
Abstract
Liquefaction-induced settlement in saturated loose soils is a commonly geotechnical phenomenon resulted from the loss of its shear strength under moderate or high seismicity. This can have detrimental effects on building, infrastructure, and even human life. Therefore, predicting the settlement of ground caused by liquefaction plays a critical role in the geotechnical field. As the limited data for liquefaction-induced settlement obtained, an effective method should be applied to provide highly accurate prediction. The aim of this study is to propose a machine learning approach, namely multilayer perceptron (MLP), with a wide range of hyperparameters optimized by the Bayesian optimization method to predict liquefaction-induced settlement due to the Pohang earthquake in South Korea. The ground settlement and its correlation with different soil conditions were taken into account including unit weight, soil layer depth, standard penetration test blow count, and cyclic stress ratio. Moreover, other five well-known models, namely linear regression, support vector machine, robust regression, and polynomial regression, were performed to facilitate a comparison study. The experimental result indicates that while the high influence of all considerable variables on the ground settlement was obtained from the correlation coefficients, the soil layer depth factor had the highest one. Based on the Bayesian optimization, a greater prediction accuracy was observed from the proposed MLP model compared to other methods by using the evaluation metric of R-squared value. Furthermore, the developed model outperforms other machine learning methods proposed by previous studies in terms of predicting the soil settlement caused by liquefaction.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Liquefied soil settlement is a geotechnical phenomenon that occurs when saturated soil loses its strength and behaves like a liquid, leading to ground settlement or sinking. Liquefied soil settlement can have detrimental effects on buildings, infrastructure, and the overall stability of the affected area. It can result in tilting, cracking, and even collapse of structures. Therefore, the prediction of liquefied soil settlement becomes very important and has great significance in the geotechnical field. Many studies on liquefied soil have been carried out from in-situ tests [31, 35] and laboratory experiments [15, 16, 19, 26], to numerical simulation methods [4, 5, 20, 24]. Since a growing number of documents were from these testing results, some recent studies have developed an effective way to use automated computational methods to analyze or predict soil behavior from previous databases for future applications [21, 44].
Nowadays, in the era of big data combined with the strong development of computer hardware, machine learning approaches have been widely used in many different fields such as medical application [9,10,11], structural sector [22, 37], or geotechnical aspect [18, 30, 32]. Based on the amount of data obtained from the conventional methods of laboratory tests or simulation analyses, the machine learning approach can be used to evaluate soil conditions including settlement, liquefaction, or landslide [14, 17]. Park et al. [27] conducted a comparative study on seven convolutional neural networks including Xception, VGG16, InceptionV3, MobileNet, DenseNet121, NASNetMobile, EfficienNetB0 with seven optimizers, namely SGD, AdaGrad, RMSprop, Nadam, Adam, Ftrl, Adamax to classify the settlement level of the ground. The study result pointed out that the DenseNet121 architecture using the Adam optimizer performed the highest accuracy. Fang et al. [6] proposed a new approach using Artificial Neural Network combining with transfer learning to investigate the liquefaction potential of soil. Various soil liquefaction test results from the shear wave velocity test, standard penetration test, cone penetration test, and dynamic penetration test were considered. This study found that while less amount of data was investigated, the prediction was more highly accurate in comparison with other available models such as probabilistic model [3, 13, 28] or deterministic model [31]. Moreover, other two machine learning techniques, namely Artificial Neural Network and Support Vector Machine, were conducted by Samui and Sitharam [33] to predict the soil liquefaction susceptibility by using two variables of standard penetration test and cyclic stress ratio. The authors concluded that while the result highlighted the capacity of the developed models, Support Vector Machine was a better method for the investigation of the soil liquefaction potential.
Based on the literature outlined, conclusions can be drawn: (1) various developed models having its capacity for a specific task; (2) an effective approach using machine learning even with limited database; (3) predicting accurately soil ground conditions based on its properties depending on the proposed method. However, few studies have been conducted on using machine learning approach to predict the settlement of ground induced by liquefaction under the earthquake motion.
