
Abstract
This paper focuses on the identification problem of Hammerstein systems with dual-rate sampling. Using the key-term separation principle, we derive a regression identification model with different input updating and output sampling rates. To solve the identification problem of the dual-rate Hammerstein systems with the unmeasurable variables in the information vector, an auxiliary model-based recursive least squares algorithm is presented by replacing the unmeasurable variables with their corresponding recursive estimates. Convergence properties of the algorithm are analyzed. Simulation results show that the proposed algorithm can estimate the parameters of a class of nonlinear systems.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Many identification methods focus on discrete-time systems with same sampling rates [1–4]. However, in many industry applications, the inputs and outputs have different updating rates due to the sensor limits. The systems operating at different input and output sampling rates are called multirate systems [5–7]. Dual-rate systems are a class of multirate systems, where the output sampling period is an integer multiple of the input updating period [8, 9]. Dual-rate systems are often encountered in control, communication, signal processing. There exist several methods to deal with dual-rate system identification, i.e., the lifting technique [10], the polynomial transformation technique [9]. Ding et al. [11] studied the hierarchical least squares identification for linear SISO systems with dual-rate sampled-data and presented a stochastic gradient identification algorithm for estimate the parameters of the dual-rate systems. Liu et al. presented a least squares estimation algorithm for a class of non-uniformly sampled systems based on the hierarchical identification principle [12–14].
Hammerstein systems, which consist of a static nonlinear subsystem followed by a linear dynamic subsystem, can represent many nonlinear dynamic systems [15–22]. There exists a large amount of work on the parametric model identification of Hammerstein systems [23]. Some existing contributions assumed that the nonlinearity is a polynomial combination of a known order in the input [24]. Recently, Li et al. [25] presented a maximum likelihood least squares identification algorithm for input nonlinear finite impulse response moving average systems.
Recursive algorithms are a class of basic parameter estimation approaches which are suitable for on-line applications [26–29]. For decades, recursive algorithms have been used to estimate the parameters of the linear and nonlinear systems [30–32]. Xiao et al. [33] analyzed the convergence of the recursive least squares (RLS) algorithms for controlled auto-regression models. Wang [34] presented a filtering and auxiliary model-based RLS (AM-RLS) identification algorithm to estimate the parameter of output error moving average systems. This paper extends the identification algorithms from the original single-rate Hammerstein model to the dual-rate sampled-data one. The basic idea is, by means of the key-term separation principle, to present a dual-rate Hammerstein model and then derive the AM-RLS algorithm for the proposed model.
The rest of this paper is organized as follows: Sect. 2 presents the identification model of Hammerstein nonlinear systems with dual-rate sampling. Section 3 derives a AM-RLS algorithm for Hammerstein nonlinear systems with dual-rate sampling. Section 4 proves the convergence of the proposed algorithm. Section 5 provides examples to illustrate the effectiveness of the proposed algorithm. Some conclusions are summarized in Sect. 6.
2 Problem formulation
Let us introduce some notation first. The superscript T denotes the matrix transpose; the norm of a matrix \({\varvec{X}}\) is defined by \(\Vert {\varvec{X}}\Vert ^{2}:=\mathrm{tr}[{\varvec{X}}{\varvec{X}}^{\tiny \text{ T }}]\); \(\mathbf{1}_n\) being an \(n\)-dimensional column vector whose elements are all 1; \(\lambda _{\min }[{\varvec{X}}]\) represents the minimum eigenvalue of the symmetric matrix \({\varvec{X}}\); \(f(t)=O(g(t))\) represents that for \(g(t)\geqslant 0\), if there exists a positive constant \(\delta _{1}\) such that \(\Vert f(t)\Vert \geqslant \delta _{1}g(t)\).
