
Abstract
In this study, two different clustering algorithms, fuzzy c-means (FCM) and K-means with genetic algorithm, were used to identify the homogeneous regions in terms of groundwater water quality. For this purpose, data of 14 hydrochemical parameters from 108 wells were sampled in 2016, Golestan province, northeast of Iran. The results showed that the optimal clusters of the K-means and FCM were 5 and 6, respectively. The evaluation of water quality by FCM for drinking uses showed that in terms of total dissolved solid (TDS) and chlorine (Cl) parameters, cluster 3 was in an unfavorable condition. Moreover, according to the K-means algorithm, cluster 1 was in inappropriate condition in terms of the TDS and Cl. Water quality assessment by FCM for agricultural use showed that in general, cluster 3 was not in a good condition, especially for the electrical conductivity (EC) parameter. Also, according to the K-means, in general, cluster 1 had an inappropriate state for the EC and sodium adsorption ratio parameters. Investigating the hydrochemical facies of clusters using the FCM and K-means showed that in the northern half of the Golestan province, most samples are Cl–Na and in the southern half, most of the samples are HCO3–Ca. In general, by comparing the results of clustering algorithms, it was found that the FCM algorithm has better results than the K-means clustering algorithm, mainly due to consideration of uncertainty conditions in determining the class boundary.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Iran is a country with an arid and semiarid climate and relatively scant annual precipitation so that its average annual rainfall is less than one-third of the world’s. Groundwater resources in Iran and many other countries with similar climate are the most important sources of water used in agricultural and drinking purposes, so preserving the quality control of these waters is of great significance for both humans and other living organisms [1]. Due to its biological nature, agriculture is the largest consumer of water resources in many countries [2]. Moreover, the increasing rates of pollution of groundwater which are the results of human activities, such as overusing of nitrate fertilizers in agriculture, development of industrial activities, and releasing more domestic sewage, all have devastated the groundwater quality. Therefore, as the most significant issues, contamination and degradation of groundwater have doubled the problems of water scarcity in most modern societies. Since the quantity and quality of groundwater are affected by environmental factors, controlling water quality for human and other living uses is crucial. So far, a great number of studies have been done on the quality of the underground water supplies and their classification for drinking and agricultural purposes. Although the impact of groundwater from the surrounding environment is likely less than that of surface water, research has shown that along with these surface resources, the quantity and quality of groundwater are also affected by environmental factors, and even in some cases, these are more severe and here to stay. Some affecting factors are pollution of drinking water and its consequent poisoning [3]. A number of scholars, e.g., James [4], Palamuleni [5], Msonda et al. [6], Farooqi et al. [7], Kaonga et al. [8], Makkasap and Atapanajaru [9], Srinivasamoorthy et al. [10], Mumtaz et al. [11], have already studied and evaluated this issue.
Therefore, identifying the quality and quantity of groundwater as one of the most important and most vulnerable sources of water supply in recent decades is quite essential [12]. On the other hand, failure to properly understand or recognize the extent of groundwater rapid vulnerability may leave severe pollution in these resources [13]. It is also impossible to manage these resources optimally without having being thoroughly aware of their nature. Identifying the qualitative properties of groundwater, i.e., its physical, chemical, and biological characteristics, determines the type of water usage. The methods used for assessing the quality of water resources and detecting the most appropriate locations specialized for drinking and farming are among the issues that are applicably of great importance.
The best way to study the qualitative and quantitative status of groundwater is to simulate the aquifer using computer and mathematical models, which is often difficult and timely to calibrate and simulate, because a great quantity of data are required [14, 15] Another challenge in managing water resources in terms of the groundwater is the large extent and dispersion of available information which in turn practically makes the analysis of classical assessment methods limited, time-consuming, and costly, and the result analysis is with difficulty. Also, most of the methods used in underground water quality studies are graphical methods that provide the results of the analysis of water samples by various diagrams.
One drawback of these methods is the number of samples and variables. On the other hand, none of the graphical methods can differentiate the groups and test their similarities. Thus, researchers have recently used clustering, a subset of data mining, as a powerful tool for data management to increase strength, and enhance decision making. Clustering is an uncontrolled learning method for categorizing data based on their perceptions. This technique is a powerful tool for extracting the underlying structure of data sets [16]. Many researchers including Williams [17], Farnham et al. [18], Guler et al. [19], Hajalilou and Khaleghi [20], Edet et al. [21] have used cluster analysis to classify the qualitative data of water. Clustering methods are classified into two types: (1) hard or classical methods in which each element belongs to one group only, that is, the clusters do not overlap, and (2) Soft or fuzzy methods where each element with different degrees of membership belongs to all clusters [22]. However, physical and chemical properties of natural systems often change, not abruptly but continuously. Due to this continuity, statistical clusters cannot be a good separator and require forming a sequence of overlapping clusters [19, 23]. The main purpose of the clustering method, whether deterministic or fuzzy, is to divide a series of data with n samples and p variables into c homogeneous subgroup through precise categorization of the samples related to these specific clusters, so that the members of each cluster will have similar characteristics. In the clustering methods, the number and type of criteria are not fixed; hence, it has been attempted to achieve the optimum state by changing them. Since physical and chemical properties in natural systems are constantly changing, the classical statistical clusters cannot be good separators, so overlapping is inevitable in cluster sequences.
