
Abstract
The target of the current paper was to examine the performance of three Markovian and seasonal based artificial neural network (ANN) models for one-step ahead and three-step ahead prediction of monthly precipitation which is the most important parameter of any hydrological study. The models proposed here are feed forward neural network (FFNN, as a classic ANN-based models), Wavelet-ANN (WANN, as a hybrid model), and Emotional-ANN (EANN, as a modern generation of ANN-based models). The models were used to precipitation prediction of seven stations located in the Northern Cyprus. Two scenarios were examined each having specific inputs set. The scenario 1 was developed for predicting each station’s precipitation through its own data at previous time steps, while in scenario 2, the central station’s data were also imposed into the models in addition to each station’s data, as exogenous inputs. The obtained results showed the better performance of the EANN model in comparison with other models (FFNN and WANN) especially in three-step ahead prediction. The superiorities of the EANN model over other models are due to its ability in dealing with error magnification in multi-step ahead prediction. Also, the results indicated that the performance of the scenario 2 was better than scenario 1, showing improvement of modeling efficiency up to 17% and 26% in calibration and verification steps, respectively.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Precipitation is the most vital part of the hydrological cycle, and precise prediction of precipitation plays critical roles in design, planning, and management of water resources and hydraulic structures. However, due to complex, non-linear, and stochastic nature of precipitation time series, its prediction is a quite difficult task (Nourani et al. 2017; Danandeh Mehr et al. 2017; Danandeh Mehr 2018; Nourani and Molajou 2017).
The models for prediction of hydroclimate parameters (e.g., precipitation) are usually classified into two classes: white box and black box models. The white box model employs physical rules for modeling most of the relevant physical processes involved in the precipitation procedure (Nourani et al. 2018a). In contrast, the black box models apply historical data (observed data) to make predictions. Such black box models are mainly developed on the basis of statistical approaches. Although conceptual approaches are dependable methods to analyze the physics of the phenomena, they may show restrictions such as complexity, time-consuming, lack of enough data for modeling, and inaccurate results. So, once the accurate estimations for the process are more crucial than the physical interpretations, utilizing data-driven (black box) methods will be better alternative (Chau 2017; Wu and Chau 2011; Yaseen et al. 2019a, b; Danandeh Mehr et al. 2019a, b; Nourani et al. 2019a, b). In the recent decades, artificial intelligence (AI) techniques as black box methods indicated great ability in modeling the dynamic precipitation process in the presence of the non-linearity, irregularity, and uncertainty of data (Ghorbani et al. 2018; Nourani et al. 2018a, b). Several studies have indicated that the AI-based techniques can make reliable outputs in precipitation predictions with regard to the white box models (Abbot and Marohasy 2012). Feed forward neural network (FFNN) is one of the commonly used AI-based models for the precipitation modeling which is a common type of artificial neural network (ANN). Recently, FFNN has become more popular due to its ability and robustness to detect involved patterns in the various range of data. For example, Guhathakurta (2008) employed ANN for prediction of the monthly precipitation over 36 stations of India to forecast the monsoon precipitation. The model could catch nonlinear interactions among input and output data and forecast the seasonal precipitation. It was found that the most dominant input in modeling is precipitation at previous time steps (as a Markovian process). Likewise, Abbot and Marohasy (2012) predicted monthly and seasonal precipitations up to 3 months in advance over Queensland, Australia, using dynamic, recurrent, and time-delay ANNs. More recently, Khalili et al. (2016) employed the Hurst rescaled range statistical analysis to evaluate the predictability of the available data for monthly precipitation prediction for Mashhad City, Iran. Devi et al. (2017) applied ANNs for forecasting the precipitation time series using the temporal and spatial precipitation intensity data and proved wavelet Elman models as the best model for precipitation forecasting. Mehdizadeh et al. (2018) introduced two novel hybrid models of artificial neural networks-autoregressive conditional heteroscedasticity (ANN-ARCH) and gene expression programming-autoregressive conditional heteroscedasticity (GEP-ARCH) for forecasting monthly precipitation time series. They indicated that GEP-ARCH and ANN-ARCH methods could lead to reliable outcomes for the studied regions with different climatic conditions. They also revealed that ANN-ARCH method can present more reliable results with regard to GEP-ARCH method.
Despite of the great ability of ANN in predicting of the hydroclimate parameters (e.g., precipitation), this method may show shortcomings in dealing with hydrological time series which are generally non-stationary and include a wide range of scales (from a few minutes to several decades). Consequently, in this condition, data pre-processing may be an essential step to overcome similar problems and defects (Adamowski et al. 2012; Nourani et al. 2018a).
