
Abstract
Drought, as a phenomenon that causes significant damage to agriculture and water resources, has increased across the globe due to climate change. Hence, scientists are attracted to developing drought prediction models for mitigation strategies. Different drought indices (DIs) have been proposed for drought monitoring during the past few decades, most of which are probabilistic, highly stochastic, and non-linear. The present study inspected the capability of various machine learning (ML) models, including artificial neural network (ANN) and support vector regression (SVR) as original predictive models and optimized by two selected algorithms, namely, particle swarm optimization (SVR-PSO) and response surface method (SVR-RSM) to predict the meteorological drought indices of standardized precipitation index (SPI), percentage of normal precipitation (PN), effective drought index (EDI), and modified China-Z index (MCZI) on a monthly time scale. A novel model named SVR-RMS is introduced by using two calibrating processes given from RSM with two inputs and the SVR by predicted data handled with RSM given from the first calibrating procedure. For evaluating the models, different meteorological input variables in the period 1981–2020 were considered from 11 synoptic stations in arid and semi-arid climates of Iran, which frequently experience droughts. The SPI showed the highest and lowest correlation with MCZI (0.71) and EDI (0.34), respectively. The results of testing dataset (2011–2020) indicated that the SVR-RSM produced superior abilities for both accuracy and tendency compared to other models, while the SVR-PSO model is better than the ANN and SVR. The worst results of drought prediction were obtained for EDI. However, all models provided the acceptable EDI prediction in the high-temperature station of Ahvaz in the south of the country. Application of SVR-RSM as a novel hybrid model can be suggested for predicting the DIs on a short time scale in arid and semi-arid areas.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Drought incidents have become very frequent globally and have significant impacts on water resources availability, environmental health, agricultural production, and, consequently, the socio-economic of a region (Dai 2011; Yaseen et al. 2021). Based on Wilhite and Glantz (1985) classification, drought can have four categories of meteorological drought, agricultural drought, hydrological drought, and socio-economic drought (Wilhite and Glantz 1985; Nguyen-Huy et al. 2021).
Meteorological droughts, as the initiator of other drought forms, occur due to the negative departure of precipitation from the average precipitation for a particular period of time (Yaseen et al. 2021). Meteorological drought frequency is indicated by precipitation variability rather than the average precipitation of a region; thus, it may occur in any climate depending on the significant fluctuation of precipitation on the deficit aspect (Yaseen et al. 2021). For drought monitoring, a wide variety of drought indices (DIs) have been defined (Ahmed et al. 2019; Alamgir et al. 2015). However, they are often region-specific, and their applicability to a wide range of climatic conditions is restricted due to intrinsic complexity of drought (Wable et al. 2019). It is critical to determine an appropriate drought index for a given location, to prepare for drought-related problems. Numerous comparative studies on DIs are evaluated in various locations (Adisa et al. 2021; Mashari Eshghabad et al. 2014). However, the findings of different research are contentious. Many scientists, particularly in water resources management, suggest investigating the drought status through multiple indices. Decisions should not be made based on only one index due to the complexity of the drought phenomena (Eslamian et al. 2017).
The ability of drought forecasting in advance by a number of months or a few seasons is critical to mitigating the negative consequences of droughts (Dastorani and Afkhami 2011). Several forecasting techniques have been introduced to predict droughts, including Multiple Linear Regression (MLR), Markov Chain, and Autoregression Integrated Moving Average (ARIMA) (Fung et al. 2020). Predicting droughts using conventional statistical methods is challenging because the scale of some indices, such as standardized precipitation index (SPI), is not linear (Yaseen et al. 2021). Recently, machine learning (ML) algorithms have demonstrated outstanding advances in modeling DIs and meteorology (Malik et al. 2020a; Pérez-Alarcón et al. 2022; Pham et al. 2019).
Various ML models have been developed for modeling DIs including artificial neural network (ANN) basis multi-layer perceptron (Belayneh et al. 2016b; Deo and Şahin 2015a), extreme learning machine (ELM) (Deo and Şahin 2015b), support vector regression (SVR) (Belayneh et al. 2016b; Das et al. 2020), adaptive neuro-fuzzy inference system (ANFIS) (Ali et al. 2018), random forest (RF) (Park et al. 2016), M5 Tree (M5T) (Ali et al. 2018; Naderianfar et al. 2017), least-square support vector regression (LSSVR) (Deo et al. 2017), extremely randomized tree (ERT) (Rhee and Im 2017), multivariate adaptive regression spline (MARS) (Deo et al. 2017), wavelet preprocessing integrated ML models (Das et al. 2020) and nature-inspired hybrid ML models (Nabipour et al. 2020). The models' main challenge is applying a general non-linear relation that can be used for various climates and has high flexibility for non-linear relations with different inputs. However, it is difficult to introduce a perfect model with the lowest error and appropriate predictions with the highest accuracy and tendency for all climates. Abilities for both accuracy and tendency are directly dependent on the modeling structure in the training phase. Besides, there is a possibility of inaccuracy in the model development when setting up the variables of the model’s structure are inappropriate (Yaseen et al. 2021). On the other hand, each location acts differently according to the weather stochastics and historical features (Yaseen et al. 2021). The modelling approach with two calibrating processes can be provided the flexibility for highly non-linear relations for various climate stations. Therefore, optimization of ML models based on approaches, such as particle swarm optimization (PSO) and response surface method (RSM) can reduce the errors of predicted results of DIs.
This study aims to investigate the abilities of different machine learning models for meteorological DIs predictions of different geographical regions in Iran, which has suffered from several drought incidents in recent decades. Four different versions of machine learning models, including ANN, SVR, SVR-PSO, and SVR-RSM as a novel hybrid model, were evaluated in predicting precipitation-based drought indices of SPI, percentage of normal precipitation (PN), effective drought index (EDI), and modified China-Z index (MCZI) at a monthly time-scale. The historical data between 1981 and 2020 was used to develop and validate the models.
2 Materials and Methods
2.1 Case Study
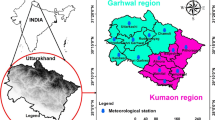
Iran has extensive climatic diversity; however, most of its area has arid and semi-arid climates. Due to the deficit or variation of rainfall, these regions frequently experience drought events that influence the country's environment and public health. This research selected 11 stations of these climates with the longest records, spread out countrywide. The locations of stations are shown in Fig. 1.

