
Abstract
Discrete implicit modeling consists in representing structural surfaces as isovalues of three-dimensional piecewise linear scalar fields, which are interpolated from available data points. Data are expressed as local constraints that can enforce the value of the scalar fields as well as their gradients. This paper illustrates some limitations of published discrete implicit methods, related to the difficulty of controlling the norm of scalar field gradient and its evolution over the interpolated domain. It is shown that important artifacts may arise due to the intrinsic dependence between variations in the norm and the direction of the scalar field gradient, from one element to its neighbors. Evidence that these artifacts are related to mesh facet direction with respect to gradient direction are given. The artifacts lead to rapid and uncontrolled variations of thickness that may induce erroneous interpolations. This paper proposes two original approaches to overcome these problems. The first one consists in iteratively adjusting the norm of scalar field gradients in the direction obtained after previous iterations. The second solution consists in optimizing the mesh used by the interpolation. This requires finding appropriate mesh facet orientation with respect to scalar field gradient. These methods demonstrate that the results of discrete implicit surface interpolation can be improved and call for further development of available interpolation schemes.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The representation of geological interfaces as equipotential surfaces of one or several scalar fields, often termed implicit modeling, has become a powerful approach to build geological models (Lajaunie et al. 1997; Cowan et al. 2003; Chilès et al. 2004; Frank et al. 2007; Calcagno et al. 2008; Hjelle et al. 2013; Caumon et al. 2013; Hillier et al. 2014; Jessell et al. 2014). This approach is particularly interesting when representing continuous stratigraphic sequence, because it allows for the representation of a conformable continuum of surfaces at once (Jessell et al. 2014). It can also be useful to represent structural elements, such as foliations and axial surface fields (Lajaunie et al. 1997; Maxelon et al. 2009; Massiot and Caumon 2010; Laurent et al. 2014). Lastly, implicit surface representation can be used as a way to parameterize geological structures (e.g., fault surface, Cherpeau et al. 2012; fault frame, Laurent et al. 2013; fold frame, Laurent et al. 2014).
In the context of modeling stratigraphic formations, the gradient of the scalar field can be related to an apparent preserved uncompacted sedimentation rate (Mallet 2004, 2014). Because thickness changes are key to characterizing basin history and folding style, an important question for implicit methods lies in their ability to accurately capture or predict thickness changes (i.e., to deal with variations of both thickness and norm of the scalar field gradient).
This paper identifies some limitations of the current implicit methods in the management of thickness variations between implicit surfaces, and proposes strategies to address these limitations in discrete methods based on piecewise linear tetrahedra. The basics of discrete implicit modeling are further explained and some undesired effect of the piecewise linearity are illustrated . Its impact on the thickness of modeled layers is illustrated, demonstrating dramatic artifacts that may be generated when the gradient norm is not sufficiently constrained.
Two approaches are proposed for improving discrete interpolation results for modeling stratigraphic layers. Section 3 presents an adapted gradient norm constraint based on an iterative process. Preliminary results show more limited and better-controlled variations of the thickness of interpolated layers as compared to a classical discrete approach. Section 4 introduces a quantification of the thickness variation with respect to mesh facet orientation. It is shown that using a mesh with optimal orientation is a good way of reducing uncontrolled thickness variations, even without additional norm constraints. Section 5 discusses the advantages and limitations of this approach, which opens new ways to overcome the limitations of published discrete approaches.
2 Implicit Modeling Schemes: Orientation Constraints and Thickness Control
Implicit modeling methods can be divided into two main approaches, depending on the way scalar fields are represented and interpolated from data: polynomial trend-based methods, and discrete methods. As gradient and thickness control may be encountered in both methods, they are first briefly presented in this section. This paper then focuses on the discrete approach, for which practical solutions are proposed.
2.1 Polynomial Trend Methods: Kriging and RBFs
In implicit methods based on Radial Basis Functions (RBFs) (Cowan et al. 2003; Hillier et al. 2014) or Kriging (Lajaunie et al. 1997; Chilès et al. 2004; Calcagno et al. 2008), scalar fields are described as a weighted combination of a global polynomial trend and an order-2 stationary residual given by the kriging or RBF weights. Therefore, local thickness variations can be accounted for in the residual, but global thickness changes must be addressed in the polynomial trend.
