
Abstract
The operational medium range rainfall forecasts of the Met Office Unified Model (UM) are evaluated over India using the Contiguous Rainfall Area (CRA) verification technique. In the CRA method, forecast and observed weather systems (defined by a user-specified rain threshold) are objectively matched to estimate location, volume, and pattern errors. In this study, UM rainfall forecasts from nine (2007–2015) Indian monsoon seasons are evaluated against \(0.5^{\circ }\times 0.5^{\circ }\) IMD–NCMRWF gridded observed rainfall over India \((6.5^{\circ }{-}38.5^{\circ }\hbox {N}, 66.5^{\circ }{-}100.5^{\circ }\hbox {E})\). The model forecasts show a wet bias due to excessive number of rainy days particularly of low amounts \(({<}1\,\hbox {mm}\,\hbox {d}^{-1})\). Verification scores consistently suggest good skill the forecasts at threshold of \(10\,\hbox {mm}\,\hbox {d}^{-1}\), while moderate (poor) skill at thresholds of \({<}20\,\hbox {mm}\,\hbox {d}^{-1}\,({<}40\,\hbox {mm}\,\hbox {d}^{-1})\). Spatial verification of rainfall forecasts is carried out for 10, 20, 40 and \(80\,\hbox {mm}\,\hbox {d}^{-1}\) CRA thresholds for four sub-regions namely (i) northwest (NW), (ii) southwest (SW), (iii) eastern (E), and (iv) northeast (NE) sub-region. Over the SW sub-region, the forecasts tend to underestimate rain intensity. In the SW region, the forecast events tended to be displaced to the west and southwest of the observed position on an average by about \(1^{\circ }\) distance. Over eastern India (E) forecasts of light (heavy) rainfall events, like \(10\,\hbox {mm}\,\hbox {d}^{-1}\) (20 and \(40\,\hbox {mm}\,\hbox {d}^{-1}\)) tend to be displaced to the south on an average by about \(1^{\circ }\) (southeast by \(1{-}2^{\circ }\)). In all four regions, the relative contribution to total error due to displacement increases with increasing CRA threshold. These findings can be useful for forecasters and for model developers with regard to the model systematic errors associated with the monsoon rainfall over different parts of India.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The rainfall during the monsoon (June to September, JJAS) season contributes over 75% of the annual rainfall in most parts of the Indian subcontinent and is the lifeline for agriculture and economy of the entire region. Forecasting of seasonal rainfall gets great attention due to ensuing drought (flood) conditions. The monsoon rainfall occurs in many sporadic weather events having spatial scales from 100 to 1000 km. The daily and weekly rainfall during the season poses a significant forecasting challenge in Numerical Weather Prediction (NWP). This is due to complex interactions involving topography, treatment of synoptic scale systems, and mesoscale convective systems (in the NWP models) and non-availability of good quality high resolution observations over land and neighboring seas.
Numerical weather prediction (NWP) models have undergone significant improvements in the last two decades and have demonstrated reasonable success and skill in short to medium-range weather forecasting (Kalnay et al. 1998; Simmons and Hollingsworth 2002; Harper et al. 2007). However, the predictability of Indian summer monsoon conditions is quite low (Goswami and Ajay Mohan 2001). Drivers of the intraseasonal variability such as the Madden-Julian oscillation modulate the frequency of occurrence of synoptic events such as lows, depressions and tropical cyclones (Maloney and Hartmann 2000; Goswami et al. 2003; Bessafi and Wheeler 2006). Accurate Quantitative Precipitation Forecasting (QPF) still remains a challenge, as evidenced by the frequent large errors in the predicted precipitation amounts and spatial distribution from NWP models. Factors contributing to these errors include errors in the initial conditions, predicted flow (dynamics), large-scale and convective rain processes (physics), grid resolution and representation of local land surface characteristics. As a result, the QPFs often have large errors in predicted position of the rain system, shape and size of the rain pattern, and magnitude or intensity of rainfall.
With the enhanced computing capability in recent years, the spatial and temporal resolution of models has also increased. Verification of high resolution forecasts using traditional metrics often suggests poor forecast skill due to the lack of exact matches among the forecast/observation pairs. Several new diagnostic spatial verification approaches have been developed recently that better reflect the quality of the forecasts. Feature-based methods and neighborhood verification approaches assess the broader forecast quality without over-penalizing the errors at grid scale. Ebert (2008), Ebert and Gallus (2009), and Gilleland et al. (2010) provide a detailed review and inter-comparison of several spatial verification methods. The Contiguous Rain Area (CRA) method is a feature-based approach that isolates systems or features of interest and evaluates their properties, namely, location, size, intensity, and pattern. It was one of the first methods to measure errors in predicted location and to separate the total error into components due to location, volume, and pattern errors (Ebert and McBride 2000; Ebert and Gallus 2009).
The aim of the paper is to investigate and quantify the rainfall forecast biases in the unified model to better predict the Indian monsoon. The medium range rainfall forecasts over India are evaluated in this study to assess the model performance during the monsoon season. The Met Office Unified Model rainfall forecasts (UM hereafter) during the nine monsoon (JJAS) seasons from 2007 to 2015 are evaluated using traditional and CRA verification techniques.
There have been quite a few studies reporting rainfall forecast verification over India based on different models (Mandal et al. 2007; Das et al. 2008; Ashrit and Mohandas 2010; Chakraborty 2010; Iyengar et al. 2011; Ashrit et al. 2015; Sharma et al. 2015). In general, these studies indicate that the average root mean squared error (RMSE) of daily rainfall is high (low) in higher (lower) rainfall regions and that RMSE increases with lead time. Spatial distributions of various performance metrics over Indian land regions show that models tend to have better forecast skill over northern and northwestern India (Iyengar et al. 2011). The detailed verification of the UM forecasts and its comparison with National Centre for Medium Range Weather Forecasting (NCMRWF) operational forecasts highlighting the biases are reported in a series of monsoon reports (Iyengar et al. 2011, 2014). The data and verification methodology are described in section 2. Section 3 gives examples of CRA method applied to rain systems over India and discusses the results in the context of regional performance. The summary and conclusions are given in section 4.
