
Abstract
ABC analysis is a widespread inventory management technique designed to classify inventory items—based on their weighted scores—into three ordered categories A, B and C, where category A contains the most important items and category C includes the least important ones. This paper proposes a new ABC classification approach which involves a non-compensatory aggregation procedure, based on a simplified ELECTRE III method, to compute the score of each inventory item. A non-compensatory aggregation scheme means that the bad scores of an item on some significant criteria could not be offset by its high performances on the other criteria. This way of proceeding prohibits this kind of items from being classified into good categories and therefore generates a more realistic ABC classification of inventory items. Since the application of the simplified ELECTRE III method requires the knowledge of some parameter values, the continuous variable neighborhood search meta-heuristic will be used for their estimation. The comparative study—conducted on two real datasets—shows that the classification of items produced by our proposed approach has generated the lowest inventory cost value among those produced by all tested classification models.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
ABC analysis is one of the most widely used techniques in inventory management to classify inventory items into three ordered categories: category A contains the most important items, category B involves items which are moderately important and category C contains items of little importance. The main idea behind the ABC classification consists in managing in an effective way a large number of items by determining the appropriate inventory control policy to use for each category of items. In this way, managers can keep inventory costs under control.
Traditional ABC analysis uses the Annual Dollar Usage (ADU) criterion to classify inventory items into one of the above-mentioned categories. However, recent literature has showed that many other criteria may be significant and should be involved in the item classification process (e.g., ordering cost, criticality, lead time, obsolescence, substitutability, order size requirement, etc.). This indicates that the performance of each inventory item is measured by a composite score issued from a multi-criteria aggregation procedure that combines the item evaluations on the different criteria and the criteria weights (and eventually other intra-criteria parameters). Items are then ordered in a descending order of their composite (or weighted) score. Finally, the following predefined distribution is applied to obtain the different categories: the top 5–10% of items constitute category A (items with highest scores), the next 20–30% of items are classified in category B and category C will involve 50–70% of the remaining items (items with lowest scores).
It should be noted that most of the existing aggregation procedures designed to compute the weighted score of each item are fully compensatory. Despite the advantages of these procedures, full compensability refers to the possibility that an item with weak performance on some significant criteria can be compensated by its high performance on other criteria and therefore it may be classified in a good category. This way of proceeding may provide scores that do not reflect the true performance of inventory items, and in this case, managers will expend precious resources by managing rigorously many insignificant items. In addition, in full compensatory aggregation scheme the criteria weights play the role of substitution rates (or trade-off coefficients) rather than the importance (or power) to be assigned to each criterion, which is their real theoretical meaning. In order to consider weights as “importance coefficients,” non-compensatory aggregation procedures must be used to construct the composite indicators (Podinovskii 1994). To the best of our knowledge, classification approaches with non-compensatory aggregation procedures are rarely tackled in the ABC analysis literature. The works of Zhou and Fan (2007), Hadi-Vencheh (2010), Lolli et al. (2014) and Liu et al. (2016) constitute some exceptions of non-compensatory classification approaches Zhou and Fan (2007), Hadi-Vencheh (2010), Lolli et al. (2014), Liu et al. (2016).
This paper proposes a new non-compensatory classification approach based on a simplified ELECTRE III method to compute the weighted scores of inventory items on which the ABC classification is based. ELECTRE III is a well-known Multi-Criteria Decision-Making (MCDM) method that aims to rank—by using a non-compensatory aggregation scheme—a set of alternatives (inventory items in our case) evaluated on a set of conflicting criteria with non-commensurable measurement scales. Since the application of ELECTRE III method requires the knowledge of some intra-criteria (e.g., indifference, preference and veto thresholds) and inter-criteria (e.g., criteria weights) parameter values, the Continuous Variable Neighborhood Search (CVNS) meta-heuristic will be used for their estimation. To analyze the performance of the proposed approach with respect to some existing classification models, a comparative study is conducted by using two real benchmark datasets: the first one is proposed by Reid (1987) and involves 47 inventory items used in a Hospital Respiratory Therapy Unit (HRTU) Reid (1987), whereas the second is proposed by Liu et al. (2016) and includes 63 inventory items used by a sports equipment manufacturer in China Liu et al. (2016). In this comparative study, the Total Relevant Cost (TRC) function (Mohammaditabar et al. (2012)) is also used to evaluate objectively the ABC classifications generated by of all tested classification approaches Mohammaditabar et al. (2012).
This paper makes three main contributions. First, the proposed classification approach adopts—through ELECTRE III method—a non-compensatory aggregation scheme to compute the global score of each inventory item, a scheme rarely tackled in the ABC inventory classification literature. A non-compensatory logic assumes that a poor score of an item on a specific criterion cannot be necessarily compensated by its good scores on the remaining criteria. Thus, when comparing an item with reasonably good scores on all criteria with an item with a very bad score on one criterion and excellent scores on all remaining criteria, a non-compensatory model (like ELECTRE III method) will be potentially in favor of the first item, whereas a full compensatory model (like the weighted sum model) will be potentially in favor of the second item. Moreover, with a non-compensatory logic, the criteria weights are not considered as “substitution rates” but rather as “coefficients of importance, i.e., the greatest weight is assigned to the most important criterion, which is their real theoretical meaning Vincke (1992), Mousseau (1995), Rogers and Bruen (1998).
Second, the proposed classification approach combines the benefits of MCDM methods and meta-heuristics in order to provide an ABC classification that minimizes an important inventory performance measure: the Total Relevant Cost (TRC). As most MCDM methods, ELECTRE III is designed to explicitly incorporate human judgements (decision-maker’s preferences), to consider a set of conflicting criteria and to deal with evaluations obtained on heterogeneous measurement scales. These advantages come with a price: ELECTRE III has relatively a large number of parameters to be set up. In MCDM context, these parameters are usually elicited through an interactive process, at the end of which the decision-maker provides their values according to his point of view: it is the Direct Elicitation Approach (DEA). However, when it is difficult for the decision-maker to provide such information in a coherent way, the Indirect Elicitation Approach (IEA) (also known as disaggregation approach) might be a suitable solution to elicit automatically the values of these parameters based on a set of pre-assigned items. It is important to underline that most of the existing IEAs are usually based on complex combinatorial optimization problems which are both difficult and time-consuming to solve using classical optimization methods. For this purpose, the CVNS meta-heuristic will be used in this paper to elicit the values of ELECTRE III parameters. The VNS (and its continuous version CVNS) is a widespread meta-heuristic designed to solve complexes combinatorial and continuous optimization problems. Its main advantages are: it provides excellent solutions in a reasonable computation time, it is easy to implement and it requires very few parameters to be set in order to obtain good results.
Third, the comparative study proposed in this paper uses both the Total Relevant Cost (TRC) and two real benchmark datasets to evaluate objectively the performance of all tested ABC classification models. For that purpose, it is important to highlight that most of the existing comparatives studies not only use one benchmark dataset (most often Reid’s dataset) for their experimental results but they are also limited to some elementary comparisons of all obtained ABC classifications (e.g., identifying inventory items which are assigned to the same category by all tested classification approaches).
The outline of this paper is as follows. The relevant literature on ABC inventory classification is presented in Sect. 2. The proposed classification approach will be detailed in Sect. 3. In Sect. 4, the comparative study of all tested classification models is reported and discussed. Finally, conclusions and perspectives for future research are reported in Sect. 5.
2 Related literature
Flores and Whybark (1986, 1987) were the first authors to consider a multi-criteria scoring of inventory items in order to classify them into ABC categories Flores and Whybark (1986, 1987). Since then, many classification approaches are proposed in the literature to solve in different ways this inventory classification problem . In spite of this extensive literature, most of the existing classification approaches may be categorized into four main classes: (i) classification approaches based on Mathematical Programming (MP) techniques, (ii) classification approaches based on Artificial Intelligence (AI) and Meta-Heuristics (MH) techniques, (iii) classification approaches based on Multi-Criteria Decision-Making (MCDM) techniques and (iv) classification approaches based on hybrid (HB) techniques.
2.1 Classification approaches based on MP techniques
The main idea behind this family of classification approaches is that a Mathematical Programming (MP) model (which may be linear or nonlinear) is used to generate a vector (or a matrix) of criteria weights (and perhaps some other parameters) in order to compute—through its objective function—a global score for each inventory item. Based on these scores, items are then classified into ABC categories according to a predefined distribution.
Ramanathan (2006) introduced the first Linear Programming (LP) model (hereafter called R-model) to solve the multi-criteria ABC inventory classification problem Ramanathan (2006). This LP model uses a weighted additive function as objective function to combine the inventory item performances on the different criteria and the criteria weights into an overall normalized score. Two major criticisms may be addressed to the R-model. First, the scoring function of the R-model, i.e., its objective function, is fully compensatory, and this means the possibility of offsetting a poor performance of an item on some criteria by sufficiently high values on other criteria. Therefore, an item with bad scores on some significant criteria could be classified, due to the full compensability, into good categories, and this can generate a non-realistic ABC classification of inventory items. Second, by applying R-model, it may occur that two items with the same weighted score will be assigned into two different (but adjacent) categories. This is due to the fact that the assignment of an item into a specific category with the R-model is determined by the position of this item in the ranking and two predefined cutting levels which set the number of items involved in each category. To overcome the first limitation of the R-model, Zhou and Fan (2007) proposed a classification approach based on two LP models (called hereafter ZF-model) Zhou and Fan (2007). The first LP model (respectively, the second)—to be maximized (respectively, to be minimized)—computes the best (respectively, the worst) score that an inventory item may have by generating the most (respectively, the least) favorable weights for this item. Then, Zhou and Fan (2007) proceed with a convex combination of these two scores (after their normalization) in order to generate the overall score of each inventory item. Ng (2007) (called hereafter NG-model) proposed an extension of the R-model in which the decision-maker can introduce additional constraints that express an ordinal ranking on the criteria weights Ng (2007). Ng (2007) has shown that its model may be written, by performing some simplifications, in a canonical form with only one equality constraint and, therefore, it can be solved without using any linear optimizer. However, it should be noted that the overall scores of inventory items generated by NG-model have the drawback of being independent of criteria weights. To overcome the weakness of the NG-model, Hadi-Vencheh (2010) (called hereafter H-model) proposed a Nonlinear Programming (NLP) model that incorporates the effects of weights in the computation of the overall score of inventory items Hadi-Vencheh (2010). The nonlinearity of the H-model is due to the constraint that assumes that the sum of the squared criteria weights is equal to 1. It should be noted that in the ABC analysis literature, many other works have tried to improve the NG-model (e.g., Jie et al. (2010), Fu et al. (2015), Zheng et al. (2017)).
It is important to underline that most above mathematical programming-based classification models consider only quantitative criteria. Classification models that take into account both quantitative and qualitative criteria are rather rare in the ABC analysis literature. To overcome this shortcoming, Hatefi et al. (2013) proposed a linear optimization model based on a DEA (Data Envelopment Analysis) model—introduced by Cook et al. (1996)—that considers both qualitative and quantitative criteria. The main aim of their optimization model is to improve the discrimination power among inventory items. Similarly, Torabi et al. (2012) modified the DEA model introduced by Hatefi and Torabi (2010)—by integrating some concepts used in the Imprecise DEA (IDEA) model developed by Zhu (2003)—in order to perform the ABC inventory classification when both quantitative and qualitative criteria are considered (Torabi et al. 2012; Hatefi et al. 2013).
2.2 Classification approaches based on AI & MH techniques
This family of classification approaches can be split into two distinct subfamilies: classification approaches based on Meta-Heuristics (MH) and classification approaches based on Artificial Intelligence (AI) techniques.
