
Abstract
The introduction of kernel function in primal-dual interior point methods represents not only a measure of the distance between the iterate and the central path, but also plays an important role in the amelioration of the computational complexity of an interior point algorithm. In this work, we present a primal-dual interior point method for linear optimization problems based on a new kernel function with an efficient logarithmic barrier term. We derive the complexity bounds for large and small-update methods respectively. We obtain the best known complexity bound for large-update given by Peng et al., which improves significantly the so far obtained complexity results based on a logarithmic kernel function given by El Ghami et al. The results obtained in this paper are the first with respect to the kernel function with a logarithmic barrier term.
Similar content being viewed by others

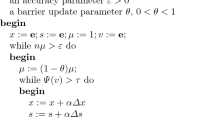

Avoid common mistakes on your manuscript.
1 Introduction
In 1984, Karmarkar [1] proposed a new polynomial method for solving linear optimization problems \(\text{(LO) }\). This method, and its variants that were developed subsequently, are now called interior-point methods \(\text{(IPMs) }\). For a survey, we refer to recent books on the subject [2,3,4]. In order to describe the idea of this paper, we need to recall some ideas underlying new primal-dual \(\text{ IPMs }\). Recently, Peng et al. [2] introduced the so-called self-regular barrier functions for primal-dual \(\text{ IPMs }\) for linear optimization. Each such barrier function is determined by its univariate self regular kernel function.
Most of \(\text{ IPMs }\) for \(\text{ LO }\) are based on the logarithmic barrier function [3, 5]. In 2001, Peng et al. [6] proposed new variants of \(\text{ IPMs }\) based on a new nonlogarithmic kernel functions. Such a function is strongly convex and smooth coercive on its domain: the positive real axis. They obtained the best known complexity results for large and small-update methods.
In 2004, Bai et al. [7] proposed new kernel function with an exponential barrier term, and introduced the first new kernel function with a trigonometric barrier term.
In 2008, El Ghami et al. [8] proposed parameterized kernel function with a logarithmic barrier term. This function generalized the kernel functions given in [3, 5]. In the same year, Bai et al. [9] proposed parameterized kernel function which is not a logarithmic barrier term in the general case. This function generalized the kernel functions given in [2, 3, 5, 8, 10].
In 2012, El Ghami et al. [11] evaluated the first new kernel function with a trigonometric barrier term given by Bai et al. [7]. Since then, research on giving new kernel function with a trigonometric barrier term continued for improving the complexity bound obtained by El Ghami et al. [11].
In 2016, Bouafia et al. [12, 13] proposed two parameterized kernel function for primal-dual \(\text{ IPMs }\) for \(\text{ LO }\). They obtained the best known complexity results for large and small-update methods. The first function in [12] generalizes the kernel function given by Bai et al. [7], whereas the second in [13] is the first kernel function with trigonometric barrier term primal-dual \(\text{ IPMs }\) for \(\text{ LO }\). This last function generalized and improved the complexity bound based on a new kernel function with trigonometric barrier term obtained in [11, 14,15,16,17,18]. The objective of this work is to generalize and improve the complexity bound based on a new kernel function with logarithmic barrier term.
The paper is organized as follows. In Sect. 2, we start with some notations and preliminaries. In Sect. 3, we present some properties of the new kernel function, as well as several properties and the growth behavior of the barrier function based on this kernel function. The estimate of the step size and the decrease behavior of the new barrier function are discussed in Sect. 4 where we present the inner iteration bound as well as the iteration bound of the algorithm. In Sect. 5, we offer a compared results of the algorithm given by El Ghami et al. [8] and the results of our algorithm. Finally, concluding remarks are given in the last section.
