
Abstract
Construction of embankments in engineering structures on soft clay soils normally encounters problems related to excessive settlement issues. The conventional methods are inadequate to analyze and predict the surface settlement when the necessary parameters are difficult to determine in the field and in the laboratory. In this study, artificial neural network systems (ANNs) were used to predict settlement under embankment load using soft soil properties together with various geometric parameters as input for each stone column (SC) arrangement and embankment condition. Data from a highway project called Lebuhraya Pantai Timur2 in Terengganu, Malaysia, were investigated. The FEM package of Plaxis v8 program analysis was utilized. The actual angle of internal friction, spacing between SC, diameter of SC, length of SC, and height of embankment were used as the input parameters, and the settlement was used as the main output. Non cross validation (NCV) and tenfold cross validation (TFCV) were used to build the ANN model. The results of the TFCV model were more accurate than those of the NCV model. Comparisons made with the predictions of the Priebe model showed that the proposed TFCV model could provide better predictions than conventional methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The special nature of soft soil deposits is the most crucial for geotechnical engineering. Soft soils are widespread all over the world, some of which are located in important cities. Civil engineering constructions in soft soil deposits are limited by their tendency to conduct excessive settlement because of low shear strength quality. Consolidation and displacements can be noticeable under construction loads because of the large void ratio and inherent compressibility of clays, which can be time consuming and tedious for the structure engineer. Persisting low shear strength is particularly hazardous when constructing a large embankment on a soft clay base, facilitating potential circular or sliding failure planes. Therefore, ground improvement schemes are necessary. In this study, a ground improvement method by stone columns (SC) is considered because it has shown to be effective in improving soft soil properties. Many studies on SC-reinforced soft soil have been carried out all over the world (Guetif et al. 2007; Kousik et al. 2008; Zhou et al. 2002; Cimentada et al. 2011; Zahmatkesh and Choobbasti 2010). However, only a few have discussed the enhancing effect of SC on soft soil properties. In general, SC can increase the bearing capacity of soft soils and enhance the drainage and dissipation of excess pore water pressure (Bo and Choa 2004). S.R. Lo et al. (2010) compared numerical results and field measurements of several ground structures and found that the usage of the finite element program yields highly accurate results.
Artificial intelligent methods are computational models capable of executing complex input–output mapping (Tien Bui et al. 2011; Pradhan and Pirasteh 2010). The calculative simplicity of the processing elements makes the network much easier than dealing with rigorous mechanistic computational methods. The capability of neural networks to perform precise modeling of complex systems lies in linking the different neurons in the network. However, artificial neural networks (ANNs) cannot provide accurate results. Rumelhart et al. (1986) developed the back-propagation algorithm for artificial neurons, which was later considered an acceptable model. It was an important step that enabled many studies to improve in many applications in various scientific disciplines. The most widely used neural network is the back-propagation neural network (BPN), which uses sigmoid function in processing input signals and back-propagation algorithm in prediction error correction. BPN has a superior function approximation capability over the radial basis function network, which has superior capability in pattern classification (Haykin 1998). However, the downside of BPN is the limited dynamic range of sigmoid function, which sometimes makes use of a large number of neurons necessary to achieve the desired accuracy.
Various approaches such as ANN have been applied in wide areas of research because of their capability to represent any nonlinear processes given the sufficient complexity of the trained networks (Shahin and Indraratna 2006; Choobbasti et al. 2009; Kasa et al. 2011a, b; Zarea et al. 2012; Kia et al. 2011; Tien Bui et al. 2012). In this study, non cross validation (NCV) and tenfold cross validation (TFCV) neural network models were applied to predict the settlement of soft soil clay reinforced by SC under a highway embankment. A comparison between these two proposed models and the predicted results of settlement soil was further discussed.
Methodology
Settlement prediction of soft clay soil improved by stone column
Currently, there are a number of available methods used for predicting and calculating settlement. These methods can be classified as either approximate methods which make important simplifying assumptions and complex methods based on fundamental elasticity and plasticity theory which model material and boundary conditions, such as finite element method. The approaches considered are as follows:
Equilibrium method
The equilibrium method is one of the simple approximate methods to calculate the settlement of sand compaction piles, as described by Aboshi et al. (1979, Barksdale and Bachus (1983), and Barksdale and Takefumi (1990). This method is quite simple and used by engineers to calculate reduction settlement for ground improvement of stone columns. This particular method as well as others is derived from one unit cell idealization, whereby stone column is modeled to be a concentric body in a composite soil mass. The applied load on a composite soil mass develops stress and causes the occurrence of stress concentration in the column. The stone column will be stiffer than the surrounding soft soil (Bergado et al. 1996). The relative stiffness of the stone column and the surround soil is affected by the magnitude of the stress concentration. The stress in surrounding clayey ground (σ c ) is then given by Eq. (1).
