
Abstract
While the original classical parameter adaptive controllers do not handle noise or unmodelled dynamics well, redesigned versions have been proven to have some tolerance; however, exponential stabilization and a bounded gain on the noise are rarely proven. Here we consider a classical pole placement adaptive controller using the original projection algorithm rather than the commonly modified version; we impose the assumption that the plant parameters lie in a convex, compact set, although some progress has been made at weakening the convexity requirement. We demonstrate that the closed-loop system exhibits a very desirable property: there are linear-like convolution bounds on the closed-loop behaviour, which confers exponential stability and a bounded noise gain, and which can be leveraged to prove tolerance to unmodelled dynamics and plant parameter variation. We emphasize that there is no persistent excitation requirement of any sort; the improved performance arises from the vigilant nature of the parameter estimator.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Adaptive control is an approach used to deal with systems with uncertain or time-varying parameters. The classical adaptive controller consists of a linear time-invariant (LTI) compensator together with a tuning mechanism to adjust the compensator parameters to match the plant. The first general proofs that adaptive controllers could work came around 1980, e.g. see [1,2,3,4,5]. However, such controllers were typically not robust to unmodelled dynamics, did not tolerate time variations well, and did not handle noise or disturbances well, e.g. see [6]. During the following two decades, a great deal of effort was made to address these shortcomings. The most common approach was to make small controller design changes, such as the use of signal normalization, deadzones, and \(\sigma \)-modification, to ameliorate these issues, e.g. see [7,8,9,10,11]. Quite surprisingly, it turns out that simply using projection (onto a convex set of admissible parameters) has proved quite powerful, and the resulting controllers typically provide a bounded-noise bounded-state property, as well as tolerance of some degree of unmodelled dynamics and/or time variations, e.g. see [12,13,14,15,16,17]. Of course, it is clearly desirable that the closed-loop system exhibits LTI-like system properties, such as a bounded gain on the noiseFootnote 1 and exponential stability. As far as the author is aware, in the classical approach to adaptive control a bounded gain on the noise is proven only in [12, 13]; however, a crisp exponential bound on the effect of the initial condition is not provided, and a minimum phase assumption is imposed. While it is possible to prove a form of exponential stability if the reference input is sufficiently persistently exciting, e.g. see [18], this places a stringent requirement on an exogenous input.
There are several non-classical approaches to adaptive control which provide LTI-like system properties. First of all, in [19, 20] a logic-based switching approach is used to sequence through a predefined list of candidate controllers; while exponential stability is proven, the transient behaviour can be quite poor and a bounded gain on the noise is not proven. A more sophisticated logic-based approach, labelled supervisory control, was proposed by Morse; here a supervisor switches in an efficient way between candidate controllers—see [21,22,23,24,25]. In certain circumstances a bounded gain on the noise can be proven—see [26, 27], and the Concluding Remarks section of [22]. A related approach, called localization-based switching adaptive control, uses a falsification approach to prove exponential stability as well as a degree of tolerance of disturbances, e.g. see [28].
Another non-classical approach, proposed by the first author, is based on periodic probing, estimation, and control: rather than estimate the plant or controller parameters, the goal is to estimate what the control signal would be if the plant parameters and plant state were known and the ‘optimal controller’ were applied. Exponential stability and a bounded gain on the noise are achieved, as well as near optimal performance, e.g. see [29,30,31]; a degree of unmodelled dynamics and time variations can be allowed. Roughly speaking, the idea is to estimate the ‘optimal control signal’ at every step; this differs from the classical approach to adaptive control wherein the goal is to (at best) obtain an asymptotic estimate of the ‘optimal control signal’. In order to carry out this estimation, a sampled data approximation of a differentiator is used, with optimality being achieved as the sampling period tends to zero. The drawback is that while a bounded gain on the noise is always achieved, it tends to increase dramatically the closer that one gets to optimality. Because of the nature of the approach, it only works in the continuous-time domain.
In this paper we consider the discrete-time setting and we propose an alternative approach to obtaining LTI-like system properties. We return to a common approach in classical adaptive control—the use of the projection algorithm to carry out parameter estimation together with the certainty equivalence principle. In the literature it is the norm to use a modified version of the ideal projection algorithm in order to avoid division by zero;Footnote 2 in this paper we prove that an unexpected consequence of this minor adjustment is that some inherent properties of the scheme have been destroyed. Here we use the original version of the projection algorithm coupled with a pole placement certainty equivalence-based controller. In the general case we impose compactness and convexity assumptions on the set of admissible parameters; however, some progress has been made at weakening the convexity requirement. We obtain linear-like convolution bounds on the closed-loop behaviour, which immediately confers exponential stability and a bounded gain on the noise; such convolution bounds are, as far as the authors are aware, a first in adaptive control, and it allows us to use a modular approach to analyse robustness and tolerance to time-varying parameters, which is a highly desirable feature. Indeed, this allows us to utilize all of the intuition that we have developed for LTI systems in the adaptive setting, something which has not been present using other techniques. To this end, the results will be presented in a very pedagogically desirable fashion: we first deal with the ideal plant (with disturbances); we then leverage that result to prove that a large degree of time variations is tolerated; we then demonstrate that the approach tolerates a degree of unmodelled dynamics, in a way familiar to those versed in the analysis of LTI systems.
In a recent short paper we consider the first-order case [32]. Here we consider the general case, which requires much more sophisticated analysis and proofs. Furthermore, in comparison to [32], here we (i) present a more general estimation algorithm, which alleviates the classical concern about dividing by zero, (ii) prove that the controller achieves the objective in the presence of a more general class of time variations, and (iii) prove robustness to unmodelled dynamics. An early version of this paper has appeared in a conference [33].
Before proceeding, we present some mathematical preliminaries. Let \(\mathbf{Z}\) denote the set of integers, \(\mathbf{Z}^+\) the set of non-negative integers, \(\mathbf{N}\) the set of natural numbers, \(\mathbf{R}\) the set of real numbers, and \(\mathbf{R}^+\) the set of non-negative real numbers. We let \({\mathbf{D}}^0\) denote the open unit disc of the complex plane. We use the Euclidean 2-norm for vectors and the corresponding induced norm for matrices, and denote the norm of a vector or matrix by \(\Vert \cdot \Vert \). We let \({l_{\infty }}( \mathbf{R}^n)\) denote the set of \(\mathbf{R}^n\)-valued bounded sequences; we define the norm of \(u \in {l_{\infty }}( \mathbf{R}^n)\) by \(\Vert u \Vert _{\infty } := \sup _{k \in \mathbf{Z}} \Vert u(k) \Vert \). Occasionally, we will deal with a map \(F: {l_{\infty }}( \mathbf{R}^n) \rightarrow {l_{\infty }}( \mathbf{R}^n)\); the gain is given by \(\sup _{ u \ne 0 } \frac{\Vert Fu \Vert _{\infty }}{\Vert u \Vert _{\infty } }\) and denoted by \(\Vert F \Vert \). With \(T \in \mathbf{Z}\), the truncation operator \(P_T: {l_{\infty }}( \mathbf{R}^n) \rightarrow {l_{\infty }}( \mathbf{R}^n)\) is defined by
We say that the map \(F: {l_{\infty }}( \mathbf{R}^n) \rightarrow {l_{\infty }}( \mathbf{R}^n)\) is causal if \(P_T F P_T = P_T F\) for every \(T \in \mathbf{Z}\).
If \({{\mathcal {S}}} \subset \mathbf{R}^p\) is a convex and compact set, we define \(\Vert {{\mathcal {S}}} \Vert := \max _{x \in {{\mathcal {S}}} } \Vert x \Vert \) and the function \(\pi _{{\mathcal {S}}} : \mathbf{R}^p \rightarrow {{\mathcal {S}}}\) denotes the projection onto \({{\mathcal {S}}}\); it is well known that \(\pi _{{\mathcal {S}}}\) is well defined.
2 The setup
In this paper we start with an nth-order linear time-invariant discrete-time plant given by
with \(y(t) \in \mathbf{R}\) being the measured output, \(u(t) \in \mathbf{R}\) the control input, \(\phi (t)\) a vector of input–output data, and \(d(t) \in \mathbf{R}\) the disturbance (or noise) input. We assume that \(\theta ^*\) is unknown but belongs to a known set \({{\mathcal {S}}} \subset \mathbf{R}^{2n}\). Associated with this plant model are the polynomials
and the transfer function \(\frac{B(z^{-1} )}{A(z^{-1} )}\).
Remark 1
It is straightforward to verify that if the system has a disturbance at both the input and output, then it can be converted to a system of the above form.
We impose an assumption on the set of admissible plant parameters.

