
Abstract
In actuality, the dead zones and failures often occur in actuators, but the existing algorithms have difficulty simultaneously tolerating dead zones and actuator failures in multi-agent systems. In this paper, the directed topology, uncertain dynamics, unknown dead zones and actuator failures are simultaneously taken into account for the multi-agent systems. By introducing distributed backstepping technique, the radial basis function neural networks and a bound estimation approach, the distributed fault-tolerant tracking controllers and relative adaptive laws for each follower are proposed, which guarantee all followers reach the synchronization and obtain the ideal tracking performance. Comparing with the existing results, it is a new attempt for strict-feedback multi-agent system to take unknown dead zones and unknown actuator failures into consideration. Moreover, the basis function vectors in RBF NNs are no longer required for controllers to decrease computational burden significantly. In the end, the efficiency of our proposed algorithm is verified by comparison simulation results.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the rapid development of computer technology, communication technology, sensors and actuators in the past two decades, it has been easier for multiple agents shown in [26, 41, 42] to work together to accomplish a group task in civil and military missions, such as formation cruise, transportation, logistics and geographic information acquisition. Compared with traditional work done by single agent, the cooperation of multiple agents can improve operational efficiency and reduce consumption significantly. Thus, the study of coordination control for multi-agent has grown rapidly. In the meanwhile, a lot of studies about coordinated control have been published. The objectives of these studies are to enable all agents to reach an agreement, including consensus [52], flocking [24], synchronization [9] and so on. In this paper, consensus is an significant performance index and research objective. As is well known, the strict-feedback form is a general form which can be used to describe many physical systems, including spring–mass–damper systems [25] and robotic systems [39]. By designing appropriate control strategies, agents can achieve synchronization of states. Therefore, many researchers have studied a lot of control strategies and tried to integrate neural networks (NNs) or fuzzy logic systems (FLS) and backstepping technique shown in [7, 21, 22, 33, 35, 36, 38, 46] so as to employ them in multi-agent systems (MASs) [32, 43]. However, in [2, 3, 8], the authors did not study high-order MASs and solve the calculations explosion problem noted in [18]. In addition, many results of consensus protocols require eigenvalue information of Laplacian matrix. It is challenging and momentous to take the directed graphs into consideration and design more general algorithms for high-order MASs.
There are many researches for strict-feedback MASs. At first, a definition of coordinated semi-global uniform ultimate bounded (CSUUB) was proposed in [47, 48]. In order to achieve formation control, based on backstepping technique, a distributed adaptive control protocol was proposed in [39]. Then, in [34], by introducing the RBF NNs, the distributed adaptive neural controllers were designed for each follower in nonlinear MASs under leader-following mode in order to track the output of leader. Further, the high-order leaders were taken into consideration in [18], whose states were estimated by distributed leader observers. However, in the above results, the unknown functions in design were approximated by the NNs or FLS, which cost a lot of time. In addition, many physical systems generally exist nonsmooth dead zones [10, 44], such as servo systems, medical systems, electric systems. It is well known that the presence of the dead zone phenomenon can result in systems instability. In order to guarantee system performance by completely eliminating or compensating for the effect of dead zones, many researchers had a deep research on systems with dead zones and put forward many adaptive control strategies shown in [4, 11, 13, 15, 16, 19, 27, 28, 37, 49]. In these results, there are few control strategies that can be employed in the MASs with dead zones [11, 34]. It can be observed that these systems studied in the above studies do not suffer unknown actuator failures. Nevertheless, actuator failures may degrade system performance and even cause safety problems, which is nonignorable.
With the development of industrial technology, it is significant for any MASs to ensure the reliability and robustness. In particular, system may lose control when actuators suffer stuck failures, resulting in huge industrial losses. An effective fault-tolerant control (FTC) algorithm can guarantee system reliability and improve efficiency. In order to protect system from the effect of actuator failures, some FTC algorithms have been proposed in [1, 50]. It can be observed that these algorithms either had a restriction on the number of failures or assumed failures happened after a finite time instant. Many researchers tried all kinds of methods to make a breakthrough. As for time-varying actuator failures, a FTC robust control protocol was proposed in [51]. So as to remove the restriction on the number of actuator failures, the FTC adaptive tracking control strategies were proposed in [20, 31, 40]. Moreover, by introducing a bound estimation method, the FTC algorithms for interconnected nonlinear systems were proposed in [29, 30] to completely compensate for the effect of unknown actuator failures. In [45], a distributed adaptive FTC algorithm for MASs was proposed. However, the above FTC results generally ignore the dead zone nonlinearities or actuator stuck failures. It is more meaningful and challenging to design appropriate controllers for MASs with unknown actuator failures and dead zones.
Motivated by the aforementioned observations, the first attempt is made to design distributed adaptive neural controllers for strict-feedback MASs with unknown actuator failures and unknown dead zones. The existence of actuator stuck failures can lead to a loss in single-input (SI) system; therefore, multiple actuators are employed in each follower to improve the robustness of systems. It is nonnegligible that the challenge of our control objective is the coexistence of unknown function, unknown actuator failures and unknown dead zones. To address it, the distributed backstepping technique, the RBF NNs and a bound estimation approach are introduced to design the distributed controllers. In final, the efficiency of our proposed algorithm can be verified by simulation results such that all signals in the result system are bounded, and the tracking errors for each follower are said to be CSUUB. In the meanwhile, for comparison, a simulation for the classical distributed algorithm is done. The main contributions are listed as follows.
