
Abstract
Drought is the most frequent natural disaster in Algeria during the last century, with a severity ranging over the territory and causing enormous damages to agriculture and economy, especially in the north-west region of Algeria. The above issue motivated this study, which is aimed to analyse and predict droughts using the Standardized Precipitation Index (SPI). The analysis is based on monthly rainfall data collected during the period from 1960 to 2010 in seven plains located in the north-western Algeria. While a drought forecast with 2 months lead-time is addressed using an artificial neural network (ANN) model. Based on SPI values at different time scales (3-, 6-, 9-, and 12-months), the seven plains of north-western Algeria are severely affected by drought, conversely of the eastern part of the country, wherein drought phenomena are decreased in both duration and severity. The analysis also shows that the drought frequency changes according to the time scale. Moreover, the temporal analysis, without considering the autocorrelation effect on change point and monotonic trends of SPI series, depicts a negative trend with asynchronous in change-point timing. However, this becomes less significant at 3 and 6 months’ time scales if time series are modelled using the corrected and unbiased trend-free-pre-whitening (TFPWcu) approach. As regards the ANN-based drought forecast in the seven plains with 2 months of lead time, the multi-layer perceptron networks architecture with Levenberg–Marquardt calibration algorithm provides satisfactory results with the adjusted coefficient of determination (\( R_{\text{adj}}^{2} \)) higher than 0.81 and the root-mean-square-error (RMSE) and the mean absolute error (MAE) less than 0.41 and 0.23, respectively. Therefore, the proposed ANN-based drought forecast model can be conveniently adopted to establish with 2 months ahead adequate irrigation schedules in case of water stress and for optimizing agricultural production.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Drought is recognized by the Intergovernmental Panel on Climate Change (Sheffield and Wood 2008) as one of the most severe climate events that needs to be mitigated to reduce its negative impact. Overall, drought is considered as a prolonged and abnormal state of water deficit (Palmer 1965; Wilhite and Glantz 1985; Dalezios et al. 1991). Nowadays, the identification of drought conditions is based on drought indices allowing, on one hand, the determination of the threshold indicating drought at different time scales and, on the other hand, the classification of conditions according to their severity and the location (Mckee et al. 1993). The index commonly used for droughts is the Standardized Precipitations Index (SPI), whose value quantifies the deviation from the average precipitation and allows comparing dry and humid years or years showing deficit or surplus (Mckee et al. 1993). The World Meteorological Organisation (WMO) adopted this index since 2009, as a global tool, in order to measure meteorological drought in the ‘Lincoln declaration on drought indices’ (Cancelliere et al. 2007). SPI is used everywhere in the framework of meteorological drought monitoring (Byun and Kim 2010; Zhang et al. 2012; Chandramouli et al. 2017) due to its simplicity, spatial invariance in the interpretation (Guttman 1998; Vicente-Serrano et al. 2010) as well as for the capability to capture and replicate the observed drought events measured by others indices (Byun and Kim 2010; Maccioni et al. 2015; Khan et al. 2018). The 3-month SPI index provides an indication of short- and medium-term moisture conditions, precipitation estimates over a season and this is appropriate in agricultural areas to highlight the nature of soil moisture (WMO 2008). The 6-month SPI provides an indication of precipitation trends over a season (Khan et al. 2008), while SPI-12 should be considered for long-term estimations to address water resources management (Khan et al. 2008). Overall, SPI is assessed for a given time scale using a probability distribution function fitting the corresponding cumulated precipitation (Mckee et al. 1993). Therefore, the estimated SPI-based severity of the drought represents the deficit or surplus over a period at a site. However, at different locations, SPI could not correspond to the same deficits or surplus of precipitation, in accordance with the average precipitation recorded at a single site. This means that SPI is site-dependent and an absolute drought comparison among sites can be done through a deepened spatial analysis (Paulo et al. 2016; Dehghani et al. 2017; Guhathakurta et al. 2017), that takes the evolution of the characteristics of drought, namely: duration, severity and intensity into account (Masud et al. 2017; Asong et al. 2018).
In this context, SPI can be also used for drought forecasting as support to a rigorous water resources management by the decision makers, especially to plan how to significantly address the agricultural irrigation which is a priority worldwide and in particular in Africa. For the drought forecasting, statistical models have been applied in the last 50 yrs as the ones proposed by Gabriel and Neumann (1962) who used the Markov chain (Lazri et al. 2015), the regression method by Torranin (1973) and linear stochastic models including autoregressive integrated moving average (ARIMA) and seasonal autoregressive integrated moving average (SARIMA) applied by Mishra and Desai (2005). However, during the last two decades, artificial intelligence (AI) models in hydrology, like the artificial neural network (ANN), fuzzy logic (FL) and support vector regression (SVR), have significantly enhanced, notably for the forecasting purposes (Rezaie-Balf et al. 2017; Dariane et al. 2018). AI model is overall used for the management and measurement of different aspects of water resources, including rainfall-runoff modelling (Shoaib et al. 2016; Tarawneh and Khalayleh 2016; Zeroual et al. 2016; Tongal and Booij 2017), soil loss prediction in wadis (Salhi et al. 2013) and evaporation forecasting (Abyaneh et al. 2011; Goyal et al. 2014). In particular, the adoption of this technique for the drought forecasting based on times series of drought indices has added a new dimension to the planning and management of water resources (Mishra and Desai 2006; Belayneh et al. 2014; Masinde 2014; Bahrami et al. 2019). Several studies showed that AI models could give better results than conventional drought modelling techniques in semi-arid regions. As far as the comparison among different AI approaches for hydrological and climatological applications is concerned, studies have shown that the support vector machine (SVM) approach is more accurate than that of ANN and FL one (He et al. 2014; Noori et al. 2015; Ghorbani et al. 2016; Huang et al. 2017). Specifically, for drought forecasting using SPI, the ANN model can forecast satisfactory up to 12 months of lead-time (Barua et al. 2010, 2012; Bari Abarghouei et al. 2013; Ali et al. 2017). Conversely, other studies showed that SVM model has enough accuracy to be used in long-term drought forecasting compared to ANNs (Tarawneh and Khalayleh 2016). Likewise hybrid models can be also adopted for drought forecasting mainly in the case of the nonstationary hydrologic time series (Jain and Kumar 2007; Wang et al. 2015). wavelet transform (WT) analysis and cuckoo search (CS) algorithm have been used to improve the forecasting ability of IA models (Jalalkamali et al. 2015). Examples of hybrid models to drought forecast based on SPIs times series are the wavelet support vector machine (WSVM) (Djerbouai and Souag-Gamane 2016; Deo Ravinesh et al. 2017a, b), Wavelet-ANN (WANN) (Belayneh et al. 2014; Zhang et al. 2017; Soh et al. 2018), wavelet-adaptive neuro-fuzzy inference system (WANFIS) (Shirmohammadi et al. 2013; Belayneh et al. 2014; Shabri 2014), wavelet extreme learning machine (W-ELM) (Deo Ravinesh et al. 2017a, b) and cuckoo search-support vector machine (CS-SVM) (Liang et al. 2016; Komasi et al. 2018).
Based on the above insights, this study has two objectives. The first is to provide a comprehensive analysis of historical droughts based on SPI analysis over the northwest Algeria. The second is to develop always for the north-western part of Algeria an ANN-based forecast model of drought events 2 months in advance, addressed to irrigation purposes. Accomplishing these two objectives may be of paramount importance to coping with the drought in Algeria, that during the last 50 years experienced one of the widest variations in rainfall regime. As regards the first objective, the climatic fluctuations in Algeria affected not only rainfall patterns, but they also created persistent and pervasive droughts conditions. Historically, the precipitation deficit has been registering since 1973 affecting differently the north of Algeria (Meddi et al. 2010). The duration and the severity of this deficit varies across north-western part of the country causing severe impacts on agricultural and socio-economic features for the strong dependence of the country’s economy on rain-fed agriculture in the large fertile farmland (Meddi and Meddi 2009). For the period 1970–2013, the continuous decrease in precipitations in areas previously considered temperate climate, caused very dry environment conditions (Meddi et al. 2010; Zeroual et al. 2017) with reservoir levels dropped up to 25% of their normal level and piezometric levels decreased below 40 m for some aquifers (Demmak 2008). This reduction has negative impact on the water supply of all sectors definitely. Moreover, future climate scenarios by 2100 based on regional climate models (RCM) showed this region more vulnerable than the centre and the eastern part of Algeria (Zeroual et al. 2019). Therefore for the plains of the north-western Algeria, there is a major challenge to sustainable water management practices (Medjerab and Henia 2005). Enhance the understanding of the spatial distribution of drought, and comparing their severity and duration among plains is thus required in order to establish adequate irrigation schedules in case of water stress. An integrated space-temporal analysis of these drought characteristics in seven plains namely, Mitidja, Ghriss, Maghnia, Sidi Bel Abbes, High, Middle and Low-Cheliff would provide valuable knowledge that is necessary for drought forecasting, as well as for the rational exploitation of these plains under the future climate change. These regions are known by their fertile farmland and during the last decades, the water shortage created serious concerns for the plains irrigation. Therefore, drought events are here assessed by their duration and severity using the SPI over various temporal scales (3, 6, 9, and 12 months) and then a comparison of the evolution of these characteristics over the seven plains is done. The temporal analysis is investigated initially without considering the effect of autocorrelation on change point and monotonic trends of SPIs time series, thereafter, the time series are modelled using the corrected and unbiased trend-free-pre-whitening (TFPWcu) approach to eliminate the autocorrelation effect on the variance of test statistics. Major spatial and temporal patterns of change points of drought events are then identified using the modified Pettitt test proposed by Serinaldi and Kilsby (2016). As far as the second objective is concerned, it attempts to coping with the persistent water shortage by developing a drought forecasting model to support decision makers to mitigate the water stress resulting from a cycle of droughts and to ensure the irrigation in plains. Studies on the drought forecast using different approaches have been addressed for the eastern and central part of Algeria (Djerbouai and Souag-Gamane 2016; Habibi et al. 2018). It is worth noting, however, that the plains of those regions have not experienced the same severity of water shortage as the west of Algeria. Therefore, to develop a drought forecasting system for the north-western part of Algeria is a priority to manage in a rigorous way water resources in agricultural irrigation. For that, considering the uncertainty associated with water scarcity and climate change, we propose an ANN-based drought forecast model using a lead time of 2 months which can be a valuable tool for irrigation and water resources management, as long as the irrigation periods starting in April until June.
