
Abstract
Precise estimation of groundwater level (GWL) might be of great importance for attaining sustainable development goals and integrated water resources management. Compared with alternative numerical models, soft computing methods are promising tools for GWL prediction, which need more hydrogeological and aquifer characteristics. The central aim of this research is to explore the performance of such well-accepted data-driven models to predict monthly GWL with emphasis on major meteorological components, including; precipitation (P), temperature (T), and evapotranspiration (ET). Artificial neural network (ANN), fuzzy logic (FL), adaptive neuro-fuzzy inference system (ANFIS), group method of data handling (GMDH), and least-square support vector machine (LSSVM) are used to predict one-, two-, and three-month ahead GWL in an unconfined aquifer. The main meteorological components (Tt, ETt, Pt, Pt-1) and GWL for one, two, and three lag-time (GWLt-1, GWLt-2, GWLt-3) are used as input to attain precise prediction. The results show that all models could have the best prediction for one month ahead in scenario 5, comprising inputs of GWLt-1, GWLt-2, GWLt-3, Tt, ETt, Pt, Tt-1, ETt-1, Pt-1. Based on different evaluation criteria, all employed models could predict the GWL with a desirable accuracy, and the results of LSSVM are the superior one.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Precise groundwater level (GWL) prediction is vital in developing water resources management strategies since they provide reliable quantitative information (Wunsch et al. 2020; Samani 2021). Recently, numerous studies have explored GWL prediction using different numerical and data-driven models (Chakraborty et al. 2020; Rezaei et al. 2021). The main drawback of physics-based models is a need for an extensive and uncertain dataset, including hydrogeological, water budget, and geophysical data. Such limitations have pushed engineers and researchers to apply data-driven methods in practice. Data-driven modeling utilizes real-time tolerance to model the hydrological events in an inaccurate and uncertain environment (Ghazi et al. 2021; Roy 2021; Antonopoulos and Gianniou 2022; Rahbar et al. 2022).
Hydrological time series exhibit nonlinear time-dependent behavior, which are too complicated to solve with standard numerical and statistical models (Rajaee et al. 2019). Recently, artificial intelligence (AI)-based methods such as artificial neural networks (ANNs), group method of data handling (GMDH), gene expression programming (GEP), least-square support vector machine (LSSVM), fuzzy logic (FL), adaptive neuro-fuzzy inference system (ANFIS), model tree (MT), multivariate adaptive regression splines (MARS), and evolutionary polynomial regression have been widely employed to predict GWL (Suryanarayana et al. 2014; Rajaee et al. 2019; Roshni et al. 2019; Mohammadrezapour et al. 2020; Ghazi et al. 2021; Mozaffari et al. 2022; Poursaeid et al. 2022). Such well-accepted models can cope with the complexity of GWL prediction and could provide relatively a better accuracy than numerical models.
Comparison of several AI-based models in GWL prediction is still highly demanded. In a study, Moghaddam et al. (2021) used combinations of parameters including GWL, groundwater withdrawal, recharge, precipitation (P), evapotranspiration (ET), and temperature (T) to predict GWL. Results pointed out that GMDH had a better outcome than the Bayesian network and ANN in GWL prediction. Shiri et al. (2020) used six AI-based models, ANN, BT, MARS, RF, GEP, and SVM, in a coastal aquifer to forecast GWL, and they figured out that GEP's outcomes were the superior one. A brief detail of studies regarding applying the AI-based models for GWL prediction is presented in Table 1. The ANN model is the most common AI-based model for GWL prediction based on Table 1.
The ANN has been recently utilized for GWL prediction (e.g., Banadkooki et al. 2020). Likewise, ANFIS and SVM have been applied to predict GWL and indicated an improvement in accuracy compared to ANN in GWL prediction (Kasiviswanathan et al. 2016; Khedri et al. 2020). Even though the ANNs, SVMs, and ANFIS have been commonly employed in GWL prediction whereas the efficiency of the GMDH model has seldomly been investigated in groundwater modeling. However, this method has been successfully applied in civil engineering, water quality management, and soil science (Najafzadeh et al. 2013; Tayebi et al. 2019; Lin et al. 2020). One of the motivations of this study is to assess the viability of the GMDH model in GWL prediction.
