
Abstract
Measurement and detection of ground information by airborne Lidar are one of the hot topics in the field of intelligent sensing in recent years. This study proposes a new point cloud classification algorithm of Mixed Kernel Function SVM to distinguish different types of ground objects. Firstly, the combined features including the coordinate values, the RGB value, normalized elevation, standard deviation of elevation, and elevation difference of point cloud data were extracted. A mixed kernel function of Gauss and Polynomial was designed. Then, one-versus-rest SVM multiple classifiers was constructed. Finally, the feature of 3D point cloud data was employed to train the SVM classifiers. The overall classification accuracies of test data were 97.69% and 99.13% for two data sets, I and II respectively. In addition, the experimental results have showed that the performance of the proposed method with mixed kernel function SVM was better than standard SVM method with Gaussian kernel function and polynomial kernel function only, which demonstrates the effectiveness of the proposed method.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The point cloud data obtained by the airborne laser scanning system is stored as discrete points (e.g., three-dimensional coordinate information (X, Y, and Z), RGB color information). Each point is unordered and there is no association between each point, which makes the classification of the point clouds a difficult issue.
In recent years, three-dimensional (3D) point cloud scene analysis has attracted more attention in the aspects of urban buildings extraction [1,2,3], vehicle and road related information extraction [4,5,6], tree extraction [7], modeling [8], and 3D digital urban reconstruction [9] with the continuous development of laser scanning technology. Many researchers have made progress in the field of 3D point cloud scene classification in recent years, however,the accuracy of point cloud classification is affected by some factors such as the noise, partial missing, discrete and uneven density distribution of point cloud data [10, 11], and diversity of features in the actual scene. One of the most important issues is how to category each point in 3D point cloud scenes. Many scholars have proposed a number of methods to classify the 3D point cloud.
Franceschi uses reflected laser intensity information to distinguish marble from limestone [12]. The intensity is an 8-bit digital number representing the distance-corrected intensity normalized to the range 0–255 and the number of points backscattering is a useful component of the signal returned (in particular, the points where saturation of the receiver occurred are excluded by the parsing software). In this way, two targets acquired at different distances but having the same reflectance at the laser wavelength return similar intensity. This algorithm is mainly used to distinguish marls from limestone, and is not applicable. Elevation and intensity airborne LiDAR data are used in Antonarakis’ paper in order to classify forest and ground types quickly and efficiently without the need for manipulating multispectral image files, using a supervised object orientated approach [13]. This algorithm needs to set some thresholds according to experience, which leads to the inapplicability of the algorithm. For urban infrastructure mobile laser scanning data classification, Pu et al. [14] proposed a two steps method which starts with an initial rough classification into three larger categories: ground surface, objects on ground, and objects off ground. This algorithm based on a collection of characteristics of point cloud segments like size, shape, orientation and topological relationships, the objects on ground are assigned to more detailed classes such as traffic signs, trees, building walls and barriers. But the complexity of this algorithm is relatively high. And the size, shape, direction and topological relationship of different objects may be similar, leading to classification errors. Recognizing the redundancy of labeling every individual data, Lim and Suter [15] proposed over-segmenting the raw data into adaptive support regions: super-voxels. The super-voxels are computed using 3D scale theory and adapt to the above-mentioned range data properties. Colors and reflectance intensity acquired from the scanner system are combined with geometry features that are extracted from the super-voxels, to form the feature descriptors for the supervised learning model. And they proposed using the discriminative Conditional Random Fields for the classification problem and modified the model to incorporate multi-scales for super-voxel labeling. Then they improved above method by introducing regional edge potentials in addition to the local edge and node potentials in the multi-scale Conditional Random Fields, and proposed using multi-scale Conditional Random Fields to classify 3D outdoor terrestrial laser scanned data [16]. In the model, the raw data points are over-segmented into an improved midlevel representation, “super-voxels”. Local and regional features are then extracted from the super-voxel and parameters learnt by the multi-scale Conditional Random Fields. Although this method shortens the operation time, the calculation method of super-voxel is complex, which leads to low classification accuracy.
