
Abstract
Hyperspectral remote sensing technology has many applications in the fields of land cover classification and examination of their changes. It seems necessary to use both spectral and spatial information in the hyperspectral image classification due to recent developments and the availability of images at higher spatial resolution. In this study, a new approach for object-based classification of hyperspectral images is introduced. In the proposed approach, first nine spatial features, including mean, standard deviation, contrast, homogeneity, correlation, dissimilarity, energy, wavelet transform and Gabor filter, are extracted from the neighboring pixels of the hyperspectral image. Then, the dimensions of the obtained features are reduced using weighted genetic (WG) algorithm. Next, the hierarchical segmentation (HSEG) algorithm is applied to the reduced features. Then, for the objects obtained from segmentation, nine spatial features, area, perimeter, shape index, strength, maximum intensity, minimum intensity, entropy, relation and adjacency, are extracted. Finally, the classification is performed using the multilayer perceptron neural network (MLP) algorithm. The proposed approach was implemented on three hyperspectral images of Indiana Pine, Berlin and Telops. According to the experimental results, the proposed approach is superior to the MLP classification method. This increase in the overall accuracy is about 12% for the Indiana Pine image, about 11% for the Berlin image, and about 8% for the Telops image.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Hyperspectral remote sensing technology has made significant progress in the last two decades. Although the ability to produce data with high spectral, spatial and radiometric features leads to better analysis, this is associated with problems that are a new experience compared to multispectral data (Chan et al., 2020). The first problem is the relatively large volume of data, it is necessary to use special hardware and software to process this large volume of data. Another problem is the time required to process this type of data (Homayouni & Roux, 2003). Nowadays, most research on hyperspectral remote sensing technology focuses on the classification of these images. Classification or convert images to a subject map is a serious challenge due to factors such as the complexity of the study area, data selection, image processing, and the algorithm used and may affect the success of classification (Acquarelli et al., 2018; Gonzalez & Woods, 2002). The lack of labeled samples in the classification process is due to the large number of hyperspectral image bands. In fact, the most important problem of hyperspectral data is that it contains hundreds of close spectral bands that cause data redundancy. On the other hand, spectral bands of hyperspectral images usually have high dependence and different signal-to-noise ratio, so the use of primary bands is not very appropriate and has poor results. The large number of spectral bands and the dependence between them cause the Hughes phenomenon (Li et al., 2011). This phenomenon means that when the training data do not change, the classification accuracy decreases with increasing spectral bands. Reducing the number of bands is one of the solutions to this problem. Various methods such as feature extraction and feature selection have been proposed for this purpose (Chang, 2003).
In general, methods for classifying hyperspectral images are divided into two categories. The first category refers to pixel-based classification methods in which each pixel is assigned to a specific class using its own spectral information without considering the information contained in neighboring pixels (Vapnik, 1995). These methods include support vector machines (SVM) and multilayer perceptron (MLP) algorithms. The second category refers to spectral-spatial classification methods that use information from neighboring pixels in addition to spectral information of pixels (Fauvel et al., 2013; Pan et al., 2020; Tarabalka et al., 2010). One of these methods is the minimum spanning forest (MSF) algorithm (Tarabalka et al., 2010). Many unknown signals are usually recorded in images due to the high sensitivity of hyperspectral sensors, for which there is no prior information. In particular, many of these signals are related to objects that are small in size and cannot be detected visually. Under these circumstances, it is not possible to identify these targets by conventional classification methods that use only spectral information, and in addition, the processing must be performed using the spatial features of the targets (Hong et al., 2020).
