
Abstract
Groundwater ecosystems have unparalleled environmental value. Accurate modeling of groundwater level (GWL) fluctuations is a vital requirement for the protection of the groundwater ecosystems. The GWL modeling is a challenge due to complexities of the underground geological structure. Among the various modeling methods, artificial intelligence (AI)-based approaches serve as desirable alternatives due to their distinctive and potent properties. One of the most practical AI-based approaches is an artificial neural network (ANN) model. The purpose of the current study was to apply time delay neural networks (TDNN) with different network structures and input delays to model the GWL fluctuations. The variables used in the construction and validation of the models were average weekly GWL from January 2002 to January 2013 in two monitoring sites in Semnan/Sorkheh plain, Iran. The study area is an arid region, where overutilization of groundwater threatens the water security in this area. The computational results of the current research demonstrated that the TDNN model is a practical tool in modeling time-series GWL compared to the other state-of-the-art AI-based approaches. Future studies are recommended to explore application of proposed model for more sustainable and effective Groundwater Resources Management (GWRM).
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Groundwater is considered a vital source of drinking water in the world (Diodato & Ceccarelli, 2006). Also, the groundwater ecosystem has been a valuable inherent because of the delivery of several massive services such as water treatment, biodegradation and elimination of different types of contaminants, nutrient storage and recycling, and droughts and flood mitigation (Griebler & Avramov, 2014; Torres-Perez et al. 2010). Any change in physical (such as groundwater level (GWL) fluctuations) and chemical nature of aquifers can significantly affect the groundwater ecosystems (Khoshand et al. 2018). The sustainable protection of groundwater ecosystem through an effective Groundwater Resources Management (GWRM) is essential to reduce the associated risks of GWL extremes in addition to ensuring access to drinking water (Kamalan et al. 2009). Long-term evaluation of GWL in aquifers is important in the GWRM, which enables quantifying the groundwater availability and also provides more comprehensive knowledge to identify the causes of GWL fluctuations (Chang et al., 2015).
The GWL fluctuations can have natural causes (such as aquifer deformation and climate change) or anthropogenic reasons (such as excessive groundwater pumping and extractions) (Mohanty et al., 2015). Precise and consistent assessments of GWL play a central role, as mentioned evaluations can deliver pivotal data on the quantitative and dynamics groundwater conditions of any aquifer (Tutmez, 2009). In addition to reducing impacts such as aquifer compaction and land surface subsidence, accurate GWL forecasts also allow for the development of appropriate GWRM (Banerjee et al., 2009).
However, physical-, statistical- and conceptual-based approaches have been widely used to predict the GWL fluctuations, faced several practical limitations such as modeling time and insufficiency of input parameter and data (Daliakopoulos et al., 2005). So, an accurate model capable of tackling the precise behavior besides time-variant trend of GWL is required for the sustainable GWRM. Under these circumstances, artificial intelligence (AI)-based models serve as desirable alternatives because of the simplicity in addition to their consistent results (Sahoo & Jha, 2013; Wang, 2019). It should be noted that the main advantages of AI models are the ability to model complicated phenomena without accurately representing the prevailing physical laws and explicitly describing physical properties (Nayak et al., 2006). Several AI-based approaches have been developed to predict and simulate the value according to the evolutionary algorithms such as ant colony optimization (ACO), genetic algorithm (GA), and artificial neural network (ANN), as optimization methods (Salehnia et al., 2019).