2.2.1 Classification approaches based on meta-heuristics
The main idea behind this family of approaches is that a meta-heuristic (e.g., Genetic Algorithm (GA), Particle Swarm Optimization (PSO), Simulated Annealing (SA), etc.) is used to elicit the parameters of the aggregation model (essentially the criteria weights) by optimizing single- or many-objective functions (e.g., minimizing an inventory cost function, minimizing the rate of misclassified items, maximizing the turnover ratio, etc.). Then, a simple weighted sum is used as aggregation model to compute the overall score of each item. Based on these scores, items are finally classified into ABC categories according to a predefined distribution.
Guvenir and Erel (1998) proposed a classification approach—called GAMIC (Genetic Algorithm for Multi-Criteria Inventory Classification)—which uses the Genetic Algorithm (GA) to learn the criteria weights and two cutoff points by maximizing the rate of well-classified items (fitness function of the GA) Guvenir and Erel (1998). Once weights are obtained, the simple weighted sum is then applied to compute the overall score of each item. Tsai and Yeh (2008) proposed a classification approach based on Particle Swarm Optimization (PSO) meta-heuristic Tsai and Yeh (2008). The aim was to learn the criteria weights, the cutoff points and the number of categories by optimizing simultaneously (through a Goal Programming (GP) modelization) or separately three objective functions: minimizing the Total Relevant Costs (TRCs), maximizing the Demand Correlation (DC) and maximizing Inventory Turnover Ratios (ITRs). Mohammaditabar et al. (2012) proposed an integrated classification approach which simultaneously categorizes the inventory items and finds the best inventory policy for each category Mohammaditabar et al. (2012). For this purpose, a bi-objective mathematical model minimizing both the dissimilarity between each pair of items and the Total Inventory Cost (TIC) is formulated. Since it is difficult to obtain the optimal solution of the above mathematical model due to the non-convexity of its objective functions, the Simulated Annealing (SA) meta-heuristic is used to find “good” solutions.
2.2.2 Classification approaches based on artificial intelligence techniques
The main idea behind these classification approaches is that a set of Artificial Intelligence (AI) techniques—such as Artificial Neural Network (ANN), Support Vector Machines (SVMs), Back Propagation Networks (BPNs) and the K-Nearest Neighbor (K-NN) algorithm—are used—such as Machine Learning (ML) algorithms—to construct the ABC classification model. Hence, the use of this type of classification approaches, whatever the application field, assumes the availability of a set of pre-assigned items to perform the learning process (e.g., Agarwal and Mittal 2019; Rosdi et al. 2019; Naderpour and Mirrashid 2019).
Partovi and Anandarajan (2002) presented a classification approach based on the Artificial Neural Network (ANN) to carry out the ABC classification of pharmaceutical inventory items Partovi and Anandarajan (2002). In their approach, two learning methods, namely Back Propagation (PB) and Genetic Algorithm (GA), are used to determine the “best” set of weights for the network. López-Soto et al. (2017) also designed a classification approach based on Artificial Neural Network (ANN) with discrete activation functions to solve the multi-criteria inventory classification problem López-Soto et al. (2017). For this purpose, a multi-start constructive algorithm—using a randomized greedy strategy—is applied to train the neural network by minimizing the number of hidden layer neurons. In addition and, in order to speed up the training process and solve large dataset instances, the proposed approach determines the neuron’s weights by solving some LP models.
In the same context, Yu (2011) proposed a comparative study where three Machine Learning techniques (Support Vector Machines (SVMs), Back Propagation Networks (BPNs) and the K-Nearest Neighbor (K-NN) algorithm) are compared to Multiple Discriminate Analysis (MDA) Yu (2011). This study was conducted by using the ABC classifications generated by four benchmark classification models [Reid model (1987), Flores et al. model (1992), R-model (2006) and Ng-model (2007)].
Kartal and Cebi (2013) proposed a classification approach based on Support Vector Machines (SVMs) to classify inventory items used in a large-scale automobile company operating in Turkey Kartal and Cebi (2013). In this approach, a Simple Additive Weighting (SAW) method is firstly used to compute the scores of items based on which an ABC classification is obtained. The SVMs are then used as learning algorithm to predict the classes of the SAW-based ABC classification. López-Soto et al. (2016) developed a classification approach based on two supervised classification techniques, namely Logical Analysis of Data (LAD) and K-Nearest Neighbor (K-NN) algorithm, in order to detect and correct familiarity bias that may appear in the ABC classification of items provided by inventory experts López-Soto et al. (2016). Lolli et al. (2017) proposed a classification approach based on two supervised classification techniques, namely Decision Trees (DTs) and Random Forests (RFs), to solve the ABC inventory classification problem Lolli et al. (2017). In this approach, the training process is performed by using a sample of items previously classified by simulating a predefined inventory control system. The computational experiments—conducted on a dataset issued from a firm producing electric resistances—show that the proposed approach outperforms the classification approach suggested by Ladhari et al. (2016) in terms of rate of misclassified items.
2.3 Classification approaches based on MCDM techniques
In general, classification approaches based on MCDM techniques proceed in two steps to classify inventory items into ABC categories. In the first step, an MCDM method—essentially the Analytic Hierarchy Process (AHP) (Saaty 1990)—is applied once to compute the criteria weights. In the second step, an aggregation rule—usually an MCDM method—is used to compute the global score of each inventory item. It is important to underline that MCDM techniques have the ability to incorporate explicitly human judgments, considering conflicting criteria and dealing with data obtained on heterogeneous measurement scales (i.e., quantitative and qualitative).
Flores et al. (1992) proposed a classification approach based on AHP method to classify inventory items into ABC categories by considering multiple criteria Flores et al. (1992). In their approach, the AHP method is used to determine the criteria weights and the Weighted Sum (WS) rule is used to compute the overall score of each inventory item. In the same context, Partovi and Burton (1993) proposed a classification approach in which the computation of the criteria weights and the item scores are both determined by AHP method Partovi and Burton (1993). The main advantage of Partovi and Burton’s model with respect to Flores et al.’s model is that the former considers both qualitative and quantitative criteria, whereas the latter considers only quantitative criteria Kaabi et al. (2018). Bhattacharya et al. (2007) proposed a classification approach based on two MCDM, namely TOPSIS technique (Technique for Order Preferences by Similarity to the Ideal Solution) (Hwang and Yoon, 1981) and AHP method, to classify inventory items into ABC categories Bhattacharya et al. (2007). The AHP method is used to determine the criteria weights, whereas the TOPSIS technique is used—as aggregation rule—to compute the overall scores of inventory items. The proposed classification approach has been applied on a real case study involving items used in a pharmaceutical company located in India. Rezaei (2007) proposed a classification approach based on Fuzzy AHP (FAHP) to assign inventory items into ABC categories Rezaei (2007). In FAHP, the pairwise comparisons of both criteria and the alternatives are made by using linguistic variables expressed by triangular fuzzy numbers. In his approach, Rezaei (2007) developed a six-step algorithm in which some basic concepts of fuzzy set theory (mathematical and comparison operators) are used in order to assign each inventory item into its corresponding category. This same algorithm was later used by Cakir and Canbolat (2008) to develop a Web-based decision support system Cakir and Canbolat (2008). Many other classification approaches that use the FAHP to solve the ABC inventory classification problem merit to be mentioned here (Kabir and Hasin 2011, 2012; Kabir et al. 2011; Çebi et al. 2010; Kiris 2013).
Although the AHP method (and its fuzzy version FAHP) has been widely used to solve the multi-criteria ABC inventory classification problem, three main criticisms may be addressed to this method. First, when the problem size, i.e., the number of criteria and/or inventory items, increases, the number of pairwise comparisons increases significantly and, therefore, this may discourage the decision-maker to use AHP given the significant cognitive effort that he/she should provide. Second, even if the problem has a reasonable size, the input data, i.e., the pairwise comparisons required to apply AHP method, are not easy to obtain from the decision-maker since it is measured on a ratio scale (e.g., how much a criterion is more important than another criterion), the most demanding measurement scale in terms of cognitive effort provided. Third, due to the limited rationality of the decision-maker, it is often difficult to obtain a low consistency index, especially when the problem size is high.
Douissa and Jabeur (2016a) have proposed a new classification approach in which the ABC classification problem is solved as a nominal sorting problem rather than a ranking problem like the most existing ABC classification models Douissa and Jabeur (2016a). In their approach, an MCDM method, called PROAFTN (PROcédure d’Affectation Floue pour la problématique de Tri Nominal), is used to assign each inventory item into the category A, B or C with which it has the most similar characteristics. Since the application of PROAFTN method requires the knowledge of some parameter values (e.g., prototypes intervals and discrimination thresholds), the Chebyshev’s theorem is used for their estimation. Li et al. (2017) proposed a new classification approach based on Stochastic Multi-criteria Acceptability Analysis (SMAA) Li et al. (2017). In their approach, the authors developed a stochastic formulation of the multi-criteria ABC inventory classification problem by considering all possible ranking orders of the criteria weights.
2.4 Classification approaches based on Hybrid techniques
Recently, an emerging research direction consists in hybridizing classification techniques issued from different families of approaches. For instance, Lolli et al. (2014) introduced a new hybrid classification approach based on the AHP method and the K-means algorithm Lolli et al. (2014). The proposed approach uses first AHP method to generate a ranking of inventory items. Then, the K-means algorithm is applied to group the most similar items with the aim of generating compact and well-separated clusters. Douissa and Jabeur (2016b) proposed an hybrid approach in which the ELECTRE III method and the VNS meta-heuristic are combined to generate a classification of inventory items Douissa and Jabeur (2016b). In their approach, the criteria weights are determined ’objectively’ by using the entropy method—instead of the AHP method—in order to avoid making a high number of pairwise comparisons. Liu et al. (2016) combined the ELECTRE III method and the Simulated Annealing (SA) meta-heuristic to tackle the compensation problem in the ABC inventory classification Liu et al. (2016). Kartal et al. (2016) presented some hybrid approaches by combining MCDM methods with machine learning (ML) models for the multi-criteria ABC analysis Kartal et al. (2016). Three different MCDM methods, namely Simple Additive Weighting (SAW), Analytic Hierarchy Process (AHP) and VIKOR,Footnote 1 were used to determine the items’ categories. Then, Naive Bayes (NB), Bayesian Network (BN), Artificial Neural Network (ANN) and Support Vector Machine (SVM) algorithms were used as supervised learning techniques to predict the pre-established items’ categories.
It is important to underline that, in the ABC analysis literature, there are many other ABC classification models that do not belong to any of the above families of approaches. Table 1 reports the main features of these “Other” classification models and all relevant classification models belonging to the four above families of approaches. The meanings of these features are explained as follows:
-
The approach to which the classification model belongs (MP, AI, MCDM,...)
-
The type of criteria considered (Quantitative, Qualitative or both, i.e., Mixed) and their weighting process which may be “subjective” when the decision-maker provides directly the criteria weights or “objective” when these weights are derived automatically from the dataset without any intervention from the decision-maker;
-
The level of compensation (full compensatory or non-compensatory) used by the classification model to compute the weighted scores of inventory items;
-
The number of the evaluation functions (single/multiple) used in the construction and the evaluation of the generated ABC classifications;
-
The decision-making problematic according to which the ABC inventory classification problem is solved: ranking problematic, sorting problematic (assignment with ordinal categories) and classification problematic (assignment with nominal categories);
-
The number of datasets used to measure the performance of the classification model;
-
The existence or the nonexistence of an inventory cost analysis to measure the performance of the classification model.
The analysis of the multi-criteria ABC inventory classification literature presented above shows that this research field has some shortcomings that can be resumed in the following points:
-
Most of the existing ABC classification models consider only quantitative criteria. Models that deal with mixed criteria (Quantitative and Qualitative) are relatively rare.
