
Abstract
One of the important recent advances in the field of hurricane/storm modelling has been the development of high-fidelity numerical simulation models for reliable and accurate prediction of wave and surge responses. The computational cost associated with these models has simultaneously created an incentive for researchers to investigate surrogate modelling (i.e. metamodeling) and interpolation/regression methodologies to efficiently approximate hurricane/storm responses exploiting existing databases of high-fidelity simulations. Moving least squares (MLS) response surfaces were recently proposed as such an approximation methodology, providing the ability to efficiently describe different responses of interest (such as surge and wave heights) in a large coastal region that may involve thousands of points for which the hurricane impact needs to be estimated. This paper discusses further implementation details and focuses on optimization characteristics of this surrogate modelling approach. The approximation of different response characteristics is considered, and special attention is given to predicting the storm surge for inland locations, for which the possibility of the location remaining dry needs to be additionally addressed. The optimal selection of the basis functions for the response surface and of the parameters of the MLS character of the approximation is discussed in detail, and the impact of the number of high-fidelity simulations informing the surrogate model is also investigated. Different normalizations of the response as well as choices for the objective function for the optimization problem are considered, and their impact on the accuracy of the resultant (under these choices) surrogate model is examined. Details for implementation of the methodology for efficient coastal risk assessment are reviewed, and the influence in the analysis of the model prediction error introduced through the surrogate modelling is discussed. A case study is provided, utilizing a recently developed database of high-fidelity simulations for the Hawaiian Islands.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Hurricane/storm risk assessment has received increased attention in the past decade, partly in response to the destructive 2004, 2005 and 2008 hurricane seasons (Dietrich et al. 2010; Kennedy et al. 2011a, b). A significant recent advance in this field has been the development of high-fidelity numerical simulation models for reliable and accurate prediction of surge responses for specific hurricane events or regions (Resio and Westerink 2008). These models permit a detailed representation of the hydrodynamic processes, albeit at a greatly increased computational effort, since they typically require thousands of computational hours for each simulation. This high computational cost has created the incentive to adopt surrogate modelling (also frequently referenced as metamodeling) and interpolation/regression methodologies that use information from existing high-fidelity simulations, that is, a database, to efficiently approximate hurricane/storm responses for different scenarios that do not belong in this database. This has been further motivated by the fact that various such databases are constantly created and updated for regional flooding and coastal hazard studies (Resio et al. 2007; Niedoroda et al. 2010; Kennedy et al. 2012).
Though different potential implementations of the aforementioned approximation approaches exist, one of the most important ones (Song et al. 2012) is within the context of the joint probability method (JPM) hurricane risk assessment framework (Ho and Myers 1975; Myers 1975), a framework that has become increasingly popular in recent years (Resio et al. 2009; Toro et al. 2010a, b; Condon and Sheng 2012). JPM relies on a simplified description of hurricane scenarios through a small number of model parameters. Description of the uncertainty in these parameters, through appropriate probability models, leads to a probabilistic characterization of the coastal risk. This risk is ultimately expressed as a probabilistic integral over the uncertain parameter space, and its estimation requires numerical evaluation of the hurricane responses for a large number of scenarios resulting from the adopted probabilistic description for the model parameters (Toro et al. 2007; Resio et al. 2009; Toro et al. 2010a). Adoption of the aforementioned high-fidelity models significantly increases the associated computational cost, making surrogate modelling approximations a critical tool (but note not the only available approach) for efficient implementation of JPM.
Motivated by these facts, low-cost, dimensional surge response functions were developed by Irish et al. (2009), but they only addressed the variation with respect to hurricane storm size, intensity, and track and were restricted to hurricane surge only and limited to specific locations of interest on the Texas coast. Udoh and Irish (2011) presented preliminary discussions for extending these surge response functions to address additional hurricane model parameters, the forward speed and heading, whereas Song et al. (2012) recently investigated the influence of regional changes in bathymetry on the surge response functions. Das et al. (2010) developed a methodology for selecting the most appropriate storm within some given database, without extending their approach to interpolation within the database. In Taflanidis et al. (2012), the use of response surface approximations (RSAs) was proposed as a surrogate model. Though this approach cannot provide the physical insight that the aforementioned dimensional surge response functions can, it has some important advantages: (1) responses for a given hurricane scenario may be calculated rapidly for hundreds of thousands of locations in the coastal region of interest, and for any modelled quantity representing hurricane impact (e.g. surge, wave height, runup), (2) variation for any parameter used to describe the hurricane characteristics may be considered, and (3) new information (when available) can be directly and immediately added in the database of high-fidelity simulations to improve accuracy. In the aforementioned study by Taflanidis et al. (2012), though, the direct use of RSAs was considered, adopting existing general guidelines for their implementation. There was no effort to investigate the optimization of their characteristics (such as selection of basis functions or normalization techniques of the response) for the specific application of interest, to discuss validation procedures or to address potential differences in the implementation for different hurricane/storm outputs.
This paper seeks to address this latter knowledge gap by discussing the systematic implementation and more importantly the optimization of moving least squares (MLS) RSAs for hurricane wave and surge predictions. We offer significant advancements in that (1) the optimal selection of the basis functions for the response surface and of the parameters of the MLS character of the approximation is examined, (2) the impact of the number of high-fidelity simulations informing the surrogate modelling is investigated, (3) different normalizations of the response are proposed to improve accuracy, (4) special attention is given to predicting the surge in inland locations for which the possibility of the location remaining dry needs to be additionally addressed, and (5) the model prediction error introduced through the surrogate modelling is explicitly optimized, and its potential impact in the analysis is investigated. As a case study, an application to the Island of Oahu in Hawaii is discussed, using the high-fidelity simulation database described in Kennedy et al. (2012).
In the following section, the general hurricane modelling approach is presented. In Sect. 3, RSAs are first reviewed, with enough information to support the understanding/insight for the optimization problem introduced later, and then, details for implementation for the problem of interest are discussed, extending to both the prediction of the surge in inland locations as well as to statistical approaches for quantifying the accuracy of RSAs for problems involving a large number of response quantities. Section 4 introduces the optimization framework, including both the formulation of the objective function and numerical tools for solving the associated optimization problem, and finally, Sect. 5 discusses the case study considered and investigates different trends in the RSA implementation.
2 Modelling and approximation assumptions
The foundation for the approximation of hurricane/storm responses through surrogate/interpolation models (Resio et al. 2009) is the parameterization of each hurricane/storm event by a small number of model parameters, corresponding to its characteristics at landfall such as (1) landfall location x o , (2) track heading θ, (3) central pressure c p , (4) forward speed v f , (5) radius of maximum winds R m , (6) tide level e t , and (7) Holland B parameter B. Typically, a constant tide level is assumed, and the Holland B term is related (using regional approximations) to the rest of the hurricane parameters (Resio et al. 2009), leading to the following definition of the model parameter vector, x, describing each hurricane scenario (for both the high-fidelity and surrogate models)
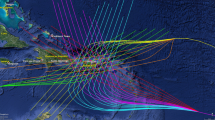
where []T denotes a matrix transpose. Note that the discussions in this paper can be directly extended to include the tide level and Holland term (or any other appropriate hurricane characteristic) as model parameters. The implicit assumption is, though, that x is low dimensional (includes <8–10 parameters). This is necessary for facilitating an efficient description through a surrogate model, without requiring an overly large database to adequately describe the variability with respect to all the model parameters. In this context, the temporal and spatial variability of the hurricane track and characteristics prior to landfall are typically addressed (Resio et al. 2009) by appropriate selection of the track-history prior to landfall (e.g. giving the track a typical curvature over time for the appropriate landfall heading), so that expected variations based on historical data are adequately described. Figure 1 shows the different tracks from the study by Kennedy et al. (2012) that will be later used in the illustrative example.