One of the most practical AI-based models is the ANN model (Sahoo & Jha, 2013). The ANNs are computing models stimulated by biological neural networks. Typically, each ANN is a set of processing units called artificial neurons, as edge-to-edge interconnection. Each artificial neuron may have several inputs and only a single output. All inputs are multiplied by the weight of the edge. The weighted data are processed through a summation function and then fed into transfer function (or activation function) that scale or compare the output of summation function with a specific threshold to get the output. Generally, any ANN is composed of separate layers, which are input, (in most cases) hidden, and output layers. It can be said that the ANN should be trained, meaning the adjustment of edge weights and thresholds for optimizing the ANN model performance. The training process can be carried out through different training algorithms including LM (Levenberg-Marquardt), BP (backpropagation), and BR (Bayesian regularization) algorithms. Moreover, there are a variety of ANNs, such as FNNs (feed-forward neural networks), RNN (recurrent neural networks), MLP (multi-layer perceptron), RBF (radial basis function), and SOM (self-organizing map). The objective of this study is developing a novel time delay neural network (TDNN) model for the prediction of GWL in Semnan/Sorkheh plain, Iran, in two sites, by considering time series data. Moreover, the performance of developing model was evaluated through different performance criteria.
2 Literature reviews
Several new types of research proposed a promising ANN model in the prediction of GWL fluctuations. Chang et al. (2015) proposed two ANN-based models for predicting the GWL in the Qinghai-Tibet plateau, China. The inputs of the first ANN model included GWL, temperature, and precipitation, while the inputs of the second one included only precipitation and temperature. Both models were trained through the LM algorithm. Attained results implied that the first model is more accurate to predict the GWL in the studied area. Gholami et al. (2015) proposed a MLP-based model (which is trained by LM algorithm) to predict annual GWL fluctuations (in two wells) in southern coasts of Caspian Sea, Iran. The inputs of this model were precipitation and tree-ring diameter. The results revealed that the annual fluctuations of GWL are predictable with a combination of dendrochronology and ANN models. Mohanty et al. (2015) investigated the accuracy of several dissimilar training algorithms, including GDX, BR, and LM, in a FNN model to predict weekly fluctuations of GWL in 18 tube wells in Kathajodi River, India; the inputs were rainfall, water level, and evaporation, river stage, and pumping rates. Their results showed that the FNN model with GDX training algorithms, encompassing 40 hidden layers, was the most suitable model with RMSE of 0.2397. The MLP model was employed for estimation the GWL in Singapore (Sun et al., 2016); the inputs included surrounding reservoir levels and rainfall, and the LM algorithms were applied for training. The results showed the ability of developed model to provide a precise prediction with one-day delay, while the accuracy of the model decreases significantly by increasing the delay to three and seven days. Ghose et al. (2018) examined the impacts of temperature, rainfall, evapotranspiration, runoff, and humidity on the monthly flocculation of GWL in Odisha, India, using the RNN model. The findings exhibited that the runoff and evapotranspiration could significantly influence the GWL, and thus the inclusion of these inputs in any ANN model to predict the GWL enhances the accuracy of model. Lee et al. (2019) examined the applicably of ANN model to predict the hourly fluctuations of GWL in different 13 wells in Yangpyeong, South Korea. The effects of Groundwater Heat Pump (GWHP) and Water Curtain Cultivation (WCC) on the GWL were examined in addition to natural inputs. It was found that the precipitation has a limited impact on the GWL and thus can be ignored from input variables. Zhang et al. (2019) have been studied the application of different ANN models for prediction of the GWL in Zhoushan Island, China. It was found that wavelet analysis is able for enhancement of the performance of the studied models. Furthermore, data pre-processing can significantly influence the performance of model through capturing/enhancing valuable information. The obtained results have been also demonstrated that wavelet-NARX (WA-NARX) has the best performance for prediction of GWL flocculation among studied models, especially for short-term periods. In another study carried out by Roshni et al. (2020), performance of emotional artificial neural network combined to genetic algorithm (EANN-GA) for monthly simulation of GWL in Konan groundwater basin (Japan) was investigated. Results have shown that EANN-GA models are more precise in comparison with the rest of studied AI-based models (including EANN and FFNN). Also, the performance of studied EANN models have had the better performance than that of FFNN and GRNN models. A FNN (with different architectures) is examined for prediction of GWL flocculation in West Delhi, India (Malik & Bhagwat, 2021). The recharge rate, population growth, and paved area were considered as input variables. The results demonstrated that the model with architecture of 3–15-1 (with activation function of log-sigmoid) can predict GWL flocculation more accurate in comparison with the rest of studied architectures. Derbela and Nouiri (2020) have been also studied prediction GWL (in Nebhana, Tunisia) by ANNs. The evapotranspiration rainfall and water table level during the period 2000–2018 were taken as input parameters. The obtained results revealed that the studied ANN model is a capable tool such that RE and RMSE values were less than 19.00 and 2.00%, respectively, and also all R2 values were close to 1.
