
Abstract
Recently, a globally convergent variant of Peaceman–Rachford splitting method (PRSM) has been proposed by He et al. In this paper, motivated by the idea of the generalized alternating direction method of multipliers, we propose, analyze and test a generalized PRSM for separable convex programming, which removes some restrictive assumptions of He’s PRSM. Furthermore, both subproblems are approximated by the linearization technique, and the resulting subproblems thus may have closed-form solution, especially in some practical applications. We prove the global convergence of the proposed method and report some numerical results about the image deblurring problems, which demonstrate that the new method is efficient and promising.
Similar content being viewed by others
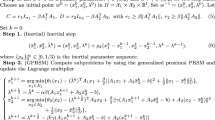


Avoid common mistakes on your manuscript.
1 Introduction
Many problems arising from compressed sensing, image deblurring, and statistical learning can be casted as the following canonical convex programming with linear constraints and a separable objective function:
where \(\theta _i:\mathcal {R}^{n_i}\rightarrow \mathcal {R} (i=1,2)\) are closed proper convex but not necessarily smooth functions, \(A_i\in \mathcal {R}^{l\times n_i} (i=1,2)\), \(b\in \mathcal {R}^l\) and \(\mathcal {X}_i\subseteq \mathcal {R}^{n_i}(i=1,2)\) are nonempty closed convex sets. Throughout our discussion, the solution set of (1) is assumed to be nonempty and the matrices \(A_1, A_2\) are assumed to have full column rank.
To solve (1), there are many efficient augmented Lagrangian method (ALM) based solvers, such as the alternating direction method of multipliers (ADMM) [1, 2], the generalized ADMM [3, 4], and the Peaceman–Rachford splitting method (PRSM) [5–9], and so on. Recently, it was discovered that the ADMM, the PRSM and their variants are quite efficient for solving some practical problems. For example, in the compressed sensing, the subproblems in the iterative schemes of these methods often have closed-form or easily computable solutions. Due to their high efficiency, these methods are well studied by many researchers.
In this paper, let us focus on the PRSM, which was original proposed in [5]. Applying it to problem (1), we get the following iterative scheme [6]:
where \({\uplambda }\in \mathcal {R}^l\) is the Lagrange multiplier associated with the linear constraints in (1) and \(\beta >0\) is a penalty parameter. Compared with the ADMM, the PRSM updates the Lagrange multiplier twice at each iteration. The PRSM is always efficient when it is convergent. However, according to [6], it “is less ‘robust’ in that it converges under more restrictive assumptions than alternating direction method of multipliers”. Thus, compared with the ADMM, the PRSM has received much less attention. To ensure the global convergence of the PRSM, He et al. [7] developed a strictly contractive PRSM (SCPRSM) by attaching an underdetermined relaxation factor r to the penalty parameter \(\beta \) in the steps of Lagrange multiplier updating, and yield the following iterative scheme:
where the parameter \(r\in (0,1)\). Obviously, when \(r=1\), the iterative scheme (3) reduces to (2). However, to ensure the global convergence of (3), the parameter r must be restricted in the interval (0, 1). The global convergence of SCPRSM was proved via the analytic framework of contractive type methods and its efficiency was verified numerically by some applications in statistical learning and image processing. Furthermore, the experiments in [7] also indicate that some aggressive values of r close to 1 (e.g., [0.8, 0.9]) are preferred.