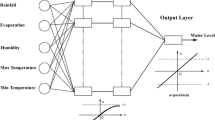
The present study evaluates the ability of various AI-based models in GWL prediction. The main aim to conduct this research could be summarized as a) modeling the behavior of a rising GWL in monitoring well while the other parts of the aquifer demonstrate a severe declining GWL; b) predicting GWL at the aquifer scale using monthly GWL, P, T, ET dataset as inputs; and c) comparing the efficiency of the FL, ANFIS, ANN, GMDH and LSSVM models in GWL prediction. To the best of the authors' knowledge and based on Table 1, limited research has been implemented to predict groundwater levels using a combination of FL, ANFIS, ANN, GMDH, and LSSVM competitive methods in GWL prediction, and there is no study in the literature which compares all these methods in GWL prediction using monthly P, T, ET datasets as inputs. Hence, this paper tried to provide more evidence on the ability of these models to predict GWL using climatic inputs. The present study sheds light on the GWL modeling in aquifers with poor hydrological and hydrogeological datasets. The outcomes of this sort of AI-based models provide a reliable perspective for decision-makers to attain sustainable water resources management goals. Figure 1 shows the procedural outline of the applied AI-based models.

Methodological framework of the proposed groundwater models
2 Methods
2.1 Artificial Neural Network (ANN)
The ANN approach is biologically inspired by the human brain (Patel et al. 2022). This model approximates the brain in two phases: (a) knowledge is obtained by the network from its environment as a result of a learning procedure, and (b) interneuron connection strengths are used to collect the obtained knowledge (Haykin 2004). The ANN procedure comprises five stages: selecting inputs, selecting an appropriate architecture, neural network construction, training and testing procedure, and finally, evaluating the developed model (Sahoo and Jha 2013). Multilayer perceptron (MLP), as the most widely used ANN in hydrological studies, was used in this study (McGarry et al. 1999). The MLP comprises three layers (input, hidden and output). The number of layers and neurons in each layer is essential to reach an optimum model structure. One hidden layer was used in the ANN model because this is sufficient for GWL prediction based on previous studies,.
MATLAB® (Mathworks 2014) software was employed to develop AI-based models in this study and Levenberg–Marquardt (LM) algorithm was implemented for ANN model. The overall framework of AI-based models is presented in Fig. 2.

The general structure of AI-based models
2.2 Fuzzy Logic (FL)
FL can overcome the intrinsic uncertainty between defined sets in mathematical form (Zadeh 1995). A fuzzy controller comprises three basic processes: fuzzification, inference, and defuzzification (Bai and Wang 2006). The fuzzification step involves transforming a crisp dataset into a fuzzy dataset or membership function (MF). The fuzzy inference system (FIS) combines MFs and fuzzy if–then rules to achieve the fuzzy output. The most useful FIS in water resources, Mamdani, Sugeno, and Tsukamoto, differ in aggregation and defuzzification. The defuzzification procedure converts the fuzzy outputs to crips results based on a fuzzy rule-based system. In this study, genfis-2 was applied to develop the FL model, which generates a Sugeno-type FIS structure using subtractive clustering and requires clustering radius as input parameters. The clustering radius was investigated for the range [0.2,0.9] based on trial and error. This parameter determines the number of clusters and fuzzy inference system rules. The smaller radius produces a model with fewer clusters and rules and vice versa (Chiu 1994).
2.3 Adaptive Neuro Fuzzy Inference System (ANFIS)
The ANFIS is a single structure that can capture the benefits of the adaptive neural network and the FIS (Jang 1993). The ANFIS is an AI-based model with a flexible statistical structure that can identify complicated nonlinearity and uncertainties due to vagueness and randomness between variables without trying to achieve an insight into the nature of the events. ANFIS models are based on the Sugeno system. The ANFIS structure utilized here consists of five layers (Fig. 2):
-
Layer 1: Fuzzy Membership, The most frequently applied MFs are: Triangular, Trapezoidal, Gaussian, Two-sided Gaussian, Generalized Bell, and Sigmoidal Z- and S-functions (Nguyen et al. 2002). There is no typical rule to find the optimum number of MFs in the ANFIS model, and the large number of MFS is commonly avoided due to increasing calculation time (Keskin et al. 2006). According to Shiri and Kisi (2011), two, three, or four MFs are enough to predict GWL.
-
Layer 2: Fuzzification, this layer utilizes a fuzzification interface to convert the crisp input dataset into levels of belongingness with linguistic values,
-
Layer 3: Normalization,
-
Layer 4: Defuzzification, converts the fuzzy outputs of the interface to a crisp output, and
-
Layer 5: Output (Jang 1993).
The SC is used in this research to divide an input space into n-subdivided particular areas by evaluating n-dimensional input data to produce clusters. The cluster radius ranging from 0 to 1 optimizes the range of influence from the cluster centroid. The number of clusters and then the number of if–then fuzzy rules increase when the cluster radius is set small since the size of the clusters comes to be small (Chiu 1994). Identifying cluster radius is a critical element in determining the number of clusters. The optimum cluster radius for the ANFIS method in this paper was chosen by the trial and error approach.
