
Abstract
As a research hotspot in the field of robotics, Simultaneous localization and mapping (SLAM) has made great progress in recent years, but few SLAM algorithms take dynamic or movable targets in the scene into account. In this paper, a robust new RGB-D SLAM method with dynamic area detection towards dynamic environments named GMSK-SLAM is proposed. Most of the existing related papers use the method of directly eliminating the whole dynamic targets. Although rejecting dynamic objects can increase the accuracy of robot positioning to a certain extent, this type of algorithm will result in the reduction of the number of available feature points in the image. The lack of sufficient feature points will seriously affect the subsequent precision of positioning and mapping for feature-based SLAM. The proposed GMSK-SLAM method innovatively combines Grid-based Motion Statistics (GMS) feature points matching method with K-means cluster algorithm to distinguish dynamic areas from the images and retain static information from dynamic environments, which can effectively increase the number of reliable feature points and keep more environment features. This method can achieve a highly improvements on localization accuracy in dynamic environments. Finally, sufficient experiments were conducted on the public TUM RGB-D dataset. Compared with ORB-SLAM2 and the RGB-D SLAM, our system, respectively, got 97.3% and 90.2% improvements in dynamic environments localization evaluated by root-mean-square error. The empirical results show that the proposed algorithm can eliminate the influence of the dynamic objects effectively and achieve a comparable or better performance than state-of-the-art methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In recent years, Simultaneous Localization and Mapping (SLAM) technology has become a fundamental prerequisite in many applications [7, 38], such as robots, driverless cars, VR, 3D reconstruction, and so on. Because of its ability to conduct navigation and perception simultaneously in an unknown environment, SLAM has attracted the attention of many scholars and gradually become a research hotspot over the past decades [7]. The framework of the modern visual SLAM system is quite mature, which consists of several essential parts: feature extraction front-end, state estimation back-end, loop closure detection, and so forth [40]. Visual SLAM, the main sensor of which is the camera, can be parted to monocular slam, RGB-D slam, and stereo slam based on camera types. The monocular camera has practical advantages on size, power, and cost, but also has several disadvantages, such as scale ambiguity, complex initialization, and weak system robustness. However, the absolute scale of the system can be obtained by using stereo or RGB-D cameras, and the stability of the system can be enhanced at the same time [19]. In order to reduce the error caused by the scale estimation, the RGB-D camera with depth information or the stereo camera that can calculate the depth are more popular in experiments and scientific research.
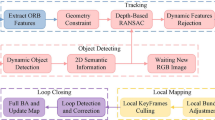
Most indoor SLAM methods are based on the assumption that the environment is static. In other words, the geometric distribution of objects in the scene is assumed to be stationary in the process. However, this is unrealistic in real life. The environment in which people live is dynamic, and there will be many variable factors in the scene such as lighting, dynamic targets, occlusion, etc. Aiming at these problems, many scholars at home and abroad have also carried out rich and detailed research. In order to improve the environmental adaptability of the positioning system, this paper mainly focuses on the research of dynamic targets in the scenes. Most state-of-the-art dynamic environment positioning methods using vision-only are neural network-based and image-based. With the development of artificial intelligence, more and more people are introducing neural networks into SLAM. These methods designed various types of convolutional neural networks to try to segment the target information in the image. The camera pose estimation accuracy is improved by removing the target. The more classic and efficient target detection algorithm is the YOLOv3 [28]. Many papers use YOLOv3 algorithm for target detection, and divide them into dynamic targets or static targets based on the types of targets. Although the CNN-based method can accurately segment the target in the scene, due to the limitation of the training dataset, its detection accuracy will be constrained by the test dataset, so the purpose of removing dynamic targets cannot be well achieved. Image-based dynamic environment detection algorithms are more inclined to traditional image processing algorithms, such as [38]. This type of algorithm also has a good performance in dynamic target segmentation, which improves the stability and adaptability of the positioning algorithm in the environment to a certain extent. Although these algorithms have improved the camera’s positioning accuracy in a dynamic environment, they have poor environment adaptability. These methods tend to classify all objects in a class of tags, such as people and cars, as dynamic, and then remove these areas directly from the images, which will not only reduce the system’s ability to understand the environment, but also lose most of the feature points of the image. This is a fatal flaw in feature-based SLAM algorithms. In this paper, the GMSK-SLAM system is proposed, which not only detects dynamic regions in the images rather than the dynamic targets but also improves the localization accuracy in a dynamic environment. In order to eliminate the influence of dynamic objects on posture estimation results, the usual methods discard all feature points on dynamic objects, which is a rough way for the whole system. In this case, even if the person in the scene does not make any posture changes,these methods still detect this person as dynamic and eliminate all feature points on this person. However, in our method, this person will be detected as a static object, the feature points will be kept and used to estimate the camera pose. The overview of this paper is shown in Fig. 1. The main contributions of this paper are identified as followed:
-
1.
A complete dynamic SLAM system in changing environments is proposed based on ORB-SLAM2 [25], which could reduce the influence of dynamic objects on camera pose estimation. The effectiveness of the system is evaluated on TUM RGB-D dataset [35]. The results indicate that GMSK-SLAM outperforms ORB-SLAM2 significantly regarding accuracy and robustness in dynamic environments.
-
2.