2 Data and methodology
2.1 Observed rainfall data over India
Rainfall analysis based on quality controlled observations is most crucial for benchmarking the capabilities and performance of NWP forecasts. The daily rainfall gridded data (over land points only) for the period of 2007–2011 used in the present study is obtained from India Meteorological Department (IMD). This gridded data is prepared based on the rainfall measurement obtained from the rain gauges, which are the most trusted information source. The interpolation method used to develop this data set is Sheperd interpolation (Shepard 1968), which is discussed in Rajeevan et al. (2006) also. NCMRWF–IMD (National Centre for Medium Range Weather Forecasting–India Meteorological Department) Merged Satellite Gauge (NMSG; Mitra et al. 2009) daily rainfall analyses has been used for the period 2012–2015. The horizontal resolution of the data (2007–2015) is at \(0.5^{\circ }\hbox { latitude}\times 0.5^{\circ }\) longitude. NMSG rainfall data is the merge product of near-real-time Tropical Rainfall Measuring Mission Multi-satellite Precipitation Analysis (TMPA)-3B42 and rain gauge data from the IMD using an objective analysis scheme. Indian monsoon rainfall represented by rainfall analysis based on IMD rain gauge (2007–2011) and NMSG (2012–2015) is more realistic than any other available dataset because of the fact that it uses additional local rain gauge observations (Mitra et al. 2013). This analyzed rainfall product therefore provides a better baseline for NWP model validation and monsoon model development. The entire observed rainfall data series (2007–2015) will be referred as OBS hereafter.
2.2 Forecast rainfall over India
The Met Office Unified Model is the numerical modeling system developed for the seamless prediction of weather and climate systems (Davies et al. 2005; Walters et al. 2011; Brown et al. 2012). This ‘seamless’ prediction system implies that the same model with different configuration across all temporal and spatial scales is used with each designed configuration is to best represent the processes which have most influence on the timescale of interest. For example, the use of a coupled ocean model is essential for accurate climate predictions, while higher resolution atmospheric model component can be more useful than running a costly ocean component for short to medium range weather forecasting. The rainfall output from the Met Office operational medium range global model configuration is used in this study. The Unified Model (UM) is continually developed, taking advantage of improved understanding of atmospheric processes and steadily increasing supercomputer power. The year to year important changes and upgrades during 2007–2015 in the model configuration are listed in table 1. The atmospheric component of unified model is based on non-hydrostatic dynamics with semi-Lagrangian advection and semi-implicit time stepping. It is a grid point model with the ability to run with a rotated pole and variable horizontal grid. A number of sub-grid scale processes are represented, including convection (Gregory and Rowntree 1990; Gregory and Allen 1991; Grant 2001), boundary layer turbulence (Brown et al. 2007), radiation (Edwards and Slingo 1996), cloud microphysics and orographic drag (Webster et al. 2003). The model is initialized using a state of the art global four-dimensional variation (4DVAR; Rawlins et al. 2007) data assimilation technique. During 2007–2015, the horizontal and vertical resolution of the global configuration improved from about 40 km and 50 levels in 2007 to about 17 km and 85 levels in 2015. Daily rainfall forecast at all lead times starting from day 1 to 5 is used for evaluation. For brevity, the results based on the evaluation of day 1 forecast are presented. It is found that results at lead times starting from day 2 to 5 are consistent with that of day 1 forecast. To carry out the evaluation of the model, the rainfall forecast is interpolated at \(0.5^{\circ }\times 0.5^{\circ }\) same as that of observed rainfall. The analysis has been carried out over the land point just to focus the model performance over land regions.
2.3 Verification methodology
2.3.1 Categorical verification approach
The forecast daily rainfall fields are verified using standard categorical verification scores, which are based on the component of the two by two contingency table elements. This approach is frequently used by operational forecasters. In this study, the metrics which are calculated and evaluated are probability of detection (POD), probability of false detection (POFD), equitable threat score (ETS), extreme dependence score (EDS), success ratio (SR), and Hansen and Kuiper’s score (HK-score). These metrics are simple and easily understood. However, these scores are generally low for higher rainfall thresholds. The detailed descriptions of these scores are available in standard references on statistical methods (e.g., Wilks 2011; Jolliffe and Stephenson 2011).
2.3.2 CRA verification method
The traditional verification scores indeed provide useful quantification of model performances. However, when we evaluate the skill of high-resolution NWP models, these metrics seem inadequate. These scores are severely affected by the very well known ‘double penalty’ problem, which is associated with errors in the predicted location of weather features (Ebert et al. 2013). Hence, an intuitively better forecast may score worse than an apparently worse forecast (Roebber et al. 2004; Rossa et al. 2008). Also, traditional verification score do not give any hint about the sources of the errors in the forecast. To address some of the shortcomings of the traditional verification scores, Ebert and McBride (2000) developed a feature based spatial verification method called as Contiguous Rain Areas (CRA) method. The CRA method quantifies the forecast rainfall location errors and also decomposes the total error into components due to errors in (i) location, (ii) volume, and (iii) pattern. The location errors in the model forecasts suggest issues with predicted flow and the model dynamics. The volume and pattern errors possibly emanate from physics and thermodynamics. The steps involved in the CRA technique are described in Ebert and Gallus (2009). A brief summary of the procedure is given here.
A CRA is defined for an observation/forecast pair based on a user specified isohyet (rain rate contour) in the forecast and/or the observations. It is the union of the forecast and observed rain entities as illustrated in figure 1. This simple approach is used to match a forecast rain system with an observed rain system under the assumption that they are associated with a common synoptic situation, which is reasonable for monsoon rain events. During the monsoon season, large parts of India regularly receive rainfall in the range up to \(10\,\hbox {mm}\,\hbox {d}^{-1}\). It was found that choice of 1, 2, and \(5\,\hbox {mm}\,\hbox {d}^{-1}\) contour frequently spread the CRA across large geographical areas, merging unrelated rain systems. CRAs defined by higher thresholds of 10, 20, 40 and \(80\,\hbox {mm}\,\hbox {d}^{-1}\) were used to better isolate the heavy rain events of interest in this study.