2.4 Group Method of Data Handling (GMDH)
Ivakhnenko (1968) proposed GMDH to solve complicated and nonlinear problems. This method generates a self-organizing model (SOM) to solve classification, prediction, and other system questions. The number of neurons, hidden layers, influential input variables, and network framework is necessarily defined in the GMDH model. GMDH as a polynomial neural network is so similar to ANNs. Ivakhnenko (1970) argues that GMDH systems can be called "systems of perceptron type" since the differences between perception and GMDH are not essential. Based Mueller et al. (1998), ANNs, statistical analysis, and statistical neural networks are deductive techniques that cannot detect complicated objects since they require a sizeable amount of a priori info. Instead, GMDH is considered a regression-based technique that combines the best of both neural networks and statistic analysis while embedding the additional fundamental property of induction (Lemke 1997). Hence, GMDH can overcome the shortfalls of ANN, while statistical neural networks can somewhat resolve them. Based on the GMDH, all model structures (e.g., neuron and layer numbers) can be defined by default. Detailed information about the GMDH could be obtained from Nariman-Zadeh et al. (2002).
2.5 Least Square Support Vector Machine (LSSVM)
Fundamental concepts of SVM and its theory have been proposed by Vapnik (1998). The broad overview capability of the SVM is deemed better than ANN because it is on the basis of structural risk minimization, while the ANN uses experimental risk minimization. The primary procedure of the SVM comprises support vectors selections that support the model framework and define their weights. A complete mathematical outline of SVM was proposed by Vapnik (1998). The LSSVM model was established by Suykens and Vandewalle (1999), based on the SVM model. It is a robust technique for resolving function estimation, nonlinear classification, and density estimation problems. LSSVM resolves one of the linear programming problems by adjusting inequality constraints in the SVM method to equality constraints (Kumar and Kar 2009). Furthermore, the LSSVM has faster training and therefore, it is superior to the SVM (Gu et al. 2010).
Various algorithms have been suggested to resolve the dual optimization problem of SVMs. The recent SVM learning algorithm is known as Sequential Minimal Optimization (SMO). SMO utilizes an analytical QP phase (Platt 1999), and as a straightforward algorithm, an SMO is able to instantly resolve the SVM problem without the necessity to use a quadratic optimizer and without any additional matrix space. The SMO was utilized in this study.
The outcome of the LSSVM model depends firmly on the suitable choice of the kernel function and adjusting the correct C and γ parameters. The present study used the polynomial kernel function for the LSSVM model because of its superior results in GWL prediction based on the used dataset in the study area. The trial-and-error procedure was applied to get the optimal parameters of the LSSVM model (Suryanarayana et al. 2014). The LSSVM was applied using LIBSVM library codes presented by Chang and Lin (2011).
3 Study Area
Qazvin Aquifer is situated in the east of Ghazvin province and it is one of the most important aquifers for agricultural purposes in Iran. Due to the absence of a stable river flow in this area, groundwater resources supply water demands for agricultural, domestic, and industrial usage. This caused 1 m drop rating in GWL yearly. Declining GWLs in the Qazvin Aquifer have caused a negative water budget balance of 300 million cubic meters and deteriorating groundwater quality.
The study area map is presented in Fig. 3. The mean annual precipitation and temperature of the study area are 330 mm and 12 °C, respectively, and elevation varies between 1000 and 3000 m above mean sea level.

Location map of the study area
4 Model Development
To predict the GWL for one-, two-, and three-month ahead over Ghazvin Aquifer, monthly GWL, temperature (T), precipitation (P), and evapotranspiration (ET) data were considered. In the present study, GWL changes were explored with an observation well. In this well, the GWL is rising, which is a different behavior related to severe declining groundwater levels in the entire aquifer. The Ghazvin Regional Water Authority issued the monthly groundwater levels for 15 years from 2005 to 2020. A monthly time interval has been deemed as the most appropriate interval for GWL prediction (Nourani and Mousavi 2016a, b). As the most commonly used interval based on previous studies (Rajaee et al. 2019), the monthly GWL interval was used in the present study. To assess the models' potential in predicting the GWL, the dataset was split into training and testing datasets (70% and 30% of total data, respectively).
5 Model Implementation
The input–output dataset undertook a normalization procedure to leave out dimension effects. GWL changes in the Qazvin Aquifer strongly rely on hydro-meteorological changes. Hence, meteorological parameters as an auxiliary dataset along with GWL data were utilized to predict GWL.
Various input combinations were assessed utilizing the predictive variables with various lag intervals from one-month "GWLt-1" to three-month prior "GWLt-3" for GWL prediction with different lead times (one- to three-month ahead). The ideal combinations based on data correlations among the inputs and GWL were used in the present study. The overall correlation analysis revealed that meteorological components followed by the GWL in one, two- and three-month lag times are the most crucial predictors of GWL. According to the correlation analysis, we could add two other combinations with P, T, and ET data in two and three-month lag times. However, the parsimonious principle was also considered in selecting the best combination besides correlation analysis. Increasing the number of model parameters (overparameterization) increased the quality of model fit between observations and simulations, leading to uncertainty in the models. When the number of parameters defined for a given model increases, information from observations is distributed among more parameters. One way to reduce uncertainty is to choose a model that compromises between a low number of parameters and a high level of performance, i.e., a parsimonious model (Hill and Tiedeman 2006; Zare et al. 2011; Samani et al. 2018). In addition, one advantage of finding optimal numbers of input parameters is the computational economy, a decrease in computation time and cost.