Benediktsson et al., in 2003, suggested the morphological profiles method as one of the spatial information extraction techniques (Benediktsson et al., 2003). The morphological profiles consist of a combination of opening, closing filters. Using the nearest neighbors is another way to use spatial information (Richards & Jia, 2006). Accordingly, Huang and Zhang, in 2009, used from the gray level co-occurrence matrix (GLCM) to classify hyperspectral data (Huang & Zhang, 2009). In their proposed method first extracted texture features from the GLCM matrix using the four measurements, the angular second moment, contrast, entropy and homogeneity, then the principal component analysis (PCA) algorithm was applied to the obtained features. Segmentation methods are another spatial information extraction method, in which objects in the image (a set of pixels with the same features) are identified based on features such as homogeneity (Tarabalka et al., 2011). It provides accurate and complete spatial information if an accurate map of objects is to be created based on the spatial structures in the image. Marker-based segmentation is a common method for obtaining accurate segmentation results, (Soille, 2003; Tarabalka et al., 2011), in which one or more pixels are selected as the marker for each spatial area of the image, then the markers obtained in the segmentation process develop and lead to a specific area in the segmentation map. In early studies, markers were generally selected from homogeneous areas, i.e., areas with the same pixel values or uniform texture (Soille, 2003). In 2007, Gómez et al. selected pixels with the same values as the marker using the image histogram (Gómez et al., 2007). Tarabalka et al., in 2011, used a marker-based hierarchical segmentation (HSEG) to extract spatial information (Tarabalka et al., 2011). They chose pixels with a high degree of belonging to each class as a marker using the SVM classification map. For this purpose, labeling of connected components was first analyzed on the SVM classification map, then for large areas generated p% of the pixels with the highest probability and pixels with a probability degree higher than the specified threshold were considered as marker for small areas. In 2017, Akbari classified hyperspectral image using weighted genetic (WG) and marker-based MSF algorithms (Akbari, 2017). In this study, he used SVM classification and watershed segmentation maps to select marker. In 2020, Akbari in another study increased the accuracy of MSF classification by an average of 8% by extracting two spatial features of wavelet transform and Gabor filter before applying the WG algorithm and considering the MLP classification map in the selection of markers (Akbari, 2020).
The results of studies show that so far, segmentation method and among different segmentation algorithms, the HSEG algorithm has achieved the best results. Also, reducing the dimensions of the spectral image and spatial features extraction before applying the segmentation algorithm has been able to increase the accuracy of the results. Therefore, this study seeks to present a new approach for spectral-spatial classification of hyperspectral images using techniques for extracting spatial features and reducing the dimensions of hyperspectral images. In the proposed approach, first nine spatial features are extracted from the primary bands of the hyperspectral image and then the optimal spectral and spatial features are selected using the WG algorithm. Then, the HSEG algorithm is implemented on the obtained features. Next, nine spatial features are extracted from segmentation map and the MLP algorithm is used to classify them.
The Proposed Approach
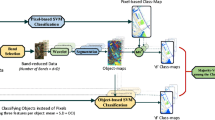
Figure 1 shows the steps of the proposed spectral-spatial classification approach.

Schema of the proposed approach
As shown in the figure, nine spatial features were first extracted from the neighborhood information of the image pixels in the proposed approach. Various properties can be extracted from image pixels as base pixel data and used to classify (Gonzalez & Woods, 2002; Zhang & Tan, 2002). The gray degree relationships of the pixels are transferred from the image space to the co-occurrence matrix space by considering a neighborhood window of appropriate size around each pixel and selecting one of the directions (Barburiceanu et al., 2021; Haralick et al., 1973; Zhang et al., 2003). Then, the values of known texture descriptors in the GLCM space are measured according to the size of the neighborhood window and the selected direction (Ciriza et al., 2017; Huang & Wang, 2006; Iqbal et al., 2021). Table 1 shows these features along with their mathematical relationships and explanations.
After extracting the spatial features, the spectral and spatial properties are reduced by the WG algorithm. Genetic algorithm is one of the metaheuristic optimization techniques (Zhuo & Zheng, 2008). It is the most common type of evolutionary algorithms for which there is no single procedure and it has iterative procedures. In the binary genetic algorithm, each chromosome has values of one and zero (Zhuo & Zheng, 2008), while in the WG algorithm, the weight values are between zero and one (Akbari, 2017). This study uses the kappa coefficient of the MLP classification to determine the value of each chromosome.
In the next step, the HSEG algorithm is applied to the reduced features. The HSEG algorithm is based on area growth method and hierarchical optimization and provides the possibility of combining non-adjacent spatial regions by the input parameter \({S}_{wght}\) (Tarabalka et al., 2011). \({S}_{wght}\) indicates the relative importance of spectral clustering against region growth. For \({S}_{wght}=0\), the HSEG algorithm combines only adjacent spatial regions with each other, and for \({S}_{wght}=1,\) adjacent and non-adjacent regions have the same weight in the composition, and finally for values between zero and one, the composition of adjacent regions compared to non-adjacent regions has a superiority of \(\frac{1}{{S}_{wght}}\). This algorithm consists of three steps: In the first step, an object is labeled to each pixel of the image independently, then a dissimilarity criterion is calculated for each pair of objects in the next step, and the pair of objects with the smallest criterion are combined. The third stage is the repetition of the second stage until there is no need to combine objects (Tarabalka et al., 2011). After segmentation, nine spatial features were extracted from the object information of the segmentation map (Chen, 2006; Li et al., 2007; Nghi & Mai, 2008; Rajadell et al., 2009). Table 2 shows these features along with their explanations and mathematical relationships. Finally, the MLP algorithm was used to classify the objects obtained from segmentation.