2 Study zone and dataset
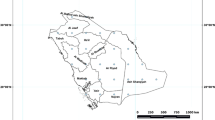
The Algerian northwest part spreads over 250 km from south to north and approximately 500 km from west to east (cf. figure 1). The territory is characterized by mild climate, and relatively high humidity. Rainfall ranges from 400 mm in the west to 900 mm in the east.

Geographical location of the seven plains included in the study.
Monthly rainfall data recorded at 20 rain-gauge stations in the seven plains for the period 1960–2010 have been used in this study. Data are extracted from dataset provided by the National Meteorology Office (ONM) and the National Hydraulic Resources Agency (ANRH) (O.N.M: http://www.meteo.dz/index.php, ANRH: http://www.anrh.dz/).
For each investigated plain, the monthly areal average precipitation was computed after determination of the weighting factor using the Thiessen polygon method. The weighting factor specifies the contribution of each rain gauge station to the total plain area (Şen 1998). In the supplementary material, we show in figure 1, the polygon surrounding each rain gauge using the Thiessen method. Furthermore, in table 1, the geographic coordinates of rain-gauges, regions of influence around each rain-gauge station and their percent to total plain area are given.
The main statistical characteristics of rainfall are calculated for each plain after determination of the monthly areal average precipitation for each plain. Their results are exhibited in table 1. SPI has been calculated on the seven plains for the period 1960–2010 at different time scales, i.e., 3, 6, 9, and 12 months. SPI is computed for each plain by fitting an appropriate probability density function to the frequency distribution of precipitation cumulated over the considered time scale (3, 6, 9, and 12 months).
3 Methods
3.1 Drought index
Thom (1958) found the two-parameter gamma probability density function can fit well precipitation time series. The gamma distribution is defined by its frequency or probability density function as:
where \( \alpha\,\, (\!> 0) \) is a shape factor, \( \beta \,\,(\!> 0) \) is a scale factor, and \( x > 0 \) is the amount of precipitation. \(\varGamma \left( \alpha \right) \) is the gamma function which is defined as:
Edwards and McKee (1997) suggested a method using the approximation of Thorn (1966) for maximum likelihood to optimally estimate \( \alpha \) and \( \beta \) as follows:
where
n is the number of precipitation observations. The resulting parameters are then used to infer the cumulative probability of an observed precipitation event for the given month or any other time scale:
Letting \( t = x /\hat{\beta } \), this equation becomes the incomplete gamma function:
Since the gamma function is undefined for \( x = 0 \) and a precipitation distribution may contain zeros, the cumulative probability becomes:
where, q is the probability of zero precipitation. The cumulative probability, H(x), is then transformed to the standard normal random variable Z with mean zero and variance one, which is the value of the SPI. Following the studies of Edwards and McKee (1997) and Lloyd-Hughes and Saunders (2002), an approximate conversion was used here, as provided by Abramowitz and Stegun (1965) to convert easily the cumulative probability to the standard normal random variable Z or SPI:
and
where
and
And \( c_{0} = 2. 515517,\;c_{1} = 0. 802853,\;c_{2} = 0. 010328,\;d_{1} = 1 .432788,\;d_{2} = 0. 189269,\;d_{3} = 0. 001308 \) (Mishra and Desai 2005). According to McKee et al. (1993), drought classes of the SPI indicate near normal conditions at −1 < SPI < 0, moderate drought at −1.5 < SPI ≤ −1, severe drought at −1.99 < SPI ≤ −1.5 and extreme drought at SPI ≤ −2.
3.2 Spatio-temporal analysis of drought
3.2.1 Limitations of SPI and drought characterization
The SPI is a standard index over a reference period. It is obtained for a different deficit of precipitation, which corresponds to the difference between the observed and the average of the time series. However, this functionality does not allow SPIs to be considered for absolute drought comparison between stations or plains if additional information is not available (Mishra 2010; Paulo et al. 2016). Local time series analysis leads to missing information on spatial characteristics; likewise, the spatial analysis does not make it possible to follow the dynamic evolution of the phenomenon. For the temporal analysis, the use of precipitation series of different lengths significantly affects the SPI values even if the same probability distribution is applied (Mishra 2010; Salvi and Ghosh 2016).
For example, Salvi and Ghosh (2016) pointed out the impact of this effect on the frequency of meteorological extreme dry and wet spells in the recent past and in the future using general circulation models as well as on parameters of the gamma distribution using the SPI values computing from different precipitation record lengths over India.
To avoid these problems, a spatio-temporal analysis based on the comparison of the evolution of the characteristics of the drought, namely, duration, gravity and intensity, is applied to the seven plains studied covering the same period from 1960 to 2010.
The SPI series (3, 6, 9, and 12 months) in the seven plains have been investigated in terms of spatio-temporal variability. The duration (D) of a drought event, as defined by Mckee et al. (1993), is the period, during which the SPI value is continuously negative and reaches at least value of −1 or less. The SPI values accumulation during this period was used by Shiau (2006) to measure the drought magnitude, which is also called drought severity (S):
where, D is the drought duration and S is the drought severity. Drought intensity is defined as severity divided by duration (Dingman 1994; Shiau 2006; Madadgar and Moradkhani 2013).
3.2.2 Trends and shifts analysis
Once the spatial evolution variability of the time series of SPI’s (3, 6, 9, and 12 months) in the seven plains was analyzed, we proceeded to the temporal variability analysis according to the two following stages: in the first, the presence and timing of abrupt changes in the SPI’s time series are checked using the non-parametric statistical test of Pettitt (Pettitt 1979), after their autocorrelation is verified (the first serial correlation ‘lag-1’ coefficient). If ‘lag-1’ serial correlation coefficient is significant at 5% level, then the modified corrected and unbiased trend free pre-whitening (TFPWcu) procedure for Pettitt test is used. This procedure has been suggested by Serinaldi and Kilsby (2016) for removing autocorrelation effects in the time series. Otherwise, the original Pettitt test is applied for detecting change point in the time series data. In the second stage, we applied the non-parametric original Mann–Kendall test (MK) and its above-mentioned modified form MMK (Hamed and Ramachandra Rao 1998) to assess the significance of existing trends in the long-term variability of the SPI’s time series.
It is worth noting that in the MK test, the data are assumed independent and randomly ordered, and this can lead to erroneous results if serial correlation is present (Hamed and Ramachandra Rao 1998). Even in the absence of a trend in the time series, the positive autocorrelation would increase the chance of significant response. Various studies have addressed this issue in order to find an appropriate approach that considers the significance of autocorrelation in the data. Some authors have suggested modifying the data itself using the prewhitening procedure (Storch and Navarra 1995), trend-free-pre-whitening (TFPW) approach (Yue et al. 2002) and corrected and unbiased trend free pre-whitening (TFPWcu) (Serinaldi and Kilsby 2016). Others have suggested the variance correction of Mann–Kendal test using an empirical formula (Hamed and Ramachandra Rao 1998) and Monte Carlo simulations (Yue and Wang 2004).
Pettitt test. The non-parametric Pettitt change point test is applied for detecting change point in the time series (Pettitt 1979). This test has been widely applied to detect a single change-point in hydrological and climate series with continuous data (Yue et al. 2002).
The Pettitt test considers that a time series of a sequence of random variables \( X_{t} \) with \( t = 1,2, \ldots \,,T, \) has a change point at time step τ if the values of \( X_{t} \) for \( t = 1,2, \ldots \,,\tau \) have the cumulative density function (CDF) \( F_{1} \left( x \right) \), and the values of \( X_{t} \) for \( t =\tau + 1,\tau + 2, \ldots \,,T \) have the CDF \( F_{2} \left( x \right) \) and \( F_{1} \left( x \right) \ne F_{2} \left( x \right), \) with the single assumption that the two CDFs are continuous.
