
Abstract
The quantitative precipitation forecast (QPF) performance for heavy rains is still a challenge, even for the most advanced state-of-art high-resolution Numerical Weather Prediction (NWP) modeling systems. This study aims to evaluate the performance of UK Met Office Unified Model (UKMO) over India for prediction of high rainfall amounts (>2 and >5 cm/day) during the monsoon period (JJAS) from 2007 to 2015 in short range forecast up to Day 3. Among the various modeling upgrades and improvements in the parameterizations during this period, the model horizontal resolution has seen an improvement from 40 km in 2007 to 17 km in 2015. Skill of short range rainfall forecast has improved in UKMO model in recent years mainly due to increased horizontal and vertical resolution along with improved physics schemes. Categorical verification carried out using the four verification metrics, namely, probability of detection (POD), false alarm ratio (FAR), frequency bias (Bias) and Critical Success Index, indicates that QPF has improved by >29 and >24% in case of POD and FAR. Additionally, verification scores like EDS (Extreme Dependency Score), EDI (Extremal Dependence Index) and SEDI (Symmetric EDI) are used with special emphasis on verification of extreme and rare rainfall events. These scores also show an improvement by 60% (EDS) and >34% (EDI and SEDI) during the period of study, suggesting an improved skill of predicting heavy rains.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Heavy rainfall events over central India region during southwest monsoon (June, July, August, September, JJAS) are often related to the passage of synoptic scale monsoon depressions. The Bay of Bengal low-pressure systems (LPS) contribute significantly to the seasonal rainfall. These LPS often lead to incessant rainfall episodes and flooding over parts of eastern and central India (Krishnamurthy and Ajayamohan 2010; Mooley and Shukla 1987; Krishnamurti et al. 1975; Sikka 1977, 2006). These heavy rainfall events (i.e., those events which are associated with the tail end of the precipitation probability distribution) are highly impactful and cause loss of life, huge damage to property, and significant disruption to local, regional, and national economies. In spite of the recent advances in the observing systems, modeling, data assimilation and NWP, accurate prediction of heavy rainfall events (location, intensity, and spatial extent) remains one of the most difficult challenges in operational meteorology.
The Indian subcontinent is highly vulnerable to the heavy rainfall events. The early warning systems are not always reaching out to the people who are affected by these heavy rainfall episodes and thus people are hardly notified and evacuated when these heavy rainfall events occur (World Bank-report No 2 2013). Most of the heavy rainfall events occur during the southwest monsoon (JJAS) (Goswami et al. 2006; Sharma et al. 2015). During the southwest monsoon season, the west coast of India, north-east of India and some parts of Central India are the most prominent regions which receive heavy rainfall (Pattanaik and Rajeevan 2010). The north-east and west coast of India are the regions which are characterized by steep orography and therefore the heavy rains occurred in these areas are often result of forced ascent over the mountains. Central India is the region where heavy rainfall occurs generally due to the synoptic scale low-pressure systems that form over the Bay of Bengal and move west-northwestward during JJAS (Goswami et al. 2006; Sikka 2006; Ajayamohan et al. 2010; Krishnamurthy and Ajayamohan 2010). The central India has been chosen for the study because of the fact that this area is most affected by the rain bearing systems which almost produce 50% of rainfall during the monsoon season every year (Yoon and Chen 2005).
This paper focuses the verification of Unified Model (UM) forecasts during the monsoon season of 2007–2015 for two rainfall thresholds of >2 cm/day (hereafter category1: CAT1) and >5 cm/day (hereafter category2: CAT2) over central India. The rationale for choosing these thresholds is discussed in Sect. 4.
