
Abstract
Ground vibration is the most detrimental effect induced by blasting in surface mines. This study presents an improved bagged support vector regression (BSVR) combined with the firefly algorithm (FA) to predict ground vibration. In other words, the FA was used to modify the weights of the SVR model. To verify the validity of the BSVR–FA, the back-propagation neural network (BPNN) and radial basis function network (RBFN) were also applied. The BSVR–FA, BPNN and RBFN models were constructed using a comprehensive database collected from Shur River dam region, in Iran. The proposed models were then evaluated by means of several statistical indicators such as root mean square error (RMSE) and symmetric mean absolute percentage error. Comparing the results, the BSVR–FA model was found to be the most accurate to predict ground vibration in comparison to the BPNN and RBFN models. This study indicates the successful application of the BSVR–FA model as a suitable and effective tool for the prediction of ground vibration.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
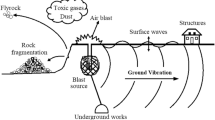
Blasting is considered as the most common method of hard rock fragmentation in mining as well as in civil construction works. Although the primary objective of blasting is to provide proper rock fragmentation and finally facilitating in loading operations, the other environmental side effects of blasting such as airblast, ground vibration, noise and flyrock are inevitable [1,2,3,4,5,6,7]. These phenomena are shown in Fig. 1.

Phenomena of blasting operation
Of all the mentioned effects, ground vibration has the most detrimental effect on the surroundings [8,9,10,11,12]. Hence, to reduce environmental effects, the prediction of ground vibration with a high level of accuracy is imperative. According to the literature [13,14,15,16,17], the peak particle velocity (PPV) is accepted as the most important descriptor to determine the blast-induced ground vibration.
A number of researchers have investigated the problem of blast-induced PPV and have provided different empirical models to predict PPV [18,19,20,21,22]. These empirical models are restricted to using maximum charge per delay (W) and distance between monitoring stations and blasting point (D) as the effective parameters on PPV. In the last few years, machine learning methods have been widely employed for solving various engineering problems [23,24,25,26,27,28,29,30,31,32,33,34,35,36]. These methods are being increasingly used to predict blast-induced PPV.
Monjezi et al. [37] used artificial neural network (ANN) to predict PPV. They compared the ANN performance with empirical models. Their results signified the superiority of ANN over empirical models in terms of performance measures. Hasanipanah et al. [10] employed classification and regression tree (CART) to predict PPV. In their study, multiple regression (MR) and several empirical models were also developed. Based on the obtained results, the CART can be introduced as a more suitable model for PPV prediction than the MR and empirical models. Zhang et al. [38] predicted the PPV using extreme gradient boosting machine (XGBoost) combined with particle swarm optimization (PSO). They also used empirical models to check the performance of their proposed model. The results indicated that the PSO-XGBoost was an accurate model to predict PPV and its performance was better than the empirical model. In another study, Bui et al. [39] proposed a combination of fuzzy C-means clustering (FCM) and quantile regression neural network (QRNN) to predict PPV, and compared the results of FCM–QRNN model with ANN, random forest (RF) and empirical models. The results showed that the accuracy of the FCM–QRNN model was higher compared with ANN, RF and empirical models in predicting the PPV.
Jiang et al. [24] explored the use of a neuro-fuzzy inference system to approximate PPV, and compared it with the MR model. They showed the superiority of neuro-fuzzy inference system over MR model in terms of approximations accuracy. The suitability of hybridizing the k-means clustering algorithm (HKM) and ANN to predict PPV was investigated by Nguyen et al. [40]. For comparison aims, support vector regression (SVR), classical ANN, hybrid of SVR and HKM, and empirical models were also employed. According to their results, the HKM–ANN model presented a superior ability to predict PPV and its results were more accurate than the other models. Fang et al. [41] evaluated the application of a hybrid imperialist competitive algorithm (ICA) and M5Rules to predict PPV. They concluded that the ICA–M5Rules method was viable and effective and provided better predictive performance as compared with other models. Recently, Ding et al. [7] hybridized the ICA with XGBoost to forecast PPV. They also applied the ANN, SVR and gradient boosting machine (GBM) to check ICA–XGBoost performance. Their computational result indicated that the ICA–XGBoost model produced better results than ANN, SVR and GBM methods.
SVR is a well-known artificial intelligence approach which has been widely used for the applications on most of the nonlinear problems in various fields such as mining and civil engineering fields [4, 6]. A view of the SVR structure is shown in Fig. 2. Note that, in the present study, the W and D parameters are the input parameters, and PPV is the output. On the other hand, the use of evolutionary algorithms such as cuckoo search, PSO, genetic algorithm, artificial bee colony and firefly algorithm (FA) in the fields of optimization has been expanding [8, 11, 12, 16]. Among those, FA is the one which has been most widely studied and used to solve various engineering problems, so far. Day by day the number of researchersinterested in FA has increased rapidly. FA proves to be more promising, robust, and efficient in finding both local and global optimum compared to other existing evolutionary algorithms [42,43,44]. A view of the FA flowchart is also shown in Fig. 3.