Experimental Results and Discussion
Hyperspectral Data
This study has used three hyperspectral images of Indiana Pine, Berlin and Telops, which are part of benchmark images in the field of hyperspectral remote sensing, to evaluate the proposed approach. The specifications of these images are summarized in Table 3. The images of Berlin and Telops are related to the Berlin’s urban area in Germany and Quebec in Canada, respectively, and the Indian Pines image is related to an agricultural land in India.
Figure 2 shows the three hyperspectral images used. In the Telops image, unlike the other two images, the pixel values are equal to the radius values, so atmospheric corrections must be made on the image before performing the tests.

Color-false combination a Indiana Pine image b Berlin image c Telops image
The classes that are specified in each image correspond to the objects in that image. As can be seen in Fig. 2, the objects of Berlin and Telops images, which are related to an urban area, are different from the objects of Indiana Pine image, which is related to an agricultural area. For each of the classes in all three image data, about 10% of the labeled samples were randomly selected as training data and the rest, i.e., about 90% as test data.
Experimental Results
Table 4 shows the value of the parameters used in WG algorithm, which are the same for the three data sets.
The value of the parameter \({\mathrm{S}}_{\mathrm{wght}}\) was considered to be 0.2 in the tests performed for the HSEG algorithm, due to the complexity of the hyperspectral images used (Tarabalka et al., 2011). As mentioned earlier, if \({\mathrm{S}}_{\mathrm{wght}}=0\), only neighboring objects are allowed to combine with each other, and if \({0<S}_{\mathrm{wght}}<1\), non-neighboring objects are allowed to combine, and if \({\mathrm{S}}_{\mathrm{wght}}=1\), neighboring and non-neighboring objects have the same weight in the composition. The MLP classification algorithm, with three hidden layers including 4, 5 and 7 neurons, was implemented and evaluated with 500 replications.
The proposed classification approach was compared with MLP, Marker-based HSEG, the proposed method by Tarabalka et al. (Tarabalka et al., 2011), and Extended-MSF, the proposed approach by Akbari (Akbari, 2020). In Marker-based HSEG algorithm, SVM classification map and Gaussian radial basis kernel were used to select the markers (Cristianini & Shawe-Taylor, 2000). The values of two parameters of penalty parameter (C) and Gaussian kernel (\(\gamma\)) in SVM algorithm were determined using cross-validation technique. Cross-validation is a standard technique for adjusting hyperparameters of predictive models. In K-fold cross-validation, the available data S are partitioned into K subsets \({S}_{1}, \dots , {S}_{k}\). Each data point in S is randomly assigned to one of the subsets such that these are of almost equal size (Hastie et al., 2008). To choose C and \(\gamma\) using K-fold cross-validation, the available data are first subdivided into K subsets. The cross-validation error is then calculated using this split error for the SVM classifiers using different values for C and \(\gamma\). Finally, C and \(\gamma\) are selected with the least cross-validation error and used to train an SVM on the complete data set S. Thus, the final values of the above parameters for Indiana Pine image are equal to C = 100, \(\gamma\) = 0.001, Berlin image equal to C = 200, \(\gamma\) = 0.01 and Telops image equal to C = 256 and \(\gamma\) = 0.1. Then, the labeling of the connected components was analyzed based on eight neighborhood pixels in the SVM classification map, and for areas with more than 20 pixels, 5% of the pixels most likely to belong to a class were selected as marker pixels. For small areas, less than 20 pixels, pixels with a probability of more than one threshold were selected as the marker pixels. The selected threshold is equal to the lowest probability among 2% of the highest probabilities of the whole image. In the Extended-MSF algorithm, for each object in the watershed segmentation map, the class-related pixels with the largest population of SVM and MLP classification maps are kept, and then pixels with the same class are maintained, and pixels in each object with the highest degree of belonging to a class are selected as marker.
In order to evaluate the accuracy of the tests performed, first, the error matrix was formed using reference map, then the parameters of overall accuracy (OA), kappa coefficient (K) and producer accuracy related to each class were extracted (Tarabalka et al., 2010).
a) Indiana Pine Image
The classification maps obtained using the MLP, Marker-based HSEG, Extended-MSF and the proposed approach are shown in Fig. 3. As shown, the map obtained from the proposed approach has less noise compared to other algorithms.