- 1.
As the authors acknowledge, so far, the existing studies about MASs do not simultaneously take the unknown actuator failures and unknown dead zones into consideration. They cannot guarantee the ideal tracking performance can be obtained as the presence of unknown actuator failures and unknown dead zones. It is the first time to propose the novel distributed neural control approach for a class of MASs with unknown actuator failures and unknown dead zones. Each follower is modeled by strict-feedback system with unknown actuator failures and unknown dead zones input as well as unknown nonlinear dynamics.
- 2.
By introducing a bound estimation method, the estimates for the effects of unknown failures, unknown dead zones and unknown control gain are developed with only locally available information. Compared with the results on MASs by classical control, the failures and dead zones in the systems can be completely unknown. And the assumption that a known positive scalar exists and satisfies some restrictions for the slopes of dead zone, failure or control gain function is removed.
The remainder of this paper is organized as follows: The characteristics of the system and related knowledge are described in Sect. 1. Section 3 describes the design of distributed consensus protocol and stability analysis. The simulation results of spring–mass–damper control system are provided in Sect. 4. Section 5 describes the conclusion of this paper. In Table 1, the main notation used throughout this paper is stated.
2 System formulation and preliminaries
2.1 Graph theory
It is supposed that there is a directed graph \({\mathbb {G}}=({\mathbb {V}},{\mathbb {E}})\) in this paper, where \({\mathbb {V}}=\{{1},\ldots ,{N}\}\) and \({\mathbb {E}}\subseteq {\mathbb {V}}\times {\mathbb {V}}\) denote the set of N nodes and the set of relative edges between N nodes, respectively. The edge is marked \(({j},{i})\in {\mathbb {E}}\), representing the node j sends information to node i and then the node i obtains this information, but not vice versa. Moreover, \({N}_{i}=\{{j}\vert ({j},{i})\in {\mathbb {E}}\}\) denotes a set of neighbors j of node i. It is worth mentioning that the directed path (j, i) in directed graph is more than one. For example, it can be composed of a sequence of successive edges. In this paper, we consider leader-following mode. Therefore, it is critical that there exist at least one root node and some other nodes which can get information from the root nodes. In addition, the adjacent matrix \({A}=[a_{ij}]\in {R}^{N\times N}\) describes the topology of a weighted digraph \({\mathbb {G}}\), where \(a_{ij}>0\) if \(({j},{i})\in {\mathbb {E}}, j\ne i\), and \(a_{ij}=0\) otherwise. Finally, \({D}=\mathrm{diag}[d_{1},\ldots , d_{N}]\) is defined as the in-degree matrix of directed graph, where \(d_{i}=\sum _{j=1,j\ne i}^{N}a_{ij}\) is the weights of node \(v_{i}\). \(L = D - A\). Then, \(b=[ b_{1},\ldots ,b_{N}] ^{\mathrm{T}}\) , with \(b_{i}>0\) if the i th follower connects with the leader and \(b_{i}=0\) otherwise. \(B={\mathrm { diag}}[ b_{1},\ldots ,b_{N}]\).
2.2 System formulation
In this paper, the MASs adopt leader-following mode, including \( N (N > 2)\) followers marked 1 to N and a leader marked 0. The dynamic of the ith follower is described as strict-feedback form with actuator failures and dead zones:
where \({\bar{x}}_{i,s}=\left[ x_{i,1},x_{i,2},\ldots ,x_{i,s}\right] \in {R}^s\)\( (s=1,\ldots ,n_{i})\) is the state vector. The function \(f_{i,s}({\bar{x}}_{i,s})~ (s=1,2,\ldots ,n_i)\) is continuous and unknown. The output \(y_{i} \in {R}\) is from the ith follower. The input \(u_{i}=\sum _{q=1}^{M_i}\omega _{i,q}u_{i,q} \in {R}\) is the sum of control input \(u_{i,q}\). \(\omega _{i,q}\) is a bounded control gain of (i, q)th actuators and unknown, while the sign of \(\omega _{i,q}\) is known. \(u_{i,q}\) denotes the output of the (i, q) th actuator. \(n_i\) denotes the order of the ith follower’s system. \(M_i\) denotes the number of actuators in the ith follower.
Remark 1
Many physical systems can be modeled by Eq. (1), such as spring–mass–damper systems [25], robotic systems [39], electromechanical system [13] and helicopter system [5]. The actuator failures and dead zones generally exist in the actuators. The actuator failure denotes that the actuator used to execute the control command in the control loop cannot execute the control command correctly due to the gain change or deviation. The dead zone of the actuator means that the actuator does not operate when the input signal of the actuator is small, and only when the input signal of the actuator reaches a certain value, the actuator acts. In addition, the combination of unknown failures and unknown dead zones is widely applied in practice. Therefore, system (1) takes the unknown function, multiple actuators, unknown dead zones and failures into account. So far, there has not been any result on adaptive neural control to be reported for this system.
According to the failure models shown in [29, 30] and the existence of actuator stuck failures, the following mathematic model (2) is employed to describe actuator failures in this paper:
where \(\rho _{i,q,h}\) denotes actuator efficiency and \(\rho _{i,q,h} \in [0,1]\). h denotes the number of actuator failures. \({\bar{\nu }}_{i,q,h}(t)\) is unknown but bounded. The time constants \(t^{\mathrm{st}}_{i,q,h}\) represent the time instant of actuator failure starts. \(t^{\mathrm{en}}_{i,q,h}\) represents the time instant of its ends. For convenience, in this paper, \(0\le t^{\mathrm{st}}_{i,q,1}\le t^{\mathrm{en}}_{i,q,1}\le t^{\mathrm{st}}_{i,q,2}\le t^{\mathrm{en}}_{i,q,2}\le \cdots \le + \infty \) is defined. Moreover, \(v_{i,q}(t)\) denotes the output of dead zones for (i, q)th actuator. According to model (2), there are three cases of actuator failures:
(1)\(\rho _{i,q,h} \ne 0\) and \({\bar{\nu }}_{i,q,h} = 0\)
In this case, actuator loses partial performance while operating. It is known as partial loss of effectiveness (PLOE).
(2) \(\rho _{i,q,h} = 0\) and \({\bar{\nu }}_{i,q,h} \ne 0\)