The ability of wavelet transforms (WTs) in decomposing the non-stationary hydrological time series to sub-series at several time scales can be an effective tool for the interpreting of hydrological phenomena. WT as a mathematical function is utilized to decompose the main signals into some sub-signals and elevates the ability of the model by extracting the useful information at different scales (Nourani et al. 2019a, b). In predicting precipitation, the hybrid Wavelet-ANN (WANN) as a hybrid model is a useful method which applies the WT to get the several frequencies of the precipitation time series and ANN to forecast the future precipitation. Previous studies highlighted the great abilities of the hybrid WANN models in the optimization and forecasting of the hydrological processes such as precipitation modeling (Nourani et al. 2019a, b).
Notwithstanding the reliable performance of hybrid WANN model in precipitation modeling, there are some flaws which can be addressed in WANN modeling. For example, the data-processing phase should be performed separated from ANN model’s framework (Sharghi et al. 2018, 2019). Furthermore, while previous studies demonstrated that the data pre-processing via WT could modify the efficiency of the model through diverse timescales, the improvements in small timescales (like daily or hourly) are not quite tangible as it is in large-scale time series (such as monthly and seasonally). The reason of the difference in tangibility is that the seasonal patterns in most of the hydrological processes especially precipitation have more domination in large timescales (see Shiri and Kisi 2010; Kisi and Cimen 2012).
Recently, emotional artificial neural network (EANN) models have been developed and applied as a modern generation of classic ANN-based models by combining the artificial emotions and ANN technique (Lotfi and Akbarzadeh 2014, 2016). From the biological perspective, neurophysiological reactions of animals can be influenced by hormonal processes. Hence, animals may respond different behaviors to the same event at different moods. According to the biological concept, the incorporation of artificial emotion and ANN can improve the performance of the network via the feedback loop between neuron and hormone systems (Nourani et al. 2019c).
The current study represents the first application of EANN model in multi-step ahead prediction of precipitation. To demonstrate the precision of the EANN model, the results of the single-step-ahead and multi-step-ahead precipitation forecast generated by EANN were compared with the results of FFNN (as a Markov model) and WANN models. The combination of inputs used in the mentioned models is proposed in two different scenarios. In scenario 1, the precipitation for each station forecasted using its previous time steps data. In scenario 2, the inputs which used in forecasting models consist of multi-station data from previous time steps.
2 Materials and methods
2.1 Used data and efficiency criteria
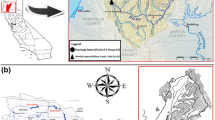
Cyprus is a quite large island with a land area of approximately 9250 km2 which is located in the south of Turkey and east of the Mediterranean Sea (see Fig. 1). Cyprus has two main mountain ranges—the Troodos Massif in the southwest and the Pentadaktylos (Kyrenia) range along the northern coast, which gives Cyprus high topographical variability (Price et al. 1999; Griggs et al. 2014).

(a) Situation map of study area. (b) Location of stations
Since in the proposed methodology, it was tried to find relationship between the precipitation patterns of different stations, consideration of data from far away stations over the whole island may lead to poor performance of modeling and therefore, only a few stations scattered in the northern part of Cyprus were considered in the modeling. In this way, the data from seven main stations of Northern Cyprus which are freely available in meteorological service agency of Northern Cyprus used to predict the precipitation (see Fig. 1). (1) At Ercan International Airport, the summer seasons are arid, hot, and clear, and the winter seasons are windy, cold, and mostly clear. During a year, the temperature characteristically differs from 4 to 35 °C and is hardly below 0 °C or above 37 °C. (2) Famagusta’s (Gazimağusa) climate is classified as warm and temperate. In winter, there is much more precipitation in Famagusta than in summer. The average temperature in Famagusta is 19.3 °C, and the mean precipitation is 407 mm. (3) The prevailing climate in Lefkoniko (Geçitkale) is known as a local steppe climate. During the year, there is little precipitation in Lefkoniko, and the mean annual temperature is 19.1 °C. (4) Kyrenia (Girne) station’s climate is warm and temperate, and the mean annual precipitation is 382 mm. The winters are rainier than the summers. In Kyrenia, the mean annual temperature is 19.6 °C. Precipitation has an average of 449 mm. (5) Gelveri (Guzelyurt) has a local steppe climate. There is little precipitation throughout the year. In Gelveri, the mean annual values of temperature and precipitation are respectively 18.5 °C and 363 mm. (6) Nicosia (Lefkoşa) has a hot semi-arid climate because of its low annual temperature and precipitation range. Nicosia experiences long, hot, dry summers, and cool to mild winters, with most of the precipitation occurring in winter. (7) Gialousa (Yeni Erenkoy)’s climate is classified as warm and temperate. There is more precipitation in the winter than in the summer in Gialousa. The mean temperature in Gialousa is 18.7 °C, and about 520 mm of precipitation falls annually.