The null hypothesis H0, which assumes there is no change in the \( X_{t} \) time series, is tested against the alternative hypothesis (H1) of change point using the non-parametric statistic defined as:
where \( U_{t,T} \) is defined as the sign (sgn) function between the difference of each pair of value of the two sequences \( X_{i} \, \,{\text{and }}X_{j} \):
with the sign function: sgn(y) = 1 if y > 0, 0 if y = 0, −1 if y < 0.
The change-point of the series is located at \( K_{T} \), provided that the non-parametric statistic is significant.
The significance probability (p) associated with the value \( K_{T} \) is approximately given by:
when p is smaller than the specific significance probability, for example, p = 0.05 in this study, the null hypothesis is rejected.
TFPWcu adapted for the Pettitt test. To redress the Pettitt test problem in the case of presence of serial dependence in the chronological series, Serinaldi and Kilsby (2016) have suggested the corrected and unbiased TFPWcu procedure for Pettitt test. The objective of this approach is to remove the autocorrelation effect. The determination of change point by this algorithm requires the following steps as it is mentioned in Serinaldi and Kilsby (2016):
-
1.
If the value of the \( K_{T} \) obtained by Pettitt test using original data is significant, then, the position \( \tau \) of the possible change point is used to split the time series in two sub-series (before and after \( \tau \)). The difference of the medians or means, \( \hat{\mu }_{b} \) and \( \hat{\mu }_{a} \), of the two sub-series is computed as \( \varDelta = \hat{\mu }_{b} - \hat{\mu }_{a} \), and used to remove the step change as follows:
$$ x_{t} = y_{t} - {\varDelta} \cdot 1_{{\left\{ {t > \left. \tau \right\}} \right.}}. $$(17)Here \( 1_{{\left\{ {t > \left. \it\tau \right\}} \right.}} \) is the indicator function, \( x_{t} {\text\,{and}}\,y_{t} \) are data after step change removal and original data before step change removal, respectively, at time t in the time series.
The value of the lag-1 autocorrelation \( \hat{\rho } \) of \( x_{t} \) is estimated and corrected for bias using two stage bias corrections. At the first stage, it is corrected for autocorrelation of fractional Gaussian noise (fGn) process or Hurst–Kolmogorov process as follows (Koutsoyiannis 2003):
where \( T^{{\prime }} \) is effective sample size for the first-order autoregressive [AR(1)] process and may be obtained as follows (Koutsoyiannis and Montanari 2007):
The computation for second stage bias correction may be carried out similar to Marriott and Pope (1954), but using following generalized formulae suggested by Mudelsee (2001):
After getting the bias corrected lag-1 autocorrelation coefficient \( \hat{\rho }^{ *} \), AR(1) structure is removed to get uncorrelated series \( \varepsilon_{t}^{ \prime} \) of residuals as follows:
Finally, a pre-whitened series \( x_{t}^{\prime\prime} \) is obtained by combining uncorrelated series of residuals and step change. The following pre-whitened series is used for examining the significance of change point using Pettitt test.
Modified Mann–Kendall test (MMK). The Mann–Kendall test (Mann 1945; Kendall 1975) is a commonly used non-parametric trend test. However, the null hypothesis corresponds to the case where the data are independent and random. Hamed and Ramachandra Rao (1998) revealed that the serial correlation falsified trends in auto-correlated time series. The existence of positive autocorrelation in the data increases the probability of detecting trend when actually it does not exist, while a negative autocorrelation decreases the probability of detecting significant trend. Therefore, to eliminate the influence of the serial correlation, Hamed and Ramachandra Rao (1998) derived an empirical formula to modify the Mann–Kendall test.
3.3 Artificial neural networks
Artificial neural networks (ANNs) are non-linear mathematical models of ‘black-box’ type. In practice, this approach is used to define a deterministic relationship between process variables when no a priori known about the physical nature of its generating (Govindaraju 2000). This is particularly useful for drought forecasting, where the phenomenon is a stochastic and little is understood about the processes that may cause it (Mishra and Desai 2005). In this paper, the multilayer perceptron (MLP) feed-forward network was used to forecast the SPI at 2 months lead-time at different time scales (3, 6, 9, and 12 months). This type is the simplest and most commonly used artificial neural network design in the water resources variables and hydrological domains. Moreover, most studies have shown that MLP can perform better than conventional approaches in modelling and forecasting non-linear and non-stationary time series (Kim and Valdés 2003; Mishra and Desai 2005; Belayneh and Adamowski 2012; Aher et al. 2017). Here, a MLP feed-forward network of three-layer is used for drought SPI forecast. The MLP calculates a single output such as the forecasted SPI up to 2 months ahead. This one depends on the number of previous SPIs over time (t−n) received by first layer as input variables (n is the number of time lag in month and varies between 1 and 12 months) and the number of nodes in each hidden layer (N).
The output SPI (t) is obtained by forming a linear combination between input (previous SPIs over time (t−n)) and their weight values Wij. The result computes the hidden layer output through some non-linear activation function. Beyond that, this operation is repeated for the output neuron. These two processes are explicitly given in equation (24).
where \( \varphi_{h} \;{\text{and }}\varphi_{o} \) are the activation functions of the hidden neuron and the output neuron, respectively; \( w_{ij} \,{\text{and }}w_{jk} \) are the vector of weights connecting the neurons between the input layer \(\langle\langle{i}\rangle\rangle\) and the hidden layer \(\langle\langle{j}\rangle\rangle\) and between the hidden layer \(\langle\langle{j}\rangle\rangle\) and output layer \(\langle\langle{k}\rangle\rangle\), respectively; \( b_{jo} \;{\text{and }}b_{ko} \) are the bias for the jth hidden neuron and kth output neuron, respectively; and \( n \;{\text{and }}m \) are the number of neurons in the input layer and the hidden layer, respectively. The most commonly used form of \( \varphi \left( . \right) \) in (1) is the sigmoid function, given as:
3.3.1 Data preparation
In order to forecast the SPIi (t) 2 months ahead (i = 3, 6, 9, and 12 months), various combinations of antecedent SPI (t−n) can be used as model input. Each of SPI series has been standardized and centred, to avoid any saturation effect that may be caused by the use of sigmoid function, before being divided into two sets (Mishra and Desai 2005). Training data of about 70% (1960–1996) are used for calibration of the vector of weights \( (w_{jk} , w_{ij} ) \) of the ANN with a selection of neuron number in the hidden layer (N) and activation function. The resulting ANN is then evaluated on independent validation data (1997–2010).
Several models of ANN have been designed and examined, based on the variation of the number of input and neurons in hidden layer (N) in order to optimize and refine the non-linearity existing between input and output variables. For each SPI series at different time scales for the seven plains, nine ANN designs were selected based on the different combination of variables of the temporal series of SPI before the time (t−2). The nine ANN designs are constructed as table 2 shows. In the supplementary material, we illustrate in figure 2, the schematization of input and output data to forecast SPI-3 2 months lead time with 3 inputs and 3 neurons in hidden layer (3-3-1 ANN architecture).

Comparison of SPI in the seven plains (1960–2010) at various time scales (3, 6, 9, and 12 months).
To determine the optimum input combinations that should be included in the model and the number of neurons (N) in the hidden layer, a trial and error procedure is used (Hirose et al. 1991; Mishra and Desai 2006; Choi et al. 2008; Trenn 2008; Sheela and Deepa 2013; Zeroual et al. 2016) during the calibration and testing phases of the ANN model. Nodes in hidden layer also allow taking the presence of non-stationary in the series into account, such as trends and seasonal variations (Maier and Dandy 1996). The two activation functions used are as follows: sigmoid function in hidden layer and a linear function in output layer. Previous studies showed that both functions allow approaching the existing non-linear relationship between SPIs (Bari Abarghouei et al. 2011). After construction of the nine ANN designs presented in table 2, the Levenberg–Marquardt (LM) back-propagation (BP) algorithm is used for the MLP feed-forward network calibration. Details on the algorithm can be found in Zeroual et al. (2016).
3.3.2 Model performance criteria
Once the lag is adopted, data collection for validation has been provided to the network. This time, only the input vectors have been transmitted to the model. Model performances are evaluated through several indicators, as the adjusted coefficient of determination (\( R_{\text{adj}}^{2} \)), root-mean-square-error (RMSE) and the mean absolute error (MAE) between SPIs observed and SPIs forecasted by ANN model.
in which \( {\text{SPI}}_{{i\left( {\text{obs}} \,\right)}} \), \( {\text{SPI}}_{{i\left( {\text{sim}} \right)}} \), \( {\text{SPI}}_{{\left( {\text{mean}} \right)}} \) represent, respectively, the observed, forecasted and mean standardized precipitation index; n is the total number of \( {\text{SPI}} \) data, p is the number of regression coefficients and \( R^{2} \) is the determination coefficient. A good model should have a lower RMSE and MAE which indicates low accumulated errors (Willmott and Matsuura 2005; Chai and Draxler 2014; Tian et al. 2018) and \( R_{\text{adj}}^{2} \) close to the unity. The latter has been suggested to judge goodness of model when several input variables are used. Adjusted R2 penalizes the adding variables that do not improve model.