The instantaneous thickness of strata described by an implicit function \(\varphi (x,y,z)\) is given by the inverse of the norm of the gradient. The ability of typical second-order polynomial drift function to approximate general types of thickness variations seems limited. We are not aware of discussions about the impact of this observation in the literature. This suggests that further research may be needed to define trend functions appropriately capturing thickness changes.
2.2 Discrete Implicit Modeling and Gradient Norm Variations
In the following, the basics of discrete implicit modeling are briefly presented (Sect. 2.2.1). With this approach, problems of gradient and thickness control come as two main limitations (Sect. 2.2.2): (1) the lack of layer thickness control and (2) possible rapid variations in gradient norm, referred to as gradient collapse or gradient burst.
2.2.1 Principles of Discrete Implicit Modeling
Discrete implicit modeling represents geological surfaces as isosurfaces of a piecewise linear scalar field \(\varphi _{}\), interpolated within a set of three-dimensional elements (Moyen et al. 2004; Frank et al. 2007; Caumon et al. 2013; Souche et al. 2013; Mallet 2014; Collon-Drouaillet et al. 2015). Linear tetrahedron elements are generally used as they provide a simple linear interpolation in three-dimensional space and can be progressively refined (Frank et al. 2007) and adapted to discontinuities such as faults (Caumon et al. 2013). Available data and spatial continuity are expressed as a series of linear equations that are solved to find optimal values for the mesh nodes.
This piecewise discrete approach has a number of interesting features: (1) interpolated model can be locally controlled by element size and shape, which makes it possible to easily generate geometric features based both on data and on prior knowledge. For instance, fold hinges may be localized between data points using dip domains (Caumon et al. 2013) and geometric features may be added with stochastic simulation (Caumon 2010; Mallet and Tertois 2010). (2) The way each geological constraint is applied can be locally weighted in each element, for example based on the reliability of the information. (3) Interpolation complexity mainly depends on the number of elements (Frank et al. 2007), which makes it possible to use large numbers of data and control points.
In each tetrahedron, an interpolated scalar field \(\varphi _{}\)and its gradient \({\nabla \varphi _{}}\) are defined by the following linear equations, where \(\varphi _{c}\)is a vector holding the values of the corners of the mesh, \(\mathbf {M}\)and \(\mathbf {T}\)are matrices defined by the geometry of the tetrahedron (Frank et al. 2007), and \(\cdot \) denotes the dot product.

Discrete two-dimensional interpolation of a scalar field representing stratigraphy. a Mesh (a set of connected triangles) and data used to define the interpolation. The values imposed on the two isolines are 0 (left hand side line) and 1 (right hand side line). b Interpolated scalar field
These two equations are used to transform each data point into a linear equation (Frank et al. 2007). A regularization term is added to describe how the scalar field should evolve between the data points. This is implemented by minimizing the variation of \({\nabla \varphi _{}}\) between neighbor elements. A linear equation is produced for each pair of connected elements (i, j). Because neighbors share a facet, their gradient can only vary in the direction \(n_{ij}\) normal to this common facet. For this reason, a minimum variation in gradient is enforced by constraining the projection of the gradient onto vector \(n_{ij}\) not to vary between elements i and j.
The resulting set of linear equations is gathered into a linear system. This system is solved in the least square sense, which yields a scalar field that balances all data and smoothness constraints.
Classical constraints (Fig. 1a), derived from (1) and (2), can enforce: (1) the value of \(\varphi _{}\) at observed location; (2) the components of \({\nabla \varphi _{}}\) at observed location; (3) the variation of \({\nabla \varphi _{}}\) between given elements. Additional constraints can be developed to improve the control of this scalar field and introduce new information into this basic system (Frank et al. 2007; Massiot and Caumon 2010). For example, it is possible to only constrain the direction of \({\nabla \varphi _{}}\) without fully specifying the values of its components. This can be implemented using the property that the dot product of two orthogonal vectors is null, together with (2). The following two constraints are then written to enforce the observed direction \(w\)at a given location as a direction for \({\nabla \varphi _{}}\), using any two non parallel vectors \(u\) and \(v\), orthogonal to \(w\)
Alternatively, the direction of \({\nabla \varphi _{}}\) may be controlled by another scalar field (Massiot and Caumon 2010; Laurent et al. 2013), by constraining \({\nabla \varphi _{}}\) to be orthogonal to the controlling scalar field gradient in each tetrahedron of a given region (Fig. 5a).
