
Abstract
Image segmentation is the basis of image analysis, object tracking, and other fields. However, image segmentation is still a bottleneck due to the complexity of images. In recent years, fuzzy clustering is one of the most important selections for image segmentation, which can retain information as much as possible. However, fuzzy clustering algorithms are sensitive to image artifacts. In this study, an improved image segmentation algorithm based on patch-weighted distance and fuzzy clustering is proposed, which can be divided into two steps. First, the pixel correlation between adjacent pixels is retrieved based on patch-weighted distance, and then the pixel correlation is used to replace the influence of neighboring information in fuzzy algorithms, thereby enhancing the robustness. Experiments on simulated, natural and medical images illustrate that the proposed schema outperforms other fuzzy clustering algorithms.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Due to wide application and great importance in different computer vision tasks [11, 14, 15], image segmentation has been extensively studied for decades. In essence, image segmentation is to divide a given image into multiple disjointed parts [16]. Therefore, image segmentation can change the representation of a given image to something that is more meaningful and easier to analyze. For example, image segmentation in computer vision is typically used to locate objects and boundaries, and assigns a label to the pixels that sharing certain characteristics. In medical image analysis, image segmentation is the division of a medical image into different organs or tissues, or the division of a tissue into normal or abnormal parts, which is helpful for clinical decision support systems [19, 26]. Currently, various algorithms are proposed for image segmentation, such as fuzzy clustering algorithms [9, 12, 18], CNN-based algorithm [20], graph-based algorithms [10], Markov random field (MRF) [25], active contour model [29], watershed method [6], threshold-based algorithms [22], and so on. The goal of this paper is to explore the fuzzy clustering algorithms.
Fuzzy C-means, abbreviated as FCM, is a typical fuzzy clustering algorithm in image segmentation. In FCM, one pixel can be assigned to multiple clusters with different membership at the same time. Compared with those “hard” algorithms, such as k-means, more information can be retained during image segmentation, and better results will be retrieved [8]. In traditional fuzzy clustering algorithms, the essence of image segmentation is to minimize the weighted distance between the pixels and corresponding clustering centers. However, traditional fuzzy clustering algorithms are sensitive to image artifacts because they do not consider spatial information. To solve this problem, many improved algorithms were proposed, such as a bias-corrected version of FCM(BCFCM) [1], a fast generated fuzzy c-means(FGFCM) [5], the fuzzy local information C-means clustering algorithm(FLICM) [17], and so on. In these improved algorithms, various neighboring information were added to the objective function, and the segmentation results are enhanced to some extent. However, when the noise level is high, the results of these algorithms are poor, which will be presented later. To enhance the results, more information are utilized in the process of image segmentation, not limited to information provided by neighboring pixels. Hence, these information are called non-local information. Though the performance is better, the efficiency is poor due to considering more information. Therefore, an improved fuzzy clustering algorithm is required to be proposed, in which pixel correlation between adjacent pixels will be accurately measured, and a smaller search window is sufficient to improve the efficiency while retaining good performance.
The rest of the paper is organized as follows. Section 2 give an introduction of typical fuzzy clustering algorithms, as well as the advantages and disadvantages of the corresponding algorithms. The improved segmentation algorithm will be described in Section 3, and then the segmentation results of different algorithms on various images will be presented. Based on the segmentation results, error analysis will be presented in Section 5. Finally, a short but important conclusion will be drawn.
2 Related work
This section will introduce typical fuzzy clustering algorithms for image segmentation, including FCM, BCFCM, enhanced FCM(EnFCM) [24], FLICM, and improved FCM with non-local information [27].
