
Abstract
The squeezing behavior of surrounding rock can be described as the time-dependent large deformation during tunnel excavation, which appears in special geological conditions, such as weak rock masses and high in situ stress. Several problems such as budget increase and construction period extension can be caused by squeezing in rock mass. It is significant to propose a model for accurate prediction of rock squeezing. In this research, the support vector machine (SVM) as a machine learning model was optimized by the whale optimization algorithm (WOA), WOA-SVM, to classify the tunnel squeezing based on 114 real cases. The role of WOA in this system is to optimize the hyper-parameters of SVM model for receiving a higher level of accuracy. In the established database, five input parameters, i.e., buried depth, support stiffness, rock tunneling quality index, diameter and the percentage strain, were used. In the process of model classification, different effective parameters of SVM and WOA were considered, and the optimum parameters were designed. To examine the accuracy of the WOA-SVM, the base SVM, ANN (refers to the multilayer perceptron) and GP (refers to the Gaussian process classification) were also constructed. Evaluation of these models showed that the optimized WOA-SVM is the best model among all proposed models in classifying the tunnel squeezing. It has the highest accuracy (approximately 0.9565) than other un-optimized individual classifiers (SVM, ANN, and GP). This was obtained based on results of different performance indexes. In addition, according to sensitivity analysis, the percentage strain is highly sensitive to the model, followed by buried depth and support stiffness. That means, ɛ, H and K are the best combination of parameters for the WOA–SVM model.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Tunnel squeezing refers to the occurrence of large amount of deformation in surrounding rock mass rock, which is normally more than the designed deformation. This phenomenon, which takes a long time to form, causes many difficulties during and after construction of tunnels [6, 11, 69]. The squeezing behavior of surrounding rock can be described as the time-dependent large deformation during tunnel excavation, which is essentially related to creep created by exceeding the ultimate shear stress [8, 19, 25, 59, 69]. Different studies showed that the compressive surrounding rock has the deformation features of large deformation amount, long deformation duration, high deformation speed, large destruction range of surrounding rock and various forms of supporting structure failures [19]. There are objective and subjective factors for the occurrence of tunnel squeezing, where the objective conditions involve rock properties, tectonic stress, tunnel dimensions, rock type, high in situ stress and large radius or span [8]. On the other hand, the typical subjective factors are associated with support installation, in which the deformation can be restrained if the support is installed on time [27, 42, 62]. Tunnel squeezing may cause several unwanted issues, e.g., budget increase, construction period extension and construction safety [8, 22]. In order to overcome these issues, many attempts have been done by various scholars, and they suggested several approaches for predicting tunnel squeezing, including empirical, semiempirical and theoretical methods [4, 24, 32, 33, 61, 68]. With the development of the computer science and various available technologies, numerical simulation and classical statistics methods have been widely used in tunnel squeezing prediction [13, 23, 37,38,39, 65].
In recent years, the successful applications of machine learning (ML) methods in solving regression, classification and time-series problems in science and engineering have been reported by many researchers all around the world [2, 3, 30, 31, 40, 41, 52, 77,78,79, 81, 82, 85,86,87,88,89, 92, 93, 95, 97,98,99,100,101,102]. These methods have been used by researchers in the areas of geotechnical [15, 55, 66, 99] and tunnel engineering [76, 82, 84] and also to solve problem related to tunnel squeezing [50, 65]. To estimate tunnel squeezing, ML techniques like artificial neural network (ANN), decision tree (DT), naive Bayes (NB) and support vector machine (SVM) have been used in the literature. As an example, Shafiei et al. [65] used and introduced a SVM classifier model, which was trained and tested based on 198 samples, in particular having two predictor variables (buried depth, H, and rock tunneling quality index, Q). The accuracy of their proposed model is 84.1%. In another interesting investigation, Sun et al. [71] constructed a multi-class SVM prediction model based on 117 samples. There were four predictor variables (H, Q, diameter, D, and support stiffness, K,) in the multi-class SVM model, and it was able to receive an accuracy of 88.1%. Zhang et al. [87, 88] established a classifier ensemble based on 166 cases, which includes five different ML classifiers: ANN, SVM, DT, k-nearest neighbor (KNN), and NB. The five variables, i.e., H, D, Q, K and strength stress ratio (SSR), were selected as input parameters for the classifier ensemble, and the final accuracy was obtained as 96%. Huang et al. [35] proposed a hybrid model of SVM mixed by back-propagation (BP) for identifying squeezing and non-squeezing problem based on a total of 180 data samples. In the SVM-BP model, the four indicators including H, K, D and Q were considered as model inputs. The accuracy of the SVM-BP model was obtained as 92.11%. In addition, other methods and accuracy comparison results are shown in Table1. In light of above discussion, the performance of the combined classifiers/models is higher than the single classifier. However, in most of the cases, the combined classifier models are complex with the lowest level of practicality, when the number of classifiers increases. To solve this problem, this article only uses a single classifier SVM. SVM has high generalization performance and can solve problems like small samples and high dimensionality [63]. According to the existing research, we can also found that support vector machines have become popular in engineering. Many researchers have applied support vector machines to tunnel extrusion prediction. It can be roughly divided into two applications. On the one hand, it uses SVM regression to predict the deformation of the tunnel [39, 72, 91]. On the other hand, it uses SVM classification to determine whether the tunnel will be squeezed. So far, most of the existing forecasting methods can be used to distinguish between squeezing and non-squeezing. However this article refers to the multi-class SVM proposed by Sun et al. [71] and introduces a SVM-based prediction model to predict the severity of tunnel squeezing. However, the difference is that we consider the effects of the percentage strain (ɛ). There are several commonly considered predictor variables in this field, which are H, K, D, K and SSR. It seems that there is a need to consider effects of other important parameters on tunnel squeezing like the percentage strain (ɛ). The mentioned parameters were rarely used as input parameter in the proposed ML classifier models. Table 2 is the list of commonly used predictors.
Additionally, with the deepening of research, optimization algorithms are gradually introduced into machine learning methods to optimize hyper-parameters, such as whale optimization algorithm (WOA), gray wolf optimization (GWO), Harris Hawks optimizer (HHO) and moth-flame optimization (MFO). Therefore, various hybrid models have gradually formed such as GWO-SVM [80, 83], WOA-SVM [95], MFO-SVM, GS-SVM [46], HHO-SVM [92], WOA-XGBoost, GWO-XGBoost, BO-XGBoost [64, 101, 102] and SCA-RF [92]. The above research shows that the hybrid model has better performance than a single machine learning method. Therefore, the whale optimization algorithm is introduced to improve the prediction performance of multi-class SVM. Whale optimization algorithm (WOA) has simple structure, few parameters, strong search ability and easy to implement [7].
Finally, an optimized classifier model (WOA-SVM) is proposed to predict the severity of tunnel squeezing based on five parameters, that is, buried depth (H), support stiffness (K), rock tunneling quality index (Q), diameter (D), and the percentage strain (ɛ). Firstly, we establish a database containing above five surrounding rock indicators based on the existing literature and then preprocessing these data. Then, the WOA-SVM model was trained and tested of tunnel squeezing. This study copes with not only the development of the WOA-SVM model used for the anticipating of squeezing problems, but also the sensitivity analysis of predictor variables. Finally, in order to verify the advantage of the model proposed, an evaluation and comparison on the performance of different classifier models (WOA-SVM, ANN, SVM, and genetic programming, GP) based on the same database were implemented. The performance and accuracy of the mentioned models will be assessed and discussed to select the best model in predicting tunnel squeezing.
2 Predictor selection and database description
According to the published literatures, the research group collected 114 historical cases of tunnel squeezing from various locations like Greece, Bhutan, India, Austria, China, Nepal and Venezuela [1, 6, 18, 20, 32, 51, 62, 67, 71]. There are six parameters in each case where five of them (K, H, Q, D and ɛ) were set as input variables to predict tunnel squeezing. Among these six parameters, H, Q and D are often appeared in empirical formulas, such as \(H = 350Q^{0.33}\) and \(H = 275N^{0.33} B^{ - 0.1}\), which are proposed by Goel and Singh [27, 68]. The three parameters reflect the influence of in situ stress, surrounding rock properties and tunnel size on squeezing. The support stiffness is selected as the input parameter. The reason is that the support stiffness plays an important role in controlling the excessive deformation caused by the interaction between the support pressure and the rock mass deformation response [13]. SSR and ɛ are usually used as grading indicators such as in the research conducted by Jethwa et al. (1984), Barla [8] and Aydan et al. [4, 5].
In this study, we adopt the classification standard proposed by Hoek and Marinos [33]. Therefore, non-squeezing (NS) (with ε < 1%), minor squeezing (MS) (with 1% ≤ ε < 2.5%) and severe-to-extreme squeezing (SES) (with ε ≥ 2.5%) were represented by class 0, class 1 and class 2, respectively. A correlation scatter matrix was performed to know more about the used parameters, as shown in Fig. 1. The diagonal of the matrix presents probability distributions for each squeezing class, the lower panels show pairwise scatter plots of three classes of squeezing data along the axis and the upper triangle presents the Pearson's correlation coefficients. It can be clearly seen that all indicators have no relatively meaningful correlation with each other, and there is no clear separation among NS, MS and SES. The mentioned input and output parameters will be used in the next stage for classification modeling of tunnel squeezing.