2.2.2 Intrinsic Limitations of the Gradient Norm Control
The core of the discrete interpolation scheme resides in the regularization term, which minimizes the variation of \({\nabla \varphi _{}}\) between neighbor elements. Its implementation relies on the continuity of the scalar field, which is ensured by the fact that neighbor elements share the corners of their common facet. This relationship between neighbors also introduces limitations in the interpolation.

Gradient norm variation with varying direction constraints. The left hand side triangle has a constrained gradient direction and norm. In the other triangle, only the gradient direction is controlled. An increasing angle is set from 0\(^{\circ }\) (a) to 44\(^{\circ }\) (c). As a result, the norm of the gradient in the second triangle increases from a to c, which cannot be controlled in this particular setting
Figure 2 presents a basic two-dimensional example of neighborhood relationship, considering two triangular elements. This example demonstrates how the gradient in both triangles is interdependent because of the shared corners. The left hand side triangle is constrained with a fixed vertical unit gradient, with fixed corner values. The gradient in the other triangle is constrained with an angle from 0\(^{\circ }\) (Fig. 2a), to 30\(^{\circ }\) (Fig. 2b), and 44\(^{\circ }\) (Fig. 2c).
The difference in gradient direction implicitly constrains the norm of the gradient in the second triangle. To honor the difference of values along the shared edge, the second triangle needs values that grow at a faster rate when the angle increases. The norm of its gradient rapidly increases when the relative angle increases. This simple example illustrates how the gradient norm and direction are intimately linked and represents a good example of gradient burst.
Although this configuration appears over-constrained, it illustrates how each shared edge decreases the degree of freedom of the system. This phenomenon causes the loss of a degree of freedom as soon as a circle of connected triangles is formed. It is also interesting to point out with this example that setting an angle of 45\(^{\circ }\) in the right hand side triangle would not be possible because the variation of value along the shared edge could not be honored.
In more complex examples, this intrinsic link between gradient norm and direction leads to undesired behaviors. Constraints on the dip of an interpolated stratigraphy result in uncontrolled variations in layer thickness. This situation is illustrated with two synthetic case studies (Figs. 3, 5, 6, 9).

Case study 1: interpolation of a circular scalar field. a The reference scalar field, with the mesh used for the interpolation. b Two samples are taken and used as data for the interpolation, which constrain both the value (dot) and the gradient (vector) of the interpolated scalar field. c The resulting scalar field (plain lines and shading) differs from the reference field (dotted lines), showing errors in both the norm (d) and the direction of the scalar field (e)
Figure 3 tests the ability of the interpolator to reconstruct a scalar field which represents a series of constant thickness layers bent around the lower left corner of the picture (Fig. 3a). This can be seen as an idealized isopach fold, with an axial surface dipping 45\(^{\circ }\) to the left and with an interlimb angle of 90\(^{\circ }\). Two data points that sample the exact value and gradient of the scalar field around the lower left corner of the picture are considered (Fig. 3b). The resulting scalar field is very different from the reference field. Figure 3c shows an overlay of the reference scalar field isolines (dotted lines) on top of the interpolated scalar field. The norm of the scalar field gradient appears to be smaller than expected, in particular in the top-left and bottom-right corners (Fig. 3d), which implies an increase in layers thickness in these regions. Errors in the orientation of the scalar field are also produced, growing from 0\(^{\circ }\) along the diagonal to 30\(^{\circ }\) in the top-left and bottom-right corners. These errors illustrate how the interpolation accommodates the variation of direction in the data by varying both the orientation and the thickness of the interpolated scalar field.
In some configurations, the interpolated scalar field might be an appropriate representation of stratigraphic layering. But in general, geological layers would tend to have a relatively constant thickness or show slow, progressive variations. Stratigraphic orientations may vary more rapidly. In this particular example, only the orientation of the reference scalar field is changing whilst the thickness remains constant. This is not captured by the interpolation and results in erroneous orientation and thickness.

Analysis of sensitivity to a mesh refinement, b orientation data density, and c relative weight of regularization term. The reference scalar field is shown for comparison on the right hand side. Its isovalues are also shown on each realization (dotted lines)
2.2.3 Analysis of Sensitivity to Mesh and Data Density
Figure 4 illustrates the sensitivity of the interpolation to: (a) mesh density, (b) density of orientation data, and (c) relative weight of the regularization term and data constraints. None of these three factors succeed in improving the obtained results. The resultant scalar fields show both erroneous orientations and overestimated thickness.