Put a dynamic area detection in an independent thread, which combining the GMS (Grid-based Motion Statistics)feature points detection algorithm [4] with k-means cluster algorithm [22] to filter out a dynamic portion of the scene, like walking people. Different from other methods, this paper innovatively proposes the concept of dynamic area, and focuses on dynamic regions rather than dynamic objects. The application of dynamic regions eliminates the limitation of the algorithm and is applicable to both rigid targets and deformable targets. Thus, the performance of the localization module is improved in respect of robustness and accuracy in dynamic scenarios.
-
3.
GMSK-SLAM creates a separate thread to detect dynamic areas, which greatly improves the operating efficiency and robustness of the system. The proposed system could run the tracking thread and the dynamic area detection thread in parallel, thus allowing our system to read read-time performance.

The overview of GMSK-SLAM
The rest of this paper is organized as follows. First, visual SLAM and SLAM in dynamic environment related work are discussed in Section 2. The main work is described and demonstrated in Section 3 in detail, and a series of evaluation results and dataset test are presented in Section 4. Finally, the conclusion is made in Section 5.
2 Related work
2.1 Visual SLAM
Simultaneous Localization and Mapping (SLAM) [22] has been developed for about thirty years and has become a crucial technology in the field of robotics, automation, and computer vision. Recent years, researchers have proposed many effective open-source SLAM methods, such as Catragrapher [39], Hector SLAM [34], Gmapping [14], Karto SLAM [16], which are based on laser sensor SLAM and monoSLAM [6], ORB-SLAM [26], LSD-SLAM [9], RGB-D SLAM [8],DSO [10], and SVO SLAM [12], which are based on visual slam.
Especially for visual SLAM, visual SLAM has drawn the attention of researchers because of its low cost and small size. In 2007, Davison A. J. proposed Mono-SLAM [6] for the first time to implement a monocular real-time slam system. This work extends the range of robotic systems in which SLAM can be usefully applied but also opened up new areas. Subsequently, the PTAM [15] (Parallel Tracking and Mapping) is proposed by Klein, which firstly divided front-and-end in SLAM into two threads: one thread is mainly responsible for estimating camera posture, another mainly for restoring 3D information of feature points, which called mapping. At the same time, during the mapping and tracking processes, PTAM adopted keyframes strategy, used keyframes to estimate camera pose, which improved the accuracy of mapping and tracking. In 2014, the LSD-SLAM [9] proposed by Engel firstly achieved semi-dense scenes reconstruction in ordinary CPU, and operated directly on image pixels. Meanwhile, Forster proposed a fast Semi-direct monocular Visual Odometry (SVO) [12], which combined the feature point and direct tracking optical flow methods. Later, frameworks such as DSO [10] and VINS-Mono [37] have been proposed on after another. In two algorithms of extracting feature points of SLAM, the feature method also has its advantages. On the one hand, feature extraction and matching can ensure the accuracy of pose estimation in the SLAM tracking process. On the other hand, the feature method can extract more effective information from visual images, such as semantics, object recognition, feature localization, etc. In general, feature-based SLAM is more respected by scholars. There are also some excellent SLAM methods based on feature tracking. ORB-SLAM uses ORB (Oriented FAST and rotated BRIEF [5]) feature points [31] to match two consecutive frames and calculate camera pose, back-end use bundle adjustment method to optimize pose and map points, loop closing module transfer images to words by bag of words, and use the optimization method to make global optimization. The ORB-SLAM2 [25] framework is the successor of the classic SLAM thread model. It can work with monocular, stereo, and RGB-D three types of sensors. It follows most of the ideas in PTAM and adds initialization module, loop closing detection module, loop closing rectification module, and relocation module. However, these methods are unable to distinguish the features in static and dynamic objects, which leads to the deterioration of SLAM systems because of erroneous data association and faults in motion estimation. Therefore, it is necessary to make further exploration for it still has many shortcomings in dealing with dynamic environment problems.
2.2 SLAM in dynamic environments
A basic assumption of most current SLAM methods is that the environment is static. Nevertheless, active objects like humans and cars, always exist in many real-world scenes. Therefore, these methods originally to perform SLAM in a static environment cannot work well in complex dynamic environments. To solve this problem, we need to recognize moving areas or objects from the environment and exclude these objects or areas before pose estimation.
For dynamic environment problems, in recent years, researchers have proposed different methods to reduce camera pose errors. There are two main categories of methods, one is based on various convolutional neural networks, such as FCN (Full convolutional network) [20], SegNet [1] and YOLO [29], etc., the other is based on the traditional image process, such as optical flow technique. Optical flow is generated if movements exist in the image, so static background and moving target could be distinguished by computing the inconsistency of optical flow. Seungwon Oh [27] proposed the Dynamic Extended Kalman Filter SLAM based on the independence of the dynamic landmarks. Jia-Ning Li [18] proposed a scalable dense frame-to-frame model SLAM system based on KinectFusion algorithm. Fang [11] used optimum-estimation and uniform sampling methods to detect dynamic objects. In 2017, Sun [36] proposed an improving RGB-D SLAM method, which acted as a pre-processing stage to filter out data that were associated with moving objects. In 2018, Bahraini [2] proposed an approach to segment and track multiple moving objects by using Multi Level-RANSAC. Kajal Sharma [33] proposed a novel approach to mapping and localization which is based on detecting stable and invariant landmarks in consecutive RGB-D frames of the robot dataset. Muhamad [32] surveyed the problems of visual SLAM and Structure from Motion (SfM) In dynamic environments. Zhang [41] integrated a deep CNN model to improve the accuracy of terrain segmentation and make it more robust against wild environments. In 2019, Sang Jun Lee [17] presented a sampling-based method that improved the speed and accuracy of the existing Visual Bag of Words models. They first proposed sampling of image features considering their density to speed up the quantization. In the same year, Runzhi Wang [38] proposed a new RGB-D SLAM with moving object detection for dynamic indoor scenes, which is based on mathematical models and geometric constraints and can be incorporated into the SLAM process as a data filtering process. Mu [23] proposed a novel features Selection algorithm in a dynamic environment, which is merged into MSCKF based on trifocal tensor geometry.