The convexity part of the above assumption is common in a branch of the adaptive control literature—it is used to facilitate constrained parameter estimation, e.g. see [34], and it is a key assumption in arguably the simplest technique to ensuring that the associated pole placement adaptive controller has tolerance to a degree of unmodelled dynamics and to noise, e.g. see [12,13,14,15,16,17, 35]. That being said, in Sect. 8 we will show that it is possible to weaken this to assuming that \(\theta ^* \in {{\mathcal {S}}}_1 \cup {{\mathcal {S}}}_2\) with each \(S_i\) convex and compact, and for each \(\theta ^* \in {{\mathcal {S}}}_1 \cup {{\mathcal {S}}}_2\), the corresponding pair of polynomials \(A(z^{-1} ) \) and \(B(z^{-1} )\) are coprime; however, we will require that all closed-loop poles be placed at zero, and a more complicated controller will be required. The boundedness part of the assumption is less common, but it is quite reasonable in practical situations; it is used here to ensure that we can prove uniform bounds and decay rates on the closed-loop behaviour.
The main goal here is to prove a form of stability, with a secondary goal that of asymptotic tracking of an exogenous reference signal \(y^* (t)\); since the plant may be non-minimum phase, there are limits on how well the plant can be made to track \(y^*(t)\). To proceed, we use a parameter estimator together with an adaptive pole placement control law. At this point, we discuss the most critical aspect—the parameter estimator.
2.1 Parameter estimation
We can write the plant as
Given an estimate \({\hat{\theta }} (t)\) of \(\theta ^*\) at time t, we define the prediction error by
this is a measure of the error in \({\hat{\theta }} (t)\). The common way to obtain a new estimate is from the solution of the optimization problem
yielding the ideal (projection) algorithm
Of course, if \(\phi (t)\) is close to zero, numerical problems can occur, so it is the norm in the literature (e.g. [3, 34]) to replace this by the following classical algorithm: with \(0< \alpha < 2\) and \(\beta > 0\), defineFootnote 3
This latter algorithm is widely used and plays a role in many discrete-time adaptive control algorithms; however, when this algorithm is used, all of the results are asymptotic, and exponential stability and a bounded gain on the noise are never proven. It is not hard to guess why—a careful look at the estimator shows that the gain on the update law is small if \(\phi (t)\) is small. A more mathematically detailed argument is given in the following example.
Remark 2
Consider the simple first-order plant
with \(a_1 \in [-2, -1]\) and \(b_1 \in [1,2]\). We use the estimator (3) with \(\alpha \in (0,2)\) and \(\beta >0 \), and, as in [12,13,14,15,16,17], we use projection to keep the parameters estimates inside \({{\mathcal {S}}}\) so as to guarantee a bounded-input bounded-state property. Further suppose that \(y^*=d=0\), and that a classical pole placement adaptive controller places the closed-loop pole at zero: \(u(t) = {\frac{{\hat{a}}_1 (t)}{ {\hat{b}}_1 (t)}} y(t) =: {\hat{f}} (t) y(t) \). Suppose that
so that \({\hat{f}} (0) = - 0.5\) and \(-a_1 + b_1 {\hat{f}} (0 ) = 1.5\), i.e. the system is initially unstable. An easy calculation verifies that \({\hat{f}} (t) \in [-2, - 0.5]\) and \( - a_1 + b_1 {\hat{f}} (t) \in [ 0, 1.5 ] \) for \(t \ge 0\), which leads to a crude bound on the closed-loop behaviour: \(| y(t) | \le (1.5)^t {\varepsilon }\) for \(t \ge 0\). With \(N( {\varepsilon }) := \text{ int } [ \frac{1}{2 \ln (1.5)} \ln ( \frac{1}{{\varepsilon }} ) ]\), it follows that
A careful examination of the parameter estimator shows that
From the form of \({\hat{f}} (t)\), it is easy to prove that if \(\frac{{\varepsilon }}{\beta }\) is small enough,Footnote 4 then we have \(| -a + b_1 {\hat{f}} (t) | \ge 1.25 \) for \( t \in [0, N( {\varepsilon }) ]\), in which case
since \(N({\varepsilon }) \rightarrow \infty \) as \({\varepsilon }\rightarrow 0\), we see that exponential stability is not achieved. A similar kind of analysis can be used to prove that a bounded gain on the noise is not achieved either.
Now we return to the problem at hand—analysing the ideal algorithm (2). We will be using the ideal algorithm with projection to ensure that the estimate remains in \({{\mathcal {S}}}\) for all time. With an initial condition of \({\hat{\theta }} (t_0) = \theta _0 \in {{\mathcal {S}}}\), for \(t \ge t_0\) we set
which we then project onto \({{\mathcal {S}}}\):
Because of the closed and convex property of \({{\mathcal {S}}}\), the projection function is well defined; furthermore, it has the nice property that, for every \(\theta \in \mathbf{R}^{2n}\) and every \(\theta ^* \in {{\mathcal {S}}}\), we have
i.e. projecting \(\theta \) onto \({{\mathcal {S}}}\) never makes it further away from the quantity \(\theta ^*\).
2.2 Revised parameter estimation
Some readers may be concerned that the original problem of dividing by a number close to zero, which motivates the use of classical algorithm, remains. Of course, this is balanced against the soon-to-be-proved benefit of using (4)–(5). We propose a middle ground as follows. A straightforward analysis of \(e(t+1)\) reveals that
which means that
Therefore, if
then the update to \({\hat{\theta }} (t)\) will be greater than \(2 \Vert {{\mathcal {S}}} \Vert \), which means that there is little information content in \(e(t+1)\)—it is dominated by the disturbance. With this as motivation, and with \(\delta \in (0, \infty ]\), let us replace (4) with
in the case of \(\delta = \infty \), we will adopt the understanding that \( \infty \times 0 = 0 \), in which case the above formula collapses into the original one (4). In the case that \(\delta < \infty \), we can be assured that the update term is bounded above by \(2 \Vert {{\mathcal {S}}} \Vert + \delta \), which should alleviate concerns about having infinite gain. We would now like to rewrite the update to make it more concise. To this end, we now define \({\rho _{\delta }}: \mathbf{R}^{2n} \times \mathbf{R}\rightarrow \{ 0,1 \}\) by
yielding a more concise way to write the estimation algorithm update:
once again, we project this onto \({{\mathcal {S}}}\):
Remark 3
If the disturbance \(d( t )=0\), then the estimation algorithm (7)–(8) has a nice scaling property. In this case, if \(\phi (t) \ne 0\) then \({\rho _{\delta } ( \phi (t) , e(t+1))}=1\), so (7) becomes
so if \(\phi (t)\) is replaced by \(\gamma \phi (t)\) with \(\gamma \ne 0\), then \({\check{\theta }} (t+1)\) (and \({\hat{\theta }} (t+1)\)) remains the same. Hence, scaling the pair (y(t), u(t)) makes no difference to the estimator, which is clearly a desirable feature; notice that the classical algorithm (3) does not enjoy that property. This is the first clue that this algorithm may provide closed-loop properties not provided by the classical algorithm (3).
2.3 Properties of the estimation algorithm
Analysing the closed-loop system behaviour will require a careful examination of the estimation algorithm. We define the parameter estimation error by
and the corresponding Lyapunov function associated with \({\tilde{\theta }} (t)\), namely \(V(t) : = {\tilde{\theta }} (t)^T {\tilde{\theta }} (t) \). In the following result we list a property of V(t); it is a generalization of what is well known for the classical algorithm (3).

Proof
See Appendix. \(\square \)
2.4 The control law
The elements of \({\hat{\theta }} (t)\) are partitioned in a natural way as
Associated with \({\hat{\theta }} (t) \) are the polynomials
While we can use an \((n-1)\)th-order proper controller to carry out pole placement, it will be convenient to use an nth-order strictly proper controller, such as in [15, 16, 36,37,38]. In particular, we first choose a 2nth-order monic polynomial
so that \(z^{2n} A^* (z^{-1} )\) has all of its zeros in \({\mathbf{D}}^o\). Next, we choose two polynomial
which satisfy the equation
given the assumption that the \({\hat{A}} ( t , z^{-1} )\) and \({\hat{B}} ( t , z^{-1} )\) are coprime, it is well known that there exist unique \({\hat{L}} (t, z^{-1} )\) and \({\hat{P}} (t,z^{-1} )\) which satisfy this equation. Indeed, it is easy to prove that the coefficients of \({\hat{L}} (t, z^{-1} )\) and \({\hat{P}} (t,z^{-1} )\) are analytic functions of \({\hat{\theta }} (t) \in {{\mathcal {S}}}\).
In our setup we have an exogenous signal \(y^* (t)\). At time t we choose u(t) so that
So the overall controller consists of the estimator (7)–(8) together with (11).Footnote 5
It turns out that we can write down a state-space model of our closed-loop system with \(\phi (t) \in \mathbf{R}^{2n}\) as the state. Proceeding as in Kreisselmeier [37], only two elements of \(\phi \) have a complicated description:
With \(e_i \in \mathbf{R}^{2n}\) the ith normal vector, if we now define
then the following key equation holds:
notice that the characteristic equation of \({\bar{A}} (t)\) always equals \(z^{2n} A^* ( z^{-1} )\). Before proceeding, define
Remark 4
While the proposed adaptive controller (7)–(8) together with (11) is nonlinear, when it is applied to the plant the closed-loop system enjoys the homogeneity property. More precisely, fix the initial parameter estimate \(\theta _0\) and starting time \(t_0 \in \mathbf{Z}\); suppose that an initial condition, reference signal, and disturbance signal combination \(( \phi _0, r, d)\) yields a system response of \( \phi \), and with \(\gamma \in \mathbf{R}\) suppose that an initial condition, reference signal, and disturbance signal combination of \(( \gamma \phi _0, \gamma r, \gamma d)\) yields a system response of \( \phi ^{\gamma }\). Using induction it is easy to prove thatFootnote 6
Hence, with minimal effort we see that the closed-loop behaviour enjoys one of the two required properties of a linear system, namely that of homogeneity. While it does not enjoy the other property needed for linearity, we will soon see that we are still able to prove linear-like convolution bounds on the closed-loop behaviour.
3 Preliminary analysis
The closed-loop system given in (13) arises in classical adaptive control approaches in slightly modified fashion, so we will borrow some tools from there. More specifically, the following result was proven by Kreisselmeier [37], in the context of proving that a slowly time-varying adaptive control system is stable (in a weak sense); we are providing a special case of his technical lemma to minimize complexity.Footnote 7

Remark 5
We apply the above proposition in the following way. Suppose that \(\sigma \in (0,1)\), \(\gamma _1 >1\), \(\alpha _i \ge 0\), \(\beta _i \ge 0\) are such conditions (i) and (ii) hold. If \(\mu \in ( \sigma , 1 )\), then it follows that \(\frac{\mu }{\gamma _1^{1/N}} - \sigma > 0 \) for large enough \(N \in \mathbf{N}\), so condition (iii) will hold as well as long as \(\alpha _2 \) and \(\beta _2\) are small enough.
In applying Proposition 2, the matrix \({\bar{A}} (t)\) will play the role of \(A_{nom} (t)\). A key requirement is that Condition (i) holds: the following provides relevant bounds. Before proceeding, let

