
Abstract
Context
GPS telemetry collars and their ability to acquire accurate and consistently frequent locations have increased the use of step selection functions (SSFs) and path selection functions (PathSFs) for studying animal movement and estimating resistance. However, previously published SSFs and PathSFs often do not accommodate multiple scales or multi-scale modeling.
Objectives
We present a method that allows multiple scales to be analyzed with SSF and PathSF models. We also explore the sensitivity of model results and resistance surfaces to whether SSFs or PathSFs are used, scale, prediction framework, and GPS collar sampling interval.
Methods
We use 5-min GPS collar data from pumas (Puma concolor) in southern California to model SSFs and PathSFs at multiple scales, to predict resistance using two prediction frameworks (paired and unpaired), and to explore potential bias from GPS collar sampling intervals.
Results
Regression coefficients were extremely sensitive to scale and pumas exhibited multiple scales of selection during movement. We found PathSFs produced stronger regression coefficients, larger resistance values, and superior model performance than SSFs. We observed more heterogeneous surfaces when resistance was predicted in a paired framework compared with an unpaired framework. Lastly, we observed bias in habitat use and resistance results when using a GPS collar sampling interval longer than 5 min.
Conclusions
The methods presented provide a novel way to model multi-scale habitat selection and resistance from movement data. Due to the sensitivity of resistance surfaces to method, scale, and GPS schedule, care should be used when modeling corridors for conservation purposes using these methods.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Given increasing human development and the fragmentation of natural habitats, wildlife populations are becoming ever more isolated. Wildlife corridors can mitigate this isolation by maintaining the exchange of individuals and their genes between populations (Crooks and Sanjayan 2006). Modeling corridors often requires resistance-to-movement surfaces where ‘resistance’ represents the opposition an organism may encounter as it moves through a landscape, either in terms of movement ability, survival or both.
Though resistance is commonly estimated with static detection points, the use of observed movement steps or paths is considered more appropriate as the these data explicitly represent passage through the landscape (Richard and Armstrong 2010; Zeller et al. 2012). Movement may be defined as the straight-line steps between consecutive points (Fortin et al. 2005), or the entire pathway of an individual (Cushman and Lewis 2010; Elliot et al. 2014). These are referred to as step selection functions (SSFs) and path selection functions (PathSFs), respectively. Both methods are derived from classic resource selection functions (RSFs) that employ a ‘used’ versus ‘available’ design to estimate species–habitat relationships (Manly et al. 2002), and are analogous to modeling selection at Johnson’s third order of habitat selection (selection of habitat patches within the home range; Johnson 1980). In SSFs, the ‘used’ data are the landscape variables measured along each step between consecutive points. ‘Available’ data are obtained by generating random steps (drawn from the empirical distribution of step lengths and turning angles) from the start point of each used step (Fig. 1a). Landscape variables are then measured along these random steps. In PathSFs, the entire path is used to calculate the ‘used’ data and that same path is randomly shifted and rotated from the used path to generate ‘available’ paths (Fig. 1b). SSFs and PathSFs are modeled in a conditional (a.k.a. case-controlled) logistic regression framework where each used step or path is paired with those that are randomly generated (Agresti 2002; Fortin et al. 2005). This framework allows for a realistic comparison between used and available (Compton et al. 2002; Fortin et al. 2005) and allows for context-dependent modeling (Zeller et al. 2014). The regression models are then used to predict the relative probability of movement across a study area at each grid cell, the inverse of which is used as the resistance surface. It is important to note that, though these predictions are made using the regression coefficients from the conditional logistic regression models, they are applied to the study area in an unpaired framework (more on this below).

Conceptual illustration of a used and available steps for a traditional, single scale step selection function, b used and available paths for a traditional, single scale path selection function, c our proposed multi-scale method for step and path selection functions, using a kernel to estimate different scales of available habitat and d illustrates the true path used by an individual (made up of 5-min steps) over an hour-long period and the pseudopath over that same time period. The pseudopath represents the path that one would obtain with a 60-min GPS collar fix interval
For SSFs, the acquisition interval of the GPS collar determines the temporal scale of analysis, which, in turn, is inextricably tied to the spatial scale of analysis (Thurfjell et al. 2014). For example, at a 1-h acquisition interval, the distribution of random steps will represent movements only ranging as far as the steps achieved over that hour-long period. The sampling of the landscape at this 1-h interval becomes the spatial scale of the analysis (ignoring grain size), regardless of whether this matches the strongest scale, or ‘characteristic scale’ (Holland et al. 2004) of response of the target species. The current SSF framework only allows for the examination of a single scale and thereby runs the risk of missing the true scale, or scales, of response. In turn, this may lead to inaccurate estimates of selection and resistance (Wheatley and Johnson 2009; Norththrup et al. 2013). This issue also affects most PathSFs, in that only a single coarse scale is examined. However, Elliot et al. (2014) shifted the random paths at varying distances from the used path to explore various scales and construct multi-scale models. This is an improvement to the single-scale PathSF, but it does not allow for examination of scales that are smaller than the radius of the path, which can be quite large, and precludes investigating finer spatial scales to which an individual may be responding. Given the importance of multi-scale modeling for habitat selection and resistance, SSFs and PathSFs would be much improved if various scales, from fine to coarse, could be examined and included in the models.
Using SSFs and PathSFs to estimate resistance first involves predicting the relative probability of movement across the study area. In current SSF and PathSF applications, relative probability of movement has been predicted across a surface through the following formula (following Manly et al. 2002):
Here, the regression coefficients are those derived from the conditional logistic regression models, which are multiplied by the predictor variables (x) as measured at each pixel in the landscape. Though the regression coefficients are estimated from assessing what is along each used step or path and what is available around each step or path, the predictions are made in the absence of available data—in an unpaired framework. This results in each pixel of a given landscape feature (e.g., forest) having the same relative predicted probability of movement, regardless of its surroundings. By incorporating the available data around each pixel in the landscape, probability of movement can be estimated in a truly paired context-dependent framework. This allows for a unique probability of movement to be estimated for each pixel in the landscape, where the value of a pixel reflects the attributes of that pixel as well as the attributes surrounding that pixel (e.g., a pixel of forest surrounded by an urban area would likely have a much different relative probability value than a pixel of forest surrounded by forest). To determine the utility of a paired framework for predicting movement and estimating resistance for wildlife, this approach should be explored and compared to the unpaired framework.
