
Abstract
In this paper, a class of new Magnus-type methods is proposed for non-commutative Itô stochastic differential equations (SDEs) with semi-linear drift term and semi-linear diffusion terms, based on Magnus expansion for non-commutative linear SDEs. We construct a Magnus-type Euler method, a Magnus-type Milstein method and a Magnus-type Derivative-free method, and give the mean-square convergence analysis of these methods. Numerical tests are carried out to present the efficiency of the proposed methods compared with the corresponding underlying methods and the specific performance of the simulation Itô integral algorithms is investigated.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
It is now generally accepted that stochastic differential equations (SDEs) can describe some problems more accurately than deterministic differential equations. For example, input data may be uncertain or systems may be subject to internal or external random fluctuations. It is often difficult to obtain explicit expressions of exact solutions for SDEs and so numerical methods become an important tool to provide good approximations.
In this paper, our main focus is the numerical approximations of the semilinear Itô SDEs
where Wj(t), j = 1,…,m, are independent Wiener processes on a complete probability space \(({\varOmega }, \mathcal {F}, \mathbb {P})\) with a filtration \(\left \{\mathcal {F}_{t}\right \}_{t>0}\) satisfying the usual conditions. Here gj: \( \mathbb {R}^{d} \rightarrow \mathbb {R}^{d}\), j = 1,…,m, are nonlinear functions of y and \(A_{j} \in \mathbb {R}^{d \times d}\), j = 0,…,m, are constant matrices. The random initial value satisfies \(\mathbb {E}\left \|y_{0}\right \|^{2}<\infty \) and \(\mathbb {E}\) is the expectation.
Numerical integrators for (1) in the sense of Itô and Stratonovich are thoroughly studied in [1] based on the stochastic Runge–Kutta Lawson methods under the following commutative conditions
where [A,B] = AB − BA is called the Lie-product or matrix commutator of A and B. Under this commutative condition, Euler and Milstein versions of exponential methods are investigated in [2], and the strong convergence analysis of these two methods is given. Their numerical results show that these exponential methods are more effective than the corresponding underlying methods. Under similar commutative conditions, Yang, Burrage and Ding [3] investigate (1) in the sense of Stratonovich and construct structure-preserving stochastic exponential Runge–Kutta methods to the case of time independent matrix A0 = A(t), Ak = 0, k = 1,…,m. There is also some interesting work on the exact solution and the corresponding numerical solution under the commutative condition where A0 is a constant matrix and Ak = 0, k = 1,…,m. For example, an exponential Euler method is constructed for the stiff problem and it is applied to solve an ion channel model in [4]. A class of weak second-order exponential Runge–Kutta methods is investigated for non-commutative SDEs in [5].
It is worth noting that when the commutative condition is not established, even the solution of the linear system cannot be expressed explicitly. We know that Magnus gave the deterministic Magnus expansion [6] in 1954, which expresses the solution as an exponential infinite matrix series. This topic has been further studied in [7,8,9]. In recent years, the Magnus-type expansion for SDEs has attracted an increasing number of researchers. The Magnus expansion for linear autonomous Stratonovich SDEs was derived by Burrage and Burrage [10]. They compare the truncated Magnus expansion with stochastic Runge–Kutta methods with the same convergence order and concluded that the Magnus expansion enjoys a considerably smaller error coefficient. The authors of [11] consider the Magnus expansion for the linear and nonlinear Stratonovich SDEs and the convergence analysis is given based on binary rooted trees. In [12] a new explicit Magnus expansion is applied to solve a class of Stratonovich SDEs and the authors show that the Magnus expansion can preserve the positivity of the solution. A new version of Magnus expansion for linear Itô SDEs is derived in [13] and the authors have analyzed the convergence of the Magnus expansion and applied it to solve semi-discrete stochastic partial differential equations (SPDEs). In [14], for SPDEs driven by multiplicative noise, the authors first use the finite element method to discretize space, and then construct a Magnus-type method in the time direction.
We have to say that when the commutative condition is not established, the corresponding theoretical results on exponential numerical methods for the corresponding semi-linear problem are sparse. This is the motivation for us to consider a new class of Magnus-type integrators for the semi-linear problem (1).
The structure of this paper is organized as follows. In Section 2, we will give a brief review of the use of the Magnus formula in both linear non-autonomous ordinary differential equations (ODEs) and linear SDEs. In Section 3, we will derive a new class of Magnus-type integrators for the semi-linear problem (1) by the application of the Magnus expansion for linear non-commutative SDEs. In Section 4, we will give the results of the mean-square convergence analysis of the Magnus-type methods proposed in Section 3. In Section 5, we will compare three algorithms for simulating iterated Itô integrals and some details of numerical implementation will be presented on low-dimensional SDEs and a high-dimensional SDE obtained from a discretized SPDE, which illustrate the efficacy of Magnus-type methods.