Basic storm tracks (A–E) considered in the study (Kennedy et al. 2012). In parenthesis, the angle of final approach (track heading) θ (clockwise from South) is indicated
For characterizing, now, the hurricane/storm response in the coastal region examined multiple variables may be of interest. Examples include (1) the storm surge (ζ) (still water level, defined as the average sea level over a several minute period, (2) the significant wave height (H s ) (possibly along with the corresponding peak period T p ), (3) the wave runup level) defined as the sea level including runup of wind waves on the shore, or (4) the time that normally dry locations are inundated. Response variables (1)–(3) may refer to maximum responses over the entire hurricane history, or to responses at specific time instances prior to landfall. In this setting, let z(x) denote the vector of response quantities of interest (wave, surge, and so forth) throughout all locations of interest. This vector, used ultimately to describe the hurricane/storm impact, will be referenced herein as the response vector. The ith component of vector z(x) is denoted by z i (x) and pertains to a specific response variable [any of the (1)–(4)] for a specific coastal location. The augmentation of these responses ultimately provides the n z -dimensional vector z(x). One significant advantage of the RSA advocated here is that no constraint is imposed for n z (i.e. multiple response outputs can be simultaneously addressed). Also, no special characteristics are exploited for z(x) thus providing versatility to the developed methodologies. Such characteristics could have been, for example, assumptions for specific variation patterns with respect to the components of x (as is utilized in dimensional response function approximations).
For a specific hurricane/storm scenario, described by the model parameter vector x, z(x) can be accurately estimated by numerical simulation, once an appropriate high-fidelity model is established (Resio and Westerink 2008; Westerink et al. 2008). Surrogate modelling methodologies can provide an approximation to z(x) using an available database of such high-fidelity simulations. If \( {\hat{\mathbf{z}}}({\mathbf{x}}) \) denote this approximation to z(x), then the relationship between z i (x) and \( \hat{z}_{i} ({\mathbf{x}}) \) is ultimately
where ε i is the prediction error between the surrogate model and the high-fidelity model, assumed to be zero mean (since the contrary indicates a bias) Gaussian random variable with standard deviation \( \sigma_{{\varepsilon_{i} }} \). This choice of probability distribution incorporates the largest amount of uncertainty (Taflanidis and Beck 2010), in terms of Information Entropy, under the constraints that only the mean and variance are known. The standard deviation \( \sigma_{{\varepsilon_{i} }} \), assumed herein to be independent of x (note that different assumptions could be made, that would though increase the complexity of estimating this standard deviation), can be finally approximated by comparison of the high-fidelity and surrogate models over a set of hurricane scenarios chosen to serve as validation points. This then completely defines the prediction error ε i and the relationship between z i (x) and \( \hat{z}_{i} ({\mathbf{x}}) \) in a probabilistic sense. Note that additional modelling errors can be incorporated in the relationship (2), for example the errors introduced by the approximate description of hurricane by a small dimensional vector x (Resio et al. 2009; Taflanidis et al. 2012) or the errors associated with the assumptions made about tides.
As discussed in the introduction, an important application of these concepts for modelling and approximation of hurricane/storm impacts is within the context of probabilistic hurricane risk assessment. Appendix 1 reviews briefly this implementation, focusing on the implications of using surrogate modelling methodologies and addressing the prediction error ε i .
3 Response surfaces for hurricane/storm response approximation
3.1 Problem formulation
Let \( {\bf {x}}\,=\,\left[{x_1}\cdots{{x_n}_{x}}\right]\,\in\,\Re\,^{n_x} \) be the n x dimensional vector of free variables defining the hurricane characteristics [with n x = 5 for definition (1)], \( {\bf {z}}\,=\,\left[{z_1}\cdots{z_{n_{z}}}\right]\,\in\,\Re\,^{n_z} \) the augmented vector of response quantities of interest, and assume that a database is available consisting of N h evaluations (frequently referenced as observations) of the response vector {z h; h = 1, …, N h } for different hurricane scenarios {x h; h = 1, …, N h }, obtained through an appropriate high-fidelity simulation model. An important characteristic for this database is the need to adequately describe the variability with respect to all hurricane parameters (i.e. all components of vector x). When developing such databases, this is established by considering for each hurricane characteristic x i a sufficient number of parameter values and then combining these values for all components of x to create a canonical grid, excluding combinations that are deemed improbable based on regional historical data. Further insight for this task may be found in (Resio et al. 2009).
Once the database is established, response surface methodologies can use its information to provide an approximation to z. For this purpose, the database is partitioned into three different subsets (not necessarily exclusive), a larger subset (this is the main subset) of N S simulations {x I; I = 1, …, N S } used to establish the surrogate model (frequently called support points), and two other small subsets, one with N c simulations used for optimizing the characteristics (tuning the parameters) of the response surface (frequently called control points) {x c; c = 1, …, N c }, and one with N E simulations {x p; p = 1, …, N E } used to evaluate the accuracy of the surrogate model (frequently called validation points). Note that when finally implementing the RSA (i.e. not at the development stage), the control and validation points should be added to the support points (expand the available database for informing RSA).
Instead of directly providing an estimate for z, the response surface can be established for a normalized or transformed response variable vector \( {\bf {y}}\,=\,\left[{y_1}\cdots{y_{n_{z}}}\right]\,\in\,\Re\,^{n_{z}} \), where the transformation is intended to improve accuracy and avoid numerical problems, for example when z is strictly a positive quantity but it is difficult to establish a surrogate model that can satisfy this requirement. Two common transformations we will investigate are
where μ i and σ i are the mean and standard deviation, respectively, for z i over the observation set {z h i h = 1, …, N h }
Note that the first transformation in (3) leads to a zero mean (over the observation set) variable y i with unit standard deviation, whereas the second can be implemented only when z i is strictly positive. These two transformations will be referenced herein as linear and log, respectively. They are both invertible, thus provide a one-to-one correspondence between each y i and z i , and once the approximation for y i has been established, the corresponding z i can be directly calculated.
3.2 Review of moving least squares response surface approximation for a scalar output
Response surfaces (Myers and Montgomery 2002) express any y i (x), through j = 1, …, N B preselected basis functions b j (x): \(\Re\,^{n_x}\) → ℜ through introduction of coefficients a ij {x}, that can be constant or depend on the location x for which the interpolation is established. The notation {.} is introduced to denote the latter potential dependence, and the RSA is ultimately expressed as
where b(x) is the vector of basis functions and a i {x} is the vector containing the coefficients for the basis functions. A common choice for basis functions is a full second order polynomial
leading to the following definitions for vectors b and a i .