In this case, actuator loses total performance while operating. That is, \(u_{i,q} = {\bar{\nu }}_{i,q,h}\) , and \(u_{i,q}\) cannot be controlled by signal \(\nu _{i,q}\). Thus, this case is total loss of effectiveness (TLOE).
(3) \(\rho _{i,q,h} = 0\) and \({\bar{\nu }}_{i,q,h}(t) = 0\)
It is a special example of TLOE, \(u_{i,q}=0\).
By defining:
model (2) is rewritten as
where \(|{\bar{\nu }}_{i,q}(t)|\le \bar{{\bar{\nu }}} _{i,q}\), and \(\bar{{\bar{\nu }}}_{i,q}\) is a positive constant. In addition, model (3) satisfies: the multi-agent system can still normally operate, even if the ith agent suffers \(n_i-1\) actuator stuck failures.
In this paper, the dead zones are considered to occur in front of actuator failures. Therefore, the output of dead zones is defined as \(\nu _{i,q}=D\left( {\tau _{i,q}}\right) \):
where \(m_{i,q,r} \ne 0 \) is the right slope of dead zones in the (i, q)th actuator. \(m_{i,q,l} \ne 0 \) is the left slope of dead zones in the (i, q)th actuator. \(\vartheta _{i,q,r}\ge 0\) and \(\vartheta _{i,q,l}\ge 0\) denote the breakpoint of dead zones. \(\tau _{i,q} \in {R} \) is the (i, q)th control input to be designed.
In practice, \(h _{i,q}\left( t\right) \) is a bounded function.
Compared with the results in [1, 50, 51], the failures here remove the restrictions on the number of failures and allow the existence of stuck failures. According to (1), (3), (5), the model of MASs (1) can be rewritten as
where the input of the ith agent is \(u_i(t)\):
In this paper, the leader node is in the form:
where \(f_0\left( x_0,t\right) \) is continuous, satisfying: (a) \(|f_0\left( x_0,t\right) | \le g\left( x_0\right) \), (b) \(|x_0\left( t\right) | \le X_M\), (c) \(\Vert f_0(\breve{{x}}_{0}, t)-f_0({x}_{0},t)\Vert \le L_f \Vert \breve{{x}}_{0}- {x}_{0}\Vert \), \(\forall \breve{ {x}}_{0}, {x}_{0} \in {R}\), \( t \ge t_0\). \(g(x_0)\) is a continuous function. \(X_M\) is a positive constant. \(L_f\) is the Lipschitz constant and independent of \(x_0\) and t. For the leader-following mode in this paper, the leader should be the root of spanning trees in \({\mathbb {G}}\).
Remark 2
As stated in [34], if the leader is not the root of spanning trees, followers may not receive the signals from the leader such that they cannot track the leader. To achieve effective tracking, it is reasonable to require the leader which is the root of spanning tree. As shown later, the \(g\left( x_0\right) \), \(X_M\) are used to design controllers, but they do not have any effect on the final controllers, which means their true values do not require to be known.
Definition 1
[12] The distributed consensus tracking errors for nonlinear followers (1) under the communication graph are said to be CSUUB, if the positive constants \(c_{1}\), \(c_{2}\), \(\beta _{1}\), \(\beta _{2}\) and a time \(T\ge 0\) are independent of \(t_{0}\) for each \(\alpha _{1}\in (0,c_{1})\) and \(\alpha _{2}\in (0,c_{2})\) such that \(\Vert y_{i}(t_{0})-r(t_{0})\Vert \le \alpha _{1}\Rightarrow \Vert y_{i}(t)-r(t)\Vert \le \beta _{1}\) and \(\Vert y_{i}(t_{0})-y_{j}(t_{0})\Vert \le \alpha _{2}\Rightarrow \Vert y_{i}(t)-y_{j}(t)\Vert \le \beta _{2}\)\(\forall t\ge t_{0}+T\), \(i,j=1,\ldots ,N\) and \(i\ne j\).
The purpose of this paper is to design controllers for each follower with actuator failures and dead zones. The control protocol is to guarantee the followers can synchronize and track the leader, and all the signals in the closed-loop systems are bounded.
Lemma 1
[23] For \(\forall {\bar{\epsilon }} > 0 \) and \(\varkappa {R} \), the following inequality holds;
where \(\varrho =0.2785\).
2.3 RBF neural networks
As is well known, the advantage of neural networks is its uniform approximation ability, which can approximate any continuous unknown function in theory. Therefore, the following lemma holds:
Lemma 2
[6] There exists a neural network such that
where \(f(z), z \in {R}^q\) is a continuous function defined on a compact set \(\varPhi \subset R^q\). \(\sigma (z)\) is the basis function vector, \(\sigma (z)=[{{\bar{\sigma }}}_1(z),\ldots ,{{\bar{\sigma }}}_l(z)]^\mathrm{T} \in {R}^l\). \({\xi } = [{\bar{\xi }}_1, \ldots , {\bar{\xi }}_l]^\mathrm{T} \in {R}^l\) is the weight vector. l represents the number of neurons.
According to Lemma 2, there exists an approximation error \(\varepsilon \) such that
where \(\xi ^{*} \in {R}^{l} \) denotes the ideal weight vector: \( \xi ^{*T} := arg \min _{\xi {R}^l} \{\sup _{z\in \varOmega }|f(z)-\xi ^{\mathrm{T}}\sigma (z)|\}; \) the radial basis function \({{\bar{\sigma }}}_i(z)\) commonly adopts Gaussian function (14):
where \(\eta _i\in {R}\) is the width of the Gaussian function, \(\kappa _i=[\kappa _{i1},\kappa _{i2},\ldots ,\kappa _{iq}]^{\mathrm{T}}\) is the center of receptive field. In [34], the efficiency of RBF neural networks has been proven. Hence, the RBF NNs are employed in designing this paper.
Remark 3
This paper focuses on semi-global adaptive RBF NNs coordination control for strict-feedback MASs. Note that the FLS can also obtain the similar results. If Gaussian function is selected as fuzzy membership function, inequality (15) holds for FLS, where l represents the total number of fuzzy rules. As shown later, the number of adaptive parameters for neural weights is independent of the neurons. Similarly, the number of adaptive parameters for fuzzy weights is independent of the fuzzy rules. Consequently, the true value of l does not affect the design of controllers, no matter what.
3 Distributed NN controllers design and stability analysis
The distributed adaptive consensus protocol for MASs with dead zones and actuator failures is designed in this section. In addition, the stability of the closed-loop system is also analyzed in this section.
At first, the synchronization error of the ith follower is defined as:
Then, the following change of coordinates is made:
where the \(z_{i,s}\) is the state error in the sth step for the ith follower. \(\alpha _{i,s-1}\) denotes a visual control signal in the \((s-1)\)th step for the ith follower. The virtual control signals are in the following form:
where \(c_{i,s}\) and \(a_{i,s}\)\((s=1, \ldots , n_i-1)\) are design positive constant, \({\hat{\theta }}_{i}\) is the estimation of the constants \(\theta _i\):
\({\hat{\beta }}_i\) and \(\hat{{\bar{\lambda }}}_i\), respectively, represent the estimation of the unknown constants \({\beta }_i\) and \({\bar{\lambda }}_i\), as shown in (41). The estimation errors are \(\tilde{{\theta }_{i}}= {\theta }_{i}- {\hat{\theta }}_{i}\), \({\tilde{\beta }}_{i}= \beta _{i}- {\hat{\beta }}_{i}\), \(\tilde{{\bar{\lambda }}}_{i}={\bar{\lambda }}_{i} - \hat{\bar{\lambda }}_{i}\). Then, the adaptive laws are:
where \(r_i\) and \(\mu _{i}\) are design positive constants.
In addition, the actual controller \(\tau _{i,q}\) is:
where
Remark 4
The main results are shown in (18–23). Compared with the results in [34], it can be seen that the basis function of RBF NNs is ignored. As well known, the basis function of RBF NNs can be replaced with 1 by scaling. In the traditional adaptive neural control, the computational burden for estimation parameter about NNs usually is \(\sum _{s=1}^{n_i}l_s\), while the computational burden decreases to \({n_i}\) in [17] or \(l_s\) in [34]. By combining the pioneering works in [17, 34], the estimation parameter \(\theta _i\) is defined in (19). Based on this definition, the computational burden reduces from \(\sum _{s=1}^{n_i}l_s\) to 1, which is an improvement for the traditional adaptive control.
In the following, the designing of the virtual control signals, the final input signals of actuators and the adaptive laws will be described.
Step 1: Based on (19), consider the following Lyapunov function candidate:
According to (16), we have the time derivative of \(z_{i,1}\):
Therefore, the time derivative of \(V_{i,1}\) is:
where
According to (1), \(f_{i,1}\) is unknown. Thus, the virtual control input \(\alpha _{i,1}\) cannot be designed by \({\bar{f}}_{i,1}\). As Lemma 2 shows, the RBF NNs can be utilized to describe \({\bar{f}}_{i,1}\) such that
According to the fact \(\sigma ^{\mathrm{T}} _{i,1}\sigma _{i,1} \le l_{i,1}\) and Young’s inequality, we get:
Substituting (29) into (27) , we have:
Substituting (18) into (30) , we get:
where \(\varphi _{i,1}=\dfrac{1}{2}a_{i,1}^{2}+\dfrac{1}{2}\bar{\varepsilon }_{i,1}^{2}\).
Step s\(\left( 2\le s \le n_{i}-1\right) \): Consider the following Lyapunov function candidate:
According to (17), the time derivative of \(V_{i,s}\) is:
By using Lemma1, we have:
Substituting (34) into (33) , we have
where
Similar to step 1, \(f_{i,s}\) is unknown. Thus, the virtual control input \(\alpha _{i,s}\) cannot be defined by \({\bar{f}}_{i,s}\). As Lemma 2 shows, the RBF NNs can be utilized to describe \({\bar{f}}_{i,s}\) such that
According to the fact \(\sigma ^{\mathrm{T}} _{i,s}\sigma _{i,s} \le l_{i,s}\) and Young’s inequality, we get:
Substituting (37) into (35) , we get:
Substituting (18) into (38) , we get:
where
Step \(n_i\) : According to (9) and (17), the time derivative of \(z_{i,n_i}\) is:
where \(\lambda _{i}=\sum _{q=1}^{M_i}\omega _{i,q}\left( \rho _{i,q}(t)h_{i,q}(t)+{\bar{\nu }}_{i,q}(t)\right) \) .
As the fact \(\sum _{q=1}^{M_i}\left| \omega _{i,q}\right| \rho _{i,q} \ge \max \left\{ \left| \omega _{i,1}\right| {\rho }_{i,1},\ldots ,\left| \omega _{i,M_i}\right| {{\rho }}_{i,M_i}\right\} > 0\), we have:
Define:
Remark 5
By introducing a bound estimation method, the estimates for the effects of unknown failures and unknown dead zones are developed with only locally available information. Compared with the results on MASs by classical control, the failures and dead zones in the systems can be completely unknown.
Remark 6
The unknown virtual control gain function \(\omega _{i,q}\) is considered in (41); therefore, the effects of unknown control gain are also estimated. If \(\rho _{i,q}(t) = k_{i,q}(t) = 1\) and \(h_{i,q}(t) = {\bar{\nu }}_{i,q}(t) = 0\), the input \(u_i\) is only affected by control gain \(\omega _{i,q}\), i.e., \(u_i(t)=\sum _{q=1}^{M_{i}}\omega _{i,q}\tau _{i,q}(t)\). It is worth noting that the inequality \(0< \sum _{q=1}^{M_i}\left| \omega _{i,q}\right| < \infty \) is required to ensure the boundedness of \(\eta _i\) and \({\bar{\lambda }}_{i}\) such that \(0< \eta _i < \infty \), \(0 \le {\bar{\lambda }}_{i} < \infty \).
Consider the following Lyapunov function candidate:
Based on (40), the time derivative of \(V_{i,n_i}\) is:
By using Lemma1, we have
Therefore,
where
Similar to step 1, \(f_{i,n_i}\) is unknown. Thus, the virtual control input \(\alpha _{i,n_i}\) cannot be defined by \({\bar{f}}_{i,n_i}\). As Lemma 2 shows, the RBF NNs can be utilized to describe \({\bar{f}}_{i,n_i}\) such that
According to the fact \(\sigma ^{\mathrm{T}} _{i,n_i}\sigma _{i,n_i} \le l_{i,n_i}\) and Young’s inequality, we get:
Thus,
Based on (24), we have:
By introducing (23), we have:
Substituting (20), (21), (22), (39), (49), (50), (51) into (48), we have:
where \( \varphi _{i,n_i}=\varphi _{i,n_i-1} +\frac{1}{2}a_{i,n_i}^{2} +\frac{1}{2}{\bar{\varepsilon }}_{i,n_i}^{2} +\varrho {\bar{\varepsilon }}_{i,n_i} . \) From the work in [14], we have,
Based on the Young’s inequality, we have:
According to Lemma1, we have:
Finally, substituting (53), (54) and (55) into (52) , we have
Through the above design procedure, the following theorem comes out:
Theorem 1
For the MASs (1) with unknown actuator failures (2) and unknown dead zones (4), adopting the adaptive laws (20), (21), (22) and controllers (23), the followers will synchronize and track the leader. The tracking errors \(\left\| y-y_0\right\| \) in the total closed-loop system are CSUUB. By tuning the design parameters, the following inequality holds:
where \(y = [y_1, y_2, \ldots , y_N]^{\mathrm{T}}\), \({\overline{y}}_0 = [y_0, y_0, \ldots , y_0]^{\mathrm{T}}\).
Proof
See Appendix. \(\square \)
Remark 7
As shown in (63), the smaller tracking error can be obtained by increasing the parameters \(k_{i,0}\), \(\mu _{i}\) and reducing the parameters \(a_{i,m}\), \(c_{i,m}\), \(r_i ~(i=1, \ldots , N, ~m=1, \ldots , n_i)\). As a trade-off, such an operation may cause a relatively large amplitude of control signal. Note that it is difficult for the desired tracking errors to be designed only by tuning a design parameter. Thus, all these design parameters should be tuned properly according to the control constraint and requirement.
4 Simulation example
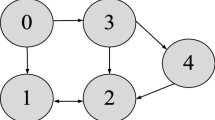
A practical example shown in [25] is given to verify the effectiveness of the proposed algorithm. As shown in Fig. 1, a six-node digraph \({\mathbb {G}}\) represents five followers marked i\((i=1,2,3,4,5)\) and a leader marked 0. Moreover, each follower adopts different spring–mass–damper control system, which is controlled by two torques \(u_{i,1}\). The followers are modeled as:
where \(m_i\) denotes mass of the ith follower. k denotes the stiffness of the spring. c denotes the damping coefficient. Moreover, \(x_{i,1}\), \(x_{i,2}\) and \(y_{i}\) represent speed, acceleration and position, respectively. The parameters are chosen as Table 2.