It is well known that the generalized ADMM [3, 4] includes the original ADMM as a special case, and can numerically accelerate the original ADMM with some values of the relaxation factor. Therefore, inspired by the relationship between the ADMM and the generalized ADMM, we propose the following generalized version of the SCPRSM:
where \(\alpha \in (0,2)\), \(r\in (0,2-\alpha )\) are two relaxation factors, and \(G_1\succ 0\), \(G_2\succeq 0\) or \(G_1\succeq 0\), \(G_2\succ 0\). Here for a matrix G, \(G\succ 0\) (resp., \(\succeq 0\)) means that G is positive definite (resp., semidefinite). Note that: (I) We don’t attach any relaxation factor before \(\beta \) in the second update of the Lagrangian multiplier. The reasons are: (i) If we attach a factor, then the matrix H (defined in (8)) will be nonsymmetric; (ii) As pointed out in [7], aggressive values of r are preferred in (3). (II) At each iteration, the iterative scheme (3) require solving a constrained subproblem with respect to \(x_1\), which is in the form
with a given vector \(a_1\in \mathcal {R}^l\). When \(A_1\ne I_{n_1}\), this subproblem is not easy to solve even when \(\mathcal {X}_1=\mathcal {R}^{n_1}\), and the resolvent of \(\partial \theta _1\), that is \((I_{n_1}+\frac{1}{\beta }\partial \theta _1)^{-1}(\cdot )\), has a closed-form representation. Thus some iterative solver is needed to get an approximate solution of this subproblem. However, in this case, we can set \(G_1=\tau I_{n_1}-\beta A_1^\top A_1\) in the \(x_1\) subproblem of (4) with the requirement \(\tau >\beta \Vert A_1^\top A_1\Vert \), where \(\Vert \cdot \Vert \) denotes the spectral norm of a matrix. With this choice, the quadratic term \(\frac{\beta }{2}\Vert A_1x_1+A_2x_2^k-b\Vert ^2\) is linearized, and the \(x_1\)-subproblem in (4) reduces to estimating the resolvent of \(\partial \theta _1\):
where \(u^k=\frac{1}{\tau }(Gx_1^k-\beta A_1^\top A_2x_2^k+A^\top {\uplambda }^k+\beta A_1^\top b)\), and thus it has closed-form solution. For example, when \(\theta _1(x_1)=\Vert x_1\Vert _1\) (here \(\Vert x_1\Vert _1=\sum _{i=1}^{n_1}|(x_1)_i|\)) or \(\theta _1(x_1)=\Vert x_1\Vert \) (here \(\Vert \cdot \Vert \) denotes the Euclidean 2-norm), then
or
where \(\mathrm {sign}(\cdot )\) is the sign function.
The rest of this paper is organized as follows. In Sect. 2, we give some preliminaries and characterize (1) by the variational inequality problem. In Sect. 3, we describe the generalized PRSM and prove its global convergence in detail. In Sect. 4, we apply the proposed method to solve the image deblurring problem and verify its numerical efficiency. Finally, we give some concluding remarks in Sect. 5.
2 Preliminaries
In this section, we summarize some preliminaries which are useful for further discussions. In particular, we characterize problem (1) by the variational inequality problem.
First, we define some auxiliary variables which will help us alleviate the notation in the following analysis. Set \(x=(x_1,x_2)\), which is a column vector by stacking vectors \(x_1,x_2\). Similarly, set \(w=(x,{\uplambda })\) and \(\theta (x)=\theta _1(x_1)+\theta _2(x_2)\). By invoking the first-order optimality condition for convex programming, we reformulate problem (1) as the following variational inequality problem (denoted by VI(\(\mathcal {W},F,\theta )\)): Finding a vector \(w^*\in \mathcal {W}\) such that
where \(\mathcal {W}=\mathcal {X}_1\times \mathcal {X}_2\times \mathcal {R}^l\), and
Obviously, the mapping F(w) defined in (6) is affine with a skew-symmetric matrix; it is thus monotone. We denote by \(\mathcal {W}^*\) the solution set of (5). Then, \(\mathcal {W}^*\) is nonempty under assumption of the solution set of problem (1), and if \(w^*=(x_1^*,x_2^*,{\uplambda }^*)\in \mathcal {W}^*\), then \((x_1^*,x_2^*)\) is a solution of (1).
Now, we define some matrices in order to present our analysis in a compact way. Set
and
The matrices M, Q, H just defined have the following nice properties.
Lemma 2.1
If \(\alpha \in (0,2)\), \(r+\alpha <2\) and \(G_1\succ 0, G_2\succeq 0\) or \(G_1\succeq 0\), \(G_2\succ 0\), then we have
-
(1).
The matrices M, Q, H defined, respectively, in (7), (8) have the following relationship:
$$\begin{aligned} HM=Q. \end{aligned}$$(9) -
(2).
If \(G_1\succ 0, G_2\succeq 0\), then \(H\succ 0\); If \(G_1\succeq 0\), \(G_2\succ 0\), then
$$\begin{aligned} H_1=\left( \begin{array}{ccc} \frac{1}{r+\alpha }\beta A_2^\top A_2+G_2&{}\frac{1-r-\alpha }{r+\alpha }A_2^\top \\ \frac{1-r-\alpha }{r+\alpha }A_2&{}\frac{1}{\beta (r+\alpha )}I_l \end{array}\right) \succ 0. \end{aligned}$$ -
(3).