The locations of the studied meteorological stations
The climate type of different stations was found based on de Martonne aridity index (IDM). This index was calculated based on precipitation and temperature data for the period 1981–2020 using the following equation (Shahabfar and Eitzinger 2013):
where IDM = the de Martonne aridity index, P = annual mean precipitation (mm) and T = mean annual air temperature (oC). Therefore, meteorological stations of Ahvaz, Bandar-Abbas, Isfahan, Kerman, Semnan, and Zahedan are located in arid climate (\({I}_{DM}<10\)) and other stations, including Hamedan, Mashhad, Sanandaj, Shiraz, and Zahedan, were in semi-arid climate areas (\(10\le {I}_{DM}<20\)).
2.2 Data
The meteorological data for 1981–2020 was obtained from Iran Meteorological Organization (IRIMO). These data as climatic input variables of modeling include monthly rainfall, and the monthly average of wind speed, temperature, relative humidity, and sunshine hours. The statistics of climatic parameters on the monthly scale at different study stations are presented in Appendix Table 5. Also, Fig. 2 depicts the flowchart of the modeling process in this study.

Schematic flowchart illustrating the methodology of the study
2.3 Drought Indices
2.3.1 SPI
The standardized precipitation index (SPI) is used for defining and monitoring drought and was first developed by McKee et al. (1993). It is based on the cumulative probability of precipitation data and can assign a numerical value to provide the ground for comparison of various climatic regions. The advantages of SPI are simplicity, application of accessible rainfall data, statistically robust, and calculability for multiple time scales (Keyantash and Dracup 2002).
The long-term precipitation data is fitted to a gamma distribution determined to fit the precipitation distribution properly (Dayal et al. 2016). The fitting of gamma distribution with parameters \(\alpha\) and \(\beta\), was done using maximum likelihood estimation (Dayal et al. 2016).
Then it transformed to a normal distribution so that the average SPI for an area and certain period of time is zero (McKee et al. 1993). This converted probability is the SPI, mostly ranges between -2.0 and + 2.0, with extremes values outside this range occurring 5% of the time (Edwards and Mckee 1997). The complete mathematical procedure is available in the works of Jain et al. (2015); McKee et al. (1993); Edwards and Mckee (1997).
2.3.2 PN
The percentage of normal precipitation (PN) is one of the simplest indices applied for assessing the drought in an area. It is particularly effective when used for a specific location or season. This index can be calculated for different time scales through the following equation (Boustani and Ulke 2020; Mahmoudi et al. 2019):
In this equation: Xi = precipitation amount in a given series (month, season, year) and \(\overline{X }\) = the amount of normal precipitation (mean of long-term, at least 30 years) (Boustani and Ulke 2020). This index is always positive and theoretically unrestricted (Mashari Eshghabad et al. 2014) (Table 1).
2.3.3 EDI
The effective drought index (EDI) was first developed by Byun and Wilhite (1999) for monitoring the severity and duration of drought periods. The EDI is defined based on the effective precipitation concept, which is determined using a time-dependent reduction function of daily or monthly rainfall and needs a minimum of 30-years of data to compute the average effective precipitation. The EDI is calculated as a function of the precipitation amount needed to return to normal (PRN). Where PRN is determined using the deviation of monthly effective precipitation from the mean for every month (Jain et al. 2015; Mahmoudi et al. 2019).
To compute the EDI, firstly the effective precipitation for the current month (EPj) is calculated (Eq. (3)):
where Pi is the precipitation ‘m-1’ months before the present month and N denotes the duration of preceding period. Calculating the standard deviation and mean values of EP for each month, time series of EP values is converted to deviations from the mean (DEP). Then the PRNj values and EDI are calculated using the following equations:
where STD (PRN) is the standard deviation of PRN values of the corresponding month.
2.3.4 MCZI
The China-Z index (CZI) index was first widely applied by the National Meteorological Center of China in 1995. It is based on the cube root transformation of Wilson-Hilferty with the assumption that the rainfall data fit the Pearson Type III distribution (Kendall and Stuart 1977). In order to decrease the variation in the data set, the modified China-Z index (MCZI) was developed by Wu et al. (2001), wherein, the calculation is similar to CZI except that, instead of the mean, we use the median in the statistical formulation of the index. The MCZI’s amount in the jth month for the ith period can be calculated as following (Sridhara et al. 2021):
which \(i=\) time scale of interest and \(j=\) the current month, \({\varphi }_{j}=\) standard variable, \({M}_{e}=\) median value of all rainfall over time, \({C}_{s}=\) time zones present the coefficient of skewness coefficient for rainfall data, \({X}_{j}=\) the amount of rainfall that has become normal dispersion over time and \(n=\) sum of time zones (Boustani and Ulke 2020).
The DIs have a defined range of values to show the severity of a droughts. Table 1 presents the severity range of different meteorological indices evaluated in this study (Mahmoudi et al. 2019; Mashari Eshghabad et al. 2014; Sridhara et al. 2021). Also, the statistics of calculated DIs on the monthly scale for various stations are shown in Appendix Table 6.
2.4 Machine Learning Models
2.4.1 ANN Models
The ANN model applied in this study has a feed-forward Multi-Layer Perceptron (MLP) architecture trained using the Levenberg–Marquardt (LM) backpropagation algorithm. MLPs have been adopted extensively in hydrologic prediction or forecasting because of their simplicity (Piri et al. 2009).
MLPs involve a set of layers (nodes), including an input layer, one or more hidden layers, and an output layer (Kim and Valdés 2003):
where m = number of hidden neurons, N = number of samples, \({x}_{i}\) = ith input of variables at time step t; \({w}_{ji}\) = weight which connects the ith and jth neurons in the input layer and in the hidden layer, respectively; \(bj\) = bias for the jth hidden neuron; \(\varphi_{j}\) = activation function of the hidden neuron; \({w}_{j}\) = weight that connects the jth and kth neurons in the hidden layer and in the output layer, respectively; \(b\) = bias for the kth output neuron; \(\varphi\) = activation function of the output neuron; and \(\widehat{y}\) is the predicted the kth output at time step t (Kim and Valdés 2003).
Figure 3 depicts an ANN model’s architecture, with the signals transmitting layer by layer in a forward direction through the network (Dikshit et al. 2020). More detailed information on ANN architectures is provided by Paulraj and Sivanandam (2009); Khan et al. (2020); Khan (2018); Das et al. (2020).

