
Abstract
An integrated probabilistic risk assessment methodology is developed for the purpose of quantifying the life safety level of people present in buildings in the context of fire safety design. Multiple risk based concepts and tools have been developed in previous research to objectify performance based design methods for simple building types and layouts. However, these available models lack an integrated approach for challenging building designs and moreover they are not adequately coupled, most often resulting in a significant computational effort. Hence, there is a need for a practical and efficient framework for dealing with complicated building layouts and different occupancy types. Therefore, a computationally efficient quantitative risk assessment method is developed that provides a framework by combining deterministic sub-models and probabilistic techniques to quantify the fire safety level by means of failure probabilities, individual and societal risk. The deterministic framework is supported by analytical and numerical models. The probabilistic framework is supported by response surface modelling, sampling techniques and limit state design. Following the theoretical description of the model, a case study of a five storey commercial shopping mall of 25,000 m2 is elaborated and discussed as proof of concept. Multiple fire, building and occupant variables are implemented in the model. Three different fire safety designs are compared, resulting in quantified risks between 10−6 and 10−8. The case study proves the validity of the newly developed integrated methodology for this type of buildings and its benefits in fire safety engineering.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
During the past decades, modern building design has become more and more influenced by fire safety considerations [1]. Regulations, standards and guidelines have been developed and extended in such a way that the impact of these requirements have become increasingly significant in the decision making process [2, 3]. Therefore, building fire safety regulations get increasingly more attention from different stakeholders and are continuously being reviewed by fire safety and law experts.
Historically, two main regulatory compliance methods have been developed. These are prescriptive and performance based design (PBD) approaches [4, 5]. Prescriptive designs are principally developed based on trial and error experiences from past fire incidents revealing particular issues in safety. In a prescriptive fire safety regulatory system it is implicitly assumed that when all the rules of the regulation are applied, the fire safety level is acceptable [6, 7]. Prescriptive codes are very practical for the design of buildings within the intended scope of the regulation. However, advancements in architectural creativity, functional demands, structural engineering as well as material sciences make it possible to execute buildings with complex configurations which cannot always be built in accordance with these existing codes. Additionally, prescriptive fire safety regulations do not provide insight into the obtained fire safety level and compliance with these code requirements does not ensure that all buildings are constructed to the same level of safety [8, 9]. Hence, in this paper, a probabilistic risk assessment method is developed that gives the possibility of quantifying the fire safety level that is actually achieved in case buildings are designed according to prescriptive codes.
As the field of Fire Safety Engineering (FSE) has evolved, more and more countries changed their legislation regarding fire safety and have proceeded to design buildings in function of objectives and performance. Developed regulatory formats are objective-based and performance-based (e.g. deterministic and risk-informed methods), where the implicit acceptable safety level in prescriptive rules now becomes explicit by showing the verified safety level. The advantage is that these codes promote flexibility [10], innovativeness [6] and cost-effectiveness [11]. Additionally, the actual safety level can be quantified [12]. The disadvantage is that the method relies upon the competences of the user. The qualitative or descriptive nature of the performance requirements is sometimes criticized for being subject to interpretations and lacking quantifiable or verifiable performance requirements and criteria. Therefore, efforts are done to reduce the ambiguity of these codes shifting from performance based with total freedom towards performance based methods with prescribed scenarios and parameters to be implemented in the analysis [10, 13]. This is potentially a significant advancement in achieving a uniform safety level. However, still, no unbiased method has been developed that includes the effect of the uncertainty of the input parameters with respect to the obtained safety factor from ASET/RSET (available/required safe egress time) analyses [14]. Therefore, in the proposed quantitative risk assessment (QRA) method, parameter uncertainties and the reliability of safety systems are consistently taken into account by means of probabilistic distributions that have direct impact on the obtained safety factor.
Risk based methods provide the possibility to take parameter uncertainty into account. However, currently, no standards exist that outline detailed methodologies to guide a fire risk analysis. Some codes are under review to provide new and more in-depth procedures [15]. Most of the guidance is provided in standards [16,17,18], engineering rules of good practice [19, 20] and in literature studies [21,22,23,24,25]. These guidelines provide a lot of insight into performing proper risk analysis. Nevertheless, they often lack detail or only focus on specific parts of the method or problem at hand. Therefore, in the past decades multiple quantitative risk analysis models have been developed [9]. The main advantage of these risk models is the level of quantification in relation to the speed of execution. The disadvantages are the limited scope and the lack of accuracy of the sub-models (e.g. smoke spread and evacuation). In order to deal with these disadvantages, efforts are done to develop new methods that broaden the scope and increase the accuracy [26,27,28]. Despite that these methods provide a significant improvement in the accuracy of the submodels (e.g. field models, human behaviour and toxicity analysis) and probabilistic techniques (e.g. response surface modelling and importance sampling), they still show significant disadvantages. Important shortcomings are that the models are only validated for simple cases, they still require large amount of computational power and the probabilistic techniques focus on single parts of the risk based models (e.g. on smoke spread). Hence, in the following chapters, an integrated methodology is developed that enables to analyse complex building configurations in an automated way, using advanced simulation techniques in order to cope with the large amount of data involved in response predictions, which are otherwise not possible on the basis of simplified methods. To this intent, the earlier model developed by the authors [29] is extended for evacuation and consequence analysis.
In the following sections, the objectives of the research is discussed (Sect. 2), the method is explained (Sects. 3 and 4), a case study is elaborated as proof of concept (Sect. 5), the results and limitations of the method are discussed (Sect. 6) and the conclusions are presented (Sect. 7).
2 Objectives of the Developed Methodology
The goal of the research presented in this paper is to objectify the safety level of prescriptive and performance based designs. This is achieved by means of implicitly linking the degree of conservative values of the input parameters, through probabilistic methods, to the output results. In comparison to traditional models using safety factors this is a significant improvement. Additionally, the residual risk takes into account the reliability of safety systems. This is probabilistically integrated into the effectiveness of the safety systems (efficacy × reliability). Because of the probabilistic approach it is crucial to find a trade-off between implementing an accurate method (submodels and probabilistic techniques) and reducing the computational demand. The purpose is to develop an efficient method that allows for future application in the private industry.
The suggested method needs to have different deterministic submodels that can deal with challenging building types. They need to be integrated into the probabilistic framework in a way that provides for an efficient probabilistic analysis and still allows to take all types of buildings and occupant configurations into account. The results should be expressed in tangible and comparable values (FN-curves and design failure probabilities).
3 Global Framework
The proposed fire risk analysis model consists of a series of deterministic sub-models [27, 29] combined with probabilistic techniques to define the overall fire safety risk to occupants. The main framework consists out of 7 steps and is inspired by international guidelines on performance based risk analysis [12, 30, 31].
In the first step of the global framework, the building configuration and scope details are described. The specific boundary conditions with respect to occupancy, building and environmental characteristics are defined. Important aspects that will have an impact on the definition of the fire safety design are analysed. After the definition of the scope, the goals and objectives are defined in step 2. The main objective is to achieve the pre-defined life safety level. Additional objectives can focus on a specific sub-category of occupant groups (e.g. elderly and disability) or when specific risks are expected (e.g. underground and nuclear).
In the third step, the performance criteria are developed based on the described goals, stakeholder and design objectives [12]. Depending on the problem description stated above, two types of performance evaluation can be defined. The first type of evaluation involves relative comparisons of different fire safety designs [19, 28]. This is called the relative safety level for occupants (RSO). The safety levels of each of these fire safety designs are quantified and the design with the higher safety factor is considered safer. This method can be conducted to compare different fire safety systems and is typically used when applying performance based designs in a prescriptive based regulatory systems when the building design deviates in certain aspects from the prescriptive legislation (e.g. maximum compartment surface area and maximum walking distance to exit). The second type of evaluation can be defined as one in which the fire safety design is compared with absolute criteria derived from legislation, standards and guidelines [32, 33]. The quantification of the absolute criteria is not the objective of this paper. More research on this topic can be found in [34, 35]. In this paper, the performance criteria are considered risk based. For both relative and absolute evaluation, three types of criteria can be defined for the quantification of the acceptable risk level. The first criterion considers the probability of failure defined as the probability of a fatality over a period of time or given that a fire occurs [19]. The second criterion is defined in terms of the individual risk (IR) [27, 33]. The third criterion is expressed as the societal risk that represents the risk to a group of people and is typically visualized by means of an FN-curve.
In the fourth step, the fire safety design is developed. The fire safety concept should be designed based on the main principles of fire safety design rules of good practice [12]. In most cases, these are initially defined based on prescriptive requirements. Once the fire safety design is developed, the deterministic and probabilistic analysis is conducted in step 5. The full elaboration of the proposed methodology is discussed in the following section by a step-by-step approach. In the sixth step, the performance criteria are evaluated by means of comparison of the results with the individual and societal risk obtained in step 5. If the obtained results meet the risk criteria, the outcome is positive and the final design can be selected in step 7. If not, the fire safety design should be modified, by either changing the configuration or adding more safety measures, and the procedure should be repeated. When multiple designs are selected, the most cost effective design that meets the minimum acceptable limit or reference design can be selected. This is done by keeping the whole life-cycle into account.
4 Probabilistic Framework
In Fig. 1, an overview of the proposed probabilistic framework is depicted. The method is divided in 11 sub-steps explained below and is implemented in the open source code Python [36] and Matlab [37].