Where n = stress concentration factor, a s = area replacement ratio, μ c = ratio of stress in cohesive soil to average stress, and σ = applied stress.
The settlements occurring below the stone column reinforced ground is generally calculated in the normal method.
The level of improvement of soft soil by stone column is dependent upon the stress concentration factor n (as reflected in μ c ), the initial effective stress in the clay, and the magnitude of applied stress σ. The Eq. (2) indicates that if other factors are constant, a greater reduction in settlement is achieved for longer columns and smaller applied stress increments. The reduction settlement is calculated from conventional one-dimensional consolidation theory.
Where S t is the total settlement, σ c is the change in stress in clay soil, σ is the acting stress, σ o is the initial effective stress, C c is the compression index, e o is the initial void ratio, and H is the vertical height of stone column.
When using the equilibrium method, settlements occurring beneath the reinforced ground must be considered separately using conventional consolidation or elastic settlement analysis.
The Priebe method
Priebe (1991), Arukrajah and Affendi (2002), and Bo and Choa (2004) provides a design procedure for vibro-replacement construction of stone columns. Priebe (1995) adapted, extended, and provided design procedures with design charts for various aspects of stone column design, including settlement reduction, bearing capacity, shear strength values of improved ground, and liquefaction. An equation is provided below for predicting the improvement factor no based on the cross-sectional area of the column, the area of the unit cell, and the coefficient of active earth pressure. The series of equations used to calculate settlement depend on the basic improvement factor, no, and consider the coefficient of earth pressure to be one as presented below.
Where;
Where n o = basic improvement factor, A c = area of column, A = unit cell area, μ s = Poisson’s ratio, K ac = Rankine’s active earth pressure, and ∅c = stone column material friction angle.
The Priebe method quantifies the improvement that results from the inclusion of the stone column without densification of the soil between stone columns. This design method refers to the improving effect of stone column in a soil.
Greenwood and Kirsch (1984) concluded that the simplicity of the Priebe method applying an improvement ratio to conventional consolidation is attractive to engineers, which results as the method being widely used. The Priebe method is a common method of design in practice.
Description of data
A highway project called Lebuhraya Pantai Timur2, which has a length of 173 km, is currently being constructed between Kuantan and Kula Terengganu in the state of Terengganu in Malaysia. The map in Fig. 1 indicates the location of the two project sites. The geotechnical design works include ground improvement of the existing foundation to sustain the imposed dead and traffic loads for highways. A proposal for the improvement of soft clay soil requires borehole information acquired from several stretches of soft soils to be analyzed thoroughly. This information provides details of the soil layers, water content, and position of the ground water level. Piezometer tubes are installed into the ground to measure changes in the ground water level for a specific period. Ground site investigations also involve in situ and laboratory tests, area photographs, and geological maps. The probable soil conditions and limits to which method can be employed in the design can be determined from the data.

Location plan of the LPT2 Expressway project in Malaysia
These data were also used to calibrate and validate the neural network models obtained from the FEM package of Plaxis v8 program analysis (PLAXIS 2002). Each condition had 288 cases.
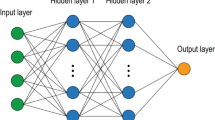
Neural network modeling
ANN is a system formed by computational units called neurons, which can highly interconnect with each other. The ANN system can learn, recall, and generalize from training data (Attoh-Okine 2002). In this study, ANNs with TFCV and NCV models were used to predict settlement. The models were divided into two sets: training and test. Table 1 and Fig. 2 show the values of some variables used in ANN and the structure of ANN used in this research for predicting settlement. To design a neural network, several architectures of ANN models were examined by varying the number of hidden layers and neurons in each hidden layer and the training function parameters (Beale and Jackson 1990; Flood and Kartam 1994a, b). The powerful neural network model was obtained after a number of trials using three layers (i.e., input, hidden, and output). A total of 30 nodes, 15 nodes, and 1 node were found distributed in the neurons of the input, hidden, and output layers, respectively. In the structure of a neural network, the number of neurons in each hidden layer is trained once the error of the network reaches a minimum value (Banimahd et al. 2005). All neural models use three types of algorithm, namely trainlm, trainscg, and traingdx. The mean square error (MSE) and the coefficient of determination (R 2) of the parameters in both training and testing are defined as follows:

Structure of ANN used in this research for predicting settlement
The coefficient of determination R is a measure of scatter or the lack of it between two sets of data and is given as follows:
Where y m and y p are measured and predicted parameters, respectively, and σ is the standard deviation.