According to the above explanations, five combinations implemented in this study are:
-
1.
GWLt-1, GWLt-2, GWLt-3;
-
2.
GWLt-1, GWLt-2, GWLt-3, Tt, ETt, Pt;
-
3.
GWLt-1, GWLt-2, GWLt-3, Tt, ETt, Pt, Pt-1;
-
4.
GWLt-1, GWLt-2, GWLt-3, Tt, ETt, Pt, Pt-1, ETt-1;
-
5.
GWLt-1, GWLt-2, GWLt-3, Tt, ETt, Pt, Pt-1, ETt-1, Tt-1.
GWLt-1, GWLt-2, GWLt-3 are GWLs with various lag times from the one-month "t-1" to three-month "t-3"; Tt, ETt and Pt are the temperature, evapotranspiration and precipitation at the current month and vice versa. The mentioned combinations were employed to achieve the most optimum prediction for every lead time (GWLt+1, GWLt+2, GWLt+3).
6 Efficiency Criteria
Various statistical criteria were utilized to assess the effectiveness of the implemented methods, comprising correlation coefficient (R), Nash–Sutcliffe efficiency (NSE), mean absolute error (MAE), and root means squared error (RMSE). The closer the value of R and NSE to one, the higher the estimation capability of the model will be, and vice versa. The values of MAE and RMSE close to zero indicate better model efficiency.
7 Results and Discussion
7.1 Results of the ANN Model
The structural design of the ANN is a critical stage of the modeling since an improper model's structure can cause under/over-fitting and computational overload problems. Three-layered ANN was considered to predict GWL. Based on different combinations, designed ANN models were trained and then tested to predict GWLt+1, GWLt+2, and GWLt+3. Preliminary findings of the present study showed that one hidden layer was enough to find a relationship between GWL and the other predictor inputs. Overall, a trial and error process was used to define the neuron numbers in the hidden layer. The optimum number of nodes in the hidden layer for input combination five was identified as 6 (Table 2).
The outcomes of the ANN model demonstrate that combination five as input and GWLt+1 as output are reasonable (Table 2). In fact, RMSE and MAE are low, R and NSE are close to 1 for this case. This might be owing to the increasing input variables in combination 5. Performance of ANN deteriorated after 1-month ahead prediction. For the best combination of ANN, FL, ANFIS, GMDH, and LSSVM methods, the scattering curves and time-variation charts were plotted to compare different models (Fig. 4).

The observed and simulated GWL utilizing the ANN (top panel), FL (top middle panel), ANFIS (middle panel), GMDH (bottom middle panel) model and LSSVM (bottom panel) models in the GWLt+1 for the combination 5
7.2 Results of the Fuzzy Logic (FL) Model
FL model was applied for all five combinations to predict GWLs for one-, two- and three-month ahead (Table 2). The range of the radius parameter altered from 0.2 to 0.9 by trial-and-error approach considering minimum RMSE and MAE between observed and simulated GWL. The optimal parameter radius was 0.8 for combinations 1 and 2 and 0.9 for combinations 3, 4 and 5.
The result of the FL models shows that combination 5 indicated high ability in the training step but the model ability was not reasonable in the testing step based on the values of RMSE, MAE, R, and NSE (see Table 2).
7.3 Results of the ANFIS Model
The ANFIS was also employed for the GWL prediction using different input combinations. The structure of the ANFIS was decided based on trial–error for every input combination. Finding optimal cluster radius is an important issue in ANFIS efficiency. Smaller radii produces many small clusters and numerous rules; however, large radii result in a few large clusters in the dataset (having fewer rules) (Sanikhani and Kisi 2012). Table 2 illustrates the evaluation criteria of ANFIS in GWL simulation and prediction. The model with combination five as input and GWLt+1 as output in the training step could present the best results for GWL simulation than other combinations. However, the model ability is not reasonable in the testing step based on RMSE, MAE, R, and NSE (see Table 2).
7.4 Results of the GMDH Model
The GMDH model, as an intelligent tool, showed promising results to predict fluctuations in GWL for one-, two- and three-time horizons. A GMDH model structure with four layers and 15 neurons was considered for GWL prediction. The model results indicated that the model attained the desired outcomes with the fourth layer, ten neurons in the first layer, 15 neurons in the second and third layers, and one in the fourth layer. Table 2 illustrates the evaluation criteria of the GMDH in GWL simulation and prediction. In this method, also combination five was indicated as a suitable input dataset to predict the GWLt+1. Figure 4 displays observed and simulated GWL results produced by the GMDH model.
