
Abstract
Advances in the artificial intelligence-based models can act as robust tools for modeling hydrological processes. Neural network architectures coupled with learning algorithms are considered as useful modeling tools for groundwater-level fluctuations. Emotional artificial neural network coupled with genetic algorithm (EANN-GA) is one such novel hybrid neural network which has been used in the present study for the forecasting of groundwater levels at three sites (Site H3, Site H4.5, and Site H9) in a coastal aquifer system. This study was conceived to address and investigate the efficiency of the ensemble model (EANN-GA) for forecasting one-month ahead groundwater level and to compare its performance with emotional artificial neural network (EANN), generalized regression neural network (GRNN), and the conventional feedforward neural network (FFNN). Variations in the rainfall, tidal levels, and groundwater levels are selected as inputs for the development of EANN-GA, EANN, GRNN, and FFNN models. Suitable goodness-of-fit criteria such as Nash–Sutcliffe efficiency (NSE), bias, root mean squared error (RMSE), and graphical indicators are used for assessing the efficiency of the developed models. The improvement in the performance of the EANN-GA model over the developed EANN, GRNN, and FFNN models in terms of NSE is 0.81, 6.02, and 9.56% at Site H3; 4.35, 5.50, and 22.68% at Site H4.5; and 1.05, 7.18, and 21.75% at Site H9. Thus, it can be inferred that the EANN-GA model outperforms the developed EANN model, GRNN model, and FFNN model. Further, this paper examines the predictive capability of extreme events by the EANN-GA, EANN, GRNN, and FFNN models. The RMSE values of the EANN-GA model at all peak points are found as 0.27, 0.23, and 0.10 m at sites H3, H4.5, and H9, respectively, and the results indicate superior performance of EANN-GA model. To check the generalization ability of the developed EANN-GA models, they are validated with the data of another site (Site I2) located in the same coastal aquifer. Superior prediction capability and generalization ability make the EANN-GA model a better alternative for predicting groundwater levels. Overall, this study demonstrates the effectiveness of EANN-GA in modeling spatio-temporal fluctuations of groundwater levels. It is also concluded that the EANN-GA model yields remarkably better predictions of extreme events, and hence, it could be a promising technique for developing alarm systems for real-world water problems.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The wealth of any nation lies in its rich natural resources. Groundwater is one of our most valuable natural resources, and in developing countries, it acts as a poverty alleviation tool by delivering groundwater directly to poor communities with less cost [1]. Unfortunately, over-usage of groundwater and growing population together make our ecosystems unendurable and unstable. Hence, the sustainable management of groundwater resources is vital for satisfying the needs of present and future generations.
Excessive pumping in coastal aquifer exerts more pressure on groundwater level, and hence, coastal aquifers are more vulnerable to over-exploitation and groundwater contamination. Numerous studies on seawater intrusion [2, 3], groundwater-quality [4, 5], and groundwater-level fluctuations [6,7,8] are carried out worldwide in coastal aquifers. However, differently shaped water-land boundaries of coastal aquifers differ significantly in groundwater-level fluctuations due to tidal response differences. This necessitates more studies on numerical modeling of coastal aquifers. Li et al. [9] presented an analytical solution for tide-induced groundwater-level fluctuations in a coastal aquifer bounded by L-shaped coastlines. Huang et al. [10] derived solutions for U-shaped tidal aquifer to characterize groundwater-level variations induced by rainfall and tidal waves. These studies show that the data collection and numerical modeling techniques are tedious for accurate responses of such aquifers. Moreover, the prediction accuracy of any chaotic time series is very much dependent on the model and on the learning algorithm. However, the uses of such models are restricted due to intensive labor and data requirement. Under such circumstances, where data source is limited or scarce, empirical models are recommended to provide reasonable results.
Artificial neural networks (ANNs) are such empirical models, which have been widely used in hydrological applications for the past few decades. ANN has proved to be suited particularly in dealing with groundwater flow problems, where the flow is nonlinear and highly dynamic in nature [11]. Plenty of literature in this field [12,13,14,15,16,17,18,19,20] proves the success of ANN models in satisfactory groundwater flow simulations. ANN is very popular among the empirical models due to its self-learning, self-adaptive, and high generalization capability. However, the conventional FFNN has some significant drawbacks, such as high computational complexity, low training speed, and the convergence rate that makes it hard to meet the requirements of prediction and classification problems [21]. Generalized regression neural network (GRNN) is a special form of radial basis function network, which provides high modeling accuracy compared to FFNN models and it significantly reduces the complexity in computation [22]. The GRNN models have found its application in the field of water resources engineering [23, 24]. However, GRNN applications are limited in the field of groundwater-level forecasting studies.
In the last decade or so, tools such as the coupled use of conventional neural networks and biologically motivated learning algorithms in improving the accuracy have attracted the researchers and scientists in various fields of engineering. Several researchers have reported in the literature about the hybrid technique in water resources engineering as well as in various other fields of engineering. Hybrid ANN models usually outperform in a majority of the groundwater flow forecasting problems [25, 26]. Such ensemble models take the strengths of constituent networks, while their weaknesses are neutralized [27,28,29,30]. Nourani et al. [16] compared the performances of three hybrid neural networks and reported a 15.3% increase on average in the performance of feedforward neural network through the application of wavelet transformation. A hybrid of particle swarm optimization (PSO) with GA is an effective hybrid optimization strategy, and it is generally used for determining the radial basis function neural networks parameters [31]. The major advantage of using GA over other optimization techniques is that GA is not sensitive to initial guesses for parameters to be optimized [32]. Several studies with GA-based optimization have been used in different fields like optimization for the computer simulation of gas generation and transport in landfills [33,34,35].
As the era of the hybrid neural network is progressing, [36] introduced an interesting and revolutionary brain-inspired emotional neural networks. It is a single-layered feedforward neural network that benefits from the excitatory, inhibitory, and expandatory neural connections as well as the winner-take-all competitions in the human brain’s nervous system. The main advantage of the EANN is its ability to model through hormonal glands. From the biological perspective, the mood and emotions of animals due to the performance of hormone glands affect the neurophysiological response of the animals. EANN is closer to the human emotional process and gives accurate results in learning applications [37]. Lotfi and Akbarzadeh [38] developed EANN by conjoining emotional concepts for problems like clustering, pattern recognition, and prediction.