2.1 FCM
Fuzzy C-means was proposed by Dunn and later extended by Bezdek [4]. In FCM, the membership μij ∈ [0,1] is introduced to measure the belonging of pixels to corresponding clusters. If μij = 0, the j-th pixel does not belong to the i-th cluster, and if μij = 1, the j-th pixel is surely to be the member of the i-th cluster. In essence, the target of FCM is to minimize the weighted distance between pixels and corresponding clusters. Formally,
where C is the pre-defined number of clusters, n is the number of pixels in the given image, xj is the intensity value of the j-th pixel, vi is the i-th cluster center, and m > 1 is the parameter to control the fuzziness of the results. In fuzzy clustering algorithms, the membership μij is under the constraints \({\sum }_{i=1}^{C} \mu _{ij}=1\) for all pixels. To minimize the objective function in (1), Lagrange multiplier method is adopted, and the following function will be constructed.
Based on \(\frac {\partial J}{\partial v_{i}}=0\) and \(\frac {\partial J}{\partial \mu _{ij}}=0\), the cluster center and the membership can be updated iteratively in the process of minimizing (1), formalized as follows.
When the objective function in (1) is minimized, the segmentation is accomplished by defuzzification. That is to say, the j-th pixel will be classified to the k-th cluster, where
As is shown in (1), only the pixel intensity is utilized. When the pixel is contaminated by image artifacts, FCM performs poor and cannot achieve good performance. Also, the objective function is minimized by updating the membership and cluster center iteratively, resulting in poor efficiency. In order to solve these problems, many researchers improved FCM by considering more information in the process of image segmentation. Typical improved ones are introduced in subsequent subsections.
2.2 BCFCM
To overcome the sensitivity of FCM to image artifacts, Ahmed proposed a bias-corrected version of FCM, denoted as BCFCM. In BCFCM, neighboring information is utilized to enhance the performance, and the target is to classify the neighboring pixels into the same cluster as much as possible. The objective function of BCFCM is defined as
where Nj is the set of neighboring pixels centering around the j-th pixel, and NR is the corresponding cardinality. α is one parameter, controlling the impact of neighboring pixels on the central one.
As is shown in (6), the distance between the neighboring pixels and related clusters will affect the membership of the central pixel to corresponding clusters. Concretely, if dir is large, μij in the latter part will be small to minimize the objective function, meaning the belonging of the central pixel to related cluster is depressed. On the contrary, when dir is small, that is, the neighboring pixel is close to the cluster, the membership of central pixel can be large. By considering these neighboring information, BCFCM is more insensitive to image artifacts, compared with FCM. However, considering more information means low efficiency. Aiming at this problem, Chen proposed two improved algorithms of BCFCM [7], named BCFCMS1 and BCFCMS2. In the two improved versions, neighboring information will be retrieved with median or mean filter beforehand, and the efficiency can be improved.
2.3 EnFCM
To improve the efficiency of FCM in image segmentation, Szilagyi proposed EnFCM, an enhanced version of FCM. In EnFCM, image segmentation is performed on the histogram of the given image and can accomplish in less than 1 second. This is because that the number of pixels is much higher than that of intensity levels. In EnFCM, the objective function is defined as
where γj is the number of pixels with intensity value j. Obviously, γj satisfies \({\sum }_{j=0}^{255}\gamma _{j}=n\). To improve the robustness, the given image will be filtered beforehand. Formally,
where \(x^{\prime }_{i}\) and xi are the intensity values of the i-th pixel in the filtered and original image, and the meanings of other symbols are the same as those in BCFCM. In BCFCM and EnFCM, the impact factor of neighboring pixels on the central one is controlled by α, which is one constant and is often adjusted by try and error. Commonly, not all neighboring pixels have similar intensities with the central pixel, which means that classifying the neighboring pixels and the central pixel into one cluster is not suitable. Aiming at this problem, Cai proposed FGFCM, in which α is replaced with the pixel correlation between corresponding pixels.
2.4 FLICM