Multiple linear regression model
A multiple linear regression (MLR) model of settlement was built to test the relationship between settlement of SC and its determinants. This model was compared with the ANN model. The following multiple regression equation was used to predict the settlement SC for the dataset as follows:
Where for a set of i successive observations, the predicted and variable y is a linear combination of an offset β o , a set of k predictor variables x with matching β coefficients, and a residual error e. The β values are commonly derived through the ordinary least squares method. When the regression equation is used in a predictive mode, e is omitted because its expected value is zero. Regression models are inherently linear, although curvilinear relationships can be incorporated through polynomial terms in the regression. Known relationships can be prespecified by transforming a nonlinear predictor variable into a more linear form before using it in the model.
Network training and validation
NCV model
The settlement soft soil data were partitioned into training and validation data, with the former being used to develop the network and the latter to verify the predictive quality of the trained model. Up to 75 % of the database was used for training; the remaining 25 % of the data were used for testing the network prediction. As much as possible, the training data were made to capture the widest variations in input and output patterns in the database. This process is performed to avoid having extreme data in the testing set, which could make the true generalization capability of the model impossible to assess within the domain of the training data, as in the case of completely randomized selection (Shahin et al. 2004). The MSE values after using three types of training algorithm (i.e., trainlm, trainscg, and traingdx) as an indicator of the accuracy of the results are shown in Table 2.

Input data before and after training for NCV model (training algorithm trainlm)
TFCV model
The standard machine learning method TFCV is used to train and test ANN models. The test sample dataset should never be used with the training process of ANN. In TFCV, the data were separated into ten sections that were roughly equal in size. In the first iteration, nine of these subsets were combined and used for training. The remaining set was used for testing the performance of our ANN on unnoticed cases. We repeated this process for ten iterations until all subsets were used once for testing. The TFCV model was also used to assess the robustness of ANN.
The early stopping procedure was used to prevent the ANN model from overfitting and to keep it generalizable to future cases (Bishop 1995; Mitchell 1997). Generalizability is the capability of a model to prove a similar predictive effect and gives the right results of input data not seen during the training process. It can be measured by the performance of error frequency for training data or error frequency for novel data. When the model (i.e., the network) is powerful, the risk increases in that it learns peculiarities specific for the training samples where losing generalization occurs; therefore, training prematurely (“early stopping”) must be stopped to avoid the overfitting phenomenon (Haykin 1999).
The ANN model is designed to have a large number of hidden nodes, as ANNs with a large number of hidden nodes generalize better than networks with a small number of hidden nodes when trained with back propagation and “early stopping” (Caruana et al. 2001; Lawrence et al. 1997; Weigend 1994).
The TFCV neural network model is an alternative neural network type with a trainable activation classified date and a capability to achieve the desired accuracy. In this study, the capability of the TFCV neural network model in simulating the settlement behavior of reinforced soft clay under high way embankment was investigated. In the training process, the model attempts to distinguish and recognize the data and makes the forecasting values very close to the actual event (Figs. 3 and 4).

Input data before and after training for TFCV model (training algorithm trainlm)
Relation importance of input (RI)
In 1991, Garson invented a simple technique to interpret the important relation between input parameters by examining the connected weights of the training network (Goh 1994; Shahin et al. 2002a). A connection weight approach was used to evaluate the importance of inputs (i.e., SC and embankment parameters) to predict output (settlement) in ANNs. The connection weight method is used to sum up the products of the input-hidden and hidden-output connection weights between each input neuron and output neuron for all input variables (Olden et al. 2004). The relative importance of input variable i is determined from the following formula:
Where RI i is the relative importance (expressed in percentage) of the variable i in the input layer on the output variable, j is the index number of the hidden node, W ij is the connection weight between input variable i and hidden node j, and W jk is the connection weight between hidden node j and the output node k.