\(Q^\top +Q-M^\top HM\succeq 0.\)
Proof
-
(1)
$$\begin{aligned} HM= & {} \left( \begin{array}{ccc} G_1&{}\quad 0&{}\quad 0\\ 0&{}\quad \frac{1}{r+\alpha }\beta A_2^\top A_2+G_2&{}\quad \frac{1-r-\alpha }{r+\alpha }A_2^\top \\ 0&{}\quad \frac{1-r-\alpha }{r+\alpha }A_2&{}\quad \frac{1}{\beta (r+\alpha )}I_l \end{array}\right) \left( \begin{array}{ccc}I_{n_1}&{}0&{}0\\ 0&{}I_{n_2}&{}0\\ 0&{}-\beta A_2&{}(r+\alpha ) I_l\end{array}\right) \\= & {} \left( \begin{array}{ccc}G_1&{}0&{}0\\ 0&{}\beta A_2^\top A_2+G_2&{}(1-r-\alpha )A_2^\top \\ 0&{}-A_2&{}\frac{1}{\beta }I_l \end{array}\right) =Q. \end{aligned}$$
Then the first assertion is proved.
-
(2)
The proof is divided into two cases. Case (I) If \(G_1\succ 0, G_2\succeq 0\). For any \(w=(x_1,x_2,{\uplambda })\ne 0\), since \(r>0,\alpha \in (0,2)\) and \(r+\alpha <2\), we get
$$\begin{aligned}&w^\top Hw \nonumber \\&\quad =\Vert x_1\Vert _{G_1}^2+\Vert x_2\Vert _{G_2}^2+\left. \frac{1}{r+\alpha } \right. (\beta \Vert A_2x_2\Vert ^2+2(1-r-\alpha ){\uplambda }^\top A_2x_2+\frac{1}{\beta }\Vert {\uplambda }\Vert ^2)\nonumber \\&\quad \ge \Vert x_1\Vert _{G_1}^2+\Vert x_2\Vert _{G_2}^2+\left. \frac{2}{r+\alpha } \right. \min \{2-r-\alpha ,r+\alpha \}\Vert A_2x_2\Vert \cdot \Vert {\uplambda }\Vert , \end{aligned}$$(10)where the inequality follows from the Cauchy-Schwartz inequality. If \(x_1\ne 0\), then from (10), we have \(w^\top Hw>0\). Otherwise \((x_2,{\uplambda })\ne 0\): if \(x_2=0\) or \({\uplambda }=0\), then from the equality in (10) and the full column rank of \(A_2\), we also have \(w^\top Hw>0\); if \(x_2\ne 0\) and \({\uplambda }\ne 0\), then from (10) again, we have \(w^\top Hw>0\). Thus, \(H\succ 0\). Case (II) If \(G_1\succeq 0, G_2\succ 0\). For any \(v=(x_2,{\uplambda })\ne 0\), as the above discussion, we have \(v^\top H_1v>0\). Thus, \(H_1\succ 0\).
-
(3)
$$\begin{aligned}&Q^\top +Q-M^\top HM\\&\quad =Q^\top +Q-M^\top Q\\&\quad =\left( \begin{array}{ccc}G_1&{}0&{}0\\ 0&{}G_2&{}0\\ 0&{}0&{}\frac{2-(r+\alpha )}{\beta }I_l\end{array}\right) \succeq 0, \end{aligned}$$
where the inequality follows from \(r+\alpha <2\) and \(G_1\succ 0, G_2\succeq 0\) or \(G_1\succeq 0\), \(G_2\succ 0\). The proof is complete. \(\square \)
3 Algorithm and global convergence
In this section, we first describe the generalized PRSM (denoted by GPRSM) for VI(\(\mathcal {W},F,\theta )\) formally. Then, we establish its global convergence in a contraction perspective.

For further analysis, we define an auxiliary sequence \(\{\hat{w}^k\}\) as
Thus, from (4) and (11), we get
and
which together with (7) and (11) shows that
Now, we start to prove the global convergence of GPRSM.
Lemma 3.1
If \(A_ix_i^k=A_ix_i^{k+1}(i=1,2)\) and \({\uplambda }^k={\uplambda }^{k+1}\), then \(w^{k+1}=(x_1^{k+1},x_2^{k+1},{\uplambda }^{k+1})\) produced by the GPRSM is a solution of VI(\(\mathcal {W},F,\theta \)).
