
Abstract
The split feasibility problem (SFP) captures a wide range of inverse problems, such as signal processing, image reconstruction, and so on. Recently, applications of \(\ell _1\)-norm regularization to linear inverse problems, a special case of SFP, have been received a considerable amount of attention in the signal/image processing and statistical learning communities. However, the study of the \(\ell _1\)-norm regularized SFP still deserves attention, especially in terms of algorithmic issues. In this paper, we shall propose an algorithm for solving the \(\ell _1\)-norm regularized SFP. More specifically, we first formulate the \(\ell _1\)-norm regularized SFP as a separable convex minimization problem with linear constraints, and then introduce our splitting method, which takes advantage of the separable structure and gives rise to subproblems with closed-form solutions. We prove global convergence of the proposed algorithm under certain mild conditions. Moreover, numerical experiments on an image deblurring problem verify the efficiency of our algorithm.
Similar content being viewed by others

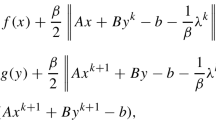
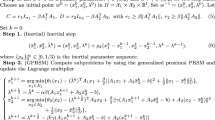
Avoid common mistakes on your manuscript.
1 Introduction
The split feasibility problem (SFP), which was first introduced by Censor and Elfving [12] to model phase retrieval problems, models a variety of inverse problems. Its recent applications to the medical treatment of intensity-modulated radiation therapy and medical imaging reconstruction [7, 11, 13, 15–17] have inspired more studies theoretically and practically.
The mathematical formulation of SFP is indeed a feasibility problem that amounts to finding a point \(x^*\in {\mathbb {R}}^n\) with the property
where \({\mathcal {C}}\) and \({\mathcal {Q}}\) are nonempty, closed and convex subsets of \({\mathbb {R}}^n\) and \({\mathbb {R}}^m\), respectively, and \(A: {\mathbb {R}}^n\rightarrow {\mathbb {R}}^m\) is a linear operator.
It is known that SFP (1.1) includes a variety of real-world inverse problems as special cases. For instance, when \({\mathcal {Q}}=\{b\}\) is singleton, SFP (1.1) is reduced to the classical convexly constrained linear inverse problem, that is, finding a point \(x^*\in {\mathbb {R}}^n\) such that
This problem has extensively been studied in the literature (see [29, 30, 45, 48, 51] and the references therein). Due possibly to the unclear structure of the general constraint set \({\mathcal {Q}}\), SFP (1.1) has however been received much less attention than its special case (1.2). As a matter of fact, certain algorithms that work for (1.2) seemingly have no straightforward counterparts for SFP (1.1). For instance, it still remains unclear whether the dual approach for (1.2) proposed in [45] (see also [48]) can be extended to SFP (1.1).
The SFP (1.1) can be solved by optimization algorithms since it is equivalent to the constrained minimization problem:
[Here \(P_{{\mathcal {Q}}}\) is the projection onto \({\mathcal {Q}}\) (see (2.1)).] Among the existing algorithms for SFP (1.1), the CQ algorithm introduced by Byrne [7, 8] is the most popular; it generates a sequence \(\{x^k\}\) through the recursion process:
This is indeed the gradient-projection algorithm applied to the minimization problem (1.3) (it is also a special case of the proximal forward-backward splitting method [24]). Recent improvements of the CQ algorithm with relaxed stepsizes and projections can be found in [26, 46, 55, 57, 60].
It is often the case that SFP (1.1) and (1.2) are ill-posed, due to possible ill-conditionedness of A. As a result, regularization must be reinforced. In fact, for the past decades, regularization techniques have successfully been used for solving (1.2), in particular, the unconstrained case of \({\mathcal {C}}={\mathbb {R}}^n\); see [30, 32, 39, 49] and the references therein. Regularization methods for SFP (1.1) have however been quite a recent topic; see [10, 14, 55, 58] where the classical Tikhonov regularization [51] is used to promote stability of solutions. In contrast with Tikhonov’s regularization, the \(\ell _1\)-norm regularization for (1.2) has been paid much more attention recently, due to the fact that the \(\ell _1\)-norm induces sparsity of solutions [6, 22, 27, 31, 56]. A typical example is the lasso [50] (also known as basis pursuit denoising [22]) which is the minimization problem:
where \(b\in {\mathbb {R}}^m\) and \(\sigma >0\) is a regularization parameter.
The \(\ell _1\)-norm regularization of SFP (1.1) is the following constrained minimization problem:
which can also be recast as
Notice that the lasso (1.4), the basis pursuit (BP) and basis pursuit denoising (BPDN) of Chen et al. [22] (see also [9, 27, 31, 53, 56]) are special cases of (1.5) and (1.6).
Compared with (1.4), the \(\ell _1\)-regularized SFP (1.6) has been received much less attention. In fact, as far as we have noticed, (1.6) has been considered only in [38], in which certain properties of the solution set of (1.6) were discussed, leaving algorithmic approaches unattached.