The aim of this study was to propose a multilayer perceptron (MLP) with optimized hyperparameters through Bayesian optimization to predict liquefaction-induced settlement due to the Pohang earthquake in South Korea. By considering different soil characteristics, unit weight, soil layer depth, standard penetration test blow counts, and cyclic stress ratio were applied as input parameters for this study. Notably, Bayesian optimization has been widely used owing to several advantages over grid search and random search for hyperparameter tuning of MLP models. In practice, it was often favored when computational resources were limited or seeking the best possible configuration within a reasonable time frame was applied.
The rest of the paper was organized as follows: A brief introduction to the MLP architecture, Bayesian optimization, and model performance evaluation metrics is presented in Sect. "Preliminaries." Section "Proposed model and Experiments" describes the used dataset, experimental results, and discussion. The conclusions are drawn in Sect. "Conclusion."
Preliminaries
Fundamental concepts are briefly introduced including multilayer perceptron (MLP) network, Bayesian optimization, and evaluation metrics.
MLP Architecture
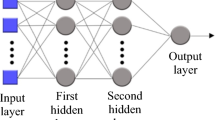
A multilayer perceptron (MLP) is a specific type of feedforward neural network architecture that consists of multiple layers of neurons, including an input layer, one or more hidden layers, and an output layer [29]. Figure 1 illustrates an MLP architecture with two hidden layers. Adjacent layers of artificial neurons are interconnected with learned weights and biases, using activation functions to introduce non-linearity. The network learns to make accurate predictions for tasks by adjusting its internal parameters to minimize prediction errors during training process.

MLP architecture
The MLPs are versatile and widely used model for various machine learning tasks, including classification and regression, by adjusting their architecture and hyperparameters. They have been foundational in the field of deep learning and have paved the way for more complex neural network architectures like convolutional neural networks and recurrent neural networks.
Bayesian Optimization
Bayesian optimization has been known as a popular technique for tuning hyperparameters of machine learning models [7]. It is an iterative optimization method that uses Bayesian inference to build a probabilistic model of the objective function (e.g., model performance) and then employs this model to efficiently explore the hyperparameter space.
By iteratively selecting hyperparameters to evaluate based on a surrogate model, Bayesian optimization can efficiently search the hyperparameter space, often requiring fewer evaluations compared to grid search or random search. It is a powerful approach for finding optimal hyperparameter settings in machine learning models [39, 40, 42].
Evaluation Metrics
The evaluation of model performance is a critical step in the machine learning approach. Several common evaluation metrics were applied in this study to evaluate the performance of regression models including mean square error (MSE), root mean square error (RMSE), mean absolute error (MAE), and R-squared (R2). These evaluation metrics are expressed by the following equations:
where, n referred to the number of data points; \({y}_{i}\) referred to the actual value at the \({i}{{\text{th}}}\) sample; \(\widehat{{y}_{i}}\) referred to the predicted value at the \({i}{{\text{th}}}\) sample; \(\overline{y }\) referred to the mean true values.
Proposed Model and Experiments
Dataset
For a comparative study with other researches, the same dataset with Park et al. [25], which is found in Appendix A, was applied in this study. The dataset was obtained from the UBCSAND constitutive effective stress model [23]. The UBCSAND model estimates the shear-induced deformation on the basis of standard penetration test (SPT) data from in-situ test. The SPT data were gained from five different borehole locations near the epicenter of the Pohang Earthquake in South Korea. It consisted of 100 data points (20 data points for each borehole) along with corresponding settlement values. The distribution of settlements (bar charts) in the dataset normalized by the total area of the histogram equaling to 1 and its distribution estimated by a kernel density estimator (solid line) using Seaborn library [41] are presented in Fig. 2. It indicates that while the ground settlement was in a wide range of between 0.0 and 3.5 mm, it showed a high density from 0.0 to 0.9 mm in which soil layers revealed a slight effect by Pohang earthquake.