The schematic of artificial neural network (ANN) architecture
In this study, the ANN model applied to predict the drought indices was created with MATLAB (R.2014b). Different activation functions of linear, logistic and sigmoid were evaluated and the sigmoid (\(y=\frac{1}{1+{e}^{-x}}\)) and linear functions were chosen as the activation functions of the hidden and output layers, respectively. The LM backpropagation algorithm was used to train the model because of its efficiency and reduced calculation time in training models (Adamowski and Chan 2011). A perceptron multi-layer ANN model has been used which has six inputs and a network with a hidden layer with nine nodes. The optimal number of input neurons was 20 which was found using trial and error, with the number of neurons that showed the lowest root mean square error (RMSE) value in the training set being selected.
2.4.2 SVR Model
Support vector regression (SVR), introduced by Vapnik (1995), is available to solve prediction problems and is a regression aspect version of a support vector machine (SVM). This model has been used successfully in various fields, including regression and forecasting issues of hydrology.
Unlike ANN, which employs the empirical risk minimization code, SVR uses the structural risk minimization code from statistical learning theory (Belayneh et al. 2014). Furthermore, ANN seeks to reduce training error, but the SVR aims to minimize generalization error (Dikshit et al. 2020).
Using different kernel function types, such as ‘linear’, ‘poly’, ‘rbf’, and ‘sigmoid’, SVR has previously been used to model both short-term and long-term droughts (Belayneh et al. 2014). In this study, the kernel type of ‘rbf’ was applied as it has proven efficient presented in below equation (Dikshit et al. 2020).
where xi, xj, i = 1, 2,..n, x ∊ Rk are inputs that by mapping the input data form original space into a higher dimensional feature space provide a nonlinear relation.
On the other hand, the model is influenced by three different parameters: gamma (\(\gamma\)) as the active function scale parameter, positive constant (C), and epsilon (\(\varepsilon\)) as the insensitive factor (Belayneh et al. 2016a). The first parameter is a constant and manages the model's complexity, the second parameter is a positive constant representing capacity control, and the third parameter reflects the loss function, which defines the regression vector without all of the input data (Kisi and Cimen 2011). The parameter selection in this study was according to the trial-and-error technique, and the combination that produced the least root mean square error (RMSE) score was used. A detailed description of the theory and formulation of SVR can be found in Panahi et al. (2020), Vapnik (1995), Gunn (1998). In this study, the codes were written in MATLAB software version 2014b to implement predictive models. After standardizing the data, to reduce the range of data changes, the optimal values of the model characteristics, including C = 50,000, \(\upvarepsilon =0.1\), \(\gamma =1\times {e}^{-7}\) were determined by the network optimization algorithm and the Gaussian kernel function was selected.
2.4.3 Hybrid SVR Models
The parameters of the SVR model must be carefully defined to achieve a successful implementation of the model and obtain acceptable accuracy. In general, the SVR model's satisfactory performance relies on the correct selection of parameters, which can be regarded as an optimization problem and require identifying the global optimal approach to get the best performance possible so far. The association of the SVR model with the selected algorithms (PSO and RSM) can create SVR-PSO and SVR-RSM hybrid models. Figure 4 depicts the flowcharts of the proposed SVR hybrid models.

Schematic flowchart of modeling process of SVR-PSO algorithm
Kennedy and Eberhart (1995) developed PSO, which is one of the most widely used swarm intelligent algorithms for solving optimization problems. It enthused its basic idea from the movement of bird flocks in nature. The algorithm has been effectively applied in solving a variety of issues, such as engineering, feature selections, data clustering, optimization, and short-term load prediction (Deng et al. 2019). In each iteration of model, particles try to find the best position. The position (\(X)\) and velocity (\(V\)) of particles are updated mathematically according to the following equations:
where \({V}_{new}=\) the new velocity of a particle, \({X}_{pbest}=\) the best position of the particle, gbest = the best global position from various particles in each iteration, \(w\) = the coefficient of inertia, \({r}_{1}\) and \({r}_{2}\) = random coefficients, \({C}_{1}\) and \({C}_{2}\) = acceleration coefficients and \({X}_{new}\) = the new position of the next iteration. More details about PSO can be found in Mirjalili et al. (2020), Kennedy and Eberhart (1995) and Malik et al. (2020b).
2.4.4 SVR-RSM Model
The reliable model with high-capacity and low-computational burden for applying DIs is the main issue for developing the hybrid SVR models. Keshtegar et al. (2016) showed that using a model with two regression processes provided accurate predictions for the complex problem with highly non-linear effects. The advanced hybrid ML model provided by SVR and RSM named SVR- RSM, where we applied two regression procedures, can be provided an accurate prediction with high performances in the training model. It should be noted that introducing the SVR-RSM for predictions of DIs has not been investigated by searching the open literature; thus, this model was developed for the prediction of concrete shear wall capacity (Keshtegar et al. 2021), pan evaporation (Keshtegar et al. 2016), and development length of reinforcing bar in concrete beams (Keshtegar and Yaseen 2021). Consequently, the SVR-RSM model is introduced as a novel model for predicting the DIs. The hidden layer of SVR-RSM was computed based on the RSM, which is applied for inputs of SVR. The RSM determines the data handled points in the hidden layer of the hybrid SVR-RSM model. Therefore, the flexibility of the predicted SVR model, which the input database provided by RSM calibrates, is increased to obtain a non-linear relation. Two calibration processes applied in SVR-RSM is introduced as below steps:
Step 1
RSM is applied for the first calibration of the handled database in the hidden layer using two input variables.
-
(i)
Give two individual input variables as \({x}_{i}{,x}_{j}\).
-
(ii)
Calibrate the RSM based on the training data set (O) using two variables by the following relation:
$${\varphi }_{ij}={a}_{0}+{a}_{1}{x}_{i}+{a}_{2}{x}_{j}{+a}_{3}{x}_{i}^{2}+{a}_{4}{x}_{j}^{2}+{a}_{5}{x}_{i}{x}_{j}$$(14)
In which,\({\varphi }_{ij}\) represents the predicted database for the data-handling node, which is calibrated using two input variables as \({x}_{i}{,x}_{j}. {a}_{0-}\) \({a}_{5}\) are weights which are determined for every prior as below:
where
In this data provided by RSM with weights of \({a}_{0-}\) \({a}_{5}\), the cross-linear correlation of input variables of \({x}_{i}{ and x}_{j}\) is considered by term \({x}_{i}{x}_{j}\), and \({P}^{T}\) relates the transfer of vector P.
