
Abstract
An effective forecast of the drought definitely gives lots of advantages in regard to the management of water resources being used in agriculture, industry, and households consumption. To introduce such a model applying simple data inputs, in this study a regional drought forecast method on the basis of artificial intelligence capabilities (artificial neural networks) and Standardized Precipitation Index (SPI in 3, 6, 9, 12, 18, and 24 monthly series) has been presented in Fars Province of Iran. The precipitation data of 41 rain gauge stations were applied for computing SPI values. Besides, weather signals including Multivariate ENSO Index (MEI), North Atlantic Oscillation (NAO), Southern Oscillation Index (SOI), NINO1+2, anomaly NINO1+2, NINO3, anomaly NINO3, NINO4, anomaly NINO4, NINO3.4, and anomaly NINO3.4 were also used as the predictor variables for SPI time series forecast the next 12 months. Frequent testing and validating steps were considered to obtain the best artificial neural networks (ANNs) models. The forecasted values were mapped in verification sector then they were compared with the observed maps at the same dates. Results showed considerable spatial and temporal relationships even among the maps of different SPI time series. Also, the first 6 months forecasted maps showed an average of 73 % agreements with the observed ones. The most important finding and the strong point of this study was the fact that although drought forecast in each station and time series was completely independent, the relationships between spatial and temporal predictions remained. This strong point mainly referred to frequent testing and validating steps in order to explore the best drought forecast models from plenty of produced ANNs models. Finally, wherever the precipitation data are available, the practical application of the presented method is possible.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Drought is a phenomenon which occurs in every climate, and its cost to natural and agricultural ecosystems as well as societies is enormous. Drought as a complicated recurrent natural hazard and disaster (Paulo and Pereira 2007) appears slowly in time (Cancelliere et al. 2007a, b) and gradually (Mishra and Desai 2005a). Some drought features are its intensity, frequency, duration, spatial extent, and a creeping feature that threats the water storages. Nowadays, governments and international organizations focus their attention on the increasing threat of water stress in most regions of the world (Tsakiris et al. 2013). Therefore, developing a successful drought mitigation plan is one of the first priorities for many researchers, scientist, decision makers, and managers.
Undoubtedly, in order to prevent or diminish huge costs of drought, it must be managed. This approach should be followed based on an early warning system. Drought forecast is a critical element in drought risk management (Özger et al. 2012). According to the United Nations (UN) Strategy for Disaster Reduction (ISDR), an early warning system involves (a) monitoring and predicting components, (b) risk knowledge, (c) disseminating information, and (d) response (Hao et al. 2014). In spite of the importance of all these terms, it seems that the drought forecast plays a key role for taking accurate mitigation strategies (Belayneh and Adamowski 2012; Belayneh et al. 2014) and developing an early warning system. Though most factors that trigger droughts cannot be prevented, accurate, relevant, and timely forecasts can be used to mitigate their impacts (Masinde 2013). The importance of drought forecasting is being heightened by the scarcity of water occurring too frequently around the world in recent years (Mo et al. 2009).
Different drought forecast approaches and procedures have been followed and implemented. These contain a wide range of methods such as implementation of geometric probability distribution (Yevjevich 1967), run theory (Moradi et al. 2011; Saldariaga and Yevjevich 1970; Sen 1976, 1977), alternating renewal–reward model (Kendall and Dracup 1992), renewal processes, using Markov chains (Jiang and Chen 2009; Lohani and Loganathan 1997; Lohani et al. 1998; Ochola and Kerkides 2003; Paulo and Pereira 2007; Sen 1990; Steinemann 2003), stochastic time series models (Chung and Salas 2000; Durdu 2010; Han et al. 2010; Mishra and Desai 2005a; Modarres 2007; Yurekli and Kurunc 2006), and artificial intelligence procedures particularly artificial neural networks (Bari Abarghouei et al. 2011; Barua et al. 2010; Belayneh and Adamowski 2012; Chen et al. 2012; Dastorani et al. 2010; Erol Keskin et al. 2011; Masinde 2013; Mishra and Desai 2006; Morid et al. 2007; Özger et al. 2012; Woli et al. 2013). Other methods such as pattern recognition techniques and physical based models have been pointed out by Mishra and Desai (2005a).
Among all the various utilized drought forecast, methods the artificial intelligence, particularly artificial neural networks (ANNs), because of their capabilities in forecasting precipitation and drought even with their complications, have received a great consideration and application (Chow and Cho 1997; Cutore et al. 2009; Karmakar et al. 2008, 2009a, b; Long et al. 1997; Shrivastava et al. 2012; Singh and Borah 2013; Wu et al. 2010). The outstanding ANNs forecast performance announced is due to its ability to overcome the nonlinear characteristics of the natural systems.
Also, about the drought index, it should be mentioned that selection of an integrated index for quantifying drought severity is a challenge for decision makers in developing water resources and operation management policies (Karamouz et al. 2009). However, for this purpose, many methods have been proposed such as Palmer Drought Severity Index (PDSI, Palmer 1965), Palmer Hydrological, Drought Severity Index (PHDI, Van Rooy 1965), Reconnaissance Drought Index (RDI, Tsakiris et al. 2007, 2008; Tsakiris and Vangelis 2005), and Standardized Precipitation Index (SPI, McKee et al. 1993). Although many introduced indices have their own advantages and disadvantages, SPI has been accepted and applied as a simple and efficient method for quantifying drought severities by many researches. The ability to produce different SPI time series of precipitation values makes it possible to analyze different types of drought such as meteorological, hydrological, and agricultural droughts. SPI is comparable in time and space (Guttman 1998; Hayes et al. 1999) and can be calculated at different time scales to monitor droughts with respect to different usable water resources (Vicente-Serrano et al. 2010).
Although there are valuable researches to forecast drought using artificial intelligences, few ones have considered the regional pattern of the forecasted precipitation fluctuations or droughts. The majorities of the announced and reported studies have considered the rainfall anomalies or drought forecasting in the scale of one or few synoptic or rain gauge stations. In fact, the spatial and temporal relationships between the forecasted data in different meteorological stations have not fully analyzed. Therefore, this study forecasts drought in 41 rain gauge stations in Fars Province of Iran by using ANNs models and SPI in different time scales including 3, 6, 9, 12, 18, and 24 months. Fars Province plays a crucial role in the agricultural productions and food security of Iran. Thus, an efficient and flexible drought forecast model which provides adequate time to develop an applicable early warning approach is essential.
In order to promote the forecasting process, time series of weather signals including Multivariate ENSO Index (MEI), North Atlantic Oscillation (NAO), Southern Oscillation Index (SOI), NINO1+2, anomaly NINO1+2, NINO3, anomaly NINO3, NINO4, anomaly NINO4, NINO3.4, and anomaly NINO3.4 were implemented as inputs of ANNs models alongside SPI time series. In order to increase the reliability of the predictions and the results of the model, the drought forecasting process in each rain gauge stations and each time series of SPI passed four main steps namely training, testing, validation, and verification sectors. During the first step, frequent ANNs models were trained and then tested. Next, the successful models of the previous step were validated ten times in the third step and then the most successful models were selected to be verified. Finally, the verification sectors were analyzed in the spatial and temporal relationships among the prediction maps and also compared with the observed maps. Verification phases can determine to what extent the models and produced maps would be reliable.
Selecting desirable lag and lead times is fully flexible in the presented procedure. In the current study, we selected 12 months ahead as the lead time. This time period gives decision makers and specialists adequate time to schedule water supply and demand particularly for irrigation activities. The main output of this forecast involves 12 drought forecasted maps (each map for each lead time) for each SPI time series. Therefore, for all the SPI time series, 72 drought forecasting maps were generated. Finally, it should be said that the presented method in this study can be easily implemented by other researchers and scientists in different corners of the world to access a simple, affordable, flexible, and efficient model in regard to drought forecast.