Proposed probabilistic framework of the QRA-method (corresponding to step 5 in the general framework)
4.1 Parameter and Scenario Input
In step 1 of the probabilistic framework, the main representative design fire scenarios are selected. These scenarios are chosen based on the building configuration (e.g. building type, height, adjacent buildings and structure type), environmental conditions (e.g. effect of wind and outside temperature), occupant characteristics (e.g. occupancy type and load) and fire safety design (e.g. safety systems and procedures). Design fires are chosen based on project specific parameters (e.g. atrium and open office plan) in combination with rules of good practice [38, 39].
In step 2, the most important input variables are chosen based on a preceding sensitivity analysis [40]. For the considered variables, distributions are determined based on statistical data, fault tree analysis and engineering judgement [31]. In Tables 1 and 2, a list of variables is given of the most relevant parameters in fire life safety analysis for a case study of a commercial building [41, 42]. Parameters 1–8 and 13–14 are occupancy dependent. In theory, all these parameters should be implemented in the event tree analysis in step 3. However, in order to prevent an extensive event tree, the variables are divided into discrete and continuous parameters. The discrete variables are addressed in the bow-tie structure (Table 2). The continuous variables are addressed at the end of the event tree by means of the response surface model (RSM) (Table 1). The separation between the two types of variables is done for reasons of computational and operational efficiency (e.g. location of the fire). Moreover, some variables cannot be considered in continuous form due to their discrete nature (e.g. activation or failure of safety systems and the state of doors). It should be pointed out that, due to lack of one complete source of information, data is taken from various sources and then combined in the model. Therefore, the data provided in this paper should be considered for illustration purpose only and may not be generally applicable. For example, studies show that the probability of fire starting can vary significantly among different countries [43].
In Table 1, for every variable, an indication is given of the order of importance with respect to the results. The first order parameters are considered the most significant. This means that only parts of the domain close to the limit state need to be analysed. The second order parameters are still substantial but less sensitive than the first order ones. For these parameters, a large part of the domain needs to be analysed. Third order parameters, e.g. ambient temperature, material properties, are the least significant and are not addressed as a variable in this study. For these parameters mean values are taken as nominal values.
In Table 2, several discrete parameters are given which will be implemented in the event tree. The focus is put on the reliability of the safety systems. For every safety system, the reliability is presented by a PERT distribution with corresponding parameters for overall reliability. In the table, the most critical component is presented with respect to the main cause of system failure. The presented reliability data is valid under the consideration of proper design, installation, testing and maintenance. In case of low testing and maintenance quality the reliability levels drop significantly. In case of sprinkler systems, the most frequent reason for sprinkler system failure, ranging from 33% to 100% of the reported failures, is that the system was shut off after reparation or maintenance. One possibility to increase the reliability of sprinkler systems is to provide an electrical monitoring system that monitors the state of the main sprinkler valve. This way the reliability can be increased towards 95% to 99.9% [48]. Similarly, the reliability of smoke and heat control (SHC) systems can be increased when the critical components are monitored. The parameter “Smoke barrier door” is a combination of the probability of fire doors being blocked open and the probability of self-closing doors failing to close correctly on demand. The lower value 0.5 in Table 2 is the combination of the two probabilities suggested in [15].
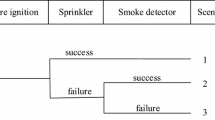
In the step 3, a bow-tie model is generated. The bow-tie technique requires formation of fault trees at the left side and branch scenarios (event trees) at the right side of a particular event (e.g. start of fire, detection and sprinkler activation). The ignition frequency data depends on the size of the building [50]. The event tree is structured based on pathway factors (fire location, sprinkler activation, door opening state, etc.) [31]. In Fig. 2, the conceptual representation of the event tree structure is presented. The developed scenarios include the effectivity of the safety systems by combining the efficacy and reliability in the multiple scenarios. Thus, in addition to standard approaches, partial success or failure of safety systems is taken into account.