Histogram of settlements with kernel density estimator
For each sample, unit weight (γ), soil layer depth (d), standard penetration test blow count (N1(60)), cyclic stress ratio (CSR), and liquefaction-induced settlement (S) were obtained. The correlation between the variables γ, d, N1(60), CSR, and S is shown in Fig. 3. The correlation coefficient was in the range [− 1, 1]. A negative value indicated a negative correlation, and vice versa for negative value. A value of zero represented no correlation between variables. It was observed that γ and d had a more impact on S than N1(60) and CSR. It was worth noting that γ was positively correlated, and d was negatively correlated.

Correlation between variables
Noting that four soil characteristics including γ, d, N1(60), and CSR were considered as input parameters in this study, while S value was the output parameter of the MLP model. All input parameters were on a similar scale to prevent certain features from dominating the learning process due to their larger values. MinMaxScaler technique was used to normalize these input parameters to a range from − 1 to 1. For training purposes, the data set was divided into three subsets including the training set containing 64 samples, the validation set consisting of 16 samples, and the rest for the testing set. The training set and the validation set were used to train the model and tune the model's hyperparameters, respectively, whereas the testing set was used to evaluate the trained model.
Tuning Hyperparameters
To select suitable hyperparameters for the proposed model, the search space was taken into account depending on the complexity of a specific task to help avoid an unnecessary computational expense of the model in terms of estimating optimal or near optimal hyperparameters. From the literature, eight hyperparameters were exhibited in this study including the number of dense layers, the neurons per dense layer, activation per dense layer, dropout rate, optimizer, learning rate, epochs, and batch size [1, 10, 22, 29, 38]. The present study used Bayesian optimization method with Optuna library to estimate the best set of hyperparameters of the model. Due to the mathematical tractability and simplicity [8, 36], the normal distribution is used as a prior distribution to optimize the hyperparameters of the MLP model. The objective function applied in this study was the mean square error. The search space and optimal hyperparameters are detailed in Table 1. It was clearly found that while different hidden layers between 1 and 3 were utilized, an optimal MLP model contained two hidden layers. The first hidden layer had 13 neurons by using the selu activation function, regardless of dropout rate. However, the second hidden layer had 8 neurons by using the elu activation function with a dropout rate of 0.1. Regarding the search space for the optimizer, the search space with four selected optimizers, namely SGD, AdaGrad, RMSprop, and Adam was examined. The Bayesian optimization process indicated Adam algorithm as the estimated optimizer. As a result, the compiling and training process of the present model used Adam optimization with an initial learning rate of 0.01. The batch size and epochs were set up to 64 and 1700, respectively.
For a better understanding of optimization procedure, the history of the optimization process is presented in Fig. 4. The process of optimizing the hyperparameters was performed with 100 trials based on Bayesian optimization method to minimize the mean squared error on the validation set. It can be seen that the best value of the objective function converged to almost zero after about 50 trials. Noting that different hyperparameters may have less or more effect on the objective value or the performance of the model. Therefore, the influence of the hyperparameters on the objective value was conducted and is shown in Fig. 5. It is clearly seen that the learning rate has the greatest effect on the objective value, which accounted for a value of 56% followed by the dropout rate of 23%. By contrast, a minor effect was found from the number of dense layers and the batch size by a value of less than 1%.

Optimization history after 100 trials

Influence of hyperparameters on objective values
Performance of MLP
The optimized MLP model, which had the estimated hyperparameters as shown in Table 1, was used for the task of predicting settlement caused by liquefaction. The convergence history in loss values is shown in Fig. 6. The result revealed that overfitting and underfitting problems did not occur during the training and validation processes. The loss values on both procedures decreased rapidly from the initial stage to a few epochs and steadily converged to approximately zero after obtaining about 500 epochs. The convergence was quite stable, and the apparent fluctuation in the loss values for both training and validation sets was not found. This pattern resulted in the high performance of the developed model. Table 2 represents the performance evaluation metrics of the proposed method using mean square error (MSE), root mean square error (RMSE), mean absolute error (MAE), and R-squared (R2). The proposed MLP provided 0.201 MSE, 0.084 RMSE, 0.289 MAE, and 0.895 R2.