2 Material and methods
2.1 Study area
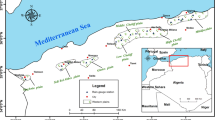
Fars Province of Iran with Shiraz as the center is located in the central and southern parts of the country (Fig. 1). Its climate is arid and semi-arid. Its area is about 122,607 km2. It is located between (27° 03′) and (31° 42′) the northern latitude and (50° 30′) and (55° 36′) the eastern longitude. Its average annual precipitation varies between 100 mm in the southern parts to more than 400 mm in the northern parts (Soufi 2004). For many years, Fars has had remarkable records in crop production, especially wheat yield. Agriculture plays an important role in production and supply of employment and food security in Iran (Ahani et al. 2012). More than 10 % of total Iran agricultural productions are produced in Fars Province; therefore, it plays a crucial role in the country’s food security. However, this province is seriously struggling with droughts and the agricultural sector as one of the most vulnerable parts has seriously suffered the frequent, intensive, and long-term droughts particularly in recent years. Besides other reasons that increase the vulnerability of agricultural sectors to droughts such as climate changes and global warming which cause an increasing trend of temperature or evapotranspiration in Iran and certainly Fars Province and surrounding areas (Ahani et al. 2012; Kousari et al. 2013), perhaps one of the main causes is the intensive withdrawal of ground water and consequently falling the ground water tables during the past decades. The falling of these valuable water storages decreases the resistance of ecosystems for coping with droughts.

The location of Fars Province in Iran and also the distribution map of surveyed rain gauge satiations in Fars Province
2.2 Relevant data
Monthly time series of precipitation of 41 rain gauge stations in Fars Province during 1970–2010 were considered to compute the SPI time series. Figure 1 shows the spatial distribution of these stations in the Fars Province. Moreover, Hammer et al. (2001) stated that some types of drought prediction are possible due to some of the year-to-year variations in climate are associated with that are coherent on a large scale and this has provided a scientific basis for skillful prediction. They explained that the most dramatic, most energetic, and best-defined pattern of inter-annual variability is the global set of climatic anomalies referred to as ENSO (El Niño and the Southern Oscillation). ENSO is a commonly used index to study the main features of climate fluctuations (Meza 2005). Many researchers in different parts of the world have investigated these time series to enhance their predictions (Aherne et al. 2006; Anderson et al. 2001; Choi et al. 2011; Dezfuli et al. 2010; Farokhnia et al. 2011; Gelcer et al. 2013; Hammer et al. 2001; Jones et al. 2000; Mabaso et al. 2007; Özger et al. 2009; Shrestha and Kostaschuk 2005; Ubilava and Helmers 2013). Therefore, in this study besides using SPI time series in different time scales, the time series of weather signals including MEI (Wolter and Timlin 1998), NAO, SOI, NINO1+2, ANOM NINO1+2, NINO3, ANOM NINO3, NINO4, ANOM NINO4, NINO3.4, and ANOM NINO3.4 were obtained from the National Oceanic & Atmospheric Administration, NOAA Research (http://www.esrl.noaa.gov/psd/data/climateindices/list/) and used.
2.3 SPI computation
SPI is computed when the frequency distribution of precipitation is fitted on a particular probability density function and then it is transformed to a standardized normal distribution. The input data are the summation of precipitation values in accordance with the desired time scale. For instance, in order to provide the input data of three monthly SPI time series, each value in special time (t) is calculated by the summation of precipitation values of t − 2, t − 1, and t. The time scales are usually considered in monthly term; however, other time scales can also be considered. The short time series of SPIs are implemented for assessment of short-term water resources such as soil moisture, while the long SPI time series can be applied for long-term water supplies.
In the most cases, the frequency distributions of precipitation are far from normal distribution and demonstrate the extent of skewness. Thus, the probability density function such as gamma can be considered instead. According to (Mishra and Desai 2005b), the gamma distribution is defined by its probability density function as stated below:
Where α >0 is shape factor and β >0 represents the scale factor of distribution. x >0 refers to the precipitation values. The Γ (α) indicates the gamma function, which is shown as:
For computation of α and β, Edwards and McKee (1997) have suggested a method using the approximation of Thom (1958) for maximum likelihood as below:
Where
n is the number of observations.
Based on the derived parameters from the above equations, the cumulative probability function is fitted to input data which is the precipitation time series in specific time scale as below:
Then, t is substituted for \( \frac{x}{\beta } \) and formed Eq. 7 to an incomplete gamma function as follows:
Since the gamma function is not defined for x equal to zero, while a precipitation distribution may contain zeros, particularly in arid and semi-arid regions, the cumulative probability becomes:
q represents the probability of precipitation equal to zero. The cumulative probability, H(x), then must be transformed to the standard normal random variable (Z) with the zero mean and the variance equal to1, which is the value of SPI. According to the studies of Edwards and McKee (1997) and Hughes and Saunders (2002), an approximate conversion has been used during the present research, as provided by Abramowitz and Stegun (1965), as an alternative:
And
Where
And
And c 0 = 2.515517, c 1 = 0.802853, c 2 = 0.010328, d 1 = 1.432788, d 2 = 0.189269, and d 3 = 0.001308 (Mishra and Desai 2005b).
Time series of SPI in different time scales including 3, 6, 9, 12, 18, and 24 monthly time series were considered as part of inputs in this study.
2.4 Artificial neural networks
Maier and Dandy (2000) stated that although the concept of artificial neurons was first introduced in 1943 (McCulloch and Pitts 1943), research into applications of ANNs has blossomed by the introduction of the backpropagation training algorithm for feed-forward ANNs in 1986 (Rumelhart et al. 1986). ANNs as the most general artificial intelligent methods are the collection of some neurons with specific structure formed based on the relationship between neurons in different layers (Kisi and Sanikhani 2015). The advantages of ANNs over other statistical models are as follows: they do not require a prior knowledge of the process because ANNs have black box properties; they have the inherent property of nonlinearity; they are able to represent the time–space variability; they have adaptability to represent the change of problematic environments (Woong Kim and Valdés 2003); model complexity can be varied simply by changing the transfer functions or network architectures and unlike some statistical models; ANN models can be extended easily from univariate to multivariate cases (Maier and Dandy 2001).
It is vital to adopt a systematic approach in the development of ANN models and to take some factors into account such as data pre-processing, the determination of adequate model inputs and a suitable network architecture, parameter estimation (optimization), and model validation (Maier and Dandy 2001). In addition, careful selection of a number of internal model parameters is required (Maier and Dandy 2000).
2.5 Preprocessing of initial data for modeling
For training the ANNs models, the first step is a provision of input and target data sets for each rain gauge station. The input data contain the SPI values and mentioned weather signals with determined lag time. The target data involve a set of SPI value (lead-time) in order to forecast. Using lead-time and lag-time both are optional however, considering a better choice of lead and lag times would considerably improve the final results. As stated by Paulo and Pereira (2007), an adequate lead-time, i.e., the period between the release of the prediction and the actual onset of the predicted hazard, is more important than the accuracy of the prediction (Easterling 1989). In addition, determination of lag-time has a great influence on the outcomes of the forecasts. In general, the combination of input and target data including the determination of inputs sets, their lags, and the lead time will substantially enhance the accuracy and efficiency of the final model.