7.5 Results of the LSSVM Model
Similarly, the LSSVM was likewise used to predict GWL. In this study, trial and error determined the C = [0.2, 1] and γ = 5 as optimum parameters. The polynomial kernel function was chosen to represent the resemblance of vectors in the training dataset in a feature space over polynomials of the initial dataset.
Table 2 shows the MSE, MAE, R, and NSE for various LSSVM structures. This model shows that combination five can achieve accurate and reliable prediction results for one-month ahead GWL. Figure 4 illustrates the observed and simulated GWL using the LSSVM.
7.6 Comparison According to Computational Effort and Run Times
Computational expense is often a significant limitation of real-time prediction systems. Here, we apply ML techniques to predict GWL to replace a computationally intensive physics-based model with the trained ML models. The running times for ANN, FL, ANFIS, GMDH, and LSSVM for the combination one and one-month lead times are 3.47, 1.96, 2.15, 1.35, and 0.28 s, respectively. The results show that LSSVM has a faster estimation speed than the other developed models. Also, the epoch number is an essential factor. An appropriate iteration number can enhance the model performance in both calibration and validation steps and prevent the model from being over-trained. The calibration of different models with different structures and different calibration epoch numbers revealed that 100–200 epochs satisfy all models' calibration.
7.7 Comparison of the Implemented Models
The statistical criteria for the optimum input combination (i.e., combination five) and one-month lead time were assessed to evaluate models' performance and explore the best method. Performance measures of the black-box methods indicated that the values of the evaluation criteria did not vary significantly, and all methods demonstrated satisfactory results in GWL prediction in Qazvin Plain.
A model is supposed to be ideal with the optimized results if the NSE criterion on the estimated values is very close to 1 or the value of NSE is more than 0.8 (Moriasi et al. 2015). Based on Table 2, it is apparent that all methods at the training step provide enough precision for GWL simulation with NSE greater than 0.8. However, the superior performance is seen for the LSSVM model based on NSE values. Based on RMSE and R values, the LSSVM also demonstrates the best precision. In fact, the low RMSE and high R values in the LSSVM represent that the GWL prediction using the LSSVM is precise for the study area.
The models’ accuracy is further compared graphically in Fig. 4 in the form of a time variation graph and scatterplot. From the graphs provided in the first columns, we can see the detailed variation of models’ predictions and observed ones, and the graphs given in the second column show how each models’ predictions are scattering and fit line equations, and R2 values give information about the fitting accuracy of the models. From the hydrographs and scatterplots, it is apparent that the simulations of LSSVM are closely following the observed GWL values and less scattered than the other four models. The deviations between simulations and observed values are clearly seen for the ANN, FL, ANFIS and GMDH models. LSSVM cannot catch some extreme GWL values, and the limited number of samples can explain this since we use monthly time intervals.
Additionally, one of the significant attributes of the applied models in GWL prediction is providing the most important statistics of the observed GWL, i.e., minimum, maximum, mean, median, upper and lower quintiles. In Fig. 5, the box plots are presented for the GWL changes. The chart for one month ahead prediction and combination 2 (Fig. 5a) indicates that the GMDH is consistent with the observed maximum GWL fluctuation.

The observed and predicted GWL results using the five models for the combination 2 in the GWLt+1 (a), GWLt+2 (b), GWLt+3 (c) lead months in the observation well
Likewise, the FL method has the least compatibility. A similar inference can be drawn for the minimum changes of the observed GWL. The results indicate that the GMDH cannot be suitable enough to predict maximum and minimum values for two and three-month ahead GWL. For two and 3-month ahead, the LSSVM outperformed the other methods in predicting the main statistics for combination 2 (Fig. 5b, c).
In brief, the present study indicates the superiority of the LSSVM method to the other methods. However, all models can predict short-term GWL and the higher the number of influential dependent variables, the better the network's performance. These results reinforce the outcomes of the previous studies (Miraki et al. 2019; Mirarabi et al. 2019; Nadiri et al. 2017; Guzman et al. 2019; Natarajan and Sudheer 2020).