The segmentation results of the improved algorithms mentioned above are affected greatly by related parameters, which should be adjusted in the process of segmentation. Aiming at this problem, Krinidis and Chatzis proposed FLICM. In FLICM, one fuzzy factor is proposed to replace α in BCFCM and EnFCM, which is defined as follows.
where djr is the Euclidean distance between the j-th pixel and the r-th pixel. With Gij, the objective function of FLICM can be defined as follows.
As shown in (10), there is no other parameters except the number of clusters. That is to say, FLICM is free of parameters. With the application of Gij, the membership of all pixels in the neighboring pixels, whether they are contaminated by image artifacts or not, will converge to a similar value [12]. Therefore, FLICM can enhance the robustness of fuzzy algorithms.
2.5 NLFCM
Though the algorithms mentioned above can retrieve good results in image segmentation, they perform poor when noise level is high. To enhance the results farther, Zhang et al. improved FLICM with non-local information(NLFCM). In the fuzzy factor of NLFCM, the relationship between neighboring pixels is measured by pixel correlation instead of Euclidean distance. As is shown in BCFCM and FLICM, only neighboring pixels have impact on the central pixel due to the limited size of Nj. In NLFCM, pixel correlation is pre-computed, and can be well incorporated into the fuzzy factor of FLICM. With the help of pixel correlation, more and more information can be utilized in the process of image segmentation, not limited to neighboring pixels. In NLFCM, the fuzzy factor is defined as follows.
where S(j,k) is the pixel correlation between the j-th pixel and the k-th pixel, and \({w_{j}^{r}}\) is the search window centering around the j-th pixel with radius r. With the novel fuzzy factor, NLFCM can utilize more information and can retrieve good performance. However, utilizing more information means low efficiency. It will take more than several hours for NLFCM to perform segmentation and the efficiency cannot be accepted.
2.6 Motivation
As mentioned before, different improved algorithms have their disadvantages. To retrieve good performance, an improved FCM algorithm will be presented in this study, which is the improved version of NLFCM and FLICM. The essence of the proposed algorithm is to make those similar pixels play positive role in image segmentation. In the proposed algorithm, the most important task is to measure pixel correlation accurately. Compared with NLFCM, the size of the search window in the proposed algorithm does not need to be so large, and the efficiency can be improved greatly. In addition, with accurate pixel correlation, those “true” similar pixels will play positive role in image segmentation, resulting in good performance and improved efficiency.
Therefore, the proposed algorithm can be divided into two steps. First, pixel correlation model between adjacent pixels will be designed and then pixel correlation will be fused into image segmentation to enhance the robustness.
3 Improved fuzzy clustering algorithm based on pixel correlation
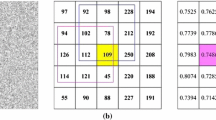
As mentioned before, when the pixel correlation is measured accurately, a small search window is supposed to be sufficient to improve the segmentation efficiency while retaining good performance. Therefore, it is important to create an accurate pixel correlation model. In FGFCM, pixel correlation is related to pixel intensity and pixel position. However, when the image is contaminated with image artifacts, the intensity of the pixel is not the true value, and pixel correlation cannot reflect the relationship between adjacent pixels. To improve the robustness, pixel correlation was improved in our previous work [27], which is defined as the similarity between corresponding image patches. However, conventional patch similarity cannot reflect the pixel correlation [23]. Let’s illustrate this problem by using the example in Fig. 1. We will compute pixel correlation between the center pixel (with intensity value 211) with adjacent pixels (with intensity values 229 and 35). As is well shown, the pixel with intensity value 229 should be classified into the same cluster of the central pixel, while the pixel with intensity value 35 should not. However, by adopting conventional pixel correlation model, the difference between corresponding patches is the opposite, shown in Fig. 1(c). Therefore, pixel correlation model based on image patch distance cannot reflect the relationship between neighboring pixels, which is the starting point of this paper.

