
Abstract
This paper presents a novel deep learning model for real-time prediction of shield moving trajectory during tunnelling. The proposed model incorporates a wavelet transform (WT) into Adam-optimised long short-term memory (LSTM) (WT-Adam-LSTM). The WT is employed to remove the irrelevant noise of data in the time and frequency domains, which allows the sequence pattern to be detected easily. The Adam algorithm is used to increase the reliability and optimise the gradient training process of the LSTM neural network for a given time series. The developed model considers the shield performance database, complex geological conditions, soil geometry, and operational parameters. A case study of a tunnel section under Bao'an International Airport was employed to verify the performance of the proposed model. A comparison with other models, i.e. recurrent neural network, LSTM, and support vector regression, was also made. The results show that WT-Adam-LSTM provides an effective solution and can achieve better results compared with other models.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Due to the increasing demand for reliability and safety of systems, shield tunnelling has become one of the most popular methods for constructing tunnels and infrastructure facilities [22]. Many subway tunnels in China have been constructed using the shield tunnelling technique because of its distinct advantages over other conventional methods. However, shield tunnelling frequently encounters technical problems such as difficult geological conditions, shield machine malfunctions, and positional deviation during tunnelling [5, 28, 31]. These problems can lead to increased risks, high cost, and even damage to the machine.
Positional deviation between the shield movement trajectory and designed tunnel axis has a significant effect on the quality of tunnel construction. The designed tunnel axis is an optimal path for the shield tunnel. Shield tunnelling misalignment results in the shield tunnel path deviating from the designed tunnel axis. The inaccurate control of the shield movement trajectory is the main cause for misalignment, and the error caused by misalignment can lead to several operation hazards [32, 33]. Moreover, oversized misalignment may change the excavation route, which can cause hazards during tunnelling [11, 23]. The complex underground geological structure, different frictional resistance of shield parts, and highly complex shield systems make it difficult to control the shield movement trajectory. To facilitate tunnel alignment control, the information of pose and trajectory recorded by the automatic navigation system needs to be adapted in real time. Currently, a feedback technique is used to control the shield performance in practice. A delayed control based on feedback can result in unexpected hazards after the deviation. Therefore, the shield operation needs to be predicted to increase the reliability and avoid severe deviation and snakelike motion.
Shield performance control is closely related to the experience of the driver with a limited degree of accuracy according to their intuition and experience. To achieve high-precision forecasting of shield performance, some attempts have been made to investigate the mechanism and scientific prediction during shield tunnelling [11]. Most existing studies employed traditional machine learning (ML) methods to adjust tunnel performance. For instance, Elbaz et al. [6] integrated adaptive neurofuzzy inference system (ANFIS) with genetic algorithm to implement an appropriate model for predicting tunnel performance. Another study proposed a multi-objective optimisation model for identifying soil parameters during excavation [12]. However, network accuracy remains unsatisfactory when dynamic and nonlinear time-series data are encountered. Owing to the development of modern computational programs, deep learning techniques have demonstrated outstanding performance as they can process sequence data such as time series. However, as a prerequisite for establishing an accurate model using deep learning techniques, two main issues regarding the data set obtained for the tunnel control system should be solved: noisy data induced by the shield measurement system and the large dimension of data that includes many irrelevant information. Further, when establishing a deep learning method to predict the shield movement trajectory based on a well-prepared data set, the following two challenges need to be addressed.
-
(1)
Temporal correlation The prediction of the shield movement trajectory is considered a time series forecasting issue. As the direction of changes among data is necessary for prediction, it is important to design an effective model to manage temporal features.
-
(2)
Imbalance Geological conditions can be obtained from limited borehole data, which implies that the amount of geological data is far less than that of the operational data. This imbalance between geological and operational data makes it difficult for a neural network model to produce an accurate prediction.
To tackle the challenges mentioned above, in the present study, we proposed a novel deep learning model that incorporates wavelet transform (WT) into the Adam-optimised LSTM technique (WT-Adam-LSTM). The WT is utilised to reduce the complexity of the forecasting model. The long-term characteristic established in the LSTM framework is imagined to capture the relationship between data features measured from the recorded system, which results in a better forecast for its future performance. The proposed model is trained to learn the temporal correlation among data, thereby forecasting the future shield movement trajectory. To the best of our knowledge, this is the first attempt to apply the proposed model for adjusting the shield movement trajectory using geological data and a data-driven technique. The kriging interpolation approach is applied to estimate the geological conditions at unsampled locations. The proposed model uses geological in situ data and operational parameters to learn the knowledge of the shield movement trajectory effectively and to achieve accurate prediction with high efficiency. A tunnel case study in Shenzhen, China, was employed to present the performance of the proposed model in a real field. In addition, the accuracy of the proposed model was verified and compared with those of existing traditional models. To confirm the significance of the results, the well-known nonparametric Friedman test was conducted. Once the shield movement trajectory can be predicted, the operator can control the machine beforehand.
2 Methodology
Deep learning presents an advanced system for smart manufacturing using a large amount of data owing to its features of complex system configuration abilities [27, 33]. Therefore, a hybrid deep learning approach trained by inputting in situ data is used to forecast the future shield moving trajectory. The schematic framework for the performance prediction of the shield movement based on integrating WT with Adam-optimised LSTM neural network is described (Fig. 1).