CRA formed by overlap of forecast and observations.

Verification of forecast (left) rainfall over India valid for \(17{\mathrm{th}}\) June, 2013. Observed rainfall and the skill scores (using a \(1\,\hbox {mm}\,\hbox {d}^{-1}\) threshold) are also shown.
Firstly, the CRA objects are identified in observation and forecast pair for a threshold (e.g., \(10\,\hbox {mm}\,\hbox {day}^{-1}\)). In the next step a pattern matching technique is used for estimating the location error. Here the forecast field is horizontally translated over the observed field until the best match is obtained. The geometric distance between the centers of gravity (COG) in the observed and estimated fields forms the location error or vector displacement. The best match between the two entities can be determined either by (a) maximizing the correlation coefficient, (b) minimizing the total squared error, (c) maximizing the overlap of the two entities, or by (d) overlaying the centers of gravity of the two entities. For a good forecast, all of the methods will give very similar location errors. In the present study, the best match is determined by maximizing the correlation, as was also done by Ebert and Gallus (2009). The mean squared error (MSE) and its decomposition (location error, volume error and pattern error) are computed as shown below (see Grams et al. 2006, for details of the derivation).
where the component errors are estimated as
In the above expressions \(F'\) and \(O'\) are the mean forecast and observed precipitation values after shifting the forecast to obtain the best match, \(S_{F}\) and \(S_{O}\) are the standard deviations of the forecast and observed precipitation, respectively, before shifting. The spatial correlation between the original forecast and observed features (r) increases to an optimum value \((r_{{\textit{OPT}}})\) in the process of correcting the location via pattern matching. The number of ‘good matches’ corresponds to the number of forecasts that matched well with observations when the optimum correlation \((r_{{\textit{OPT}}})\) was (statistically) significantly greater than zero (accessed via two tailed t-test).

CRA verification results for forecast rainfall over Uttarakhand state of India valid for \(17{\mathrm{th}}\) June, 2013. The CRA is defined using a \(40\,\hbox {mm}\,\hbox {d}^{-1}\) threshold.
2.3.3 Example of CRA verification over India
The rainfall within the monsoon season is generally associated with low pressure systems and monsoon depressions. These depressions and low pressure systems sometimes interact with mid-latitude westerly trough and produce copious rainfall leading to flooding (Dube et al. 2014). The evaluation of such rainfall systems is of special interest, including their displacement, volume and pattern errors. We consider an example of a very heavy rain leading to flooding situation over state Uttarakhand in India on \(17{\mathrm{th}}\) June, 2013. The heavy rainfall over Uttarakhand was associated with a monsoon low pressure system, which originate in Bay of Bengal and starts moving northwestwards with large amount of moisture. When the moist air from Bay of Bengal interacted with mid-latitude westerly trough, strong low level convergence were developed which led to deep convention over Uttarakhand (Dube et al. 2014; Joseph et al. 2014; Rajesh et al. 2016). Figure 2 shows the rainfall verification statistics with several commonly used quantitative precipitation forecast (QPF) on the national scale for day 1 forecast valid on \(17{\mathrm{th}}\) June 2013 from UM rainfall forecast. The detailed definitions of the statistics shown in figure 2 are available in Wilks (2011). The UM day 1 forecast valid for \(17{\mathrm{th}}\) June 2013 indicates that the forecast (as compared to observation) has larger number of raining grids 698 (479), lower average rain rate of \({\sim }28\,\hbox {mm}\,\hbox {d}^{-1}\) (\(40\,\hbox {mm}\,\hbox {d}^{-1}\)) and lower maximum rain rate \(105\,\hbox {mm}\,\hbox {d}^{-1}\) (\(248\,\hbox {mm}\,\hbox {d}^{-1}\)). The spatial correlation of 0.66 and the categorical skill scores for rain exceeding 1 mm (equitable threat score of 0.28, Hanssen and Kuipers score of 0.51) indicate moderate skill at predicting the location of the rain. Also, the value of mean absolute error is about \(9\,\hbox {mm}\,\hbox {d}^{-1}\) and the root mean square error (RMSE) is about \(17\,\hbox {mm}\,\hbox {d}^{-1}\). This is mainly due to the observed rainfall over Uttarakhand, parts of Gujarat and the west coast of India being severely underestimated by the model. The value of false alarm ratio is 0.48, probability of detection is 0.75 and the bias score is 1.45. This is because the model predicts low rainfall amounts over Gujarat region as well as west coast, while excessive widespread light rains (1–5 and \(5{-}10\,\hbox {mm}\,\hbox {d}^{-1}\)) over eastern India.

Observed (upper left) and forecast (day 1, 3 and 5) mean JJAS rainfall \((\hbox {mm}\,\hbox {d}^{-1})\) over India during 2007–2015.

Observed and UKMO day 1 forecast number of rainy days (rainfall \({>}1\) mm/day) during JJAS 2012. The boxes show four domains that are used to investigate regional variation in forecast performance.

Rainfall forecast verification scores for day 1 forecasts verified against observed rainfall: (a) probability of detection (POD), (b) success ratio (SR), (c) probability of false detection (POFD), (d) frequency bias (BIAS), (e) equitable threat score (ETS), and (f) Hanssen and Kuipers score (HK score).

Forecast vs. observed mean rain intensity over four regions of India (NE, SW, E and NE) for three different CRA thresholds.

Same as in figure 7, but for maximum rain intensity.