It should be noted that the application of ANN is not limited to the area of the current research. Several previous studies applied successfully this technique in various fields of research such as chemical engineering (Bhowmik et al., 2019; Debnath et al., 2016), water management (Sang et al., 2015), and biology (Debnath et al., 2016).
Previous researches mainly have mainly focused on the impact of different time-independent inputs on the prediction of GWL flocculation using different ANN models, but mostly ignored the impacts of time-dependent inputs. Moreover, the majority of GWL forecasting researches have been investigated the long-time GWL flocculation forecasting (mainly due to the computational burden) and thereby short-time GWL flocculation forecasting is relatively new.
3 Material and methods
In the following sections a concise description of used material and methods in the current research is provided.
3.1 Study area
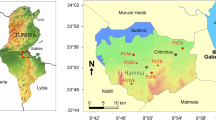
The Semnan/Sorkheh plain is located in the north and northwest of Semnan province in the central north of Iran. The study area is positioned between longitudes 53° 3′ E and 53° 35′ E and latitudes 35° 22′ N and 35° 39′ N. The total area of Semnan/Sorkheh plain is approximately 703 km2 (which is under the authority of Semnan province) and is limited to Peyghambroon and Chaghandaroon mountains from north, Sebaradaran mountain from east, Siahtape and Lasjerd heights from west, and Hajiabad heights and Biabanak plain from South (Fig. 1).

Study area and details of monitoring sites
The main climate of Semnan/Sorkheh plain is a hot desert climate that is very hot and rainless in summers and relatively warm in winters. The precipitation (the average annual value) is 139.5 mm (Iranian Meteorological Organization, 2016). The temperature may reach to 44 °C in summer and may drop less than − 11 °C in winter (Iranian Meteorological Organization, 2016). The altitude (average value) is 1152 m from sea in the study area. The plain is surrounded by salt crust (which is called Namak Lake), sand fields, and alluvial plains in the southeast and east, and fluvial plains and highlands in the northwest and west. It should be noted that no distinct permanent river in the study area was identified, and water discharge from seasonal streams is very limited. Therefore, it can be concluded that a major resource of freshwater supports industrial, domestic, and agricultural activities in the study area. Recently, the GWL has a sharp drop in the plain, which can be due to a decrease in stream flows and heavy pumping of groundwater.
3.2 Data collection and monitoring
The GWL data were collected by weekly monitoring GWL in two monitoring sites (Fig. 1) from January 2002 to January 2013. The measurements were taken manually. The characteristics of mentioned sites are presented in Fig. 1.
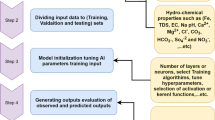
The first 522-week data (from January 2002 to January 2012) were used to develop the model, which randomly divided into three subsets of 366 weeks (70%) for training, 78 weeks (15%) for validation, and 78 weeks (15%) for testing the developed model. Training, validation, and testing processes were implemented to enhance the performance of model. Practically, the training data include the number of input values and the corresponding output values (generally defined as the target). The model is firstly fitted on a training dataset in order to determine the initial parameters of the model (such as bias and weights), and then the results are compared with the target, for each set of training dataset. Different values of model parameters are tried to adjust values of parameters that the computed output values most closely match to the target values. After completing the training stage, the fitted model is applied for the second dataset, which is known as the validation dataset. This set of dataset delivers an unbiased assessment of a model fit on the training dataset while adjusting the hyperparameters of model (such as number of hidden layer). The validation datasets are also used for regularizing by early stop, which will stop the training process by increasing the error in the validation dataset. Finally, the model parameters are applied just once to the testing dataset. It should be noted that the testing dataset is not used at all during training and validation processes. The testing process can estimate that the developed model will be presented exactly when using unseen data.