The main purpose of this paper is to introduce an implementable splitting algorithm for solving the \(\ell _1\)-regularized SFP (1.6) via the technique of alternating direction method of multipliers (ADMM) [33] in the framework of variational inequalities. Towards this we use the trick of variable splitting to rewrite (1.6) as
where f(x) is defined as in (1.3). Now ADMM, which has been widely used in the areas of variational inequalities, compressive sensing, image processing, and statistical learning (cf. [2, 6, 19, 21, 35, 36, 40, 56, 59]), works for (1.7) as follows: Given the k-th iterate \({\mathbf {w}}^k:=(x^k,z^k,\lambda ^k)\in {\mathcal {C}}\times {\mathbb {R}}^n\times {\mathbb {R}}^n\); the \((k+1)\)-th iterate \({\mathbf {w}}^{k+1}:=(x^{k+1},z^{k+1},\lambda ^{k+1})\) is obtained by solving three subproblems

where \(\{\lambda ^k\}\) is a sequence of Lagrangian multipliers and \(\gamma >0\) is a penalty parameter for violation of the linear constraints. The advantage of ADMM lies in its full exploiture of the separability structure of (1.7). Nevertheless, the subproblem (1.9) may not be easy enough to get solved due to the existence of the constraint set \({\mathcal {C}}\). To overcome this difficulty we will combine the techniques of linearization of ADMM and the proximal point algorithm [41] to propose a new algorithm, Algorithm 1 in Sect. 3. The main contribution of this paper is to prove the global convergence of this algorithm and apply it to solve image deblurring problems.
The rest of this paper is structured as follows. In Sect. 2, we summarize some basic notation, definitions and properties that will be useful for our subsequent analysis. In Sect. 3, we analyze the subproblems of ADMM for (1.7) and propose an implementable algorithm by incorporating the ideas of linearization and the proximal point algorithm into the new algorithm. Then, we prove global convergence of the proposed algorithm under some mild conditions. In Sect. 4, numerical experiments on image deblurring problems are carried out to verify the efficiency and reliability of our algorithm. Finally, concluding remarks are included in Sect. 5.
2 Preliminaries
In this section, we summarize some basic notation, concepts and well known results that will be useful for further discussions in subsequent sections.
Let \({\mathbb {R}}^n\) be an n-dimensional Euclidean space. For any two vectors \(x, y\in {\mathbb {R}}^n\), \(\left\langle x,\;y\right\rangle \) denotes the standard inner product. Furthermore, for a given symmetric and positive definite matrix M, we denote by \(\Vert x\Vert _M=\sqrt{\left\langle x, M x\right\rangle }\) the M-norm of x. For any matrix A, we denote \(\Vert A\Vert \) as its matrix 2-norm.
Throughout this paper, we denote by \(\iota _{\varOmega }\) the indicator function of a nonempty closed convex set \(\varOmega \), i.e.,
The projection operator \(P_{\varOmega ,M}\) from \({\mathbb {R}}^n\) onto the nonempty closed convex set \(\varOmega \) under M-norm is defined by
For simplicity, let \(P_{\varOmega }\) be the projection operator under Euclidean norm. It is well-known that the projection \(P_{\varOmega ,M}\) (in \(\varOmega \)) can be characterized by the relation
(The proof is available in any standard optimization textbook, such as [5, p. 211].) Next we introduce Moreau’s notion [42] of proximity operators which extends the concept of projections.
Definition 2.1
Let \(\varphi :{\mathbb {R}}^n\rightarrow {\mathbb {R}}\cup \{+\infty \}\) be a proper, lower semicontinuous and convex function. The proximity operator of \(\varphi \), denoted by \(\mathbf{prox}_\varphi \), is defined as an operator from \({\mathbb {R}}^n\) into itself and given by
It is clear that \(P_{\varOmega }=\mathbf{prox}_\varphi \) when \(\varphi =\iota _{\varOmega }\). Moreover, if we denote by \(\mathbf{I}\) the identity operator on \({\mathbb {R}}^n\), then \(\mathbf{prox}_\varphi \) and \((\mathbf{I}-\mathbf{prox}_\varphi )\) share the same nonexpansivity of \(P_\varOmega \) and \((\mathbf{I}-P_\varOmega )\). The reader is referred to [23, 24, 42] for more details.
Definition 2.2
Let \(\varphi :{\mathbb {R}}^n\rightarrow {\mathbb {R}}\cup \{+\infty \}\) be a proper, lower semicontinuous and convex function. The subdifferential of \(\varphi \) is the set-valued operator \(\partial \varphi :{\mathbb {R}}^n\rightarrow 2^{{\mathbb {R}}^n}\), given by, for \(x\in {\mathbb {R}}^n\),
According to the above two definitions, the minimizer in the definition (2.2) of \(\mathbf{prox}_\varphi (x)\) is characterized by the inclusion
Definition 2.3
A set-valued operator T from \({\mathbb {R}}^n\) to \(2^{{\mathbb {R}}^n}\) is said to be monotone if
A monotone operator is said to be maximal monotone if its graph is not properly contained in the graph of any other monotone operator.
It is well-known [47] that the subdifferential operator \(\partial \varphi \) of a proper, lower semicontinuous and convex function \(\varphi \) is maximal monotone.
Definition 2.4
Let \(g:{\mathbb {R}}^n\rightarrow {\mathbb {R}}\) be a convex and differentiable function. We say that its gradient \(\nabla g\) is Lipschitz continuous with constant \(L>0\) if
Notice that the gradient of the function f defined in (1.6) is \(\nabla f=A^\top (\mathbf{I}-P_\varOmega )A \). It is easily seen that \(\nabla f\) is monotone and Lipschitz continuous with constant \(\Vert A\Vert ^2\), i.e.,
3 Algorithm and Its Convergence Analysis
We are aimed in this section to invent a new algorithm, Algorithm 1 below, and prove its global convergence under certain mild conditions.