The errors can be further quantified in the rainfall distribution using CRA technique. Figure 3 shows the CRA verification using a \(40\,\hbox {mm}\,\hbox {d}^{-1}\) rainfall threshold to isolate the heavy rainfall over Uttarakhand. The CRA is bounded by the domain \(26^{^{\circ }}{-}31.5^{^{\circ }}\hbox {N}\) and \(77^{^{\circ }}{-}85^{\circ }\hbox {E}\). The observed and forecast rainfall with the \(40\,\hbox {mm}\,\hbox {d}^{-1}\) contour (in bold) is shown in spatial map. The scatter diagram on the right indicates the correspondence between observed and forecast rainfall after shifting the forecast rainfall slightly in south to correct the location error. The numbers shown below the scatter plot are (i) number of grids with rainfall excess of \(40\,\hbox {mm}\,\hbox {d}^{-1}\) (ii) the average rain rate \((\hbox {mm}\,\hbox {d}^{-1})\) (iii) the maximum rain \((\hbox {mm}\,\hbox {d}^{-1})\) and (iv) the rain volume \((\hbox {km}^{3})\) in the observations and forecasts. In the forecasts, the number of grids with rainfall exceeding \(40\,\hbox {mm}\,\hbox {d}^{-1}\) in the forecasts is 59 as against 66 in observations. The maximum rain (highest rain amount) is lower \((105\,\hbox {mm}\,\hbox {d}^{-1})\) than the observed value \((248\,\hbox {mm}\,\hbox {d}^{-1})\), the forecast average rain rate and volume in the CRA are \(53\,\hbox {mm}\,\hbox {d}^{-1}\) and \(13\,\hbox {km}^{3}\) as against observed values of \(64\,\hbox {mm}\,\hbox {d}^{-1}\) and \(16\,\hbox {km}^{3}\), respectively. The forecast has a RMSE of \(48\,\hbox {mm}\,\hbox {d}^{-1}\), which is mainly contributed by errors in pattern (86%).
Thus, CRA method can be effectively used to diagnose and quantify the rainfall forecast errors and its components for different individual cases of rainfall events. Statistics of error components based on large number of rainfall events can be used to establish the robust behavior of the models and nature of the biases. Following section provides a detailed discussion of verification results based on long record observations and forecasts.
3 Results of rainfall forecast verification
In this section, verification results of UM rainfall forecasts over India during nine (2007–2015) monsoon seasons are presented. First, the results of traditional verification metrics are briefly discussed in sections 3.1 and 3.2 to indicate overall forecast performances and biases over India. This is followed by detailed discussion on the results of CRA verification method in section 3.3.
3.1 Mean monsoon rainfall during 2007–2015: Observations and forecast
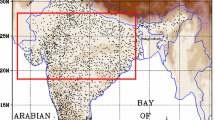
The long period average of seasonal mean rainfall distribution over India monsoon region is a good measure of model’s basic performance. Figure 4 shows the seasonal mean rainfall (JJAS) over the Indian monsoon region averaged over 2007–2015 from observed rainfall and UM model forecasts. The panels compare the observed mean rainfall amounts and distribution with day 1, 3 and 5 forecasts. The domain average rainfall values presented at top right of the each panel suggest that the model has a tendency of wet bias. Model forecasts are able to capture large scale characteristics of rainfall maxima along the Western Ghats, Arakan-Yoma mountain chains (Myanmar coast) and northeastern India up to day 5. The forecasts also successfully capture the rainfall minima over eastern peninsula and over northwest India. The longitudinal (west to east) gradient in rainfall amount is quite realistic over peninsula and northern parts of India. Large rainfall biases (wet) are also observed over northern India and Indo-Gangetic plains. This feature is quite common during each monsoon season up to 2013 (Iyengar et al. 2011). One of the possible reason behind is that the low level winds (850 hPa; not shown) over the Gangetic plains typically show strong easterly bias (Iyengar et al. 2011). However, there is a considerable reduction in easterly bias (and rainfall wet bias) during the monsoon season of 2014 and 2015 (figure not shown). Some of these improvements in the forecast rainfall during recent years may be attributed to the increased horizontal resolution \(({\sim }17\,\hbox {km})\), a new dynamical core (ENDGame) and a revised physics package (GA6.1) (Prakash et al. 2016; Rakhi et al. 2016).
The spatial distribution of average rainy day counts \(({>}1\,\hbox {mm}\,\hbox {d}^{-1})\) over Indian region (land points only) during the nine monsoon seasons of 2007–2015 is presented in figure 5. The panels (i) and (ii) show the observed and forecast count of rainy days. It was found that model features high number of rainy days as compared to observations. The difference between the two is striking with the forecasts having a higher number of rainy days, in nearly all parts of India. The forecasts have an excessive number of rainy days, throughout the SW, E and NE regions of India. Even over most of the dry region of NW the model predicts a relatively higher number of rainy days.
The wet bias indicated by the domain averaged rainfall amounts in figure 4 could be partly attributed to excessive number of rainy days predicted in the model, particularly over dry regions of India. This is likely to result in large number of false alarms, particularly for low rainfall thresholds, that can affect the skill scores, as will be shown in the next section.
3.2 Categorical verification scores
The categorical verification scores for the UM day 1 forecasts over India are summarized using Box and Whisker plots in figure 6. Scores are computed for each rainfall threshold based on all the observation/forecast pairs of each day during the nine monsoon seasons and represent the grid scale QPF performance that may be expected on any given day.
The panels in the top row (figure 6a and b) show the Probability of Detection (POD) and Success Ratio (SR). While POD indicates the fraction of observed ‘yes’ events forecast correctly, the SR indicates the fraction of forecast ‘yes’ events that were actually observed. Both scores range from 0 to 1 with 1 being a perfect score. While POD does not depend on false alarms, the SR takes it into account. Both the scores have high values for rainfall thresholds below \(10\,\hbox {mm}\,\hbox {d}^{-1}\), while moderate skill below rainfall threshold of \(20\,\hbox {mm}\,\hbox {d}^{-1}\) and poor skill beyond \(40\,\hbox {mm}\,\hbox {d}^{-1}\). Since SR accounts for the false alarms, it has relatively lower values compared to POD for 1 and \(10\,\hbox {mm}\,\hbox {d}^{-1}\) threshold.
