
Abstract
At present, the seismic exploration of mineral resources such as unknown oil fields and natural gas fields has become the focus and difficulty. The Tarim Oilfield located in the desert area of northwest China has many uncertainties due to complicated geological structure and resource burial conditions. And the seismic record collected carries various noises, especially random noise with complex features, including non-stationary, non-Gaussian, nonlinear and low frequency. The seismic events are contaminated by random noise. Also the effective signal of desert seismic record is in the same frequency band as the random noise. These situations have brought great difficulties in denoising by conventional methods. In this paper, a noise reduction framework based on linear discriminant analysis effective signal detection in desert seismic record is proposed to solve this problem. At first, the method utilizes the difference between the effective signals and the noise in the low-dimensional space. The seismic data are divided into the effective signal cluster and the noise cluster. Then, the effective signal is extracted to realize the position of the seismic events. Finally, the conventional filter is matched to obtain better denoising results. The framework is applied to synthetic desert seismic records and real desert seismic records. The experimental results show that denoising capability after detecting effective signals is obviously better than those of conventional denoising methods. The accuracy of the seismic effective signal detection is higher, and the seismic events’ continuity is maintained better.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Working conditions and field conditions may cause low signal-to-noise ratio (SNR) and low resolution. Many seismic denoising methods have been proposed, including median filter (Bednar 1983), f–x deconvolution (Canales 1984), f–k filter (Stewart and Schieck 1989) and curvelet thresholding (Neelamani et al. 2008). In 2012, non-local mean (NLM) filter was applied to land seismic random noise suppression (Bonar and Sacchi 2012; Shang et al. 2013) and achieved good noise suppression effect. However, in the complicated desert seismic records, conventional methods of seismic noise reduction including non-local mean filter have turned out to be ineffective. Therefore, the research on detecting the desert seismic events, improving the resolution of effective signals and reducing noise is of great significance for desert seismic exploration.
In order to solve the above problems, the dimension reduction theory and clustering theory in machine learning are introduced into desert seismic signal processing to compensate for the lack of non-local mean filter for desert seismic signals. Common methods for dimension reduction include principal component analysis (PCA) (Anderson 1963; Tipping and Bishop 2014), linear discriminant analysis (LDA) (Ye et al. 2006; Bandos et al. 2009; Yu and Yang 2001; Yang et al. 2005) and manifold learning (Meng et al. 2017). PCA is an unsupervised linear dimension reduction algorithm. Its purpose is to maximize the variance of projection sample points after projecting high-dimensional data into low-dimensional space. The sample points are scattered as much as possible. In desert seismic events, the seismic data in the low-dimensional space only realize the dispersion of sample points and cannot distinguish effective signal points from noise data points. In this respect, LDA is superior to PCA. LDA is a supervised linear dimension reduction. So, it can achieve data classification while reducing dimensions.
The LDA was developed from Fisher discriminant analysis which was first proposed by Fisher (1936) on the two classification problem (Fisher 1936). It assumes that the covariance matrices for all types of sample points are the same and full rank. Therefore, LDA can be used not only for two classifications, but also for multiple classifications. LDA obtains the optimal sample projection direction by training a known sample of a desert seismic signal training set. When this projection direction is used for new desert seismic data, effective signals and noise can be separated in a low-dimensional space. Then, the effective signal is extracted to locate the seismic events. Finally, the non-local means filter is used for noise removal. Experiments have shown that the results obtained by this method are better than directly using the non-local means filter or f–x deconvolution.
Random noise reduction framework
This framework mainly includes two parts which are signal detection and filtering. In this paper, we select LDA as the signal detection method in this framework. LDA relies on the learning of the training sample set. The selection of the training set will directly determine whether the new seismic data can separate effective signals and noise when projected into the low-dimensional space. Therefore, the similarity in each feature between the synthetic seismic signals in the training set and the real desert seismic signals is extremely important.
Linear discriminant analysis
The idea of LDA is described as: Given the training set, the samples in the training set are projected onto a line in a certain way, so that the same type of projection data points are as close to each other as possible, and the heterogeneous projection data points are far away from each other. When a new data set is encountered, it is projected onto the same line and the classification of the new sample is obtained based on the position of the projected data points on the line.