-
Despite the various benefits of non-compensatory aggregation scheme (discussed in detail in Introduction section), the use of such scheme in the existing ABC classification models during the item scoring process remains insufficient.
-
Although the ABC analysis is, by nature, an ordinal classification problematic, most of the existing ABC classification models treat it as ranking problematic and then they apply a predefined distribution to assign each inventory item into a specific category. It will be shown in Conclusion section that this way of proceeding may generate some inconsistencies.
-
Most of the above research works use only one benchmark dataset (most often Reid’s dataset) in order to compare the performance of their classification models with respect to some other existing models.
-
Most of the existing classification models determine their ABC classifications of inventory items without considering any inventory performance measure such as the inventory cost. In fact, these models generate their ABC classifications by maximizing the score of each inventory item, minimizing the divergence with respect to a subjective ABC classification provided by the decision-maker, etc.
-
Most of the existing classification models use a single-objective-based evaluation function in the item scoring process. The use of the multi-objective scheme remains very limited.
In this work, our aim is to overcome some of the above shortcomings by proposing a new classification approach that combines a simplified version of ELECTRE III method to compute the item scores and the meta-heuristic CVNS to estimate the ELECTRE III parameters. It is important to note that ELECTRE III is an MCDM method that considers mixed (quantitative and qualitative) criteria and uses a non-compensatory aggregation scheme to compute the item scores. In addition, our proposed classification approach considers the Total Relevant Cost (TRC) as an inventory performance measure in the generation of the ABC classification of inventory items. Finally, to evaluate the performance of our proposed classification approach with respect to some existing classification models, two real benchmark datasets will be used.

3 The proposed classification approach
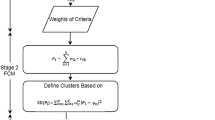
The detailed pseudocode of the proposed classification approach is presented in Algorithm 1. Essentially, two major components constitute the proposed classification approach: a simplified version of the ELECTRE III method is used to compute the global score of each item, and the Continuous Variable Neighborhood Search (CVNS) meta-heuristic is used to estimate the simplified ELECTRE III parameters.
The main aim of the proposed classification model is to find a set of values for ELECTRE III parameters that provides the best classification of inventory items, i.e., a classification that minimizes the Total Relevant Cost (TRC). Hence, in each iteration, the CVNS generates a vector of parameters
for all criteria where \(q_i\), \(p_i\), \(v_i\) and \(w_i\) are, respectively, the indifference threshold, the preference threshold, the veto threshold and the weight of the criterion i\((i=1,2,\ldots ,n)\). This vector (or solution) is generated in the neighborhoods of the current solution (vector of parameters) by applying a shaking operation. The generated vector is then used by ELECTRE III to compute a global score for each item. Based on these scores, an ABC classification of inventory items is provided and evaluated by using the Total Relevant Cost (TRC) function. If any improvement is reached (i.e., a smaller value of TRC), the algorithm will update its vector of parameters (or solution) or, in the opposite case, will move to the next neighborhood (in the same or in the next neighborhood structures, as the case may be). The process is repeated until the stopping condition is met. The general framework of the proposed classification approach is presented in Fig. 1.

Framework of the proposed classification approach
In what follows, the main components of the proposed classification approach will be detailed: the simplified ELECTRE III method and the Continuous Variable Neighborhood Search (CVNS) meta-heuristic.
3.1 The simplified ELECTRE III method
The ELECTRE III method—a French abbreviation of the expression ELimination Et Choix Traduisant la REalité (Elimination and Choice Expressing the Reality)—is a well-known Multi-criteria Decision-Making (MCDM) method which was originally introduced by Roy (1978) in order to enhance some earlier ELECTRE methods (ELECTRE I and II) with the aim of explicitly incorporating the fuzzy (imprecise and uncertain) nature of decision making Roy (1978). Indeed, ELECTRE III method aims to rank a set of alternatives (e.g., projects, candidates, inventory items, etc.) evaluated according to a set of conflicting and non-commensurable criteria.

The ELECTRE III method stands out from the other MCDM methods in at least two fundamental characteristics. First, it explicitly takes into account the uncertainty and imprecision associated with the pairwise comparisons of the alternatives by using the concept of indifference, preference and veto thresholds (or shortly the pseudo-criterion concept). For example, when the difference of scores between two alternatives \(a_i\) and \(a_k\) on a criterion \(g_j\) is sufficiently small, i.e., below a given indifference threshold \(q_j\), the ELECTRE III method will consider these two alternatives as indifferent. Second, ELECTRE III uses a non-compensatory aggregation scheme, i.e., a very bad performance on one criterion may not be compensated by good performances on the other criteria. This way of proceeding will promote the alternatives that perform globally well on the different criteria. Furthermore, in non-compensatory aggregation scheme, criteria weights are interpreted as “importance coefficients”—which is their true theoretical meaning—whereas in fully compensatory aggregation scheme these weights play the role of substitution rates. It is important to underline that ELECTRE III method has been successfully applied in a wide range of real-world applications. An extensive literature review on methodologies and applications based on this method may be found in the recent paper of Govindan and Jepsen (2016). The detailed pseudocode of the simplified ELECTRE III method is reported in Algorithm 2.
ELECTRE III method uses pairwise comparisons of alternatives (in our case inventory items) in order to rank them. Each pairwise comparison is characterized by a binary outranking relation, called S. The construction of the outranking relation S is based upon two fundamental concepts: the concordance and the discordance. Indeed, Roy (1978) defined the outranking relation S as follows: an alternative \(a_i\) outranks an alternative \(a_k\) (or \({a_i}\)S\({a_k}\)) if and only if there are enough arguments to decide that \(a_i\) is at least as good as \(a_k\) (concordance concept) while there is no essential reason to refute that statement (discordance concept). Since in ELECTRE III method the outranking relation is defined as a valued (or fuzzy) relation, it is defined by an index measuring the credibility degree of the outranking relation, i.e., of the assertion “\(a_i\) is at least as good as \(a_k\).” Finally, as any outranking methods, ELECTRE III proceeds into two steps to provide a ranking of inventory items:
-
1.
The construction of a valued outranking relation for each pair of inventory items (\(a_i\),\(a_k\)) by measuring the credibility degree of the assertion “\(a_i\) is at least as good as \(a_k\)”;
-
2.
The exploitation of these valued outranking relations in order to produce a ranking of the inventory items.
Before presenting the computation details of the valued outranking relation, the concept of Discrete MCDM (D-MCDM) problem—which represents the basic input dataset for ELECTRE III method—should be introduced. A D-MCDM is usually defined by the following triplet (A, F, E), where:
is a set of m alternatives (or inventory items),
is a set or a family of n criteria and
is a set of \(n \times m\) evaluations so that \(g_j(a_i)\) represents the performance (or the evaluation) of the alternative \(a_i\) on the criterion \(g_j\). Without loss of generality, It’s assumed that the greater the value of \(g_j(a_i)\), the better the alternative \(a_i\).
3.1.1 The construction of the valued outranking relation
To measure the credibility degree of the assertion “\(a_i\) outranks \(a_k\),” the following four steps should be performed:
-
1.
Compute—for each criterion \(g_j\) and for each pair of items (\(a_i\),\(a_k\))—the partial concordance index, denoted by \({C_j}(a_i,a_k)\), as follows:
$$\begin{aligned} {C_j}\left( {a_i,a_k} \right) = \left\{ \begin{array}{ll} 0 &{} \quad \text{ if } \quad \;{g_j}(a_k) - {g_j}(a_i) \ge {p_j}\\ \\ \frac{{{p_j} + {g_j}(a_i) - {g_j}(a_k)}}{{{p_j} - {q_j}}} &{}\quad \text{ otherwise }\\ \\ 1&{}\quad \text{ if } \quad \;{g_j}(a_k) - {g_j}(a_i) \le {q_j} \end{array} \right. \end{aligned}$$(1)where \(q_j\) and \(p_j\) are, respectively, the indifference and the preference thresholds of the criterion j. The indifference threshold represents the greatest performance difference on the criterion \(g_j\) for which the decision-maker remains indifferent between two alternatives \(a_i\) and \(a_k\). The preference threshold represents the smallest performance difference on the criterion \(g_j\) for which the decision-maker is able to make a clear preference for one alternative over another. The use of \(q_j\) and \(p_j\) in ELECTRE III is not only to nuance the distinction between weak and strong preference, but also to take into account the imperfect character of input data. When the discrimination thresholds \(q_j\) and \(p_j\) are associated with a criterion \(g_j\), it is called pseudo-criterion. Finally, the partial concordance index \({C_j}(a_i,a_k)\) measures the level to which the criterion \(g_j\) supports the assertion “\(a_i\) is at least as good as \(a_k\)" or "\(a_i\) outranks \(a_k\).”
-
2.
Compute—for each pair of items (\(a_i\),\(a_k\))—the global concordance index, denoted by \(C(a_i,a_k)\), as follows:
$$\begin{aligned} C\left( {a_i,a_k} \right) = \frac{{\sum \nolimits _{j = 1}^n {{w_j} \times {C_j}\left( {a_i,a_k} \right) } }}{{\sum \nolimits _{j = 1}^n {{w_j}} }} \end{aligned}$$(2)where \(w_j\) is the relative importance coefficient of the criterion \(g_j\). Let us point out that \(w_j\) is an intrinsic value and reflects the voting power of the criterion , i.e., the higher the \(w_j\), the more important the criterion is. Furthermore, each weight \(w_j\) neither depends on the range of the criterion scale nor on the encoding chosen to express the evaluation (score) on this scale Figueira et al. (2005). Thus, in ELECTRE III, the criteria weights \(w_j\) do not act as substitution rates as in fully compensatory aggregation scheme. Finally, the global concordance index \(C(a_i,a_k)\) measures the strength of arguments which agree with the assertion "\(a_i\) is at least as good as \(a_k\)" or "\(a_i\) outranks \(a_k\)".
-
3.
Compute—for each criterion \(g_j\) and for each pair of items (\(a_i\),\(a_k\))—the partial discordance index, denoted by \({D_j}(a_i,a_k)\), as follows:
$$\begin{aligned} {D_j}\left( {a_i,a_k} \right) = \left\{ \begin{array}{ll} 1 &{}\quad \text{ if } \quad \;{g_j}(a_k) - {g_j}(a_i) \ge {v_j}\\ \\ \frac{{{g_j}(a_k) - {g_j}(a_i) - {p_j}}}{{{v_j} - {p_j}}} &{}\quad \text{ otherwise }\\ \\ 0 &{}\quad \text{ if } \quad \;{g_j}(a_k) - {g_j}(a_i) \le {p_j} \end{array} \right. \end{aligned}$$(3)where \(v_j\) is the veto threshold of the criterion \(g_j\) and represents the limit of tolerance that the decision-maker is willing to accept for any compensation. In other words, if the evaluation of \(a_k\) is at least \(v_j\) greater than the evaluation of \(a_i\) on a given criterion \(g_j\), then the decision-maker may refuse the assertion "\(a_i\) outranks \(a_k\)" without regarding their evaluations on the other criteria. Thus, the integration of the veto threshold in the computation of the partial discordance index reinforces the non-compensatory effects in ELECTRE III. Finally, the partial discordance index \({D_j}(a_i,a_k)\) measures—according to the criterion \(g_j\)—the strength of arguments which disagree with the assertion "\(a_i\) is at least as good as \(a_k\)" or "\(a_i\) outranks \(a_k\)".
-
4.
