
Abstract
Modern technology fusions are referred to as a significant source in remote sensing. It is one of the various sources that incorporate the use of active Light Detection and Ranging (LiDAR) as well as passive optical hyperspectral imaging spectrometers. Obtaining definite measurements correlated with the structural form and function of objects is the main advantage of this combination. It enables the discrimination of an object depending on its structural characteristics and spectral properties. The merging feature level is utilized in order to obtain benefits from both datasets. However, optimum parameter determination and feature subset selection have a profound result on the classification performance of the fusion combination of the data. The support vector machine (SVM) parameters, as well as the feature subset by particle swarm optimization (PSO), have a complex relationship when combined; thus, they are determined throughout this study to improve the final classification results. In addition to the original hyperspectral data, products of spectral reflectance, vegetation indicators and personal computer devices (PCs) are derived and separated out from hyperspectral data. However, LiDAR data-based digital surface model (DSM) is available. For further explanation of structural information, many textual forms, coarsenesses, slopes and morphological profiles, a derivative and statistical form of geographics are calculated. Tests demonstrated that the suggested technique for the accuracy of the classification could improve to approximately 6% with respect to the outcomes of the hyperspectral imagery classification. The findings achieved also demonstrate the improvement of classification for the group of residential, commercial and trees, which are approximately 30%, 40% and 18%, respectively.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In the last few years, there has been an astonishing inclination in curiosity regarding the use of environmental monitoring and land management by the fusion of data (remote sensing) of various sensors such as LiDAR, multispectral, SAR data, aerial and hyperspectral imaging (Forzieri et al. 2013; Latifi et al. 2012; Jones et al. 2010). The hyperspectral remote sensing images have a main role since they have identical land-cover classes that are recognized spectrally (Chang 2007).
The source of this data is depicted by an elevated spectral resolution, which generally culminates in hundreds of observation bands. Depending on the spectral richness, applications are in need of high discriminations in the spectral domain, such as material quantification and target recognition, (Yuen and Richardson 2010; Melgani et al. 2004). In contrast, LiDAR may also be used in the following ways: to provide 3D information from surfaces and to identify objects with multiple heights in regards to mapping (Lodha et al. 2006). LiDAR is particularly used in vegetated and built-up locations since it has the qualification of capturing 3D-monitored surfaces (Forzieri et al. 2013). On the other hand, Pirnazar et al. (2018) performed three classification methods to assess the use of fuzzy algorithms in increasing the accuracy of extracted land-use maps in the Maragheh region. The Advanced Visible and Near Infrared Radiometer type 2 (AVNIR-2) sensor images generated from the Advanced Land Observing Satellites (ALOS) were used for land use classification. The achieved results from the methods used showed that the classifications generated by the object-oriented classification method were more accurate than those of the pixel-based method. Based on their results obtained, the use of high spatial resolution images and appropriate algorithms to extract features of land use categories for environmental research was recommended by them.
There are two major differences between LiDAR and hyperspectral images. The information contained in hyperspectral images provides detailed descriptions of the signatures of spectral classes in the absence of information regarding the height of ground (Dalponte et al. 2008). However, the information contained within LiDAR data provides details regarding height but none about spectral signatures. Based on the accuracy, robustness, and availability of LiDAR data and hyperspectral images, the unification of the two data in a unified system of classification has an immense capability to determine more accurate and dependable classification results. Even so, categorizing this high-dimensional feature is challenging and common parametric works undergo the Hughes occurrence.
While many studies reported using different multisensory data such as Multispectral and LiDAR, only a small number of findings were obtainable when both of these data sources were incorporated into classification tasks (Latifi et al. 2012; Jones et al. 2010). This study aims to introduce an ideal hybrid classification system by the synchronous determination of the SVM classifier parameters and the selection of features through a swarm optimization process for combining hyperspectral imagery and LiDAR data. The novelty of this work is the determination of the Support Vector Machine (SVM) parameters as well as the feature subset by Particle Swarm Optimization (PSO), which have a complex relationship when combined. Consequently, it improves the final classification results.
Related work
Throughout these past years, various researches have been executed on fusion or integration of LiDAR data and hyperspectral images in differing applications. These researches are, namely, classification of metropolitan areas, determination of tree species, separation of vegetative classes, forest structure analysis, and coastal mapping (Alonzo et al. 2014; Latifi et al. 2012; Zhang et al. 2012; Jones et al. 2010; Brook et al. 2010; Dalponte et al. 2008; Elaksher and Engineering 2008; Koetz et al. 2008; Mundt et al. 2006). The study of the uses obtained from the integration of LiDAR data and hyperspectral images is organized into two categories: hierarchical procedures and concurrent dataset processing. Hierarchical procedure assessment is the process in which one dataset precedes the others so that it can be recognized as a pre-processed phase. Generally, LiDAR data is utilized to segregate two-dimensional and three-dimensional objects followed by the application of hyperspectral images to distinguish among the diverse object species such as roofing materials (Zhang et al. 2012; Niemann et al. 2009). Furthermore, certain tests conclude that there is a need for the geometrical correction of hyperspectral images based on LiDAR data (Brook et al. 2010). In addition Lemp and Weidner (2005) and Sugumaran and Voss (2007) state that LiDAR may also be applied to hyperspectral images and segmentation to organize segments in accordance to object classification.
The synchronous processing of LiDAR data and hyperspectral images is also categorized into two groups. In the first group, the information at the pixel level in different datasets is merged to yield a uniform data set. Some researchers showed hyperspectral bands, which either consisted of a band selection or were not based on PCA, MNF, ICA, etc. and were examined along with LiDAR data and its properties (Latifi et al. 2012; Jones et al. 2010; Dalponte et al. 2008). In the second group, each analysis of the dataset was produced individually, and all pixels were classified within varied sources. The final order was then concluded by merging the convenient decisions (Shimoni et al. 2011; Lee and Tuell 2003).
A variety of studies were presented in the first group according to the stability of fusion which takes into account all the information available in a system of decision-making as well as its capability to endure the data of the various sensors, particularly by extracting features. To model forest structure, the fusion of hyper-spectral bands and LiDAR features were utilized by the application of the genetic algorithm (GA), which was used for the selection of feature subsets (Latifi et al. 2012). A subset of hyperspectral bands was merged with the imaging data of two LiDARs (intensity and nDSM) and then fused with the SVM and Gaussian mixture model results of the image classified (Dalponte et al. 2008).
The process of conversion was preformed according to the pixel-level merging of hyper-spectral imagery and CHM channels in order to compute the Canopy Height Model (CHM) from the first LiDAR return and minimum noise fraction (MNF). The bands that were preserved as entering data for the SVM classifier were the first 26-eigenvalue bands (Liu et al. 2011).
Based on reliable results from the previous procedures, the method presented herein is established from the classification of the unification of hyperspectral and LiDAR features. Regardless, the majority of the literature concentrates on certain applications, particularly species discrimination and vegetation modelling. For the purpose of classifying objects in complex areas, numerous features are produced which consist of original hyperspectral bands, several spectral indices from hyperspectral imagery as well as some textural features from LiDAR data in order to discriminate among all classes (roads, buildings, grass, trees, etc.). The optimization of the performance of high-dimensional data constituted some of the procedures that were suggested in the literature, which are organized into three categories: classifier parameter determination (Liu et al. 2014; Zhang et al. 2012), feature selection (Rashedi et al. 2014; Unler et al. 2011) and simultaneous use of the first two groups (Samadzadegan et al. 2012).
The effectiveness of the classifier depends on its parameters. These parameters have a fundamental outcome in which the grid search is used as a standard way to establish them (Hsu et al. 2003a). Furthermore, the accuracy of classification, calculation time, the size of the training sample, and the financial impact linked with these features were affected by the selection of the feature subset (Lin et al. 2008a). Based on the reliance on parameters and features, concurrent determination of parameters and choice of feature give the best precise outcomes. This was indicated by numerous researches that were concentrated on the optimization of these two circumstances (O'Boyle et al. 2008).
The superiority of the technique presented was indicated by the use of PSO to obtain the SVM kernel and margin parameters in the classification of hyperspectral imagery in which its findings were compared with the grid search procedure (Liu et al. 2014).
An additional critical stage in high-dimensional data classification is the selection of the feature. Rashedi et al. (2014) introduced an enhanced style of the binary gravitational search algorithm, which was utilized as a device for choosing the optimum subset of features with the intention of enhancing the classification accuracy. The dominating classification performance is acquired by simultaneous classifier determination as well as a selection of features by ant colony optimization (Samadzadegan et al. 2012).
Recent research in multi-source hyperspectral and LiDAR data fusion for urban land use mapping was conducted by Feng et al. (2019) and depended on a modified two-branched convolutional neural network (CNN) to improve its classification accuracy. Their results showed that the overall accuracy of such method was up to 92%, and the classification accuracy increased by more than 3% when compared with the feature-stacking method. The same technique was investigated by Wang et al. (2019) using a dual-branch convolutional neural network (DB-CNN); the 3D CNN was applied in hyperspectral imagery. In addition, the 2D CNN with cascade blocks was applied on LiDAR data to extracted elevation in order to exploit the multi-scale features. Their results showed that the capability of classification performance was more powerful than some existing techniques. On the other hand, Li et al. (2019) proposed a new method for integrated hyperspectral and LiDAR data classification by utilizing SSLPNPE (superpixel segmentation-based local pixel neighbourhood preserving embedding). This method is based on extinction profiles (EPs), superpixel segmentation, and local pixel neighbourhood preservation (LPNPE). The author extracted EP features from both sources of data and fused them by SSLPNPE, and the samples were labelled and assigned by the classifier. Their results indicated that the suggested technique was fast and effective in such data fusion.
In this study, a classification system is introduced that optimizes hybrid classification, which simultaneously specifies SVM parameters of the classifier as well as selecting a feature subset to improve the final classification capability of the collected hyperspectral images and LiDAR data.
Hyperspectral and LiDAR data fusion in features based on classification
Within this study, hyprespectral imagery and LiDAR data based on the optimum hybrid classification is introduced according to the Particle Swarm Optimization. Figure 1 illustrates the flowchart of the suggested technique. There are three main parts: SVM-based rating engine, generation of the hybrid feature space and optimization with binary particle swarm optimization.