Loss history
The outperformance of the proposed model can be compared to the existing machine learning methods applying to geotechnical engineering. A new approach was developed by Fang et al. [6] named Fang’s model using transfer learning and fine-tuning with a pre-trained model via the Artificial Neural Network. A total of 1069 cases were applied to predict the liquefaction potential of soil using shear-wave velocity test dataset. Fang’s model performance provided 76% accuracy. Furthermore, a comprehensive study was conducted on Fang’s model using other sources of standard penetration test, cone penetration test, and dynamic penetration test, applied by other methods. Fang’s model showed a high accuracy even using 20% dataset for fine-tuning compared to other approaches using full database. Although the present proposed model using MLP to predict the liquefaction-induced settlement outperforms Fang’s model using ANN to predict the soil liquefaction potential based on the accuracy metric, the performance of the developed model highly depended on the specific task and the dataset quality as aforementioned discussion in the literature. However, the inadequate validation for the present study was only based on Fang’s model.
Moreover, a similar approach to Fang’s model can be seen from Park et al. [25] named Park’s model by using the Artificial Neural Network for the same database with the current study to predict the earthquake-induced settlement. However, Park’s model suggested two models with different variables: model 1 using d, N1(60), CSR, and model 2 using d, N1(60), CSR. An R-squared value of 0.86 and 0.74 was obtained from model 1 and model 2, respectively. Moreover, the same goal and dataset to Park’s model and the present study’s model were also conducted by Ahmad et al. [1] named Almad’s model. Two machine learning methods of random forest and reduced error pruning tree were presented in Almad’s model. An R-squared value of 0.78 and 0.60 was obtained from Random Forest model and Reduced Error Pruning Tree model, respectively. The findings found from the literature using different approaches such as Artificial Neural Network, Random Forest, or Reduced Error Pruning Tree for the same or different dataset validated the efficiency of the proposed method in the present study. In other words, it is highly recommended to develop a suitable model with limited data.
For a better understanding of the settlement prediction for the purpose of geotechnical engineering, the comparison between the predicted values obtained from the model and the actual values of settlement in the testing set is illustrated in Fig. 7. A better model was obtained when the data points were as close as to the line y = x, which was displayed by an R2 value closer to 1. These values are represented in Table 3. It was found that while some predicted values obtained from MLP model were highly deviating from the actual values, an overall accuracy of high R2 value indicated a high performance of the proposed model. A higher accuracy was expected by large amount of experimental data for the confident application of machine learning approach to evaluate the settlement of the ground in the field based on another available test database.

Comparison of predicted values and actual values
As aforementioned discussion in the literature, a comparative study using different models was conducted on the same database. The results of the proposed MLP model were compared with five other well-known machine learning models including linear regression, support vector machine, robust regression, elastic net regression, and polynomial regression. The architecture of these models can be found from the previous studies [2, 12, 34, 43]. The comparison between the actual values and the corresponding predicted values in different machine learning models is shown in Fig. 8. It can be seen qualitatively that the polynomial regression model and the proposed MLP model predict better outcomes than the others.

Comparison of predicted values and actual values in six various models
For an accurate and comparative assessment of the robustness of the regression models, the quantification of the goodness of the models represented by the R2 value is summarized in Table 4. The proposed MLP model gives superior results with an R2 value of 0.895, followed by the polynomial regression model and the support vector machine with R2 values of 0.808 and 0.663, respectively. The remaining three models show a poor prediction result with R2 values less than 0.5.
Conclusion
This study proposes an MLP model where the hyperparameters are optimized through Bayesian optimization to predict the liquefaction-induced settlement due to the Pohang earthquake. The experimental results show that the learning rate has the greatest influence on the model performance. The proposed optimal MLP model accurately predicts the settlement values as indicated by the R2 value of 0.895, which is better than five other machine learning models, namely linear regression, support vector machine, robust regression, elastic net regression, and polynomial regression in the same task. The proposed model is simple and has a high generalization ability on new datasets. Moreover, as the limitation of a relatively small samples (only 100 data points), the model developed in this study outperforms existing models proposed by other authors with the same databases. However, it should be noted that while the effectiveness of the proposed model uses MLP method combining with Bayesian optimization in the prediction of liquefied soil settlement, it may be unable to perform a high accuracy for other assessments of soil conditions such as slope stability, landslide, or seepage analysis. Additionally, the present study can be referred to further studies for a more comprehensive approach regarding the machine learning application in geotechnical engineering.