2 Notations and preliminaries
2.1 Notations
Let \(\mathbb {R}^{n}\) be the n-dimensional Euclidean space with the inner product \(\langle .,.\rangle \) and \(\left\| {.}\right\| \) be 2-norm. \(\mathbb {R}_{+}^{n}\) and \(\mathbb {R}_{++}^{n}\) denote the set of n-dimensional nonnegative vectors and positive vectors respectively. For \(x,\ s\in \mathbb {R}^{n}\), \(x_{\min }\) and xs denote the smallest component of the vector x and the componentwise product of the vector x and s respectively. We denote by \(X=diag(x)\) the \(n\times n\) diagonal matrix with components of the vector \(x\in \mathbb {R}^{n}\) are the diagonal entries. Finally, e denotes the n-dimensional vector of ones. For \(f\left( x\right) ,\ g\left( x\right) :\) \(\mathbb {R}_{++}^{n}\rightarrow \mathbb {R}_{++}^{n},\) \(f\left( x\right) =\mathbf {O}\left( g\left( x\right) \right) \) if \(f\left( x\right) \le C_{1}g\left( x\right) \) for some positive constant \(C_{1} \)and \(f\left( x\right) ={\varvec{\Theta }}\left( g\left( x\right) \right) \) if \(C_{2}g\left( x\right) \) \(\le f\left( x\right) \le C_{3}g\left( x\right) \) for some positive constant \(C_{2}\) and \(C_{3}\).
2.2 Preliminaries
In this paper, we deal with primal-dual methods for solving the standard \(\text{ LO }\):

where \(A\in \mathbb {R}^{m\times n}\), \(rank(A)=m\), \(b\in \mathbb {R}^{m}\) and \(c\in \mathbb {R}^{n}\), and its dual problem

In 1984, Karmarkar [1] proposed a new polynomial-time method for solving \(\text{ LO }\). This method and its variants that were developed subsequently are now called \(\text{ IPMs }\). For a survey, we refer to recent books on the subject as Peng et al. [2], Roos et al. [3], Ye [4] and Bai et al. [19]. Without loss of generality, we assume that (P) and (D) satisfy the interior-point condition \(\text{(IPC), }\) i.e. there exist \((x^{0}\),\(y^{0}\),\(s^{0})\) such that
It is well known that finding an optimal solution of (P) and (D) is equivalent to solving the following system
The basic idea of primal-dual \(\text{ IPMs }\) is to replace the third equation in (2), the so-called complementarity condition for (P) and (D), by the parameterized equation \(xs=\mu e,\) with \(\mu >0\). Thus we consider the system
Surprisingly enough, if the \(\text{ IPC }\) is satisfied, then there exists a solution for each \(\mu >0\), and this solution is unique. It is denoted as \((x(\mu ),y(\mu ),s(\mu ))\), and we call \(x(\mu )\) the \(\mu \)-center of (P) and \((y(\mu ),s(\mu ))\) the \(\mu \)-center of (D). The set of \(\mu \)-centers (with \(\mu \) running through all positive real numbers) gives a homotype path, which is called the central path of (P) and (D). The relevance of the central path for \(\text{ LO }\) was recognized first by Megiddo [20] and Sonnevend [21]. If \(\mu \rightarrow 0\), then the limit of the central path exists, and since the limit points satisfy the complementarity condition, the limit yields optimal solutions for (P) and (D). From a theoretical point of view, the \(\text{ IPC }\) can be assumed without loss of generality. In fact we may, and will, assume that \(x^{0}=s^{0}=e\). In practice, this can be realized by embedding the given problems (P) and (D) into a homogeneous self-dual problem, which has two additional variables and two additional constraints. For this and the other properties mentioned above, see [3]. The \(\text{ IPMs }\) follow the central path approximately. We describe briefly the usual approach. Without loss of generality, we assume that \((x(\mu ),y(\mu ),s(\mu ))\) is known for some positive \(\mu \). For example, due to the above assumption, we may assume this for \(\mu =1\), with \(x(1)=s(1)=e\). We then decrease \(\mu \) to \((1-\theta )\mu \) for some fixed \(\theta \in ] 0,1[\), and we solve the following Newton system:
This system defines uniquely a search direction \((\varDelta x,\varDelta y,\varDelta s) \). By taking a step along the search direction, with the step size defined by some line search rules, we construct a new triple (x, y, s). If necessary, we repeat the procedure until we find iterates that are “close” to \((x(\mu ),y(\mu ),s(\mu ))\). Then \(\mu \) is again reduced by the factor \(1-\theta \), and we apply Newton’s method targeting the new \(\mu -\)centers, and so on. This process is repeated until \(\mu \) is small enough, say until \(n\mu \le \epsilon \); at this stage we have found an \(\epsilon -\)solution of problems (P) and (D). The result of a Newton step with step size \(\alpha \) is denoted as
where the step size \(\alpha \) satisfies \(0<\alpha \le 1\). Now, we introduce the scaled vector v and the scaled search directions \( d_{x}\) and \(d_{s}\) as follows:
System (4) can be rewritten as follows:
where \(\overline{A}=\frac{1}{\mu }AV^{-1}X,\) \(V=diag(v),\) \(X=diag(x)\). Note that the right-hand side of the third equation in (7) is equal to the negative gradient of the logarithmic barrier function \({\varvec{\Phi }}_{L}\left( v\right) \) , i.e., \(d_{x}+d_{s}=-\nabla {\varvec{\Phi }}_{L}\left( v\right) \), system (7) can be rewritten as follows:
where the barrier function \({\varvec{\Phi }}_{L}(v):\ \mathbb {R}_{++}^{n}\rightarrow \mathbb {R}_{+}\) is defined as follows:
We use \({\varvec{\Phi }}_{L}\left( v\right) \) as the proximity function to measure the distance between the current iterate and the \(\mu -\)center for given \( \mu >0\). We also define the norm-based proximity measure, \(\delta (v)\) \(:\ \mathbb {R}_{++}^{n}\rightarrow \mathbb {R}_{+}\), as follows
We call \(\psi \left( t\right) \) the kernel function of the logarithmic barrier function \({\varvec{\Phi }}\left( v\right) \). In this paper, we replace \(\psi \left( t\right) \) by a new kernel function \(\psi _{LB}\left( t\right) \) and \({\varvec{\Phi }}\left( v\right) \) by a new barrier function \({\varvec{\Phi }}_{LB}\left( v\right) \), which will be defined in Sect. 3. Note that the pair (x, s) coincides with the \(\mu -\)center \((x(\mu ),s(\mu ))\) if and only if \(v=e\). It is clear from the above description that the closeness of (x, s) to \(\left( x(\mu ),s(\mu )\right) \) is measured by the value of \({\varvec{\Phi }}_{LB}\left( v\right) \) with \(\tau >0\) as a threshold value. If \({\varvec{\Phi }}_{LB}\left( v\right) \le \tau \), then we start a new outer iteration by performing a \(\mu -\)update; otherwise, we enter an inner iteration by computing the search directions at the current iterates with respect to the current value of \(\mu \) and apply (5) to get new iterates. If necessary, we repeat the procedure until we find iterates that are in the neighborhood of \((x(\mu ),s(\mu )).\) Then \(\mu \) is again reduced by the factor \(1-\theta \) with \(0<\theta <1\), and we apply Newton’s method targeting the new \(\mu -\)centers, and so on. This process is repeated until \(\mu \) is small enough, say until \(n\mu <\epsilon \); at this stage we have found an \(\epsilon -\)approximate solution of \(\text{ LO }\). The parameters \(\tau ,\theta \) and the step size \(\alpha \) should be chosen in such a way that the algorithm is optimized in the sense that the number of iterations required by the algorithm is as small as possible. The choice of the so-called barrier update parameter \(\theta \) plays an important role in both theory and practice of \(\text{ IPMs }\) . Usually, if \(\theta \) is a constant independent of the dimension n of the problem, for instance, \(\theta = 1/2\), then we call the algorithm a large-update (or long-step) method. If \(\theta \) depends on the dimension of the problem, such as \(\theta =1/n\) , then the algorithm is called a small-update (or short-step) method. The generic form of the algorithm is shown in Fig. 1.