3 Methodology
This section mainly describes the details of the proposed method. Firstly, the architecture chart of the framework of GMSK-SLAM is presented in Fig. 1. Secondly, we briefly explain the GMS feature matching algorithm used in this paper. Subsequently, the k-means clustering algorithm that is used for distinguishing dynamic areas from the image is introduced. Finally, the dynamic area rejection method is demonstrated, which combines the area detection and the moving consistency check to filter out dynamic feature points.
3.1 Framework of GMSK-SLAM
In practice, the two critical factors to evaluate autonomous robots are accurate pose estimation and its reliability in harsh environments. In recent years, ORB-SLAM2 is very popular in visual-only SLAM and has excellent performance. However, ORB-SLAM2 is still facing some problems, such as it not expressive enough in dynamic environment. Hence, we propose an enhanced robust system based on ORB-SLAM2, which can not only enhance environment adaptability but also improve the positioning accuracy. GMSK-SLAM combines the GMS feature matching algorithm with the k-means cluster algorithm, which can perform pose tracking on dynamic scenes and with the better positioning accuracy.
As shown in Fig. 1, four threads run in parallel in GMSK-SLAM: tracking, dynamic area detection, local mapping, and loop closing. RGB images and Depth images are captured by a RGB-D camera in the scenes. The raw RGB images are processed in the tracking thread and dynamic area detection thread simultaneously. The tracking thread extracts ORB feature points by ORB feature matching, then checks moving consistency of feature points and saves the potential outliers. Then the tracking thread waits for the image that has been detected by dynamic area detection thread. In the dynamic area detection thread, GMSK-SLAM uses the GMS feature matching algorithm to match feature points and the sliding windows model to count filled-matching points, then adopts the k-means cluster algorithm to distinguish the dynamic area and static area. After the detection result arrives, the ORB feature points outliers located in moving objects will be discarded. Finally, the camera pose matrix is calculated by matching the rest of the stable feature points.
3.2 Feature matching by GMS
In the dynamic area detection thread, the system uses the GMS feature matching algorithm to enhance matching results which is an efficient and real-time feature matching algorithm. The limitation of the classical feature matching algorithms (SIFT [21], SURF [3], Hamming Distance, Brute Force Matcher, FANN [24], ORB[13, 30]) is that the algorithm with strong robustness has low matching speed, while the algorithm with high matching speed has poor robustness. However, compared to traditional algorithms, the advantage of GMS is that the algorithm has better performance in terms of time and accuracy.
GMS algorithm is an evaluation method based on matching to the support of neighborhood feature points. It mainly filters the feature matching after ORB feature extraction and BF matching. Figure 2 shows the matching schematic diagram of the two images. For image pairs {Ia, Ib}, they have {N, M} features respectively, and χ = {x1, x2⋯, xi, ⋯, xj, ⋯, xN} is the matching set from Ia to Ib, where xi = (ai, bi). GMS method separates χ into the sets of true and false matches by analyzing the local support of each match. Let region pairs {a, b} which each with {n, m} additional features respectively are respective regions of {Ia, Ib}, and fa with correct matching probability t denotes one of n supporting features in regions a. GMS method assumes that there are M possible locations of fa’s nearest neighbor matching lying. Then we can get:
Where \( {f}_a^b \) denotes that fa ‘s nearest neighbor is a feature in region b, \( {f}_a^b \) denotes that fa matches wrongly, and β is a weighting factor that is added to accommodate a violation of the assumption by having a repeating structure. Let Pt, Pf denote the probability of \( {f}_a^t \) and \( {f}_a^f \) respectively.

Schematic diagram of GMS neighborhood feature point support principle
Then, it can be approximated that the distribution of Si which is a neighborhood support measurement of match xi has a couple of binomial distribution:
Thus, it can be separated true and false matches by the score of S and an appropriate threshold. Due to the large area of motion smoothing, a more generalized score can be given in (5):
Where K refers to the number of adjacent disjoint grids in the grid region. And the distributions of Si are as follows:
The mean value and variance of Si are as follows:
Grid framework is adopted to make score computing independent of feature numbers. According to prior knowledge, the image is divided into G = 20 × 20 overlapping cells. In order to improve the robustness, grouping cell-pairs based on a smooth lateral motion assumption shown in Fig. 3 are used. Making a grid selection by rotation the potential on all potential scales and choosing the best result can solve the problem of image rotation and scale changing, the desired threshold can be given as:
Where α is an adjusting parameter. In practice, the number of mf is small, while the value of α is large. Thus, the number of τ can be approximated to:

The basic motion kernel
The algorithm to match feature points is shown in Algorithm 1. Significantly, the input of Algorithm 1 is a pair of images Ia and Ib, while the output is the set of properly matched feature points, inliers. Additionally, G denotes the number of grids, |χik| and |χij| represent the matched quantities of the grid, Si and τ can calculated by Eqs. (6) and (10).