References
Ahmad M, Tang X, Ahmad F (2021) Evaluation of liquefaction-induced settlement using random forest and REP tree models: taking pohang earthquake as a case of illustration. Nat. Hazards—Impacts Adjust. Resil., Noroozinejad Farsangi E (ed). IntechOpen
Bobde A, Narnaware V, Tawari S, Thomas A (2022) Robust time series forecasting via time differencing and stacking. In: 2022 Int. Conf. Smart Gener. Comput. Commun. Netw. SMART GENCON. IEEE, pp 1–8
Cao Z, Youd TL, Yuan X (2013) Chinese dynamic penetration test for liquefaction evaluation in gravelly soils. J Geotech Geoenviron Eng 139(8):1320–1333. https://doi.org/10.1061/(ASCE)GT.1943-5606.0000857
Doan N-P, Nguyen B-P, Park S-S (2023) Seismic deformation analysis of earth dams subject to liquefaction using UBCSAND2 model. Soil Dyn Earthq Eng 172:108003. https://doi.org/10.1016/j.soildyn.2023.108003
Doan N-P, Park S-S, Lee D-E (2020) Assessment of Pohang earthquake-induced liquefaction at Youngil-man port using the UBCSAND2 model. Appl Sci 10(16):5424. https://doi.org/10.3390/app10165424
Fang Y, Jairi I, Pirhadi N (2023) Neural transfer learning for soil liquefaction tests. Comput Geosci 171:105282. https://doi.org/10.1016/j.cageo.2022.105282
Frazier PI (2018a) A tutorial on bayesian optimization. arXiv
Frazier PI (2018b) A tutorial on Bayesian optimization. arXiv.org. Accessed 26 Dec 2023. https://arxiv.org/abs/1807.02811v1
Hashimoto F, Kakimoto A, Ota N, Ito S, Nishizawa S (2019) Automated segmentation of 2D low-dose CT images of the psoas-major muscle using deep convolutional neural networks. Radiol Phys Technol 12(2):210–215. https://doi.org/10.1007/s12194-019-00512-y
Ho TT, Kim G-T, Kim T, Choi S, Park E-K (2022) Classification of rotator cuff tears in ultrasound images using deep learning models. Med Biol Eng Comput 60(5):1269–1278. https://doi.org/10.1007/s11517-022-02502-6
Ho TT, Kim WJ, Lee CH, Jin GY, Chae KJ, Choi S (2023) An unsupervised image registration method employing chest computed tomography images and deep neural networks. Comput Biol Med 154:106612. https://doi.org/10.1016/j.compbiomed.2023.106612
Huang D, Cabral R, De la Torre F (2015) Robust regression. IEEE Trans Pattern Anal Mach Intell 38(2):363–375
Juang CH, Jiang T, Andrus RD (2002) Assessing probability-based methods for liquefaction potential evaluation. J. Geotech Geoenviron Eng 128(7):580–589. https://doi.org/10.1061/(ASCE)1090-0241(2002)128:7(580)
Kumar P, Sihag P, Sharma A, Pathania A, Singh R, Chaturvedi P, Mali N, Uday KV, Dutt V (2021) Prediction of real-world slope movements via recurrent and non-recurrent neural network algorithms: a case study of the Tangni landslide. Indian Geotech J 51(4):788–810. https://doi.org/10.1007/s40098-021-00529-4
Le T-T, Park S-S, Woo S-W (2022) Cyclic response and reconsolidation volumetric strain of sand under repeated cyclic shear loading events. J Geotech Geoenviron Eng 148(12):04022109. https://doi.org/10.1061/(ASCE)GT.1943-5606.0002919
Le T-T, Park S-S, Woo S-W, Tran L (2022b) Cyclic response and post-cyclic settlement of sand experiencing repeated earthquakes. CIGOS 2021 Emerg. Technol. Appl. Green Infrastruct., Lecture Notes in Civil Engineering, Ha-Minh C, Tang AM, Bui TQ, Vu XH, Huynh, DVK (eds). Springer Nature, Singapore, pp 1015–1023