Generic algorithm
In most cases, the best complexity result obtained for small-update IPMs is \(\mathbf {O}( \sqrt{n}\log \frac{n}{\epsilon })\). For large-update methods the best obtained bound is \(\mathbf {O}( \sqrt{n}\log n\log \frac{n}{\epsilon })\), which until now has been the best known bound for such methods [6, 7].
In this paper, we define a new kernel function with logarithmic barrier term and propose primal–dual interior point methods which improve all the results of the complexity bound for large-update methods based on a logarithmic kernel function for \(\text{ LO }\). More precisely, based on the proposed kernel function, we prove that the correspondent algorithm has \(\mathbf {O}\left( qn^{\frac{q+1}{2q}}\log \frac{n}{\epsilon }\right) \) complexity bound for large-update method and \(\mathbf {O}\left( q^{2}\sqrt{n}\log \frac{n}{\epsilon }\right) \) for small-update method. Another interesting choice is q dependent with n, which minimizes the iteration complexity bound. In fact, if we take \(q=\frac{\log n}{2}\), we obtain the best known complexity bound for large-update methods namely \(\mathbf {O}\left( \sqrt{n}\log n\log \frac{n}{\epsilon }\right) \). This bound improves the so far obtained complexity results for large-update methods based on a logarithmic kernel function given by El Ghami et al. [8].
3 Properties of the kernel function and the barrier function
3.1 Properties of the new kernel function
In this section, we investigate some properties of the new kernel function with a logarithmic barrier term which are essential to our complexity analysis. We call \(\psi \left( t\right) \): \(\mathbb {R}_{++}\rightarrow \mathbb {R}_{+}\) a kernel function if \(\psi \) is twice differentiable and satisfies the following conditions:
Now, we define a new function \(\psi _{LB}\left( t\right) \) as follows:
For convenience of reference, we give the first three derivatives with respect to t as follows:
Obviously, \(\psi _{LB}\left( t\right) \) is a kernel function and
In this paper, we replace the function \({\varvec{\Phi }}\left( v\right) \) in (8) with the function \({\varvec{\Phi }}_{LB}\left( v\right) \) as follows:
where
and \(\psi _{LB}\left( t\right) \) is defined in (12). Hence, the new search direction \((\varDelta x,\varDelta y,\varDelta s)\) is obtained by solving the following modified Newton system:
Note that \(d_{x}\) and \(d_{s}\) are orthogonal because the vector \(d_{x}\) belongs to null space and vector \(d_{s}\) to the row space of the matrix \(\overline{A} \).
Since \(d_{x}\) and \(d_{s}\) are orthogonal, we have
We use \({\varvec{\Phi }}_{LB}\left( v\right) \) as the proximity function to measure the distance between the current iterate and the \( \mu -\)center for given \( \mu >0\). We also define the norm-based proximity measure, \(\delta (v)\): \(\mathbb {R}_{++}\rightarrow \mathbb {R}_{+}\), as follows:
Lemma 3.1
For \(\psi _{LB}\left( t\right) \), we have the following.
\(\psi _{LB}\left( t\right) \) is exponentially convex for all \(t>0\); that is,




Proof
For (a), using (13), we have
And by Lemma 2.1.2 in [2], we have the result.
For (b), using (13), we have \(\psi _{LB}^{\prime \prime \prime }\left( t\right) <0\), so we have the result.
For (c), using (13), we have
For (d), using Lemma 2.4 in [7], (b) and (c), we have the result. This completes the proof. \(\square \)
Lemma 3.2
For \(\psi _{LB}\left( t\right) \), we have
Proof
For (20), since \(\psi _{LB}\left( 1\right) =\psi _{LB}^{\prime }\left( 1\right) =0,\psi _{LB}^{\prime \prime \prime }\left( t\right) <0,\) \(\psi _{LB}^{\prime \prime }\left( 1\right) =\frac{q+3}{2},\) and by using Taylor’s Theorem, we have
for some \(\xi ,\) \(1\le \xi \le t.\) This completes the proof. \(\square \)
Let \(\sigma : [ 0,+\infty [ \rightarrow [ 1,+\infty [ \) be the inverse function of \(\psi _{LB}\left( t\right) \) for \(t\ge 1\) and \( \rho :\left[ 0,+\infty \left[ \rightarrow \right] 0,1\right] \) be the inverse function of \(\frac{-1}{2}\psi _{LB}^{\prime }\left( t\right) \) for all \(t\in ] 0,1] \). Then we have the following lemma.