SSFs and PathSFs have become more accessible due to the increased use of GPS telemetry collars and their ability to acquire relatively accurate, consistent, and frequent locations. However, GPS collar acquisition intervals can vary widely, from less than 5 min to 6 h and beyond. Fortin et al. (2005) and Coulon et al. (2008) state that SSFs do not assume an individual follows the straight line between points, but rather test whether selection of steps is related to what lies between these points. Still, predictor variables are most-often measured on the straight line, or a buffered area around the line (Thurfjell et al. 2014). Therefore, SSFs and PathSFs may be subject to bias when the acquisition interval is too long to accurately reflect movement for a species. Though no studies to date have examined the potential bias introduced by acquisition intervals for SSFs and PathSFs, studies focused on movement distance and home range size have found that as sampling intervals increase (1) paths of individuals become less tortuous and exponentially shorter in length (Mills et al. 2006), (2) movement rates decrease (Joly 2005), (3) minimum convex polygon home range estimates become smaller (Mills et al. 2006; Brown et al. 2012), and (4) areas utilized by an individual may be underrepresented, while areas avoided by an individual may be overrepresented (Brown et al. 2012). This final finding is of particular concern for inference from SSFs and PathSFs, and further research is needed to determine how sensitive movement models, resistance surfaces and corridors are to GPS collar acquisition interval.
Our objective is to explore these potential issues of scale, prediction framework, and GPS collar acquisition interval when using SSF and PathSFs for modeling movement and resistance. We use GPS collar data from pumas (Puma concolor) in southern California acquired at 5-min intervals, to (1) present a novel SSF/PathSF method that can examine movement at multiple scales, (2) use this new method to identify the characteristic scale(s) of response of pumas and create both single and multi-scale models, (3) predict probability of movement and resistance across our study area in a both a paired and an unpaired framework, and (4) investigate whether acquisition intervals greater than 5 min introduce bias in habitat selection and resistance results. We also determine the sensitivity of resistance surfaces to scale, prediction framework, and acquisition interval. Finally, as an illustration of how differences in scale, prediction framework, and acquisition interval may affect conservation decisions, we use circuit theory to model connectivity across a subsection of our study area for several scales of analysis including multi-scale models.
Methods
Study area and data collection
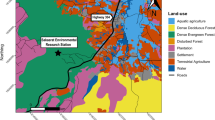
The study area, as previously described in Zeller et al. (2014), was located in the Santa Ana Mountains of southern California (Fig. 2). Between October 2011 and March 2014, ten pumas (six female and four male) were fitted with Lotek 4400 S GPS collars programmed to acquire locational fixes every 5 min (Lotek Wireless, Inc., Canada). Collar duration ranged from 9 to 71 days (median = 29). Long-term positional accuracy of the GPS collars from manufacturer tests is 5–10 m, though accuracy may decrease with certain vegetation types and topographical conditions (Chang personal communication). Two-dimensional fixes with a positional dilution of precision >5 were removed to avoid the use of data that may have large spatial errors, as recommended by Lewis et al. (2007). The final data set consisted of 75,716 fixes across the 10 individuals (range = 1650–18,464; median = 7147). Due to the low number of individuals, sexes were pooled in the analyses.

Southern California study area showing land cover types used in the analysis
We used land cover types from the California wildlife–habitat relationship database as independent variables in our RSFs. These categorical habitat data were obtained from the CalVeg geospatial data set (USDA Forest Service 2007) in vector format at the 1:24,000 scale, which we rasterized at a 30 m resolution. Though there were 25 mapped land cover types present in the study area, many types had very low occurrence (<1 %), therefore, we aggregated these 25 types into nine classes based on descriptions from the California Department of Fish and Wildlife (1988). The aggregated land cover classes and their percentages of the study area were as follows: chaparral (45 %), urban (19 %), coastal scrub (14 %), annual grassland (6 %), coastal oak woodlands (5 %), agriculture (5 %), riparian areas (3 %), perennial grassland (2 %), and naturally barren or open areas (1 %) (Fig. 2). There has been little vegetation change in the study area between the time the CalVeg data set was produced and the time the puma data was collected. Though the Santiago Fire affected portions of the western flank of the Santa Ana Mountains, the vegetation types remained the same pre- and post-fire.
Multi-scale SSF and PathSF method
SSFs and PathSFs traditionally use random steps or paths for estimating ‘available’, thus constraining the available area to the longest step/path lengths observed. When we free ourselves from using random steps and paths, we have more flexibility to explore multiple scales. Specifically, if we use a density kernel around the step or path we obtain a census of the proportion of available land cover types and avoid issues of selecting a certain number of steps or paths from the random sample (Norththrup et al. 2013). The density kernel may be weighted by an appropriate distribution; in our case, we used an empirically-derived Pareto distribution as our kernel (as described in Zeller et al. 2014), representing different distances traveled over specific time intervals (e.g., 5, 60 min, etc.). At the 5-min interval, the radius of the Pareto kernel was small resulting in a small available area sampled around each step or path (e.g., Fig. 1c). The radii of the Pareto kernel increased with increasing time intervals (e.g., Fig. 1c), thereby allowing us to sample different scales around each step or path. A more detailed description of our method is provided below.
Used steps
All data analyses were performed using R software (R Core Team 2013). We first calculated the distance of each step between consecutive points and identified all steps that measured 200 m or more; the 200 m distance threshold was to ensure that steps represented actual ‘movement’ through the landscape rather than local ‘resource use’ (see Zeller et al. 2014). We buffered each movement step by a 30 m fixed-width buffer to account for GPS error (Rettie and McLoughlin 1999) and incorporate the immediate environment around each step. We calculated our ‘used’ data for the SSFs as the proportion of land cover types along each buffered step.
Used paths
Because we only had 10 individuals, using the entire path for our path analysis would have resulted in an insufficiently small sample size. Therefore, we subset the entire path of each individual into 24-h paths, which resulted in a more reasonable sample size of n = 315. As with the steps, we buffered the paths by a 30 m fixed-width buffer and calculated the proportion of land cover types within this buffer. This was the ‘used’ data for our PathSFs. Because inferences about habitat use and resistance might be affected by the time of day at which a 24-h path begins, we ran 12 subsets; the first subset started at midnight, the next subset started at 2 a.m., etc. We ran a PathSF model (more on this below) for each subset separately and we averaged the regression coefficients across all 12 subsets to obtain a final model.