Support vector machine (SVM) [17] is one of the most widely used classification methods in remote sensing field. Golovinskiy et al. [18] investigates the design of a system for recognizing objects in 3D point clouds of urban environments. They divided the system into four steps: locating, segmenting, characterizing, and classifying clusters of 3D points. They first cluster nearby points to form a set of potential object locations with hierarchical clustering. Then, the points near these locations are divided into foreground and background sets using graph cutting algorithm and an eigenvector based on its shape and context is established for each point group. Finally, SVM with polynomial kernels function is used to train classifiers and classify objects into semantic groups, such as cars, streetlights, trees and fire hydrants. But the algorithm has high complexity and low classification accuracy. Mallet [19] decomposed full waveform data and extracted waveform feature variables including echo amplitude and radiation characteristics, and used SVM method with Gaussian kernels function to divide urban areas into buildings, grounds and vegetation, but these methods do not fully consider the characteristics an applicability of the algorithm. However, because the shape features are not clear enough, the classification effect is poor.
The data in this paper is point cloud data collected by laser LiDAR, which has the characteristics of disorder, unstructured data and no grid. The steps of meshing and image fusion of point cloud data are subtracted, and the errors in the process of generating grid from three-dimensional point cloud data are reduced. It is generally known that the selection of kernel function of support vector machine has an important influence on the classification result of SVM algorithm [20]. In view of this, the single kernel function used in the past is no longer suitable for point cloud data classification. This paper proposed an improved support vector machine with a novel mixed kernel function to classify 3D point cloud data. Firstly, Compound features of point cloud data are extracted, including RGB color, normalized elevation, the deviation of normalized elevation and difference of elevation and constructed the feature vectors. Then, a part of the data is randomly selected as the training sample to train a one-versus-rest SVM classifier. Finally, the SVM classifier is employed to classify the remained data. As we all know, the Gauss kernel function has the interpolation ability, and it is good at extracting the local properties of samples. It is a kind of kernel function with strong local learning ability. But the overall situation is weak. Relatively speaking, the polynomial kernel function is good at extracting the global characteristics of samples, although its interpolation ability is relatively weak. Therefore, the mixed kernel function proposed in this paper combined the advantages of the Gauss kernel function and the Polynomial kernel function, and the combined kernel function has good learning ability and strong generalization ability. The experimental results showed that proposed method has a better classification effect and robustness compared with the conventional SVM method.
2 Method
2.1 Experimental Data
Three experiment data sets were used in this paper. The experiment data set I was from Institute of Geodesy and Photogrammetry of Department of Civil, Environmental and Geomatic Engineering of ETH Zurich [21]. The experiment data set II was collected using Navlab11 equipped with side looking SICK LMS laser scanners and used in push-broom. The data was collected around CMU campus in Oakland, Pittsburgh, PA [22]. The experiment point clouds data set III was obtained by laser scanners [23].
The first 3D point dataset was collected from a region of Bill Stein, Germany, including a series of different urban scenes: churches, streets, railroad tracks, squares, villages, football fields, castles, and so on. These 3D point data can be classified into 8 categories as shown in Table 1, containing: ① Artificial terrain: mainly pavement; ② Natural terrain: most of them are grassland; ③ High vegetation: trees and large shrubs; ④ Low vegetation: flowers or small shrubs which less than 2 meters; ⑤ Buildings: churches, cities hall, station, apartment, etc.; ⑥ Artificial landscapes, such as garden walls, fountains and so on; ⑦ Scanning artifact: artifacts caused by moving objects dynamically during the recording of static scanning; ⑧ Cars. The 3D point cloud data was shown in Fig. 1a by using the Cloud Compare software.