Fuzzy clustering explores the fuzzy nature available in data. Fuzzy logic was first introduced by Zadeh in 1965 [24] and converted many inaccurate and ambiguous concepts, variables, and systems into mathematical formulation. One of the most widely used methods for solving clustering problems is fuzzy c-means (FCM) method [25]. In this way, proper grounds are provided for reasoning, inference, control, and decision making while dealing with uncertainty. Various algorithms have been also suggested for fuzzy and non-fuzzy clustering by various researchers [25]. In non-phase clustering, each sample belongs only to a single cluster, while in fuzzy clustering, each sample belongs to a series of clusters with different degrees of membership. Identification of homogeneous regions in terms of groundwater quality in Golestan province of northern Iran using fuzzy and K-means clustering methods combining genetic algorithm was performed.
Numerous studies have been conducted on using fuzzy clustering methods in investigating the quality of groundwater. For example, in order to study the content of soil pollutants in ocean sediments, Chang and Chang [26] applied the classical cluster analysis (K-means) and FCM for the data set. Their research results showed that the fuzzy clustering provides acceptable results due to the uncertain boundaries between the clusters and the overlap between the classes. Likewise, Guler and Thyne [22] examined the distribution of groundwater hydrochemistry facies in the southeastern California region using FCM and hierarchical clustering analysis (HCA). The results also represented that both FCM and HCA methods could be used for the identification of physical and chemical processes, mainly due to the chemical changes in the groundwater, but FCM priority over HCA has led to a more effective distribution of chemical facies.
Tutmez et al. [27] conducted a research on groundwater EC modeling using a neuro-fuzzy inference system. The results revealed that clustering methods for grouping groundwater based on pollution parameters were acceptable. Later, Guler et al. [28] evaluated the impact of human activities on the hydro-geochemical characteristics of groundwater in the Tarsus coastal plain, Turkey, using multivariate statistical methods, fuzzy clustering, and GIS techniques. The results of fuzzy clustering showed the groundwater samples in four different classes, which were internalized using the ordinary Kriging method. Sivasankar et al. [29] evaluated fuzzy clustering of groundwater quality parameters in the Rameswaram area in southern India, and the results showed that seasonal changes from summer to winter caused fluctuations in the quality parameters of groundwater in both samples and clusters. Goyal and Gupta [23] also identified a homogeneous rainfall regime in the northeastern region of India using the fuzzy clustering method. The findings showed that the FCM method was much better than K-means to identify such homogeneous regions. Pourjabbar et al. [30] also investigated the hierarchical fuzzy clustering method for the data contaminated with heavy metals released from a mine in Germany. The research results showed that fuzzy algorithm is a promising tool for analyzing and interpreting geological and hydrogeological data, which own inherent ambiguities and uncertainties. Zou [31] conducted a research on groundwater quality analysis using the K-means algorithm in Haihe River, China. The results revealed that both theoretical method and simulation algorithm are effective ways for analyzing the water quality of the river. In addition, the K-means algorithm was used for the matrix of more complex, high-dimensional data. Caniani et al. [32] conducted an experiment on the hierarchical classification of the groundwater pollution using fuzzy logic in Basilicata, Italy. The results also showed that the fuzzy logic is a useful and objective tool for environmental planning. Orkavalan et al. [33] evaluated groundwater quality using cluster analysis in Erode region, Tamilnadu, India. They focused on the determination of physical–chemical parameters and examined by WHO standards. Based on the literature, the most of these experiments, the graphical methods are based on Horton’s methods and the results are presented using diagrams such as Schuler, Piper, and the like. Because of the limitations of these methods in terms of the number of samples, the complexity of structure and their determinism, using multivariate statistical methods such as cluster analysis to determine the homogeneity of the groundwater, is qualitatively reasonable. In the clustering methods, the number and type of criteria are not fixed; hence, it has been attempted to achieve the optimum state by changing them. Various algorithms have been also suggested for fuzzy and non-fuzzy clustering by various researchers. In non-phase clustering, each sample belongs only to a single cluster, while in fuzzy clustering, each sample belongs to a series of clusters with different degrees of membership. Therefore, the aim of this study was to apply two clustering methods, namely K-means and fuzzy c-means, in determining homogeneous regions in terms of water quality in both deterministic and fuzzy states, to evaluate the quality of the classified areas for drinking and farming and their hydrochemical facies, and to identify the most critical areas in Golestan province which is one of the most important agricultural areas in northern Iran.
2 Materials and methods
2.1 Study area and data
Golestan province is situated in the geographic location from 54° to 56°E longitudes and from 36°30′ to 38°15′N latitudes, between the provinces of Mazandaran, Semnan, and Northern Khorasan, Iran. The province, with an area of 204.607 km2, accounts for 33.1% of the total area of the country. Due to its geographic location, Golestan has a variety of climates. A part of the eastern part of the Alborz mountain range stretching from the west to the east of the province has a great tendency toward the northeast, and the altitude of its mountains is gradually decreasing. At the base of these heights, especially in the south and east of the province, there are plains composed of subtropical deposits of fine grains and coarse grains with abundant groundwater aquifers beneath which can be exploited in the form of wells and aqueducts. A large part of the Golestan province is in the form of plains with two types of weather.