Proposed method algorithm
To merge LiDAR data and hyperspectral imagery, spectral and structural features are incorporated in a hybrid feature space. Noisy bands are eliminated and hyperspectral image data are pre-processed, and then various vegetation indices of spectral reflectance and principle components are retrieved. After that, they are interpolated into the initial hyperspectral bands to yield the spectral feature space. In contrast, the roughness, slope, derivative morphological profile (DMP), geostatistical descriptors as well as the analysis of the texture on DSM are taken from LiDAR data and form the structural feature space. The hybrid feature space is defined by merging the spectral and structural feature space. Then, the data is converted into the range [0, 1] to decrease numerically complicated data by the normalization technique.
SVM is chosen as the classifier regarding its steadiness in high dimensional space (Melgani et al. 2004). The classification of high-dimensional data by an SVM classifier showed two profound obstacles: the selection of feature subsets and the defined SVM parameter.
SVM parameters consist of:(a) arrangement parameter C, which defines a compromise between minimizing the complications of the model and minimizing the training error and (b) Kernel parameters σ for Gaussian (Wu et al. 2007). In choosing a model that carries out an extensive search and a set of parameter values with the most suitable fitness, the grid search method, which is a conventional method, is used (Hsu et al. 2003b). It is important to note that in actual valued circumstances when choosing an accurate model selection using high-resolution grids, an extended time duration is required. In the classification of high-dimensional data sets by SVM, finding the optimum feature subset is another crucial procedure (Lin et al. 2008b; Tan et al. 2008).
The Binary PSO is used to affect the outcomes of the SVM parameters and selection features simultaneously based on the optimization algorithm. This is because the utilization of Binary PSO results in optimized values for its parameters, and suitable feature subsets must be selected to optimize the classification of this hybrid feature space based on SVM.
Generation of Hybrid Feature Space
In the decision-making system, feature space is an important factor that influences the straightforward performance and the preciseness of the results. Thus, feature space is generated depending on hyperspectral imagery and LiDAR data during the initial stage of the technique presented.
-
Spectral Features
Abundant sources about spectral information are contained within the original hyperspectral bands; however, certain indicators such as PCA components, indices of vegetation, and spectral derivatives may provide further information. As a result, PCA conversion is used with the hyperspectral images, and the initial three PCs are selected for implementation into feature space. After that, 30 indices of vegetation are calculated to distinguish vegetation classes from further classes. The indices of vegetation and their equivalent derivation equations can be found in the detailed description in Hamzeh et al. (2013). The equations are listed in Table 1.
Spectral reflectance signature derivatives can take over notable features of the different categories of land cover. Bao et al. (2013) stated that a finite divided difference approximation algorithm with a finite band separation can be used to estimate derivatives. The first-order spectral derivative can be noted accordingly:
and are denoted as wavelengths which are equivalent to bands l and k. is the value of spectral reflectance of the wavelength. is the value of spectral reflectance of the wavelength.
It is assumed that and. Lastly, the spectral feature space can be generated using the integration of the original hyperspectral bands, its PCs, vegetation indicators and spectral derivatives.
-
Structural features
Height information can be derived from the LiDAR-based DSM, but more structural features must be created to enhance their capability to distinguish among classes. For an accurate analysis of DSM, multiple kinds of features are extracted, namely, roughness texture analysis, slope, derivative morphological profile and geographical statistical descriptor. The grey level presence matrix (GLCM) method is applied within this study to take second-rate statistical synthesis features from DSM. The relative frequency with which two pixels occur is the matrix element P (i, j | ∆x, ∆y), which are disconnected by a pixel distance (∆x, ∆y) within a specific neighbourhood, where one has an intensity of I and the other has a density of j. In this research 16 features, as shown in Table 2, are taken from the GLCM matrix (Haralick et al. 1973), where G is the gray level number, Px (i) and Py (j) are the sum of the ith row, and the jth column is calculated Px + y (i) and Px-y (i) are given by Eqs. (2) and (3), respectively.
$$P_{x-y}\left(k\right)=\begin{array}{c}\sum\nolimits_{i=1}^G\sum\nolimits_{j=1}^GP(i,j)\\i+j=k\end{array},k=2,\cdots.,2$$(2)$$P_{x-y}\left(k\right)=\begin{array}{c}\sum\nolimits_{i=1}^G\sum\nolimits_{j=1}^GP(i,j)\\\vert i-j\vert=k\end{array},k=0,\cdots,G-1$$(3)
Roughness is an additional structural feature that can be taken from DSM. Consequently, the standard error of the transformed z coordinates in the neighbourhood describes terrain roughness. By using the least square method, the plane is fixed in individual neighbourhoods and then the fixed height standard error is set to “onˮ. With the use of a roughness map, texture analysis is performed and contributes to a better roughness analysis (Whelley et al. 2013). Furthermore, by using the normal vector of the gained plane, the slope of individual neighbourhoods in the DSM is also calculated which influences the contribution to the gradient feature in the structural feature area.
Another method for feature extraction is known as the derived morphological profile (DMP) and is used to determine the size and shape of objects according to morphology, which is accomplished by rebuilding. Suppose \({\gamma }_{\lambda }^{*}\) and \({\rho }_{\lambda }^{\ast}\) to be operators of opening and closing morphology through reconstruction using a structural element SE = λ. Moreover, Π_γ (x) and Π_ρ (x) are the opening and closing profiles at pixel x of the DSM which is expressed respectively by Eqs. (4) and (5).
A measure of the inclination profile opening closures for each step is stored in the growing SE string and it is defined as the DMP which can be denoted as a vector. The opening profile derivative and the closing profile derivative are respectively defined by Eqs. (6) and (7),
Generally, Eq. (8) represents the derivative of the morphological profile ∆x or DMP.
where n equals the whole number of iteration, c = 1,…,2n, and |n–c|= Morphological Transformation Size (Benediktsson et al. 2003).
The reliance of the spatially correlated points x and x + h is explained by Geo-statistical features. The later interval within the regional variable distribution Z (x) is denoted by h. Three descriptions are composed of semi-variogram, madogram and rodogram which are calculated by Eqs. 9–11, respectively (Chica-Olmo and Abarca-Hernández 2004).
N (h) denotes the number of deceleration pairs separated by h.
Finally, a space of structural features is created by incorporating DSM, its textural features, roughness, regression, DMP and Geo-statistical descriptions.
SVM classification
The support vector machine (SVM) is an educational method extracted from the statistical education system. It perfectly computes an excessively separate hyper-plane in which it elevates the border that lies between the two classes. In cases where samples are not separated in the original area, it is used to set the kernel functions of data in the dimensions of space consisting of a higher resolution linear function (Abe 2010).
Where a dataset that consists of n samples is provided\(\{({x}_{i},{y}_{i})|i=1,...,n\}\), the vector of the feature with k components is denoted by \({x}_{i}\in {R}^{k}\) and the label \({x}_{i}\) is indicated by \({y}_{i}\in \{-\mathrm{1,1}\}\). The SVM searches for a hyper-plane \(w.\varphi (x)+b=0\) in a high dimensional space, which has the ability to distinguish the data from classe’s 1 and -1 with a maximum border. The vector of weight is denoted by w, an offset term is found perpendicular to the hyper-plane b and the mapping function that maps data in a high dimensional space to segregate the linear data with a low training error is denoted by . The minimization of the standard of w is the same as zooming the border. Therefore, the SVM is trained to explain the following minimization formula:
Ci denotes the regulation parameter that imposes a trade-off between a number of erroneous classifications in training data and border enlargement with slack variables denoted by ξi.
By solving the problem of minimization in Eq. 12, the decision function is obtained as follows:
where are the constants, named Lagrange multipliers are defined in the process of minimization. SV is compatible with the set of support vectors, and the training samples for which the associated Lagrange multiples are greater than zero. The functions of the kernel calculate point products among any couple of samples in the feature space. Gaussian RBF is defined by Eq. 14 and is a popular kernel that is applied within this study
The module of classification serves a major role in the assessment of the appropriateness function in the suggested technique, where SVM is a workout during practice data and (invisible) data is used to assess trained SVM. The assessment is performed by creating a confusion matrix and computing accuracy indicators.
Parameters of SVM and feature subset selection depending on BPSO
The PSO is an algorithm based on population to simulate the common demeanor of birds in a flock. The PSO algorithm is a community of people, particles dispensed in a candidate arrangement that is located in an examined space. According to existing speed, intellective abilities and involvement in society, they iteratively make strides in their arrangement and move directly to an ideal location (Engelbrecht 2007).
The location is denoted by \({X}_{i}^{t}=\{{x}_{i1},{x}_{i2},\cdots ,{x}_{iD}\}\) and \({V}_{i}^{t}=\{{v}_{i1},{v}_{i2},\cdots ,{v}_{iD}\}\) are the locations as well as the velocity of particle i,respectively, at time t in dimensional (D) search space. During each cycle, the velocity and location of particle i change as follows:
\({pbest}_{i}=\left\{{p}_{i1},\cdots , {p}_{iD}\right\}\) denotes a single best contribution of particle i. \(gbest=\{{g}_{1},\cdots ,{g}_{D}\}\) is the greatest globally among all particles. c_1 and c_2 respectively denote the intellectual ability and social factor. Random variables in [0, 1] are represented by and, respectively. Binary PSO is introduced in order to address binary search space by PSO where the solutions are characterized by binary strings. This revises the standard PSO in the location update step according to the sigmoid function.
BPSO consists of particles that denote the solution filtered by binary chains. To define the SVM parameter simultaneously and to choose a subset of features in combining LiDAR and hyper-spectral data, the solution contains four parts: kernel parameter, regularization parameter, structural features, and spectral features as depicted in Fig. 2. The component’s interval of the first and second equals the spectral features (nhyper) and structural features (nLidar), respectively. To match the binary nature of the process of feature selection, the actual values of regularization and kernel parameters are converted into binary coding. The length of the kernel (nk) and regularization (nc) parameters rely on the range of parameters and the necessary accuracy.