When too few elements are used, the results present dramatic thickness overestimation. Figure 4a shows that increasing the mesh density reduces this effect. This improvement is limited and further increasing the mesh density does not completely remove thickness over-estimation nor orientation errors in the bottom right and top left corners.
Figure 4b illustrates that this effect becomes even more important when the number or orientation data points increase. Using more data points improves interpolated scalar field direction but increases the thickness over-estimation. As shown in Fig. 2, the interpolator can only account for the variation of orientation by increasing layer thickness. Increasing the weight of the regularization constraint could limit the variation of thickness. Figure 4c shows that increasing the weight of the regularization term (i.e., decreasing the data relative weight) limits the variation of orientation. This yields erroneous orientations without succeeding in correcting the thickness errors.
Finally, the only obvious way to really improve the quality of the result is by considering more value data points, but this is not a practical solution as the density of available data is generally not controlled.

Case study 2: a case of gradient collapse observed when interpolating using orientation constraints. a The scalar field used as a direction constraint. b Interpolation result. Other constraints are a data point in the center of the model with value 0 and a gradient vector [1, 0, 0], parallel to the orientation scalar field. The interpolated scalar field shows relatively good orientation and variation above and under the data point, but the gradient norm rapidly decreases in other directions, which also perturbs the gradient direction. c A front view of the resulting interpolation
2.2.4 Gradient Collapse with Orientation Constraints
Figure 5 presents a second case study, where an additional scalar field \(\psi \) is used for constraining the orientation of \(\varphi \). This is implemented by minimizing the dot product between \({\nabla \varphi }\) and \({\nabla \psi }\). This type of constraint is used by Laurent et al. (2013), to build a fault frame orthogonal to a given fault surface, and in Massiot and Caumon (2010) to constrain the fold axis direction of a folded stratigraphy. This situation, where the density of orientation constraints is relatively high compared to value or gradient norm constraints, can result in unexpected behavior of the interpolated scalar field. In this example, the gradient norm rapidly decreases away from the data point located in the center of the model, which is referred to as a gradient collapse. This anomaly results in an uncontrolled increase of layer thickness and a perturbation of the scalar field orientation.
2.2.5 Discussion of Direction and Thickness Constraints
The situations described in the previous examples seem to be generally avoided in classical use of discrete implicit modeling. This can be attributed to the fact that a higher number of value or norm constraints are available to prevent the interpolated gradient norm from varying too much. However, the results presented in this paper suggest that this problem may still arise, to a lesser extent.
Figure 4 illustrates the difficulty of improving interpolation results by modifying the mesh density or relative weights of constraints. It also shows that extracting more orientation control points from available data would not be a practical solution. In the following sections, it is demonstrated that interpolation results might still be improved. Two avenues are proposed and explored to solve the issues of gradient collapse and norm control: an iterative gradient norm constraint (Sect. 3) and a condition of optimal mesh to minimize the effect of gradient lock (Sect. 4).
3 Iterative Gradient Norm Constraint
Observations from the previous section suggest that defining an additional constraint capable of controlling the norm of the gradient would help to avoid undesired gradient norm variation and to control layers thickness at a given location. This section proposes a strategy to make such constraints possible by defining a linear norm constraint (Sect. 3.1) and by applying it in an iterative process (Sect. 3.2). Results are presented in Sect. 3.3.
3.1 Definition of a Gradient Norm Constraint
It is not trivial to specify the norm of the gradient at a given location without constraining its direction. Where the direction of the gradient is not known, the norm would be defined with the following general equation
where \(\left\| \cdot \right\| \) refers to the norm, and \(L_{}\) refers to the thickness of the layer involved.
Equation (6) is not linear with respect to \(\varphi _{c}\), so it cannot be directly integrated into the linear system. The resolution of such a system would require quadratic matrix systems, which are more complex to solve (Schurbet et al. 1974). It is proposed to use a more simplistic approach where the gradient norm constraint can still be expressed as a linear equation. If a unit direction vector \({u}\) is given as an estimate of the gradient direction, Eq. (7) provides an approximation of the gradient norm \(\widetilde{\left\| {\nabla \varphi _{}}\right\| }\)
This time, (7) is linear with respect to \(\varphi _{c}\), and can be integrated into the linear system.