Compute—for each pair of items (\(a_i\),\(a_k\))—the valued outranking relation, i.e., the credibility degree \(\sigma (a_i,a_k)\) of the assertion "\(a_i\) outranks \(a_k\)", as follows:
$$\begin{aligned} \sigma \left( {a_i,a_k} \right) = \left\{ \begin{array}{l} C(a_i,a_k)\quad if\quad {D_j}(a_i,a_k) \le C(a_i,a_k)\;\forall j\\ \\ \text{ Otherwise } \\ \\ C(a_i,a_k) \times \prod \limits _{{D_j}(a_i,a_k) > C(a_i,a_k)} {\frac{{1 - {D_j}(a_i,a_k)}}{{1 - C(a_i,a_k)}}} \end{array} \right. \end{aligned}$$(4)Let us point out that the credibility index \(\sigma (a_i,a_k)\) corresponds to the concordance index weakened by possible veto effects.
3.1.2 Exploitation of valued outranking relation
The original exploitation procedure of ELECTRE III starts by deriving from valued outranking relations and through an iterative process two complete pre-orders: in the first the alternatives are classified from the best to the worst (descending distillation), whereas in the second the alternatives are classified from the worst to the best (ascending distillation). A final partial pre-order is then derived by performing the intersection of the above two complete pre-orders. Two main reasons motivated us to adapt/simplify the original exploitation procedure of ELECTRE III, hence the term “simplified” ELECTRE III in this work. First, this procedure is not easy to understand by the decision makers due to its complexity in the generation of the intermediate total pre-orders (ascending and descending distillations). Second, this exploitation procedure does not attribute scores to the alternatives (these scores are required to generate the ABC classification) but rather it generates an incomplete (or partial) pre-order on the alternative set A. (Some pairs of alternatives may be incomparable.) For this purpose, the exploitation procedure of PROMETHEE II (Mareschal et al. 1984) will be used generate—from the credibility degrees \(\sigma (a_i,a_k)\)—an overall score for each alternative. This overall score is obtained by performing the following three steps:
-
1.
Compute the positive outranking flow of each alternative \(a_i\) as follows:
$$\begin{aligned} {\varPhi ^ + }\left( a_i \right) = \frac{1}{{m - 1}}\sum \limits _{x \in A, x \ne a_i}^{} {\sigma \left( {a_i,x} \right) } \end{aligned}$$(5)The positive outranking flow expresses how an alternative \(a_i\) outranks all the others, i.e., its strength. Thus, the greater the value of \(\varPhi ^ +(a_i)\), the better the alternative \(a_i\).
-
2.
Compute the negative outranking flow of each alternative \(a_i\) as follows
$$\begin{aligned} {\varPhi ^ - }\left( a_i \right) = \frac{1}{{m - 1}}\sum \limits _{x \in A, x \ne a_i}^{} {\sigma \left( {x,a_i} \right) } \end{aligned}$$(6)The negative outranking flow expresses how an alternative \(a_i\) is outranked by all the others, i.e., its weakness. Thus, the lower the value of \(\varPhi ^ -(a_i)\), the better the alternative \(a_i\).
-
3.
Compute the net outranking flow (or the overall score) of each alternative \(a_i\) as follows:
$$\begin{aligned} \varPhi \left( a_i \right) = {\varPhi ^ + }\left( a_i \right) - {\varPhi ^ - }\left( a_i \right) \end{aligned}$$(7)A higher value of the net outranking flow \(\varPhi (a_i)\) reflects higher attractiveness of the alternative \(a_i\). Based on these overall scores \(\varPhi (a_i)\) (for all \({a_i} \in A\)), a ranking on the alternative set A may be generated.
The simplified ELECTRE III method steps are summarized in Fig. 2.

Simplified ELECTRE III method steps
3.1.3 Inferring the ELECTRE III parameters
In order to apply the ELECTRE III method, the following set of intra-criteria (discrimination thresholds) and inter-criteria (criteria weights) parameters should be specified:
-
The indifference thresholds vector q = (\({q_1}\), ...,\({q_n}\)).
-
The preference thresholds vector p = (\({p_1}\), ...,\({p_n}\)).
-
The veto thresholds vector v= (\({v_1}\), ...,\({v_n}\)).
-
The criteria weights vector w = (\({w_1}\), ...,\({w_n}\)).
It is important to note that these parameters should fulfill the following conditions: \(q_j,p_j,v_j,w_j \ge 0\) and \(q_j \le p_j \le v_j\) (for \(j=1\ldots n\)). In MCDM literature, determining the parameter values of ELECTRE methods was the purpose of many research papers. Two main approaches are often proposed to elicit these parameters: the Direct Elicitation Approach (DEA) and the Indirect Elicitation Approach (IEA). In the first approach, the decision-maker provides, through an interactive questioning with the analyst, the values of these parameters. The aim of this interaction is to ensure that the provided parameters values represent properly the decision-maker judgments and preference system Jabeur and Guitouni (2009). Furthermore, DEA assumes that the decision-maker has good understanding of the decision-making problem in hand. However, in most decision-making situations, providing directly the values of these parameters represents a difficult task for the decision-maker due to many reasons such as the high number of parameters used by the aggregation model, the imprecise nature of the data and the misunderstanding of the parameters meaning. Thus, the DEA is often time-consuming and may discourage the decision-maker from participating in the interactive process. To overcome the drawbacks of the DEA, the IEA proposes to infer automatically the values of these parameters based on decision examples obtained from the decision-maker. In MCDM literature, this second approach is also called Preference Desegregation Approach (PDA) (e.g., Siskos et al. 1998; Dias et al. 2002; Dias and Mousseau 2006). It is essential to underline that there exists in the MCDM literature another approach, called Ad Hoc Approach (AHA), for setting the parameter values (mainly the discrimination thresholds) of some ELECTRE methods (e.g., Kangas et al. 2001; Huck 2009; Banias et al. 2010; Liu and Zhang 2011). Indeed, AHA proposes predefined formulas in order to compute default values for the parameters. In Table 2, all relevant papers dealing with different approaches proposed to elicit the parameters of ELECTRE methods are presented.
Mousseau and Dias (2004) proposed some adaptations of the original valued outranking relation used in the ELECTRE III and ELECTRE TRI methods in order to make easier the resolution of complex inference optimization programs Mousseau and Dias (2004). In their disaggregation approach (IEA approach), these authors infer some parameters values of the above two outranking methods (all ELECTRE TRI parameters, the criteria weights \(w_j\) and the cutting level \(\lambda \) for ELECTRE III) by using the holistic judgements provided by the decision-maker. Note that the parameters inference in the proposed approach is carried out through the resolution of some linear programming models—used as aggregation models—that aim to minimize an “Error Function.” Later, Dias and Mousseau (2006) presented partial inference procedures to infer veto-related parameters with the aim of better reproducing—by fixing the values of remaining parameters of the model—a set of outranking statements (i.e., examples that ELECTRE methods generate) provided by a decision-maker Dias and Mousseau (2006). These authors have shown that their proposed procedures lead to the development of linear programming, 0–1 linear programming or separable programming problems, depending on the type of the outranking relation used. (In this work, the original outranking relation of ELECTRE III and two of its variants are used.) It should be noted that all these mathematical programming models are not solved once, but rather several times through an interactive learning process in which the decision-maker continuously revises the information that he provides based on results learned from previous iterations.
Augusto et al. (2008) proposed a multi-criteria approach—based on ELECTRE III method—to rank the performance of Portuguese firms operating in different economic sectors Augusto et al. (2008). Based on the results of this study, a set of economic and financial indicators are proposed as benchmarks for Portuguese firms in order to enhance their performance. In their proposed approach, the authors use the revised method of cards of Simos (Figueira and Roy (2002)) to elicit the criteria weights w = (\({w_1}\), ...,\({w_n}\)). In this approach, the discrimination thresholds are constant values and provided directly by the decision-maker.
Kangas et al. (2001) proposed to use two outranking methods, namely PROMETHEE II Brans et al. (1986) and ELECTRE III Roy (1978), in order to support decision-making problem in forestry planning Kangas et al. (2001). In these methods, three sets of the discrimination threshold values are tested:
-
1.
-
\({q_j}\) = 0
-
\({p_j}\) = \(\mathop {\max }\limits _i({g_j}({a_i})) - \mathop {\min }\limits _i ({g_j}({a_i}))\)
-
\({v_j}\) = \(+ \infty \)
-
-
2.
-
\({q_j}\) = \(0.1 \times (\mathop {\max }\limits _i ({g_j}({a_i})) - \mathop {\min }\limits _i ({g_j}({a_i})))\)
-
\({p_j}\) = \(0.5 \times (\mathop {\max }\limits _i ({g_j}({a_i})) - \mathop {\min }\limits _i ({g_j}({a_i})))\)
-
\({v_j}\) = \(\mathop {\max }\limits _i({g_j}({a_i})) - \mathop {\min }\limits _i({g_j}({a_i}))\)
-
-
3.
-
\({q_j}\) = \(0.1 \times (\mathop {\max }\limits _i ({g_j}({a_i})) - \mathop {\min }\limits _i ({g_j}({a_i})))\)
-
\({p_j}\) = \(0.5 \times (\mathop {\max }\limits _i ({g_j}({a_i})) - \mathop {\min }\limits _i ({g_j}({a_i})))\)
-
\({v_j}\) = \(0.75 \times (\mathop {\max }\limits _i({g_j}({a_i})) - \mathop {\min }\limits _i ({g_j}({a_i})))\)
-
Huck (2009) used an integrated approach combining forecasting and MCDM methods in order to select stocks for pairs trading from the S&P 100 index Huck (2009). In this approach, ELECTRE III method is applied to obtain a ranking of stocks. For this purpose, the ELECTRE III thresholds are computed according to the following rules:
-
\({q_j}\) = \(\sigma \left( {{g_j}({a_1}),{g_j}({a_2}),\ldots ,{g_j}({a_m})} \right) = \sqrt{\frac{1}{m}\sum \nolimits _{i = 1}^m {{{\left( {{g_j}({a_i}) - {{{\bar{g}}}_j}} \right) }^2}} } \) where \({{\bar{g}}_j} = \frac{1}{m}\sum \nolimits _{i = 1}^m {{g_j}({a_i})} \)
-
\({p_j}\) = \(2 \times {q_j}\)
-
\({v_j}\) = \(+ \infty \)
Banias et al. (2010) proposed a methodological framework—based on ELECTRE III—to find the optimal location for construction and demolition waste management Banias et al. (2010). The proposed approach is successfully implemented in the Region of Central Macedonia, Greece. In order to elicit the criteria thresholds, the authors propose the following rules:
-
\({p_j}\) = \(\frac{1}{m} \times (\mathop {\max }\nolimits _i ({g_j}({a_i})) - \mathop {\min }\nolimits _i ({g_j}({a_i})))\)
-
\({q_j}\) = \(0.3 \times {p_j}\)
-
\({v_j}\) = \(+ \infty \)
Liu and Zhang (2011) proposed a supplier selection model based on an improved ELECTRE III method Liu and Zhang (2011). In this model, the criteria weights are determined by using the information entropy to avoid subjectivity of the obtained weights. In order to elicit the discrimination thresholds for each criterion, the authors propose the following rules:
-
\({q_j}\) = \(\alpha \times (\mathop {\max }\limits _i ({g_j}({a_i})) - \mathop {\min }\limits _i ({g_j}({a_i})))\) where \(\alpha \in \left[ {0.05,\;0.1} \right] \)
-
\({p_j}\) = \(\beta \times {q_j}\) where \(\beta \in \left[ {3,\;10} \right] \)
-
\({v_j}\) = \(\gamma \times (\mathop {\max }\limits _i ({g_j}({a_i})) - \mathop {\min }\limits _i ({g_j}({a_i})))\) where \(\gamma \ge 3\)
According to Mousseau and Dias (2004), disaggregation approaches (or IEA) have been largely used for additive models but only few advances have been made for outranking methods. This is due to the fact that parameters inference in outranking models often leads to complex and nonlinear optimization problems which are difficult to solve with the classical optimization techniques. This paper proposes an IEA—based on the Continuous Variable Neighborhood Search (CVNS) meta-heuristic—to infer the parameters q, p, v and w of the simplified ELECTRE III method. The main aim of the proposed IEA is to find the “Best” set of parameter values, i.e., a set generating an ABC classification of inventory items that minimizes an inventory cost function. Finally, the proposed IEA will be compared—by using two real datasets—to some parameters elicitation approaches presented above. The purpose of this comparative study is to analyze the quality of the ABC classifications of inventory items—in terms of minimizing an inventory cost function—generated by all tested elicitation approaches.