Representation of solution for BPSO
The fitness function is utilized to assess the particle solution. The binary solution of the first and second parts determines that the feature must be determined by setting “1” in the ith bit. The feature is ignored if the value is “0ˮ of the ith feature in the mixed feature space. In order to determine the SVM parameters, the binary format of the third and fourth parts of the solution is transformed to an actual value by Eq. 17.
where the actual value of the bit string is denoted by p and the maximum and minimum values for the parameter p are denoted by minp and maxp, which are specified by the user. The bit length per parameter is denoted by l, and d is the bit string of a decimal value.
The findings could include fewer specific features and a higher precision of classification. The fusion of both of them represents the assessment function. In addition, by generating a single fitness function that integrates two goals, problems of multiple criteria can be resolved. The objective function can be expressed using Eq. 18:
where the value of fitness is denoted by f, the constant parameter in [0, 1] is denoted by ρ, Kappa coefficient is used to obtain precision according to Congalton and Green (2019). The number of the specific features is denoted by Nf, and the number of total features (spectral and structural features) is denoted by N.
Based on the optimization part of Fig. 1, filtered solutions that are shaped randomly on the first cycle are generated. Then each particle represented by a filter solution is assessed by Eq. (18). The particles with the highest accuracy of classification are selected, and a subset of the lowest specific features is identified as the best global solution for the population with the lowest fitness value. Furthermore, every particle compares its current location with all the prior locations that have been utilized, and the best personal position is determined. The particle velocity is then updated by Eq. (19), and the particle displacement is computed. In order to determine the new location that displays a subset of a new feature and parameters of the SVM, the sigmoid function is used for the vector of velocity, which is shown in Eq. 20. Lastly, according to Eq. 21, the particle’s position x_id^t is calculated which represents the ith component of its latest location (feature space or the parameters of the SVM).
The vector of random numbers derived from a uniform distribution among 0 and 1 is denoted by. The algorithm begins with the initial locations and velocities, and the velocity components of all particles are updated at each iteration by Eq. (19), and then the sigmoid function is used to transfer them to the range of [0,1]. After that, a binary chain is built as a novel location for the particles. Until a termination criterion such as maximum iteration is fulfilled, and according to the swarm intelligence theory, these steps are iterated. The fitness function, in addition to the precision of classification and dimensions of feature space, is enhanced repeatedly.
Area of study and data collection
-
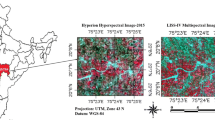
The location of the study area
The area of study is based in Houston in the southeast of Texas, USA (Fig. 3), which covers an area of roughly 5 sq. km and the UTM coordinate system, zone 46R of the site extends from 724,464.24 m to 729,185.16 m Easting and 3,289,673.87 to 3,290,736.40 Northing. The width and the height of it is (4,720.92*1,062.53) m.
-
The datasets
The datasets that were used throughout this research are supplied by the 2013 IEEE GRSS Data Fusion Contest (URL: http://www.grssieee.org/community/technical-commitees/data-fusion/) and comprise airborne hyperspectral imagery, training data, validation data and LIDAR point cloud data. The LiDAR data used throughout this research were obtained on June 22, 2012, in the time between 14:37:55 and 15:38:10 UTC (Coordinated Universal Time). Five returns were recorded by the sensor as well as intensity information at a platform altitude of 609.6 m, having an average point spacing of 0.74 m. Throughout this study, the intensity of LiDAR data was not calibrated and the atmospheric effects were neglected. The hyperspectral imagery data were obtained on June 23, 2012, in the period between 17:37:10 and 17:39:50 UTC. The sensor used was CASI and its height above the ground is 1676.4 m, in the 380–1050 region. There are 144 spectral bands. The hyperspectral imagery was calibrated to at-sensor spectral radiance units (SRUs), which are equal to the units’ μWcm − 2sr − 1 nm − 1. The spectral and spatial resolutions were 4.5 nm and 2.5 m, respectively.
-
The data of training and validation
In this study, 12 classes were defined: (1) grass; (2) artificial grass; (3) road; (4) soil; (5) railway; (6) parking lot; (7) tennis court; (8) running track; (9) water; (10) trees; (11) building and (12) highway. Both the training and validation samples for the classification were supplied by the The 2013 IEEE GRSS Data Fusion Contest (URL: http://www.grss-ieee.org/community/technical-commitees/data-fusion/).