For a given data set \(D = \{ ({\mathbf{x}}_{{\mathbf{i}}} ,y_{i} )\}_{i = 1}\), \(y_{i} \in \{ 0,1\}\), let \(X_{i}\), \({\varvec{\upmu}}_{{\mathbf{i}}}\) and \(\Sigma _{{\mathbf{i}}}\), respectively, be a set of examples, a mean vector and a covariance matrix. When all the sample data are projected onto a straight line \({\varvec{\upomega}}\), the projections of the centers of the two types of sample data on the straight line are \({\varvec{\upomega}}^{\rm T} {\varvec{\upmu}}_{{\mathbf{0}}}\) and \({\varvec{\upomega}}^{\rm T} {\varvec{\upmu}}_{{\mathbf{1}}}\). The covariances of the two types of samples are, respectively, \({\varvec{\upomega}}^{\rm T} \sum\nolimits_{0} {\varvec{\upomega}}\) and \({\varvec{\upomega}}^{\rm T} \sum\nolimits_{1} {\varvec{\upomega}}\). According to the basic idea of the LDA algorithm, the similar sample data points should be as close as possible and the heterogeneous sample data points should be far away from each other. Then, the covariance matrix of the same type of projection sample points \({\varvec{\upomega}}^{\rm T} \sum\nolimits_{0} {\varvec{\upomega}} + {\varvec{\upomega}}^{\rm T} \sum\nolimits_{1} {\varvec{\upomega}}\) should be as small as possible, and the distance of the projection center of the heterogeneous sample points \(\| {{\varvec{\upomega }}^{\rm T} {\varvec{\upmu }}_{{\mathbf{0}}} - {\varvec{\upomega }}^{\rm T} {\varvec{\upmu }}_{{\mathbf{1}}} } \|_{2}^{2}\) should be as far as possible, which can get the maximum goal as follow (Ye et al. 2006):
“Within-class scatter matrix” is defined as (Fukunaga 1990):
“Between-class scatter matrix” is defined as (Fukunaga 1990):
Then, Eq. (1) can be simplified as follow:
Equation (4) is the maximization goal of the LDA algorithm. That is the “generalized Rayleigh quotient” of \({\mathbf{S}}_{{\mathbf{b}}}\) and \({\mathbf{S}}_{{\varvec{\upomega}}}\).
In order to get a determinate \({\varvec{\upomega}}\), we must normalize the denominator of Eq. (4), and let \({\varvec{\upomega}}^{\rm T} {\mathbf{S}}_{{\varvec{\upomega}}} {\varvec{\upomega}} = 1\), then, Eq. (4) can be equivalent to:
By Lagrange multiplier method, Eq. (5) can be equivalent to:
where \(\lambda\) is the Lagrangian multiplier. It can be seen the feature vector of \({\mathbf{S}}_{{\varvec{\upomega}}}^{ - 1} {\mathbf{S}}_{{\mathbf{b}}}\).
For a new data set \({\mathbf{X}}\), its low-dimensional projection data set \({\mathbf{Y}}\) can be expressed as:
Training set
LDA needs a corresponding training set. However, there is no mature available training set for desert seismic signals. Therefore, an appropriate training set needs to be generated to process the real desert seismic signal.
To generate the training set, it is necessary to understand the characteristics of sample data. In the denoising process of seismic prospecting, random noise is often assumed to be stationary and Gaussian. According to the statistical analysis, the desert seismic random noise is not strictly stationary, but locally stationary. Moreover, we can get that the desert random noise is non-Gaussian through the Gaussian property test (Zhong et al. 2015a, b). In terms of linearity, Zhong et al. (2015a, b) proved that desert seismic random noise is nonlinear.
In general seismic signal inversion process, Ricker waves are used to synthesize seismic signals. Taking into account the complexity of desert seismic signals and its generalization performance, general zero-phase waves and mixed-phase waves are added to the training set. Previous studies of the desert seismic signals have shown that the frequency of their effective signals is around 30 Hz. The frequency range of noise is from several Hertz to twenty Hertz (Li and Li 2016; Li et al. 2017). In order to ensure the richness of frequency components, there are a total of 11 frequency components of seismic wavelets in the training set, including 20 Hz, 22 Hz, 24 Hz, 26 Hz, 28 Hz, 30 Hz, 32 Hz, 34 Hz, 36 Hz, 38 Hz and 40 Hz. In the desert seismic signal training set, the synthesize desert noise is used in the noise part (Li and Li 2016; Li et al. 2017). Its characteristics are very similar to the real desert noise.