Moeinossadat SR, Ahangari K, Shahriar K (2018) Control of ground settlements caused by EPBS tunneling using an intelligent predictive model. Indian Geotech J 48(3):420–429. https://doi.org/10.1007/s40098-017-0253-7
Muduli PK, Das SK (2014) CPT-based seismic liquefaction potential evaluation using multi-gene genetic programming approach. Indian Geotech J 44(1):86–93. https://doi.org/10.1007/s40098-013-0048-4
Murali Krishna A, Madhav MR, Kumar K (2014) Ground engineering with granular inclusions for loose saturated sands subjected to seismic loadings. Indian Geotech J 44(2):205–217. https://doi.org/10.1007/s40098-013-0085-z
Nguyen T-N (2023) A numerical study on the frictional resistance adjacent the pile tip in clayey sand. 990–1003
Nguyen T-N, Tran LV, Cuong PV, Tran TD (2023) Prediction of liquified soil settlement based on Artificial neural network. In: Proc. Third Int. Conf. Sustain. Civ. Eng. Archit., Lecture Notes in Civil Engineering. Springer Nature Singapore, Singapore, pp 1208–1214
Nguyen T-N, Tran V-T, Woo S-W, Park S-S (2022) Image segmentation of concrete cracks using SegNet. Intell. Things Technol. Appl., Lecture Notes on Data Engineering and Communications Technologies. Nguyen N-T, Dao N-N, Pham Q-D, Le HA (eds). Springer International Publishing, Cham, pp 348–355
Park S-S (2008) Liquefaction evaluation of reclaimed sites using an effective stress analysis and an equivalent linear analysis. KSCE J Civ Environ Eng Res 28(2C):83–94
Park S-S, Doan N-P, Nong Z (2021) Numerical prediction of settlement due to the Pohang earthquake. Earthq Spectra 37(2):652–685. https://doi.org/10.1177/8755293020957345
Park S-S, Ogunjinmi PD, Woo S-W, Lee D-E (2020) A simple and sustainable prediction method of liquefaction-induced settlement at Pohang using an artificial neural network. Sustainability 12(10):4001. https://doi.org/10.3390/su12104001
Park S-S, Tran D-K-L, Nguyen T-N, Woo S-W, Sung H-Y (2023) Effect of loading frequency on the liquefaction resistance of poorly graded sand. Adv. Geospatial Technol. Min. Earth Sci., Environmental Science and Engineering, Nguyen LQ, Bui LK, Bui X-N, Tran HT (eds). Springer International Publishing, Cham, pp 95–104
Park S-S, Tran V-T, Doan N-P, Hwang K-B (2022) Evaluation of damage level for ground settlement using the convolutional neural network. CIGOS 2021 Emerg. Technol. Appl. Green Infrastruct., Lecture Notes in Civil Engineering, Ha-Minh C, Tang AM, Bui TQ, Vu XH, Huynh DVK (eds). Springer Singapore, Singapore, pp 1261–1268
Pirhadi N, Hu J, Fang Y, Jairi I, Wan X, Lu J (2021) Seismic gravelly soil liquefaction assessment based on dynamic penetration test using expanded case history dataset. Bull Eng Geol Environ 80(10):8159–8170. https://doi.org/10.1007/s10064-021-02423-y
Ramchoun H, Amine M, Idrissi J, Ghanou Y, Ettaouil M (2016) Multilayer perceptron: architecture optimization and training. Int J Interact Multimed Artif Intell 4(1):26–30. https://doi.org/10.9781/ijimai.2016.416
Rana H, Babu GLS (2022) Object-oriented approach for landslide mapping using wavelet transform coupled with machine learning: a case study of Western Ghats, India. Indian Geotech J 52(3):691–706. https://doi.org/10.1007/s40098-021-00587-8