Conceptual representation of the use of discrete parameters in the event-tree approach
4.2 The Response Surface Model
In step 4, a response surface model is developed. The basic concept of a response surface model is to approximate the responses in the analysed domain of input possibilities for a specific model without relying upon the physics of the system. This can be desired when the modelling of the response becomes physically too complex. It is often used when the limit state function [51] is implicitly [28] formulated (e.g. structural engineering) which is the case for the numerical models considered in the current framework. In RSM, the results of a finite set of detailed model simulations are translated in a meta-model, that does not explicitly model the physics. Based on a limited set of support points, a response surface is generated that predicts the global field of responses. The choice of the support points is determined by the method chosen for Design of Experiments (DoE) (see subsequent section).
The deterministic evaluation of the support points is conducted by means of multiple sub-models. The sub-models chosen for the scope of the paper are the smoke spread, evacuation and toxicity model. These models each provide intermediate results and interact with each other by means of a link between them. For example, the output from the smoke spread model is used to determine the visibility range in the evacuation model.
In Fig. 3, a sequential method of three sub-models is shown: the smoke spread, the evacuation and the consequence model. The input for smoke spread model is divided into primary and secondary parameters. The primary type are parameters that have a significant impact on the fluid dynamics in the smoke spread sub-model, e.g. fire growth, fire area and ventilation conditions. The secondary type of variables are parameter inputs which are considered to have significantly less impact on the movement of smoke, e.g. average toxicity yields and heat of combustion. The variability of these parameters is taken into account outside the computational expensive model by an analytical model (Consequence model [27]). This is done to reduce the dimensionality and the number of simulations and increase the efficiency of the model with respect to previous methods. The output from the smoke spread sub-model is generated based on a limited learning set. The response model is then used to generate input data in terms of visibility, toxicity and temperature components for the evacuation model. The validation of the RSM for radiation is an ongoing research. In a similar approach and as an extension to the research presented in [29], the evacuation model is analysed. Similar to the smoke spread model, the variables are split up in primary (occupant density and affiliation) and secondary variables (susceptibility and VE-rate). In this context, a significant reduction of computational power is achieved. The output from the evacuation model is then used to perform the consequence analysis. This model will determine the consequences for each occupant in terms of injury or fatality. In the last step, the reliability analysis is performed by limit state design. The limit state design is coupled to Fractional Effective Dose (FED) in which the individual risk in terms of the probability of fatality is calculated. Next, the societal risk is visualized by means of an FN-curve.

Representation of the response surface modelling approach in combination with multiple deterministic sub-models (smoke spread, evacuation and consequence modelling)
4.3 RSM for Smoke Spread Modelling
In step 5, parameter values of the variables to execute the deterministic analyses are chosen. The total computational time is reduced by only implementing the primary input variables that affect the main physics of smoke movement (Fig. 3) The chosen variables are the fire growth coefficient α, the heat release rate per unit area (HRRPUA) and the maximum fire area (Amax). Other primary variables can be the sprinkler activation time, the wind effect, etc. Table 1 summarizes the distributions for these variables.
Next, the support points are defined for the deterministic analysis. Sample combinations need to be chosen that give sufficient information to generate an accurate response surface model. From research is concluded that fractional factorial design is a suitable DoE [29]. The samples should be chosen to cover the domain of the expected limit state that extends to the highest failure probability (\( P_{f} \)), i.e. the closest part of the limit state design from the origin in standard normal space (Fig. 4).

