
Abstract
Artificial neural network and a statistical model have been applied in a laboratory scale trickle bed reactor (TBR) to investigate the SO2 removal efficiency of activated carbon. The performance of artificial neural network (ANN) model has been compared with the statistical model based on central composite experimental design. Two independent variables, which affect the amount of SO2 removal by the liquid phase in the TBR, were selected; namely liquid flow rate and gas flow rate. Amount of SO2 removal was chosen as the dependent variable (target data). A second order statistical model has been considered to show the dependence of the amount of SO2 removal on the operating parameters. A back-propagation ANN has been used to develop a model relating to the amount of SO2 removal. A series of experiments have been conducted on the basis of the statistics-based design of experimental method. It is observed that a neural network architecture having one input layer with two neurons, one hidden layer with three neurons, one output layer with one neuron and an epoch size of 20 gives better prediction. The predictions are more accurate than those obtained from regression models.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
One of the foremost air-polluting emissions is sulfur-dioxide gas (SO2). SO2 combines with water vapor in the air and then this gas forms droplets of sulfuric acid, which fall to the ground as acid rain, causing harm to every living and non-living things.
This introduces an important environmental problem. Today one of the processes used for the removal of SO2 in flue gases is the trickle bed reactor (TBR). The trickle bed reactor where a liquid phase and gas phase flow concurrently downward through packed bed of catalyst particle, while any reaction takes place. The advantages of the system such as working at low liquid flow rates, low gas–solid and gas–liquid mass transfer resistance in gas–liquid–solid catalytic reactions, and non-stop processing with intermittent fluid flow make the trickle bed reactors preferable [1, 13, 16, 17]. The trickle bed reactor is extensively used in hydrotreating and hydrodesulfurization in the refining industry, in hydrogenation, oxidation and hydrodenitrogenation in the petrochemical, biochemical, and water treatment industries [4].
The artificial neural network (ANN) has developed rapidly. Neural network has the ability to learn from the pattern acquainted before. The network is trained with sufficient number of sample data sets and then it can make predictions when new input data sets of the similar pattern are given. Hence, ANN is successfully used in many industrial areas as well as in research areas for the prediction of various complex parameters from simple input parameters [5, 7].
In order to determine the operating conditions in the laboratory scale trickle bed reactor, a statistical model and an artificial neural network have been used. Standard statistical methods generally place constraints. Nevertheless, to apply ANN, further studies on larger dataset for prediction may be needed and ANN model has to be smooth, otherwise the neural network can be unstable or can provide poor learning capacity and proposed a new learning algorithm for neural networks approximation [11, 12]. The experimental data used in the preparation of this statistical model were obtained by the use of experimental design (two-level factorial or central composite etc.) which has been used over a wide range of industrial process [9, 10].
In the statistical model, two-level factorial experimental design and active experimentation have been used in mathematical modeling of the industrial process and optimization. This experimental modeling technique allows the determination of the regression equation in a very short time. The parameters (factor) such as liquid flow rate and gas flow rate are changed according to the predetermined levels. When S and K represent the level of one parameter and the number of parameters, respectively then the number of experiments for linear model can be shown as N = S K. A central composite experimental design was used in the non-linear model. Each numeric factor is varied over 5 levels plus and minus alpha (1.41 axial points), plus and minus 1 (factorial points) and the center point to check for infeasible extremes. For this, minimum nine experiments are required.
Response surface methodology comprises a group of statistical techniques for model building and model exploitation. By careful design and analysis of experiments, it seeks to relate a response to the levels of a number of predictors or input variables that affect it. It allows calculations to be made of the response at intermediate levels, which were not experimentally studied, and shows the direction where to move if we wish to change the input levels so as to increase the response. Response surface methodology using experimental design was utilized to determine the response of two input variables [9].