3.2 Continuous Variable Neighborhood Search (CVNS)
The Variable Neighborhood Search (VNS) is a well-known meta-heuristic which was developed by Nenad Mladenovic and Pierre Hansen in 1997 in order to solve combinatorial and global optimization problems Mladenović and Hansen (1997). The basic idea behind the VNS meta-heuristic is based—as most modern meta-heuristics—on two complementary principles: (i) intensification in which a local search algorithm is carried out in order to improve the current solution and (ii) diversification in which a perturbation operation is performed with the aim of extending the space of explored solutions. More precisely, VNS proceeds with a systematic change of neighborhood both within a descent phase to find a local optimum (intensification) and in a perturbation phase (diversification) to get out of the corresponding valley (Hansen et al. 2010). Three main advantages characterize the VNS meta-heuristic: it usually provides excellent approximate solutions in a reasonable time, it has very few parameters to be set and finally it is easy to implement. Although the VNS meta-heuristic has been originally designed to solve combinatorial optimization problems, it was extended to address continuous optimization problems. Applications of VNS involve a wide range of critical areas, including data mining, scheduling, vehicle routing, graph theory, etc. For an exhaustive survey of the different extensions of VNS meta-heuristic and their applications, the reader may be referred to (Hansen et al. 2010).
In this work, the VNS meta-heuristic will be used to estimate the parameter vector (p, q, v, w) of the simplified ELECTRE III method. Since all these parameters are real numbers, the Continuous variant of VNS, called (CVNS), will be used for this purpose. Finally, the pseudocode of CVNS meta-heuristic, as described in Mladenović et al. (2008), is detailed in Algorithm 3.

It is important to underline that in this work a solution x in the CVNS represents the parameter vector (p, q, v, w) of the simplified ELECTRE III method which is expressed as follows:
where \(q_j\), \(p_j\), \(w_j\) and \(w_j\) are, respectively, the indifference threshold, the preference threshold, the veto threshold and the weight (relative importance) of the criterion \(g_j\). Thus, the dimension of each solution vector x is equal to 4n since for each of the n criteria four parameters should be estimated. Let us recall that all these parameters are real number and should verify the following two conditions: \(0 \le {q_j} \le {p_j} \le {v_j}\;\forall j = 1\ldots n\) and \(\sum \nolimits _{j = 1}^n {{w_j} = 1}\). To ensure that the generated solution x is valid, i.e., it fulfills the above conditions, the following generation strategy will be used:
-
1.
For each criterion \(g_j\), an indifference threshold \(q_j\) is randomly generated between \(\mathop {\min }\nolimits _{i,k \, i\ne k} (|{g_j}({a_i}) - {g_j}({a_k})|)\) and \(\mathop {\max }\nolimits _{i,k \, i\ne k} (|{g_j}({a_i}) - {g_j}({a_k})|)\). The lower bound is to ensure that the indifference threshold has an effect on the computation of the valued outranking relation, whereas the upper bound is used to avoid the situation where all alternatives are indifferent to each other;
-
2.
For each criterion \(g_j\), a preference threshold \(p_j\) is randomly generated between \(q_j\) and \(\mathop {\max }\nolimits _{i,k \, i\ne k} (|{g_j}({a_i}) - {g_j}({a_k})|)\).
-
3.
For each criterion \(g_j\), a veto threshold \(v_j\) is randomly generated between \(p_j\) and \(\mathop {\max }\nolimits _{i,k \, i\ne k} (|{g_j}({a_i}) - {g_j}({a_k})|)\).
-
4.
For each criterion \(g_j\), a weight \(w_j\) is randomly generated in an interval of real numbers (e.g., (0,1), (0,100), etc.). The generated weights are then normalized by using the following formula: \({w_j}^N = \frac{{w_{_j}}}{{\sum \nolimits _{j = 1}^n {w_{_j}} }}\)
As initialization step, a set of neighborhood structures \({{N}_k}\;k = 1\ldots {k_{\max }}\) should be defined in CVNS in order to guide in a systematic way the search for better solutions through the solution space S. Note that \(N_k(x)\) is the set of solutions in the \(k^{th}\) neighborhood of x and its geometry is designed by using two components, namely a metric \({\rho _k}\) and a radius \(r_k\), in the following manner:
where \(r_k\) is the radius (or the size) of the neighborhood \(N_k(x)\) that should be monotonically nondecreasing with k and \({\rho _k}\) is a metric function which may be defined, for instance, as \({\ell _p}\) distance, let:
In this work and, before running the CVNS meta-heuristic (in Experimental results section), the following set of its designing parameters (among many others) should be specified (Mladenović et al. 2008):
-
The stopping condition which may be the maximum CPU time allowed for the search, the maximum number of iterations or the maximum number of iterations between two improvements;
-
The number of neighborhood structures \(k_\mathrm{max}\) used in the search;
-
The geometry of neighborhood structures \({{N}_k}\;k = 1\ldots {k_{\max }}\) defined by the pair (\({\rho _k},r_k\)), i.e., the metric used to compute the distance between two solutions and the magnitude of the neighborhood;
-
The distributions used to obtain the random solution y from the neighborhood \(N_k(x)\) in the shaking step;
-
The local optimizer used in the local search step.
It is important to note that the numerical values to be assigned to these designing parameters may be either obtained from an extensive computational analysis or directly provided by the user. In addition, it is possible to reduce the number of parameters that the user must provide by fixing some of them in advance based on the results of a preliminary extensive computational analysis. The CVNS meta-heuristic starts by generating an initial solution x, a set of neighborhood structures \({{N}_k}\;k = 1\ldots {k_{\max }}\), some random distributions (e.g., uniform distribution) to be used in the shaking step and a stopping condition. The first step, denoted the shaking step, consists in generating randomly a solution vector y from the neighborhood of the incumbent solution vector x, i.e., \(y \in N_k(x)\). For this purpose, many distributions may be used, including uniform distribution, normal distribution, etcFootnote 4. The random moves of the shaking step allow both to escape from local minima and to diversify the space of explored solutions. In the second step, a Local Search (LS) algorithm is applied by using the solution y as initial solution in order to generate a local optimum, denoted by \(y'\). Two main strategies may be followed in the LS algorithm: the best improvement and the first improvement strategies. In the first, all the neighborhood of y is explored and the best solution found is selected. In the second strategy, the neighborhood of y is explored until the first solution which is better than y is obtained. In the last step, called neighborhood change, two cases may occur. In the first case, the obtained local optimum \(y'\) is not better than the last best solution (or incumbent) x according to an evaluation/objective function f, i.e., \(f\left( {y'} \right) \ge f\left( x \right) \) (for a minimization function); in this case, the process is iterated using the next neighborhood structure, i.e., \(k \leftarrow k + 1\). In the second case, the obtained local optimum \(y'\) is better than the last best solution (or incumbent) x, i.e., \(f\left( {y'} \right) < f\left( x \right) \) (for a minimization function); in this case, the solution x is updated by setting x to \(y'\) (\(x \leftarrow y'\)) and the process is iterated using the first neighborhood structure, i.e., \(N_1(x)\). Finally, the above three steps are repeated until a stopping condition is met.
3.2.1 Objective function
In the proposed classification approach, the Total Relevant Cost (TRC)—suggested by Mohammaditabar et al. (2012)—will be used as objective/evaluation function both to evaluate each ABC classification of inventory items and to guide the CVNS meta-heuristic to determine the “best” set of the simplified ELECTRE III parameter values. Indeed, the TRC measures the total cost of the obtained ABC classification by considering the ordering cost for each placed order, the setup cost of each item when it is replenished and the holding cost of carrying items in stock Mohammaditabar et al. (2012). According to Mohammaditabar et al. (2012), the TRC is considered as one of the most important performance measures that can be used to improve the effectiveness of the inventory management. Hence, the TRC of an ABC classification is computed as follows:
where \({T_z} = \sqrt{\frac{{2(\sum \nolimits _{i\mathrm{{ }} \in \mathrm{{ }}{\mathrm {category}}(z)} {{S_i}} )}}{{\sum \nolimits _{i\mathrm{{ }} \in \mathrm{{ }}{\mathrm {category}}(g)} {{D_i}{h_i}} }}}\) is the optimal joint replenishment cycle of any item \(a_i\) belonging to the category z (\(z = A, B, C\)). In the above formula, it is assumed that items of the same category z have the same replenishment cycle. \({S_i}\), \({D_i}\) and \({h_i}\) are the setup cost, the demand and the holding cost per unit of time of item \(a_i\), respectively.
4 Experimental results
To illustrate the proposed classification approach and to test its performances with respect to some other existing classification models, two common benchmark datasets will be used: the dataset proposed by Reid (1987) and the dataset provided by Liu et al. (2016).
4.1 Experimental results with Reid’s dataset
This dataset includes 47 inventory items used in a Hospital Respiratory Therapy Unit (HRTU) and evaluated according to four criteria: (1) the Annual Dollar Usage (ADU), (2) the Average Unit Cost (AUC), (3) the Lead Time (LT) and (4) the Critical Factor (CF). The first three criteria are quantitative, whereas the last criterion is qualitative. Since most of prior works (e.g., Ng (2007), Zhou and Fan (2007), Hadi-Vencheh (2010), Chen (2011) and many others) did not consider categorical criteria, the Critical Factor (CF) criterion has been omitted in this study only for comparison purposes. In this first comparative study, our proposed classification approach will be compared with six other classification models, namely R-model (Ramanathan 2006), ZF-model (Zhou and Fan 2007), NG-model (Ng 2007), H-model (Hadi-Vencheh 2010), Peer-model (Chen 2011) and TOPSIS-based model (Chen 2012).
For the implementation of the CVNS meta-heuristic, some technical choices have been made on its parameters:
-
The number of neighborhood structures\(k_\mathrm{max}\) is fixed to 6.
-
The neighborhood structures\({{N}_k}\;k = 1\ldots 6\) are defined by the metric \({\ell _2} = {\rho _2}(x,y) = \sqrt{\sum \nolimits _{t = 1}^{12} {{{\left( {x{}_t - {y_t}} \right) }^2}} }\), i.e., the Euclidian distance.
-
The radii\(r_k\)\(k = 1\ldots 6\) are predefined values verifying the following order \({r_1}< {r_2}< \ldots < {r_6}\)
-
The stopping condition is set to a maximal number of iterations which is equal to 30.
-
The uniform distribution is used to obtain the random solutions from the neighborhood \({N}_k(x)\) in the shaking step.
-
The best improvement local search method is used as local optimizer.