As it was mentioned previously, the data of several weather signals have been gathered as a part of input data besides the SPI value time series. It is clear that some of these weather signals have more correlation with the SPI time series and as a result more influence. While, some of them even show more correlation in particular lags. Therefore, this correlation should be investigated. In regard to find more correlative input parameters (weather signals) and the effective lags, the R correlation values between each time series of SPI in particular rain gauge stations and weather signals in 0 to 20 lags were determined. Figure 4 in the results section shows a sample of this process. Of course, the correlation analyses for each station (41 stations) and each time series of SPI (6 time series) in different lags were performed. This process was repeated 246 times. Finally, the five more correlative weather signals were allowed to contribute in the modeling. The most considerable correlations were almost seen in the first to sixth lags. Thus, the number of lags was set to 6. Although the number of lead-times also can be determined through the try and error approach as well as one which explained by Morid et al. (2007), the number of lead-times was set to 12 months. This number of lead times gives an opportunity to have sufficient time for making decision by experts and decision makers. These procedure can be exhibited as following:
Where SPIj involves the 3, 6, 9, 12, 18, and 24 monthly SPI time series and i = 1:n − 6 − 22 − 12 where n is the length of time series. The values of 6, 22, and 12 refer to the lag times, data for validation, and verification parts, respectively. The reasons why 22 and 12 were chosen will be discussed. The above matrix shows that how the input and output data have been prepared. In fact, the five most common weather signals with considerable correlation have been showed in the matrix. However, other mentioned weather signals depending on the rain gauge stations and time series of SPI may be contributed to this modeling.
Prior to the training process, the input and target data were normalized by the following equation (Bari Abarghouei et al. 2011; Rahimikhoob 2010):
Where Xn and X 0 represent the normalized and original data, respectively. Also, X min and X max represent the minimum and maximum values of the original data.
2.6 Preparing of training, testing, validation, and verification subsets
It is a common practice to split the available data into two subsets: a training set and an independent validation set (Maier and Dandy 2000). Auto-calibration by ANNs models or training should be evaluated by validation. As Voinov (2008) stated, there was a need to check that if the model really did what it was designed to do. This model testing may assume various procedures and stages some of which are called validation and verification. For example, we may want to double check that the model is based on correct assumptions, that the code has no bugs, and that the output is properly presented and interpreted. This would be the model verification stage, or we may want to run the model on an independent set of input data and see how it performs then, which will be called the validation process in some cases (Voinov 2008). Also Beven (2003) has defined the validation as a process of evaluation of models to confirm that they are acceptable representations of the system. Also he stated that philosophers of science have some problems with the concept of validation and it may be better to use evaluation or confirmation rather than validation. According to Voinov (2008), there is still some confusion on terminology and sometimes the words validation and verification are used interchangeably. Overall, these are important steps which should be considered in order to obtain a better model performance.
While some studies consider split the data into two subsets of training and independent validation sets, determination of more subsets especially in regard to validation phase can provide this opportunity to evaluate the performance of an ANN model with the more reliability. In fact, the efficiency of the model should be examined in more than one step to select most powerful and accurate models. Therefore, dividing the validation phase in three subsets of testing, validation, and verification has been followed in the current study. It is particularly useful for controlling, overcoming, and reducing the degree of overparametrization. According to Beven (2003), overparametrization of neural net models relative to the information in the learning set is an issue of this type of model (as in any empirical model). The danger of overparametrization is that in general it will lead to greater uncertainty in prediction or extrapolation, particularly in prediction or extrapolation beyond the range of the learning or calibration set. A good performance in fitting the learning set does not guarantee a good performance of prediction when the conditions go outside the range seen in the learning set (Beven 2003).
Figure 2 shows the schematic feature of split input-target data in these various phases. This figure indicates that the majority of data has been allocated in training step and the rest for testing. The same as lots of reported researches, at least 70 % of data was allocated for training and the remaining was left for validating. In Fig. 2, the test subsets were located among training data which showed with narrow vertical black lines. They were randomly selected and separated from the training data. In spite of validating data which were completely independent from the training ones, the testing data were not completely independent from the training subset because of preparedness of input and target data with creating a shift throughout the time series. It is clear in Fig. 2. Although these selected subsets of testing data can be applied to evaluate the performance of the models, they do not guarantee to choose the accurate models. In fact, the testing process should be accompanied with another step which is validation phase.

Schematic figure of splitting the input-target data into training, testing, validating, and verifying subsets. It is clear that prolonging SPI time series reduces time series lengths. The white sections are associated with training subsets while the vertical black lines among the training parts illustrate testing subsets. The validation and verification parts also can be seen in the end of the time series
According to Fig. 2, validation subsets involved a part of the input-target data which were completely distinguished from the training data. Validation phase was repeated ten times for each station and each SPI time series. This was done instead of considering just one evaluation process in order to decrease the uncertainties of the predictions and to find the best performed models. The lead-time is set to 12 with ten repetitions; therefore, 22 input-target rows have been specified for validation process.
The last subset was associated with verification process. In order to control and check that the output was presented and interpreted properly, the last 12 input-target rows were specified for verification process. These values were used as observed values to map the drought severity as observed maps and also to compare with the final forecasted values produced by the models which were mapped, too. Exploring the forecast maps and finding the spatial and temporal relationships among various produced maps can be considered in the verification phase.
2.7 Training process of ANN
After configuring input parameters of neural network models, the next step is to train these models with the required settings. The training process requires a set of examples which contain proper network behavior. During training, the weights and biases of the network are iteratively adjusted to minimize the performance (Bari Abarghouei et al. 2011). Multilayer perceptron (MPL) feed-forward networks have been considered in this study. There are a variety of neural network models and learning procedures. Two classes of neural networks that are usually used for prediction applications are feed-forward networks and recurrent networks. Both of these networks are often trained using back-propagation (BP) algorithm (Bari Abarghouei et al. 2011; Dastorani et al. 2010).
In this study, various BP training algorithms were primarily analyzed which included gradient descent back-propagation (gd), gradient descent with adaptive learning rate back-propagation (gda), gradient descent with momentum and adaptive learning rate back-propagation (gdx), Levenberg-Marquardt backpropagation (lm), and scaled conjugate gradient back-propagation (scg). Different transfer functions in the hidden and output layers were considered, too. According to the number of repetition or epoch, network architecture which is discussed in the next section, and initial try and error, gdx was considered as more efficient BP for drought forecasting with the tangent sigmoid function in the hidden layer and linear one in output layer and the repetition on was set equal to 700.
2.8 Determining the network architecture
Network architecture refers to the number of connection weights (free parameters) and the way information flows through the network. Determination of an appropriate network architecture is one of the most important, but also one of the most difficult tasks in the model building process (Maier and Dandy 2000). In addition, Hornik et al. (1989) proved that just one layer of hidden units is sufficient for approximation of any complex nonlinear function for ANNs with any desired accuracy. ANN requires the determination of the number of hidden nodes (process elements) for each hidden layer. Bishop (1995) believed that there was no theory for determining the optimum value for these internal variables of an ANN model to approximate any given function. However, as it has been pointed out by Mishra and Desai (2006), in the case of popular one-hidden-layer networks, some guidelines have been reported for the number of neurons in the hidden layer. If n is the number of input nodes, “2n + 1” (Hecht-Nielsen 1990; Lippmann 1987), “2n” (Wong 1991), and “n” (Tang and Fishwick 1993) are suggested for the hidden neuron numbers to result a more accurate forecast. Also, according to the study of Rahimikhoob (2010), the number of nodes in the input and output layers depends on the number of input and output variables, respectively. It is clear that there are different approaches for determination of number of neurons in hidden layer and it has remained a subjective matter. Since no specific guideline exists to choose the optimum number of hidden neurons for a given problem, this network parameter can often be optimized by try and error. In this study, the input neurons were selected the same as the number of input variables, i.e., 6 neurons, the output nodes were equal to 12 (equal to the number of outputs and 12 months lead times), and the number of neurons in the hidden layer were a range of 7 to 10. In fact, the numbers of neurons in hidden layer were initially set from 1 to 15. As the result of try and error, a range of 7 to 10 was found the most successful.
2.9 Performance criteria
Root mean square error (RMSE) and correlation coefficient (R) criteria were used as model performance criteria. RMSE is the most commonly used performance criteria in hydrological modeling. Its ideal value is zero. The range of R value differs from −1 to 1 for fully inverse and direct correlation, respectively. While zero represents no correlation.
