
Abstract
This paper presents a simple, efficient, yet robust approach, named joint-scale local binary pattern (JLBP), for texture classification. In the proposed approach, the joint-scale strategy is developed firstly, and the neighborhoods of different scales are fused together by a simple arithmetic operation. And then, the descriptor is extracted from the mutual integration of the local patches based on the conventional local binary pattern (LBP). The proposed scheme can not only describe the micro-textures of a local structure, but also the macro-textures of a larger area because of the joint of multiple scales. Further, motivated by the completed local binary pattern (CLBP) scheme, the completed JLBP (CJLBP) is presented to enhance its power. The proposed descriptor is evaluated in relation to other recent LBP-based patterns and non-LBP methods on popular benchmark texture databases, Outex, CURet and UIUC. Generally, the experimental results show that the new method performs better than the state-of-the-art techniques.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Texture classification is widely used in many fields, such as image processing, computer vision and pattern recognition. It has attracted considerable attention during the past decades [8, 19, 34], and [35]. Recently, the local binary pattern (LBP) [23] has attracted the interest of the researchers for its simplicity, discriminative power, computational efficiency and robustness to illumination changes. It has been extensively exploited in many applications for its advantages, such as texture analysis and classification, face recognition, motion analysis, image retrieval, and medical image analysis [1].
Since Ojala’s work [23], various LBP codes have been developed to improve its performance. Different from the original local structure (P, R) of LBP, more topology structures have been introduced, such as ellipse topology [15], multi-scale block LBP (MB-LBP) [16], three-patch LBP and four-patch LBP [37], pyramid LBP (PLBP) [25], local mesh patterns (LMP) [20], average LBP (ALBP) [13] and the other geometries such as horizontal line, vertical line, horizontal-vertical cross, diagonal cross and disc shape, explored in local quantized pattern (LQP) [10]. To reduce the influence of noise, many anti-noise codes have been developed, such as local ternary pattern (LTP) [33] and the Improved LTP [38], noise-resistant LBP (NR-LBP) [26], robust LBP (RLBP) [2], binary rotation invariant and noise tolerant feature (BRINT) [17], local contrast pattern (LCP) [31], and completed robust LBP (CRLBP) [40]. For the original LBP, each pixel in the neighborhood is firstly turned to binary form by comparing its gray value with that of the central pixel. Different from such scheme, more encoding methods have been given for better performances, such as completed LBP (CLBP) [6], local binary count (LBC) [39], adaptive median binary pattern (AMBP) [7], robust differential circle patterns (RDCP) [30], local extreme co-occurrence pattern (LECoP) [36], center-symmetric LBP (CS-LBP) [9], orthogonal combination of LBP (OC-LBP) [41], concave–convex LBP (CCLBP) [32], perpendicular LBP (PLBP) [21] and local structure patterns (LSP) [29]. In addition, the scale- and rotation-invariant descriptors have been put forward to overcome the sensitivity of scaling, rotation, viewpoint variations, such as rotation- and scale-invariant LBP [4], pairwise rotation invariant co-occurrence LBP [24], scale and rotation invariant LBP [14], local frequency descriptors (LFD) [18], and the rapid transform-based rotation invariant descriptor [12].
In [23], the multi-scale scheme was introduced for multiresolution analysis, and it has been applied in many LBP-based codes. However, the main idea of the scheme is only the simple concatenation of the features extracted under each scale. For example, the LBP\(_{8,1+16,2+24,3}^\mathrm{riu2}\) denotes the concatenation of LBP\(_{8,1}^\mathrm{riu2}\), LBP\(_{16,2}^\mathrm{riu2}\) and LBP\(_{24,3}^\mathrm{riu2}\). That is to say, LBP\(_{8,1}^\mathrm{riu2}\), LBP\(_{16,2}^\mathrm{riu2}\) and LBP\(_{24,3}^\mathrm{riu2}\) are extracted firstly, and then, they are concatenated simply as LBP\(_{8,1+16,2+24,3}^\mathrm{riu2}\). It is clear that the mutual integration of the scales, (8,1), (16,2) and (24,3), is not taken into account in the multi-scale scheme.
Further, the LBP and many of its extended operators capture the texture from local regions because they may produce intractable long dimensionality histograms as the number of sampling points increases. In other words, those methods are appropriate for describing the micro-textures but not suitable for depicting the macro-textures. In [17], Liu et al. proposed an anti-noise operator, the BRINT, for texture classification, which can capture the macro-textures by a new sampling scheme. However, the BRINT still uses Ojala’s multi-scale scheme [23] directly. Different from the traditional ideas, Ren et al. [27] and [28] proposed to reduce the dimensionality of LBP features by selecting an optimal subset of neighbors to compose the local structure. The new scheme can well solve the LBP-structure-learning problem and capture the intrinsic characteristics of image patches at different locations and scales.
The main interest of our paper is to develop a new operator, called joint-scale local binary pattern (JLBP), for texture classification. The new method can fuse different scales and capture the micro- and macro-textures at the same time. Firstly, we fuse different scales together by a simple arithmetic operation. After that, the descriptor is developed from the mutual-integration multi-scale local patches based on the conventional LBP. Further, motivated by the CLBP approach [6], the completed JLBP (CJLBP) is presented to enhance its power.