The general formula for constructing Ricker waves as:
The general formula for constructing zero-phase waves as:
The general formula for constructing mixed-phase waves as:
where \(A\) is the amplitude, \(f_{0}\) is the dominant frequency and \(t_{0}\) is the time delay.
The LDA training set requires the noisy signal and the corresponding position noise as two types of training data. Therefore, Ricker waves noised by synthetic desert random noise and synthetic random desert noise are used as two kinds of sample data in the training set. Sample data of general zero-phase waves and mixed-phase waves and corresponding frequency components are also obtained in this way. Every frequency component of each phase wave extracted 50 traces. Finally, 1650 noisy signal samples and corresponding 1650 noise samples are obtained, which together constitute a training set for training to learn the best projection direction \({\varvec{\upomega}}\).
Desert seismic random noise reduction
We set a desert seismic record \(X = \{ x_{ij} \}\), where \(i = 1 \cdots N\) is data point and \(j = 1 \cdots D\) is trace number. The first part: LDA effective signal detection. The projection direction \({\varvec{\upomega}}\) can be obtained by training sample set. Then, it is compared to a sliding window, which slides from top to bottom to reduce dimension of new desert seismic data, and obtaining low-dimensional projection data points. At this time, the low-dimensional data points have been divided into two categories labeled by the K-means clustering algorithm when \(k = 2\) (Hartigan and Wong 1979). The effective signal is reserved for detection. The second part: The filter is used to get the denoising result. By above description, we choose the sliding window method to reduce the dimension. The advantage of this method is that it can fully guarantee the relationship between data points, so that the data in the low-dimensional space still maintain the original relationship, and further ensure the accuracy of clustering. The computational cost of the method is dominated by training the cost of the projection direction \({\varvec{\upomega}}\) and clustering. The additional complexity associated with dimension reduction and the computation required to extract effective signal data points is negligible. Because of the small amount of sample data, the computational time is only a few minutes.
The noise reduction steps from desert seismic data based on LDA effective signal detection are given as follows:
Set a desert seismic record \(X = \left\{ {x_{ij} } \right\}\), where \(i\) is data point and \(j\) is trace number.
-
1.
Generate the training set to get the within-class scatter matrix, between-class scatter matrix and the mean values of the two sample data points.
-
2.
According to Eq. (6), we get the best projection direction \({\varvec{\upomega}}\); compare it to a window; and take the length of the window as 40 points.
-
3.
From Eq. (7), the single-trace desert seismic record is processed. The sliding window moves downward by one point to reduce dimension. In order to avoid losing data points in the process of window sliding dimension reduction, we add zero to the beginning and ending of the original data.
-
4.
Cluster the data of low dimensional by the K-means clustering algorithm to get the noise points and signal points; extract the signal data points to achieve effective signal detection.
-
5.
The non-local mean filter is used to get the denoising results.
Experiments and results
Synthetic desert seismic record
Aiming to test the feasibility of this method, we apply it to a synthetic desert seismic record (Fig. 1) which has 50 traces and each trace has 1400 data points with dominant frequency of 30 Hz and 35 Hz. The amplitude of signal is 1 and the sampling frequency is 500 Hz, as shown Fig. 1a. We add synthetic desert seismic noise to this record and make the SNR = − 8.0619 dB. It is shown in Fig. 1b. The SNR is defined as follows (Meng et al. 2017):
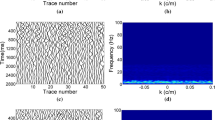
where \(s(i,t)\) is the clean synthetic desert seismic signal, \(x(i,t)\) is the noisy signal, \(i = 1 \cdots N\) is data point and \(t = 1 \cdots M\) is trace number. We replace the signal detection method of the denoising framework with PCA, and the non-local mean filter is selected as filtering part to form a comparative test. In addition, f–x deconvolution and curvelet thresholding are used as contrast experiments. The results are shown in Fig. 2. Figure 3 shows the residual results of synthetic desert seismic record by using five methods. Figure 2a describes the processing results under the denoising framework proposed in this paper. Figure 2b shows the results of processing with a non-local mean filter. Figure 2c illustrates the results of a comparative test using PCA to detect the effective signal. The results of f–x deconvolution and curvelet thresholding are shown as Fig. 2d, e, respectively. It can be seen that the result of the non-local mean filter is not satisfactory. In Fig. 3b, effective signals have residue and the random noise is hardly reduced. It also illustrates the shortcomings of non-local mean filtering in random noise reduction in desert seismic record. The results of f–x deconvolution and curvelet thresholding are better. But, they are not the best results. We can see the seismic events clearly. And the amplitude of effective signals has attenuation, as shown in Fig. 3d, e. In the same framework, the detection method is changed to PCA. The random noise is reserved more. And the noise part and the effective signal part are distinguished by a higher error rate, which makes it difficult to achieve the desired denoising effect. In the denoising framework introduced in this paper, the noise part and effective signal part of every trace can be accurately clustered when LDA is to detect effective signal. The output SNR of above methods is listed in Table 1. Figure 4 shows frequency–wavenumber spectra (FK spectra) of Figs. 1a, b and 2a–e. Comparing with Fig. 4a and Fig. 4c, we can see that the FK spectrum of clean synthetic desert seismic record and synthetic desert seismic record after denoising is very similar, and the denoising effect is obvious. In Fig. 4d, e, g, the noise reduction is not obvious; low-frequency noise is not reduced. The effective signal is also partially lost. In Fig. 4f, the part of effective signals is not clear. Therefore, the method proposed in this paper has the best denoising effect.