4 Results
Results are presented in two levels showing: (1) the spatio-temporal characterization and comparison of drought episodes over the seven studied plains at different time scales during the period 1960–2010 and (2) the assessment of artificial neural network (ANN) in drought prediction at 2 months ahead based on the SPI.
4.1 Spatio-temporal comparison of drought
4.1.1 Spatio-temporal variability
The SPI are computed for the 3-, 6-, 9-, and 12-month time steps using monthly precipitation data from the seven studied plains for the period 1960–2010. To do end, the cumulated precipitation at the different temporal scales is fitted to the gamma probability distribution. We note that all of the time series are well fitted by a gamma distribution at the 5% level of significance. Several recent studies have found similar results (Maccioni et al. 2015).
In figure 2, we compare the SPI drought index in the seven plains (1960–2010) at various time scales (3, 6, 9, and 12 months). As can be seen, the time series reveal a situation mostly dominated by drought (negative SPI) on the seven plains. The temporal analysis of SPI allows ascertaining that ‘extreme drought’ character is not dominant for the whole area and for different scales.
Inspecting figure 2, and referring to computed SPI for 3 months (i.e., SPI3), the values vary in the range [−1.5, +4.6]. The smallest negative values are observed in the Lower Cheliff plain during the period 1987 and 1988 and in the Ghriss plain for 2006 and 2007; while the maximal positive value of SPIs are observed in Mitidja plain during the period 1974 and 1975. For SPI6, values vary between [−2, +4.3]; the minimum value is observed in the plain of Low Cheliff during the period 2005–2006, while the maximum positive SPI is observed in the Ghriss plain during the period 1964–1965. For SPI9, values were included between [−2.6, +3.7]; the lower value was recorded for the period 1982–1983 at Sidi Bel-Abbés plain, while the higher positive value was noted in Ghriss plain during the period 1964–1965.
For SPI12, values were included between [−2.9, +3.9]; the lowest negative values of SPI were found in the Sidi Bel-Abbés plain in the period (1982, 1983), while the higher positive value of SPI has been recorded in Mitidja plain during the period (1972, 1973). Therefore, it is evident that the time scale of SPI unfolds a key role in identifying the frequency of drought, such as also found in Spain by Vicente-Serrano et al. (2010), who showed that the drought frequency changed according to the time scale. Based on these results, it is noted that plains of Lower Cheliff, Sidi Bel-Abbés and Ghriss are the most affected by drought during the study period regardless the SPI time scale adopted, and the 1983 recorded a classification of extreme drought in Sidi Bel-Abbès plain.
Figure 3 shows a comparison of the severity expressed by equation (13) of all of the drought events that occurred for each time scale for the seven plains within the study period 1960–2010, where the horizontal lines length represents the duration in months. We distinguish a high vulnerability to drought in both Sidi Bel-Abbés and Maghnia plains during the decade 1980–1990. These two plains are located in the extreme west of Algeria, which was severely affected by drought events during this decade.

Drought occurrence from 1960 to 2010 in the seven plains based on SPI at various time scales (3, 6, 9, and 12 months).
The Sidi Bel-Abbés plain experienced the most severe drought episodes in each 3-, 6- and 12-month time scales. They are characterized by maximum severities of 11.8, 19.6, 61.4 and maximum duration of 11, 22, 59 months, respectively. While at 9 months time scale, Maghnia plain has known the most severe drought with a maximum duration of 43 months.
At 6- and 12-month time scales, drought episodes have decreased in both duration and severity passing from Sidi Bel-Abbés plain, which represents the most affected region, and shifting to Maghnia, Low Cheliff, Ghriss, Middle Cheliff and Mitidja plains, respectively. Finally, the Upper Cheliff plain is the slightly affected area by such events. This plain is characterized by a collection of mountains, which plays the role of a barrier between the Mediterranean Sea and the highlands, and by high precipitation exceeding the mean values. Furthermore, we notice that the drought events distribution is similar in severity at 3 months time scale to that at 6 and 12 months.
4.1.2 Trends and shifts analysis
The previous survey shows that the seven plains have been subjected to a persistent drought over the last five decades, although the intensity of this drought changes from one plain to the next. In what follows, we check the occurrence of breaks and trends in the average values of SPI to explain the persistence of this drought. The different time series of SPI (3, 6, 9, and 12 months) in the seven plains have been checked for autocorrelation before applying trend and break tests. The lag-1 serial correlation coefficient for all SPIs series were computed for the study period and results of lag-1 autocorrelation coefficients (\( \hat{\rho } \)) are shown in figure 4. Thus, all SPI time series are found to be auto-correlated at lag-1 at 5% level (for all p-values < 0.05).

Lag-1 autocorrelation coefficients (\( \hat{\rho } \)) for SPI series in the seven plains (1960–2010) at various time scales (3, 6, 9, and 12 months).
Firstly, we identify change points in the different time scale using original Pettitt’s test. In table 3, we present the results of test statistic KT, p-value and the year where the change point was found. Without removing the effects of autocorrelation, the change point was identified at 5% significance level at the end of the 1970s and the early 1980s for all SPI time scales except for the Mitidja plain where the change point occurred in the second half of the 1980s decade. To remove the effect of autocorrelation in the time series, we applied modified Pettitt’s test after prewhitening SPI series using TFPWcu technique. For Pettitt test using TFPWcu as suggested by Serinaldi and Kilsby (2016), auto-correlated SPI time series at 3, 6, 9, and 12 months’ time scales were divided into two sub-series based on possible change point identified from original Pettitt’s test. The difference of mean (Δ), lag-1 autocorrelation \( (\hat{\rho } \)) after elimination of shift, first phase corrected (\( \rho_{k}^{ *} \)) and second phase corrected \( (\hat{\rho }^{ *} \)) lag-1 autocorrelation coefficients are exhibited in table 3.
After removal autocorrelation, it can be seen in table 3 that the autocorrelation coefficient considerably decreased. Then the corrected SPI series were tested for change point by using Pettitt’s test. Results of Pettitt’s test applied at 5% significance were changed compared with results applied on the original SPI series where KT values are decreased while the p-values are increased. For the new SPI series, the change points are observed only at the 9- and 12-months scales at the end of the 1970s and the beginning of the 1980s.
For example, for 12 months, the Ghriss plain has firstly recorded a shift at the SPIApr–Feb 1976. The Sidi Bel-Abbés and the Low, Middle and High Cheliff SPI series have all identified a shift in the same period from November to October 1979. After, the SPI Maghnia series has shown the change point in SPIDec–Nov 1980 and finally Mitidja plain in the SPIDec–Nov 1986.
We note that, after the change point, the SPI series tend significantly to dry conditions (negative trends) as shown in figure 2 where the drought events duration have increased and became more severe starting with the Sidi Bel-Abbés and Maghnia plain in 1980. For the time series that have not spotted a change point (3 and 6 months’ time scale), the tendency towards dry conditions using MMK is not significant at 5% significance level (cf. figure 5).

Z scores derived from the MMK method for SPIs series in the seven plains (1960–2010) at various time scales (3, 6, 9, and 12 months). The two red lines represent the theoretical critical n values of the MMK test at the 5% probability level.
4.2 Drought forecasting by artificial neural networks (ANN)
After the input and output variables selection across each of the seven plains, we examined the nine ANN designs indicated in table 2 to find the best model structure that can capture the non-stationarity and non-linearity in the SPI series and can be used to forecast SPI (t) 2 months ahead. To this end, the sigmoid activation function was used as the transfer function. During the calibration of a three-layer model, connexion coefficients (weight) between different layers are computed in such a way that model outputs are as close as possible to the desired outputs.
The goal of optimization during calibration phase is to minimize error between forecasted and observed outputs, by modifying iteratively the weight matrices W and bias vectors according to the gradient of cost function. The gradient is estimated by a method specific to neurons network: back propagation (BP) of errors by the use of Levenberg–Marquardt (LM) algorithm. For each testing model, the number of neurons (N) is taken between 2 and 25, and thereafter the optimum was found by using the trial and error methods.
Results of the best ANN design in terms of statistics performance (\( R_{\text{adj}}^{2} \), RMSE and MAE) at each plain and at different time scales are shown in table 4. Considering calibration results, it can be observed that the best model ANN design was found to vary from one plain to another and from one-time scale to another. Similar results were found for the optimal number of hidden neurons (N). Over all plains and at different time scales, the number of hidden neurons (N) was found in accordance with the laws 2n and 2n + 1. These results were advocated by Lippmann (1987), Wong (1991), and Tang and Fishwick (1993) in the case of a Multilayer Perceptron neural network where n is the number of inputs.
