
Abstract
Recycled aggregate concrete is used as an alternative material in construction engineering, aiming to environmental protection and sustainable development. However, the compressive strength of this concrete material is considered as a crucial parameter and an important concern for construction engineers regarding its application. In the present work, the 28-days compressive strength of recycled aggregate concrete is investigated through four artificial intelligence techniques based on a meta-heuristic search of sociopolitical algorithm (i.e. ICA) and XGBoost, called the ICA-XGBoost model. Based on performance indices, the optimum among these developed models proved to be ICA-XGBoost model. Namely, findings demonstrated that the proposed ICA-XGBoost model performed better than the other models (i.e. ICA-ANN, ICA-SVR, and ICA-ANFIS models) in estimating compressive strength of recycled aggregate concrete. The suggested model can be used in construction engineering in order to ensure adequate mechanical performance of the recycled aggregate concrete and allow its safe use for building purposes.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Urbanisation is an unquestionable trend in developing countries. The construction of infrastructure systems, as well as buildings, is an essential requirement for urbanisation. However, this trend has led to a series of negative effects [1, 2]. From an environmental point of view, a large number of natural aggregates have been exploited for construction purposes [3,4,5,6]. This has a serious negative impact on the environment due to construction materials mining activities, such as blasting, loading/unloading, transporting, crushing, to name a few [7,8,9,10,11,12]. Moreover, the amount of demolition and construction waste has also increased significantly, due to urban development, especially regarding construction waste from old, demolished buildings [13,14,15]. Aiming towards the achievement of sustainable development, many scientists have researched and applied recycled aggregate concrete (RAC) in construction. This has a double benefit, as construction and demolition waste is managed sustainably, while the exploitation of natural construction materials is considerably lower, thus succeeding in lowering the environmental impact of concrete and preventing the degradation of the ecological environment [16,17,18,19,20]. However, the main disadvantages of RAC are low compression load capacity, and low elastic modulus [21,22,23]. Therefore, an accurate prediction of the compressive strength (CS) of RAC is a necessity, which can allow the safe use of RAC in buildings.
To this aim, artificial intelligence (AI) has been extensively studied and applied as a robust computer engineering tool in the service of construction engineering [24,25,26]. For predicting CS of RAC, Duan et al. [27] successfully used an ANN with 168 sets of data, highlighting the excellent potential of the ANN model for forecasting CS of RAC in their study. MLR and nonlinear regression analysis have also been applied for predicting CS of RAC, in a study of Younis, Pilakoutas [28]. The same research revealed that recycled tires’ steel fibres could improve the CS of RAC. Deshpande et al. [29] also used ANN to predict CS of RAC with promising results. ANN is one of the most popular and widely used algorithms; however, it displays also some drawbacks, mainly poor prediction capacity, especially when the range of the testing dataset coincides with the training data. ANN also has a limited prediction performance when the number of datasets, used to develop and train the model, is limited in number. These drawbacks lead to the junction of ANNs with fuzzy logic (FL) and ANFIS algorithm. In another study, Khademi et al. [30] investigated the predictability of three AI techniques in predicting CS of RAC, namely ANN, ANFIS, and MLR. They concluded that the ANN model was capable of predicting CS of RAC more accurately, achieving an R2 of 0.919 and a MSE of 19.768. The ANFIS algorithm, however, displays a weakness in the determination of the weights in the membership function; thus, some optimisation algorithm (or meta-heuristic algorithms) was applied to solve the disadvantages of ANFIS and enhance the model’s performance [31, 32]. Several AI algorithms such as SVM and ELM have been applied; however, these algorithms have some disadvantages (e.g. large time and memory for computing large datasets; slow learning speed, poor computational scalability) [33,34,35]. In one study, Abdollahzadeh et al. [36] used GEP to predict CS of RAC, showing the high applicability of the GEP model for the CS prediction of RAC. Their GEP model was thus introduced as a tool for predicting CS of RAC containing silica fume. However, several issues, such as optimisation of GEP, comparison with the benchmark algorithms, were not considered in their study. The feasibility of deep learning theory (i.e. convolutional neural networks—CNN) in AI was also considered by Deng et al. [37] for predicting CS of RAC; 74 sets of concrete block were investigated to this purpose. Higher generalisation ability, higher efficiency, and higher precision than the traditional methods were the main findings in their study for the CNN model. Analogous techniques for estimating CS of RAC can be found in the following papers [38,39,40,41]. More details of CS prediction, as well as more extended state-of-the-art on AI techniques developed and used for the prediction of CS, can be found in [42,43,44,45,46,47].
The review of the related literature highlights the importance of the issue under examination in construction engineering. Although a number of research have been conducted for predicting CS of RAC [48,49,50,51,52,53,54,55,56,57,58], further research is still necessary to find a robust algorithm capable of revealing the different aspects of its design and which can allow its generalised use. Furthermore, in the present study, four new hybrid AI techniques, including hybrid algorithms of XGBoost, ANN, ANFIS, and SVR with ICA optimisation algorithm called ICA-XGBoost, ICA-ANN, ICA-SVR, and ICA-ANFIS were developed and applied for predicting CS of RAC. The results of this research add further insight into this very interesting and necessary subject in the field of civil and construction engineering.
2 Experimental data
According to our review of the relevant literature, the CS of RAC is influenced by many factors, such as the fine aggregate density (FA) portion used, the water–cement ratio (WCR), the recycled coarse aggregate density (RCA), the water–total material ratio (WTMR), water absorption (WA), and the natural coarse aggregate density (NCA) [37, 41, 59]. Therefore, 209 RAC experimental results aiming to determine the CS of RAC were conducted, based on the influencing mentioned above factors. The experiments were performed in the laboratory, applying different mixing ratios and parameters. Through the experimental procedure implemented, the WA of RAC samples was determined in the range of 0.338 to 21.604%; WCR lay in the range of 0.307 to 0.736; FA lay in the range of 278.1 to 1211.8 kg/m3; RCA lay in the range of 0 to 1324.2 kg/m3; NCA lay in the range of 0 to 1340.3 kg/m3, and WTMR lay in the range of 0.035 to 0.2. Aiming to indicate the 28-day compressive strength (CS) of RAC samples, the servo press machine 2000 kN was used. Strain gauges were used to measure the deformation of RAC samples through pressure sensors. Experimental results were recorded with the CS of RAC lies in the range of 15.01 to 73.08 MPa, with different mixing ratios. In the present study, WA, WCR, FA, RCA, NCA, and WTMR were considered as the input variables, whereas the CS of RAC at 28 days was selected as the output variable. In Figs. 1 and 2, the properties of the RAC datasets used were depicted.

