
Abstract
In order to explore the relationship between the welding process and welded quality, a multiple sensor fusion system was built to obtain the photodiode and visible light information during the welding. Features of keyhole, plasma and spatters were extracted from five sensors, including two photodiode sensors, one spectrometer sensor, one ultraviolet and visible light sensing camera and one auxiliary illumination sensing camera, 15 features were analyzed by normalization and principle component analysis, and principle component numbers was chosen as input parameters of support vector machine classification, Three weld quality types were defined according to the weld seam width and weld depth. The overall accuracy of training data was 98%, and the overall accuracy of testing data was 91%, respectively. Experimental results showed that the estimation on welding status was accurate and effective, thus providing an experimental example of monitoring high-power disk laser welding quality.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Laser welding has been an increasingly important pole of advanced competitive manufacturing technology during several decades (Shayganmanesh and Khoshnoud 2016). With its advantages of potential benefits on saving material cost, high welding speed and small effected zone, recent years have seen an increasing demand on advanced monitoring and intelligent control in order to improve the manufacturing quality and efficiency (Chen et al. 2016; Huang and Kovacevic 2011). In the welding, the workpiece was vaporized by a high density of power within a very short time. The molten zone tends to be dug by the pressure, which was produced by the intense vaporization. This made the irradiated zone keyhole (Shanmugam et al. 2010). For the study of this complex process, several sensing methods for monitoring were reported recently. A high speed camera has been applied to detect weld pool during the laser welding, and back propagation neural network and genetic algorithm were used to improve the accuracy of the weld appearance (Zhang et al. 2015). A infra-red (IR) camera was employed for monitoring and control of the welding process (Chandrasekhar et al. 2015). The coupling mechanism between the melt flow and the metallic vapor was analyzed by observing their behavior using a high-speed camera (Luo et al. 2016; Gao et al. 2013). Magneto-optical sensor was used to obtain weld position in micro-gap welding (Gao et al. 2016), and seam tracking was achieved by using Kalman filtering method (Gao et al. 2015). However, the information acquired by one sensor alone is limited, and the stability might be influenced when the environmental noise are taken into consideration. Currently, a solution to this problem is to combine different kinds of sensors. A multiple-optics sensing system consisting of four different sensors, including two photodiode sensors and two visual sensors, was designed for monitoring laser welding of stainless steel, the relationship between light emission and welding status was discussed (You et al. 2013). The behavior of molten pool, which could be affected by the absorbed energy distribution in the keyhole, was the key factor to determine the spatters formation during laser welding. The relatively sound weld seam could be obtained during laser welding with the focal position located inside the metal (Li et al. 2014). The relationship between an incident beam and a keyhole was investigated by an X-ray transmission in-site observation system or a high-speed video camera with diode-laser illumination (Kawahito et al. 2011). A pressure gauge and a high speed camera were applied to obtain dynamic data and the refraction effect of the induced plasma was discussed (Chen et al. 2015). Intelligent sensing algorithm, such as artificial neural networks and principal component analysis, was studied and could improve the accuracy of quality inspection (Ai et al. 2015; Wan et al. 2016).

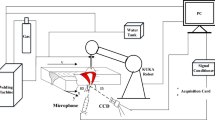
Experimental set up of high power laser welding a experimental set up of high power laser welding with multisensors, b photo of experimental set up
This paper presents a multiple sensors detecting system for the real time laser welding. The system consisted of five sensors, including two photodiode sensors, one spectrometer and two visual sensors. Visible light intense and reflected light intense were obtained by the ultraviolet and visible light senor and the reflected light sensor, respectively. Images of plasma and spatters were captured by a visible visual camera. Images of keyhole were captured by another camera. Through image processing technology, features of the plume, spatters and keyhole were acquired and these features were contributed to set up a support vector machine (SVM) classification model.