Data (a) band 5 from Hyperspectral Imagery and (b) DSM of LiDAR data
Tests and results
Several tests were completed on LiDAR-derived DSM in order to assess the suggested technique. These tests were acquired by the NSF-funded Center for Airborne Laser Mapping (NCALM) and Compact Airborne Spectrographic Imager (CASI) hyperspectral imagery, where both of them showed the same spatial resolution of 2.5 m, as shown in Fig. 3. There are 144 spectral bands found in hyperspectral imagery within the range of 380–1050 nm. In addition, the associated DSM consists of a height above mean sea level (MSL) in meters, which is identified as the Geoid 2012A model. There are 15 classes with roughly 190 samples within each class in the ground truth. Two regions covered small areas in the area of study, a tennis court and a running track, were discarded.
The 13 classes of land cover were analyzed separately by spectral and structural analysis. The first step was accomplished by accumulating the spectral profiles of the classes. The spectral reflectance of certain vegetation classes such as tree class as well as the three kinds of grass (manufactured, strong, and stressed) was addressed. Additionally, hyperspectral imagery can discriminate the various grass types due to the ability of the grass to show adequate differentiation in spectral reflectance. In contrast, LiDAR is unable to produce excess information in the classification of grass kinds when pointing to similar geometrical structures and height. Although trees and healthy grass have similar spectral profiles, when referring to the height difference, the merging of LiDAR and hyper-spectral data enables the improvement of discrimination of both elements.
Spectral profiles are also shown for highway, road and railway, which are the second kinds of classes. In this case, there is a lack of informational data for discrimination from hyperspectral imagery since there is no identification of an essential difference among their reflectance. In addition, LiDAR data proposes no usefulness in the discrimination of these two classes as they fail to show systematic height variations. Thus, throughout this research, highway, road and railway are seen as one class (highway and road). The classification among these classes may be enhanced by the application of object-based classification, which takes spatial information such as context into account.
In metropolitan areas, the residential and commercial buildings are the main objects, which comprise the two classes of buildings. However, the buildings may contain distinct colours as well as roofing materials that yield different spectra. In the range of the spectra, several distinct classes were specified. Nevertheless, LiDAR data supplies height information in the DSM providing a significant use in building classification.
Soil, water and parking lots 1 and 2 are considered as four additional and separate classes. The spectral and structural similarities between the two parking lots where they are fused are regarded as one in the spectral reflectance of other classes composed of the parking lot, soil and water. The soil demonstrates spectral behaviour similar to buildings. In addition, LiDAR facilitates the separation of these two classes. Moreover, due to its unique structural profile, the water class is identified without any difficulties using hyperspectral imagery.
The distribution of height of each class in the DSM is shown in Fig. 4, which is used to analyse the structural state of samples in 10 classes. Each box consists of the following: (1) the mark in the centre that is denoted as the median; (2) the edges, which are the 25th and 75th percentiles; (3) the whiskers, which expand to the most extreme data points and are not regarded as outliers; and (4) those that are considered outliers and are designed separately. The expectancy of LiDAR is verified since the height distribution of each class shows that 3D classes are discriminable such as a trees, residences, and commercial buildings.