The coefficients a i {x} are calculated by selecting a set of N S > N B support points, {x I; I = 1, …, N S } (subset of the available high-fidelity simulations) and by minimizing a weighted mean squared error over these points between y i (x) and its approximation, leading to the following choice (Taflanidis et al. 2012).
where the following quantities were defined
and diag[.] stands for a diagonal matrix. W{.} ultimately corresponds to the diagonal matrix of weights \( w\left( {d({\mathbf{x}};{\mathbf{x}}^{I} )} \right) \) for each support point x I, and these weights are dependent on the distance d between that point and the point x for which the approximation is established
with v k representing the relative weight for each component of x k (Taflanidis 2012).
The introduction of the distance-dependent weights establishes for each configuration x a weighted local averaging of the information obtained by the support points that are closer to it. Without these weights, the coefficient vector, a i , would be constant over the whole domain for x, which means that a global approximation would be established (global least squares). The accuracy of global approximations depends significantly on the selection of the basis functions, which should be chosen to resemble y i (x) as closely as possible, something that is not always straightforward. The MLS circumvents such problems by establishing the aforementioned weighted local approximation for a i {x} around each point in the interpolation domain (Breitkopf et al. 2005). Still, the efficiency of the MLS interpolation depends on the weighting function chosen, which should prioritize support points that are close to the approximation point and should vanish after an influence radius D d . This radius should be selected so that a sufficient number of neighbouring supporting points are included to avoid singularity in the solution for a i {x}, or equivalently so that M in (9) is invertible (this means that at least N B support points need to be included within the domain defined by D d , though typically a much higher value is suggested). The exponential type of weighting function will be used in this study
where c and k are free parameters to be selected (optimised) for improved accuracy. The relative weights v k ultimately define the moving character of the approximation within the different directions in the x space and should be chosen to (1) establish a normalization for the different components of x, but more importantly (2) provide higher importance for components that have larger influence on the values of z i (x) (Taflanidis 2012).
Finally combining Eqs. (5) and (8) yields the MLS RSA expression
which involves simple matrix manipulations and requires for each configuration x evaluation only of the basis vector b(x) at that point as well as of matrices M −1{x} and L{x} through Eq. (9). Once y i is obtained, then, z i may be directly calculated by the inverse of the initial respective transformation in Eq. (3). Note that the information from the database for z i (and ultimately y i ) influences only vector F i ; thus, updated information (from new high-fidelity simulations) can be directly incorporated into it. It is important to also stress that this response surface approach uses no implicit assumptions for the characteristics of z i , as such can be used for any response variable of interest.
Figure 2 presents an illustrative example for a 2-D problem; it includes a plot of the exact function z i (x) [part (a)], the location of the support points and the value of z i (x) at these points [part (b)] and finally, the global and MLS approximations using quadratic basis functions [parts (c), (d)], respectively. In this case, a quadratic approximation provides a poor fit to z i (x), and so the global response surface cannot efficiently describe z i (x). On the other hand, the MLS approach provides an accurate response surface approximation to z i (x).

Illustrative example for response surface approximation implementation
3.3 Evaluation of fit and relationship to prediction error
The fit of the RSA may be judged by evaluating some statistical measure of accuracy for the difference between \( \hat{z}_{i} \) and \( z_{i} \) for some database of validation points {x p; p = 1, …, N E } (subset of the available high-fidelity simulations). Two such measures commonly used are the coefficient of determination R 2 i and the mean percent error ME i . The first is given by
and denotes the proportion of variation in the data that is explained by the response surface model. A larger value of R 2 i (i.e. a value closer to 1) indicates a good fit. The mean percent error ME i is
Smaller values (i.e. close to zero) for ME i correspond to better fit in this case.
Finally, the standard deviation of the prediction error ε i can be estimated based on these validation points as (Grimmett and Stirzaker 2001)
This completely defines the probability model for the prediction error ε i since it has been already assumed to follow a zero mean Gaussian distribution. This standard deviation provides a third measure for evaluating the fit of the response surface approximation, one that is directly related to the statistical relationship between z i and \( \hat{z}_{i} \) as expressed by Eq. (2). Smaller values for \( \sigma_{{\varepsilon_{i} }} \) indicate better fit. For meaningful evaluation, this fit \( \sigma_{{\varepsilon_{i} }} \) needs to be normalized with respect to some proper threshold (note that contrary to the R 2 i and ME i , this third fit-measure \( \sigma_{{\varepsilon_{i} }} \) is not unitless, and thus, it needs to be normalised for proper comparisons) with the standard deviation for z i over the observation database, σ i , providing an appropriate candidate. This leads then to the normalized prediction error standard deviation
3.4 Response surface approximations for entire response vector z
The approximation for the entire vector z, consisting of the response quantities of interest in our coastal region (as discussed in Sect. 2), is finally established by approximating each y i through Eq. (12) and is ultimately expressed in a simple matrix form as
The initial output vector z is then calculated by the inverse of the respective transformation in Eq. (3). Thus, the MLS response surface approximation simultaneously provides the entire response vector of interest (that is a separate surrogate model does not need to be implemented independently for each response variable). Note that the expressions for b(x) and M{x} are identical to the case for scalar y i ; thus, the computational burden for approximating the entire y is similar to the one for approximating simply one of its components y i .
The overall fit of the response surface approximation can be then evaluated by averaging the coefficient of determination and mean error (ME) over all different response variables. This then provides the average coefficient of determination, AR2, and average mean error, AME, given, respectively, by
Similarly, with respect to the prediction error statistics, we have the average standard deviation, AS, or the average normalized standard deviation ANS
3.5 Implementation for surge prediction for inland locations
Though the response surface approximation described in Sect. 3.2 is a generalized one, that is, it does not depend on the characteristics of the response quantity z i , its implementation for inland locations needs to additionally address the challenge that they do not always get inundated (in other words dry locations might remain dry for some storms). Though some scenarios in the database include full information for the storm surge ζ i (when location i gets inundated), some provide only the information that the location remained dry.
One solution to this problem is to develop a surrogate model (Burges 1998) for the binary response quantity describing the condition of the location, that is, either wet or dry. This would require, of course, a separate surrogate model formulation for those components of the response vector (surge in inland locations). If we additionally need to know the storm surge, ζ i , some alternative approach needs to be established, one that allows each scenario in our database to provide full, exact or approximate information for ζ i . To facilitate this, the following approach is proposed. The storm surge ζ i is described with respect to the mean sea level as reference point. When a location remains dry, the incomplete information for the exact storm surge for it is resolved by selecting (approximating) as its storm surge the one corresponding to the nearest location (nearest node in our high-fidelity numerical model) that was inundated. Figure 3 illustrates this approximation for an example with a 1-D transect (note that this approach is ultimately applied in the context of the full high-fidelity model grid, not simply with respect to 1-D transects). Once the database is adjusted for ζ i (for the scenarios for which the location remained dry), the response surface approximation for ζ i follows directly the steps discussed in Sect. 3.2. Comparison of ζ i to the elevation of the location (defined with respect to the mean sea level as a reference point) provides finally the answer as to whether the location was inundated or not, whereas the storm surge elevation for the inundated locations is calculated by subtracting these two quantities. The latter is defined here as the height of inundation with respect to the ground. Thus, this approach allows us to gather simultaneous information about both the inundation (binary answer; yes or no) as well as the storm surge elevation. More importantly, it falls within the generalized response surface model discussed in the Sect. 3.2, as such it can be simultaneously implemented along with the other components of response vector z, as presented in Sect. 3.4. Of course, it does involve the approximation illustrated in Fig. 3 for enhancing the database with complete information for ζ i for all hurricane scenarios.