The review results show that in all likelihood, no studies have been conducted in groundwater till date except the breakthrough of EANN applicability in rainfall–runoff modeling [39]. This study is noted as the first and foremost work in the hydrological engineering. However, the efficiency of EANN in other fields of engineering is still unknown, and moreover, the predictive capability of the extremities is also not available in the literature. In the digital era, the application of artificial intelligence (AI) in different fields of water resources engineering has been shown to be effective over the past few decades. Any new concept in AI fascinates the users about the applicability of the models in water resources engineering. Regarding the applicability of EANN technique to the field of subsurface hydrology, several questions may be raised. To address the scientific curiosity about the applicability of EANN in the field of subsurface hydrology, two novel architectures, EANN and EANN-GA, are conceived in this study. A hybrid approach is followed for forecasting 1-month ahead groundwater level using EANN and then by integrating EANN technique with GA (EANN-GA). The results of these models are compared with the results of generalized regression neural network (GRNN) and the conventional feedforward neural network (FFNN) model. In addition, an attempt has also been made in this study to explore the usability of such models in predicting extreme events. Thus, this paper provides a scientifically and technically sound methodology for the simulation of extreme groundwater levels using real-world data. This work also focuses on the generalization ability of the developed EANN models by testing the model architectures using another station data of the same coastal aquifer.
2 Literature review of EANN applications
Only a few researchers have enjoyed the credit of working with EANN models. Among those, [40] proposed brain emotional learning-based ANN and proved that emotional stimulus can be processed quicker than any other regular stimulus. Lotfi et al. [37] used EANN for wind power forecasting and reported the superiority of EANN over the conventional ANN in terms of accuracy and stability. Lotfi and Akbarzadeh [41] used evolutionary technique GA for fine-tuning of the EANN parameters, which enhanced the model performance. They conjugated previously developed emotional ensembled artificial algorithms to develop EANN-GA models. Apart from the biological parameters, EANN has a few internal parameters which are emotionally or dynamically interrelated with the internal parameters: an input layer, an output layer, hidden layers, and weights of the links [39]. No coupling of external parameters is found in EANN except a few parameters, which are dynamically conjugated with inputs, outputs, and linked weights of ANN model. Babaie et al. [42] compared the performances of EANN models with MLP and ANFIS in forecasting a warning system and found a better performance of EANN than MLP and ANFIS. Khashman [43] used EANN model for facial recognition and found an improvement in the learning and generalization capability over other conventional neural network models. EANN models have also performed better in the blood-cell identification study [44]. Lotfi and Akbarzadeh [41] proved the universal approximation property of EANN models through their study. In this study, winner-take-all EANN model results are compared with other conventional soft computing techniques and the results revealed superior performance of the winner-take-all EANN model approach in curve fitting, pattern recognition, classification, and prediction techniques. It is apparent from the aforementioned reviews that emotional neural networks are more efficient than the conventional types of neural network in different fields of engineering. Owing to its inherent features, the hybrid EANN-GA technique has great potential in the field of hydrological sciences because most of the hydrological processes are highly influenced by the extremities explained as either high or low flows, wet or dry days, etc. In a recent study on rainfall–runoff modeling [39], greater efficiency of the EANN model than the FFNN model has been reported. The results of this study indicated 13% and 34% improvements during training and verification, respectively. The reason for higher efficiency of the EANN model in this study is due to its ability to recognize and to distinguish the emotional variables of rainfall like wet and dry days.
3 Overview of ANN models used
The structures of the four ANN models (FFNN, GRNN, EANN, and EANN-GA) used in this study along with their features are briefly described in subsequent subsections.
3.1 Feedforward neural network (FFNN)
Feedforward neural network is a commonly used and effectively applied neural network in the field of water resources engineering. The network is comprised of interconnections of neurons, and it collectively acts as a system. The network topology includes input nodes (corresponding to the number of inputs), output nodes (corresponding to the number of outputs), and hidden nodes (number of nodes in the hidden layer). Two transfer functions: one at the hidden layer and the other at output layer, are involved in the network development. Sigmoid function is selected as transfer function in the present study. In the FFNN system, each node in the input layer and the hidden layers is linked and is given a signal strength called “weight.” Similarly, nodes in the hidden layer and the output layer are also connected with links carried with weights. Transfer function at the hidden layer provides an output that acts as inputs to the output layer. The output generated from the output layer is compared with the target. If the error generated between the calculated output and the target is within the permissible range, the model developed can be adopted as a favorable one. If the error generated is not acceptable, then errors are back propagated and the weights of the links are modified and the process is repeated. There exists no hard rule for the training of the FFNN model to obtain an optimal neural network. The training algorithm selected is “Levenberg–Marquardt Backpropagation (L-M BP)” algorithm. The nodes in the hidden layer are selected based on the lowest value of root mean squared error (RMSE) [12].
3.2 Generalized regression neural network (GRNN)
The GRNN model is first introduced by Specht [45], and it does not need an iterative training procedure as in the case of backpropagation method. The GRNN model works on the basis of the probabilistic functional network. The GRNN comprises of input layer, pattern (radial) layer, summation (regression) layer, and output layer. The number of inputs and outputs decides the number of neurons in the input layer and output layer. The nodes of the input layer are linked to each node of the pattern layer with weighted connections. Each output of the pattern layer is connected to the two summations units in the summation layer: numerator units and denominator units. Numerator units (N) provide the weighted sum of the pattern layer, and denominator units (D) provide the unweighted sum of the pattern layer. The output layer determines the output by dividing the numerator with denominator part of the summation layer [24]. Higher accuracy is ensured in forecasting since it uses Gaussian functions. The forecasting trials with the GRNN models were carried out for different spread parameters, and the performance criteria were calculated for each trial until a best fit is obtained. The advantages of GRNN are as follows: (1) The training for the network architecture development is simple and quick; (2) no prior estimation of hidden layers and nodes in each hidden layer is required; and (3) high capability of nonlinear mapping and (4) a global convergence of GRNN are ensured [46]. The mathematical basis for the GRNN model development is nonlinear regression analysis between the input and output parameters. The output variable (Y) relative to the influencing input variables (X) can be calculated using the following expression [47].
where n represents the number of training data set, \(\sigma\) represents the smoothing parameter, and Di is the Euclidean distance between X and Xi. The detail description of the GRNN model development is available in [22, 46].