More than two-thirds of this plain have arid and semiarid weather, which goes up to the north and to the border of Iran–Turkmenistan. Another one-third area which is located as a green band across the south and the arid and semi-arid areas in the north has a moderate climate and is highly cultivated. Most towns and villages of the province are also located in this green area. In terms of agriculture, it is considered as one of the most productive parts of the country, mostly irrigated by the surface waters and the underground water resources. Therefore, it is important to study the quality of groundwater in this area.
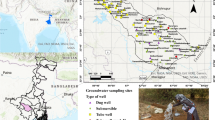
In order to identify homogeneous regions in terms of groundwater quality in Golestan province, 14 qualitative parameters of groundwater which were within the study scope (including Ca, Mg, K, Th, SO4, EC, TDS, Cl, Hco3, Anion, pH, SAR, Kation, and Na) collected from 108 wells in 2016 were selected. The location of the wells is shown in Fig. 1. These wells are located in the cities of Gorgan, Gonbad, Agh Ghala, Galikesh, Azadshahr, Kalaleh, Daland, Kordkoi, Bandar Gaz, and Ali Abad.

Location of sample wells in Golestan province aquifer
In Table 1, mean, maximum, minimum, and standard deviations of the data used in this study are presented. In order to study the homogeneous regions, the groundwater quality in Golestan province which has a matrix including the number of wells and hydrochemical parameters was used as a model entry to the K-means and FCM clustering algorithms for classifying the samples in homogeneous groups. In clustering methods, the number of clusters should be given to the model and the number of optimum clusters should be determined with trial and error, but in this study, the optimal number of clusters was determined utilizing genetic algorithm in both methods. After calculating the optimal number of clusters, homogeneous regions were zoned in terms of quality using ArcGis 10.2 software. The Levene homogeneity test was also used to compare the degree of homogeneity between the K-means and FCM. In order to determine the quality of clusters for agricultural and drinking purposes, the means of these parameters of center groups were compared with those of the Schuler and Wilcox classification. Also, Piper’s diagram was used to show the hydrochemical facies of the classes.
2.2 Clustering methods
2.2.1 K-means algorithm
One of the commonly used clustering algorithms is K-means algorithm, which is also a partitioning technique. This algorithm was first introduced in 1967 by MacQueen [34]. In this algorithm, the center C is randomly defined for each cluster. Next, any data belonging to the input dataset are linked to the closest center. When there are no data to check, the first phase is over. Then, new centers for the masses obtained from the previous phase are recalculated. After that, a connection is established between the data of each set and the nearest center. C replaces its position at any time until no more change occurs in its place. In this case, the algorithm comes to its end [34]. The objective function of the K-means method is expressed to cluster the set of objects X into C clusters (Eq. 1) in which the clustering process of this objective function is minimized.
where \( \Vert x_{i} - v_{j} \Vert^{2} \) calculates the distance between data \( x_{i} \) of the center cluster \( v_{j} \) and usually uses Euclidean distance based on Eq. (2):
The center of the jth mass is calculated by Eq. (3):
where Ni is the number of members of the set Ai and Ai is the members of the ith cluster.
The problem with K-means is that it is trapped in the local optimum points. The solutions obtained from this algorithm depend on the selected points or centers of the problematic cluster. That is, if proper centers are selected for early clusters, good clustering is achieved. Moreover, the initial number of clusters should also be specified. The results also depend on the initial cluster centers so that it is not possible to expect optimal and thorough investigation in the clustering states. To deal with this problem, genetic algorithm is used in which the objective function is the mean average silhouette width that is one of the criteria used for evaluating the K-means algorithm.
2.2.2 Average silhouette width index
The silhouette width is comparable for any given standard data, and it indicates whether it is better to remain in its own cluster or to move to another cluster [34]. The silhouette width for the ith data in the cluster k is equal to:
where Ii is the mean of the ith distance to all the kth cluster data and Oi is the minimum distance between the ith data and the other clusters. (The distance between data and a cluster that does not belong to them shows the mean distance of the data to all data of that cluster.) Therefore, the value of SWi ranges between + 1 and 1. The closer the SWi to + 1, the more accurate the ith data of the cluster. Accordingly, the average silhouette width will be the average of all silhouettes. Moreover, an optimal clustering is optimal and has a maximum mean silhouette width [35]. In this study, first, the optimal number of clusters is determined using the genetic algorithm whose target function is the average silhouette width, and then, the K-means algorithm was used to identify the homogeneous regions.
2.2.3 Fuzzy C-means clustering algorithm
The FCM algorithm, proposed by Dunn [36] and Bezdek [25], is widely used for regional frequency analysis [37]. The FCM that is a modified form of the K-means method works mainly based on the fuzzy logic in which the discussion of the membership function and the membership of a sample is presented in several clusters. One of the most important assumptions in this method is that the total membership degree of each sample in the whole cluster should be equal to 1.
where c is the number of clusters and uik is the degree of sample membership in the ith cluster.
By assuming the n sample and measuring the element m for them, the following algorithm must be followed to divide the samples into a c cluster with a known center:
- 1.
First, for each sample/cluster ratio, a random membership degree is assigned.
- 2.