Indiana Pine data set; a MLP classification map, b Marker-based HSEG classification map, c Extended-MSF classification map, d Proposed approach classification map, e Reference map
Figure 4 and Table 5 show the values of the accuracy parameters of the classification maps obtained from the hyperspectral image of Indiana Pine. As shown, the proposed approach increases the kappa coefficient parameter by about 13, 8 and 5% compared to MLP, Marker-based HSEG and Extended-MSF algorithms, respectively. Also, the accuracy of all classes has been increased by the proposed approach and has reached over 90%.

Comparison of the values of the two parameters of overall accuracy and kappa coefficient for the classification algorithms used in Indiana Pine image
b) Berlin Image
Figure 5 shows the classification maps for the Berlin hyperspectral image. As can be seen, the proposed approach map contains homogeneous regions compared to other algorithms. This shows the importance of using spatial information in the classification process.

Berlin data set; a MLP classification map, b Marker-based HSEG classification map, c Extended-MSF classification map, d Proposed approach classification map, e Reference map
The values of the accuracy parameters of the classification maps obtained from the Berlin hyperspectral image are shown in Fig. 6 and Table 6. In this image, the proposed approach has also increased the accuracy. This increase in kappa coefficient parameter by 11, 8 and 3% is compared to MLP, Marker-based HSEG and Extended-MSF algorithms, respectively. Also, in all classes except soil class, the classification accuracy of the proposed approach is higher than the accuracy of Extended-MSF. This decrease in soil class can be due to the small number and high dispersion of its pixels, that it can reduce the role of spatial information in the classification process. The spectral complexity of the Berlin image can also be effective in reducing the accuracy of the soil class. In the case of two classes of Build-up and Impervious, which had low accuracy, their accuracy was increased by 17 and 13% using the proposed approach compared to the MLP algorithm, which emphasizes the importance of using spatial information in these two classes.

Comparison of the values of the two parameters of overall accuracy and kappa coefficient for the classification algorithms used in the Berlin image
c) Telops Image
Figure 7 shows the classification maps and the reference map of the Telops hyperspectral image. As shown, the proposed map consists of homogeneous regions with less noise than other algorithms.

Telops data set; a MLP classification map, b Marker-based HSEG classification map, c Extended-MSF classification map, d Proposed approach classification map, e Reference map
The values of the accuracy parameters of the classification maps obtained from the Telops hyperspectral image are shown in Fig. 8 and Table 7. In this image, like two images of Indiana Pine and Berlin, the proposed approach increases the accuracy by 8, 5 and 3% in the kappa coefficient parameter compared to the MLP, Marker-based HSEG and Extended-MSF algorithms, respectively. Also, the accuracy of the classes in the proposed approach is increased compared to other algorithms.

Comparison of the values of two parameters of overall accuracy and kappa coefficient for classification algorithms used in Telops image
Quantitative and qualitative results obtained from tests performed on three hyperspectral images emphasize the importance of information extracted from neighborhood pixels and segmentation map objects. Of course, the role of dimensional reduction in this study cannot be ignored. For classification of hyperspectral images, a large number of bands sometimes cause intense computational load and produce inaccurate results. In the proposed approach, the WG algorithm was used for subspace analysis of hyperspectral images and spatial features. WG algorithm uses the information of all bands, by assigning a value between zero and one in each band, as the weight of the band. In fact, a population is created with a group of individuals created randomly with the weight between zero and one. In WG algorithm, the bands with less information are allocated less weight.
The proposed framework was able to take advantage of spectral and spatial information simultaneously for an accurate classification of hyperspectral images. The method yields reliable results for different data sets. Despite having reliable results for the classification of homogeneous regions, the proposed approach has a drawback similar to almost all the spectral-spatial techniques: It produces a smooth classification map in comparison with pixelwise classifications. Therefore, it risks impairing results near the borders between regions where mixed pixels are often encountered. Spectral unmixing techniques can be potentially used for an accurate analysis of border regions.