3.3 Artificial neural networks
The ANNs can be categorized into dynamic and static neural network models. The main difference between mentioned categories is that the order of inputs does not affect the output in the static ANNs, but significantly influence the output in the dynamic ANNs (Beale et al., 1992). One of the dynamic ANNs used in the current study is time delay neural network (TDNN). The TDNN can be considered as an extended MLP that combines the robustness and discriminative power of neural network with a time-delayed architecture. The TDNN can deal with the problems of time variant that are scaled and translated over time. In comparison with the conventional ANN methods, the neurons can store the history of their input in the TDNN and accordingly the network as a whole is able to adapt not only to a set of patterns, but also to a set of pattern sequences (Kaiser, 1994). On the other word, the TDNN links and compares current input to history of inputs (Waibel et al., 1989). In addition, the TDNN architecture reduces invariance under shifts in time as well as the number of independent connection parameters (Sugiyama et al., 1991).
The ANN-based models can have several hyperparameters and parameters, while bias can be considered as one of the fundamental one. The bias acts as a specific type of neuron, called as bias neuron. Each ANN consists of neurons that are elements which take input and apply an activation function to it. The bias neuron is a distinct one added to each layer that is able to store a certain value.
In the TDNN, the input to each node consists of the outputs of the previous nodes in the current time step \((t)\) as well as the previous time steps \((t, t-1, \ldots t-d+1)\), ( \(d\) is the desired time delay). The general expression for TDNN is given by:
In the above expression, \({x}_{t+1}\) pertains to the observation at time step \(t+1\), f is defined a transfer function, \({x}_{i }(i = t, t-1 \ldots t-d+1)\) is the input time series, et+1 is error that should be minimized. The typical TDNN structure and related artificial neuron are illustrated in Fig. 2.

a Typical TDNN with one hidden layer; b typical artificial neuron
In the current research, the LM algorithm was applied for training developed TDNN models. Previous studies demonstrated that the mentioned algorithm is the most appropriate one for the GWL prediction (Banerjee et al., 2009; Kouziokas et al., 2018; Sahoo & Jha, 2013; Sreekanth et al., 2011; Sun et al., 2016). The LM algorithm can be considered as modified classic Newton algorithm, which has been applied to minimize the problems in optimum solutions (Rajaee et al., 2019). Furthermore, tangent-sigmoid and liner activation functions were applied in the hidden and output layers, respectively. The sigmoid function is a continuous and differentiable function which is increasing in the defined domain monotonically (Ravansalar & Rajaee, 2015). The properties of developed TDNN model are summarized in Table 1. It should be noted that the use of raw data can directly cause a reduction in the accuracy of TDNN model (Wagh et al., 2018), and therefore, all input data were pre-processed in this study.
The data pre-processing results in higher accuracy and lower computational performance. The data pre-processing is generally conducted to modify the size of input dataset, remove any noisy dataset, and provide smoother relationships (Mohd Nawi et al., 2013). Several techniques have been developed in the literature for the data pre-processing, such as z-score normalization, min–max normalization, and scaling normalization (Mohd Nawi et al., 2013). According to the literature review (Bhowmik et al., 2018), the min–max normalization technique was applied in the current study and all the datasets were normalized in the range of zero to one through:
where X is variable, and Xmax and Xmin are the maximum and the minimum values of variables, respectively. It should be mentioned that the framework of current research is illustrated in Fig. 3.