Histograms of the database parameters

Description of the RAC dataset used
For description of the database used, the mean values, maximum, minimum, and standard deviation (STD) values are presented in Table 1. Basically, some of the RAC variables could be dependent on each other. High positive or negative amounts of the correlation coefficient among the input variables can lead to poor efficiency of the approaches. Besides, it can make difficult explaining the influences expository variables on the respond. Subsequently, the correlation coefficients between all possible variables have been specified and presented in Table 2. It should be noted that the values of the correlation matrix are symmetric to its main diagonal (italicized values in Table 2). There are no significant correlations among the independent input variables (Table 2).
3 Background of intelligent techniques used
3.1 Imperialist competitive algorithm (ICA)
The ICA was proposed by Atashpaz-Gargari, Lucas [60] obtained by simulating human social evolution for solving optimisation issues. It is known as one of the evolution algorithms which may decode continuous function with high performance [61,62,63]. Actually, ICA is a global search algorithm that is developed based on imperialist competition and social policies [64]. Therefore, the most powerful empire can overcome different colonies along with their resource. Other realms can compete together to obtain the territory when an empire collapses. The ICA core may be demonstrated by the eight steps below. Figure 3 shows the pseudo-code of the ICA.

The ICA’s pseudo-code
-
1.
Create initial empires and search spaces by randomly;
-
2.
Colony assimilation: the position of colonies is changed according to the location of the countries;
-
3.
Accidental modifications occur in the features of each country as a revolution;
-
4.
Swapping the territory position for the empire. A colony with a better position can rise and control the empire, and it will replace the previous empire;
-
5.
The empires compete to conquer the other’s colonies;
-
6.
The weaker empires will be defeated and eliminated. The entire colonies of the weaker empires will be lost. In this step, natural selection rules are applied;
-
7.
Check the stop criteria. If the stop criteria are satisfied, then stop the competitive process. Otherwise, return to the step of colony assimilation (step 2).
-
8.
End.
3.2 Extreme gradient boosting (XGBoost)
For the first one, Chen, He [65], the XGBoost is an ensemble tree algorithm developed. After that, it is enhanced according to the gradient boosting (GB) Friedman [66] decision. It may deal with both classification and regression issues efficiently because the boosted trees are generated and worked parallel [67]. In XGBoost, an objective function (OA) is defined based on the conditions of gradient boosting conditions. It is taken into account as the core of the XGBoost algorithm, and similar to many different optimisation methods. Like the GB machine and GB decision tree, XGBoost proposes a reliable and fast model for different engineering simulations based on the parallel boosting trees [10]. Actually, in order to increase the precision of estimations, it can symbolise a soft computing library, which can combine novel algorithms together with approach of GB decision tree.
The XGBoost can be described as below:
Let \(D = \left\{ {(x_{i} ,y_{i} )} \right\}\) is a dataset including of n samples as well as m features (\(\left| D \right| = n,x_{i} \in R^{m} ,y_{i} \in R\)). The suggested tree ensemble model uses z additive functions for approximating the system response as:
in which F is the space of regression trees. It is defined as:
q stands as the tree structure, T and w are the number of leaf nodes and their weights. In addition, the fk term considered a function, which shows to w and q corresponded to an independent tree.
In order to optimise the ensemble tree along with to decrease errors, the OA of XGBoost can be minimised as follows:
l stands as a convex function (i.e. loss function) which is applied to determine the difference between exact and calculated values, \(y_{i}\) is considered as a measured value,\(\hat{y}_{i}\) stands as a predicted value. For minimising the errors, the number of iteration (t) is used, whereas \(\varOmega\) is the penalty factor for the complication of the regression tree approach:
3.3 Support vector regression (SVR)
For estimating problems, Cortes and Vapnik [68] introduced SVM with the capability of wide application as a benchmark machine learning approach. It has two essential branches (i.e. support vector classification (SVC) and support vector regression (SVR) that SVR is utilised as the most usual figure of SVM [69, 70]. The nature of SVR coming from target values, which detect a \(\varphi (x)\) function for mapping data to flat space aiming to achieve a space as flat as feasible. By considering two forms of nonlinear and linear regression, solving complex problems is l [71].
As can be seen in Fig. 4, optimised and linear regression problems may be performed by a convex optimisation of calculation with constraints and solutions by SVR for the linear regression problems.

Linear SVR
In terms of nonlinear regression problems, optimisation and nonlinear regression problems by SVR can be used with a convex optimisation of calculation along with kernel functions for transforming the dataset in a higher dimensional of the dataset in the feature space. The kernel functions with two different forms that are the most commonly used, including radial and also polynomial basis function are additionally shown in Fig. 5.

Nonlinear SVR
3.4 Artificial neural network (ANN)
ANN has wide applications in different areas. This approach has been introduced since the 1970s [6, 72,73,74,75,76]. ANN is a family of approaches in AI that is constructed based on the learning capability of the human brain. Basically, the ANN model structure has a layer in input and hidden layer(s) as well as a layer in output [77]. The essential parameters of ANN were the neurons or nodes known as their connections and processing elements [78, 79]. In the input layer, the input neurons provide the input signals (i.e. properties of the dataset). Accurately, in the present work, the nodes in input achieve the messages of WA, WCR, FA, RCA, NCA, and WTMR. Then, the hidden nodes get the signal from the input neurons and implementing a computational with weights. They are then delivered to the subsequent nodes for the next calculations [80]. For simple regression problems, an ANN system with only one hidden layer can provide the outcome predictions with the acceptable [81]. The ANN algorithm that has two hidden layers is commonly utilised for more complex problems [82, 83]. Also, the output nodes in the output layer achieve signals from nodes in hidden layers and computational of output amounts. In the present paper, for the ANN model, the CS of RAC is utilised and used as an output variable. Figure 6 shows the architecture of the ANN algorithm that is useful to estimate the CS of RAC.