Illustration of selection of storm surge for an example with a 1-D transect. Corrections for the surge in location 3 are shown
4 Optimal selection for response surface characteristics
For a specific set of support points {x Ι; I = 1, …, N S }, the effectiveness, that is, fit, of the response surface approximation given by Eq. (17) depends on
-
(a)
Selection of type of basis functions b(x).
-
(b)
Selection of the parameters of the weighting function w{d(x; x I )}, for example c, k and D d for the weighting function given by Eq. (11).
-
(c)
Selection of the weighting vector v for the distance norm in Eq. (10).
Let s correspond to the vector representing these choices, then an optimal selection for s may be obtained by optimizing some expression that measures the fit of the response surface approximation. The choice for s should be the same for the entire response vector z as it is computationally impractical to implement Eq. (12) for each of the response quantities z j separately, rather than for the entire vector as in Eq. (17). Thus, the selected measure should quantify the fit over all response quantities of interest. Any of the expressions provided in the previous section in Eqs. (18) or (19) can be used for this purpose, but the prediction error statistics are a more appropriate choice since they directly characterize the difference between z i and \( \hat{z}_{i} \). These expressions, though, should be evaluated for a set of control points (from the available high-fidelity simulations) {x c; c = 1, …, N c }, that are different from the validation points. This is important so that the effectiveness of the response surface approximation is evaluated using a different part of the database from the one used to optimize its characteristics.
Using the relationships in Eq. (19), two different objective functions are thus defined
where s ultimately influences the approximation \( \hat{z}_{i} ({\mathbf{x}}) \), a dependence that is not explicitly noted to simplify notation. The first objective function [Eq. (20)] corresponds to summation of square errors (estimated over the control points) for all response variables, whereas the second [Eq. (21)] additionally incorporates weights for each of the response variables, chosen as the variance over the initial observation points. Thus, the second choice incorporates a normalization for each of the response variables towards the overall objective function. Similarly, weights can be incorporated for each of the response quantities, to prioritize accuracy for the responses in a specific region. This can be established by combining the term \( (1/\sigma_{i}^{2} ) \) with additional weights q i for each z i . Response components for which it is considered critical to have better accuracy (for example, surge in locations of importance such as emergency evacuation routes) should be given higher weights q i to increase their contribution towards the overall objective function value.
The selection for the optimal s, denoted s*, corresponds then to a nonlinear minimization problem
which may be solved through any appropriate numerical optimization algorithm. Note that the relationship between \( f({\mathbf{s}}) \) and s is not necessarily convex neither smooth. An easy explanation for the latter is the following. Selection of s impacts the distance d and thus the exact support points included in the domain D d for each x (note that since the weights for the remaining support points are zero they ultimately do not inform the surrogate model for that x). Thus, changes in s can lead to abrupt changes in the predictions for some z i (when the support points informing the surrogate model change) and ultimately abrupt changes to f(s) (depending on the contribution of those z i ’s to the total objective function). Thus, algorithms appropriate for global, non-smooth optimization problems—such as direct-search methods or genetic algorithms— should be chosen. In this study, the powerful numerical optimization toolbox TOMLAB is used (Holmstrom et al. 2009), which offers a wide range of state-of-the-art algorithms appropriate for nonlinear, global optimization applications.
It should be pointed out that this optimization approach, relying on a single set of control points, creates some dependency of the optimization results on the exact control points chosen, especially if these are not appropriately selected to represent the entire range of the observation points. Thus, it may promote a surrogate model that provides a targeted fit for scenarios with specific characteristics (the ones corresponding to these control points). Two alternative approaches exist for circumventing this problem (Loweth et al. 2010). In the first one, called leave-one-out cross-validation method, each observation point is removed from the data set to serve as a control point; then, the response surface is built using the remaining points, and the error between the approximated and actual response is calculated for the removed point. This is repeated for each of the observation points, and the total value of the error is calculated by summing all these individual contributions. The second approach, called k-fold method, is similar, but instead of systematically leaving out each observation point in turn, a random subset of k points is used as control points whilst the remaining points are used to build the surrogate model. The error is calculated between the approximate and actual values at each of the k control points, and this process is repeated multiple times with the total error calculated by summing over all repeated k-folds. Both these approaches, though, increase significantly the cost for evaluating the objective function (and performing the optimization) as they require formulation of the surrogate model multiple times, for different parts of the initial database. In this study, since we are primarily interested in exploring different trends (i.e. examine multiple cases), the single set of control points approach is adopted, as it reduces the computational burden of the optimization effort.
5 Case study
The proposed framework for response surface implementation for hurricane (and storm) wave/surge approximation is demonstrated here for an application to the Hawaiian Islands, focusing on the region around Oahu and using the database described in the study by Kennedy, et al. (2012). Both maximum (over the hurricane duration) significant wave heights H s and surge levels ζ will be used as response quantities of interest, and different cases will be considered for the response surface implementation to investigate (a) the impact of the transformations in Eq. (3), (b) the influence of the different objective functions (20) and (21), (c) the differences in the approximation for different response quantities, and (d) the impact of the number of support points informing the surrogate model. A brief review of the characteristics for the high-fidelity simulations is given first, and then, the discussion focuses on the surrogate modelling optimization. Finally, illustrative results are shown for implementation of the developed surrogate model for risk assessment, emphasizing the computational benefits.
5.1 High-fidelity model details
The model used in the development of the database of high-fidelity data to predict the surge and wave response was a combination of the ADCIRC and SWAN numerical models (Kennedy et al. 2012). The computational domain for the high-fidelity model encompasses a large portion of the northern Pacific Ocean from 0 to 35° North and from 139 to 169° West. The unstructured Hakou-2010-r2 grid (Kennedy et al. 2012) resolves the deep ocean with 10-km elements, incorporates all the main Hawaiian Islands (Hawai’i, Maui, Kaho’olawe, Lana’i, Moloka’i, Oahu, Kauai, and Ni’ihau), represents Oahu with significant detail up to 30 m resolution and extends inland to the 4-m-elevation contours. Figure 4 shows the grid for the high-fidelity model, which incorporates 1,590,637 vertices and 3,155,738 triangular elements. The coarsest resolution at the domain edge is up to 10 km, and finest resolution of 30 m is found in complex coastal areas and overland. For the numerical simulation, SWAN applies 10-min time steps, while ADCIRC applies 1-s time steps. A SWAN + ADCIRC simulation runs in 16 wall clock min/day of simulation on 1,024 cores on Diamond, a 2.8 GHz dual quad core-based cluster with a 20 Gb/s InfiniBand network (http://www.erdc.hpc.mil/). On the average, each simulation required over 1500 CPU hours to complete. The Hakou-2010-r2 model was validated by simulating tides and by hindcasting hurricane-Iniki (1992) and comparing to measured water levels as well as wave data. More details on the model itself and the validation may be found in Kennedy et al. (2012).