The research framework
3.4 Model performance criteria
Coefficient of determination (R2), root-mean-square error (RMSE), mean absolute error (MAE), absolute average deviation (AAD) were employed for assessment of the performance of proposed models (Bhowmik et al., 2018). The RMSE determines the discrepancy between the predicted and real values, and thereby, the most accurate model has the lowest RMSE. The R2 is a statistical measure to express the proportion of the initial uncertainty of the model. The R2 = 1 (which is unlikely to occur) means exact fit between predicted and observed values. The mentioned statistical criteria can be calculated as:
where N is the number of observations, \({x_{i} }\) and \({x_{i} }\) are the observed and predicted data values, respectively.
4 Results and discussion
In the current study, several TDNN architectures with different numbers of time delay (1, 3, and 8 weeks) and hidden layers (2, 4, and 8 hidden layers) were used to simulate the GWL. The initial numbers of tapped delay and hidden layers were selected according to the recommendations in the literature.
The TDNN architecture with the best performance criteria (the lowest RMSE, AAD and MAE, as well as the highest R2 value) within three training, validation, and testing stages was considered to have ideal number of hidden layers. The derived performance criteria in all stages (including the training, validation, and testing) are presented in Tables 2, 3, and 4. As seen in Tables 2, 3, and 4, the RMSE AAD, MAE values were decreased in both monitoring sites (while the R2 value was increased) in each of specific delay times when number of hidden layers increases from 2 to 8, such that TDNN7, 8, and 9 have higher values of R2(training), R2(validation), and R2(testing) in comparison with TDNN1, 2, and 3, respectively. Moreover, in each of specified number of hidden layers, where the delay times increase from 1 to 8 weeks, the R2 value increases in the both monitoring sites, while the values of RMSE AAD, MAE decrease. Therefore, it can be concluded that the TDNN9 has the best performance among all developed models with R2(training), R2(validation), and R2(testing) of 0.991, 0.998, and 0.981 (in the Site 1) and 0.965, 0.960, and 0.952 (in the Site 2), respectively. However, some models yielded smaller RMSEs, AADs, and MAEs (and higher R2 values) for training but relatively high errors for validation and testing, and so that were not selected as the best model.
Figures 4 and 5 compare the predicted (according to the optimum number of hidden layers which is 8) and the observed GWL fluctuations in the studied wells. The variable values of RMSE (0.17–0.34 in the Site 1 and 0.19–0.43 in the Site 2) and R2 (0.78–0.98 in the Site 1 and 0.55–0.95 in the Site 2) can be seen during testing models. In comparison with the previous relevant researches (Daliakopoulos et al., 2005; Ebrahimi & Rajaee, 2017; Mohanty et al., 2010; Nayak et al., 2006; Taormina et al., 2012; Yoon et al., 2011), which employed ANN models for the GWL estimation, the obtained results are satisfactory that implies the application of TDNN models to predict the GWL is a suitable approach, even if there are limited data on the physical characteristics and condition of the aquifer (Mohanty et al., 2015). As illustrated in Figs. 4 and 5, the estimated values in the Site 2 have more flocculation/error when comparing with the Site 1. Considering the location and features of the studied area, it can be found that the anthropogenic reasons (especially excessive groundwater pumping and extractions) are more highlighted in the Site 2, thereby causing higher prediction error. Mohanty et al. (2015) also reported that efficient prediction of GWL in high groundwater-consuming sites is challenging through AI-based models because of the presence of several uncertainty factors.

Comparison of simulated versus observed GWL at site 1 (TDNN model with 8 hidden layers)

Comparison of simulated versus observed GWL at site 2 (TDNN model with 8 hidden layers)
The performance of the developed models was examined in the three time delays of 1, 3, and 8 weeks. It can be seen that the values of RMSE increase and R2 decrease by prolonging the time delay such that the time delay of 8 weeks provides the best match between predicted and observed GWL fluctuations at all the sites, probably due to the effects of some anthropogenic and natural causes, including runoff from seasonal rivers and seasonal precipitations, as well as the emergence of GWL pumping with a delay of several weeks.