3.3 Emotional neural network (EANN)
EANN is an improved version of FFNN, where emotions play a significant role in the model development. The necessity and concepts of emotions in the field of artificial intelligence were highlighted by [48]. This concept has greater advantages than the neuron-centric view. Emotions create a response in the mind that arises naturally, through a conscious effort. This emerged as the concept of “Neuromodulation,” which is a way to quantify and characterize emotional dynamics. In engineering applications, any response simulation is performed by incorporating the emotions to improve the learning capability of neural networks. When an input pattern enters the cerebral cortex, neurons respond to how much “mood” behavior of the controlled agencies varies. Hence, it is expected to enhance the information capacity of the model as a result of implementing these individual responses of the nodes. This concept is embedded in EANN that makes it different from the conventional FFNN.
The architecture of EANN model is depicted in Fig. 1. Solid arrows in this figure show the procedure associated within the EANN model development, and the dotted lines indicate hormonal modulatory pathways. The advantage of EANN is the reversible flow of information from inputs to outputs and vice versa. The cell of the EANN (I–III) can not only send information to EANN (IV) but also produce hormones (VIII). These hormones are shown by global variables, which sums the hormone output of one-time step of all cells of the EANN (VII). The overall summation of hormone value of the EANN is calculated as follows:

Architecture of emotional artificial neural network
The hormones in the system (H) act as dynamic coefficients which differ with inputs and target data samples. Through the training phase, they can impact on weights (I), net function (II), and activation function (III). The net response of ith neuron (Yi) is the total of all the weighted hormonal functions on activation functions. The output of the ith neuron with three hormonal glands of Ha, Hb, and Hc is computed using following equation:
In Eq. (3), Term 1 shows the applied weight to the activation function (f ()) containing both statistic (constant) neural weight of \(\lambda_{i}\) and dynamic hormonal weight of \(\sum\nolimits_{h} {\sigma_{i,h} } H_{h}\). Term 2 stands for applied weight to the net function (summation), Term 3 indicates applied weight to the input value of \(X_{i,j}\) coming from the jth neuron of the previous layer, and Term 4 shows the bias of net function, which contains the neural and hormonal weights of \(\alpha_{i}\) and \(\sum\nolimits_{h} {\chi_{i,h} H_{h} }\). Finally, the last term (Term 5) contributes to the activation function, where neural and hormonal weights are contributed as \(\delta_{i}\) and \(\sum\nolimits_{h} {\rho_{i,h} H_{h} }\), respectively.
The output of the cell is calculated as a factor of the output of the response function as:
All the hormones of Eq. (1) are produced by:
where \({\text{glandity}}_{i,h}\) is a parameter representing the production factory of all hormones in the cell.
The degree in which a cell functions as a neural cell or as a gland for a given hormone is calculated by weights (V, VI). Also, Eq. (3) shows that the weights of neural and hormonal routes have a prominent role in the emotional neural network. The competitive weights of glandity should be adjusted to properly find the final output, and this is updated by the process of training. Emotional backpropagation algorithm is used as the learning algorithm for the development of EANN model. In the emotional BP algorithm, emotional parameters like anxiety coefficient (µ) and confidence coefficient (k) are also used along with the conventional parameters such as learning rate and momentum rate for reducing the network error. The values of µ and k are varied in the training process to get the lowest values of anxiety and highest values of confidence coefficient at the end of training process [36].
3.4 Emotional neural network with genetic algorithm (EANN-GA)
In the EANN-GA model, genetic algorithm is applied to optimize network crisp weights of the EANN model [34]. A real-coded GA is used in this study to find the optimum weights in all the functions of single cell to obtain the best solution for the problem. The optimized model is trained by varying population size and generations. Thus, through global optimization technique, all the data flow component weights are trained in such a manner that global best possible values are used for the calibration process in the algorithm. Another added advantage is that a more reliable agreement is shown between observed and computed values of the target can be achieved at a greater pace and accuracy. The other details are furnished in [38, 39].
3.5 Emotional ANN parameters
The EANN model enjoys a low computational complexity. EANNs are tremendously impacted by the linkages among amygdala, orbitofrontal cortex, and thalamus, in which sensory cortex provides information to neurons in amygdala, the elaborated features from the thalamus by max operator, and the inhibitory connections from the orbitofrontal cortex. In EANN-GA model, the hormonal weights play significant roles which are optimized using a GA coupled with the model. In the present configuration [(c) in “Appendix”], nine thalamal cortex weights, three orbitofrontal weights, three amygdala weights, and six thalamus–amygdala weights are optimized using GA. The advantage of this type of algorithm is inductive learning through synaptic weight adjustments and deductive learning by the automatic adaptation of system knowledge of the domain environment through the modification of network topology. Such hybrid neural network architectures are proficient in finding out the weights of each link of different layers, the processing elements for each layer and the connectivity between processing elements [21].
3.6 EANN versus FFNN
As discussed in Sect. 3.1, FFNN is generally a three-layer system, where input layer feed forwards the inputs to the hidden layer. The hidden nodes present in the hidden layer enhance the ability of FFNN to model complex relationships and passes the information to the activation function associated with the output layer. The output layer provides the model output. When the FFNN is trained by the backpropagation algorithm, the overtraining issue can be a serious concern due to the smaller number of learning samples and a greater number of the calibration parameters.
On the other hand, the logical ability to think with emotions makes a remarkable influence in FFNN. In the EANN model, the hormonal parameters are linked to the different layers of the network, which aids in distinguishing different situations of the system during the learning period. This model has a reactive and deliberative mechanism to diversify the behavioral patterns of the problems to be analyzed in the EANN architecture. This architecture has the ability to generate emotions from the input data selected during the training process. The emotions may actuate or repress the specific perceptual and cognitive schemes that improve (or utmost) the perception and handling of specific stimuli. In this way, emotion-aided modeling improves the decision making process of any systems [42]. Another feature that differs from FFNN is that apart from the map information of input layer to output layer, the elements of feedback system in EANN change the behavior of the cells based on dynamic hormone levels. The “out-function” of the FFNN differs from the EANN analog which is called as “Hill-function.” The “Hill-function” is strongly influenced by hormones during runtime, but the “out-function” of the FFNN is usually static during runtime [36].