Proof
Deriving the first-order optimality condition of \(x_1\)-subproblem in (4), for any \(x_1\in \mathcal {X}_1\), we have
By the definition of \(\hat{{\uplambda }}^k\) in (11) and using \(\hat{x}_1^k=x_1^{k+1}\), the above inequality can be written as
Similarly, from the \(x_2\)-subproblem in (4), we have
By (11), we have
Substituting this into (14) and using \(\hat{x}_2^k=x_2^{k+1}\), we have
In addition, follows from (11) again, we have
Then, combining (13), (15), (16), for any \(w=(x_1,x_2,{\uplambda })\in \mathcal {W}\), it holds that
Then, recalling the definition of Q in (7), the above inequality can be written as
In addition, if \(A_ix_i^k=A_ix_i^{k+1}(i=1,2)\) and \({\uplambda }^k={\uplambda }^{k+1}\), then we have \(A_ix_i^k=A_i\hat{x}_i^k(i=1,2)\) and \({\uplambda }^k=\hat{{\uplambda }}^k\). Thus,
which together with (17) indicates that
This implies that \(\hat{w}^k=(\hat{x}_1^k,\hat{x}_2^k,\hat{{\uplambda }}^k)\) is a solution of VI(\(\mathcal {W},F,\theta \)). Since \(\hat{w}^k=w^{k+1}\), therefore \(w^{k+1}\) is also a solution of VI(\(\mathcal {W},F,\theta \)). This completes the proof. \(\square \)
According to (17), the accuracy of \(\hat{w}^k\) to a solution of VI(\(\mathcal {W},F,\theta \)) is measured by the quantity \((w-\hat{w}^k)^\top Q(w^k-\hat{w}^k)\). In the next lemma, we further refine this term and express it in terms of some quadratic terms.
Lemma 3.2
Let the sequence \(\{w^k\}\) be generated by the GPRSM. Then, for any \(w\in \mathcal {W}\), we have
where \(N=Q+Q^\top -M^\top HM.\)
Proof
Setting \(a=w, b=\hat{w}^k, c=w^k, d=w^{k+1}\) in the identity
we obtain
Combining the above inequality, (9) and (12), we have
For the last term of (19), we have
Substituting the above equality into (19), we obtain (18). The proof is complete.
\(\square \)
The following theorem indicates the the sequence generated by the GPRSM is Fejèr monotone with respect to \(\mathcal {W}^*\).
Theorem 3.1
Let \(\{w^k\}\) be the sequence generated by the GPRSM. Then, for any \(w^*\in \mathcal {W}^*\), we have
Proof
Setting \(w=w^*\) in (17) and (18), we get
On the other hand, by \(w^*\in \mathcal {W}^*\) and the monotonicity of F, we have
Adding the above two inequalities yields (20). The theorem is proved.
We are now ready to prove the global convergence of the proposed GPRSM. \(\square \)
Theorem 3.2
Let \(\{w^k\}\) be the sequence generated by the GPRSM. Then, if \(\alpha \in (0,2), r\in (0,2-\alpha )\) and \(G_1\succeq 0, G_2\succ 0\) or \(G_1\succ 0, G_2\succeq 0\), the sequence \(\{w^k\}\) converges to some \(w^\infty \), which belongs to \(\mathcal {W}^*\).
Proof
Since \(\alpha \in (0,2), r\in (0,2-\alpha )\) and \(G_1\succ 0, G_2\succeq 0\) or \(G_1\succeq 0, G_2\succ 0\), by (20), we have
The following proof is divided into three cases.
Case (I) If \(G_1\succ 0, G_2\succ 0\), by Lemma 2.1, we have \(H\succ 0\). Then, by (21), the sequence \(\{w^k\}\) is bounded. Furthermore, summing (20) over \(k=0,1,\ldots ,\infty \), it yields
which implies that
Then, by (17), we can get
Since the sequence \(\{\hat{w}^k\}\) is bounded, it has at least one cluster point. Let \(w^\infty \) be a cluster point of \(\{\hat{w}^k\}\) and the subsequence \(\{\hat{w}^{k_j}\}\) converges to \(w^\infty \). It follows from (22) that
which implies that \(w^\infty \in \mathcal {W}^*\). From \(\lim _{k\rightarrow \infty }\Vert w^k-\hat{w}^{k}\Vert _H=0\) and \(\{\hat{w}^{k_j}\}\rightarrow w^\infty \), for any given \(\epsilon >0\), there exists an integer l, such that
Therefore, for any \(k\ge k_l\), it follows from the above two equalities and (21) that
This shows that the sequence \(\{w^k\}\) converges to \(w^\infty \in \mathcal {W}^*\).