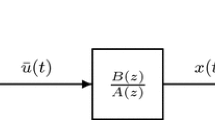
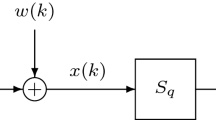
Consider a dual-rate Hammerstein output error system shown in Fig. 1, where \(y(k)\) is the measured output, \(u(k)\) and \(\bar{u}(k)\) are the input and output of the nonlinear subsystem, respectively, \(S_{qh}\) is a sampler with period \(qh\) (\(q\) being a positive integer), which yields a discrete-time signal \(y(kq)\). The input–output data available are \(\{u(k): k=0,1,2,\ldots \}\) at the fast rate, and \(\{y(kq): k=0, 1, 2,\ldots \}\) at the slow rate. Thus, the intersample outputs \(\{y(kq+i), i=1,2,\ldots ,q-1\}\), are not available. Here, we refer to \(\{u(k),y(kq)\}\) as the dual-rate measurement data. \(\bar{u}(k)\) is assumed to be a linear combination of known nonlinear basis functions \({\varvec{f}}:=(f_1,f_2,\ldots ,f_n)\) [35, 36]:
\(G(z):=\frac{B(z)}{A(z)}\) is the transfer function of the linear subsystem, and \(A(z)\) and \(B(z)\) are the polynomials in \(z^{-1}\) (\(z^{-1}\) is the unit backward shift operator, i.e., \(z^{-1}u(k)=u(k-1)\)):
From Fig. 1, we have
Replacing \(k\) in (2) with \(kq\) gives
Equation (3) can be expressed as
Referring to [37], without loss of generality, we set the coefficient of the key-term \(\bar{u}(kq)\) on the right-hand side to be 1 (i.e., \(\beta _0=1\)). Inserting (1) into (5) gives
The objective of this paper is to present a RLS algorithm to estimate the parameters \(\alpha _i,\,\beta _i\) and \(\gamma _i\) for the dual-rate Hammerstein output error systems using the key-term separation principle and the auxiliary model identification idea.

The Hammerstein system with dual-rate sampling
3 The auxiliary model-based RLS algorithm
This section derives the AM-RLS algorithm for the dual-rate sampled-data Hammerstein output error model.
Define the information vector \({\varvec{\varphi }}(kq)\) and the parameter vector \({\varvec{\theta }}\) as
Equation (6) can be written in a regressive form,
Define a quadratic criterion function,
Let \(\hat{{\varvec{\theta }}}(kq)\) be the estimate of \({\varvec{\theta }}\) at time \(kq\). Minimizing \(J({\varvec{\theta }})\), gives the following RLS algorithm:
Because the information vector \({\varvec{\varphi }}(kq)\) in (8) contains unknown inner variables \(w(kq-j)\) and \(\bar{u}(kq-j)\), the standard least squares method fails to give the estimate of the parameter vector \({\varvec{\theta }}\). The solution is based on the auxiliary model identification idea [38–40]: to replace the unmeasurable term \(w(kq+i)\) in \({\varvec{\varphi }}(kq)\) with its estimate,
Replacing \(\gamma _i\) in (2) with its estimate \(\hat{\gamma }_i(kq)\), we can get the estimate \(\hat{u}(kq+i)\) of \(\bar{u}(kq+i)\):
Define the estimate of \({\varvec{\varphi }}(kq)\):
Using \(\hat{{\varvec{\varphi }}}(kq)\) in place of \({\varvec{\varphi }}(kq)\) in (8) and (10), we have
Equations (9), (11)–(15) form the AM-RLS algorithm for system by using the key-term separation principle, which can be summarized as
To initialize the algorithm, we take \(\hat{{{\varvec{\theta }}}}(0)\) to be a small real vector, e.g., \(\hat{{{\varvec{\theta }}}}(0)=\mathbf{1}_{n_0}/p_0\) and with \(p_0\) normally a large positive number (e.g., \(p_0=10^6\)), and \({\varvec{P}}(0)=p_0{\varvec{I}}\) with \({\varvec{I}}\) representing an identity matrix of appropriate dimension.
4 Convergence of parameter estimation
In this section, we focus on analyzing the convergence properties of the proposed RLS algorithm which is under weak conditions. Assume that \(\{v(kq),\mathcal {F}_{kq}\}\) is a martingale difference sequence defined on a probability space \(\{\varOmega ,\mathcal {F},P\}\), where \(\{\mathcal {F}_{kq}\}\) is the \(\sigma \) algebra sequence generated by \(\{v(kq)\}\). The noise sequence \(\{v(kq)\}\) satisfies the following assumptions [41, 42]:
Defining \(r(kq)=\mathrm{tr}[{\varvec{P}}^{-1}(kq)]\), it follows that
Theorem 1
For the systems in (7) and the algorithm (16)–(21), if assumptions (A1) and (A2) hold, for any \(c>1\), the parameter estimation error associated with the AM-LS algorithm for the dual-rate sampled-data Hammerstein output error model satisfies:
Proof
Define the parameter estimation error vector
where
Define a non-negative definite function
Using (7), (24), and (25), we have
Here, we have used the relation
Since \(\tilde{y}(kq),\,\hat{{\varvec{\varphi }}}^{\tiny \text{ T }}(kq){\varvec{P}}(kq)\hat{{\varvec{\varphi }}}(kq)\), and \(T(kq-q)\) are uncorrelated with \(v(kq)\) and \({\mathcal {F}}_{kq-q}\) are measurable, taking the conditional expectation on both sides with respect to \({\mathcal {F}}_{kq-q}\) and using (A1) and (A2) give
Let
Since \({\varvec{P}}^{-1}(kq)\) is non-decreasing, we have
Applying the martingale convergence theorem to the above inequality, we conclude that \(V(kq)\) converges a.s. to a finite random variable \(V_{0}\), i.e.,
From the definition of \(V(kq)\), we have
This gives the conclusion of Theorem 1. \(\square \)
Remark
Theorem 1 shows that if the noise has a bounded variance, then the parameter estimates converge to the true values.