The data averaged over a month (as \( \frac{\sum {P}_i}{N_m} \), where Pi is daily precipitation and Nm is the number of days of each month) were obtained from these seven meteorological stations for 36 years (1982–2017), from January 1, 1982, to December 31, 2017. The characteristics of the stations and also the statistics of the data from the stations are presented in Table 1.
Usually, as a conventional method, linear correlation coefficient (CC) is computed between potential inputs and output to select most dominant input variables for the AI methods such as FFNN (Partal and Cigizoglu 2008; Danandeh Mehr et al. 2019a, b). However, implementation of CC for dominant input selection has been already criticized (e.g., see Nourani et al. 2018b) since for modeling a nonlinear process by a nonlinear approach like FFNN, it will be more feasible to employ a non-linear criterion (e.g., Mutual Information, MI). This is because that despite a weak linear relation, strong non-linear relationships might be existing among input and output parameters. The MI value between random variables of M and N can be written in the form of Yang et al. (2000):
where m and n are the probability distributions of variables M and N; E(m) and E(n) show respectively the entropies of distributions m and n, and E(m,n) is their joint entropy as:
where PMN (m,n) is the joint distribution. The normalized MI values between the observed precipitation time series of all seven stations relative to each other were calculated and tabulated in Table 2. According to Table 2, overall, Ercan’s precipitation data are more non-linearly correlated with the precipitation time series of other stations, maybe due to its central position with regard to the others.
For instance, the auto-correlation function (ACF) plots (correlogram) of Ercan and Nicosia precipitation time series are presented in Fig. 2. According to Fig. 2, the precipitation time series of some stations such as Ercan station are more auto-correlated with 1- and 12-month lags, whereas the precipitation time series of some other stations such as Nicosia station are more auto-correlated with 1-, 2-, and 12-month lags. As noticed previously, CC is unable to recognize the non-linear relation between time series. Therefore, in the following, the normalized MI was employed to determine the non-linear relation between precipitation time series and their lag times. So, it was recognized that the precipitation time series are mostly correlated non-linearly with 1- and 12-month lags in all stations which denotes to both auto-regressive (Markovian) and seasonality of the process (see Fig. 2).

ACF plot and Normalized MI diagram for (a, b) Ercan station and (c, d) Nicosia station
Prior to the modeling, the monthly average precipitation data were first normalized by (Bisht et al. 2015):
where Pnorm is the normalized value of the P(t); and Pmax(t) and Pmin(t) are the max and min values of the observed data, respectively. For training and verifying purposes, the data were divided to two sub-sets. About 75% of whole data were used for calibration, and the rest 25% of data were utilized for verifying the trained methods.
The “root mean square error (RMSE)” and “determination coefficient (DC)” were utilized to assess the efficiency of the prediction models as (Sharghi et al. 2018):
where n is the number of data, Oi is the observed value, Ci is the predicted (computed) value, and \( \widehat{O} \) is the average amount of the observed data. Previous studies indicated that any hydro-environmental method may be adequately evaluated by DC and RMSE criteria (Legates and McCabe 1999).
Also, due to the critical role of the extreme (peak) values in precipitation predicting, Eq. 6 was applied to measure the performance of the model to take the extreme (peak) values of precipitation time series as (Sharghi et al. 2018, 2019):
where DCpeak denotes to DC of peak data; N stands for the number of peak data; and Opi, Cpi, and \( \widehat{O} \) show the observed, predicted, and average amount of the observed peak (extreme) data, respectively.
In this study, the modeling was done via two scenarios. In scenario 1, each station’s own data at pervious time steps were used for predicting the same station’s precipitation at a current time step, while in scenario 2, another station’s data in addition to each station’s data were used for modeling to enhance the prediction performance.
-
Scenario 1:
In scenario 1, it is tried to predict the precipitation using its previous time steps data. So, the prediction of the precipitation could be patterned as:
where \( {P}_{t-1}^i,{P}_{t-2}^i,{P}_{t-12}^i \) are the precipitation data of ith station corresponding to time steps t-1, t-2, and t-12 (or 1, 2, and 12 months (1 year)) ago. Thus, predicted precipitation data \( {P}_t^i \) at time step t is computed as a function of previously precipitation at time steps t-1, t-2, and t-12.
-
Scenario 2:
In scenario 2, the prediction Eq. 7 is modified by introducing precipitation data \( {P}_t^{Ercan} \) from Ercan precipitation station. Hence, the general mathematical of the scenario 2 can be formulated as:
Even though the scenario 2 with a more complex formula utilizes more input data, it is expected that this scenario has more accurate outputs with regard to scenario 1.