Experiment set up
A disk laser was used in the experiment, the maximum power was 16 kW, the laser wavelength was 1030 nm, and the laser beam diameter was \(200\,\upmu \hbox {m}\). Five different sensors were used to detect the process of laser welding. First, two photodiode sensors were applied to obtain thermal radiation and the reflected light intensity, respectively. Second, a spectrometer was applied to obtain the spectral distribution in the welding. Third, an NAC-FX-6 monochrome high-speed camera was used to observe the molten pool and keyhole surface by illuminating laser (976 nm, 30–40 W) onto works piece. Fourth, an NAC-FX-6 color high speed camera with an optical filter (300–750 nm) was used to catch the images of plasma and spatters, as shown in Fig. 1a, the photo of experimental set up was shown in Fig. 1b. The laser power was set on 15 kW, welding speed was 8 m/min, and the flow rate of the protecting gas Ar was 30 L/min, while the defocus was set on \({+}2\) at the beginning, and change uniformly to \({-}4\) at the end, this process took 0.9 s, and two experiments were made for the training and test data of SVM classification model, respectively (You et al. 2016). And the one of the weld seam and the signal obtained by the five sensors were shown Table 1. The weld seam type was sorted based on the weld seam width and the weld depth.

Process of AI and UVV sensor image. a Image processing for AI image, b image processing for UVV image
The classifications of three weld seam types are shown in Table 1, which indicates the quality of the weld seam of three different situations based on weld seam width and depth, and the sample obtained by five sensors are performed corresponding to each type. Type 0 presents the weld seam defect, whereas the weld depth is desirable. Type 1 presents the weld seam and weld depth are both desirable. Type 2 presents weld seam is desirable, whereas the weld depth is defect. Sensor 1 and senor 2 show the trend of visible light intense and the reflected light intense are different in the three types. The size of plasma is small in type 0, whereas it is big in type 2, and there are many spatters in type 0, whereas in type 1 and type 2, as shown from sensor 3. Signals of sensor 4 show that the size of the keyhole of type 3 is the largest in the three type, and the type 2 is smaller than type 1. Accordingly, differences among the signals are of great help to a successful classification.
Feature extraction
Imaging processing
The keyhole was the region of interest in auxiliary illumination image, it contains four features: (a) keyhole size (Wa); (b) keyhole perimeter (Wp); (c) keyhole width (Wx) and (d) keyhole length (Wy). Keyhole size was calculated by the amount of white pixel in binary image. Keyhole perimeter was calculated by the amount of white pixel of the edge of the keyhole image. Keyhole width was defined as the maximum at the x axis, while the keyhole length was defined as the maximum at the y axis. The processing of AI and UVV sensor image is shown in Fig. 2.
There were two regions of interest in ultraviolet and visible light image: (1) plasma and (2) spatters. Plasma and spatters can be recognized by imaging process technology, respectively. There were three features interested in the plasma image: plasma area (Pa); (b) plasma width (Px) and (c) plasma height (Py). The area of plasma was calculated by the amount of white pixel in plasma image. Plasma width and plasma height were defined as the maximum amount of white pixel at the x axis and the y axis in plasma image, respectively. There were four features calculated in the spatters image: (a) spatters area(Sa); (b)spatters number(Sn); (c) spatters image centroid (Scx, Scy), which could reflect the general trend of the spatters.

Features and weld seam photos of training data. aCurves of photodiode, spectrometer and AI sensor features, bcurves of plasma and spatters features, ctop view of weld seam, dside view of weld seam

Features and weld seam photos of testing data acurves of photodiode, spectrometer and AI sensor features, bcurves of plasma and spatters features ctop view of weld seam, dside view of weld seam
The signals obtained by the spectrometer showed the range of spectral lines. Two wave bands 975 nm (Sp1) and 650 nm (Sp2) were chosen as spectral features. The feature Sp1 obtained information of reflection of illustration lightness, and the feature Sp2 could reflect the welding state. Two groups of signals obtained by the photodiode showed the visible light intensity (V) and reflective light intensity (R), which were chosen as features. The intensity of visible light and reflective light both have connection with the welding stability. Thus, there were 15 features extracted from 5 sensors, including the signal of 650 nm (Sp1), the signal of 975 nm (Sp2), visible light intensity(V), reflected light intensity(R), keyhole area(Wa), keyhole perimeter(Wp), keyhole width(Wx), keyhole length(Wy), plasma area(Pa), plasma width(Px), plasma height(Py), spatters area(Sa), spatters number(Sn), and spatters cancroids (Scx, Scy), as shown in Formula 1. The curves of features, weld seam top photo and side photo are shown in Figs. 3 and 4.