Available areas/scales of analysis
As described above and in Zeller et al. (2014), we estimated ‘available’ using a Pareto-weighted kernel around each step or path. To model multiple scales, we increased the time interval over which the Pareto distribution parameters were estimated and calculated available areas for each interval/scale separately. We estimated the parameters of the Pareto distribution as follows:
-
(1)
We selected 19 different time intervals over which to empirically estimate the Pareto kernel. These intervals consisted of the 5-min time interval, the 20-min interval, and then every 20 up to 360 min (6 h).
-
(2)
We subset the 5-min data at these different time periods and calculated the displacement distance between each point. This provided us with the distribution of displacement distances for each time period.
-
(3)
We then fit a generalized Pareto function to the distribution of displacement distances for each time interval using the gpd.fit function in the gPdtest package (Estrada and Alva 2011). We set the radius of the available area at the 97.5 percentile of the Pareto distribution, or the maximum observed displacement distance, whichever was smaller.
Hereafter, we refer to the radius of each Pareto kernel as the scale of analysis. Our scale reflects the size or extent of the ecological neighborhood (as defined by the kernel) around the step/path, not the spatial grain of the data, which we held constant at 30 m for all analyses. These scales ranged from 532 to 7390 m (Appendix 1). To obtain a kernel around a step or path for a scale, we distributed points uniformly along each step or path at a distance determined by the radii of the Pareto kernel for that scale. We then placed the Pareto kernel over each point and calculated the proportion of land cover types weighted by the Pareto kernel. The available data for each step or path at each scale was obtained by calculating the mean proportion of land cover types across all the Pareto kernels distributed along its length. Note, because the available areas are weighted by the Pareto distribution, they more heavily weight areas closer to the used step or path and the scales should not be thought of as a uniform buffer around each used step or path.
Statistical analysis
We provide a flow chart summarizing our statistical analyses procedure in Appendix 2.
For the step and path data we paired each used step or path with the available area for that same step or path at a scale and ran conditional logistic regression models. We specified the conditional logistic regression models as described in Zeller et al. (2014), using the differences in the proportion of each land cover type between each used step or path and its corresponding available area as the predictor variables. In this specification, the response variable is always 1 and there is no model intercept (Agresti 2002). Because we are using the proportion of each land cover type as predictor variables, we do not have a single land cover variable with the categories coded as dummy variables, but instead have a single predictor variable for each of our nine land cover types.
We ran simple conditional logistic regression models at each scale for each land cover type separately. We also ran multiple conditional logistic regression models at each scale using the land cover type with the weakest effect in the simple regressions as our reference class. Correlation among our predictor variables was relatively low (maximum Pearson correlation coefficient = −0.48), allowing us to retain all predictor variables in our models. We attempted to run conditional logistic mixed effects logistic regression models, using individual puma as the random effect, but our models often failed to converge. Therefore, we did not use the mixed effects framework and simply used the glm function in R for our modeling.
To develop the conditional multi-scale logistic regression models, we identified the characteristic scale of response from the simple conditional logistic regression models as the scale with the largest absolute regression coefficient. We then used the characteristic scale for each land cover type to construct a multi-scale, multiple logistic regression model for our step and path data.
Model performance
For each of our single- and multi-scale multiple logistic regression models, we performed a 10-fold cross validation using the methods recommended by Johnson et al. (2006) and evaluated the predictive performance of the models using Lin’s (1989) concordance correlation coefficient (CCC) as applied in Zeller et al. (2014). Because the SSFs and PathSFs had different sample sizes, we could not use an information criterion approach for model selection across all step and path models. Within the SSFs and PathSFs, however, we did have the same sample sizes and therefore calculated Akaike’s information criterion (AIC; Burnham and Anderson 2002) for SSFs and PathSFs separately.
Predicting probability of movement and resistance
As noted in the “Introduction” section, previous SSFs and PathSFs that have used the have predicted the relative probability of movement values across an area of interest in an unpaired framework, using only the attributes at each pixel. This method does not consider the attributes of surrounding pixels. In order to predict probability of movement in the fully paired framework that was used to develop the models, we first calculated the proportion of land cover types in a 30-m fixed-width buffer at each pixel in our study area (which is akin to the ‘used’ data in the regression models). For a scale of interest, we then placed a Pareto kernel around each pixel and calculated the proportion of land cover types within this kernel (which is akin to the ‘available’ data in the regression models). We calculated the differences in the proportion of land cover types between each focal pixel and the surrounding kernel and used these as our predictor variables. Incorporating the information around each pixel allowed us to predict a unique probability of movement for every pixel across the study area using all the information that went into building the model. We also predicted the relative probability of movement in the traditional unpaired framework for comparison.
For our paired and unpaired probability of movement surfaces, we calculated resistance by taking the inverse of the probability of movement values. We did not rescale or truncate these values because we did not want to introduce any unnecessary subjectivity into the resistance surfaces. We chose to estimate resistance instead of conductance (which would simply be the raw predicted surface) because resistance surfaces are one of the most popular ways to estimate connectivity and model corridors (Zeller et al. 2012). We estimated paired and unpaired resistance surfaces at the 532, 2618, 3505, 4296, 5275, and 7390 m scales as well as for the multi-scale models for steps and paths.
Acquisition interval bias/pseudo paths
To investigate possible bias introduced by longer acquisition intervals, we subset the 5-min data so that it only contained point locations every 60 min. These data represent the steps/paths one would obtain with an hourly GPS collar acquisition interval. We refer to the 5-min data as the true steps/paths and the 60-min data as our pseudo steps/paths (Fig. 1d). We calculated used and available for the pseudo steps and paths, ran simple and multiple conditional logistic regressions for SSFs and PathSFs, and predicted resistance in the paired framework as described above.
We considered the paths from the 5-min data as our truth and assessed bias by calculating the mean absolute difference between the regression coefficients obtained from the models using the 5-min paths and those using the pseudo paths for each land cover type at each scale as well as for the multi-scale model. We then averaged the differences across cover types at each scale to measure overall bias.
Sensitivity of predicted resistance surfaces and corridor locations to scale, prediction framework, and acquisition interval
We visually assessed the resistance surfaces from our different scales, prediction frameworks, and acquisition intervals and noted disparities. We also compared the distribution of resistance values between resistance surfaces.