Correlation scatter matrix of cumulative distributions and statistical evaluations for the squeezing database
3 Concepts of predictive models
3.1 Support vector machine (SVM)
The SVM has high generalization performance and does not require prior knowledge of specific models; therefore, it is widely used to solve problems in different fields, for example, finance [47], energy [34], hydrological research [58], mechanical engineering [16, 48], civil engineering [63, 85] and other fields. Of course, SVM is also widely used for tunnel extrusion prediction [38, 65]. The initial concept of SVM is to input the training data set and output the separating classification decision function with the largest geometric interval [12, 16, 34, 47,48,49, 74]. The SVM has been widely used to solve multivariate classification and regression problems [45, 54, 58], although it is a binary classification model on nature. The advantage of the SVM model lies in the ability to transform nonlinear problems into linear problems in high-dimensional feature spaces with the help of kernel functions [54].
In practical problems, it is difficult to find a hyperplane that can separate different categories of samples when the training sets are nonlinearly separable in the sample space. To solve this problem, there is a need to allow SVM for making mistakes on some datasets. Therefore, the sense of "soft margin" was introduced into the SVM model. In this way, the optimization objective functions of SVM can be expressed in the following [45, 46, 73, 92, 95]:
where \(l_{0/1}\) is 0/1 loss function, which can measure the deviation degree and can be defined as follows:
With the introduction of slack variables \(\xi_{i}\) and penalty factors \(C\) (the regularization constant), the original optimization problem can be rewritten as follows:
By introducing the Lagrangian multipliers (\(\alpha_{i} \ge 0,^{{}} u_{i} \ge 0\)), the Lagrangian function is constructed to solve problems with constraints:
When the partial derivative of the above formula to W, b, \(\xi_{i}\) is zero, the Lagrange dual problem can be described as follows:
Optimization problems with inequality constraints need to meet the following conditions.
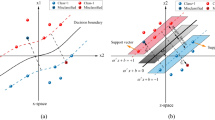
To overcome nonlinear classification and clustering issues, it is essential to choose the appropriate kernel function \(\Phi_{K} (x,z)\) as a substitute for inner product to construct and solve the convex quadratic programming issue [16, 34, 47]. That means Eq. (5) becomes Eq. (7). In this way, the input data can be mapped into a high-dimensional feature spaces [47], as shown in Fig. 2.

Mapping data from two dimensional to three dimensional
Then, we will obtain \(w\) and b after calculation of the optimal solution \(\alpha^{*}\) \(\left( {\alpha^{*} { = }\left( {\alpha_{1}^{*} ,\alpha_{2}^{*} ,...,\alpha_{m}^{*} } \right)^{T} } \right)\) by the SMO (sequential minimal optimization) algorithm [73]. Finally, the classification decision function can be described as:
3.2 Whale optimization algorithm (WOA)
Inspired by the bubble-net attacking technique which is humpback whale’s unique predation method, Mirjalili [53] suggested the WOA algorithm for solving and optimizing problems. Therefore, the WOA is widely used in energy, image processing and machine vision, structural optimization, management and other fields [53]. Humpback whales like to hunt a group of krill or small fish near the water surface. They are gradually evolved a special hunting method called foam feeding, that’s because they move slowly. Whale can construct a spiral path with a decreasing radius by creating bubbles for enforcing fish schools to approach the surface and then catching them [43, 57]. WOA concept can be described as (1) encircling prey, (2) bubble-net attacking method and (3) search for prey, which are discussed in detail as follows (in order to distinguish, the bold letters in the following formula represent vectors):
-
Encircling prey
The exact position of prey cannot be easily identified; therefore, the system considers the solution of the current candidate for the target prey [57]. In the next step, after recognizing the best search agent \((X^{*} ,Y^{*} )\), there is a need for the other search agents \((X,Y)\) to upgrade their locations using Eqs. 10 and 11. The nearby solutions around the best or optimized solution can be according to Eqs. 12 and 13 (Fig. 3).
where \({\mathbf{A}}\) and \({\mathbf{C}}\) represent the coefficient vectors, and the value of \({\mathbf{A}}\) is restricted to [1]. Parameter of \({\mathbf{a}}\) can be decreased from 2 to 0 in the search process, and it can be calculated by \({\mathbf{a}}{ = }2{ - }{{2t} \mathord{\left/ {\vphantom {{2t} {T_{\max } }}} \right. \kern-\nulldelimiterspace} {T_{\max } }}\) (\(t\) and \(T_{\max }\) represent the current number and the maximum number of iterations, respectively). Factors \({\mathbf{r}}_{1}\) and \({\mathbf{r}}_{2}\) are random vectors in the range of [1]; \({\varvec{X}}_{\left( t \right)}\) and \({\varvec{X}}_{\left( t \right)}^{*}\) denote the current whale position vector and the best whale solution vector (the possible location of the prey) in the tth iteration, respectively.