Proof
See Appendix. \(\square \)
4 The main result

Remark 6
We see from (12) that r(t) is a weighted sum of \(\{ y^* (t) ,..., y^* ( t-n+1 ) \}\). Hence, there exists a constant \({\bar{c}}\) so that the bound (14) can be rewritten as
Remark 7
Theorem 1 implies that the system has a bounded gain (from d and r to y) in every \(p-\)norm. More specifically, for \(p= \infty \) we see immediately from (14) that
Furthermore, for \(1 \le p < \infty \) it follows from Young’s Inequality applied to (14) that
Remark 8
Most pole placement adaptive controllers are proven to yield a weak form of stability, such as boundedness (in the presence of a nonzero disturbance) or asymptotic stability (in the case of a zero disturbance), which means that details surrounding initial conditions can be ignored. Here the goal is to prove a stronger, linear-like, convolution bound, so it requires a more detailed and nuanced analysis. A key tool is Proposition 2, which was introduced by Kreisselmeier [37] to analyse slowly time-varying adaptive pole placement problems. It has been used in a number of places in the adaptive control literature, including the work of [15, 16, 35], all of whom utilize the classical projection algorithm (3). However, as pointed out in Remark 2, an adaptive controller based on the classical projection algorithm (3) does not, in general, provide exponential stability or a bounded gain on the noise, regardless of how small the parameter \(\beta >0\) is; indeed, what is proven in [15, 16] is that for every set of initial conditions and every pair of exogenous disturbance and reference signal inputs, the state \(\phi (t)\) is bounded, i.e. the system enjoys the bounded-input bounded-state property. What is surprising and unexpected is that for \(\beta =0\), the closed-loop system enjoys much nicer properties, and clearly this does not follow in any obvious way by taking the limit as \(\beta \rightarrow 0\) of what is proven in the classical setup of [15, 16].
Remark 9
The approach taken in our proof is motivated by our earlier work on the first-order one-step-ahead adaptive controller [32]; here we use Kreisselmeier’s result on time-varying systems given in Proposition 2 in place of a lemma used in [32] for time-varying first-order systems. While the layout of our proof has a superficial similarity to that to [15, 16], in that we both partition the timescale in terms of the size of state (in the case of [15, 16]) or the size of the disturbance scaled by the state (here), on closer inspection it is clear that they differ significantly.
Remark 10
With \({\hat{G}} (t, z^{-1} ) =\sum _{i=1}^{2n} {\hat{g}}_i (t) z^{-i} := {\hat{B}} (t, z^{-1} ) {\hat{P}} (t,z^{-1} )\) it is possible to use arguments like those in [34] to prove, when the disturbance d is identically zero, a weak tracking result of the form
Since the main goal of the paper is on stability issues, we omit the proof. However, we do discuss step tracking in a later section.
Proof
Fix \(\delta \in (0, \infty ]\) and \(\lambda \in ( {\underline{\lambda }}, 1)\). Let \(t_0 \in \mathbf{Z}\), \(\theta _0 \in {{\mathcal {S}}}\), \(\theta ^* \in {{\mathcal {S}}}\), \(\phi _0 \in \mathbf{R}^{2n}\), and \(y^*, d\in {l_{\infty }}\) be arbitrary. Define r via (12). Now choose \(\lambda _1 \in ( {\underline{\lambda }} , \lambda )\).
We have to be careful in how to apply Proposition 2 to (13)—we need the \(\Delta (t)\) term to be something which we can bound using Proposition 1. So define
it is easy to check that
and that
which is a term which plays a key role in Proposition 1. We can now rewrite (13) as
If \({\rho _{\delta } ( \phi (t) , e(t+1))}=1\) then \(\eta (t) =0\), but if \({\rho _{\delta } ( \phi (t) , e(t+1))}= 0\) then
but we also know that
combining these equations we have
which implies that \(\Vert \phi (t) \Vert \le \frac{1}{\delta } | d(t) | \); it is easy to check that this holds even when \(\delta = \infty \). Using (17) we conclude that
We now analyse (16). We let \(\Phi (t, \tau )\) denote the transition matrix associated with \( {\bar{A}} (t) + \Delta (t)\); this matrix clearly implicitly depends on \(\theta _0\), \(\theta ^*\), d and r. From Lemma 1 there exists a constant \(\gamma _1\) so that
and for every \(t > k \ge t_0\), we have
Using the definition of \(\Delta \) given in (15) and the Cauchy–Schwarz inequality, we also have
At this point we consider two cases: the easier case in which there is no noise, and the harder case in which there is noise.
Case 1: \(d(t) = 0\), \(t \ge t_0\).
Using the bound on \(\eta (t)\) given in (18), in this case (16) becomes
The bound on V(t) given by Proposition 1 simplifies to
Since \(V( \cdot ) \ge 0\) and \( V( t_0 ) = \Vert \theta _0 - \theta ^* \Vert ^2 \le 4 \Vert {{\mathcal {S}}} \Vert ^2\), this means that
Hence, from (20) and (21) we conclude that
Now we apply Proposition 2: we set
Following Remark 3 it is now trivial to choose \(N \in \mathbf{N}\) so that \(\frac{\lambda }{ \gamma _1^{1/N}} - \lambda _1 > 0 \), namely
which means that
From Proposition 2 we see that there exists a constant \(\gamma _2\) so that the state transition matrix \(\Phi ( t, \tau )\) corresponding to \({\bar{A}} (t) + \Delta (t)\) satisfies
If we now apply this to (22), we end up with the desired bound:
Case 2: \(d(t) \ne 0\) for some \(t \ge t_0\).
This case is much more involved since noise can radically affect parameter estimation. Indeed, even if the parameter estimate is quite accurate at a point in time, the introduction of a large noise signal (large relative to the size of \(\phi (t)\)) can create a highly inaccurate parameter estimate. To proceed, we partition the timeline into two parts: one in which the noise is small versus \(\phi \) and one where it is not; the actual choice of the line of division will become clear as the proof progresses. To this end, with \({\varepsilon }>0 \) to be chosen shortly, partition \(\{ j \in \mathbf{Z}: j \ge t_0 \}\) into two sets:
clearly \(\{ j \in \mathbf{Z}: \;\; j \ge t_0 \} = S_{\mathrm{good}} \cup S_{\mathrm{bad}} \). Observe that this partition clearly depends on \(\theta _0\), \(\theta ^*\), \(\phi _0\), d and \(r/y^*\). We will apply Proposition 2 to analyse the closed-loop system behaviour on \(S_{\mathrm{good}}\); on the other hand, we will easily obtain bounds on the system behaviour on \(S_{\mathrm{bad}}\). Before doing so, we partition the time index \(\{ j \in \mathbf{Z}: j \ge t_0 \}\) into intervals which oscillate between \(S_{\mathrm{good}}\) and \(S_{\mathrm{bad}}\). To this end, it is easy to see that we can define a (possibly infinite) sequence of intervals of the form \([ k_i , k_{i+1} )\) satisfying:
-
(i)
\(k_1 = t_0\), and
-
(ii)
\([ k_i , k_{i+1} )\) either belongs to \(S_{\mathrm{good}}\) or \(S_{\mathrm{bad}}\), and
-
(iii)
if \(k_{i+1} \ne \infty \) and \([ k_i , k_{i+1} )\) belongs to \(S_{\mathrm{good}}\) (respectively, \(S_{\mathrm{bad}}\)), then the interval \([ k_{i+1} , k_{i+2} )\) must belong to \(S_{\mathrm{bad}}\) (respectively, \(S_{\mathrm{good}}\)).
Now we turn to analysing the behaviour during each interval.
Sub-Case 2.1: \([ k_i , k_{i+1} )\) lies in \(S_{\mathrm{bad}}\).
Let \(j \in [ k_i , k_{i+1} )\) be arbitrary. In this case either \(\phi (j) = 0\) or \(\frac{[ d(j)]^2}{ \Vert \phi (j) \Vert ^2} \ge {\varepsilon }\) holds. In either case we have
From (13) and (17) we see that
If we combine this with (24), we conclude that
Sub-Case 2.2: \([ k_i , k_{i+1} )\) lies in \(S_{\mathrm{good}}\).
Let \(j \in [ k_i , k_{i+1} )\) be arbitrary. In this case \(\phi (j) \ne 0\) and
which implies that
From Proposition 1 we have that
using (27) and the fact that \(0 \le V( \cdot ) \le 4 \Vert {{\mathcal {S}}} \Vert ^2\), we obtain
Hence, using this in (20) and (21) yields
as well as
Now we will apply Proposition 2: we set
With N chosen as in Case 1 via (23), we have that \({\underline{\delta }} := \frac{\lambda }{ \gamma _1^{1/N}} - \lambda _1 > 0 \); we need
which will certainly be the case if we set \({\varepsilon }:= \frac{ {\underline{\delta }}^2}{8 \gamma _1^2 ( \gamma _1 N + 1 )^2} \). From Proposition 2 we see that there exists a constant \(\gamma _4\) so that the state transition matrix \(\Phi (t , \tau )\) corresponding to \({\bar{A}} (t) + \Delta (t)\) satisfies
If we now apply this to (16) and use (18) to provide a bound on \(\eta (t)\), we end up with
This completes Sub-Case 2.2.
Now we combine Sub-Case 2.1 and Sub-Case 2.2 into a general bound on \(\phi (t)\). Define
It remains to prove
Claim
The following bound holds:
Proof of the Claim
If \([k_1 , k_2 ) = [t_0, k_2) \subset S_{\mathrm{good}}\), then (29) holds for \(k \in [t_0 , k_2 ]\) by (28). If \([t_0 , k_2 ) \subset S_{\mathrm{bad}}\), then from (26) we obtain
which means that (29) holds for \(k \in [t_0 , k_2 ]\) for this case as well.
We now use induction—suppose that (29) holds for \(k \in [k_1 , k_i ]\); we need to prove that it holds for \(k \in ( k_i, k_{i+1} ]\) as well. If \( [k_i, k_{i+1}) \subset S_{\mathrm{bad}}\) then from (26) we have
which means that (29) holds for \(k \in ( k_i, k_{i+1} ]\). On the other hand, if \([k_i, k_{i+1}) \subset S_{\mathrm{good}}\), then \(k_i -1 \in S_{\mathrm{bad}}\); from (26) we have that
Using (28) to analyse the behaviour on \([k_i , k_{i+1}]\), we have
as desired. \(\square \)
This completes the proof. \(\square \)
5 Tolerance to time variations
The linear-like bound proven in Theorem 1 can be leveraged to prove that the same behaviour will result even in the presence of slow time variations with occasional jumps. So suppose that the actual plant model is
with \(\theta ^* (t) \in {{\mathcal {S}}}\) for all \(t \in \mathbf{R}\). We adopt a common model of acceptable time variations used in adaptive control: with \(c_0 \ge 0\) and \({\varepsilon }>0\), we let \(s( {{\mathcal {S}}} , c_0, {\varepsilon })\) denote the subset of \({l_{\infty }}( \mathbf{R}^{2n})\) whose elements \(\theta ^*\) satisfy \(\theta ^* (t) \in {{\mathcal {S}}}\) for every \(t \in \mathbf{Z}\) as well as
for every \(t_1 \in \mathbf{Z}\). We will now show that, for every \(c_0 \ge 0\), the approach tolerates time-varying parameters in \(s( {{\mathcal {S}}} , c_0, {\varepsilon })\) if \({\varepsilon }\) is small enough.