To get a cursory sense of how differences in resistance surfaces might translate to differences in corridors, we performed a connectivity analysis in the Temecula corridor region within our study area. This area has received much attention as the last viable link between the Santa Ana puma population and populations in the Peninsular Range of southern California (Ernest et al. 2014; Vickers et al. 2015). Although there is no standard way to evaluate congruence among predicted corridors, recent conservation attention has been paid to identifying locations for road crossing structures across interstate 15 (I-15), the major barrier in this linkage. Therefore, we chose locations where modeled corridors cross I-15 as a simple but meaningful way to compare model predictions (Cushman et al. 2014). We used CircuitScape (McRae et al. 2013) to create current density maps (McRae et al. 2008) between protected areas on either side of I-15. We then identified the top 20 pixels along I-15 with the most current flow that might be considered as locations for road crossing structures. In this context, ‘current flow’ represents the number of random walkers that would move through a pixel as they passed between protected areas. We noted the location of each of these pixels for each resistance model as well as differences in these locations between resistance models. We recognize there are myriad methods for modeling connectivity across resistance surfaces (Cushman et al. 2013), but as this was not the focus of our paper, we only selected the one method as an illustrative example of how differences in resistance surfaces may translate into differences in connectivity.
Results
Characteristic scales of response and step versus path selection functions
The regression coefficients were sensitive to scale. Although puma response to most land cover types was consistently positive or negative across scales, annual grassland and agriculture resulted in a change of sign with scale (Fig. 3).

Regression coefficients for land cover types used in the simple conditional logistic regression SSF and PathSF models across the 19 scales of analysis
For both SSFs and PathSFs, pumas responded most strongly to annual grassland, barren, chaparral, coastal scrub, and perennial grassland at finer scales and to agriculture and urban at coarser scales (Fig. 3). Despite these general similarities, the exact characteristic scale between SSFs and PathSFs differed for every cover type except chaparral (Fig. 3). The land cover types that exhibited the greatest difference in characteristic scales between SSFs and PathSFs were coastal oak woodland and riparian (Fig. 3).
The simple conditional logistic regression models from the SSF and PathSFs resulted in different regression coefficients (Fig. 3). These differences could be pronounced, as evidenced by riparian and urban land cover types. With the exception of annual grassland, the PathSFs generally resulted in much larger (positive or negative) regression coefficients than the SSFs.
Model performance
Both SSFs and PathSFs performed well across scales, with the exception of the PathSF model for the 532 m scale (Fig. 4). Model performance for both SSFs and PathSFs tended to increase as scale increased and with the exception of the finest scale, the PathSFs outperformed the SSFs (Fig. 4). The best model performance for the SSFs was achieved at the 6555 m scale (0.976) and for the PathSFs at the 7390 m scale (0.992). Interestingly, the multi-scale models did not have the highest CCC value, though for both SSFs and PathSFs they were similar to the best model (0.943 and 0.982, respectively). We also calculated AIC values for the models. Because the SSFs and PathSFs had different sample sizes, we could not compare AIC values between the two methods, but within SSFs and PathSFs, AIC values decreased with increasing scale (Appendix 3). The multi-scale model had the lowest AIC value for the SSFs and the 6555 m scale had the lowest AIC value for the PathSFs.

Predictive performance, as measured by the concordance correlation coefficient, of multiple conditional logistic regression SSF and PathSF models at all scales and for the multi-scale model
Acquisition interval bias
Our 60-min pseudo data (representing GPS data collected at an hour-long acquisition interval) resulted in biased regression coefficients compared with our 5-min data (Fig. 5; Appendix 4). As expected, biases were higher for the PathSFs than the SSFs (Fig. 5). Appendix 4 provides the regression coefficients for each land cover type for the SSFs using the true step data and using the 60-min pseudo steps. In general, for land cover types that were preferred, the pseudo steps crossed these cover types less frequently, resulting in smaller regression coefficients and sometimes resulting in a change in sign from preference to avoidance. In fact, for the annual grassland and barren cover types, the true steps show a consistent preference for these types across scales while the pseudo steps show a consistent avoidance across scales. The opposite effect was generally seen for land cover types that were avoided. For these, the pseudo-steps crossed more of these cover types than were actually used, resulting in reduced avoidance, and in the case of coastal scrub, preference.

Bias in regression coefficients at a 60-min acquisition interval. Bias was calculated by taking the mean absolute difference between the regression coefficients obtained from the multiple SSF and PathSF models using the true 5-min data and those using the 60-min pseudo data for each land cover type at each scale and for the multi-scale models. We then averaged the differences across cover types at each scale
Sensitivity of predicted resistance surfaces and corridors to scale, prediction framework, and acquisition interval
There were notable differences in the ranges of resistance values between SSFs and PathSFs, among scales, and among prediction frameworks (e.g., paired and unpaired; Fig. 6; Appendices 5, 6). In keeping with the regression coefficient results above, resistance values derived from PathSFs tended to be higher than those derived from SSFs (Fig. 6; Appendices 5, 6). Also, resistance values at finer scales were generally smaller than resistance values at coarser scales. Increasing resistance with scale can be explained by the generally increasing strength of avoidance with scale. As avoidance of a land cover type increased, the relative predicted probability of movement decreased. Taking the inverse of these small values to predict resistance resulted in high resistance values. Note that increasing selection with scale does not result in dramatic changes to the resistance surface since, using the method described above, the lowest value possible will always be 1.

Resistance surfaces obtained from the SSF models. The first column contains the resistance surfaces predicted in the unpaired framework, the second column contains resistance surfaces predicted in the paired framework, and the last column contains resistance surfaces predicted with pseudo steps in the paired framework. The first row contains the resistance surfaces from the smallest scale model, the middle row the mid-scale model, and the last row the multi-scale model. Resistance surfaces for the PathSFs are provided in Appendix 5
The maximum resistance values from predicting resistance in the paired framework tended to be larger than those obtained from predicting resistance in the unpaired framework (Appendix 5). The other notable difference between the frameworks was that, since the unpaired framework was not context-dependent, it resulted in the same resistance value for a cover type regardless of its context. Because urban, comprising 19 % of the study area, was the most avoided land cover type and resulted in the highest resistance values, the 91st–100th quantiles for the unpaired surfaces were the same (Appendix 5). We can visualize the consistency among cover types in the first columns of Fig. 6 (SSF results) and Appendix 6 (PathSF results). The resistance surfaces from the paired frameworks are context dependent and rely not only on what is at each pixel, but what is surrounding each pixel. For example, when a puma is in a pixel that is comprised of coastal oak woodland, a land cover type they prefer, moving from coastal oak woodland to less optimal habitat will result in an increased resistance. This is seen in the second columns of Fig. 6 and Appendix 6, in the southeastern part of the study area where coastal oak woodland patches have the lowest resistance but are surrounded by a band of high resistance. Another example is in urban areas. Moving into an urban area has a high resistance, however, once inside an urban area, there is no difference between the proportion of urban in the used and available and thus, the resistance is not as high. In general, the resistance surfaces derived from the paired models are characterized by much greater spatial heterogeneity in resistance and a much greater range of resistance values (Fig. 6; Appendix 6).