Representation of the selection of support points depending on the estimated location of the limit state for two dimensional space
In order to specify the optimal support points to generate the RSM, several aspects have to be taken into account. The first step is to choose a representative domain for every variable. Not the entire domain is chosen because only a specific part of the domain is expected to significantly contribute to the value of \( P_{f} \), as e.g. the fire grows too slowly, the fire area is too small and the sprinkler extinguishes the fire. In Table 3, the suggested ranges are shown for the analysed variables. The choice of the ranges for every variable is based on a preliminary iteration in which first a broad parameter range was chosen and subsequently narrowed down. For example, the support points for the fire growth coefficient in a specific scenario can initially vary from slow to ultra-fast. After narrowing down, the risk analysis can be conducted for values from fast to ultrafast.
In the second part of step 5, the DoE is chosen based on full factorial design [52, 53]. For every variable, a minimum of three values are chosen [52]. This gives a total of 3n or 27 simulations. The chosen input combinations are presented in Table 3. The lower limit (LL) values are adopted based on the method described above. The upper limit (UL) is taken based on physical boundaries (max fire area and maximum fire growth). The mean values (MV) are based on the linear or logarithmic average between the lower and higher limit. In order to test the convergence of the model, 10% additional random samples are evaluated to analyse the convergence rate of the developed RSM (see step 7).
In step 6, the training set is evaluated by means of the deterministic smoke spread sub-model [29]. The corresponding input parameters are implemented and the scenarios are evaluated. Two models are considered: a zone model (e.g. Branzfire or CFAST) for simple compartment configurations and a field model FDS [54] for complex layouts. The output of the smoke spread sub-model is provided in terms of 3D-value values for every time step.
The RSM is generated in step 7. Two methods are particularly useful for response surface modelling in the framework of life safety analysis [29, 55]. These are the Interpolating Moving Least Squares (IMLS) method and the Polynomial Chaos Expansion (PCE) method. Each method has a different approach for estimating the response surfaces and are proven to be sufficiently accurate for the intended purpose [29]. The IMLS is a more accurate method when strongly irregular patterns are observed (e.g. close to the fire, high turbulence or irregular sampling techniques). The advantage is that the method fits the best surface for the chosen support point. The PCE estimates one response surface for the entire domain independent of the chosen support points. The model provides a more accurate method when less irregular patterns are observed (e.g. field far from the fire or low turbulence). In this paper, the PCE method is chosen for the analysis because of its higher accuracy for this type of configurations [29]. In general, the PCE method consists of two steps. First, it estimates a response surface based on the support points for the chosen domain. In the second step, for every new combination of input variables the RSM estimates the outcome by addressing the response surface. PCE is based on the homogeneous chaos theory proposed by Wiener [56]. PCE is a powerful surrogate modelling technique that aims at providing a functional approximation of a computational model through its spectral representation on a suitably built basis of orthogonal polynomial functions. The proposed methodology is explained in more detail in [29].
In order to prevent overfitting of the response surface model, a linearization of the regression analysis is conducted. When performing a regression analysis, the larger the number of parameters in the surrogate model, the better the fit to the original model. However, the higher the number of terms, the higher the complexity and the higher the probability of overfitting. In general, overfitting occurs when the number of unknown parameters in the regression model are equal or more than the size of the training set. To overcome this problem of overfitting, the L2 regularization or ridge regression [57] is applied. For every chosen set of parameters in the surrogate model, the method determines a cost function \( J\left( \beta \right) \) in which an additional term is added to penalize higher degree fitting surrogates. The cost function is defined as follows [57]:
With m the size of the training set, p the number of parameters and λ the regularization or shrinkage parameter. This parameter causes the coefficients to shrink as much as possible so that preference is given to lower order response surface models. From several case studies it is found that a λ-value between 0.01 and 0.3 is optimal.
The implementation of the procedure in the PCE method is according to the following equation:
The full derivation of the procedure and variable clarification is elaborated in [29]. Once the RSM is generated, a convergence analysis is performed, after step 7 and 9, to analyse the dependency of the chosen support points on the generated RSM. Convergence is considered to be achieved when the response surface estimation error is below a predefined error margin. An error margin lower than 5% is suggested [28]. The calculation of the error is formulated as:
where \( \epsilon \) is the average error of all the responses (time and location), yi is the response value (toxicity, temperature and radiation) for the i-th response and yi−1 is the outcome before the i-th response. If the results are not converged, the process has to be repeated. Additional samples need to be generated and the procedure has to be rerun until convergence has been reached. In case of using Latin Hypercube Sampling (LHS) [58], an increase in the number of samples will change the sampling pattern. Therefore, the entire sampling pool needs to be resampled. When using Sobol Sampling [59], this is not the case. Only the additional samples have to be evaluated because the technique generates sample values under consideration of the previously sampled points. This is an important advantage of Sobol Sampling. Both the addition of the convergence analysis and Sobol Sampling with RSM for smoke spread and evacuation modelling in risk analysis is an important improvement in the context of increasing accuracy in fire risk analysis.
In step 8 (see Fig. 1), the DoE is generated for the probabilistic analysis of the smoke spread RSM using a similar approach. For common buildings types and standard boundary conditions, a reduction of the domain can be done based on past experience. For more complex cases a conservative approach can be followed that stepwise narrows the domain down. The probability of the neglected domain should be included. This is accomplished by incorporating a weight factor with respect to the part of the domain taken into account. The following weight factor for smoke spread WFSS is applied:
where \( F_{X} \left( x \right)_{\alpha } , F_{X} \left( x \right)_{HRRPUA} \) and \( F_{X} \left( x \right)_{A} \) are the cumulative distribution values for the fire growth coefficient, HRRPUA and the maximum fire area, respectively. The values are taken from Table 3. The weight factor will be multiplied by the final failure probabilities to take the entire domain of the distributions into account. The weight factor is multiplied by the “failure probability” after the reliability analysis.
In step 9, the output results are obtained by addressing the RSM for the chosen input combinations. For every sample defined in step 8, the outcome is predicted by the RSM generated in step 7. It should be mentioned that extrapolation should not be applied to avoid large errors in the model.
4.4 RSM for Evacuation Modelling
Once the output results from the smoke spread RSM are obtained, the procedure loops back to step 5 and the output is provided as input for the evacuation analysis. Normally, for every smoke spread sample, a probabilistic evacuation analysis needs to be performed. However, this is not efficient because many samples of similar evacuation scenarios would be evaluated. In order to make the analysis more efficient, the evacuation can be decoupled from the smoke spread model when the effect of smoke visibility on the movement dynamics is taken into account. This effect is represented by analyzing three scenarios instead. The first scenario is considered the best case scenario when only one person is affected by a low smoke density and has a reduced walking speed. All the other occupants are not influenced and therefore the impact of smoke on walking speed is negligible. This scenario is considered an evacuation scenario in smoke free conditions. All the evacuation scenarios providing less severe smoke conditions give the same results in terms of movement dynamics. The second scenario is the worst case scenario when the visibility conditions are the most negative. This is considered to occur when the soot yield is not higher than 99.73% of the cases which is three times the standard deviation on the conservative side. The third scenario is chosen in between the two former scenarios based on the average of the soot yield parameter.
Next, the support points for deterministic evacuation analysis are chosen. In order to reduce the total computational time, only the primary input variables that affect the main physics in terms of evacuation dynamics are take into account (Fig. 3). The variables occupant density (OD), affiliation (exit familiarity), pre-evacuation time, shoulder width and movement speed are considered significant parameters affecting the output. An additional important parameter can be detection sensitivity or activation of the alarm in case manual intervention is necessary. In Table 1, the distributions for these variables are listed. The secondary parameters considered are the respiratory minute volume (VE-rate) and susceptibility of people to smoke. These parameters are analysed in the consequence model.
The support points are generated for evaluating the deterministic analysis. To determine these points, several aspects have to be investigated. The first aspect is to choose a representative domain for every variable. In analogy to step 5 in the smoke spread sub-model, only a specific part of the domain is chosen in which fatalities are predicted. No fatalities are expected to occur in particular domains that have too small population density or the response is too fast. In the table below, the suggested ranges are shown. The choice of the ranges for every variable is based on preliminary iteration in which first a broad parameter range was chosen and subsequently narrowed down. The ranges are selected for higher occupant densities and are broader for the variable affiliation because fatalities can be expected even for optimal exit choice.
The DoE is chosen based on full factorial design. For every variable, a minimum of four values are chosen to address the irregularity of the responses [29]. This gives a total of 4n or 16 simulations (Table 4). The values are chosen and generated in analogy to the smoke spread sub-model.
In step 6, the training set is evaluated by means of the deterministic evacuation sub-model similarly with the theory obtained from [29]. Several evacuation models are investigated of which Pathfinder [60] and JuPedSim [61] are implemented in the framework. Pathfinder is suggested for practical applications because of the high efficiency in practical use. JuPedSim is implemented for flexibility and research purpose. This model can be adapted to special conditions because it is open source. However, it needs more engineering time for the set-up of the building geometry. The two evacuation sub-models consist of a combination of different models in which occupant movement, human behaviour and interaction with the environment is taken into account.
Once the training set is evaluated, the RSM is developed similar to the RSM for the smoke spread sub-model (step 7). The full derivation is developed in analogy to step seven and therefore it's not repeated here. In step 8, the DoE is generated for probabilistic evacuation analysis. Only a part of the domain is analysed for the same reason as discussed above. Samples with low occupant densities will not give a significant added valued to the results. Therefore, it is chosen to narrow the domain down and give a weight to the results.
In order to take into account the probability of occurrence, the following weight factor WFEvac for evacuation is applied:
where \( F_{X} \left( x \right)_{OD} \) and \( F_{X} \left( x \right)_{Aff} \) are the cumulative distribution values for the occupant density and affiliation towards the main exit. The weight factor will be multiplied with the final failure probabilities to account for the entire domain of the distributions. The weight factor is multiplied with the failure probability after applying the reliability analysis. Once the input combinations are chosen, the samples are evaluated by using the response surface model for evacuation in step 9.
4.5 Consequence Analysis
Next, once the results from the evacuation RSM are obtained, the procedure loops back to step 8 (Fig. 1). The output is used as input for the consequence analysis sub-model. A DoE is generated for the probabilistic consequence analysis. The secondary variables that are not included in the previous sub-models are implemented in the consequence sub-model. This is done to reduce the variability of the more computational affording models by only using parameters that have an important impact on the smoke spread (smoke spread model) and evacuation dynamics (evacuation model). Because of this approach, the application of CFD models becomes feasible for these type of risk analysis methods which is considered as an important step in the development of complex risk models. The secondary parameters are implemented in the consequence model because the model is an analytical model that efficiently evaluates the deterministic scenarios [27]. The effect of the variables CO-yield (γCO), HCN-Yield (γHCN), Heat of Combustion (HoC), Susceptibility (D), Respiratory minute volume (V-rate) is simulated. A similar sampling technique is chosen for step 8 as discussed before.
Next, the consequences for life safety are determined in step 9. The effect is quantified through combining toxicity and heat (convective and radiation) effects into the term Fractional Incapacitation Dose (FID) [27, 62]. This value determines whether a person will manage to escape or get incapacitated. According to the definition of the FID, it is considered that a person who reaches an FID equal to unity or higher will not be able to survive the fire scenario. The FID is calculated by means of the consequence model according to [27].
4.6 Reliability Analysis
In step 10, the “failure probability” in relation to the specific scenario is calculated. The combined result of the analysis will be expressed in an FID value. Therefore, the following limit state is applied:
In case a sufficient number of occupants obtain an FID ≥ 1, a direct failure can be calculated in which the number of subscenarios (determined by Sobol Sampling) containing one or more occupants with an FID ≥ 1 is divided by the total number of subscenarios considered in the specific event tree scenario:
This calculation procedure is performed for every event tree scenario and the final failure probability is obtained:
where nscen are the number of scenarios. The branch probabilities are determined by multiplying the corresponding frequencies of the pathway factors (e.g. ventilation conditions or safety system state) which are determined by fault tree analysis. In step 11, the individual and the societal risk are calculated for all the different scenarios. The societal risk is represented by means of an FN-curve.
5 Case Study
5.1 Configuration
The probabilistic life risk analysis model is applied to a case study. The objective of the case study is to present the method and analyse the applicability of the model for this type of projects. The case study embodies the configuration of a multi-purpose commercial building (step 1). The shopping mall provides different types of merchandise (e.g. clothes, multimedia, healthcare and beauty shop) over a total surface area of 25,000 m2 (Fig. 5). The building consists of one main compartment of 5 floors from level − 1 to level 3 with a surface area of about 5000 m2 per floor and ceiling heights between 3 m and 4 m. Figure 6 shows a schematic floor plan of the ground floor. The floors are interconnected by 4 escalators (orange marking) distributed over two central openings. Emergency exits are positioned on each floor by means of 4 compartmentalized staircases (blue marking). Four exits are foreseen for evacuation of people on the ground floor. Level − 1, 0, 1 and 2 are only used for commercial purposes. At level 3, a restaurant of 2000 m2 is located in the same compartment. In this case study no external influences (e.g. wind, seasons and fire brigade) or bottlenecks (e.g. merging flows and direct access to street) are taken into account. The building is considered to be occupied by customers (90%) who are not familiar with the building and staff (10%) who are familiar with the building. The occupant density is presented in Table 1 and based on an average of 1 occupant per 5 m2 [47]. The occupants are considered to have mean pre-evacuation times between 60 s and 120 s (Table 1) [47].