5 Conclusion
In the present study, several TDNN models with various structures and time delays have been developed for forecasting GWL fluctuation in Semnan/Sorkheh plain, Iran, in two different monitoring sites. The LM algorithm was used for training all developed TDNN models. The derived results were compared through two different performance criteria (including R2 and RMSE). In almost all of studied TDNN structures, the models with longer time delays showed the most accurate performance in comparison with the models with shorter time delays, so that the models with the time delay of 8 weeks have the highest accuracy for prediction the GWL. Furthermore, the performance of TDNN with different structures was examined through varying the number of hidden layers to 2, 4, and 8. The results revealed that the TDNN models with 8 hidden layers have the highest R2 value and the lowest RMSE value. Generally, the developed TDNN models exhibited appropriate performance under uncertain conditions according to the derived R2 and RMSE values, indicating that the TDNN models are able to minimize the uncertainties. The results obtained from this study also support these findings and show the superiority of the developed ANN to predict the GWL fluctuations. This model can be beneficial for similar research to model the GWL fluctuations. The well-developed TDNN models by local decision makers can facilitate more effective GWRM.
References
Banerjee, P., Prasad, R. K., & Singh, V. S. (2009). Forecasting of groundwater level in hard rock region using artificial neural network. Environmental Geology, 58(6), 1239–1246. https://doi.org/10.1007/s00254-008-1619-z.
Beale, M. H., Hagan, M. T., & Demuth, H. B. (1992). Neural network ToolboxTM 7 user’s guide. www.mathworks.com.
Bhowmik, M., Deb, K., Debnath, A., & Saha, B. (2018). Mixed phase Fe2O3/Mn3O4 magnetic nanocomposite for enhanced adsorption of methyl orange dye: Neural network modeling and response surface methodology optimization. Applied Organometallic Chemistry, 32(3), e4186.
Bhowmik, M., Debnath, A., & Saha, B. (2019). Fabrication of mixed phase CaFe2O4 and MnFe2O4 magnetic nanocomposite for enhanced and rapid adsorption of methyl orange dye: Statistical modeling by neural network and response surface methodology. Journal of Dispersion Science and Technology 1–12.
Chang, J., Wang, G., & Mao, T. (2015). ‘Simulation and prediction of suprapermafrost groundwater level variation in response to climate change using a neural network model. Journal of Hydrology, 529, 1211–1220. https://doi.org/10.1016/j.jhydrol.2015.09.038.
Daliakopoulos, I. N., Coulibaly, P., & Tsanis, I. K. (2005). Groundwater level forecasting using artificial neural networks. Journal of Hydrology, 309(1–4), 229–240. https://doi.org/10.1016/j.jhydrol.2004.12.001.
Debnath, A., Majumder, M., Pal, M., Das, N. S., Chattopadhyay, K. K., & Saha, B. (2016). Enhanced adsorption of hexavalent chromium onto magnetic calcium ferrite nanoparticles: Kinetic, isotherm, and neural network modeling. Journal of Dispersion Science and Technology, 37(12), 1806–1818.
Derbela, M., & Nouiri, I. (2020). Intelligent approach to predict future groundwater level based on artificial neural networks (ANN). Euro-Mediterranean Journal for Environmental Integration, 5(3), 1–11.
Diodato, N., & Ceccarelli, M. (2006). Computational uncertainty analysis of groundwater recharge in catchment. Ecological Informatics, 1(4), 377–389.
Ebrahimi, H., & Rajaee, T. (2017). Simulation of groundwater level variations using wavelet combined with neural network, linear regression and support vector machine. Global and Planetary Change. https://doi.org/10.1016/j.gloplacha.2016.11.014.