Point cloud data
The second 3D point data set was recorded from the Oakland area, American, which is scanned by a 3D laser scanner mounted on the mobile platform. As shown in Table 2 the data set contains five types objects: ① Vegetation; ② Wire; ③ Pole/Trunk; ④ Ground; ⑤ Facade (the face of a building). The 3D point cloud data was shown in Fig. 1b.
The third 3D point data set are provided by Graphics and Media Lab (GML), Moscow State University, which is scanned by a 3D laser scanner mounted on the mobile platform. As shown in Table 3 the data set contains five types’ objects: ① Ground; ② Building; ③ Car; ④ High vegetation; ⑤ Low vegetation. A part of the 3D point cloud data was shown in Fig. 1c.
2.2 Feature Extraction of Point Cloud Data
Considering the characteristics of the laser point cloud data, some feature such as the color (RGB) value of each point cloud data, the normalized elevation, the elevation standard deviation, the elevation difference, the curvature feature, and the intensity from the point cloud data can be used as effective feature for classification [23]. In this paper, the coordinate values, the RGB value, normalized elevation, standard deviation of elevation and elevation difference were selected to construct the feature vectors based on the following parameters:
-
RGB (the color characteristics of each point.)
-
Normalized elevation, the absolute height information of the terrain, obtained by calculating the difference between DSM (Digital Surface Model) and DEM (Digital Elevation Model), in which DEM is obtained by the filtering method.
$$H_{nor} = H_{dsm} - H_{dem}$$(1) -
The elevation standard deviation is the microscopic reflection characteristic of the elevation variation in the local neighborhood of the laser foot point. The formula is as shown in Eq. (2).
$$\left\{ {\begin{array}{*{20}l} {HSTD = \sqrt {\frac{1}{n - 1}\sum\limits_{i = 1}^{n} {(H_{i} - \bar{H})^{2} } } } \hfill \\ {\bar{H} = \frac{1}{n}\sum\limits_{i = 1}^{n} {H_{i} } } \hfill \\ \end{array} } \right.$$(2) -
Difference of elevation, that is, the difference between the highest and lowest values of the laser foot elevation in the local neighborhood.
$$H_{d} = H_{\hbox{max} } - H_{\hbox{min} }$$(3)
Finally, the feature vector was built by the elements mention above, was fined as following.
2.3 Proposed Mixed Kernel Function of SVM
For nonlinear two classification problems, the SVM algorithm solves the constraint optimization problems of quadratic prog-ramming function [24] 错误!未找到引用源。. For data sets \((x_{i} ,y_{i} ),\;i = 1,2, \ldots ,l\), \(y_{i} \in (1, - 1)\), where xi are the features of data, and yi are the la-bels of the data class.
The optimal classification plane can be calculated the maximum value in Eq. (5) under the constraint condition Eq. (6).
Under the Constraint condition
where \(K(x_{i} ,x_{j} )\) is a kernel function.
The mixed kernel function proposed in the paper was defined as following:
Under the constraint condition, \(\lambda_{1} { + }\lambda_{2} { = }1\), \(0 \le \lambda_{1} \le 1\), \(0 \le \lambda_{2} \le 1\).
After solving the optimal solutions corresponding to the above coefficients, the optimal classification function is obtained as (8).
where \(x\) is an unknown vector, \(\text{sgn} ( \cdot )\) is a symbolic function.
2.4 Design of SVM Classifier
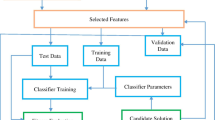
The one-versus-rest (OVR) classification method was used to convert multiple categories classification issue into two categories classification. The schematic diagram of OVR classification method is shown in Fig. 2. To classify K categories, the corresponding number of SVM classifiers was needed as shown in Fig. 3. Thus, eight and five SVM classifiers were employed to classify data set I and data set II/III respectively. Because of the huge number of 3D points data, 18491 and 157,805 points was selected randomly as training and test set respectively for data set I, as shown in Table 4. The number of 9414 and 84,691 points was selected randomly as training and test set respectively for data set II. The number of 10,742 and 1,063,247 points was selected randomly as training and test set respectively for data set III.