The two panels in the middle row (figure 6c and d) show Probability of False Detection (POFD) and Bias Score or Frequency Bias (BIAS). The POFD, also known as false alarm rate, indicates what fraction of ‘no’ events were incorrectly forecast as ‘yes’ events. POFD varies from 0 to 1 with 0 being a perfect score. The POFD values indicate that forecasts have high false alarms at low rainfall thresholds \(({<}10\,\hbox {mm}\,\hbox {d}^{-1})\). The Frequency Bias (BIAS) indicates how the observed and forecast frequency of ‘yes’ events compare. BIAS varies from 0 to \(\infty \) with 1 indicating a perfect forecast, BIAS \({>}1\) indicating over-forecasting and BIAS \({<}1\) indicating under-forecasting. The BIAS in figure 6 suggests the model is over-forecasting rain occurrence, particularly at lower thresholds \(({<}10\,\hbox {mm}\,\hbox {d}^{-1})\).
Similarly, the panels in the bottom row (figure 6e and f) show the Box and Whisker plots for, the Equitable Threat Score (ETS) and Hanssen and Kuipers score (HK Score). While ETS tells how the forecast ‘yes’ events correspond to observed ‘yes’ events (accounting for random hits), HK Score tells how well the forecasts separate the ‘yes’ and ‘no’ events. For both scores, 0 denotes no skill and 1 means a perfect score. The ETS and HK show low values \(({<}0.5)\) of the score at all rainfall thresholds. While both scores indicate poor performance of the NWP system in predicting the higher rainfall amounts, it must be noted that these scores feature double penalty. Verification of forecasts based on CRA method is presented in the next section to quantify the spatial errors and error components.
3.3 CRA verification results for monsoon seasons (2007–2015)
The rainfall over different parts of India can be associated with different synoptic regimes as well as having different topography and proximity to neighboring seas. The four regions shown in figure 6 can be considered as rainfall zones for CRA verification. The rainfall over northeastern India (NE) and the southwestern peninsula (SW) strongly reflects the effects of the low level monsoon flow and the orographic enhancement over the mountains. The rainfall over eastern India (E) can be associated with the monsoon trough and southeasterly flow from the Bay of Bengal. The monsoon trough extends from northwestern India to the head of the Bay of Bengal. The low pressure systems that develop over the Bay of Bengal and track in the westerly and northwesterly direction also significantly contribute to the rainfall over eastern India (E). Some of the low pressure systems track far inland in the westerly and northwesterly direction to produce rainfall spells over the arid and dry regions of northwest India (NW). However, the rainfall over the NW region is sometimes associated with eastward passage of an upper-level trough/low in the mid-latitude westerlies and their interaction with the inland low pressure systems.

Spatial distributions (scatter plots on left (a)) and frequency (shaded contour plots on right (b)) of CRA displacements for individual rainfall zones and CRA thresholds. The x- and y-axes are in degrees longitude and latitude, respectively.
The CRA verification results are presented for each zone based on the central location of the CRA. Based on the good CRA matches, the scatter plots in figures 7 and 8 show the association among the observed and forecast average rainfall as well as observed and maximum rain intensity for rain systems located in each of the four zones, respectively. The scatter of mean rain intensity (figure 7) and maximum rain intensity (figure 8) over all four zones (NW, SW, E and NE) consistently suggest underestimation of rain intensity in the forecasts especially for the rainfall threshold beyond \(20\,\hbox {mm}\,\hbox {d}^{-1}\). For rainfall threshold of \(10\,\hbox {mm}\,\hbox {d}^{-1}\), the mean rainfall intensity is overestimated while maximum rain intensity is underestimated in the model forecast over all four zones. This indicates that the wet bias in the forecast is mainly contributed by the large number of low amount of rainfall \(({<}10\,\hbox {mm}\,\hbox {d}^{-1})\).

Box–Whisker plots summarizing the correlation, x-err, y-err, and vector errors (degrees) over four rain zones.
The average CRA verification statistics (after obtaining the best match of the forecast with the observations) using OBS data are compiled in table 2. Figures 9 and 10 complement the information in table 2. Figure 9 shows the scatter plots to indicate how the displacement errors (x-error and y-error) are clustered or distributed about the observed positions (origin). This allows one to understand how the nature of errors varies from region to region. The scatter plots are presented on the left for four regions (rows) and four thresholds (columns) (figure 9a). Corresponding to each of the scatter plot, shaded panels on the right (figure 9b) show the fraction (%) of points clustering about the origin. The numbers shown in bracket, in each of the panels gives the total number of CRAs or events (daily). In figure 10, it can be noted that over the NW region, for all thresholds CRAs \((10{-}80\,\hbox {mm}\,\hbox {d}^{-1})\), the forecast location errors are mostly distributed in southeastern quadrant of the origin. Corresponding shaded panels on the right (NW) indicates fractions (%) of CRAs clustered about the origin. For \(10\,\hbox {mm}\,\hbox {d}^{-1}\) threshold, about 6% (of total 272 CRAs) are closely packed near the origin within \(\pm 1^{\circ }\). About 4% of the cases are distributed within \(\pm 2.5^{\circ }\) with majority of CRAs elongated in southeastern quadrants. Similarly, for \(20\,\hbox {mm}\,\hbox {d}^{-1}\) threshold, about 6% (of total 385 CRAs) are closely packed near the origin within \(\pm 1.5^{\circ }\) with mostly distributed in southeastern quadrants. For higher threshold \((40\,\hbox {mm}\,\hbox {d}^{-1})\) CRAs, more than 12% (199 of CRAs) are clustered about \(1^{\circ }\) to the south.
Similarly, the second row in figure 9(a and b) corresponds to southwest region at all four thresholds. Over the SW region, the scatter of the position errors (panels on left) shows a systematic southeast to northwest orientation typical of the rainfall along the west coast of India with a majority of forecasts displaced to the northwest to southeast quadrant to the observed event. For 10 and \(20\,\hbox {mm}\,\hbox {d}^{-1}\) rainfall threshold, 10–12% of CRAs are clustered about \(0.5^{\circ }\) to the south while the location of more than 12% of CRAs is about \(1^{\circ }\) south with respect to observed position at \(40\,\hbox {mm}\,\hbox {d}^{-1}\).