Schematic framework for the dynamic prediction of shield movement
2.1 Wavelet transform
The WT is a mathematical method resulting from a typical fusion of common analyses. The WT can develop the localisation idea of short-time Fourier transforms, and its coefficients reflect the local information of the signal in both the time and frequency domains [18]. Thus, this technique is efficient in simultaneously obtaining functions and displaying their local information through a time–frequency domain [4]. The discrete wavelet transform (DWT) is an effective WT model; it simplifies the application of the WT, and therefore, it is used in this study. The DWT can decompose the signal \(x\left( t \right)\) to multi-resolution and time-shifting characteristics [4, 7], and it is defined as
where \(a\) and \(b\) are discrete, \(a = a_{0}^{j} , b = ka_{0}^{j} b_{0} , a_{0} > 1, b_{0} > 0, j \in z, k \in z,\) \(j\) is the frequency resolution, and k is the time of the transform.
The Mallat algorithm, which is an efficient tool to establish the relation between WT and multi-resolution analysis, is used to employ a fast DWT [17]. In the multi-resolution analysis of wavelets, j is utilised to determine the resolution at different scales. For the original signal, the main contour is analysed on a large scale, while the detailed information is analysed on a small scale. Then, the decomposition results are analysed by the stepwise increase in \(j\). The time series function is decomposed as [17]
where \(A_{n} \left( t \right)\) refers to the original signal \(x\left( t \right)\), and \(D_{n} \left( t \right)\) is the elaborated portion related to the noisy data in the level decomposition n.
2.2 Adam-optimised LSTM network
The LSTM network is an extended version of the recurrent neural network architecture and has an extraordinary capability to learn long-range dependencies in various fields [14]. The LSTM network has memory blocks connected by layers rather than neurones. Every block includes gates that control the output and status of the block. Figure 2 shows the memory cell of the LSTM unit. In the training process, the LSTM structure can efficiently handle the problems of gradient explosion and gradient disappearance. The LSTM provides a cell state (c) for maintaining long-term data and utilises the three gates including input gate, output gate, and forget gate to adjust it. The calculated approaches related to the three gates of LSTM are given below [14].

Working principle of LSTM neural network [30]
Forget gate (\(f_{t}\)) specifies the information that needs to be disposed from the block, and it is formulated as
where \(h_{t - 1}\) is the previous output and \(x_{t}\) and \(\sigma\) are the input values and sigmoid function, respectively. The input gate (\(i_{t}\)) conditionally specifies the values entered to update the cell state (\(c_{t}\)); it can be formulated as
The output gate (\(h_{t}\)) conditionally determines what to output according to the input and block memory, and it can be formulated as
At every time (\(t\)), input features are estimated by input (\(x_{t}\)) and the prior hidden state (\(h_{t - 1}\)), and the tanh function refers to pushing the values between − 1 and 1, where
The memory cell is optimised using input features (\(c_{t}\)) and the partial forgetting of the prior memory cell (\(c_{t - 1}\)), which yields
Eventually, the hidden output state (\(h_{t}\)) is estimated using the output gate (\(o_{t}\)) and cell state (\(c_{t}\)), where
In Eqs. 3–6, the matrices \(w_{f}\), \(w_{i}\), \(w_{o}\), and \(w_{c}\) are weight matrices; vectors \(b_{f}\), \(b_{i}\), \(b_{o}\), and \(b_{c}\) are the bias vectors; and \(h_{t}\) refers to the value of the memory cell at time \(t\). \(f_{t}\), \(i_{t}\), and \(o_{t}\) indicate the forget, input, and output gate values at time \(t\). ° denotes the element-wise product [1].
The LSTM training process adjusts backpropagation within a time algorithm, which is similar to the traditional backpropagation algorithm. Optimisation is performed to achieve system parameters that can frequently reduce the cost function. To accelerate the LSTM training performance, the gradient training algorithm uses the Adam algorithm based on [1, 10]. A schematic of the hybrid WT-Adam-optimised LSTM is shown in Fig. 3. We calculated the loss function for the data sets to verify the forecasting of our proposed model against the real values from the tunnel. This loss function is utilised for estimating the deviation among the predicted value of the model and the measured value, and it can reflect the accuracy of the prediction. The formula is defined as the mean square error.