Proof
Fix \(\delta \in ( 0, \infty ]\), \(\lambda _1 \in ( {\underline{\lambda }} ,1)\), \(\lambda \in ( {\underline{\lambda }} , \lambda _1 )\) and \(c_0 > 0\). Let \(t_0 \in \mathbf{Z}\), \(\theta _0 \in {{\mathcal {S}}}\), \(\phi _0 \in \mathbf{R}^{2n}\), and \(y^*, d \in \ell _{\infty }\) be arbitrary. With \(m \in \mathbf{N}\), we will consider \(\phi (t)\) on intervals of the form \([t_0 + im , t_0 + (i+1)m ]\); we will be analysing these intervals in groups of m (to be chosen shortly); we set \({\varepsilon }= \frac{c_0}{m^2}\), and let \(\theta ^* \in s( {{\mathcal {S}}} , c_0, {\varepsilon })\) be arbitrary.
First of all, for \(i \in \mathbf{Z}^+\) we can rewrite the plant equation as
Theorem 1 applied to (32) says that there exists a constant \(c>0\) so that
The above is a difference inequality associated with a first-order system; using this observation together with the fact that \(c \ge 1\), we see that if we define
with \(\psi (t_0 + im) = \Vert \phi (t_0 + im ) \Vert \), then
Now we analyse this equation for \(i =0,1,..., m-1\).
Case 1: \(|{\tilde{n}} (t) | \le \frac{1}{2c} ( \lambda _1 - \lambda ) \Vert \phi ( t ) \Vert \) for all \(t \in [ t_0 + im , t_0+ (i+1)m ]\).
In this case
which means that
This, in turn, implies that
Case 2: \(|{\tilde{n}} (t) | > \frac{1}{2c} ( \lambda _1 - \lambda ) \Vert \phi ( t ) \Vert \) for some \(t \in [ t_0 + im , t_0+ (i+1)m ]\).
Since \(\theta ^* (t) \in {{\mathcal {S}}}\) for \(t \ge t_0\), we see
This means that
which means that
This, in turn, implies that
On the interval \([t_0 , t_0 + m^2]\) there are m subintervals of length m; furthermore, because of the choice of \({\varepsilon }\) we have that
A simple calculation reveals that there are at most \(N_1 := \frac{4 c_0 c}{ \lambda _1 - \lambda }\) subintervals which fall into the category of Case 2, with the remaining number falling into the category of Case 1. Henceforth, we assume that \(m > N_1\). If we use (33) and (34) to analyse the behaviour of the closed-loop system on the interval \([t_0 , t_0 + m^2]\), we end up with a crude bound of
At this point we would like to choose m so that
notice that \(\frac{2 \lambda _1}{\lambda _1 + \lambda } > 1\), so if we take the log of both sides, we see that we need
which will clearly be the case for large enough m, so at this point we choose such an m. It follows from (35) that there exists a constant \(\gamma _2\) so that
Indeed, the same bound holds regardless of the interval of analysis:
Solving iteratively yields
We now combine this bound with the bounds which hold on the good intervals (33) and the bad intervals (34) and conclude that there exists a constant \(\gamma _3\) so that
as desired. \(\square \)
6 Tolerance to unmodelled dynamics
Due to the linear-like bounds proven in Theorems 1 and 2, we can use the Small Gain Theorem to good effect to prove the tolerance of the closed-loop system to unmodelled dynamics. However, since the controller, and therefore the closed-loop system, is nonlinear, handling initial conditions is more subtle: in the linear time-invariant case we can separate out the effect of initial conditions from that of the forcing functions (\(r/y^*\) and d), but in our situation they are intertwined. We proceed by looking at two cases—with and without initial conditions. In all of the cases we consider the time-varying plant (30) with \(d_{\Delta } (t)\) added to represent the effect of unmodelled dynamics:
To proceed, fix \(\delta \in (0, \infty ]\), \(\lambda _1 \in ( {\underline{\lambda }} ,1)\) and \(c_0 \ge 0\); from Theorem 2 there exists a \(c_1>0\) and \({\varepsilon }>0\) so that for every \(t_0 \in \mathbf{Z}\), \(\phi _0 \in \mathbf{R}^{2n}\), \(\theta _0 \in {{\mathcal {S}}}\), \(y^*, d \in \ell _{\infty }\), and \(\theta ^* \in s( {{\mathcal {S}}} , c_0, {\varepsilon })\), when the adaptive controller (7), (8) and (11) is applied to the time-varying plant (37), the following bound holds:
6.1 Zero initial conditions
In this case we assume that \(\phi (t) = 0\) for \(t \le t_0\); we derive a bound on the closed-loop system behaviour in the presence of unmodelled dynamics. Suppose that the unmodelled dynamics is of the form \(d_{\Delta } (t) = ( \Delta \phi )(t)\) with \(\Delta : {l_{\infty }}( \mathbf{R}^{2n}) \rightarrow {l_{\infty }}(\mathbf{R}^{2n})\) a (possibly nonlinear time-varying) causal map with a finite gain of \(\Vert \Delta \Vert \). It is easy to prove that if \(\Vert \Delta \Vert < \frac{1 - \lambda _1}{c_1 } \), then
i.e. a form of closed-loop stability is attained. Following the approach of Remark 7, we could also analyse the closed-loop system using \(l_p\)-norms with \(1 \le p < \infty \).
6.2 Nonzero initial conditions
Now we consider the case of unmodelled LTI dynamics when the plant has nonzero initial conditions, and we develop convolution-like bounds on the closed-loop system. To this end suppose that the unmodelled dynamics are of the form
with \(\Delta _j \in \mathbf{R}^{1 \times 2n }\); the corresponding transfer function is \(\Delta (z^{-1}) := \sum _{j=0}^{\infty } \Delta _j z^{-j} \). It is easy to see that this model subsumes the classical additive uncertainty, multiplicative uncertainty, and uncertainty in a coprime factorization, which is common in the robust control literature, e.g. see [39], with the only constraint being that the perturbations correspond to strictly causal terms. In order to obtain linear-like bounds on the closed-loop behaviour, we need to impose more constraints on \(\Delta (z)\) than in the previous subsection: after all, if \(\Delta (z^{-1}) = \Delta _p z^{-p}\), it is clear that \(\Vert \Delta \Vert = \Vert \Delta _p \Vert \) for all p, but the effect on the closed-loop system varies greatly—a large value of p allows the behaviour in the far past to affect the present. To this end, with \(\mu >0\) and \(\beta \in (0,1)\), we shall restrict \(\Delta (z^{-1})\) to a set of the form
It is easy to see that every transfer function in \( {{\mathcal {B}}} ( \mu , \beta ) \) is analytic in \(\{ z \in \mathbf{C}: | z | > \beta \}\), so it has no poles in that region.
Now we fix \(\mu >0\) and \(\beta \in (0,1)\) and let \(\Delta ( z^{-1}) \) belong to \({{\mathcal {B}}} ( \mu , \beta )\); the goal is to analyse the closed-loop behaviour of (37) for \(t \ge t_0\) when \(d_{\Delta }\) is given by (39). We first partition \(d_{\Delta }(t) \) into two parts—that which depends on \(\phi (t)\) for \(t \ge t_0\) and that which depends on \(\phi (t)\) for \(t < t_0\):
It is clear that
If \(\phi (t)\) is bounded on \(\{ t \in \mathbf{Z}: t < t_0 \}\) then \(\sum _{j=1}^{\infty } \beta ^{j} \Vert \phi ( t_0-j) \Vert \) is finite, in which case we see that \(d_{\Delta }^- (t)\) goes to zero exponentially fast; henceforth, we make the reasonable assumption that this is the case. It turns out that we can easily bound \(d_{\Delta }(t)\) with a difference equation. To this end, consider
with \({m} (t_0) = m_0 := \sum _{j=1}^{\infty } \beta ^{j} \Vert \phi ( t_0-j) \Vert \); it is straightforward to prove that
This model of unmodelled dynamics is similar to that used in the adaptive control literature, e.g. see [10].

Proof
Fix \(\beta \in (0,1)\) and \(\lambda _2 \in ( \max \{\lambda _1 , \beta \} , 1 )\). The first step is to convert difference inequalities to difference equations. To this end, consider the difference equation
together with the difference equation based on (40):
It is easy to use induction together with (38), (40), and (41) to prove that
If we combine the difference equations (42) with (43), we end up with
Now we see that \(A_{cl} ( \mu ) \rightarrow \left[ \begin{array}{cc} \lambda _1 &{} 0 \\ \beta &{} \beta \end{array} \right] \) as \(\mu \rightarrow 0\), and this matrix has eigenvalues of \( \{ \lambda _1 , \beta \}\). Now choose \({\bar{\mu }} > 0\) so that all eigenvalues are less than \(( \frac{\lambda _2}{2} + \frac{1}{2}\max \{ \lambda _1 , \beta \} ) \) in magnitude for \(\mu \in (0 , {\bar{\mu }} ]\), and define \({\varepsilon }:= \frac{\lambda _2}{2} - \frac{1}{2}\max \{ \lambda _1 , \beta \}\). Using the proof technique of Desoer in [40], we can conclude that for \(\mu \in (0 , {\bar{\mu }} ]\), we have
if we use this in (45) and then apply the bounds in (44), it follows that
as desired. \(\square \)
7 Step tracking
If the plant is non-minimum phase, it is not possible to track an arbitrary bounded reference signal using a bounded control signal. However, as long as the plant does not have a zero at \(z=1\), it is possible to modify the controller design procedure to achieve asymptotic step tracking if there is no noise/disturbance. So at this point assume that the corresponding plant polynomial \(B( z^{-1} )\) has no zero at \(z=1\) for any plant model \(\theta ^* \in {{\mathcal {S}}}\). To proceed, we use the standard trick from the literature, e.g. see [34]: we still estimate \(A(z^{-1} )\) and \(B( z^{-1}) \) as before, but we now design the control law slightly differently. To this end, we first define
and then let \(A^* ( z^{-1} )\) be a \(2 (n+1)\)th monic polynomial (rather than a 2nth one) of the form
so that \(z^{2(n+1)} A^* (z^{-1} )\) has all of its zeros in \({\mathbf{D}}^o\). Next, we choose two polynomial
which satisfy the equation
since \({\tilde{A}} ( t , z^{-1} ) \) and \({\hat{B}} ( t , z^{-1} )\) are coprime, there exist unique \({\tilde{L}} (t, z^{-1} )\) and \({\hat{P}} (t,z^{-1} )\) which satisfy this equation. We now define
at time t we choose u(t) so that
We can use a modified version of the argument used in the proof of Theorem 1 to conclude that a similar type of result holds here; we can also prove that asymptotic step tracking will be attained if the noise is zero and the reference signal \(y^*\) is constant. The details are omitted.
8 Relaxing the convexity requirement
The convexity and coprimeness assumptions on the set of admissible plant parameters play a crucial role in obtaining the nice closed-loop properties provided in Theorems 1–3. Here we will show that it is possible to weaken the convexity requirement if the goal is to place all closed-loop poles at zero, although it is at the expense of using a more complicated controller. Our proposed approach is modelled on the first-order one-step-ahead control setup (see [32, 41]) which is deadbeat in nature; of course, here the plant may not be first order, which increases the complexity. While we would like to remove the convexity requirement completely, at present we are only able to weaken it. So in this section we replace Assumption 1 with