3.1 Algorithm
We begin with more analysis on the algorithm (1.8)–(1.9). The subproblem (1.9) is a constrained optimization problem which might not be easy enough to be solved efficiently. To make ADMM implementable for some constrained models, it is suggested directly linearizing the constrained subproblem [i.e., (1.9)] [18, 20, 52]. Clearly, an immediate benefit is that the solutions to the subproblems can be represented explicitly. It is noteworthy that direct linearization on ADMM must often be imposed strong conditions (e.g., strict convexity) for global convergence. Notice that the linearization on ADMM yields an approximate function involving a proximal term. Since the proximal point algorithm (PPA) [41] is one of the most powerful solvers in optimization, which not only provides a unified algorithmic framework including ADMM as its special case [28], but also, as Parikh and Boyd [44] emphasized, works under extremely general conditions, we combine the ideas of linearization on ADMM and PPA to propose an implementable splitting algorithm which has easier subproblems with closed-form solutions and shares similar convergence results to the PPA’s. More concretely, our idea is that we first add a proximal term to the subproblem (1.8), and the resulting subproblem has a closed-form solution via the shrinkage operator. We then linearize the function f at the latest iterate \(x^k\) in such a way that the subproblem (1.9) is simple enough to possess a closed-form expression. Following these two steps, we get an intermediate Lagrangian multiplier via (1.10).
Taking a revisit on the linearization procedure, we see that the resulting subproblem is essentially a one-step approximation of ADMM, which might not be the best output for the next iterate. Accordingly, we add a correction step with lower computational costs to update the output of the linearized ADMM (LADMM) for the purpose of compensating the approximation errors caused by linearization. A notable feature is that the correction-step can improve the numerical performance in terms of taking fewer iterations than LADMM, in addition to relaxing the conditions for global convergence and inducing a strong convergence result as [4].
Basing upon the above analysis, we will design an algorithm that inherits the advantages of ADMM and PPA. Our algorithm is a two-stage method, consisting of a prediction step and a correction step. Below, we mainly state the details of the prediction step. First, we generate the predictor \({\widetilde{z}}^k\) via
where \(\rho _2\) is a positive constant. The reason of imposing an proximal term \(\frac{\rho _2}{2}\left\| z-z^k\right\| ^2\) is to regularize the z-related subproblem. Besides, we can further derive a stronger convergence result theoretically with the help of such proximal term. Obviously, (3.1) can be rewritten as
Consequently, using the shrinkage operator [24, 56], we can solve the last minimization and express \({\widetilde{z}}^k\) in closed-form as
Recall that the shrinkage operator ‘\({{\mathrm{\text {shrink}}}}(\cdot ,\cdot )\)’ is defined by
where the ‘sign’, ‘\(\max \)’, and the absolute value function ‘\(|\cdot |\)’ are component-wise, and ‘\(\odot \)’ denotes the component-wise product.
For the x-related subproblem, the minimization subproblem (1.9) is not simple enough to have closed-form solution due to the nonlinearity of the function f. We may treat the nonlinearity of f by linearization. As a matter of fact, given \(\left( x^k,{\widetilde{z}}^k,\lambda ^k\right) \), we linearize f at \(x^k\) to get an approximate subproblem of (1.9), that is,
where \(\rho _1\) is a suitable constant for approximation. With a pair of predictors \(({\widetilde{x}}^k,{\widetilde{z}}^k)\), we generate the last predictor of \(\lambda \) via
Finally, with the predictor \({\widetilde{{\mathbf {w}}}}^k=\left( {\widetilde{x}}^k,{\widetilde{z}}^k,\widetilde{\lambda }^k\right) \), we update the next iterate with a correction step to compensate the approximation errors caused by the linearization of ADMM. This correction step together with the proximal regularization further relaxes the convergence requirements and improves the numerical performance (see Sect. 4).
Before presenting the splitting algorithm, for the sake of convenience, we denote \(\eta _1(x,{\widetilde{x}}):=\nabla f(x) -\nabla f({\widetilde{x}})\), \(I_n\) the n-dimensional identity matrix, and
Then, the corresponding algorithm is described formally in Algorithm 1.

Remark 3.1
It is worth pointing out that Algorithm 1 is not limited to solve the \(\ell _1\)-norm regularized SFP. When we use a general regularizer \(\varphi (z)\) instead of \(\sigma \Vert z\Vert _1\) in subproblem (3.1), then (3.1) amounts to
By invoking the definition of the proximity operator given in (2.2), the above scheme can be rewritten as
Therefore, Algorithm 1 is easily implementable as long as the above proximity operator has explicit representation. We refer the reader to [23] for more details of proximity operators.
Remark 3.2
The direction \({\mathbf {d}}\left( {\mathbf {w}}^k,{\widetilde{{\mathbf {w}}}}^k\right) \) defined by (3.10) apparently involves the matrix inverse of M. This is however not a computational worry since M is a block scalar matrix and its inverse is trivially obtained.
Remark 3.3
Even if we deal with the special case of \({\mathcal {Q}}:=\{b\}\) in the ADMM algorithm (1.8)–(1.10), the second subproblem (1.9) is still not easy to solve under the assumption \({\mathcal {C}}\ne {\mathbb {R}}^n\) or \(A\ne I_n\). When we further consider special cases \({\mathcal {C}}\subset {\mathbb {R}}^n_{+}\), an interesting work [61] showed that the resulting problem can be recast as
where \(e:=(1,1,\ldots ,1)^\top \). Accordingly, applying ADMM to (3.11) yields an implementable algorithm such that all subproblems have closed-form solutions. However, for general settings on \({\mathcal {C}}\) and \({\mathcal {Q}}\), we can not directly formulate \(\Vert z\Vert _1\) as \((z^\top e)\) and the nonlinearity of \(f(x)=\frac{1}{2}\Vert Ax-P_{{\mathcal {Q}}}(Ax)\Vert ^2\) also results in a subproblem without explicit representation. Comparatively speaking, our formulation for (1.6) and linearization are more suitable for general convex sets \({\mathcal {C}}\) and \({\mathcal {Q}}\).