The new scheme has been demonstrated experimentally with the LBP-based methods [6, 7, 17, 39, 40] and [29] and two training-based methods VZ_MR8 in [34] and VZ_Joint in [35] (i.e., non-LBP methods) for texture classification on three widely used texture databases, Outex [22], CUReT [3] and UIUC [11]. The results show that the proposed method performs better than the state-of-the-art techniques. It is also worth noting that the dimension of the feature vectors of our method is much smaller than that of the state-of-the-art techniques.
The remainder of this paper is organized as follows. We first briefly review the background of the LBP and CLBP in Sect. 2. Section 3 presents the detailed analysis of the new proposed JLBP, followed by the extensive experimental results on the widely used texture databases. Finally, we give the conclusion of the paper.
2 Related works
2.1 Local binary patterns
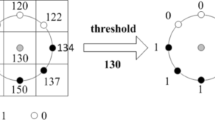
The original LBP operator was introduced in [19] for texture analysis. It works by thresholding a neighborhood with the gray level of the central pixel. The LBP code is produced by multiplying the thresholded values by weights given by powers of two and adding the results in a clockwise way. It was extended to achieve rotation invariance, optional neighborhoods and stronger discriminative capability in [23]. For a neighborhood (P, R), it is commonly referred to \(\text {LBP}_{P,R}\)
where \(s(x) =\{1,0\}\) for \(x \ge 0\) and \(x < 0\), \(P\) is the number of the sampling pixels on the circle, \(R\) is the radius of the circle, \(p_{\mathrm {c}}\) corresponds to the gray value of the central pixel, and \(p_{i}\) denotes the gray value of each sampling pixel on the circle. To extract the most fundamental structure and rotation invariance patterns from LBP, the uniform and rotation invariant operator \(\text {LBP}_{P,R} ^ \text {riu2} \) [23] is given as:
where the superscript ’riu2’ refers to the rotation invariant uniform patterns that have a \(U\) value (\(U\le 2\)). The uniformity measure \(U\) corresponds to the number of transitions from 0 to 1 or 1 to 0 between the successive bits in the circular representation of the binary code \(\text {LBP}_{P,R}\), which is defined as:
For \(\text {LBP}_{P,R}^\text {riu2}\), all nonuniform patterns are classified as one pattern. The mapping from \(\text {LBP}_{P,R}\) to \(\text {LBP}_{P,R}^\text {riu2}\), which has \(P+2\) distinct output values, can be implemented with a lookup table.
2.2 Complete LBP
Guo et al. [6] proposed the complete LBP (CLBP) by combining CLBP_S, CLBP_M and CLBP_C to improve the discriminative power. The CLBP_S descriptor is exactly the same as the original LBP descriptor. The CLBP_M performs a binary comparison between the absolute value of the difference between the central pixel and its neighbors and a threshold, which is written as
where \( m_{i}\) denotes the absolute gray level difference between the ith neighborhood pixel and the central pixel, and \( m_{i} = |p_{i}-p_{\mathrm {c}}| \), a denotes the mean value of \(m_{i}\) from the whole image.
The CLBP_C thresholds the central pixel against the global mean gray value of the whole image, and it is defined as
where \(\mu \) is set as the average gray level of the whole image.
3 Joint-scale LBP
3.1 Joint-scale LBP
The multi-scale scheme was firstly introduced for multiresolution analysis in [23], and it has been widely used in the LBP-based methods. The main idea of such scheme is that the features are firstly extracted under each scale by altering the sampling parameters (the radius and the number of sampling points). Then, the corresponding histograms of multiple scales are concatenated together for multi-scale application. The proposed joint-scale LBP (JLBP) is totally different. For JLBP, multiple scales are fused together firstly by a simple arithmetic operation. Then, the JLBP code is extracted from the mutual integration of local patches based on LBP. For simplicity, we firstly give the definition of JLBP based on two scales.
Let \(R_{1}\) and \(R_{2}\) denote two scales (i.e., radius of the neighborhood as LBP). Different from the topology structure (P, R) of LBP, the new topology structure is written as \((K,R_{1},R_{2})\), where K is the number of the sampling points. The proposed JLBP is defined as:
where \(p_{i,R_{l}}\) (\(l=1,2\)) is the gray valve of the sampling point on the scale \(R_{l}\). Obviously, for JLBP, the two scales \(R_{1}\) and \(R_{2}\) are combined together firstly by the simple additive operation \((p_{i,R_{1}} + p_{i,R_{2}})\), and then, JLBP\(_{K,R_{1},R_{2}}\) code is computed by the similar way as LBP.
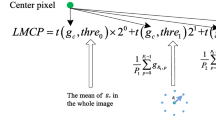
The working principle of the JLBP is illustrated in Fig. 1, where \(p_\mathrm {c}\) is the gray level of the central pixel, \(p_{1,R_{1}}, \ldots , p_{K-1,R_{1}}\) and \(p_{1,R_{2}}, \ldots , p_{K-1,R_{2}}\) denote the gray values of the sampling points on scales \(R_{1}\) and \(R_{2}\), respectively.

The principle of JLBP
By the approach in [23], we can also define the uniform JLBP as JLBP\(^{u2}_{K,R_{1},R_{2}}\), rotation invariant JLBP as JLBP\(^{ri}_{K,R_{1},R_{2}}\) and rotation invariant and uniform JLBP as JLBP\(^{riu2}_{K,R_{1},R_{2}}\).