Both R and RMSE are computed based on the number of paired observations (n), predicted or estimated values, and the observed values as follows:
Where P is predicted and O is observed and n is the length of each observed or predicted series.
2.10 Interpolating and mapping of predictions
The results were interpreted by the performance criteria and visual relationships between the predicted and observed values through the graphs. However, verifying the forecasts, exploring the data, and finding logical results were more possible through the maps. As a wide range of drought prediction maps for different time series of SPI were produced, seeking a particular correlation among them showed the correctness of the predictions and if they could meet the experts’ expectations. Moreover, having a range of consecutive drought severity maps for a particular area provides important information about drought severity, onset, cessation, duration, and spatial distribution.
Since the lead time in the current study has been adapted to 12 months; therefore, 24 maps for each time series of SPI were produced. Twelve maps were associated with the observed maps (those data which had been separated for verification phase) and other 12 ones were related to forecasted values. IDW was utilized to interpolate the predictions spatially. IDW as one of the most frequently used deterministic models in spatial interpolation is fast and requires no assumptions of the input data (ArcGIS 2008). It is based on the assumption that the attribute value of an unsampled point is the weighted average of known values within the neighborhood (Lu and Wong 2008). IDW is a well-known method. To find more details, check Ahani et al. (2012) and Chen and Liu (2012).
Besides the mentioned use of IDW characteristics, it was used to spot the outliers or heterogeneities predictions. IDW interpolation will recognize a dramatically different point in neighbor samples, but does not overlook this variation by smoothing. Therefore, analyzing the generated maps will be more convenient. More details about the mapping process were considered in Ahani et al. (2012). The forecasted SPI values after being mapped were reclassified in four classes: SPI < −1 as drought conditions (D), −1 < = SPI < 0 showed the normal near to drought conditions (ND), 0 < = SPI < 1 illustrated the normal near to wet status (NW), and finally SPI > = 1 related to wet conditions (W). These classes have been shown in red, yellow, green, and blue colors, respectively. The different processes of forecasting the SPI time series were shown in Fig. 3.

The flowchart of the different forecast processes of SPI time series
3 Results
The results involved a wide range of tables and figures according to test, validation, and verification phases for various ANNs models (in the case of considering the number of neurons in the hidden layers) for 3, 6, 9, 12, 18, and 24 monthly SPI time series in 41 rain gauge stations. Because it was impossible to present all the results, we presented some of them as examples and focused on the predicted maps as the valuable ones which contain the most important findings of this work.
Firstly, the findings of correlations of weather signals with various SPI time series will be surveyed. Figure 4 showed the R correlations with 0 to 20 lags of weather signals including MEI, NAO, SOI, NINO1+2, ANOM NINO1+2, NINO3, ANOM NINO3, NINO4, ANOM NINO4, NINO3.4, and ANOM NINO3.4 with different time series of SPI in four selected rain gauge stations, i.e., Eqlid, Emadeh, Sivand, and Beyram. These correlation values have been exhibited as images. As it can be found, 3, 6, 9, and 18 time series of SPI indicated more correlations than 12 and 24 monthly ones. Also, in the first order, NINO1+2 and NINO3, and in the second order, NINO4 and NINO3.4 showed the strong correlations with the SPI time series. Twelve and 24 monthly SPI time series were exceptions. Although the images of correlations between 3, 6, 9, and 18 monthly SPI time series and weather signals were to some extent similar for different rain gauge stations, different patterns of correlations can be found in regard to 12 and 24 monthly SPI values.

The correlations between 0 and 20 lag of weather signals and different time series of SPI in four selected rain gauge stations, i.e., Eqlid, Emadeh, Sivand, and Beyram. In horizontal x-axis 1 to 11 represent MEI, NAO, SOI, NINO1+2, ANOM NINO1+2, NINO3, ANOM NINO3, NINO4, ANOM NINO4, NINO3.4, and ANOM NINO3.4, respectively
Table 2 showed the mean of RMSE and R in the testing and validating phases by the lag of 6 months and different number of neurons in the hidden layer for 3-, 6-, 9- and 12-, 18-, and 24-month SPI time series in Eqlid rain gauge station, respectively. Although such a table was produced for each 41 rain gauge stations, only Eqlid station table was presented here. The table gave this opportunity to decide which model was more appropriate. As it can be seen, the differences between mean of RMSE and R of testing and validating phases for different SPI time series were to some extent considerable, though these values for each SPI time series (for example, three monthly one) with small differences were approximately similar . It indicated that most of produced models were eligible to contribute in further processes, i.e., forecasting steps. However, it was logical to select the highest accuracy model which had the minimum RMSE or the maximum R correlation coefficient in order to be allowed to enter the forecast process. Nevertheless, the lowest RMSE in testing phases accompanied the lowest RMSE in validating phases in the most cases. It was detectable for R values, too.
We spoke about the mean of RMSE and R in testing and validating phases. These referred to 12 RMSE and R prediction values in testing steps of each month and also 10 stages of validating process. These were made more clear in Figs. 4 and 5 which exhibit the contrast between 3 months SPI of observed values and predicted in testing and validating phases, respectively.

The results of test process for three monthly SPI time series in Eqlid rain gauge station
Figure 5 included 12 sub-figures with determined titles. Each title described the number of lead month(s) and also the RMSE and R values for the related test. In fact, these sub-figures demonstrated how successful the applied ANN model worked to predict SPI values in a specific lead time. As a result, the ANN model which had eight neurons in the hidden layer with architecture of (6, 8, 12) also marked in Table 1 was selected for further process.
Ten times validation phases were exhibited in Fig. 6. RMSE of each validation process has been shown as sub-figures. These figures showed how the predicted values of 3 months SPI time series during total 12 months accord with the observed ones (12 months of predictions and 10 months for the shift in the number of months to have 10 times validations). Also, the model in validation phase could guess the fluctuations and behaviors of the measured SPI time series.

The results of validation process in 10 sections for three monthly SPI time series in Eqlid rain gauge station. The last figure showed forecasted values
As mentioned before, another step was forecasting the drought severities. The selected model (here gdx with the architecture of (6, 8, 12)) has been used for this purpose. In fact, the final row of Fig. 6 was associated with the forecasted values. The values of 3 months SPI during June 2008–May 2009 that were the first outcomes of the selected models showed the lowest RMSE or highest R in testing and validating phases. Such outputs from different SPI time series and rain gauge stations contributed to generate the maps of drought severities. This process was the second and the last outcome of the current drought modeling.
Figures 7, 8, 9, 10, 11, and 12 contain 12 maps of forecasted (first and second rows of maps) and 12 ones of observed (third and 4th rows of maps) drought severities classes for 3, 6, 9, 12, 18, and 24 monthly SPI time series, respectively. There were four classes in these maps, including D, ND, NW, and W which represented drought with red color, normal near to drought with yellow, normal near to wet with green, and W with blue, respectively. The forecasted maps contain 12 months for each type of SPI spanned from June 2008 to May 2009.

The forecasted and observed maps for three monthly SPI time series in Fars Province from June 2008 to May 2009

The forecasted and observed maps for six monthly SPI time series in Fars Province from June 2008 to May 2009

The forecasted and observed maps for nine monthly SPI time series in Fars Province from June 2008 to May 2009

The forecasted and observed maps for 12 monthly SPI time series in Fars Province from June 2008 to May 2009

The forecasted and observed maps for 18 monthly SPI time series in Fars Province from June 2008 to May 2009

The forecasted and observed maps for 24 monthly SPI time series in Fars Province from June 2008 to May 2009
In a general view, the agreement between the observed and forecasted maps was tangible in various degrees. These similarities were more obvious in the first 6 months from June to November 2008 than December 2008 to May 2009. Actually, in most cases, the difference between the observed and predicted maps was detected only in one class. For example, the regions in the observed maps having W class were appeared in the form of NW in the forecasted maps. The degree of similarities between the forecasted and observed maps was presented in Table 2 in percentage. In fact, these similarities consist of two groups: in the first group there were absolute agreements between the maps, but in the second one the similarities were explored by overlooking one class of error. This table demonstrated that the more the number of lead months, the less the absolute agreements between the forecasted and observed maps. As a result, 100 % agreement would not be seen. However, by overlooking one different class, the percentages of agreements would considerably increase and even 100 % of similarities in the first five lead months could be observed.