3.2 Iterative Estimation of Gradient Direction Vector

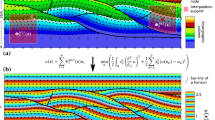
Iterative norm constraint process. A first estimation of the gradient direction is obtained with a classical interpolation. A gradient norm constraint is then iteratively applied based on these directions. The weight of the constraint is progressively increased. A relatively coarse mesh is used to make the orientation of the scalar field in each element clearly visible
The main difficulty in using (7) is finding a good estimation of the possible gradient direction for each element where the constraint is to be applied. Ideally, this direction would be derived from the result of the interpolation process, which is not possible as the final solution is not known when defining the constraints. To overcome this hurdle, an iterative process is proposed (Fig. 6), where \({u}\) is defined as the direction of the gradient obtained at the previous iteration. This process is initialized using a first interpolation without norm constraint.
To avoid propagating erroneous gradient direction throughout the iterations, it is proposed to progressively incorporate this constraint into the system instead of applying it all at once. Three possible strategies are considered:
-
(i)
Increasing the relative weight of the constraint.
-
(ii)
Applying the constraint in a growing number of randomly selected elements.
-
(iii)
Applying the constraint within a growing region around data points.
The following case studies show that this process progressively corrects the direction in which the norm is constrained and attenuates undesired norm variations.

Application of the iterative gradient norm constraint to case study 1 (Fig. 3). Isolines of the reference scalar field are shown (dotted lines) for comparison with the interpolated scalar field (plain lines). The norm constraint is applied: a with an increasing weight: 0.02 (a1), 0.1 (a2) and 1 (a3); b with an increasing number of elements: \(10\,\%\) (b1), \(50\,\%\) (b2) and \(100\,\%\) (b3); c within a growing radius from the data: 1 (c1), 7 (c2) and 28 (c3)
3.3 Results of Iterative Gradient Norm Control
3.3.1 Case Study 1: Comparison of Iteration Strategies
The iterative norm correction is applied on case study 1, using the same dataset as in Fig. 3. The process is initialized with the direction of the gradient of the scalar field obtained using a classical interpolation. The gradient norm constraint is then progressively introduced at each iteration. The three proposed strategies have been tested (Fig. 7):
-
(i)
The weight progressively grows from 0.01 to 1.
-
(ii)
The percentage of affected elements progressively grows from 1 to \(100\,\%\).
-
(iii)
The radius in which elements are constrained goes from 0.1 to 28, which covers the whole model.
One hundred iterations have been run in each case. The norm constraint weight is set to 1 in case B and C. In each case, the weight of the regularization constraint remains 0.1.
For each strategy, the interpolation result is progressively corrected and becomes similar to the reference scalar field (Fig. 3a). Small variations are still visible, but the interpolated scalar fields show a good general behavior. Both thickness and layer orientation are honored. It is difficult to compare the three strategies based on this example because they affect different aspect of the interpolation. It can still be observed that progressively increasing the number of constrained elements (randomly or with a growing radius) seems to provide results that are slightly closer to the reference solution.
3.3.2 Case Study 2: Correcting Gradient Collapse
The second case study shows how the iterative gradient norm control can reduce the problems of gradient collapse illustrated in Fig. 5. In this three-dimensional example, an orthogonality constraint is used, in addition to a data point placed in the center of the model with a value of 0 and gradient of [1, 0, 0]. The scalar field used for the orientation constraint is shown in Fig. 8a. The scalar field obtained by a classical interpolation (Fig. 8b) has two issues: (1) the range of values that are obtained is smaller than expected, because the gradient norm decreases rapidly when moving away from the data point, and (2) the obtained orientations are not correct as they show a bend in the isosurfaces, particularly visible on the vertical faces of the model.

Application of the iterative gradient norm constraint to case study 2. a A scalar field is used as an orientation constraint as in Fig. 5. b The initial scalar field obtained with a value and gradient control point located in the center of the volume, and a constraint of orthogonality to the scalar field shown in a. c The iterative process succeeds in progressively correcting the gradient norm and direction. The constraint is applied in a growing radius around the data point. Results are shown for a radius of 5 (c1), 10 (c2) and 20 (c3)
The gradient constraint is iteratively applied with a growing radius (from 1 to 20, over 20 iterations). Both the problems of norm and direction are progressively fixed (Fig. 8c), and the final results correspond to the expected straight isosurfaces honoring the orthogonality constraint.