In this study, statistical methods and artificial neural network were used to make prediction on the percentage of SO2 removed by the liquid phase in a TBR with periodic liquid flow and activated carbon bed using air + SO2 mixture as gas phase and distilled water as the liquid phase. Leaving apart some stray cases, ANN is able to predict the amount of SO2 removal with reasonably low prediction error. For the set of data used for constructing the network, the mean square errors are comparatively lower in the neural network model than the regression model.
2 Materials and methods
The experiments for the catalytic oxidation of SO2 in the flue gas were performed in a laboratory scale TBR. Specifications of the TBR used in the experiments were given in Table 1. In this study activated carbon granules were used as the catalyst. SO2 gas and air carrier gas were mixed and fed to the system from the top. In the liquid phase distilled water was fed to the system from the top of the reactor. The experimental system was shown in Fig. 1.

Scheme of experimental setup
The activated carbon granules (0.841–1.19 mm) were washed with water at 90°C for 30 min, then dried at 120°C and made ready for the use. To create a uniform flow the catalyst bed was filled with inert glass beads to a height of 3.5 cm, between these zones there existed the activated carbon granules forming the active zone with a height of 13 cm. The experiments were performed at various liquid and gas flow rates keeping the SO2% constant (gas stream containing 2.84% SO2 by volume) at periodic operation. The experiments made periodically continued for 45 min.
In the experiments the liquid leaving the column at each period was analyzed titrimetrically. A 10 ml sample was taken from the liquid, 0.1 M hydrogen peroxide (H2O2) solution was added in order to convert sulfurous acid into sulfuric acid. Sulfuric acid was titrated with standardized 0.1 N sodium hydroxide and phenolphthalein indicator and SO2 absorbed in the liquid phase was determined.
The gas stream leaving the TBR was passed through absorption bottle containing hydrogen peroxide solution and the amount of SO2 in the gas phase was determined titrimetrically [17].
3 Statistical modeling
In order to calculate the amount of SO2 removed, values of gas and liquid flow rate were evaluated by utilizing the response surface methodology. In this method, the form of the relationship between the independent variables is unknown. Therefore a suitable function expressing the relationship between the dependent and independent variables can be obtained by using statistical models. Their form, which is studied in this work, are shown below:
The relationship between coded (X i ) and real (U i ) values is shown below:
In these equation X i (i = 1,…,n) are the coded values of the liquid flow rates and gas flow rates respectively, b i are the model coefficients. Y i are the measured values of the amount of SO2 removal. In the experimental design there are n variables (factors). These factors are controlled at different levels. In these types of designs one works in dimensionless coordinate system using the above definitions.
The model coefficients b i , were calculated by Using Design Expert software and shown in Sect. 4.
4 The results of statistical modeling
In the preparation of the design matrix the coded values of the parameters are used. The reason for this is to render the parameters dimensionless thus makes the calculations dimensionless. The levels of these parameters are given in Table 2. For this reason nine experiments were done to identify the regression model. The design matrix included coded values of the independent and uncoded dependent variables. Table 3 shows the interrelation between the coded independent variables. The column (Table 3) under X0 contains the dummy variable, which is equal to 1 in order for the model to include an intercept. All the weights will be unity.
Final equation in terms of coded factors:
Final equation in terms of actual factors:
Quadratic model fitted the experimental data well. For this the above equations were based on quadratic model. Table 4 was given lack of fit test, which explained the fitness of the above model with respect to maximum SO2 removal. Model summary statistics were given in Table 5. According F values of the quadratic model being the higher order polynomial, low standard deviation and high R squared statistics were selected among linear and 2FI. ANOVE for response surface quadratic model gave the sum of squares and degrees of freedom for the model terms from which mean square of the model terms were calculated. F value of the quadratic model and individual model terms helped in finding their significance. The model F value of 35.43 implies that the model was significant. Values of “Prob > F” less than 0.05 indicate significant model terms. Thus A, A2 were significant model terms (Table 6).