2 Magnus formula
In this section we will briefly review the Magnus formula in both a linear deterministic setting and a linear stochastic setting.
2.1 Magnus formula for linear non-autonomous ODEs
Consider the non-autonomous linear initial value problem
This problem is investigated in [6] where the d × d matrix A(t) is non-commutative. The solution is given in the form
where \({\varOmega }\left (0,t\right )\) is the combination of integrals and nested Lie brackets of A, i.e.,
For this problem, the Magnus expansion has received some attention in the past few decades, see [15].
2.2 Magnus formula for linear SDEs
We consider autonomous linear SDE given by
where W0(t) = t. The d ×d matrices Aj are constant and I is the identity d ×d-matrix. When the commutative condition (2) is satisfied, the exact solution of (5) can be expressed explicitly by
where \(\gamma ^{\ast }=\frac {1}{2}\). When the commutative condition is not established, the solution of (5) cannot be expressed explicitly. The solution to (5) is given in the form \(Y(t)=\exp ({\varOmega }(0,t))I\) by Kamm and his coauthors [13] in the Itô setting. Here we apply the relationship between Itô and Stratonovich integrals [17] to obtain the expansion of the Itô case through Ω(0,t) given by Burrage and Burrage [10] in the Stratonovich setting,
where \(\hat {A}_{0}=A_{0}-\gamma ^{\ast }{\sum }_{j=1}^{m}{A_{j}^{2}}\) and \(\hat {A}_{j}=A_{j},~j\geq 1\). In the rest of this paper, we denote the iterated Itô integral as
The relationship between Itô and Stratonovich integrals [17] is
where l(α) is the length of the index α and IA is the indicator function, i.e., IA = 1 if A is true, otherwise IA = 0. The expansion (6) can also be obtained through the expansion rules in [13] and the convergence of the Magnus expansion for (5) is given by the following lemma.
Lemma 1
[13] LetA0,A1,…,Am be constant matrices. For T > 0 let \(Y=\left (Y({t})\right )_{t \in [0, T]}\) be the solution to (5) in the Itô case. There exists a strictly positive stopping time τ ≤ T such that:
-
(i)
Y (t) has a real logarithm \({\varOmega }(0,t) \in \mathbb {R}^{\mathrm {d\times d}}\) up to time τ, i.e.,
$$ Y({t})=e^{{\varOmega}(0,t)}, \quad 0 \leq t<\tau; $$ -
(ii)
the following representation holds \(\mathbb {P}\)-almost surely:
$$ {\varOmega}(0,t)={\sum}_{n=0}^{\infty} {\varOmega}^{[n]}(0,t), \quad 0 \leq t<\tau, $$where Ω[n](0,t) is the n th term in the stochastic Magnus expansion (6);
-
(iii)
there exists a positive constant C, only dependent on \(\left \|A_{0}\right \|, \ldots ,~\left \|A_{m}\right \|,~T\) and d, such that
$$ \mathbb{P}(\tau \leq t) \leq C t, \quad t \in[0, T]. $$
3 A class of new Magnus-type methods for semi-linear SDEs
We shall now derive Magnus-type methods of mean-square order 1/2 and 1.0 for semi-linear SDEs (1). Throughout this paper, consider a partition t0 = 0 < t1 < ⋯ < tN = T of the interval [0,T] with constant step size h = tj − tj− 1, j = 1,⋯ ,N, and let yn be the approximation of exact solution. To make sure of the existence of the unique solution of (1), we first give the following important result.
Theorem 1
[16] There exists a constant L > 0 such that the global Lipschitz condition holds: for \(y,~z\in \mathbb {R}^{d},\)
Then there exists a unique solution y(t) to (1).
Here we only require the Lipschitz condition as the linear growth condition
is automatically satisfied from the Lipschitz condition in the autonomous case, see [18].
For the semi-linear Itô SDEs (1), we assume that the exact solution has the form
where Y (t) is the solution of the linear equation (5), and \(\tilde {y}(t)\) is to be determined. Using the Itô chain rule to y(t), we have
Comparing this with (1) shows that (8) is a solution of (1) if and only if
So, \(\mathrm {d}\tilde {y}\) has the form
Since
then we get
where \(\tilde {g}_{0}=g_{0}-{\sum }_{j=1}^{m}A_{j}g_{j}\).
It needs to be said that this transformation is also applicable to the case where the Aj(t) depend on time t, that is, the non-autonomous case, but this paper focuses on the case of (1). Numerical methods will be derived by using this form. Different approximations to the integrals in the above equation will yield different numerical schemes, and we will consider Magnus-type Euler (ME) and Magnus-type Milstein (MM) methods.