As shown in table 4, RMSE and MAE for the validation phase of the best ANN design range from 0.22 to 0.41 and 0.12 to 0.23, respectively. The lowest value of RMSE was for the GHRISS plain at 12-month time scale and the highest for the Low Cheliff and GHRISs plains at 3-month time scale, while the adjusted coefficient of determination (\( R_{\text{adj}}^{2} \)) values obtained during validation phase range from 0.81 to 0.94.
Initially, for SPI3 (table 4) with 5 inputs and 9 neurons in hidden layer, results showed that \( R_{\text{adj}}^{2} \) of Maghnia plain is the highest compared with those of other plains, with an \( R_{\text{adj}}^{2} \) equal to 0.934, RMSE value of 0.22 and MAE equal to 0.159.
The \( R_{\text{adj}}^{2} \) for Maghnia plain is also the highest value (0.934) for SPI9 with 6 inputs and 12 neurons in hidden layer, and the RMSE and MAE values is 0.21 and 0.145, respectively (cf. table 4). However, for SPI6, the high Cheliff with 5 inputs and 12 neurons in hidden layer and the Sidi Bel-Abbés plains 6 inputs and 9 neurons in hidden layer showed better results with \( R_{\text{adj}}^{2} \) values equal to 0.89 and RMSE values equal to 0.29 and to 0.31, respectively. Finally, for SPI12 (table 4), the highest values of \( R_{\text{adj}}^{2} \), RMSE and MAE equal to 0.943, 0.23 and to 0.142, respectively, have been recorded for the plain of Low Cheliff with 8 inputs and 15 neurons in the hidden layer.
In addition, we note that, comparing ANN models performance in all time scales, the highest value of \( R_{\text{adj}}^{2} \) and lowest value of RMSE and MAE was found for SPI12. The good agreement between SPIs and observed at plains and those predicted by ANN at different time scales can be inferred through the box-plot shown in figure 6. The agreement at 12 months time scale between the values of SPI observed and the values forecasted by ANN clearly appears also in figure 7. The same agreement was found at 3-, 6- and 9-month timescale. This was exhibited in figures S3, S4 and S5 (supplementary material).

Box plot for observed and predicted SPI values for the seven studied plains (1997–2010) at different SPI time scales (red colour line: median; box: first and third quartiles; whiskers: 99% confidence interval; + marker: outlier).

Comparison of observed and forecasted SPI12 during the validation phase for the seven studied plains.
The foregoing clearly shows the powerful ability of ANNs regarding 2 months early drought prediction despite the high spatial and temporal variability of SPI in such area located in the transitional climate between arid (in the south) and Mediterranean (in the north). This variability was captured in modelling by the use of different designs and structures of the neural network. Thus, the mentioned models and their structure can be used for water resources planning and management and its use is also recommended for the neighbouring regions characterized with very limited availability of water resources.
5 Discussion
Drought forecasting and spatio-temporal variability analysis over the seven plains using SPIs series and their characteristics, namely drought severity and duration at 3, 6, 9, and 12-month scale has shown three major significant results:
-
1.
As regards spatio-temporal drought characterization, drought events have further occurred and are characterized by severity and duration rises for all studied plains during the end of 1970s, early 1980s and end of 1980s decade, except for the Ghriss and Sidi Bel-Abbés plains rising in the first half-decade of 2000. These drought spells have been confirmed where crop yields are decreased and the minimum water level in dams has been recorded especially in the west of the country. During the mentioned periods of SPIs at different time scales, the driest phase was located in the extreme west of Algeria: plains of Maghnia, Ghriss and Sidi Bel-Abbés. They have experienced a large rainfall deficit and required sustained irrigation to support agricultural production. These regions are known by their fertility and productivity. Baali and Amine (2015) found same results in the North of Morocco (Saïss plain). According to the 5th IPCC report (Dai et al. 2004; Stocker et al. 2013), the increase in droughts frequency and severity in the area surrounding the Mediterranean Sea was due to the climate change that involves warmer temperatures, altered precipitation patterns and increased climatic variability. Moreover, these observations have been confirmed by the temporal variability of drought analysis, through SPI, using many statistical tests have shown, for all time scales and all plains, the increase in the number and the intensification of dry conditions as well. The results also revealed the influence of serial correlation in time series on detecting trends and change point. Where the trends to dry conditions when the pre-whitened SPI time series on the different time scales become significant only at 9- and 12-month scales. The same for the change points, where they have been reproduced on the pre-whitened SPI series only in 9- and 12-month scale series with a slight change, whether precede or pursue the primary change-point. These results are thus confirmed with existing studies (Onyutha 2016; Piyoosh and Ghosh 2017) where serial correlation is recognized for having impact on trends detection in auto-correlated time series, which may falsify the tests for detecting trends and change points.
The change points have pointed out that the rise of drought events was significant only for the second half of 1970s, early 1980s and end of 1980s decade at 9 and 12 months scales. These results are coherent with previous studies showing an increase in drought frequency, duration and severity in the southern part of the Mediterranean basin in the second half of the 20th century (Peñuelas et al. 2001; Hoerling et al. 2012; Ramadan et al. 2013; Tramblay et al. 2013; Spinoni et al. 2014). Likewise, Hoerling et al. (2012) have reported the change in cold-season precipitation of Mediterranean region during 1902–2010 period and the intensification of this trend towards drier conditions with raised drought frequency after 1970. Moreover, Mariotti (2010) found that the Mediterranean region has experienced 10 of the 12 driest winters since 1902, just in the last 20 years. Similar results were obtained separately for local studies in the Mediterranean region and other semi-arid regions like Raymond et al. (2016) for north Algeria, Maccioni et al. (2015) and Abenavoli et al. (2016) in Italy, Dabanlı et al. (2017) in Turkey, Estrela and Vargas (2012) in Spain and Bari Abarghouei et al. (2011) in Iran.
-
2.
As far as the spatial distribution is concerned, the severity of drought events amplifies from east to west and this is more marked at 9 months and annual scale. These effects can be explained by the geographical location of the plains, i.e., the extreme west of the Mediterranean Basin influenced by Atlantic variations and Azores anticyclones, where the Maghnia, Sidi Bel-Abbés and Ghriss plains are located. This atmospheric circulations produce generally a peaceful climatic weather and dry condition (Xoplaki et al. 2004). The Cheliff plains and Mitidja plain are positioned amid the western and eastern Mediterranean Basin that are influenced by El Niño-Southern Oscillation (ENSO) revealed in previous studies (Meddi et al. 2010; Zeroual et al. 2017).
-
3.
As SPIs chronological series are autoregressive of order 1, we opted for prediction from 2 months ahead. Moreover, the choice for prediction by artificial neural networks is set on the forecast ability of this technique in the cases of non-stationary time-series (Allende et al. 2002). The neural network models with different designs give satisfying results despite the non-stationary of SPIs time-series.
Thus, the mentioned models can be used for water resources planning and management in order to adjust 2 months earlier the agricultural activities demand according to the spatial patterns of drought trend. Two months ahead are sufficient as long as the rainy months are from November to March in this area and the agriculture demand is in the spring season (April to June).
Therefore, we consider that 2 months forward are satisfactory to develop a drought warning system in the seven plains based on meteorological information for the best management of irrigation processes, by SPI3 evaluation and water resources, by SPI6, SPI9, SPI12, respectively. Results obtained for the forecast are a decision-making tool for water resources management and especially for irrigation in the investigated plains.
6 Conclusions
The vast and fertile plains of north-western Algeria are known by their important contribution to the self-sufficiency of the country in terms of food-processing production. In recent decades, the amplification of drought events and the increase of rainfall deficit caused drastic impacts on water supply and agriculture in this area. Frequent occurrence of droughts will further intensify local imbalance between supply and demand of water resources. Thus, the investigation of meteorological drought variability and drought prediction approaches are necessary to more sustainable water resource management in the context of drought monitoring.
This work, by analysing the spatial and temporal variability of meteorological drought based on the standardized precipitation index ‘SPI’ series at different time scales during the period 1960–2010, has shown a well identified dry trend in the whole study zone in terms of severity and duration rising from east to west especially after about 1976 and 1981. As a consequence, we expected that significant persistence of drought events in the near future may be enduring.
Finally, a feed-forward three-layer ANN models were used for prediction of drought 2 months ahead using the SPI series at different time scales (3, 6, 9, 12 months). The best performance of ANN models for drought forecasting was acquired based on the analysis of the adjusted coefficient of determination (\( R_{\text{adj}}^{2} \)), the root-mean-square-error (RMSE) and the mean absolute error (MAE). Results indicate that ANN models provided a satisfactory forecast outcome and the best design of ANN model is examined with different input structures and has been validated against the seven studied plains. Hence, the best Levenberg–Marquardt back propagation networks design was found different from a plain to another and among the time scales.