Second, by using the initial membership degree and the coordinates of the center of the clusters, it is necessary to calculate the coordinates of the new center of the clusters from Eq. (6):
$$ v_{ij} = \frac{{\sum\nolimits_{k = 1}^{n} {u_{ik}^{q} x_{kj} } }}{{\sum\nolimits_{k = 1}^{n} {u_{ik}^{q} } }} $$(6)where vij is the ith changing value from the center of the jth cluster, uik is the degree of membership of kth sample to ith cluster, and xkj is the value of the jth variable in the kth sample. q is the fuzzy amount in the jth variable in the kth sample which is known as fuzziness coefficient. In the case of q, there is no definite theory, but it is considered to be somewhere between 1.3 and 3 [38].
- 3.
After calculating new cluster centers, it is necessary to measure the degree of membership of each sample to the center of each cluster. It is done based on one of the distance measurement methods and according to Eq. (7). The Euclidean distance is also used here.
$$ u_{ik} = \frac{{\left( {d_{ik}^{2} } \right)^{{{\raise0.7ex\hbox{${ - 1}$} \!\mathord{\left/ {\vphantom {{ - 1} {q - 1}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${q - 1}$}}}} }}{{\sum\nolimits_{k = 1}^{c} {\left( {d_{ik}^{2} } \right)^{{{\raise0.7ex\hbox{${ - 1}$} \!\mathord{\left/ {\vphantom {{ - 1} {\left( {q - 1} \right)}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\left( {q - 1} \right)}$}}}} } }} $$(7)where dik is the distance between the kth sample and the center of the ith cluster. The Euclidean distance is calculated based on Eq. (2).
- 4.
Using Eq. (8), the objective function of the variable j is obtained in an environment where the fuzzy coefficient is q:
$$ J = \mathop \sum \limits_{i = 1}^{c} \mathop \sum \limits_{k = 1}^{n} u_{ik }^{q} d_{ik}^{2} = \mathop \sum \limits_{i = 1}^{c} \mathop \sum \limits_{k = 1}^{n} u_{ik }^{q} \Vert x_{k} - v_{i}\Vert^{2} $$(8) - 5.
Repeat calculations until the distance between the calculated target functions is lower than the predetermined critical value (↖) in two successive stages, i.e., between 10−5 and 10−3 [37].
In this method, first, three variables of c (number of classes), q (fuzziness coefficient), and ↖ (critical value) are predefined.
One of the disadvantages of FCM method is its inability to deal with noisy data (data in which the belonging value to both clusters is same). Also, the number of clusters and cluster centers must also be specified by the user. The quality of this method is heavily dependent on the number of early clusters and the initial location of cluster centers. If the problem has a minimum value, the FCM will work fine, but in case of several local minima, based on the centers initially determined, they converge to the nearest minimum and allow trapping in the local minima. Therefore, if the initial answer is near the overall minimal, it will converge to the desired solution [39]. To solve this problem, the combination of multi-objective genetic algorithms for clustering, described in Wikaisuksakul [40], is considered as one of the most commonly used optimization techniques in problem-solving process. In this research, the combination of genetic algorithm and FCM is used as a two-objective function.
The first objective function, presented in Eq. (8), that indicates intra-class compression is the FCM function itself, and another objective function that optimizes cluster dispersion is shown in Eq. (9).
The flowchart used for the genetic algorithm and the FCM is shown in Fig. 2.

The flowchart used for the genetic algorithm and the FCM
3 Results
3.1 Optimal number of clusters with FCM and K-means algorithms
As previously mentioned, unlike the previous studies which were determined by trial and errors, the optimal number of clusters in both K-means and FCM was determined using the genetic algorithm and based on what was already stated in the section of Materials and methods. The parameters used in the genetic algorithm in the FCM model include selection by using a tournament, a one-point combination method, and a one-point mutation method. The selection operation is implemented using a random roulette generator on the fitness value of a population’s chromosomes. The optimal number of the obtained clusters and the number of wells in each cluster recorded for both algorithms in 2016 are shown in Table 2. Also, the convergence diagram of the models with their number of repetitions is shown in Fig. 3.

The convergence diagram of the algorithms with optimal repetitions for the FCM algorithm
As shown in Table 2, the number of clusters in the two algorithms is not same, and the optimal number of clusters in the FCM is 6, and in the K-means, it is 5.
3.2 Clustering results
Given the clustering of K-means algorithm based on the silhouette width index as well as on the FCM clustering, the average values of the hydrochemical parameters of groundwater in the study area in 2016 are presented in Table 3.
The distribution of samples in each cluster according to the qualitative parameter classification by each algorithm is shown in Fig. 4.

Zoning of hydrochemical parameters from average cluster center values for the studied algorithms
As shown in Fig. 4, the zoning of the quality parameters in some regions in the K-means algorithm is quite different from that of the FCM. For example, in the K-means algorithm, the areas of Gorgan, Ali Abad Katoul, Bandar Gaz, and Kordkoi are in the same class, but in the FCM model, these areas are separated in some classes. For example, Kordkoi and Bandar Gaz are placed in one class and Ali Abad and Gorgan are in other classes. It was also inferred that in K-mean classification, changes in class boundaries are quite clear and abrupt, but in FCM, due to considering uncertainties used in determining the borders of the classes, changes occur gradually.
3.3 Comparison of homogeneity in the studied algorithms
To check the homogeneity of the classifiable data by the fuzzy (FCM) and the definite (K-means) algorithms, the Levene homogeneity test was used in R software. The results of the homogeneity test are shown in Table 4 and Figs. 5 and 6.