The ANN structure for estimating the CS of RCA
3.5 Adaptive neuro-fuzzy inference system (ANFIS)
ANFIS is one of the ANN branches, which is developed based on a combination of ANN and a fuzzy system [84]. It was introduced by [85] first in 1993 and was widely applied in many fields [32, 86,87,88,89,90]. In ANFIS, the membership functions are assigned and adjusted by the training capability of ANN. The BP algorithm is used to adjust the parameter of the ANN model until the error is satisfied [91].
In ANFIS, IF–THEN rules are used to predict any problems. Assume x and y are the inputs, and z is the output in a fuzzy inference system. The IF–THEN rules are then applied, as illustrated in Fig. 7.

IF-THEN rules of ANFIS model
In theoretical, ANFIS includes five layers (except input and output layers), as shown in Fig. 8:

Architecture of ANFIS
-
Layer 1: Generating the membership grades (\(\mu A_{1} ,\,\mu A_{2} ,\,\mu B_{1} ,\,\mu B_{2}\)) from the inputs (i.e. a and y) by adaptively act.
$$O_{1,i} = \mu_{{A_{i} }} (x) \;{\text{for}}\;i = 1,2\;{\text{or}}\;O_{1,i} = \mu_{{B_{i} - 2}} (y)\;{\text{for}}\;i = 3,4$$(5)where i is the number of input variables.
-
Layer 2: Getting an output using AND/OR rule node, called firing strengths.
$$O_{2,i} = \mu_{{A_{i} }} (x)\mu_{{B_{i} }} (y),\,i = 1,2, \ldots$$(6) -
Layer 3: Computing the normalised firing strength by an average node.
$$O_{3,i} = \bar{\varpi }_{i} = \frac{{\varpi_{i} }}{{\varpi_{1} + \varpi_{2} }},i = 1,2, \ldots$$(7) -
Layer 4: Turning the parameters of p, q, and r and showing them as consequent nodes.
$$O_{4,i} = \bar{\varpi }_{i} f_{i} = \bar{\varpi }_{i} (p_{i} x + q_{i} y + r_{i} )$$(8) -
Layer 5: Computing the total average of output. This layer uses a sum of input signals to calculate output nodes.
$$O_{5,i} = f = \sum\limits_{i} {\bar{\varpi }_{i} f_{i} }$$(9)
4 Framework of the proposed ica-xgboost model
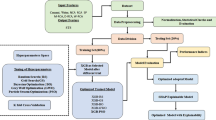
As regarded above, the primary purpose of this work is to present a novel technique of AI for predicting the CS of RAC based on the XGBoost model and the ICA optimisation, called ICA-XGBoost technique. Accordingly, the RAC dataset with different mixing ratios and different CS has been divided into two sections for testing and training purposes, as the first stage. Of the total dataset, 80% of the data (approximate 169 experimental datasets) was used for the development of the ICA-XGBoost model, whereas the remaining 20% (approximate 40 experimental datasets) was used for testing the precision of the developed ICA-XGBoost model. In the second stage, an initial XGBoost model is developed based on the training dataset. Subsequently, the hyper-parameters of the developed XGBoost model are chosen as the main parameters to optimise by the ICA. Before optimising the hyper-parameters of the initial XGBoost model, the settings of ICA need to be established in the third stage. Then, the ICA-XGBoost model was generated in the fourth stage by adjusting the factors of the initial XGBoost model (by the established ICA optimisation). In this way, the accuracy of the XGBoost model can be enhanced. To check the improvement of the ICA-XGBoost model, the fitness of the generated ICA-XGBoost model was evaluated via error values, i.e. RMSE, as the fifth stage. Stopping criteria is checked through the RMSE for the sixth stage. If the model errors are satisfied with the stop condition (i.e. lowest RMSE), the optimisation process by ICA is horned there. Subsequently, the testing dataset with 40 experimental datasets was used to re-check the accuracy/error level of the developed ICA-XGBoost model, as the final stage. The optimisation procedure of the XGBoost model by the ICA for predicting the CS of RAC is shown in Fig. 9.

Optimisation procedure of the XGBoost model by the ICA for predicting the CS of RAC
5 Development of the models
As described in Fig. 8, the original dataset includes 209 experimental results and was divided into two parts (80/20) before proceeding to develop predictive models. Note that the dataset was divided randomly. Also, all the stated models are generated based on the same training dataset.
5.1 ICA-XGBoost model
For the development of the ICA-XGBoost model, an initial XGBoost model was developed with the following hyper-parameters: subsample percentage (\(\varsigma\)), boosting iterations (k), minimum loss reduction (\(\gamma\)), max tree depth (d), shrinkage (\(\eta\)), minimum sum of instance weight (\(\mu\)), and subsample ratio of columns (\(\delta\)). Subsequently, the ICA’s parameters were established for optimising the hyper-parameters of the XGBoost model. In the present work, the ICA’s parameters were set up as follow:
-
The number of initial countries (Ncountry): a trial and error procedure with various Ncountry was conducted with Ncountry of 50, 100, 150, 200, 250, 300, 350, 400, 450, 500, respectively.
-
The initial imperialists (Nimper): 30
-
The lower–upper limit of the optimisation region (L): [− 10, 10]
-
The assimilation coefficient (As): 2.8
-
The revolution of each country (r): 0.6
-
The maximum number of iterations (Ni): 1000 times
After establishing the parameters of the ICA, imperial competition is implemented to find the most substantial empire, corresponding to the most optimal values of the XGBoost model with the lowest RMSE. The competition process was repeated 1000 times to ensure the obtained values are the most optimal. Eventually, an optimal ICA-XGBoost model was found with the following parameters: \(\varsigma\) = 0.427, k = 856, \(\gamma\) = 4.288, d = 3, \(\mu\) = 2, \(\eta\) = 0.022, and \(\delta\) = 0.692. The optimisation process of the XGBoost model by the ICA is shown in Fig. 10.