Conclusions
Hyperspectral sensors capture images in hundreds of narrow spectral channels. The detailed spectral signatures for each spatial location provide rich information about an image scene, making it easier to distinguish physical materials and objects from one another. Although pixel-based classification techniques have resulted in high classification accuracy rates when using hyperspectral data, the incorporation of the spatial context into classification procedures yields even better accuracy rates. This study has introduced a new approach for spectral-spatial classification of hyperspectral images. The three factors of extracting information from pixels, reducing dimensions and extracting information from segmentation map objects were used in the proposed approach, which is based on the HSEG algorithm. For this purpose, nine features of mean, standard deviation, contrast, homogeneity, correlation, dissimilarity, energy, wavelet transform and Gabor filter were extracted from the initial hyperspectral image as the information of the nearest neighbors. Then, the WG algorithm was used to reduce the dependence between the spectral and spatial features obtained. The HSEG algorithm, which is one of the most accurate spatial information extraction algorithms in hyperspectral images, was used to segment the image. Then, nine features of area, perimeter, shape index, strength, maximum intensity, minimum intensity, entropy, relation and adjacency were extracted from the segmentation map objects to classify the obtained objects. The proposed approach was implemented on three hyperspectral images of the Indiana Pine, Berlin and Telops. According to the results of practical experiments, the proposed approach has a quantitative and qualitative advantage over the MLP algorithm. This advantage is 13, 11 and 8% in the kappa coefficient parameter in Indiana Pine, Berlin and Telops images, respectively. The reason for the greater increase in the accuracy of the Indiana Pine image compared to the other two images can be the complexity of the image, the presence of noise bands and the high dependence of the Indian Pines image bands, which indicates the need to use the band reduction process before classification. Also, the accuracy of the classes in the proposed approach in all three images has increased compared to other algorithms. The only exception is the soil class in the Berlin image, which could be due to its small number and high dispersion of its pixels. Future studies will investigate the effect of different spatial properties on each of the classes in the image, in which special spatial features to each class can be used to classify them to reduce computation time.
Change history
02 January 2023
A Correction to this paper has been published: https://doi.org/10.1007/s12524-022-01632-6
References
Acquarelli, J., Marchiori, E., Buydens, L. M. C., Tran, T., & Laarhoven, T. V. (2018). Spectral-spatial classification of hyperspectral images: Three tricks and a new learning setting. Remote Sensing, 10, 1156.
Akbari, D. (2020). Improving spectral-spatial classification of hyperspectral imagery by using extended minimum spanning forest algorithm. Canadian Journal of Remote Sensing, 46, 146–153.
Akbari, D. (2017). Improving spectral–spatial classification of hyperspectral imagery using spectral dimensionality reduction based on weighted genetic algorithm. Journal of the Indian Society of Remote Sensing, 45, 927–937.
Barburiceanu, S., Terebes, R., & Meza, S. (2021). 3D texture feature extraction and classification using GLCM and LBP-based descriptors. Applied Sciences, 11, 1–25.
Benediktsson, J. A., Pesaresi, M., & Arnason, K. (2003). Classification and feature extraction for remote sensing images from urban areas based on morphological transformations. IEEE Transactions on Geoscience and Remote Sensing, 41, 1940–1949.
Chan, R. H., Kan, K. K., Nikolova, M., & Plemmons, R. J. (2020). A two-stage method for spectral–spatial classification of hyperspectral images. Journal of Mathematical Imaging and Vision, 62, 790–807.
Chang, C. I. (2003). Hyperspectral Imaging: Techniques for spectral detection and classification. Orlando: Kluwer Academic.
Chen, Z. (2006). Research on high resolution remote sensing image classification technology. Beijing: Institute of Remote Sensing Applications of Chinese Academy of Science.
Ciriza, R., Sola, I., Albizua, L., Álvarez-Mozos, J., & González-Audícana, M. (2017). Automatic detection of uprooted orchards based on orthophoto texture analysis. Remote Sensing, 9, 1–22.
Cristianini, N., & Shawe-Taylor, J. (2000). An Introduction to support vector machines and other Kernel-based learning methods. Cambridge University Press.
Fauvel, M., Tarabalka, Y., Benediktsson, J. A., Chanussot, J., & Tilton, J. C. (2013). Advances in spectral-spatial classification of hyperspectral images. Proceedings of the IEEE, 101, 652–675.
Gómez, O., González, J. A., & Morales, E. F. (2007). Image segmentation using automatic seeded region growing and instance-based learning. in Proc. 12th Iberoamerican Congress Pattern Recognition, Valparaiso, Chile, 192–201.
Gonzalez, R. C., & Woods, R. E. (2002). Digital Image Processing. Prentice Hall, 617–626.