Different vector positions highlighting the best solutions
-
Bubble-net attacking method
The humpback whales and their bubble-net attacking behavior can be mathematically simulated by designing two procedures, which are shrinking encircling and spiral updating. The spiral equation is described in the following equation:
where the shape of the logarithmic spiral depends on \(b\) which is a constant, \(l\) is a random vector which distributed uniformly within [-1,1]. The distances between the ith search agent and the target prey are presented by \({\mathbf{R^{\prime}}}{ = |}{\mathbf{X}}_{(t)}^{*} - {\mathbf{X}}_{(t)} |\).
The shrinking encompassing mechanism and the spiral updating location have an equivalent probability to be selected by the humpback whale in the process of position updating. The process of simulation can be demonstrated as follows:
where \(p\) is an arbitrary number in the range of [1].
-
(3) Search for prey
In order to update the whale places during the exploration phase, the equation of the model is presented as follows:
where \({\mathbf{X}}_{rand}\) denotes the whale location vector which is selected randomly.
3.3 Multilayer perceptron (MLP)
In this paper, ANN refers to multilayer perceptron (MLP). Multilayer perceptron (MLP) is promoted from a single-layer perceptron. The main feature is that it has multiple neuron layers. Generally, the first layer of MLP is called the input layer, the middle layer is the hidden layer and the last layer is the output layer. MLP does not specify the number of hidden layers, so the appropriate number of hidden layers can be selected according to actual processing requirements. These hidden layers have different numbers of hidden neurons. The neurons in each hidden layer have the same activation function, and there is no limit to the number of neurons in each layer in the hidden layer and the output layer.
3.4 The Gaussian process (GP)
GP means Gaussian process classification. The Gaussian process is a general supervised learning method for solving regression and probability classification problems. The advantages are: (1) predictions can explain observations. (2) The prediction is probabilistic, so that the empirical confidence interval can be calculated. (3) Versatility.
4 Modeling results and discussion
4.1 Evaluation criteria
The ROC (receiver operating characteristic) curve is very popular in the performance evaluation phase of ML classifiers [87, 94, 96]. The ROC curve can be presented in a form of Cartesian coordinate system, in which FPR (false-positive rate) and TPR (true-positive rate) represent as the horizontal axis and the vertical axis, respectively. The key indicator of performance evaluation in the ROC curve is the AUC value that is defined as the area under the ROC curve. The larger AUC values, the higher the classification accuracy of the model or the better performance. On the other hand, accuracy and Cohen’s kappa can be also considered as performance indicators. The Kappa coefficient measures the effect of classification by evaluating the consistency between the prediction results of the model and the actual classification results. A normal range for results of kappa is in the range of 0–1. If this range is divided into five different classes, there are: 1) slight consistency (0 ~ 0.20), 2) fair consistency (0.21 ~ 0.40), 3) moderate consistency (0.41 ~ 0.60), 4) substantial consistency (0.61 ~ 0.80) and 5) almost perfect consistency (0.81 ~ 1.00). In addition to accuracy and Kappa, precision, recall and F1 can also be considered as performance indicators [87, 93]. The mentioned performance indicators (accuracy, Kappa, precision, recall and F1-score) can be computed based on the confusion matrix, as shown in Fig. 4. Based on the confusion matrix, MCC also was introduced as performance indicators. Matthews correlation coefficient is an index used in machine learning to measure the classification performance. This indicator considers true positives, true negatives, false positives and false negatives. It is generally considered to be a relatively balanced indicator, and it can be applied even when the sample content of the two categories differs greatly. MCC is essentially a correlation coefficient that describes the actual classification and the predicted classification. Its value range is [-1,1], 1 indicates a perfect prediction of the subject, and a value of 0 indicates that the predicted result is not as good as a random prediction, -1 means that the predicted classification is completely inconsistent with the actual classification. The calculation formula is as follows:

Confusion matrix and performance indicators
4.2 WOA-SVM model development and validation
Main steps for constructing WOA-SVM model in predicting tunnel squeezing are as follows:
-
Step 1: Data preparation: The database collected from the existing literature has a total number of 114 cases. The source of the cited cases and the necessary information are listed in appendix. A. According to the most commonly used division ratio of 80%/20%, based on the Pareto principle [64, 75, 100], we randomly divide dataset into 80% training set and 20% testing set for model development and model validation, respectively [71].
-
Step 2: Initializing parameters of the SVM model. There are several main parameters in the SVM model, including the penalty parameter of the objective function (“C”), the kernel function and the coefficient of the kernel function (“g”). The hyper-parameters “C” and “g” need to be optimized by WOA algorithm. In this research, the kernel function is determined with the help of the model decision boundary diagram. The SVM model transforms the linearly inseparable problem into linearly separable with the help of the kernel functions like linear, polynomial, radial basis function (RBF), and sigmoid. According to the model decision boundary diagram in Fig. 5, it is easy and feasible to detect that the database in this article is close to linearly separable. Therefore, the linear kernel was applied to input parameter mapping for the SVM model.
-
Step 3: The relevant parameters of the WOA and their ranges are the constant \(b\), two random number \(l \in [ - 1,1]\) and \(r \in [0,1]\)\([0,1]\). It is necessary to determine and design the optimal hyper-parameters (C and g) of SVM using the WOA. Therefore, a WOA-SVM hybrid model can optimize the ability of the SVM classifier in predicting tunnel squeezing through WOA algorithm. The specific optimization process of the proposed WOA-SVM is shown in Fig. 6.
-
Step 4: Fitness evaluation of WOA-SVM model and determination of the optimal population size. It is necessary for developing a reliable WOA-SVM model with the best performance to fix the optimal population number. This is because swarm size has a significant impact on the performance of the WOA model. To search the optimal population number, five different swarm sizes (i.e., 50, 80, 100, 150 and 200) were selected and used in the process of model development. The fitness curve presented in Fig. 7 shows that the adaptation value changes with the number of iterations. When the number of iterations is greater than or equal to 80, the fitness values of the five fitness curves generated by the WOA-SVM model will tend to be stable. Table 3 presents the results of performance evaluation (accuracy and Kappa) for the optimization WOA-SVM model based on the training and testing sets. Based on this table and considering all performance indexes, the optimal population or swarm size was selected as 150 with accuracy = 0.9565 and Kappa = 0.9288.