Results and discussion
Result comparisons
The capability of ANN to conform to learning is supported by the degree of acceptability of the model training and testing. The convergence of the testing data with the forecasting data is represented as standard for quality and robustness model. The MLR model was developed using the same input and output parameters and then compared with the ANN model. The results indicate that the estimated R is relatively low (R = 0.9117).
Figures 3a, b and 4a, b show the training data of the BPN using the training algorithm (trainlm) for each TFCV and NCV models. Before the training process, all the points’ dates appeared isolated, and no matching with the field data was performed. However, after training, the model appeared to make all the points’ dates close to the actual dates.
The BPN that uses training algorithm (trainlm) provided good quality of the network’s prediction compared with another algorithm for each TFCV and NCV models. As shown in Tables 2 and 3, TFCV produced higher efficiency for training (0.9935) and testing (0.9716) than did NCV (0.9909 and 0.9691, respectively).
In Fig. 5a, b, the BPN network outputs are compared with the training of TFCV and NCV models, respectively. TFCV simulations had better correlation and exceeded the training data (R = 0.996771 for TFCV and 0.99605 for NCV).

Comparison of actual versus predicted settlement. a Tenfold cross validation ANN and b non cross validation ANN
The predictions of the TFCV and NCV models are compared with the measured and predicted data in Fig. 6a, b, respectively. After tracking and monitoring all data points, all measured and predicted data points matched, except for a few points along the curve (Fig. 6a). The NCV model in Fig. 6b had a different data behavior (measured with predicted data). However, a difference was noted in the third plot. This result indicates that the TFCV model has a high level of learning and a high quality of prediction. Further comparison of forecasting values of ANN, MLR, and Priebe models was also made against the measured values (Fig. 7). The figure clearly shows that ANN (TFCV model) provides the closest estimate of settlement and is therefore the most accurate.

Comparison of actual versus predicted settlement. a Non cross validation ANN and b tenfold cross validation ANN

Performance comparison of various settlement prediction methods
Parametric study and sensitivity analysis
An attempt was made to identify which of the input parameters has the most effect on the settlement behavior of SC bedded in soft clay (model output). Thus, a sensitivity analysis was carried out on the neural network. The whole computation was repeated for each output neuron. Figure 8 demonstrates the summary of determining the relative importance of the input variables of the TFCV model.

Relative importance of input variables of the TFCV artificial neural model using Eq. (11)
The results of the parametric study carried out to assess the generalization ability of the TFCV model are presented in Fig. 8. Results showed a good agreement between the TFCV model response and the expected settlement behavior of SC when subjected to embankment loading. The angle of internal friction had the highest importance (72 %), whereas the diameter of SC had the lowest importance (2 %) when compared with the other input variables. The predicted settlement decreased as the angle of internal friction of material SC and as the diameter and length of SC increased (Fig. 9). The predicted settlement increased with increasing spacing between SC and the height of the embankment. The consistent decrease in the predicted settlement with increment in parameters (Fig. 9) and the increase with increment in another two parameters indicate a good agreement between the TFCV model and the actual settlement. Soft clay with SC shows improved settlement behavior, and soft soil properties affect the settlement behavior of soft clay (Priebe 1991, 1995). The settlement varied proportionally with spacing between SC and height of the embankment. With regard to the behavior of foundation soil, the height of the embankment varied inversely with settlement. The settlement started with small values under light load (1 to 3 m fill embankment), after which a heavy load of embankment material produced high values of settlement. This result agrees with the study carried out.

Sensitivity of tenfold cross validation model for friction internal angle of SC, spacing between SC, diameter of SC, length of SC, and high of embankment
Conclusions
In this study, two geotechnical applications were performed using ANN to simulate the settlement curve. The development of the two models TFCV and NCV was based on the use of the proposed simple input data. The input data consisted of the angle of internal friction, spacing between SC, diameter, length of SC, and height of the embankment. The other parameters were soil types and installation methods. Based on R2, MSE, and settlement quality, a significant improvement was observed in the comparison of the results of the models using variance algorithms. The trainlm algorithm gave better results than the other models. The ANN model had the lowest RMSE values for in-sample and out-of-sample forecasting. These results indicate that the nonlinear ANN model can generate a better fit than the MLR model.