5 Numerical examples
In this section, three examples are given to illustrate effectiveness of the AM-RLS algorithm.
Example 1
Consider the following Hammerstein system with dual-rate sampling,
In simulation, \(\{u(k)\}\) is taken as a persistent excitation signal sequence with zero mean and unit variance, and \(\{v(k)\}\) as a white noise sequence with zero mean and variance \(\sigma ^{2}=0.50^{2}\) and \(\sigma ^{2}=2.00^{2}\), respectively. Applying the proposed algorithm in (16)–(21) to estimate the parameters \((\alpha _i,\beta _i,\gamma _i)\) of this system, the parameter estimates and their errors with different noise variances are shown in Tables 1 and 2. The parameter estimation errors \(\delta :=\Vert \hat{{\varvec{\theta }}}(kq)-{\varvec{\theta }}\Vert /\Vert {\varvec{\theta }}\Vert \) versus \(k\) are shown in Fig. 2.

The estimation errors \(\delta \) versus \(k\) with \(\sigma ^2=0.50^2\) and \(\sigma ^2=2.00^2\) in Example 1

The estimation errors \(\delta \) versus \(k\) with \(\sigma ^2=0.50^2\) for Example 2
Example 2
Consider a Hammerstein system in Example 1 with
Example 3
Consider a nonlinear subsystem in Example 1 with
The simulation conditions of Examples 2 and 3 are the same as in Example 1 with the noise variance \(\sigma ^{2}=0.50^{2}\). The parameter estimation errors \(\delta \) versus \(k\) are shown in Figs. 3 and 4.

The estimation errors \(\delta \) versus \(k\) with \(\sigma ^2=0.50^2\) for Example 3
From Tables 1 and 2 and Figs. 2, 3, and 4, we can draw the following conclusions:
-
It is clear that the estimation errors become smaller (in general) as the recursive step \(k\) increases—see Tables 1 and 2.
-
A higher noise level results in a slower convergence rate of the parameter estimates; after about \(k=5000\), the parameter estimates converge to their true values—see the error curves in Fig. 2 and the estimation errors of the last columns of Tables 1 and 2.
-
Under the same noise level, a complex model structure results in a slower convergence rate—see Figs. 3 and 4.
-
Increasing the complexity of the nonlinear subsystem causes a slower convergence rate than increasing the complexity of the linear subsystem—see Figs. 3 and 4.
6 Conclusions
In this paper, we present a RLS identification algorithm for dual-rate sampled-data Hammerstein nonlinear systems. Using the key-term separation principle, we construct the identification model of Hammerstein nonlinear systems with dual-rate sampling. All the model parameters can be estimated by the AM-RLS algorithm. The simulation results verified the effectiveness of the proposed algorithm. The method in the paper can combine iterative methods [43–47] to study identification problems for other linear or nonlinear systems [48–52].