3.3.3 Case Study 3: Folded Layers
Figure 9 presents a third synthetic example showing a cross section with four data points defining an anticlinal structure. The norm of the gradient of the control points is 5 for each point. The value of the scalar field is constrained to be 0 for the top two data points and is not constrained for the other two. The result obtained with a classical interpolation shows a sudden decrease of the gradient norm in the region between the data points (Fig. 9a2). It is due to the variation of the direction of the gradient set on data points around this area. This variation is accommodated by varying both the direction and the gradient norm of the scalar field.

Gradient norm constraint and norm values. a1 A scalar field is interpolated from 4 data points with scalar field value and gradient constraint (dots and arrows). The scalar field locally honors the data point direction and gradient norm around the data points, but the gradient norm decreases in between the data points (a2). This results in an increase in the thickness of interpolated layers. b1–d1 Iterative gradient norm constraint is applied with an increasing weight. b2–d2 This process progressively makes the gradient norm values closer to the data point norm (data gradient norm: 5)
When applying a gradient norm correction (Fig. 9b–d), the norm of the gradient of the scalar field gets closer to the control point values. This also has consequences on the resulting geometry of the interpolated fold.
4 Optimization of Shared Facet Orientation
Section 3 introduces additional constraints that can be used to improve the scalar field interpolation. This section proposes another approach which focuses on the mesh used for the interpolation.
Figure 2 demonstrates that the thickness variation between neighbor elements is controlled by their relative gradient direction. When varying the orientation of their common facet, it appears that the effect of thickness variation can be limited by finding a better orientation. A first step towards a mesh improvement would be to quantify this relationship. To that end, two neighbor triangles are considered, where the orientation of the scalar field is known (Fig. 10).

Thickness variation in neighbor elements. a Two neighbor triangles \(t_1\) and \(t_2\) containing an interpolated layer (dashed lines). b A blow-up around the shared facet which illustrates the layer thickness \(L_{}\) and orientations used in (9)
It is possible to find an optimal orientation for the shared facet knowing the angle \(\delta \) between the two gradient directions. In each triangle, the orientation of the shared facet is defined by its angle with the gradient direction, respectively, denoted \(\alpha _1\) and \(\alpha _2\). These angles are linked by the following relationship: \(\alpha _2 = \delta - \alpha _1\). The apparent thickness \(L_{}{_i}\) along the shared facet is obtained by projecting the actual thickness, \(L_{}{_1}\) and \(L_{}{_2}\), onto the facet direction.
The thickness ratio \({L_{}{_2}}/{L_{}{_1}}\) is then expressed by the following equation
It appears that \(L_{}{_2}\) can be the same as \(L_{}{_1}\) in two situations. A first trivial solution comes for \(\delta \) equals 0, because \(\cos {(-\alpha _1)}\) equals \(\cos {\alpha _1}\). The ratio \({L_{}{_2}}/{L_{}{_1}}\) is then equal to 1.
Another set of solutions is obtained with the following condition
These results suggest that another avenue for improving discrete scalar field interpolation would be to use an optimal mesh where each facet honors one of these conditions: (1) the direction of the gradient is the same on both sides of the facet, or (2) the facet bisects the angle between the gradient directions on both sides.

Optimization of the interpolation support. The same dataset as in Figs. 3 and 7 is used. The isolines of the reference solution are shown as dotted lines. A mesh with, respectively, 2, 4, 8 and 20 elements is used in examples a–d. Good results are obtained with few elements, without using the gradient norm constraints from Sect. 3
In very simple cases, it is possible to define the parameters of such a mesh. For example with the data configuration used in Figs. 3 and 7, the ideal facets would converge towards the bottom left corner of the picture. Figure 11 shows that an interpolation based on such a mesh is able to progressively vary the direction of the scalar field gradient without affecting the norm. This suggests that, in more general cases, a better mesh could result in a better interpolation without unexpected gradient norm variations. However, it is not trivial to define an algorithm to build a mesh based on these characteristics in the general case. First, it depends on the direction of the interpolated gradient, which is part of the solution of the interpolation. This suggests that an iterative process could be used, as in Sect. 3.
Another limitation comes from the possible contradiction between the ideal position of neighbor facets. Figure 12 presents a slightly more complex mesh with two layers of triangles. Here, only one facet of each triangle can be oriented in the ideal position which lowers the quality of the result. The isolines of the resulting scalar field do not match the reference isolines (Fig. 12a, b). This effect becomes limited when using a higher number of elements because the orientation of the limiting facets becomes very close to the optimal position (Fig. 12c). An implementation of this criterion could be developed in an optimization process with a cost function based on (9).