The optimisation process of the XGBoost model by the ICA for predicting the CS of RAC
5.2 ICA-ANN model
For the development of the ICA-ANN model, the similar techniques and the same training dataset were used. Note that all the parameters of the ICA are the same as those used for the development of the ICA-XGBoost model. However, unlike the XGBoost model, an ANN model with the backpropagation algorithm was selected as the background of the optimisation. Indeed, an ANN model includes two hidden layers (i.e. ANN 6-16-21-1), which was developed for the prediction of the CS of RAC in the Python platform. The min–max scale method was used to transfer the input data in the range of -1 to 1 to avoid overfitting. Herein, the weights and biases of the ANN 6-16-21-1 model were optimised by the ICA. RMSE also utilised to analyse the performance of the optimisation process for the ICA-ANN model, as shown in Fig. 11. Finally, the optimal ICA-ANN model was determined with the optimal weights and biases, as shown in Fig. 12.

The optimisation process of the ANN model by the ICA for predicting the CS of RAC

The ICA-ANN structure for estimating the CS of RAC
5.3 ICA-SVR model
Similar to the ICA-XGBoost and ICA-ANN models, the ICA-SVR model was developed based on the optimisation of ICA for the SVR model. The same training dataset and parameters of the ICA were applied as those used for the previous models (i.e. ICA-XGBoost and ICA-ANN models). In this regard, the radial basis function of the kernel is utilised for the development of the SVR model. Hence, the sigma (\(\sigma\)) and cost (C) are optimised by the ICA to enhance the accuracy of the SVR model. Lowest RMSE was used as the final goal for the development of the ICA-SVR model. Finally, an optimal ICA-SVR model was developed with C of 27.509 and \(\sigma\) 0.015. The optimisation process of the ICA-SVR model for predicting the CS of RAC is shown in Fig. 13.

The optimisation process of the SVR model by the ICA for predicting the CS of RAC
5.4 ICA-ANFIS model
For the ICA-ANFIS modelling, an initial ANFIS model is developed as the first step; after that, the ICA was applied to optimise the developed ANFIS model. The parameters of the membership functions of the generated ANFIS model were optimised/trained by the ICA in this task. The same training dataset and ICA’s parameters were applied as those developed the previous models (i.e. ICA-XGBoost, ICA-ANN, and ICA-SVR models). A fitness function, i.e. RMSE, also utilised to assess the precision of the optimisation process for the ICA-ANFIS model. Ultimately, the optimal ICA-ANFIS model was found with the number of fuzzy terms of 15 and maximum iterations of 24. The training process of the ICA-ANFIS algorithm on the training dataset is shown in Fig. 14.

The optimisation process of the ANFIS model by the ICA for predicting the CS of RAC
6 Statistical criteria for model assessment
Once the models were developed, the testing dataset includes 40 experimental datasets, which were used to evaluate the accuracy in practical engineering of the models. Five statistical criteria, such as RMSE, R2, MAE, MAPE, and VAF, were suggested to evaluate the models’ performances, as follow:
k stands as the number of instances; \(\bar{y}\), \(y_{{i{\text{RAC}}}}\), and \(\hat{y}_{{i{\text{RAC}}}}\) show the average, measured, and modelled amounts of the response variable, respectively.
Furthermore, the following new recently proposed [92,93,94,95], the a10-index, engineering index to the reliability evaluations of the expanded AI models have been used:
M stands as the number of dataset sample, and also m10 is the number of samples along with a value of experimental rate value/estimated value in the range of 0.90 and 1.10. It is important to note that for a complete predictive approach, the values of a10-index were considered to be unity. The suggested a10-index possesses the advantage. Note that their value showed a physical engineering meaning. It is noted that the amount of the samples which satisfies calculated amounts with a deviation of ± 10% has compared to experimental data.
Also, a ranking method and colour intensity were utilised to classify the developed models.
7 Results and discussion
The performance of the developed soft computing models (ICA-XGBoost, ICA-ANN, ICA-SVR, and ICA-ANFIS) regarding the prediction of compressive strength of recycled aggregate concrete is evaluated quantitatively both in training and testing phase (Table 3) through the six performance indexes (a10-index, RMSE, MAE, MAPE, VAF, and R2) that have been previously presented.
Before the actual assessment of the models, one must first investigate and determine whether the well-known and frequent issue of “overfitting” has occurred (overfitting problem in machine learning). A reliable manner in which this issue can be assessed is related to the comparison of the difference performance indices, among training data and testing data. When overfitting occurs, the performance indices for the training phase are quite satisfactory; however, the performance indices for the validation phase are quite lower. The smaller the difference between the performance indices of these phases, the lower the possibility that overfitting has occurred. Specifically, when the difference in the indices R2 and VAF is less than 5%, the probability of overfitting occurrence is extremely low. Thus, based on the values displayed in Table 3, overfitting of the models developed within this research has been avoided.
Based on the results presented in Table 3 and having ensured that the overfitting problem has not occured, the optimum AI model is the developed ICA-XGBoost model, which ensures, for the case of testing datasets, the optimum values for all the performance indices. In contrast, the ICA-ANFIS model indices indicate that its performance is the lowest among all models.
Considering the parameters (operators) of the proposed ICA-XGBoost, ICA-ANN, ICA-SVR, and ICA-ANFIS models, it can be concluded that although the settings of the ICA are the same, however, the accuracy of the models are different. This finding shows different prediction power of the different algorithm, as well as the ICA, seems more suitable when combined with the XGBoost model for estimating the CS of RAC. Figure 15 illustrates the accuracy of the predicted values by the different hybrid models in determining the CS of RAC in terms of scatter plot. Also, a comparison of measured and predicted values by different models is shown in Fig. 16 in terms of histogram. According to Fig. 16, all applied models have efficiency for predicting CS of RAC.

Illustrating the accuracy of the estimated values by the individual models

A comparison of measured and estimated values of the models
Furthermore, in Fig. 17 the ratio of the experimental values concerning the predicted values is depicted, for the datasets which were used for testing the reliability of the proposed ICA-XGBoost optimum neural network in terms of compressive strength prediction. Noted that all samples utilised for the testing process possess a deviation lower than ± 10% (points are among the two dotted lines in Fig. 15).