Further, the topology structure of JLBP can be extended to combine multiple scales, which is denoted as (\(K, R_{1}, R_{2}, \ldots , R_{L}\)). L is a positive integer and \(L = 1, 2, 3, 4, \ldots \). The improved JLBP can be written as:

Comparison of computing multi-scale JLBP and LBP codes
In Eq. (7), the multiple scales are fused together by the simple arithmetic operation, \(\sum _{l=1}^{L} p_{i,R_{l}}\). When \(L = 1\), the JLBP is exactly the same as the original LBP.
It is clear that the proposed JLBP descriptor has the same advantages as the LBP-based methods, such as simplicity, computational efficiency and robustness to illumination changes. On the other hand, the dimensionality of JLBP remains the same at different scales (For example, the dimensionality of JLBP\(_{8, R_{1}, R_{2}, \ldots , R_{L}}^\mathrm{riu2}\) remains 10, regardless the change of L.), which makes it easy to depict the macro-textures of a larger area. That is to say, the new method overcomes the problem that the LBP-based methods are difficult to describe the macro-textures. Further, to obtain noise robustness, the sampling scheme proposed in [17] is employed in the paper, which will be discussed in the next subsection.
3.2 Sampling points
From the definition of JLBP, we know that the sampling points on each scale should be set the same. The sampling methods proposed in [23] and [17] are combined together in the paper.
Similar to the sampling scheme of the original LBP approach [23], we sample pixels around a central pixel \(p_\mathrm {c}\). In addition, the number of points sampled around the central pixel is restricted to be \(K \times t\) (t is a positive integer) on the scale of \(R_{l}\) (\(l=1, 2, 3, \ldots , L\)) as the scheme in [17], and the points sampled on scale \(R_{l}\) are denoted as \(\mathbf g _{Kt,R_{l}} = [{g_{0,R_{l}},g_{1,R_{l}},\ldots , g_{Kt-1,R_{l}}}]^\mathrm { T }\). After that, the \(\mathbf g _{Kt,R_{l}}\) is transformed to K points, and the transformed \(p_{i,R_{l}}\) is calculated as:
Based on the sampling scheme, Fig. 2a, b gives the comparison of computing JLBP and LBP descriptors.
For JLBP, the given image area is denoted as a topology structure of (8,1,2), where \(K=8\), \(R_{1}=1\) and \(R_{2}=2\). For \(R_{1}=1\), there are 8 sampled points. For \(R_{2}=2\), there are 16 sampled points, and they should be transformed to 8 points by Eq. (8) firstly. After that, the JLBP code is calculated by Eq. (6).
For LBP, the image area is firstly divided into two patches, (8,1) and (16,2). Then, the codes of \(\text {LBP}_{8,1}\) and \(\text {LBP}_{16,2}\) are computed separately. Finally, the \(\text {LBP}_{8,1}\) and \(\text {LBP}_{16,2}\) are concatenated together as the final feature.
Obviously, JLBP captures the texture from the whole area (i.e., the local structure (8,1) and (16,2) is fused together), so it is easy to describe the texture of a larger area. While, the LBP handles different scales separately, it is not as better as JLBP to capture the macro-textures. Further, by choosing the radius, JLBP is also easy to capture the micro-textures of a local region.
3.3 Completed joint-scale LBP
Motivated by the striking classification performance of the Completed LBP (CLBP) proposed by Guo et al. [6], we also proposed the Completed Joint-scale LBP (CJLBP) descriptor. As CLBP, CJLBP also contains three operators: CJLBP_S, CJLBP_M and CJLBP_C. The CJLBP_S is exactly the same as the JLBP. The CJLBP_C is defined the same as CLBP_C.
Combined by the definitions of CLBP_M (Eq. 4) and JLBP (Eq. 7), the CJLBP_M is defined as:
where \(m_{i,R_{l}} = |p_{i,R_{l}} - p_{\mathrm {c}}|\) and \(a^{(R_{l})}\) denotes the mean value of \(m_{i,R_{l}}\) from the whole image, which is computed by the same method as [6]. When \(L = 1\), the CJLBP_M descriptor is exactly the same as the CLBP_M descriptor, and the CJLBP descriptor is exactly the same as the CLBP descriptor. Further, the two-dimensional joint (2D-joint) and the three-dimensional joint (3D-joint) of the proposed CJLBP_S, CJLBP_M and CJLBP_C can also be built, respectively, for texture representation as [6].
It is also clear that the CLBP operators are not appropriate for depicting the macro-textures because of the higher dimensionality. In comparison with those CLBPs, the CJLBPs produce much smaller feature vectors. For example, CLBP_SMC\(_{24,3}^\mathrm{riu2}\) produces a 1352-bin histogram, while, CJLBP_SMC\(_{8,R_{1},R_{2},\ldots , R_{L}}^\mathrm{riu2}\) only produces a 200-bin histogram. Further, the dimension of the proposed operators remains unchanged regardless of the variation of the joint scales.
3.4 Multiple CJLBPs
It has been proved that the multi-scale scheme (the concatenation of individual LBPs) [23] can enhance the power of LBP and other LBP-based methods, such as [6] and [17]. The proposed approach could derive many CJLBPs, which makes it suitable to capture the texture structures at different scales. In this case, the histograms of the individual CJLBPs can also be concatenated together for better performance as the multi-scale scheme in [23]. For example, the two individual CJLBPs, CJLBP\(_{8,1,2}\) and CJLBP\(_{8,2,3}\), are concatenated together and denoted as CJLBP\(_{8,1,2+8,2,3}\).