Robertson PK, (Fear) Wride C (1998) Evaluating cyclic liquefaction potential using the cone penetration test. Can Geotech J 35(3):442–459. https://doi.org/10.1139/t98-017
Sabbar AS, Chegenizadeh A, Nikraz H (2019) Prediction of liquefaction susceptibility of clean sandy soils using artificial intelligence techniques. Indian Geotech J 49(1):58–69. https://doi.org/10.1007/s40098-017-0288-9
Samui P, Sitharam TG (2011) Machine learning modelling for predicting soil liquefaction susceptibility. Nat Hazards Earth Syst Sci 11(1):1–9. https://doi.org/10.5194/nhess-11-1-2011
Shen S, Jiang H, Zhang T (2012) Stock market forecasting using machine learning algorithms. Dep. Electr. Eng. Stanf. Univ. Stanf. CA, pp 1–5
Singbal P, Chatterjee S, Choudhury D (2020) Assessment of seismic liquefaction of soil site at Mundra Port, India, using CPT and DMT field tests. Indian Geotech J 50(4):577–586. https://doi.org/10.1007/s40098-019-00395-1
Snoek J, Larochelle H, Adams RP (2012) Practical Bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. Curran Associates, Inc.
Tran TV, Nguyen B-P, Doan N-P, Tran D (2023) Performance of different CNN-based models on classification of steel sheet surface defects. J Eng Sci Technol JESTEC 18:554–562
Tran VT, To TS, Nguyen T-N, Tran TD (2022) Safety helmet detection at construction sites using YOLOv5 and YOLOR. Intell. Things Technol. Appl., Lecture Notes on Data Engineering and Communications Technologies. Nguyen N-T, Dao N-N, Pham Q-D, Le HA (eds). Springer International Publishing, Cham , pp 339–347
Turner R, Eriksson D, McCourt M, Kiili J, Laaksonen E, Xu Z, Guyon I (2021) Bayesian optimization is superior to random search for machine learning hyperparameter tuning: analysis of the black-box optimization challenge 2020. In: Proc. NeurIPS 2020 Compet. Demonstr. Track. PMLR, pp 3–26
Victoria AH, Maragatham G (2021) Automatic tuning of hyperparameters using Bayesian optimization. Evol Syst 12(1):217–223. https://doi.org/10.1007/s12530-020-09345-2
Waskom M (2021) Seaborn: statistical data visualization. J Open Source Softw 6(60):3021. https://doi.org/10.21105/joss.03021
Wu J, Chen X-Y, Zhang H, Xiong L-D, Lei H, Deng S-H (2019) Hyperparameter optimization for machine learning models based on Bayesian optimizationb. J Electron Sci Technol 17(1):26–40. https://doi.org/10.11989/JEST.1674-862X.80904120
Yang H, Chan L, King I (2002) Support vector machine regression for volatile stock market prediction. Intell. Data Eng. Autom. Learn.—IDEAL 2002, Lecture Notes in Computer Science, Yin H, Allinson N, Freeman R, Keane J, Hubbard S (eds). Springer Berlin Heidelberg, Berlin, Heidelberg, pp 391–396
Zhang W, Li H, Li Y, Liu H, Chen Y, Ding X (2021) Application of deep learning algorithms in geotechnical engineering: a short critical review. Artif Intell Rev 54(8):5633–5673. https://doi.org/10.1007/s10462-021-09967-1
Funding
This work was supported by a National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIT) (No. NRF-2018R1A5A1025137).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Van Nguyen, N., Van Le, L., Nguyen, TN. et al. Prediction of Liquefied Soil Settlement Using Multilayer Perceptron with Bayesian Optimization. Indian Geotech J (2024). https://doi.org/10.1007/s40098-024-00894-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40098-024-00894-w