Obviously, the relationships and the similarities between the maps could be investigated in another aspect that is the spatial and temporal relationships among various forecasted maps. According to spatial relationships of the forecasted maps, there were important notes to emphasize. First, in most cases, the regional patterns of drought severities were preserved in the forecast process; therefore, a particular class of drought severity spanned a part of the study area and sometimes the whole area. Then, some classes of drought severities were detected as smaller areas such as a point surrounded by the wider class. However, it should be noted that these classes did not have considerable difference and they were in neighbor classes. For instance, the red color D classes have been surrounded by the yellow ND class or V.S. in most cases the far classes could not be detected on the maps.
Considering the temporal relationships between the forecasts and identifying particular classes of drought severities revealed some associations between the previous and the next maps. For example, Fig. 7 which included the observed and the forecasted maps of drought severities for three monthly SPI time series showed that the D class regions remained unchanged in the sequenced maps from June to September 2008. As it can be seen, two small regions during June 2008 have shown the D class. In the next map, during July 2008, some other small areas have appeared. In the north of the study area, D class has covered more areas. It was established during August and September 2008 then disappeared in October and replaced by the ND class, in the next maps. On the other hand, in some regions of the northwestern and southern part of the study area, the NW class appeared and immediately covered the whole area of Fars Province during November. As it can be seen, in the next forecasted maps, the NW and W classes covered all parts of the study area until May 2009 when the ND became the dominant class. Hence, different classes were obviously in transition in forecasted maps. This feature was found for other time series of SPI and even different time series. For example, the red D class regions in August and September 2008 for three monthly SPI time series could be found in the forecasted maps of six monthly SPI in similar dates. However, it was more dominant in the six monthly SPI maps than the three ones in the mentioned dates. As a result, it can be said that the spatial and temporal relationships of the forecasted drought severity maps has been preserved in the forecasting process.
4 Discussion
The most important feature of this study is the high correlation and integrated performance of the selected models while their training processes were completely independent. Each selected model was trained, tested, and validated independently; however, after mapping (in verification phase), the maps showed the regional pattern of drought and they considerably preserved their temporal and spatial relationships. There are some points which show the capabilities of the current methods presented in this study in forecasting the drought in a regional scale.
First, immediate transitions of different classes of drought severities should be accepted by caution. Since a particular area rarely shows completely different pattern of drought severity from surrounding regions, manifestation and appearance of strange and non-homogenous class of drought severity among other types of drought can be a type of error. It should be mentioned that although the near classes such as W and NW or NW and ND can be detected in a region, the neighboring of far classes such as D and W should be analyzed by caution. As results of this study showed, there are not considerable types of sudden transition or jumping in the presented maps and such status and independent produced models verify and justify that generally the acceptable type of drought forecasting have been done. In fact, the regional patterns of drought illustrate the existing of same forecasts in the neighbor stations.
Someone may ask that the intensities of drought in the maps have changed gradually, while the immediate alteration (for example, alteration from D to W conditions) also is possible and particularly by Markov chains they can be easily detected. It should be said that even throughout a complete SPI time series, transitions from neighbor classes especially normal ones have more frequency than sudden alterations, and in the case of 12 months of forecasting, their chance decreases considerably. In the temporal scale, immediate transition through different classes is possible; however, in the spatial scale, sudden changes of non-neighbor classes may be a sign of error.
Second, all the forecasted maps in different time series contain some information which relies in accordance to other ones and they do not disaffirm each other. For an example, concentration on a map such as forecasted one in August 2008 in Fig. 7 can reveal important notes. For the three monthly SPI, it shows a sub-region in the north with D status, while other parts mainly have been covered by ND. ND and D are the neighbor classes and therefore, a strange class of drought is not seen in this map. Also, the previous and after maps, i.e., forecasted ones in July and September 2008, exhibit to some extent similar patterns of D in the north and ND in remaining areas. The logical changes or alterations over the after forecasted maps also can be detected. Same results can be found for other maps of other time series of SPI. It justifies that not only the spatial patterns of forecasted maps has been respected, the temporal relationships among the forecasted maps also has been preserved during this regional drought forecasting.
Moreover, deeper view over the forecasted maps shows that there are detectable relationships between the maps of different time series of SPI. For an example, three monthly SPI are also associated with the same date maps of other time series of SPI and particularly the map of SPI 6 in August 2008 also shows that the majority of study area have been covered by D status and remaining ones have been covered by ND. Of course, the three monthly SPI maps in August 2008 involve the information of drought for the mentioned month and 2 months in previous; however, the SPI 6 maps in August 2008 contain the status of drought in this date and five previous months. Therefore, some differences in the format of drought severities classes are expected as well as ones which detected between these two maps. When the SPI is prolonged and reach to 12, 18, and 24 monthly ones, it is clear that the status of drought generates from the more previous months, and therefore, a map such as one in August 2008 reflects the drought circumstances from the long time in previous months. Interestingly, the maps which show the W in the January and February of 2009 in three monthly SPI maps have been followed by similar classes in six monthly ones, the NW or ND in the next prolonged time series of SPI. Once again, it justifies that the presented model considers spatial and temporal relationships during the forecasting process.
Third, also, the results in Table 2 showed that the agreements of forecasted and observed maps are considerable particularly in the first 6 months of predictions. Some of them showed more than 90 % of agreement. For example, the first four lead months of 3 monthly SPI as well as three ones in 12 monthly SPI maps showed these high ranks of accordance. Interestingly, by considering the overlook of one class different, this accordance reaches to 100 % for the first five lead months in all types of SPI and it remains to considerable percentages of accordance for remaining lead months. Furthermore, the conformity between each observed and estimated map for 12 and 24 monthly SPI maps as well as the results of percentage of accordance without overlooking one class of difference in Table 2 showed that these agreements dramatically reduced after six or seven lead months toward the end of lead months. The poor correlation between the weather signals in different lags with 12 and 24 monthly SPI time series was also detected in Fig. 4, and therefore, these weaker performances of predictions can refer to these low correlations.
Anyway, the results showed that the presented procedure in the current study can successfully forecast the drought severities for different SPI time series in Fars Province of Iran. The results shows that the average of percentage of accordance between the observed and forecasted maps in the first 6 months for all SPI time series is equal to 73 %. This value is 50 % for all 12 lead months and for all SPI time series. While, by considering the overlook of one class of difference, this value reaches to nearby 100 % for the first six lead months, and for all 12 lead months, it is equal to 95 % of accordance. Of course, it is clear that one class of error in predictions also can be a valuable achievement for many purposes such as water resource management as well as environmental management. As an example, when the model for a particular area predicts NW circumstances, by considering one class of error, the NW, ND, or W conditions are expected. It is obvious that in the practice, the programing and preparedness for NW status is in more accordance to those for W or ND conditions than D one. When a model predicts NW, it explains that in the future, the occurrences of normal or wet statuses are more probable than drought one. However, the prediction of ND can be a warning of drought.
The strong points of these predictions refer to some reasons which should be emphasized here. Preparedness of causal input data, frequent trained, tested, and evaluated ANNs models, and verification of final models were the strong points of these study. In drought forecasting, the preparedness of causal input data should be considered. As Fig. 4 showed, some weather signals have more correlations with the SPI time series and they indicated these correlations with several lags. Therefore, it is clear that they should be participated in modeling as more effective input parameters.