2 Data and Methodology
2.1 Observed Rainfall Data
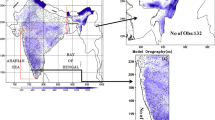
The geographical domain with the distribution of Indian Meteorological Department (IMD) rain gauges over India during the monsoon is shown in Fig. 1. The box represents the core monsoon zone (18–28N, 68–88E, Rajeevan et al. 2010) which is chosen as the domain of the present study. Rainfall analysis based on quality-controlled observations is critical for verification of the NWP forecasts. The IMD’s gridded daily rainfall data set for the period 2007–2011 is used in the present study. The gridding method of rainfall for the period 2007–2011 is based on Shepard interpolation (1968) and is also discussed in Rajeevan et al. (2006). For the years 2012–2015, NCMRWF-IMD (National Centre for Medium Range Weather Forecasting—Indian Meteorological Department) merged satellite-gauge (NMSG; Mitra et al. 2009) rainfall analyses have been used. The spatial resolution of the data is at 0.5° latitude × 0.5° longitude. NCMRWF-IMD rainfall data are the merged product of near-real-time Tropical Rainfall Measuring Mission Multi-satellite Precipitation Analysis (TMPA)-3B42 and rain gauge data from the India Meteorological Department (IMD) using an objective analysis scheme. This merge data set captures Indian monsoon rainfall more realistically and is superior to other available rainfall data sets over the Indian monsoon region because it uses additional local rain gauge observations (Mitra et al. 2013). This analyzed rainfall product, therefore, provides a better baseline for NWP model validation and monsoon model development. The entire observed rainfall data series (2007–2015) will be referred as OBS hereafter.

Geographical domain over India used for rainfall verification showing terrain elevation (km) and typical distribution of the rain gauge network on any day during the monsoon season
2.2 Model Forecast Rainfall over India
The Met Office Unified Model (UM) is the numerical modeling system developed and used at the Met Office in the United Kingdom (UK) (Davies et al. 2005). This study uses the rainfall forecasts from the Met Office operational medium range global model configuration. The Unified Model (UM) is continually developed, taking advantage of improved understanding of atmospheric processes and steadily increasing computing power. The Met Office upgrades its operational NWP configurations up to four times per year. The atmospheric model uses non-hydrostatic dynamics with semi-Lagrangian advection and semi-implicit time stepping. It is a grid point model with the ability to run with a rotated pole and variable horizontal grid. A number of sub-grid scale processes are represented, including convection (Gregory and Rowntree 1990; Gregory and Allen 1991; Grant 2001), boundary layer turbulence (Brown et al. 2007), radiation (Edwards and Slingo 1996), cloud microphysics and orographic drag (Webster et al. 2003). The model is initialized using a state-of-the-art global four-dimensional variational (4DVAR; Rawlins et al. 2007) data assimilation technique. During 2007–2015, the horizontal and vertical resolution of the global configuration improved from about 40 km and 50 levels in 2007 to about 17 km and 85 levels in 2015.
3 Verification Strategy
The forecast daily rainfall fields are verified using standard categorical verification scores based on the two by two contingency table elements. This approach is frequently used by operational forecasters. In this study, the metrics which are calculated and evaluated are frequency bias (Bias), probability of detection (POD), false alarm ratio (FAR) and Critical Success Index (CSI). These metrics are simple and easily understood. However, these scores are generally low for higher rainfall thresholds. High rainfall amounts or heavy rain events are rare and generally, occur with small sample size where standard scores asymptotically degenerate towards zero. Apart from the standard categorical verification, recent progress also has been made in the verification of rare events (Casati et al. 2008; Ebert et al. 2013; Ashrit et al. 2015). Extreme Dependency Score (EDS; Stephenson et al. 2008; Ghelli and Primo 2009), extremal dependence Indices (EDIs; Ferro and Stephenson 2011) and symmetric extremal dependence index (SEDI; Ferro and Stephenson 2011) are some of the new metrics which could be used to verify the rare events. Instead of degenerating, these scores converge to a meaningful limit for rare and extreme events. In the present study, these metrics are also used for the rainfall thresholds of CAT1 and CAT2.
3.1 Verification Metrics
Most commonly used verification scores focus on the correspondence between the forecast and observed events (Murphy 1993). However, these scores are inadequate for verification of rare and extreme events (Stephenson et al. 2008). In the present study, occurrence of rainfall equal to or exceeding a specified threshold during last 24 h is considered an event. We consider an event as a hit (a) when prediction of an event matches with the observation on a grid point. On the other hand, an event on a grid point predicted but it is not observed, we denote it as a false alarm (b). A miss (c) occurs when an event is not predicted but it is actually observed. Finally, correct rejection (d) is when an event does not occur and model does not predict. These four variables are called as the component of the 2 × 2 contingency table.
Various categorical scores are computed from the components of the contingency table. POD, also known as hit rate, is defined as the ratio of the number of correct forecasts (number of hits: a) to the number of observed events (a + c) and the FAR is the ratio of the number of false alarms (b) to the number of forecasts made (a + b). The CSI, also known as threat score, is the ratio of number of hits (a) to all events either forecast or observed (a + b + c). All three scores range from 0 to 1, with 1 being a perfect score in case of POD as well as CSI and 0 for perfect FAR. It is important to note that a perfect forecast system would produce only hits and correct rejections with no false alarm and no missed events.