Conventional pixel correlation on synthetic image. a original image; b pixel intensity in Fig. 1(a); c corresponding patch distance
3.1 Pixel correlation model
As mentioned before, pixel correlation is important for improving efficiency and retaining good performance. With accurate pixel correlation, similar pixels will be classified into the same cluster, and thereby enhance the robustness. In our previous work [13, 28], pixel correlation is computed on the basis of patch similarity. However, edge information is not considered, resulting in inaccurate pixel correlation, as is shown in Fig. 1(c). Therefore, to retrieve satisfying performance, more similar pixels should be considered, and the key problem is to retrieve accurate pixel correlation. Aiming at this problem, the proposed pixel correlation will make the best of spatial information and edge information at the same time. For the central pixel p and neighboring pixel q, the proposed method to retrieve the pixel correlation is formalized in Algorithm 1.

We will take the figure in Fig. 1(a) to illustrate the procedure, and we will compute the pixel correlation between the central pixel and 8 neighboring pixels.
First, we will construct the image patches centering around corresponding pixels, shown in Fig. 2. Figure 3 presents patch difference between the central patch and neighboring patches, and corresponding weight on different directions will be computed, shown in Fig. 4. Then, the weighted distance between patches is computed in Fig. 5, and finally pixel correlation is retrieved, presented in Fig. 6.