The proposed TFCV model was more accurate in prediction than the NCV model. The sensitivity analysis indicates that the prediction of the settlement by the TFCV model is in agreement with the underlying physical behavior of settlement prediction based on documented prior knowledge. The properties of material on SC in this case had high relative importance (72 %) compared with the other parameters. Based on the parametric study, the TFCV model responded reasonably well to various input parameters in a manner consistent with the anticipated behavior of soft clay soil reinforced with SC in a highway embankment in the LPT2 project.
References
Aboshi H, Ichimoto E, Enoki M, Proc KH (1979) The compozer-A method to improve characteristics of soft clays by inclusion of large diameter sand columns. In: International conference on soil reinforcement: Reinforced earth and other techniques, Paris. pp 211–216
Arukrajah A, Affendi A (2002) Vibro replacement design of high-speed railway embankments. Paper presented at the 2nd World Engineering Congress, Kuching, Malaysia
Attoh-Okine N (2002) Combining use of rough set and artificial neural network in doweled-pavement performance modelling-a hybrid approach. J Transp Eng (ASCE) 128(3):270–275
Banimahd M, Yasrobi SS, Woodward PK (2005) Artificial neural network for stress–strain behavior of sandy soils: knowledge based verification. Comput Geotech 32:377–386
Barksdale RD, Bachus RC (1983) Design and construction of stone columns, Vol. I, and Vol. II. FHWA/RD-83/026. Federal Highway Administration, Washington
Barksdale RD, Takefumi T (1990) Design, construction and testing of sand compaction piles, symposium on deep foundation improvements: Design Construction and Testing. ASTM Publications, Las Vegas
Beale R, Jackson T (1990) Neural computing: an introduction. Institute of Publishing, Bristol
Bergado DT, Anderson LR, Miura N, Balasubrananiam AS (1996) Improvement of soft Bangkok clay using vertical drains. Geotext Geomembr 12:615–663
Bishop C (1995) Neural networks for pattern recognition. Oxford University Press, New York
Bo MW, Choa V (2004) Reclamation and ground improvement. Thomson Learning, Singapore
Caruana R, Lawrence S, Giles C (2001) Overfitting in neural networks: backpropagation, conjugate gradient, and early stopping. In: Leen TK, Dietterich TG, Tresp V (eds) Advances in Neural Information Processing Systems, vol 13. MIT Press, Cambridge
Choobbasti AJ, Farrokhzad F, Barari A (2009) Prediction of slope stability using artificial neural network (case study: Noabad, Mazandaran, Iran). Arab J Geosci 2(4):311–319. doi:10.1007/s12517-009-0035-3
Cimentada A, Da Costa A, Cañizal J, Sagaseta C (2011) Laboratory study on radial consolidation and deformation in clay reinforced with stone columns. Can Geotech J 48(1):36–52. doi:10.1139/T10-043
Flood I, Kartam N (1994a) Neural network in civil engineering. II: systems and applications. J Comput Civ Eng (ASCE) 8(2):149–162
Flood I, Kartam N (1994b) Neural network in civil engineering. I: principles and understandings. J Comput Civ Eng ASCE 8(2):131–148
Goh A (1994) Seismic liquefaction potential assessed by neural network. J Geotech Eng 120(9):1467–1480
Greenwood DA, Kirsch K (1984) Specialist ground treatment by vibratory and dynamic methods. In: State of the Art Report, Piling and Ground Treatment, Thomas Telford. pp 17–45
Guetif Z, Bouassida M, Debats JM (2007) Improved soft clay characteristics due to stone column installation. Comput Geotech 34(2):104–111. doi:10.1016/j.compgeo.2006.09.008
Haykin S (1998) Neural networks: a comprehensive foundation. Prentice Hall, New Jersey
Haykin S (1999) Neural networks. A comprehensive foundation, 2nd edn. Prentice Hall, Upper Saddle River
Kasa A, Chik Z, Taha MR (2011a) Prediction of external stability for geogrid-reinforced segmental walls. Key Eng Mater 462–463:1319–1324
Kasa A, Chik Z, Taha MR (2011b) Prediction of internal stability for geogrid-reinforced segmental walls. Adv Mater Res 163–167:1854–1857