Gholami, V. C. K. W., Chau, K. W., Fadaee, F., Torkaman, J., & Ghaffari, A. (2015). Modeling of groundwater level fluctuations using dendrochronology in alluvial aquifers. Journal of Hydrology, 529, 1060–1069. https://doi.org/10.1016/j.jhydrol.2015.09.028.
Ghose, D., Das, U., & Roy, P. (2018). Modeling response of runoff and evapotranspiration to predict water table depth in arid region using dynamic recurrent neural network. Groundwater for Sustainable Development, 6, 263–269. https://doi.org/10.1016/j.gsd.2018.01.007.
Griebler, C., & Avramov, M. (2014). Groundwater ecosystem services: A review. Freshwater Science, 34(1), 355–367.
Iranian Meteorological Organization. (2016). Weather statics and records of Arak, Markazi, Iran. http://www.irimo.ir/index.php?newlang=eng.
Kaiser, M. (1994). Time-delay neural networks for control. IFAC Proceedings Volumes, 27(14), 967–972.
Kamalan, H., Khoshand, A., & Tabiatnejad, B. (2009). An investigation on efficiency of MTBE removal from water by adsorption to porous soil. In 2009 2nd international conference on environmental and computer science (pp. 360–363).
Khoshand, A., Fathi, A., Zoghi, M., & Kamalan, H. (2018). Seismic stability analyses of reinforced tapered landfill cover systems considering seepage forces. Waste Management & Research, 36(4), 361–372.
Kouziokas, G. N., Chatzigeorgiou, A., & Perakis, K. (2018). Multilayer feed forward models in groundwater level forecasting using meteorological data in public management. Water Resources Management, 32(15), 5041–5052. https://doi.org/10.1007/s11269-018-2126-y.
Lee, S., Lee, K. K., & Yoon, H. (2019). Using artificial neural network models for groundwater level forecasting and assessment of the relative impacts of influencing factors. Hydrogeology Journal, 27(2), 567–579. https://doi.org/10.1007/s10040-018-1866-3.
Malik, A., & Bhagwat, A. (2021). Modelling groundwater level fluctuations in urban areas using artificial neural network. Groundwater for Sustainable Development, 100484.
Mohanty, S., Jha, M. K., Kumar, A., & Sudheer, K. P. (2010). Artificial neural network modeling for groundwater level forecasting in a river island of eastern India. Water Resources Management, 24(9), 1845–1865. https://doi.org/10.1007/s11269-009-9527-x.
Mohanty, S., Jha, M. K., Raul, S. K., Panda, R. K., & Sudheer, K. P. (2015). Using artificial neural network approach for simultaneous forecasting of weekly groundwater levels at multiple sites. Water Resources Management, 29(15), 5521–5532. https://doi.org/10.1007/s11269-015-1132-6.
Mohd Nawi, N., Atomia, W. H., & Rehman, M. Z. (2013). The effect of data pre-processing on optimized training of artificial neural networks. Procedia Technology, 11, 32–39.
Nayak, P. C., Satyaji Rao, Y. R., & Sudheer, K. P. (2006). Groundwater level forecasting in a shallow aquifer using artificial neural network approach. Water Resources Management, 20(1), 77–90. https://doi.org/10.1007/s11269-006-4007-z.
Rajaee, T., Ebrahimi, H., & Nourani, V. (2019). A review of the artificial intelligence methods in groundwater level modeling. Journal of Hydrology. https://doi.org/10.1016/j.jhydrol.2018.12.037.
Ravansalar, M., & Rajaee, T. (2015). Evaluation of wavelet performance via an ANN-based electrical conductivity prediction model. Environmental Monitoring and Assessment. https://doi.org/10.1007/s10661-015-4590-7.
Roshni, T., Jha, M. K., & Drisya, J. (2020). Neural network modeling for groundwater-level forecasting in coastal aquifers. Neural Computing and Applications, 32, 12737–12754.