Mean value analysis of features
The mean value of 15 features of Type 0, Type 1 and Type 2 were calculated, and compared to the overall mean value. The mean values of most features in type 2 were larger than the mean values in overall, whereas mean values of most features in type 0 were smaller than the mean values in overall. The mean values of the training samples features and the testing samples features were shown in Tables 2 and 3, respectively. And the mean value of features of training and testing samples were shown in Figs. 5 and 6 with bars,which the comparison of the value could be outlined immediately.
Feature normalization and selected by PCA
Principal component analysis (PCA) is widely used to analyze high-dimensional data. And it is well known that PCA helps to decrease the number of redundant features. Feature values were obtained from different sensors, and large value may have grater interference than small ones. In order to eliminate the differential data and relieve interference, each feature variable was normalized with Formula (2). Feature vector \(x_{i}(t)\) consists the feature above, and its number is M, and every feature sample number is N, which is 450, so total \(15\times 450\) (\(M\times N)\) samples were processed. The normalized formula could be expressed as,
where \(x_{\mathrm{max}}\) and \(x_{\mathrm{min}}\) are the maximal and minimal values, all the feature values \(\hat{{x}}(t)\) were within the same range between \(-1\) and 1 after normalization. PCA transformed \(\hat{{x}}_i \) into a new vector \(Z_{i}\), i.e.,
where B is the \(M\times M\) orthogonal matrix, and the ith eigenvector of the D is the ith colimn \(b_{i}\), and solving the eigen value problem, i.e.,
where \(\lambda _{i}\) is one of the eigen value of D, and \(b_{i}\) is the corresponding eigenvector, the component \(Z_{i}\) can be calculated as the orthogonal transformations of \(\hat{{x}}_i \), i.e.,

Mean value of features of the training samples showed in figure bars

Mean value of features of the testing samples showed in figure bars
Experiment of SVM classification
Principle of SVM classification model
Support Vector Machine is based on statistical learning theory and structural risk minimization, which has the advantage of getting model with good generalization ability through high-dimensional small sample learning. The kernel function is used and the calculation process is independent for the sample dimension. SVM decision function can be described as (He and Li 2016; Scholkopf et al. 1997).

SVM train experiment. aCVA of different PC numbers, bCVA reached 98% when \(C=3.0314\) and \(g=0.5743\), c estimated result of SVM train experiment

SVM test experiment. aCVA of different PC numbers, b estimated result of SVM test experiment
where \(y_{i}\) is a class label corresponding to the ith training or testing sample, N is the number of samples, \(a_{i}\) is a Lagrange parameter, d is a bias, and \(k(z_i,z_j )\) is the kernel function, There are four representative kernel functions taken into consideration: linear kernel function, polynomial function, sigmoid function and radial basis function(RBF), The Gaussian radial basis function was chosen as the kernel function for taking the non-linearity, complexity and applicability into consideration.
where g is a kernel parameter. This RBF kernel maps the samples into a higher dimensional space, and linear classification can be conducted. The discriminant function can be calculated by solving the following dual optimization problem:
where \(x_{i}\) is a support vector corresponding to nonzero \(a_{i}\), and C is the regularization constant that decides on the degree of classification errors.
parameter selection for SVM
SVM parameters, C and g were selected by training the training data. Grid search technique was used to improve the training accuracy and to ensure the parameter optimization. The range of C and g was from \(2^{-8}\) to \(2^{8}\), search step of C and g was be set on 1, the threefold cross-validation accuracy of the SVM model was calculated,
where \(c_{j}\) is the successful classification number of j fold cross-validation, and \(n_{t}\) is the sample number of cross-validation test.