8 Conclusions
A well-accepted range of ML models was used to predict GWL with compelling precision in the present study. The methodology assumed that groundwater dynamics are generally dominated by hydrogeological and meteorological factors like monthly groundwater level, precipitation, temperature, and evapotranspiration. The models were trained (calibrated) and tested (verified) using monthly GWL data from Qazvin Aquifer. Different combinations with 3, 6, 7, 8, and 9 antecedent inputs comprising GWLt-1, GWLt-2, GWLt-3, Tt, ETt, Pt, Tt-1, ETt-1, Pt-1 were explored for GWL prediction with different lead times (one to three months ahead). The performances of the various methods were explored through statistical indices (R, RMSE, MAE, and NSE) to recognize the superior method that can simulate the increasing trend of the GWL and provide a reasonable prediction. Four statistical indicators related to predictive efficacy showed that the LSSVM methods had the best precision in the GWL prediction, although all methods can yield convincing results to predict GWL. The findings showed that all the models achieved satisfactory results for one- and two-month ahead GWL. However, three months ahead, the performance of the models was not satisfactory enough. The results also showed that increasing the number of input variables from 3 to 9 considerably increased the accuracy and precision of the model's results. Also, this study shows the ML method's ability to simulate the behavior of a rising GWL in a monitoring well in the urban area of the aquifer while the other parts of the aquifer demonstrate a severe declining GWL.
Availability of Data and Materials
The data, models, and codes generated or used during the study are available from the corresponding author by request.
References
Antonopoulos VZ, Gianniou SK (2022) Analysis and modelling of temperature at the water-atmosphere interface of a lake by energy budget and ANNs models. Environ Process 9(1):1–20
Bai Y, Wang D (2006) Fundamentals of fuzzy logic control—fuzzy sets, fuzzy rules and defuzzifications. In Advanced fuzzy logic technologies in industrial applications (pp. 17–36). Springer, London
Banadkooki FB, Ehteram M, Ahmed AN, Teo FY, Fai CM, Afan HA, El-Shafie A (2020) Enhancement of groundwater-level prediction using an integrated machine learning model optimized by whale algorithm. Nat Resour Res 29(5):3233–3252
Chakraborty S, Maity PK, Das S (2020) Investigation, simulation, identification and prediction of groundwater levels in coastal areas of Purba Midnapur, India, using MODFLOW. Environ Dev Sustain 22(4):3805–3837
Chang CC, Lin CJ (2011) LIBSVM: a library for support vector machines. ACM Trans Intell Syst Technol (TIST) 2(3):1–27
Chiu SL (1994) Fuzzy model identification based on cluster estimation. J Intell Fuzzy Syst 2(3):267–278
Derbela M, Nouiri I (2020) Intelligent approach to predict future groundwater level based on artificial neural networks (ANN). Euro-Mediterranean J Environ Integ, 5(3), 1-11
Ghazi B, Jeihouni E, Kalantari Z (2021) Predicting groundwater level fluctuations under climate change scenarios for Tasuj plain, Iran. Arab J Geosci 14(2):1–12
Gong Y, Zhang Y, Lan S, Wang H (2016) A comparative study of artificial neural networks, support vector machines and adaptive neuro fuzzy inference system for forecasting groundwater levels near Lake Okeechobee, Florida. Water Resour Manage 30(1):375–391
Gu Y, Zhao W, Wu Z (2010) Least squares support vector machine algorithm. J Tsinghua Univ (science and Technology) 7:1063–1066
Guzman SM, Paz JO, Tagert MLM, Mercer AE (2019) Evaluation of seasonally classified inputs for the prediction of daily groundwater levels: NARX networks vs support vector machines. Environ Model Assess 24(2):223–234
Haykin S (2004) Neural networks: a comprehensive foundation. Prentice Hall, New Jersey
Hill MC, Tiedeman CR (2006) Effective groundwater model calibration: with analysis of data, sensitivities, predictions, and uncertainty. John Wiley & Sons
Huang F, Huang J, Jiang SH, Zhou C (2017) Prediction of groundwater levels using evidence of chaos and support vector machine. J Hydroinf 19(4):586–606
Ivakhnenko AG (1968) The group method of data of handling; a rival of the method of stochastic approximation. Soviet Automatic Control 13:43–55
Ivakhnenko AG (1970) Heuristic self-organization in problems of engineering cybernetics. Automatica 6(2):207–219
Jang JS (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23(3):665–685
Kasiviswanathan KS, Saravanan S, Balamurugan M, Saravanan K (2016) Genetic programming based monthly groundwater level forecast models with uncertainty quantification. Model Earth Syst Environ 2(1):27
Keskin ME, Taylan D, Terzi O (2006) Adaptive neural-based fuzzy inference system (ANFIS) approach for modelling hydrological time series. Hydrol Sci J 51(4), 588-598