Directed graph of leader and followers
As shown in Fig. 1, the edge weights \(a_{ij}\) and the pinning gains \(b_i\) are set to 1. Therefore, the adjacency matrix of followers is:
In addition, the adjacency matrix of leader is \(B=\mathrm{diag}\{1,1,0,0,0\}\).
The parameters of dead zones (2) are: \(m_{1,1,r} = 1, m_{1,1,l} = 1.3, \vartheta _{1,1,r} = 0.3, {} \vartheta _{1,1,l} = 0.52, m_{1,2,r} = 0.7, m_{1,2,l} = 1.3, \vartheta _{1,2,r} = 0.7, {} \vartheta _{1,2,l} = 4, m_{i,q,r} = 0.8, m_{i,q,l} = 1.2, \vartheta _{i,q,r} = 4.8\) and \(\vartheta _{i,q,l} = 1.8\), \(i=2,3,4,5\), \(q=1,2\).
The following failure models are considered:
where \(t_1=2k\), \(t_2=2k+1\), \(t_3=2k+2\), \(k=0,1,\ldots \).
According to (10), the dynamics of the leader is designed as
Scenario 1—In this scenario, the design parameters are set to be \(c_{1,1}=c_{2,1}=4.85,c_{3,1}=c_{4,1}=c_{5,1}=15, c_{i,2}=1, r_{i}=30, a_{i,1}=20, a_{i,2}=0.5, k_{i,0}=0.001\), and \(\mu _{i}=0.001, i=1,2,3,4,5\). Then, the initial states of followers are set to be \(x_{1}\left( 0\right) =[0.9, 0]^{\mathrm{T}}, x_{2}\left( 0\right) =[0.8, 0]^{\mathrm{T}}, x_{3}\left( 0\right) =[0.7, 0]^{\mathrm{T}}, x_{4}\left( 0\right) =[0.6, 0]^{\mathrm{T}}, x_{5}\left( 0\right) =[0.5, 0]^{\mathrm{T}}\). The initial states of adaptive parameters are: \({\hat{\beta }}_{i}\left( 0\right) =0, {\hat{\lambda }}_{i}\left( 0\right) =0\) and \({\hat{\theta }}_{i}\left( 0\right) =0,~i=1,2,3,4,5\).