4 Experimental results
To evaluate the performance of the proposed operators in texture classification, we have carried out a series of experiments on three representative texture databases, i.e., the Outex database [22], Columbia-Utrecht Reflection and Texture (CUReT) database [3] and UIUC database [11]. The Nearest Neighbor Classifier (NNC) and the chi-square distance are used together as the dissimilarity measure as [6] and [39].
We also compare the proposed CJLBP with some state-of-the-art LBP-based algorithms, CLBP [6], Completed LBC (CLBC) [39], CRLBP [40], BRINT [17], AMBP [7] and LSP [29] besides the two non-LBP methods VZ_MR8 [34] and VZ_Joint [35]. For the sampling scheme, we chose the BRINT2 proposed in [17] and set \(K=8\).

The Outex dataset includes 24 different texture classes
4.1 Experimental results on Outex database
The Outex dataset is one of the well-known databases used for the evaluation of texture classification, which includes 24 texture classes shown in Fig. 3. We chose Outex_TC_0010 (TC10) and Outex_TC_0012 (TC12) in the experiments, where TC10 and TC12 are collected under three different illuminants (’horizon’, ’inca’, and ’t184’) and nine different rotation angles (\(0^{\circ }\), \(5^{\circ }\), \(10^{\circ }\), \(15^{\circ }\), \(30^{\circ }\), \(45^{\circ }\), \(60^{\circ }\), \(75^{\circ }\), and \(90^{\circ }\)). There are 20 nonoverlapping \(128 \times 128\) texture samples for each class under each condition.
For TC10, samples of illuminant ’inca’ and angle \(0^{\circ }\) in each class are adopted for classifier training and the other eight rotation angles with the same illumination are used as testing suits. Hence, there are 480 \( \left( 24 \times 20 \right) \) models and 3840 \( \left( 24 \times 8 \times 20 \right) \) validation samples. For TC12, all the \( 24 \times 20 \times 9 \) samples captured under illumination ’tl84’ or ’horizon’ are used as the test data.
Table 1 gives the experimental results of different methods, where the results of VZ_MR8 and VZ_Joint are reproduced from [6], and the results of other methods are taken directly from the cited papers. From Table 1, we can draw the following conclusions.
-
For CJLBP_Ss, the proposed operators, CJLBP_S\(_{8,2,4}^\mathrm{riu2}\) (87.51 %) and CJLBP_S\(_{8,4,8}^\mathrm{riu2}\) (87.27 %) perform better than CLBP_S\(_{24,3}^\mathrm{riu2}\) (86.96 %).
-
For CJLBP_Ms, the proposed operator CJLBP_M\(_{8,4,8}^\mathrm{riu2}\) achieves better score (85.91 %) than CLBP_M\(_{24,3}^\mathrm{riu2}\) (85.11 %).
-
In the 2D-joint way, CLBP_S_M\(_{24,3}^\mathrm{riu2}\) produces higher score (95.41 %) than CLBP_S_M\(_{16,2}^\mathrm{riu2}\) (93.18 %) and CLBP_S_M\(_{8,1}^\mathrm{riu2}\) (86.85 %). The proposed operators, CJLBP_S_M\(_{8,2,4}^\mathrm{riu2}\), CJLBP_S_M\(_{8,2,5}^\mathrm{riu2}\), CJLBP_S_M\(_{8,4,8}^\mathrm{riu2}\) and CJLBP_S_M\(_{8,1,3,4}^\mathrm{riu2}\) give better scores, 95.55, 95.87, 96.05 and 95.43 % than CLBP_S_M\(_{24,3}^\mathrm{riu2}\). Further, their feature dimensionality (100 bins) is less than one-sixth of CLBP_S_M\(_{24,3}^\mathrm{riu2}\) (676 bins).
-
In the 3D-joint way, the CLBC_CLBP (the concatenation of CLBC_SMC\(_{24,3}^\mathrm{riu2}\) and CLBP_SMC\(_{24,3}^\mathrm{riu2}\)) performs the best among the methods discussed in [6] and [39]. Yet, the introduced CJLBP_SMC\(_{8,2,3}^\mathrm{riu2}\) (96.85 %), CJLBP_SMC\(_{8,2,4}^\mathrm{riu2}\) (97.33 %), CJLBP_SMC\(_{8,2,5}^\mathrm{riu2}\) (97.13 %), CJLBP_SMC\(_{8,4,8}^\mathrm{riu2}\) (96.45 %) and CJLBP_SMC\(_{8,1,3,4}^\mathrm{riu2}\) (97.36 %) work better than CLBC_CLBP (96.35 %) with a far smaller number of features.
-
For the multiple CJLBPs, CJLBP_SMC\(_{8,4,8+8,1,3,4}^\mathrm{riu2}\) (400 bins) (the concatenation of CJLBP_SMC\(_{8,4,8}^\mathrm{riu2}\) and CJLBP_SMC\(_{8,1,3,4}^\mathrm{riu2}\)) are used as an example. It increases the classification accuracy by 2.39, 0.88, 0.48, 0.42 2.26 and 1.82 % over the LBP-based methods, CLBP_SMC\(_{8,1+16,2+24,3}^\mathrm{riu2}\) [6], CRLBP (\(\alpha = 1)\) [40], BRINT2_CS_CM (MS9, NNC) [Using nine scales (MS9) and Nearest Neighbor Classifier (NNC)], BRINT2_CS_CM (MS9, SVM) (Using nine scales (MS9) and support vector machine (SVM) classifier) [17], CLSP\(_{24,3}^\mathrm{riu2}\) and RLSP\(_{24,3}^\mathrm{riu2}\) [29], respectively. The results also show that it gives higher score than AMBP\(_{P,R,L_{1}}^\mathrm{riu2}/W/\Gamma \) [7].