3.2 Convergence Analysis
In this section we prove the global convergence of Algorithm 1. We begin with stating a fundamental fact derived from the first-order optimality condition, that is, problem (1.7) is equivalent to the variational inequality (VI) of finding a vector \({\mathbf {w}}^*\in \varOmega \) with the property
with
where \(\zeta \in \partial (\sigma \Vert \cdot \Vert _1)(z)\). The global convergence of Algorithm 1 will be established within the VI framework.
Lemma 3.1
Suppose that \({\mathbf {w}}^*\) is a solution of (3.12). Then, we have
Proof
First, the iterative scheme (3.4) can be easily recast into a VI, that is,
Using (3.5) and rearranging terms of the above inequality yields
where \(\eta _1\left( x^k,{\widetilde{x}}^k\right) \) is given in (3.6).
Similarly, it follows from (3.1) and, respectively, (3.5) that

where \(\zeta ^k\in \partial \left( \sigma \Vert \cdot \Vert _1\right) \left( z^k\right) \). Upon summing up (3.14)–(3.16), we can rewrite it into a compact form as follows
Setting now \({\mathbf {w}}:={\mathbf {w}}^*\) in the above inequality and noticing the fact that \(x^*=z^*\), we get
Equivalently,
Since f and \(\sigma \Vert \cdot \Vert _1\) are convex functions, it is easy to derive that the function F defined in (3.12) is monotone. It turns out that
This together with (3.18) further implies that
The desired inequality (3.13) now immediately follows from the above inequality and the definition of \(\phi \left( {\mathbf {w}}^k,{\widetilde{{\mathbf {w}}}}^k\right) \) given by (3.9). \(\square \)
Indeed, the above result implies that \(-{\mathbf {d}}\left( {\mathbf {w}}^k,{\widetilde{{\mathbf {w}}}}^k\right) \) is a descent search direction of the unknown distance function \(\frac{1}{2}\Vert {\mathbf {w}}-{\mathbf {w}}^*\Vert ^2_M\) at the point \({\mathbf {w}}={\mathbf {w}}^k\). Below, we show that the stepsize defined by (3.8) is reasonable. To see this we define two functions
and
Note that the function \(\varTheta (\alpha )\) may be viewed as the progress-function to measure the improvement obtained at the k-th iteration of Algorithm 1. We need to maximize \(\varTheta (\alpha )\) for seeking an optimal improvement.
Lemma 3.2
Suppose that \({\mathbf {w}}^*\) is a solution of (3.12). Then we have
where
Proof
It follows from (3.19) and (3.20) that
where the last inequality follows from Lemma 3.1. \(\square \)
Since \(q(\alpha )\) is a quadratic function of \(\alpha \), it is easy to find that \(q(\alpha )\) attains its maximum value at the point
It then turns out that, for any relaxation factor \(\tau >0\),
To ensure that an improvement can be obtained at each iteration, we should limit \(\tau \in (0,2)\) so that the right-hand side in the above relation is positive. However, we suggest to choose \(\tau \in [1,2)\) for fast convergence in practice (see Sect. 4).
Lemma 3.3
Suppose that \(\rho _1\ge \Vert A\Vert ^2\). Then, the step size \(\alpha _k\) defined by (3.8) is bounded away below from zero; that is, \(\inf _{k\ge 1}\alpha _k\ge \alpha _{\min }>0\) for some positive constant \(\alpha _{\min }\).
Proof
An appropriate application of the Cauchy–Schwartz inequality
implies that
Consequently, it follows from (3.9) and (3.10) that
where the second inequality follows from the Cauchy–Schwartz inequality and the Lipschitz continuity of \(\nabla f\), and the last inequality from the introduction of the constant \(C_{\min }:=\min \left\{ \frac{\gamma }{2},\;\rho _2,\;\frac{1}{2\gamma }\right\} .\)
On the other hand, it follows again from the Cauchy–Schwartz inequality and monotonicity of \(\nabla f\) that
where \(C_{\max }:=\max \left\{ \frac{(\rho _1 + \gamma )^2 +\Vert A\Vert ^4}{\rho _1+\gamma },\;\rho _2,\;\frac{1}{\gamma } \right\} \). Thus, combining (3.23) and (3.24) immediately yields
The assertion of this lemma is proved. \(\square \)
Theorem 3.1
Suppose that \(\rho _1\ge \Vert A\Vert ^2\) and let \({\mathbf {w}}^*\) be an arbitrary solution of (3.12). Then the sequence \(\{{\mathbf {w}}^k\}\) generated by Algorithm 1 satisfies the following property
Proof
From (3.7), (3.22) and (3.23) together with Lemmas 3.1 and 3.3, it follows that
We obtained the desired result. \(\square \)
Theorem 3.2
Suppose that \(\rho _1\ge \Vert A\Vert ^2\). Then, the sequence \(\{{\mathbf {w}}^k\}\) generated by Algorithm 1 is globally convergent to a solution of VI (3.12).