2.2 FFNN and EANN models
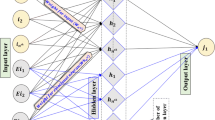
The feed forward neural network (FFNN) as a branch of ANN models has been extensively applied to model different components of the hydrologic cycle (Anmala et al. 2000). A FFNN with three layers of input, output, and hidden, trained by back propagation (BP) algorithm has shown appropriate efficiency in nonlinear hydrological modeling tasks (ASCE 2000; Hornik et al. 1989). It should be noted that NNTOOL of MATLAB was used for ANN modeling and a code was developed for EANN. On the other side, an EANN model is the improved version of a conventional ANN including an emotional system which emits artificial hormones to modulate the operation of each neuron, and in a feedback loop, the hormonal parameters are also adjusted by inputs and output of the neuron (Nourani et al. 2019c; Sharghi et al. 2018, 2019). The schematic of an inner neuron from FFNN and EANN has been depicted in Fig. 3.

By comparison of these two neurons, it is deduced that in contrast to the FFNN in which the information flows only in the forward direction, a neuron of EANN can reversibly get and give information from inputs and outputs and also can provide hormones (e.g., Ha, Hb, and Hc). These hormones as dynamic coefficients are initialized according to the pattern of input (and target) samples and then are modified through the training iterations. Through training phase, they can impact on all components of the neuron (i.e., weights, I, net function, II, and activation function, III, in Fig. 2). In Fig. 3b, the solid and dotted lines respectively show neural and hormonal routs of information. In the EANN model, the output of the ith node with three hormones of Ha, Hb, and Hc is computed as (Nourani et al. 2019c):
where the artificial hormones are calculated as (Nourani et al. 2019c):
In Eq. 9, the applied weight to the activation function (f) is shown by Term (1). It involves the constant neural weight of γi as well as the dynamic hormonal weight of \( \sum \limits_{\mathrm{h}}{\mathit{\partial}}_{\mathrm{i},\mathrm{h}}{H}_{\mathrm{h}} \). The applied weight to the summation function is shown by Term (2), the applied weight to the Xi,j (an input from jth node of the former layer) is shown by Term (3), and the bias of the summation function (including both constant neural weight (μi) and dynamic hormonal weight \( \left(\sum \limits_{\mathrm{h}}{\psi}_{\mathrm{i},\mathrm{h}}{H}_{\mathrm{h}}\right) \)) is shown by Term (4).
The sharing of the overall hormonal level of EANN model (i.e., Hh) among the hormones should be controlled by ∂i, h, χi, h, Φi, j, k, and ψi, h factors which in turn, the ith node output (Yi) will make hormonal feedback of Hi,h to the network as (Nourani et al. 2019c):
where the glandity factor should be calibrated in the training stage of the EANN model to prepare suitable hormone size to the glands. Several designs could be applied to initialize the hormonal values of Hh according to the input samples. Subsequently, considering the output of the network (Yi) and Eqs. 10 and 11, the hormonal values are updated through the learning process to get a suitable match between calculated and observed time series.
2.3 WANN model
Both the FFNN and WANN models are included of three layers, training of error back propagation algorithm. The input layer of the WANN model includes the precipitation time series de-composed to several sub-time series by wavelet transform. It should be noticed that the WT deals with different time scales. The approximation sub-series known as a large-scale sub-signal and the dith/djth detailed sub-series which state short-scale sub-signals are the components of the WT that follows the superposition principle (the combination of them sets the main signal). It should be mentioned that there are different types of mother wavelet which are used in accordance with the type of the process. In this study, “Daubechies-4 (db4)” mother wavelet was used which is more appropriate for hydrological time series decomposition (Danandeh Mehr et al. 2013). Figure 4 shows the schematic structure of the WANN model. After decomposition of the time series by WT, the obtained sub-series are fed into an ANN model.

The schematic diagram of WANN model
3 Results and discussion
FFNN, WANN, and EANN models were separately created via the proposed scenarios 1 and 2. For precipitation prediction of the stations, monthly precipitation data were separately imposed into FFNN, WANN, and EANN models to predict 1-month-ahead precipitation values. Therefore, the structure set of the FFNN, WANN, and EANN models depends on the preference of the precipitation process. The monthly precipitation values are described by both Markovian and seasonal properties (Kisi and Cimen 2012). For this reason, the current precipitation P(t) is related to its previous time steps, P(t-1) and P(t-2), as well as its value at 12 months ago, P(t-12). Consequently, the input values as P(t-1), P(t-2), and P(t-12) were applied to the FFNN, WANN, and EANN models to predict precipitation at time step t (P(t)) for scenario 1 (including more lagged precipitation values, i.e., P(t-3) and P(t-4) did not show higher MI with output and could not improve the efficiency of the modeling). For scenario 2, one more input, Ercan’s station precipitation value as exogenous input, was also considered (in addition to the input of scenario 1) as another input neuron to enhance the prediction performance.