Overall process of the proposed WT-Adam-LSTM neural network
2.3 Framework of shield movement forecasting model
To achieve the dynamic forecasting of shield movement trajectory during tunnelling, we present a hybrid deep learning technique, referred to as the WT-Adam-LSTM model. There are four steps to construct the framework of the shield tunnelling trajectory from the utilised database. Each step is discussed below.
-
Step 1 Data description. The proposed model was applied to predict the shield movement trajectory through a tunnel project of the Guangzhou–Shenzhen intercity railway project. Geological and operational data are utilised to illustrate the applicability of the model.
-
Step 2 Data set preparation. Appropriate data are selected to describe the behaviour of the shield machine during the tunnelling process. To adapt geological data with operational parameters, the kriging interpolation technique is used to provide a rough estimation of a certain soil parameter between the sampling locations based on existing geological information. This interpolation technique is an advanced geostatistical procedure used to match the deterministic output model as a realisation of a random process for efficient prediction.
-
Step 3 Data decomposition. The wavelet transform denoising method, referred to as WT, is applied to preprocess the training data and decompose the shield machine parameter. Then, the rebuilding process is conducted to fuse the new denoised data sequence with the geological data to improve model accuracy.
-
Step 4 LSTM with a deep network in the temporal dimension contains a memory block to store the historical time series information, and a multi-step-ahead predictive variable is generated over considerable training in the supervised learning model. This model is robust in detecting the difference pattern while lying in a time series.
3 Case study
3.1 Project description
The Guangzhou–Dongguan–Shenzhen intercity railway project represents one of the largest infrastructure projects located on the coast of the Pearl River Delta of Guangdong, China. The construction project links Guangzhou Xintang Railway Station, Guangzhou, and Bao'an International Airport, Shenzhen. To verify the applicability of the proposed model, a tunnel section among Bao'an Airport North Station and Bao'an Airport Station, located in the zone of airport terminal 3, was used for simulation and analysis. The length of the studied section is approximately 3.3 km, with a buried depth ranging from 8.0 to 22.0 m. The tunnel was excavated using an earth pressure balance (EPB) shield machine. The boring of this section began in April 2016 and finished in May 2017. A 1.6-m-wide and 400-mm-thick segment ring was installed using a wing-type vacuum erector. The ring is configured as six segments and one tapered key.
3.2 Data preparation
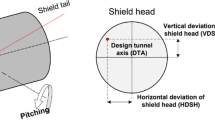
To ensure the ability of the shield machine to drill soil based on the designed tunnel axis, it is necessary to measure its attitude and position accurately. For describing the attitude and position during tunnelling, six important parameters are effectively used as output shield operational parameters [14]. These factors are the horizontal deviation for the shield head (HDSH), vertical deviation for the shield head (VDSH), horizontal deviation for shield tail (HDST), vertical deviation for shield tail (VDST), roll (R), and pitch (P). These output parameters are required to form a model for presenting the behaviour of the shield tunnelling path. Figure 4 shows the geographic coordinate system for the shield moving trajectory.

Graphic and machine coordinate system of shield machine
3.2.1 Data preprocessing
Before performing the analysis, the shield tunnelling performance data should be preprocessed based on dimensional data. The operational parameters of the shield machine are carefully monitored with the aid of a data acquisition and recording system. To regulate the dimensions of the monitoring data, the data should be collected and averaged in the daily reports. The engineers refer to these reports on a daily basis for making decisions during the tunnelling process to analyse the shield performance. As mentioned previously, this research focussed on the shield movement trajectory in a heterogeneous ground. The heterogeneous in situ data utilised geological data from the field investigation reports and operation data from the TBM monitoring system. Geological data were collected from 32 boreholes drilled along the tunnel. Laboratory tests, such as uniaxial compressive strength and plasticity index, were performed to determine the mechanical properties and formations. The plasticity index of the soil encountered by the shield machine varies from 11.90 to 25.10. The variation of the groundwater table along the tunnel path was between 1.63 and 3.63 m below the ground surface. The tunnel passes through several geological profiles (Fig. 5), such as silty clay, schist rock, and moderately to highly weathered granite.

Topography of the project site along the tunnel zone
3.2.2 Geostatistical analysis of shield tunnelling
Geological data contain geological information on the borehole locations, while operation data contain the operational information along the tunnel alignment. Since only 32 (out of 2048) ring sections have the corresponding geological information, there is an imbalance between the operating data of the shield machine labelled by geological types and unlabelled operating data. Thus, to design a good predictor, it is essential to investigate the advanced features relevant to geological information from the labelled data [29]. The kriging interpolation approach is adopted here to estimate the geological conditions based on a variogram model obtained from the data [2]. It has been utilised to achieve linear equitable predictions at unmeasured locations, and it relies on the spatial variance expression of the property in terms of a semivariogram. This technique identifies and reduces estimation uncertainties, thereby reducing self-estimated forecast errors [8]. To apply geostatistical analysis, the semivariance of variables in different positions is calculated based on semivariogram function that represents a function of the distance among the two positions. The semivariance is calculated from data in which a random parameter is a well-correlated space as a function of separation distance. The semivariance estimates the spatial variation in a variable as [21]
where \(\gamma \left( h \right)\) is the semivariogram value for the data pair in which \(h\) denotes the distance between \(z\left( {x_{i} } \right)\) and \(z\left( {x_{i} + h} \right)\) locations, and \(n\) is the number of pairs \(z\left( {x_{i} } \right)\) over distance \(h\). Please refer to the ‘‘Appendix’’ for specific meanings of the aforementioned parameters and the related interpolation equations. In order to verify the reliability of kriging results, root-mean-square error (RMSE) and root-mean-square standardised prediction error (RMSSE) were used based on comparing the known and estimated values at the same location, as shown in (Eqs. 10–11):
Among them, \(\sigma_{{k_{{\left( {xi} \right)}} }}^{2}\) refers to the kriging variance for the ith data point, \(z\left( {x_{i} } \right)\) is the measured value at location \(x_{i}\), \(z^{*} \left( {x_{i} } \right)\) is the calculated value at location \(x_{i}\), and i is the sample number.
3.3 Data features
In our study, we selected the key dimensions of the established data based on previous researchers. As listed in Table 1, 19 input parameters are selected and used as [I1, I2, …, I19] for the dynamic prediction of the shield movement trajectory. In this regard, the forecasting of the shield movement trajectory in the next time phase was generated through the fully connected output layers. A laser navigation system was utilised to record the real-time position and attitude of the shield machine. In this system, pitch and roll are used to represent the shield attitude, whereas HDST, VDST, HDSH, and VDSH are used to represent the shield position. These parameters are selected as output parameters of the forecasting model, which represent the most important control indexes for shield driving. Because the prediction accuracy of the shield movement trajectory is affected by the continuity of the data, the following two conditions are adopted. (1) The data in each ring along the tunnel path are not missing, and (2) the sequence of data among the current ring and the next one is continuous. After denoising the above-mentioned data, they are fused into new categorical data. Therefore, we selected the data from ring 378 to ring 1578, each of which has a length of approximately 1.6 m. Given these conditions, the operation and geological data are generated for adjusting the tunnel performance along the tunnel path. Because the shield machine status differs based on different geological conditions, the conditions of the shield machine can reflect these geological conditions. Figure 6 shows the performance of some shield operational parameters, which reflects relevant geological information.