Based on measures of performance evaluation, we found that the Artificial Neural Network models can represent an effective tool for predicting monthly SPI and an accurate drought warning system with 2 months lead-time based on meteorological drought information. These findings may be helpful for decision makers in order to establish adequate irrigation schedules in case of water stress and for optimizing agricultural production.
References
Abenavoli M R, Leone M, Sunseri F, Bacchi M and Sorgonà A 2016 Root phenotyping for drought tolerance in bean landraces from Calabria (Italy); J. Agron. Crop Sci. 202 1–12, https://doi.org/10.1111/jac.12124.
Abramowitz M and Stegun I A 1965 Handbook of mathematical functions with formulas, graphs, and mathematical tables (Vol. 55); Courier Corporation.
Abyaneh H Z, Nia A M, Varkeshi M B, Marofi S and Kisi O 2011 Performance evaluation of ANN and ANFIS models for estimating garlic crop evapotranspiration; J. Irrig. Drain. Eng., https://doi.org/10.1061/(ASCE)IR.1943-4774.0000298.
Aher S, Shinde S, Guha S and Majumder M 2017 Identification of drought in Dhalai river watershed using MCDM and ANN models; J. Earth Syst. Sci. 126(2) 21.
Ali Z, Hussain I, Faisal M, Nazir H M, Hussain T, Shad M Y, Mohamd Shoukry A and Hussain Gani S 2017 Forecasting drought using multilayer perceptron artificial neural network model; Adv. Meteorol., https://doi.org/10.1155/2017/5681308.
Allende H, Moraga C and Salas R 2002 Artificial neural networks in time series forecasting: A comparative analysis; Kybernetika 38(6) 685–707.
Asong Z E, Wheater H S, Bonsal B, Razavi S and Kurkute S 2018 Historical drought patterns over Canada and their teleconnections with large-scale climate signals; Hydrol. Earth Syst. Sci. 22(6) 3105–3124.
Bahrami M, Bazrkar S and Zarei A R 2019 Modeling, prediction and trend assessment of drought in Iran using standardized precipitation index; J. Water Clim. Change 10(1) 181–196.
Baali A and Amine C 2015 Etude de l’impact des variations pluviométriques sur les fluctuations piézométriques des nappes phréatiques superficielles en zone semi-aride (Cas de la plaine de SAΪSS, Nord du Maroc); Eur. Sci. J. 11(27).
Bari Abarghouei H, Kousari M R and Asadi Zarch M A 2013 Prediction of drought in dry lands through feedforward artificial neural network abilities; Arab. J. Geosci., https://doi.org/10.1007/s12517-011-0445-x.
Bari Abarghouei H, Kousari M R and Asadi Zarch M A 2011 Prediction of drought in dry lands through feedforward artificial neural network abilities; Arab. J. Geosci. 6 1417–1433, https://doi.org/10.1007/s12517-011-0445-x.
Barua S, Ng A W M and Perera B J C 2012 Artificial neural network-based drought forecasting using a nonlinear aggregated drought index; J. Hydrol. Eng. 17 1408–1413, https://doi.org/10.1061/(ASCE)HE.1943-5584.0000574.
Barua S, Perera B J C, Ng A W M and Tran D 2010 Drought forecasting using an aggregated drought index and artificial neural network; J. Water Clim. Chang., https://doi.org/10.2166/wcc.2010.000.
Belayneh A and Adamowski J 2012 Standard precipitation index drought forecasting using neural networks, wavelet neural networks, and support vector regression; Appl. Comput. Intell. Soft Comput., https://doi.org/10.1155/2012/794061.
Belayneh A, Adamowski J, Khalil B and Ozga-Zielinski B 2014 Long-term SPI drought forecasting in the Awash River Basin in Ethiopia using wavelet neural networks and wavelet support vector regression models; J. Hydrol., https://doi.org/10.1016/j.jhydrol.2013.10.052.
Byun H R and Kim D W 2010 Comparing the effective drought index and the standardized precipitation index; In: Economics of drought and drought preparedness in a climate change context, López-Francos A.(comp.), López-Francos A.(collab.). Options Méditerranéennes. Sér. A. Séminaires Méditerranéens, Vol. 95, pp. 85–89.
Cancelliere A, Mauro G Di Bonaccorso B and Rossi G 2007 Drought forecasting using the standardized precipitation index. Water Resour. Manag., https://doi.org/10.1016/j.jhydrol.2013.10.052.
Chai T and Draxler R R 2014 Root mean square error (RMSE) or mean absolute error (MAE)? – Arguments against avoiding RMSE in the literature; Geosci. Model Dev., https://doi.org/10.5194/gmd-7-1247-2014.
Chandramouli C V, Kaoukis N, Karim M and Dorworth L 2017 Uses of precipitation-based climate indices in drought characterization; J. Hydrol. Eng. 22 05017013, https://doi.org/10.1061/(ASCE)HE.1943-5584.0001536.
Choi B, Lee J H and Kim D H 2008 Solving local minima problem with large number of hidden nodes on two-layered feed-forward artificial neural networks; Neurocomputing 71(16–18) 3640–3643.
Dabanlı İ, Mishra A K and Şen Z 2017 Long-term spatio-temporal drought variability in Turkey; J. Hydrol. 552 779–792, https://doi.org/10.1016/j.jhydrol.2017.07.038.
Dai A, Trenberth K E and Qian T 2004 A global dataset of palmer drought severity index for 1870–2002: Relationship with soil moisture and effects of surface warming; J. Hydrometeorol. 5 1117–1130, https://doi.org/10.1175/JHM-386.1.
Dalezios N R, Papazafiriou Z G, Papamichail D M and Karacostas T S 1991 Drought assessment for the potential of precipitation enhancement in northern Greece; Theor. Appl. Climatol., https://doi.org/10.1007/BF00867995.
Dariane A B, Farhani M and Azimi S 2018 Long term streamflow forecasting using a hybrid entropy model; Water Resour. Manag. 32 1439–1451, https://doi.org/10.1007/s11269-017-1878-0.
Dehghani M, Saghafian B, Rivaz F and Khodadadi A 2017 Evaluation of dynamic regression and artificial neural networks models for real-time hydrological drought forecasting; Arab. J. Geosci. 10(12) 266, https://doi.org/10.1007/s12517-017-2990-4.
Demmak A 2008 Drought in Algeria 1975–2000 – Impact on water resources and control strategy [La sécheresse en Algérie des années 1975–2000 – Impact sur les ressources en eau et stratégie de lutte]; 2nd MEDA Water Reg. Event, 28–30 April 2008, Marrakech, Morocco, https://doi.org/10.1016/J.IJSBE.2014.04.006.
Deo Ravinesh C, Kisi O and Singh V P 2017a Drought forecasting in eastern Australia using multivariate adaptive regression spline, least square support vector machine and M5Tree model; Atmos. Res. 184 149–175, https://doi.org/10.1016/j.atmosres.2016.10.004.
Deo Ravinesh C, Tiwari M K, Adamowski J F and Quilty J M 2017b Forecasting effective drought index using a wavelet extreme learning machine (W-ELM) model; Stoch. Environ. Res. Risk Assess. 31 1211–1240, https://doi.org/10.1007/s00477-016-1265-z.
Dingman S 1994 Physical Hydrology; Prentice Hall. Inc., New Jersey.
Djerbouai S and Souag-Gamane D 2016 Drought forecasting using neural networks, wavelet neural networks, and stochastic models: Case of the Algerois Basin in North Algeria; Water Resour. Manag., https://doi.org/10.1007/s11269-016-1298-6.
Edwards D C 1997 Characteristics of 20th century drought in the United States at multiple time scales (No. AFIT-97-051); Air Force Inst of Tech Wright-Patterson Afb Oh.
Estrela T and Vargas E 2012 Drought management plans in the European Union. The case of Spain; Water Resour. Manag., https://doi.org/10.1007/s11269-011-9971-2.
Gabriel K R and Neumann J 1962 A Markov chain model for daily rainfall occurrence at Tel Aviv; Quart. J. Roy. Meteorol. Soc. 88 90–95, https://doi.org/10.1002/qj.49708837511.
Ghorbani M A, Zadeh H A, Isazadeh M and Terzi O 2016 A comparative study of artificial neural network (MLP, RBF) and support vector machine models for river flow prediction; Environ. Earth Sci., https://doi.org/10.1007/s12665-015-5096-x.
Govindaraju R S 2000 Artificial neural networks in hydrology. I: Preliminary concepts; J. Hydrol. Eng. 5 115–123, https://doi.org/10.1061/(ASCE)1084-0699(2000)5:2(115).
Goyal M K, Bharti B, Quilty J, Adamowski J and Pandey A 2014 Modeling of daily pan evaporation in subtropical climates using ANN, LS-SVR, Fuzzy Logic, and ANFIS; J. Expert Syst. Appl., https://doi.org/10.1016/j.eswa.2014.02.047.
Guhathakurta P, Menon P, Inkane P M, Krishnan U and Sable S T 2017 Trends and variability of meteorological drought over the districts of India using standardized precipitation index; J. Earth Syst. Sci. 126(8) 120.