After the identification of the statistical model for the process, the 3D contour plot of the effect of two significant variables on the amount of SO2 removal by the liquid phase in the TBR was shown in Fig. 2. Figure 2 showed that the range of liquid flow rate affected the amount of SO2 removal very little.

3D diagram showing the effect of gas and liquid flow rate on the amount of SO2 removal
5 Artificial neural network
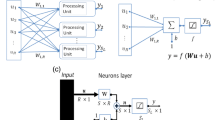
The development of the ANN approach has been very fast for 30 years. An important characteristic of ANN is the ability to learn from the pattern acquainted before. Once the training of the network is achieved, with sufficient number of sample data sets, it can make predictions on the basis of its previous learning. Therefore, this technique has been used in many researches such as industrial process control, modeling, optimization, system design. Before interpreting new information, training must be done. Some algorithms are available for the training of neural networks. One of them is the back propagation algorithm which is the most popular, effective and easy to use multilayer neural networks. The feed forward back propagation neural network (BPANN) consists of at least three layers which are input layer, several hidden layers and output layer. Each layer consists of a number of elementary processing units which are mentioned as neurons. Each neuron in the input layer is connected to its hidden layer through weights. Also there is connection between hidden and output layers. The number of neurons in the hidden layer is chosen directly according to the problem to be solved. The number of input and output neurons is chosen as the number of input and output variables, respectively.
Bias values are introduced to differentiate between the different processing units in the transfer functions. All the neurons in the back propagation network except the ones in the input layer are associated with a bias neuron and a transfer function. The bias which has a constant input of 1 is like a weight, while the transfer function filters the sum of the signals that is received from the neuron mentioned. These transfer functions map the neuron mentioned. These transfer functions are simple step functions which can be linear or non-linear. The design and application of these transfer functions depends on the purpose of the neural network. The computed output vectors change corresponding to the solution. These vectors are produced by the output layer.
The net input values in the hidden layer are given by the following equation
where Xi, Wij, bj and n are the input units, the weight on the connection of ith input and jth neuron, the bias neuron, and the number of input units, respectively.
The net output from hidden layer is given below:
where F is the transfer function.
The total input to the kth unit is expressed as
where, bk and Wjk are the bias neuron and the weight between jth neuron and kth output, respectively. The total output is given as
An input pattern and a corresponding desired output pattern present a network in the learning process. The network evaluates its own output pattern using its weights which are mostly incorrect, and thresholds by comparing the actual output with the desired output.
In the training procedure of the network, data are processed through the input layer to hidden layer until it passes the output layer. Comparison of the output and the measured values are achieved in this layer. The error is processed back through the network which updates the individual weights of the connections and the biases of the individual neurons. The input and output data vectors are called as training pairs. The process which is mentioned above is repeated for all the training pairs in the data set. The end is generally defined as a threshold minimum which the network error converged to. The threshold minimum is defined by a cost function which includes the root mean squared error (RMS) or summed squared error (SSE).
The connection of the jth neuron with a number of input is shown in Fig. 3.

Structure of a multi-layer feed forward neural network
Back propagation process is responsible for updating the network weights based on minimizing the mean squared error between the output values and the target values in output layer. This is defined as training of the network. The following rule is utilized for the descent down error surface.
where η and E present the learning rate parameter and the error function, respectively.
To update the weights for the (n + 1)th pattern the following equation can be written
To obtain the connections between the hidden and output layers, a similar logic is applied. In all the training patterns, this procedure is repeated and this is called a cycle or epoch. To reach the user-specified final error, the procedure is repeated as many epochs as needed. The user-specified goal which may be reached successfully, is the measure of how well the network has learned [3, 5, 14].