Experimental to the predicted values of compressive strength based on the ICA-XGBoost
According to Box-plot finding (Fig. 18), ICA-XGBoost and ICA-ANN algorithms could predict the minimum value of CS of RAC properly, but neither ICA-XGBoost and ICA-ANN nor other applied models could not predict maximum value accurately. The ICA-XGBoost algorithm has a higher performance in terms of median values, followed by ICA-ANN, ICA-SVR and ICA-ANFIS models. ICA-ANFIS and ICA-SVR algorithms have a higher prediction power in predicting third quartile (Q3) and first quartile (Q1), respectively.

Box-plot for the models’ performance in the testing phase
Based on the result of the Taylor diagram (Fig. 19), the proposed ICA-XGBoost model outperforms other models (correlation coefficient higher than 0.99) followed by ICA-SVR, ICA-ANN, and ICA-ANFIS, respectively. This can be related to computing capability of different algorithms, and as each model have advantages and disadvantages, thus different models should be applied and the best one selected for future studies. Recently applied hybrid algorithms have been rapidly increased, and most of the literature review shows that hybrid algorithm can enhance the prediction power of the standalone algorithms. Khosravi et al. [96] applied standalone ANFIS as well as ANFIS hybrid with genetic, imperialist competitive, and differential evolution algorithms for reference evaporation estimation. Finally, they stated that all hybrid algorithms have a higher prediction power than standalone algorithms. Khozani et al. [97] applied four standalone algorithms of RF, RT, REPT, and M5P as well as a hybrid algorithm of bagging-M5P model for apparent shear stress prediction. They finally stated that hybrid algorithm outperforms others. XGBoost as one of the flexible models has some advantages, such as it can work on both regression and classification problems, parallel processing, and it can work effectively with large and multidimensional datasets [8, 98, 99].