The type of the neural network employed in the FFNN models was a three-layer feed-forward perceptron (with input, output, and hidden layers). To access the best performance of the FFNN model in precipitation simulation, the Levenberg-Marquardt scheme of backpropagation algorithm has been utilized for training FFNN because of its higher convergence rate. Also, the sigmoid Tangent activation function has been utilized as the non-linear kernel of neural networks in this research. The network training process was stopped when the error rate was increased in the verification data. A noticeable issue, particularly in FFNN modeling, which should be considered, is selecting the suitable architecture of mentioned models, i.e., the number of hidden neurons and the number of iterations. It should be noted that 10–1000 training epoch numbers and 1–60 hidden neurons were examined to find the optimum FFNN models. The best elements were obtained by trial-error. The best results by FFNN models for one-step-ahead and three-step-ahead precipitation predictions of all stations are shown in Tables 3 and 4 for both scenarios 1 and 2, respectively. It is evident that the low number of training iterations may cause incomplete training and on the other hand, a large number of epoch can lead to the over-fitting issue.
As it can be seen in Table 4, similar to the single step ahead forecasting, the same input data were considered to be applied to the FFNN model to perform the multi-step ahead (3-month ahead) forecasting. According to the results presented in Tables 3 and 4, the accuracy of the classic FFNN is reduced significantly in the three-step ahead prediction of monthly precipitation due to non-linearly magnification of the error at each time step when the predicted value, which is involved a small error at each time step, is used in the next time step as the current input. For an instant, in Gelveri station, the performance of FFNN model was reduced in training phase by 35% and 27%, for three-step ahead prediction compared to 1-month ahead prediction for scenarios 1 and 2, respectively.
The Markovian characteristic of the precipitation phenomenon was considered by the classic FFNN model, while the seasonality was ignored. To handle the seasonal properties of the precipitation process, the wavelet analysis was linked to the FFNN as hybrid WANN model. Via the WANN modeling, the precipitation time series were decomposed at level 4 into 5 sub-time series (one approximation and four detailed sub-series) by the WT in order to consider the seasonal pattern of the process. WT was used to decompose precipitation time series at level 4 in monthly modeling since 24 = 16 months mode is near to 12. The obtained sub-series were then considered as the candidate inputs of the ANN (FFNN) model. Based on the past studies, the decomposition levels mentioned above and mother wavelet db4 were used with the discrete wavelet-transform (Danandeh Mehr et al. 2013). In order to reduce the dimension of the input vector, occasionally the generated outcomes of the wavelet-transform necessitate feature extraction or interpretation before the mathematical modeling. It should be noted that the feature extraction in this study has done through the application of MI. The best results by WANN models for one-step-ahead and three-step-ahead precipitation predictions of all stations are shown in Tables 5 and 6 for both scenarios 1 and 2, respectively.
The most significant point that can be inferred from the single-step ahead forecasting of the WANN performance is its efficiency with regard to the non-stationary nature of the input time series of the process, which may be resolved by employing the wavelet transform as a suitable data pre-processing tool. It is obvious that the monthly time series not only include fewer samples, but also their seasonal behavior is much remarkable than the Markovian feature (the current precipitation value has the highest relation with the same month’s value in the previous year). Therefore, WANN could overcome both seasonal and autoregressive (Markovian) characteristics of the process. Therefore, WANN showed an acceptable performance for monthly modeling via both scenarios 1 and 2 (see Table 5).
As it can be seen in Table 6, similar to FFNN model, the performance of the WANN model reduced as the prediction horizon is increased because the error is overstated non-linearly and effects the overall accuracy of the modeling. For an instant, in Yeni erenköy station, the accuracy of the WANN was reduced in training phase by 19% and 20%, for three-step ahead predictions of monthly precipitation compared to 1-month ahead prediction for scenarios 1 and 2, respectively.
In spite of the relative efficiency of WANN, the increment of the input data has been caused the considerable increase of the calculation time. Another issue noticed is the diversity of DCs among the verification and training steps. Although in the verification step, the precision of the WANN model has been increased slightly compared to the FFNN model, its precision is still far from the training stage. It should be noted that the WANN model is highly dependent on the number of input data, and the number of samples which is generally fewer in the verification step than the training step.