3.3 Dynamic area detection algorithm
In this sub-section, the principle and pipeline of dynamic area detection method is introduced. Recently, people gradually combine semantic recognition with SLAM to make robots understand surrounding. Many researchers use the neural network to detect every object in the scene, which greatly limits the range of application. Those papers roughly define people or cars as dynamic depends on the test environment, which is partly speculative. It can be assumed that the test environment is in a crowded street, although using the convolution neural network can detect every pedestrian accurately, all these objects are regarded as the dynamic objects and eliminated out of images. Additionally, these methods often have an assumption that there are enough feature points in the image, and the distribution of feature points is even, which are actually untenable. The dynamic area detection method proposed by this paper ignores these assumptions, breaks through the limitation of target types and realizes dynamic region segmentation without classification.
GMSK method combines GMS feature matching with the k-means cluster method to detect dynamic areas for the first time. GMS feature matching method can improve matching stability and reduce the probability of false matching, while k-means cluster method can automatically divide a bunch of unlabelled data into categories, ensuring that the same kind of data have similar characteristics. Inspired by these advantages, the GMSK dynamic region detection algorithm is proposed.
Given a set of d-dimensional real vector data {x1, x2, ⋯, xn}. K-means clustering perform partitioning tasks of the n observation into K(<n) set S = {S1, S2, ⋯Sk} to minimize the within-cluster sum of distance functions of each point in the cluster to K-center. The formula below shows the K-means function:
In the feature-based SLAM system, two consecutive frames of the images are generally used for feature matching to perform system initialization and pose tracking. However, in order to better represent the algorithm, in this section, we select two discontinuous images for algorithm simulation. As can be seen from the first row of the Fig. 4, dense feature points were extracted from the image. It can be seen from the figures that the distribution of feature points is dense and uneven. Then the GMS algorithm is used to match the feature points of the image pair. The second row of the Fig. 4 show the matching results of feature points. In the figures, the feature points that match successfully are displayed in red, and the feature points that failed to match are displayed in green. Feature points on moving objects will cause inaccurate estimation of camera pose in the back-end system, so these points need to be pre-processed by algorithms to reduce the impact on the system. It can be found from the second row of the Fig. 4 that on the back of the man in the plaid shirt, there are significantly more green points than red points, the same thing happens in the man’s face on the left. Through the above analysis, it can be considered that in these regions, the probability of failure of feature point matching is greater than the probability of success.

Steps of dynamic area detection algorithm
After detecting and matching all feature points in the images, then we use the sliding windows to statistics the number of unmatched feature points. Firstly, according to prior knowledge, we use 400 grids to divide the images evenly, which aims to divide the whole image into multiple grids to easily distinguish the dynamic area and static area. We use the sliding window model to realize the statistics of the number of unmatched feature points in every grid. According to the formula (5), \( \overline{S_l} \) is used to represent the score of an unmatched feature point pair in the grid, and \( \overline{X_i} \) represents the number of unmatched feature point pairs in the grid.
In every grid, δ can be calculated by using the sliding window model:
Here, Nun denotes the number of unmatched feature points in the grid, Nm denotes the number of matched feature points in the grid. Through the distribution of feature points in the images, we can roughly distinguish the dynamic region and the static region of the images.
The next step, adopt the k-means cluster algorithm to cluster the number of unmatched feature points in the image. By using the grid to segment the images, it can be known that δ in each grid is representative. In this paper we use the K-means cluster algorithm to divide the dynamic grids and static grids. In the K-means algorithm, assuming that input samples S = X1, X2, …, Xm, then chose K category center, u1, u2, …, uk. For every sample Xi, define labeli as:
Then, updating each category center to the mean of all samples belonging to that category. At last, repeat until the change in the category center is less than a certain threshold. In this paper, since the feature points need to be divided into dynamic regional feature points and static regional feature points, we set K as 2.
K-means algorithm divides the number of unmatched feature points into two parts, one part represents the static grids of the image, another part represents the dynamic region of the image. The third row of the Fig. 4 show the detection results, it can be seen that parts of the two experiments in the image are divided into a single category, and distinguished from the static environment. As shown in the figures, the area in the red box is defined as the dynamic region, which focuses on the people in the images. It can be seen from the raw input figures, there are two experimenters in the pictures. The sitting experimenter has no major posture changes in the two images, while another posture changes greatly. In response to this difference, the proposed algorithm cleverly uses the relationship between the number of feature matches to detect part of the experimenter’s body structure with obvious posture changes in the picture as a dynamic area, while retaining other parts. This region-based segmentation algorithm has not been considered and implemented by other algorithms.
The algorithm to detect dynamic area is shown in Algorithm 2. Significantly, the output of Algorithm 2 is a pair of images Ia and Ib, while the output is the dynamic areas groups. Additionally, G of the Step4 denotes the number of grids, Num and Nm represents the quantities of unmatched feature points and matched feature points of each grid, respectively. The value of δi can be calculated by Eq. (13), K denotes that the data will be clustered into two categories, μk represents the centre of mass, which starts with a random number.