Performance of shield operational parameters during tunnelling
3.4 Benchmark of existing prediction models
3.4.1 RNN model
The recurrent neural network (RNN) is a powerful deep learning method in which nodes are linked in a loop, and the internal state of the network can display dynamic timing behaviour. In this model, the network memorises the preceding data and implements it for the calculation of the present output; the nodes are connected between the hidden layers. In RNN, the hidden state (\(h_{t}\)) is generated based on the input of the current time step and the hidden state of the prior time step, as follows [32]:
where \(b\) refers to bias vector; \(W\) and \(U\) denote the weights of input x and weight matrices of hidden state h, respectively. In this study, this network is established as follows: the input layer is established with 19 nodes and two fully connected layers, both of which have 10 hidden nodes, and the output layer, which has 6 nodes.
3.4.2 Support vector regression
The support vector regression (SVR) method was applied to solve the regression and classification problems, which improved model accuracy and avoided over-fitting. The SVR aims to discover a function with the maximum deviation from the real vectors of all the presented data and present it as flat as possible. The method can be set nonlinearly in the original data x, in a feature area with high dimensions, and it can solve the linear regression problems in this feature space. In this study, a polynomial kernel function was selected to adjust the model. The polynomial kernel function degree was estimated by trial and error and was set as 1.
4 Results and analysis
4.1 Data decomposition and parameter setting
The hybrid deep learning model is proposed to present the relationships between data and selected parameters during tunnelling. The mechanical performance of the shield machine has two work positions: advancement state and non-advancement state. To achieve an accurate prediction for shield movement, the data of the non-advancement state are first eliminated, while raw data are denoised based on DWT. The basic functions of wavelets such as Haar, Coiflets, Biorthogonal, and Symlets are defined as families. Among these families, Daubechies achieved good results, as summarised in Table 2. To determine the best wavelet basis function, mean square error (MSE) is utilised as indicators for calculating the denoising effect. The Daubechies wavelet family (db5), which achieved the best denoising effect, is a candidate for the mother wavelet (Fig. 7). The evaluation criterion is defined as
where \(\overline{{y_{i} }}\) and \(y_{i}\) refer to the predicted and desired value corresponding to the input xi and n is the amount of data. The simulations showed that the level 5 class can successfully reduce noise data with minimum error. Thus, we adopted the Daubechies wavelet as the mother wavelet and five decomposition levels in the proposed model to denoise the data.

Performance of wavelet Daubechies basis functions
4.1.1 Denoising
During the tunnelling process, the operational parameter values vibrate to a large extend due to the unstable construction conditions and the measurement errors of sensors. Therefore, data denoising is essential to remove background noise and measurement error. To remove the noise in the collected time series data, the shield operational parameters including TF, CT, CR, AR, PR, SR, SPU, SPM, SPB, FU, FB, C, GP, and GV were denoised based on Daubechies wavelet. This method was successfully utilised previously by Zhang et al. [31] for denoising the shield operational parameter. This wavelet can overcome the drawbacks of Fourier transform and achieve the simultaneous transformation of signal in time and frequency domain. Regarding the simulation process, denoising signal on the parameter of advance rate is performed as an example (see Fig. 8). As shown in this figure, the noise is reduced and the signal processing becomes smoother and conducive for improving model accuracy. To provide a visual sense for the wavelet basis function, the statistical analyses for different denoising parameters are presented in Table 3.