The schematic diagram of OVR classification method

The flow chart of classification method
Test data was inputted to SVM classifiers. Two rules were designed to determine which category the test data belong to.
-
1.
If only one classifier outputs a positive value, the result is the corresponding category.
-
2.
Otherwise, the category of the test data is selected as the maximum value of the discriminant function.
2.5 Evaluation Criteria
The confusion matrix as shown in Table 5 was used for evaluating the performance of proposed method. The italic in Table 5 showed the ratio which was calculated from the classification result. Each column value in the Table 4 represents the number of point clouds of the prediction category after classification. Each row value represents the number of the real point cloud in the actual point cloud. The accuracy refers to the ratio of the number of points correctly divided into a certain category to the total number of real reference points.
The overall classification accuracy of all categories is defined as Eq. (9)
The classification accuracy of predicted category 1 is defined as Eq. (10)
The classification accuracy of the true category 1 is defined as Eq. (11)
3 Results
The classification results of proposed method with parameters \(\lambda_{1} = 0.7\), \(\lambda_{2} = 0.3\) and true classification labels of data set I were shown in Fig. 4a, b, respectively. While, Fig. 5a, b showed the classification results of proposed method with parameter \(\lambda_{1} { = }0.7\) and \(\lambda_{2} { = }0.3\) and true classification labels of data set II. And, Fig. 6a, b showed the classification results of proposed method with parameters \(\lambda_{1} { = }0.7\), \(\lambda_{2} { = }0.3\) and true classification labels of data set III. Different colors in Figs. 4, 5 and 6 represent different categories.

The classification result of data set I

The classification result of second data set II

The classification result of second data set III
The overall classification accuracy using SVM method with Gaussian, polynomial, and proposed kernel function was shown in Fig. 7. The average classification accuracy of Gaussian kernel function and polynomial kernel function is 89.22% and 86.01% respectively. While, the average classification accuracy of the proposed mixed kernel function with parameter \(\lambda_{1} = 0.7,\lambda_{2} = 0.3\), \(\lambda_{1} = 0.5,\lambda_{2} = 0.5\) and \(\lambda_{1} = 0.2,\lambda_{2} = 0.8\) were 99.34%, 94.64% and 94.87%, respectively. The performances of the proposed method with mixed kernel function were higher than the conventional method with Gaussian and polynomial kernel function. The highest classification accuracy was achieved by proposed mixed kernel function SVM with parameter \(\lambda_{1} { = }0.7\) and \(\lambda_{2} { = }0.3\).

Comparison of classification results
Tables 6, 7 and 8 showed the confusion matrix of classification results of data set I, II and III respectively with the mixed kernel function parameter \(\lambda_{1} { = }0.7\),\(\lambda_{2} { = }0.3\). The bold showed the highest classification rates in the Tables 6, 7 and 8.
The precision and the recall of the six categories were higher than 90%. The highest precision and recall were 99.8% and 99.6%, respectively. The precision and the recall of low vegetation category were higher than 80%. Only Scanning artifact category was 23.22% and 32.12%. These results were classified correctly in data set I.
For five categories in data set II, the precision and recalls were almost higher than 87%. The highest precision and recall were 100% achieved by Wire category, because the point number of Wire category was only 33. While the lowest precision and recall were 86.55% and 88.64%, respectively. These results showed the 3D points were classified successfully in data set II.
For five categories in data set III, the precision and recalls were almost higher than 86%. The highest precision and recall were 100% achieved by Car category, because the point number of Car category was only 1833. While the lowest precision and recall were 86.55% and 88.64%, respectively. These results showed the 3D points were classified successfully in data set III.