Over eastern India (E), all the rainfall threshold CRAs tend to forecast to the east and southeast of the observed location for 10 to \(40\,\hbox {mm}\,\hbox {d}^{-1}\) CRAs. For rainfall threshold of 10 and \(20\,\hbox {mm}\,\hbox {d}^{-1}\), 6% of total CRAs are mostly distributed about \(1.5^{\circ }\) southeast to the observed location, while more than 8% of total CRAs are clustered around \(1^{\circ }\) southeast. One point should be noted here is, as the rainfall thresholds increase, CRAs are clustered close or near to observed location, which means that the rainfall bias has been reduced in predicting high rainfall amounts \(({>}40\,\hbox {mm}\,\hbox {d}^{-1})\). Forecast rainfall in the NE region tends to be systematically predicted to the south of the observed location. It can be seen that majority of the CRAs are located (more than 12% of total) around \(1^{\circ }\) south to observed location at rainfall threshold of \(40\,\hbox {mm}\,\hbox {d}^{-1}\).
Similar distributions are evident in the day 3 and 5 forecasts (not shown). Figure 10 shows the distributions of the position errors and spatial correlations using Box–whisker plots.
The mean pattern correlation (and RMSE in \(\hbox {mm}\,\hbox {d}^{-1}\)) are presented in table 2. The pattern correlation (and RMSE) values range from 0.31 to 0.51 (and \(20.3{-}25.7\,\hbox {mm}\,\hbox {d}^{-1}\)) for 10, 20 and \(40\,\hbox {mm}\,\hbox {d}^{-1}\) CRA thresholds. It is evident in figure 10 also. These can be considered robust since they are based on a large sample. Also, the numbers (in front of each zone) in the bracket represent the CRAs for each threshold in table 2. For a higher CRA threshold \((80\,\hbox {mm}\,\hbox {d}^{-1})\), the pattern correlation (0.5–0.6) and RMSE values \((56{-}65\,\hbox {mm}\,\hbox {d}^{-1})\) are higher since the focus is on a smaller area of heavier rain, but due to the much smaller sample size these mean results contain greater uncertainty.

Box–Whisker plots summarizing the RMSE and contribution to total error from displacement error, volume error and pattern error over four zones.
The mean displacement errors are given in degrees latitude and longitude in table 2. Positive (negative) values of x-displacement error indicate that rain events are forecast to the east (west) of the observed location. Similarly, positive (negative) values of y-displacement error indicate that rain events are forecast to the north (south) of the observed location. From figure 10 and table 2, it can be seen that x-error is positive over all zones, which reflects that the rainfall systems are predicted toward the east of observed position. The largest mean x-displacement error is in the eastern region (E) with forecasts located at an average of \(1.5^{\circ }\) longitude eastwards for CRAs defined by the \(10\,\hbox {mm}\,\hbox {d}^{-1}\) threshold. This is consistent with the reported slow movement of the low pressure systems (Iyengar et al. 2011, 2014) in model forecasts over eastern India after landfall. The magnitude of x-displacement error in eastern India (E) is seen to decrease for higher CRA thresholds. This clearly suggests that in eastern India (E), the location of heavier rain is predicted with greater accuracy than the lighter rain events. The mean north–south displacement errors given by y-displacement error are relatively moderate with mean values less than \(1^{\circ }\) latitude in eastern India (E).
The contributions to the total error due to displacement, volume and pattern are also summarized in table 2 and also in figure 11. In all the four regions, the contribution from pattern error forms the highest share for the 10 and \(20\,\hbox {mm}\,\hbox {d}^{-1}\) CRAs, which tend to have larger areas. The relative contributions of pattern error (displacement error) decreases (increases) over all four zones for CRAs of all thresholds (particularly over eastern India (E)).
The panels in figure 11 show the RMSE \((\hbox {mm}\,\hbox {d}^{-1})\) and the percentage contribution to total error due to location, volume and pattern error. Not surprisingly, the RMSE is least for \(10\,\hbox {mm}\,\hbox {d}^{-1}\) CRAs with generally lower spread as this sample includes a larger proportion of lighter rainfall events. The 20, 40 and \(80\,\hbox {mm}\,\hbox {d}^{-1}\) CRAs show higher RMSEs and greater variability. The contribution from pattern error is dominant in all four regions for 10 and \(20\,\hbox {mm}\,\hbox {d}^{-1}\) CRAs with the median value ranging from 45% \((10\,\hbox {mm}\,\hbox {d}^{-1})\) in the SW region to 75% \(10\,\hbox {mm}\,\hbox {d}^{-1}\) in the E region. The median contribution to error due to displacement is ranging from 15–25% for all regions for \(10\,\hbox {mm}\,\hbox {d}^{-1}\) CRAs. This low relative contribution \(({\sim }20\%)\) from displacement in the E region is surprising, given the large systematic eastward errors seen in figures 10 and 11, but the pattern error in this region is very large and dominates the total error. Contribution of volume error over the NE region increases with rainfall threshold. Contributions from volume error are generally least except in the SW region, where they are responsible for a similar proportion as the displacement errors are up to \(40\,\hbox {mm}\,\hbox {d}^{-1}\).
4 Summary and conclusions
In the present study, an attempt has been made to investigate and quantify the rainfall forecast biases in the unified model as part of an overall scientific challenge to better predict the Indian monsoon. This study has examined the performance of the Met Office Unified Model (UM) over India for 9 years (2007–2015) during the monsoon season using IMD rain gauge observations (2007–2011) and NCMRWF–IMD rainfall observations (2012–2015). This rainfall data is best estimate of the rainfall analysis available over India.
The model forecasts show a wet bias resulting from an excessive number of rainy days compared to observations all over India. Systematic errors in the forecast rain systems are estimated using CRA analysis with 10, 20, 40 and \(80\,\hbox {mm}\,\hbox {d}^{-1}\) threshold for four regions: the northwest (NW), southwest (SW), east (E) and northeast (NE). The mean and maximum rain amounts tended to be underestimated at higher rainfall thresholds \(({>}20\,\hbox {mm}\,\hbox {d}^{-1})\). This confirms the wet bias in the model is due to the overestimation of low rainfall amounts.