Tracking performance for systems without dead zones and failures

Tracking performance for systems with dead zones and failures

Tracking errors \(e_{i,1}\) for systems without dead zones and failures

Tracking errors \(e_{i,1}\) for systems with dead zones and failures

Trajectories of states \(x_{i,2}\) for systems without dead zones and failures

Trajectories of states \(x_{i,2}\) for systems with dead zones and failures

Adaptation parameters \({\hat{\theta }}_i\) for systems without dead zones and failures

Adaptation parameters \({\hat{\theta }}_i\) for systems with dead zones and failures

Adaptation parameters \({\hat{\beta }}_i\) for systems without dead zones and failures

Adaptation parameters \({\hat{\beta }}_i\) for systems with dead zones and failures

Adaptation parameters \({\hat{\lambda }}_i\) for systems without dead zones and failures

Adaptation parameters \({\hat{\lambda }}_i\) for systems with dead zones and failures
The simulation results are shown in Figs. 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 and 14. The tracking performances for systems without dead zones and failures are shown in Fig. 2, while the tracking performances for systems with dead zones and failures are shown in Fig. 3. Meanwhile, the corresponding tracking errors \(e_{i,1}=|y_{i}(t)-y_{0}(t)|\) are shown in Figs. 4 and 5, respectively. Figures 6 and 7 show the difference about the trajectories of state \(x_{i,2}\) between the systems without dead zones and failures and systems with dead zones and failures. According to Figs. 2, 3, 4, 5, 6 and 7, it can be observed that actuator failures and dead zones have obvious effects on the system, but the effects are eliminated fleetly by the proposed controllers. The adaptive parameters are depicted in Figs. 8, 9, 10, 11, 12 and 13. Figure 14 demonstrates the boundedness of input\(\tau _{i,j}\) and dead zone output \(\nu _{i,j}\), \(i=1, \ldots , 5,~ j=1,2\). It can be seen from Fig. 14 that the failures cause some jumps in the control inputs, but they are controllable. From all the above simulation results, we can know that all the followers reach the synchronization and obtain ideal tracking performance. Moreover, all the signals in the closed-loop system are bounded. Therefore, the effectiveness of the proposed algorithm has been validated.
Scenario 2—For comparison purposes, we have compared the proposed control method in this paper through simulation. Specifically, the following three control methods are considered.
Method I: the proposed distributed fault-tolerant control method (DFTCM);
Method II: the adaptive fuzzy control method;
Method III: the direct robust control method;

Trajectories of control for systems with dead zones and failures: a input\(\tau _{1,1}\) and dead zone output \(\nu _{1,1}\); b input\(\tau _{1,2}\) and dead zone output \(\nu _{1,2}\) ; c input\(\tau _{2,1}\) and dead zone output \(\nu _{2,1}\) ; d input\(\tau _{2,2}\) and dead zone output \(\nu _{2,2}\) ; e input\(\tau _{3,1}\) and dead zone output \(\nu _{3,1}\) ; f input\(\tau _{3,2}\) and dead zone output \(\nu _{3,2}\) ; g input\(\tau _{4,1}\) and dead zone output \(\nu _{4,1}\) ; h input\(\tau _{4,2}\) and dead zone output \(\nu _{4,2}\) ; i input\(\tau _{5,1}\) and dead zone output \(\nu _{5,1}\) ; j input\(\tau _{5,2}\) and dead zone output \(\nu _{5,2}\)