Frequency Bias (Bias) is used to understand the overforecast–underforecast of precipitation. Bias is calculated as the ratio of the number of predicted events (a + b) to the observed events (a + c) exceeding a given threshold. The Bias ranges from 0 to infinity with 1 being a perfect forecast. Bias can help in identifying whether the forecast system has a tendency to underforecast (BIAS <1) or overforecast (BIAS >1) events.
The detail discussions on the above verification scores are presented in earlier studies (Mason 1989; Sukovich et al. 2014; Ashrit et al. 2015). Stephenson et al. (2008) proposed a new verification measure known as extreme dependency scores (EDS). EDS is a useful candidate to quantify the performance of deterministic modeling system for rare binary events. For rare events, it converges to a meaningful values rather than degenerating. This new verification measure summarizes the performance of deterministic forecasts of rare binary events. EDS converges to a meaningful limit for rare events instead of degenerating. Following Coles et al. (1999), the EDS is defined as:
where H is hit rate and p = (a + c)/total is the base rate, the relative frequency with which the event was observed to occur. Rare events, therefore, correspond to low base rates.
EDS has few disadvantage like it is sensitive to hedging and base rate dependent and ignores information about false alarms and correct rejections. Therefore, EDS is non-informative about forecast bias, and a forecasting system with a good EDS could be very biased. Therefore, one should present EDS together with the frequency bias as a function of threshold to provide a complete summary of forecast performance. To overcome the shortcomings of EDS, Ferro and Stephenson (2011) has proposed two new measures known as Extremal Dependence Index (EDI) and Symmetric EDI (SEDI). EDI and SEDI are defined as:
where F = b/(b + d) is false alarm rate and is defined as the number as the number of false alarms (b) divided by the number of times the event did not happen, or the fraction of nonevents that were incorrectly forecast. EDI and SEDI are base rate independent, insensitive to hedging and have non-degenerate limits.
4 Results of Rainfall Forecast Verification
4.1 Evaluation of Forecast Rain Occurrence During 2007–2015
The mean seasonal rainfall over the Indian monsoon region for 2007–2015 is shown in Fig. 2 from observed rainfall and UKMO model forecasts. Rainfall is chosen for Day 1, Day 2, and Day 3 for evaluation. As discussed in the introduction, forecasting of rainfall over India and tropics, in general, is a challenge for the NWP models. While the models generally capture large scale features of the monsoon rainfall distribution, they fail to reproduce the regional peculiarities. This is evident even in the observed and forecasts seasonal mean rainfall over India. The box in the observed rain plot (Fig. 2a) represents our area of study for categorical verification. The forecasts successfully capture the gross features of mean monsoon rainfall in terms of higher rainfall amounts (1.5–2.5 cm/day) along the west coast and reducing rainfall amounts (<0.6 cm/day) eastwards over the peninsula. Similarly, the model captures high rainfall amounts (1.5–2.5 cm/day) over northeast India and reducing rainfall amounts westwards over northwest India. The model shows large biases in rainfall over northern India adjoining the Himalayas. This feature is typical and can be seen during each of the monsoon seasons up to 2013 (Iyengar et al. 2011). The low-level winds (850 hPa; not shown) over the Gangetic plains typically show strong easterly bias (Iyengar et al. 2011) which partly explains the rainfall bias over that region. During the monsoon season of 2014 and 2015 (figure not shown), this easterly biases have been reduced and subsequently, rainfall associated with easterly biases has also decreased in recent monsoon seasons of 2014 and 2015. Improvement in the skill of UKMO model forecast may be attributed to the increased horizontal resolution (~17 km), a new dynamical core (ENDGame) and a revised physics package (GA6.1) (Rakhi et al. 2016; Prakash et al. 2016).