DSM height for 10 classes
Feature Space Generation
When processing both LiDAR data and hyperspectral images, feature space creation is performed. The hyperspectral image is obtained by a CASI sensor and consists of 144 bands. These bands deliver an ample source of spectral information. Furthermore, 30 indicators of vegetation cover are calculated (Table 1). In addition, spectral effect derivatives are calculated along the five band step length leading to 139 features being added to the spectral feature space. For hyperspectral images, the PCA transformation is used, and the first three PCs are chosen with over 99% of the eigenvalues to complete the spectral feature space. Thus, there are 316 descriptors within the spectral feature space.
The basis of structural information is the DSM extracted from LiDAR data. The texture analysis of DSM is accomplished according to the 16 GLCM features that are taken. Then, text 16, which describes the roughness map, is calculated. The grade is an additional descriptor that is useful for classification and is extracted from DSM. Furthermore, DMP is produced by using the Structure Element size SE = 3, 5, …, 15 pixels which produce 14 features. Lastly, geostatic descriptors are created by the size of the window, interval 15 and [1,1], respectively. Then, by integrating all 52 of these features, the structural feature space is created. By the unification of the structural feature space and spectral, a fusion image with information content that is ample is created for individual pixels and feature space with 368 pixel-based classification features.
Yields of the classification of SVM
The classifier of SVM is used for evaluating the hybrid feature space quality. By using LIBSVM via the Matlab interface, the SVM classification was achieved (Chang et al. 2011). In the classification procedure, the selection of an evaluation scale was the major problem. The coefficient of Kappa and overall accuracy were generally used to define the accuracy of classification. In addition, the khat index was used for measuring the accuracy of individual classes (Kumar 2004). These standards were applied for the comparison of classification findings and were calculated by using the misperception matrix. In addition Fauvel et al. (2008), used McNemar’s Test, which was Performed according to the standardized typical test statistic for calculating statistical significance of differences as expressed in Eq. 22.
Sample numbers that were classified correctly and incorrectly by classifier 1 and classifier 2 are denoted by f12. The precision of classifier 1 and 2 are assumed to be significant statistically if and only if | Z |> 1.96. The Z mark shows the accuracy between classifier 1 and classifier 2 and indicates which one is more precise than the other (Z > 0) or vice versa (Z < 0).
The truth samples, which are basic, are categorized into testing, training, or verification data sets. The SVM classifier is categorized depending on training data where the optimum parameters are adjusted by data examination. In addition, the rating capacity is assessed by invisible data confirmation. Depicted in Table 3 are the number of randomly selected training, test and validation samples in individual classes. Areas that were located in the “3D Objects groupˮ are the category tree, commercial and residential areas out of the 10 classes. By combining LiDAR data and hyper-spectral data, classification findings may be increased. For 2D objects, an effective tool for distinguishing between them is hyper-spectral data. In LiDAR data, 2D objects are usually organized as ground levels; however, the data is also beneficial in splitting 2D and 3D objects.
Standard SVMs are initially used for independently assessing each dataset for the possibility of LiDAR data and hyperspectral images for a metropolitan classification. Then, the next step is to use the standard SVMS for the spectral and structural feature space and lastly for the hybrid image. The performance of SVM is impacted by its parameters as shown in Fig. 5. Thus, grid search is used to specify parameters of SVM where the kernel parameters and regularization are respectively in the range of [2–5, …, 26], [21, …, 210].

Effect of SVM parameters on classification precision (a) Regularization parameter when Gamma = 0.25 (b) Kernel parameter when C = 4
The findings of the classification of SVM in addition to the specific parameters of three datasets are depicted in Table 4. The results gained show that LiDAR data is not within the required accuracy for dataset classification. In addition, hyper-spectral data indicates similar outcomes with respect to the hybrid images. In spite of that, hybrid images still show higher performance by combining two data sets that contain a diverse content of information.
The highest accuracy of classification for hybrid images confirms the capability of the suggested feature level fusion. Additionally, the results obtained show that the spectral and structural properties improve the accuracy of classification compared to the hyperspectral images and LiDAR data respectively, which approve the effectiveness of feature extraction methods. Figure 6 shows the McNemar hybrid image test results for hyperspectral images, LiDAR data and spectral and structural features.

McNemar’s assessment for hybrid image with respect to hyperspectral imagery, LiDAR data, spectral and structural features
In Fig. 6, the statistical analysis also reveals that the hybrid image enhances the classification outcome compared to the individual raw data set and its feature extraction space. Further detailed results for assessing the behaviour of each category are shown in Fig. 7 and Fig. 8. Each class precision is calculated for the hyper-spectral, LiDAR, spectral features, structural features and hybrid image. Figure 7 shows the precision of the 3D classes, which confirms the proposed assumption using a hybrid image for enhancing classification performance.