Results and discussion
Figure 7 shows the classification result of experiment with training data. As shown in Fig. 7a, the CVA of type 0 is low in the few principle components, with the principle components increase, the CVA of type 0 increases quickly, whereas the CVA of type 1 and type 2 maintain high, and the total CVA becomes stable when the principle component is larger than 9. So the number of principle component is determined 10 for parameter optimization at the follow experiment. Figure 7b shows the result of parameter optimization, best CVA is obtained when C is equal to 3.30314 and g is equal to 0.57435. Figure 7c shows the classification of three types. Most of the samples were correctly sorted, few samples of type 0 was sorted to type 1.
So the SVM model was established by using the optimal parameter C and g from training the training data. The test experiment was performed based on the SVM model, and the classification results with the principle components changing are shown in Fig. 8a, the CVA of type 0 reach biggest when the principle component is 3, and shaking at 60% when the the number of principle component increase larger than 3, the CVA of type 1 and type 2 have a little decrease with the number of principle component increases, while still keeping above 80%. The total CVA is keeping above 80% and reaches the 91% when principle component is 3. Figure 8b shows the specific classification of each type, as can be seen, some sample of type 0 is sorted to type 1, and some sample of type 1 is incorrectly sorted to type 2, few sample of type 1 is sorted to type 0. Substantially, the overall classification accuracy has a high level from 80 to 91%.
In order to verify the accuracy of the SVM classification model, a three layer conjugate gradient back propagation (CGBP) neural network classification experiment was carried out, which has been widely applied in pattern recognition. 15 principle components and 3 weld seam types were considered as inputs and outputs, respectively. So there were 15 inputs and 3 outputs in the network, and sigmoid function was used as the transfer function. There were S neurons in the hidden layer. Six experiments of different S neurons (\(S=6,8,10,12,14,16\)) were carried out. Table 4 shows the accuracy of training and testing sample using neural network with different S. When S was chosen as 8, the overall accuracy of testing samples was the best 71.8%, while the overall classification accuracy of the proposed model was higher (80–91%).
Conclusions
This paper introduces welded status recognition based on SVM classification model, the training and testing data were obtained by using multisensory system, including photodiode sensor, ultraviolet and visible light sensor and auxiliary illumination sensor. Features of welding process were extracted by using image processing technology. A automatic weld seam status identification and classification is proposed in this paper, which of novelties include: firstly, three types of welded seam were defined based on the welded seam’s width and depth, and the difference of sensor signal among the three types was discussed; secondly, the PCA-SVM was adopted to process the training and testing data, in order to classify the weld seam status accurately. The trained SVM model was used to give a judgment of three types of weld status. The result of experiments proved that the SVM model could be applied to judge three types of weld status, which were determined by weld seam width and weld depth. The overall inspection accuracy can reach 91%. Compared with the CGBP neural network, the accuracy of proposed model is superior. To be more detailed, the classification accuracy of type 0, type1, and type 2 are 73, 93 and 98%, respectively. Experiment results show that the classification model is effective distinguishing different weld status, and provide foundations for identification of weld processing. The current research has some practical significance for laser welding under multiple conditions.
References
Ai, Y., Shao, X., Jiang, P., Li, P., Liu, Y., & Yue, C. (2015). Process modeling and parameter optimization using radial basis function neural network and genetic algorithm for laser welding of dissimilar materials. Applied Physics A, 121, 555–569.
Chandrasekhar, N., Vasudevan, M., Bhaduri, A. K., & Jayakumar, T. (2015). Intelligent modeling for estimating weld bead width and depth of penetration from infra-red thermal images of the weld pool. Journal of Intelligent Manufacturing, 26, 59–71.
Chen, H. C., Bi, G., Lee, B. Y., & Cheng, C. K. (2016). Laser welding of CP Ti to stainless steel with different temporal pulse shapes. Journal of Materials Processing Technology, 231, 58–65.
Chen, Q., Tang, X., Lu, F., Luo, Y., & Cui, H. (2015). Study on the effect of laser-induced plasma plume on penetration in fiber laser welding under subatmospheric pressure. International Journal of Advanced Manufacturing Technology, 78, 331–339.
Gao, X. D., Mo, L., Xiao, Z., Chen, X., & Katayama, S. (2016). Seam tracking based on Kalman filtering of micro-gap weld using magneto-optical image. International Journal of Advanced Manufacturing Technology, 83, 21–32.