Observed (upper left) and Forecast (Day 1, Day 2, and Day 3) mean rainfall (cm/day) over India during JJAS 2007–2015
4.2 Frequency of Rainfall Events
The average (2007–2015) number of rainy day counts (>0.1 cm/day, shaded) over CMZ during the monsoon season is presented in Fig. 3. The top panels (observed) show frequency for CAT1 (left) and CAT2 events (right) displayed in contours, respectively. Similarly, the bottom panels show frequencies for UKMO Day-3 forecast. It can be seen from the observations (Fig. 3a, b) that count of rainy days (shaded) is high over the eastern part of the domain and it is decreasing from east to west. However, in the forecasts (bottom panels, Fig. 3c, d), the count of rainy days (shaded) is high over a large part of domain except for north-west. The contribution of CAT1 and CAT2 events (contours) constitute a small fraction of observations and in the forecast, as seen from the four panels. It is evident that model has a higher average number of rainy days than in the observations. On the other hand, the average numbers of CAT1 and CAT2 events are almost similar in observations and forecasts. It means that the wet bias in the model is mainly due to light rain.

Observed (upper panels a, b) and UKMO Day-3 Forecast (lower panels c, d) number of rainy days (rainfall >0.1 cm/day in shaded). Contours shows the number of rainy days (rainfall >2 cm/day: left panel, rainfall >5 cm/day: right panel) during JJAS 2007–2015
The frequency of rainfall occurrence in excess of different thresholds is shown in Fig. 4 for the observed data sets during 2007–2015. This rainfall frequency graph shown here is over CMZ. It can be seen that frequency of occurrence of rainfall for CAT1 and CAT2 events is less than 15 and 10%, respectively. Thus, to focus on extreme and rare events for verification of NWP rainfall forecast, CAT1 and CAT2 have been chosen to represent extreme and rare events.

Observed rainfall frequency distribution over the domain (18–28N, 68–88E) during monsoon seasons of 2007–2015
4.3 Rainfall Forecast Verification Using Standard Scores
Categorical verification scores of four metrics of interest for two precipitation thresholds of CAT1 and CAT2 during monsoon season 2007–2015 over the core monsoon Zone are displayed in Fig. 5. The evaluation has been carried out for Day 1, Day 2, and Day 3. We have tested our results using 95% bootstrap estimation (figures not shown; please see supplementary Figure S1) but the results are so much robust that they hardly changed. The verification metrics used in the study are Bias POD, FAR and CSI. It is evident from the Fig. 5 that the overall performance of the model has been improved from 2007 to 2015 except in 2010 for both the rainfall threshold of CAT1 and CAT2, although the seasonal CSI values have been decreased with increased rainfall threshold in all Day-1, Day-2 and Day-3 Forecasts (Fig. 5j–l). During the monsoon season of 2010, 10 low-pressure systems and 2 well-marked low-pressure systems formed over the Bay of Bengal which produced a widespread rainfall over the Eastern coast and Central India (Sharma et al. 2015). The overall performance of monsoon during 2010 was normal despite no formation of monsoon depression or depression over the Bay of Bengal. It is found that model has an excessive occurrence of light rain which in turn reflects that contribution of heavy rainfall events is very less. This may be the possible reason of CSI to be dipped down during the monsoon season 2010 in all Day-1, Day-2 and Day-3 forecasts.

Bias (a–c), probability of detection (POD; d–f), false alarm ratio (FAR; g–i) and Critical Success Index (CSI; j–l) computed for Day-1 Day-2 and Day-3 forecasts for CAT1 and CAT2 rainfall thresholds during JJAS 2007–2015
It can be seen from the Fig. 5d–f that POD has improved for both rainfall thresholds of CAT1 and CAT2 in all lead times of Day 1 to Day 3 from 2007 to 2015 (except in 2010). It means that hit rate has increased for each of rainfall threshold. While an increased hit rate can be because of more events being correctly forecast, it is independent of false alarms (Sukovich et al. 2014). However, examination of FAR from Day 1 to Day 3 (Fig. 5g–i) shows a decrease, which indicates that the improvement in POD is a result of a more accurate forecast, rather than just more forecast being made. This implies that the improvement in the overall skill of the model over the nine monsoon seasons is real and not an artifact of more forecast being issued or the verification metric chosen.
Further, we examine Frequency Bias during the monsoon season of 2007–2015 for CAT1 and CAT2 rainfall threshold for Day-1 to Day-3 forecast shown in Fig. 5a–c. It can be seen in Fig. 5a–c, the model under-predicts the forecast for each threshold of CAT1 and CAT2 in all seasons. For CAT1 rainfall threshold, relatively small bias (fewer underestimates) is seen in all forecasts from Day-1 to Day-3, and near to perfect score 1 except 2010 while the events belong to CAT-2 rainfall threshold deviates more to the perfect score up to 2012.