Outcomes of classification for 3D objects depending on SVM classifier

Outcomes of classification for 2D objects depending on SVM classifier
Figure 7 illustrates that the accuracy of classification for the hybrid image is enhanced up to 29% for 3D object classes in relation to the classification results using a single dataset. The accuracy of 2D classes in SVM classification for LiDAR, hyperspectral, structural features, spectral features and hybrid image data are shown in Fig. 8.
Figure 8 also shows that the hybrid image accomplishes a similar higher precision to the highest degree of classes. However, many repetitions and conflict features result in lower classification performance in two categories: stressful grass and healthy.
Parameter determination and selection of feature based on BPSO
In spite of the fact that the hybrid image enhances the precision of the classification, many related and iterative features lead to lower classification performance. Furthermore, essential elements of classification are other SVM parameters. The parameters of SVM affect the choice of feature set and vice versa. Therefore, in this section, adjusting SVM parameters simultaneously and the selection of a subset of features is set on a BPSO basis. Table 5 consists of significant values for BPSO. The duration of the binary chain is proportional to the dimensionality of the search space. Other parameters are adjusted by expertness.
Figure 9 demonstrates the closeness schemas for the BPSO processes in spectral and features of the structural and hybrid image. The value of fitness is shown to be the best in every generation. As shown in Eq. 18, the parameter of weight in the objective function is fixed to ρ = 0.8, which estimates 80% of appropriate accuracy and 20% to the dimensions of the feature area.

The value of fitness for global best in individual iterations of BPSO
The figure above depicts and enhancement in the value of fitness, which is higher than the hybrid image in terms of spectral and structural features. As aforementioned, the function of fitness contains two elements: the coefficient of Kappa and the dimension of feature space. For assessing the diversity in classification accuracy, Fig. 10 illustrates the coefficient of Kappa for global best results relying on iterations.

Kappa coefficient for global best in each iteration of BPSO
In order to assess the diversity of the dimensions of features in the procedure of optimization, Fig. 11 displays the number of features selected in the most global format based on iterations. In addition, Fig. 11 also shows that the size of the smallest sub-set element (162 features) was chosen in order to consider the hybrid image of a grouping of specific spectral features (153) and specific structural features (16) independently.

Quantity of chosen features for global best in individual iterations of BPSO
The results gained produce improvements in classification accuracy and significantly diminish the dimensions of the feature area. Table 6 epitomizes the specific features of the suggested technique for spectral feature space, hybrid images, and structural feature space.
Table 7 includes a number of selected features, the regularization parameter values, kernel and accuracy of classification to verify and validate the data set, which is defined by the suggested technique for the area of spectral, hybrid and structural features.
Table 7 shows an analysis that reveals that the best performance is provided when using the suggested technique of the hybrid image for each data set independently. Additionally, the entire quantity of features specified in the spectral and structural feature space is better in comparison to the hybrid images. A more thorough accuracy assessment for each class of the 3D and 2D categories is shown in Fig. 12 and Fig. 13, respectively.

Outcomes of classification for 3D objects depending on the proposed technique

Outcomes of classification for 2D objects depending on the proposed method
Figure 12 shows that the structural classification of properties based on the suggested classification system yields respectable findings for 3D objects (above 98%). In addition, the height information of these categories in mixed images leads to further accurate results with regard to the spectral feature classification, only up to 16% enhancement in the commercial category. Figure 13 shows the accuracy of the classification of 2D objects.
As shown in Fig. 8, combining LiDAR data and ultra-spectral image classification performance leads to lower performance of some classes compared to the ultra-spectral data classification. Nevertheless, by choosing the best feature space and adjusting SVM parameters simultaneously, this obstacle and 2D categories of the exact or better accuracy can be fixed by the use of improved hybrid image compared to the use of spectral feature space only (Fig. 13).
The McNemar Test was used for the improvement process of the result analysis statistically. Figure 14 shows the value of Z which is the outcome of simultaneously specifying the SVM parameters and choosing the feature against the standard SVM result.

McNemar’s assessment for the outcome of optimization depending on BPSO with respect to standard SVM yields
Figure 14 demonstrates that individual values of Z for both verifications and data checking is greater than 1.96. This value confirms the statistical enhancement of the suggested optimization procedure compared to the standard SVM. Figure 15 shows the discrimination of the results achieved between the standard SVM over the original dataset (hyperspectral and LiDAR) and the proposed method in case of accurate classification and statistical analysis of the result.