From the CircuitScape current density surfaces, we identified the top 20 pixels along I-15 that had the most current, or greatest flow of individuals. These locations are shown, along with the current surfaces in Fig. 7 (SSFs) and Appendix 7 (PathSFs). Locations varied among SSFs and PathSFs and among scales. Locations were more similar at the same scale across methods (SSFs vs. PathSFs) and frameworks (unpaired vs. paired) than within the same method or framework across scales, indicating scale is a major factor in connectivity differences.

SSF CircuitScape current density surfaces (log10 transformed) and road pixels with the highest current densities. The vertical line represents interstate-15, the black dots represent the top 20 pixels along I-15 with the highest current density. The first column contains current maps resulting from predicting resistance in the unpaired framework, the second column contains maps predicted in the paired framework, and the last column contains maps predicted with 60-min pseudo steps in the paired framework. The first row contains the current maps from the smallest scale model, the middle row the mid-scale model, and the last row the multi-scale model. Current density maps for the PathSFs are provided in Appendix 6
Using the 60-min pseudo paths in the SSFs and PathSFs resulted in sometimes markedly different resistance surfaces and biased the road crossing locations (last column, Figs. 6, 7; Appendices 6, 7). For example, resistance surfaces tended to be biased high, particularly for SSFs. In addition, for the SSF models, crossing locations for the biased SSFs (based on the pseudo steps) tended to miss potential crossing locations in the middle section of I-15 that were picked up with the models based on true paths. These biased SSFs also identified crossing locations that were not present in any of the models that used the true paths (Fig. 7).
Discussion
We found that pumas have multiple characteristic scales during movement events. In our population, pumas exhibited a mostly bi-modal response to scale; characteristic scales were at a coarse scale for urban and agriculture, and at a fine scale for the remaining cover types, highlighting the importance of modeling movement at multiple spatial scales. We found regression coefficients to be extremely sensitive to scale. For example, for the PathSFs, regression coefficients ranged from −10 to −30 for the urban cover type, and −4 to −15 for the chaparral cover type. Regression coefficients also were prone to sign changes for some cover types, indicating different conclusions may be reached regarding habitat preference or avoidance with different scales. We found that regression coefficients from the PathSF models were generally greater than those from the SSF models and that characteristic scales differed between the SSFs and the PathSFs, indicating that choice of method may influence inference about movement and resistance (more on this below).
With the exception of the finest scale, SSF and PathSF models performed well across all scales (CCC >0.8) and PathSF models outperformed SSF models. Though the multi-scale models performed extremely well, they did not outperform some of the coarser, single-scale models.
Resistance surfaces differed between SSFs and PathSFs, with the PathSFs having higher resistance values than the SSFs. This was undoubtedly due to the greater avoidance of some cover types in the PathSFs compared with the SSFs.
Resistance surfaces also differed across scales. The finest scale produced the lowest range of resistance values, especially for the SSFs, and resistance generally increased with scale. This is again a reflection of the coefficients becoming more negative for certain cover types as scale increased. Increase in selection or avoidance with scale may be attributed to the fact that more of the landscape is sampled at larger scales. For example, when smaller scales are used, the available areas are more similar to the used areas and the models do not have much power to discern between selection and avoidance, resulting in weak regression coefficients. As scales broaden, the available areas represent a wider pool of conditions, enabling the model to more powerfully reflect differences in selection choices made by individuals.
The greatest conceptual difference in resistance surfaces was seen between predicting resistance in the unpaired versus the paired framework. In the unpaired resistance surfaces, it is evident that each cover type had a single resistance value regardless of its landscape context, whereas in the paired framework, each pixel had a unique value depending on its landscape context. This created more heterogeneous surfaces (more on this below). We found these differences among SSFs and PathSFs, scale, and prediction framework carried through to estimates of connectivity and road crossing locations.
Lastly, we found that regression coefficients, resistance surfaces, and corridors were sensitive to GPS collar acquisition interval. There was a consistent 3–4-fold difference in regression coefficients between the true 5-min steps/paths and the 60-min steps/paths. For some land cover types, using a longer acquisition interval resulted in a change of sign in the regression coefficient. Not surprisingly, CircuitScape current maps and road crossing locations were different between models that used the true paths versus those that used the pseudo paths. Therefore, a mismatch between GPS collar acquisition interval and species vagility may ultimately bias corridor conservation planning when using SSFs and PathSFs.
There is ample literature demonstrating that organisms select habitat at multiple spatial scales (see review by McGarigal et al. accepted). These multi-scale relationships have traditionally been modeled using RSFs based on point, or detection, data (e.g., DeCesare et al. 2012; Martin and Fahrig 2012; Zeller et al. 2014), not movement data. We believe this is due to the fact that methodological limitations with SSFs and PathSFs have constrained the exploration of scaling relationships and multi-scale models. However, there has been some exploration of scales with PathSFs. After Cushman et al. (2010) presented the first PathSF methodology which, involves shifting and rotating random paths to sample available habitat (Fig. 1b). Reding et al. (2013) was the first to incorporate more than one scale. Their paper on bobcats used buffers of two sizes around both the used and available paths in order to compare selection at these scales and combine the two scales into a single model. Elliot et al. (2014) used the original Cushman et al. (2010) method but changed the extent to which paths were shifted in order to explore multiple scales and construct multi-scale models. However, the Elliot et al. (2014) method does not allow for examination of fine scales. Here, we offer an improvement to SSF and PathSF methods for modeling habitat selection during movement at multiple scales and with multi-scale models. Our method is easily reproducible and can accommodate any number of biologically justified scales.