5 Rainfall Forecast Verification Using Extreme Scores
Categorical scores (like CSI, POD, etc.) are less skillful for higher thresholds (Ashrit et al. 2015). These scores could be used to monitor the forecast improvements and model performance. Although categorical scores improve from 2007 to 2015, yet these scores deteriorate in higher lead times.
Recent progress has been made to overcome such issues. Verification metrics proposed by Ferro and Stephenson (2011) to verify the rarely occurring events are Extreme Dependency Score (EDS), Extremal Dependence Index (EDI) and Symmetric EDI (SEDI). These scores measure the association between the observed and forecast rare events. These scores range from −1 to 1 with 0 meaning no skill and 1 indicating the perfect score. Alhough EDS does not diminish to 0, it has several undesirable properties like it is base rate dependent, sensitive to hedging, and varies from −1 to 1 etc. EDI and SEDI overcome most of the drawbacks since they have a non-degenerative limit, and are base rate independent, insensitive to hedging (Ferro and Stephenson 2011).
Figure 6 shows EDS, SEDI and EDI scores (collectively called as EDS family of scores) for nine monsoon seasons. The scores shown in Fig. 6 are higher in magnitude compared to the categorical scores (CSI, POD and FAR) shown in Fig. 5. Further, we note that EDS family of scores consistently shows increasing trend in recent years. Interestingly, unlike in Fig. 5, the magnitude of scores in Fig. 6 (EDS, EDI, and SEDI) for CAT1 and CAT2 is not too different. This indicates that the model performance in predicting CAT1 and CAT2 rainfall events is equally good. The improvement in the skill of predicting CAT1 and CAT2 rainfall events in recent years is also strikingly similar. This suggested that the model improvements due to resolution, physics, and dynamics have yielded improved skill in predicting CAT1 (>2 cm/day) and CAT2 (>5 cm/day) rainfall events.

Extreme Dependence Score (EDS; a–c), Extremal Dependence Index (EDI; d–f) and Symmetric EDI (SEDI; g–i) computed for Day-1 Day-2 and Day-3 forecasts for CAT1 and CAT2 rainfall thresholds during JJAS 2007–2015
6 Summary
Rainfall over India during the monsoon season features immense variability in space, time and intensity, posing a great challenge to accurate prediction of rainfall events in the NWP models. As discussed early in this paper (Fig. 3), the high-intensity rainfall events (CAT2) constitute a small (large) fraction of the total number of rainy days over eastern (western) parts of CMZ yet these events cause significant impact over central and western India. This study evaluates the performance of UKMO model rainfall forecasts for CAT1 and CAT2 events in short range forecast up to Day 3. The verification is carried out for nine monsoon seasons (2007–2015). The conclusions are:
-
The forecasts successfully capture the observed features of mean monsoon rainfall. The high rainfall amounts along the west coast and reducing rainfall amounts eastwards over the peninsula are correctly predicted. Also, the model captures high rainfall amounts over northeast India and reducing rainfall amounts westwards. However, the forecasts show large biases (wet bias) over northern India adjoining Himalayas.
-
The wet biases reflected in the excessive number of rainy days (>0.1 cm/day) over eastern India and adjoining Himalayas.
-
While CAT1 (>2 cm/day) accounts for a large fraction of rainy days, CAT2 events constitute a small fraction (yet significant) particularly over central and western part of CMZ. Both these aspects of CAT1 and CAT2 events are reasonably brought out in the forecasts.
-
Standard verification metrics (CSI, POD and FAR) show the overall improvement (by >29, >24, and >24%, respectively) in performance for CAT1 during from 2007 to 2015. The improvement is particularly impressive for CAT2 where >89% in case of CSI and POD while >19% in FAR.
-
Verification metrics for extreme and rare events (EDS, EDI and SEDI) also show consistent improvement by 60% (EDS) and >34% (EDI and SEDI) for CAT2 rainfall events.
Although heavy rain events beyond CAT2 rainfall threshold cause severe flooding every season, a meaningful and statistically significant evaluation is still a challenge because of diminishing sample size for higher thresholds. Forecasting and verification of such heavy rain events need very high-resolution models (Mesoscale models, cloud resolving models, etc.) and observations (Doppler radar-derived rainfall). Additionally, a long record of such high-resolution observations and forecasts are critical for evaluating model performance in predicting heavy rain events. The current study is based on forecast and observations during recent years which highlights the evaluation strategy for heavy rain events for example CAT2 events. This study can form a benchmark for evaluating high-resolution model rainfall forecasts in India in coming years.