Comparison of the results of an original dataset based on standard SVM and the obtained result of the proposed method (a) Kappa Coefficient (b) Z value
As illustrated in Fig. 15(a), creating a mixed image and then optimizing the system of classification enhances the classification of hyperspectral images by approximately 12%. The suggested technique removes 206 surplus features from the hybrid image. Therefore, not only does it decrease the feature space dimensions and reduce the complications of the calculation but also enhances the overall and accuracy of a classification, and this results in a dependable classification system for the hybrid image data. Furthermore, Fig. 15(b) shows the value of Z for the findings of optimized hybrid images with respect to LiDAR data and hyperspectral images that demonstrate the significant improvement in the suggested technique. Table 8 shows the suggested technique in comparison to the precision of each class, in standard SVM.
Table 8 depicts that the accuracy obtained for all classes is the same or improved slightly based on the suggested technique, considering the use of a smaller feature subset in both verification and checking data. In addition, the enhancement inaccuracy of the two significant categories in metropolitan areas (residential and commercial) is large.
The outcomes achieved demonstrate the capability of the suggested technique in integrating LiDAR data and hyperspectral images in metropolitan classification with a great number of classes. Although hyperspectral images are unsuccessful in building classification (residential and commercial), it obtains acceptable results. However, in metropolitan areas, one of the most significant objects is buildings, so LiDAR data notably enhances the grouping precision of these categories. The suggested technique proficiently combines these two data sources to output accurate classification findings.
Conclusion
Throughout this research, the outline for the optimization of a classification system of a hybrid was explored to merge LiDAR data and hyperspectral data according to BPSO. The utilization of CASI hyperspectral image data and a DSM extracted from LiDAR data were experimented. Moreover, various spectral and structural features were withdrawn from hyperspectral and LiDAR data. Even though SVM is considered a suitable classifier for high-dimensional space, its execution is optimized by the direct combination of the determination of parameters and the feature subsets that are chosen.
The outcome of the experiments that were performed throughout this research showed that using 3D information from LiDAR data as well as high spectral information of hyperspectral data contributed to the enhancement of the classification performance, particularly for 3D objects like buildings and trees (see Table 3, Fig. 7 and Fig. 12). Despite that, for some classes, significant contrasts were not found between hyper-spectral and hybrid feature space since they showed no difference in height such as soil and grass see (Table 3 and Table 8).
The classification accuracy is increased by 7% in addition to the removal of 206 surplus features, which is accomplished by the elevated efficiency of the optimization of the hybrid classification system according to BPSO. Thus, the optimum hybrid classification system yields increased accuracy in a more comprehensible space. By removing surplus features, per class accuracy is also enhanced (see Fig. 15). According to the outcomes of hyperspectral and LiDAR data classification exclusively, all classes within the hybrid system either have advanced or are in the same accuracy.
The results that were accomplished throughout this paper are beneficial for improving classification performance, particularly for 3D object features such as buildings and trees. The proposed technique used in this study is proficient and combines both sources of data to output accurate classification findings.
The author recommends conducting additional investigations for future work as follows.
-
1.
Evaluating more textual features from LiDAR data and spectral indicators by hyperspectral images by using the last pulse along with the first pulse or full-waveform LiDAR data. Also, using a multi-purpose optimization technique to define SVM parameters and define a set of sub-characteristics, automatic determination of BPSO parameters (for example, the size of the population, w, c1, c2) and evaluation of the possibility of different meta-heuristic algorithms, specifically optimization algorithms that are swarm-based.
-
2.
Compare the performance of the SVM classifier as a machine learning classifier with classifiers, which have different mathematical models such as artificial neural networks (ANN) and/or classification trees.
-
3.
Integrating SVM and ANN in a parallel form to take advantage of the complementary behaviours of the two algorithms.
References
Abe S (2010) Feature selection and extraction. In Support vector machines for pattern classification. Springer, pp. 331–341
Alonzo M, Bookhagen B, Roberts DaJRSOE (2014) Urban tree species mapping using hyperspectral and lidar data fusion. Remote Sensing of Environment 148:70–83. https://doi.org/10.1016/j.rse.2014.03.018
Bao J, Chi M, Benediktsson JA, JIJOSTIaEO and Sensing R (2013) Spectral derivative features for classification of hyperspectral remote sensing images: Experimental evaluation, IEEE J. Sel. Top. Appl. Earth Observat. Remote Sens 6(2):594–601. https://doi.org/10.1109/JSTARS.2013.2237758
Benediktsson JA, Pesaresi M, Amason KJITOG and Sensing R (2003) Classification and feature extraction for remote sensing images from urban areas based on morphological transformations 41(9):1940–1949. https://doi.org/10.1109/TGRS.2003.814625
Brook A, Ben-Dor E, Richter R (2010) Fusion of hyperspectral images and LiDAR data for civil engineering structure monitoring. In 2010 2nd Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing. IEEE, pp. 1–5. https://doi.org/10.1109/WHISPERS.2010.5594872
Chang C-C, Lin C-J, JaTOIS and Technology (2011) LIBSVM: a library for support vector machines 2(3):1–27. https://doi.org/10.1145/1961189.1961199
Chang C-I (2007) Hyperspectral data exploitation: theory and applications. New York, NY, USA: Wiley & Sons
Chica-Olmo M, Abarca-Hernández F (2004) Variogram derived image texture for classifying remotely sensed images. In Remote sensing image analysis: including the spatial domain. Springer, pp. 93–111. https://doi.org/10.1007/978-1-4020-2560-0_6
Congalton RG, Green K (2019) Assessing the accuracy of remotely sensed data: principles and practices. CRC Press
Dalponte M, Bruzzone L, Gianelle D, JITOG and Sensing R (2008) Fusion of hyperspectral and LIDAR remote sensing data for classification of complex forest areas 46(5):1416–1427. https://doi.org/10.1109/TGRS.2008.916480
Elaksher AFJO, Engineering LI (2008) Fusion of hyperspectral images and lidar-based dems for coastal mapping 46(7):493–498. https://doi.org/10.1016/j.optlaseng.2008.01.012
Engelbrecht AP (2007) Computational intelligence: an introduction. John Wiley & Sons
Fauvel M, Benediktsson JA, Chanussot J, Sveinsson J, RJITOG and Sensing R (2008) Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles 46(11):3804–3814. doi. https://doi.org/10.1109/TGRS.2008.922034
Feng Q, Zhu D, Yang J and Li B JIIJOG-I (2019) Multisource hyperspectral and lidar data fusion for urban land-use mapping based on a modified two-branch convolutional neural network 8(1):28. https://doi.org/10.3390/ijgi8010028.