Image patches centering around related pixels

Computation of the difference between the central patch and neighboring patches

Computation of the weight of the central pixel in different directions

Computation of the weighted distance between the central patch and neighboring patches

Computation of pixel correlation between the central pixel and neighboring pixels
As is shown in the proposed pixel correlation model, corresponding weights on different directions will be computed first, and the patch-weighted distance will be retrieved. Finally, the pixel correlation between neighboring pixels and the central one is computed. With the help of the weight in (13), pixel correlation is reasonable than that in our previous work [27]. Specially, pixel correlation between the central pixel(with intensity value 211) and the upper pixel(with intensity value 229) is larger than that between the central pixel and the lower pixel(with intensity value 35). Though the patch distance between the first two patches is larger than that between the latter two patches, the pixel correlation is more suitable after adopting patch-weighted distance.
3.2 Improved segmentation algorithm based on pixel correlation
As is shown in NLFCM, considering more non-local information can retrieve good performance, but with low efficiency. The proposed segmentation algorithm will improve the efficiency by limiting the size of search window, and can retain good performance with the help of accurate pixel correlation. Generally speaking, the proposed algorithm is on the basis of NLFCM, formalized in Algorithm 2.

3.3 Theoretical analysis
In our previous work, we have found that neighboring information play an important role in image segmentation [28]. To improve the robustness, more pixels are utilized to guide image segmentation, not limited to neighboring ones. In essence, the target of utilizing neighboring information is to classify the similar pixels in the vicinity and the central pixel into the same cluster. Therefore, measuring the correlation between pixels is very important. Generally speaking, pixel correlation depends on the intensity difference and spatial distance. For example, pixel correlation is inversely proportional to the Euclidean distance in FLICM. In FGFCM, pixel correlation is the product of spatial correlation and intensity correlation. In EnFCM, BCFCM, pixel correlation is assigned as one constant α.
Traditional pixel correlation in NLFCM is based on patch distance |Ip − Iq|. However, pixels with smaller patch distance may belong to different clusters, such as the case in Fig. 1. In the proposed segmentation algorithm, pixel correlation is computed on the weighted patch distance, which can utilize spatial information and patch distance concurrently. If the neighboring pixel is different from the central pixel, corresponding patch distance plays less role in computing pixel correlation. The proposed patch correlation is different from our previous work, and can enhance the robustness.
3.4 Complexity analysis
Suppose the radius of the search window is r, and the size of the search window is (2r + 1) × (2r + 1). The complexity of the proposed algorithm is O(n(2r + 1)2CI), where I is the pre-defined number of iterations. With the increment of the radius r, more information can be utilized to enhance the robustness, shown in Fig. 7. As is shown in Fig. 7, less noise exists with the increment of the radius. However, with the increment of the radius, fuzziness will appear in the segmentation results, especially near the boundaries. Therefore, the radius r will be assigned as 2 in the proposed algorithm to balance the efficiency and the segmentation results.