Step 2
SVR model applied as the second calibration trained based on calibrated database in the first step by RSM.
In the hybrid SVR—RSM model, the predicted data is used to transfer inputs with a non-linear map by polynomial function with the cross term. But the mapping data by RSM as inputs are predicted based on a relation using Kernel functions in SVR. The database in the hidden layer provided by RSM has dimensions similar to DIs. By applying the SVR model, the non-linear effect of the model is considered by the Kernel function applied in SVR with Gaussian relation. It means we have a highly non-linear relation for this problem.
2.5 Train and Test
For the development of prediction models (i.e., SVR, SVR-PSO, SVR-RSM, and ANN), all input data were split into two sets: 75% (1981–2010) for the training of models and 25% (2011–2020) for testing (Chen et al. 2020; Baptista et al. 2013; Özkaya et al. 2021).
The model performance analysis was done using the testing dataset to provide an unbiased estimation of the model performance. The initial parameters data set for SVR, SVR-PSO, and SVR-RSM model training and testing are provided in Table 2.
2.6 Measuring Prediction Accuracy
The performance accuracy of predicted models was investigated using different statistical performance indicators and by graphical assessment (i.e., time-series plot, scatter plot, and Taylor diagram). These statistical indicators express the level of certainty of the models and were given by the equations in Table 3 (Keshtegar et al. 2016; Nash and Sutcliffe 1970; Willmott 1981; Harmel and Smith 2007).
In Eqs. (17)–(21), \({DI}_{o}\)= the observed value, \({DI}_{p}\) = the predicted value, \(N\) = the number of data points, \({\overline{DI} }_{o}=\frac{1}{N}\sum_{i=1}^{N}{DI}_{o}\) and \({\overline{DI} }_{p}=\frac{1}{N}\sum_{i=1}^{N}{DI}_{p}\) (Table 3).
The R2 indicates the degree of the linear correlation between the predicted and observed data (Das et al. 2020). The RMSE shows the average difference between predicted and observed data. The lower RMSE value of a model indicates a better performance.
The NSE (\(-\infty \le NSE\le 1\)) is calculated using the relationship between the predicted and observed mean deviations (Nash and Sutcliffe 1970). It can demonstrate the correlation between the predicted and observed data and this indicator is more useful for assessing the goodness-of-fit of a model compared to R2. It is because R2 is insensitive to proportional differences between model simulation and observations (Keshtegar et al. 2016).
For the non-linear models, NSE can be negative. The NSE value close to 1 is more satisfactory, and a negative NSE shows an unacceptable model performance (Singh et al. 2005; Moriasi et al. 2007). NSE alone, like RMSE, is not a sufficient indicator (Jain and Sudheer 2008). Together with RMSE, they produce a set of model selection criteria that balance each other’s limitations (Zhong and Dutta 2015).
Willmott’s Index of agreement (WI) is a descriptive index that can be used to make a cross-comparison between different models (\(0\le WI\le 1\)). \(WI = 0\) shows null agreement (no correlation) and \(WI = 1\) indicates total agreement (perfect fit). While R2 is highly sensitive to extreme values, the factor WI can be used to solve this problem using Eq. (20). (Harmel and Smith 2007). Compared to R2, WI is also better suited for model assessment because it was created to be a measure of the degree to which a model’s predictions are error-free rather than a measure of correlation (Keshtegar et al. 2016).
To find the best predicted indices, the confidence index (CI) was used, which was calculated based on multiplying the Nash Sutcliffe model efficiency coefficient (Eq. (19)) by the Willmott’s Index of agreement (Eq. (20)). The \(CI = 0\) indicates null confidence and \(CI = 1\) shows total confidence.
3 Results
The mean SPI over 40 years for different meteorological stations is shown in Fig. 5. Results showed the higher average SPI values during the low rainfall period of June to September (summer season) for different stations.

The mean SPI over 40 years for different meteorological stations
The mean 40-year results of the Pearson coefficient correlation (R2) between the monthly DIs of all studied stations are illustrated in Table 4. The highest correlation between indices was found between SPI and MCZI in different stations, which was more than 0.55 with an average value of 0.71. The stations of Kerman and Sanandaj showed the lowest R2 among all stations between SPI and MCZI. Also, Table 4 reveals a good correlation between SPI and PN indices (0.59) for different stations; however, a poor correlation was observed in Ahvaz station (0.31). Among different indices, PN and EDI showed the lowest correlation coefficient, with the value of 0.22 as the average for all stations. The range of correlation between these two indices was 0.08 (in Ahvaz) to 0.30 (in Semnan). Similarly, the correlation variation between MCZI and EDI for all stations was low in the range of 0.21 (in Ahvaz) to 0.40 in Zahedan.
In general, a strong correlation between different DIs was recorded in Tabriz, Semnan, and Zahedan, with the average values of 0.56, 0.51, and 0.51, respectively, and a poor correlation was obtained for Ahvaz, Bandar-Abbas, and Hamedan with the average values of 0.33, 0.40 and 0.41 (Table 4). It corresponds with the monthly average SPI time series extracted from the 40-year data of different stations, which indicated that the stations of Ahvaz, Zahedan, and Bandar-Abbas showed the highest values of 1.67, 1.32, and 1.11, respectively, and the stations of Tabriz, Mashhad and Semnan showed the lowest values of 0.03, 0.08 and 0.12, respectively (Table 4).
The graphical assessment among different predictive models in terms of performance for testing dataset (2011–2020) is presented in the Heatmap diagrams in Fig. 6. In a 4 × 4 matrix, the dark blue color indicates the worst statistical performance, while the yellow color shows the best performance in the figure. The results are obtained based on the average values of different stations for the sake of brevity. The SVR-RSM showed the best performance for all DIs based on statistical indices. Besides, the maximum number of dark red cells (the worst predictive model) was demonstrated by the SVR model. The SVR-PSO and ANN showed similar results for various DIs; however, for PN, the ANN showed the worst performance among all DIs.