Grid size for high-fidelity computational model
5.2 High-fidelity simulation database and partitioning
The available database consists of hurricane scenarios corresponding to five basic storm tracks, depicted in Fig. 1, representing different angles of final approach (i.e. track headings) θ with histories selected based on information from regional historical storms. Three different values for the central pressure c p were used, 940, 955 and 970 mbar, three different forward velocities v f were considered, 7.5, 15 and 22 knots, and three radius of maximum winds, R m , 30, 45 and 60 km, were utilized in the development of the database. Landfall x o was defined as the longitudinal point where each hurricane crosses 21.3° North, and in the database used for this study, corresponding to hurricanes with important impact on Oahu, 12 different landfall locations are considered corresponding to landfalls of 157.60, 157.85, 158.10, 158.30, 158.60, 158.90, 159.20, 159.50, 159.80, 160.00, 160.40, 160.70° West. A total of 603 storms are available in the database, which is partitioned into three different sets. One set consisting of 23 storms (chosen randomly) that serve as the control points {x c; c = 1, …, N c } for the optimization of the response surface characteristics, another set of 20 storms (also chosen randomly) that serve as the validation points {x p; p = 1, …, N E } for evaluating the accuracy of the approximation, and the remaining set of 560 storms that correspond to the support points {x I; I = 1, …, N S } used to develop the surrogate model. An additional subset is considered for the support points, by excluding some landfall locations, to obtain a subset with a reduced number of support points. This subset consists of only 370 storms, corresponding to landfall locations of 157.60, 158.10, 158.30, 158.90, 159.20, 159.80, 160.10, 160.40° West (landfall locations evenly chosen among the initial database). The observation points that were not considered as support points are added in this case to the validation set, leading to N S = 370 and N E = 210. The control points remain the same for this subset as for the one with N S = 560.
5.3 General characteristics of the response surfaces
Two different types of hurricane response characteristic will be examined. The first one is the significant wave height in the regions extending from 156 to 160° West and 20 to 23° North on a canonical grid consisting of a total n z = 9,053 points (excluding the inland areas of the Hawaiian Islands). The second one is the surge in n z = 77,175 locations around the coast of Oahu. These locations correspond to inland nodes (up to the 4 m elevation contour) in our high-fidelity numerical model that were inundated in at least one storm of our database. The response surface approximation for each of these outputs will be separately examined, to provide insight about the differences between them.
Polynomials up to second degree (quadratic) are considered as basis functions b(x) [with full quadratic basis functions corresponding to case illustrated in Eq. (7)] with the exact degree for the polynomial for each hurricane parameter corresponding to a variable to be optimized (this ultimately corresponds to a constraint for the degree of the polynomial with respect to each x i ). This leads to N B = 21 basis functions based on Eq. (6) if second order polynomials are considered for all components of x. Parameters for which the optimal basis is identified to be linear will be denoted as ‘linear’ (the remaining will be quadratic). For the weight function, the one given by Eq. (11) is adopted with D d adaptively selected so that it includes 60 support points with c, k corresponding to additional variables to be optimized. This choice falls within the common guidelines for selection of D d , to include a range of points 2–4 times N B [this relates to having M in Eq. (9) be invertible while giving priority only to support points in close proximity] (Choi et al. 2001). Note that slightly higher values for this number are suggested in the literature when the MLS RSA is intended to be used for moderate extrapolations (i.e. to predict the impact for scenarios with model parameters that fall outside the domain of the support points), but this topic falls outside our scope here (we are primarily interested in using RSA for interpolation). Finally, the weight v k used for the distance norm of Eq. (10) is selected for each parameter as v k = r k /σ k , where σ k is the standard deviation for x k in the database {x h; h = 1, …, N h } and is used to normalize the distance norm, whereas r k is a weight variable, to be optimized, used to provide an importance factor to the model parameters. Larger values for r k indicate stronger influence along that direction in the model parameter space for evaluating the distance norm. Note that the approximation in Eq. (8) is not impacted by scaling of w{d}; thus, only the relative ratio between the v k ’s, and equivalently r k ’s, (and not their exact values) influence the established response surface. This means that only four out of the five r k ’s need to be optimized, with the exact selection of the r k to have a certain value or that specific value having no influence on the established surrogate model. In our case, r 1 is always chosen as 1.
Thus, the vector s of variables that can be optimized for the response surface approximation includes (1) the degree of the basis function for each hurricane parameter, (2) the variables c, k for the weighting function, and (3) the weight (importance) variable r k ’s for determining v k . The optimization is actually performed in two stages. In the first stage, a specific value is set for variables (1), and the optimal values of variables (2) and (3) are obtained through the optimization described in Eq. (20). In the second stage, different choices for (1) are considered, and the overall optimal solution s* is finally identified. Apart from the full optimization (for entire vector s) sub-optimization problems are also investigated. The first one considers full quadratic basis functions (so no optimization for the polynomial degree) and allows for optimization of only c, k and r k ’s, and the second additionally assumes r k = 1 and considers only optimization for c and k.
Finally, with respect to transformation for response and objective function selection, three different cases are examined here. The first two correspond to the linear transformation in Eq. (3) and consider Eq. (20) [first case] and (21) [second case] as the objective function. They are denoted as linear and linear n , respectively. The third one corresponds to the log transformation in Eq. (3) and considers Eq. (21) as the objective function. It is denoted as log n .
For all cases, only the results for the fit of the response surface approximation are presented here with respect to all the four quantities discussed in Sect. 3.4. The optimal s* is then presented in Appendix 2 (Table 7) which also includes (Table 6) a summary of all cases considered along with their characteristics, that is, the number of support points, transformation for response and objective function selections, and optimization problem solved. These tables include all the different optimal models from the different optimization sub-problems discussed above. To simplify the presentation, each case considered is given an identification (ID) number; then, the optimal response surface characteristics are referenced in the Appendix 2 with respect to that ID number.
5.4 Significant wave height
For the significant wave height, Fig. 5 presents the contours for the mean and standard deviation over the database. Table 1 presents the results for the optimal response surface for the three different optimization cases (linear, linear n and log n ) and for two different sets of support points. Table 2 presents the results for the different optimization sub-problems for case linear n . It also includes the instance that no optimization is performed, and typical values (Choi et al. 2001) are used for the response surface characteristics (full quadratic function, r k ’s = 1, c = 0.4, k = 1). Finally, Fig. 6 presents the contours for the ME for the optimal linear n surrogate model for (a) 560 [case ID = 2] (b) 370 support points [case ID = 5].

Statistics for the wave height over the database. a Mean, b Standard deviation

Mean error (ME) for optimal linear n surrogate model for a 560 [case ID = 2] and b 370 support points [case ID = 5]
It is evident from Table 1 that when the entire database is used (560 support points), the developed surrogate models provide a very good approximation, with average MEs less that 2.5 % and coefficient of determination over 98 %. It should be pointed out that the latter demonstrates that the developed approximate model describes the variability within the data very well, a feature that is very important for risk assessment applications for which the accuracy over an ensemble of scenarios is more crucial than the accuracy on individual basis (as multiple scenarios contribute ultimately to the total risk). When the number of support points is reduced (370), the accuracy of the response surfaces significantly reduces, especially for the log n transformation. This shows that the density of landfall locations in the initial database was important for adequately describing the variability of the response in this case study. The linear n transformation is proven to provide an overall better fit, which is the reason it is chosen for presenting the results in Table 2 for the sub-optimization problems (note though that based on the studies we performed for the other transformations, the trends are fairly similar). Comparing the linear and linear n cases shows that the normalization of the different response quantities in the objective function definition provides some accuracy/robustness to the optimization results; this is expected as it ultimately prevents the optimization to be dominated by response quantities (wave heights in this case) that have higher values and thus higher relative errors. The most important result coming, now, from Table 2 is the significance of performing an explicit optimization for the characteristics of the RSA model; the performance improvement for the optimal case over the case for no optimization is significant. It also shows that optimizing for the exact basis functions can provide a considerable improvement when the number of support points is smaller, whereas the explicit optimization for r i ’s, which ultimately dictate the moving character of the surrogate model within the different direction in the model parameter space x, also has a significant impact, especially for a smaller number of support points. This discussion clearly shows that the optimization for the characteristics of the response surface approximation can provide important accuracy benefits.