-
The proposed CJLBP_SMC\(_{8,4,8+8,1,3,4}^\mathrm{riu2}\) yields 6.02 and 7.19 % improvement over the two non-LBP methods, VZ_MR8 [34] (610 bins) and VZ_Joint [35] (610 bins). Further, our method is train free, and requires no costly data-to-cluster assignments. Even, all the 3-D joint operators and 2-D joint operators (except CJLBP_S_M\(_{8,1,2}^\mathrm{riu2}\)) given in the paper are also better than VZ_MR8 and VZ_Joint.
-
Based on the results, CJLBP_SMC\(_{8,4,8+8,1,3,4}^\mathrm{riu2}\) represents the best performance (99.01 %).
It is obvious that there are many combinations of CJLBPs. We have tested the other three combinations, CJLBP_SMC\(_{8,1,2+8,1,3}^\mathrm{riu2}\), CJLBP_SMC\(_{8,2,4+8,2,5}^\mathrm{riu2}\), and CJLBP_SMC\(_{8,2,5+8,1,3,4}^\mathrm{riu2}\) besides CJLBP_SMC\(_{8,4,8+8,1,3,4}^\mathrm{riu2}\). Their average classification rates are 96.32, 98.61, and 97.57 %, respectively. It can be simply concluded that the combinations will achieve better results if the individual CJLBPs performs good.
On the other hand, better results may be produced by applying different number of sampling points (K). For example, CJLBP_S\(_{12,2,3}^\mathrm{riu2}\) (\(K=12\)) could achieve 91.30, 83.98 and 78.58 % for TC10, TC12 (’t184’) and TC12 (’horizon’), and it has about 2.11, 2.10 and 2.94 % improvement over CJLBP_S\(_{8,2,3}^\mathrm{riu2}\), respectively.

The 61 textures in the CURet dataset
4.2 Experimental results on CUReT database
For the CUReT database, we use the same subset of images which was previously used in [6, 39, 40] and [17]: 61 classes of textures were captured at different viewpoints and illumination orientations (illustrated in Fig. 4) and each class has 92 samples. In the experiments, N (N = 46, 23, 12, 6) images per class are selected randomly for training and the remaining (92\(~-~N\)) (46, 69, 80, 86) for testing.
Table 2 depicts the classification scores over a hundred random splits for different techniques. We also note that the results of VZ_MR8 and VZ_Joint are reported directly from [6]; the results of other methods are taken directly from the cited papers except CLBP_S_M\(_{24,3}^\mathrm{riu2}\) and CLBP_SMC\(_{24,3}^\mathrm{riu2}\) which are our implementation. Some findings could be obtained as follows from Table 2.
-
The CLBP_S\(_{24,3}^\mathrm{riu2}\) and CLBP_M\(_{24,3}^\mathrm{riu2}\) achieve better results than those of the CJLBP_Ss and CJLBP_Ms, respectively.
-
In the 2D-joint way, CLBP_S_M\(_{24,3}^\mathrm{riu2}\) [6] produces the classification rates of 94.01, 89.83, 83.89 and 73.66 % for 46, 23, 12 and 6 training samples, respectively. The presented CJLBP_S_Ms, CJLBP_S_M\(_{8,1,3}^\mathrm{riu2}\), CJLBP_S_M\(_{8,2,3}^\mathrm{riu2}\), CJLBP_S_M\(_{8,2,4}^\mathrm{riu2}\), CJLBP_S_M\(_{8,2,5}^\mathrm{riu2}\), CJLBP_S_M\(_{8,4,7}^\mathrm{riu2}\) and CJLBP_S_M\(_{8,1,2,3}^\mathrm{riu2}\) produce higher scores than CLBP_S_M\(_{24,3}^\mathrm{riu2}\). It is also worth noting that the length of the feature vectors of our methods and CLBP_S_M\(_{24,3}^\mathrm{riu2}\) is 100 and 676, respectively.
-
In the 3D-joint way, CLBP_SMC\(_{24,3}^\mathrm{riu2}\) presents the classification rates of 95.27, 91.86, 85.33 and 76.09 % for 46, 23, 12 and 6 training samples, respectively [6]. For the CJLBP_SMCs, CJLBP_SMC\(_{8,1,3}^\mathrm{riu2}\), CJLBP_SMC\(_{8,2,3}^\mathrm{riu2}\), CJLBP_SMC\(_{8,2,4}^\mathrm{riu2}\), CJLBP_SMC\(_{8,2,5}^\mathrm{riu2}\), CJLBP_SMC\(_{8,4,7}^\mathrm{riu2}\) and CJLBP_SMC\(_{8,1,2,3}^\mathrm{riu2}\) present better performance than CLBP_SMC\(_{24,3}^\mathrm{riu2}\). Further, the dimensionality of the proposed CJLBP_SMCs (200 bins) is less than one-sixth of CLBP_SMC\(_{24,3}^\mathrm{riu2}\) (1352 bins).