The idea is to use an estimator for each of \({{\mathcal {S}}}_1\) and \({{\mathcal {S}}}_2\), and at each point in time we choose which one to use in the control law. Before proceeding, define
8.1 Parameter estimation
For each \({{\mathcal {S}}}_{i}\) and \({{{\hat{\theta }}}}_i(t_0)\in {{\mathcal {S}}}_{i}\), we construct an estimator which generates an estimate \({\hat{\theta }}_{i}(t)\in {{\mathcal {S}}}_{i}\) at each \(t>t_{0}\). Motivated by (4) and (5), the associated prediction error is defined as
and the parameter update law is given by
(For ease of exposition, we do not use the more general version of the estimator equation in (7) and (8).) Associated with this estimator is the parameter estimation error \({{\tilde{\theta }}}_i(t):= {\hat{\theta _i}}(t)-\theta ^*\) as well as the corresponding Lyapunov function \(V_i(t):={{\tilde{\theta }}}_i(t)^T {{\tilde{\theta }}}_i(t)\).
8.2 The switching control law
The elements of \({\hat{\theta }}_i(t)\) are partitioned as
associated with these estimates are the polynomials
Next, we choose the following polynomials
to place all closed-loop poles at zero, so we need
Given the assumption that the \({{\hat{A}}}_i ( t , z^{-1} )\) and \({{\hat{B}}}_i ( t , z^{-1} )\) are coprime, we know that there exist unique \({{\hat{L}}}_i (t, z^{-1} )\) and \({{\hat{P}}}_i (t,z^{-1} )\) which satisfy this equation; it is also easy to prove that the coefficients of \({{\hat{L}}}_i (t, z^{-1} )\) and \({{\hat{P}}}_i (t,z^{-1} )\) are analytic functions of \({\hat{\theta _i}} (t) \in {{\mathcal {S}}}_i\).
We can now discuss the candidate control law to be used. Define the controller gain by
and a switching signal \(\sigma :{\mathbf{Z}}\mapsto \{1,2\}\) that decides which gain to use at any given point in time. A natural choice for a control law is
the above control law is similar to that given in (11) but with the controller gains chosen between the two choices at each point in time.
The most obvious choice of \(\sigma (t)\) is to define it by
While this works in every simulation that we have tried, the proof remains elusive.
Hence, we try another approach, which is based on our earlier work in the first-order one-step-ahead setting [41], and exploits the deadbeat nature of the problem. Using the natural notation of \({{\bar{A}}}_{\sigma (t)}(t)\) to represent the \({{\bar{A}}}(t)\) matrix of (12) as well as \({{\hat{r}}}(t):=\sum _{j=1}^{n} {{\hat{p}}}_{\sigma (t),j}(t)y^*(t-j+1)\), the closed-loop behaviour is captured by
While \({{\bar{A}}}_{\sigma (t)}(t)\) is a deadbeat matrix for every t, the product
will not usually have all eigenvalues at zero. Hence, the method of analysis used in [41] will not work for the proposed control law (50). A natural attempt to alleviate the problem is to hold \(\sigma (t)\) constant in (50) for 2n steps at a time; the difficulty now is that \({{\bar{A}}}_{\sigma (t)}(t)\) is still changing since \({\hat{\theta }}_{i}(t)\) still changes. A natural solution to this problem is to update the estimators every 2n steps as well; the difficulty here is that we end up with no information about \(e_{i}(t+1)\) between the updates, so the closed-loop system is not amenable to analysis. So our proposed solution procedure will need to be different: we are going to change \(\sigma (t)\) every \(N\ge 2n\) steps; we keep the estimators running, but adjust the control parameters every \(N\ge 2n\) steps as well. The effect of this will become clear in the proof of the main result of this section. To this end, we define a sequence of switching times as follows: we initialize \({{\hat{t}}}_0:=t_0\) and then define
So now define the associated controller parameters by
the switching signal by
and the suitably revised definition of \(r(\cdot )\):
We now define the control law as
What remains to be defined is the choice of switching signal \(\sigma ({{\hat{t}}}_\ell )\). To this end, we define a performance signal \(J_i:\{{{\hat{t}}}_0,{{\hat{t}}}_1,\ldots \}\mapsto \mathbf{R}\) for estimator i, which produces a measure of “accuracy” of estimation; for \(\ell \in \mathbf{Z}^+\), we define
Before proceeding, assume that \(\theta ^*\in {{\mathcal {S}}}\), so there exists one or more \(j\in \{1,2\}\) so that \(\theta ^{*}\in {{\mathcal {S}}}_{j}\); throughout the remainder of this section, let \(i^{*}\) denote the smallest such j. With \(\sigma ({{\hat{t}}}_0)=\sigma _0\), we use the following switching rule:
for the case when \(J_1({{\hat{t}}}_\ell )=J_2({{\hat{t}}}_\ell )\), we (somewhat arbitrarily) select \(\sigma ({{\hat{t}}}_{\ell +1})\) to be 1. Before presenting the main result of this section, we first show that the logic in (56) yields a desirable closed-loop property.

Proof
Fix \(t_0\in \mathbf{Z}\), \({\phi _0 \in {\mathbf{R}}^{2n}}\), \(\sigma _{0}\in \{1,2\}\), \(N\ge 1,\) \({\theta ^{*}\in {{\mathcal {S}}}}\), \({\hat{\theta _i}} (t_0)\in {{\mathcal {S}}}_{i}\) (\(i=1,2\)), and \(y^*,d \in \ell _{\infty }\); let \(\ell \ge 0\) be arbitrary. We know that \(\theta ^{*}\in {{\mathcal {S}}}_{i^*}\). Assume that (a) does not hold, i.e. \( J_{\sigma ({{\hat{t}}}_\ell )}({{\hat{t}}}_{\ell }) > J_{i^*}({{\hat{t}}}_{\ell })\); then according to (56), this means that \(\sigma ({{\hat{t}}}_{\ell +1})=i^*\), i.e. (b) will hold. \(\square \)
In the above we do not make any claim that \(\theta ^{*}\in {{\mathcal {S}}}_{\sigma (t)}\) at any time; it only makes a statement about the size of the prediction error. It turns out that this is enough to ensure that closed-loop stability is attained. Next, we present the main result of this section.
8.3 The result

Proof
See Appendix. \(\square \)
Remark 11
The approach taken in this proof differs a fair bit from that of Theorem 1 and does not make use of Kreisselmeier’s result given in Proposition 2. Indeed, we spend the first half of the proof converting the closed-loop system into a first-order difference inequality which describes the closed-loop system every 2N steps, and the remainder of the proof consists of a modification of the arguments from our earlier work on the first-order one-step-ahead controller [32] to fit this new setting.
Remark 12
It turns out that the controller presented in this section enjoys the same tolerance to slowly time-varying parameters and to unmodelled dynamics as the one designed for the case of \({{\mathcal {S}}}\) convex. First of all, the proof for the case of unmodelled dynamics is identical to that of Theorem 3. Second of all, the proof for the case of time-varying parameters given in Theorem 2 just requires a small adjustment: simply choose the free parameter \(m > N_1\) to be an integer multiple of N. Here we have made use of one of the most desirable features of the approach, namely that of modularity.
Remark 13
It is natural to ask if the proposed approach would work if \({{\mathcal {S}}}\subset \bigcup _{i=1}^p {{\mathcal {S}}}_i\) with each \({{\mathcal {S}}}_i\) compact and convex sets and for which the corresponding pair of polynomials \(A(z^{-1} ) \) and \(B(z^{-1} )\) are coprime. (After all, if \({{\mathcal {S}}}\) is simply compact we can use the Heine–Borel Theorem to prove the existence of such \({{\mathcal {S}}}_i\)’s.) While the proposed controller (48), (49), (54), (55) and (56) is well defined in this case, we have been unable to prove that it will work; a potential problem is that the switching algorithm could oscillate between two bad choices and never (or rarely) choose the correct one. We are presently working on a more complicated switching algorithm which does not have that problem.
9 Some simulation examples
Here we start with an example which satisfies Assumption 1; in Sect. 9.1 we focus on stability and in Sect. 9.2 we expand this to step tracking. We then move to an example which satisfies Assumption 2 and illustrate the switching controller of Sect. 8.
9.1 Stability
Here we provide an example to illustrate the benefit of the proposed adaptive controller. To this end, consider the second-order plant
with \(a_1 (t)\in [0 , 2]\), \(a_2 (t) \in [1, 3 ]\), \(b_1 (t) \in [0,1]\), and \(b_2 (t) \in [-5, -2]\). If the parameters were fixed, then every admissible model is unstable and non-minimum phase, which makes this a challenging plant to control; indeed, it has two complex unstable poles together with a zero that can lie anywhere in \([2, \infty )\). Last of all, for simplicity set \(\delta = \infty \).
In this subsection we consider the problem of stability only—we set \(y^* = 0\). First, we compare the ideal algorithm (4)–(5) (with projection onto \({{\mathcal {S}}}\)) with the classical one (3) (suitably modified to have projection onto \({{\mathcal {S}}}\)); in both cases we couple the estimator with the adaptive pole placement controller (11) where we place all closed-loop poles at zero. In the case of the classical estimator (3), we arbitrarily set \(\alpha = \beta =1\). Suppose that the plant parameters are constant: \((a_1,a_2,b_1,b_2) = (2,3,1,-2)\), but the initial estimate is set to the midpoint of the interval. In the first simulation we set \(y(0) = y(-1) =0.01\) and \(u(-1)=0\) and set the noise d(t) to zero—see the top plot of Fig. 1. In the second simulation we set \(y(0)= y(-1)=u(-1)=0\) and the noise to \(d(t) = 0.01*\sin (5 t)\)—see the bottom plot of Fig. 1. In both cases the controller based on the ideal algorithm (4)–(5) is clearly superior to the one based on the classical algorithm (3).