Also, the performance of different models should be tested, evaluated, and finally verified. As in current study, many models were trained and each model tested, and after that, validated ten times. Some researches suffice to train and test sections. However, in order to increase the reliability of the models’ performances, they should be validated, and it involves the implementation of some parts of input data which absolutely have not contributed in training section. This is a good opportunity for researchers to find how strong their model is and is their model aware from the main trues behind the problem. However, instead of having one validation process, this study considered the repetition of evaluation process ten times to promote the accuracy of the results. It is obvious that a model which shows better performance in ten times of evaluation is more reliable than one which have been analyzed and examined in a sole process. Also, the preprocessing of networks and previous tries and errors for the selection of BP algorithms significantly has a positive effectiveness to produce more homogenous models, and therefore, such work should be seriously done before further processing to select more appropriate BP algorithms.
Furthermore, the total selected results wholly were investigated in the verification part. Verifying of the results involves the seeking of logical relationships throughout the results. Mapping the results and exploring the spatial and temporal relationships over the maps and also comparison of the observed and predicted maps can considerably increase the reliability of the results which can be more acceptable for the executive managers and decision makers. Therefore, the verification phase a is very important step of this modeling process which cannot be underestimated. The strong and weak points of drought forecasting process can be clarified by the verification phase. Without this step, many possible errors and also strong point of the drought forecasting may be hidden.
The continuous forecasted and observed values of SPI after interpolation by IDW map were reclassified into four classes of drought. The number of classes was selected based on the models’ performances. Model performances to some extent can cover the one unite of SPI. For example, Fig. 6 showed the RMSEs are less than 1. Therefore, classifying the SPI values to four classes can cover this model performance. While, producing eight classes of drought may be successfully obtained with the RMSE values less than 0.5. The ability of presented method to reach this accuracy can be followed by using other types of methods in artificial intelligences such as ANFIS and SVR alongside the ANNs and also implementation of other technique for preprocessing of initial data such as Principle Component Analysis (PCA), stepwise regression, etc. which will be followed in our future works.
The lead time of this study was set to 12 months ahead. Although the lead time can be set to optional value, as it was mentioned in previous, the results of this study showed that without ignoring one class difference, the forecasting accuracy of the model for the first 6 months was more than 70 % and it was equal to 50 % for the total lead months and total time series of SPI. It shows that by increasing the number of lead times, the accuracy of the model is decreased. However, the awareness of probable drought severities in the next 6 months also is valuable for many purpose particularly agricultural activities and water resource allocation and planning. This results is very useful for locations where heavy reliance on rain-fed agriculture and they are highly vulnerable to impacts of droughts. Since the drought influences the wide range of people and all parts of the ecosystems, such the forecasting models are very applicable in integrated watershed management approach. Many activities and objectives which are associated with integrated watershed management systems such as food security, cropping patterns, increasing of productivity, soil and water conservation, smart or precision agriculture, water resources allocation, crisis management (mainly associated with the drought and flood), etc. are ones which need such the forecasting model in order to achieve better performances and more efficiency. Undoubtedly, without an effective drought mitigation strategies and comprehensive and integrated programing make any region highly vulnerable to impacts of droughts.
Another important point with should be addressed is associated with simplicity of this model. It is a simple model which its input data can be easily found in any parts of the world and its structure makes the models as potential candidate for the operational purposes and drought preparedness. It can help managers to prepare drought mitigation strategies and the presented method is a potential candidate for addressing the drawbacks in drought forecasting.
5 Conclusion
Early drought warning systems are essential tools to mitigate the drought hazard. Drought forecast plays crucial role in successfulness of such systems. Plenty methods have been applied by many researchers in different parts of the world particularly through the application of artificial intelligences. Frequent successful performance of drought predictions through ANNs by many researchers have been reported in different parts of world. However, to the best of our knowledge, rarely of them have considered to a regional scale and contributing several stations for drought mapping. While, verification of results through different time series and mapping the results can reveal important notes about successfulness of applied model. Also, the models for drought prediction that is one of the the most important natural hazards and disasters should pass several steps to get an acceptable result including training, testing, validation, and verification. Of course, the initial tries and errors to find optimum method and concentration on the more efficient procedures is an important note that should not be underestimated. The models especially advanced statistical ones such as ANNs which mainly focus on auto-calibration and give the weights and importance of the inputs by frequent iterations, since they have different options in modeling process (such as the number of inputs and wide varieties in their selections, neurons in hidden layer, number of hidden layers, number of iterations or epochs, kinds of objective functions, types of BP algorithms or even other kinds of ANNs model), their outputs will change with any alteration. It makes them to remain as a subjective matter and getting an explicit and certain output is impossible. However, it is important to note that the model should pass the different steps of training, testing, validation, and verification. Based on these steps, it can be found whether the model is aware from the nature of phenomenon or not. Also, initial try and error efforts help the researchers to concentrate on more adaptive and appropriate models instead of long time testing of other possible ones. It is really a time-consuming process and this approach of focus on more successful methods passed from initial surveys can reduce this restriction.
In order to obtain successful performance of drought forecasting, these steps should be followed:
-
1.
A drought index in accordance to the circumstances mainly available data should be selected.
-
2.
Other effective time series of data such as weather signals should be provided and most effective ones on the drought time series should be selected. Investigation in the time series and finding the correlations and selecting the appropriate lags should be considered.
-
3.
The appropriate model in accordance to conditions should be selected. It is clear that the most robust models especially ones which are adaptive to nonlinear nature of the drought phenomena can bring more accurate results of the drought forecasting. Here, ANN model was selected.
-
4.
Initial input data should be divided in four sections involving training, testing, and validating and verification ones.
-
5.
By trial and error and referring to previous experiences of the researches and researchers, the appropriate BP should be chosen. Number of hidden layer also is an important choice which should be considered here.
-
6.
Frequent models of ANNs in regard to the number of neurons in hidden layer for each time series of SPI in each weather station should be trained.
-
7.
From the trained models, most successful ones should be allowed to pass to validation process through the testing phase.
-
8.
In validation phase, models should be validated. The number of validation process should be more than one. Here, 10 times were seemed.
-
9.
Most successful models in validation phase should be allowed to participate in mapping the results. Various time series of drought should be mapped.
-
10.
The forecasted maps should be compared with the observed ones in verification process. Also, the relationships between the maps of particular SPI time series and also among different SPI time series should be checked. Both spatial and temporal relationships should be respected.
Last but not least, the drought has still remained as one of the most dangerous hazards as well as complicated phenomenon which need more and more efforts to be known. Although drought forecasting in regional time scale in this study has been seriously followed, and several steps have been passed to reach an acceptable and logical forecast, the sophisticated nature of this type of hazard should not be underestimated and efficiency of the presented model must be enhanced to reach better performance of drought forecasting.