3D model of the five storey shopping mall (green are staircases, yellow are central voids) (Color figure online)

Ground plan of floor level 0 for option 1 with fire safety measures: sprinkler and SHC (Color figure online)
The goal (step 2) of the QRA-analysis is to determine the life safety in case of fire. The defined risk criteria (step 3) are threefold. The first objective is defined in terms of a failure probability of 10−4 fatalities per year for the entire building [63]. The second objective is expressed as an acceptable individual risk of 10−6 fatalities per individual per year [63]. The third objective is defined in terms of the societal risk. The acceptable societal risk level is presented by an FN-curve with starting point 10−4 for N = 1 with a slope of − 1 between 1 and 10 fatalities and a slope of − 2 from 10 fatalities on to represent risk adversity [64]. The acceptable risk for fatalities higher than 10 people is applied according to what is suggested in the Netherlands. No ALARP criterion is defined.
5.2 Developing Fire Safety Design Alternatives and Input Parameters
In this case study, three developed fire safety designs (step 4) will be analysed (step 5) and eventually evaluated against the pre-defined risk criteria (step 6). The first and the second option both follow the main considerations of the Belgian prescriptive requirements regarding passive and active fire safety systems for safe evacuation, structural stability and fire brigade assistance. The requirements are in analogy to other countries with a prescriptive framework (e.g. France and Netherlands). The three options have several common and different features. The common features are structural stability (R60), compartmentation of staircases (EI60), number and width of emergency exits, automatic smoke detection and standard alarm system. The alarm system is a delayed 120 s after initial detection. This method is typically applied in larger commercial buildings in Belgium and allows the security to confirm the fire and reduce the risk of false alarm. The distinctive features of the different options relate to vertical compartmentation and active safety systems. More in detail, in the first option, all the floors are considered as a single compartment. The fire safety design consists of a SHC and sprinkler system. The fire safety concept is designed according to the rules of good practice. The SHC-system is designed in accordance with the EN12101-5 (Fig. 6) and primarily composed of natural (1/3) and mechanical (2/3) air supply (mechanical front doors) and mechanical extraction of 60,000 m3/h of smoke divided over multiple extraction points on the incident floor. Every floor is divided into two SHC-zones with a fixed smokescreen in between. The sprinkler system is an ordinary hazard (OH) 3 installation in accordance with the NBN EN 12,845 [65]. An ASET/RSET analysis is performed to evaluate the performance of the design. In the second option, a complete prescriptive solution is designed: a sprinkler system is implemented, the floor levels are compartmentalized and every floor is divided in compartments smaller than 2500 m2 (Fig. 7). The compartments are connected by three self-closing doors in case of fire. In the third option, the same fire safety design is applied as option 1. However, no SHC-system is implemented. The purpose of this option is to determine the effect of the SHC-system on the safety level.

Ground plan of floor level 1 for option 2 with compartmentation in the middle of every floor
Next, the probabilistic and deterministic analysis is performed. In step 1 of the probabilistic analysis, the main design fire scenarios are defined. Three representative design scenarios are considered. These are a fire in the open commercial area (1), a fire in a small storage room with open door (2) and a fire in the restaurant (3). In step 2, the most important input variables are defined. The variables discussed in Table 1 are adopted for the case study. For every first order parameter (Table 1), the cumulative density distributions (CDF’s) are presented for smoke spread in Fig. 8 and evacuation in Fig. 9. In these figures, the adopted parameter values for traditional performance based analysis tools (e.g. BS PD7974, C/VM2 and CIBSE) are depicted to show the conservatism of these parameter values. The grey hatched areas are the analysed domains in the probabilistic analysis. It is shown in the figures that most of the standards and guidelines use fixed parameters. These parameters mostly lean towards the conservative side (right part of the figures) of the distribution with respect to the available literature.

CDF of the fire growth rate and the maximum fire size for the shopping mall

CDF of the occupant density and the pre-evacuation time for the shopping mall
5.3 Probabilistic and Deterministic Analysis
The bow-tie model is generated for every design scenario (step 3). To construct the event tree, multiple pathway factors are considered. These are the location of the fire (5 floors, 3 zone and 2 room types), sprinkler activation (activation and failure), SHC performance (activation and total failure), detection (normal, sprinkler and delayed), alarm performance (normal and delayed) and failure of passive systems (e.g. door shutter failure of self-closing door). The event tree is constructed similar to Fig. 2. In total 24 event tree scenarios are considered important to be analysed for the smoke spread response surface analysis. The other scenarios are only analysed for one combination of parameters. They are not analysed by means of RSM sensitivity because they are considered similar to one of the 24 scenarios (e.g. symmetrical configuration), not significant because of negligible consequences (e.g. sprinkler extinguishment) or can be interpolated (e.g. intermediate floors). An important boundary condition of the model is that the staircases are considered smoke free during the evacuation for all scenarios. This is a limitation of the model because failure of a fire door causes smoke leakage towards the staircase which will have a major impact on the safety level.
An initial ignition frequency of 0.0904 fires per year is taken into account [50]. The probabilities of the branch scenarios are determined by the combination of the probabilities of the pathway factors. These probabilities are obtained through fault tree analysis and analysis of historical data [15, 48, 49]. The probability data used in the case study is presented in Table 2. For the case study considered, the analysis is done with the provided PERT distributions.
In step 4, the PCE RSM is chosen for the case study, because of its efficiency and high accuracy for the region of interest which is the far field of fire in step 5, the support points are generated. The sample set suggested in Table 3 is analysed by means of the smoke spread sub-model FDS version 6 [54] in step 6. In Fig. 10, a cross-section of the smoke spread for a conservative fire scenario (α = 0.012 kW/s2, HRRPUA = 450 kW/m2, Amax = 100 m2) is shown on the ground floor in the left part of the compartment at 250 s after ignition. In this scenario, a SHC-system is implemented and considered to have a reliability of 0.5 [48]. The smoke spreads through the central openings to the other floors relatively quickly.