Proof
Let \({\mathbf {w}}^*\) be a solution of (3.12). It is immediately clear from (3.25) that
That is, the sequence \(\{\Vert {\mathbf {w}}^k-{\mathbf {w}}^*\Vert _M\}\) is decreasing. In particular, the sequence \(\{{\mathbf {w}}^k\}\) is bounded and the
By rewriting (3.25) as
we immediately conclude that
It turns out that \(\lim _{k\rightarrow \infty } \Vert x^k-{\widetilde{x}}^k\Vert =0\) and that the sequences \(\{{\mathbf {w}}^k\}\) and \(\{{\widetilde{{\mathbf {w}}}}^k\}\) have the same cluster points. To prove the convergence of the sequence \(\{{\mathbf {w}}^k\}\), let \(\{{\mathbf {w}}^{k_j}\}\) be a subsequence of \(\{{\mathbf {w}}^{k}\}\) that converges to some point \({\mathbf {w}}^{\infty }\); hence, the subsequence \(\{{\widetilde{{\mathbf {w}}}}^{k_j}\}\) of \(\{{\widetilde{{\mathbf {w}}}}^{k}\}\) also converges to \({\mathbf {w}}^{\infty }\).
Now taking the limit as \(j\rightarrow \infty \) over the subsequence \(\{k_j\}\) in (3.17) and using the continuity of F, we arrive at
Namely, \({\mathbf {w}}^{\infty }\) solves VI (3.12).
Finally, substituting \({\mathbf {w}}^{\infty }\) for \({\mathbf {w}}^*\) in (3.27) and using the fact that \(\Vert {\mathbf {w}}^k-{\mathbf {w}}^{\infty }\Vert _M\) is convergent, we conclude that
This proves that the full sequence \(\{{\mathbf {w}}^{k}\}\) converges to \({\mathbf {w}}^{\infty }\). \(\square \)
4 Numerical Experiments
The development of implementable algorithms tailored for \(\ell _1\)-norm regularized SFP [(even if for its special case of (1.2)] is in infant stage. Our main goal here is not to investigate the competitiveness of this approach with other algorithms, but simply to illustrate the reliability and the sensitivity with respect to some involved parameters of the presented method. Certainly, we also report some results to support our motivation by comparing Algorithm 1 (abbreviated as ‘ISM’) with ADMM and the straightforward linearized ADMM (we use “LADMM” for short) corresponding to (3.2), (3.4) and (3.5). Specifically, we demonstrate the application of the three algorithms to an image deblurring problem and report some preliminary numerical results to achieve the aforementioned goals.
All codes were written by Matlab 2010b and run on a Lenovo desktop computer with Intel Pentium Dual-Core processor 2.33GHz and 2Gb main memory.
The problem under test here is a wavelet-based image deblurring problem, which is a special case of (1.5) with a box constraint \({\mathcal {C}}\) and \({\mathcal {Q}}:=\{b\}\). More concretely, the model for this problem can be formulated as:
where b represents the (vectorized) observed image, the matrix \(A:=BW\) consists of a blur operator B and an inverse of a three stage Haar wavelet transform W, and the set \({\mathcal {C}}\) is a box area in \({\mathbb {R}}^{n}\). Indeed, if the image is considered with double precision entries, then the pixel values lie in \({\mathcal {C}}:=[0,1]\), and an 8-bit gray-scale image corresponds to \({\mathcal {C}}:=[0,255]\). Notice that the unconstrained alternative of (4.1), i.e., \({\mathcal {C}}:={\mathbb {R}}^n\), is more popular in the literature (see, for instance, [1, 3, 37]). However, as shown in [18, 20, 34, 43], more precise restoration, especially for binary images, may occur by absorbing an additional box constraint \({\mathcal {C}}\) into the model. In this section, we are concerned with the constrained model (4.1) and investigate the behavior of Algorithm 1 for this problem.
In these experiments, we adopt the reflective boundary condition and set the regularization parameter \(\sigma \) as 2e\(-\)5. We test eight different images, which were scaled into the range between 0 and 1, i.e., \({\mathcal {C}}:=[0,1]\), and corrupted in the same way used in [3]. More specifically, each image was degraded by a Gaussian blur of size \(9\times 9\) and standard deviation 4 and corrupted by adding an additive zero-mean white Gaussian noise with standard deviation \(10^{-3}\). The original and degraded eight images are listed in Figs. 1 and 2, respectively.

Original images. Left to right, top to bottom shape.jpg (\(128\times 128\)); chart.tiff (\(256\times 256\)); satellite (\(256\times 256\)); church (\(256\times 256\)); barbara (\(512\times 512\)); lena (\(512\times 512\)); man (\(512\times 512\)); boat (\(512\times 512\))

Observed images
We first define the usual signal-to-noise ratio (SNR) in decibel (dB) to measure the quality of the recovered image, i.e.,
where x is a clean image and \(\tilde{x}\) is a restored image. Clearly, a larger SNR value means that we restored a better image. Without loss of generality, we use
to be the stopping criterion throughout the experiments. Throughout, we report the number of iterations (Iter.); computing time in seconds (Time), and SNR values (SNR).
We first investigate the numerical behavior of our ISM for (4.1). Notice that the global convergence of our ISM is built up under the assumption \(\rho _1\ge \Vert A\Vert ^2\). We thus set \(\rho _1=1.5\Vert A\Vert ^2\) throughout the experiments. Below, we test ‘chart.tiff’ image and investigate the performance of the rest of parameters involved in our method. For the relaxation parameter \(\tau \), we set \(\gamma =0.02\), \(\rho _2=0.01\), and test three cases of \(\tau =\{1.0\), 1.4, \(1.8\}\). For the penalty parameter \(\gamma \), we take \(\tau =1.8\), \(\rho _2=0.01\) and then consider four cases of \(\gamma =\{0.1\), 0.02, 0.001, \(0.0001\}\). Finally, we set \(\tau =1.8\) and \(\gamma =0.02\) to investigate the performance of \(\rho _2\) with \(\rho _2=\{1\), 0.05, 0.1, \(0.01\}\). For each case, we plot the evolution of SNR with respect to iterations in Fig. 3.