Finally, comparison of Figs. 6 and 5 does not indicate any correlation between the errors of the surrogate model and the statistics of the initial database of observation points. Comparison between the two cases presented in Fig. 6 shows that though the regional trends are similar, there also exist significant differences, that is, errors in some regions relatively increase when the fewer support points are used. This further demonstrates that the distribution of the landfall location for the support points can have an impact on the spatial variability of the errors established through the response surface approximation (since the difference in the surrogate models considered is ultimately with respect to the distribution of the landfall locations of the support points) .
5.5 Storm surge
For the storm surge, the database is initially augmented following the discussion in Sect. 3.3. Close to 30 % of the database points required updating using the proposed approach. Tables 3 and 4 present the optimization results, in a similar format as Tables 1 and 2. In this case, an additional measure is introduced to evaluate the efficiency of response surface approximation; the percentage of misclassified locations with respect to inundation, that is, the percentage of points that were classified as inundated when they were actually dry or classified as dry when they were inundated. A subset of the locations is also created, considering the points that were wet for all simulations; these correspond to 15,867 nearshore locations in our grid. These are locations for which no modification was required in our initial database for developing the surrogate model (as discussed in Sect. 3.3). In parenthesis in both tables, the statistics for this subset are presented. Finally, Fig. 7 presents a comparison between predicted and exact storm surge for all 20 validation scenarios for 50 locations (out of the 77,175) randomly selected.

Comparison between approximated and exact storm surge elevation for 50 locations
The results in Tables 3 and 4 indicate the same trends with Tables 1 and 2; the fit when the entire database is used is very good (Table 3), with the optimization for the exact type of basis functions and the values, or r i ’s having an important role, especially for the surrogate model informed by a reduced number of support points (Table 4). Though the errors increase here compared to the ones for the wave height, when the evaluation is constrained to the 15,867 nearshore locations in the grid that always remain wet, this difference is very small. Thus, the larger errors for the surge can be attributed to the challenges associated with the inland locations that may remain dry. Even for those cases, though, the surrogate model provides an overall adequate fit when the entire database is used, with a small rate of misclassifications (below 3 %). The quality of this fit is further demonstrated by the results in Fig. 7.
5.6 Combined output
A final study is performed by combining the different type of outputs (wave height and surge) into a single response vector z and performing the optimization for the response surface approximation. Table 5 presents the results by evaluating the fit separately for the wave height or surge (only AME and ANS fit measures are reported due to space limitations); it also presents the results for the optimal cases established when developing surrogate models only for the wave height or surge response outputs (as described in the previous two sections). The results show that there is indeed a reduction in accuracy for either of the response quantities when the optimization does not explicitly have it as a target. That reduction is though not large. The combined optimization yields results that are closer to the optimization for surge, which is expected since the number of surge points used were larger (ratio of almost 9:1), and thus, relative contribution towards the total error is larger. This discussion indicates that the response surface surrogate model can perform adequately for simultaneously predicting both the response quantities of interest here, but also that a surrogate model that targets a specific response quantity can offer an improved accuracy. The later demonstrates that, if possible (in terms of computational cost), separate surrogate models should be developed and implemented for each of the response quantities.
Finally, looking collectively (extending to all cases considered in the previous three sections) at the results in Table 7 of Appendix 2, it can be inferred that the landfall location and angle of final approach (especially the former) (1) have in general a greater importance in affecting hurricane responses and that (2) the responses exhibit larger variability with respect to these two parameters. These two attributes are indicated, respectively, by the fact that (1) larger optimal values for r i ’s are identified for them and that (2) in no case is a linear basis function identified as optimal for them.
5.7 Example of risk assessment implementation
To demonstrate a possible implementation of the proposed surrogate modelling approach, the optimal response surface surrogate model is used to estimate hurricane risk, based on the theoretical and computational framework discussed in Appendix 1, for the hurricane illustrated in Fig. 8 approaching landfall to Oahu. This corresponds to the real-time hurricane risk assessment implementation that has been advocated in (Taflanidis et al. 2012). The estimated mean values for hurricane parameters [landfall longitude, heading at landfall in degrees measured clockwise from south; central pressure in mbar; forward speed in knots; radius of maximum winds in km] are chosen as

Hurricane track and characteristics used in the illustrative risk assessment implementation
For defining p(x), these parameters are assumed to follow independent Gaussian distributions with mean values given in Eq. (23) and standard deviations selected here as [based on estimation errors for a time until landfall equal to 42 h (Taflanidis et al. 2012)]
Hurricane risk is evaluated through Eq. (29) using N = 2,000 samples. Figure 9 shows [part (a)] the probability that the significant wave height will exceed 9 m and [part (b)] the wave height with probability of being exceeded 5 %. Then Fig. 10 shows the probability that the surge will exceed threshold β for two locations, the first with coordinates 21.2999°N, 158.1101°W (near Pearl Harbor) and the second with coordinates 21.3101°N, 157.9302°W (close to the old runway in the airport). Results with and without including the prediction error of Eq. (2) (due to the surrogate modelling) are shown in this figure. The comparison indicates that the prediction error can have a significant impact on the calculated risk (though not always), and it will lead to more conservative estimates for rare events (with small probabilities of occurrence). This demonstrates that it is important to explicitly incorporate it in the risk estimation framework. These trends agree with the results published recently by Resio et al. (2012) within the context of storm surge risk estimation. Then, Fig. 11 presents similar results for the wave height; it shows the probability that the wave height will exceed threshold β for two locations, the first with coordinates 21.29°N, 157.92°W (close to the coast) and the second with coordinates 21.17°N, 158.34°W (in the open sea). In this case, the higher accuracy of the surrogate model (smaller prediction error variance as discussed in previous sections) leads to smaller (relatively to Fig. 10) impact of the prediction error on the calculated exceedence probabilities. It is important to note that, like in the case of Fig. 10, the impact of including the prediction error is higher when looking at rare events, that is, for small probabilities of exceedence.