Thereafter, the EANN models (as another Markov algorithm) with the identical structure (same input and output) were created to predict the precipitation time series of the stations. As it was mentioned in Sect. 2.2, the incorporation of artificial emotion and ANN can improve the performance of the network via the feedback loop between neurons and hormones systems. The EANN model was utilized for precipitation predicting of the stations, and the results are presented in Tables 7 and 8 for one-step ahead and three-step ahead prediction, respectively. As it can be seen in Tables 7 and 8, the number of the hormone for scenario 1 is higher than scenario 2 because of employing the observed data from the Ercan station as exogenous input in simulating other stations’ precipitation.
As it is shown by Tables 3, 4, 5, 6, 7, and 8, the results of the models (FFNN, WANN, and EANN) in scenario 1 show a bit better performance for Ercan station than other stations in the verification phase since this station is located in central and higher parts of the island in contrast to the other stations which are located in shore lines and are impacted more significantly by the irregular variations of the sea condition. This can also be confirmed by the standard variation values presented in Table 1 which show lower values for this station. Also, the results demonstrated in the Tables 7 and 8 indicate that the epoch numbers of both EANN and WANN models-based are remarkably lower than the FFNN model. The difference between the epoch numbers of the models derives from the fast process of training in EANN and WANN models. The external component of EANN model (hormones) and wavelet decomposition part of the WANN model may afford with the training iterations. The results indicated that the EANN model could deal with both seasonal and autoregressive characteristics of the process and it can accurately capture the signal features particularly peak values and obtained comparatively high efficiency, while WANN and FFNN models could not overcome the under/overestimation of the peak values.
In scenario 2, the models of the Kyrenia station in verification step showed better efficiency than others. This can be due to its proximity to Ercan station. In other words, not only the small distance between Kyrenia and Ercan stations but also the predominant wind direction over the island (which is from northwest to southeast) make the precipitation pattern of both stations more similar with regard to the others. This can also be clearly seen from Table 2 which shows higher MI value between these two stations.
Considering the outcomes of both scenarios, because of using Ercan station’s data as exogenous input (in addition to each station’s own data), the results of scenario 2 were better than scenario 1, showing improvement of modeling efficiency up to 17% and 26% in calibration and verification steps, respectively. For instance, Figs. 5, 6, 7, and 8 illustrate the results of the models for the calibration and verification steps and scatter plots for the verification step for Nicosia and Gialousa stations based on scenarios 1 and 2, respectively.

(a) Observed versus computed precipitation time series by FFNN, WANN, and EANN models. (b) Observed versus computed (a detail) and scatter plots for verification step for (c) EANN and (d) WANN models via scenario 1 for Nicosia station

(a) Observed versus computed precipitation time series by FFNN, WANN, and EANN models. (b) Observed versus computed (a detail) and scatter plots for verification step for (c) EANN and (d) WANN models via scenario 2 for Nicosia station

(a) Observed versus computed precipitation time series by FFNN, WANN, and EANN models. (b) Observed versus computed (a detail) and scatter plots for verification step for (c) EANN and (d) WANN models via scenario 1 for Gialousa station

(a) Observed versus computed precipitation time series by FFNN, WANN, and EANN models. (b) Observed versus computed (a detail) and scatter plots for verification step for (c) EANN and (d) WANN models via scenario 2 for Gialousa station
As it can be seen from Tables 3, 4, 5, 6, 7, and 8 and Figs. 5, 6, 7, and 8, generally in most cases, the performance of EANN model was better than other models; however, in some cases, the WANN model’s performance was better than others. According to Tables 3, 4, 5, 6, 7, and 8 and scatterplots in Figs. 5, 6, 7, and 8, the superiority of EANN to capture the peak points of precipitation time series in all of the stations compare to FFNN has been illustrated in calculated values of DC peak. Based on the Markovian characteristic of the process, for prediction of the system state at the upcoming time step, autoregressive models use the states of the process at designated earlier time steps. Therefore, the imposition of an instantaneous external force to the network typically may lead to underrating the peak values in autoregressive models. In this condition, the network will experience an emotional situation which is dissimilar to normal situations of the network. Therefore, in the training process of the model, a hormone from the emotional part of EANN acts as a dynamic component which reputedly sends the feedback to other parts of the system and adjusts the mode for the emotional condition. From the mathematical perspective, the dynamic hormones get activated in the occurrence of unusual conditions. With no need for any external data processing unit, the dynamic hormones magnify and modify the weights of the network within the EANN framework. Conversely, during the training process of FFNN, the network does not capture the severe variations of the system. Consequently, when a statistical component of the network begins the training using the data of normal condition, an unexpected advent of severe precipitation values in the input data can diversify the trained components. Then, by returning the condition of the system to its normal state, the confusion keeps continuing in the training process. This is why appropriate training of FFNN models typically requires long data sets with regard to the EANN method.