Synthetic desert seismic record. a Clean synthetic desert seismic record. b Synthetic desert seismic records with SNR = − 8.0619 dB

Processing results of synthetic desert seismic record. a Proposed method results. b Non-local mean filter results. c Non-local mean filter results after PCA detection. df–x deconvolution results. e Curvelet thresholding results

Residual comparison of synthetic desert seismic record before and after denoising. a Removed noise using proposed method. b Removed noise using non-local mean filter. c Removed noise using non-local mean filter after PCA detection. d Removed noise using f–x deconvolution. e Removed noise using curvelet thresholding

FK spectra of synthetic desert seismic record. a FK spectra of clean synthetic desert seismic record. b FK spectra of synthetic desert seismic records. c FK spectra of proposed method results. d FK spectra of non-local mean filter results. e FK spectra of non-local mean filter results after PCA detection. f FK spectra of f–x deconvolution results. g FK spectra of curvelet thresholding results
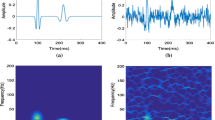
Figure 5 shows the result of single-trace processing. Figure 5a shows the clean synthetic record, synthetic noisy records, K-means clustering results, signal detection results and filtering results of 38th trace after signal detection using LDA, respectively. Figure 5b shows results after using PCA to detect signal. The results show that the accuracy of LDA in signal detection is much higher than that of PCA and also proves the rationality of selecting LDA as the detection method in this denoising framework. Figure 6 is the plots of the amplitude comparison of effective signals. Compared with the contents of the blue box, the effective signal amplitude keeps great under the denoising framework, and the part of the noise is removed completely (Fig. 6a). However, using the other four ways to denoise, their amplitude have some attenuation, and a lot of random noise is preserved (Fig. 6b–e). Although the valley of partial Ricker waves is incomplete, it is obvious that the effective signal after denoising remains better under this framework.