Numerical performance of our ISM with different parameters
It can be easily seen from the first plot in Fig. 3 that larger \(\tau \) performs better than the smaller ones, which also supports the theoretical analysis in Sect. 3 [see Lemma 3.2 and (3.22)]. From the last two plots in Fig. 3, however, smaller \(\gamma \) and \(\rho _2\) bring better performance relatively. Indeed, we can choose \(\rho _2=0\) due to \(\eta ({\mathbf {w}},{\widetilde{{\mathbf {w}}}})\) defined in (3.6) can be simplified as \(\eta _1(x,{\widetilde{x}})\). Of course a suitable \(\rho _2>0\) may have benefits for stable performance in certain applications, because \(\frac{\rho _2}{2}\Vert z-z^k\Vert ^2\) serves a similar role as Tikhonov regularization. Though we can not demonstrate (possibly impossible, indeed) the best choices of the parameters for all problems, the results in Fig. 3 provide a direction for us to choose them empirically.
According to the above data, we now take \(\tau =1.8\), \(\gamma =0.02\), \(\rho _2=0.01\) and report the numerical results of our ISM under different stopping tolerances ‘tol’. More specifically, we set four different tolerances \(\text {tol}=\{10^{-3}\), \(5\times 10^{-4}\), \(10^{-4}\), \(5\cdot 10^{-5}\}\) in (4.2) and summarize the corresponding results in Table 1.
The data in Table 1 show that the number of iterations is increasing significantly when we set a smaller tolerance ‘tol’. However, our method is still efficient for the case of \(\mathrm{tol}\ge 5\times 10^{-4}\). More importantly, our ISM is easily implementable due to its simple subproblems.

Recovered images by the three methods. From top to bottom: ISM, LADMM and ADMM
Hereafter, we turn to compare ISM with LADMM and ADMM showing the necessity of linearization and correction step. For the parameters involved in LADMM and ADMM, we follow the same settings of ISM, that is, \(\rho _1=1.5\Vert A\Vert ^2\) for LADMM and \(\gamma =0.02\) for both LADMM and ADMM. Here, we set the tolerance as \(\mathrm{tol}=10^{-5}\) and reported the corresponding results in Table 2. Note that the subproblem (1.9) of ADMM does not have closed-form solution. We thus implemented the projected Barzilai–Borwein method in [25] to pursuit an approximate solution to this problem and allow a maximal number of 30 for the inner loop. Accordingly, we also report the inner iteration (denoted by “InIt.”) of ADMM in Table 2. The recovered images are listed in Fig. 4.
As shown in Table 2, we can see that ADMM requires fewest iterations to recover a satisfactory image. However, ADMM needs a time-consuming inner loop to pursuit an approximate solution such that ADMM takes more computing time than ISM and LADMM, which can be clearly seen from the number of inner iterations. Thus, the linearization is necessary for the problem under consideration. Comparing ISM and LADMM, we can see that ISM takes fewer iterations to get higher SNR than LADMM, but more computing time. This supports that our correction step can improve the performance of ISM in terms of iterations. Since the correction step requires to compute \(\eta _1(x^k,{\widetilde{x}}^k)\), ISM needs one more discrete cosine transform and its inverse, which thus takes more computing time than LADMM. From the recovered images in Fig. 4, the three methods can recover desirable images. In summary, all experiments in this section verify the efficiency and reliability of our ISM.
5 Conclusions
We have considered the \(\ell _1\)-norm regularized SFP, which is an extension of the timely \(\ell _1\)-norm regularized linear inverse problems, but has been received much less attention. Due to the nondifferentiability of \(\ell _1\)-norm regularizer, many traditional iterative methods in the literature of SFP can not be directly applied to the \(\ell _1\)-regularized model. Therefore, we have proposed a splitting algorithm, which exploits the structure of the problem such that its subproblems are simple enough to have closed-form solutions under the assumptions that projections onto the sets \({\mathcal {C}}\) and \({\mathcal {Q}}\) are readily computed. Our preliminary numerical results have supported the idea of the application of \(\ell _1\)-norm regularization to SFP, and verified the reliability and efficiency of Algorithm 1. Recently, an extension of SFP, i.e., multiple-set split feasibility problem (MSFP), has been received considerable attention, e.g., see [13, 54, 62, 63]. Therefore, to investigate the application of \(\ell _1\)-norm regularization to MSFP and the applicability of the proposed algorithm to the regularized MSFP is our future work. On the other hand, as stated in [38], larger regularization parameter \(\sigma \) in (1.6) will yields sparser solutions, and it is difficult to choose \(\sigma \) that fits well for all problems. Thus, how to choose a suitable \(\sigma \) automatically in algorithmic implementation is also our further investigation.