The displacement errors are scattered but show some systematic trends, depending on the CRA threshold. In the NW region, the forecast events are frequently displaced by about \(1^{\circ }\) to the north, of the observed position. Over eastern India (E) forecasts for lighter rainfall events tend to be displaced about \(1^{\circ }\) to the east, while heavier forecast rainfall events are displaced southeast to the observed location by about \(1^{\circ }\). Southerly forecast displacements are most common in the NE region.
For 10 and \(20\,\hbox {mm}\,\hbox {d}^{-1}\) CRAs, the contribution from pattern error is dominant in all four regions, and the contribution from volume error is generally least. The relative contribution to total error due to displacement tends to increase with increasing CRA threshold as the relative contribution from pattern error decreases.
The information on the dominant contribution to the total error in any region may be useful guidance for the forecaster. For example, over the plains adjoining the Himalayas, it is often seen that the UM forecasts produce excess rainfall mainly associated with a prominent easterly bias in the 850 hPa winds (Iyengar et al. 2011). Another example is the rainfall associated with the Bay of Bengal low pressure systems, where the predicted low pressure systems in the model make a rather slower than observed west northwesterly movement. The impact of position errors are reflected in figures 10 and 11 for region E.
The detailed analysis presented in this study can help the model developers and forecasters to understand the systematic errors associated with forecast characteristics of monsoon rainfall over different parts of India. A similar analysis of QPFs from other modeling systems will provide robust measures of bias, accuracy, and relative error components in forecast rain systems over India. Additionally, plausible sources of forecast errors including grid resolution, model initialization, and physical processes will be addressed in the future studies.
References
Ashrit R and Mohandas S 2010 Mesoscale model forecast verification during monsoon 2008; J. Earth Syst. Sci. 119(4) 417–446.
Ashrit R, Sharma K, Dube A, Iyengar G R, Mitra A K and Rajagopal E N 2015 Verification of short-range forecasts of extreme rainfall during monsoon; Mausam 66 375–386.
Bessafi M and Wheeler M C 2006 Modulation of south Indian Ocean tropical cyclones by the Madden-Julian oscillation and convectively-coupled equatorial waves; Mon. Weather Rev. 134 638–656.
Brown A R, Beare R J, Edwards J M, Lock A P, Keogh S J, Milton S F and Walters D N 2007 Upgrades to the boundary layer scheme in the Met Office NWP model; Bound.-Layer Meteorol. 118 117–132.
Brown A, Milton S, Cullen M, Golding B, Mitchell J and Shelly A 2012 Unified modeling and prediction of weather and climate: A 25-year journey; BAMS 1865–1878.
Chakraborty A 2010 The skill of ECMWF medium range forecasts during the year of tropical convection 2008; Mon. Weather Rev. 138 3787–3805.
Das S, Ashrit R, Iyengar G R, Mohandas S, Das Gupta M, George J P, Rajagopal E N and Dutta S K 2008 Skills of different mesoscale models over Indian region during monsoon season: Forecast errors; J. Earth Syst. Sci. 117(5) 603–620.
Davies T M, Cullen J P, Malcom A J, Mawson M H, Staniforth A, White A A and Wood N 2005 A new dynamical core for the Met Office’s global and regional modeling of the atmosphere; Quart. J. Roy. Meteorol. Soc. 131 1759–1782.
Dube A, Ashrit R, Ashish A, Sharma K, Iyengar G R, Rajagopal E N and Basu S 2014 Forecasting the heavy rainfall during Himalayan flooding – June 2013; Weather Clim. Extrem. 4 22–34.
Ebert E E 2008 Fuzzy verification of high-resolution gridded forecasts: A review of proposed framework; Meteorol. Appl. 15 51–64.
Ebert E E and McBride J L 2000 Verification of precipitation in weather systems: Determination of systematic errors; J. Hydrol. 239 179–202.
Ebert E E and Gallus Jr W A 2009 Towards better understanding of Contiguous Rain Areas (CRA) method of spatial verification; Wea. Forecasting 24 1401–1415.
Ebert E, Wilson L, Weigel A, Mittermaier M, Nurmi P, Gill P, Göber M, Joslyn S, Brown B, Fowler T and Watkins A 2013 Progress and challenges in forecast verification; Meteorol. Appl. 20 130–139.
Edwards J M and Slingo A 1996 Studies with a flexible new radiation code. I: Choosing a configuration for a large-scale model; Quart. J. Roy. Metorol. Soc. 122 689–719.
Gilleland E, Ahijevych D A, Brown B G and Ebert E E 2010 Verifying forecasts spatially; Bull. Am. Meteor. Soc. 1365–1373.
Goswami B N and Ajay Mohan R S 2001 Intra-seasonal oscillations and inter-annual variability of the Indian summer monsoon; J. Climate 14 1180–1198.
Goswami B N, Ajaya Mohan R S, Xavier P K and Sengupta D 2003 Clustering of low pressure systems during the Indian summer monsoon by intraseasonal oscillations; Geophys. Res. Lett. 30 1431, https://doi.org/10.1029/2002GL016734.
Grams J S, Gallus W A, Wharton L S, Koch S, Loughe A and Ebert E E 2006 The use of a modified Ebert-McBride technique to evaluate mesoscale model QPF as a function of convective system morphology during IHOP 2002; Wea. Forecasting 21 288–306.
Grant A L M 2001 Cloud base mass fluxes in the cumulus capped boundary layer; Quart. J. Roy. Meteor. Soc. 127 407–421.
Gregory D and Allen S 1991 The effect of convective scale downdraughts upon NWP and climate; Proceedings of 9 \({th}\) AMS conference on NWP, Denver, USA, pp. 122–123.
Gregory D and Rowntree P R 1990 A mass flux convection scheme with representation of cloud ensemble characteristics and stability-dependent closure; Mon. Weather Rev. 118 1483–1506.
Harper K, Uccellini L W, Kalnay E, Carey K and Morone L 2007 \(50{{\rm th}}\) anniversary of numerical weather prediction; Bull. Am. Meteor. Soc. 88 639–650.