Gao, X. D., Wen, Q., & Katayama, S. (2013). Analysis of high-power disk laser welding stability based on classification of plume and spatter characteristics. Transactions of Nonferrous Metals Society of China, 23, 3748–3757.
Gao, X. D., Zhen, R. H., Xiao, Z. L., & Katayama, S. (2015). Modeling for detecting micro-gap weld based on magneto-optical imaging. Journal of Manufacturing Systems, 37, 193–200.
He, K. F., & Li, X. J. (2016). A quantitative estimation technique for welding quality using local mean decomposition and support vector machine. Journal of Intelligent Manufacturing, 27, 525–533.
Huang, W., & Kovacevic, R. (2011). A neural network and multiple regression method for the characterization of the depth of weld penetration in laser welding based on acoustic signatures. Journal of Intelligent Manufacturing, 22, 131–143.
Kawahito, Y., Matsumoto, N., Abe, Y., & Katayama, S. (2011). Relationship of laser absorption to keyhole behavior in high power fiber laser welding of stainless steel and aluminum alloy. Journal of Materials Processing Technology, 211, 1563–1568.
Li, S., Chen, G., Katayama, S., & Zhang, Y. (2014). Relationship between spatter formation and dynamic molten poolduring high-power deep-penetration laser welding. Applied Surface Science, 303, 481–488.
Luo, Y., Tang, X., Deng, S., Lu, F., Chen, Q., & Cui, H. (2016). Dynamic coupling between molten pool and metallic vapor ejection for fiber laser welding under subatmospheric pressure. Journal of Materials Processing Technology, 229, 431–438.
Scholkopf, B., Sung, K.-K., Burges, C. J. C., Girosi, F., Niyogi, P., Poggio, T., et al. (1997). Comparing support vector machines with Gaussian Kernels to radial basis function classifiers. IEEE Transactions on Signal Processing, 45(11), 2758–2765.
Shanmugam, N. S., Buvanashekaran, G., & Sankaranarayanasamy, K. (2010). Experimental investigation and finite element simulation of laser beam welding of AISI 304 stainless steel sheet. Experimental Techniques, 9–10, 25–36.
Shayganmanesh, M., & Khoshnoud, A. (2016). Investigation of laser parameters in silicon pulsed laser conduction welding. Lasers in Manufacturing and Materials Processing, 3, 50–66.
Wan, X. D., Wang, Y. X., & Zhao, D. W. (2016). Quality monitoring based on dynamic resistance and principal component analysis in small scale resistance spot welding process. International Journal of Advanced Manufacturing Technology. doi:10.1007/s00170-016-8374-1.
You, D. Y., Gao, X. D., & Katayama, S. (2013). Multiple-optics sensing of high-brightness disk laser welding process. NDT&E International, 60, 32–39.
You, D. Y., Gao, X. D., & Katayama, S. (2016). Data-driven based analyzing and modeling of MIMO laser welding process by integration of six advanced sensors. International Journal of Advanced Manufacturing Technology, 82, 1127–1139.
Zhang, Y. X., Gao, X. D., & Katayama, S. (2015). Weld appearance prediction with BP neural network improved by genetic algorithm during disk laser welding. Journal of Manufacturing Systems, 34, 53–59.
Acknowledgements
This work was partly supported by the National Natural Science Foundation of China (51675104), the Science and Technology Planning Public and Construction Project of Guangdong Province, China (Grant No. 2016A010102015), the Research Fund Program of Guangdong Provincial Key Laboratory of Computer Integrated Manufacturing (Grant No. CIMSOF2016008), and the Science and Technology Planning Project of Foshan, China (Grant No. 2014AG10015). Many thanks are given to Katayama Laboratory of Osaka University, for their assistance of laser welding experiments.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Liu, G., Gao, X., You, D. et al. Prediction of high power laser welding status based on PCA and SVM classification of multiple sensors. J Intell Manuf 30, 821–832 (2019). https://doi.org/10.1007/s10845-016-1286-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10845-016-1286-y