Denoising signal of WT for the advance rate parameter
4.1.2 Hyperparameters
The LSTM part has a high learning ability to implement forecasts for processing sequence data. The LSTM has the main variables that can affect the accuracy and performance of the proposed model; these variables are the input size, epochs, optimisers, and batch size. To ensure the optimal configuration of the hyperparameters, grid search algorithm was used based on the training data set. The core of the grid search algorithm is to utilise the control variable approach for quantifying the effect of multiple variables on the model prediction. This study has a total of 1200 data sets, split into two subsets. Approximately 75% of the data sets are the training set, and the other 25% are the testing set. In particular, the training set is used to train the model and update the model parameters. For the testing set, the hyperparameters are adjusted, and the optimal model is selected to predict data. The essence of optimisation is to determine the parameters of system that can reduce the loss function through iteration. Currently, the popular optimisation methods are root-mean-square prop (RMSprop), adaptive gradient (AdaGrad), stochastic gradient descent (SGD), adaptive moment estimation (Adam), etc. Yang et al. [26] indicated that the SGD method that is a classical optimisation algorithm costs longer running time. Recently, Kingma and Lei Ba [13] combined the advantages of RMSProp and AdaGrad to propose Adam optimiser. The updated step length is estimated by considering the mean value of the gradient (first moment estimation) and the variance of the uncentred gradient (second moment estimation) of the gradient. In this study, different algorithms are tried to optimise the LSTM and the results are displayed in Table 4. Considering the running time and prediction accuracy, the Adam optimiser outperforms the other two algorithms. Since Adam’s optimiser is easy to implement and convenient for non-stationary [26], it was applied in the LSTM as an effective algorithm for optimising the weights of the neural network (Table 5). In this work, two main functions—optimiser and loss function—are necessary to build the neural network model. Adam and MSE are selected to assemble the Keras model as the optimisation algorithm and loss function, respectively. The flow chart utilised to display how Adam works in adapting the network is shown in Fig. 3.
4.2 Evaluation criteria for predictive performance
To evaluate the accuracy and efficiency of the proposed method, the correlation coefficient (R2) and mean absolute error (MAE) were used as evaluation criteria. The simulations of this work were processed using Keras running on an Intel(R) Core™ i7-4790 CPU at 3.60 GHz with a 8 GB RAM. To validate the geological data of unobserved points, the cross-validation results of the kriging interpolation were used, as shown in Table 6. The lowest RMSE and RMSSE closest to 1 indicate that the kriging interpolation is effective to create spatial visualisation for various geological data.
To fit the deep learning model, 300 epochs were set. As shown in Fig. 9, the proposed model converged the optimal fitness function after about 100 epochs and then converged to the minimum with subtle local oscillations. This shows that the proposed model reached the optimal solution with 300 epochs, and the search operation can be stopped.

Convergence behaviour of the proposed WT-Adam-LSTM model
4.3 Effectiveness of the proposed method
In this study, several parameters are considered to forecast the time sequence of the position and attitude of the shield machine during tunnelling. Herein, six parameters including HDST, HDSH, VDST, VDSH, roll, and pitch are considered as output parameters, as described in the previous section. To describe the effective performance of the forecasting model, the relation between the recorded and predicted data for the six output parameters including HDST, HDSH, VDST, VDSH, roll, and pitch, are presented. As shown in Fig. 10, the result observed that the forecasted values were almost consistent with the recorded values. Regarding the classification phase, the hybrid WT-Adam-LSTM model can effectively forecast the position and attitude of the shield machine. To prove the effectiveness of DWT used in this study, our wavelet transform-Adam-LSTM model was compared with three state-of-the-art models—RNN, LSTM, and SVR—for better prediction of the shield movement trajectory. To ensure the fairness and equality in comparison, the hybrid model and these three classic models embrace the same evaluation index, input model, programming environment, and data set.