Lemma 3.3
For \(\psi _{LB}\left( t\right) \), we have
Proof
For (21), let
By (19), we have
then
which implies that
By (20), we have
so
For (22), let
By the definition of:
and by the definition of \(\psi _{LB}\left( t\right) \), we have
which implies that
This completes the proof. \(\square \)
Lemma 3.4
Let \(\sigma : [ 0,+\infty [ \rightarrow [ 1,+\infty [ \) be the inverse function of \(\psi _{LB}\left( t\right) \) for \(t\ge 1\). Then we have
Proof
Using (d), and Theorem 3.2 in [7], we can get the result. This completes the proof. \(\square \)
Lemma 3.5
Let \(0\le \theta <1\), \(v_{+}=\frac{v}{\sqrt{1-\theta }},\) If \(\ {\varvec{\Phi }}_{LB}\left( v\right) \le \tau ,\) then we have
Proof
Since \(\frac{1}{\sqrt{1-\theta }}\ge 1\) and \(\sigma \left( \frac{{\varvec{\Phi }}_{LB}\left( v\right) }{n}\right) \ge 1\), then \(\frac{\sigma \left( \frac{{\varvec{\Phi }}_{LB}\left( v\right) }{n}\right) }{\sqrt{1-\theta }}\ge 1 \).
And for \(t\ge 1,\) we have
Using Lemma 3.4 with \(\beta =\frac{1}{\sqrt{1-\theta }}\), (21), and \({\varvec{\Phi }}_{LB}\left( v\right) \le \tau ,\) we have
This completes the proof. \(\square \)
Denote
then \(\left( {\varvec{\Phi }}_{LB}\right) _{0}\) is an upper bound for \({\varvec{\Phi }}_{LB}\left( v_{+}\right) \) during the process of the algorithm.
3.2 An estimation for the step size
In this section, we compute a default step size \(\alpha \) and the resulting decrease of the barrier function. After a damped step we have
Using (6), we have
So, we have \(v_{+}=\sqrt{\frac{x_{+}s_{+}}{\mu }}=\sqrt{\left( v+\alpha d_{x}\right) \left( v+\alpha d_{s}\right) }. \)
Define, for \(\alpha >0\), \(f\left( \alpha \right) ={\varvec{\Phi }}_{LB}\left( v_{+}\right) -{\varvec{\Phi }} _{LB}\left( v\right) . \)
Then \(f\left( \alpha \right) \) is the difference of proximities between a new iterate and a current iterate for fixed \(\mu \). By (a), we have
Therefore, we have \(f\left( \alpha \right) \) \(\le \) \(f_{1}\left( \alpha \right) \), where
Obviously, \(f\left( 0\right) =\) \(f_{1}\left( 0\right) =0\). Taking the first two derivatives of \(f_{1}\left( \alpha \right) \) with respect to \(\alpha \), we have
For convenience, we denote \(v_{1}=\min \left( v\right) ,\ \delta =\delta (v),\ {\varvec{\Phi }}_{LB}= {\varvec{\Phi }}_{LB}\left( v\right) \).
Lemma 3.6
Let \(\delta (v)\) be as defined in (11). Then we have
Proof
Using (19), we have
so \(\delta (v)\ge \sqrt{\frac{1}{2}{\varvec{\Phi }}_{LB}\left( v\right) }\). This completes the proof. \(\square \)
Remark 3.1
Throughout the paper, we assume that \(\tau \) \(\ge 1\). Using Lemma 3.6 and the assumption that \({\varvec{\Phi }}_{LB}\left( v\right) \ge \tau ,\) we have \(\delta (v)\ge \sqrt{\frac{1}{2}}\).