Taylor diagram for models’ evaluation and comparison
Generally, as this kind of research such as compressive strength of recycled aggregate concrete prediction including the relationship between input variables and between inputs and output are not simple and have a nonlinear relationship and simple and empirical models do not have sufficient accuracy. Thus, the more nonlinear and flexible models, the higher prediction power. AI algorithms with nonlinear structure especially hybrid models are more flexible and robust than standalone models [31]; therefore, hybrid algorithm can enhance the prediction power of standalone algorithms and completely proper to prediction of phenomena with complex process.
8 Conclusion
Recycled aggregate concrete is a promising material which could replace typical concrete. Its extensive use can contribute, not only towards the improvement of economic efficiency, but also towards sustainable development through the reduction in concrete’s environmental impact. However, due to the influence of mortar and cement remnants from the original concrete on the surface of the recycled aggregates, its 28-days compressive strength is often inferior to that of typical concrete. Therefore, an accurate prediction of the 28-days compressive strength is necessary to optimise this concrete material and to ensure its safe application for building purposes.
In the present work, four different AI models have been trained and developed for the prediction of compressive strength of recycled aggregate concrete. Among these models, the ICA-XGBoost model is proposed as the optimum. Namely, based on the newly proposed performance a10-index, all samples utilised for the testing process possess a deviation lower than ± 10% in relation to the actual experimental values, proving the developed model as a useful tool for researchers, engineers, as well as for supporting not only teaching, but also interpretation of the mechanical behaviour of recycled aggregate concrete. Furthermore, based on the proposed ICA-XGBoost technique, recycled aggregate concrete can be used safely for construction purposes, when specific parameters are fulfilled and may thus, in the future, serve as an essential, environmentally friendly building material.
References
Asteris PG, Mokos VG (2019) Concrete compressive strength using artificial neural networks. Neural Comput Appl. https://doi.org/10.1007/s00521-019-04663-2
Apostolopoulou M, Douvika MG, Kanellopoulos IN, Moropoulou A, Asteris PG (2018) Prediction of compressive strength of mortars using artificial neural networks. In: Proceedings of the 1st international conference TMM_CH, transdisciplinary multispectral modelling and cooperation for the preservation of cultural heritage, Athens, Greece, 10–13
Silva R, De Brito J, Dhir R (2015) The influence of the use of recycled aggregates on the compressive strength of concrete: a review. Eur J Environ Civ Eng 19(7):825–849
Tu T-Y, Chen Y-Y, Hwang C-L (2006) Properties of HPC with recycled aggregates. Cem Concr Res 36(5):943–950
Shang Y, Nguyen H, Bui X-N, Tran Q-H, Moayedi H (2019) A novel artificial intelligence approach to predict blast-induced ground vibration in open-pit mines based on the firefly algorithm and artificial neural network. Nat Resour Res. https://doi.org/10.1007/s11053-019-09503-7
Nguyen H, Moayedi H, Foong LK, Al Najjar HAH, Jusoh WAW, Rashid ASA, Jamali J (2019) Optimizing ANN models with PSO for predicting short building seismic response. Eng Comput. https://doi.org/10.1007/s00366-019-00733-0
Nguyen H, Drebenstedt C, Bui X-N, Bui DT (2019) Prediction of blast-induced ground vibration in an open-pit mine by a novel hybrid model based on clustering and artificial neural network. Nat Resour Res. https://doi.org/10.1007/s11053-019-09470-z
Zhang X, Nguyen H, Bui X-N, Tran Q-H, Nguyen D-A, Bui DT, Moayedi H (2019) Novel soft computing model for predicting blast-induced ground vibration in open-pit mines based on particle swarm optimization and XGBoost. Nat Resour Res. https://doi.org/10.1007/s11053-019-09492-7
Zhou J, Li X, Mitri HS (2018) Evaluation method of rockburst: state-of-the-art literature review. Tunn Undergr Sp Technol 81:632–659
Zhou J, Li E, Yang S, Wang M, Shi X, Yao S, Mitri HS (2019) Slope stability prediction for circular mode failure using gradient boosting machine approach based on an updated database of case histories. Saf Sci 118:505–518
Zhang S, Bui X-N, Trung N-T, Nguyen H, Bui H-B (2019) Prediction of rock size distribution in mine bench blasting using a novel ant colony optimization-based boosted regression tree technique. Nat Resour Res. https://doi.org/10.1007/s11053-019-09603-4
Zhang H, Nguyen H, Bui X-N, Nguyen-Thoi T, Bui T-T, Nguyen N, Vu D-A, Mahesh V, Moayedi H (2020) Developing a novel artificial intelligence model to estimate the capital cost of mining projects using deep neural network-based ant colony optimization algorithm. Resour Policy 66:101604
Rao A, Jha KN, Misra S (2007) Use of aggregates from recycled construction and demolition waste in concrete. Resour Conserv Recycl 50(1):71–81
Asteris PG, Moropoulou A, Skentou AD, Apostolopoulou M, Mohebkhah A, Cavaleri L, Rodrigues H, Varum H (2019) Stochastic vulnerability assessment of masonry structures: concepts, modeling and restoration aspects. Appl Sci 9(2):243
Asteris PG, Apostolopoulou M, Skentou AD, Moropoulou A (2019) Application of artificial neural networks for the prediction of the compressive strength of cement-based mortars. Comput Concr 24(4):329–345
Limbachiya M, Leelawat T, Dhir R (2000) Use of recycled concrete aggregate in high-strength concrete. Mater Struct 33(9):574
Poon C-S, Chan D (2007) The use of recycled aggregate in concrete in Hong Kong. Resour Conserv Recycl 50(3):293–305
Poon C, Kou S, Lam L (2002) Use of recycled aggregates in molded concrete bricks and blocks. Constr Build Mater 16(5):281–289
Oikonomou ND (2005) Recycled concrete aggregates. Cem Concr Compos 27(2):315–318
Shi X, Wang Q, Zhao X, Collins F (2011) Strength and ductility of recycled aggregate concrete filled composite tubular stub columns. In: Incorporating sustainable practice in mechanics of structures and materials, London, UK, pp 83–89
Wang Y, Chen J, Geng Y (2015) Testing and analysis of axially loaded normal-strength recycled aggregate concrete filled steel tubular stub columns. Eng Struct 86:192–212
Tam VW, Soomro M, Evangelista ACJ (2018) A review of recycled aggregate in concrete applications (2000–2017). Constr Build Mater 172:272–292
Asteris PG, Ashrafian A, Rezaie-Balf M (2019) Prediction of the compressive strength of self-compacting concrete using surrogate models. Comput Concr 24:137–150
Zhou J, Li X, Mitri HS (2016) Classification of rockburst in underground projects: comparison of ten supervised learning methods. J Comput Civ Eng 30(5):04016003
Zhou J, Li X, Shi X (2012) Long-term prediction model of rockburst in underground openings using heuristic algorithms and support vector machines. Saf Sci 50(4):629–644
Liu T, Zhang C, Cao P, Zhou K (2020) Freeze-thaw damage evolution of fractured rock mass using nuclear magnetic resonance technology. Cold Reg Sci Technol 170:102951