With our method, we found that individuals were not always operating at a single scale during movement and that multi-scale responses may be present. For some land cover types, we obtained stronger responses at coarser spatial and temporal scales. This is similar to Elliot et al. (2014) who found that lions in southern Africa select preferred vegetation types at fine spatial scales, and avoided anthropogenic risk, such as urban areas, at broad spatial scales. For our pumas, the coarse-scale response to urban and agricultural areas may be due to knowledge of the landscape including the location of large areas of human development. We used data from pumas that had established home ranges; however, results may vary with data from pumas that are dispersing in areas previously unknown to them. For dispersing individuals, it would not be surprising to find that habitat selection during movement occurs at much finer scales, since an individual may be reacting only to what is in their immediate perceptual range, not prior knowledge. Further research is needed to determine if characteristic scales for pumas differ between resident and dispersing individuals.
When estimating resistance, detection data is the most often-used data type, mainly due to the fact that it is relatively easy to acquire compared with movement data (Zeller et al. 2012). However, using step or path data to estimate resistance is conceptually more appealing since it explicitly represents movement. When step data is available, path data is typically available as well since it is simply a series of steps and one is left to select one approach over the other. Cushman et al. (2010) promoted PathSFs as being superior to SSFs given the fact that spatial and temporal autocorrelation of observations can be avoided, while maintaining the biologically important spatial patterns of movement. Given the larger regression coefficients and better model performance of PathSFs compared to SSFs, our results also support the use of PathSFs over SSFs. The differences in regression coefficients and resistance surfaces between SSFs and PathSFs may reflect the different types of movement these two approaches represent. We used a distance threshold for our step data so that the steps in our SSF explicitly represented movement events. Conversely, our paths represent all the behaviors in which an individual was engaged throughout the course of a day. Though the paths, as a trajectory of movement over a time period, are a representation of movement, they capture both the directed movement an individual may take when traveling between resource use patches as well as the slow, more tortuous movement an individual may take while acquiring resources. For estimating resistance, it may be argued that, as an individual moves about the landscape, they may be making directed movement as well as acquiring resources, again indicating that PathSFs may be the method of choice.
To our knowledge, this was the first study to conduct a PathSF for pumas and only the third to conduct an SSF. Dickson et al. (2005) and Dickson and Beier (2007) used an SSF approach to estimate habitat selection during movement for pumas in our same study area. Their steps were at 15-min intervals and they used a compositional analysis to rank cover types (from most to least preferred) as riparian, scrub, chaparral, grassland, woodland, and urban. With the exception of scrub and chaparral, these results agree with what we found in our SSFs. Differences may be due to different sample sizes, or the fact that compositional analyses cannot be conducted in the conditional logistic regression framework used herein. As noted in Dickson et al. (2005), previous research using point data found pumas avoid grasslands, apparently due to lack of stalking cover. However, during movement pumas may prefer grassland for increased mobility. Similarly, we found pumas to prefer naturally barren areas during movement. These results highlight the importance of accounting for behavioral state in modeling habitat selection since inferences based on movement can be different from those based on resource use (Squires et al. 2013; Elliot et al. 2014; Zeller et al. 2014). As this paper was aimed at testing various considerations for running SSF and PathSF models, we wanted to simplify the models and results by using only land cover classes as predictor variables. Future analyses for pumas in this study area could be improved by using other geospatial layers known to affect puma habitat selection including slope, topographic ruggedness, and roads (Burdett et al. 2010; Kertson et al. 2011; Wilmers et al. 2013).
The conditional logistic regression models allow for a biologically relevant comparison between used and available (Compton et al. 2002; Fortin et al. 2005) and the potential for using a context-dependent modeling approach (Zeller et al. 2014). For these reasons, extending the conditional framework to predicting the relative probability of movement and resistance is attractive. In previous studies, conditional logistic regression has been used to estimate the regression coefficients for the independent variables in a model, however these regression coefficients are then used in an unpaired framework to predict the relative probability of movement across a study area. We incorporated the available area around each pixel in the study area in our predicted surfaces for a truly paired approach to modeling resistance. In such a surface, resistance was estimated from each location on the landscape, putting the individual in the context of their surroundings. These surfaces are clearly applicable for individual-based modeling where individuals are making choices as they move through the landscape. However, using the paired approach needs further exploration. These surfaces may pose problems for modeling connectivity in certain landscapes because they may not adequately account for the absolute fitness costs of making any particular decision. For example, in the paired resistance surfaces the difficulty of entering an urban area (a strongly avoided land cover type) from an adjacent, preferred habitat reflects not only the relative fitness tradeoffs of moving into the urban area (i.e., the relative cost of moving into the urban area is high compared to moving away from the urban area), but also perhaps the “absolute” fitness costs of making that decision (i.e., moving through urban land cover confers a high fitness cost). However, once an individual moves inside the urban area, the context-dependent resistance is low because the relative cost of moving to another cell of urban is relatively low since the tradeoffs are all the same, even though the absolute fitness costs of moving through any cell of urban is still very high. The paired surface also produced concerning rings of high resistance around urban areas which, for moving into an urban area makes biological sense, but does not make biological sense for moving out of an urban area. In general, the paired resistance surfaces capture the relative fitness costs of making context-dependent decisions, whereas the unpaired surfaces capture the absolute fitness costs of making any decision. Given these issues, the utility of these surfaces used singly or in combination for corridor modeling is an area ripe for further research.
GPS collar acquisition intervals are often selected by weighing the desire to collect fixes at regularly short intervals against the desire for a long-lasting collar. We found, for studying movement in the context of SSFs and PathSFs, that collecting fixes at short intervals was critical in reducing bias in regression coefficients and resistance estimates. In previous SSFs, acquisition intervals have ranged from 1 min (Potts et al. 2014) to 1 day (Richard and Armstrong 2010) for birds, 1 h (van Beest et al. 2012) to 6 h (Coulon et al. 2008) for ungulates, and 30 min (Squires et al. 2013) to 4 h (Roever et al. 2010) for carnivore species. More research is needed to determine the appropriate intervals for studying movement for a species, but in general the optimal interval will be short (no more than a few minutes) for highly vagile species that do not travel on straight paths. Indeed, it is possible that an interval <5 min would be better for pumas than the 5-min data used in this paper. Thurfjell et al. (2014) recommended performing pilot studies to determine the appropriate acquisition interval and highlighted the relative ease with which this may be done given remote options for downloading data and programming the GPS collars. Employing SSFs and PathSFs as we have done here, by calculating predictor variables along the step or path, should be done with great caution if it is suspected that the acquisition interval is too infrequent to capture true movement paths. Investigating the use of Brownian bridge models between points (Thurfjell et al. 2014) may alleviate bias, but at the cost of diluting specific species–habitat relationships along true movement paths.