Model decision boundary before and after optimization: (a) SVM; (b) WOA-SVM

The whole analysis process of WOA-SVM classifier model

Optimization of WOA-SVM with different population values
4.3 Analysis and comparison of classification performance
The optimized classifier model based on the training set needs to be validated based on testing datasets. The test datasets were randomly selected from the database prepared, i.e., 20% of the total cases (23 test samples). It is important to mention that they have not participated in the training process of the model. We will analyze and compare classification performance from different perspectives such as confusion matrix, performance evaluation indicators, violin graphs and so on. From the confusion matrix, we can get the accuracy, Kappa, MCC and other performance evaluation indicators and use then analyzing and comparing the classification performance of different models on the basis of these evaluation indicators. To examine the accuracy of the WOA-SVM model, the methods of GP, ANN and SVM were built for classification purpose of the same samples. The results of the verification are shown in Fig. 8, which represents the confusion matrix of four classification models (WOA-SVM, SVM, ANN and GP) for testing datasets. It is not difficult to observe that the WOA-SVM classifier demonstrates better performance than the other built models. Compared with the other un-optimized classifier models, the WOA-SVM classification model has the highest accuracy (approximately 0.9565). In addition, the Kappa values obtained for different classifiers from high to low are: 0.929 (WOA-SVM), 0.913 (ANN), 0.696 (SVM) and 0.565 (GP). In addition to accuracy and Kappa mentioned above, the number of cases classified correctly can be obtained from the main diagonal of the confusion matrix.

Confusion matrix different prediction methods: a WOA-SVM; b ANN; c SVM; and d GP
The above analysis has shown that the WOA-SVM model has certain advantages. In order to present the difference between measured tunnel squeezing results and the predicted ones obtained from different classifiers, the resultant classification results are demonstrated in Fig. 9. We can see the 23 samples of the test dataset on the horizontal axis and the class of the sample on the vertical axis (class0: non-squeezing; class1: minor squeezing; class2: severe-to-extreme squeezing). There is a sample with the actual class: class 1 in Fig. 9a, which was misclassified as class 0, and this sample was defined as case No. 20. However, there are more than one sample in Fig. 9 (b, c and d), which was misclassified. The WOA-SVM model is more accurate and safer in predicting the level of tunnel squeezing.

Actual and predicted classification results on test datasets
The above analysis aims to evaluate the classification performance of the model as a whole. However, imbalanced dataset may have a great impact on the prediction results of the model, but it is not enough to detect this influence based on the accuracy rate alone. Therefore, precision, recall, F1 and ROC curves were also applied and calculated to assess the prediction performance of WOA-SVM, SVM, ANN and GP models. Table 4 tabulates precision, recall and F1-score of different classification models based on non-squeezing (NS), minor squeezing (MS) and severe-to-extreme squeezing(SES). According to this table, the WOA-SVM model was able to receive a better performance and higher level of accuracy. Based on the above analysis, for the optimized ML classifier, the classification performance of the optimized SVM model was significantly improved compared to the base model which is SVM.
ROC curves and AUC values of different individual classifiers for different classes are shown in Fig. 10. According to Fig. 10a, the AUC values based on the class 0 were calculated as 1, 0.99, 0.78, 0.93 and 0.94 for WOA-SVM, ANN, GP and SVM approaches, respectively. Figure 10b and c demonstrates AUC values of different classifiers based on class 1 and class 2, respectively. The specific values can be obtained from the figure. In Fig. 10, the AUC values obtained from the WOA-SVM model based on class 0, class 1 and class 2 are 1, 0.93 and 1, respectively. Obviously, the WOA-SVM model is the preferred ML classifier for squeezing degree prediction.

ROC curves and AUC values for different individual classifiers: a non-squeezing problems; b minor squeezing problems; c severe-to-extreme squeezing problems
In order to understand the capability of our proposed model better, we have drawn Taylor graph for train and test sets separately, as shown in Fig. 11. Taylor chart is often used to evaluate the accuracy of a model. Commonly used accuracy indicators are MCC, standard deviation and root-mean-square error (RMSE). Generally speaking, the scattered points in the Taylor diagram represent the model, the radial line represents the MCC, the horizontal and vertical axis represents the standard deviation and the dashed line represents the root-mean-square error. The Taylor chart is a change from the previous scatter chart, which can only show two indicators to express the accuracy of the model. Similarly, we still can see that the WOA-SVM model is the preferred ML classifier for squeezing degree prediction.

Taylor graph a test sets, b train sets
The above analysis is based on the test set. Below we will analyze and compare the performance of the model based on all the sample data in this article. The violin chart includes a combined specifications of the box plot and the kernel density plot. The main application of this chart is to present the probability density and distribution of datasets. Figure 12 shows the distribution and probability density of prediction accuracy for different classifier models considering all 114 samples. The prediction accuracy of WOA-SVM model is higher than the other classification models, and the distribution of accuracy is more concentrated, which sufficiently illustrates that the hybrid model (WOA-SVM) has visible advantages in squeezing prediction.

The violin chart presented for different classifier models
4.4 Sensitivity analysis of predictor variables
The key to predicting tunnel squeezing is the selection of appropriate input parameters. The research of Huang et al. [35] showed that the coupling effect of different parameters has different effects on tunnel squeezing prediction. Therefore, it is particularly important to evaluate the contribution of input parameters to the developed model. The Shapley Additive Explanations was used to obtain the importance of predictive variables to WOA-SVM classification model. The calculation formula is shown as [100]:
where N represents the set of all features in the data set, \(S\) is the set after index \(i\) is removed, the importance of feature \(i\) to the model output is represented by \(\Phi_{i}\), \(x_{s}\) represents the vector of input features in set \(S\), and the contribution of features is calculated with the corresponding function \(q\).
In practical applications, the prediction results based on the predictor variables with high contribution rates to model are more reliable and accurate. There are five features in this work, and the importance of predictor variables to the WOA-SVM classification model was calculated (Fig. 13). It can be intuitively seen that the percentage strain (ɛ) is the most important parameter in predicting tunnel squeezing, followed by K and H parameters. Due to the imbalance dataset of this article, the contribution of the parameters to model based on different types of data (class0, class1 and class2) was assessed (Fig. 13b) According to Fig. 13, ɛ is still the most influential parameter on the model for all classes. However, for class 1 and class 2, the parameter K ranks second only to ɛ in the contribution rate rankings, followed by H. For class 0, the parameter H ranks second only to ɛ, followed by K. In summary, the parameters that have important contribution to the WOA-SVM model are: ɛ, K, H and D.

