weight of each criterion.
Based on the output from Shannon’s entropy, the greatest weight is for critical factor whereas the least weight belongs to the lead-time criterion (see Table 3). After calculating the weight, it is time to evaluate the items according to the four criteria listed.
TOPSIS is used for this purpose. The value obtained by TOPSIS for each item is rounded to four decimal numbers and set in Table 4. Since the items with the same value should be placed in one class, a column called the number of repetitions is considered in Table 4.
The number shown in this column means the number of items with the same value. In order to determine the scope of each class according to Pareto’s law, goal programming is used. Information on the model parameters is set in Table 5.
Based on the carried-out classification, of the 47 items available, 10 items are in class A, 11 items in class B and 26 items in class C (see Table 6).
After classification, it is time for validation of the model. Validity of the proposed model is evaluated in three ways. The first method is the use of the multivariate analysis of variance (MANOVA) and discriminant analysis (DA). These two tests are carried out with the purpose of assessing whether the separation between the items is statistically significant. In MANOVA, the hypothesis is investigated regarding the equality of the vector of the means of the three obtained categories. In Table 7, MANOVA results are listed based on the values of Wilkes, Hotelling and the largest root. According to the results of this test, the aforementioned hypothesis is rejected. Thus, at least one of the existing categories has an acceptable difference in terms of the mean of one or more criteria of the surveys compared to the other categories.
In DA, presence or absence of difference between classes is examined based on values obtained by the items in the criteria. In fact, in DA, function or functions of the variables on which the classification is based are presented, and then the statistical significance of this function or functions is investigated. If significant, at least one of the extracted functions can refer to the existence of distinction between the categories. According to the description given, of the two functions extracted, the first function with statistic value is significant (P value), meaning that a proper distinction is created between the categories (see Table 8).
The second method determines the degree of overlap between the results of the model and those of other methods and compares them with each other. For this purpose, the classification presented in this study is compared with the classification of four other methods (see Table 9) in terms of similarities.
The method is to evaluate the percent of similarity with other methods and then compare the similarity of the proposed method with the other methods of the groups. Table 10 shows the results of similarity compared to the other methods.
It should be noted that each of these four methods, using different criteria, classifies items listed in Table 2. In 10 comparisons carried out, the number of times to which the proposed method had more similarity was 8, and only in one case, with difference of only 9%, the proposed method had less percent of similarity.
The third section is devoted to the validation of knowledge in terms of number and value of each class. According to Table 11, class A valued at more than 51% of 21% of the total items is in the first place, followed by class B with values close to 28% from 23% of the items and class C with values of 20% of more than 55%.
In the proposed model, it is attempted to take into account Pareto’s law as much as possible. On this basis, regarding the class number criterion, class B, A and C have the minimum deviations of zero, 1.2, and 5%, respectively. Regarding the value criterion, classes C, B and A with deviations of zero, 0.2 and 9.7% are in the position from one to three, respectively. This classification has less deviation compared to similar studies. To illustrate this claim, the classification in the study by Bhattacharya et al. [14] using TOPSIS can be noted, and its results can be compared with the classification of the proposed model. Table 12 shows the criteria and performance of 50 alternatives used in Bhattacharya et al.’s study.
In the study by Bhattacharya et al., classes A, B and C with 20, 40, and 40% have the value of 26, 44.71 and 40%, respectively (see Table 13). This is while, using the proposed model, class A has 16% of the items with a value of 61%, class B has 28% of the items with a value of 23%, and class C has 54% of the items with a value of 15%. As is evident, the existing deviations in the classification with Bhattacharya et al.’s method have far greater value and number than the model proposed in this study (see Table 14).
5 Conclusions and future research
The ABC multi-criteria classification can be useful for companies that are faced with a large number of various inventory items. Regarding the ABC classification, many models have been proposed. However, in most of these models, either the final classification is based on the number of factors or the value belongs to each class. This is while taking into account both the listed criteria is of the requirements of the ABC classification. This article has attempted to use methods that provide a multi-attribute model in the classification of items to cover both the mentioned criteria to the extent possible. The first step is to calculate the value of each item in the model using Shannon’s entropy. The second step is to determine the value of each item and rank it using TOPSIS. Simultaneous use of Shannon’s entropy and TOPSIS for weighting and evaluating alternatives leads to ranking of items with correct distance from each other. After determining the value of each item, they should be classified. The final classification is carried out using goal programming. In order to assess the proposed model, three methods of statistical analysis are used to determine the similarity in classification compared with other methods as well as bit-to-bit analysis in each class. Given that the proposed model performs classification in terms of Crisp state, the use of fuzzy logic in any part of the model to enhance the accuracy of the results is suggested as future activities in undertaking research in this area.