Snapshot of the smoke spread for a specific fire scenario on the ground floor
After evaluation of the support points, the smoke spread RSM is generated (step 7). In Fig. 11, an example is presented of the response surface model for the smoke spread. The results are depicted for CO-concentrations in front of exit 1 (point A1) at 450 s after ignition (t0). For the visualization, the fire growth area and maximum fire area, which are considered the most sensitive variables [29], are shown while the HRRPUA is kept constant at 450 kW/m2 (average value). The point is chosen at 450 s because around this time the evacuation is at its full development.

Representation of the smoke spread RSM for CO-concentrations at 450 s in location A1 at 2.0 m height (Color figure online)
The concentration of toxic species, temperature and thermal radiation intensity are calculated at multiple locations. In Fig. 12, the resulting temperatures at 450 s are depicted on the ground floor for the sample combination S1: α = 0.101 kW/s2, HRRPUA = 575 kW/m2 and Amax = 88 m2. The results show a clear separation of the floor into two SHC zones due to the fixed smoke curtain in the middle.

Estimated temperatures on the ground floor for the sample combination S1 at 450 s
Next, the DoE are determined to obtain a uniform representation of the analysed domain (step 8). For each scenario 100 samples are generated and simulated in step 9 (blue points Fig. 11). The results are used as input for the evacuation analysis (loop to step 5). The support points for the evacuation RSM are generated (step 5). The sample is analysed by means of the evacuation model Pathfinder (step 6). In Fig. 13, an evacuation simulation is depicted for a scenario with normal affiliation and high occupant density at 450 s after ignition. The scenario takes a fire on the ground floor into account.

Location of the occupants for a fire on the ground floor at 450 s after ignition
After evaluation of the support points, the evacuation RSM is generated (step 7). In Fig. 14, the application of the response surface model for the evacuation sub-model is visualized. The results are depicted for CO-concentrations in front of exit 1 (point A1) at 450 s. The variables affiliation towards the main exit and occupant density are analysed while the fire parameters are kept constant for each fire scenario.

Representation of the evacuation RSM of CO-concentrations at 450 s in point A1
Similarly to the smoke spread sub-model, a convergence analysis is performed to determine the accuracy of the RSM. After the convergence analysis, the DoE for the evacuation results are generated and evaluated (step 8 and 9) and the procedure loops back to step 8 to conduct the consequence analysis. The five remaining variables provided in Table 1 are implemented and the DoE is performed to obtain a uniform representation of the analysed domain (step 8). For each event tree scenario, a total of 1003 (smoke spread, evacuation and consequence sub-model) samples are generated and analysed in step 9 by means of the analytical sub-model [27, 62].
6 Results
In Fig. 15, the results for two event tree scenarios for option 1 are presented in terms of FID-values. The left figure depicts the scenario when both sprinkler and SHC fail and the right figure when only the sprinkler fails, both for a random set of the sampling data. The results show that within the analysed domain most of the occupants are able to escape in non-critical smoke conditions, which means that sample points are chosen on the safe side of the limit state. On the other hand, some of the occupants obtain an FID higher than one which means that multiple sample points are at the unsafe side of the limit state. The two event tree scenarios depict different results because the limit state shifts, from left to right, due to the implementation of different safety systems, causing safer conditions. In the left figure more people are affected by smoke conditions. In the right figure, a SHC-system is implemented increasing tenability conditions. A curve fitting analysis is performed, based on the Sum of Square Error (SSE), for each event tree scenario to determine the probability density function and the failure probability (orange line Fig. 15). For the left figure, a gamma distribution was obtained, for the right figure, a lognormal distribution was derived. The results are calculated for each event tree scenario and for the three fire safety designs.

Histogram of the FID-data and fitted PDF for two event tree scenarios of option 1: (left) failure of sprinkler and SHC and (right) when only sprinkler fail (Color figure online)
In step 10, the failure probability is calculated for every scenario and in step 11 the final failure probability and risk are calculated. The results obtained for the failure probability and the individual risk are presented in Table 5. The results show that the three options are within the pre-defined acceptable safety limits. The second option obtains the highest safety margin. The third option results in the lowest safety margin.
In Fig. 16, the societal risk is presented in terms of an FN-curve. The three fire safety designs and acceptable limit are depicted. The three options are below the acceptable limit which means that these designs can be selected. Option 2 with sprinklers and compartmentation obtains the highest safety level which means that, for this case study, compartmentation provides a higher safety margin than a SHC-system. Two reasons can be outlined. The first reason for the higher impact of compartmentation is because less people are exposed to the smoke due to the physical separation of smoke from other sub-compartments and from the staircases in the model. Smoke spread in staircases due to door barrier failure is not included in the model. It is expected that the risk level will increase when failure of the smoke barriers, that protect the staircase, is taken into account. Most likely, the effect of this scenario will not be equivalent for the three fire safety designs. The SHC will have an important role in avoidance of smoke spread in the staircases due to the creation of under pressure in the incident compartment. The second reason for the lower impact is due to the low reliability of the SHC with respect to other safety systems. Increasing the reliability will increase the safety margin.

Representation of the FN-curves of the three fire safety designs and the chosen acceptable limit
The final selection of the fire safety design can be further determined using a cost–benefit analysis (life cycle cost) or in terms of functionality (open plan) and flexibility (changing walls). Other systems can be implemented to increase the safety system or omitted to increase functionality (alarm delay).
An additional analysis is performed to analyse the equivalency of option 1 and 2. Both designs comply with the Belgium legislative framework. However, the designs show different safety levels. In order to obtain an equal safety level for both designs, option 1 can be reverse engineered to determine which reliability the SHC-system needs to provide to achieve equivalency. In order to determine this safety level, the reliability of the SHC-system is increased until the risk is equal for both fire safety designs. The visualization of the equal safety level is shown in Fig. 17. The green areas represent lower risk for option 1 and the red areas represent lower risk for option 2. A reliability of 0.88 is calculated which is a significant increase with respect to the average reliability of 0.5. The higher reliability level can be achieved when important failure characteristics of the system are reduced (Table 2). Another possibility is to improve and optimize the SHC design to reduce the presence of toxic and hot gases in the incident compartment. In this way, the consequences are reduced instead of the frequencies. The elaborated case study depicts the strength of the proposed method in terms of quantifying the acceptable safety level and comparing multiple design options in a relative short time. This is considered an important step in the next generation of risk analysis methods and design tools.