Guttman N B 1998 Comparing the Palmer drought index and the standardize precipitation index; J. Am. Water Resour. Assoc. 34 113–121, https://doi.org/10.1111/j.1752-1688.1998.tb05964.x.
Habibi B, Meddi M, Torfs P J, Remaoun M and Van Lanen H A 2018 Characterisation and prediction of meteorological drought using stochastic models in the semi-arid Chéliff–Zahrez basin (Algeria); J. Hydrol.: Regional Studies 16 15–31.
Hamed K H and Ramachandra Rao A 1998 A modified Mann–Kendall trend test for autocorrelated data; J. Hydrol. 204 182–196, https://doi.org/10.1016/S0022-1694(97)00125-X.
He Z, Wen X, Liu H and Du J 2014 A comparative study of artificial neural network, adaptive neuro fuzzy inference system and support vector machine for forecasting river flow in the semiarid mountain region; J. Hydrol., https://doi.org/10.1016/j.jhydrol.2013.11.054.
Hirose Y, Yamashita K and Hijiya S 1991 Back-propagation algorithm which varies the number of hidden units; Neural Networks, https://doi.org/10.1016/0893-6080(91)90032-Z.
Hoerling M, Eischeid J, Perlwitz J, Quan X, Zhang T and Pegion P 2012 On the increased frequency of Mediterranean drought; J. Clim. 25 2146–2161, https://doi.org/10.1175/JCLI-D-11-00296.1.
Huang F, Huang J, Jiang S H and Zhou C 2017 Prediction of groundwater levels using evidence of chaos and support vector machine; J. Hydroinformatics 19(4) 586–606.
Jain A and Kumar A M 2007 Hybrid neural network models for hydrologic time series forecasting; Appl. Soft Comput. 7(2) 585–592.
Jalalkamali A, Moradi M and Moradi N 2015 Application of several artificial intelligence models and ARIMAX model for forecasting drought using the standardized precipitation index; Int. J. Environ. Sci. Technol., https://doi.org/10.1007/s13762-014-0717-6.
Kendall M G 1975 Rank correlation measures; Charles Griffin, London, Vol. 202, 15p.
Khan M I, Liu D, Fu Q and Faiz M A 2018 Detecting the persistence of drying trends under changing climate conditions using four meteorological drought indices; Meteorol. Appl. 25(2) 184–194.
Khan S, Gabriel H F and Rana T 2008 Standard precipitation index to track drought and assess impact of rainfall on watertables in irrigation areas; Irrig. Drain. Syst. 22 159–177, https://doi.org/10.1007/s10795-008-9049-3.
Kim T-W and Valdés J B 2003 Nonlinear model for drought forecasting based on a conjunction of wavelet transforms and neural networks; J. Hydrol. Eng. 8 319–328, https://doi.org/10.1061/(ASCE)1084-0699(2003)8:6(319).
Komasi M, Sharghi S and Safavi H R 2018 Wavelet and cuckoo search-support vector machine conjugation for drought forecasting using standardized precipitation index (case study: Urmia Lake, Iran); J. Hydroinfor. 20 975–988, https://doi.org/10.2166/hydro.2018.115.
Koutsoyiannis D 2003 Climate change, the Hurst phenomenon, and hydrological statistics; Hydrol. Sci. J. 48 3–24, https://doi.org/10.1623/hysj.48.1.3.43481.
Koutsoyiannis D and Montanari A 2007 Statistical analysis of hydroclimatic time series: Uncertainty and insights; Water Resour. Res. 43(5), https://doi.org/10.1029/2006WR005592.
Lazri M, Ameur S, Brucker J M, Lahdir M and Sehad M 2015 Analysis of drought areas in northern Algeria using Markov chains; J. Earth Syst. Sci. 124(1) 61–70.
Liang Y, Niu D, Ye M and Hong W-C 2016 Short-term load forecasting based on wavelet transform and least squares support vector machine optimized by improved cuckoo search; Energies, https://doi.org/10.3390/en9100827.
Lippmann R P 1987 An introduction to computing with neural nets; IEEE ASSP Mag. 4 4–22, https://doi.org/10.1109/MASSP.1987.1165576.
Lloyd-Hughes B and Saunders M A 2002 A drought climatology for Europe; Int. J. Climatol. 22 1571–1592, https://doi.org/10.1002/joc.846.
Maccioni P, Kossida M, Brocca L and Moramarco T 2015 Assessment of the drought hazard in the Tiber river basin in central Italy and a comparison of new and commonly used meteorological indicators; J. Hydrol. Eng. 20 05014029, https://doi.org/10.1061/(ASCE)HE.1943-5584.0001094.
Madadgar S and Moradkhani H 2013 Drought analysis under climate change using copula; J. Hydrol. Eng. 18 746–759, https://doi.org/10.1061/(ASCE)HE.1943-5584.
Maier H R and Dandy G C 1996 The use of artificial neural networks for the prediction of water quality parameters; Water Resour. Res. 32 1013–1022, https://doi.org/10.1029/96WR03529.
Mann H B 1945 Nonparametric tests against trend; Econometrica J. Econometric Soc. 13 245–259.
Mariotti A 2010 Recent changes in the mediterranean water cycle: A pathway toward long-term regional hydroclimatic change? J. Clim. 23 1513–1525, https://doi.org/10.1175/2009JCLI3251.1.
Marriott F H C and Pope J A 1954 Bias in the estimation of autocorrelations; Biometrika 41(3/4) 390–402.
Masinde M 2014 Artificial neural networks models for predicting effective drought index: Factoring effects of rainfall variability; Mitig. Adapt. Strat. Gl. 19(8) 1139–1162.
Masud M B, Khaliq M N and Wheater H S 2017 Projected changes to short- and long-duration precipitation extremes over the Canadian Prairie Provinces; Clim. Dyn., https://doi.org/10.1007/s00382-016-3404-0.
McKee T B, Doesken N J and Kleist J 1993 The relationship of drought frequency and duration to time scales; Proceedings of the 8th Conference on Applied Climatology, Boston, MA: Am. Meteorol. Soc. 17(22) 179–183.
Meddi H and Meddi M 2009 Variabilité des précipitations annuelles du Nord-Ouest de l’Algérie; Sci. Chang. Planétaires/Sécheresse 20 57–65.
Meddi M, Assani A A and Meddi H 2010 Temporal variability of annual rainfall in the Macta and Tafna Catchments, northwestern Algeria; Water Resour. Manag. 24 3817–3833, https://doi.org/10.1007/s11269-010-9635-7.
Medjerab A and Henia L 2005 Régionalisation des pluies annuelles dans l’Algérie nord-occidentale/Regionalisation of annual rainfall in the north-western parts of Algeria; Rev. Geogr. Est. 45(2) 1–14, http://journals.openedition.org/rge/501.
Mishra A K and Desai V R 2005 Drought forecasting using stochastic models; Stoch. Environ. Res. Risk Assess. 19 326–339, https://doi.org/10.1007/s00477-005-0238-4.
Mishra A K and Desai V R 2006 Drought forecasting using feed-forward recursive neural network; Ecol. Modell. 198 127–138, https://doi.org/10.1016/j.ecolmodel.2006.04.017.
Mishra A K and Singh V P 2010 A review of drought concepts; J. Hydrol. 391(1–2) 202–216.
Mudelsee M 2001 Note on the bias in the estimation of the serial correlation coefficient of AR (1) processes; Stat. Pap. 42(4) 517–527.
Noori R, Deng Z, Kiaghadi A and Kachoosangi F T 2015 How reliable are ANN, ANFIS and SVM techniques for predicting longitudinal dispersion coefficient in natural rivers? J. Hydraul. Eng. 142(1) 04015039.
Onyutha C 2016 Statistical uncertainty in hydrometeorological trend analyses; Adv. Meteorol., https://doi.org/10.1155/2016/8701617.
Palmer W C 1965 Meteorological Drought; U.S. Weather Bur. Res. Pap. No. 45.
Paulo A, Martins D and Pereira L S 2016 Influence of precipitation changes on the SPI and related drought severity. An analysis using long-term data series; Water Resour. Manag. 30 5737–5757, https://doi.org/10.1007/s11269-016-1388-5.
Peñuelas J, Lloret F and Montoya R 2001 Severe drought effects on Mediterranean woody flora in Spain; Forest Sci. 47(2) 214–218.
Pettitt A N 1979 A non-parametric approach to the change-point problem; Appl. Stat. 28 126–135, https://doi.org/10.2307/2346729.
Piyoosh A K and Ghosh S K 2017 Effect of autocorrelation on temporal trends in rainfall in a valley region at the foothills of Indian Himalayas; Stoch. Environ. Res. Risk Assess. 31 2075–2096, https://doi.org/10.1007/s00477-016-1347-y.
Ramadan H H, Beighley R E and Ramamurthy A S 2013 Temperature and precipitation trends in Lebanon’s Largest River: The Litani Basin; J. Water Resour. Plan. Manag. 139 86–95, https://doi.org/10.1061/(ASCE)WR.1943-5452.0000238.