4 Conclusions
The current research has presented the first application of EANN model (as a new generation of ANN-based models) for precipitation forecasting. To assess the efficiency of the EANN model for multi-step ahead prediction of monthly precipitation of the seven stations located in the TRNC, its results were compared with the results of hybrid WANN and conventional FFNN models. Two scenarios were considered with different input variables that in scenario 1, each station’s own pervious data were used for modeling, while in scenario 2, the central station’s (Ercan station) data were also employed in addition to each station’s own data. The results of two employed scenarios indicated that scenario 2 had better performance and could enhance the modeling efficiency up to 26%, in the verification step because of employing the observed data from the Ercan station as exogenous input.
The analysis of the results in terms of computed DC, RMSE, and DCpeak values shows that the EANN model provides better results with regard to the other models (WANN and FFNN) specially to capture the peak points. Also, the results derived from the fast process of training in EANN and WANN models with regard to the FFNN model. In other word, the hormones of the EANN model and wavelet decomposition part of the WANN model may afford with the training iterations.
With the recent developments in the ANN-based models, although EANN model has been reliably employed to model time series of various hydroclimatic variables (including precipitation), it is obvious that for a particular problem, different outcomes may be obtained from different models over different spans of the time series. With this regard, and as a research plan for the future, it is suggested that different ensemble approaches would provide the results with minimum error variance.
References
Abbot J, Marohasy J (2012) Application of artificial neural networks to rainfall forecasting in Queensland, Australia. Adv Atmos Sci 29(4):717–730
Anmala J, Zhang B, Govindaraju RS (2000) Comparison of ANNs and empirical approaches for predicting watershed runoff. J Water Resour Plann Manage 126(3):156–166
Adamowski J, Chan E, Prasher S, Ozga-Zielinski B, Sliusareva A (2012) Comparison of multiple linear and non-linear regression, autoregressive integrated moving average, artificial neural network, and wavelet artificial neural network methods for urban water demand forecasting in Montreal, Canada. Water Resour Res 48(1):1156–1168
ASCE Task Committee on Application of Artificial Neural Networks in Hydrology (2000) Artificial neural networks in hydrology. II: hydrologic applications. J Hydrol Eng 5(2):124–137
Bisht D, Joshi MC, Mehta A (2015) Prediction of monthly rainfall of Nainital region using artificial neural network and support vector machine. Int J Adv Res Innov Ideas Educ 1(3):2395–4396
Chau KW (2017) Use of meta-heuristic techniques in rainfall-runoff modelling. Water 9(3):186
Danandeh Mehr A (2018) Month ahead rainfall forecasting using gene expression programming. J Earth Environ Sci 1(2):63–70
Danandeh Mehr A, Kahya E, Olyaie E (2013) Streamflow prediction using linear genetic programming in comparison with a neuro-wavelet technique. J Hydrol 505:240–249
Danandeh Mehr A, Nourani V, Hrnjica B, Molajou A (2017) A binary genetic programming model for teleconnection identification between global sea surface temperature and local maximum monthly rainfall events. J Hydrol 555:397–406
Danandeh Mehr A, Jabarnejad M, Nourani V (2019a) Pareto-optimal MPSA-MGGP: a new gene-annealing model for monthly rainfall forecasting. J Hydrol 571:406–415
Danandeh Mehr A, Nourani V, Khosrowshahi VK, Ghorbani MA (2019b) A hybrid support vector regression-firefly model for monthly rainfall forecasting. Int J Environ Sci Technol 16(1):335–346
Devi SR, Arulmozhivarman P, Venkatesh C (2017) ANN based rainfall prediction - a tool for developing a landslide early warning system. In: Advancing culture of living with landslides- workshop on world landslide forum. pp 175–182
Ghorbani MA, Kazempour R, Chau KW, Shamshirband S, Ghazvinei PT (2018) Forecasting pan evaporation with an integrated artificial neural network quantum-behaved particle swarm optimization model: a case study in Talesh, northern Iran. Eng Appl Comput Fluid Mech 12(1):724–737
Guhathakurta, P (2008) Long lead monsoon rainfall prediction for meteorological sub-divisions of India using deterministic artificial neural network model. Meteorology and Atmospheric Physics 101(2):93–108