Tracking performance for comparison with our proposed method

Tracking errors for comparison with our proposed method
For clarity, the comparative simulation results about one of the followers are presented in Figs. 15 and 16. It can be seen from the simulation result that, in terms of the tracking control performance, the proposed DFTCM is the best among the three tested control methods. This is mainly because the objective of Method II and Method III is to cope with the internal or external disturbances such that the insensitivity of result system is achieved. During control operation, the effect caused by the dead zones and actuator failures is regarded as the disturbance-like effect and not treated by any special treatment. Therefore, the obtained result is relatively conservative in the sense that the tracking performance is not very ideal. Different from Method II and Method III, the proposed DFTCM can be utilized to estimate the effect caused by unknown dead zones and unknown actuator failures by adaptive laws and compensate for it. As reflected in Figs. 15 and 16, the desired trajectory can be obtained for the MASs regardless of the existence of unknown actuator failures and unknown dead zones by our proposed Method I.
5 Conclusion
This paper mainly focuses on the MASs with unknown dead zones and unknown actuator failures. By introducing distributed backstepping technique, RBF NNs and a bound estimation approach, the proposed control protocol has been proposed to ensure that all followers reach an agreement and obtain the ideal tracking performance. It is the first time to design distributed adaptive neural control protocol for strict-feedback MASs with unknown actuator failures and unknown dead zones. In this paper, the effect of stuck failures and the restriction on the number of actuator failures have been taken into account. Note that the basis function of RBF NNs has been ignored by considering the definition of estimation parameter \(\theta _i\) to reduce computational burden efficiently. In the end, the effectiveness of Theorem 1 has been illustrated by simulation results.
In this study, we have investigated the coordination control problem for MASs with unknown dead zones and unknown actuator failures. However, it is often required in practice that the consensus can be reached in finite time as such a feature offers numerous benefits including faster convergence rate, better disturbance rejection and robustness against uncertainties. Thus, our future work will focus on this topic.
References
Cai, J., Wen, C., Su, H., Liu, Z.: Robust adaptive failure compensation of hysteretic actuators for a class of uncertain nonlinear systems. IEEE Trans. Autom. Control 58(9), 2388–2394 (2013)
Chen, K., Wang, J., Zhang, Y., Liu, Z.: Second-order consensus of nonlinear multi-agent systems with restricted switching topology and time delay. Nonlinear Dyn. 78(2), 881–887 (2014)
Chen, K., Wang, J., Zhang, Y., Liu, Z.: Consensus of second-order nonlinear multi-agent systems under state-controlled switching topology. Nonlinear Dyn. 81(4), 1871–1878 (2015)
Chen, M., Ge, S.S., Ren, B.: Adaptive tracking control of uncertain MIMO nonlinear systems with input constraints. Automatica 47(3), 452–465 (2011)
Chen, M., Shi, P., Lim, C.: Adaptive neural fault-tolerant control of a 3-dof model helicopter system. Syst. Man Cybern. 46(2), 260–270 (2016)
Chen, W., Ge, S.S., Wu, J., Gong, M.: Globally stable adaptive backstepping neural network control for uncertain strict-feedback systems with tracking accuracy known a priori. IEEE Trans. Neural Netw. 26(9), 1842–1854 (2015)
Chen, Z., Li, Z., Chen, C.L.P.: Adaptive neural control of uncertain mimo nonlinear systems with state and input constraints. IEEE Trans. Neural Netw. 28(6), 1318–1330 (2017)
Dai, H., Chen, W., Xie, J., Jia, J.: Exponential synchronization for second-order nonlinear systems in complex dynamical networks with time-varying inner coupling via distributed event-triggered transmission strategy. Nonlinear Dyn. 92(3), 853–867 (2018)
Gutierrez, H., Morales, A., Nijmeijer, H.H.: Synchronization control for a swarm of unicycle robots: analysis of different controller topologies. Asian J. Control 19(5), 1822–1833 (2017)
He, Y., Wang, J., Hao, R.: Adaptive robust dead-zone compensation control of electro-hydraulic servo systems with load disturbance rejection. J. Syst. Sci. Complex. 28(2), 341–359 (2015)
Hua, C., Zhang, L., Guan, X.: Distributed adaptive neural network output tracking of leader-following high-order stochastic nonlinear multiagent systems with unknown dead-zone input. IEEE Trans. Syst. Man Cybern. 47(1), 177–185 (2017)
Jin, Y.S.: Distributed consensus tracking for multiple uncertain nonlinear strict-feedback systems under a directed graph. IEEE Trans. Neural Netw. Learn. Syst. 24(4), 666–672 (2013). https://doi.org/10.1109/TNNLS.2013.2238554
Li, Y., Tong, S., Liu, Y., Li, T.: Adaptive fuzzy robust output feedback control of nonlinear systems with unknown dead zones based on a small-gain approach. IEEE Trans. Fuzzy Syst. 22(1), 164–176 (2014)
Li, Y., Yang, G.: Adaptive fuzzy decentralized control for a class of large-scale nonlinear systems with actuator faults and unknown dead zones. Syst. Man Cybern. 47(5), 729–740 (2017)
Liu, Y., Tang, L., Tong, S., Chen, C.L.P.: Adaptive NN controller design for a class of nonlinear mimo discrete-time systems. IEEE Trans. Neural Netw. 26(5), 1007–1018 (2015)
Liu, Y., Tong, S.: Adaptive fuzzy identification and control for a class of nonlinear pure-feedback mimo systems with unknown dead zones. IEEE Trans. Fuzzy Syst. 23(5), 1387–1398 (2015)
Liu, Z., Lai, G., Zhang, Y., Chen, X., Chen, C.L.P.: Adaptive neural control for a class of nonlinear time-varying delay systems with unknown hysteresis. IEEE Trans. Neural Netw. 25(12), 2129–2140 (2014)
Liu, Z., Su, L., Ji, Z.: Neural network observer-based leader-following consensus of heterogenous nonlinear uncertain systems. Int. J. Mach. Learn. Cybern. 9(9), 1435–1443 (2018)
Liu, Z., Wang, F., Zhang, Y., Chen, X., Chen, C.L.P.: Adaptive tracking control for a class of nonlinear systems with a fuzzy dead-zone input. IEEE Trans. Fuzzy Syst. 23(1), 193–204 (2015)
Lv, W., Wang, F.: Adaptive tracking control for a class of uncertain nonlinear systems with infinite number of actuator failures using neural networks. Adv. Differ. Equ. 2017(1), 374 (2017)
Lv, W., Wang, F., Li, Y.: Adaptive finite-time tracking control for nonlinear systems with unmodeled dynamics using neural networks. Adv. Differ. Equ. 2018(1), 159 (2018)
Lyu, Z., Liu, Z., Xie, K., Chen, C.L.P., Zhang, Y.: Adaptive fuzzy output-feedback control for switched nonlinear systems with stable and unstable unmodeled dynamics. IEEE Trans. Fuzzy Syst. pp. 1–1 (2019)
Polycarpou, M.M., Ioannou, P.A.: A robust adaptive nonlinear control design. Automatica 32(3), 423–427 (1996)
Su, H., Qiu, Y., Wang, L.: Semi-global output consensus of discrete-time multi-agent systems with input saturation and external disturbances. ISA Trans. 67, 131–139 (2017)