-
CJLBP_SMC\(_{8,1,2+8,4,7+8,1,2,3}^\mathrm{riu2}\) (600 bins) (the concatenation of CJLBP_SMC\(_{8,1,2}^\mathrm{riu2}\), CJLBP_SMC\(_{8,4,7}^\mathrm{riu2}\) and CJLBP_SMC\(_{8,1,2,3}^\mathrm{riu2}\)) is used as an example of multiple CJLBPs. It has about 1.19, 2.92, 3.37 and 1.26 % improvement for 46, 23, 12 and 6 training samples over CRLBP (\(\alpha = 8\)) (1352 bins) [40]. It also performs better than CLBP_SMC\(_{8,1+16,3+24,5}^\mathrm{riu2}\) [6], AMBP\(_{P,R,L_{1}}^{ri}/W/\Gamma \) [7], BRINT2_CS_CM (MS9, NNC) [17], CLSP\(_{16,2}^\mathrm{riu2}\) and RLSP\(_{16,2}^\mathrm{riu2}\) [29].
-
The BRINT2_S_M (MS9, NNC) [17] has better performance than CJLBP_SMC\(_{8,1,2+8,4,7+8,1,2,3}^\mathrm{riu2}\). Firstly, it is because the BRINT2_S_M uses the rotation invariant patterns (’ri’). Further, more scales are concentrated together (MS9) for BRINT2_S_M than CJLBP_SMC\(_{8,1,2+8,4,7+8,1,2,3}^\mathrm{riu2}\). We expect that the proposed method would give an improved classification rate by the same schemes as [17]. Additionally, CJLBP_SMC\(_{8,1,2+8,4,7+8,1,2,3}^\mathrm{riu2}\) is the only one example of the proposed CJLBP scheme.
-
The two learning techniques, VZ_MR8 and VZ_Joint, also yield better performance than the proposed operator, CJLBP_SMC\(_{8,1,2+8,4,7+8,1,2,3}^\mathrm{riu2}\). It should be noted that the feature dimensionality of ours (600 bins) is no more than one fourth of the two training-based methods (2440 bins). Additionally, our method is train free and requires no costly data-to-cluster assignments.

The UIUC dataset includes 25 different texture classes
4.3 Experimental results on UIUC database
The UIUC texture database includes 25 texture classes (illustrated in Fig. 5) and 40 images (\(640 \times 480\)) in each class. The database contains materials imaged under significant viewpoint variations. In the experiments, we also use the same subset of images which has previously been used in [6, 39], and [40]: N (\(N =\) 20, 15, 10, 5) images per class were selected randomly for training and the remaining (40\(~-~N\)) (20, 25, 30, 35) for testing.
The experimental results in [39] show that CLBC yields higher scores than CLBP [6] on UIUC database, which demonstrates that CLBC offers high tolerance for significant viewpoint and scale changes.
Table 3 gives the average accuracy over 100 randomly splits of the training and test sets. In Table 3, the results of CLSP, RLSP, Multi_CLBC and CRLBP are taken directly from the cited references, the results of VZ_MR8 and VZ_Joint are taken from [5], the results of AMBM\(_{P,R,L_{1}}^{ri}/W/\Gamma \), BRINT2_S_M(MS9, NNC), BRINT2_CS_CM(MS9, NNC), and CLBC are our implementation. From Table 3, the following observations could be made.
-
The CJLBP_S\(_{8,2,4}^\mathrm{riu2}\), CJLBP_S\(_{8,2,5}^\mathrm{riu2}\) and CJLBP_S\(_{8,3,4,8}^\mathrm{riu2}\) achieve better results than CLBC_S\(_{24,3}\).
-
All the CJLBP_Ms (except CJLBP_M\(_{8,1,2}^\mathrm{riu2}\)) produce better scores than CLBC_M\(_{24,3}\).
-
In the 2D-joint way, the introduced CJLBP_S_M\(_{8,2,4}^\mathrm{riu2}\), CJLBP_S_M\(_{8,2,5}^\mathrm{riu2}\) and CJLBP_S_M\(_{8,3,4,8}^\mathrm{riu2}\) present better performance than CLBC_S_M\(_{24,3}\). In particular, CJLBP_S_M\(_{8,3,4,8}^\mathrm{riu2}\) yields about 4.02, 4.45, 5.08, 5.99 % improvement over CLBC_S_M\(_{24,3}\) for 20, 15, 10 and 5 training samples, respectively. Further, the proposed operators enjoy more compact representation (100 bins) than CLBC_S_M\(_{24,3}\) (625 bins).
-
In the 3D-joint way, the presented CJLBP_SMCs, CJLBP_SMC\(_{8,2,3}^\mathrm{riu2}\), CJLBP_SMC\(_{8,2,4}^\mathrm{riu2}\), CJLBP_SMC\(_{8,2,5}^\mathrm{riu2}\) and CJLBP_SMC\(_{8,3,4,8}^\mathrm{riu2}\) present better performance than CLBC_SMC\(_{24,3}\). Further, CJLBP_SMC\(_{8,3,4,8}^\mathrm{riu2}\) yields the best results; it has about 3.18, 3.15, 3.82, 3.48 % improvement for 20, 15, 10 and 5 training samples over CLBC_SMC\(_{24,3}\), respectively. The CJLBP_SMCs also have much more compact representation (200 bins) than CLBC_SMC\(_{24,3}\) (1250 bins).