4 Discussion and Conclusion
This paper presented a point cloud classification algorithm based on support vector machine (SVM) with new mixed kernel function. Firstly, the coordinate values, the RGB value, normalized elevation, standard deviation of elevation and elevation difference of 3D point cloud data were feature selected. Then, by combining Gaussian and polynomial kernel functions, a mixed kernel function is constructed. Eight and five one-versus-rest SVM classifiers were trained to classify the 3D point data. The averaged classification results of three data sets were 97.69%, 99.13% and 96.20%, which suggested proposed method classify the 3D point data successively.
The Kernel Function commonly used in SVM mainly has the following four categories [25], including linear kernel function, Polynomial kernel function, Gaussian kernel function, and sigmoid kernel function. Gaussian kernel function is the most widely used, which is a locally strong kernel function, which can map a sample into a higher dimensional space. Polynomial kernel function can map the low dimensional input space to the characteristic space of the high latitude. In this paper, a mix kernel by combining Gaussian kernel function and Polynomial kernel function were proposed, and the classification results of proposed method was better than Gaussian kernel function and Polynomial kernel function only.
The experimental results of three sets of point cloud data from different regions show that the classification algorithm proposed in this paper has high accuracy for various scenes, improves the robustness of the algorithm, and has certain practicability and research value. But the algorithm also has some shortcomings. Because of the large number of data sets, the training speed of the classifier is a little slow as shown in Table 9.
The classification result was compared with three other methods. The first method (method I) was the one described in [25], using a combination of BoW (Bag of Words) and LDA (Latent Dirichlet Allocation). The second method (method II) used the point-based features to classify point clouds. The third method (method III) is the one described in [26], using geometric and intensity information, and features are selected using Joint Boost to classification. The proposed method achieved average accuracy 97.67%, which is better than method I 95.3%, method II 92%, and method III 95.15%, which suggest the effectiveness of proposed method.
References
Weinmann, M., Jutzi, B., & Hinz, S. (2015). Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. Isprs Journal of Photogrammetry & Remote Sensing, 105, 286–304.
Demantké, J., Vallet, B., & Paparoditis, N. (2012). Streamed vertical rectangle detection in terrestrial laser scans for facade database production. The ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 1(3), 99–104.
Xu, L., Kong, D., & Li, X. (2014). On-the-fly extraction of polyhedral buildings from airborne LiDAR data. IEEE Geoscience and Remote Sensing Letters, 11(11), 1946–1950.
Serna, A., & Marcotegui, B. (2014). Detection, segmentation and classification of 3D urban objects using mathematical morphology and supervised learning. Isprs Journal of Photogrammetry & Remote Sensing, 93(7), 243–255.
Yu, Y., Li, J., & Guan, H. (2014). Semiautomated extraction of street light poles from mobile LiDAR point-clouds. IEEE Transactions on Geoscience and Remote Sensing, 53(3), 1374–1386.
Liu, R., Lu, X., & Yue, G. (2017). An automatic extraction method of road from vehicle-borne laser scanning point clouds. Geomatics & Information Science of Wuhan University, 42(2), 250–256.
Kankare, V., Puttonen, E., & Holopainen, M. (2016). The effect of TLS point cloud sampling on tree detection and diameter measurement accuracy. Remote Sensing Letters, 7(5), 495–502.
Livny, Y., Yan, F., & Olson, M. (2010). Automatic reconstruction of tree skeletal structures from point clouds. ACM Transactions on Graphics, 29(6), 1–8.
Musialski, P., Wonka, P., & Aliaga, D. G. (2013). A survey of urban reconstruction. Computer Graphics Forum, 32(6), 146–177.
Guo, B., Huang, X., & Zhang, F. (2013). Points cloud classification using joint boost combined with contextual information for feature reduction. Acta Geodaetica et Cartographica Sinica, 42(5), 715–721.