References
Abramowitz M, Stegun A (1965) Handbook of mathematical formulas, graphs, and mathematical tables. Dover Publications Inc, New York
Ahani H, Kherad M, Kousari M, Rezaeian-Zadeh M, Karampour M, Ejraee F, Kamali S (2012) An investigation of trends in precipitation volume for the last three decades in different regions of Fars Province, Iran. Theor Appl Climatol 109:361–382
Aherne J, Larssen T, Cosby BJ, Dillon PJ (2006) Climate variability and forecasting surface water recovery from acidification: modelling drought-induced sulphate release from wetlands. Sci Total Environ 365:186–199
Anderson ML, Kavvas ML, Mierzwa MD (2001) Probabilistic/ensemble forecasting: a case study using hydrologic response distributions associated with El Niño/Southern Oscillation (ENSO). J Hydrol 249:134–147
ArcGIS (2008) ArcGIS desktop 9.3 Demos. http://esri.com. 2008-06-26. Retrieved 2009-04-16
Bari Abarghouei H, Kousari M, Asadi Zarch M (2011) Prediction of drought in dry lands through feedforward artificial neural network abilities. Arab J Geosci:1–17
Barua S, Perera BJC, Ng AWM, Tran D (2010) Drought forecasting using an aggregated drought index and artificial neural network. Journal of Water and Climate Change 1:193–206
Belayneh A, Adamowski J (2012) Standard precipitation index drought forecasting using neural networks, wavelet neural networks, and support vector regression. Applied Computational Intelligence and Soft Computing 2012:13
Belayneh A, Adamowski J, Khalil B, Ozga-Zielinski B (2014) Long-term SPI drought forecasting in the Awash River Basin in Ethiopia using wavelet neural network and wavelet support vector regression models. J Hydrol 508:418–429
Beven KJ (2003) Rainfall-runoff modelling: the primer. Wiley, Chichester
Bishop C (1995) Neural networks for pattern recognition. Oxford University Press, Oxford
Cancelliere A, Mauro GD, Bonaccorso B, Rossi G (2007a) Drought forecasting using the Standardized Precipitation Index. Water Resour Manage 21:801–819
Cancelliere A, Mauro GD, Bonaccorso B, Rossi G (2007b) Stochastic forecasting of drought indices. In: Rossi G, Vega T, Bonaccorso B (eds) Methods and tools for drought analysis and management. Springer, Netherlands, pp 83–100
Chen F-W, Liu C-W (2012) Estimation of the spatial rainfall distribution using inverse distance weighting (IDW) in the middle of Taiwan. Paddy Water Environ 10:209–222
Chen J, Jin Q, Chao J (2012) Design of deep belief networks for short-term prediction of drought index using data in the Huaihe River basin. Math Probl Eng 2012:16
Choi K-S, Oh S-B, Byun H-R, Kripalani RH, Kim D-W (2011) Possible linkage between East Asian summer drought and North Pacific Oscillation. Theor Appl Climatol 103:81–93
Chow TWS, Cho SY (1997) Development of a recurrent Sigma-Pi neural network rainfall forecasting system in Hong Kong. Neural Comput & Applic 5:66–75
Chung C, Salas J (2000) Drought occurrence probabilities and risks of dependent hydrologic processes. J Hydrol Eng 5:259–268
Cutore P, Di Mauro G, Cancelliere A (2009) Forecasting Palmer Index using neural networks and climatic indexes. J Hydrol Eng 14:588–595
Dastorani MT, Afkhami H, Sharifidarani H, Dastorani M (2010) Application of ANN and ANFIS models on dryland precipitation prediction (case study: Yazd in Central Iran). J Appl Sci 10:2387–2394
Dezfuli A, Karamouz M, Araghinejad S (2010) On the relationship of regional meteorological drought with SOI and NAO over southwest Iran. Theor Appl Climatol 100:57–66
Durdu Ö (2010) Application of linear stochastic models for drought forecasting in the Büyük Menderes River basin, western Turkey. Stoch Environ Res Ris Assess 24:1145–1162
Easterling WE (1989) Coping with drought hazard: recent progress and research priorities. In: Siccardi F, Bras RL (eds) Natural disasters in European Mediterranean countries. US National Science Foundation and National Research Council of Italy, Perugia, pp 231–270
Edwards D, McKee T (1997) Characteristics of 20th century drought in the United States at multiple timescales. Colorado State University Fort Collins, Climatology Report
Erol Keskin M, Terzi Ö, Dilek Taylan E, Küçükyaman D (2011) Meteorological drought analysis using artificial neural networks. Sci Res Essays 6:4469–4477
Farokhnia A, Morid S, Byun H-R (2011) Application of global SST and SLP data for drought forecasting on Tehran plain using data mining and ANFIS techniques. Theor Appl Climatol 104:71–81
Gelcer E, Fraisse C, Dzotsi K, Hu Z, Mendes R, Zotarelli L (2013) Effects of El Niño Southern Oscillation on the space–time variability of Agricultural Reference Index for Drought in midlatitudes. Agric For Meteorol 174–175:110–128
Guttman NB (1998) Comparing the Palmer drought index and the Standardized Precipitation Index. J Am Water Resour Assoc 34:113–121
Hammer GL, Hansen JW, Phillips JG, Mjelde JW, Hill H, Love A, Potgieter A (2001) Advances in application of climate prediction in agriculture. Agric Syst 70:515–553
Han P, Wang PX, Zhang SY, Zhu DH (2010) Drought forecasting based on the remote sensing data using ARIMA models. Math Comput Model 51:1398–1403
Hao Z, AghaKouchak A, Nakhjiri N, Farahmand A (2014) Global integrated drought monitoring and prediction system. Scientific Data
Hayes M, Wilhite DA, Svodoba M, Vanyarkho O (1999) Monitoring the 1996 drought using the standardized precipitation index. Bull Am Meteorol Soc 80:429–438
Hecht-Nielsen R (1990) Neurocomputing. Addison-Wesley, Menlo Park
Hornik K, Stinchcombe M, White H (1989) Multilayer feedforward networks are universal approximators. Neural Network:359–366
Hughes B, Saunders M (2002) A drought climatology for Europe. Int J Climatol 22:1571–1592
Jiang X-C, Chen S-F (2009) Application of weighted Markov SCGM(1,1)c model to predict drought crop area. Systems Engineering - Theory & Practice 29:179–185
Jones JW, Hansen JW, Royce FS, Messina CD (2000) Potential benefits of climate forecasting to agriculture. Agric Ecosyst Environ 82:169–184
Karamouz M, Rasouli K, Nazif S (2009) Development of a hybrid index for drought prediction: case study. J Hydrol Eng 14:617–627
Karmakar S, Kowar MK, Guhathakurta P (2008) Development of an 8-parameter probabilistic artificial neural network model for long-range monsoon rainfall pattern recognition over the smaller scale geographical region–district, 2008 ICETET ‘08 First International Conference on Emerging Trends in Engineering and Technology., pp 569–574
Karmakar S, Kowar MK, Guhathakurta P. (2009a) Evolving and evaluation of 3LP FFBP deterministic ANN model for district level long range monsoon rainfall prediction. J Environ Sci Eng 51(2):137-144
Karmakar S, Kowar MK, Guhathakurta P (2009b) Long-range monsoon rainfall pattern recognition and prediction for the subdivision ‘EPMB’ Chhattisgarh using deterministic and probabilistic neural network, 2009 ICAPR ‘09 Seventh International Conference on Advances in Pattern Recognition., pp 367–370
Kendall DR, Dracup JA (1992) On the generation of drought events using an alternating renewal-reward model. Stochastic Hydrol Hydraul 6:55–68
Kisi O, Sanikhani H (2015) Prediction of long-term monthly precipitation using several soft computing methods without climatic data. Int J Climatol. doi: 10.1002/joc.4273
Kousari MR, Ahani H, Hakimelahi H (2013) An investigation of near surface wind speed trends in arid and semiarid regions of Iran. Theor Appl Climatol 1–16
Lippmann RP (1987) An introduction to computing with neural nets. IEEE ASSP Mag 4:4–22
Lohani VK, Loganathan GV (1997) An early warning system for drought management using the Palmer drought index. J Am Water Resour Assoc 33:1375–1386
Lohani VK, Loganathan GV, Mostaghimi S (1998) Long-term analysis and short-term forecasting of dry spells by Palmer drought severity index. Nord Hydrol 29:21–40