The Heatmap diagrams of comparison of different drought indices and predictive models for testing dataset (2011–2020)
Taylor diagram is another graphical presentation applied to evaluate the employed models (Fig. 7). The results of Taylor diagrams for testing data showed good consistency with the calculated performance indices. Figure 7 shows that for the average value of EDI of different stations, the lowest agreement exists between the SVR (yellow circle) with other models. This model provided the lowest correlations (0.45) and the highest variation (1.5). Similarly, SVR showed the worst results for SPI and MCZI prediction; however, ANN showed the lowest agreement with other models for the PN index. Among different models, ANN had the lowest variation for predicting various DIs, followed by hybrid models and ANN. Results showed among all DIs, the highest R2 of different models was obtained for indices of PN (0.97), SPI (0.92), and MCZI (0.92), and the lowest R2 was found for EDI (0.64). However, the highest RMSE was found for PN, and the lowest RMSE was observed for MCZI among all IDs. Overall, SVR-RSM had the closest distance to observed data (gray point), indicating the lowest RMSE and highest correlation for this model and, therefore, its superiority compared to other predictive models; RSM-PSO and ANN follow it.

Taylor diagram of the average value of observed and predicted drought indices for different stations by ANN, SVR, SVR-PSO, and SVR-RSM models
Figure 8 shows the zoning map of the selected stations based on the mean RMSE values of IDs for various models during the selected statistical period. The red and blue color shows the highest and lowest RMSE values, respectively. Results showed the highest accuracy of EDI, SPI, PN, and MCZI, were obtained in Ahvaz, Tabriz, Mashhad, and Zahedan stations, respectively, and the worst results were found in Zahedan, Ahvaz, Ahvaz, and Hamedan, respectively. While the minimum values of RMSE for PN, SPI, and MCZI indices were in the semi-arid climate stations, the minimum one for EDI was obtained in an arid climate station of Ahvaz. The maximum values of RMSE were obtained in an arid station for PN and EDI and in a semi-arid environment for SPI and MCZI.


The zoning map of the selected stations based on the mean RMSE values of IDs for various models during test period (2011–2020)
Based on the results, SVR-RSM provided the best results among different models. Therefore, the linear correlation between observed and predicted SPI values at all stations was evaluated using scatter plots (Fig. 9). All predicted points in different stations are aligned to the perfect line (45° line), which indicates an acceptable performance of the SVR-RSM model. The results revealed that the prediction of SPI using the SVR-RSM model has a strong correlation for all stations (more than 0.97).

Results of scatter plot for correlation between the predictive and observed average value of SPI index in different stations for testing dataset (2011–2020)
4 Discussion
Drought is a part of any climate’s nature, occurring in various regions occasionally. The meteorological drought over a 40-year period is monitored and predicted in this study for the diverse climates of Iran. Powerful tools to monitor drought play a vital role in mitigating this phenomenon. Drought indices are key determinants of drought monitoring and modeling as they simplify the complex interrelationships among climate and climate-related parameters.
According to statistical analysis before modeling, a strong correlation was observed between SPI and MCZI in all stations with different climates and a poor correlation was found between SPI and EDI, especially in the station of Ahvaz (Table 4). The correlation between SPI and MCZI was obtained 109.5% more than that between SPI and EDI and 19.4% more than that between SPI and PN. The results are in agreement with Shahabfar and Eitzinger (2013), which compared the correlation between six meteorological drought indices of SPI, MCZI, CZI, PN, Z-score, and the aridity index of E. de Martonne (I) for various time scales in different climates of Iran from 1950 to 2005. Among all evaluated indices, the strongest relationship was reported between SPI and MCZI, particularly in rainy periods in Coastal wet regions. They indicated the degree of the relationships is related to the season and the climatic region. In the current research, our results showed a higher correlation within DIs in stations with lower monthly SPI and drier conditions according to Fig. 5 and the SPI ranges of Table 1.
Four different machine learning basis predictions named ANN, SVR, SVR-PSO, and SVR-RSM were compared in the current work. These models are used to connect multi-inputs and output responses. Predictive models' structure and modeling processes significantly affected DIs' accuracy and tendency.
Based on the results, SVR showed the least accuracy in DIs prediction, followed by the ANN model. The ANN model has three main layers as well as the SVR model as input, hidden, and output layers. In the ANN model, the active function as sigmoid relation transfers the nodes in the previous layer into the current layer. The weights and biases applied in the multi-linear function are used to connect the nodes of the current layer to the previous layer. The hidden layer nodes are manually given to provide the ANN model's non-linear relation. This ANN model is trained by Levenberg–Marquardt backpropagation, produced by an optimization method for providing the ANN model.
Consequently, the training procedure, the active function to provide the non-linear relation, the number of the hidden nodes in the hidden layer, and the number of hidden layers are the main parameters of the ANN models, and these factors and procedures are the main gapes in modeling relation of ANN models. In SVR models, the hidden nodes are computed based on the Kernel function; thus, input nodes as n-element are transferred to the m-nodes that m is commonly related to the number of training data points. The centers of the kernel function are given based on the input variables in the training phase. The shape parameter of the kernel function is manually assigned to provide the smooth property of the Kernel prediction. The connection between predicted data using the Kernel function and output response is needed to apply several parameters of the SVR model named as C and ε using Lagrangian multiplier optimization. The kernel basis regression based on several model parameters is used in SVR, while ANN is structured by the multiple-linear function with transferring active function.
Our study showed a lower performance of SVR in predicting drought indices compared to the ANN algorithm. According to a study conducted by Dikshit et al. (2020) in New South Wales, Australia, ANN is better than SVR in determining temporal trends of drought on a regional scale. They reported better prediction results for both models at longer time scales. However, the results of previous studies on the relative performance of both models are controversial. For example, Lima et al. (2013) investigated precipitation forecasting and found SVR has better predictions when the mean absolute error (MAE) is regarded as the performance metric, and ANN performs better when the mean squared error (MSE) is viewed as the performance metric. Similarly, Chevalier et al. (2011) reported that both algorithms have comparable performance when the training dataset is larger in size. However, in our study, the number of data for different levels of training and testing during monthly simulation scenarios of DIs prediction over the 40-year study period was 480 for each input parameter.