A comparison of the ideal algorithm (solid) and the classical algorithm (dashed) with a nonzero initial condition and no noise (top plot) and a zero initial condition and noise (bottom plot)
Now we compare the two adaptive controllers when applied to a time-varying version of the plant with unmodelled dynamics, a zero initial condition, and a nonzero noise. More specifically, we set
For the unmodelled part of the plant, we use a term of the form discussed in Sect. 6.2:
We plot the result in Fig. 2. We see that the controller based on the ideal algorithm is clearly superior to the one based on the classical algorithm, in the sense that the average size of the output y(t) is smaller (by a factor of about three), and the parameter estimates are more accurate; the latter property stems from the fact that the classical estimator tends to have a low gain when the signals are small, unlike the ideal estimator.

The system behaviour with time-varying parameters and unmodelled dynamics; the parameters are dashed and the estimates are solid. The ideal algorithm is used in the left-most plots, while the classical algorithm is used in the right-most plots
9.2 Step tracking
The plant in the previous subsection has a large amount of uncertainty, as well as a wide range of unstable poles and non-minimum phase zeros, which means that there are limits on the quality of the transient behaviour even if the parameters were fixed and known. Hence, to illustrate the tracking ability we look at a subclass of systems: one with \(a_1\) and \(b_1\) as before, namely \(a_1 (t)\in [0 , 2]\) and \(b_1 (t) \in [0,1]\), but now with \(a_2 = 1\) and \(b_2 = -3.5\). With fixed parameters the corresponding system is still unstable and non-minimum phase.
We simulate the closed-loop pole placement step tracking controller of Sect. 7 with a zero initial condition, initial parameter estimates at the midpoints of the admissible intervals, and with time-varying parameters:
with a nonzero disturbance:
and a square wave reference signal of \(y^*(t) = \text{ sgn } [ sin (0.01t)]\). We plot the result in Fig. 3; we see that the parameter estimates crudely follows the system parameters, with less accuracy than in the previous subsection, partly due to the fact that the constant setpoint dominates the estimation process and leads to higher inaccuracy. As a result, y(t) does a good job of following \(y^*\) on average, but with the occasional flurry of activity when the parameter estimates are highly inaccurate. When the noise is increased fivefold at \(k=2500\), the behaviour degrades only slightly.

The pole placement tracking controller with time-varying parameters and small noise; the parameters are dashed and the estimates are solid
9.3 Removing convexity assumption
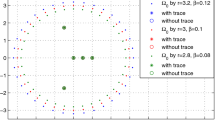
Next we illustrate the case when the set of admissible plant parameters satisfies Assumption 2 but not Assumption 1; we will consider a second-order plant with \(\theta ^*\) belonging to \({{\mathcal {S}}}\subset {{\mathcal {S}}}_1 \cup {{\mathcal {S}}}_2\), with \({{\mathcal {S}}}_1 \) equal to the set \({{\mathcal {S}}}\) of the previous example and \({{\mathcal {S}}}_2 \) equal to \({{\mathcal {S}}}_1\) but with a sign added on the \(b_i\) parameters:
notice that convex hull of \({{\mathcal {S}}}_1 \cup {{\mathcal {S}}}_2\) includes the case of having \(b_1 = b_2=0\), which means that the corresponding system is not stabilizable. We will apply the proposed controller of Sect. 8 to the time-varying plant with a zero initial condition and reference signal, and a nonzero noise. Specifically, we set \(a_1(t)\) and \(a_2(t)\) as in Sect. 9.1:
but now we set \(b_1(t)\) and \(b_2(t)\) to be
We apply the proposed switching controller consisting of the estimator (48), (49), the control law (54), the performance signal (55) and the switching rule (56); we choose \(N=2n=4\). Here we also set \(y^{*}=0\), \(y(0)=y(-1)=u(-1)=0\) and the noise to \(d(t)=0.01\sin (5t)\). Initial parameter estimates \({\hat{\theta }}_i(0)\) are set to the midpoints of each respective interval, and we set \(\sigma _0=2\).
The result for this case is plotted in Fig. 4; we see that the controller does a reasonable job, even though the switching algorithm often chooses the wrong model. Larger transients (than in the simulation of Sect. 9.1) occasionally ensue, but on average the adaptive controller provides good performance. Furthermore, the estimator does a fairly good job of tracking the time-varying parameter.

The upper plot shows the system output. The next four plots show the parameter estimates \({\hat{\theta }}_{\sigma ({{\hat{t}}}_\ell )}({{\hat{t}}}_\ell )\) (dashed) and actual plant parameters (solid). The bottom plot shows the switching signal \(\sigma ({{\hat{t}}}_\ell )\) (dashed) and the correct index (solid)
10 Summary and conclusions
Here we show that if the original, ideal, projection algorithm is used in the estimation process (subject to the assumption that the plant parameters lie in a convex, compact set), then the corresponding pole placement adaptive controller guarantees linear-like convolution bounds on the closed-loop behaviour, which confers exponential stability and a bounded noise gain (in every p-norm with \(1 \le p \le \infty \)), unlike almost all other parameter adaptive controllers. This can be leveraged to prove tolerance to unmodelled dynamics and plant parameter variation. We emphasize that there is no persistent excitation requirement of any sort; the improved performance arises from the vigilant nature of the ideal parameter estimation algorithm.
As far as the author is aware, the linear-like convolution bound proven here is a first in parameter adaptive control. It allows a modular approach to be used in analysing time-varying parameters and unmodelled dynamics. This approach avoids all of the fixes invented in the 1980s, such as signal normalization and deadzones, used to deal with the lack of robustness to unmodelled dynamics and time-varying parameters.
In the present paper the standard assumption is that the set of plant parameters lies in a compact and convex set. In Sect. 8 we relaxed the convexity requirement a bit: there the goal is to place all poles at the origin, and the convexity requirement is weakened to requiring that the set of admissible parameters lie in the union of two convex sets; two parameter estimators are used together with a switching algorithm to choose which estimator to use at each point in time. We are working at removing the convexity requirement altogether: the idea is to utilize the Heine–Borel theorem to prove that the compact set of admissible parameters lies in a finite union of convex set (for which the corresponding numerator and denominator polynomials are coprime), use a parameter estimator for each, and then design a switching algorithm to switch between them. While the (natural extension of) the switching algorithm for the case of two convex sets does not appear to work in the general case, we are presently analysing a more complicated algorithm.
We are presently working on extending the approach to the model reference adaptive control setting; the analysis is turning out to be more complicated than here, in large part due to the facts that the controller is not strictly causal (as it is here) and that a system delay (or the relative degree of the plant transfer function) creates additional complexity. Extending the approach to the continuous-time setting may prove challenging, since a direct application would yield a non-Lipschitz continuous estimator, which brings with it mathematical solvability issues.
Notes
Since the closed-loop system is nonlinear, a bounded-noise bounded-state property does not automatically imply a bounded gain on the noise.
It is common to make this more general by letting \(\alpha \) be time-varying.
Here \(\beta >0\) is fixed, so this is equivalent to \({\varepsilon }\) being small enough.
We also implicitly use a pole placement procedure to obtain the controller parameters from the plant parameter estimates; this entails solving a linear equation.
In addition, if we define \({\hat{\theta }} (t)\) and \({\hat{\theta }}^{\gamma } (t)\) in the natural way, then it is easy to prove that for \(\gamma \ne 0\) we have
$$\begin{aligned} {\hat{\theta }}^{\gamma } (t) = {\hat{\theta }} (t) , \; t \ge t_0 . \end{aligned}$$Furthermore, in [37] it is assumed that \(\alpha _i \) and \(\beta _i \) are strictly greater than zero, but it is trivial to extend this to allow for zero as well.
The choice of N and the value of the switching signal \(\sigma (t)\) play no role.
References
Feuer A, Morse AS (1978) Adaptive control of single-input, single-output linear systems. IEEE Trans Autom Control 23(4):557–569
Morse AS (1980) Global stability of parameter-adaptive control systems. IEEE Trans Autom Control 25:433–439
Goodwin GC, Ramadge PJ, Caines PE (1980) Discrete time multivariable control. IEEE Trans Autom Control 25:449–456
Narendra KS, Lin YH (1980) Stable discrete adaptive control. IEEE Trans Autom Control 25(3):456–461
Narendra KS, Lin YH, Valavani LS (1980) Stable adaptive controller design, Part II: proof of stability. IEEE Trans Autom Control 25:440–448
Rohrs CE et al (1985) Robustness of continuous-time adaptive control algorithms in the presence of unmodelled dynamics. IEEE Trans Autom Control 30:881–889
Middleton RH, Goodwin GC (1988) Adaptive control of time-varying linear systems. IEEE Trans Autom Control 33(2):150–155
Middleton RH et al (1988) Design issues in adaptive control. IEEE Trans Autom Control 33(1):50–58
Tsakalis KS, Ioannou PA (1989) Adaptive control of linear time-varying plants: a new model reference controller structure. IEEE Trans Autom Control 34(10):1038–1046
Kreisselmeier G, Anderson BDO (1986) Robust model reference adaptive control. IEEE Trans Autom Control 31:127–133
Ioannou PA, Tsakalis KS (1986) A robust direct adaptive controller. IEEE Trans Autom Control 31(11):1033–1043
Ydstie BE (1989) Stability of discrete-time MRAC revisited. Syst Control Lett 13:429–439
Ydstie BE (1992) Transient performance and robustness of direct adaptive control. IEEE Trans Autom Control 37(8):1091–1105
Naik SM, Kumar PR, Ydstie BE (1992) Robust continuous-time adaptive control by parameter projection. IEEE Trans Autom Control 37:182–297
Wen C, Hill DJ (1992) Global boundedness of discrete-time adaptive control using parameter projection. Automatica 28(2):1143–1158
Wen C (1994) A robust adaptive controller with minimal modifications for discrete time-varying systems. IEEE Trans Autom Control 39(5):987–991
Li Y, Chen H-F (1996) Robust adaptive pole placement for linear time-varying systems. IEEE Trans Autom Control 41:714–719
Narendra KS, Annawswamy AM (1987) A new adaptive law for robust adaptation without persistent excitation. IEEE Trans Autom Control 32:134–145
Fu M, Barmish BR (1986) Adaptive stabilization of linear systems via switching control. IEEE Trans Autom Control AC–31:1097–1103
Miller DE, Davison EJ (1989) An adaptive controller which provides Lyapunov stability. IEEE Trans Autom Control 34:599–609
Morse AS (1996) Supervisory control of families of linear set-point controllers–Part 1: exact matching. IEEE Trans Autom Control 41:1413–1431
Morse AS (1997) Supervisory control of families of linear set-point controllers–Part 2: robustness. IEEE Trans Autom Control 42:1500–1515
Hespanha JP, Liberzon D, Morse AS (2003) Hysteresis-based switching algorithms for supervisory control of uncertain systems. Automatica 39:263–272
Vu L, Chatterjee D, Liberzon D (2007) Input-to-state stability of switched systems and switching adaptive control. Automatica 43:639–646
Hespanha JP, Liberzon D, Morse AS (2003) Overcoming the limitations of adaptive control by means of logic-based switching. Syst Control Lett 49(1):49–65
Morse AS (1998) A bound for the disturbance to tracking error gain of a supervised set-point control system. In: Normand-Cyrot D (ed) Perspectives in control. Springer, London
Vu L, Liberzon D (2011) Supervisory control of uncertain linear time-varying systems. IEEE Trans Automat Control 1:27–42
Zhivoglyadov PV, Middleton RH, Fu M (2001) Further results on localization-based switching adaptive control. Automatica 37:257–263
Miller DE (2003) A new approach to model reference adaptive control. IEEE Trans Autom Control 48:743–757
Miller DE (2006) Near optimal LQR performance for a compact set of plants. IEEE Trans Autom Control 51:1423–1439
Vale JR, Miller DE (2011) Step tracking in the presence of persistent plant changes. IEEE Trans Autom Control 56:43–58
Miller DE (2017) A parameter adaptive controller which provides exponential stability: the first order case. Syst Control Lett 103:23–31
Miller DE (2017) Classical discrete-time adaptive control revisited: exponential stabilization. In: 1st IEEE conference on control technology and applications, pp 1975–1980. The submitted version is posted at arXiv:1705.01494
Goodwin GC, Sin KS (1984) Adaptive filtering prediction and control. Prentice Hall, Englewood Cliffs
Jerbi A, Kamen EW, Dorsey J (1993) Construction of a robust adaptive regulator for time-varying discrete-time systems. Int J Adapt Control 7:1–12
Praly L (1984) Towards a globally stable direct adaptive control scheme for not necessarily minimum phase system. IEEE Trans Autom Control 29:946–949
Kreisselmeier G (1986) Adaptive control of a class of slowly time-varying plants. Syst Control Lett 8:97–103
Kreisselmeier G, Smith MC (1986) Stable adaptive regulation of arbitrary \(n^{th}\)-order plants. IEEE Trans Autom Control 31:299–305
Zhou K, Doyle JC, Glover K (1995) Robust and optimal control. Prentice Hall, New Jersey
Desoer CA (1970) Slowly varying discrete time system \(x_{t+1} = A_t x_t\). Electron Lett 6(11):339–340
Shahab MT, Miller DE (2018) Multi-estimator based adaptive control which provides exponential stability: the first-order case. In: 2018 IEEE 57th conference on decision and control (to appear)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This research was supported by a grant from the Natural Sciences Research Council of Canada.
11 Appendix
11 Appendix
Proof of Proposition 1:
Since projection does not make the parameter estimate worse, it follows from (7) that
so the first inequality holds.
We now turn to energy analysis. We first define \(\tilde{{\check{\theta }}} (t):= {\check{\theta }} (t) - \theta ^*\) and \({\check{V}} (t) := {\tilde{\check{\theta }}}(T)^T {\tilde{\check{\theta }}}(t) \). Next, we subtract \(\theta ^*\) from each side of (7), yielding
Then
Now let us analyse the three terms on the RHS: the fact that \(W_1(t)^2= W_1(t)\) allows us to simplify the first term; the fact that \(W_1 (t) W_2 (t) = W_2 (t)\) means that the second term is zero; \(W_2 (t)^T W_2 (t) = {\rho _{\delta } ( \phi (t) , e(t+1))}\frac{1}{ \phi (t)^T \phi (t)}\), which simplifies the third term. We end up with
Since projection never makes the estimate worse, it follows that
\(\square \)
Proof of Lemma 1:
Fix \(\delta \in ( 0 , \infty ]\) and \(\sigma \in ( {\underline{\lambda }} , 1) \). First of all, it is well known that the characteristic polynomial of \({\bar{A}} (t)\) is exactly \(z^{2n} A^* (z^{-1})\) for every \(t \ge t_0\). Furthermore, it is well known that the coefficients of \({\hat{L}} (t, z^{-1} )\) and \({\hat{P}} (t,z^{-1} )\) are the solution of a linear equation, and are analytic functions of \({\hat{\theta }} (t) \in {{\mathcal {S}}}\). Hence, there exists a constant \(\gamma _1\) so that, for every set of initial conditions, \(y^* \in {l_{\infty }}\) and \(d \in {l_{\infty }}\), we have \(\sup _{t \ge t_0} \Vert {\bar{A}} (t) \Vert \le \gamma _1\).
To prove the first bound, we now invoke the argument used in [40], who considered a more general time-varying situation but with more restrictions on \(\sigma \). By making a slight adjustment to the first part of the proof given there, we can prove that with \(\gamma _2 := \sigma \frac{ (\sigma + \gamma _1 )^{2n-1}}{ ( \sigma - {\underline{\lambda }} )^{2n}}\), then for every \(t \ge t_0\) we have \(\Vert {\bar{A}} (t) ^k \Vert \le \gamma _2 \sigma ^{k} , \;\; k \ge 0 \), as desired.
Now we turn to the second bound. From Proposition 1 and the Cauchy–Schwarz inequality, we obtain
Now notice that
The fact that the coefficients of \({\hat{L}} (t, z^{-1} )\) and \({\hat{P}} (t,z^{-1} )\) are analytic functions of \({\hat{\theta }} (t) \in {{\mathcal {S}}}\) means that there exists a constant \(\gamma _3 \ge 1\) so that
so we conclude that the second bound holds as well. \(\Box \)
In order to prove Theorem 4, we need some preliminary results. The first step is to extend Proposition 1 to the case when \(\theta ^*\) may not lie in \({{\mathcal {S}}}_{i}\).