Clustering result of single-trace processing. a Clean synthetic record, synthetic noisy records, K-means clustering results, signal detection results and filtering results of 38th trace after signal detection using LDA, respectively. b Clean synthetic record, synthetic noisy records, K-means clustering results, signal detection results and filtering results of 38th trace after signal detection using PCA, respectively

Amplitude comparison of signals of 38th trace. a Proposed method results. b Non-local mean filter results. c Non-local mean filter results after PCA detection. df–x deconvolution results. e Curvelet thresholding results
It is known from the above description that the results of filtering after the detection are mainly dependent on the accuracy of the clustering after reducing the dimension of the data. To further prove the superiority of the method, the experiments, processing synthetic seismic records with SNR = 2.5583 dB, − 3.7059 dB, − 6.1335 dB, − 8.2854 dB, − 10.4649 dB and − 13.7081 dB, respectively, are repeated 200 times to calculate the accuracy of clustering. The results are shown as shown in Table 2. The accuracy of clustering is defined as follows:
where \(n\) is the point number of synthetic desert seismic record, \(m\) is the number of points accurately clustered. The clustering accuracy of the two detection methods and K-means methods decreases with the reduction in SNR. The accuracy rate of using the unsupervised PCA to detect is greatly influenced by the SNR. The accuracy rate can reach 96.19% when the SNR is high. When the SNR is low, the accuracy rate will also be greatly reduced. On the contrary, the accuracy rate of using the supervised LDA to detect is less affected. Although the accuracy rate of LDA is not very different with PCA at the high SNR, the accuracy rate of LDA is far greater than PCA at low SNR. These all proved that LDA detection method has higher noise tolerance and better accuracy. The accuracy of directly clustering without detection method is lower than that of using detection method. It is difficult to achieve the purpose of effective signal detection. Therefore, in the face of the characteristics of low SNR of the desert seismic records, it is reasonable and effective to choose the LDA to detect the seismic events and then use the filter to denoise. At the same time, in the case of different input SNR, we quantitatively analyze the output SNR of several selected methods. The result is shown in Fig. 7. According to Fig. 7, we can see that the denoising framework proposed in this paper is the best to improve the SNR. However, when the detection method in this denoising framework is replaced by PCA, the improvement effect of the denoising framework on the output SNR will be reduced. And the output SNR is also influenced by the input SNR more seriously than other methods. Besides, we analyze the mean square error (MSE) of different denoising methods, and the results are shown in Fig. 8. MSE is defined as follows:
where \(s\left( {i,t} \right)\) is the clean synthetic desert seismic signal, \(x^{\prime } \left( {i,t} \right)\) is the denoisy signal, \(i = 1 \cdots N\) is data point and \(t = 1 \cdots M\) is trace number. It can be seen that the MSE of the method proposed in this paper is the smallest, which is most similar to the clean synthetic desert seismic signal. From this point of view, we know that the denoising effect introduced in this paper is also optimal.

Performance comparison of selected method for various input SNR

MSE comparison of selected method for various input SNR
In general, the framework introduced in this paper is very effective in random noise reduction. It is also reasonable to select LDA for effective signal detection.
Real desert seismic record
The real desert seismic record with a total of 101 traces is used to analyze the practical application ability of this framework, as shown in Fig. 9a. Figure 9b describes the result of using the random noise reduction framework introduced in the paper. It can be obtained that the resolution and the continuity of the seismic events are significantly improved. The parts of the effective signal become clearer. The areas where the denoising effect has been significantly improved have been marked with red boxes. Figure 9c shows the result of using non-local mean filter to denoise. It can be seen that the noise is reduced slightly. The denoising effect is not obvious. The resolution of the seismic events is not improved. Their continuity has not been obviously ameliorated. Figure 9d illustrates the result that first using the PCA method to detect the effective signal and then using the non-local mean filter to denoise. The resolution and continuity of the seismic events have not been improved. f–x deconvolution achieves acceptable results (Fig. 9e), but this result is inferior to that of Fig. 9b in terms of continuity and clarity of the seismic events. The result of curvelet thresholding is also not ideal, as shown Fig. 9f. Compared with the denoising effect of all the areas marked by the red boxes in Fig. 9, the method presented in this paper can show better denoising performance. Meanwhile, we also compare the difference before and after denoising by using selected methods (Fig. 10). From the removed noise, we can see that the denoising framework can remove the noise thoroughly. In Fig. 10a, there is almost no residual effective signal. In removed noise of other methods, not only the random noise reduction is not complete, but also the effective signal remains (Fig. 10b–e).

Processing results of real desert seismic record. a Real desert seismic records. b Proposed method results. c Non-local mean filter results. d Non-local mean filter results after PCA detection. ef–x deconvolution results. f Curvelet thresholding results

Residual comparison of real desert seismic record before and after denoising. a Removed noise using proposed method. b Removed noise using non-local mean filter. c Removed noise using non-local mean filter after PCA detection. d Removed noise using f–x deconvolution. e Removed noise using curvelet thresholding
In summary, this method is highly advantageous compared with the non-local mean filter and curvelet thresholding. It is also better than f–x deconvolution which is the most traditional method of seismic signal denoising. The supervised LDA detection method is better than the unsupervised PCA detection method. It also shows the advantage of supervised LDA in dimension reduction.