3.1 Magnus-type Euler method
If the integrals in (10) are approximated as follows
where \({{\varOmega }}^{[1]}(t_{n},t_{n+1})= {\sum }_{j=0}^{m} {\hat {A}}_{j} {\int \limits }_{t_{n}}^{t_{n+1}}\mathrm {d}W_{j},\) ΔWjn = Wj(tn+ 1) − Wj(tn), j ≥ 1, ΔW0n = tn+ 1 − tn, the following ME method is obtained,
In particular, when gj = 0, j ≥ 1, and if
is selected instead of \(\exp ({{\varOmega }}^{[1]}(t_{n},t_{n+1}))\), the resulting numerical scheme is mean-square 1 order convergent, which is actually a special case of the MM methods that we will give below. Next, we choose a higher order approximation for the diffusion terms, and then we obtain the MM method.
3.2 Magnus-type Milstein method
Note that \(\hat {Y}(t)=\exp \left (-{\varOmega }\left (t_{n}, t\right )\right )\) is the solution of the following linear Itô SDE,
Applying the Itô–Taylor theorem to the stochastic integral
Then we obtain the MM scheme
where
As a particular example, we apply the MM method to solve the damped nonlinear Kubo oscillator (21) in Section 5 with m = 2, ω0 = ω1 = ω2 = 1, β0 = − 1, β1 = − 1/2, β2 = 0 and α = 0. It is
where
As seen above, the disadvantage of the MM method is that a large number of derivatives and matrix operations need to be calculated for each step as the number of the nonlinear noise terms increases, which greatly reduces the efficiency of the method. From this point, it is natural to think of a Magnus-type Derivative-free (MDF) method, that is, use finite differences instead of these derivatives.
3.3 Magnus-type Derivative-free method
The MDF method can be derived from the MM method by replacing these derivatives with finite differences,
where
We obtain the MDF method
where \(\hat {\mathbf {H}}_{jl}=g_{j}(Y_{l})-g_{j}(y_{n})+(\exp (-A_{l}\sqrt {h})-I)g_{j} (y_{n}).\)
4 Convergence analysis
In this section we will give the mean-square convergence results for both the ME method and the MM method. From [19], we review the following fundamental convergence theorem of one-step numerical methods.
Lemma 2
Suppose that the one-step approximation yt+h has order of accuracy p1 for the mathematical expectation of the deviation and order of accuracy p2 for the mean-square deviation; more precisely, for arbitrary t0 ≤ t ≤ T − h, \(y(t)=y\in \mathbb {R}^{d}\) the following inequalities hold:
with p2 ≥ 1/2, p1 ≥ p2 + 1/2, i.e., the approximation is consistent in the mean order p1 and in the mean-square order p2. Then for any N and k = 0,1,...,N the following inequality holds:
i.e., the method is convergent of order p2 − 1/2 in the sense of mean-square.
The following theorems show the convergence results of the Magnus-type method. We suppose that the coefficients of (1) satisfy the linear growth condition and the global Lipschitz condition. We also assume uniformly bounded derivatives up to order 2 for the MM method and MDF method. Let y(tn + h) be the exact evaluation of (1) at tn+ 1 starting from y(tn) = yn. We will estimate the p1, p2 for the Magnus-type method satisfying
Theorem 2
Let yn be an approximation to the solution of (1) using the ME method. Then for any N and k = 0,1,...,N the following inequality holds:
i.e., the ME method is convergent of order 1/2 in the sense of mean-square.
Proof
For the ME method, it can be readily shown that
where
For term P1, since \(\exp ({\varOmega }(t_{n},t_{n+1}))y_{n}\) is the solution of (5), we can easily find
For P2, adding and subtracting \(\exp ({\varOmega }(t_{n},t_{n+1})){\int \limits }_{t_{n}}^{t_{n+1}}\tilde {g}_{0}(y_{n})\mathrm {d}s\) give
we can easily find
For P3, adding and subtracting \(\exp ({\varOmega }({t_{n},t_{n+1}})){\int \limits }_{t_{n}}^{t_{n+1}}{g}_{j}(y_{n})\mathrm {d}W_{j}(s)\) gives
Similar to term P2, we can get
With (15), (16) and (17), we have p1 = 2, p2 = 1. From Lemma 2, we know that the ME method is of mean-square order 0.5. □
For the MM methods, we can obtain the following convergence results.
Theorem 3
Let yn be an approximation to the solution of (1) using the MM method. Then for any N and k = 0,1,...,N the following inequality holds:
i.e., the MM method is convergent of order 1 in the sense of mean-square.
Proof
For the MM method, through direct calculation, we find
where
For term P1, since \(\exp ({\varOmega }({t_{n},t_{n+1}}))y_{n}\) is the solution of (5), we can easily see through an Itô-Taylor expansion
For P2, adding and subtracting \(\exp ({\varOmega }({t_{n},t_{n+1}})){\int \limits }_{t_{n}}^{t_{n+1}}\tilde {g}_{0}(y_{n})\mathrm {d}s,\) we have
and
For term P3, since
where
we have
which gives
From (18), (19) and (20), p1 = 2, p2 = 3/2. Hence by Lemma 2, we see that the MM method is of mean-square order 1. □
The following theorem describes the convergence of the MDF method. The proof is analogous to that of Theorem 3 and we omit it.