4 Methodology
4.1 Study area and data
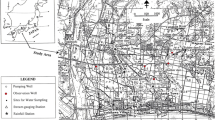
A coastal aquifer located in the Konan groundwater basin of Japan (Fig. 2) has been selected for demonstrating the efficiency of the conventional FFNN and hybrid ANN models. In this basin, groundwater plays a vital role in ensuring future water supply due to the limited availability of surface water resources during winters (dry periods), and hence, groundwater is considered as the sole source of water supply to cope with the looming freshwater crisis [49].

Location of the groundwater-monitoring sites used in this study
The groundwater flow of this basin is from north to south into the Pacific Ocean. For this study, four sites/wells were selected in the coastal portion of the basin which are located close to the Pacific Ocean. These four sites/wells are named as H3, H4.5, H9, and I2 (Fig. 2). In this study, the data of sites H3, H4.5, and H9 were used for model development and the data of site I2 were used for the validation of the developed models. Monthly groundwater-level data for the period April 1998 to December 2004 were obtained from Kochi Prefectural Office, Kochi City, Japan. The rainfall data for this period were obtained from Gomen Meteorological Station, while the seawater-level data from January 1998 to December 2004 were obtained from www.psmsl.org for Kochi II Port (latitude: 33.5 and longitude: 133.58, station ID: 1184). The nature of groundwater levels and seawater levels is shown in Fig. 3a, b.

a Dendrogram cluster analysis for wells and b monthly seawater level for the port Kochi II
The clustering of the wells/sites (Fig. 3a) in the light of groundwater levels demonstrates that wells H4.5 and H9 are grouped in a single cluster and afterward joined to well I2 and then to well H3. It is a preliminary analysis to show the nature of groundwater-level variations in different wells. Figure 3b displays a small decrease in the seawater level during 2000–2001 as compared to the rise in seawater level from 2002 onwards. This shows that the region is significantly experiencing a tidal variation. Furthermore, Fig. 4 shows the monthly variation of rainfall along with the monthly variation of groundwater levels at the four sites/wells. In the basin, the mean annual rainfall is about 2600 mm. More than 50% of the total annual rainfall occurs during June to September, and the rainfall events are usually distributed throughout the year.

Variation of monthly rainfall with groundwater level
4.2 Selection of data length for model training and testing
4.2.1 Gamma test and M-test
Gamma test and M-tests are efficient data analysis tools, which help in reducing non-parametric noises present in the data sets [50]. Gamma test and M-test provide the adequate length of data set to train a predictive model in a perfect way. These tests estimate the error variance present in a given data set [51].
Assume a data set in the form {(\(x_{i} ,y_{i}\)), \(1 < i \le M\)}, where x is the potential input vector and y is the corresponding output vector. The system can be represented as:
In Eq. (5), f is a smooth function and r is a random variable that represents the noise present in the input vector. The other terms involved are Euclidean distance and gamma statistic (Γ). The detailed description of Euclidean distance and gamma statistics is given in [50]. Gamma statistic (Γ) is calculated as follows [52]:
where xN[i,k] = kth nearest neighbor in terms of Euclidean distance to x[i], |.| = Euclidean distance, δM(k) = delta, and ϒM(k) = gamma. A least-square fit regression line between [δM(k) and ϒM(k)] is plotted and its intercept on the vertical axis gives Γ (δM(k) → 0, ϒM(k) → Var(k)).
Gamma statistic calculates for increasing data sets and is plotted against the number of data sets. This procedure is known as M-test. The number of data points that is necessary for Γ to stabilize is considered as the least number of data sets for the model development. If the line does not stabilize for the given data set, then more data are required for the model development. The major advantage of gamma test and M-test is that it eliminates the use of trial-and-error method for the selection of data length required for model development.
4.3 Development of ANN models
In this study, the model development includes categorizing the potential input variables from the data collected and optimizing the neural network for obtaining the best architecture. Potential input variables are found by correlation analysis using R Studio [53], which leads to the final selection of nodes in the input layer. In addition, two lead times of groundwater level (1 month ahead and 2 months ahead) are tested as possible inputs for predictions. Conventional FFNN, GRNN, and hybrid neural network models such as EANN and EANN-GA are developed in this study. For the model development, based on gamma test and M-test, 80% of the available data set is used for model training and the remaining 20% for testing. All the computations necessary for the model development were performed using MATLAB 2015 software. The model architectures used for FFNN, GRNN, and EANN-GA are appended in “Appendix.”
4.3.1 FFNN model
In the FFNN model, backpropagation Levenberg–Marquardt training algorithm is used. The data for training and testing were normalized between 0 and 1 for better model performances. The activation function used for hidden layer and output layer is tangent sigmoid function [54]. Only one hidden layer is adopted for this model. The best architecture for each number of hidden nodes in the hidden layer was determined through trial-and-error procedure. Large set of hidden nodes in the hidden layer may overfit the data and may lead to less generalization capability of the network and less number may lead to underfitting. During the training process of the network development, the hidden nodes are varied. In each step of learning/training, for each hidden node, connection weights and the other internal parameters are adjusted and the architecture is developed. Best architecture (having lowest RMSE value) is selected among the models developed.
4.3.2 GRNN model
The GRNN models were developed for all selected sites. The model architectures were generated for different smoothing parameter values (spread), and the performance criteria were evaluated for each developed model. The smoothing parameter varies from 0.01 to 0.5 with a step of 0.01. Best architecture is selected based on lowest RMSE and highest NSE.
4.3.3 EANN model
In the EANN model, artificial hormones are emitted which modulates the function of each neuron in the model as shown in the Fig. 1. As discussed in Sects. 3.3 and 3.4, the hormones are generated according to the input and output samples and are modified continuously through different iterations during the training phase. In this phase, they can impact on weights, activation function, net function, and all other components of the neuron. All the input data are normalized and then used for training and testing.