Interpolation on a mesh made of two layers of triangles. Here, only one of the facet of each triangle is placed in the optimal orientation. a As a result, the interpolated scalar field does not fit the reference isolines (dotted lines). b, c Increasing the number of triangles generates facets whose orientation is closer to the theoretical optimum, which improves the interpolation result

An attempt to correct gradient collapse in Fig. 5. a Initial interpolation: the orientation of the scalar field is correct in the center part (i.e., vertical), but becomes inclined when moving away from the data point. b–d Results after a few iterations of the norm correction process with an increasing weight. The orientation is first improved together with the norm (b) but further iterations fail to converge towards the data point orientation (c). Increasing the weight of the norm constraint is not enough to correct the orientation (d)
5 Limitations and Discussion
The examples presented above show interesting results but some caveats remain. For the iterative gradient control process, the constraints presented in Sect. 3.1 require that the gradient norm value is known beforehand and remains relatively constant. This would probably not be possible in the general case. To overcome this hurdle, the gradient norm could be estimated from the data and interpolated in the model. Another approach would be to constrain the variation of norm between neighbor elements considering the gradient direction obtained at previous iteration. Adapting the weight of the norm constraint is also a way to control how constant the resulting norm would be. For example, a moderate weight would enforce a globally constant norm while allowing some local variations (e.g., in Fig. 9b).
This method is also limited by a lack of theoretical proof of convergence. In particular, the system may propagate erroneous orientation generated at the initialization step. For example, in Fig. 13, this approach is applied to the result obtained in Fig. 5, where a strong gradient collapse can be observed. The norm constraint succeeds in limiting the norm variations but propagates erroneous initial orientations. This result is in part due to the complex orientation constraints that are applied (Fig. 5a), but also results from the wrong general orientation of the initial interpolation which is kept throughout the iterations. In this case, the norm constraint is not sufficient to correct the gradient direction. This problem suggests that this process may not be robust enough in its current form to be applied in any case study, even if it proves useful for correcting some interpolation results as shown above.
A method to detect and correct erroneous directions used in the norm correction process needs to be developed. A solution could be to use local weighting around the data points, as suggested by the positive results obtained using the growing radius strategy (Fig. 6c). This could lead to a solution combining discrete interpolation scheme and radial basis functions (RBFs). Alternatively, a process to independently interpolate gradient directions would be another way to progressively correct these misleading initial orientations.
6 Conclusions
This paper addresses the limitations of the discrete implicit modeling method related to the norm of the scalar field gradient. The first contribution is to clearly identify and illustrate these limitations with simple examples. They demonstrate that the norm and the direction of the gradient of an interpolated scalar field are closely related. Classical interpolation is not able to independently control these two aspects of scalar field spatial variation.
This paper presents two avenues for improving discrete interpolation schemes: (1) An iterative gradient constraint, with different strategies to progressively apply this constraint. (2) A mesh optimization criterion for minimizing thickness variation between neighbor elements by finding optimal facet orientation. The preliminary results obtained with both methods are encouraging and suggest that the proposed method may help improve discrete interpolation.
The limitations of the proposed methods are also shown. Its main limitation is its potential difficulty to converge to an appropriate solution in some circumstances (Fig. 13). These limitations could make this approach difficult to apply to more complex case studies in its current form. However, using an iterative scheme proves useful for defining norm constraints and progressively correcting what the classical discrete approach may fail to interpolate in only one first iteration. The mesh considerations presented in this paper should lead to more work on mesh definition for interpolation purposes.
The solutions presented in this paper should not be taken as mature and practical, yet. They clearly demonstrate that it is possible to improve current interpolation schemes available for geomodeling. Two promising directions have been proposed for further research: (1) iterative regularization and (2) mesh optimization.