Sahoo, S., & Jha, M. K. (2013). Groundwater-level prediction using multiple linear regression and artificial neural network techniques: A comparative assessment. Hydrogeology Journal, 21(8), 1865–1887. https://doi.org/10.1007/s10040-013-1029-5.
Salehnia, N., Ansari, H., Kolsoumi, S., & Bannayan, M. (2019). Climate data clustering effects on arid and semi-arid rainfed wheat yield: A comparison of artificial intelligence and K-means approaches. International Journal of Biometeorology, 63(7), 861–872. https://doi.org/10.1007/s00484-019-01699-w,63(7):pp.861-872.
Sang, Y. F., Wang, Z., & Liu, C. (2015). Wavelet neural modeling for hydrologic time series forecasting with uncertainty evaluation. Water Resources Management, 29(6), 1789–1801.
Sreekanth, P. D., Sreedevi, P. D., Ahmed, S., & Geethanjali, N. (2011). Comparison of FFNN and ANFIS models for estimating groundwater level. Environmental Earth Sciences, 62(6), 1301–1310. https://doi.org/10.1007/s12665-010-0617-0.
Sugiyama, M., Sawai, H., & Waibel, A. H. (1991). Review of TDNN (time delay neural network) architectures for speech recognition. In IEEE international symposium on circuits and systems (pp. 582–585).
Sun, Y., Wendi, D., Kim, D. E., & Liong, S. Y. (2016). Application of artificial neural networks in groundwater table forecasting-a case study in a Singapore swamp forest. Hydrology and Earth System Sciences, 20(4), 1405–1412. https://doi.org/10.5194/hess-20-1405-2016.
Taormina, R., Chau, K. W., & Sethi, R. (2012). Artificial neural network simulation of hourly groundwater levels in a coastal aquifer system of the Venice lagoon. Engineering Applications of Artificial Intelligence, 25(8), 1670–1676. https://doi.org/10.1016/j.engappai.2012.02.009.
Torres-Perez, J., Huang, Y., Bazargan, A., Khoshand, A., & McKay, G. (2020). Two-stage optimization of Allura direct red dye removal by treated peanut hull waste. SN Applied Sciences, 2(3), 1–12.
Tutmez, B. (2009). Assessing uncertainty of nitrate variability in groundwater. Ecological Informatics, 4(1), 42–47.
Wagh, V., Panaskar, D., Muley, A., Mukate, S., & Gaikwad, S. (2018). Neural network modelling for nitrate concentration in groundwater of Kadava River basin, Nashik, Maharashtra, India. Groundwater for Sustainable Development, 7, 436–445. https://doi.org/10.1016/j.gsd.2017.12.012.
Waibel, A., Hanazawa, T., Hinton, G., Shikano, K., & Lang, K. J. (1989). Phoneme recognition using time-delay neural networks. IEEE Transactions on Acoustics, Speech, and Signal Processing, 37(3), 328–339.
Wang, G. (2019). Machine learning for inferring animal behavior from location and movement data. Ecological informatics, 49, 69–76.
Yoon, H., Jun, S. C., Hyun, Y., Bae, G. O., & Lee, K. K. (2011). A comparative study of artificial neural networks and support vector machines to predict groundwater levels in a coastal aquifer. Journal of Hydrology, 396(1–2), 128–138. https://doi.org/10.1016/j.jhydrol.2010.11.002.
Zhang, J., Zhang, X., Niu, J., Hu, B. X., Soltanian, M. R., Qiu, H., & Yang, L. (2019). Prediction of groundwater level in seashore reclaimed land using wavelet and artificial neural network-based hybrid model. Journal of Hydrology, 577, 123948.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Khoshand, A. Application of artificial intelligence in groundwater ecosystem protection: a case study of Semnan/Sorkheh plain, Iran. Environ Dev Sustain 23, 16617–16631 (2021). https://doi.org/10.1007/s10668-021-01361-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10668-021-01361-9