References
Ajayamohan, R. S., Merryfield, W. J., & Kharin, V. V. (2010). Increasing trend of synoptic activity and its relationship with extreme rain events over central India. Journal of Climate, 23, 1004–1013.
Ashrit, R., Sharma, K., Dube, A., Iyengar, G. R., Mitra, A. K., & Rajagopal, E. N. (2015). Verification of short-range forecasts of extreme rainfall during monsoon. Mausam, 66, 375–386.
Brown, A. R., Beare, R. J., Edwards, J. M., Lock, A. P., Keogh, S. J., Milton, S. F., et al. (2007). Upgrades to the boundary layer scheme in the Met Office NWP model. Boundary-Layer Meteorology, 118, 117–132.
Casati, B., Wilson, L. J., Stephenson, D. B., Ghelli, A., Pocernich, M., Damrath, U., et al. (2008). Forecast verification: Current status and future directions. Meteorological Applications, 15, 3–18.
Coles, S., Heffernan, J., & Tawn, J. (1999). Dependence measures for extreme value analyses. Extremes, 2, 339–365.
Davies, T., Cullen, M. J. P., Malcolm, A. J., Mawson, M. H., Staniforth, A., White, A. A., et al. (2005). A new dynamical core for the Met Office’s global and regional modeling of the atmosphere. Quarterly Journal Royal Meteorological Society, 131, 1759–1782.
Ebert, E., Wilson, L., Weigel, A., Mittermeier, A. M., Nurmi, P., Gill, P., et al. (2013). Progress and challenges in forecast verification. Meteorological Applications, 20, 130–139.
Edwards, J. M., & Slingo, A. (1996). Studies with a flexible new radiation code Part I. Choosing a configuration for a large-scale model. Quarterly Journal Royal Meteorological Society, 122, 689–719.
Ferro, C. A. T., & Stephenson, D. B. (2011). Extremal dependence indices: Improved verification measures for deterministic forecasts of rare binary events. Weather and Forecasting, 26, 699–713.
Ghelli, A., & Primo, C. (2009). On the use of the extreme dependency score to investigate the performance of an NWP model for rare events. Meteorological Applications, 16, 537–544.
Goswami, B. N., Venugopal, V., Sengupta, D., Madhusoodanan, M. S., & Xavier, P. K. (2006). Increasing trend of extreme rain events over India in a warming environment. Science, 314, 1442–1445.
Grant, A. L. M. (2001). Cloud base mass fluxes in the cumulus capped boundary layer. Quarterly Journal Royal Meteorological Society, 127, 407–421.
Gregory, D., & Allen, S. (1991). The effect of convective scale downdraughts upon NWP and Climate. In Proceedings of 9th AMS conference on NWP, Denver, USA (pp. 122–123).
Gregory, D., & Rowntree, P. R. (1990). A mass flux convection scheme with representation of cloud ensemble characteristics and stability-dependent closure. Monthly Weather Review, 118, 1483–1506.
Iyengar, G., Ashrit, R., Dasgupta, M. M., Chourasia, M., Sharma, K., Prasad, V. S., Rajagopal, E. N., Mitra, A.K., Mohandas, S., & Harenduprakash, L. (2011). NCMRWF &UKMO Global Model forecast verification: Monsoon 2010. NMRF/MR/02/2011.
Krishnamurthy, V., & Ajayamohan, R. S. (2010). Composite Structure of monsoon low-pressure systems and its relation to Indian rainfall. Journal of Climate, 23, 4285–4305.
Krishnamurti, T. N., Kanamitsu, M., Godbole, R., Chang, C. B., Carr, F., & Chow, J. H. (1975). Study of a monsoon depression (I): Synoptic structure. Journal of the Meteorological Society of Japan, 53, 227–239.
Mason, I. (1989). Dependence of the critical success index on simple climate and threshold probability. Australian Meteorological Magazine, 37, 75–81.
Mitra, A. K., Bohra, A. K., Rajeevan, M. N., & Krishnamurti, T. N. (2009). Daily Indian precipitation analyses formed from a merge of rain-gauge with TRMM TMPA satellite-derived rainfall estimates. Journal of the Meteorological Society of Japan, 87A, 265–279.