Haralick, R. M., Shanmugam, K., & Dinstein, I. (1973). Textural features for image classification. IEEE Transactions on Systems, Man, and Cybernetics, SMC-3, 610–621. https://doi.org/10.1109/TSMC.1973.4309314
Hastie, T., Tibshirani, R., & Friedman, J. (2008). The Elements of Statistical Learning. Springer, Verlag, section 4.3
Homayouni, S., & Roux, M. (2003). Material Mapping from Hyperspectral Images using Spectral Matching in Urban Area. IEEE Workshop on Advances in Techniques for analysis of Remotely Sensed Data, NASA Goddard center, Washington DC, USA.
Hong, D., Wu, X., Ghamisi, P., Chanussot, J., Yokoya, N., & Zhu, X. X. (2020). Invariant attribute profiles: A spatial-frequency joint feature extractor for hyperspectral image classification. IEEE Transactions on Geoscience and Remote Sensing, 58, 3791–3808.
Huang, C. L., & Wang, C. J. (2006). A GA-based feature selection and parameter optimization for support vector machines. Expert Systems with Application, 31, 231–240.
Huang, X., & Zhang, L. (2009). A comparative study of spatial approaches for urban mapping using hyperspectral rosis images over pavia city, northern Italy. International Journal of Remote Sensing, 30, 3205–3221.
Iqbal, N., Mumtaz, R., Shafi, U., & Zaidi, S. M. H. (2021). Gray level co-occurrence matrix (GLCM) texture based crop classification using low altitude remote sensing platforms. PeerJ Computer Science, 7, 1–26.
Li, S., Wu, H., Wan, D., & Zhu, J. (2011). An effective feature selection method for hyperspectral image classification based on genetic algorithm and support vector machine. Knowledge-Based Systems, 24, 40–48.
Li, X., Zhao, S., Rui, Y., & Tang, W. (2007). An object-based classification approach for high-spatial resolution Imagery. In Geoinformatics 2007: Remotely Sensed Data and Information, Proc. of SPIE Vol. 6752 67523O-1
Mallat, S. (1999). A wavelet tour of signal processing. San Diego: Academic Press.
Nghi, D. H., & Mai, L. C. (2008). An object-oriented classification techniques for high resolution satellite imagery. In Proceedings of the International Symposium on Geoinformatics for Spatial Infrastructure Development in Earth and Allied Sciences.
Pan, E., Mei, X., Wang, Q., Ma, Y., & Ma, J. (2020). Spectral-spatial classification for hyperspectral image based on a single GRU. Neurocomputing, 387, 150–160.
Rajadell, O., Garc´ıa-Sevilla, P., & Pla, F. (2009). Textural features for hyperspectral pixel classification, in IbPria09, Lecture Notes in Computer Science 5524, 208-216.
Richards, J. A., & Jia, X. (2006). Remote sensing digital image analysis: An introduction. Berlin: Springer.
Shaw, G., & Manolakis, D. (2002). Signal processing for hyperspectral image explotation. IEEE Signal Processing Magazine, 19, 12.
Soille, P. (2003). Morphological image analysis (2nd ed.). Berlin: Springer.
Tarabalka, Y., Chanussot, J., & Benediktsson, J. A. (2010). Segmentation and classification of hyperspectral images using minimum spanning forest grown from automatically selected markers. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 40, 1267–1279.
Tarabalka, Y., Tilton, J. C., Benediktsson, J. A., & Chanussot, J. (2011). A marker-based approach for the automated selection of a single segmentation from a hierarchical set of image segmentations. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 5, 262–272.
Vapnik, V. (1995). The nature of statistical learning theory. New York: Springer.
Zhang, J., & Tan, T. (2002). Brief review of invariant texture analysis methods. Pattern Recognition, 35, 735–747.
Zhang, Q., Wang, J., Gong, P., & Shi, P. (2003). Study of urban spatial patterns from spot panchromatic imagery using textural analysis. International Journal of Remote Sensing, 24, 4137–4160.
Zhuo, L., & Zheng, J. (2008). A Genetic Algorithm Based Wrapper Feature Selection Method for Classification of Hyperspectral Image Using Support Vector Machine. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 397–402.
Acknowledgements
The authors would like to thank the University of Zabol (UOZ-GR-9618-68) for its financial support, German Aerospace Centre (DLR) and Telops Inc. (Québec, Canada) for providing the hyperspectral data sets used in this research.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised.
About this article

Cite this article
Akbari, D., Ashrafi, A. & Attarzadeh, R. A New Method for Object-Based Hyperspectral Image Classification. J Indian Soc Remote Sens 50, 1761–1771 (2022). https://doi.org/10.1007/s12524-022-01563-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12524-022-01563-2