From Lemmas 4.1–4.4 in [7], we have the following Lemmas 3.7–3.10, because \(\psi _{LB}(t)\) is kernel function and \(\psi _{LB}^{\prime \prime }(t)\) is monotonically decreasing.
Lemma 3.7
([7]) Let \(f_{1}\left( \alpha \right) \) be as defined in (24) and \(\delta (v)\) be as defined in (11). Then we have \(f_{1}^{\prime \prime }\left( \alpha \right) \le 2\delta ^{2}\psi _{LB}^{\prime \prime }\left( v_{\min }-2\alpha \delta \right) \). Since \(f_{1}\left( \alpha \right) \) is convex, we will have \(f_{1}^{\prime }\left( \alpha \right) \le 0\) for all \(\alpha \) less than or equal to the value where \(f_{1}\left( \alpha \right) \) is minimal, and vice versa.
The previous Lemma leads to the following three Lemmas:
Lemma 3.8
([7]) \(f_{1}^{\prime }\left( \alpha \right) \le 0\) certainly holds if \(\alpha \) satisfies the inequality
Lemma 3.9
([7]) The largest step size \(\overline{\alpha }\) holding (26) is given by \(\overline{\alpha }=\frac{\rho \left( \delta \right) -\rho \left( 2\delta \right) }{2\delta }\).
Lemma 3.10
([7]) Let \(\overline{\alpha }\) be as defined in Lemma 3.9. Then \( \overline{\alpha }\ge \frac{1}{\psi _{LB}^{\prime \prime }\left( \rho \left( 2\delta \right) \right) }\).
Lemma 3.11
Let \(\rho \) and \(\overline{\alpha }\) be as defined in Lemma 3.10. If \({\varvec{\Phi }}_{LB}\left( v\right) \ge \tau \ge 1\), then we have \(\overline{\alpha }\ge \frac{2}{2+\left( q+1\right) \left( 8\delta +2\right) ^{\frac{q+1}{q}}}\).
Proof
Using Lemma 3.10, (13) and (22) we have
This completes the proof. \(\square \)
Denoting
we have that \(\widetilde{\alpha }\) is the default step size and that \( \widetilde{\alpha }\le \overline{\alpha }\).
Lemma 3.12
(Lemma 3.12 in [2]) Let h be a twice differentiable convex function with \(h(0) = 0\), \(h^{\prime }(0) < 0\), which attains its minimum at \(t^{*}> 0\). If \(h^{\prime \prime }\) is increasing for \(t\in [0, t^{*}]\), then
In this respect the next result is important.
Lemma 3.13
(Lemma 4.5 in [7]) If the step size \(\alpha \) satisfies \(\alpha \) \(\le \overline{\alpha }\), then
Lemma 3.14
Let \(\widetilde{\alpha }\) be the default step size as defined in (27) and let
Then
Proof
Since \({\varvec{\Phi }}_{LB}\left( v\right) \ge 1\), then from (25), we have
Using Lemma 3.13 (4.5 in [7]) with \(\alpha =\widetilde{\alpha }\) and (27), we have
This completes the proof. \(\square \)
4 Complexity of the algorithm
4.1 Inner iteration bound
After the update of \(\mu \) to \(\left( 1-\theta \right) \mu \), we have
We need to count how many inner iterations are required to return to the situation where \({\varvec{\Phi }}_{LB}\left( v\right) \le \tau \) . We denote the value of \({\varvec{\Phi }}_{LB}\left( v\right) \) after the \(\mu \) update as \(\left( {\varvec{\Phi }}_{LB}\right) _{0}\); the subsequent values in the same outer iteration are denoted by \(\left( {\varvec{\Phi }}_{LB}\right) _{k}\), \( k=1,2,...,K\), where K denotes the total number of inner iterations in the outer iteration. The decrease in each inner iteration is given by (28). In [7], we can find the appropriate values of \(\kappa \) and \(\gamma \in \) ]0, 1] :
Lemma 4.1
Let K be the total number of inner iterations in the outer iteration. Then we have
Proof
By Lemma 1.3.2 in [2], we have \(K\le \frac{\left( {\varvec{\Phi }} _{LB}\right) _{0}^{\gamma }}{\kappa \gamma }=\left( 148\sqrt{2} q\right) \left[ \left( {\varvec{\Phi }}_{LB}\right) _{0}\right] ^{\frac{q+1}{2q} }\). This completes the proof. \(\square \)
4.2 Total iteration bound
The number of outer iterations is bounded above by \(\frac{\log \frac{n}{ \epsilon }}{\theta }\) (see [3] Lemma \(\mathbf {II}\).\(\mathbf {17}\), page \(\mathbf {116}\)). By multiplying the number of outer iterations by the number of inner iterations, we get an upper bound for the total number of iterations, namely,
For large-update methods with \(\tau =\mathbf {O}\left( n\right) \) and \(\theta ={\varvec{\Theta }}\left( 1\right) \), we have
In case of a small-update methods, we have \(\tau =\mathbf {O}\left( 1\right) \) and \(\theta ={\varvec{\Theta }}\left( \frac{1}{\sqrt{n}}\right) \). Substitution of these values into (28) does not give the best possible bound. A better bound is obtained as follows.