Variable contribution analysis: a overall analysis; b analysis of variables for non-squeezing problems, minor squeezing problems, and high squeezing problem
In order to verify the above conclusions, we randomly selected a sample from three different classes, and the probabilistic interpretation of the sample is given in Figs. 14–16. That means that Figs. 14, 15 and 16 demonstrate that the five parameters (ɛ, K, D, Q and H) have different contributions to the prediction of class0, class1 and class2. Figure 14 presents the process of the sample selected was considered class0 by WOA-SVM model according to input parameters. According to the information in Fig. 14, it can be easily observed that the probabilities of the sample to class0, class1 and class2 are 0.69, 0.24 and 0.07, respectively. Therefore, the final prediction result is class0 (light squeezing problem), and parameters ε, H and K are decisive predictor variables, where ε plays a decisive role in the prediction results.

Probabilistic interpretation of the non-squeezing category
Similarly, Fig. 15 displays the process of the sample selected was judged to be class1. The sample will be judged to be class0, class1 and class2 with corresponding probability of 0.09, 0.52 and 0.39, respectively. Finally, this sample is considered as class1 (moderate squeezing problem). The decisive predictor variables are different from that presented in Fig. 14, and they are ε, H and D. Nevertheless, parameters ε still has the deepest effect on the proposed model. Figure 16 demonstrates that the sample will be regarded as class0, class1 and class2 with corresponding probability of 0.05, 0.28 and 0.67, respectively. Obviously, this sample is ultimately considered as class2 (high squeezing problem), and the percentage strain (ɛ) is the most important parameter for predicting tunnel squeezing, followed by the parameters K and H. In other words, Figs. 14, 15 and 16 illustrate that the parameters ɛ, K, H and D have a considerable impact on the WOA-SVM model, while ɛ is the most important input parameter among them.