Khedri A, Kalantari N, Vadiati M (2020) Comparison study of artificial intelligence method for short term groundwater level prediction in the northeast Gachsaran unconfined aquifer. Water Supply 20(3):909–921
Kouziokas GN, Chatzigeorgiou A, Perakis K (2018) Multilayer feed forward models in groundwater level forecasting using meteorological data in public management. Water Resour Manage 32(15):5041–5052
Kumar M, Kar IN (2009) Nonlinear HVAC computations using least square support vector machines. Energy Convers Manage 50(6):1411–1418
Lemke F (1997) Knowledge extraction from data using self-organizing modeling technologies. In Proceedings of the SEAM’97 Conference
Lin L, Li S, Sun S, Yuan Y, Yang M (2020) A novel efcient model for gas compressibility factor based on GMDH network. Flow Meas Instrum 71:101677
Mathworks M (2014) Fuzzy logic toolbox. User’s Guide, The Mathworks, Massachusetts
McGarry KJ, Wermter S, MacIntyre J (1999) Knowledge extraction from radial basis function networks and multilayer perceptrons. In IJCNN’99. International Joint Conference on Neural Networks. Proceedings (Cat. No. 99CH36339) (vol. 4, pp. 2494–2497). IEEE
Miraki S, Zanganeh SH, Chapi K, Singh VP, Shirzadi A, Shahabi H, Pham BT (2019) Mapping groundwater potential using a novel hybrid intelligence approach. Water Resour Manage 33(1):281–302
Mirarabi A, Nassery HR, Nakhaei M, Adamowski J, Akbarzadeh AH, Alijani F (2019) Evaluation of data-driven models (SVR and ANN) for groundwaterlevel prediction in confned and unconfned systems. Environ Earth Sci 78(15):489
Moghaddam HK, Milan SG, Kayhomayoon Z, Azar NA (2021) The prediction of aquifer groundwater level based on spatial clustering approach using machine learning. Environ Monit Assess 193(4):1–20
Mohammadrezapour O, Kisi O, Pourahmad F (2020) Fuzzy c-means and K-means clustering with genetic algorithm for identification of homogeneous regions of groundwater quality. Neural Comput Appl 32(8):3763–3775
Moosavi V, Mahjoobi J, Hayatzadeh M (2021) Combining group method of data handling with signal processing approaches to improve accuracy of groundwater level modeling. Nat Resour Res 30(2):1735–1754
Moriasi DN, Gitau MW, Pai N, Daggupati P (2015) Hydrologic and water quality models: Performance measures and evaluation criteria. Trans ASABE 58(6):1763–1785
Mozaffari S, Javadi S, Moghaddam HK, Randhir TO (2022) Forecasting groundwater levels using a hybrid of support vector regression and particle swarm optimization. Water Resour Manage 1–18
Mueller JA, Ivachnenko AG, Lemke F (1998) GMDH algorithms for complex systems modelling. Math Comput Model Dyn Syst 4(4):275–316
Nadiri AA, Gharekhani M, Khatibi R, Sadeghfam S, Moghaddam AA (2017) Groundwater vulnerability indices conditioned by supervised intelligence committee machine (SICM). Sci Total Environ 574:691–706
Naganna SR, Beyaztas BH, Bokde N, Armanuos AM (2020) On the evaluation of the gradient tree boosting model for groundwater level forecasting. Knowledge-Based Engr and Sci, 1(01), 48-57
Najafzadeh M, Barani GA, Azamathulla HM (2013) GMDH to predict scour depth around a pier in cohesive soils. Appl Ocean Res 40:35–41
Nariman-Zadeh N, Darvizeh A, Darvizeh M, Gharababaei H (2002) Modelling of explosive cutting process of plates using GMDH-type neural network and singular value decomposition. J Mater Process Technol 128(1–3):80–87
Natarajan N, Sudheer C (2020) Groundwater level forecasting using soft computing techniques. Neural Comput Appl 32(12):7691–7708
Nguyen HT, Prasad NR, Walker CL, Walker EA (2002) A first course in fuzzy and neural control. CRC Press
Nourani V, Mousavi S (2016a) Spatiotemporal groundwater level modeling using hybrid artifcial intelligencemeshless method. J Hydrol 536:10–25
Nourani V, Mousavi S (2016b) Spatiotemporal groundwater level modeling using hybrid artificial intelligence-meshless method. J Hydrol 536:10–25
Patel MB, Patel JN, Bhilota UM (2022) Comprehensive modelling of ANN. In Research Anthology on Artificial Neural Network Applications (pp. 31–40). IGI Global
Platt JC (1999) Fast training of support vector machines using sequential minimal optimization, advances in kernel methods. Supp Vect Learn 185–208
Poursaeid M, Poursaeid AH, Shabanlou S (2022) A comparative study of artificial intelligence models and a statistical method for groundwater level prediction. Water Resour Manage 1–21
Rahbar A, Mirarabi A, Nakhaei M, Talkhabi M, Jamali M (2022) A comparative analysis of data-driven models (SVR, ANFIS, and ANNs) for daily Karst spring discharge prediction. Water Resour Manage 1–21
Rajaee T, Ebrahimi H, Nourani V (2019) A review of the artificial intelligence methods in groundwater level modeling. J Hydrol 572:336–351