Su, X., Liu, Z., Lai, G., Chen, C.L.P., Chen, C.: Direct adaptive compensation for actuator failures and dead-zone constraints in tracking control of uncertain nonlinear systems. Inf. Sci. 417, 328–343 (2017)
Tian, B., Fan, W., Su, R., Zong, Q.: Real-time trajectory and attitude coordination control for reusable launch vehicle in reentry phase. IEEE Trans. Ind. Electron. 62(3), 1639–1650 (2015)
Tong, S., Li, Y.: Adaptive fuzzy output feedback control of mimo nonlinear systems with unknown dead-zone inputs. IEEE Trans. Fuzzy Syst. 21(1), 134–146 (2013)
Tong, S., Wang, T., Li, Y., Zhang, H.: Adaptive neural network output feedback control for stochastic nonlinear systems with unknown dead-zone and unmodeled dynamics. IEEE Trans. Syst. Man Cybern. 44(6), 910–921 (2014)
Wang, C., Wen, C., Guo, L.: Decentralized output-feedback adaptive control for a class of interconnected nonlinear systems with unknown actuator failures. Automatica 71(71), 187–196 (2016)
Wang, C., Wen, C., Lin, Y.: Decentralized adaptive backstepping control for a class of interconnected nonlinear systems with unknown actuator failures. J. Frankl. Inst. Eng. Appl. Math. 352(3), 835–850 (2015)
Wang, C., Wen, C., Lin, Y.: Adaptive actuator failure compensation for a class of nonlinear systems with unknown control direction. IEEE Trans. Autom. Control 62(1), 385–392 (2017)
Wang, F., Chen, B., Lin, C., Li, X.: Distributed adaptive neural control for stochastic nonlinear multiagent systems. IEEE Trans. Syst. Man Cybern. 47(7), 1795–1803 (2017)
Wang, F., Chen, B., Lin, C., Zhang, J., Meng, X.: Adaptive neural network finite-time output feedback control of quantized nonlinear systems. IEEE Trans. Syst. Man Cybern. 48(6), 1839–1848 (2018)
Wang, F., Liu, Z., Zhang, Y., Chen, B.: Distributed adaptive coordination control for uncertain nonlinear multi-agent systems with dead-zone input. J. Frankl. Inst. Eng. Appl. Math. 353(10), 2270–2289 (2016)
Wang, F., Liu, Z., Zhang, Y., Chen, C.L.P.: Adaptive fuzzy visual tracking control for manipulator with quantized saturation input. Nonlinear Dyn. 89(2), 1241–1258 (2017)
Wang, F., Liu, Z., Zhang, Y., Chen, X., Chen, C.L.P.: Adaptive fuzzy dynamic surface control for a class of nonlinear systems with fuzzy dead zone and dynamic uncertainties. Nonlinear Dyn. 79(3), 1693–1709 (2015)
Wang, H., Chen, B., Lin, C.: Adaptive fuzzy control for pure-feedback stochastic nonlinear systems with unknown dead-zone input. Int. J. Syst. Sci. 45(12), 2552–2564 (2014)
Wang, M., Wang, C., Shi, P., Liu, X.: Dynamic learning from neural control for strict-feedback systems with guaranteed predefined performance. IEEE Trans. Neural Netw. 27(12), 2564–2576 (2016)
Wang, W., Huang, J., Wen, C., Fan, H.: Distributed adaptive control for consensus tracking with application to formation control of nonholonomic mobile robots. Automatica 50(4), 1254–1263 (2014)
Wang, W., Wen, C.: Adaptive compensation for infinite number of actuator failures or faults. Automatica 47(10), 2197–2210 (2011)
Wen, G., Chen, C.L.P., Feng, J., Zhou, N.: Optimized multi-agent formation control based on an identifier-actor-critic reinforcement learning algorithm. IEEE Trans. Fuzzy Syst. 26(5), 2719–2731 (2018)
Wen, G., Chen, C.L.P., Liu, Y.: Formation control with obstacle avoidance for a class of stochastic multiagent systems. IEEE Trans. Ind. Electron. 65(7), 5847–5855 (2018)
Xu, C., Zheng, Y., Su, H., Chen, M.Z.Q., Zhang, C.: Cluster consensus for second-order mobile multi-agent systems via distributed adaptive pinning control under directed topology. Nonlinear Dyn. 83(4), 1975–1985 (2016)
Yan, H., Li, Y.: Adaptive nn prescribed performance control for nonlinear systems with output dead zone. Neural Comput. Appl. 28(1), 145–153 (2017)
Yang, Y., Yue, D.: Distributed adaptive fault-tolerant control of pure-feedback nonlinear multi-agent systems with actuator failures. Neurocomputing 221, 72–84 (2017)
Yin, S., Shi, P., Yang, H.: Adaptive fuzzy control of strict-feedback nonlinear time-delay systems with unmodeled dynamics. IEEE Trans. Syste. Man Cybern. 46(8), 1926–1938 (2016)
Yoo, S.J.: Distributed adaptive containment control of uncertain nonlinear multi-agent systems in strict-feedback form. Automatica 49(7), 2145–2153 (2013)
Yoo, S.J.: Distributed consensus tracking for multiple uncertain nonlinear strict-feedback systems under a directed graph. IEEE Trans. Neural Netw. 24(4), 666–672 (2013)
Zhang, T., Ge, S.S.: Adaptive neural network tracking control of mimo nonlinear systems with unknown dead zones and control directions. IEEE Trans. Neural Netw. 20(3), 483–497 (2009)
Zhang, Z., Chen, W.: Adaptive output feedback control of nonlinear systems with actuator failures. Inf. Sci. 179(24), 4249–4260 (2009)
Zhang, Z., Xu, S., Guo, Y., Chu, Y.: Robust adaptive output-feedback control for a class of nonlinear systems with time-varying actuator faults. Int. J. Adapt. Control Signal Process. 24(9), 743–759 (2010)
Zong, X., Li, T., Zhang, J.: Consensus conditions of continuous-time multi-agent systems with additive and multiplicative measurement noises. SIAM J. Control Optim. 56(1), 19–52 (2018)
Acknowledgements
This study was supported in part by the National Natural Science Foundation of China under Grant 61573108, in part by the Natural Science Foundation of Guangdong Province 2016A030313715, and in part by Guangdong Province Universities and Colleges Pearl River Scholar Funded Scheme.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: Proof of Theorem 1
Appendix: Proof of Theorem 1
The following overall Lyapunov function candidate function V is employed to analyze the stability in the total closed-loop system:
Then, (56) is rewritten as
If the following compact set holds, \({\dot{V}} < 0\),
which implies that
According to the similar results in [14], all the signals in the closed-loop system are bounded. Based on the work in [34], we have \(\left\| y-y_0\right\| \le \Vert z_{.1}\Vert /\left( {\underline{\sigma }}\right. \left. (L + B)\right) \), where \({\underline{\sigma }}(L + B)\) is the minimum singular value of \(L + B\), \(z_{.1} = [z_{1,1}, z_{2,1}, \ldots , z_{N,1}]^{\mathrm{T}}\). It can be shown that, for \(\forall {\bar{\varepsilon }} > 0 \),
It is worth mentioning that the desired tracking error \(\left\| y-y_0\right\| \) can be controlled in a small neighborhood by tuning the parameters \(k_{i,0}\), \(r_i\), \(a_{i,m}\), \(c_{i,m}\)\((i=1, \ldots , N, ~ m=1, \ldots , n_i)\). In order to obtain the desired tracking error, the parameters \(k_{i,0}\), \(r_i\), \(a_{i,m}\), \(c_{i,1}\), \(\mu _{i}\), \({\bar{\varepsilon }}_{i,m}\) would be tuned in a appropriate set. According to Definition 1, the distributed consensus tracking error \(\left\| y-y_0\right\| \) in the closed-loop system is CSUUB.
The proof is completed.
Rights and permissions
About this article

Cite this article
Liu, D., Liu, Z., Chen, C.L.P. et al. Distributed adaptive neural control for uncertain multi-agent systems with unknown actuator failures and unknown dead zones. Nonlinear Dyn 99, 1001–1017 (2020). https://doi.org/10.1007/s11071-019-05321-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-019-05321-x