Determining the Kernel function and the associated model parameters are the main challenges in the SVR modeling approach. It is done using a trial-and-error method, which increases the processing time due to increased dataset size. The number of trials to optimize the model will increase with higher uncertainty among model parameters. About the ANN, more accurate models can be developed by adjusting the number of neurons in the hidden layer. Besides, in the current study, the monthly time scale was considered for models; however, according to Dikshit et al. (2020), longer-time scales would better predict the DIs compared to shorter time scales. It might be due to the significant correlation between climate indices and drought at longer time periods.
Our study showed the performance of SVR model would improve after it was revealed in hybrid form. Different statistical parameters in the Taylor and heat map graphs indicated the superiority of the SVR-RSM followed by the SVR-PSO model. The optimization methods are applied to find the optimum condition of the modeling SVR parameters.
In the current work, the PSO and RSM are used as optimization approaches to tune the SVR model parameters. The modeling procedure of hybrid SVR-PSO is a time-consuming model due to the random search of parameters. Thus an efficient modeling approach is developed based on two modeling procedures as RSM combined with SVR. The input variables of SVR are determined by the RSM in the first calibrating procedure. The inputs of SVR are calibrated based on two individual inputs of the basic variables then the model of SVR is trained using calibrating data obtained by 2-input. The parameters of SVR models in SVR-RSM are manually given while these parameters are searched by optimization approach in SVR-PSO. The basic variables are directly used in the ANN and SVR-PSO, while the SVR-RSM model is trained based on the calibrated input variables by RSM. However, in SVR-RSM, the best parameters of SVR are the main challenge for the contribution of this model, and the effective regressed data points given by the RSM are a challenge for providing an accurate model.
The results of the zoning map showed acceptable drought modeling for both arid and semi-arid environments in the studied area. However, the results are inconsistent for different drought indices. EDI showed the more accurate prediction for Ahvaz station, probably due to the high temperature in this arid location.
The scatter plot of SPI prediction using SVR-RSM as the model with the highest accuracy was evaluated for different stations. The SPI index was chosen for the comparison of stations due to its confirmed reliability. Besides, this index has been applied in numerous studies to investigate drought variability, despite its recent introduction (Yaseen et al. 2021). Mahmoudi et al. (2019) reported the SPI and EDI indices as the first and second best drought monitoring indices in Iran based on evaluating different drought indices of 41 synoptic stations over a period of 28 years (1985–2013). Similarly, Morid et al. (2006) indicated that SPI and EDI outperform five other studied DIs in their research to design a drought monitoring system for Tehran province in Iran using 32 years of data. Results of the scatter plot showed a high R2 for predicting SPI using the SVR-RSM model in all stations, indicating its capability to predict SPI drought in different climates. Based on the results, the SVR-RSM was identified as a more suitable, robust, and reliable model than the other evaluated models for monthly drought forecasting in the studied area.
Therefore, machine learning methods can be applied as a preliminary step to predict droughts on a regional scale, which could prove to be useful for policymakers. Future research should look at more development in hybrid models, which could provide greater insights into drought prediction and its characteristics, especially in arid areas with severe consequences of drought incidents.
5 Conclusions
The prediction of the drought indices is a vital factor in water management, especially in the regions such as Iran with large dry areas. The accurate prediction of DIs using the machine learning approaches is a gap for the best management. In the current work, using meteorological data as input variables, four modeling methods named ANN and SVR as original predictive models and two hybrid approaches named SVR-PSO and SVR-RSM were inspected for predicting precipitation-based DIs of SPI, PN, EDI, and MCZI. The hybrid SVR models were coupled with the optimization approach of PSO, which is used to find the best hyper parameters of SVR, and were combined by RSM with two regression approaches for providing the data handling by RSM in the first regression step, and the SVR predicted models in second regression calibrated by data provided by RSM. Eleven synoptic stations throughout Iran were selected for evaluating the models using soft computing approaches calibrated by the advanced intelligence models. Based on this research, the following conclusions can be drawn:
The SPI showed the highest correlation with MCZI and the lowest correlation with EDI. Higher correlation between IDs was observed in the locations with a lower average of monthly SPI values and drier conditions according to the SPI ranges.
The metrological inputs were the effective parameters for the prediction of DI obtained from the results of four models.
The hybrid model named SVR-RSM was the best model among others for all predicted data of the studied locations. The results showed the high accuracy of this model for both arid and semi-arid environments according to visual inspection and statistical performance criteria.
Based on the results, the worst predicted index was obtained as EDI. However, EDI showed the acceptable prediction with accurate results for one location (Ahvaz) due to having the high temperature in this station. Therefore, it can be extracted that the temperature may significantly affect EDI in dry regions.
The RSM with SVR algorithm is highly recommended as a non-linear model to provide a novel hybrid model for the prediction of monthly SPI as a reliable DI on a regional scale in arid and semi-arid areas of Iran. The deep learning models are the flexible approach for prediction of the nonlinear events, thus these models can be compared for predicting the drought indices in future.
Availability of Data and Materials
Some data are available from the corresponding author upon requests.