Proof
Since projection does not make the parameter estimate worse, it follows from (48) and (49) that when \(\phi (t)\ne 0\),
and when \(\phi (t)=0\),
The result follows by iteration. \(\square \)
The next result produces a crude bound on the closed-loop behaviour.
Proposition 4
Consider the plant (1) and suppose that the controller consisting of the estimator (48), (49) and the control law (54) is applied.Footnote 8 Then for every \(p\ge 0\), there exists a constant \({{\bar{c}}}\ge 1\) such that for every \(t_0\in \mathbf{Z}\), \(t\ge t_0\), \(\phi _0\in \mathbf{R}^{2n}\), \({\theta ^{*}\in {{\mathcal {S}}}}\), \({\hat{\theta _i}} (t_0)\in {{\mathcal {S}}}_{i}\) (\(i=1,2\)) and \(y^*,d \in {\varvec{\ell }}_{\infty }\):
Proof
Fix \(p\ge 0\). Let \(t_0\in \mathbf{Z}\), \(t\ge t_0\), \(\phi _0\in \mathbf{R}^{2n}\), \({\theta ^{*}\in {{\mathcal {S}}}}\), \({\hat{\theta _i}} (t_0)\in {{\mathcal {S}}}_{i}\) (\(i=1,2\)) and \(y^*,d \in {\varvec{\ell }}_{\infty }\) be arbitrary. From (1) we see that
From (54) and Assumption 2, we have that there exists a constant \(\gamma \) so that
From the definition of \(\Vert \phi (t+1)\Vert \), we have that
Combining these three bounds, we end up with
Solving iteratively, we have
Put \({{\bar{c}}}:={{\bar{a}}}^{p}\) to conclude the proof. \(\square \)
We now state a technical result which we used in [32] to analyse the first-order one-step-ahead adaptive control problem.