The method we present for conducting SSFs and PathSFs is promising for modeling multi-scale species–habitat relationships during movement. It is also promising for estimating resistance, since using movement data in the form of steps or paths (vs. static point data) may be the most appropriate way to build resistance surfaces. However, many questions remain. First, like previous research teams, we have assumed that the inverse of the predicted relative probability of presence from RSFs translates directly to resistance, but there is no empirical evidence that this is the case. Second, more inquiry is needed to determine whether predicting resistance in the paired framework is superior to the unpaired framework, or whether some hybrid of these two resistance surfaces, representing a combination of relative and absolute fitness costs, is more appropriate. Related to these two points, methods are needed to compare amongst resistance surfaces derived via different data types and methods (Beier et al. 2008). Cushman et al. (2014) provide a robust method to compare the ability of resistance surfaces to predict actual crossing locations of individuals, however, methods are needed to assess the performance of entire resistance surfaces (not just road crossing locations). Third, more research is warranted to determine the appropriate GPS collar acquisition interval for species so as to reduce bias. Finally, more research is needed to determine how species respond to landscape features at different scales during movement.
We hope the results provided herein will be useful for further inquiry into how wildlife respond to landscape features during movement events. We provide a novel method for modeling movement at multiple scales within SSFs and PathSFs. Given our results, when there is a choice, we recommend PathSF models be used over SSF models. Due to the sensitivity of movement models and resulting resistance surfaces to scale, prediction framework and GPS collar schedule, much care should be used when modeling corridors for conservation purposes using these methods.
References
Agresti A (2002) Categorical data analysis, 2nd edn. Wiley, Hoboken, p 419
Beier P, Majka D, Spencer WD (2008) Forks in the road: choices in procedures for designing wildlife linkages. Conserv Biol 22:836–851
Brown DD, LaPoint S, Kays R, Heidrich W, Kummeth F, Wikelski M (2012) Accelerometer-informed GPS telemetry: reducing the trade-off between resolution and longevity. Wildl Soc Bull 36:139–146
Burdett CL, Crooks KR, Theobald DM, Wilson KR, Boydston EE, Lyren LM, Fisher RN, Vickers TW, Morrison SA, Boyce WM (2010) Interfacing models of wildlife habitat and human development to predict the future distribution of puma habitat. Ecosphere 1:1–21
Burnham KP, Anderson DR (2002) Model selection and multimodel inference: a practical information-theoretic approach, 2nd edn. Springer, New York. ISBN 978-0-387-22456-5
California Department of Fish and Game (1988) A guide to wildlife habitats of California. In: Mayer KE, Laudenslayer Jr WF (eds) State of California Resources Agency. Department of Fish and Game, Sacramento, p 166. http://www.dfg.ca.gov/biogeodata/cwhr/wildlife_habitats.asp#Tree. Accessed 29 Jan 2013
Compton BW, Rhymer JM, McCollough M (2002) Habitat selection by wood turtles (Clemmys insculpta): an application of paired logistic regression. Ecology 83:833–843
Coulon A, Morellet N, Goulard A, Cargnelutti B, Angibault JM, Hewison AJM (2008) Inferring the effects of landscape structure on roe deer (Capreolus capreolus) movements using a step selection function. Landscape Ecol 23:603–614
Crooks KR, Sanjayan M (2006) Connectivity conservation: maintaining connections for nature. In: Crooks KR, Sanjayan M (eds) Connectivity conservation. Cambridge University Press, Cambridge, p 1
Cushman SA, Lewis JS (2010) Movement behavior explains genetic differentiation in American black bears. Landscape Ecol 25:1613–1625
Cushman SA, Chase M, Griffin C (2010) Mapping landscape resistance to identify corridors and barriers for elephant movement in South Africa. In: Cushman SA, Huettmann (eds) Spatial complexity, informatics, and wildlife conservation. Springer, Japan, pp 349–367. ISBN 978-4-431-87770-7
Cushman SA, McRae B, Adriaensen F, Beier P, Shirley M, Zeller K (2013) Biological corridors and connectivity. In: Macdonald DW, Willis KJ (eds) Key topics in conservation biology 2. Wiley-Blackwell, Hoboken, pp 384–404
Cushman SA, Lewis JS, Landguth EL (2014) Why did the bear cross the road? Comparing the performance of multiple resistance surfaces and connectivity modeling methods. Diversity 6:844–854
DeCesare NJ, Hebblewhite M, Schmiegelow F, Hervieux D, McDermid GJ, Neufeld L, Bradley M, Whittington J, Smith KG, Morgantini LE, Wheatley M, Musiani M (2012) Transcending scale dependence in identifying habitat with resource selection functions. Ecol Appl 22:1068–1083
Dickson BG, Beier P (2007) Quantifying the influence of topographic position on cougar (Puma concolor) movement in southern California, USA. J Zool 271:270–277
Dickson BG, Jenness JS, Beier P (2005) Influence of vegetation, topography, and roads on cougar movement in southern California. J Wildl Manag 69:264–276
Elliot NB, Cushman SA, Macdonald DW, Loveridge AJ (2014) The devil is in the dispersers: predictions of landscape connectivity change with demography. J Appl Ecol. doi:10.1111/1365-2664.12282
Ernest HB, Vickers TW, Morrison SA, Buchalski MR, Boyce WM (2014) Fractured genetic connectivity threatens a southern California puma (Puma concolor) population. PLoS ONE 9(10):e107985. doi:10.1371/journal.pone.0107985
Estrada EG, Alva JAV (2011) Package gPdtest: bootstrap goodness-of-fit test for the generalized Pareto distribution. http://cran.r-project.org/web/packages/gPdtest/index.html. Accessed 11 Feb 2015
Fortin D, Beyer HL, Boyce MS, Smith DW, Duchesne T, Mao JS (2005) Wolves influence elk movements: behavior shapes a trophic cascade in Yellowstone National Park. Ecology 86:1320–1330