Forzieri G, Tanteri L, Moser G, Catani F JIJOaEO and Geoinformation (2013) Mapping natural and urban environments using airborne multi-sensor ADS40–MIVIS–LiDAR synergies 23:313–323. https://doi.org/10.1016/j.jag.2012.10.004
Hamzeh S, Naseri AA, Alavipanah SK, Mojaradi B, Bartholomeus HM, Clevers JG, Behzad M JIJOaEO and Geoinformation (2013) Estimating salinity stress in sugarcane fields with spaceborne hyperspectral vegetation indices 21:282–290. https://doi.org/10.1016/j.jag.2012.07.002
Haralick RM, Shanmugam K, Dinstein I HJITOS, Man and Cybernetics (1973) Textural features for image classification (6):610–621. https://doi.org/10.1109/TSMC.1973.4309314
Hsu C-W, Chang C-C and Lin C-J (2003a) A practical guide to support vector classification. Taipei
Hsu CW, Chang CC Lin CJ (2003b) A practical guide to support vector classification. Citeseer
Jones TG, Coops NC and Sharma T JRSOE (2010) Assessing the utility of airborne hyperspectral and LiDAR data for species distribution mapping in the coastal Pacific Northwest, Canada 114(12):2841–2852. https://doi.org/10.1016/j.rse.2010.07.002
Koetz B, Morsdorf F, Van Der Linden S, Curt T, Allgöwer B JFE and Management (2008) Multi-source land cover classification for forest fire management based on imaging spectrometry and LiDAR data 256(3):263–271. https://doi.org/10.1016/j.foreco.2008.04.025
Kumar, M. (2004) Feature selection for classification of hyperspectral remotely sensed data using NSGA-II. In Water Resources Seminar, Citeseer.)
Latifi H, Fassnacht F, Koch B JRSOE (2012) Forest structure modeling with combined airborne hyperspectral and LiDAR data 121:10–25. https://doi.org/10.1016/j.rse.2012.01.015
Lee M, Tuell G (2003) A technique for generating bottom reflectance images from SHOALS data. In US Hydrographic Conference, Biloxi, MS.)
Lemp D and Weidner U (2005) Improvements of roof surface classification using hyperspectral and laser scanning data. In Proc. ISPRS Joint Conf.: 3rd Int. Symp. Remote Sens. Data Fusion Over Urban Areas (URBAN), 5th Int. Symp. Remote Sens. Urban Areas (URS). Citeseer, pp. 14–16
Li Y, Ge C, Sun W, Peng J, Du Q and Wang K, JRS (2019) Hyperspectral and LiDAR data fusion classification using superpixel segmentation-based local pixel neighborhood preserving embedding 11(5):550. https://doi.org/10.3390/rs11050550
Lin S-W, Ying K-C, Chen S-C, Lee Z-J, JESWA (2008a) Particle swarm optimization for parameter determination and feature selection of support vector machines 35(4):1817–1824. https://doi.org/10.1016/j.eswa.2007.08.088
Lin SW, Ying KC, Chen SC, Lee ZJ (2008) Particle swarm optimization for parameter determination and feature selection of support vector machines. Expert Syst Appl 35(4):1817–1824. https://doi.org/10.1016/j.eswa.2007.08.088
Liu L, Pang Y, Fan W, Li Z, Li M (2011) Fusion of airborne hyperspectral and LiDAR data for tree species classification in the temperate forest of northeast China. In 2011 19th International Conference on Geoinformatics. IEEE, pp. 1–5. https://doi.org/10.1109/GeoInformatics.2011.5981118
Liu Q, Jing L, Wang L, Lin Q (2014) A Method of Particle Swarm Optimized SVM Hyper-spectral Remote Sensing Image Classification. In IOP Conference Series: Earth and Environmental Science. IOP Publishing, vol. 17, pp. 012205
Lodha SK, Kreps EJ, Helmbold DP, Fitzpatrick D (2006) Aerial LiDAR data classification using support vector machines (SVM). In Third International Symposium on 3D Data Processing, Visualization, and Transmission (3DPVT'06). IEEE, pp. 567–574. https://doi.org/10.1109/3DPVT.2006.23
Melgani F, Bruzzone L, JITOG and Sensing R (2004) Classification of hyperspectral remote sensing images with support vector machines 42(8):1778–1790. https://doi.org/10.1109/TGRS.2004.831865
Mundt JT, Streutker DR, Glenn N, FJPE and Sensing R (2006) Mapping sagebrush distribution using fusion of hyperspectral and lidar classifications 72(1):47–54. doi. https://doi.org/10.14358/PERS.72.1.47
Niemann KO, Frazer G, Loos R and Visintini F (2009) LiDAR-guided analysis of airborne hyperspectral data. In 2009 First Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing. IEEE, pp. 1–4. https://doi.org/10.1109/WHISPERS.2009.5289029
O'boyle NM, Palmer DS, Nigsch F and Mitchell JB, JCCJ (2008) Simultaneous feature selection and parameter optimisation using an artificial ant colony: case study of melting point prediction 2(1):1–15
Pirnazar M, Hasheminasab H, Karimi AZ, Ostad-Ali-Askari K, Ghasemi Z, Haeri-Hamedani M, Mohri-Esfahani E, Eslamian S, JIJOGEI (2018) The evaluation of the usage of the fuzzy algorithms in increasing the accuracy of the extracted land use maps 17(4):307-321
Rashedi E, Nezamabadi-Pour H, JJOI and Systems F (2014) Feature subset selection using improved binary gravitational search algorithm 26(3):1211–1221. https://doi.org/10.3233/IFS-130807
Samadzadegan F, Hasani H, Schenk T, JPE and Sensing R (2012) Determination of optimum classifier and feature subset in hyperspectral images based on ant colony system 78(12):1261–1273. https://doi.org/10.14358/PERS.78.11.1261
Shimoni M, Tolt G, Perneel C and Ahlberg J (2011) Detection of vehicles in shadow areas using combined hyperspectral and lidar data. In 2011 IEEE International Geoscience and Remote Sensing Symposium. IEEE, pp. 4427–4430. https://doi.org/10.1109/IGARSS.2011.6050214
Sugumaran R, Voss M (2007) Object-oriented classification of LIDAR-fused hyperspectral imagery for tree species identification in an urban environment. In 2007 Urban Remote Sensing Joint Event. IEEE, pp. 1–6. https://doi.org/10.1109/URS.2007.371845
Tan F, Fu X, Zhang Y, Bourgeois AG (2008) A genetic algorithm-based method for feature subset selection. Soft Comput Fusion Found Methodologies Appl 12(2):111–120
Unler A, Murat A, Chinnam R, BJIS (2011) mr2PSO: A maximum relevance minimum redundancy feature selection method based on swarm intelligence for support vector machine classification 181(20):4625–4641. https://doi.org/10.1016/j.ins.2010.05.037
Wang J, Zhang J, Guo Q, Li T (2019) Fusion of Hyperspectral and Lidar Data Based On Dual-Branch Convolutional Neural Network. In IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium. IEEE, pp. 3388–3391. https://doi.org/10.1109/IGARSS.2019.8899332
Whelley PL, Glaze LS, Calder ES, Harding DJ, JITOG and Sensing R (2013) LiDAR-derived surface roughness texture mapping: application to Mount St. Helens pumice plain deposit analysis 52(1):426–438. https://doi.org/10.1109/TGRS.2013.2241443
Wu C-H, Tzeng G-H, Goo Y-J and Fang W-C, JESWA (2007) A real-valued genetic algorithm to optimize the parameters of support vector machine for predicting bankruptcy 32(2):397–408. https://doi.org/10.1016/j.eswa.2005.12.008
Yuen PW and Richardson M, JTISJ (2010) An introduction to hyperspectral imaging and its application for security, surveillance and target acquisition 58(5):241–253. https://doi.org/10.1179/174313110X12771950995716
Zhang C, Qiu F, JPE and Sensing R (2012) Mapping individual tree species in an urban forest using airborne lidar data and hyperspectral imagery 78(10):1079–1087. https://doi.org/10.14358/PERS.78.10.1079
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible Editor: Biswajeet Pradhan
Rights and permissions
About this article

Cite this article
Abdulrahman, F.H. Hyperspectral and LiDAR data fusion in features based classification. Arab J Geosci 14, 2730 (2021). https://doi.org/10.1007/s12517-021-09031-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12517-021-09031-w