References
Ding, F.: System Identification—New Theory and Methods. Science Press, Beijing (2013)
Ding, F.: System Identification—Performances Analysis for Identification Methods. Science Press, Beijing (2014)
Liu, Y.J., Xiao, Y.S., Zhao, X.L.: Multi-innovation stochastic gradient algorithm for multiple-input single-output systems using the auxiliary model. Appl. Math. Comput. 215(4), 1477–1483 (2009)
Liu, Y.J., Sheng, J., Ding, R.F.: Convergence of stochastic gradient estimation algorithm for multivariable ARX-like systems. Comput. Math. Appl. 59(8), 2615–2627 (2010)
Liu, X.G., Lu, J.: Least squares based iterative identification for a class of multirate systems. Automatica 46(3), 549–554 (2010)
Liu, Y.J., Xie, L., et al.: An auxiliary model based recursive least squares parameter estimation algorithm for non-uniformly sampled multirate systems. Proc. Inst. Mech. Eng. 223(4), 445–454 (2009)
Ding, F., Qiu, L., Chen, T.: Reconstruction of continuous-time systems from their non-uniformly sampled discrete-time systems. Automatica 45(2), 324–332 (2009)
Ding, J., Shi, Y., et al.: A modified stochastic gradient based parameter estimation algorithm for dual-rate sampled-data systems. Digit. Signal Process. 20(4), 1238–1249 (2010)
Ding, F., Liu, X.P., Yang, H.Z.: Parameter identification and intersample output estimation for dual-rate systems. IEEE Trans. Syst. Man Cybern. A 38(4), 966–975 (2008)
Ding, F., Chen, T.: Hierarchical identification of lifted state-space models for general dual-rate systems. IEEE Trans. Circuits Syst. I 52(6), 1179–1187 (2005)
Ding, J., Ding, F., et al.: Hierarchical least squares identification for linear SISO systems with dual-rate sampled-data. IEEE Trans. Autom. Control 56(11), 2677–2683 (2011)
Liu, Y.J., Ding, F., Shi, Y.: Least squares estimation for a class of non-uniformly sampled systems based on the hierarchical identification principle. Circuits Syst. Signal Process. 31(6), 1985–2000 (2012)
Ding, F., Chen, T.: Hierarchical gradient-based identification of multivariable discrete-time systems. Automatica 41(2), 315–325 (2005)
Ding, F., Chen, T.: Hierarchical least squares identification methods for multivariable systems. IEEE Trans. Autom. Control 50(3), 397–402 (2005)
Chen, J., Zhang, Y., et al.: Gradient-based parameter estimation for input nonlinear systems with ARMA noises based on the auxiliary model. Nonlinear Dyn. 72(4), 865–871 (2013)
Hu, P.P., Ding, F.: Multistage least squares based iterative estimation for feedback nonlinear systems with moving average noises using the hierarchical identification principle. Nonlinear Dyn. 73(1–2), 583–592 (2013)
Ding, F., Ma, J.X., Xiao, Y.S.: Newton iterative identification for a class of output nonlinear systems with moving average noises. Nonlinear Dyn. 74(1–2), 21–30 (2013)
Deng, K.P., Ding, F.: Newton iterative identification method for an input nonlinear finite impulse response system with moving average noise using the key variables separation technique. Nonlinear Dyn. (2014). doi:10.1007/s11071-013-1202-3
Shen, Q.Y., Ding, F.: Iterative estimation methods for Hammerstein controlled autoregressive moving average systems based on the key-term separation principle. Nonlinear Dyn. (2014). doi:10.1007/s11071-013-1097-z
Wang, D.Q., Ding, F., Chu, Y.Y.: Data filtering based recursive least squares algorithm for Hammerstein systems using the key-term separation principle. Inf. Sci. 222, 203–212 (2013)
Ding, F., Shi, Y., Chen, T.: Auxiliary model-based least-squares identification methods for Hammerstein output-error systems. Syst. Control Lett. 56(5), 373–380 (2007)
Wang, D.Q., Ding, F., Liu, X.M.: Least squares algorithm for an input nonlinear system with a dynamic subspace state space model. Nonlinear Dyn. 75(1-2), 49–61 (2014)
Ding, F., Shi, Y., Chen, T.: Gradient-based identification methods for Hammerstein nonlinear ARMAX models. Nonlinear Dyn. 45(1–2), 31–43 (2006)
Xiao, Y.S., Yue, N.: Parameter estimation for nonlinear dynamical adjustment models. Math. Comput. Model. 54(5–6), 1561–1568 (2011)
Li, J.H., Ding, F., Yang, G.W.: Maximum likelihood least squares identification method for input nonlinear finite impulse response moving average systems. Math. Comput. Model. 55(3–4), 442–450 (2012)
Ding, F., Duan, H.H.: Two-stage parameter estimation algorithms for Box–Jenkins systems. IET Signal Process. 7(8), 646–654 (2013)
Shi, Y., Fang, H.: Kalman filter based identification for systems with randomly missing measurements in a network environment. Int. J. Control 83(3), 538–551 (2010)