-
For the multiple CJLBPs, CJLBP_SMC\(_{8,1,2,3+8,3,4,8}^\mathrm{riu2}\) (600 bins) (the concatenation of CJLBP_SMC\(_{8,1,2,3}^\mathrm{riu2}\) and CJLBP_SMC\(_{8,3,4,8}^\mathrm{riu2}\)) is used as an example and it reaches the classification rates of 95.13, 93.80, 91.11 and 84.49 % for 20, 15, 10 and 5 training samples, respectively. It presents better results with more compact feature than the Multi_CLBC (R = 1, 2, 3, 4, 5) [39], CLSP\(_{16,2}^\mathrm{riu2}\) and RLSP\(_{16,2}^\mathrm{riu2}\) [29], AMBP\(_{P,R,L_{1}}^{ri}/W/\Gamma \) [7], BRINT2_CS_CM (MS9, NNC) and BRINT2_S_M(MS9, NNC) [17], VZ_MR8 [34], VZ_Joint [35] and CRLBP(\(\alpha = 1)\) [40].

Classification accuracy comparison for L = 2, 3, 4 and 5
4.4 The influence of the parameter L
It can be seen that L (Eqs. 7, 9) is the key parameter for the proposed scheme. To discuss the influence of L, we choose CJLBP_S\(^\mathrm{riu2}\), CJLBP_M\(^\mathrm{riu2}\) and CJLBP_S_M\(^\mathrm{riu2}\) as examples, and 50 randomly trails are tested, respectively, for \(L=2, 3, 4\) and 5. The maximization, minimization, average and variance (denoted as ’Max’, ’Min’, ’Ave’ and ’Var’) of the classification rates for the three examples are given in Table 4 and the comparison of the average and variance is also given in Fig 6. Further, Table 5 shows the feature extraction and classification time (time complexity) of these three examples averaged by 50 trials. Some findings could be obtained from the results that
-
All the three examples achieve relatively better results when \(L = 3\) or 4.
-
The variances of the classification accuracy reduce with the increase of L.
-
The bigger the L, the higher is the time complexity of the CJLBPs.
-
Generally, \(L = 3\) or 4 is the best option for the CJLBPs according to the average classification rate, the variance and the time complexity.
5 Conclusion
In this paper, we have discussed the demerit of the original LBP and its extensions firstly. To avoid the shortcomings, we have presented a new robust scheme, JLBP. The new method also has the advantages of LBP and its extensions, such as the simplicity, discriminative power, computational efficiency, robustness to illumination changes, noise robustness. Further, it can easily capture the macro-textures by the fusion of varieties of scales. In addition, CJLBP has been introduced to enhance its power. The proposed scheme is shown to exhibit very good performance on popular benchmark texture database. In the future work, we will extend the proposed approach to focus on additional information (such as choosing ’ri’ feature and discussing varieties of K values) and additional scales to improve performances even further.
References
Brahnam, S., Jain, L.C., Nanni, L., Lumini, A.: Local binary patterns: new variants and applications. Springer, NY (2014)
Chen, J., Kellokumpu, V., Zhao, G., Pietikäinen, M.: Rlbp: Robust local binary pattern. In: Proc. the British Machine Vision Conference (BMVC 2013), Bristol, UK (2013)
Dana, K.J., Van Ginneken, B., Nayar, S.K., Koenderink, J.J.: Reflectance and texture of real-world surfaces. ACM Trans. Graph. (TOG) 18(1), 1–34 (1999)
Davarzani, R., Mozaffari, S., Yaghmaie, K.: Scale- and rotation-invariant texture description with improved local binary pattern features. Signal Process. 111, 274–293 (2015)
Guo, Z., Li, Q., Zhang, L., You, J., Zhang, D., Liu, W.: Is local dominant orientation necessary for the classification of rotation invariant texture? Neurocomputing 116, 182–191 (2013)
Guo, Z., Zhang, L., Zhang, D.: A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 19(6), 1657–1663 (2010)
Hafiane, A., Palaniappan, K., Seetharaman, G.: Joint adaptive median binary patterns for texture classification. Pattern Recogn. (2015)
Han, J., Ma, K.K.: Rotation-invariant and scale-invariant gabor features for texture image retrieval. Image Vision Comput. 25(9), 1474–1481 (2007)
Heikkilä, M., Pietikäinen, M., Schmid, C.: Description of interest regions with local binary patterns. Pattern Recognit. 42(3), 425–436 (2009)
Hussain, S.U., Napoleon, T., Jurie, F.: Face recognition using local quantized patterns. Br. Mach. Vis. Conf., pp 99.1–99.11 (2012)
Lazebnik, S., Schmid, C., Ponce, J.: A sparse texture representation using local affine regions. IEEE Trans. Pattern Anal. Mach. Intell. 27(8), 1265–1278 (2005)
Li, C., Li, J., Gao, D., Fu, B.: Rapid-transform based rotation invariant descriptor for texture classification under non-ideal conditions. Pattern Recognit. 47(1), 313–325 (2014)
Li, C., Zhou, W., Yuan, S.: Iris recognition based on a novel variation of local binary pattern. Vis. Comput. 31(4), 1419–1429 (2015)
Li, Z., Liu, G., Yang, Y., You, J.: Scale-and rotation-invariant local binary pattern using scale-adaptive texton and subuniform-based circular shift. IEEE Trans. Image Process. 21(4), 2130–2140 (2012)
Liao, S., Chung, A.C.: Face recognition by using elongated local binary patterns with average maximum distance gradient magnitude. In: Computer Vision-ACCV 2007, pp. 672–679. Springer (2007)