Theorem 4
Let yn be an approximation to the solution of (1) using the MDF method. Then for any N and k = 0,1,...,N the following inequality holds:
Thus the MDF method is convergent of order 1 in the sense of mean-square.
5 Implementation and numerical tests
Using the Milstein or MM method to generate numerical approximations, the iterated integrals (7) are included in the numerical scheme. For i = j, there is such a relationship \(I_{i i}\left (t_{n}, t_{n}+h\right )=\frac {1}{2}(({\varDelta } W_{in})^{2}-h)\). For i≠j, this issue has been fully described in [20, 21] and [22] by Kuznetsov and Wiktorsson from a different perspective, respectively. Both of them expand the iterated integrals (7) into infinite series, and then truncate the infinite series to approximate the iterated integrals. A brief overview is given in the Appendix.
To compare the convergence rate of the truncated series, for different step sizes and m = 2, we respectively give the minimum truncated terms indices qw, qt, qp of the Wiktorsson’s algorithm, Kuznetsov’s algorithm with the orthonormal system of trigonometric functions and Legendre polynomials in Table 1. We can see that Wiktorsson’s algorithm requires smaller truncated indices to achieve the mean square error \(O\left (h^{3}\right )\), especially for a smaller step size h, which also means that Wiktorsson’s algorithm needs to simulate fewer random variables.
In order to show the specific performance of the three algorithms, for the integral I21, choosing h = 2− 6, the mean \((\mathbb {E}(I_{21})=0)\) and standard deviation \(((\mathbb {E}(I_{21})^{2})^{1/2}=h/\sqrt {2}\approx 0.01105)\) are calculated in Table 2 with 2000 samples. Their mean and standard deviation are almost in the same range. At the same time, the numerical tests in the next will also show that using Kuznetsov and Wiktorsson algorithms in practical implementation can give almost the same simulation results for different step size.
For the rest of this section, the performances of the introduced Magnus-type methods are presented and then compared with classical stochastic methods, namely the Euler–Maruyama method and the Milstein method. For convenience, let M (W) denote the mean-square order 1.0 Milstein method, where the iterated Itô integrals are simulated by Wiktorsson’s algorithm. Let M (Kt) and M (Kp) denote the mean-square order 1.0 Milstein method, where the iterated Itô integrals are simulated by Kuznetsov’s algorithm with the orthonormal system of trigonometric functions and Legendre polynomials, respectively. This shorthand notation also applies to the MM method and the MDF method.
To present the performance of Wiktorsson’s and Kuznetsov’s algorithms for the iterated Itô integrals, we will compare the number of random variables required by Wiktorsson’s and Kuznetsov’s algorithms in each iteration as a measure of computational effort. The exponential function needs to be calculated during the implementation of the numerical algorithm, which is not the subject of this article, so we compare the time required by Wiktorsson’s and Kuznetsov’s algorithms to generate random variables as a measure of the efficiency. In all numerical simulations, we choose the minimum truncation number.
5.1 Damped nonlinear Kubo oscillator
As a first numerical test, we consider the damped nonlinear Kubo oscillator
with \(g_{j}: \mathbb {R}^{2} \rightarrow \mathbb {R}\), where t ∈ [0,T] and \(\omega _{j},~\beta _{j}\in \mathbb {R}\). This problem is investigated in [24] with βj = 0. We also let m = 2 and
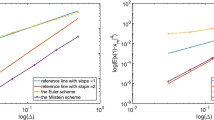
Since we do not know the exact solution of (21), the reference solution is produced by the Milstein method with a small step h = 2− 19. Set the parameters ω0 = 2, ω1 = 0.5, ω2 = 0.2,β0 = − 0.5, β1 = − 0.2, β2 = − 0.1 and initial value y0 = (1,1). The mean-square convergence order of ME method, MM method and MDF method is presented in Fig. 1. Here, the mean-square error
is calculated at the time T = 1 for a set of increasing time steps h = 2i, i = − 11, …, − 2. As some of the lines are on the top of each other, we use separate figures to show the performance of Wiktorsson’s and Kuznetsov’s algorithms in Fig. 1. From Fig. 1a, we can see that the Magnus-type methods enjoy considerably smaller error coefficient compared to the Euler–Maruyama method and the Milstein method and the performance of the three simulations of the iterated Itô integral is similar. It can be seen from Fig. 2a that when the step size is large (i.e., the error is large), Wiktorsson’s and Kuznetsov’s algorithms perform similarly in terms of calculation time. As the step size becomes smaller (i.e., the error becomes smaller), Wiktorsson’s algorithm performs better, as it can be seen in (b) that the number of random variables that need to be simulated at each step of Wiktorsson’s algorithm is less. In addition, Kuznetsov’s algorithm with polynomial functions is slightly better than Kuznetsov’s algorithm with trigonometric functions in terms of calculation time and the number of random variables that need to be simulated at each step. The increment for different steps is given by