Once the parameter vector (q, p, v, w) is generated by the (CVNS) meta-heuristic, the simplified ELECTRE III is first applied to compute the overall score of each inventory item \(a_i\) (\(i = 1\ldots m\)). Then, the inventory items are ranked in a decreasing order of their scores. Finally, based on this ranking, an ABC classification is built by respecting the commonly used distribution proposed by Flores et al. (1992): the first ten ranked items are classified in category A (about 21% of total items), the last 23 ranked items are classified in category C (about 49% of total items) and the remaining 14 items are classified in category B (about 30% of total items). In order to evaluate each obtained ABC classification according to TRC function, the values of the setup cost \(S_i\), the demand per unit time \(D_i\) and the holding cost \(h_i\) of each item \(a_i\) should be set. For this purpose, the same values proposed by Mohammaditabar et al. (2012) will be used, let:
-
\({S_i} = LT({a_i}) \times \xi \) (where \(\xi = 1\) in our case) \(\forall i = 1\ldots m\)
-
\({D_i} = \frac{{ADU({a_i})}}{{AUC({a_i})}}\)\(\forall i = 1\ldots m\)
-
\({h_i} = 0.1 \times AUC({a_i})\)\(\forall i = 1\ldots m\)
The Reid’s dataset details and the ABC classifications obtained by all tested classification models are reported in Table 3.
It is obvious that our proposed classification approach, hereafter called (ELIII-CVNS), generates an ABC classification relatively different from those produced by all other tested models. These differences may be clearly observed in Table 4 which reports the Rate of Items that are Identically Classified (RIIC) by each pair of tested classification models. In this context, two RIIC merit to be explained and discussed. The ABC classification provided by ELIII-CVNS model has the lowest RIIC compared to those obtained by classification models based on MP techniques, especially the R-model with a RIIC of 40.04%. This low RIIC may be explained by the following two facts. First, the process of items scoring in both models, i.e., ELIII-CVNS model and R-model, are quite different: in ELIII-CVNS model this process is guided by the minimization of the Total Relevant Cost (TRC) function, whereas in the R-model this process is directed by the optimization of each item score. Second, the levels of compensation in the aggregation schemes of both models are almost opposite: ELIII-CVNS uses a non-compensatory aggregation scheme due to the application of the simplified ELECTRE III method, whereas R-model uses a full compensatory aggregation scheme through its objective function expressed by a weighted sum. On the other hand, the ABC classifications provided by H-model and Ng-model are the most similar since they have obtained the highest RIIC of 95.7%. This high RIIC may be explained by the fact that the H-model is a simple extension/improvement of the Ng-model. By applying ELIII-CVNS, the following criteria weight vector is obtained w = (\(w_\mathrm{AUC}\) = 0.183, \(w_\mathrm{ADU}\) = 0.691, \(w_\mathrm{LT}\) = 0.126). Although the H-model and the Ng-model use the same criteria weight ordering, i.e., the ADU is the most important criterion followed by the AUC and the LT criteria, as constraints in their respective mathematical formulation, the ABC classification produced by ELIII-CVNS model is relatively different from that obtained by H-model (RIIC = 55.3%) or Ng-model (RIIC = 59.6%).

Obtained TRC values over the test runs
To show the effect of the non-compensation of ELIII-CVNS model in the computation of the item scores, let us take two examples. Items \(a_{13}\) and \(a_{29}\) have the highest score on the LT criterion; however, their scorings on both ADU and AUC criteria are below average. These two items are classified in category A by all classification models, except our model which classify \(a_{13}\) in category B and \(a_{29}\) in category C. Since all tested classification models (except ELIII-CVNS model) use full compensatory aggregation scheme, it is quite natural that the bad performances of \(a_{13}\) and \(a_{29}\) on both ADU and AUC criteria are compensated by their good performances on LT criterion and, thus, both items are classified in category A. However, the classification of these two items, according to the ELIII-CVNS model, has been treated differently. Indeed, item \(a_{13}\) is assigned by ELIII-CVNS model to a lower category, i.e., category B, due to its scorings below average on both ADU and AUC criteria given that these two criteria are the most important for this classification model (\(w_\mathrm{AUC}\) = 0.183, \(w_\mathrm{ADU}\) =0.691). Thus, the highest scoring of item \(a_{13}\) on (LT) criterion does not compensate its low scoring on both ADU and AUC criteria. On the other hand, item \(a_{29}\) has a very weak performance on the ADU, which is the most important criterion for ELIII-CVNS model. Thus, despite the good performances of \(a_{29}\) on both AUC and LT criteria, this item is assigned to the category C which confirms the non-compensatory aggregation scheme used in ELIII-CVNS model.
After 30 test runs, the ABC classification obtained by ELIII-CVNS approach seems to be the most efficient since it obtained the lowest TRC value (1122.7789$) among the ABC classifications produced by all tested models (see Table 5). It is important to note that this TRC value is the mean value of the 30 test runs, where 1119.78$ and 1127.13$ are, respectively, the best and the worst obtained TRC values. The variation in the TRC values over the 30 test runs is presented in Fig. 3.
4.2 Experimental results with Liu et al.’s dataset
This dataset includes 63 inventory items used by a manufacturer of sports equipments operating in China and evaluated according to the following four criteria: (1) the Average Unit Cost (AUC), (2) the Annual (RMB) Usage (ARMBU), (3) the Lead Time (LT) and (4) the Turnover Ratio (TR). It is important to note that all the above criteria are numerical. In this second comparative study, our proposed classification approach will be compared with six classification models, namely The R-model (Ramanathan 2006), the ZF-model (Zhou and Fan 2007), the H-model (Hadi-Vencheh 2010), the NG-model (Ng 2007), the AHP-based model of Lolli et al. (2014) and the ELECTRE III-based model of Liu et al. (2016).
For the implementation of the CVNS meta-heuristic, the same parameter setting used for Reid’s dataset will be reused, except for the number of neighborhood structures \(k_\mathrm{max}\) which is fixed to 10.
Once the parameter vector (q, p, v, w) is generated by the CVNS meta-heuristic, the simplified ELECTRE III is first applied to compute the overall score of each inventory item \(a_i\) (\(i = 1\ldots m\)). Then, the inventory items are ranked in a decreasing order of their scores. Finally, based on this ranking, an ABC classification is built according to the distribution proposed by Liu et al. (2016): the first seven ranked items are classified in category A (about 11% of total items), the last 31 ranked items are classified in category C (about 49% of total items) and the remaining 25 items are classified in category B (about 40% of total items).
In order to evaluate—according to the TRC function—each ABC classification obtained from Liu et al.’s dataset, the values of the setup cost \(S_i\), the demand per unit time \(D_i\) and the holding cost \(h_i\) of each item \(a_i\) will be set as follows:
-
\({S_i} = \mathrm{LT}({a_i}) \times \mathrm{TR}({a_i})\)\(\forall i = 1\ldots m\)
-
\({D_i} = \frac{{{\mathrm {ARMBU}}({a_i})}}{{\mathrm{AUC}({a_i})}}\)\(\forall i = 1\ldots m\)
-
\({h_i} = 0.1 \times \mathrm{AUC}({a_i})\)\(\forall i = 1\ldots m\)
Table 6 summarizes Liu et al.’s dataset details and reports the ABC classifications produced by all tested classification models.
As shown in Table 6, the proposed ELIII-CVNS approach generates an ABC classification relatively different from those produced by all tested classification models. This difference is justified by the same reasons mentioned and discussed during the result analysis of Reid’s dataset: (i) the process of item scoring in ELIII-CVNS model is guided by the minimization of the Total Relevant Cost (TRC) function, whereas in the most of other tested classification models this process is directed by the optimization of the item scores, and (ii) the levels of compensation used, i.e., ELIII-CVNS uses a non-compensatory aggregation scheme, whereas some of the other tested classification models use a full compensatory aggregation scheme. In order to alleviate the text, the direct comparison of the obtained ABC classifications will not be reiterated with Liu et al.’s dataset. Indeed, this second dataset will be essentially used to analyze the performance of the different threshold setting rules in the context of the ELECTRE family of methods.
4.2.1 Comparison between different thresholds setting rules
As stated earlier, the application of the simplified ELECTRE III method requires the knowledge of the values of a set of parameters, including thresholds (q, p, v). This paper proposed an IEA based on CVNS meta-heuristic in order to estimate automatically these thresholds. Thus, the main aim of this IEA is to provide a set of values for the simplified ELECTRE III parameters that generates an ABC classification of inventory items with competitive TRC, as required by the decision-maker. To evaluate the benefit of such IEA, the generated thresholds will be compared with those produced by some other existing setting rules. For this purpose, five ELECTRE III threshold setting rules—proposed, respectively, by Kangas et al. (2001), Huck (2009), Banias et al. (2010), Liu and Zhang (2011) and Liu et al. (2016)—will be considered. Table 2 reports the mathematical formulations of these different threshold setting rules. From Table 2, Table 7 is derived by considering more than one variant of the threshold setting rules proposed by Kangas et al. (2001) and Liu and Zhang (2011). In total, there are nine sets of threshold values to be tested: the eight sets reported in Table 7 and issued from the threshold setting rules of Table 2 plus the set of threshold values generated by our proposed IEA, i.e., the ELIII-CVNS classification approach. Note that when the veto threshold \(v_j\) is set to \(+ \infty \), this means that \(v_j\) is not considered in the computation of the valued outranking relation and, therefore, in the item score. Table 8 presents all sets of threshold values and reports some descriptive statistics on the criteria set of Liu et al.’s (2016) dataset.
It is important to underline that the application of the proposed ELIII-CVNS classification approach on Liu et al.’s dataset provides the following vector of the criteria weights: \(w = (w_\mathrm{AUC} = 0.2, w_\mathrm{ARMBU} = 0.23, w_\mathrm{LT} = 0.3, w_\mathrm{TR} = 0.27\)). When looking at w, it can be observed that the criteria weights are relatively close to each other, which is not the case with the Reid’s dataset. Thus, with this second dataset, the criteria weights will not have a significant discriminatory power in the construction of the ABC classifications. To test the quality—in terms of minimizing the TRC function—of each set of threshold values, the parameter vector, i.e., threshold and weight vectors, is first introduced in the simplified ELECTRE III method to generate the item scores. Then, an ABC classification is produced by ranking items in a descending order of their score. Finally, the obtained ABC classification is evaluated by using the TRC function. Table 9 reports the ABC classifications issued from all sets of threshold values and their corresponding TRC.
It should be noted that the set of threshold values issued from ELIII-CVNS approach has produced—among all sets generated from different threshold setting rules—the most effective ABC classification since it obtained the smallest TRC value which is equal to 61642.32$ (see Table 9). This result stated that Ad Hoc Approaches (AHAs), as all rules presented in Table 7, are less efficient than our IEA (illustrated by the ELIII-CVNS classification approach) in setting the threshold values. Table 10 reports the RIIC per category between the ABC classification generated by ELIII-CVNS and each ABC classification produced by all tested threshold setting rules. Our proposed ABC classification, i.e., issued from ELIII-CVNS approach, and that obtained by using the threshold setting rule of Liu et al. (2016) have a RIIC of 68.3%. This relatively low RIIC may be explained by the meaningful difference between the threshold vector generated by ELIII-CVNS approach and that proposed by Liu et al. (2016) classification model, mainly on the AUC and ARMBU criteria.
4.3 Assumptions and limitations
The
main assumptions that will be considered in this work are essentially related to the item evaluations on the different criteria. Hence, only item evaluations known with certainty and measured on at least ordinal measurement scale will be considered.
Despite the advantages of our proposed classification approach, it presents—as any classification model—some limits. The first limit may be explained as follows: when the ABC inventory classification problem is treated as a ranking problematic, it may occur that two items with the same weighted score will be assigned into two adjacent categories. This is due to the fact that—with such problematic—the assignment of an item into a specific category is determined by both its position in the item ranking and two predefined cutting levels which set the number of items involved in each category. Despite the existence of many inventory performance measures in the literature, the second limit of this work consists in using only the Total Relevant Cost (TRC) to compare the performance of our proposed classification approach with respect to some existing classification models.