4.3.4 EANN-GA model
In addition to the above model phase, GA is applied to optimize the weights of EANN. Training process is repeated with different chromosome numbers and population sizes. Generally, GA optimizes the cost function to find the best solution for the problem under study.
4.4 Evaluation of model performance
To evaluate the performance of the developed models, three goodness-of-fit criteria are used. They are Nash–Sutcliffe efficiency (NSE), root mean squared error (RMSE) [55], and bias, which are calculated for each model using the following equations:
where \(h_{oi}\) = observed groundwater level, \(h_{ci}\) = calculated groundwater level, \(\overline{{h_{oi} }}\) = mean of the observed groundwater levels, and N = number of observations.
5 Results and discussion
5.1 Potential inputs and data length
The tentative inputs selected for the analysis are precipitation at t time P(t), precipitation at (t − 1) time P(t − 1), groundwater level at t time GL(t), and seawater level at t time SL(t) for 1-month ahead groundwater response GL(t + 1) and 2-month ahead groundwater response GL(t + 2). The results of correlation analyses for GL(t + 1) and GL(t + 2) are presented in Table 1. This table reveals that for GL(t + 1), a relatively accurate correlation (i.e., higher values of correlation coefficient) exists for P(t), SL(t), and GL(t), whereas there exists no potential inputs for GL(t + 2) because of weak correlation (i.e., very low values of correlation coefficient). Hence, this study is restricted to GL(t + 1) only and the potential inputs selected are P(t), SL(t), and GL(t) resulting in three nodes in the input layer. The data from April 1998 to December 2004 are used for the model development.
Figure 5a shows the results of gamma test for 80 data sets at Site H-3. The value of gamma statistic for 80 data sets is found as 0.3876. Similarly, Γ is calculated for entire length of data set and Γ values are plotted against different data sets as shown in Fig. 5b. Subsequently, gamma test and M-test were carried out for sites H 4.5 and H-9 and Γ values are plotted in Fig. 5b. It is apparent from this figure that the fluctuations in the gamma statistic decrease as the length of data set increases. Approximately after 80% of the data length for all the three sites, the gamma statistic produces less fluctuation, and hence, it is selected as the optimum length of inputs for the training of the models.

Results of (a) gamma statistic for 80 data sets at Site H-3, and M-test for (b) sites H-3, H-4.5, and H-9
5.2 Performance of the models
After the development of models for all the three sites, the performance assessment of the developed models is inevitable to find out the best model. Using four models, the monthly groundwater-level forecasting for 1 month ahead for sites H3, H4.5, and H9 has been quantified. The number of nodes in the input layer is three and the output layer is one. Three-layered FFNN architecture is developed with 3–10–1 network for Site H3, Site H4.5, and Site H9. The best performance criteria for GRNN models were obtained for smooth parameter 0.1 for Site H3, 0.08 for Site H4.4, and 0.12 for Site H9. For the best EANN and EANN-GA models, the activation function is found as “tangent sigmoid function” for all the three sites. Apparently, accurate/reasonable results are found for 80% of training data set and 20% of testing data set at all the three sites. After model development, there are nine thalamal cortex weights, three orbitofrontal weights, three amygdala weights, six thalamus–amygdala weights, and one bias weight for each EANN model and EANN-GA model.
Figure 6a–c illustrates the comparison of observed groundwater levels and the groundwater levels simulated by the developed FFNN, GRNN, EANN, and EANN-GA models at the three sites. These figures indicate more or less satisfactory groundwater-level forecasts for the 1-month lead time by the three models. However, to evaluate the performance of the three models quantitatively, statistical indicators were computed which are shown in Table 2. It is observed that there is significantly improved performance of the EANN-GA models as compared to the conventional FFNN model and GRNN model. An improvement of 9.56%, 22.68%, and 21.75% in terms of model efficiency (NSE) is apparent for sites H3, H4.5, and H9, respectively. Unlike the FFNN model, there is only a marginal improvement in the performance of EANN-GA over EANN model. The percentage improvement in NSE is 0.81, 4.35, and 1.05 for sites H3, H4.5, and H9, respectively. The improvement of EANN-GA over GRNN models is 6.02, 5.50, and 7.18 for sites H3, H4.5, and H9, respectively. The difference in the level of improvement among the sites could be attributed to the site-specific variation in the characteristics of groundwater levels due to aquifer heterogeneity (Figs. 3, 4). Machine learning models work on the principle of pattern recognition, and hence, they are usually data/site-specific. Consequently, the performance of such models is most likely to vary from location to location. The values of the statistical indicator bias for the three sites are shown in Table 3, which reveals that Site H3 is negatively biased for the FFNN model, sites H3 and H4.5 are negatively biased for GRNN model, sites H3 and H9 are negatively biased for EANN model, and Site H9 is negatively biased for the EANN-GA model. Here, negative bias indicates over-prediction by the models. Thus, the three performance indicators indicate that the EANN-GA models outperform the EANN, GRNN, and FFNN models in yielding 1-month lead time forecasts at all the three sites.

Monthly groundwater-level forecasting for 1-month lead time at: a Site H3, b Site H4.5, and c Site H9
Moreover, scatter plots of observed and simulated groundwater levels along with R2, 95% confidence interval, and prediction interval were examined for all the models in order to judge their performance in a comprehensive manner. The prediction interval represents the quantification of the uncertainty of a model. For instance, such scatter plots for the EANN-GA models of the three sites are illustrated in Fig. 7a–c. These plots also suggest superior prediction capability of the EANN-GA models, with R2 values ranging from 0.86 to 0.74 for the 1-month ahead forecasting of groundwater levels at the three sites.

Scatter plots of observed versus simulated groundwater levels along with R2, 95% confidence interval, and prediction interval for the EANN-GA model at: a Site H3, b Site H4.5, and c Site H9
Another graphical indicator for assessing the model performance is “Taylor diagram.” Taylor diagrams are used to graphically summarize the proximity of the results of model to match with the observed values in terms of indices like RMSE, correlation coefficient, and standard deviation. Taylor diagram can generate better conclusions about model performances. Figure 8a–c shows Taylor diagrams for sites H3, H4.5, and H9. In Fig. 8a, the EANN-GA model shows greater correlation coefficient, lesser RMSE, and standard deviation close to the standard deviation of the observed values. Figure 8b, c also indicates the similar finding of superior performance of the EANN-GA models.