SVR structure [88]

FA flowchart
An accurate prediction of PPV can be very practical, especially for drilling engineers to design an optimum blast pattern and to prevent the detrimental effects of blasting. The present study proposes a novel artificial intelligence approach to predict PPV with a high level of accuracy. The proposed approach is based on an improved bagged SVR (BSVR) combined with FA. In other words, the FA was used to modify the weights of the SVR model. For comparison aims, back-propagation neural network (BPNN) and radial basis function network (RBFN) models were also applied.
2 Database source
The used datasets in this study were gathered from Shur River dam region in Iran. For this work, 87 blasting events were monitored and the values of requirement parameters were carefully measured. In this regard, the values of W and D, as the most effective parameters on PPV [45, 46], were measured for all monitored blasts. To measure the D parameter, the GPS (global positioning system) was used. Also, the value of W was measured through controlling the blast-hole charge. For recording the values of PPV, MR2002-CE SYSCOM seismograph was also installed in different locations of sites. More details regarding the used datasets in this study are given in Table 1. Additionally, the frequency histograms of the input (W and D) and output (PPV) parameters are shown in Fig. 4. According to this Fig, in case of the W parameter, 15, 16, 44 and 12 data were varied in the range of 0–500 kg, 500–700 kg, 700–1000 kg and 1000–1500 kg, respectively. Regarding the D parameter, 22, 25, 18 and 22 data were varied in the range of 0–400 m, 400–550 m, 550–700 m and 700–1000 m, respectively. Also, for the PPV parameter, 20, 27, 22 and 18 data were varied in the range of 0–5 mm/s, 5–6.5 mm/s, 6.5–8 mm/s and 8–10 mm/s, respectively. In modeling of BSVR–FA, BPNN and RBFN, the datasets were divided into two phases, namely training and testing phases. In this regard, 80% and 20% of whole data were assigned as training and testing datasets, respectively. In other words, 70 and 17 datasets were used to construct and test the models, respectively.

Frequency histograms of the W, D and PPV parameters
3 Methodology
The bagging algorithm and SVR methods were used to develop the hybrid model BSVR, whereas the FA was used for improving the performance of SVR. Bagging depends on the ideas of bootstrapping and aggregating, and was introduced by Breiman [47, 48]. The bagging algorithm has been applied extensively in engineering, economy, and ecology, but is uncommon in the field of PPV prediction. Bagging is one of the vital ensemble algorithms, wherein the randomly sampled approach is used in the training set for n times with substitution [49]. In the bagging model, all training sets are produced with the original training set size. In the proposed model, the training set (TS) consists of n observations TS = {(x1, y1), (x2, y2), …, (xn, yn)}. Hence, the bth bootstrap instance of the training set TS is denoted by the replacement of n elements of TSb (b = 1, 2, …, n). The bagging estimator is denoted as \(\phi = \left( {x,Z} \right)\) which predicts Y with the relative mean and given as follows:
Let P be the probability input x makes with the class yi. Also, the probability predictor that is correct for the produced state at x is:
Hence, the total probability of correct prediction is indicated as:
where the probability distribution of x is determined by \(P_{x} d\left( x \right)\).
In this step, bagging SVR can be exploited to develop the accuracy of the ground vibration prediction. In SVR, the relation between the input variable xi and predicted variable yi is distinguished by f(x) as follows:
where \(\varphi \left( x \right)\) maps the input variables into a multi-dimensional space as a kernel function, b demonstrates bias, and \(\omega_{n}\) defines the weight of the nth data for input variables [49]. w and b are specified as coefficients for minimizing the convex problem function like the phrase below:
where
in which C implicates a positive constant with the responsibility of the trade-off between an estimation error and the weight vector, the loss function is determined by \(G_{\varepsilon } \left( {y_{n} , f\left( {x_{n} } \right)} \right)\) which is called ε-insensitive, and ε is the radius of tube size [48].
All essential computations in the input variable are performed by the kernel function without any calculation of the explicit \(\varphi \left( x \right)\). In the current study based on the best performance in the literature, the kernel function is defined by \(K\left( {x_{i} ,x_{j} } \right) = \varphi \left( {x_{i} } \right)\varphi \left( {x_{j} } \right)\), where the Gaussian function is applied as follows [49]:
where \(\sigma\) implicates the kernel function parameter. The parameters of ε, C, and \(\sigma\) must be chosen in advance. In Algorithm 1, the total step of bagging the SVR predictor is indicated.