References
Hadi-Vencheh, A., Mohamadghasemi, A.: A fuzzy AHP-DEA approach for multiple criteria ABC inventory classification. Expert Syst. Appl. 38(4), 3346–3352 (2011)
Kabir, G.: Multiple criteria inventory classification under fuzzy environment. Int. J. Fuzzy Syst. Appl. (IJFSA) 2(4), 76–92 (2012)
Ramanathan, R.: ABC inventory classification with multiple-criteria using weighted linear optimization. Comput. Oper. Res. 33(3), 695–700 (2006)
Guvenir, H.A., Erel, E.: Multicriteria inventory classification using a genetic algorithm. Eur. J. Oper. Res. 105(1), 29–37 (1998)
Yu, M.-C.: Multi-criteria ABC analysis using artificial-intelligence-based classification techniques. Expert Syst. Appl. 38(4), 3416–3421 (2011)
Flores, B.E., Whybark, D.C.: Implementing multiple criteria ABC analysis. J. Oper. Manag. 7(1–2), 79–85 (1987)
Ng, W.L.: A simple classifier for multiple criteria ABC analysis. Eur. J. Oper. Res. 177(1), 344–353 (2007)
Rezaei, J., Dowlatshahi, S.: A rule-based multi-criteria approach to inventory classification. Int. J. Prod. Res. 48(23), 7107–7126 (2010)
Chen, J.-X.: Multiple criteria ABC inventory classification using two virtual items. Int. J. Prod. Res. 50(6), 1702–1713 (2012)
Flores, B.E., Clay Whybark, D.J.I.J.O.O., Management, P.: Multiple criteria ABC analysis. Int. J. Oper. Prod. Manag. 6(3), 38–46 (1986)
Flores, B.E., Olson, D.L.: Dorai VJM (1992) Management of multicriteria inventory classification. Math. Comput. Model. 16(12), 71–82 (1992)
Partovi, F.Y., Hopton, W.E.J.P., Journal, I.M.: The analytic hierarchy process as applied to two types of inventory problems. Prod. Inventory Manag. J. 35(1), 13 (1994)
Gajpal, P.P., Ganesh, L., Rajendran, C.: Criticality analysis of spare parts using the analytic hierarchy process. Int. J. Prod. Econ. 35(1–3), 293–297 (1994)
Bhattacharya, A., Sarkar, B., Mukherjee, S.: Distance-based consensus method for ABC analysis. Int. J. Prod. Res. 45(15), 3405–3420 (2007)
Zhou, P., Fan, L.: A note on multi-criteria ABC inventory classification using weighted linear optimization. Eur. J. Oper. Res. 182(3), 1488–1491 (2007)
Tsai, C.-Y., Yeh, S.-W.: A multiple objective particle swarm optimization approach for inventory classification. Int. J. Prod. Econ. 114(2), 656–666 (2008)
Chu, C.-W., Liang, G.-S., Liao, C.-T.J.C.: Controlling inventory by combining ABC analysis and fuzzy classification. Comput. Ind. Eng. 55(4), 841–851 (2008)
Rezaei, J.: A note on multi-criteria inventory classification using weighted linear optimization. Yugosl. J. Oper. Res. 20(2), 293–299 (2010)
Hadi-Vencheh, A.: An improvement to multiple criteria ABC inventory classification. Eur. J. Oper. Res. 201(3), 962–965 (2010)
Xiao, Y.-Y., Zhang, R.-Q., Kaku, I.: A new approach of inventory classification based on loss profit. Expert Syst. Appl. 38(8), 9382–9391 (2011)
Torabi, S.A., Hatefi, S.M., Pay, B.S.: ABC inventory classification in the presence of both quantitative and qualitative criteria. Comput. Ind. Eng. 63(2), 530–537 (2012)
Kabir, G., Ahsan, M., Hasin, A.: Framework for benchmarking online retailing performance using fuzzy AHP and TOPSIS method. Int. J. Ind. Eng. Comput. 3(4), 561–576 (2012)
Kiriş, Ş.: Multi-criteria inventory classification by using a fuzzy analytic network process (ANP) approach. Informatica 24(2), 199–217 (2013)
Kabir, G., Akhtar Hasin, M.A.: Multi-criteria inventory classification through integration of fuzzy analytic hierarchy process and artificial neural network. Int. J. Ind. Syst. Eng. 14(1), 74–103 (2013)
Lolli, F., Ishizaka, A., Gamberini, R.: New AHP-based approaches for multi-criteria inventory classification. Int. J. Prod. Econ. 156, 62–74 (2014)