Taylor diagrams for: a Site H-3, b Site H4.5, and c Site H9. Contour lines represent RMSE values in m
Finally, Fig. 9 shows the results of random walk test for the results of groundwater-level forecasting by the FFNN, GRNN, EANN, and EANN-GA models at the three sites. Random walk test is based on the sign test and is independent of distributional assumptions for simulation errors [56]. In this analysis, the model results of each site can be compared at every step. In Fig. 9, the upward path movement shows that the EANN-GA model is more skillful else, FFNN model is more skillful. Thus, the path followed by the EANN-GA model results is moving in the upward direction, which indicates that the EANN-GA modeling approach is more skillful (improved prediction ability) than the conventional FFNN approach for all the sites under study. The 95% interval for N number of forecast events is shown as ± 2√N. The hypothesis of equally skillful forecasts is rejected when the particle moves out of ± 2√N interval. Figure 9 also depicts the skillful test for EANN models and GRNN models over FFNN models. When compared to all developed models, EANN-GA models are more skillful for all selected sites.

Results of random walk test for sites H-3, H-4.5, and H-9
All the analyses discussed above indicate the superior performance of the EANN-GA model over the EANN model, GRNN model, and the conventional FFNN model. In other words, the performance indices also show the predictive capability of EANN model and GRNN model over FFNN model. The better performance of EANN-GA and EANN models attributed better capturing of the extreme events present in the input neurons. The emotions may be analogous to stresses in the inputs. Extreme variations in the input signals are the extreme events of monthly rainfall as well as high and low fluctuations for seawater-level inputs.
The superior performance of the EANN-GA model over EANN is due to the optimization of the internal parameters by the genetic algorithm. The execution time in the EANN-GA model has improved compared to other developed models with higher accuracy. The other major advantages of EANN models found are as follows: (1) These models have more hormonal parameters which can interact with input, output values, and statistical weights than classical ANN architecture; (2) since each input and output neurons modulate the hormonal parameters, dynamic transfer of information is possible in EANN than conventional neural networks; (3) through training the EANN, all neuron elements have the hormonal affect; and (4) EANN needs only single hidden layer for parameter evaluation, whereas FFNN needs multiple hidden layers for the same and (5) speedy execution with higher accuracy. However, EANN architecture cannot model the behavior of changing environments on an evolutionary time scale. Further research could be how these emotions respond rapidly to changing climate [39].
5.3 Model performance for the prediction of extreme events
The prediction of extreme events is generally used for development of alarm systems [42]. The prediction accuracy depends on the model and the learning algorithms. It is evident from the earlier studies that brain emotional learning has a high generalization property. Babaie et al. [42] tested the emotional learning interpretations of brain for forecasting a system designed for warning. The results showed better predictions, and it was proposed that it could be useful for developing a warning system in real-time problem with a large data set. For scientific curiosity, in this study, the authors have also included an analysis to explore the capability of the selected models in yielding prediction accuracy of peak points of groundwater levels. The prediction accuracy for all the points at positive peak points and at negative peak points in terms of an error index (RMSE) is shown in Table 4. It is observed that the performance of the EANN-GA model in predicting peak points is better compared to the EANN, GRNN, and FFNN models as indicated by the least RMSE for the EANN-GA model according to each group of peak points. Thus, the EANN-GA model provides much better predictions of extreme events and hence, it can serve as a useful tool for predicting peak events.
5.4 Validating EANN-GA models
In order to test the practicality and generalization ability of the developed EANN-GA models for sites H3, H4.5, and H9, the models were further validated using the data of Site I2, which is located in the same aquifer. The validation results are summarized in Table 5, which indicate that the developed EANN-GA models are capable of forecasting the groundwater level of other site with a greater accuracy. It is evident from the results that the EANN-GA model is a better alternative than the conventional soft computing models to accurately predict groundwater-level fluctuations. Interestingly, this research finding implies that the EANN-GA model can be used as an optional soft computing technique over physically based models when event forecasting is more important than understanding underlying groundwater phenomena.
6 Conclusions
The expedition of artificial intelligence in science is praiseworthy. Latest in the field of artificial intelligence is capturing emotions in the input data sets for simulations by neural networks. In this paper, the applicability and efficiency of the conventional FFNN model, GRNN model, hybrid EANN, and EANN-GA models are demonstrated through a case study in a coastal aquifer system. Groundwater-level data from three sites H3, H4.5, and H9 are used for monthly groundwater-level forecasts, and the data from Site I2 (located in the same aquifer) are used for validation of the developed models. Potential inputs for developing FFNN, GRNN, EANN, and EANN-GA models at each site are selected based on the correlation analysis. The length of data for training and testing of the models is decided using gamma test and M-test. Suitable statistical indicators and graphical indicators are used to critically evaluate the performances of the developed models. Finally, the generalization ability and the prediction capability of extreme events of the developed EANN-GA models are examined.
The results of the EANN-GA models are compared with those of the EANN, GRNN, and conventional FFNN models. Statistical indicators revealed that the 1-month ahead groundwater-level forecasts yielded by the EANN-GA models are more accurate and reliable at all the three sites compared to the EANN, GRNN, and FFNN models. The performance of EANN models presented in this study also exhibits greater accuracy improvement than that of GRNN and FFNN models. Improved performance of the EANN-GA and EANN models could be due to the effective capture of extreme events in the input variables. Graphical indicators like visual comparison of simultaneous plots of observed and simulated groundwater levels, scatter plots, Taylor diagram, and random walk test indicated superior performance of the EANN-GA models. The viability and generalization ability of the developed EANN-GA models are also found to be satisfactory. Further, it was found that the performance of the EANN-GA models in predicting extreme events is better than EANN models and much better than the GRNN and FFNN models. This enhances the application domain of the EANN-GA technique in the field of hydrology for developing warning systems.