.
For improving the performance of BSVR, the importance of parameters in BSVR are justified by the firefly algorithm (FA). The FA, introduced by Yang [50], is fundamentally based on the light intensity variation, which defines the fitness function solution. The light intensity variation fluctuates with any alteration in the interval (r) amongst two fireflies, which is expressed as follows [51]:
where \(I\left( r \right)\) signifies the light intensity for r and \(I_{0}\) holds out the light intensity original at r = 0. The coefficient of light absorption is determined by \(\gamma\). Hence, the attractiveness of a firefly is specified as follows [51]:
where the attractiveness is represented by \(\beta\), and \(\beta_{0}\). defines the attractiveness with zero distance. The movement of flies from ‘i’ to ‘j’ is represented by the following equation [51]:
In most of the majority, the value of the absorption coefficient is in the interval of 0.1 and 10. In many cases, the value of 1 is chosen for \(\beta_{0}\) and \(a \in \left[ {0,1} \right]\) [52]. In Fig. 5, the flowchart illustrates the modeling of BSVR–FA to the prediction of PPV. Extensive details about the FA can be found in [53,54,55].

Flowchart of BSVR–FA
4 Back-propagation neural network (BPNN)
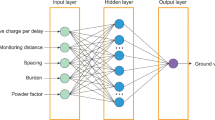
The simple BPNN has three layers that includes an input layer, a hidden layer, and an output layer [56]. Its back-propagation functioning performs the training and testing steps. The topology of the suggested BPNN has been exhibited in Fig. 6.

Structure of BPNN
The input data in every layer are adjusted by interconnection weight between the layers (wji), which demonstrates the relation of the ith node of the current layer to the jth node of the next layer [56]. The key role of the hidden layer is to process the input layer information. The sum of total activation is assessed by a sigmoid transfer function. All steps of the BPNN algorithm is represented in Algorithm 2.

5 Radial basis function network (RBFN)
Fundamentally, the RBFN is compounded by the number of simple and extremely interconnected neurons, which can be organized into many layers [57]. The main idea of RBFN is presented on the basis of the comparison between radial basis function (RBF) and multi-layer perceptron (MLP). For a network with fewer hidden layers, the RBF has much faster convergence than MLP. Also, the RBF network is generally prior to MLP when low-dimensional problem needs to be solved. For better understanding, the RBFN flowchart is shown in Fig. 7. The below steps generally explain the RBFN algorithm:
-
1.
The number of hidden neurons are specified by “K”.
-
2.
Based on the center of K-means clustering, the position of RBF is tuned.
-
3.
Calculate σ using the maximum distance among two hidden neurons.
-
4.
Calculate actions for RBF node closer in the Euclidian space
-
5.
Train the output nodes.