Kia MB, Pirasteh S, Pradhan B, Mahmud AR, Sulaiman WNA, Moradi A (2011) An artificial neural network model for flood simulation using GIS: Johor River Basin, Malaysia. Environ Earth Sci 67(1):251–264. doi:10.1007/s12665-011-1504-z
Kousik D, Chandra S, Basudhar PK (2008) Response of multilayer geosynthetic-reinforced bed resting on soft soil with stone columns. Comput Geotech 35(3):323–330
Lawrence S, Giles C, Tsoi A Lessons in neural network training: overfitting may be harder than expected. In: the Fourteenth National Conference on Artificial Intelligence, 1997. pp 540–545
Lo SR, Zhang R, Mak J (2010) Geosynthetic-encased stone columns in soft clay: a numerical study. Geotext Geomembr 28(3):292–302. doi:10.1016/j.geotexmem.2009.09.015
Mitchell T (1997) Machine learning. McGraw Hill, Burr Ridge
Olden JD, Joy MK, Death RG (2004) An accurate comparison of methods for quantifying variable importance in artificial neural networks using simulated data. Ecol Model (178:389–397
PLAXIS D-V (2002) In: Brinkgreve RBJ (ed) Finite element code for soil and rock analysis, User manual. Delft University of Technology & Plaxis bv, The Nederlands
Pradhan B, Pirasteh P (2010) Comparison between prediction capabilities of neural network and fuzzy logic techniques for landslide susceptibility mapping. Disaster Adv 3(2):26–34
Priebe HJ (1991) Vibro-replacement – design criteria and quality control. Deep Foundation Improvements Design, Construction and Testing. ASTM STP 1089, ASTM
Priebe HJ (1995) The design of vibro-replacement. In: Proceedings of the Institution of Civil Engineers, Ground Engineering, vol 10. pp 31–37
Rumelhart DE, McClelland JL, Group. TPR (1986) Parallel Distributed Processing: Explorations in the Microstructure of Cognition, vol (Chapter 8) Volume 1. Foundations. MIT Press, Cambridge
Shahin MA, Indraratna B (2006) Modeling the mechanical behavior of railway ballast using artificial neural networks. Can Geotech J 43(11):1144–1152. doi:10.1139/t06-077
Shahin MA, Jaska MB, Maier HR (2002) Predicting settlement of shallow foundation using neural networks. J Geotech Geoenviron Eng ASCE 128(9):785–793
Shahin MA, Maier HR, Jaksa MB (2004) Data division for developing neural networks applied to geotechnical engineering. J Comput Civ Eng (ASCE) 18(2):105–114
Tien Bui D, Pradhan B, Lofman O, Revhaug I, Dick OB (2011) Landslide susceptibility mapping at Hoa Binh province (Vietnam) using an adaptive neuro fuzzy inference system and GIS. Comput Geosci 45:199–211
Tien Bui D, Pradhan B, Lofman O, Revhaug I, Dick OB (2012) Landslide susceptibility assessment in the Hoa Binh province of Vietnam using artificial neural network. Geomorphology 171–172:12–19
Weigend A (1994) On overfitting and the effective number of hidden units. In: Mozer A, Smolensky P, Touretzky DS, Elman JL, Weigend AS (eds) Connectionist Models Summer School. Lawrence Erlbaum Associates, Hillsdale, pp 335–342
Zahmatkesh A, Choobbasti AJ (2010) Settlement evaluation of soft clay reinforced with stone columns using the equivalent secant modulus. Arab J Geosci 5(1):103–109. doi:10.1007/s12517-010-0145-y
Zarea M, Pourghasemi HR, Vafakhah M, Pradhan B (2012) Landslide susceptibility mapping at Vaz watershed (Iran) using an artificial neural network model: a comparison between multilayer perceptron (MLP) and radial basic function (RBF) algorithms. Arab J Geosci. doi:10.1007/s12517-12012-10610-x
Zhou C, Yin J-H, Ming J-P (2002) Bearing capacity and settlement of weak fly ash ground improved using lime, fly ash or stone columns. Can Geotech J 39(3):585–596. doi:10.1139/t02-011
Acknowledgments
The authors would like to thank Universiti Kebangsaan Malaysia (UKM) for GUP-2012-03 research grant in this work and the Department of civil and structural engineering, for the use of computer laboratory.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Chik, Z., Aljanabi, Q.A., Kasa, A. et al. Tenfold cross validation artificial neural network modeling of the settlement behavior of a stone column under a highway embankment. Arab J Geosci 7, 4877–4887 (2014). https://doi.org/10.1007/s12517-013-1128-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12517-013-1128-6