References
Adamowski J, Chan HF (2011) A wavelet neural network conjunction model for groundwater level forecasting. J Hydrol 407(1–4):28–40
Adisa OM, Masinde M, Botai JO (2021) Assessment of the dissimilarities of EDI and SPI measures for drought determination in South Africa. Water 13(1):82
Ahmed K, Shahid S, Chung E-S, Wang X-j, Harun SB (2019) Climate change uncertainties in seasonal drought severity-area-frequency curves: Case of arid region of Pakistan. J Hydrol 570:473–485
Alamgir M, Shahid S, Hazarika MK, Nashrrullah S, Harun SB, Shamsudin S (2015) Analysis of meteorological drought pattern during different climatic and cropping seasons in Bangladesh. JAWRA J Am Water Resour Assoc 51(3):794–806
Ali M, Deo RC, Downs NJ, Maraseni T (2018) An ensemble-ANFIS based uncertainty assessment model for forecasting multi-scalar standardized precipitation index. Atmos Res 207:155–180
Baptista FD, Rodrigues S, Morgado-Dias F (2013) Performance comparison of ANN training algorithms for classification. In IEEE 8th International Symposium on Intelligent Signal Processing. Funchal, Portugal, pp 115–120
Belayneh A, Adamowski J, Khalil B (2016) Short-term SPI drought forecasting in the Awash River Basin in Ethiopia using wavelet transforms and machine learning methods. Sustain Water Resour Manag 2(1):87–101
Belayneh A, Adamowski J, Khalil B, Ozga-Zielinski B (2014) Long-term SPI drought forecasting in the Awash River Basin in Ethiopia using wavelet neural network and wavelet support vector regression models. J Hydrol 508:418–429
Belayneh A, Adamowski J, Khalil B, Quilty J (2016b) Coupling machine learning methods with wavelet transforms and the bootstrap and boosting ensemble approaches for drought prediction. Atmos Res 172:37–47
Boustani A, Ulke A (2020) Investigation of meteorological drought indices for environmental assessment of Yesilirmak Region. J Environ Treat Tech 8(1):374–381
Byun H-R, Wilhite DA (1999) Objective quantification of drought severity and duration. J Clim 12(9):2747–2756
Chen Y, Song L, Liu Y, Yang L, Li D (2020) A review of the artificial neural network models for water quality prediction. Appl Sci 10(17):5776
Chevalier RF, Hoogenboom G, McClendon RW, Paz JA (2011) Support vector regression with reduced training sets for air temperature prediction: a comparison with artificial neural networks. Neural Comput Appl 20(1):151–159
Dai A (2011) Drought under global warming: a review. Wiley Interdiscip Rev Clim Change 2(1):45–65
Das P, Naganna SR, Deka PC, Pushparaj J (2020) Hybrid wavelet packet machine learning approaches for drought modeling. Environ Earth Sci 79(10):1–18
Dastorani MT, Afkhami H (2011) Application of artificial neural networks on drought prediction in Yazd (Central Iran). Desert, 16(1):39–48
Dayal KS, Deo RC, Apan AA (2016) Application of hybrid artificial neural network algorithm for the prediction of standardized precipitation index. In IEEE Region 10 Conference (TENCON). Singapore, pp 2962–2966
Deng W, Yao R, Zhao H, Yang X, Li G (2019) A novel intelligent diagnosis method using optimal LS-SVM with improved PSO algorithm. Soft Comput 23(7):2445–2462
Deo RC, Kisi O, Singh VP (2017) Drought forecasting in eastern Australia using multivariate adaptive regression spline, least square support vector machine and M5Tree model. Atmos Res 184:149–175
Deo RC, Şahin M (2015a) Application of the artificial neural network model for prediction of monthly standardized precipitation and evapotranspiration index using hydrometeorological parameters and climate indices in eastern Australia. Atmos Res 161:65–81
Deo RC, Şahin M (2015b) Application of the extreme learning machine algorithm for the prediction of monthly Effective Drought Index in eastern Australia. Atmos Res 153:512–525
Dikshit A, Pradhan B, Alamri AM (2020) Temporal hydrological drought index forecasting for New South Wales. Australia Using Machine Learning Approaches Atmosphere 11(6):585
Edwards DC, McKee TB (1997) Characteristics of 20th century drought in the United States at multiple time scales. Atmospheric Science Paper 63:1–30
Eslamian S, Ostad-Ali-Askari K, Singh VP, Dalezios NR, Ghane M, Yihdego Y, Matouq M (2017) A review of drought indices. Int J Constr Res Civ Eng 3:48–66
Fung K, Huang Y, Koo C, Soh Y (2020) Drought forecasting: A review of modelling approaches 2007–2017. J Water Clim Change 11(3):771–799
Gunn SR (1998) Support vector machines for classification and regression. ISIS Technical Report 14(1):5–16
Harmel RD, Smith PK (2007) Consideration of measurement uncertainty in the evaluation of goodness-of-fit in hydrologic and water quality modeling. J Hydrol 337(3–4):326–336
Jain SK, Sudheer K (2008) Fitting of hydrologic models: a close look at the Nash-Sutcliffe index. J Hydrol Eng 13(10):981–986
Jain VK, Pandey RP, Jain MK, Byun H-R (2015) Comparison of drought indices for appraisal of drought characteristics in the Ken River Basin. Weather Clim Extremes 8:1–11
Kendall MG, Stuart A (1977) The advanced theory of statistics. Vol. 1: Distribution theory. Griffin, London
Kennedy J, Eberhart R (1995) Particle swarm optimization. In Proceedings of IEEE International Conference on Neural Networks, Perth, Australia, pp 1942–1948
Keshtegar B, Nehdi ML, Trung N-T, Kolahchi R (2021) Predicting load capacity of shear walls using SVR–RSM model. Appl Soft Comput 112:107739
Keshtegar B, Piri J, Kisi O (2016) A nonlinear mathematical modeling of daily pan evaporation based on conjugate gradient method. Comput Electron Agric 127:120–130
Keshtegar B, Yaseen ZM (2022) Reinforcing bar development length modeling using integrative support vector regression model with response surface method: New approach. ISA Transactions 128:423–434
Keyantash J, Dracup JA (2002) The quantification of drought: an evaluation of drought indices. Bull Am Meteor Soc 83(8):1167–1180
Khan GM (2018) Artificial neural network (ANNs). In Evolution of artificial neural development. Springer, Cham, pp 39–55
Khan N, Sachindra D, Shahid S, Ahmed K, Shiru MS, Nawaz N (2020) Prediction of droughts over Pakistan using machine learning algorithms. Adv Water Resour 139:103562
Kim T-W, Valdés JB (2003) Nonlinear model for drought forecasting based on a conjunction of wavelet transforms and neural networks. J Hydrol Eng 8(6):319–328
Kisi O, Cimen M (2011) A wavelet-support vector machine conjunction model for monthly streamflow forecasting. J Hydrol 399(1–2):132–140
Lima AR, Cannon AJ, Hsieh WW (2013) Nonlinear regression in environmental sciences by support vector machines combined with evolutionary strategy. Comput Geosci 50:136–144
Mahmoudi P, Rigi A, Kamak MM (2019) Evaluating the sensitivity of precipitation-based drought indices to different lengths of record. J Hydrol 579:124181