Griggs C, Pearson C, Manning SW, Lorentzen B (2014) A 250-year annual precipitation reconstruction and drought assessment for Cyprus from Pinus brutia ten. Tree-rings. Int J Climatol 34:2702–2714
Hornik K, Stinchcombe M, White H (1989) Multilayer feedforward networks are universal approximators. Neural Networks 2:359–366. https://doi.org/10.1007/s00704-019-02904-x
Khalili N, Khodashenas SR, Davary K, Mousavi B, Karimaldini F (2016) Prediction of rainfall using artificial neural networks for synoptic station of Mashhad: a case study. Arab J Geosci 9(624)
Kisi O, Cimen M (2012) Precipitation forecasting by using wavelet-support vector machine conjunction model. Eng Appl Artif Intell 25(4):783–792
Legates DR, McCabe GJ Jr (1999) Evaluating the use of goodness-of-fit measures in hydrologic and hydroclimatic model validation. Water Resour Res 35(1):233–241
Lotfi E, Akbarzadeh-T MR (2014) Practical emotional neural networks. Neural Netw 59:61–72
Lotfi E, Akbarzadeh-T MR (2016) A winner-take-all approach to emotional neural networks with universal approximation property. Inf Sci 347:369–388
Mehdizadeh S, Behmanesh J, Khalili K (2018) New approaches for estimation of monthly rainfall based on GEP-ARCH and ANN-ARCH hybrid models. Water Resour Manag 32(2):527–545
Nourani V, Molajou A (2017) Application of a hybrid association rules/decision tree model for drought monitoring. Glob Planet Chang 159:37–45
Nourani V, Sattari MT, Molajou A (2017) Threshold-based hybrid data mining method for long-term maximum precipitation forecasting. Water Resour Manag 31(9):2645–2658
Nourani V, Davanlou Tajbakhsh A, Molajou A (2018a) Data mining based on wavelet and decision tree for rainfall-runoff simulation. Hydrol Res 50(1):75–84
Nourani V, Razzaghzadeh Z, Hosseini Baghanam A, Molajou A (2018b) ANN-based statistical downscaling of climatic parameters using decision tree predictor screening method. Theor Appl Climatol. https://doi.org/10.1007/s00704-018-2686-z
Nourani V, Molajou A, Davanlou Tajbakhsh A, Najafi H (2019a) A wavelet based data mining technique for suspended sediment load modeling. Water Resour Manag 33(5):1769–1784
Nourani V, Davanlou Tajbakhsh A, Molajou A, Gokcekus H (2019b) Hybrid Wavelet-M5 Model tree for rainfall-runoff modeling. J Hydrol Eng 24(5). https://doi.org/10.1061/(ASCE)HE.1943-5584.0001777
Nourani V, Molajou A, Najafi H, Mehr AD (2019c) Emotional ANN (EANN): a new generation of neural networks for hydrological modeling in IoT. In: Artificial Intelligence in IoT. Springer, Cham, pp 45–61
Partal T, Cigizoglu HK (2008) Estimation and forecasting of daily suspended sediment data using wavelet-neural networks. J Hydrol 358(3–4):317–331
Price C, Michaelides S, Pashiardis S, Alperta P (1999) Long term changes in diurnal temperature range in Cyprus. Atmos Res 51(2):85–98
Sharghi E, Nourani V, Najafi H, Molajou A (2018) Emotional ANN (EANN) and wavelet-ANN (WANN) approaches for Markovian and seasonal based modeling of rainfall-runoff process. Water Resour Manag 32(10):3441–3456
Sharghi E, Nourani V, Molajou A, Najafi H (2019) Conjunction of emotional ann (eann) and wavelet transform for rainfall-runoff modeling. J Hydroinf 21:136–152. https://doi.org/10.2166/hydro.2018.054
Shiri J, Kisi O (2010) Short-term and long-term streamflow forecasting using a wavelet and neuro-fuzzy conjunction model. J Hydrol 394:486–493
Wu CL, Chau KW (2011) Rainfall–runoff modeling using artificial neural network coupled with singular spectrum analysis. J Hydrol 399(3–4):394–409
Yang HH, Vuuren SV, Sharma S, Hermansky H (2000) Relevance of timefrequency features for phonetic and speaker-channel classification. Speech Comm 31:35–50
Yaseen ZM, Sulaiman SO, Deo RC, Chau KW (2019a) An enhanced extreme learning machine model for river flow forecasting: state-of-the-art, practical applications in water resource engineering area and future research direction. J Hydrol 569:387–408
Yaseen ZM, Ebtehaj I, Kim S, Sanikhani H, Asadi H, Ghareb MI, Bonakdari H, Mohtar WH, Al-Ansari N, Shahid S (2019b) Novel hybrid data-intelligence model for forecasting monthly rainfall with uncertainty analysis. Water 11(3):502
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Nourani, V., Molajou, A., Uzelaltinbulat, S. et al. Emotional artificial neural networks (EANNs) for multi-step ahead prediction of monthly precipitation; case study: northern Cyprus. Theor Appl Climatol 138, 1419–1434 (2019). https://doi.org/10.1007/s00704-019-02904-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-019-02904-x