References
Afonso, M., Bioucas-Dias, J., Figueiredo, M.: Fast image recovery using variable splitting and constrained optimization. IEEE Trans. Image Process. 19, 2345–2356 (2010)
Bai, Z., Chen, M., Yuan, X.: Applications of the alternating direction method of multipliers to the semidefinite inverse quadratic eigenvalue problems. Inverse Probl. 29, 075,011 (2013)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2, 183–202 (2009)
Beck, A., Teboulle, M.: Gradient-based algorithms with applications to signal recovery problems. In: Palomar, D.P., Eldar, Y.C. (eds.) Convex Optimization in Signal Processing and Communications, pp. 33–88. Cambridge University Press, New York (2010)
Bertsekas, D., Tsitsiklis, J.: Parallel and Distributed Computation, Numerical Methods. Prentice-Hall, Englewood Cliffs, NJ (1989)
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3, 1–122 (2010)
Byrne, C.: Iterative oblique projection onto convex sets and the split feasibility problem. Inverse Probl. 18, 441–453 (2002)
Byrne, C.: A unified treatment of some iterative algorithms in signal processing and image reconstruction. Inverse Probl. 20, 103–120 (2004)
Cai, J., Osher, S., Shen, Z.: Linearized Bregman iterations for compressed sensing. Math. Comput. 78, 1515–1536 (2009)
Ceng, L., Ansari, Q., Yao, J.: Relaxed extragradient methods for finding minimum-norm solutions of the split feasibility problem. Nonlinear Anal. 75, 2115–2116 (2012)
Censor, Y., Bortfeld, T., Martin, B., Trofimov, A.: A unified approach for inversion problems in intensity-modulated radiation therapy. Phys. Med. Biol. 51, 2353–2365 (2006)
Censor, Y., Elfving, T.: A multiprojection algorithm using Bregman projections in product space. Numer. Algorithms 8, 221–239 (1994)
Censor, Y., Elfving, T., Kopf, N., Bortfeld, T.: The multiple-sets split feasibility problem and its applications for inverse problems. Inverse Probl. 21, 2071–2084 (2005)
Censor, Y., Gibali, A., Reich, S.: Algorithms for the split variational inequality problem. Numer. Algorithms 59, 301–323 (2012)
Censor, Y., Jiang, M., Wang, G.: Biomedical Mathematics: Promising Directions in Imaging, Therapy Planning, and Inverse Problems. Medical Physics Publishing Madison, Wisconsin (2010)
Censor, Y., Motova, A., Segal, A.: Perturbed projections and subgradient projections for the multiple-sets split feasibility problem. J. Math. Anal. Appl. 327, 1244–1256 (2007)
Censor, Y., Segal, A.: Iterative projection methods in biomedical inverse problems. In: Censor, Y., Jiang, M., Louis, A. (eds.) Mathematical Methods in Biomedical Imaging and Intensity-Modulated Radiation Therapy (IMRT), pp. 65–96. Edizioni della Normale, Pisa (2008)
Chan, R., Tao, M., Yuan, X.: Constrained total variation deblurring models and fast algorithms based on alternating direction method of multipliers. SIAM J. Imaging Sci. 6, 680–697 (2013)
Chan, R., Yang, J., Yuan, X.: Alternating direction method for image inpainting in wavelet domain. SIAM J. Imaging Sci. 4, 807–826 (2011)
Chan, R.H., Tao, M., Yuan, X.: Linearized alternating direction method of multipliers for constrained linear least squares problems. East Asian J. Appl. Math. 2, 326–341 (2012)
Chen, C., He, B., Yuan, X.: Matrix completion via alternating direction method. IMA J. Numer. Anal. 32, 227–245 (2012)
Chen, S., Donoho, D., Saunders, M.: Automatic decomposition by basis pursuit. SIAM Rev. 43, 129–159 (2001)
Combettes, P., Pesquet, J.: Proximal splitting methods in signal processing. In: Bauschke, H., Burachik, R., Combettes, P., Elser, V., Luke, D., Wolkowicz, H. (eds.) Fixed-Point Algorithms for Inverse Problems in Science and Engineering, Springer Optimization and Its Applications, vol. 49, pp. 185–212. Springer, New York (2011)
Combettes, P.L., Wajs, V.R.: Signal recovery by proximal forward-backward splitting. Multiscale Model. Simul. 4, 1168–1200 (2005)
Dai, Y., Fletcher, R.: Projected Barzilai–Borwein methods for large-scale box-constrained quadratic programming. Numerische Mathematik 100, 21–47 (2005)
Dang, Y., Gao, Y.: The strong convergence of a KM-CQ-like algorithm for a split feasibility problem. Inverse Probl. 27, 015007 (2011)
Donoho, D.: Compressed sensing. IEEE Trans. Inform. Theory 52, 1289–1306 (2006)
Eckstein, J., Bertsekas, D.: On the Douglas—Rachford splitting method and the proximal point algorithm for maximal monotone operators. Math. Program. 55, 293–318 (1992)
Eicke, B.: Iteration methods for convexly constrained ill-posed problems in Hilbert space. Numer. Funct. Anal. Optim. 13, 413–429 (1992)
Engl, H., Hanke, M., Neubauer, A.: Regularization of Inverse Problems. Kluwer Academic Publishers Group, Dordrecht, The Netherlands (1996)
Figueiredo, M., Nowak, R., Wright, S.: Gradient projection for sparse reconstruction: application to compressed sensing and other inverse problems. IEEE J. Sel. Top. Signal Process. 1, 586–598 (2007)
Frick, K., Grasmair, M.: Regularization of linear ill-posed problems by the augmented Lagrangian method and variational inequalities. Inverse Probl. 28, 104,005 (2012)
Gabay, D., Mercier, B.: A dual algorithm for the solution of nonlinear variational problems via finite element approximations. Comput. Math. Appl. 2, 16–40 (1976)