Malik A, Kumar A, Salih SQ, Kim S, Kim NW, Yaseen ZM, Singh VP (2020a) Drought index prediction using advanced fuzzy logic model: Regional case study over Kumaon in India. PLoS ONE 15(5):e0233280
Malik A, Tikhamarine Y, Souag-Gamane D, Kisi O, Pham QB (2020b) Support vector regression optimized by meta-heuristic algorithms for daily streamflow prediction. Stoch Env Res Risk Assess 34(11):1755–1773
Mashari Eshghabad S, Omidvar E, Solaimani K (2014) Efficiency of some meteorological drought indices in different time scales (case study: Tajan Basin, Iran). Ecopersia 2(1):441–453
McKee TB, Doesken NJ, Kleist J (1993) The relationship of drought frequency and duration to time scales. In Proceedings of the 8th Conference on Applied Climatology. Anaheim, United States, 17(22): 179–183
Mirjalili S, Song Dong J, Lewis A, Sadiq AS (2020) Particle swarm optimization: theory, literature review, and application in airfoil design. In: Mirjalili S, Song Dong J, Lewis A (eds) Nature-inspired optimizers, Springer, Cham, pp 167–184
Moriasi DN, Arnold JG, Van Liew MW, Bingner RL, Harmel RD, Veith TL (2007) Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans ASABE 50(3):885–900
Morid S, Smakhtin V, Moghaddasi M (2006) Comparison of seven meteorological indices for drought monitoring in Iran. Int J Climatol J R Meteorol Soc 26(7):971–985
Nabipour N, Dehghani M, Mosavi A, Shamshirband S (2020) Short-term hydrological drought forecasting based on different nature-inspired optimization algorithms hybridized with artificial neural networks. IEEE Access 8:15210–15222
Naderianfar M, Piri J, Kisi O (2017) Pre-processing data to predict groundwater levels using the fuzzy standardized evapotranspiration and precipitation index (SEPI). Water Resour Manag 31(14):4433–4448
Nash JE, Sutcliffe JV (1970) River flow forecasting through conceptual models part I—A discussion of principles. J Hydrol 10(3):282–290
Nguyen-Huy T, Deo RC, Yaseen ZM, Prasad R, Mushtaq S (2021) Bayesian Markov chain Monte Carlo-based copulas: factoring the role of large-scale climate indices in monthly flood prediction. In Intelligent data analytics for decision-support systems in hazard mitigation. Springer, Singapore, pp 29–47
Özkaya SG, Durur H, Baygin M, Kazaz İ (2021) Artificial neural network and image processing based compressive strength prediction. Erzincan Univ J Sci Technol 14(2):408–421
Panahi M, Sadhasivam N, Pourghasemi HR, Rezaie F, Lee S (2020) Spatial prediction of groundwater potential mapping based on convolutional neural network (CNN) and support vector regression (SVR). J Hydrol 588:125033
Park S, Im J, Jang E, Rhee J (2016) Drought assessment and monitoring through blending of multi-sensor indices using machine learning approaches for different climate regions. AgrForest Meteorol 216:157–169
Sivanandam M, Paulraj S (2009) Introduction to artificial neural networks. Vikas Publishing House, New Delhi
Pérez-Alarcón A, Garcia-Cortes D, Fernández-Alvarez JC, Martínez-González Y (2022) Improving monthly rainfall forecast in a watershed by combining neural networks and autoregressive models. Environ Process 9(3):1–26
Pham QB, Abba SI, Usman AG, Linh NTT, Gupta V, Malik A, Costache R, Vo ND, Tri DQ (2019) Potential of hybrid data-intelligence algorithms for multi-station modelling of rainfall. Water Resour Manag 33(15):5067–5087
Piri J, Amin S, Moghaddamnia A, Keshavarz A, Han D, Remesan R (2009) Daily pan evaporation modeling in a hot and dry climate. J Hydrol Eng 14(8):803–811
Rhee J, Im J (2017) Meteorological drought forecasting for ungauged areas based on machine learning: Using long-range climate forecast and remote sensing data. AgrForest Meteorol 237:105–122
Shahabfar A, Eitzinger J (2013) Spatio-temporal analysis of droughts in semi-arid regions by using meteorological drought indices. Atmosphere 4(2):94–112
Singh J, Knapp HV, Arnold J, Demissie M (2005) Hydrological modeling of the Iroquois river watershed using HSPF and SWAT 1. JAWRA J Am Water Resour Assoc 41(2):343–360
Sridhara S, Chaithra G, Gopakkali P (2021) Assessment and monitoring of drought in Chitradurga district of Karnataka using different drought indices. J Agrometeorol 23(2):221–227
Vapnik V (1995) The nature of statistical learning theory. Springer, New York, USA
Wable PS, Jha MK, Shekhar A (2019) Comparison of drought indices in a semi-arid river basin of India. Water Resour Manag 33(1):75–102
Wilhite DA, Glantz MH (1985) Understanding: the drought phenomenon: the role of definitions. Water Int 10(3):111–120
Willmott CJ (1981) On the validation of models. Phys Geogr 2(2):184–194
Wu H, Hayes MJ, Weiss A, Hu Q (2001) An evaluation of the standardized precipitation index, the China-Z Index and the statistical Z-Score. Int J Climatol J R Meteorol Soc 21(6):745–758
Yaseen ZM, Ali M, Sharafati A, Al-Ansari N, Shahid S (2021) Forecasting standardized precipitation index using data intelligence models: regional investigation of Bangladesh. Sci Rep 11(1):1–25
Zhong X, Dutta U (2015) Engaging Nash-Sutcliffe efficiency and model efficiency factor indicators in selecting and validating effective light rail system operation and maintenance cost models. J Traffic Transp Eng 3:255–265
Author information
Authors and Affiliations
Contributions
B. Keshtegar designed and developed the theoretical formulations. Data collection and analysis were performed by M. Abdolahipour. The computations and modeling were done by J. Piri. The first draft of the manuscript was written by M. Abdolahipour and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethical Approval
Not applicable.
Consent to Participate
Not applicable.
Consent to Publish
The authors agree to publish in the journal.
Competing Interests
The Authors declare no conflict of interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Highlights
• Using different meteorological input variables, the capability of four machine learning models was evaluated for prediction of short-term drought indices.
• A novel hybrid model is proposed for prediction of drought indices.
• The SVR-RSM showed superior performance in prediction of monthly drought indices.
• For arid and semi-arid areas, the hybrid SVR models showed more accurate results.
•A higher correlation between meteorological drought indices was observed in drier conditions.
Appendix
Appendix
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Piri, J., Abdolahipour, M. & Keshtegar, B. Advanced Machine Learning Model for Prediction of Drought Indices using Hybrid SVR-RSM. Water Resour Manage 37, 683–712 (2023). https://doi.org/10.1007/s11269-022-03395-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-022-03395-8