Real-time prediction data for output variable: a HDSH, b HDST, c VDSH, d VDST, e Pitch, and f Roll
The temporal line graphs of recorded versus predicted values for the attitude and position of the shield machine (Fig. 10) display that among the three state-of-the-art models—RNN, LSTM, and SVR, the LSTM prediction values are most closely to the recorded values, whereas SVR model revealed significant variance than other models. Obviously, when dealing with the calculation of time series data, the prediction accuracy of the hybrid deep learning network is much higher than that of the classical and traditional artificial intelligent models. Table 7 summarises the results of the predicted data from the proposed WT-Adam-LSTM with respect to six output parameters. The proposed model achieved the highest accuracy in the prediction of the attitude and position compared to other parameters. The value of correlation coefficient for all output parameters using the proposed method is more than 0.91. These results emphasise that using the proposed model, the prediction values follow the recorded values well. The proposed WT-Adam-LSTM prediction model is different from classical machine learning models. The novelties and key characteristics of the proposed deep learning model are the perfect integration of the following aspects: (1) analysis of high-dimensional data; (2) DWT, which can be used for removing the irrelevant noise of data in the time and frequency domains; and (3) the characteristics of long-term dependency included in the LSTM model optimised to capture a common relationship with time series data measured from the monitored system, which results in high forecasting for model behaviour.
It is necessary to note that the DWT addresses extreme values as outliers under certain conditions before implementing the prediction. The WT-Adam-LSTM model is based on the denoising data whose forecasting goal is time series data with lower extremes, which induces the forecasting results processed by DWT to be sometimes inferior to those without DWT. Therefore, the assessment performance of the prediction model should not depend on one index, but on the performance of multiple indicators. Hence, the MAE was also used for the model evaluation. The network structures and hyperparameter setting of the WT-Adam-LSTM technique are the same as those of the LSTM model, as previously mentioned. The main difference is that the data fed into the WT-Adam-LSTM method were exposed to DWT to reduce noise. These four methods were compared based on the test data set. Therefore, the average MAE of the six output parameters with respect to every model was calculated. The results show that the performances of SVR, RNN, LSTM, and WT-Adam-LSTM models optimised gradually, resulting in MAE values of 6.921, 4.839, 3.754, and 2.512 on the test data set, respectively. This result reflects that the WT in the LSTM model we developed plays a key role. WT eliminates the background noise of recorded data and makes hidden patterns and trends of data sequence easily detected. In contrast, the results of SVR model show that the classical ML model without considering temporal effect does not perform well with the time.
To provide a visual sense for the forecasting WT-Adam-LSTM model, the scatter plot of the error between the recorded and predicted data is analysed in Figs. 11 and 12, respectively. For the attitude parameters of the shield machine (Fig. 11), the error of the proposed model is largely concentrated around zero deviation line, which illustrates the good agreement between the recorded values from shield machine and model outputs. Figure 12 shows the scatter plot of the error graph for the position (roll and pitch) parameters. As displayed in Fig. 12, the lowest deviations of the data sets are commonly in the range of ± 5% for pitch, indicating the precise prediction of the WT-Adam-LSTM model. The highest deviations of the data sets are commonly in the range of ± 40% for roll. The possible reason of this phenomenon is due to the input parameters we chosen have limited effect on roll. In addition, the roll data sequences fluctuations are gentle; therefore, the same variance patterns can be easily detected compared to the other five out parameters.

Forecasting error for output variable: a HDSH, b HDST, c VDSH, and d VDST

Forecasting error for output variable; a pitch and b roll
4.3.1 Model performance and comparison
In engineering application, a data acquisition and recording station can make auxiliary decision by using the data processing platform embedded with WT-Adam-LSTM prediction model for the shield moving trajectory. The time data, automatic repetition, and daily position monitoring first will be entered into the model. Extrapolation based on the trajectory data will then be performed for the next process. The corresponding correction measures based on the prediction results will be produced as the outputs. The most valuable use of this method is the implementation of the prediction model for restraining the shield tunnelling misalignment. Once the proposed model forecasts that the shield position and posture will have a significant deviation, the driver can adjust the shield operating parameters beforehand to mitigate shield tunnelling misalignment by using correction measures based on the prediction results.
To show the prediction accuracy of the developed model compared with the existing studies, recent research on tunnel performance is reviewed in Table 8. Many studies utilised only shield operational data, whereas our developed model utilises not only shield operational data but also geological mechanical data and tunnel geometry. The developed model can consider more features from the project; thus, the scholars can acquire more effective results and perform further analysis based on it. The error of the developed model is much smaller than many other studies. Moreover, the proposed model can not only forecast the shield movement trajectory but can also provide accurate statistical characteristics of the tunnel deviation, which helps in the tunnel design and in drilling planning.
4.3.2 Model reliability
To analyse the significant superiority of the proposed WT-Adam-LSTM model, a Friedman test is applied [3]. Based on Friedman test, the null hypothesis was simulated as there are no differences among results. Ranks are ranged from 1 (least error) to k (highest error) and represented by \(r_{i}^{j}\) (1 ≤ j ≤ k). In this study, we have k = 4 prediction models and the average ranking \(\left( {R_{j} } \right)\) obtained in all data sets can be computed as follows:
where \(r_{i}^{j}\) refers the model ranking j on data set i and \(N\) is the total number of data sets.
The Friedman analysis compares the average ranks, Rj of various models on the used data sets. The Friedman analysis is estimated in Eq. 15 based on null hypothesis, which states that all models operate similarly.
where \(X_{r}^{2}\) represents the distribution of chi-squared with k − 1 degrees of freedom and \(k\) is the number of algorithms. In the event that the \(X_{r}^{2}\) value is large enough, the null hypothesis is declined. The ranks estimated based on the Friedman test are presented in Fig. 13. In addition, The Friedman statistical results (\(X_{r}^{2}\) = 8.25) are higher than the critical value at the 0.05 confidence level (\(X_{r}^{2}\) = 7.39) based on Sheskin [19] that shows that the null hypothesis is declined. Hence, there are substantial differences between the applied methods.

Friedman ranks of the applied models
4.3.3 Data deficiency
To check the parameters efficiency, the geological and geometrical parameters including GWL, CL, SC, UCS, and Qc are supposed to be unavailable and the ability of the WT-Adam-LSTM model is investigated. Hence, if these parameters are missing and not utilised as inputs in the established model, the prediction of position parameter (i.e. pitch parameter) for the shield moving trajectory is shown in Fig. 14. The results of pitch display that the quality of fit abruptly decreases from R2 = 0.94 to R2 = 0.62, which shows that the missing key parameters can notably affect the model performance. These results agreed with Zhang et al. [31], which demonstrated that the geological parameters are vitally important to soil–tunnel interaction for real-time prediction. In other words, Zhang et al. [30] indicated that the geological conditions represent core parameters for the prediction of ground responses to tunnelling.