Box diagram for class meanings and samples for FCM and K-means algorithms

Elliptic diagram for classes of FCM and K-means algorithms
As shown in the table of the means of the variances, the mean square error of the fuzzy model (0.0000392) is less than that of the K-mean model (0.0000412) indicating that the homogeneity of the classes in the FCM is more than in the K-means algorithm as shown in Figs. 5 and 6 as well.
Considering the results presented in Figs. 5 and 6, it can be inferred that due to significance of uncertainties in determining the class boundaries, the fuzzy method has better results than the K-means clustering algorithm. Investigating the quality parameters of groundwater in the study area was done in terms of drinking and farming, and determining the hydrocarbon facies was set in the deterministic and the fuzzy states.
3.4 Analysis of hydrochemical parameters for drinking purpose
In Fig. 7, based on the mean values of the hydrochemical parameters of the ground water, the Schuler diagrams are obtained from the cluster centers. They are prepared for the FCM and K-means algorithms.

Schuler diagram for the FCM and K-means (silhouette width index) based on cluster center values
3.4.1 FCM algorithm for drinking purpose
Based on the Schuler diagram illustrated in Fig. 7 and Table 3, in terms of drinking, the water hardness is only optimal in cluster 1 and in the other 5 clusters, it is acceptable. Accordingly, the amount of sulfur ions in all clusters is optimal. TDS means total soluble solids in water which are equal to the total concentration of all the ions in water, and the TDS amount (500 mg/l) is desirable for drinking water. According to the Schuler diagram, cluster 3 is in an inappropriate level, cluster 4 is good, and clusters 1, 2, 5, and 6 have acceptable quality. Since the number of samples in the cluster 3 is small, it can be inferred that the majority of the regions have acceptable quality standards for drinking. Water-soluble salts are usually cations and anions. The salty taste of the water is due to high concentration of chloride ion. Moreover, any significant increase in chlorine concentration of water is a sign of its potential contamination. According to Table 3 and its comparison with the Schuler diagram, the chlorine content is only unsuitable in cluster 3 and the remaining clusters are of good quality. In general, by examining the results using the fuzzy model, it can be concluded that cluster 3 is not suitable for drinking in terms of TDS and chlorine. According to Fig. 3, cluster 3 involves the cities of Kalaleh, Bandar Gaz, Azad Shahr, and Agh Ghala and generally the northern parts of the province which mostly covers agricultural areas.
3.4.2 K-means algorithm for drinking purpose
Based on the Schuler diagram, the hardness of the water is moderate in cluster 1 and in the other four clusters, it is acceptable for drinking. The amount of sulfate in cluster 1 is within the acceptable limits for drinking and in other four clusters, it is good. The amount of TDS in cluster 1 is within the acceptable limits, and in other four clusters, it is also good for drinking. The amount of chlorine in cluster 1 is within the medium range, in cluster 2, it is in an acceptable level, and in the other three clusters, it is within the good range for drinking. In general, it can be inferred that, in the definite condition, cluster 1 has an inappropriate state in terms of TDS and chlorine and involves the cities of Gonbad, Agh Ghala, and Daland.
3.5 Analysis of hydrochemical parameters for agricultural purpose
Based on the mean values of the hydrochemical parameters of the ground water, the Wilcox charts are obtained from the cluster centers (Fig. 8). They were prepared for the FCM and K-means algorithms.

Wilcox diagram for the FCM and K-means means (silhouette width index) based on cluster centers values
3.5.1 FCM algorithm for agricultural purpose
Water-soluble solids, presented in the compounds of the water, are measured by electrical conductivity (EC). According to Table 3 and the Wilcox quality classification, the EC value only in cluster 3 has a poor agricultural quality and the rest of the clusters are of good quality. The sodium absorption ratio (SAR) is an important factor in determining the suitability of water for agricultural purposes. The higher the sodium absorption ratio, the better the water is for irrigation. As shown in Table 3, the SAR content in all clusters is within good level and only Class 3 range is located near the acceptable area. In general, cluster 3 has not an acceptable limit in terms of agriculture, especially regarding the EC parameter. These conditions are observed in the cities of Kalaleh, Bandar Gaz, Azad Shahr, Agh Ghala, and Bandar Turkmen, and mostly in the northern province, which includes the most agricultural areas.
3.5.2 K-means algorithm for agricultural purpose
The EC in cluster 1 is within an unacceptable range, in clusters 2, 3, and 4, it is within the medium range, and in cluster 4, it is in an acceptable level. The SAR value in cluster 1 is within acceptable limits, and in the rest of the clusters, it is in good range. In general, it can be said that, in a definite state, cluster 1 has an inappropriate state in terms of EC and SAR parameters covering the cities of Gonbad, Agh Ghala, and Daland. Also, except the limited areas of Gorgan, Ali Abad, and Bandar Gaz, and all southwestern parts of the province, other regions of the province are exposed to salinity.
3.6 Determination of hydrochemical facies
In this research, the Piper diagram is used as the main chart in determining the hydrochemical facies (Fig. 9). In the Piper diagram, simultaneous comparison of many samples of groundwater quality is possible in the form of relative concentrations. The Piper chart can be used as an essential indicator for measuring the performance of clustering techniques.