3.4 Dynamic area rejection
In this sub-section, we combine dynamic area detection results and moving consistency check results to complete the establishment of dynamic area: the area is moving or not moving, and at the same time, remove the feature points of the dynamic area. If there are a certain number of dynamic points produced by moving consistency check fall in the contours of a segmented object, then this area is determined to be moving.
After confirming the dynamic area, the next important problem to be solved is the elimination of feature points among the dynamic areas. The proposed strategy is that if the area in the image is determined to be moving, then remove all the feature points located in the moving area. In this way, outliers can be eliminated precisely. Figure 5 demonstrate the results of dynamic region rejection, the first row of the figures show the distribution of the feature points extracted by the ORB algorithm, the second row show the images after the outliers have been removed. In the images, people in black T-shirt and people in checked shirt belong to dynamic objects. Most of the papers directly remove this part of the feature points. But in the green box area of the figures, the person’s legs did not move and should not regard as moving targets. Therefore, the maintenance of feature points in these parts will greatly increase the number of available feature points. The areas selected by the red box represent the moving parts of the dynamic targets. Removing these feature points can effectively reduce the impact of dynamic objects in the scene for camera pose estimation.

Comparison of dynamic regional feature points before and after removal
4 Results and discussion
In this section, experimental results and related discussion would be presented to demonstrate the effectiveness of the proposed method. Firstly, the symbols used for the experiment are as follows:
-
‘GMSK-SLAM’ denotes the proposed method in this paper.
-
‘ORB-SLAM2’ denotes the traditional Simultaneous localization and mapping method, which is described in [25].
-
‘The latest method’ denotes the state-of-art method proposed by Wang. in 2019, which is described in [38].
-
‘Truth’ denotes the ground truth obtained by an external motion capture system.
-
‘Difference’ denotes the difference between the estimated trajectory and the truth trajectory.
Different dynamic environments’ sequences in the TUM data set are used to assess the localization accuracy of the presented RGB-D SLAM scheme. Additionally, we evaluate our presented framework by comparing it with other state-of-the-art SLAM system for better illustrating the effectiveness of the proposed system. The TUM dataset is a scenic dataset of the Technical University of Munich, including 50 laboratory and outdoor sequences. The RGB and depth images were recorded at a frame rate of 30 Hz and a 640 × 480 resolution. Ground-truth trajectories obtained from a high-accuracy motion-capture system are provided in the TUM datasets. The proposed algorithm is operated on a laptop with an Intel i7CPU, 16G of memory, and Ubuntu16.04. GPU acceleration was not adopted during the experiments. Firstly, GMSK-SLAM was compared with the traditional method, ORB-SLAM2, on the TUM fr3_walking_xyz sequence to verify the effectiveness and necessity of detecting dynamic areas and removing outliers. Secondly, to demonstrate the characteristics of high precision for different dynamic environments, the experiments are carried out on more TUM datasets. Finally, compared GMSK-SLAM with a new method proposed by Wang. in 2019 to check if the proposed method is more reliable in dynamic environments.
4.1 Evaluation using TUM RGB-D dataset
The TUM RGB-D dataset [35] provides several sequences in dynamic environments with accurate ground truth obtained with an external motion capture system, such as walking, sitting, and desk. The TUM dataset is divided into high-dynamic datasets and low-dynamic datasets. The desk sequence describes a scene in which a person sits at a desk in an office. In the sitting sequences, two persons sit at a desk with a little gesture. These two scenarios can be considered lowly dynamic environments. In the walking sequences, two persons walk through an office scene. Walking sequences can be used to evaluate the robustness of the proposed method because it is in highly dynamic scenes with quickly moving objects. Since some people walk back and forth in the walking sequences, the walking sequences are mainly used for our experiments. People in these sequences could be regarded as high-dynamic objects, and they are the most difficult problem to deal with. The sitting sequences are also used, but they are considered as low-dynamic sequences as the person in them just moves a little bit.
ORB-SLAM2 is recognized as one of the most outstanding and stable SLAM algorithms at present, so a comparison made between ORB-SLAM2 and GMSK-SLAM is of great significance. Figure 6 shows the trajectory comparison between ORB-SLAM2 and GMSK-SLAM in high dynamic fr3_walking_xyz sequence. In Fig. 6, the blue lines represent the trajectory estimated by ORB-SLAM2 and GMSK-SLAM algorithm, and the black represents the truth trajectory, while lines in red show the difference between estimation and ground truth. The longer the red lines, the greater the trajectory error. As can be seen, in the same coordinate scale, due to adding dynamic areas detection thread, the errors are significantly reduced in GMSK-SLAM, the global estimated trajectory shows a tendency of convergence, and the estimated trajectory is much closer to the true trajectory.