Prediction of shield position parameter without considering geological and geometrical parameters
5 Conclusions
This study presents a deep learning model to predict dynamic shield movement trajectory during tunnelling. In the proposed technique, kriging interpolation and a key feature selection approach were analysed to address the imbalance and temporal behaviour. The major conclusions are provided below.
-
(1)
The WT-Adam-LSTM model provides a method for predicting the dynamic behaviour of shield movement in terms of attitude and position parameters. The proposed model uses the computation parameters tailored to the studied tunnel section to predict shield movement. This approach can deal with imbalanced and temporally correlated data, and thus, it can help improve prediction accuracy.
-
(2)
The proposed model showed a better prediction accuracy than the RNN and LSTM models. The results can facilitate decision-makers in predicting the tunnelling path, supporting efficient construction management, particularly in the stage of developing construction plans.
-
(3)
The proposed model considered both the geological conditions and operational parameters simultaneously. The proposed model can help the driver adjust the operating shield parameters in advance. In addition, the proposed model lays the foundation for an automatic driving system.
-
(4)
The proposed model is verified through a case study of the Guangzhou–Shenzhen railway project. For more validation, the prediction results from the proposed neural network are compared with the results of three state-of-the-art methods: SVR, LSTM, and RNN. The proposed method shows a better prediction performance than the other three methods. This is because the SVR model cannot preserve the prior information and learn time series data that result in limited forecasting ability for long-term time-series prediction data.
References
Chang Z, Zhang Y, Chen W (2019) Electricity price prediction based on hybrid model of Adam optimized LSTM neural network and wavelet transform. Energy 187:115804. https://doi.org/10.1016/j.energy.2019.07.134
Chiles J, Delfiner P (1999) Geostatistics: modelling spatial uncertainty. Wiley, New York
Choi E, Cho S, Kim DK (2020) Power demand forecasting using long short-term memory (LSTM) deep-learning model for monitoring energy sustainability. Sustainability 12:1109. https://doi.org/10.3390/su12031109
Conejo AJ, Plazas M, Espinola R, Molina AB (2005) Day-ahead electricity price forecasting using the wavelet transform and ARIMA models. IEEE Trans Power Syst 2005(20):1035–1042
Elbaz K, Shen SL, Cheng WC, Arulrajah A (2018) Cutter-disc consumption during earth-pressure-balance tunnelling in mixed strata. Geotech Eng ICE Proc 171(4):363–376. https://doi.org/10.1680/jgeen.17.00117
Elbaz K, Shen SL, Zhou AN, Yuan DJ, Xu YS (2019) Optimization of EPB shield performance with adaptive neuro-fuzzy inference system and genetic algorithm. Appl Sci 9(4):780. https://doi.org/10.3390/app9040780
Esfetang NN, Kazemzadeh R (2018) A novel hybrid technique for prediction of electric power generation in wind farms based on WIPSO, neural network and wavelet transform. Energy 149:662–674. https://doi.org/10.1016/j.energy.2018.02.076
Gao S, Zhu Z, Liu S, Jin R, Yang G, Tan L (2014) Estimating the spatial distribution of soil moisture based on Bayesian maximum entropy method with auxiliary data from remote sensing. Int J Appl Earth Obs Geoinf 32:54–66
Gao X, Shi M, Song X, Zhang C, Zhang H (2019) Recurrent neural networks for real-time prediction of TBM operating parameters. Autom Constr 98:225–235. https://doi.org/10.1016/j.autcon.2018.11.013
Han L, Zhang R, Chen K (2019) A coordinated dispatch method for energy storage power system considering wind power ramp event. Appl Soft Comput J 84:105732. https://doi.org/10.1016/j.asoc.2019.105732
Huang HW, Li QT, Zhang DM (2018) Deep learning based image recognition for crack and leakage defects of metro shield tunnel. Tunn Undergr Space Technol 77:166–176
Jin YF, Yin ZY, Zhou WH, Huang HW (2019) Multi-objective optimization-based updating of predictions during excavation. Eng Appl Artif Intell 78:102–123. https://doi.org/10.1016/j.engappai.2018.11.002
Kingma DP, Ba JL (2015) A method for stochastic optimization. In: The 3rd international conference on learning representations (ICLR), San Diego, 2015, pp 1–15
Kumar TA, Julie EG, Robinson YH, Jaisakthi SM (2021) Simulation and analysis of mathematical methods in real-time engineering applications. Wiley. ISBN 978-1-119-78537-8
Li J, Li P, Guo D, Li X, Chen Z (2021) Advanced prediction of tunnel boring machine performance based on big data. Geosci Front 12:331–338. https://doi.org/10.1016/j.gsf.2020.02.011
Liu Z, Li L, Fang X, Qi W, Shen J, Zhou H, Zhang Y (2021) Hard-rock tunnel lithology prediction with TBM construction big data using a global-attention-mechanism-based LSTM network. Autom Constr 125:103647. https://doi.org/10.1016/j.autcon.2021.103647