By (20), with
we have
Using (21), we have
where we also used that \(1-\sqrt{1-\theta }=\frac{\theta }{1+\sqrt{1-\theta } }\le \theta \) and \({\varvec{\Phi }}_{LB}(v) \le \tau \), using this upper bound for \(\left( {\varvec{\Phi }}_{LB}\right) _{0}\), we get the following iteration bound:
note now \(\left( {\varvec{\Phi }}_{LB}\right) _{0}=\mathbf {O}\left( q\right) \), and the iteration bound becomes \(\mathbf {O}\left( q^{2}\sqrt{n} \log \frac{n}{\epsilon }\right) \) iteration complexity.
5 Comparison of algorithms
To prove the effectiveness of our new kernel function and evaluate its effect on the behavior of the algorithm, we offer a comparison between the following two kernel functions with a logarithmic barrier term and the results of their correspondent \(\text{ IPMs }\) algorithms.
-
1)
The first kernel function, given by El Ghami et al. [8], is noted kernel function LE, defined by
$$\begin{aligned} \psi _{LE}\left( t\right) =\frac{t^{1+p}-1}{1+p}-\log t, \ \ \ p\in [0,1], t>0. \end{aligned}$$ -
2)
Our new kernel function is noted kernel function LB, defined in (12) by
$$\begin{aligned} \psi _{LB}\left( t\right) =\frac{t^{2}-1-\log t}{2}+\frac{t^{1-q}-1}{2\left( q-1\right) }, \ \ \ q>1, t>0. \end{aligned}$$
6 Conclusion
In this paper, our objective is to propose a new efficient parameterized logarithmic kernel function for developing a new descent direction and improve the algorithmic complexity of the interior-point method proposed. We have analyzed large-update and small-update versions of the primal-dual interior algorithm described in Fig. 1 which is based on the new kernel functions defined by (12). The results obtained in this paper represent important contributions to improve the convergence and the complexity analysis of primal-dual \(\text{ IPMs }\) for \(\text{ LO }\). So far, and to our knowledge, these results are the best known complexity bound for large-update with a logarithmic barrier term.