Segmentation results with different radius. a original image; b segmentation result with r = 1; c segmentation result with r = 2; d segmentation result with r = 3
4 Simulated experiments
In this section, we will perform the proposed algorithm with FCM-related algorithms, including FCM, FCMS, FGFCM, EnFCM, FLICM and NLFCM. To show the advantage of the proposed algorithm, we will perform these algorithms on 3 kinds of images, including synthetic images, natural images and medical ones. Also, we will add different noise on these images and we will compare the robustness of these algorithms. The assignments of related parameters are tabulated in Table 1.
To compare these algorithms quantitatively, three measures will be adopted, including segmentation accuracy, partition coefficient [2] and partition entropy [3]. Segmentation accuracy(SA) is defined as the number of pixels classified correctly divided by the number of all pixels, formalized as follows.
where Ci is the set of pixels in the i-th cluster in the reference image such that \({\sum }_{j=1}^{C} |C_{i}|=n\), and Ai is the set of pixels classified into the i-th cluster correctly. Obviously, one segmentation algorithm with higher segmentation accuracy is preferable.
The partition coefficient VPC and partition entropy VPE are defined on the membership of the pixels and formalized as
For a good segmentation algorithm, we hope any pixel belongs to one cluster with big membership as much as possible. That is to say, a good algorithm means low fuzziness. Therefore, an algorithm with high partition coefficient and low partition entropy is preferable.
4.1 Synthetic images
First we will perform the proposed algorithm on 2 synthetic images, and different kinds of noise will be added. The first synthetic image has two classes, and the size is 128 × 128. The other synthetic image has four classes, and there are 256 × 256 pixels. The synthetic images are illustrated in Figs. 8a and 9a. To outperform the advantage of the proposed algorithm, Gaussian noise of 20% and 30% is added to these synthetic images, shown in Figs. 8b and 9b. We will compare the segmentation results of FCM-related algorithms, including FCM, BCFCM, EnFCM, FGFCM, FLICM and NLFCM. The segmentation results of corresponding algorithms are shown in Figs. 8c–h and 9c–h, respectively.

Experiments on the first synthetic image of different algorithms. a reference image ; b image with Gaussian noise of 20%; c FCM; d BCFCM; e EnFCM; f FGFCM; g FLICM; h NLFCM; i Proposed algorithm

Experiments on another synthetic image. a reference image; b image with Gaussian noise of 30% degree; c FCM; d BCFCM; e EnFCM; f FGFCM; g FLICM; h NLFCM; i Proposed algorithm
As is shown in Fig. 8, image noise still exists in the segmentation results of FCM, EnFCM, FGFCM, FLICM and NLFCM, while disappear in the results of BCFCM and the proposed algorithm. In Fig. 9, image noise still exists in the results of FCM, EnFCM, FGFCM, FLICM and NLFCM, while disappear in the results of BCFCM and the proposed algorithm. However, only 3 clusters exist in the result of BCFCM, different from the reference image. To summarize, the results of the proposed algorithm is the better than those of other FCM-related algorithms visually.
To compare these algorithms objectively, we compare the SAs of these algorithms, shown in Table 2. It is illustrated from Table 2 that with the increment of noise level, the segmentation accuracies of all algorithms degrade. Though BCFCM, FGFCM and FLICM can gain better segmentation accuracy, the proposed algorithm outperforms these algorithms when the noise level is high.
Also, the partition coefficients and partition entropies of these algorithms are compared, tabulated in Table 3. As is shown from Table 3, the segmentation accuracies of all algorithms degrade with the increment of noise level. The proposed algorithm is comparatively stable and of high accuracy, especially when the noise level is high.
4.2 Medical images
To illustrate the advantage of the proposed algorithm, we compare these algorithms on medical images. As is well known, medical image segmentation is still one bottleneck in medical image processing due to the existence of partial volume effect(PVE), intensity inhomogeneity(IIH) and noise. In this subsection two brain images are adopted to illustrate the advantage of the proposed scheme, one is a MRI(Magnetic Resonance Imaging) image, and the other is a CT(Computed Tomography) image. The sizes of the two images are 181 × 217 and 256 × 255, respectively. As is well known, there are 4 clusters in the brain image: background, cerebral spinal fluid (CSF), gray matter (GRY) and white matter (WHT). As is well known, medical images are commonly contaminated by Rician noise. In our experiments, Rician noise is generated by a code obtained from Ged Ridgway [21]. The first brain image is contaminated by 30%(s = 30) and the other is by 10%(s = 10), shown in Figs. 10b and 11b. The segmentation results of different algorithms are tabulated in Figs. 10c–h and 11c–h, respectively.