Mallat SG (1989) A theory for multiresolution signal decomposition: the wavelet representation. IEEE Trans Pattern Anal Mach Intell 11:674–693
Ramsey JB (1999) The contribution of wavelets to the analysis of economic and financial data. Philos Trans R Soc Biol Sci 1999(357):2593–2606
Sheskin DJ (2003) Handbook of parametric and nonparametric statistical procedures. Chapman and Hall/CRC, Boca Raton
Shi G, Qin C, Tao J, Liu C (2021) A VMD-EWT-LSTM-based multi-step prediction approach for shield tunneling machine cutterhead torque. Knowl-Based Syst 228:107213. https://doi.org/10.1016/j.knosys.2021.107213
Stavropoulou M, Xiroudakis G, Exadaktylos G (2010) Spatial estimation of geotechnical parameters for numerical tunneling simulations and TBM performance models. Acta Geotech 5(2):139–150
Tan Y, Jiang W, Luo W, Lu Y, Xu C (2018) Longitudinal sliding event during excavation of Feng-Qi Station of Hangzhou Metro Line 1: postfailure investigation. J Perform Constr Facil 32(4):04018039
Tan Y, Wei B, Lu Y, Yang B (2019) Is basal reinforcement essential for long and narrow subway excavation bottoming out in Shanghai soft clay? J Geotech Geoenviron Eng 145(5):05019002. https://doi.org/10.1061/(ASCE)GT.1943-5606.0002028
Wang R, Li D, Chen EJ, Liu Y (2021) Dynamic prediction of mechanized shield tunneling performance. Autom Constr 132:103958. https://doi.org/10.1016/j.autcon.2021.103958
Webster R, Oliver MA (2001) Geostatistics for environmental scientists (statistics in practice). Wiley, Hoboken. https://doi.org/10.1002/9780470517277
Yang G, Wang Y, Li X (2020) Prediction of the NOx emissions from thermal power plant using long short term memory neural network. Energy 192:116597. https://doi.org/10.1016/j.energy.2019.116597
Zhang WG, Li HR, Li YQ, Liu HL, Chen YM, Ding XM (2021) Application of deep learning algorithms in geotechnical engineering: a short critical review. Artif Intell Rev. https://doi.org/10.1007/s10462-021-09967-1
Zhang WG, Li HR, Wu CZ, Li YQ, Liu ZQ, Liu HL (2020) Soft computing approach for prediction of surface settlement induced by earth pressure balance shield tunneling. Undergr Space 6(4):353–363. https://doi.org/10.1016/j.undsp.2019.12.003
Zhang P, Yin Z-Y, Jin YF, Ye GL (2020) An AI-based model for describing cyclic characteristics of granular materials. Int J Numer Anal Methods Geomech 44(9):1315–1335. https://doi.org/10.1002/nag.3063
Zhang P, Wu HN, Chen RP, Dai T, Meng FY, Wang HB (2020) A critical evaluation of machine learning and deep learning in shield-ground interaction prediction. Tunn Undergr Space Technol 106:103593. https://doi.org/10.1016/j.tust.2020.103593
Zhang YK, Gong GF, Yang HY, Lia WJ, Liu J (2020) Precision versus intelligence: autonomous supporting pressure balance control for slurry shield tunnel boring machines. Autom Constr 114:103173. https://doi.org/10.1016/j.autcon.2020.103173
Zhang N, Zhang N, Zheng Q, Xu YS (2021) Real-time prediction of shield moving trajectory during tunnelling using GRU deep neural network. Acta Geotech. https://doi.org/10.1007/s11440-021-01319-1
Zhou C, Xu H, Ding L, Wei L, Zhou Y (2019) Dynamic prediction for attitude and position in shield tunneling: a deep learning method. Autom Constr 105:102840. https://doi.org/10.1016/j.autcon.2019.102840
Acknowledgements
The research work was funded by “The Pearl River Talent Recruitment Program” in 2019 (Grant No. 2019CX01G338) and Guangdong Province and the Research Funding of Shantou University for New Faculty Member (Grant No. NTF19024-2019).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
The interpolation equations and their explanations are illustrated below [25]:
Having measured n data values,\(z\left( {x_{1} } \right)\), \(z\left( {x_{2} } \right)\), …, \(z\left( {x_{n} } \right)\) at \(x_{1}\), \(x_{2}\), …, \(x_{n}\) locations, the basic principles of kriging approach can be formulated by estimating the \(z^{*} \left( {x_{0} } \right)\) at the unknown location of x0 with the following equation:
where \(z^{*} \left( {x_{0} } \right)\) is the estimated value for the unmeasured point x0; \(z\left( {x_{i} } \right)\) refers to the measured value of variable z at point xi; λ is the interpolation weight coefficient; n is the total number of values required for the interpolation.
The minimum variance of error (σk) is required to achieve the optimal estimation, where
For the unbiased prediction, the resulting constraint should be specified, where
Rights and permissions
About this article

Cite this article
Shen, SL., Elbaz, K., Shaban, W.M. et al. Real-time prediction of shield moving trajectory during tunnelling. Acta Geotech. 17, 1533–1549 (2022). https://doi.org/10.1007/s11440-022-01461-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11440-022-01461-4