a Global trajectory estimated by ORB-SLAM2, b Global trajectory estimated by GMSK-SLAM
After the global trajectory comparison, we further compare the trajectory accuracy of each axis. The ATE (Absolute Trajectory Error), which represents the difference between the estimated trajectory and the ground-truth, is used as the evaluation metric. It directly indicates the localization accuracy of the system. In particular, an easy-to-use open-source package evo is employed for the evaluation (github.com/MichaelGrupp/evo). The Fig. 7 show the estimated trajectories of GMSK-SLAM and ORB-SLAM2 on the highly dynamic datasets. The blue lines and the green lines represent the trajectory of GMSK-SLAM and ORB-SLAM2, respectively. The grey dotted lines represent the ground-truth of the trajectory reference. As can be seen from Fig. 7, the coincidence degree of blue lines and grey lines is larger than that of green lines and grey lines, which means the estimation accuracy of the proposed method plays superior performance than the ORB-SLAM2 in every axe. We also use the evo tool to plot the APE (Absolute Pose Error) of the fr3_walking_xyz sequence in the TUM dataset (Fig. 8). Figure 8 shows the APE distribution of the GMSK-SLAM and ORB-SLAM2 system throughout the tracking. As we can see in the green line of Fig. 8, when there are pedestrians in the field of view of the camera, the APE values increase dramatically. However, the APE values of the blue line at those same moments are greatly reduced, because the influence of pedestrians has been eliminated with our algorithm. In addition to ATE and APE. We also use RMSE to value the positioning accuracy of the whole GMSK-SLAM system.

The trajectory of ORB-SLAM2 and GMSK-SLAM

The Absolute Pose Error results of GMSK-SLAM and ORB-SLAM2
RMSE can evaluate the degree of change in the data, the smaller the RMSE value is, the more accurate the prediction model can be in describing the experimental data. We compute the RMSE of ATE to test the accuracy of the algorithm. In the presented GMSK-SLAM system, the RMSE of ATE of X-axis is only 1.8365 × 10−4m, Y-axis is 0.0017 m and the Z-axis is 1.9623 × 10−4m. While, the RMSE of ATE X-axis is 0.2686 m, Y-axis is 0.0156 m, and the Z-axis is 0.04 m with ORB-SLAM2. The above experiments show that the applicability of the GMSK-SLAM algorithm in dynamic environment is greater than that of ORB-SLAM2. To further test the applicability of GMSK-SLAM in different environment, a variety of dynamic environments are selected for testing. The quantitative comparison results are shown in Tables 1 and 2, where xyz, static, rpy, and half in the first column stand for four types of camera ego-motions, for example, xyz represents the camera moves along the x-y-z axes. We present the values of RMSE, Mean Error, and Standard Deviation (S.D.) in this paper, while RMSE and S.D. are more concerned because they can better indicate the robustness and stability of the system. The S.D. values in the tables are calculated as follows:
Where μ denotes the mean of x1, x2, …xN. The Mean Error in the tables is calculated as follows:
The values of improvement of GMSK-SLAM compared to the original ORB-SLAM2 are also calculated. The improvement is calculated by the following formula:
Where η denotes the value of improvement, αORB denotes the value of ORB-SLAM2 and αDMSK denotes the value of GMSK-SLAM.
As can be seen from Tables 1 and 2, GMSK-SLAM can make the performance in most high-dynamic sequences get an order of magnitude improvement. In terms of ATE, the RMSE and S.D. improvement values can reach up to 98.8% and 97.5% respectively. The results indicate that GMSK-SLAM can improve the robustness and stability of the SLAM system in high-dynamic environments significantly. Therefore, from tables, it can be found that the accuracy of GMSK-SLAM is significantly greater than ORB-SLAM2, which demonstrates that it is necessary to detect and remove moving objects in dynamic environments. The estimation of camera pose mainly depends on the extraction and matching of feature points for ORB-SLAM2, so optimizing the feature points in dynamic environments would greatly increase the accuracy of attitude and position.
For practical applications, real-time performance is a crucial indicator to evaluate the SLAM system. We test the time required for some major modules to process. The results are shown in Table 3. The average time in the main thread to process each frame is 57.3ms, including dynamic area detection, visual odometry estimation, pose graph optimization. Compared with previous non-real-time methods to filter out dynamic objects, such as [36], GMSK-SLAM is more satisfied with the needs of the real time.
It can be seen from the above analysis, in a variety of complex and changing scenarios, the proposed method in this paper still can maintain high positioning accuracy. Compared with traditional ORB-SLAM2, the RMSE accuracy are all improved almost 90% in different environment. Experiments in various scenarios prove that the proposed algorithm has high accuracy and good stability when dealing with different complex dynamic environments. Therefore, the algorithm in this paper is more suitable for the environment perception and location in the actual dynamic scene.
4.2 Comparison with other method
In this section, the proposed method is compared with a state-of-the-art method, which was proposed by Wang [38] in 2019. This method clustered the filled depth images and used them to segment moving objects. The latest method treats people as dynamic in any situation, even the person is in a static state. However, the proposed GMSK-SLAM innovatively detects dynamic areas rather than dynamic objects, determining dynamic or static area depends on the number of matching feature points. Such a method is more realistic. The GMSK-SLAM algorithm maintains the static feature points in dynamic objects effectively, which greatly increases the number of useful feature points. A qualitative comparison between the proposed GMSK-SLAM algorithm and the latest method for dynamic environment is provided in Fig. 9. These quantitative evaluations were carried out using the TUM RGB-D datasets.