References
Karmarkar, N.K.: A new polynomial-time algorithm for linear programming. In: Proceedings of the 16th Annual ACM Symposium on Theory of Computing, vol. 4, pp. 373–395 (1984)
Peng, J., Roos, C., Terlaky, T.: Self-Regularity: A New Paradigm for Primal-Dual Interior Point Algorithms. Princeton University Press, Princeton (2002)
Roos, C., Terlaky, T., Vial, J.P.: Theory and Algorithms for Linear Optimization, An Interior Point Approach. Wiley, Chichester (1997)
Ye, Y.: Interior Point Algorithms, Theory and Analysis. Wiley, Chichester (1997)
El Ghami, M.: New Primal-Dual Interior-Point Methods Based on Kernel Functions. PhD Thesis, TU Delft, The Netherlands (2005)
Peng, J., Roos, C., Terlaky, T.: A new and efficient large-update interior point method for linear optimization. J. Comput. Technol. 6, 61–80 (2001)
Bai, Y.Q., El Ghami, M., Roos, C.: A comparative study of kernel functions for primal-dual interior point algorithms in linear optimization. SIAM J. Optim. 15(1), 101–128 (2004)
El Ghami, M., Ivanov, I.D., Roos, C., Steihaug, T.: A polynomial-time algorithm for \(\text{ LO }\) based on generalized logarithmic barrier functions. Int. J. Appl. Math. 21, 99–115 (2008)
Bai, Y.Q., Lesaja, G., Roos, C., Wang, G.Q., El Ghami, M.: A class of large-update and small-update primal-dual interior-point algorithms for linear optimization. J. Optim. Theory Appl. 138, 341–359 (2008)
Bai, Y.Q., Roos, C.: A polynomial-time algorithm for linear optimization based on a new simple kernel function. Optim. Methods Softw. 18, 631–646 (2003)
El Ghami, M., Guennoun, Z.A., Bouali, S., Steihaug, T.: Interior point methods for linear optimization based on a kernel function with a trigonometric barrier term. J. Comput. Appl. Math. 236, 3613–3623 (2012)
Bouafia, M., Benterki, D., Yassine, A.: Complexity analysis of interior point methods for linear programming based on a parameterized kernel function. RAIRO Oper. Res. 50, 935–949 (2016)
Bouafia, M., Benterki, D., Yassine, A.: An efficient primal-dual interior point method for linear programming problems based on a new kernel function with a trigonometric barrier term. J. Optim. Theory Appl. 170, 528–545 (2016)
Peyghami, M.R., Hafshejani, S.F., Shirvani, L.: Complexity of interior point methods for linear optimization based on a new trigonometric kernel function. J. Comput. Appl. Math. 255, 74–85 (2014)
Peyghami, M.R., Hafshejani, S.F.: Complexity analysis of an interior point algorithm for linear optimization based on a new proximity function. Numer. Algoritm. 67, 33–48 (2014)
Cai, X.Z., Wang, G.Q., El Ghami, M., Yue, Y.J.: Complexity analysis of primal-dual interior-point methods for linear optimization based on a new parametric Kernel function with a trigonometric barrier term. Abstr. Appl. Anal., pages Art. ID 710158, 11, (2014)
Kheirfam, B., Moslem, M.: A polynomial-time algorithm for linear optimization based on a new kernel function with trigonometric barrier term. YUJOR 25(2), 233–250 (2015)
Li, X., Zhang, M.: Interior-point algorithm for linear optimization based on a new trigonometric kernel function. Oper. Res. Lett 43(5), 471–475 (2015)
Bai, Y. Q., Roos, C.: A primal-dual interior point method based on a new kernel function with linear growth rate. In: Proceedings of the 9th Australian Optimization Day, Perth, Australia (2002)
Megiddo, N.: Pathways to the optimal set in linear programming. In: Megiddo, N. (ed.) Progress in Mathematical Programming: Interior Point and Related Methods, pp. 131–158. Springer, New York (1989)
Sonnevend, G.: An “analytic center” for polyhedrons and new classes of global algorithms for linear (smooth, convex) programming. In: Prekopa, A., Szelezsan, J., Strazicky, B. (eds.) System Modelling and Optimization: Proceedings of the 12th IFIP-Conference, Budapest, Hungary, 1985, Lecture Notes in Control and Inform. Sci, vol. 84, pp. 866–876. Springer, Berlin (1986)
Acknowledgements
The authors are very grateful and would like to thank the anonymous referees for their suggestions and helpful comments which significantly improved the presentation of this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Bouafia, M., Benterki, D. & Yassine, A. An efficient parameterized logarithmic kernel function for linear optimization. Optim Lett 12, 1079–1097 (2018). https://doi.org/10.1007/s11590-017-1170-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11590-017-1170-5