Long J, Ying L, Zhenshan L (1997) Comparison of long-term forecasting of June–August rainfall over Changjiang-Huaihe Valley. Adv Atmos Sci 14:87–92
Lu GY, Wong DW (2008) An adaptive inverse-distance weighting spatial interpolation technique. Comput Geosci 34:1044–1055
Mabaso MLH, Kleinschmidt I, Sharp B, Smith T (2007) El Niño Southern Oscillation (ENSO) and annual malaria incidence in Southern Africa. Trans R Soc Trop Med Hyg 101:326–330
Maier HR, Dandy GC (2000) Neural networks for the prediction and forecasting of water resources variables: a review of modelling issues and applications. Environ Model Softw 15:101–124
Maier HR, Dandy GC (2001) Neural network based modelling of environmental variables: a systematic approach. Math Comput Model 33:669–682
Masinde M (2013) Artificial neural networks models for predicting effective drought index: factoring effects of rainfall variability. Mitig Adapt Strateg Glob Change:1–24
McCulloch WS, Pitts W (1943) A logical calculus of the ideas imminent in nervous activity. Bulletin and Mathematical Biophysics 5:115–133
McKee TB, Doesken NJ, Kleist J (1993) The relationship of drought frequency and duration to time scales. In: Proc 8th conference on applied climatology, Anaheim, California., pp 179–184
Meza FJ (2005) Variability of reference evapotranspiration and water demands. Association to ENSO in the Maipo River basin, Chile. Glob Planet Chang 47:212–220
Mishra AK, Desai VR (2005a) Drought forecasting using stochastic models. Stoch Environ Res Ris Assess 19:326–339
Mishra AK, Desai VR (2005b) Drought forecasting using stochastic models. Stoch Environ Res Risk Assessment 19:326–339
Mishra AK, Desai VR (2006) Drought forecasting using feed-forward recursive neural network. Ecol Model 198:127–138
Mo KC, Schemm J-KE, Yoo S-H (2009) Influence of ENSO and the Atlantic Multidecadal Oscillation on drought over the United States. J Clim 22:5962–5982
Modarres R (2007) Streamflow drought time series forecasting. Stoch Environ Res Ris Assess 21:223–233
Moradi HR, Rajabi M, Faragzadeh M (2011) Investigation of meteorological drought characteristics in Fars Province, Iran. CATENA 84:35–46
Morid S, Smakhtin V, Bagherzadeh K (2007) Drought forecasting using artificial neural networks and time series of drought indices. Int J Climatol 27:2103–2111
Ochola WO, Kerkides P (2003) A Markov chain simulation model for predicting critical wet and dry spells in Kenya: analysing rainfall events in the Kano Plains. Irrig Drain 52:327–342
Özger M, Mishra AK, Singh VP (2009) Low frequency drought variability associated with climate indices. J Hydrol 364:152–162
Özger M, Mishra AK, Singh VP (2012) Long lead time drought forecasting using a wavelet and fuzzy logic combination model: a case study in Texas. J Hydrometeorol 13:284–297
Palmer WC (1965) Meteorological drought. Research paper no 45. US Department of Commerce Weather Bureau, Washington
Paulo AA, Pereira LS (2007) Prediction of SPI drought class transitions using Markov chains. Water Resour Manage 21:1813–1827
Rahimikhoob A (2010) Estimation of evapotranspiration based on only air temperature data using artificial neural networks for a subtropical climate in Iran. Theor Appl Climatol 101:83–91
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning internal representations by error propagation. In: Rumelhart DE, McClelland JL (eds) Parallel distributed processing. MIT Press, Cambridge
Saldariaga J, Yevjevich V (1970) Application of run-lengths to hydrologic series Hydrol Paper. Colorado State University Publication, Colorado State University, Fort Collins, CO
Sen Z (1976) Wet and dry periods of annual flow series. J Hydrol Div ASCE 106:99–115
Sen Z (1977) Run sums of annual flow series. J Hydrol 35:311–324
Sen Z (1990) Critical drought analysis by second-order Markov chain. J Hydrol 120:183–202
Shrestha A, Kostaschuk R (2005) El Niño/Southern Oscillation (ENSO)-related variability in mean-monthly streamflow in Nepal. J Hydrol 308:33–49
Shrivastava G, Sanjeev K, Manoj Kumar K, Guhathakurta P (2012) Application of artificial neural networks in weather forecasting: a comprehensive literature review. International Journal of Computer Applications 51:17–29
Singh P, Borah B (2013) Indian summer monsoon rainfall prediction using artificial neural network. Stoch Environ Res Ris Assess 27:1585–1599
Soufi M (2004) Morpho-climatic classification of gullies in Fars Province, southwest of Iran. In: ISCO 2004e 13th international soil conservation organisation conference, Brisbane
Steinemann A (2003) Drought indicators and triggers: a stochastic approach to evaluation 1. JAWRA 39:1217–1233
Tang Z, Fishwick PA (1993) Feedforward neural nets as models for time series forecasting. ORSA J Comput 5:374–385
Thom H (1958) A note on gamma distribution. Mon Weather Rev 86:117–122
Tsakiris G, Vangelis H (2005) Establishing a drought index incorporating evapotranspiration. European Water 9(10):3–11
Tsakiris G, Pangalou D, Vangelis H (2007) Regional drought assessment based on the Reconnaissance Drought Index (RDI). Water Resour Manage 21:821–833
Tsakiris G, Nalbantis I, Pangalou D, Tigkas D, Vangelis H (2008) Drought meteorological monitoring network design for the Reconnaissance Drought Index (RDI), 1st International Conference “Drought Management: Scientific and Technological Innovations”. Zaragoza–Spain
Tsakiris G, Nalbantis I, Vangelis H, Verbeiren B, Huysmans M, Tychon B, Jacquemin I, Canters F, Vanderhaegen S, Engelen G, Poelmans L, Becker P, Batelaan O (2013) A system-based paradigm of drought analysis for operational management. Water Resour Manage 27:5281–5297
Ubilava D, Helmers CG (2013) Forecasting ENSO with a smooth transition autoregressive model. Environ Model Softw 40:181–190
Van Rooy MP (1965) A rainfall anomaly index independent of time and space. Notos 14:43
Vicente-Serrano SM, Begueria S, Lopez-Moreno JI (2010) A multiscalar drought index sensitive to global warming: the standardized precipitation evapotranspiration index. J Clim 23:1696–1718
Voinov AA (2008) Sensitivity, calibration, validation, verification. In: Sven Erik J, Brian F (eds) Encyclopedia of ecology. Academic, Oxford, pp 3221–3227
Woli P, Jones J, Ingram K, Paz J (2013) Forecasting drought using the agricultural reference index for drought (ARID): a case study. Weather Forecast 28:427–443
Wolter K, Timlin MS (1998) Measuring the strength of ENSO—how does 1997/98 rank? Weather 53:315–324
Wong FS (1991) Time series forecasting using backpropagation neural networks. Neurocomputing 2:147–159
Woong Kim T, Valdés JB (2003) A nonlinear model for drought forecasting based on conjunction of wavelet transforms and neural networks. ASCE J Hydrolog Eng 8:319–328
Wu CL, Chau KW, Fan C (2010) Prediction of rainfall time series using modular artificial neural networks coupled with data-preprocessing techniques. J Hydrol 389:146–167
Yevjevich V (1967) An objective approach to definitions and investigations of continental hydrologic droughts. Hydrol Papers Colorado State University, Fort Collins, CO
Yurekli K, Kurunc A (2006) Simulating agricultural drought periods based on daily rainfall and crop water consumption. J Arid Environ 67:629–640
Acknowledgments
The authors gratefully appreciate the Yazd University and gratefully appreciate the Cadastre group (Management Center for Strategic Projects) in Fars Organization of Agricultural Jahad for their support and providing research facilities.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Kousari, M.R., Hosseini, M.E., Ahani, H. et al. Introducing an operational method to forecast long-term regional drought based on the application of artificial intelligence capabilities. Theor Appl Climatol 127, 361–380 (2017). https://doi.org/10.1007/s00704-015-1624-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-015-1624-6