a The convergence rate of the ME method, MM method and MDF method for solving (21) with \(g_{0}(y(t))=\frac {1}{5}\left (y_{1}+y_{2}\right )^{5}\), g1(y(t)) = 0 and \(g_{2}(y(t))=\frac {1}{3}\left (y_{1}+y_{2}\right )^{3}\). b Kuznetsov’s algorithms with the orthonormal system of trigonometric functions. c Kuznetsov’s algorithms with the orthonormal system of Legendre polynomials. d Wiktorsson’s algorithm

Comparison of Wiktorsson’s and Kuznetsov’s algorithm in average computing time and number of random variables at each step for (21) with a set of increasing time steps h = 2i, i = − 11, …, − 2. a Average computing time. b Number of random variables at each step
5.2 SDE with linear non-commutative noise
We consider the following SDE [2] in \(\mathbb {R}^{4},\) with
where r = 4, \(\quad \mathbf {F}(y)=(F_{1},F_{2},F_{3},F_{4}), \quad F_{j}=\frac {y_{j}}{1+\left |y_{j}\right |},~j=1,~2,~3,~4,\) and initial value y(0) = y0. dW(t) = (dW1(t),dW2(t),dW3(t),dW4(t)). Here A0 takes the form
which usually comes from a discrete Laplacian operator. Consider the following non-commutative noise
Then, we have
Simulations with α = 0.5, β = 1 and y0 = (1,1,1,1)⊤ are carried out until the time T = 1 with a set of increasing time steps h = 2i, i = − 11, …, − 3. The mean-square convergence order of the ME method and the MM method is presented in Fig. 3. In each case 2000 samples are generated as before. Here, the reference solution is produced by the Milstein method with the step h = 2− 16. Figure 3 compares the cases for r = 4, α = 0.8, β = 1 in (a) and compares the cases for r = 4, α = 2, β = 0.1 in (b). We see that the case r = 4, α = 0.8, β = 1 enjoys a smaller error than the mildly stiff case r = 4, α = 2, β = 0.1. Figure 4a shows that Wiktorsson’s and Kuznetsov’s algorithms perform similarly in terms of calculation time. This is because the truncation index of Wiktorsson’s algorithm is related to m, so when m and the step size are both large, Kuznetsov’s algorithm is a sensible choice. In addition, Kuznetsov’s algorithm with polynomial functions is also slightly better than Kuznetsov’s algorithm with trigonometric functions in terms of calculation time and the number of random variables that need to be simulated at each step for m = 4. As the step size decreases, Wiktorsson’s algorithm has obvious advantages in the number of random variables at each step.

The convergence rate of the ME method and the MM method for solving (22) with m = 4 in a r = 4, α = 0.8, β = 1 and in b r = 4, α = 2, β = 0.1

Comparison of the algorithms in computing time and number of random variables at each step with a set of increasing time steps h = 2i, i = − 11, …, − 3. Here r = 4, α = 0.8 and β = 1. a Average computing time. b Number of random variables at each step
5.3 Stochastic Manakov equation
In order to confirm the performance of the methods for high-dimensional SDEs, we consider the stochastic Manakov system
where \(u=u(t, x)=\left (u_{1}, u_{2}\right )\in \mathbb {C}^{2}\) with \(t \geqslant 0\) and \(x \in \mathbb {R}\). The symbol ∘ means that the stochastic integrals are established in the sense of Stratonovich and \(\gamma \geqslant 0\) is the noise intensity. Here \(|u|^{2}u=\left (\left |u_{1}\right |^{2}+\left |u_{2}\right |^{2}\right )u\) is the nonlinear term, and σ1,σ2 and σ3 are the Pauli matrices taking the form
The stochastic Manakov system (23) is usually used to describe pulse propagation in randomly birefringent optical fibers. The existence and uniqueness of the solution have been obtained in [25]. The equivalent Itô form is
where \(C_{\gamma }=\mathrm {i}+\frac {3 \gamma }{2}\). Applying the central finite-difference scheme to discretize the space interval by N + 2 uniform points
we get the non-commutative SDE
with
where
and the matrices A0, A1, A2 and A3 are defined by
First, we set a = 20, h = 0.001 and Δx = 2/5 to simulate (23) with the MM method on the time interval [0,3]. The evolution of \(\left |u_{1}\right |^{2}\) and \(\left |u_{2}\right |^{2}\) is given in Fig. 5. We can see that the results of the MM method show the energy exchange due to stochastic noise and nonlinearity. These results are similar to the structure-preserving method in [26].