Representation of the FN-curves of the three fire safety designs with increased reliability of the SHC-system (Color figure online)
7 Discussion and Limitations
The analysis in this paper was restricted to the proof of concept of applying the proposed method to a challenging case study. In order to perform the case study, several simplifications with respect to the input parameters and modelling were done. More specifically, data for input parameters was combined from various sources and can therefore only be considered for illustration purpose. Scenarios considering failure states of safety systems (e.g. SHC) were simplified to increase the efficiency. Multiple modelling assumptions were done regarding fire location, occupant behaviour, etc. Given these boundary conditions, the elaboration of the case study provided results for the individual risk between 10−4 and 10−6. Although, these results are within the desired range of results (below the FN-curve), the focus should not be put on the absolute findings. The strength of the method is in the relative comparison between the fire safety designs. In this way, the assumptions made in the design have a lower impact. When the accuracy of parameter inputs increases, the updated input parameters can be implemented directly in the model and more emphasis can be put on fire safety design by means of the absolute risk criteria.
Further, additional limitations have been observed during the development and application of the case study. First, no interdependencies between input parameters are implemented, as literature in relation to these interdependencies/correlations between parameters is rather scarce. However, the method gives an option to implement correlations between variables. In this way, when new evidence in relation to these interdependencies becomes available, these interdependencies can be implemented directly in the method. Second, the method still requires a significant number of support points. Additional investigation needs to be done to reduce the number of solver evaluations. A possible method could be to couple field models with zone and network models to reduce the computational time, in analogy to research performed in tunnel fire safety [27]. Third, the present paper contains an application only for a multiple-purpose commercial building. Other challenging case studies have not been analysed yet. Fourth, several submodels are still under development. For example, the staircase submodel that represents the probabilistic failure of fire doors and smoke spread in staircases is still under development. Fifth, only partial validation was done and further validation and testing of more case studies is necessary to determine the overall accuracy of the model [29]. Finally, although the analysis of parameter uncertainty is implemented in the method, also the effect of model uncertainties should be considered. However, the latter poses a large research challenge as no such information is readily available.
In future research the discussed limitations will be analysed and solutions will be investigated to overcome them. The focus will be put on further validation of the RSM for individual submodels and for the overall method against different types of challenging case studies. The model will be optimized to reduce the computational effort by means of increased efficiency of probabilistic techniques and simplified sub-models. Model uncertainty will be investigated and quantified to map the overall uncertainty.
8 Conclusions and Future Work
The present paper proposed a probabilistic QRA-model to quantify the life safety risk of occupants in the context of the creation of a fire safety design in buildings. The proposed method illustrates that important steps have been taken to objectify the safety level of fire safety designs by linking the degree of conservative values of the input parameters to the output safety factor obtained by the FSE. Furthermore, the residual risk takes into account the effectiveness of the safety systems. The application of the elaborated method to a case study of a shopping mall illustrates the possibility of analyzing building designs with multiple occupancy types, safety systems and challenging building layout within a reasonable amount of time. Execution in the order of 2 to 4 weeks is expected due to the significant reduction of the computational demand by means of the optimized probabilistic techniques. This makes the method applicable for the private industry. Three different fire safety designs were compared in which 14 continuous and 5 discrete variables were analysed. Results in the form of failure probability, individual risk and societal risk were calculated to offer the possibility to determine the safest and cost effective design within the chosen safety margin. The reliability of safety systems can be either put as an input parameter or the required reliability can be determined to obtain an equivalent safety level. Based on its methodology it is now possible to quantify the uncertainty of the input parameters with respect to the results. Additionally, the performance and safety level of current codes and standards using state-of-the-art numerical methods can be quantified and compared.
The resulting failure probabilities can subsequently be used as a quantitative metric for alternative building designs. Based on the elaboration given in this paper, alternative designs can be compared on the basis of their failure probabilities to each other and against a pre-defined safety level. Furthermore, the method allows for direct comparison of scenarios and the most relevant and sensitive scenarios can be identified. This is considered a significant improvement in risk analysis design tools.
References
Maluk C, Woodrow M, Torero JL (2017) The potential of integrating fire safety in modern building design. Fire Saf J 88:104–112. https://doi.org/10.1016/j.firesaf.2016.12.006
Meacham BJ (2004) Decision-making for fire risk problems: a review of challenges and tools. J Fire Prot Eng 14:149–168. https://doi.org/10.1177/1042391504040262
Fischer K, De Sanctis G, Kohler J et al (2015) Combining engineering and data-driven approaches: calibration of a generic fire risk model with data. Fire Saf J 74:32–42. https://doi.org/10.1016/j.firesaf.2015.04.008
Meacham B, Bowen R, Traw J, Moore A (2005) Performance-based building regulation: current situation and future needs. Build Res Inf 33:91–106
Meacham BJ (1998) The evolution of performance based codes and fire safety design methods, NIST-GCR-98-761. United States
Spinardi G (2016) Fire safety regulation: Prescription, performance, and professionalism. Fire Saf J 80:83–88. https://doi.org/10.1016/j.firesaf.2015.11.012
Wolski A, Dembsey N, Meacham BJ (2000) Accommodating perceptions of risk in performance-based building fire safety code development. Fire Saf J 34:297–309
Meacham BJ (2000) International experience in the development and use of performance-based fire safety design methods: evolution, current situation and thoughts for the future. In: The 6th international symposium on fire safety science, pp 59–76
Hadjisophocleous G, Fu Z (2004) Literature review of fire risk assessment methodologies. Int J Eng Perform Based Fire Codes 6:28–45
Alvarez A, Meacham BJ, Dembsey N, Thomas J (2013) Twenty years of performance-based fire protection design: challenges faced and a look ahead. J Fire Prot Eng 23:249–276. https://doi.org/10.1177/1042391513484911
Alvarez A (2012) An integrated framework for the next generation of risk-informed performance-based design approach used in fire safety engineering. WPI, Worcester
SFPE (2007) SFPE engineering guide to performance-based fire protection. SFPE,Worchester
Fleischmann CM (2011) Is prescription the future of performance-based design? In: The 10th international symposium on fire safety science, Christchurch, New Zealand, pp 77–94
Kong D, Lu S, Frantzich H, Lo SM (2013) A method for linking safety factor to the target probability of failure in fire safety engineering. J Civ Eng Manag 19:S212–S221. https://doi.org/10.3846/13923730.2013.802718