Duan Z-H, Kou S-C, Poon C-S (2013) Prediction of compressive strength of recycled aggregate concrete using artificial neural networks. Constr Build Mater 40:1200–1206
Younis KH, Pilakoutas K (2013) Strength prediction model and methods for improving recycled aggregate concrete. Constr Build Mater 49:688–701
Deshpande N, Londhe S, Kulkarni S (2014) Modeling compressive strength of recycled aggregate concrete by artificial neural network, model tree and non-linear regression. Int J Sustain Built Environ 3(2):187–198
Khademi F, Jamal SM, Deshpande N, Londhe S (2016) Predicting strength of recycled aggregate concrete using artificial neural network, adaptive neuro-fuzzy inference system and multiple linear regression. Int J Sustain Built Environ 5(2):355–369
Khosravi K, Mao L, Kisi O, Yaseen ZM, Shahid S (2018) Quantifying hourly suspended sediment load using data mining models: case study of a glacierized Andean catchment in Chile. J Hydrol 567:165–179
Khosravi K, Panahi M, Bui DT (2018) Spatial prediction of groundwater spring potential mapping based on an adaptive neuro-fuzzy inference system and metaheuristic optimization. Hydrol Earth Syst Sci 22(9):4771–4792. https://doi.org/10.5194/hess-22-4771-2018
Zhang J-P, Li Z-W, Yang J (2005) A parallel SVM training algorithm on large-scale classification problems. In: 2005 International conference on machine learning and cybernetics, IEEE, pp 1637–1641
Zhang R, Ma J (2008) An improved SVM method P-SVM for classification of remotely sensed data. Int J Remote Sens 29(20):6029–6036
Huang G-B, Wang DH, Lan Y (2011) Extreme learning machines: a survey. Int J Mach Learn Cybern 2(2):107–122
Abdollahzadeh G, Jahani E, Kashir Z (2016) Predicting of compressive strength of recycled aggregate concrete by genetic programming. Comput Concr 18(2):155–163
Deng F, He Y, Zhou S, Yu Y, Cheng H, Wu X (2018) Compressive strength prediction of recycled concrete based on deep learning. Constr Build Mater 175:562–569
Dantas ATA, Leite MB, de Jesus Nagahama K (2013) Prediction of compressive strength of concrete containing construction and demolition waste using artificial neural networks. Constr Build Mater 38:717–722
Omran BA, Chen Q, Jin R (2016) Comparison of data mining techniques for predicting compressive strength of environmentally friendly concrete. J Comput Civ Eng 30(6):04016029
Khademi F, Jamal SM (2016) Predicting the 28 days compressive strength of concrete using artificial neural network. I-manager’s J Civ Eng 6(2):1–6. https://doi.org/10.26634/jce.6.2.5936
Naderpour H, Rafiean AH, Fakharian P (2018) Compressive strength prediction of environmentally friendly concrete using artificial neural networks. J Build Eng 16:213–219
Asteris PG, Nikoo M (2019) Artificial bee colony-based neural network for the prediction of the fundamental period of infilled frame structures. Neural Comput Appl 31(9):4837–4847. https://doi.org/10.1007/s00521-018-03965-1
Asteris PG, Kolovos KG (2019) Self-compacting concrete strength prediction using surrogate models. Neural Comput Appl 31(1):409–424
Asteris PG, Nozhati S, Nikoo M, Cavaleri L, Nikoo M (2019) Krill herd algorithm-based neural network in structural seismic reliability evaluation. Mech Adv Mater Struct 26(13):1146–1153
Asteris P, Roussis P, Douvika M (2017) Feed-forward neural network prediction of the mechanical properties of sandcrete materials. Sensors 17(6):1344
Sarir P, Chen J, Asteris PG, Armaghani DJ, Tahir MM (2019) Developing GEP tree-based, neuro-swarm, and whale optimization models for evaluation of bearing capacity of concrete-filled steel tube columns. Eng Comput. https://doi.org/10.1007/s00366-019-00808-y
Liu T, Zhang C, Zhou K, Tian Y (2019) Freeze-thaw cycling damage evolution of additive cement mortar. Eur J Environ Civ Eng. https://doi.org/10.1080/19648189.2019.1615992
Ni H-G, Wang J-Z (2000) Prediction of compressive strength of concrete by neural networks. Cem Concr Res 30(8):1245–1250
Topcu IB, Sarıdemir M (2008) Prediction of compressive strength of concrete containing fly ash using artificial neural networks and fuzzy logic. Comput Mater Sci 41(3):305–311
Kewalramani MA, Gupta R (2006) Concrete compressive strength prediction using ultrasonic pulse velocity through artificial neural networks. Autom Constr 15(3):374–379
Alshihri MM, Azmy AM, El-Bisy MS (2009) Neural networks for predicting compressive strength of structural light weight concrete. Constr Build Mater 23(6):2214–2219
Sobhani J, Najimi M, Pourkhorshidi AR, Parhizkar T (2010) Prediction of the compressive strength of no-slump concrete: a comparative study of regression, neural network and ANFIS models. Constr Build Mater 24(5):709–718
Khademi F, Akbari M, Jamal SM, Nikoo M (2017) Multiple linear regression, artificial neural network, and fuzzy logic prediction of 28 days compressive strength of concrete. Front Struct Civ Eng 11(1):90–99
Yaseen ZM, Deo RC, Hilal A, Abd AM, Bueno LC, Salcedo-Sanz S, Nehdi ML (2018) Predicting compressive strength of lightweight foamed concrete using extreme learning machine model. Adv Eng Softw 115:112–125
Chopra P, Sharma RK, Kumar M (2016) Prediction of compressive strength of concrete using artificial neural network and genetic programming. Adv Mater Sci Eng 2016:1–10. https://doi.org/10.1155/2016/7648467
Nikoo M, Torabian Moghadam F, Sadowski Ł (2015) Prediction of concrete compressive strength by evolutionary artificial neural networks. Adv Mater Sci Eng 2015:1–8. https://doi.org/10.1155/2015/849126
Ling H, Qian C, Kang W, Liang C, Chen H (2019) Combination of support vector machine and k-fold cross validation to predict compressive strength of concrete in marine environment. Constr Build Mater 206:355–363
Behnood A, Golafshani EM (2018) Predicting the compressive strength of silica fume concrete using hybrid artificial neural network with multi-objective grey wolves. J Clean Prod 202:54–64
Behnood A, Olek J, Glinicki MA (2015) Predicting modulus elasticity of recycled aggregate concrete using M5′ model tree algorithm. Constr Build Mater 94:137–147
Atashpaz-Gargari E, Lucas C (2007) Imperialist competitive algorithm: an algorithm for optimization inspired by imperialistic competition. In: 2007 IEEE congress on evolutionary computation. IEEE, pp 4661–4667
Hosseini S, Al Khaled A (2014) A survey on the imperialist competitive algorithm metaheuristic: implementation in engineering domain and directions for future research. Appl Soft Comput 24:1078–1094
Elsisi M (2019) Design of neural network predictive controller based on imperialist competitive algorithm for automatic voltage regulator. Neural Comput Appl 31(9):5017–5027. https://doi.org/10.1007/s00521-018-03995-9
Shirazi AZ, Mohammadi Z (2017) A hybrid intelligent model combining ANN and imperialist competitive algorithm for prediction of corrosion rate in 3C steel under seawater environment. Neural Comput Appl 28(11):3455–3464
Le LT, Nguyen H, Dou J, Zhou J (2019) A comparative study of PSO-ANN, GA-ANN, ICA-ANN, and ABC-ANN in estimating the heating load of buildings’ energy efficiency for smart city planning. Appl Sci 9(13):2630
Chen T, He T (2015) Xgboost: extreme gradient boosting. R package version 04-2
Friedman JH (2002) Stochastic gradient boosting. Comput Stat Data Anal 38(4):367–378