Probabilistic interpretation of the minor squeezing category

Probabilistic interpretation of the high squeezing category
5 Conclusion
We proposed an optimized classifier model (WOA-SVM) to estimate the potential of tunnel squeezing according to 114 cases. There were five input parameters (H, K, D, Q and ɛ) considered in the modeling of all ML models in this study (WOA-SVM, ANN, SVM and GP). In order to assess the performance of different classifier models based on the same database, accuracy, kappa, precision, recall, F1-score and the AUC were calculated. The aim of the sensitivity analysis of predictor variables is to evaluate the contribution of input parameters to the model. The main results of this study are summarized as follows.
-
(1)
The WOA algorithm can effectively optimize the hyper-parameters of the SVM classifier and improve its classification performance. The WOA-SVM classification model has the highest accuracy (approximately 0.9565) than other un-optimized individual classifiers (SVM, ANN and GP). However, the model has a good classification effect, even if the data are unbalanced.
-
(2)
The results of the sensitivity analysis indicate that ɛ, H and K are the best combination of parameters for WOA-SVM model, where the percentage strain (ɛ) is the most influential factor on the WOA-SVM model, the parameter K ranks second only to ɛ in the contribution rate rankings, followed by H.
So far, most of the existing forecasting methods can distinguish between squeezing and non-squeezing. This article refers to the multi-class SVM proposed by Sun et al. [71] and introduces the whale optimization algorithm to optimize the prediction performance of the multi-class SVM. Therefore, the WOA-SVM model has higher prediction accuracy than empirical methods, ordinary binary SVM and multi-class SVM and can predict the severity of tunnel squeezing. However, compared with numerical simulation, the influencing factors considered by this paper are obviously limited. In addition, in the actual construction process, it is difficult to obtain more accurate input parameter values. According to the research of Zhang et al. [73,74], the prediction performance of the classifier ensemble model is higher than that of the individual classifier. In future, other advanced single classifiers can be introduced to construct a classifier ensemble. On this basis, the introduction of suitable optimization algorithms can greatly improve the prediction accuracy of the model. In addition, expanding the existing database can improve the generalization ability of the integrated model.
References
Ajalloeian R, Moghaddam B, Azimian A (2017) Prediction of rock mass squeezing of T4 tunnel in Iran. Geotech Geol Eng 35(2):747–763. https://doi.org/10.1007/s10706-016-0139-y
Armaghani DJ, Harandizadeh H, Momeni E, Maizir H, Zhou J (2021a) An optimized system of GMDH-ANFIS predictive model by ICA for estimating pile bearing capacity. Artif Intell Rev, 1–38
Armaghani DJ, Yagiz S, Mohamad ET, Zhou J (2021) Prediction of TBM performance in fresh through weathered granite using empirical and statistical approaches. Tunnell Undergr Space Technol 118:104183
Aydan O, Akagi T, Kawamoto T (1993) The squeezing potential of rocks around tunnels; theory and prediction. Rock Mech Rock Eng 26(2):137–163. https://doi.org/10.1007/BF01023620
Aydan Ö, Akagi T, Kawamoto T (1996) The squeezing potential of rock around tunnels: theory and prediction with examples taken from Japan. Rock Mech Rock Eng 29(3):125–143. https://doi.org/10.1007/BF01032650
Azizi F, Koopialipoor M, Khoshrou H (2019) Estimation of rock mass squeezing potential in tunnel route (case study: Kerman water conveyance tunnel). Geotech Geol Eng 37(3):1671–1685. https://doi.org/10.1007/s10706-018-0714-5
Bansal S, Rattan M (2019) Design of cognitive radio system and comparison of modified whale optimization algorithm with whale optimization algorithm. Int J Inf Technol. https://doi.org/10.1007/s41870-019-00346-2
Barla G (2001) Tunnelling under squeezing rock conditions. Mechanics—Advances in Geotechnical Engineering and Tunnelling, 169–268. http://scholar.google.com/scholar?hl=en&btnG=Search&q=intitle:Tunnelling+under+squeezing+rock+conditions#0
Barton N, Lien R, Lunde J (1974) Engineering classification of rock masses for the design of tunnel support. Rock Mech Felsmechanik Mécanique Des Roches 6(4):189–236. https://doi.org/10.1007/BF01239496
Basnet CB (2013) Evaluation on the squeezing phenomenon at the headrace tunnel of Chameliya Hydroelectric Project, Nepal
Bhasin R, Grimstad E (1996) The use of stress-strength relationships in the assessment of tunnel stability. Tunnell Undergr Space Technol 11(1):93–98
Chapelle O, Haffner P, Vapnik VN (1999) Support vector machines for histogram-based image classification. IEEE Trans Neural Netw 10(5):1055–1064
Chen Y, Li T, Zeng P, Ma J, Patelli E, Edwards B (2020) Dynamic and probabilistic multi-class prediction of tunnel squeezing intensity. Rock Mech Rock Eng 53(8):3521–3542. https://doi.org/10.1007/s00603-020-02138-8
Choudhari JB (2007) Closure of underground opening in jointed rocks. PhD Thesis, IIT Roorkee, Roorkee, India
Dai Y, Khandelwal M, Qiu Y, Zhou J, Monjezi M, Yang P (2022) A hybrid metaheuristic approach using random forest and particle swarm optimization to study and evaluate backbreak in open-pit blasting. Neural Comput Appl. https://doi.org/10.1007/s00521-021-06776-z
Du M, Zhao Y, Liu C, Zhu Z (2021) Lifecycle cost forecast of 110 kV power transformers based on support vector regression and gray wolf optimization. Alex Eng J 60:5393–5399. https://doi.org/10.1016/j.aej.2021.04.019
Dube AK (1979) Geomechanical evaluation of tunnel stability under failing rock conditions in a Himalayan Tunnel. Department of Civil Engineering, University of Roorkee, Roorkee, India
Dwivedi RD, Goel RK, Singh M, Viladkar MN, Singh PK (2019) Prediction of ground behaviour for rock tunnelling. Rock Mech Rock Eng 52(4):1165–1177. https://doi.org/10.1007/s00603-018-1673-0
Dwivedi RD, Singh M, Viladkar MN, Goel RK (2013) Prediction of tunnel deformation in squeezing grounds. Eng Geol 161:55–64. https://doi.org/10.1016/j.enggeo.2013.04.005
Farhadian H, Nikvar-Hassani A (2020) Development of a new empirical method for Tunnel Squeezing Classification (TSC). Q J Eng GeolHydrogeol. https://doi.org/10.1144/qjegh2019-108
Feng X, Jimenez R (2015) Predicting tunnel squeezing with incomplete data using Bayesian networks. Eng Geol 195:214–224. https://doi.org/10.1016/j.enggeo.2015.06.017
Frough O, Torabi SR, Yagiz S (2015) Application of RMR for estimating rock-mass–related TBM utilization and performance parameters: a case study. Rock Mech Rock Eng 48(3):1305–1312
Ghasemi E, Gholizadeh H (2019) Prediction of squeezing potential in tunneling projects using data mining-based techniques. Geotech Geol Eng 37(3):1523–1532. https://doi.org/10.1007/s10706-018-0705-6
Ghiasi V, Ghiasi S, Prasad A (2012) Evaluation of tunnels under squeezing rock condition. J Eng Des Technol 10(2):168–179. https://doi.org/10.1108/17260531211241167
Gioda G, Cividini A (1996) Numerical methods for the analysis of tunnel performance in squeezing rocks. Rock Mech Rock Eng 29(4):171–193. https://doi.org/10.1007/BF01042531
Goel R (1994) Correlations for predicting support pressures and closures in tunnels. Ph.D. thesis, Nagpur University, Nagpur, India
Goel RK, Jethwa JL, Paithankar AG (1995) Tunnelling through the young Himalayas—a case history of the Maneri-Uttarkashi power tunnel. Eng Geol 39(1–2):31–44. https://doi.org/10.1016/0013-7952(94)00002-J
Goel RK, Jethwa JL, Paithankar AG (1995a) Tunnelling through the young Himalayas—a case history of the Maneri-Uttarkashi power tunnel. Eng Geol 39(1–2):31–44