Proof of Theorem 4:
Fix \(\lambda \in (0,1)\) and \(N\ge 2n\). Let \(t_0\in \mathbf{Z}\), \({\phi _0 \in {\mathbf{R}}^{2n}}\), \(\sigma _{0}\in \{1,2\}\), \({\theta ^{*} \in {{\mathcal {S}}}}\), \({\hat{\theta _i}} (t_0)\in {{\mathcal {S}}}_{i}\) (\(i=1,2\)), and \(y^*,d \in \ell _{\infty }\) be arbitrary; as usual, we let \(i^*\) denote the smallest \(j\in \{1,2\}\) which satisfies \(\theta ^{*}\in {{\mathcal {S}}}_{j}\).
As mentioned at the beginning of Sect. 8, the proposed controller is based on the first-order one-step-ahead control setup [41], although it is more complicated. The proof also uses similar ideas as those used in [41], but as our system is more complicated, it should not be surprising that the proof is significantly different and much more complicated. Hence, before proceeding we provide a proof outline: using the definition of \({{\hat{t}}}_\ell \) given in Sect. 8.2:
-
1.
first, we define a state-space equation describing \(\phi (t)\) which holds on intervals of the form \([{{\hat{t}}}_\ell ,{{\hat{t}}}_{\ell +1})\);
-
2.
second, we analyse this equation, getting a bound on \(\Vert \phi ({{\hat{t}}}_{\ell +1})\Vert \) in terms of \(\Vert \phi ({{\hat{t}}}_{\ell })\Vert \) and the exogenous inputs;
-
3.
we apply Lemma 2 and Proposition 4 to obtain a bound on \(\Vert \phi ({{\hat{t}}}_{\ell +2})\Vert \) in terms of \(\Vert \phi ({{\hat{t}}}_{\ell })\Vert \); i.e. we analyse two intervals at a time;
-
4.
fourth, we then analyse the associated difference inequality (relating \(\Vert \phi ({{\hat{t}}}_{\ell +2})\Vert \) in terms of \(\Vert \phi ({{\hat{t}}}_{\ell })\Vert \)) in a way similar (though not identical) to that used in [41].
Step 1: \(\underline{\hbox {Obtain a state-space model describing } \phi (t) \hbox { for } t\in [{{\hat{t}}}_{\ell },{{\hat{t}}}_{\ell +1}).}\)
By definition of the prediction error (47) and by the property of the switching signal (53) being constant on \([{{\hat{t}}}_{\ell },{{\hat{t}}}_{\ell +1})\), we have
From the control law (54) and the control gains (52), we have
We now derive a state-space equation for \(\phi (t)\) in much the same way as (13) was derived; we first define
then, in light of (61) and (62), the following holds:
notice the additional term \(\left[ {\hat{\theta }}_{\sigma ({{\hat{t}}}_\ell )}(t)-{\hat{\theta }}_{\sigma ({{\hat{t}}}_\ell )}({{\hat{t}}}_\ell )\right] \) on the right-hand side which (13) does not have.
Step 2: \(\underline{\hbox {Obtain a bound on } \Vert \phi ({{\hat{t}}}_{\ell +1})\Vert \hbox { in terms of } \Vert \phi ({{\hat{t}}}_{\ell })\Vert .}\)
In (63) we have \({{\bar{A}}}_{\sigma ({{\hat{t}}}_\ell )}({{\hat{t}}}_\ell )\in \mathbf{R}^{2n\times 2n}\) to be a constant matrix with all eigenvalues equal to zero; since \(N\ge 2n\), clearly
So, solving (63) for \(\phi ({{\hat{t}}}_{\ell +1})\) yields
It follows from the compactness of \({{\mathcal {S}}}\) and the \({{\mathcal {S}}}_i\)’s that \(\left\| \left[ {{{\bar{A}}}_{\sigma ({{\hat{t}}}_\ell )}({{\hat{t}}}_\ell )}\right] ^j\right\| ,\; j=0,1\ldots ,N-1\), is bounded above by a constant which we label \(c_1\). Using this fact together with Proposition 3 which provides a bound on the difference between parameter estimates at two different points in time, we obtain
By definition of the prediction error, if \(\phi (j)=0\) then
and if \(\phi (j)\ne 0\), then
Incorporating this into the above inequality yields
Since \({{\hat{t}}}_{\ell +1}-{{\hat{t}}}_{\ell }=N\), it follows from Proposition 4 that there exists a constant \(c_2\) so that the following holds:
so, substituting (66) into (65) and using the definition of the performance signal \(J_{\sigma ({{\hat{t}}}_\ell )}(\cdot )\) given in (55) it follows that there exists a constant \(c_3\) so that
Step 3: \(\underline{\hbox {Apply Lemma}~2 \hbox { and Proposition}~4 \hbox { to obtain a bound on } \Vert \phi ({{\hat{t}}}_{\ell +2})\Vert \hbox { in terms of }}\) \(\underline{\Vert \phi ({{\hat{t}}}_{\ell })\Vert .}\)
From Lemma 2 either
or
If (68) is true, then we can substitute this into (67) to obtain a bound on \(\Vert \phi ({{\hat{t}}}_{\ell +1})\Vert \) in terms of \(J_{i^*}({{\hat{t}}}_{\ell })\) and then apply Proposition 4 to get a bound on \(\Vert \phi ({{\hat{t}}}_{\ell +2})\Vert \) in terms of \(\Vert \phi ({{\hat{t}}}_{\ell +1})\Vert \) and the exogenous inputs; it follows that there exists a constant \(c_4\) so that
On the other hand, if (69) is true, we can use (67) to get a bound on \(\Vert \phi ({{\hat{t}}}_{\ell +2})\Vert \) in terms of \(J_{i^*}({{\hat{t}}}_{\ell +1})\), and then apply Proposition 4 to get a bound on \(\Vert \phi ({{\hat{t}}}_{\ell +1})\Vert \) in terms of \(\Vert \phi ({{\hat{t}}}_{\ell })\Vert \); it follows that there exists a constant \(c_5\) so that
If we define \(\alpha ({{\hat{t}}}_\ell ):= \max \{J_{i^*}({{\hat{t}}}_\ell ),J_{i^*}({{\hat{t}}}_{\ell +1})\}\), then there exists a constant \(c_6\) so that (70) and (71) can be combined to yield
Step 4: Analyse the first-order difference inequality (72).
First, we change notation in (72) to facilitate analysis:
Next, we will analyse (73) to obtain a bound on the closed-loop behaviour; we consider two cases—one with noise and one without.
Case 1: \(d(t)=0\) for all \(t\ge t_0\).
From Proposition 1 and the definition of \(\alpha (\cdot )\), we have
If we use this bound in the second occurrence of \(\alpha ({{\hat{t}}}_{2j})\) in (73), we obtain
Since \(\lambda \in (0,1)\) and \(c_6\ge 1\), then it follows that \(\lambda _1:=\frac{\lambda ^{2N}}{c_6}\in (0,1)\). By Lemma 3(i) if we define \(c_9:=c_7^{\frac{c_7+1}{2}}(\frac{1}{\lambda _1})^{\frac{c_7}{\lambda _1^2}+1}\) and use the fact that \(\alpha ({{\hat{t}}}_{2j})\ge 0\), we see that
which, in turn, implies that
Solving (75) iteratively and using this bound, we obtain
Using Proposition 4 to obtain a bound on \(\phi (t)\) between \({{\hat{t}}}_{2j}\) and \({{\hat{t}}}_{2j+2}\), we conclude that there exists a constant \(c_{10}\) so that
Case 2: \(d(t)\ne 0\) for some \(t\ge t_0\).
We now analyse the case when there is noise entering the system. Here the analysis will use a similar (but not identical) approach to that of Case 2 in the proof of Theorem 1. Motivated by Case 1, in the following we will be applying Lemma 3(ii) with a larger bound than in (74); define \( c_{11}:=8(1+N){\bar{\mathbf{{s}}}}^2\). We also define \(\lambda _{1}=\frac{\lambda ^{2N}}{c_6}\) and \(\nu := \left\lceil { \frac{ {\frac{c_{11}+1}{2}}\ln {(c_{11})} +(4{\frac{c_{11}}{\lambda _1^2}}+1)(\ln {(2)}-\ln {(\lambda _1)})}{\ln {(2)}}}\right\rceil .\)
We now partition the timeline into two parts: one in which the noise is small versus \(\phi \) and one where it is not. With \(\nu \) defined above, we define
clearly \(\{ j \in \mathbf{Z}: \;\; j \ge t_0 \} = S_{\mathrm{good}} \cup S_{\mathrm{bad}} \). We can clearly define a (possibly infinite) sequence of intervals of the form \([k_l,k_{l+1})\) which satisfy:
-
(i)
\(k_{0}=t_0\) serves as the initial instant of the first interval;
-
(ii)
\([k_l,k_{l+1})\) either belongs to \(S_{\mathrm{good}}\) or \(S_{\mathrm{bad}}\); and
-
(iii)
if \(k_{l+1}\ne \infty \) and \([k_l,k_{l+1})\) belongs to \(S_{\mathrm{good}}\) then \([k_{l+1},k_{l+2})\) belongs to \(S_{\mathrm{bad}}\) and vice versa.
Now we analyse the behaviour during each interval.
Sub-Case 2.1: \([k_l,k_{l+1})\) lies in \(S_{\mathrm{bad}}\).
Let \(j\in [k_l,k_{l+1})\) be arbitrary. In this case
in either case
Also, applying Proposition 4 for one step, there exists constant \(c_{13}\) so that
Then for \(j\in [k_l,k_{l+1})\), we have
Sub-Case 2.2: \([k_l,k_{l+1})\) lies in \(S_{\mathrm{good}}\).
Let \(j\in [k_l,k_{l+1})\) be arbitrary. First, suppose that \(k_{l+1}-k_l\le 4N\). From Proposition 4 it can be easily proven that there exists a constant \(c_{14}\) so that
Now suppose that \(k_{l+1}-k_l>4N\). This means, in particular, that there exist \(j_1<j_2\) so that
To proceed, observe that \(\Vert \phi (j)\Vert \ne 0\) and
With \(0\le j_1<j_2\), it follows from Proposition 1 and the definition of \(\alpha (\cdot )\) that
using the bound given in (82) which holds on \([k_l,k_{l+1})\), this becomes
If \(j_2-j_1\le \nu \) then
so by Lemma 3(i), with \(\lambda _1\) defined above, if we define \(c_{15}:=c_{11}^{\frac{c_{11}+1}{2}}(\frac{2}{\lambda _1})^{\frac{4c_{11}}{\lambda _1^2}+1}\), then
If \(j_2-j_1>\nu \), then by Lemma 3(ii) and our choice of \(\nu \) we have that
as well.
Now we can proceed to solve (73). The first step is to use (85) to bound the second occurrence of \(\alpha ({{\hat{t}}}_{2j})\) in (73), yielding
If we solve this iteratively and use the bounds in (86) and (87), we see that
We can now use Proposition 4:
-
to provide a bound on \(\Vert \phi (t)\Vert \) between consecutive \({{\hat{t}}}_{2j}\)’s;
-
to provide a bound on \(\Vert \phi (t)\Vert \) on the beginning part of the interval \([k_l,k_{l+1})\) (until we get to the first admissible \({{\hat{t}}}_{2j}\));
-
to provide a bound on \(\Vert \phi (t)\Vert \) on the last part of the interval \([k_l,k_{l+1})\) (after the last admissible \({{\hat{t}}}_{2j}\)).
We conclude that there exist a constant \(c_{17}\ge c_{14}\) so that
Now we combine Sub-Case 2.1 and Sub-Case 2.2 into a general bound on \(\phi \). The following analysis is almost identical to the one at the end of the proof of Theorem 1. Define \(c_{18}:=\max \{c_{17},c_{13}, c_{13}c_{17}\}\).
Claim
The following bound holds:
Proof of the Claim
If \([k_0,k_1)=[t_0,k_1)\subset S_{\mathrm{good}}\), then (91) is true for \(t\in [k_0,k_1]\) by (90). If \([k_0,k_1)\subset S_{\mathrm{bad}}\), then from (80) we obtain
which means that (91) holds on \([k_0,k_1]\) for this case as well.
We now use induction: suppose that (91) is true for \(t\in [k_0,k_l]\); we need to prove it holds for \(t\in (k_l,k_{l+1}]\) as well. If \(k\in [k_l,k_{l+1}) \subset S_{\mathrm{bad}}\), then from (80) we see that
which means (91) holds on \((k_l,k_{l+1}]\). On the other hand, if \([k_l,k_{l+1}) \subset S_{\mathrm{good}}\), then \(k_{l}-1\in S_{\mathrm{bad}}\); from (80) we have that
Using (90) to analyse the behaviour on \([k_l,k_{l+1}]\), we have
which implies that (91) holds. \(\square \)
This concludes the proof. \(\square \)
Rights and permissions
About this article

Cite this article
Miller, D.E., Shahab, M.T. Classical pole placement adaptive control revisited: linear-like convolution bounds and exponential stability. Math. Control Signals Syst. 30, 19 (2018). https://doi.org/10.1007/s00498-018-0225-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00498-018-0225-1