Space-time evolution of the intensity of the first component (left) and the second component (right)
Then, simulations with a = 50 and Δx = 2/5 are carried out until the time T = 1/2 with a set of increasing time steps h = 2i, i = − 13, …, − 7. The mean-square convergence order of the ME method and the MM method is presented in Fig. 6. In each case 500 samples are generated. Here, the reference solution is produced by the Milstein method with the step h = 2− 16. In Fig. 7, (a) shows that Wiktorsson’s and Kuznetsov’s algorithms perform similarly in terms of calculation time. Wiktorsson’s algorithms is better than Kuznetsov’s algorithms in terms of calculation time and the number of random variables that need to be simulated in each step. This is because as the step size decreases, the number of noise terms m has less impact on the truncation index of Wiktorsson’s algorithm. In addition, as the step size decreases, the difference between Kuznetsov’s algorithm with polynomial functions and Kuznetsov’s algorithm with trigonometric functions is not significant.

The convergence rate of the ME and the MM method with a = 50 and Δx = 2/5, T = 1/2 and a set of increasing time steps h = 2i, i = − 13, …, − 7

Comparison of the algorithms in computing time and number of random variables at each step with a set of increasing time steps h = 2i, i = − 13, …, − 7. Here a = 50, Δx = 2/5 and T = 1/2. a Average computing time. b Number of random variables at each step
Remark 1
Here we use the built-in expmdemo2 function in Matlab to calculate \(\exp ({\varOmega }^{[1]}(t_{n},t_{n+1}))\) and \(\exp ({\varOmega }^{[2]}(t_{n},t_{n+1}))\) using a Taylor series. For such high-dimensional problems, each path requires considerable computational time. Although the calculation of exponential function is not the subject of this article, the application of efficient techniques (such as Krylov subspace methods) will have a significant impact on the Magnus-type methods to address very high-dimensional semilinear SDEs.
Remark 2
In the high-dimensional problem (25), we choose mildly stiff matrices A0 as opposed to the nonlinear term. When the stiffness is very strong, our methods require a small step size. For this type of stiff high-dimensional complex-valued SDEs, the combination of the SROCK methods [27, 28] and the Magnus method will be an interesting work that we will consider in future work.
Remark 3
With the specific performance in the above three test examples, we see that for the simulation of iterated Itô integrals, when the step size is large and the number of noise terms is large, Kuznetsov’s algorithm with polynomial functions is superior, and when the step size is smaller, Wiktorsson’s algorithm is better.
6 Conclusion
We have derived Magnus-type methods, based on Magnus expansion for non-commutative linear SDEs, for noncommutative Itô stochastic differential equations with semi-linear drift term and semi-linear diffusion terms. By truncating the Magnus series, the ME method, the MM method and the MDF method have been constructed. We have investigated the mean-square convergence of these methods and shown the same mean-square convergent order as the corresponding method, that is, the ME method is order 0.5, and the MM and MDF method is order 1.0. Then, we have compared two types of algorithms for simulating iterated Itô integrals. Numerical tests have been carried out to present the efficiency of the proposed methods for low-dimensional SDEs and a high-dimensional SDE from discretized SPDE.
Finally, we should make the following remarks. We can apply our methods to non-autonomous semi-linear SDEs, where we only need to truncate the non-autonomous Magnus expansion. However, the linear stability analysis of numerical methods for high-dimensional stochastic differential equations with non-commutative noises is quite complicated, especially for complex coefficient matrices. The mean-square stability analysis of Magnus-type methods for such problems is a motivation for future work. In addition, weak convergence Magnus methods will be a good choice to avoid simulating iterated stochastic integrals.