6 The results of ANN technique
In our case, more inputs are available and the outputs. Fernandes and Lona [6] noted that one hidden layer is generally enough and according to Tamura and Tateishi [15] if N − 1 neurons are utilized in the hidden layer (where N presents the number of inputs), the NN will give an exact prediction. This recommendation works well when the system has several inputs and the correlation between the data set (inputs and outputs) is not very complex; otherwise their recommendation will not always work and it is advanced that 8–20 neurons in the hidden layer for better precision and shorter training time are better to choose. If the number of outputs is equal to or higher than four and they are dependent to each other then a second hidden layer might be needed for better predictions.
To train a NN, considerable number of data points is needed as a starting point. The use of 20 times the number of inputs x outputs are recommended [6]. This number is mainly greater than the number of points that made training insensitive to extra data. And it is recommended that the number of total hidden neurons should be about four times greater than the number of inputs x outputs displayed in many hidden layers, using these numbers, prediction errors between 2 and 10% are obtained. By reducing the number of data points, the prediction errors can be increased. Neural networks may not predict well in some cases near the borders of their training range. Extending the training range can minimize the border problem. In this case the region of interest falls within ±41% of the top range.
In this study, we selected the feed forward BPANN. The transfer function in the hidden layers was differentiable tan-sigmoid function (tansig). The transfer function in the output layer was linear function (purelin). The BPANN was categorized as 2 + 3 + 1, which means one input layer with two neurons which are the values from gas flow rate and liquid flow rate, two hidden layer with two and three neurons and one output layer with one neuron. SO2 removal is the target value of the neuron in the output layer. Data obtained from experimental design was used for training of the ANN and the data of other experimental were used for testing the trained network. The training data set was given to the network and a feed forward algorithm automatically adjusted the weights so that the output response to input values was as close as possible to the desired response. Prediction was made and results were compared with the desired value. Then the prediction error was distributed across the network in a manner, which allowed the interconnection weights to be modified according to the scheme specified by the learning rule. This process was repeated while the prediction error decreased. Two training algorithms, gradient descent (traingd) and levenberg Marquardt (trainlm) were used to train the BPANN. Traingd works by updating the weights and biases in the direction of negative gradient of mean squared errors (MSE). Trainlm is based on the Levenberg–Marquardt optimization. It is a very efficient training algorithm as it includes improvement technologies to increase the speed and reliability [2, 8]. These two algorithms both work by iteratively adjusting the weights and biases of the network to minimize the performance function. The performance function is the MSE between the output and the target values. Figures 4 and 5 show the training curves of these two algorithms. The training epochs (iterations) for trainlm were 20, while the epochs for traingd were 2,000. These observations indicate that the training function of trainlm is much faster than traingd. The Levenberg–Marquardt algorithm was selected to retain in ANN training and prediction.

Training curve of gradient descent algorithm

Training curve of Levenberg–Marquardt algorithm
7 ANN and statistical model prediction
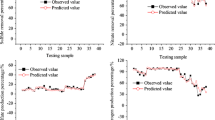
After constructing and training, the output of the ANN was compared with the experimental data for the trained and test data sets in Figs 6 and 7, respectively. Also the output of the ANN was compared with the statistical model data for the trained and test data sets (Table 7) in Figs 6 and 7, respectively. Experimental data are distributed along the ANN predicted line which indicates the ANN prediction is better than statistical model data.

Comparison of ANN and statistical model performance (b, c: training data set used for a)

Comparison of ANN and statistical model performance (test data)
8 Conclusions
Artificial neural network has been used in order to predict the SO2 removal efficiency of activated carbon in a trickle bed reactor and the performance of ANN model has been compared with the statistical model. The artificial neural network is able to predict the properties with reasonably low prediction error. For the set of data used for constructing the network, the mean square errors are comparatively lower in the neural network model than the statistical regression model. In the present work, the practical usage of the theoretical findings is useful for the design/scaling up of a safer processing and control of trickle bed reactor.