Goel RK, Jethwa JL, Paithankar AG (1995b) Indian experiences with Q and RMR systems. Tunn Undergr Space Technol 10(1):97–109
Goh ATC, Zhang W (2012) Reliability assessment of stability of underground rock caverns. Int J Rock Mech Min Sci 55:157–163. https://doi.org/10.1016/j.ijrmms.2012.07.012
Goh ATC, Zhang W, Zhang Y, Xiao Y, Xiang Y (2018) Determination of earth pressure balance tunnel-related maximum surface settlement: a multivariate adaptive regression splines approach. Bull Eng Geol Env 77(2):489–500. https://doi.org/10.1007/s10064-016-0937-8
Hoek E (2001) Big tunnels in bad rock 2000 Terzaghi Lecture. ASCE J Geotech Geoenviron Eng 127(9):726–740
Hoek E, Marinos P (2000) Predicting tunnel squeezing problems in weak heterogeneous rock masses. Tunnels and Tunnelling International, 1–20. http://www.rockscience.com/hoek/references/H2000d.pdf
Hu G, Xu Z, Wang G, Zeng B, Liu Y, Lei Y (2021) Forecasting energy consumption of long-distance oil products pipeline based on improved fruit fly optimization algorithm and support vector regression. Energy. https://doi.org/10.1016/j.energy.2021.120153
Huang Z, Liao M, Zhang H, Zhang J, Ma S (2020) Predicting the tunnel surrounding rock extrusion deformation based on SVM-BP model with incomplete data. Mod Tunnel Technol (S1), https://doi.org/10.13807/j.cnki.mtt.2020.S1.017.
Jethwa JL (1981) Evaluation of rock pressures in tunnels through squeezing ground in lower Himalayas, University of Roorkee, Roorkee, India
Jimenez R, Recio D (2011) A linear classifier for probabilistic prediction of squeezing conditions in Himalayan tunnels. Eng Geol 121:101–109. https://doi.org/10.1016/j.enggeo.2011.05.006
Kang Y, Wang J (2010a) A support-vector-machine-based method for predicting large-deformation in rock mass. 7th International Conference on Fuzzy Systems and Knowledge Discovery, FSKD 2010, 1176–1180. https://doi.org/10.1109/FSKD.2010.5569148
Kang, Y., & Wang, J. (2010b). A support-vector-machine-based method for predicting large-deformation in rock mass. Proceedings - 2010 7th International Conference on Fuzzy Systems and Knowledge Discovery, FSKD 2010, 1176–1180. https://doi.org/10.1109/FSKD.2010.5569148
Khandelwal M (2011) Blast-induced ground vibration prediction using support vector machine. Eng Comput 27(3):193–200
Khandelwal M, Monjezi M (2013) Prediction of backbreak in open-pit blasting operations using the machine learning method. Rock Mech Rock Eng 46(2):389–396
Kimura F, Okabayashi N, Kawamoto T (1987) Tunnelling through squeezing rock in two large fault zones of the enasan tunnel II. Rock Mech Rock Eng, 151–166
Kotary DK, Nanda SJ, Gupta R (2021) A many-objective whale optimization algorithm to perform robust distributed clustering in wireless sensor network. Appl Soft Comput 110:107650. https://doi.org/10.1016/j.asoc.2021.107650
Kumar N (2002) Rock mass characterization and evaluation of supports for tunnels in Himalaya. PhD Thesis, IIT Roorkee, Roorkee, India
Li E, Yang F, Ren M, Zhang X, Zhou J, Khandelwal M (2021) Prediction of blasting mean fragment size using support vector regression combined with five optimization algorithms. J Rock Mech Geotech Eng. https://doi.org/10.1016/j.jrmge.2021.07.013
Li E, Zhou J, Shi X, Armaghani DJ, Yu Z, Chen X, Huang P (2021) Developing a hybrid model of salp swarm algorithm-based support vector machine to predict the strength of fiber-reinforced cemented paste backfill. Eng Comput 37(4):3519–3540
Liu M, Luo K, Zhang J, Chen S (2021) A stock selection algorithm hybridizing grey wolf optimizer and support vector regression. Expert Syst Appl. https://doi.org/10.1016/j.eswa.2021.115078
Liu Y, Wang L, Gu K (2021) A support vector regression (SVR)-based method for dynamic load identification using heterogeneous responses under interval uncertainties. Appl Soft Comput. https://doi.org/10.1016/j.asoc.2021.107599
Lyu F, Fan X, Ding F, Chen Z (2021) Prediction of the axial compressive strength of circular concrete-filled steel tube columns using sine cosine algorithm-support vector regression. Compos Struct. https://doi.org/10.1016/j.compstruct.2021.114282
Mahdevari S, Torabi SR (2012) Prediction of tunnel convergence using Artificial Neural Networks. Tunn Undergr Space Technol 28(1):218–228. https://doi.org/10.1016/j.tust.2011.11.002
Majumder D, Viladkar MN, Singh M (2017) A multiple-graph technique for preliminary assessment of ground conditions for tunneling. Int J Rock Mech Min Sci 100:278–286. https://doi.org/10.1016/j.ijrmms.2017.10.010
Mehrdanesh A, Monjezi M, Khandelwal M, Bayat P (2021) Application of various robust techniques to study and evaluate the role of effective parameters on rock fragmentation. Eng Comput, 1–11
Mirjalili S, Mirjalili SM, Saremi S, Mirjalili S (2020) Whale optimization algorithm: Theory, literature review, and application in designing photonic crystal filters. Stud Comput Intell. https://doi.org/10.1007/978-3-030-12127-3_13
Mohammadi B, Mehdizadeh S (2020) Modeling daily reference evapotranspiration via a novel approach based on support vector regression coupled with whale optimization algorithm. Agric Water Manag. https://doi.org/10.1016/j.agwat.2020.106145
Monjezi MKM (2013) Prediction of backbreak in open-pit blasting operations using the Machine Learning Method. 389–396. https://doi.org/10.1007/s00603-012-0269-3
NEA (2002) Geology and geotechnical report, volume IV-A and geological drawings and exhibits, volume V-C, in project completion report, N. E. Authority, Kaligandaki “A” Hydroelectric Project, Syanga, Nepal
Okwu MO, Tartibu LK (2021) Whale Optimization Algorithm (WOA). Stud Comput Intell 927:53–60. https://doi.org/10.1007/978-3-030-61111-8_6
Pai P-F, Hong W-C (2007) A recurrent support vector regression model in rainfall forecasting. Hydrol Process 21(6):819–827. https://doi.org/10.1002/hyp
Panet M (1996) Two case histories of tunnels through squeezing rocks. Rock Mech Rock Eng 29(3):155–164. https://doi.org/10.1007/BF01032652
Panthi KK (2011) Effectiveness of post-injection grouting in controlling leakage: a case study. J Water, Energy Environ. 8:14–18
Panthi KK (2014) Predicting tunnel squeezing: a discussion based on two tunnel projects. 2013. https://doi.org/10.3126/hn.v12i0.9027
Panthi KKÃ, Nilsen B (2007) Uncertainty analysis of tunnel squeezing for two tunnel cases from Nepal Himalaya. Int J Rock Mech Mining Sci 44:67–76. https://doi.org/10.1016/j.ijrmms.2006.04.013
Parsa P, Naderpour H (2021) Shear strength estimation of reinforced concrete walls using support vector regression improved by Teaching–learning-based optimization, Particle Swarm optimization, and Harris Hawks Optimization algorithms. J Build Eng. https://doi.org/10.1016/j.jobe.2021.102593
Qiu Y, Zhou J, Khandelwal M, Yang H, Yang P, Li C (2021) Performance evaluation of hybrid WOA - XGBoost, GWO - XGBoost and BO - XGBoost models to predict blast - induced ground vibration. Eng Comput. https://doi.org/10.1007/s00366-021-01393-9
Shafiei A, Parsaei H, Dusseault MB (2012)Rock squeezing prediction by a support vector machine classifier. 46th US Rock Mechanics / Geomechanics Symposium 2012, 489–503. https://doi.org/10.13140/RG.2.1.3836.3040
Shi XZ, Zhou J, Wu BB, Huang D, Wei W (2012) Support vector machines approach to mean particle size of rock fragmentation due to bench blasting prediction. Trans Nonferr Metals Soc China Eng Ed 22(2):432–441. https://doi.org/10.1016/S1003-6326(11)61195-3
Shrestha GL (2005) Stress induced problems in Himalayan tunnels with special reference to squeezing. In: Faculty of Engineering Science and Technology Department of Geology and Mineral Resources Engineering: Vol. Doctoral t (Issue November). https://ntnuopen.ntnu.no/ntnu-xmlui/handle/11250/248703