Case (II) If \(G_1\succ 0, G_2=0\), by Lemma 2.1, we also have \(H\succ 0\). Then, by (21), the sequence \(\{w^k\}\) is also bounded. Furthermore, summing (20) over \(k=0,1,\ldots ,\infty \), it yields
which implies that
Note that the optimality condition for the \(x_2\) subproblem in (4) can be written:
Since (24) is true for any integer \(k\ge 0\), thus we have
Setting \(x_2=x_2^k\) and \(x_2=x_2^{k+1}\) in (24) and (25), respectively, we get
and
Adding the above two inequalities, we get
On the other hand, from the equality above (12), we have
where the inequality follows from (26). The above inequality, (23) and \(x_2^{k+1}=\hat{x}_2^k\) imply that
By the full column rank assumption of \(A_2\), we get
Therefore, by (17), we also have the inequality (22). The following proof is similar to that of Case (I).
Case (III) If \(G_1=0, G_2\succ 0\), by Lemma 2.1, we have \(H_1\succ 0\). Thus, from (21), we can deduce
where \(v=(x_2,{\uplambda })\). Thus the sequence \(\{v^k\}\) is bounded, and
Thus, the sequence \(\{\hat{v}^k\}\) is also bounded. On the other hand, by (11), we have
This and the full column rank of \(A_1\) imply the sequences \(\{x_1^k\}\) and \(\{\hat{x}_1^k\}\) are also bounded. Overall, the sequences \(\{w^k\}\) and \(\{\hat{w}^k\}\) are bounded. In addition, by (17), we can get (22). Thus, a cluster point of the sequence \(\{\hat{w}^k\}\) is a solution of VI(\(\mathcal {W},F,\theta \)). From \(\lim _{k\rightarrow \infty }\Vert v^k-\hat{v}^{k}\Vert _{H_1}=0\) and \(\{\hat{v}^{k_j}\}\rightarrow v^\infty \), for any given \(\epsilon >0\), there exists an integer l, such that
Therefore, for any \(k\ge k_l\), it follows from the above two equalities and (27) that
This shows that the sequence \(\{v^k\}\) converges to \(v^\infty \). Then, by (28) again, the sequence \(\{w^k\}\) converges to \(w^\infty \in \mathcal {W}^*\). This completes the proof. \(\square \)
4 Numerical experiments
In this section, we apply GPRSM to solving some constrained image deblurring problems, and compare its numerical performance with the linearized ADMM [10]. All the codes were written by Matlab 7.10 and were conducted on ThinkPad notebook with Pentium(R) Dual-Core CPU T4400@2.2GHz, 2GB of memory.
Given original image concatenated into an n-vector \(\bar{x}\in \mathcal {R}^n\), and let \(A\in \mathcal {R}^{n\times n}\) be a blurring operator (integral operator) acting on the image. Let \(\omega \in \mathcal {R}^n\) be the Gaussian noise added onto the image. The observed image \(c\in \mathcal {R}^n\) can be modeled by \(c=A\bar{x}+\omega \). The constrained image deblurring problem (CIDP\(_{\uplambda }\)) is to recover \(\bar{x}\) from c, which can be depicted as
where \(l,u\in \mathcal {R}^n_+\); \(B\in \mathcal {R}^{n\times n}\) is a regularization operator (differential operator); \(\mu ^2\in \mathcal {R}\) is the regularization parameter; \(x\in \mathcal {R}^n\) is the restored image. The box constraints \(l\le x\le u\) represent the dynamic range of the image (e.g., \(l_i=0\) and \(u_i=255\) for an 8-bit gray-scale image).