Conclusions
In this paper, we have used LDA effective signal detection method to form a framework to reduce random noise of desert seismic record. By learning the two kinds of data in the training set and reducing dimension, the low-dimensional signal data and noise data can be divided accurately in low SNR scenarios and the effective signal data can be extracted accurately. When the same projection direction is applied to the new seismic data, the signal is also divided into two kinds of effective signal and noise. The effective signal is extracted better. Then, the filter is used to denoise, so that the denoising effect is obviously improved. We test the capacity of this framework on both synthetic and real desert seismic record. Compared with conventional methods, such as using non-local mean filter directly, f–x deconvolution and curvelet thresholding, this method can achieve better results. When the LDA detection way is replaced by PCA, the results become worse. In conclusion, the desert seismic record noise reduction method based on LDA effective signal detection can accurately detect the effective signal and finally obtain good denoising effect. Using machine learning to process seismic signals is a new idea. In future work, we will try to find a classification algorithm to reduce the desert seismic random noise, rather than relying on filters. Of course, we can also find new features in the transform domain to classify seismic data and ultimately achieve noise removal.
References
Anderson TW (1963) Asymptotic theory for principal component analysis. Ann Math Stat 34(1):122–148
Bandos TV, Bruzzone L, Camps-Valls G (2009) Classification of hyperspectral images with regularized linear discriminant analysis. IEEE Trans Geosci Remote Sens 47(3):862–873
Bednar JB (1983) Applications of median filtering to deconvolution, pulse estimation, and statistical editing of seismic data. Geophysics 48(12):1598–1610
Bonar D, Sacchi M (2012) Denoising seismic data using the nonlocal means algorithm. Geophysics 77(1):5
Canales LL (1984) Random noise reduction. Seg Tech Program Expand Abstr 3(1):329
Fisher RA (1936) The use of multiple measurements in taxonomic problems. Ann Hum Genet 7(2):179–188
Fukunaga K (1990) Introduction to statistical pattern classification. Academic Press, London
Hartigan JA, Wong MA (1979) Algorithm as 136: a k-means clustering algorithm. J R Stat Soc 28(1):100–108
Li GH, Li Y (2016) Random noise of seismic exploration in desert modeling and its applying in noise attenuation. Chin J Geophys 59:682–692
Li G, Li Y, Yang B (2017) Seismic exploration random noise on land: modeling and application to noise suppression. IEEE Trans Geosci Remote Sens 55(8):4668–4681
Meng Y, Li Y, Zhang C, Zhao H (2017) A time picking method based on spectral multimanifold clustering in microseismic data. IEEE Geosci Remote Sens Lett 14(8):1273–1277
Neelamani R, Baumstein AI, Gillard DG, Hadidi MT, Soroka WL (2008) Coherent and random noise attenuation using the curvelet transform. Lead Edge 27(2):240–248
Shang S, Han LG, Lv QT, Tan CQ (2013) Seismic random noise suppression using an adaptive nonlocal means algorithm. Appl Geophys 10(1):33–40
Stewart RR, Schieck DG (1989) 3-d f-k filtering. Seg Tech Program Expand Abstr 8(1):1123
Tipping ME, Bishop CM (2014) Mixtures of probabilistic principal component analyzers. Neural Comput 11(2):443–482
Yang J, Frangi AF, Yang JY, Zhang D, Jin Z (2005) Kpca plus lda: a complete kernel fisher discriminant framework for feature extraction and recognition. IEEE Trans Pattern Anal Mach Intell 27(2):230–244
Ye J, Janardan R, Li Q, Park H (2006) Feature reduction via generalized uncorrelated linear discriminant analysis. IEEE Trans Knowl Data Eng 18(10):1312–1322
Yu H, Yang J (2001) A direct lda algorithm for high-dimensional data—with application to face recognition. Pattern Recognit 34(10):2067–2070
Zhong T, Li Y, Wu N, Nie P, Yang B (2015a) A study on the stationarity and Gaussianity of the background noise in land-seismic prospecting. Geophysics 80(4):V67–V82
Zhong T, Yue L, Ning W, Nie P, Yang B (2015b) Statistical properties of the random noise in seismic data. J Appl Geophys 118:84–91
Acknowledgements
This work is supported by the National Natural Science Foundation of China (Grants 41730422 and 41774117).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ma, H., Yan, J., Li, Y. et al. Desert seismic random noise reduction based on LDA effective signal detection. Acta Geophys. 67, 109–121 (2019). https://doi.org/10.1007/s11600-019-00250-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11600-019-00250-0