Segmentation results of Brain image from BrainWeb. a reference image; b image with Rician noise of 30% degree; c FCM; d BCFCM; e EnFCM; f FGFCM; g FLICM; h NLFCM; i Proposed algorithm

Actual Brain image segmentation results. a original image; b image with Rician noise of 10% degree; c FCM; d BCFCM; e EnFCM; f FGFCM; g FLICM; h NLFCM; i Proposed algorithm
As is shown in Fig. 10, image artifacts still exist in the results of FCM, BCFCM, EnFCM and FGFCM, while many details miss in the results of FLICM and NLFCM. Comparatively, the segmentation results of the proposed algorithm is better than those of other algorithms. From the results in Fig. 11, we can see that the proposed algorithm can not only improve the insensitivity to image artifacts, but also retain the image details as much as possible.
To illustrate the advantage of the proposed algorithm, we compare the partition coefficients and partition entropies of corresponding algorithms, tabulated in Table 4. As is shown from Table 4, the two measures of the proposed algorithm are in the top three, meaning the results of the proposed algorithm are of less fuzziness.
4.3 Natural images
Also, we perform the proposed algorithm on natural images. The two images are from [12], and the size of these two images is 190 × 123. In order to illustrate the robustness of the proposed algorithm, Salt&Pepper noise(15% degree) and Gaussian noise(15% degree) are added to the images, shown in Figs. 12b and 13b, and the segmentation results are presented in Figs. 12c–h and 13c–h.

Natural image segmentation results(C = 2). a original image; b image with Salt&Pepper noise of 15% degree; c FCM; d BCFCM; e EnFCM; f FGFCM; g FLICM; h NLFCM; h Proposed algorithm

Natural image segmentation results(C = 3). a original image; b image with Gaussian noise of 15% degree; c FCM; d BCFCM; e EnFCM; f FGFCM; g FLICM; h NLFCM; i Proposed algorithm
Since the number of clusters is pre-defined as 2, the segmentation of Fig. 12 can be seen as saliency detection. From Fig. 12, we can see that there is still much noise in the segmentation results of FCM, BCFCM, EnFCM and FGFCM, and the results of FLICM, NLFCM and the propose algorithm are much better visually. Further, the details of the NLFCM and the proposed algorithm are better than that of FLICM. The performance of Fig. 13 is to compare the algorithms in crowded images with many classes. In crowded images, the difficult thing is to decide the number of clusters. Based on Four Color Theorem in graph theory, when the number of clusters is assigned as 4, any adjacent clusters can be labelled differently. However, when the intensity values of adjacent regions are similar, many details are lost in the segmentation results of FCM-related algorithms. From the results of Fig. 13, it is obvious that image artifacts still exist in the results of FCM, BCFCM, EnFCM and FGFCM. The result of FLICM is a bit blurred and more details are lost in the boundary regions of NLFCM. Compared with other algorithms, the proposed algorithm can retrieve the best visual effect.
Also, we compute the partition coefficients and the partition entropies of related algorithms, tabulated in Table 5. From Table 5, the two parameters of the proposed algorithm are either the best, or comparable with the best parameter value, meaning less fuzziness in the segmentation results. Considering the visual effect and the objective evaluation provided by related parameters, the proposed algorithm is preferable.
5 Error analysis and possible improvements
While the proposed algorithm achieves an impressive performance on different kinds of images, there are still some pixels that are misclassified in the segmentation results, especially the pixels near the boundary region. We enlarge the segmentation result in Fig. 9 to illustrate this problem, shown in Fig. 14. As is shown in Fig. 14b, the pixels near the boundary region is misclassified. In our opinion, this is due to the fact that all clusters are considered in the process of image segmentation. When the number of clusters is assigned as 2, the pixel either belongs to this cluster, or is the member of the other cluster. Hence, this phenomena does not exist when the number of clusters is 2, just as the results in Fig. 8. However, when the number of clusters is greater than 2, it is difficult to classify the pixels near the boundary region. The membership of these pixels may have similar value to all clusters, resulting in the case in Fig. 14b.