Holland JD, Bert DG, Fahrig L (2004) Determining the spatial scale of species’ response to habitat. Bioscience 54:227–233
Johnson D (1980) The comparison of usage and availability measurements for evaluating resource preference. Ecology 61:65–71
Johnson CJ, Nielsen SE, Merrill EH, Mcdonald TL, Boyce MS (2006) Resource selection functions based on use-availability data: theoretic motivation and evaluation methods. J Wildl Manag 70:347–357
Joly K (2005) The effects of sampling regime on the analysis of movements of overwintering female caribou in east-central Alaska. Rangifer 25:67–74
Kertson BN, Spencer RD, Marzluff JM, Hepinstall-Cymerman J, Grue CE (2011) Cougar space use and movements in the wildland-urban landscape of western Washington. Ecol Appl 21:2866–2881
Lewis JS, Rachlow JL, Garton EO, Vierling LA (2007) Effects of habitat on GPS collar performance: using data screening to reduce location error. J Appl Ecol 44:663–671
Lin LI (1989) A concordance correlation coefficient to evaluate reproducibility. Biometrics 1:255–268
Manly BF, Mcdonald L, Thomas DL, Mcdonald TL, Erickson WP (2002) Resource selection by animals: statistical design and analysis for field studies, 2nd edn. Kluwer Academic Publishers, Dordrecht
Martin AE, Fahrig L (2012) Measuring and selecting scales of effect for landscape predictors in species–habitat models. Ecol Appl 22:2277–2292
McGarigal K, Wan H, Zeller KA, Timm BC, Cushman SA (accepted) Multi-scale habitat modeling: A review and outlook. Landscape Ecol
McRae BH, Dickson BG, Keitt TH, Shah VB (2008) Using circuit theory to model connectivity in ecology, evolution, and conservation. Ecology 89:2712–2724
McRae BH, Shah VB, Mohapatra TK (2013) Circuitscape 4 user guide. The Nature Conservancy. http://www.circuitscape.org. Accessed 19 May 2015
Mills KJ, Patterson BR, Murray DL (2006) Effects of variable sampling frequencies on GPS transmitter efficiency and estimated wolf home range size and movement distance. Wildl Soc Bull 34:1463–1469
Norththrup JM, Hooten MB, Anderson CR Jr, Wittemyer G (2013) Practical guidance on characterizing availability in resource selection functions under a use-availability design. Ecology 94:1456–1463
Potts JR, Mokross K, Stouffer PC, Lewis MA (2014) Step selection techniques uncover the environmental predictors of space use patterns in flocks of Amazonian birds. Ecol Evol 24:4578–4588
R Core Team (2013) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna. http://www.R-project.org/. Accessed 15 May 2013
Reding DM, Cushman SA, Gosselink TE, Clark WR (2013) Linking movement behavior and fine-scale genetic structure to model landscape connectivity for bobcats (Lynx rufus). Landscape Ecol 28:471–486
Rettie WJ, McLoughlin PD (1999) Overcoming radio telemetry bias is habitat-selection studies. Can J Zool 77:1175–1184
Richard Y, Armstrong DP (2010) Cost distance modeling of landscape connectivity and gap-crossing ability using radio-tracking data. J Appl Ecol 47:603–610
Roever CL, Boyce MS, Stenhouse GB (2010) Grizzly bear movements relative to roads: application of step selection functions. Ecography 33:1113–1122
Squires JR, DeCesare NJ, Olson LE, Kolbe JA, Hebblewhite M, Parks SA (2013) Combining resource selection and movement behavior to predict corridors for Canada lynx at their southern range periphery. Biol Conserv 157:187–195
Thurfjell H, Ciuti S, Boyce MS (2014) Applications of step-selection functions in ecology and conservation. Mov Ecol 2:4
USDA Forest Service (2007) CalVeg: FSSDE.Eveg-Tile47A_02_v2. Pacific Southwest Region Remote Sensing Lab, McClellan
Van Beest FM, Van Moorter B, Milner JM (2012) Temperature-mediated habitat use and selection by a heat-sensitive northern ungulate. Anim Behav 84:723–735
Vickers TW, Sanchez JN, Johnson CK, Morrison SA, Botta R, Smith T, Cohen BS, Huber PR, Ernest HB, Boyce WM (2015) Survival and mortality of pumas (Puma concolor) in a fragmented, urbanizing landscape. PlosONE. doi:10.1371/journal.pone.0131490
Wheatley M, Johnson C (2009) Factors limiting our understanding of ecological scale. Ecol Complex 6:150–159
Wilmers CC, Wang Y, Nickel B, Houghtaling P, Shakeri Y, Allen ML, Kermish-Wells J, Yovovich V, Williams T (2013) Scale dependent behavioral responses to human development by a large predator, the puma. PLoS ONE. doi:10.1371/journal.pone.0060590
Zeller KA, McGarigal K, Whiteley AR (2012) Estimating landscape resistance to movement: a review. Landscape Ecol 27:777–797
Zeller KA, McGarigal K, Beier P, Cushman SA, Vickers TW, Boyce WM (2014) Sensitivity of landscape resistance estimates based on point selection functions to scale and behavioral state: pumas as a case study. Landscape Ecol 29:541–557
Acknowledgments
We thank B. Compton and E. Plunkett, for assistance with computational capacity, D. Dawn, D. Krucki, C. Bell, P. Bryant, D. Stewart, and K. Krause for field assistance. We would also like to thank the following landowners/managers: The Nature Conservancy, California Department of Fish and Wildlife, Orange County Parks Department, The New Irvine Ranch Conservancy, Audubon Starr Ranch Reserve, Riverside County Parks Department, and the Cleveland National Forest. This material is based upon work supported by the National Science Foundation under NSF DGE-0907995, a Kaplan Graduate Award, The Nature Conservancy, Orange County Transportation Corridor Agency, The Nature Reserve of Orange County, and the McBeth Foundation.
Author information
Authors and Affiliations
Corresponding author
Additional information
Special issue: Multi-scale habitat modeling.
Guest Editors: K. McGargial and S.A. Cushman.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Zeller, K.A., McGarigal, K., Cushman, S.A. et al. Using step and path selection functions for estimating resistance to movement: pumas as a case study. Landscape Ecol 31, 1319–1335 (2016). https://doi.org/10.1007/s10980-015-0301-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10980-015-0301-6