In short, the extremes of input parameters which contribute significantly to the accuracy of groundwater-level forecasts are well captured in the hybrid algorithm. The more complex hydrological processes like groundwater level can be simulated with a greater accuracy using EANN and EANN-GA. The successful application of EANN technique in the field of groundwater hydrology can really make a renaissance in this field. More and more region-specific studies under different hydrogeologic and climatic settings should be carried out for the comprehensive evaluation of the emerging EANN technique. The potentiality of capturing emotions in the groundwater level simulation can persuade the researchers of other fields to explore its capability at a wider level. The sensitivity level of the emotions on groundwater-level forecasts is another potential area of future research. The major limitation of this study is the performance analysis of other optimization techniques along with EANN architecture.
References
IWMI (2001) The strategic plan for IWMI 2000–2005. IWMI, Colombo
Ketabchi H, Mahmoodzadeh D, Ataie-Ashtiani B, Simmons CT (2016) Sea-level rise impacts on seawater intrusion in coastal aquifers: review and integration. J Hydrol 535:235–255. https://doi.org/10.1016/j.jhydrol.2016.01.083
Mehdizadeh SS, Karamalipour SE, Asoodeh R (2017) Sea level rise effect on seawater intrusion into layered coastal aquifers (simulation using dispersive and sharp-interface approaches). Ocean Coast Manag 138:11–18. https://doi.org/10.1016/j.ocecoaman.2017.01.001
Dieng NM, Orban P, Otten J et al (2017) Temporal changes in groundwater quality of the Saloum coastal aquifer. J Hydrol Reg Stud 9:163–182. https://doi.org/10.1016/j.ejrh.2016.12.082
Molinari A, Chidichimo F, Straface S, Guadagnini A (2014) Assessment of natural background levels in potentially contaminated coastal aquifers. Sci Total Environ 476–477:38–48. https://doi.org/10.1016/j.scitotenv.2013.12.125
Barlow PM, Reichard EG (2010) Saltwater intrusion in coastal regions of North America. Hydrogeol J 18:247–260. https://doi.org/10.1007/s10040-009-0514-3
Kong J, Xin P, Hua G-F et al (2015) Effects of vadose zone on groundwater table fluctuations in unconfined aquifers. J Hydrol 528:397–407. https://doi.org/10.1016/j.jhydrol.2015.06.045
Levanon E, Shalev E, Yechieli Y, Gvirtzman H (2016) Fluctuations of fresh-saline water interface and of water table induced by sea tides in unconfined aquifers. Adv Water Resour 96:34–42. https://doi.org/10.1016/j.advwatres.2016.06.013
Li H, Jiao JJ, Luk M, Cheung K (2002) Tide-induced groundwater level fluctuation in coastal aquifers bounded by L-shaped coastlines. Water Resour Res 38:2002
Huang F-K, Chuang M-H, Wang GS, Yeh H-D (2015) Tide-induced groundwater level fluctuation in a U-shaped coastal aquifer. J Hydrol 530:291–305
Maier HR, Dandy GC (2000) Neural networks for the prediction and forecasting of water resources variables: a review of modelling issues and applications. Environ Model Softw 15:101–124
Coulibaly P, Anctil F, Aravena R, Bobée B (2001) Artificial neural network modeling of water table depth fluctuations. Water Resour Res 37:885–896. https://doi.org/10.1029/2000WR900368
Daliakopoulos IN, Coulibaly P, Tsanis IK (2005) Groundwater level forecasting using artificial neural networks. J Hydrol 309:229–240. https://doi.org/10.1016/j.jhydrol.2004.12.001
Jha MK, Sahoo S (2015) Efficacy of neural network and genetic algorithm techniques in simulating spatio-temporal fluctuations of groundwater. Hydrol Process 29:671–691. https://doi.org/10.1002/hyp.10166
Mohanty S, Jha MK, Kumar A, Panda DK (2013) Comparative evaluation of numerical model and artificial neural network for simulating groundwater flow in Kathajodi-Surua Inter-basin of Odisha, India. J Hydrol 495:38–51. https://doi.org/10.1016/j.jhydrol.2013.04.041
Nourani V, Alami MT, Vousoughi FD (2015) Wavelet-entropy data pre-processing approach for ANN-based groundwater level modeling. J Hydrol 524:255–269. https://doi.org/10.1016/j.jhydrol.2015.02.048
Nourani V, Kisi Ö, Komasi M (2011) Two hybrid artificial intelligence approaches for modeling rainfall–runoff process. J Hydrol 402:41–59
Nourani V, Mogaddam AA, Nadiri AO (2008) An ANN-based model for spatiotemporal groundwater level forecasting. Hydrol Process 22:5054–5066
Sahoo S, Jha MK (2013) Groundwater-level prediction using multiple linear regression and artificial neural network techniques: a comparative assessment. Hydrogeol J 21:1865–1887. https://doi.org/10.1007/s10040-013-1029-5
Supreetha BS, Nayak PK, Shenoy NK (2015) Groundwater level prediction using hybrid artificial neural network with genetic algorithm. Int J Earth Sci Eng 8:2609–2615
Mei Y, Tan G, Liu Z (2017) An improved brain-inspired emotional learning algorithm for fast classification. Algorithms. https://doi.org/10.3390/a10020070
Ni YQ, Li M (2016) Wind pressure data reconstruction using neural network techniques: a comparison between BPNN and GRNN. Measurement 88:468–476
Luo Q, Wu J, Yang Y et al (2016) Multi-objective optimization of long-term groundwater monitoring network design using a probabilistic Pareto genetic algorithm under uncertainty. J Hydrol 534:352–363. https://doi.org/10.1016/j.jhydrol.2016.01.009
Cigizoglu HK (2005) Application of generalized regression neural networks to intermittent flow forecasting and estimation. J Hydrol Eng 10:336–341
Sun AY, Wang D, Xu X (2014) Monthly streamflow forecasting using Gaussian process regression. J Hydrol 511:72–81
Roshni T, Jha MK, Deo RC, Vandana A (2019) Development and evaluation of hybrid artificial neural network architectures for modeling spatio-temporal groundwater fluctuations in a complex aquifer system. Water Resour Manag 33:1–17