Abbreviations
- b i :
-
Statistical model coefficients
- U i :
-
Real value of the parameters
- U iav :
-
Average values of the parameters
- U * i :
-
Average value of the independent variables at centre points
- ΔU i :
-
Incremental value of the parameters
- U 1 :
-
Liquid flow rate
- U 2 :
-
Gas flow rate
- X 1 :
-
Coded value of the liquid flow rate
- X 2 :
-
Coded value of the gas flow rate
- ISE:
-
Error square integral
- Yi :
-
ith experimental value of the amount of SO2 removal
- TBR:
-
Trickle bed reactor
- Prob > F :
-
Probability of seeing the observed F value if the null hypothesis is true. Small probability values call for rejection of null hypothesis. The probability equals the proportion of the area under the curve of the F distribution that lie beyond the observed F value. The F distribution itself is determined by the degrees of freedom associated with the variances being compared
- R squared:
-
A measure of the amount of deviation around the mean explained by the model
- Mean squared:
-
Sum of squares divided by DF
- Model F value:
-
A test for comparing model variance with residual variance. If the variances are close to the same the radio will be close to one and it is less likely that any of the factors have a significant effect on the response calculated by model mean square divided by residual mean square
- DF :
-
Degrees of freedom
References
Castellari AT, Haure PM (1995) Experimental study of the periodic operation of a trickle bed reactor. AIChE J 41(6):1593–1597. doi:10.1002/aic.690410624
Coşkun N, Yıldırım T (2003) The effects of training algorithms in MLP network on image classification, vol 2. In: International joint conference on neural networks (IJCNN), Portland, Oregon, USA, pp 1223–1226
Dernuth H, Beale M (1992) Matlab neural network toolbox. The Math Works Inc., Natick, pp 6.2–6.3
Dudukovic MP, Larachi F, And Mills PL (2002) Multiphase catalytic reactors: a perspective on current knowledge and future trends. Catal Rev 44:123–246. doi:10.1081/CR-120001460
Fausett L (1994) Fundamental of neural networks—architectures, algorithms, and applications. Prentice-Hall, Englewood cliffs
Fernandes FAN, Lona LMF (2005) Neural network applications in polymerization processes. Brazilian J Chem Eng 22(03):401–418
Lee KT, Bhatia S, Mohamed AR, Chu KH (2006) Optimizing the specific surface area of fly ash-based sorbents for flue gas desulfurization. Chemosphere 62(1):89–96
MATLAB (2002) Version 6.5.0 help files. Math Works Inc
Montgomery DC (2005) Design and analysis of experiments, 6th edn. Wiley, Hoboken
Nunnari G, Dorling S, Schlink U, Cawley G, Foxall R, Chatterton T (2004) Modelling SO2 concentration at a point with statistical approaches. Environ Modell Softw 19(10):887–905
Rubio JJ, Yu W (2006) A new discrete-time sliding—mode control with time-varying gain and neural identification. Int J Control 79(4):338–438
Rubio JJ, Yu W (2007) Stability analysis of nonlinear system identification vis delayed neural networks. IEEE Trans Circuits Syst II 54(2):161–165
Silveston PL, Harika J (2004) Periodic operation of three-phase catalytic reactors. Can J Chem Eng 82(6):1105–1142
Simpson PK (1990) Artificial neural system—foundation, paradigm, application and implementations. Pergamon Press, New York
Tamura S, Tateishi M (1997) Capabilities of a four-layered feedforward neural network: four layers versus three. IEEE Trans Neural Netw 8:251
Uçan HL (2001) The sorption of sulfur dioxide in a trickle bed reactor with periodic liquid flow and activated carbon bed. MS thesis, Gazi University, Ankara
Uçan HL, Özkan G, Biçer A, Pamuk V (2005) Removal of SO2 in a periodically operating TBR with activated carbon bed. Process Saf Environ Prot 83(B1):47–49
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Ozkan, G., Uçan, L. & Ozkan, G. The prediction of SO2 removal using statistical methods and artificial neural network. Neural Comput & Applic 19, 67–75 (2010). https://doi.org/10.1007/s00521-009-0236-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-009-0236-4