a Probability contours that the significant wave height will exceed 9 m and b wave height with probability of being exceeded 5 %

Probability that surge will exceed threshold β for two locations in Oahu with coordinates 21.2999°N, 158.1101°W (location 1) and 21.3101°N, 157.9302°W (location 2). Results with (dashed lines) and without (solid lines) the prediction error of the surrogate model are shown

Probability that significant wave height will exceed threshold β for two locations in Oahu with coordinates 21.29°N, 157.92°W (location 1) and 21.17°N, 158.34°W (location 2). Results with (dashed lines) and without (solid lines) the prediction error of the surrogate model are shown
The total time needed for this risk assessment is 2 min on a 3.2 GHz single core processor with 4 GB of RAM. This corresponds to a tremendous reduction of computational time compared to the high-fidelity model, which required over 1500 hours for analysing a single hurricane track. Thus, a risk computation requiring independent evaluations of the surrogate model for N = 2,000 different scenarios is still approximately 104 times faster than evaluating a single hurricane scenario using the high-fidelity model SWAN + ADCIRC. Note that ability to use a large number of evaluations in the stochastic simulation-based evaluation (29) of the risk integral (25) contribute to improved accuracy [reduced coefficient of variation (30)] for that estimate. The computational simplicity of the stochastic simulation-based estimation (29) along with the computational efficiency of the developed surrogate model also promote the development of automated risk assessment tools for hurricane/storm risk predictions, as advocated in (Taflanidis et al. 2012) and (Kijewski-Correa et al. 2012). These arguments illustrate the efficiency of the proposed theoretical and computational scheme, based on an optimized response surface approximation.
6 Conclusions
The systematic implementation and optimization of MLS response surface approximations for hurricane wave and surge response prediction were discussed in this paper. Using an existing database of high-fidelity simulations, the surrogate model can efficiently predict hurricane impact for any hurricane scenario of interest (within the bounds of the database), for any quantity of interest and for a large coastal region that might involve thousands of locations. The optimal selection of the basis functions for the response surface and of the parameters of the MLS character of the approximation were addressed. The impact of the number of high-fidelity simulations informing the surrogate modelling was investigated and different hurricane response characteristics (surge and significant wave height) were also analysed. Special attention was given to predicting the surge in inland locations for which the possibility of the location remaining dry needs to be additionally addressed. An approximate methodology was proposed here for these cases, based on a modification of the initial database; the storm surge for any location that remained dry was correlated to the closest inundated location. Though this ultimately has an impact on the accuracy of the response surface approximation, the established percentage of misclassifications (wet nodes that are identified as dry and vice versa) was small.
The results for the case study considered (Oahu Island) demonstrate that MLS response surface models can provide accurate approximations for both the wave and surge responses and can ultimately facilitate a highly efficient estimation of hurricane risk. The explicit optimization of the characteristics of the response surface model provide considerable improvements in accuracy; this pertains to both the order of basis functions used as well as to the parameters that dictate the moving character of the surrogate model. The number of support points also has an impact on the results (as is expected in any surrogate model), with the landfall locations for the support points playing a key role in the case of storm responses. Though this result will definitely depend on the topographical characteristics of the coastal region in which this methodology is implemented, it was shown in the case study for Hawaii (focusing on Oahu) that very high accuracy was established when the landfall location for the support points had an average distribution of 0.3°, with a moderate accuracy decrease when this distribution was increased to 0.5°. Overall, the landfall location and angle of approach were the two model parameters influencing the hurricane impact more, and thus the accuracy of the surrogate model. Though the proposed response surface approximation can provide an overall good fit for multiple response quantities, it was also shown that improvement in accuracy can be established when the surrogate model is optimized with specific quantities of interest in mind. This shows that the optimization of separate surrogate models should be considered when the quality of the approximation needs to be improved for specific responses of interest (for example, for waves compared to surge or for surge for different regions within the coast compared to the surge for the remaining regions). Finally, it was shown that within a risk estimation framework, the prediction error due to surrogate model approximation can have a significant impact on the calculated risk, especially for rare events (small probabilities of occurrence) for which it will typically lead to more conservative estimates.
References
Breitkopf P, Naceur H, Rassineux A, Villon P (2005) Moving least squares response surface approximation: formulation and metal forming applications. Comput Struct 83(17–18):1411–1428
Burges CJC (1998) A tutorial on support vector machines for pattern recognition. Data Min Knowl Disc 2:121–167
Choi KK, Youn B, Yang RJ (2001) Moving least squares method for reliability-based design optimization. In: 4th world congress of structural and multidisciplinary optimization
Condon AP, Sheng YP (2012) Evaluation of coastal inundation hazard for present and future climates. Nat Hazards 62:345–373
Das HS, Jung H, Ebersole B, Wamsley T, Whalin RW (2010) An efficient storm surge forecasting tool for coastal Mississippi. In: 32nd international coastal engineering conference, Shanghai, China
Dietrich JC, Bunya S, Westerink JJ, Ebersole BA, Smith JM, Atkinson JH, Jensen R, Resio DT, Luettich RA, Dawson C, Cardone VJ, Cox AT, Powell MD, Westerink HJ, Roberts HJ (2010) A high resolution coupled riverine flow, tide, wind, wind wave and storm surge model for southern Louisiana and Mississippi: part II—synoptic description and analyses of hurricanes Katrina and Rita. Mon Weather Rev 138(2):378–404
Grimmett G, Stirzaker D (2001) Probability and random processes. Oxford University Press, Oxford
Ho FP, Myers VA (1975) Joint probability method of tide frequency analysis applied to Apalachicola Bay and St. George Sound. NOAA technical report NWS 38, Washington, DC, USA
Holmstrom K, Goran AO, Edvall MM (2009) User’s guide for TOMLAB 7. Tomlab Optimization, San Diego. www.tomopt.com/tomlab/
Irish J, Resio D, Cialone M (2009) A surge response function approach to coastal hazard assessment. Part 2: quantification of spatial attributes of response functions. Nat Hazards 51(1):183–205
Kennedy AB, Gravois U, Zachry B (2011a). Observations of landfalling wave spectra during Hurricane Ike. J Waterw Port Coastal Ocean Eng 142–145. doi:10.1061/(ASCE)WW.1943-5460.0000081
Kennedy AB, Gravois U, Zachry BC, Westerink JJ, Hope ME, Dietrich JC, Powell MD, Cox AT, Luettich RL, Dean RG (2011b). Origin of the Hurricane Ike forerunner surge. Geophys Res Lett L08805. doi:10.1029/2011GL047090
Kennedy AB, Westerink JJ, Smith J, Taflanidis AA, Hope M, Hartman M, Tanaka S, Westerink H, Cheung KF, Smith T, Hamman M, Minamide M, Ota A (2012) Tropical cyclone inundation potential on the Hawaiian islands of Oahu and Kauai. Ocean Model 52–53:54–68
Kijewski-Correa T, Taflanidis AA, Kennedy AB, Kareem, Westerink JJ (2012) CYBER-EYE: integrated cyber-infrastructure to support hurricane risk-assessment. In: ATC and SEI advances in hurricane engineering conference
Loweth EL, De Boer GN, Toropov VV (2010). Practical recommendations on the use of moving least squares metamodel building. In: Thirteenth international conference on civil, structural and environmental engineering computing, Crete, Greece