Zhen, D., & Yang, B. (2015). Hierarchical extraction of multiple objects from mobile laser scanning data. Acta Geodaetica et Cartographica Sinica, 44(9), 980–987.
Franceschi, M., Teza, G., & Preto, N. (2009). Discrimination between marls and limestones using intensity data from terrestrial laser scanner. Isprs Journal of Photogrammetry & Remote Sensing, 64(6), 522–528.
Antonarakis, A. S., Richards, K. S., & Brasington, J. (2008). Object-based land cover classification using airborne LiDAR. Remote Sensing of Environment, 112(6), 2988–2998.
Pu, S., Rutzinger, M., & Vosselman, G. (2011). Recognizing basic structures from mobile laser scanning data for road inventory studies. ISPRS Journal of Photogrammetry & Remote Sensing, 66(6), S28–S39.
Lim, E. H., & Suter, D. (2009). 3D terrestrial LIDAR classifications with super-voxels and multi-scale Conditional Random Fields. Computer-Aided Design, 41(10), 701–710.
Lim, E. H. & Suter, D. (2008). Multi-scale conditional random fields for over-segmented irregular 3D point clouds classification. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. CVPRW ‘08, IEEE (pp. 1–7).
Chaudhuri, A., De, K., & Chatterjee, D. (2008). A comparative study of Kernels for the multi-class support vector machine. In IEEE International Conference on Natural Computation (pp. 3–7).
Golovinskiy, A., Kim, V. G., & Funkhouser, T. (2010). Shape-based recognition of 3D point clouds in urban environments. In IEEE, International Conference on Computer Vision (pp. 2154–2161).
Mallet, C., Bretar, F., & Roux, M. (2011). Relevance assessment of full-waveform lidar data for urban area classification. ISPRS Journal of Photogrammetry & Remote Sensing, 66(6), S71–S84.
Song, H., Xue, Y., & Zhang, L. J. (2011). Research on kernel function selection simulation based on SVM classification. Computer & Modernization, 1(8), 133–136.
Hackel, T., Savinov, N., & Ladicky, L. (2017). Semantic3d.net: A new large-scale point cloud classification benchmark. The ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, IV-1/W1, 91–98.
Shapovalov, R., & Velizhev, A. (2011). Cutting-plane training of non-associative Markov network for 3D point cloud segmentation. In 2011 International Conference on 3D Imaging, Modeling, Processing, Visualization and Transmission(3DIMPVT) (pp. 1–8).
Liu, Z. Q., Peng-Cheng, L. I., & Chen, X. W. (2016). Classification of airborne LiDAR point cloud data based on information vector machine. Optics & Precision Engineering, 24(1), 210–219.
Wang, Z., Zhang, L., & Fang, T. (2015). A multiscale and hierarchical feature extraction method for terrestrial laser scanning point cloud classification. IEEE Transactions on Geoscience and Remote Sensing, 53(5), 2409–2425.
Cramer, M. (2010). The DGPF-test on digital airborne camera evaluation overview and test design. Photogrammetrie Fernerkundung Geoinformation, 2010(2), 73–82.
Acknowledgements
This work was financially supported by National Key R&D Program of China (2018YFC1314500), National Natural Science Foundation of China (61806146), Natural Science Foundation of Tianjin City (15JCYBJC51800,15JCZDJC32800,17JCQNJC04200), Belt and road international scientific and technological cooperation demonstration project (17PTYPHZ20060), Tianjin Key Laboratory Foundation of Complex System Control Theory and Application (TJKL-CTACS-201702) and Young and Middle-Aged Innovation Talents Cultivation Plan of Higher Institutions in Tianjin.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interests regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Chen, C., Li, X., Belkacem, A.N. et al. The Mixed Kernel Function SVM-Based Point Cloud Classification. Int. J. Precis. Eng. Manuf. 20, 737–747 (2019). https://doi.org/10.1007/s12541-019-00102-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12541-019-00102-3