The trajectory of The Latest method and GMSK-SLAM
It can be seen by comparing Figs. 7 and 9 that removing dynamic objects feature points indeed can effectively improve the accuracy of trajectory. As is showed in Fig. 9, although the latest method reduces the difference between the ground truth and estimated trajectory to some extent, due to removing all feature points in dynamic objects, instead, it also reduces the number of feature points available. Figure 9 clearly demonstrates that the trajectory estimation results of the detecting dynamic region are better than that of the dynamic objects.
The RMSE of ATE in three axes are calculated as follows. As can be seen in Table 4, the proposed GMSK-SLAM has a more reliable performance than the latest method [38]. The comparison shows that the GMSK-SLAM gives greatly better results than the latest method.
In order to better illustrate the effectiveness of our algorithm, we also compare the APE with the latest method. Figure 10 shows the APE distribution of the GMSK-SLAM and the latest method throughout the tracking. As can be seen from the Fig. 10, the proposed method’s accuracy in the Fr3_walking_xyz is better than the latest SLAM system.

The Absolute Pose Error results of GMSK-SLAM and the latest method
Finally, a global comparison is made among the three algorithms in Fig. 11. It can be seen from Fig. 11, compared with the ORB-SLAM2, the position error of the GMSK-SLAM and the latest method are reduced to a certain extent. However, the latest method directly eliminates all feature points in dynamic target, which in turn reduces the number of feature points reliable. Therefore, the accuracy of the latest method is lower than the GMSK-SLAM’s.

The comparison of GMSK-SLAM, ORB-SLAM2 and the latest method
5 Conclusion
In this paper, a new complete robust dynamic area detection SLAM (GMSK-SLAM) system is proposed, which could greatly reduce the influence of dynamic objects on pose estimation. The proposed method has third innovations. First, adopting moving consistency check into the proposed method, which greatly increase the accuracy of dynamic objects detection. Second, using the GMS algorithm to match feature points and k-means algorithm to distinguish dynamic environments and static environments. Thirdly, adding a dynamic area detection in an independent thread, which greatly improves the operating efficiency and robustness of the system. The proposed system could run the tracking thread and the dynamic area detection thread in parallel, thus allowing our system to read read-time performance.
In the experimental section, the proposed GMSK-SLAM is qualitatively evaluated with the public benchmark data set TUM. On the one hand, the GMSK-SLAM is compared with the mainstream VIO system, which validly proofs that detecting dynamic area can improve the environmental applicability and stability of the algorithm. All tests show that the trajectory accuracy of the GMSK-SLAM is 90% better than the ORB-SLAM method. On the other hand, a series of experiments are conducted between GMSK-SLAM and the latest method proposed in 2019. Experiments effectively demonstrate that removing dynamic areas rather than dynamic objects significantly eliminates the interference of dynamic factor to the system. Above all, we can conclude that the proposed GMSK-SLAM algorithm has better performance than the traditional method and latest method.
In the future, we plan to consider other environmental disturbance elements, such as environmental brightness, weather conditions, and dynamic target density, etc. Besides, we intend to combine our moving areas detection method with a lightweight deep learning method, to achieve robust results of moving areas detection in challenging dynamic environments.
Data availability
Yes
References
Badrinarayanan V, Kendall A, Cipolla R (2017) Segnet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Pattern Anal Mach Intell 39(12):2481–2495
Bahraini MS, Bozorg M, Rad AB (2018) SLAM in dynamic environments via ML-RANSAC. Mechatronics 49:105–118
Bay H (2006) Surf: speeded up robust features. 9th European Conference on Computer Vision (ECCV 2006), Graz, AUSTRIA, pp 404–417
Bian JW, Lin WY, Matsushita Y (2017) GMS: Grid-Based Motion Statistics for Fast, Ultra-Robust Feature Correspondence. 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, pp 2828–2837
Calonder M, Lepetit (2010) Brief: binary robust independent elementary features. 11th European Conference on Computer Vision, Heraklion, GREECE, pp 778–792
Davison AJ, Reid ID, Molton ND (2007) MonoSLAM: real-time single camera SLAM. IEEE Trans Pattern Anal Mach Intell 29(6):1052–1067
Dissanayake MWMG, Newman P (2013) A solution to the simultaneous localization and map building (slam) problem. IEEE Trans Robot Autom 17(3):229–241
Endres F, Hess J, Engelhard N (2012) An evaluation of the RGB-D SLAM system. IEEE international conference on robotics and automation (ICRA), St Paul, MN, pp 1691-1696
Engel J, Schöps T, Cremers D (2014) Lsd-slam: large-scale direct monocular slam. In: proceedings of European conference on computer vision (ECCV), vol 8690, pp 834-849
Engel J, Koltun V, Cremers D (2018) Direct sparse Odometry. IEEE Trans Pattern Anal Mach Intell 40(3):611–625
Fang Y, Dai B (2009) An improved moving target detecting and tracking based on optical flow technique and Kalman filter. 4th International Conference on Computer Science and Education, Nanning, PEOPLES R CHINA, pp 1197–1202
Forster C, Pizzoli M, Scaramuzza D (2014) SVO: Fast Semi-Direct Monocular Visual Odometry. IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, PEOPLES R CHINA, pp 15–22
Harris C G, Stephens M J (1988) A combined corner and edge detector. Proceedings of the 4th Alvey vision conference, Manchester, England, pp 147-151
Hess W, Kohler D, Rapp H (2016) Real-time loop closure in 2D LIDAR SLAM. IEEE international conference on robotics and automation (ICRA), pp 1271-1278
Klein G, Murray D (2007) Parallel tracking and mapping for small AR workspaces. IEEE & Acm International Symposium on Mixed & Augmented Reality.