Piper diagram of the studied clustering algorithms
3.6.1 Hydrochemical facies using FCM algorithm
To compare the chemical composition of each group based on the mean of the chemical values of the cluster centers, the Piper diagram is provided in which the facies of the groups are specified. According to Table 3, it is evident that the total concentration of solutes in Class 1 is 645 mg/l. Also, according to the Piper diagrams (Fig. 9), it is indicated for groundwater samples that the main anions include sulfate (25.24%), chlorine (35.48%), and bicarbonate (39.28%), the main cations are calcium (24.25%), magnesium (12.4%), and sodium and potassium (63.35%), and the dominant type of the most samples is Na–HCO3.
In Class 2, the total concentration of salts is 728.9 mg/l. Also, the main anions are sulfate (11.69%), bicarbonate (16.37%), and chlorine (71.93%), the main cations are calcium (15.96%), magnesium (9.55%), and sodium and potassium (74.79%), and the most samples are Na–Cl.
In Class 3, the soluble concentration is 1793 mg/l. Also, according to the Piper diagrams, it is indicated for the groundwater samples that the main anions are sulfate (11.76%), chlorine (71.8%), and bicarbonate (16.45%), the main cations are calcium (15.8%), magnesium (9.55%), sodium (73.95%), and potassium (0.7%), and the most of the samples are Na–Cl.
In Class 4, the main cations are calcium (49.9%), magnesium (24.09%), and sodium and potassium (26.16%). Also, the main anions are chlorine (15.47%), sulfate (19.59%), and bicarbonate (64.96%), and the concentration of soluble salts is 473.9 mg/l, and the most of the samples are HCO3–Ca.
In Class 5, the concentration of soluble salt is 682 mg/l. The main anions are chlorine (29.25%), sulfate (24.9%), and bicarbonate (45.85%), the main cations are calcium 13.91%, magnesium (6.14%), sodium and potassium (79.95%), and the original type of the most samples is Na–HCO3.
In Class 6, the soluble salt concentration is 507 mg/l. Further, according to the Piper diagrams, it is indicated for ground water samples that the main anions are sulfate (24.29%), chlorine (22.83%), and bicarbonate (52.27%), the main cations are calcium (38.25%), magnesium (21.41%), sodium and potassium (40.24%), and the most of the samples are HCO3–Na.
3.6.2 Hydrochemical facies using K-means algorithm
The Piper diagram was provided to compare the chemical composition of each group based on the average chemical composition of the groups in a definite state. In this graph (Fig. 9), the facies of the groups are specified. According to Table 3, it is clear that the total concentration of salt in Class 1 is 2000 mg/l. Also, according to the Piper diagrams, it is indicated for the groundwater samples that the main anions are sulfate (13.18%), chlorine (73.58%), and bicarbonate (13.24%), the main cations are calcium (15.7%), magnesium (9.47%), and sodium and potassium (74.83%), and the most of the samples are Na–Cl.
In Class 2, the total concentration of salt is 841 mg/l. Also, the main anions are sulfate (18.68%), bicarbonate (40.67%), and chlorine (42.18%), the main cations are calcium (18.6%), magnesium (10.74%), and sodium and potassium (70.66%), and the most samples are Na–Cl.
In Class 3, the soluble salt concentration is 545 mg/l. Also, according to the Piper diagrams, the main anions are sulfate (27.2%), chlorine (24.37%), and bicarbonate (48.43%), the main cations are calcium 32.08%, magnesium 17%, and sodium and potassium 50.92%, and the most of the samples are Na–HCO3.
In Class 4, the main cations are calcium (47.38%), magnesium (23.47%), and sodium and potassium (29.15%), the main anions are chlorine (21.93%), sulfate (22.58%), and bicarbonate (55.49%), and the concentration of soluble salt is 582 mg/l, and the most of the samples are Na–HCO3.
In Class 5, the concentration of soluble salt is 442 mg/l. The main anions are chlorine (13.07%), sulfate (28.20%), and bicarbonate (58.73%), the main cations are calcium (47.03%), magnesium (25.91%), and sodium and potassium (27.06%), and the main type of the most sample is HCO3–Ca.
4 Discussion
The evaluation of water quality for drinking uses in the FCM algorithm showed that in terms of TDS and chlorine parameters, cluster 3 is in an unfavorable condition. This cluster included the cities of Kalaleh, Bandar Gaz, Azad Shahr, and Agh Ghala in general the northern province, which includes the most agricultural areas. Moreover, in the K-means algorithm, cluster 1 was in inappropriate condition in terms of the TDS and chlorine parameters and was dominant in the cities of Gonbad, Agh Ghala, and Daland. Water quality assessment for agricultural use in the FCM model showed that in general, cluster 3, especially the EC parameter, was not in a good condition. These conditions were observable in the cities of Kalaleh, Bandar Gaz, Azad Shahr, Agh Ghala, and Bandar Turkmen. Also, in the K-means algorithm, and in general, it can be inferred that in a definite state, cluster 1, having an inappropriate state for the EC and SAR parameters, included the cities of Gonbad, Agh Ghala, and Daland. Likewise, except for areas of Gorgan, Ali Abad, and Bandar Gaz, and all southwestern parts of the province, other regions were exposed to salinity. Investigating the hydrochemical facies of clusters using the FCM and K-mean algorithms showed that in the northern half of the Golestan province, the most samples were in the two Cl–Na and in the southern half, the most of the samples were HCO3–Ca, whereas in the FCM algorithm, within the range of the cities of Gorgan and Aliabad, in the 6th class, the dominant type of the most samples was Na–HCO3. Of course, its content is not critical in current conditions, but measures should be taken to prevent the risk of getting sodiumized.