References
Calcagno P, Chilès JP, Courrioux G, Guillen A (2008) Geological modelling from field data and geological knowledge. Part I. Modelling method coupling 3D potential-field interpolation and geological rules. Phys Earth Planet Int 171:147–157
Caumon G (2010) Towards stochastic time-varying geological modeling. Math Geosci 42(5):555–569
Caumon G, Gray GG, Antoine C, Titeux M-O (2013) 3D implicit stratigraphic model building from remote sensing data on tetrahedral meshes: theory and application to a regional model of La Popa Basin, NE Mexico. IEEE Trans Geosci Remote Sens 51(3):1613–1621
Cherpeau N, Caumon G, Caers JK, Lévy B (2012) Method for stochastic inverse modeling of fault geometry and connectivity using flow data. Math Geosci 44(2):147–168
Chilès J-P, Aug C, Guillen A, Lees T (2004) Modelling the geometry of geological units and its uncertainty in 3D from structural data: the potential-field method. In: Proc. Int. Symp. Orebody Model. Strateg. Mine Plan, Perth, Australia, pp 313–320
Collon-Drouaillet P, Steckiewicz-Laurent W, Pellerin J, Laurent G, Caumon G, Reichart G, Vaute L (2015) 3D geomodelling combining implicit surfaces and Voronoi-based remeshing: a case study in the Lorraine Coal Basin (France). Comput Geosci 77:29–43
Cowan EJ, Beatson RK, Ross HJ, Fright WR, McLennan TJ, Evans TR, Carr JC, Lane RG, Bright DV, Gillman AJ, Oshust PA, Titley M (2003) Practical implicit geological modelling. In: Fifth Int. Min. Geol. Conf., pp 17–19
Frank T, Tertois AL, Mallet JL (2007) 3D-reconstruction of complex geological interfaces from irregularly distributed and noisy point data. Comput Geosci 33(7):932–943
Hillier MJ, Schetselaar EM, de Kemp EA, Perron G (2014) Three-dimensional modelling of geological surfaces using generalized interpolation with radial basis functions. Math. Geosci., pp 931–953. http://springerlink.bibliotecabuap.elogim.com/10.1007/s11004-014-9540-3
Hjelle OY, Petersen SA, Bruaset AM (2013) A numerical framework for modeling folds in structural geology. Math Geosci 45(3):255–276
Jessell M, Aillères L, de Kemp E, Lindsay M, Wellmann F, Hillier M, Laurent G, Carmichael T, Martin R (2014) Next generation three-dimensional geologic modeling and inversion. Special Publ, SEG 18
Lajaunie C, Courrioux G, Manuel L (1997) Foliation fields and 3D cartography in geology: principles of a method based on potential interpolation. Math Geol 29(4):571–584
Laurent G, Caumon G, Bouziat A, Jessell M (2013) A parametric method to model 3D displacements around faults with volumetric vector fields. Tectonophys 590:83–93
Laurent G, Aillères L, Caumon G, Grose L (2014) Folding and poly-deformation modelling in implicit modelling approach. In: 34th Gocad Meet. Proc., pp 1–18
Mallet J-L (2014) Elements of mathematical sedimentary geology: the Geochron model. In: EAGE Publ
Mallet J-L, Tertois A-L (2010) Solid earth modeling and geometric uncertainties. In: SPE Annu. Tech. Conf. Exhib. Society of Petroleum Engineers
Mallet J-L (2004) Space-time mathematical framework for sedimentary geology. Math Geol 36(1):1–32
Massiot C, Caumon G (2010) Accounting for axial directions, cleavages and folding style during 3D structural modeling. In: 30th Gocad Meet. Proc
Maxelon M, Renard P, Courrioux G, Brändli M, Mancktelow N (2009) A workflow to facilitate three-dimensional geometrical modelling of complex poly-deformed geological units. Comput Geosci 35(3):644–658
Moyen R, Mallet J-L, Frank T, Leflon B, Royer J-J (2004) 3D-parameterization of the 3D geological space—the GeoChron model. In: Proc. ECMOR IX
Schurbet GL, Lewis TO, Boullion TL (1974) Quadratic matrix equations. Ohio J Sci 74(5):273–277
Souche L, Lepage F, Iskenova G (2013) Volume based modeling-automated construction of complex structural models. In: 75th EAGE Conf. Exhib. Inc. SPE EUROPEC
Acknowledgments
The author would like to gratefully thank anonymous reviewers, as well as Professor Guillaume Caumon and Lachlan Grose, for their very constructive comments and corrections, which helped improve this paper. This work was initiated at Monash University with the Australian Research Council Discovery Grant DP110102531 and further developed at GeoRessources (http://ring.georessources.univ-lorraine.fr/) in the framework of the “Investissements d’avenir” Labex RESSOURCES21 (ANR-10-LABX-21).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Laurent, G. Iterative Thickness Regularization of Stratigraphic Layers in Discrete Implicit Modeling. Math Geosci 48, 811–833 (2016). https://doi.org/10.1007/s11004-016-9637-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11004-016-9637-y