Kohlbrecher S, Stryk OV, Meyer J (2011) A flexible and scalable SLAM system with full 3D motion estimation. IEEE International Symposium on Safety, Security, and Rescue Robotics, Kyoto, Japan https://doi.org/10.1109/SSRR.2011.6106777
Lee SJ, Hwang SS (2019) Bag of sampled words: a sampling-based strategy for fast and accurate visual place recognition in changing environments. Int J Control Autom Syst 17(10):2597–2609
Li JN, Wang LH, Li Y (2016) Local optimized and scalable frame-to-model SLAM. Multimed Tools Appl 75(14):8675–8694
Liu GH, Zeng WL, Feng B, Xu F (2019) DMS-SLAM: a general visual SLAM system for dynamic scenes with multiple sensors. SENSORS 19(17)
Long J, Shelhamer E, Darrell T (2015) Fully Convolutional Networks for Semantic Segmentation. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, pp 3431–3440
Lowe D (2004) Distinctive image features from scale-invariant keypoints. Int J Comput Vis 60(2):91–110
MacQueen J (1965) Some Methods for Classification and Analysis of Multi-Variate Observations. Proceedings of the Fifth Berkeley Symposium on Math, Statics, and Probability, vol 1, pp 281–297
Mu X, He B, Zhang X (2019) Visual navigation features selection algorithm based on instance segmentation in dynamic environment. IEEE Access 8:465–473
Muja M, Lowe DG (2009) Fast approximate nearest neighbors with automatic algorithm configuration. VISAPP, vol 1:331–340
Mur-Artal R, Tardos JD (2017) ORB-SLAM2: an open-source SLAM system for monocular, stereo, and RGB-D cameras. IEEE Trans Robot 33(5):1255–1262
Mur-Artal R, Montiel JMM, Tardós JD (2015) ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans Robot 31(5):1147–1163
Oh S, Hahn M, Kim J (2015) Dynamic EKF-based SLAM for autonomous mobile convergence platforms. Multimed Tools Appl 74(16):6413–6430
Redmon J, Farhadi A (2018) Yolov3: an incremental improvement.arXiv e-prints,2018
Redmon J, Divvala S, Girshick R, Farhadi A (2015) You only look once: unified, real-time object detection. 2016 IEEE conference on computer vision and pattern recognition (CVPR), Seattle, WA, pp. 779–788
Rosten E, Drummond T (2006) Machine learning for high-speed corner detection. 9th European conference on computer vision (ECCV 2006), Graz, AUSTRIA, pp 430-443
Rublee E, Rabaud V, Konolige K et al (2012) ORB: an efficient alternative to SIFT or SURF. IEEE international conference on computer vision (ICCV), Barcelona, SPAIN, pp 2564-2571
Saputra MRU, Markham A, Trigoni N (2018) Visual SLAM and structure from motion in dynamic environments: a survey. ACM Comput Surv 51(2):1–36
Sharma K (2018) Improved visual SLAM: a novel approach to mapping and localization using visual landmarks in consecutive frames. Multimed Tools Appl 77(7):7955–7976
Smith RC, Cheeseman P (1986) On the representation and estimation of spatial uncertainty. Int J Robot Res 5(4):56–68
Sturm J, Engelhard N, Endres F (2012) A benchmark for the evaluation of RGB-D SLAM systems. 25th IEEE\RSJ International Conference on Intelligent Robots and Systems (IROS), Algarve, PORTUGAL, pp 573–580
Sun Y, Liu M, Meng QH (2017) Improving RGB-D SLAM in dynamic environments: a motion removal approach. Rob Auton Syst 89:110–122
Tong Q, Peiliang L, Shaojie S (2018) VINS-mono: a robust and versatile monocular visual-inertial state estimator. IEEE Trans Robot 34(4):1004–1020
Wang R, Wan W, Wang Y (2019) A new RGB-D SLAM method with moving object detection for dynamic indoor scenes. Remote Sens 11(10)
Wrobel B P (2001) Multiple view geometry in computer vision. Cambrige university press
Yu C, Liu Z, Liu X (2018) DS-SLAM: a semantic visual SLAM towards dynamic environments. 25th IEEE/RSJ international conference on intelligent robots and systems (IROS), Madrid, SPAIN, pp 1168-1174
Zhang W, Chen Q, Zhang W, He X (2018) Long-range terrain perception using convolutional neural networks. Neurocomputing 275:781–787
Acknowledgments
This work was supported in part by National Natural Science Foundation of China 52071080, Fundamental Research Funds for the Central Universities under Grant 2242021K1G008, Remaining funds cultivation project of National Natural Science Foundation of Southeast University under Grant 9S20172204.
Code available
No (Not applicable).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest/Competing interests
No
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wei, H., Zhang, T. & Zhang, L. GMSK-SLAM: a new RGB-D SLAM method with dynamic areas detection towards dynamic environments. Multimed Tools Appl 80, 31729–31751 (2021). https://doi.org/10.1007/s11042-021-11168-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-11168-5