Han, D., He, H., Yang, H., Yuan, X.: A customized Douglas--Rachford splitting algorithm for separable convex minimization with linear constraints. Numer. Math. 127, 167–200 (2014)
He, B., Liao, L., Han, D., Yang, H.: A new inexact alternating direction method for monotone variational inequalities. Math. Program. 92, 103–118 (2002)
He, B., Xu, M., Yuan, X.: Solving large-scale least squares covariance matrix problems by alternating direction methods. SIAM J. Matrix Anal. Appl. 32, 136–152 (2011)
He, B., Yuan, X., Zhang, W.: A customized proximal point algorithm for convex minimization with linear constraints. Comput. Optim. Appl. 56, 559–572 (2013)
He, S., Zhu, W.: A note on approximating curve with 1-norm regularization method for the split feasibility problem. J. Appl. Math. 2012, Article ID 683,890, 10 pp (2012)
Hochstenbach, M., Reichel, L.: Fractional Tikhonov regularization for linear discrete ill-posed problems. BIT Numer. Math. 51, 197–215 (2011)
Ma, S.: Alternating direction method of multipliers for sparse principal component analysis. J. Oper. Res. Soc. China 1, 253–274 (2013)
Martinet, B.: Régularization d’ inéquations variationelles par approximations sucessives. Rev. Fr. Inform. Rech. Opér. 4, 154–159 (1970)
Moreau, J.: Fonctions convexe duales et points proximaux dans un espace hilbertien. C. R. Acad. Sci. Paris Ser. A Math. 255, 2897–2899 (1962)
Morini, S., Porcelli, M., Chan, R.: A reduced Newton method for constrained linear least squares problems. J. Comput. Appl. Math. 233, 2200–2212 (2010)
Parikh, N., Boyd, S.: Proximal algorithms. Found. Trends Optim. 1, 123–231 (2013)
Potter, L., Arun, K.: A dual approach to linear inverse problems with convex constraints. SIAM J. Control Optim. 31, 1080–1092 (1993)
Qu, B., Xiu, N.: A note on the CQ algorithm for the split feasibility problem. Inverse Probl. 21, 1655–1665 (2005)
Rockafellar, R.: On the maximal monotonicity of subdifferential mappings. Pac. J. Math. 33, 209–216 (1970)
Sabharwal, A., Potter, L.: Convexly constrained linear inverse problems: iterative least-squares and regularization. IEEE Trans. Signal Process. 46, 2345–2352 (1998)
Schopfer, F., Louis, A., Schuster, T.: Nonlinear iterative methods for linear ill-posed problems in Banach spaces. Inverse Probl. 22, 311–329 (2006)
Tibshirani, R.: Regression shrinkage and selection via the LASSO. J. R. Stat. Soc. Ser. B 58, 267–288 (1996)
Tikhonov, A., Arsenin, V.: Solutions of Ill-Posed Problems. Winston, New York (1977)
Wang, X., Yuan, X.: The linearized alternating direction method of multipliers for Dantzig selector. SIAM J. Sci. Comput. 34, A2792–A2811 (2012)
Wright, S., Nowak, R., Figueiredo, M.: Sparse reconstruction by separable approximation. IEEE Trans. Signal Process. 57, 2479–2493 (2009)
Xu, H.: A variable Krasnosel’skii–Mann algorithm and the multiple-set split feasibility problem. Inverse Probl. 22, 2021–2034 (2006)
Xu, H.: Iterative methods for the split feasibility problem in infinite dimensional Hilbert spaces. Inverse Probl. 26, 105,018 (2010)
Yang, J., Zhang, Y.: Alternating direction algorithms for \(\ell _1\)-problems in compressive sensing. SIAM J. Sci. Comput. 332, 250–278 (2011)
Yang, Q.: The relaxed CQ algorithm solving the split feasibility problem. Inverse Probl. 20, 1261–1266 (2004)
Yao, Y., Wu, J., Liou, Y.: Regularized methods for the split feasibility problem. Abstr. Appl. Anal. 2012, Article ID 140,679, 13 pp (2012)
Yuan, X.: Alternating direction methods for covariance selection models. J. Sci. Comput. 51, 261–273 (2012)
Zhang, H., Wang, Y.: A new CQ method for solving split feasibility problem. Front. Math. China 5, 37–46 (2010)
Zhang, J., Morini, B.: Solving regularized linear least-squares problems by the alternating direction method with applications to image restoration. Electron. Trans. Numer. Anal. 40, 356–372 (2013)
Zhang, W., Han, D., Li, Z.: A self-adaptive projection method for solving the multiple-sets split feasibility problem. Inverse Probl. 25, 115,001 (2009)
Zhang, W., Han, D., Yuan, X.: An efficient simultaneous method for the constrained multiple-sets split feasibility problem. Comput. Optim. Appl. 52, 825–843 (2012)
Acknowledgments
The authors would like to thank the two anonymous referees for their constructive comments, which significantly improved the presentation of this paper. The first two authors were supported by National Natural Science Foundation of China (11301123; 11171083) and the Zhejiang Provincial NSFC Grant No. LZ14A010003, and the third author in part by NSC 102-2115-M-110-001-MY3.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
He, H., Ling, C. & Xu, HK. An Implementable Splitting Algorithm for the \(\ell _1\)-norm Regularized Split Feasibility Problem. J Sci Comput 67, 281–298 (2016). https://doi.org/10.1007/s10915-015-0078-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10915-015-0078-4
Keywords
- Split feasibility problem
- \(\ell _1\)-norm
- Splitting method
- Proximal point algorithm
- Alternating direction method of multipliers
- Linearization
- Image deblurring