References
Debrabant, K., Kværnø, A., Mattsson, N.C.: Runge–Kutta Lawson schemes for stochastic differential equations. arXiv:1909.11629 (2019)
Erdoǧan, U., Lord, G.J.: A new class of exponential integrators for SDEs with multiplicative noise. IMA J. Numer. Anal. 39, 820–846 (2019)
Yang, G., Burrage, K., Ding, X.: A new class of structure-preserving stochastic exponential Runge–Kutta integrators for stochastic differential equations. (Submitted)
Komori, Y., Burrage, K.: A stochastic exponential Euler scheme for simulation of stiff biochemical reaction systems. BIT Numer Math. 54, 1067–1085 (2014)
Komori, Y., Cohen, D., Burrage, K.: Weak second order explicit exponential Runge–Kutta methods for stochastic differential equations. SIAm J. Sci. Comput. 39, A2857–A2878 (2017)
Magnus, W.: On the exponential solution of differential equations for a linear operator. Commun. Pure Appl. Math. 7, 649–673 (1954)
Khanamiryan, M.: Modified Magnus expansion in application to highly oscillatory differential equations. BIT Numer. Math. 52, 383–405 (2012)
Iserles, A., Nørsett, SP: On the solution of linear differential equations in Lie groups. Phil. Trans. R. Soc. 357, 983–1019 (1999)
Iserles, A., MacNamara, S.: Applications of Magnus expansions and pseudospectra to Markov processes. Eur. J. Appl. Math. 30, 400–425 (2019)
Burrage, K., Burrage, P.M.: High strong order methods for non-commutative stochastic ordinary differential equation systems and the Magnus formula. Phys. D Nonlinear Phenom. 133, 34–48 (1999)
Wang, Z., Ma, Q., Yao, Z., Ding, X.: The Magnus expansion for stochastic differential equations. J. Nonlinear Sci. 30, 419–447 (2020)
Wang, X., Guan, X., Yin, P.: A new explicit Magnus expansion for nonlinear stochastic differential equations. Mathematics 8, 183 (2020)
Kamm, K., Pagliaraniy, S., Pascucciz, A.: On the stochastic Magnus expansion and its application to SPDEs. arXiv:2001.01098 (2020)
Tambue, A., Mukam, J.D.: Magnus-type integrator for non-autonomous SPDEs driven by multiplicative noise. Discrete Contin. Dyn. Syst. Ser. A. 40, 4597–4624 (2020)
Blanes, S., Casas, F., Oteo, J.A., Ros, J.: The Magnus expansion and some of its applications. Phys. Rep. Rev. Sect. Phys. Lett. 470, 151–238 (2009)
Mao, X.: Stochastic differential equations and applications. Horwood, Chichester (2007)
Burrage, P.M.: Runge–Kutta methods for stochastic differential equations. Ph.D. Thesis, Dept. Maths., Univ. Queensland (1999)
Gard, T.C.: Introduction to Stochastic Differential Equations. Marcel Dekker Inc, New York-Basel (1988)
Milstein, G.N.: Numerical integration of stochastic differential equations. Kluwer Academic Publishers, Dordrecht (1995)
Kuznetsov, D.F.: Development and application of the Fourier method for the numerical solution of Itô stochastic differential equations. Comput. Math. Math. Phys. 58, 1058–1070 (2018)
Kuznetsov, D.F.: A comparative analysis of efficiency of using the Legendre polynomials and trigonometric functions for the numerical solution of Itô stochastic differential equations. Comput. Math. Math. Phys. 59, 1236–1250 (2019)
Wiktorsson, M.: Joint characteristic function and simultaneous simulation of iterated Itô integrals for multiple independent Brownian motions. Ann. Appl. Probab. 11, 470–487 (2001)
Kloeden, P.E., Platen, E.: Numerical solution of stochastic differential equations. Applications of Mathematics: Stochastic Modelling and Applied Probability. Springer, Berlin (1995)
Debrabant, K., Kværnø, A., Mattsson, N.C.: Lawson schemes for highly oscillatory stochastic differential equations and conservation of invariants. arXiv:1909.12287 (2019)
de Bouard, A.: Gazeau., M.: A diffusion approximation theorem for a nonlinear PDE with application to random birefringent optical fibers. Ann. Appl. Probab. 22, 2460–2504 (2012)
Berg, A., Cohen, D., Dujardin, G.: Exponential integrators for the stochastic Manakov equation. arXiv:2005.04978v1 (2020)
Abdulle, A., Cirilli, S.: S-ROCK: Chebyshev methods for stiff stochastic differential equations. SIAM J. Sci. Comput. 30, 997–1014 (2008)
Komori, Y., Burrage, K.: Weak second order S-ROCK methods for Stratonovich stochastic differential equations. J. Comput. Appl. Math. 236, 2895–2908 (2012)
Acknowledgements
The authors appreciate the valuable comments of the referee.
Funding
Guoguo Yang was supported by China Scholarship Council (CSC) and the National Natural Science Foundation of China (No. 62073103 and 11701124) during his study at Queensland University of Technology. Yoshio Komori was partially supported for this work by JSPS Grant-in-Aid for Scientific Research 17K05369. Xiaohua Ding was partially supported by the National Key R&D Program of China (No. 2017YFC1405600).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 A.1 The expansion of iterated Itô stochastic integrals based on the generalized multiple Fourier series
Let \(\left \{\phi _{j}(x)\right \}_{j=0}^{\infty }\) be an orthonormal basis of the space \(L_{2}\left (\left [t_{n}, t_{n+1}\right ]\right ).\) If the trigonometric series
where r = 1, 2,…, are selected as an orthonormal basis, for the iterated Itô integral (7), using the expansion theorem in [20], the following representations are obtained,
where \(\zeta _{0}^{(i)} \underset {=}{\text { def }} W_{i}(h)/\sqrt {h}\) and \(\zeta _{j}^{(i)} \underset {=}{\text { def }} {{\int \limits }_{t}^{T}} \phi _{j}(s) d W_{i}(s)\), i = 1,…,m. The expansion (A.1) coincides with Kloeden, Platen and Wright’s (1992) algorithm [23] based on Kahunen–Loève expansion and it converges to the iterated Itô integral (7) in the mean-square sense.