Singh B, Jethwa JL, Dube AK, Singh B (1992) Correlation between observed support pressure and rock mass quality. Tunnell Undergr Space Technol Incorporat Trenchless 7(1):59–74. https://doi.org/10.1016/0886-7798(92)90114-W
Singh M, Singh B, Choudhari J (2007) Critical strain and squeezing of rock mass in tunnels. Tunn Undergr Space Technol 22(3):343–350. https://doi.org/10.1016/j.tust.2006.06.005
Sripad SK, Raju GD, Singh Rajbal, Khazanchi RN (2007) Instrumentation of underground excavations at Tala hydroelectric project in Bhutan. In: Singh R, Sthapak AK (eds) Proceedings international workshop on experiences and construction of Tala hydroelectric project Bhutan, 14–15 June, New Delhi, India, pp 269–282
Sun Y, Feng X, Yang L (2018) Predicting tunnel squeezing using multiclass support vector machines. Adv Civil Eng. https://doi.org/10.1155/2018/4543984
Tian Z, Qiao C, Teng W, Liu K (2004) Method of predicting tunnel deformation based on support vector machines. China Railway Sci (01)
Vapnik V (1995) The nature of statistical learning theory. Springer, Berlin
Vapnik V, Izmailov R (2021) Reinforced SVM method and memorization mechanisms. Pattern Recogn 119:108018. https://doi.org/10.1016/j.patcog.2021.108018
Wang SM, Zhou J, Li CQ, Armaghani DJ, Li XB, Mitri HS (2021) Rockburst prediction in hard rock mines developing bagging and boosting tree-based ensemble techniques. J Cent South Univ 28(2):527–542
Xu H, Zhou J, Asteris GP, Jahed Armaghani D, Tahir MM (2019) Supervised machine learning techniques to the prediction of tunnel boring machine penetration rate. Appl Sci 9(18):3715
Yang HQ, Li Z, Jie TQ, Zhang ZQ (2018) Effects of joints on the cutting behavior of disc cutter running on the jointed rock mass. Tunn Undergr Space Technol 81:112–120. https://doi.org/10.1016/j.tust.2018.07.023
Yang HQ, Xing SG, Wang Q, Li Z (2018) Model test on the entrainment phenomenon and energy conversion mechanism of flow-like landslides. Eng Geol 239:119–125. https://doi.org/10.1016/j.enggeo.2018.03.023
Yang HQ, Zeng YY, Lan YF, Zhou XP (2014) Analysis of the excavation damaged zone around a tunnel accounting for geostress and unloading. Int J Rock Mech Min Sci 69:59–66. https://doi.org/10.1016/j.ijrmms.2014.03.003
Yang H, Wang Z, Song K (2020) A new hybrid grey wolf optimizer-feature weighted-multiple kernel-support vector regression technique to predict TBM performance. Eng Comput. https://doi.org/10.1007/s00366-020-01217-2
Yang J, Liu Y, Yagiz S, Laouafa F (2021) An intelligent procedure for updating deformation prediction of braced excavation in clay using gated recurrent unit neural networks. J Rock Mech Geotech Eng. https://doi.org/10.1016/j.jrmge.2021.07.011
Yang J, Yagiz S, Liu YJ, Laouafa F (2021) a comprehensive evaluation of machine learning algorithms on application to predict TBM performance. Undergr Space. https://doi.org/10.1016/j.undsp.2021.04.003l
Yang H, Wang Z, Song K (2020) A new hybrid grey wolf optimizer - feature weighted—multiple kernel—support vector regression technique to predict TBM performance. Eng Comput. https://doi.org/10.1007/s00366-020-01217-2
Yagiz S, Karahan H (2011) Prediction of hard rock TBM penetration rate using particle swarm optimization. Int J Rock Mech Min Sci 48(3):427–433
Zhang H, Shi Y, Yang X, Zhou R (2021) A firefly algorithm modified support vector machine for the credit risk assessment of supply chain finance. Res Int Bus Financ. https://doi.org/10.1016/j.ribaf.2021.101482
Zhang J, Huang Y, Ma G, Yuan Y, Nener B (2021) Automating the mixture design of lightweight foamed concrete using multi-objective firefly algorithm and support vector regression. Cement Concr Compos. https://doi.org/10.1016/j.cemconcomp.2021.104103
Zhang J, Li D, Wang Y (2020) Predicting tunnel squeezing using a hybrid classifier ensemble with incomplete data. Bull Eng Geol Env 79:3245–3256. https://doi.org/10.1007/s10064-020-01747-5
Zhang W, Zhang R, Wu C, Goh ATC, Lacasse S, Liu Z, Liu H (2020) State-of-the-art review of soft computing applications in underground excavations. Geosci Front 11(4):1095–1106
Zhang W, Li H, Li Y, Liu H, Chen Y, Ding X (2021b) Application of deep learning algorithms in geotechnical engineering: a short critical review. Artif Intell Rev, 1–41
Zhang W, Wu C, Zhong H, Li Y, Wang L (2021) Prediction of undrained shear strength using extreme gradient boosting and random forest based on Bayesian optimization. Geosci Front 12(1):469–477
Zhao H (2005) Predicting the surrounding deformations of tunnel using support vector machine. Chin J Rock Mech Eng 24(4): 649–652. https://doi.org/10.3321/j.issn:1000-6915.2005.04.017
Zhou J, Dai Y, Khandelwal M, Monjezi M, Yu Z (2021) Performance of hybrid SCA-RF and HHO-RF models for predicting backbreak in open-pit mine blasting operations. Nat Resour Res 30(6):4753–4771. https://doi.org/10.1007/s11053-021-09929-y
Zhou J, Huang S, Wang M, Qiu Y (2021b) Performance evaluation of hybrid GA-SVM and GWO-SVM models to predict earthquake-induced liquefaction potential of soil: a multi-dataset investigation. Eng Comput
Zhou J, Li E, Yang S, Wang M, Shi X, Yao S, Mitri HS (2019) Slope stability prediction for circular mode failure using gradient boosting machine approach based on an updated database of case histories. Saf Sci 118(2018):505–518. https://doi.org/10.1016/j.ssci.2019.05.046
Zhou J, Qiu Y, Zhu S, Armaghani DJ, Li C, Nguyen H, Yagiz S (2021) Optimization of support vector machine through the use of metaheuristic algorithms in forecasting TBM advance rate. Eng Appl Artif Intell 97:104015. https://doi.org/10.1016/j.engappai.2020.104015
Zhou J, Li EM, Wang MZ, Chen X, Shi XZ, Jiang LS (2019b) Feasibility of stochastic gradient boosting approach for evaluating seismic liquefaction potential based on SPT and CPT case histories. J Performance Constr Facil 33(3)
Zhou J, Li XB, Mitri HS (2015) Comparative performance of six supervised learning methods for the development of models of hard rock pillar stability prediction. Nat Hazards 79(1):291–316
Zhou J, Li XB, Mitri HS (2016) Classification of rockburst in underground projects: comparison of ten supervised learning methods. J Comput Civil Eng, 30(5)
Zhou J, Chen C, Wang M, Khandelwal M (2021) Proposing a novel comprehensive evaluation model for the coal burst liability in underground coal mines considering uncertainty factors. Int J Min Sci Technol 31(5):799–812
Zhou J, Qiu Y, Khandelwal M, Zhu S, Zhang X (2021) Developing a hybrid model of Jaya algorithm-based extreme gradient boosting machine to estimate blast-induced ground vibrations. Int J Rock Mech Min Sci 145:104856
Zhou J, Qiu Y, Zhu S, Armaghani DJ, Khandelwal M, Mohamadd ET (2021) Estimation of the TBM advance rate under hard rock conditions using XGBoost and Bayesian optimization. Underground Space 6(5):506–515. https://doi.org/10.1016/j.undsp.2020.05.008
Zhou J, Qiu Y, Armaghani DJ, Zhang W, Li C, Zhu S, Tarinejad R (2021d) Predicting TBM penetration rate in hard rock condition: a comparative study among six XGB-based metaheuristic techniques. Geosci Front 12(3):101091. https://doi.org/10.1016/j.gsf.2020.09.020
Acknowledgements
This research was funded by the National Science Foundation of China (42177164) and the Innovation-Driven Project of Central South University (No. 2020CX040).
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Rights and permissions
About this article

Cite this article
Zhou, J., Zhu, S., Qiu, Y. et al. Predicting tunnel squeezing using support vector machine optimized by whale optimization algorithm. Acta Geotech. 17, 1343–1366 (2022). https://doi.org/10.1007/s11440-022-01450-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11440-022-01450-7