Zhou J, Li E, Wang M, Chen X, Shi X, Jiang L (2019) Feasibility of stochastic gradient boosting approach for evaluating seismic liquefaction potential based on SPT and CPT case histories. J Perform Constr Facil 33(3):04019024
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20(3):273–297
Basak D, Pal S, Patranabis DC (2007) Support vector regression. Neural Inf Process-Lett Rev 11(10):203–224
Nguyen H (2019) Support vector regression approach with different kernel functions for predicting blast-induced ground vibration: a case study in an open-pit coal mine of Vietnam. SN Appl Sci 1(4):283. https://doi.org/10.1007/s42452-019-0295-9
Bui X-N, Nguyen H, Le HA, Bui HB, Do NH (2019) Prediction of blast-induced air over-pressure in open-pit mine: assessment of different artificial intelligence techniques. Nat Resour Res. https://doi.org/10.1007/s11053-019-09461-0
Liu L, Moayedi H, Rashid ASA, Rahman SSA, Nguyen H (2019) Optimizing an ANN model with genetic algorithm (GA) predicting load-settlement behaviours of eco-friendly raft-pile foundation (ERP) system. Eng Comput 36(1):421–433. https://doi.org/10.1007/s00366-019-00767-4
Wang B, Moayedi H, Nguyen H, Foong LK, Rashid ASA (2019) Feasibility of a novel predictive technique based on artificial neural network optimized with particle swarm optimization estimating pullout bearing capacity of helical piles. Eng Comput. https://doi.org/10.1007/s00366-019-00764-7
Bui X, Muazu MA, Nguyen H (2019) Optimizing Levenberg–Marquardt backpropagation technique in predicting factor of safety of slopes after two-dimensional OptumG2 analysis. Eng Comput. https://doi.org/10.1007/s00366-019-00741-0
Nguyen H, Moayedi H, Foong LK, Al Najjar HAH, Jusoh WAW, Rashid ASA, Jamali J (2019) Optimizing ANN models with PSO for predicting short building seismic response. Eng Comput. https://doi.org/10.1007/s00366-019-00733-0
Moayedi H, Moatamediyan A, Nguyen H, Bui X-N, Bui DT, Rashid ASA (2019) Prediction of ultimate bearing capacity through various novel evolutionary and neural network models. Eng Comput. https://doi.org/10.1007/s00366-019-00723-2
Yegnanarayana B (2009) Artificial neural networks. PHI Learning Pvt. Ltd, New Delhi
Buscema PM, Massini G, Breda M, Lodwick WA, Newman F, Asadi-Zeydabadi M (2018) Artificial adaptive systems using auto contractive maps: theory, applications and extensions, vol 131. Springer, Berlin
Gao W, Guirao JLG, Abdel-Aty M, Xi W (2018) An independent set degree condition for fractional critical deleted graphs. Discrete Contin Dyn Syst-S 12(4&5):877–886. https://doi.org/10.3934/dcdss.2019058
Asteris PG, Armaghani DJ, Hatzigeorgiou GD, Karayannis CG, Pilakoutas K (2019) Predicting the shear strength of reinforced concrete beams using artificial neural networks. Comput Concr 24(5):469–488
Bui DT, Tuan TA, Klempe H, Pradhan B, Revhaug I (2016) Spatial prediction models for shallow landslide hazards: a comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 13(2):361–378
Nguyen H, Bui X-N, Bui H-B, Mai N-L (2018) A comparative study of artificial neural networks in predicting blast-induced air-blast overpressure at Deo Nai open-pit coal mine, Vietnam. Neural Comput Appl. https://doi.org/10.1007/s00521-018-3717-5
Apostolopoulou M, Armaghani DJ, Bakolas A, Douvika MG, Moropoulou A, Asteris PG (2019) Compressive strength of natural hydraulic lime mortars using soft computing techniques. Proc Struct Integr 17:914–923
Choubin B, Khalighi-Sigaroodi S, Malekian A, Kişi Ö (2016) Multiple linear regression, multi-layer perceptron network and adaptive neuro-fuzzy inference system for forecasting precipitation based on large-scale climate signals. Hydrol Sci J 61(6):1001–1009
Jang J-S (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23(3):665–685
Chang F-J, Chang Y-T (2006) Adaptive neuro-fuzzy inference system for prediction of water level in reservoir. Adv Water Resour 29(1):1–10
Manogaran G, Varatharajan R, Priyan M (2018) Hybrid recommendation system for heart disease diagnosis based on multiple kernel learning with adaptive neuro-fuzzy inference system. Multimed Tools Appl 77(4):4379–4399
Hong H, Panahi M, Shirzadi A, Ma T, Liu J, Zhu A-X, Chen W, Kougias I, Kazakis N (2018) Flood susceptibility assessment in Hengfeng area coupling adaptive neuro-fuzzy inference system with genetic algorithm and differential evolution. Sci Total Environ 621:1124–1141
Aghdam IN, Varzandeh MHM, Pradhan B (2016) Landslide susceptibility mapping using an ensemble statistical index (Wi) and adaptive neuro-fuzzy inference system (ANFIS) model at Alborz Mountains (Iran). Environ Earth Sci 75(7):553
Chen W, Panahi M, Pourghasemi HR (2017) Performance evaluation of GIS-based new ensemble data mining techniques of adaptive neuro-fuzzy inference system (ANFIS) with genetic algorithm (GA), differential evolution (DE), and particle swarm optimization (PSO) for landslide spatial modelling. CATENA 157:310–324
Shabri A (2014) A hybrid wavelet analysis and adaptive neuro-fuzzy inference system for drought forecasting. Appl Math Sci 8(139):6909–6918
Psyllaki P, Stamatiou K, Iliadis I, Mourlas A, Asteris P, Vaxevanidis N (2018) Surface treatment of tool steels against galling failure. In: MATEC web of conferences. EDP Sciences, p 04024
Cavaleri L, Chatzarakis GE, Trapani FD, Douvika MG, Roinos K, Vaxevanidis NM, Asteris PG (2017) Modeling of surface roughness in electro-discharge machining using artificial neural networks. Adv Mater Res 6(2):169–184
Cavaleri L, Asteris PG, Psyllaki PP, Douvika MG, Skentou AD, Vaxevanidis NM (2019) Prediction of surface treatment effects on the tribological performance of tool steels using artificial neural networks. Appl Sci 9(14):2788
Armaghani DJ, Hatzigeorgiou GD, Karamani C, Skentou A, Zoumpoulaki I, Asteris PG (2019) Soft computing-based techniques for concrete beams shear strength. Proc Struct Integr 17:924–933
Khosravi K, Shahabi H, Pham BT, Adamowski J, Shirzadi A, Pradhan B, Dou J, Ly H-B, Gróf G, Ho HL (2019) A comparative assessment of flood susceptibility modeling using multi-criteria decision-making analysis and machine learning methods. J Hydrol 573:311–323
Khozani ZS, Khosravi K, Pham BT, Kløve B, Mohtar W, Melini WH, Yaseen ZM (2019) Determination of compound channel apparent shear stress: application of novel data mining models. J Hydroinform 21(5):798–811. https://doi.org/10.2166/hydro.2019.037
Dhaliwal S, Nahid A-A, Abbas R (2018) Effective intrusion detection system using XGBoost. Information 9(7):149
Nguyen H, Bui X-N, Bui H-B, Cuong DT (2019) Developing an XGBoost model to predict blast-induced peak particle velocity in an open-pit mine: a case study. Acta Geophys 67(2):477–490. https://doi.org/10.1007/s11600-019-00268-4
Acknowledgments
This research was supported by Hanoi University of Mining and Geology (HUMG), Hanoi, Vietnam and the Center for Mining, Electro-Mechanical Research of HUMG.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Duan, J., Asteris, P.G., Nguyen, H. et al. A novel artificial intelligence technique to predict compressive strength of recycled aggregate concrete using ICA-XGBoost model. Engineering with Computers 37, 3329–3346 (2021). https://doi.org/10.1007/s00366-020-01003-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-020-01003-0