Obviously, introducing an auxiliary variable \(y\in \mathcal {R}^n\), we can change CIDP\(_{\uplambda }\) to the equivalent form
where \(\Omega =\{y|l\le y\le u\}\). In fact, (30) is a special case of (1) where \(x_1=y, x_2=x\), \(\theta _1(x_1)=\frac{1}{2}\Vert Ay-c\Vert ^2\), \(\theta _2(x_2)=\frac{\mu ^2}{2}\Vert Bx\Vert ^2\), \(A_1=-I_n, A_2=I_n, d=0\), and \(\mathcal {X}_1=\mathcal {R}^n, \mathcal {X}_2=\Omega \). Then, the iterative scheme of the GPRSM (4) for (30) is
Now, let us elaborate on the two subproblems in (31).
-
For the given \(y^k\), \(x^k\) and \({\uplambda }^k\), set \(G_1=0\). With this choice, the y subproblem in (31) is amount to solving the normal equation
$$\begin{aligned} (A^\top A+\beta I_n)y=A^\top c+\beta x^k-{\uplambda }^k. \end{aligned}$$Under the periodic boundary conditions for y, \(A^\top A\) will be a block circulant matrix with circulant blocks. Hence it can be diagonalized by the two-dimensional fast Fourier transform (FFT). Thus, the above equation can be solved exactly using two FFTs.
-
For the given \(y^{k+1}\), \(x^k\) and \({\uplambda }^{k+\frac{1}{2}}\), set \(G_2=\mu ^2(\tau I_n-B^\top B)\), where \(\tau >\Vert B^\top B\Vert \), and the x subproblem in (31) reduces to
$$\begin{aligned} x^{k+1}= & {} \mathrm {argmin}_{x\in \Omega }\left\{ \mu ^2[(Bx^k)^\top B(x-x^k)+\frac{\tau }{2}\Vert x-x^k\Vert ^2]+\frac{\beta }{2}\Vert x \right. \\&\quad \left. -\,\alpha y^{k+1}-(1-\alpha )x^k-\frac{1}{\beta }{\uplambda }^{k+\frac{1}{2}}\Vert ^2 \right\} . \end{aligned}$$The optimality condition of the above problem leads to the following variational inequality
$$\begin{aligned}&(x'-x^{k+1})^\top \left\{ \mu ^2[B^\top Bx^k+\tau (x-x^k)]+\beta (x-\alpha y^{k+1}\right. \\&\quad \left. -(1-\alpha )x^k-\frac{1}{\beta }{\uplambda }^{k+\frac{1}{2}})\right\} \ge 0,~~\forall x'\in \Omega . \end{aligned}$$Then, \(x^{k+1}\) can be given explicitly by
$$\begin{aligned} x^{k+1}=P_\Omega \left\{ \begin{aligned}\frac{1}{\mu ^2\tau +\beta }\left[ -\mu ^2B^\top Bx^k+\left( \beta -\alpha \beta +\mu ^2\tau \right) x^k+\alpha \beta y^{k+1}+{\uplambda }^{k+\frac{1}{2}}\right] \end{aligned} \right\} , \end{aligned}$$where \(P_\Omega (\cdot )\) denotes the projection operator onto \(\Omega \) under the Euclidean norm.
The test images are 256-by-256 (\(l_i=0, u_i=255\) for all \(i=1,2,\ldots ,n\)) images as shown in Fig. 1: Fruits, Peppers, Lena and Cameraman. According, \(n=256^2\) in model (1) for these images. The blurring matrix A is chosen to be the out-of-focus blur and the matrix B is taken to be the gradient matrix. The observed image c is expressed as \(c=A\bar{x}+\omega \), where \(\omega \) is the Gaussian or impulse noise. Here, we employ the Matlab scripts: \(\mathtt{A=fspecial(`average}\)’,\(\mathtt{alpha)}\) and \(\mathtt{c=imfilter(x,A,`circular}\)’,\(\mathtt{`conv}\)’)\(\,+\,\omega \), in which \(\mathtt{alpha}\) is the size of the kernel. To assess the restoration performance qualitatively, we use the peak signal to noise ratio (PSNR) defined as

The original test images: Fruits, Peppers, Lena and Cameraman
Here \(\bar{x}\) is the true image, and \(\bar{x}_{\mathrm {max}}\) is the maximum possible pixel value of the image. Furthermore, the stopping criterion of all the tested methods is
In the experiment, we apply our proposed GPRSM and the linearized ADMM in [10] (denoted by LADMM) to solve model (30) with Gaussian noise and \(\mu =0.16\). Here, we set the Gaussian noise \(\omega =\eta *\mathtt{randn(n,n)}\), and \(\eta \) is the level of noise. For the GPRSM, we set \(\alpha =1.1, \beta =0.1, r=0.89\), \(\tau =1.01\cdot \rho (B^\top B)\). For the parameters of LADMM, we use the default values in [10]. All iterations start with the blurred images. For \(\mathtt{alpha}=5\) and \(\eta =5\), the blurred images, the restored images by the two methods are showed in Fig. 2. From Fig. 2, we can see that both methods can recover the four blurred images very well, and our method is always faster than the LADMM. More numerical results are given in Table 1, and we report the CPU time (in seconds), the number of iterations (Iter) required for the whole deblurring process. The numerical results in Table 1 indicate that both methods reach almost the same restored PSNR. In addition, GPRSM is always faster than LADMM, and the number of iterations of GPRSM is always smaller than that of LADMM. Thus, GPRSM is more efficient and robustness than the famous LADMM. Furthermore, in Fig. 3, we plot the evolution of the PRSN value and the objective function value with respect to the number of iterations for the Fruits with \(\mathtt{alpha}=3\) and \(\eta \)=3. From Fig. 3, we see that, compared with the LADMM, the GPRSM is more efficient.