Segmentation results and enlarged parts(C = 4). a Segmentation result; b Enlarged parts of the box in Fig. 14a
In our opinion, there are two possible solutions for dealing with this problem. On the one hand, the boundary pixels may not be misclassified if the number of the clusters is known beforehand. For example, if the number of clusters near the boundary region is required to be equal to 2 as possible, the blurred phenomena may disappear. Therefore, additional constraints about the number of clusters can be considered. On the other hand, we can limit the number of neighboring pixels with the help of low rank priors [14]. As a result, those “true” similar pixels are utilized in image segmentation, and will make the performance satisfying.
6 Conclusion
In this paper, one improved fuzzy clustering algorithm is proposed to enhance the robustness of image segmentation. The essence of the proposed algorithm is to utilize neighboring information to guide the process of image segmentation. That is, the similar pixels are classified into the same cluster. In this paper, pixel similarity is measured by patch-weighted distance between center pixel and neighboring pixels. Experiments on synthetic, natural and medical images illustrate the proposed algorithm outperform related fuzzy algorithms. However, the efficiency of the proposed algorithm is lower than other algorithms except for NLFCM, which will be investigated in our future work.
References
Ahmed MN, Yamany SM, Mohamed N et al (2002) A modified fuzzy c-means algorithm for bias field estimation and segmentation of MRI data. IEEE Trans Med Imaging 21(3):193–199
Bezdek JC (1973) Cluster validity with fuzzy sets. J Cybern 3(3):58–73
Bezdek JC (1975) Mathematical models for systematics and taxonomy. In: Proceedings of eighth international conference on numerical taxonomy, W.H. Freeman, San Francisco, vol 3, p 143C166
Bezdek JC (1980) A convergence theorem for the fuzzy ISODATA clustering algorithms. IEEE Trans Pattern Anal Mach Intell 2(1):1–8
Cai W, Chen S, Zhang D (2007) Fast and robust fuzzy-means clustering algorithms incorporating local information for image segmentation. Pattern Recogn 40 (3):825–838
Cao M, Wang S, Wei L, Rai L, Li D, Yu H, Shao D (2018) Segmentation of immunohistochemical image of lung neuroendocrine tumor based on double layer watershed. Multimed Tools Appl
Chen S, Zhang D (2004) Robust image segmentation using FCM with spatial constraints based on new kernel-induced distance measure. IEEE Trans Syst Man Cybern B Cybern 34(4):1907–1916
Chen L, Chen CLP, Lu M (2011) A multiple-kernel fuzzy C-means algorithm for image segmentation. IEEE Trans Syst Man Cybern B 41(5):1263–1274
Chouhan SS, Kaul A, Singh UP (2018) Soft computing approaches for image segmentation: a survey. Multimed Tools Appl 77(21):284838C28537
Felzenszwalb PF, Huttenlocher DP (2004) Efficient graph-based image segmentation. Int J Comput Vis 59(2):167–181
Gharieb RR, Gendy G, Abdelfattah A et al (2017) Adaptive local data and membership based KL divergence incorporating C-means algorithm for fuzzy image segmentation. Appl Soft Comput 59:143–152
Gong M, Liang Y, Shi J et al (2013) Fuzzy C-means clustering with local information and kernel metric for image segmentation. IEEE Trans Image Process 22 (2):573–584
Guo Q, Zhang C, Zhang Y, Liu H (2016) An efficient SVD-based method for image denoising. IEEE Trans Circuits Syst Video Technol 26(5):868–880
Guo Q, Gao S, Zhang X, Yin Y, Zhang C (2018) Patch-based image inpainting via two-stage low rank approximation. IEEE Trans Vis Comput Graph 24 (6):2023–2036
Jian M, Lam K-M, Dong J, Shen L (2015) Visual-patch-attention-aware saliency detection. IEEE Trans Cybern 45(8):1575–1586
Jian M, Lam K-M (2015) Simultaneous hallucination and recognition of low-resolution faces based on singular value decomposition. IEEE Trans Circuits Syst Video Technol 25(11):1761–1772
Krinidis S, Chatzis V (2010) A robust fuzzy local information C-means clustering algorithm. IEEE Trans Image Process 19(5):1328–1337
Li C, Liu L, Sun X, et al. (2019) Image segmentation based on fuzzy clustering with cellular automata and features weighting. EURASIP Journal on Image and Video Processing
Liu H, Geng F, Guo Q et al (2018) A fast weak-supervised pulmonary nodule segmentation method based on modified self-adaptive FCM algorithm. Soft Comput 22 (12):3983–3995
Liu Y, Cheng M-M, Hu X et al (2019) Richer convolutional features for edge detection. IEEE Trans Pattern Anal Mach Intell
MathWorks image processing toolbox, Natick, MA. http://www.mathworks.com/matlabcentral/fileexchange/14237
Sezgin M, Sankur B (2004) Survey over image thresholding techniques and quantitative performance evaluation. J Electron Imaging 13(1):146–168
Sompong C, Wongthanavasu S (2017) An efficient brain tumor segmentation based on cellular automata and improved tumor-cut algorithm. Expert Syst Appl 72:231–244
Szilagyi L, Benyo Z, Szilagyi SM et al (2003) MR Brain image segmentation using an enhanced fuzzy C-means algorithm. In: Proceedings of the international conference of the ieee engineering in medicine and biology society, vol 1, pp 724–726
Sun Y, Zhang X, Ma Y, Wang Z (2012) Improved FCM schema for unsupervised ROI segmentation. J Comput Inf Syst 8(9):3671–3678
Zhang X, Zhang CM, Tang WJ et al (2012) Medical image segmentation using improved FCM. Science China (Information Sciences) 55(5):1052–1061
Zhang X, Sun Y, Wang G et al (2016) Improved fuzzy clustering algorithm with non-local information for image segmentation. Multimed Tools Appl 76(6):7869–7895
Zhang X, Guo Q, Sun Y et al (2019) Patch-based fuzzy clustering for image segmentation. Soft Comput 23(9):3081–3093. https://doi.org/10.1007/s00500-017-2955-2
Zhong L, Zhou Y-F, Zhang X-F, Guo Q, Zhang C-M (2017) Image segmentation by level set evolution with region consistency constraint. Appl Math J Chinese Univ 32(4):422–442
Acknowledgments
The authors would like to thank anonymous reviewers for their valuable comments and suggestions which lead to substantial improvements of this paper. Also, the authors would like to thank Dr. Krindis for providing the source codes and experimental pictures of FLICM. We would also thank Dr. Weiling Cai for providing the codes of FCMS1, FCMS2 and FGFCM. The authors also gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation significantly.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
All of the authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The research was supported by NSF of China under grant numbers 61873117, 61602229, 61873145, 61772253 and 61771231, NSFC Joint Fund with Zhejiang Integration of Informatization and Industrialization under Key Project grant number U1609218, the Natural Science Foundation of Shandong Province grant numbers ZR2016FM21 and ZR2016FM13.
Rights and permissions
About this article

Cite this article
Zhang, X., Jian, M., Sun, Y. et al. Improving image segmentation based on patch-weighted distance and fuzzy clustering. Multimed Tools Appl 79, 633–657 (2020). https://doi.org/10.1007/s11042-019-08041-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-019-08041-x