Soylu, B., Akyol, B.: Multi-criteria inventory classification with reference items. Comput. Ind. Eng. 69, 12–20 (2014)
Park, J., Bae, H., Bae, J.: Cross-evaluation-based weighted linear optimization for multi-criteria ABC inventory classification. Comput. Ind. Eng. 76, 40–48 (2014)
Hatefi, S.M., Torabi, S.A.: A common weight linear optimization approach for multicriteria ABC inventory classification. Adv. Decis. Sci. 2015, 1–11 (2015). https://doi.org/10.1155/2015/645746
Kaabi, H., Jabeur, K.: TOPSIS using a mixed subjective-objective criteria weights for ABC inventory classification. In: 2015 15th International Conference on Intelligent Systems Design and Applications (ISDA) pp. 473–478. IEEE, New York (2015)
Kartal, H., Oztekin, A., Gunasekaran, A., Cebi, F.: An integrated decision analytic framework of machine learning with multi-criteria decision making for multi-attribute inventory classification. Comput. Ind. Eng. 101, 599–613 (2016)
Douissa, M.R., Jabeur, K.: A new multi-criteria ABC inventory classification model based on a simplified Electre III method and the continuous variable neighborhood search. In: ILS 2016-6th International Conference on Information Systems, Logistics and Supply Chain (2016)
Kaabi, H., Alsulimani, T.: Novel hybrid multi-objectives multi-criteria ABC inventory classification model. In: Proceedings of the 2018 International Conference on Computers in Management and Business, pp. 79–82. ACM, New York (2018)
Hadi-Vencheh, A., Mohammadghasemi, A., Hosseinzadeh Lotfi, F., Khalil Zadeh, M.: Group multiple criteria ABC inventory classification using TOPSIS approach extended by Gaussian interval type-2 fuzzy sets and optimization programs, Scientia Iranica (2018). https://doi.org/10.24200/sci.2018.5539.1332 (Articles in Press)
Rauf, M., Guan, Z., Sarfraz, S., Mumtaz, J., Almaiman, S., Shehab, E., Jahanzaib, M.: Multi-criteria inventory classification based on multi-criteria decision-making (MCDM) technique. In: Advances in Manufacturing Technology XXXII: Proceedings of the 16th International Conference on Manufacturing Research, incorporating the 33rd National Conference on Manufacturing Research, September 11–13, 2018, University of Skövde, Sweden 2018, p. 343. IOS Press, Amsterdam
Zhao, M., Qiu, W.-H., Liu, B.-S.: Relative entropy evaluation method for multiple attribute decision making. Control Decis. 25(7), 1098–1100 (2010)
Hsu, P.-F., Hsu, M.-G.: Optimizing the information outsourcing practices of primary care medical organizations using entropy and TOPSIS. Qual. Quant. 42(2), 181–201 (2008)
Wu, J., Sun, J., Liang, L., Zha, Y.: Determination of weights for ultimate cross efficiency using Shannon entropy. Expert Syst. Appl. 38(5), 5162–5165 (2011)
Hwang, C.-L., Yoon, K.: Multiple Attribute Decision Making: Methods and Applications a State-of-the-Art Survey, vol. 186. Springer, Berlin (2012)
Yurdakul, M., Iç, Y.T.: Analysis of the benefit generated by using fuzzy numbers in a TOPSIS model developed for machine tool selection problems. J. Mater. Process. Technol. 209(1), 310–317 (2009)
Aouni, B., Kettani, O., Martel, J.-M.: Estimation through the imprecise goal programming model. In: Advances in Multiple Objective and Goal Programming, pp. 120–128. Springer, Berlin (1997)
Charnes, A., Cooper, W.: Analítico: management models and industrial applications of linear programming. Econometric Soc. 30(4), 841–843 (1967)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kheybari, S., Naji, S.A., Rezaie, F.M. et al. ABC classification according to Pareto’s principle: a hybrid methodology. OPSEARCH 56, 539–562 (2019). https://doi.org/10.1007/s12597-019-00365-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12597-019-00365-4