Architecture of a RBFN
The activation function in the RBFN model is a Gaussian function. Extensive details about the RBFN can be found in [57].
6 Development of the models
Based on reviewing the literature [58, 59], the principal parameters of FA are the factors of \(\beta_{0}\), \(a\), \(\gamma\), number of iteration (It) and the number of population (Npop). Using the trial and error method, the values of 1, 1 and 1000 were selected for the \(\beta_{0}\),\(a\) and It parameters, respectively. Regarding the best performance of BSVM-FA, the value of Npop is chosen 150 in the event that the values of 10, 20, 30, 40, 50, 100, 150, and 200 were examined in the BSVR–FA model. Besides, the various values of \(\gamma\) in the interval of 0.25–3 were assessed and, based on the best performance, the value of 2 is obtained for the \(\gamma\) in BSVR–FA modeling. Regarding the outcome values in BSVR–FA modeling, the optimized value of C = 257.3, \(\sigma = 1.21\), and ε = 0.69 are obtained for BSVR.
Regarding repetition of the BPNN model, the the best performance with the lowest RMSE and the highest coefficient of determination (R2) was for the 2 × 4 × 1 structure, which was two neurons in the input layer, four neurons in one hidden layer and one neuron in the output layer. Based on the best outcome in the RBFN model, the number of kernel is chosen as three, and the number of K-means iteration is selected as ten.
7 Analysis of the results
In this study, the BSVR–FA, BPNN and RBFN models are employed to predict PPV. This section compares the performance of the proposed models in predicting the PPV. To evaluate the accuracy of models, several well-known statistical indicators, namely R2, root mean square error (RMSE), mean absolute error (MAE), symmetric mean absolute percentage error (SMAPE), Leegate and McCabe index (LM), and variance account for (VAF) are used as follows [28, 60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86]:
where \({\text{PPV}}_{{\text{a}}}\) and \({\text{PPV}}_{{\text{p}}}\) are, respectively, the actual and predicted PPV values, n is the number of data, \(\overline{{{\text{PPV}}_{{\text{a}}} }}\) is the mean of actual PPVs, and var is the variance. The most ideal values for R2, RMSE, MAE, LM, SMAPE and VAF are 1, 0, 0, 1, 0 and 100%, respectively. Table 2 gives the statistical indicator values obtained from BSVR–FA, BPNN and RBFN models for both training and testing phases. From this table, the highest R2, VAF and LM values for both training and testing phases, and the lowest RMSE, MAE and SMAPE values, were obtained from the BSVR–FA model. For observing the accuracy of the BSVR–FA, BPNN and RBFN models in predicting the PPV, Figs. 8, 9 and 10 are also plotted using only testing datasets. Additionally, to demonstrate the model’s reliability and effectiveness, a mathematics-based graphical diagram, namely Taylor diagram, is prepared, as schemed in Fig. 11. From Figs. 8, 9, 10 and 11, it can be found that the BSVR–FA model was the most accurate for the prediction of PPV in the study area. The BPNN and RBFN models were identified as the next categories, respectively. In this study, a sensitivity analysis is also performed to demonstrate the relative influence of the input parameters (W and D) on the output parameter (PPV) using Yang and Zang [87] method:

Actual vs. predicted PPVs by RBFN

Actual vs. predicted PPVs by BPNN

Actual vs. predicted PPVs by BSVR–FA

Showing Taylor diagram related to the predictive models based on testing datasets
where \(y_{ik}\) is the input parameter, \(y_{{{\text{ok}}}}\) is the output parameter, and n is the number of data. The most influential parameter has the highest \(r_{ij}\) value. Using Eq. 10, the values of \(r_{ij}\) for the D and W parameters were obtained as 0.872 and 0.982, respectively. This clearly indicates that the W is the most influential parameter on the PPV in the study area.
8 Conclusion
Precise prediction of blast-induced PPV is an imperative work in the surface mines as well as tunneling projects. This paper aims to propose a BSVR–FA model to predict PPV. To check the validity of the BSVR–FA model, two well-known and classical intelligent models, namely BPNN and RBFN models were also employed. To construct the models, a comprehensive database gathered from Shur River dam region, in Iran, was used. After modeling, several statistical indicators, i.e., R2, RMSE, MAE, VAF, LM and SMAPE were used to compare the models’ performances. Based on the results of this study, we draw some conclusions:
-
1.
The BSVR–FA model yielded an excellent accuracy to predict PPV. A high R2 value of 0.996 was obtained for the BSVR–FA predictions. Further, the BPNN and RBFN results showed R2 value of 0.896 and 0.828, respectively.
-
2.
It was found that the FA is a useful tool to train the BSVR model.
-
3.
The use of BSVR–FA model can be practical in designing an optimum blast pattern and reducing the blast-induced PPV.
-
4.
The BSVR–FA can be also introduced as an accurate model to predict other problems induced by blasting such as airblast and flyrock.
References
Görgülü K, Arpaz E, Demirci A, Koçaslan A, Dilmaç MK, Yüksek AG (2013) Investigation of blast-induced ground vibrations in the Tülü boron open pit mine. Bull Eng Geol Env 72(3–4):555–564
Hasanipanah M, Armaghani DJ, Monjezi M, Shams S (2016) Risk assessment and prediction of rock fragmentation produced by blasting operation: a rock engineering system. Environ Earth Sci 75(9):808
Hasanipanah M, Shahnazar A, Amnieh HB, Armaghani DJ (2017) Prediction of air-overpressure caused by mine blasting using a new hybrid PSO–SVR model. Eng Comput 33(1):23–31
Taheri K, Hasanipanah M, Bagheri Golzar S, Majid MZA (2017) A hybrid artificial bee colony algorithm–artificial neural network for forecasting the blast-produced ground vibration. Eng Comput 33(3):689–700
Rad HN, Hasanipanah M, Rezaei M, Eghlim AL (2018) Developing a least squares support vector machine for estimating the blast-induced flyrock. Eng Comput 34(4):709–717
Keshtegar B, Hasanipanah M, Bakhshayeshi I, Sarafraz ME (2019) A novel nonlinear modeling for the prediction of blastinduced airblast using a modified conjugate FR method. Measurement 131:35–41
Ding Z, Nguyen H, Bui X et al (2019) Computational intelligence model for estimating intensity of blast-induced ground vibration in a mine based on imperialist competitive and extreme gradient boosting algorithms. Nat Resour Res. https://doi.org/10.1007/s11053-019-09548-8
Jahed Armaghani D, Hasanipanah M, Amnieh HB, Mohamad ET (2018) Feasibility of ICA in approximating ground vibration resulting from mine blasting. Neural Comput Appl 29(9):457–465
Hasanipanah M et al (2018) Prediction of an environmental issue of mine blasting: an imperialistic competitive algorithm-based fuzzy system. Int J Environ Sci Technol 15(3):551–560
Hasanipanah M, Faradonbeh RS, Amnieh HB, Armaghani DJ, Monjezi M (2017) Forecasting blast induced ground vibration developing a CART model. Eng Comput 33(2):307–316
Hasanipanah M, Naderi R, Kashir J, Noorani SA, Aaq Qaleh AZ (2017) Prediction of blast produced ground vibration using particle swarm optimization. Eng Comput 33(2):173–179
Hasanipanah M, Golzar SB, Larki IA, Maryaki MY, Ghahremanians T (2017) Estimation of blast-induced ground vibration through a soft computing framework. Eng Comput 33(4):951–959
Ghasemi E, Ataei M, Hashemolhosseini H (2013) Development of a fuzzy model for predicting ground vibration caused by rock blasting in surface mining. J Vib Control 19(5):755–770
Amiri M, Bakhshandeh Amnieh H, Hasanipanah M, Mohammad Khanli L (2016) A new combination of artificial neural network and K-nearest neighbors models to predict blast-induced ground vibration and air-overpressure. Eng Comput 32:631–644
Radojica L, Kostić S, Pantović R, Vasović N (2014) Prediction of blast-produced ground motion in a copper mine. Int J Rock Mech Min Sci 69:19–25
Hajihassani M, Jahed Armaghani D, Marto A, Mohamad ET (2015) Ground vibration prediction in quarry blasting through an artificial neural network optimized by imperialist competitive algorithm. Bull Eng Geol Env 74(3):873–886