5 Conclusion
This paper proposed a new classification approach which illustrates the benefits of cross-fertilization of Multi-Criteria Decision-Making (MCDM) methods and Meta-Heuristics (MH) in order to carry out the ABC classification of inventory items. Two main interrelated components constitute the proposed approach. In the first one, a simplified version of ELECTRE III method is applied—by using a non-compensatory aggregation scheme—to compute the weighted score of each inventory item. In the second component, an Indirect Elicitation Approach (IEA) based on the Continuous Variable Neighborhood Search (CVNS) meta-heuristic is used to set the parameter values of the simplified ELECTRE III method. Hence, the proposed approach proceeds essentially into three steps to classify inventory items into ABC categories. In the first step, a vector of the simplified ELECTRE III parameters (or solution) is generated in the neighborhoods of the current solution. The generated vector is then used (step 2) by the simplified ELECTRE III method to compute a weighted global score for each item. Based on these scores, an ABC classification of inventory items is generated by using a predefined distribution in terms of number of items that each category should contain (e.g., 10–30–60%) and evaluated by using the Total Relevant Cost (TRC) function. Finally (Step 3), if any improvement is reached (i.e., a smaller value of TRC), the classification approach will update its vector of parameters (or solution) or, in the opposite case, will move to the next neighborhood (in the same or in the next neighborhood structures, as the case may be). The process will be repeated until a stopping criterion is met.
It is important to underline that the proposed approach has at least two main advantages with respect to the existing classification models. Although most of the existing items’ scoring processes use full compensatory scheme, the non-compensatory aggregation scheme used by our classification approach has the advantage of promoting items that perform globally well on the different criteria and using in an appropriate way the relative importance of criteria so that they reflect their true theoretical meaning. Second, the main aim of our proposed classification approach is not to provide a simple ABC classification of inventory items based on their global “performance,” as is done by the most existing models, but rather to build an ABC classification based on an inventory performance measure such as the TRC in order to improve the effectiveness of the inventory management.
To estimate the performance of our proposed classification approach with respect to some other existing models, a comparative study—based on two benchmark datasets—is conducted. The computational results showed that our proposed model outperformed all other existing classification models since it has obtained the lowest TRC value for both datasets (another advantage of the proposed classification approach). In this paper, some rules to set default values for the discrimination thresholds are reviewed and tested. The experimental results showed that these rules are limited when compared to the parameter setting produced by our proposed IEA, i.e., ELIII-CVNS. In fact, the existing rules cannot be of general use since they are closely linked to the dataset from which they are derived, especially when the decision-maker cannot and/or refuse to provide directly the values of these thresholds.
In future research, at least two main interesting research directions merit to be explored. The first one consists in considering the ABC inventory classification problem as a sorting (nominal or ordinal) problematic and not as a ranking problematic as is done by the most existing classification models. In this way, the first limit of the classification approach proposed in this work may be avoided. For this purpose, an adapted version of the ELECTRE TRI (Yu 1992) method designed to assign inventory items into the ordered ABC categories can be used, for example. The second research direction consists in considering (individually or simultaneously) other inventory performance measures—such as the Safety Stock Inventory Cost (SSIC) (to be minimized), the Inventory Turnover Ratios (ITR) (to be maximized) and the Fill Rate (FR) (to be maximized)—to generate more effective classifications of inventory items.
Notes
The name VIKOR appeared in 1990 Opricovic (1990) from Serbian: VIseKriterijumska Optimizacija I Kompromisno Resenje, which means: Multi-criteria Optimization and Compromise Solution.
In this pseudocode, the computation of the cost function \(f_{TRC}\) of any solution z requires the execution of the three following steps: (1) apply the simplified ELECTRE III method by using z as parameter vector to generate a ranking of inventory items, (2) generate an ABC classification, i.e., ABC(z), by splitting the above item ranking according to a predefined distribution and (3) evaluate the generated ABC classification by using the Total Relevant Cost (TRC) function, i.e., \({f_{TRC}}\left( {\mathrm{{ABC}}\left( z \right) } \right) \).
\(w_j^N = \frac{{{w_j}}}{{\sum \limits _{i = 1}^n {{w_i}} }}\) is the normalized weight of criterion j (\(j=1\ldots n\)).
In our case, only one distribution type will be used.
References
Agarwal R, Mittal M (2019) Inventory classification using multi-level association rule mining. Int J Decis Support Syst Technol 11(2):1–12
Aktepe A, Ersoz S, Turker AK, Barisci N, Dalgic A (2018) An inventory classification approach combining expert systems, clustering, and fuzzy logic with the abc method, and an application. S Afr J Ind Eng 29(1):49–62
Arikan F, Citak S (2017) Multiple criteria inventory classification in an electronics firm. Int J Inf Technol Decis Mak 16(02):315–331
Augusto M, Lisboa J, Yasin M, Figueira JR (2008) Benchmarking in a multiple criteria performance context: an application and a conceptual framework. Eur J Oper Res 184(1):244–254
Babai MZ, Ladhari T, Lajili I (2015) On the inventory performance of multi-criteria classification methods: empirical investigation. Int J Prod Res 53(1):279–290
Banias G, Achillas C, Vlachokostas C, Moussiopoulos N, Tarsenis S (2010) Assessing multiple criteria for the optimal location of a construction and demolition waste management facility. Build Environ 45(10):2317–2326
Baykasoğlu A, Subulan K, Karaslan FS (2016) A new fuzzy linear assignment method for multi-attribute decision making with an application to spare parts inventory classification. Appl Soft Comput 42:1–17
Beheshti HM, Grgurich D, Gilbert FW (2012) ABC inventory management support system with a clinical laboratory application. J Promot Manag 18(4):414–435
Bhattacharya A, Sarkar B, Mukherjee SK (2007) Distance-based consensus method for abc analysis. Int J Prod Res 45:3405–3420
Brans J-P, Vincke P, Mareschal B (1986) How to select and how to rank projects: the promethee method. Eur J Oper Res 24(2):228–238
Cakir O, Canbolat MS (2008) A web-based decision support system for multi-criteria inventory classification using fuzzy AHP methodology. Expert Syst Appl 35:1367–1378
Çebi F, Kahraman C, Bolat B (2010) A multiattribute ABC classification model using fuzzy AHP. In: 40th International conference on computers and industrial engineering (CIE), IEEE, pp 1–6
Chen J-X (2011) Peer-estimation for multiple criteria ABC inventory classification. Comput Oper Res 38:1784–1791
Chen J-X (2012) Multiple criteria ABC inventory classification using two virtual items. Int J Prod Res 50(6):1702–1713
Chen Y, Li KW, Levy J, Hipel KW, Kilgour DM (2006) Rough-set multiple-criteria ABC analysis. In: International conference on rough sets and current trends in computing, Springer, pp 328–337
Chen Y, Li KW, Marc Kilgour D, Hipel KW (2008) A case-based distance model for multiple criteria ABC analysis. Comput Oper Res 35(3):776–796
Chen Y, Li KW, Levy J, Hipel KW, Kilgour DM (2008) A rough set approach to multiple criteria ABC analysis. Lect Notes Comput Sci 5084:35–52
Cherif H, Ladhari T (2016) A novel multi-criteria inventory classification approach: artificial bee colony algorithm with VIKOR method. In: International symposium on computer and information sciences, Springer, pp 63–71
Cherif H, Ladhari T (2016) Multiple criteria inventory classification approach based on differential evolution and electre iii. In: International conference on hybrid intelligent systems, Springer, pp 68–77
Cherif H, Ladhari T (2016) A new hybrid multi-criteria ABC inventory classification model based on differential evolution and Topsis. In: International conference on hybrid intelligent systems, Springer, pp 78–87
Chu CW, Liang GS, Liao CT (2008) Controlling inventory by combining ABC analysis and fuzzy classification. Comput Ind Eng 55:841–851
Cook WD, Kress M, Seiford L (1996) Data Envelopment Analysis in the Presence of both Quantitative and Qualitative Factors. J Oper Res Soc 47(7):945–953
Darmanto E, Subanar RW, Hartati S (2019) A new integration of AdaBoost and profile matching algorithm to improve ABC analysis for drug inventory. Int J Sci Eng Res 10(2):779–788
Dias LC, Mousseau V (2006) Inferring electre’s veto-related parameters from outranking examples. Eur J Oper Res 170(1):172–191
Dias L, Mousseau V, Figueira J, Clımaco J (2002) An aggregation/disaggregation approach to obtain robust conclusions with ELECTRE TRI. Eur J Oper Res 138(2):332–348
Douissa MR, Jabeur K (2016) A new model for multi-criteria ABC inventory classification: PROAFTN method. Procedia Comput Sci 96:550–559
Douissa MR, Jabeur K (2016) A new multi-criteria ABC inventory classification model based on a simplified electre iii method and the continuous variable neighborhood search. In: ILS 2016-6th international conference on information systems, logistics and supply chain
Eraslan E, IÇ YT. (2019) An improved decision support system for ABC inventory classification. Evol Syst. https://doi.org/10.1007/s12530-019-09276-7
Figueira J, Roy B (2002) Determining the weights of criteria in the electre type methods with a revised simos’ procedure. Eur J Oper Res 139(2):317–326
Figueira J, Mousseau V, Roy B (2005) ELECTRE methods. In Multiple criteria decision analysis: state of the art surveys, Springer, pp 133–153
Flores BE, Whybark DC (1986) Multiple criteria ABC analysis. Int J Oper Prod Manag 6(3):38–46
Flores BE, Whybark DC (1987) Implementing multiple criteria ABC analysis. J Oper Manag 7(1–2):79–85
Flores BE, Olson DL, Dorai VK (1992) Management of multicriteria inventory classification. Math Comput Model 16:71–82
Fu Y, Lai KK, Miao Y, Leung J (2015) A distance-based decision-making method to improve multiple criteria ABC inventory classification. Int Trans Oper Res 23:969–978
Ghorabaee MK, Zavadskas EK, Olfat L, Turskis Z (2015) Multi-criteria inventory classification using a new method of evaluation based on distance from average solution (EDAS). Informatica 26:435–451
Govindan K, Jepsen MB (2016) ELECTRE: a comprehensive literature review on methodologies and applications. Eur J Oper Res 250(1):1–29
Guvenir HA, Erel E (1998) Multicriteria inventory classification using a genetic algorithm. Eur J Oper Res 105(1):29–37
Hansen P, Mladenović N, Pérez JAM (2010) Variable neighbourhood search: methods and applications. Ann Oper Res 175(1):367–407
Hatefi SM, Torabi SA (2010) A common weight MCDA-DEA approach to construct composite indicators. Ecol Econ 70(1):114–120
Hatefi SM, Torabi SA (2015) A common weight linear optimization approach for multicriteria ABC inventory classification. Adv Decis Sci. https://doi.org/10.1155/2015/645746
Hatefi SM, Torabi SA, Bagheri P (2013) Multi-criteria ABC inventory classification with mixed quantitative and qualitative criteria. Int J Prod Res 52:776–786