PD7974-7 (2003) Application of fire safety engineering principles to the design of buildings—Part 7: probabilistic risk assessment. London, UK
National Fire Protection Association (2016) NFPA 551: guide for the evaluation of fire risk assessments. National Fire Protection Association, Quincy, USA
Society of Fire Protection Engineers (2006) SFPE Engineering Guide: Fire Risk Assessment.
ISO 16732-1:2012 preview fire safety engineering—fire risk assessment—Part 1: general.
Yung D (2008) Principles of fire risk assessment in buildings. Wiley, London
Chu G, Sun J (2008) Decision analysis on fire safety design based on evaluating building fire risk to life. Saf Sci 46:1125–1136. https://doi.org/10.1016/j.ssci.2007.06.011
Hall JR, Sekizawa A (1991) Fire risk analysis: general conceptual framework for describing models. Fire Technol 27:33–53. https://doi.org/10.1007/bf01039526
Alvarez A, Meacham BJ, Dembsey NA, Thomas JR (2013) A framework for risk-informed performance-based fire protection design for the built environment. Fire Technol 50:161–181. https://doi.org/10.1007/s10694-013-0366-1
Kong D, Lu S, Kang Q et al (2014) Fuzzy risk assessment for life safety under building fires. Fire Technol 50:977–991. https://doi.org/10.1007/s10694-011-0223
Pires TT, Almeida AT De, Lemos DC et al (2005) A decision-aided fire risk analysis. Fire Technol 41:25–35
Hall JR, Sekizawa A (2010) Revisiting our 1991 paper on fire risk assessment. Fire Technol 46:789–801. https://doi.org/10.1007/s10694-010-0146-0
De Sanctis G (2015) Generic risk assessment for fire safety—performance evaluation and optimisation of design provisions. ETH Zürich, Switzerland. https://doi.org/10.3929/ethz-a-010562998
Van Weyenberge B, Deckers X, Caspeele R, Merci B (2015) Development of a risk assessment method for life safety in case of fire in rail tunnels. Fire Technol 52:1465–1479. https://doi.org/10.1007/s10694-015-0469-y
Albrecht C (2014) Quantifying life safety: part I: scenario-based quantification. Fire Saf J 64:87–94. https://doi.org/10.1016/j.firesaf.2014.01.003
Van Weyenberge B, Criel P, Deckers X et al (2017) Response surface modelling in quantitative risk analysis for life safety in case of fire. Fire Saf J. https://doi.org/10.1016/j.firesaf.2017.03.020
SFPE (2016) SFPE handbook of fire protection engineering, Fifth, USA. https://doi.org/10.1007/978-1-4939-2565-0
Barry T (2002) Risk-informed, performance-based industrial fire protection. TVP, USA
BSI (1994) Draft British Standard Code of practice for the application of fire safety engineering principles to fire safety in buildings. London, UK
Meacham B (2016) Ultimate health & safety (UHS) quantification: individual and societal risk quantification for use in National Construction Code (NCC). BCA, pp 45–100
Meacham BJ, Van Straalen IJ (2017) A socio-technical system framework for risk- informed performance-based building regulation. Build Res Inf 46:444–462. https://doi.org/10.1080/09613218.2017.1299525
Hadjisophocleous GV, Benichou N (1999) Performance criteria used in fire safety design. Autom Constr 8:489–501
Oliphant TE (2007) Python for scientific computing python overview. Comput Sci Eng 9:10–20. https://doi.org/10.1109/mcse.2007.58
MathWorks T (2017) MATLAB and statistics toolbox release 2017a Version 9.2
Borg A, Njå O, Torero JL (2015) A framework for selecting design fires in performance based fire safety engineering. Fire Technol 51:995–1017. https://doi.org/10.1007/s10694-014-0454-x
Kong D, Lu S, Ping P (2017) A risk-based method of deriving design fires fore evacuation safety in buildings. Fire Technol 53:771–791. https://doi.org/10.1007/s10694-016-0600-8
Van Weyenberge B (2013) Development of a risk assessment methodology for fire in rail tunnels. Ghent University, Gent
Albrecht C (2012) A risk-informed and performance-based life safety concept in case of fire. TU, Braunschweig
Salgueiro OP, Jönsson J, Vigne G (2016) Sensitivity analysis for modelling parameters used for advanced evacuation simulations—how important are the modelling parameters when conducting evacuation modelling. In: SFPE performance-based design conference
Sandberg M (2004) Statistical determination of ignition frequency. Lund University, Lund
Nilsson M, Johansson N, Van Hees P (2014) A new method for quantifying fire growth rates using statistical and empirical data—applied to determine the effect of arson. Fire Saf Sci 11:517–530. https://doi.org/10.3801/IAFSS.FSS.11-517
Deguchi Y, Notake H, Yamaguchi J, Tanaka T (2011) Statistical estimations of the distribution of fire growth factor—study on risk-based evacuation safety design method. Fire Saf Sci 10:1087–1100. https://doi.org/10.3801/IAFSS.FSS.10-1087
Holborn PG, Nolan PF, Golt J (2004) An analysis of fire sizes, fire growth rates and times between events using data from fire investigations. Fire Saf J 39:481–524. https://doi.org/10.1016/j.firesaf.2004.05.002
Ministry of Business Innovation and Employment (2013) C/VM2 verification method: framework for fire safety design For New Zealand Building Code Clauses C1-C6 Protection from Fire
Marsh (2012) Fire system effectiveness in major buildings. Marsh, Auckland
Zhao L (1997) Reliability of stair pressurisation and zoned smoke control systems. ABCB, Victoria, Australia
Tillander K, Keski-Rahkonen O (2003) The ignition frequency of structural fires in Finland 1996–99. Fire Saf Sci 7:1051–1062. https://doi.org/10.3801/iafss.fss.7-1051
Leira BJ (2013) Optimal stochastic control schemes within a structural reliability framework. SpringerBriefs in Statistics. https://doi.org/10.1007/978-3-319-01405-0
Suard S, Hostikka S, Baccou J (2013) Sensitivity analysis of fire models using a fractional factorial design. Fire Saf J 62:115–124. https://doi.org/10.1016/j.firesaf.2013.01.031
Morris M (1991) Factorial sampling plans for preliminary computational experiments. Technometrics 33:161–174. https://doi.org/10.2307/1269043
McGrattan K, McDermott R, Floyd J, et al. (2012) Computational fluid dynamics modelling of fire. Int J Comput Fluid Dyn 26:349–361. https://doi.org/10.1080/10618562.2012.659663
Albrecht C (2014) Quantifying life safety Part II: quantification of fire protection systems. Fire Saf J 64:81–86. https://doi.org/10.1016/j.firesaf.2014.01.002
Wiener N (1938) The homogeneous chaos. J Appl Math 60:897–936. http://dx.doi.org/10.2307/2371268
Hoerl AE, Kennard RW (1970) Ridge regression: application to nonorthogonal problems. Technometrics 12:69–82. https://doi.org/10.1080/00401706.1970.10488634
Helton JC, Davis FJ (2002) Latin hypercube sampling and the propagation of uncertainty in analyses of complex systems. Reliab Eng Syst Saf 81:23–69. https://doi.org/10.1016/s0951-8320(03)00058-9
Sobol IM (1967) On the distribution of points in a cube and the approximate evaluation of integrals. USSR Comput Math & Math Phys 7:784–802. https://doi.org/10.1016/0041-5553(67)90144-9
Thornton C, O’Konski R, Hardeman B et al (2011) Pathfinder: an agent-based egress simulator. Evacuation Dyn. https://doi.org/10.1007/978-1-4419-9725-8
Ulrich A, Wagoum K, Chraibi M et al (2015) JuPedSim: an open framework for simulating and analyzing the dynamics of pedestrians. In: Conference of Transportation Research Group of India
Purser DA, Maynard RL, Wakefield JC (2016) Toxicology, survival and health hazards of combustion products. RSC, Cambridge
ISO TC 98 (2015) Iso 2394 General principles on reliability for structures, reliability of structures.
Bottelberghs PH (2000) Risk analysis and safety policy developments in the Netherlands. J Hazard Mater 71:59–84. https://doi.org/10.1016/s0304-3894(99)00072-2
CEN (2015) NBN EN 12845: 2015 Fixed firefighting systems—automatic sprinkler systems—design, installation and maintenance, Brussels, Belgium
Acknowledgements
The authors would like to thank the Flanders Innovation and Entrepreneurship (VLAIO) for supporting project number 130857 for this research.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Van Weyenberge, B., Deckers, X., Caspeele, R. et al. Development of an Integrated Risk Assessment Method to Quantify the Life Safety Risk in Buildings in Case of Fire. Fire Technol 55, 1211–1242 (2019). https://doi.org/10.1007/s10694-018-0763-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10694-018-0763-6