5 Conclusion
Iran is one of the countries with low rainfall, and its average annual precipitation is less than one-third of the world’s annual rainfall. The methods used for assessing the quality of groundwater resources and identifying appropriate harvesting opportunities for drinking and farming are issues that are really important in terms of applicability. Golestan province is one of the important agricultural areas in northern Iran. Therefore, the most groundwater resources of the region are affected by pollution from agricultural waste caused by pesticides and chemical fertilizers, as well as domestic and industrial wastewater. In this study, two methods of FCM and K-means were used to identify the homogeneous regions in terms of water quality. Also, the areas were studied for drinking and agricultural purposes, and the hydrochemical facies and the most critical areas were identified. For this purpose, the data of 14 hydrochemical parameters of 108 wells were sampled in 2016, and the mean values were used as inputs to the FCM and K-means. MATLAB software was used to run the clustering algorithms. In order to identify homogeneous regions using FCM and K-means algorithms, the number of optimum clusters was first needed to be determined. Therefore, in this research, a genetic algorithm was used to determine the optimal number of clusters. These optimal numbers were obtained as 5 and 6 for the K-means, FCM algorithms, respectively. For comparing the cluster homogeneity obtained by two algorithms, the Levene test via R software was used. The results showed that the clusters obtained from the FCM model were more homogeneous than those of the K-means algorithm. A better understanding of the position of the classes determined by the both algorithms of class mapping schemes was obtained in ArcGIS software. Changes in the class boundaries of the K-means classifications were found to be quite clear and abrupt, but the FCM, they were gradual, mainly because of the uncertainties available in determining the class boundary. In general, by comparing the results of clustering algorithms, it was found that the FCM algorithm has better results than the K-means clustering algorithm, mainly due to consideration of uncertainty conditions in determining the class boundary. It was also observed that fuzzy clustering method is a suitable way for assessing the quality of groundwater resources. One of the advantages of using fuzzy clustering in spatial distribution modeling is that the data structures and inter-relationships are identified, so they can be used to address the constraints and problems encountered in other methods. Some of such pitfalls are entropy of data, non-homogeneity of data, and impact of different environmental processes on spatial distribution. If resolved, it can provide a more accurate modeling of the problem. Therefore, in areas of high magnitude where the output of the traditional methods is less accurate, mainly because of the limited scrolling points and the high distance between them, applying this method can be used for data generation.
References
Bricker OP, Jones BF (1995) Main factors affecting the composition of natural waters. In: Salbu B, Steinnes E (eds) Trace elements in natural waters. CRC Press, Boca Raton
Mohammadrezapour O, Yoosefdoost I, Ebrahimi M (2017) Cuckoo optimization algorithm in optimal water allocation and crop planning under various weather conditions (case study: Qazvin plain, Iran). Neural Comput Appl. https://doi.org/10.1007/s00521-017-3160-z
Kathy P (2005) Water recreation and disease acute plausibility of associated infections: effects, sequelae and mortality. World Health Organization, Geneva
James CS (1999) Analytical chemistry of foods. Springer, New York, pp 136–140
Palamuleni LG (2002) Effect of sanitation facilities, domestic solid waste disposal and hygiene practices on water quality in Malawi’s urban poor areas: a case study of South Lunzu Township in the city of Blantyre. Phys Chem Earth 27(11–22):845–850
Msonda KWM, Masamba WRL, Fabiano E (2007) A study of fluoride groundwater occurrence in Nathenje, Lilongwe, Malawi. Phys Chem Earth 32(15–18):1178–1184
Farooqi A, Masuda H, Firdous N (2007) Toxic fluoride and arsenic contaminated groundwater in the Lahore and Kasur districts, Punjab, Pakistan and possible contaminant sources. Environ Pollut 145(3):839–849
Kaonga CC, Chiotha SS, Monjerezi M, Fabiano E, Henry EM (2008) Levels of cadmium, manganese and lead in water and algae; Spirogyra aequinoctialis. Int J Environ Sci Technol 5(4):471–478
Makkasap T, Satapanajaru T (2010) Spatial distribution of Cd, Zn and Hg in groundwater at Rayong province. World Academy of Science Engineering and Technology, Istanbul, p 72
Srinivasa KD, Nagesh Kumar D (2011) Classification of micro watersheds based on morphological characteristics. Hydro-environ Res 5:101–109
Mumtaz R, Baig S, Kazmi SSA et al (2018) Delineation of groundwater prospective resources by exploiting geo-spatial decision-making techniques for the Kingdom of Saudi Arabia. Neural Comput Appl. https://doi.org/10.1007/s00521-018-3370-z
Rizzo DM, Mouser JM (2000) Evaluation of geostatistics for combined hydrochemistry and microbial community fingerprinting at a waste disposal site. In: Critical transitions in water and environmental resources management. World water and environmental resources congress 2004, pp 1–11