Hu Q, Chakhar S, Siraj S, Labib A (2017) Spare parts classification in industrial manufacturing using the dominance-based rough set approach. Eur J Oper Res 262(3):1136–1163
Huck N (2009) Pairs selection and outranking: an application to the s&p 100 index. Eur J Oper Res 196(2):819–825
Ishizaka A, Lolli F, Balugani E, Cavallieri R, Gamberini R (2018) Deasort: assigning items with data envelopment analysis in ABC classes. Int J Prod Econ 199:7–15
Jabeur K, Guitouni A (2009) A generalized framework for multi-criteria classifiers with automated learning: application on FLIR ship imagery. J Adv Inf Fusion 4(2):75–92
Jamshidi H, Jain A (2008) Multi-criteria ABC inventory classification: with exponential smoothing weights. J Glob Bus Issues 2(1):61
Jemelka M, Chramcov B, Kříž P, Bata T (2017) ABC analyses with recursive method for warehouse. In: 4th International conference on control, decision and information technologies (CoDIT), IEEE, pp 960–963
Jie W, Wen W, Luo YN (2010) Research on the ABC classification based on DEA and fuzzy method for military materials. In: International conference on automation and logistics (ICAL) IEEE, pp 61–64
Kaabi H, Alsulimani T (2018) Novel hybrid multi-objectives multi-criteria ABC inventory classification model. In: Proceedings of the 2018 international conference on computers in management and business, ACM, pp 79–82
Kaabi H, Jabeur K, Enneifer L (2015) Learning criteria weights with topsis method and continuous VNS for multi-criteria inventory classification. Electron Notes Discrete Math 47:197–204
Kaabi H, Jabeur K, Ladhari T (2018) A genetic algorithm-based classification approach for multicriteria ABC analysis. Int J Inf Technol Decis Mak 17(06):1805–1837
Kabir G, Hasin MA (2011) Comparative analysis of AHP and fuzzy AHP models for multicriteria inventory classification. Int J Fuzzy Log Syst 1:1–16
Kabir G, Hasin MA (2012) Multiple criteria inventory classification using fuzzy analytic hierarchy process. Int J Ind Eng Comput 3:123–132
Kabir G, Sumi RS (2013) Integrating fuzzy delphi with fuzzy analytic hierarchy process for multiple criteria inventory classification. J Eng Proj Prod Manag 1:22–34
Kabir G, Hasin MAA , Khondokar MAH (2011) Fuzzy analytical hierarchy process for multicriteria inventory classification. In: International conference on mechanical engineering (ICME), pp 18–20
Kangas J, Kangas A, Leskinen P, Pykäläinen J (2001) MCDM methods in strategic planning of forestry on state-owned lands in Finland: applications and experiences. J Multi-Criteria Decis Anal 10(5):257–271
Karagiannis G (2018) Partial average cross-weight evaluation for ABC inventory classification. Int Trans Oper Res. https://doi.org/10.1111/itor.12594
Kartal HB, Cebi F (2013) Support vector machines for multi-attribute ABC analysis. Int J Mach Learn Comput 3(1):154
Kartal H, Oztekin A, Gunasekaran A, Cebi F (2016) An integrated decision analytic framework of machine learning with multi-criteria decision making for multi-attribute inventory classification. Comput Ind Eng 101:599–613
Kiris S (2013) Multi-criteria inventory classification by using a fuzzy analytic network process (ANP) approach. INFORMATICA 2:199–217
Ladhari T, Babai MZ, Lajili I (2016) Multi-criteria inventory classification: new consensual procedures. IMA J Manag Math 27(2):335–351
Lajili I, Babai MZ, Ladhari T (2012) Inventory performance of multi-criteria classification methods: an empirical investigation. In: 9th International conference on modeling, optimization and simulation
Lajili I, Ladhari T, Babai MZ (2013) Multi-criteria inventory classification problem: a consensus approach. In: 2013 5th International conference on modeling, simulation and applied optimization (ICMSAO), IEEE, pp 1–6
Li Z, Wu X, Liu F, Fu Y, Chen K (2017) Multicriteria ABC inventory classification using acceptability analysis. Int Trans Oper Res 26:2494–2507
Liu P, Zhang X (2011) Research on the supplier selection of a supply chain based on entropy weight and improved electre-iii method. Int J Prod Res 49(3):637–646
Liu J, Liao X, Zhao W, Yang N (2016) A classification approach based on the outranking model for multiple criteria ABC analysis. Omega 61:19–34
Lolli F, Ishizaka A, Gamberini R (2014) New AHP-based approaches for multi-criteria inventory classification. Int J Prod Econ 156:62–74
Lolli F, Ishizaka A, Gamberini R, Balugani E, Rimini B (2017) Decision trees for supervised multi-criteria inventory classification. Procedia Manuf 11:1871–1881
López-Soto D, Yacout S, Angel-Bello F (2016) Root cause analysis of familiarity biases in classification of inventory items based on logical patterns recognition. Comput Ind Eng 93:121–130
López-Soto D, Angel-Bello F, Yacout S, Alvarez A (2017) A multi-start algorithm to design a multi-class classifier for a multi-criteria ABC inventory classification problem. Expert Syst Appl 81:12–21
Ma L-C (2012) A two-phase case-based distance approach for multiple-group classification problems. Comput Ind Eng 63(1):89–97
Mareschal B, Brans JP, Vincke P et al. (1984) Promethee: a new family of outranking methods in multicriteria analysis. Technical report, ULB–Universite Libre de Bruxelles
Millstein MA, Yang L, Li H (2014) Optimizing ABC inventory grouping decisions. Int J Prod Econ 148:71–80
Mladenović N, Hansen P (1997) Variable neighborhood search. Comput Oper Res 24(11):1097–1100
Mladenović N, Dražić M, Kovačevic-Vujčić V, Čangalović M (2008) General variable neighborhood search for the continuous optimization. Eur J Oper Res 191(3):753–770
Mohamadghasemi A, Hadi-Vencheh A (2011) Determining the ordering policies of inventory items in class b using if-then rules base. Expert Syst Appl 38(4):3891–3901
Mohammaditabar D, Ghodsypour SH, O’Brien C (2012) Inventory control system design by integrating inventory classification and policy selection. Int J Prod Econ 140:655–659
Mousseau V (1995) Eliciting information concerning the relative importance of criteria. In: Advances in multicriteria analysis, Springer, pp 17–43
Mousseau V, Dias L (2004) Valued outranking relations in electre providing manageable disaggregation procedures. Eur J Oper Res 156(2):467–482
Naderpour H, Mirrashid M (2019) Classification of failure modes in ductile and non-ductile concrete joints. Eng Fail Anal 103:361–375
Ng WL (2007) A simple classifier for multiple criteria ABC analysis. Eur J Oper Res 177:344–353
Opricovic S (1990) Programski paket VIKOR za visekriterijumsko kompromisno rangiranje. In: 17th International symposium on operational research SYM-OP-IS
Otay I, Senturk E, Çebi F (2018) An integrated fuzzy approach for classifying slow-moving items. J Enterp Inf Manag 31(4):595–611
Park J, Bae H, Lim S (2011) Multi-criteria ABC inventory classification using the cross-efficiency method in DEA. J Korean Inst Ind Eng 37:358–366
Park J, Bae H, Bae J (2014) Cross-evaluation-based weighted linear optimization for multi-criteria ABC inventory classification. Comput Ind Eng 76:40–48
Partovi FY, Anandarajan M (2002) Classifying inventory using an artificial neural network approach. Comput Ind Eng 41(4):389–404
Partovi FY, Burton J (1993) Using the analytic hierarchy process for ABC analysis. Int J Oper Prod Manag 13(9):29–44
Podinovskii VV (1994) Criteria importance theory. Math Soc Sci 27(3):237–252
Puente J, de la Fuente D, Priore P, Pino R (2002) ABC classification with uncertain data. A fuzzy model vs. a probabilistic model. Appl Artif Intell 16(6):443–456
Ramanathan R (2006) ABC inventory classification with multiple-criteria using weighted linear optimization. Comput Oper Res 33:695–700
Rauf M, Guan Z, Sarfraz S, Mumtaz J, Almaiman S, Shehab E, Jahanzaib M (2018) Multi-criteria inventory classification based on multi-criteria decision-making (MCDM) technique. In: Advances in manufacturing technology XXXII: proceedings of the 16th international conference on manufacturing research, incorporating the 33rd national conference on manufacturing research, p 343
Reid RA (1987) The ABC method in hospital inventory management a practical. Prod Inventory Manag J 28(4):67
Rezaei J (2007) A fuzzy model for multi-criteria inventory classification. In: proceedings of 6th International Conference on Analysis of Manufacturing Systems (AMS2007). Lunteren, The Netherlands, pp 167–172
Rezaei J, Dowlatshahi S (2010) A rule-based multi-criteria approach to inventory classification. Int J Prod Res 48:7107–7126
Rezaei J, Salimi N (2013) Optimal ABC inventory classification using interval programming. Int J Syst Sci 46:1944–1952
Rogers M, Bruen M (1998) Choosing realistic values of indifference, preference and veto thresholds for use with environmental criteria within ELECTRE. Eur J Oper Res 107(3):542–551
Rosdi F, Salim SS, Mustafa MB (2019) An FPN-based classification method for speech intelligibility detection of children with speech impairments. Soft Comput 23(7):2391–2408
Roy B (1978) Algorithme de classement basé sur une représentation floue des préférences en présence de critères multiples. Cahiers du CERO 20(1):3–24
Saaty TL (1990) The analytic hierarchy process in conflict management. Int J Confl Manag 1:47–68
Siskos Y, Grigoroudis E, Zopounidis C, Saurais O (1998) Measuring customer satisfaction using a collective preference disaggregation model. J Glob Optim 12(2):175–195
Soylu B, Akyol B (2014) Multi-criteria inventory classification with reference items. Comput Ind Eng 69:12–20
Stanford RE, Martin W (2007) Towards a normative model for inventory cost management in a generalized ABC classification system. J Oper Res Soc 58(7):922–928
Tavassoli M, Faramarzi GR, Saen RF (2014) Multi-criteria ABC inventory classification using DEA-discriminant analysis to predict group membership of new items. Int J Appl Manag Sci 6(2):171–189
Teunter RH, Babai MZ, Syntetos AA (2010) ABC classification: service levels and inventory costs. Prod Oper Manag 19(3):343–352
Teunter RH, Syntetos AA, Babai MZ (2017) Stock keeping unit fill rate specification. Eur J Oper Res 259(3):917–925
Torabi SA, Hatefi SM, Pay BS (2012) ABC inventory classification in the presence of both quantitative and qualitative criteria. Comput Ind Eng 36:530–537
Tsai C-Y, Yeh S-W (2008) A multiple objective particle swarm optimization approach for inventory classification. Int J Prod Econ 114(2):656–666
Hadi-Vencheh A (2010) An improvement to multiple criteria ABC inventory classification. Eur J Oper Res 21:962–965
Hadi-Vencheh A, Mohamadghasemi A (2011) A fuzzy AHP-DEA approach for multiple criteria ABC inventory classification. Expert Syst Appl 38:3346–3352
Vincke P (1992) Multicriteria decision-aid. Wiley, Hoboken
Yu W (1992) Aide multicritère à la décision dans le cadre de la problématique du tri: concepts, méthodes et applications (Doctoral dissertation, Université Paris IX-Dauphine)
Yu MC (2011) Multi-criteria ABC analysis using artificial-intelligence-based classification techniques. Expert Syst Appl 38:3416–3421
Zheng S, Fu Y, Lai KK, Liang L (2017) An improvement to multiple criteria ABC inventory classification using Shannon entropy. J Syst Sci Complex 30(4):857–865
Zhou P, Fan L (2007) A note on multi-criteria ABC inventory classification using weighted linear optimization. Eur J Oper Res 182:1488–1491
Zhu J (2003) Imprecise data envelopment analysis (IDEA): A review and improvement with an application. Eur J Oper Res 144(3):513–529
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Communicated by V. Loia.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Douissa, M.R., Jabeur, K. A non-compensatory classification approach for multi-criteria ABC analysis. Soft Comput 24, 9525–9556 (2020). https://doi.org/10.1007/s00500-019-04462-w
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-019-04462-w