Mitra, A. K., Momin, I. M., Rajagopal, E. N., Basu, S., Rajeevan, M. N., & Krishnamurti, T. N. (2013). Gridded daily Indian monsoon rainfall for 14 seasons: Merged TRMM and IMD gauge analyzed values. Journal of Earth System Science, 122(5), 1173–1182.
Mooley, D. A., & Shukla, J. (1987). ‘Characteristics of the westward-moving summer monsoon low-pressure systems over the Indian region and their relationship with the monsoon rainfall’ Center for Ocean-Land-Atmosphere Interactions Report, University of Maryland. [Available from COLA, IGES, 4041 Powder Mill Road, Suite 302, Calverton, MD 20705, USA.].
Murphy, A. H. (1993). What is a good forecast? An essay on the nature of goodness in weather forecasting. Weather and Forecasting, 8, 281–293.
Pattanaik, D. R., & Rajeevan, M. N. (2010). Variability of extreme rainfall events over India during southwest monsoon season. Meteorological Applications, 17, 88–104.
Prakash, S., Mitra, A. K., Momin, I. M., Rajagopal, E. N., Milton, S. F., & Martin, G. M. (2016). The skill of short- to medium- range monsoon rainfall forecasts from two global models over India for hydro-meteorological applications. Meteorological Applications, 23, 574–586.
Rajeevan, M. N., Bhate, J., Kale, J. A., & Lal, B. (2006). High resolution daily gridded rainfall data for the Indian region: Analysis of break and active monsoon spells. Current Science, 91, 296–306.
Rajeevan, M. N., Gadgil, S., & Bhate, J. (2010). Active and break spells of the Indian summer monsoon. Journal of Earth System Science, 119(3), 229–247.
Rakhi, R., Jayakumar, A., Sreevathsa, M. N. R., & Rajagopal, E. N. (2016). Implementation and Up-gradation of NCUM in Bhaskara HPC. NMRF/TR/03/2016.
Rawlins, F., Ballard, S., Bovis, K., Clayton, A., Li, D., Inverarity, G., et al. (2007). The met office global four-dimensional variational data assimilation scheme. Quarterly Journal Royal Meteorological Society, 133, 347–362.
Sharma, K., Ashrit, R., Ebert, E. E., Iyengar, G., & Mitra, A. K. (2015). NGFS rainfall forecast verification over India using the contiguous Rain Areas (CRA) method. Mausam, 66, 415–422.
Shepard D. (1968). A two-dimensional interpolation function for irregularly spaced data. In Proceedings of the 23rd ACM National Conference, New York, USA, 27–29 August 1968.
Sikka, D. R. (1977). Some aspects of the life history, structure and movement of monsoon depressions. Pure and Applied Geophysics, 115, 1501–1529.
Sikka, D. R. (2006). A study on the monsoon low-pressure systems over the Indian region and their relationship with drought and excess monsoon seasonal rainfall. COLA Technical Report 217. USA.
Stephenson, D. B., Casati, B., Ferro, C. A. T., & Wilson, C. A. (2008). The extreme dependency score: A non-vanishing measure for forecasts of rare events. Meteorological Applications, 15, 41–50.
Sukovich, E. M., Ralph, F. M., Barthold, F. E., Reynolds, D. W., & Novak, D. R. (2014). Extreme quantitative precipitation forecast performance at the Weather Prediction Center from 2001 to 2011. Weather and Forecasting, 29, 894–911.
Webster, S., Brown, A. R., Cameron, D., & Jones, C. P. (2003). Improvements to the representation of orography in the Met Office Unified Model. Quarterly Journal of the Royal Meteorological Society, 126, 1989–2010.
World Bank (2013). Turn down the heat: climate extremes, regional impacts, and the case for resilience. In: A report for the World Bank by the Potsdam Institute for climate impact research and climate analytics. Washington, DC: World Bank. License: Creative Commons Attribution—Non Commercial–No Derivatives 3.0 Unported license (CC BY-NC-ND 3.0).
Yoon, J. H., & Chen, T. C. (2005). Water vapor budget of the Indian monsoon depression. Tellus A, 57, 770–782.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Sharma, K., Ashrit, R., Bhatla, R. et al. Skill of Predicting Heavy Rainfall Over India: Improvement in Recent Years Using UKMO Global Model. Pure Appl. Geophys. 174, 4241–4250 (2017). https://doi.org/10.1007/s00024-017-1640-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00024-017-1640-9