Iyengar G, Ashrit R, Das Gupta M, Chourasia M, Sharma K D, Prasad V S, Rajagopal E N, Mitra A K, Mohandas S and Harenduprakash L 2011 NCMRWF & UKMO global model forecast verification: Monsoon 2010; Monsoon Report, NMRF/MR/02/2011.
Iyengar G R, Ashrit R, Sharma K and Rajagopal E N 2014 Monsoon 2013: Performance of NCMRWF global assimilation–forecast system; Monsoon Report, NMRF/MR/01/2014.
Jolliffe I T and Stephenson D B 2011 Introduction in forecast verification: A practitioner’s guide in atmospheric science; John Wiley and Sons Ltd., Chichester, UK, https://doi.org/10.1002/9781119960003.
Joseph S, Sahai A K, Sharmila S, Abhilash S, Borah N, Chattopadhyay R, Pillai P A, Rajeevan M and Kumar A 2014 North Indian heavy rainfall event during June 2013: Diagnostics and extended range prediction; Clim. Dyn. 44 2049–2065.
Kalnay E, Lord S J and McPherson R D 1998 Maturity of operational numerical weather prediction: Medium range; Bull. Am. Meteor. Soc. 79 2753–2769.
Maloney E D and Hartmann D L 2000 Modulation of eastern North Pacific hurricanes by the Madden-Julian oscillation; J. Climate 13 1451–1460.
Mandal V, De U K and Basu B K 2007 Precipitation forecast verification of Indian summer monsoon with inter-comparison of the three diverse regions; Wea. Forecasting 22 428–443.
Mitra A K, Bohra A K, Rajeevan M N and Krishnamurti T N 2009 Daily Indian precipitation analysis formed from a merge of rain gauge data with TRMM TMPA satellite-derived rainfall estimates; J. Meteor. Soc. Japan 87A 265–279.
Mitra A K, Momin I M, Rajagopal E N, Basu S, Rajeevan M N and Krishnamurti T N 2013 Gridded daily Indian monsoon rainfall for 14 seasons: Merged TRMM and IMD gauge analyzed values; J. Earth Syst. Sci. 122(5) 1173–1182.
Prakash S, Mitra A K, Momin I M, Rajagopal E N, Milton S F and Martin G M 2016 The skill of short- to medium-range monsoon rainfall forecasts from two global models over India for hydro-meteorological applications; Meteorol. Appl. 23 574–586.
Rajeevan M, Bhate J, Kale J D and Lal B 2006 High resolution daily gridded rainfall data for the Indian region: Analysis of break and active monsoon spells; Curr. Sci. 91(3) 296–306.
Rajesh P V, Pattnaik S, Rai D, Osuri K K, Mohanty U C and Tripathy S 2016 Role of land state in a high resolution mesoscale model for simulating the Uttarakhand heavy rainfall event over India; J. Earth Syst. Sci. 125(3) 475–498.
Rakhi R, Jayakumar A, Sreevathsa M N R and Rajagopal E N 2016 Implementation and upgradation of NCUM in Bhaskara HPC; Technical Report, NMRF/TR/03/2016, 22p.
Rawlins F, Ballard S P, Bovis K J, Clayton A M, Li D, Inverarity G W, Lorenc A C and Payne T J 2007 The Met Office global four-dimensional variation data assimilation scheme; Quart. J. Roy. Metorol. Soc. 133 347–362.
Roebber P J, Schultz D M , Colle B A and Stensrud D J 2004 Toward improved prediction: High-resolution and ensemble modeling systems in operations; Wea. Forecasting 19 936–947.
Rossa A, Nurmi P and Ebert E 2008 Overview of methods for the verification of quantitative precipitation forecasts; In: Precipitation: Advances in Measurement, Estimation and Prediction (ed.) Michaelides S, Berlin: Springer, pp. 419–452.
Sharma K, Ashrit R, Ebert E, Iyengar G and Mitra A K 2015 NGFS rainfall forecast verification over India using the Contiguous Rain Areas (CRA) method; Mausam 66 415–422.
Shepard D 1968 A two-dimensional interpolation function for irregularly spaced data; Proceedings of the 23 \({rd}\) ACM National Conference, New York, USA.
Simmons A J and Hollingsworth A 2002 Some aspects of the improvement in skill of numerical weather prediction; Quart. J. Roy. Meteorol. Soc. 128 647–677.
Walters D N, Best M J, Bushell A C, Copsey D, Edwards J M, Falloon P D, Harris C M, Lock A P, Manners J C, Morcrette C J, Roberts M J, Stratton R A, Webster S, Wilkinson J M, Willett M R, Boutle I A, Earnshaw P D, Hill P G, MacLachlan C, Martin G M, Moufouma-Okia W, Palmer M D, Petch J C, Rooney G G, Scaife A A and Williams K D 2011 The Met Office Unified Model Global Atmosphere 3.0/3.1 and JULES Global Land 3.0/3.1 configurations; Geosci. Model Dev. 4 919–941.
Webster S, Brown A R, Cameron D and Jones C P 2003 Improvements to the representation of orography in the Met Office Unified Model; Quart. J. Roy. Meteorol. Soc. 126 1989–2010.
Wilks D S 2011 Statistical methods in the atmospheric sciences; International Geophysical Series, Academic Press.
Acknowledgements
The authors are thankful to NCMRWF scientists for the valuable and fruitful suggestions in addition to comments/feedback that were useful in finalizing the manuscript. The model forecast data used in this study is obtained from the Met Office which is duly acknowledged.
Author information
Authors and Affiliations
Corresponding author
Additional information
Corresponding editor: A K Sahai
Rights and permissions
About this article

Cite this article
Sharma, K., Ashrit, R., Ebert, E. et al. Assessment of Met Office Unified Model (UM) quantitative precipitation forecasts during the Indian summer monsoon: Contiguous Rain Area (CRA) approach. J Earth Syst Sci 128, 4 (2019). https://doi.org/10.1007/s12040-018-1023-3
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12040-018-1023-3