Razzagh S, Sadeghfam S, Nadiri AA, Busico G, Ntona MM, Kazakis N (2021) Formulation of Shannon entropy model averaging for groundwater level prediction using artificial intelligence models. Int J Environ Sci Technol 1–18
Rezaei M, Mousavi SF, Moridi A, Gordji ME, Karami H (2021) A new hybrid framework based on integration of optimization algorithms and numerical method for estimating monthly groundwater level. Arab J Geosci 14(11):1–15
Roshni T, Jha MK, Deo RC, Vandana A (2019) Development and evaluation of hybrid artificial neural network architectures for modeling spatio-temporal groundwater fluctuations in a complex aquifer system. Water Resour Manage 33(7):2381–2397
Roy DK (2021) Long short-term memory networks to predict one-step ahead reference evapotranspiration in a subtropical climatic zone. Environ Process 8(2):911–941
Sahoo S, Jha MK (2013) Groundwater-level prediction using multiple linear regression and artificial neural network techniques: a comparative assessment. Hydrogeol J 21(8):1865–1887
Sahu RK, Müller J, Park J, Varadharajan C, Arora B, Faybishenko B, Agarwal D (2020) Impact of input feature selection on groundwater level prediction from a multi-layer perceptron neural network. Frontiers in Water, 2, 573034. https://doi.org/10.3389/frwa.2020.573034
Samani S (2021) Analyzing the groundwater resources sustainability management plan in Iran through comparative studies. Groundw Sustain Dev 12:100521
Samani S, Moghaddam AA, Ye M (2018) Investigating the effect of complexity on groundwater flow modeling uncertainty. Stoch Environ Res Risk Assess 32(3):643–659
Sanikhani H, Kisi O (2012) River flow estimation and forecasting by using two different adaptive neuro-fuzzy approaches. Water Resour Manage 26(6):1715–1729
Shiri J, Kisi O (2011) Comparison of genetic programming with neuro-fuzzy systems for predicting short-term water table depth fluctuations. Comput Geosci 37(10):1692–1701
Shiri J, Kisi O, Yoon H, Kazemi MH, Shiri N, Poorrajabali M, Karimi S (2020) Prediction of groundwater level variations in coastal aquifers with tide and rainfall effects using heuristic data driven models. ISH J Hydraul Eng 1–1.
Suryanarayana C, Sudheer C, Mahammood V, Panigrahi BK (2014) An integrated wavelet-support vector machine for groundwater level prediction in Visakhapatnam, India. Neurocomputing 145:324–335
Suykens JA, Vandewalle J (1999) Least squares support vector machine classifiers. Neural Process Lett 9(3):293–300
Tayebi HA, Ghanei M, Aghajani K, Zohrevandi M (2019) Modeling of reactive orange 16 dye removal from aqueous media by mesoporous silica/crosslinked polymer hybrid using RBF, MLP and GMDH neural network models. J Mol Struct 1178:514–523
Vapnik V (1998) The support vector method of function estimation. In Nonlinear modeling (pp. 55-85). Springer, Boston, MA
Wen X, Feng Q, Deo RC, Wu M, Si J (2017) Wavelet analysis–artificial neural network conjunction models for multi-scale monthly groundwater level predicting in an arid inland river basin, northwestern China. Hydrol Res 48(6):1710–1729
Wunsch A, Liesch T, Broda S (2020) Groundwater level forecasting with artificial neural networks: a comparison of LSTM, CNN and NARX. Hydrol Earth Syst Sci Discuss 2020:1–23
Zadeh LA (1995) Fuzzy sets. In Fuzzy sets, fuzzy logic, and fuzzy systems: selected papers by Lotfi A Zadeh (pp. 394–432)
Zare A, Bayat V, Daneshkare A (2011) Forecasting nitrate concentration in groundwater using artificial neural network and linear regression models. Int Agrophys 25(2)
Acknowledgements
The authors acknowledge the Qazvin Regional Water Authority for providing part of the data.
Funding
This research received no specific grant from any funding agency.
Author information
Authors and Affiliations
Contributions
S.Smani and M. Vadiati analyzed and interpreted data and contributed to writing the manuscript. E.Zamani and Farahnaz Azizi collected data and contributed to drafting manuscript preparation. O.Kisi was involved in revising the manuscript critically for important intellectual content. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics Approval
Not applicable because this article does not contain any studies with human or animal subjects.
Consent to Participate
Not applicable.
Consent to Publish
We, the undersigned, give us consent to publish identifiable details, including text, figures, and tables in the water resource management journal.
Competing Interests
The authors declare that they have no competing interests.
Conflict of Interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Samani, S., Vadiati, M., Azizi, F. et al. Groundwater Level Simulation Using Soft Computing Methods with Emphasis on Major Meteorological Components. Water Resour Manage 36, 3627–3647 (2022). https://doi.org/10.1007/s11269-022-03217-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-022-03217-x