Li, H., Shi, Y.: Robust H-infinity filtering for nonlinear stochastic systems with uncertainties and random delays modeled by Markov chains. Automatica 48(1), 159–166 (2012)
Ding, F.: Combined state and least squares parameter estimation algorithms for dynamic systems. Appl. Math. Model. 38(1), 403–412 (2014)
Ding, J., Ding, F.: Bias compensation based parameter estimation for output error moving average systems. Int. J. Adapt. Control Signal Process. 25(12), 1100–1111 (2011)
Ding, F.: Coupled-least-squares identification for multivariable systems. IET Control Theory Appl. 7(1), 68–79 (2013)
Ding, F.: Hierarchical multi-innovation stochastic gradient algorithm for Hammerstein nonlinear system modeling. Appl. Math. Model. 37(4), 1694–1704 (2013)
Xiao, Y.S., Ding, F., et al.: On consistency of recursive least squares identification algorithms for controlled auto-regression models. Appl. Math. Model. 32(11), 2207–2215 (2008)
Wang, D.Q.: Least squares-based recursive and iterative estimation for output error moving average systems using data filtering. IET Control Theory Appl. 5(14), 1648–1657 (2011)
Ding, F., Liu, X.P., Liu, G.: Identification methods for Hammerstein nonlinear systems. Digit. Signal Process. 21(2), 215–238 (2011)
Zhou, L.C., Li, X.L., Pan, F.: Gradient based iterative parameter identification for Wiener nonlinear systems. Appl. Math. Model. 37(16–17), 8203–8209 (2013)
Vörös, J.: Parametric identification of systems with general backlash. Informatica 23(2), 283–298 (2012)
Ding, F., Ding, J.: Least squares parameter estimation with irregularly missing data. Int. J. Adapt. Control Signal Process. 24(7), 540–553 (2010)
Zhou, L.C., Li, X.L., Pan, F.: Gradient-based iterative identification for MISO Wiener nonlinear systems: application to a glutamate fermentation process. Appl. Math. Lett. 26(8), 886–892 (2013)
Li, X.L., Ding, R.F., Zhou, L.C.: Least-squares-based iterative identification algorithm for Hammerstein nonlinear systems with non-uniform sampling. Int. J. Comput. Math. 90(7), 1524–1534 (2013)
Ding, F., Chen, T.: Combined parameter and output estimation of dual-rate systems using an auxiliary model. Automatica 40(10), 1739–1748 (2004)
Ding, F., Chen, T.: Parameter estimation of dual-rate stochastic systems by using an output error method. IEEE Trans. Autom. Control 50(9), 1436–1441 (2005)
Ding, F., Liu, X.M., et al.: Hierarchical gradient based and hierarchical least squares based iterative parameter identification for CARARMA systems. Signal Process. 97, 31–39 (2014)
Ding, F.: Decomposition based fast least squares algorithm for output error systems. Signal Process. 93(5), 1235–1242 (2013)
Ding, F.: Two-stage least squares based iterative estimation algorithm for CARARMA system modeling. Appl. Math. Model. 37(7), 4798–4808 (2013)
Ding, F., Liu, X.G., Chu, J.: Gradient-based and least-squares-based iterative algorithms for Hammerstein systems using the hierarchical identification principle. IET Control Theory Appl. 7(2), 176–184 (2013)
Wang, D.Q., Ding, F.: Least squares based and gradient based iterative identification for Wiener nonlinear systems. Signal Process. 91(5), 1182–1189 (2011)
Wang, D.Q., Ding, F.: Hierarchical least squares estimation algorithm for Hammerstein–Wiener systems. IEEE Signal Process. Lett. 19(12), 825–828 (2012)
Liu, Y.J., Ding, F., Shi, Y.: An efficient hierarchical identification method for general dual-rate sampled-data systems. Automatica 50 (2014). doi:10.1016/j.automatica.2013.12.025
Zhu, D.Q., Kong, M.: Adaptive fault-tolerant control of nonlinear system: an improved CMAC based fault learning approach. Int. J. Control. 80(10), 1576–1594 (2007)
Zhu, D.Q., Gu, W.: Sensor fusion for integrated circuit fault diagnosis using a belief function model. Int. J. Distrib. Sens. Netw. 6(4), 247–261 (2008)
Zhu, D.Q., Liu, Q., Yang, Y.S.: An active fault-tolerant control method of unmanned underwater vehicles with continuous and uncertain faults. Int. J. Adv. Robot. Syst. 5(4), 411–418 (2008)
Acknowledgments
This work was supported by the National Natural Science Foundation of China, the Fundamental Research Funds for the Central Universities (JUDCF11042, JUDCF12031), the PAPD of Jiangsu Higher Education Institutions and the 111 Project (B12018)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Li, X., Zhou, L., Sheng, J. et al. Recursive least squares parameter estimation algorithm for dual-rate sampled-data nonlinear systems. Nonlinear Dyn 76, 1327–1334 (2014). https://doi.org/10.1007/s11071-013-1212-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-013-1212-1