Myers VA (1975) Storm tide frequencies on the South Carolina coast. NOAA technical report NWS-16
Myers RH, Montgomery DC (2002) Response surface methodology. Wiley, New York
Niedoroda AW, Resio DT, Toro GR, Divoky D, Reed C (2010) Analysis of the coastal Mississippi storm surge hazard. Ocean Eng 37(1):82–90
Resio DT, Westerink JJ (2008) Modeling of the physics of storm surges. Phys Today 61(9):33–38
Resio DT, Boc SJ, Borgman L, Cardone V, Cox A, Dally WR, Dean RG, Divoky D, Hirsh E, Irish JL, Levinson D, Niedoroda A, Powell MD, Ratcliff JJ, Stutts V, Suhada J, Toro GR, Vickery PJ (2007) White paper on estimating hurricane inundation probabilities. Consulting report prepared by USACE for FEMA
Resio D, Irish J, Cialone M (2009) A surge response function approach to coastal hazard assessment–part 1: basic concepts. Nat Hazards 51(1):163–182
Resio DT, Irish JL, Westering JJ, Powell NJ (2012) The effect of uncertainty on estimates of hurricane surge hazards. Nat Hazards. doi:10.1007/s11069-012-0315-1
Robert CP, Casella G (2004) Monte Carlo statistical methods. Springer, New York
Song YK, Irish JL, Udoh IE (2012) Regional attributes of hurricane surge response functions for hazard assessment. Nat Hazards. doi:10.1007/s11069-012-0309-z
Taflanidis AA (2012) Stochastic subset optimization incorporating moving least squares response surface methodologies for stochastic sampling. Adv Eng Softw 44(1):3–14
Taflanidis AA, Beck JL (2010) Reliability-based design using two-stage stochastic optimization with a treatment of model prediction errors. J Eng Mech 136(12):1460–1473
Taflanidis AA, Kennedy AB, Westerink JJ, Smith J, Cheung KF, Hope M, Tanaka S (2012) Rapid assessment of wave and surge risk during landfalling hurricanes; a probabilistic approach. ASCE J Waterw Coast Port Auth. doi:10.1061/(ASCE)WW.1943-5460.0000178
Toro GB, Niedoroda AW, Reed C (2007). Approaches for the efficient probabilistic calculation of surge hazard. In: 10th international workshop on wave hindcasting and forecasting and coastal hazards
Toro GR, Niedoroda AW, Reed CW, Divoky D (2010a) Quadrature-based approach for the efficient evaluation of surge hazard. Ocean Eng 37:114–124
Toro GR, Resio DT, Divoky D, Niedoroda A, Reed C (2010b) Efficient joint-probability methods for hurricane surge frequency analysis. Ocean Eng 37:125–134
Udoh LE, Irish JL (2011). Improvements in hurricane surge response functions: incorporating the effects of forward speed, approach angle, and sea level rise. In: International conference on vulnerability and risk analysis and management/fifth international symposium on uncertainty modeling and analysis
Westerink JJ, Luettich RA, Feyen JC, Atkinson JH, Dawson C, Roberts HJ, Powell MD, Dunion JP, Kubatko EJ, Pourtaheri H (2008) A basin- to channel-scale unstructured grid hurricane storm surge model applied to southern Louisiana. Mon Weather Rev 136(3):833–864. doi:10.1175/2007MWR1946.1
Acknowledgments
This research effort is partially supported by US Army Corps of Engineering grant W912HZ-09-C-0086 under the Surge and Wave Island Modeling Studies, Coastal Field Data Collection Program. This support is greatly appreciated. Permission to publish this work was granted by the Chief of Engineers, US Army Corps of Engineers. Also the contribution of Professor Joannes Westerink and graduate student Mark Hope, both at the University of Notre Dame, in developing and performing the high-fidelity simulations for the illustrative example is greatly appreciated.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Implementation in coastal risk assessment
Within the JPM setting, hurricane/storm coastal risk may be quantified in terms of the response \( {\hat{\mathbf{z}}}({\mathbf{x}}) \) provided by the surrogate model and a probability density function p(x) describing the uncertainty in the input hurricane parameters x. For real-time risk evaluation, that is, when predicting the risk due to an approaching hurricane, p(x) may be constructed through the estimates provided by the National Hurricane Center (http://www.nhc.noaa.gov); each component of x can be selected to follow an independent Gaussian distribution with mean equal to the forecast quantities and standard deviation equal to the associated statistical estimation error (Taflanidis et al. 2012). For long-term hurricane risk evaluation for a region, p(x) is selected based on statistical data, and it further incorporates information on occurrence rates for hurricanes, not just on relative plausibility of the model parameters (Resio et al. 2007).
Risk is ultimately expressed as some desired statistic of the response z, for example the probability that the wave height will exceed some specific threshold or the median surge. The exact selection used for these statistics leads to definition of the risk consequence measure h i [.]. Ultimately, for any component z i of the response vector, the risk, denoted H i , is provided by the multi-dimensional probabilistic integral (Taflanidis et al. 2012)
where X corresponds to the region of possible values for x. The risk consequence measure depends on the definition for H i , and it additionally addresses the prediction error ε i . Through its appropriate selection different potential hurricane risk quantifications can be addressed. For example, if H i corresponds to the expected (mean) value for some z i , \( {H}_{i} = {E}[z_{i} ] \) (where E[] denotes expectation), then (Taflanidis et al. 2012)
and the model prediction error has no impact on the risk consequence measure. If alternatively, H i corresponds to the probability that some z i will exceed some threshold β i , \( {H}_{i} = P[z_{i} > \beta_{i} ] \) (where P[] denotes probability), then (Taflanidis et al. 2012)
where F i corresponds to the cumulative distribution function for the model prediction error for z i . In this case, the statistics of the prediction error do have an impact on the risk quantification. This simplifies to
for the proposed case of Gaussian distribution for the model prediction error, where Φ[.] denotes the standard Gaussian cumulative distribution function.
Once risk for z i has been quantified by the proper selection of the consequence measure (dependent only on \( \hat{z}_{i} \)), the probabilistic integral in Eq. (25) can be estimated by stochastic simulation (Robert and Casella 2004). For the simplest approach (direct Monte Carlo), and using N samples of x randomly selected from p(x), the estimate for H i is given by
where vector x m denotes the sample of the uncertain parameters used in the mth simulation. The quality of this estimate is assessed through its coefficient of variation, δ obtained by
which decreases (i.e. estimation improves) proportionally to\( \sqrt N \). Thus, estimation of risk may be efficiently and accurately performed using the established surrogate model, as evaluation of \( \hat{z}_{i} ({\mathbf{x}}) \) requires minimal computational effort [thus a large number of samples N can be used for (29)].
Appendix 2: Summary of cases considered for response surfaces and corresponding optimal parameters
The following two tables present a summary of all cases considered (Table 6) in the case study along with the optimal parameters, that is, type of basis functions, values for c and k and for weights r k for them (Table 7). These correspond to all unique cases that were examined in Sects. 5.4, 5.5 and 5.6, by considering the full- and sub-optimization problems for the different outputs and the different normalization of response and objective function selections (more information on the selection is provided in Sect. 5.3). Each case is referenced here by its identification index, ID. Note that for parameters in Table 7 for which their basis function are not explicitly referenced as linear, the chosen polynomial degree is quadratic.
Rights and permissions
About this article
Cite this article
Taflanidis, A.A., Jia, G., Kennedy, A.B. et al. Implementation/optimization of moving least squares response surfaces for approximation of hurricane/storm surge and wave responses. Nat Hazards 66, 955–983 (2013). https://doi.org/10.1007/s11069-012-0520-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-012-0520-y