Raymond F, Ullmann A and Camberlin P 2016 Précipitations intenses sur le Bassin Méditerranéen: quelles tendances entre 1950 et 2013? Cybergeo Eur. J. Geogr. Nat Paysage document 760, https://doi.org/10.4000/cybergeo.27410.
Rezaie-Balf M, Zahmatkesh Z and Kim S 2017 Soft computing techniques for rainfall-runoff simulation: Local non-parametric paradigm vs. model classification methods; Water Resour. Manag. 31(12) 3843–3865.
Salhi C, Touaibia B and Zeroual A 2013 Les réseaux de neurones et la régression multiple en prédiction de l’érosion spécifique: cas du bassin hydrographique Algérois-Hodna-Soummam (Algérie); Hydrol. Sci. J. 58 1573–1580, https://doi.org/10.1080/02626667.2013.824090.
Salvi K and Ghosh S 2016 Projections of extreme dry and wet spells in the 21st century India using stationary and non-stationary standardized precipitation indices; Clim. Change 139(3–4) 667–681.
Şen Z 1998 Average areal precipitation by percentage weighted polygon method; J. Hydrol. Eng. 3(1) 69–72.
Serinaldi F and Kilsby C G 2016 The importance of prewhitening in change point analysis under persistence; Stoch. Environ. Res. Risk Assess. 30 763–777, https://doi.org/10.1007/s00477-015-1041-5.
Shabri A 2014 A hybrid wavelet analysis and adaptive neuro-fuzzy inference system for drought forecasting; Appl. Math. Sci. 8 6909–6918, https://doi.org/10.12988/ams.2014.48263.
Sheela K G and Deepa S N 2013 Review on methods to fix number of hidden neurons in neural networks neuro-fuzzy inference system for drought forecasting; Math. Probl. Eng., https://doi.org/10.1155/2013/425740.
Sheffield J and Wood E F 2008 Projected changes in drought occurrence under future global warming from multi-model, multi-scenario, IPCC AR4 simulations; Clim. Dyn. 31 79–105, https://doi.org/10.1007/s00382-007-0340-z.
Shiau J T 2006 Fitting drought duration and severity with two-dimensional copulas; Water Resour. Manag. 20 795–815, https://doi.org/10.1007/s11269-005-9008-9.
Shirmohammadi B, Moradi H, Moosavi V, Semiromi M T and Zeinali A 2013 Forecasting of meteorological drought using Wavelet-ANFIS hybrid model for different time steps (case study: Southeastern part of east Azerbaijan province, Iran); Nat. Hazards, https://doi.org/10.1007/s11069-013-0716-9.
Shoaib M, Shamseldin A Y, Melville B W and Khan M M 2016 Hybrid wavelet neuro-fuzzy approach for rainfall-runoff modeling; J. Comput. Civil Eng., https://doi.org/10.1061/(ASCE)CP.1943-5487.0000457.
Soh Y W, Koo C H, Huang Y F and Fung K F 2018 Application of artificial intelligence models for the prediction of standardized precipitation evapotranspiration index (SPEI) at Langat River Basin, Malaysia; Comput. Electron. Agric. 144 164–173, https://doi.org/10.1016/J.COMPAG.2017.12.002.
Spinoni J, Naumann G, Carrao H, Barbosa P and Vogt J 2014 World drought frequency, duration and severity for 1951–2010; Int. J. Climatol. 34 2792–2804, https://doi.org/10.1002/joc.3875.
Stocker T, Qin D, Plattner G and Tignor M 2013 IPCC, 2013: Climate Change 2013: The Physical Science Basis; Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel.
Storch H von Navarra A 1995 Analysis of Climate Variability, Springer-Verlag, Berlin-Heidelberg, 334p.
Tang Z and Fishwick P A 1993 Feedforward neural nets as models for time series forecasting; J. Comput. 5 374–385, https://doi.org/10.1287/ijoc.5.4.374.
Tarawneh Z and Khalayleh Y 2016 Improved estimate of multiyear drought for water resources management studies; J. Water Clim. Chang. 7 721–730, https://doi.org/10.2166/wcc.2016.151.
Thom H C S 1958 A note on the Gamma Distribution; Mon. Weather Rev. 86 117–122, https://doi.org/10.1175/1520-0493(1958)086<0117:ANOTGD>2.0.CO;2.
Thorn H C S 1966 Some methods of climatological analysis; library.wmo.int Number 81, 53p.
Tian Y, Xu Y P and Wang G 2018 Agricultural drought prediction using climate indices based on support vector regression in Xiangjiang River basin; Sci. Total Environ., https://doi.org/10.1016/j.scitotenv.2017.12.025.
Tongal H and Booij M J 2017 Quantification of parametric uncertainty of ANN models with GLUE method for different streamflow dynamics; Stoch. Environ. Res. Risk Assess. 31(4) 993–1010.
Torranin P 1973 Unpredictability of hydrological drought; In: The Second International Symposium in Hydrology, Fort Collins, Colo., Water Resources Publications, pp. 595–604.
Tramblay Y, El Adlouni S and Servat E 2013 Trends and variability in extreme precipitation indices over Maghreb countries; Nat. Hazards Earth Syst. Sci. 13 3235–3248, https://doi.org/10.5194/nhess-13-3235-2013.
Trenn S 2008 Multilayer perceptrons: Approximation order and necessary number of hidden units. IEEE Trans. Neural Networks, https://doi.org/10.1109/TNN.2007.912306.
Vicente-Serrano S M, Begueria S and Lopez-Moreno J I 2010 A multiscalar drought index sensitive to global warming: The standardized precipitation evapotranspiration index; J. Clim. 23 1696–1718, https://doi.org/10.1175/2009JCLI2909.1.
Wang L, Zeng Y and Chen T 2015 Back propagation neural network with adaptive differential evolution algorithm for time series forecasting; Expert Syst. Appl., https://doi.org/10.1016/j.eswa.2014.08.018.
Wilhite D A and Glantz M H 1985 Understanding: The drought phenomenon: The role of definitions; Water Int., https://doi.org/10.1080/02508068508686328.
Willmott C J and Matsuura K 2005 Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res., https://doi.org/10.3354/cr030079.
WMO 2008 Guide to Hydrological Practice, Volume I, Hydrology – From Measurement to Hydrological Information; 6th edn, World Meteorological Organisation, Geneva, Switzerland.
Wong F S 1991 Time series forecasting using backpropagation neural networks; Neurocomputing 2 147–159, https://doi.org/10.1016/0925-2312(91)90045-D.
Xoplaki E, González-Rouco J F, Luterbacher J and Wanner H 2004 Wet season Mediterranean precipitation variability: Influence of large-scale dynamics and trends; Clim. Dyn. 23 https://doi.org/10.1007/s00382-004-0422-0.
Yue S, Pilon P and Cavadias G 2002 Power of the Mann–Kendall and Spearman’s rho tests for detecting monotonic trends in hydrological series. J. Hydrol. 259, https://doi.org/10.1016/S0022-1694(01)00594-7.
Yue S and Wang C 2004 The Mann–Kendall test modified by effective sample size to detect trend in serially correlated hydrological series; Water Resour. Manag. 18 201–218, https://doi.org/10.1023/B:WARM.0000043140.61082.60.
Zeroual A, Assani A and Meddi M 2017 Combined analysis of temperature and rainfall variability as they relate to climate indices in Northern Algeria over the 1972–2013 period; Hydrol. Res. 48 584–595.
Zeroual A, Assani A A, Meddi M and Alkama R 2019 Assessment of climate change in Algeria from 1951 to 2098 using the Köppen–Geiger climate classification scheme; Clim. Dyn. 52(1–2) 227–243.
Zeroual A, Meddi M and Assani A A 2016 Artificial neural network rainfall-discharge model assessment under rating curve uncertainty and monthly discharge volume predictions; Water Resour. Manag. 30 3191–3205, https://doi.org/10.1007/s11269-016-1340-8.
Zhang Q, Li J, Singh V P and Bai Y 2012 SPI-based evaluation of drought events in Xinjiang, China; Nat. Hazards 64 481–492, https://doi.org/10.1007/s11069-012-0251-0.
Zhang Y, Li W, Chen Q, Pu X and Xiang L 2017 Multi-models for SPI drought forecasting in the north of Haihe River Basin, China; Stoch. Environ. Res. Risk Assess. 31 2471–2481, https://doi.org/10.1007/s00477-017-1437-5.
Acknowledgement
The authors wish to thank the National Agency of Water Resources for providing material help and data on which reported analysis are based on.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Subimal Ghosh
Supplementary materials pertaining to this article are available on the Journal of Earth Science Website (http://www.ias.ac.in/Journals/Journal_of_Earth_System_Science).
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Achour, K., Meddi, M., Zeroual, A. et al. Spatio-temporal analysis and forecasting of drought in the plains of northwestern Algeria using the standardized precipitation index. J Earth Syst Sci 129, 42 (2020). https://doi.org/10.1007/s12040-019-1306-3
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12040-019-1306-3