Liao, S., Zhu, X., Lei, Z., Zhang, L., Li, S.Z.: Learning multi-scale block local binary patterns for face recognition. In: Advances in Biometrics, pp. 828–837. Springer (2007)
Liu, L., Long, Y., Fieguth, P.W., Lao, S., Zhao, G.: Brint: Binary rotation invariant and noise tolerant texture classification. IEEE Trans. Image Process. 23(7), 3071–3084 (2014)
Maani, R., Kalra, S., Yang, Y.H.: Rotation invariant local frequency descriptors for texture classification. IEEE Trans. Image Process. 22(6), 2409–2419 (2013)
Manjunath, B.S., Ma, W.Y.: Texture features for browsing and retrieval of image data. IEEE Trans. Pattern Anal. Mach. Intell. 18(8), 837–842 (1996)
Murala, S., Wu, Q.J.: Local mesh patterns versus local binary patterns: biomedical image indexing and retrieval. IEEE J. Biomed. Health Inf. 18(3), 929–938 (2014)
Nguyen, T.N., Miyata, K.: Multi-scale region perpendicular local binary pattern: an effective feature for interest region description. Vis. Comput. 31(4), 391–406 (2015)
Ojala, T., Maenpaa, T., Pietikäinen, M., Viertola, J., Kyllonen, J., Huovinen, S.: Outex-new framework for empirical evaluation of texture analysis algorithms. In: Proc. International Conference on Pattern Recognition, vol. 1, pp. 701–706. IEEE (2002)
Ojala, T., Pietikäinen, M., Maenpaa, T.: Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 24(7), 971–987 (2002)
Qi, X., Xiao, R., Li, C.G., Qiao, Y., Guo, J., Tang, X.: Pairwise rotation invariant co-occurrence local binary pattern. IEEE Trans. Pattern Anal. Mach. Intell. 11, 2199–2213 (2014)
Qian, X., Hua, X.S., Chen, P., Ke, L.: Plbp: An effective local binary patterns texture descriptor with pyramid representation. Pattern Recognit. 44(10), 2502–2515 (2011)
Ren, J., Jiang, X., Yuan, J.: Noise-resistant local binary pattern with an embedded error-correction mechanism. IEEE Trans. Image Process. 22(10), 4049–4060 (2013)
Ren, J., Jiang, X., Yuan, J.: Learning lbp structure by maximizing the conditional mutual information. Pattern Recognit. 48(10), 3180–3190 (2015)
Ren, J., Jiang, X., Yuan, J., Wang, G.: Optimizing lbp structure for visual recognition using binary quadratic programming. Signal Process. Lett. IEEE 21(11), 1346–1350 (2014)
Shrivastava, N., Tyagi, V.: An effective scheme for image texture classification based on binary local structure pattern. Vis. Comput. 30(11), 1223–1232 (2014)
Shu, Y., Wang, T., Shao, G., Liu, F., Feng, Q.: Robust differential circle patterns based on fuzzy membership-pooling: A novel local image descriptor. Neurocomputing 144, 378–390 (2014)
Song, T., Li, H., Meng, F., Wu, Q., Luo, B., Zeng, B., Gabbouj, M.: Noise-robust texture description using local contrast patterns via global measures. Signal Process. Lett. IEEE 21(1), 93–96 (2014)
Sun, J., Fan, G., Yu, L., Wu, X.: Concave-convex local binary features for automatic target recognition in infrared imagery. EURASIP J. Image Video Process. 2014(1), 1–13 (2014)
Tan, X., Triggs, B.: Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 19(6), 1635–1650 (2010)
Varma, M., Zisserman, A.: A statistical approach to texture classification from single images. Int. J. Comput. Vis. 62(1–2), 61–81 (2005)
Varma, M., Zisserman, A.: A statistical approach to material classification using image patch exemplars. IEEE Trans. Pattern Anal. Mach. Intell. 31(11), 2032–2047 (2009)
Verma, M., Raman, B., Murala, S.: Local extrema co-occurrence pattern for color and texture image retrieval. Neurocomputing (2015)
Wolf, L., Hassner, T., Taigman, Y., et al.: Descriptor based methods in the wild. In: Proc. Workshop on Faces in’Real-Life’Images: Detection, Alignment, and Recognition (2008)
Wu, X., Sun, J., Fan, G., Wang, Z.: Improved local ternary patterns for automatic target recognition in infrared imagery. Sensors 15(3), 6399–6418 (2015)
Zhao, Y., Huang, D., Jia, W.: Completed local binary count for rotation invariant texture classification. IEEE Trans. Image Process. 21(10), 4492–4497 (2012)
Zhao, Y., Jia, W., Hu, R.X., Min, H.: Completed robust local binary pattern for texture classification. Neurocomputing 106, 68–76 (2013)
Zhu, C., Bichot, C.E., Chen, L.: Image region description using orthogonal combination of local binary patterns enhanced with color information. Pattern Recognit. 46(7), 1949–1963 (2013)
Acknowledgments
The authors would like to thank the anonymous reviewers for their valuable comments and suggestions that we refer to in this paper. We would also like to thank Dr. Guo and Dr. Zhao as well as the MVG group for sharing their codes. This work is sponsored by the NSFC (No. 61572173) and the basic and advanced technology research project of Henan Province (Nos. 132300410462, 112300410281), the research team of HPU (No. T2014-3).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Wu, X., Sun, J. Joint-scale LBP: a new feature descriptor for texture classification. Vis Comput 33, 317–329 (2017). https://doi.org/10.1007/s00371-015-1202-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-015-1202-z