From left to right: the blurred images, the restored images by GPRSM, LADMM

Comparison results for Fruits
5 Conclusions
In this paper, we have proposed a generalized PRSM, which removes some restrictive assumptions of the strictly contractive PRSM proposed by He et al., and includes the original PRSM as a special case. Under mild conditions, we have proved the global convergence of the new method. Numerical results about the image deblurring problems indicate that the new method performs better than the linearized ADMM. In the future, we shall investigate the inexact version of our generalized PRSM and apply the generalized PRSM to solve other problems, such as the statistical learning problems, the compressive sensing etc.
References
Gabay, D., Mercier, B.: A dual algorithm for the solution of nonlinear variational problems via finite-element approximations. Comput. Math. Appl. 2, 17–40 (1976)
Glowinski, R., Marrocco, A.: Approximation par elements finis dordre un, et la resolution, par penalisation-dualite, dune classe de problèmes de Dirichlet non lineaires. RAIRO Anal. Numer. 9, 41–76 (1975)
Eckstein, J., Bertsekas, D.: On the Douglas-Rachford splitting method and the proximal point algorithm for maximal monotone operators. Math. Program. 55, 293–318 (1992)
Han, D., Yuan, X.M.: Local linear convergence of the alternating direction method of multipliers for quadratic programs. SIAM J. Numer. Anal. 51(6), 3446–3457 (2013)
Peaceman, D.H., Rachford, H.H.: The numerical solution of parabolic elliptic differential equations. SIAM J. Appl. Math. 3, 28–41 (1955)
Lions, P.L., Mercier, B.: Splitting algorithms for the sum of two nonlinear operators. SIAM J. Numer. Anal. 16, 964–979 (1979)
He, B.S., Liu, H., Wang, Z.R., Yuan, X.M.: A strictly contractive Peaceman–Rachford splitting method for convex programming. SIAM J. Optim. 24(3), 1011–1040 (2014)
Bertsekas, D.P.: Constrained Optimization and Lagrange Multiplier Methods. Academic Press, New York (1982)
Sun, M., Liu, J.: A proximal Peaceman–Rachford splitting method for compressive sensing, J. Appl. Math. Comput., 2015 (Accepted)
Chan, R.H., Tao, M., Yuan, X.M.: Linearized alternating direction method for constrained linear least-squares problem. East Asia J. Appl. Math. 2, 326–341 (2012)
Acknowledgments
The authors gratefully acknowledge the helpful comments and suggestions of the anonymous reviewers. This work is supported by the National Natural Science Foundation of China (71371139, 11302188), the Shanghai Shuguang Talent Project (13SG24), the Shanghai Pujiang Talent Project (12PJC069), the foundation of Scientific Research Project of Shandong Universities (J15LI11), and the foundation of Zaozhuang University (2014YB03).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sun, M., Liu, J. Generalized Peaceman-Rachford splitting method for separable convex programming with applications to image processing. J. Appl. Math. Comput. 51, 605–622 (2016). https://doi.org/10.1007/s12190-015-0922-6
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12190-015-0922-6