Thapinta A, Hudak P (2003) Use of geographic information systems for assessing groundwater pollution potential by pesticides in Central Thailand. Environ Int J 29:87–93
Pisinaras V, Petalas C, Tsihrintzis VA, Zagana E (2007) A groundwater flow model for water resources management in the Ismarida plain, North Greece. Environ Model Assess 12:75–89
Rojas R, Dassargues A (2007) Groundwater flow modelling of the regional aquifer of the Pampa del Tamarugal, northern Chile. Hydrogeol J 15:537–551
Valente JO, Pedrycz W (2007) Advances in fuzzy clustering and its applications. Wiley, England, p 434
Williiams R (1982) Statistical identification of hydraulic connections between the surface of a mountain and internal mineral mineralized zones. Ground Water 20:466–478
Farnham IK, Stetzenbach A, Singh JK (2000) Deciphering groundwater flow systems in Oasis Valley, Nevada, using trace element geochemistry, multivariate statistics, and geographical information system. Math Geol 32:943–968
Güler C, Thyne GD, McCray JE, Turner KA (2002) Evaluation of graphical and multivariate statistical methods for classification of water chemistry data. Hydrogeol J 10(4):455–474
Hajalilou B, Khaleghi F (2009) Investigation of hydrogeochemical factors and groundwater quality assessment in Marand Municipality, northwest of Iran: a multivariate statistical approach. J Food Agric Environ 7(3–4):930–937
Edet A, Nganje Tn AJ, Ukpong AJ, Ekwere AS (2011) Groundwater chemistry and quality of Nigeria: a status review. Afr J Environ Sci Technol 5(13):1152–1169
Guler C, Thyne GD (2004) Delineation of hydrochemical facies distribution in a regional groundwater system by means of fuzzy c-means clustering. Water Resour Res 40:W12503. https://doi.org/10.1029/2004WR003299
Goyal MK, Gupta V (2014) Identification of homogeneous rainfall regimes in northeast region of India using fuzzy cluster analysis. Water Resour Manag 28:4491–4511
Zadeh LA (1965) Fuzzy sets. Inf Control 8:338–353
Bezdek JC (1981) Pattern recognition with fuzzy objective algorithms. Plenum Press, New York
Chang YC, Chang B (2003) Applying fuzzy cluster method for marine environmental monitoring data analysis. Environ Inf Arch 1:114–124
Tutmez B, Hatipoglu Z, Kaymak U (2006) Modelling electrical conductivity of groundwater using an adaptive neuro-fuzzy inference system. Comput Geosci 23(4):421–433
Guler C, Kurt M, Alpasalan M, Akbulut C (2012) Assessment of the impact of anthropogenic activities on the groundwater hydrology and chemistry in Tarsus coastal plain (Mersin, SE Turkey) using fuzzy clustering, multivariate statistics and GIS techniques. J Hydrol 414(415):435–451
Sivasankar V, Kameswari M, Msagati TAM, Venkarapathy M, Senthil Kumar M (2013) Fuzzy set approach—a tool to cluster Holy samples of groundwater quality parameters at Rameswaram South India. J Water Resour Ocean Sci 2(3):33–39
Pourjabbar A, Sarbu C, Kostarelos K, Einax J, Buchel G (2014) Fuzzy hierarchical cross-clustering of data from abandoned mine site contaminated with heavy metals. Comput Geosci 72:122–133
Zou H, Zou Z, Wang X (2015) An enhanced K-means algorithm for water quality analysis of the Haihe River in China. Int J Environ Res Public Health 12(11):14400–14413
Caniani D, Esposito G, Gori R, Mannina G (2015) Toward a new decision support system for design, management and operation of wastewater treatment plants for the reduction of greenhouse gases emission. Water 7(10):5599–5616
Orkavalan G, Madurai Chidambaram S, Mariappan V, Kandaswammy G, Natarjana S (2016) Cluster analysis to assess groundwater quality in Erode District, Tamil Nadu, India. Circuits Syst 7(6):877–890
MacQueen J (1967) Some methods for classification and analysis of multivariate observations. In: Proceedings of the 5th Berkeley symposium on mathematical statistics and probability, pp 92–97
Rousseeuw PJ (1987) Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J Comput Appl Math 20:53–65
Dunn JC (1974) A fuzzy relative ISODATA process and its use in detecting compact well-separated clusters. J Cybern 3:32–57
Rao AR, Srinivas VV (2006) Regionalization of watersheds by fuzzy cluster analysis. J Hydrol 1(4):57–79
Bezdek JC, Ehrlich R, Full W (1984) FCM: the fuzzy c-means Clustering algorithm. Comput Geosci 10(2–3):191–203
Bezdek JC, Chuah SK, Leep D (1986) Generalized K-nearest neighbor rules. Fuzzy Sets Syst 18(3):237–256
Wikaisuksakul S (2014) A multi-objective genetic algorithm with fuzzy c-means for automatic data clustering. Appl Soft Comput 24:679–691
Acknowledgements
This research was supported by university of Zabol. Omolbani Mohammadrezapour would like to thank the University of Zabol for financing this project (Grant number: UOZ-GR- 9517-33).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declared that they have no conflict of interest.
Rights and permissions
About this article

Cite this article
Mohammadrezapour, O., Kisi, O. & Pourahmad, F. Fuzzy c-means and K-means clustering with genetic algorithm for identification of homogeneous regions of groundwater quality. Neural Comput & Applic 32, 3763–3775 (2020). https://doi.org/10.1007/s00521-018-3768-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-018-3768-7