Adamowski J, Chan HF (2011) A wavelet neural network conjunction model for groundwater level forecasting. J Hydrol 407:28–40. https://doi.org/10.1016/j.jhydrol.2011.06.013
Almasri MN, Kaluarachchi JJ (2005) Modular neural networks to predict the nitrate distribution in ground water using the on-ground nitrogen loading and recharge data. Environ Model Softw 20:851–871. https://doi.org/10.1016/j.envsoft.2004.05.001
Ebrahimi H, Rajaee T (2017) Simulation of groundwater level variations using wavelet combined with neural network, linear regression and support vector machine. Glob Planet Change 148:181–191. https://doi.org/10.1016/j.gloplacha.2016.11.014
Nourani V, Ejlali RG, Alami MT (2011) Spatiotemporal groundwater level forecasting in coastal aquifers by hybrid artificial neural network-geostatistics model: a case study. Environ Eng Sci 28:217–228
Wu J, Long J, Liu M (2015) Evolving RBF neural networks for rainfall prediction using hybrid particle swarm optimization and genetic algorithm. Neurocomputing 148:136–142. https://doi.org/10.1016/j.neucom.2012.10.043
Muralitharan K, Sakthivel R, Vishnuvarthan R (2018) Neural network based optimization approach for energy demand prediction in smart grid. Neurocomputing 273:199–208. https://doi.org/10.1016/j.neucom.2017.08.017
Li H, Qin SJ, Tsotsis TT, Sahimi M (2012) Computer simulation of gas generation and transport in landfills: VI—dynamic updating of the model using the ensemble Kalman filter. Chem Eng Sci 74:69–78. https://doi.org/10.1016/j.ces.2012.01.054
Li H, Sanchez R, Joe Qin S et al (2011) Computer simulation of gas generation and transport in landfills. V: use of artificial neural network and the genetic algorithm for short- and long-term forecasting and planning. Chem Eng Sci 66:2646–2659. https://doi.org/10.1016/j.ces.2011.03.013
Li H, Tsotsis TT, Sahimi M, Qin SJ (2014) Ensembles-based and GA-based optimization for landfill gas production. AIChE J 60:2063–2071. https://doi.org/10.1002/aic.14396
Thenius R, Zahadat P, Schmickl T (2013) EMANN—a model of emotions in an artificial neural network. In: ECAL twelfth European conference on artificial, immune, neural and endocrine systems, pp 830–837
Lotfi E, Khosravi A, Nahavandi S (2014) Wind power forecasting using emotional neural networks. In: 2014 IEEE international conference on systems, man, and cybernetics, pp 311–316
Lotfi E, Akbarzadeh MR (2014) Practical emotional neural networks. Neural Netw 59:61–72. https://doi.org/10.1016/j.neunet.2014.06.012
Nourani V (2017) An emotional ANN (EANN) approach to modeling rainfall–runoff process. J Hydrol 544:267–277. https://doi.org/10.1016/j.jhydrol.2016.11.033
Moren J (2002) Emotion and learning—a computational model of the amygdala. Lund University Cognitive Science, Lund
Lotfi E, Akbarzadeh MR (2016) A winner-take-all approach to emotional neural networks with universal approximation property. Inf Sci (NY) 346–347:369–388. https://doi.org/10.1016/j.ins.2016.01.055
Babaie T, Karimizandi R, Lucas C (2008) Learning based brain emotional intelligence as a new aspect for development of an alarm system. Soft Comput 12:857–873. https://doi.org/10.1007/s00500-007-0258-8
Khashman A (2009) Application of an emotional neural network to facial recognition. Neural Comput Appl 18:309–320
Khashman A (2009) Blood cell identification using emotional neural networks. J Inf Sci Eng 25:1737–1751
Specht DF (1991) A general regression neural network. IEEE Trans Neural Netw 2:568–576
Luo X, Yuan X, Zhu S et al (2019) A hybrid support vector regression framework for streamflow forecast. J Hydrol 568:184–193
Bendu H, Deepak B, Murugan S (2017) Multi-objective optimization of ethanol fuelled HCCI engine performance using hybrid GRNN–PSO. Appl Energy 187:601–611
Fellous J-M (1999) Neuromodulatory basis of emotion. The Neuroscientist 5:283–294
Jha MK, Chikamori K, Kamii Y, Yamasaki Y (1999) Field investigations for sustainable groundwater utilization in the Konan basin. Water Resour Manag 13(6):443–470. https://doi.org/10.1023/A:1008184010262
Kemp SE, Wilson ID, Ware JA (2004) A tutorial on the gamma test. Int J Simul Syst Sci Technol 6:67–75
Roshni T, Kumari N, Renji R, Drisya J (2017) Modelling land surface temperature using gamma test coupled wavelet neural network. Adv Environ Res 6(4):265–279
Evans D, Jones AJ (2002) A proof of the gamma test. Proc R Soc Lond Ser A Math Phys Eng Sci 458:2759–2799
R Studio (2017) R Studio: integrated development environment for R. R version. Newnes, Boston
Haykin SS, Haykin SS, Haykin SS, Haykin SS (2009) Neural networks and learning machines. Pearson, Upper Saddle River, NJ
Roshni T, Md. Sajid K, Samui P (2017) Potential of regression models in projecting sea level variability due to climate change at Haldia Port, India. Ocean Syst Eng 7:319–328. https://doi.org/10.12989/ose.2017.7.4.319
DelSole T, Tippett MK (2016) Forecast comparison based on random walks. Mon Weather Rev 144:615–626
Acknowledgments
The authors would like to thank Dr. Ehsan Lotfi, Department of Computer Engineering, Torbat-e-Jam Branch, Islamic Azad University, Torbat-e-Jam, Iran, for sharing the toolbox for the EANN and EANN-GA models and also for his help in technical discussion about the EANN model development. We also sincerely thank the three anonymous reviewers and the Editor/Associate Editor for their thoughtful comments/suggestions that improved the overall quality of this paper.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: Model architectures developed
Appendix: Model architectures developed

Rights and permissions
About this article

Cite this article
Roshni, T., Jha, M.K. & Drisya, J. Neural network modeling for groundwater-level forecasting in coastal aquifers. Neural Comput & Applic 32, 12737–12754 (2020). https://doi.org/10.1007/s00521-020-04722-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-020-04722-z