If orthonormal Legendre polynomials are selected as an orthonormal basis,
the expansion is
As the expansions (A.1) and (A.2) are infinite series, we need to truncate them for practical simulation. During the implementation of the Milstein and MM methods, the mean-square error of the approximated iterated integrals should not be larger than h3, which is to ensure mean-square convergence of 1.
Truncating the infinite series (A.1) and (A.2) to q terms, we have \(I_{i j}^{q}\). From the truncated mean-square error in [21], we obtain the mean-square error for truncating (A.1)
Here we need 3h2/(2π2q) ≤ h3, so we should choose
Truncating the expansion (A.1) to q, we get the mean-square error
Here we need the mean-square error less than h3, so we should choose
Since qp ≈ 1/(8h), the truncated indices of A.1 and (A.2) both are O(1/h), and it can be calculated that the convergence speed of (A.1) is about qt/qp ≈ 1.22 times that of (A.2). This means that the approximation based on the multiple Legendre Fourier series is slightly more efficient than that based on the multiple trigonometric Fourier series.
1.2 A.2 Wiktorsson’s algorithm
If I(h) and A(h) are matrices with elements \(I_{i j}\left (t_{n}, t_{n}+h\right )\), Aii = 0 and
respectively, the approximation based on the multiple trigonometric Fourier series can be written in matrix form
where \({\varDelta } \mathbf {W}(h) \sim N\left (0, h I_{m}\right ), \mathbf {X}_{k} \sim N\left (0_{m}, I_{m}\right )\) and \(\mathbf {Y}_{k} \sim N\left (0_{m}, I_{m}\right ), k=\)1, 2,…,q are all independent. As the Lévy stochastic area has the relationship Iij − Iji = 2Aij, we only need to simulate Iij for i < j or i > j in the simulation.
Wiktorsson’s algorithm is based on approximation of the tail-sum distribution of (A.3)
which improves the rate of convergence. Let vec \(\left (\mathbf {I}(h)^{T}\right )\) be column vectors of (A.3), and the following is the procedure of Wiktorsson’s algorithm [22]:
-
1.
First simulate \({\varDelta } \mathbf {W}(h) \sim N\left (0_{m}, \sqrt {h} I_{m}\right )\).
-
2.
Simulate the truncated first q terms
$$ \tilde{A}^{(q)}(h)=\frac{h}{2 \pi} {\sum}_{k=1}^{q} \frac{1}{k} K_{m}\left( P_{m}-I_{m^{2}}\right)\left\{\left( \mathbf{Y}_{k}+\sqrt{\frac{2}{h}} {\varDelta} \mathbf{W}(h)\right) \otimes \mathbf{X}_{k}\right\} $$where \(\mathbf {X}_{k} \sim N\left (0_{m}, I_{m}\right )\) and \(\mathbf {Y}_{k} \sim N\left (0_{m}, I_{m}\right )\)
-
3.
Then simulate \(\mathbf {G}_{q} \sim N\left (0_{M}, I_{M}\right )\) and add the approximation of tail-sum distribution:
$$ \widetilde{A}^{(q)^{\prime}}(h)=\widetilde{A}^{(q)}(h)+\frac{h}{2 \pi} a_{q}^{1 / 2} \sqrt{{\Sigma}_{\infty}} \mathbf{G}_{q} $$where \(a_{q}={\sum }_{k=q+1}^{\infty } 1 / k^{2}\)
-
4.
Finally obtain the approximation vec \(\left (\mathbf {I}(h)^{T}\right )^{(q)^{\prime }}\) of vec \(\left (\mathbf {I}(h)^{T}\right )\)
$$ \operatorname{vec}\left( \mathbf{I}(h)^{T}\right)^{(q)^{\prime}}=\frac{{\varDelta} \mathbf{W}(h) \otimes {\varDelta} \mathbf{W}(h)-\operatorname{vec}\left( h I_{m^{2}}\right)}{2}+\left( I_{m^{2}}-P_{m}\right) {K_{m}^{T}} \widetilde{A}^{(q)^{\prime}}(h) $$Here Pm is the m2 × m2 permutation matrix and for the specific expression of matrices Pm please refer to [22].
The mean-square error of Wiktorsson’s algorithm [22] is
Here we also need the mean-square error less than h3, so we should choose truncated indices as
and the truncated indices qw is \(O(1/\sqrt {h})\) that is much better than O(1/h).
Rights and permissions
About this article

Cite this article
Yang, G., Burrage, K., Komori, Y. et al. A class of new Magnus-type methods for semi-linear non-commutative Itô stochastic differential equations. Numer Algor 88, 1641–1665 (2021). https://doi.org/10.1007/s11075-021-01089-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11075-021-01089-7