Jahed Armaghani D, Hajihassani M, Mohamad ET, Marto A, Noorani SA (2014) Blasting-induced flyrock and ground vibration prediction through an expert artificial neural network based on particle swarm optimization. Arab J Geosci 7:5383–5396
Duvall WI, Petkof B (1959) Spherical propagation of explosion generated strain pulses in rock Report of Investigation. US Bureau of Mines, Pittsburgh, pp 5483–5521
Ambraseys NR, Hendron AJ (1968) Dynamic behavior of rock masses, rock mechanics in engineering practices. Wiley, London
Langefors U, Kihlstrom B (1963) The modern technique of rock blasting. Wiley, New York
Gupta RN, Roy PP, Bagachi A, Singh B (1987) Dynamic effects in various rock mass and their predictions. J Mines Met Fuels 35(11):455–462
Roy PP (1991) Vibration control in an opencast mine based on improved blast vibration predictors. Min Sci Technol 12:157–165
Hasanipanah M, Armaghani DJ, Amnieh HB, Majid MZA, Tahir MMD (2018) Application of PSO to develop a powerful equation for prediction of flyrock due to blasting. Neural Comput Appl 28(1):1043–1050
Jiang W, Arslan CA, Tehrani MS, Khorami M, Hasanipanah M (2019) Simulating the peak particle velocity in rock blasting projects using a neuro-fuzzy inference system. Eng Comput 35(4):1203–1211
Asteris PG, Kolovos KG (2019) Self-compacting concrete strength prediction using surrogate models. Neural Comput Appl 31:409–424
Asteris PG, Nozhati S, Nikoo M, Cavaleri L, Nikoo M (2019) Krill herd algorithm-based neural network in structural seismic reliability evaluation. Mech Adv Mater Struct. https://doi.org/10.1080/15376494.2018.1430874
Asteris PG, Nikoo M (2019) Artificial bee colony-based neural network for the prediction of the fundamental period of infilled frame structures. Neural Comput Appl. https://doi.org/10.1007/s00521-018-03965-1
Zhou J, Nekouie A, Arslan CA, Pham BT, Hasanipanah M (2019) Novel approach for forecasting the blast-induced AOp using a hybrid fuzzy system and firefly algorithm. Eng Comput. https://doi.org/10.1007/s00366-019-00725-0
Asteris PG, Roussis PC, Douvika MG (2017) Feed-forward neural network prediction of the mechanical properties of sandcrete materials. Sensors 17(6):1344
Asteris PG, Armaghani DJ, Hatzigeorgiou Karayannis CG, Pilakoutas K (2019) Predicting the shear strength of reinforced concrete beams using Artificial Neural Networks. Comput Concr 24(5):469–488
Qi C, Ly HB, Chen Q, Le TT, Le VM, Pham BT (2019) Flocculation-dewatering prediction of fine mineral tailings using a hybrid machine learning approach. Chemosphere 244:125450. https://doi.org/10.1016/j.chemosphere.2019.125450
Yang L, Qi C, Lin X, Li J, Dong X (2019) Prediction of dynamic increase factor for steel fibre reinforced concrete using a hybrid artificial intelligence model. Eng Struct 189:309–318
Qi C, Tang X, Dong X, Chen Q, Fourie A, Liu E (2019) Towards Intelligent Mining for Backfill: a genetic programming-based method for strength forecasting of cemented paste backfill. Miner Eng 133:69–79
Luo Z, Hasanipanah M, Amnieh HB, Brindhadevi K, Tahir MM (2019) GA-SVR: a novel hybrid data-driven model to simulate vertical load capacity of driven piles. Eng Comput. https://doi.org/10.1007/s00366-019-00858-2
Yang H, Hasanipanah M, Tahir MM, Bui DT (2019) Intelligent prediction of blasting-induced ground vibration using ANFIS optimized by GA and PSO. Nat Resour Res. https://doi.org/10.1007/s11053-019-09515-3
Qi C, Fourie A, Chen Q, Tang X, Zhang Q, Gao R (2018) Data-driven modelling of the flocculation process on mineral processing tailings treatment. J Clean Prod 196:505–516
Monjezi M, Hasanipanah M, Khandelwal M (2013) Evaluation and prediction of blast-induced ground vibration at Shur River Dam, Iran, by artificial neural network. Neural Comput Appl 22(7–8):1637–1643
Zhang X, Nguyen H, Bui XN, Tran QH, Nguyen DA, Tien Bui D, Moayedi H (2019) Novel soft computing model for predicting blast-induced ground vibration in open-pit mines based on particle swarm optimization and XGBoost. Nat Resour Res. https://doi.org/10.1007/s11053-019-09492-7
Bui et al (2019) Prediction of blast-induced ground vibration intensity in open-pit mines using unmanned aerial vehicle and a novel intelligence system. Nat Resour Res. https://doi.org/10.1007/s11053-019-09573-7
Nguyen H, Drebenstedt C, Bui XN, Bui DT (2019) prediction of blast-induced ground vibration in an open-pit mine by a novel hybrid model based on clustering and Artificial Neural Network. Nat Resour Res. https://doi.org/10.1007/s11053-019-09470-z
Fang Q, Nguyen H, Bui XN, Nguyen-Thoi T (2019) prediction of blast-induced ground vibration in open-pit mines using a new technique based on Imperialist Competitive Algorithm and M5Rules. Nat Resour Res. https://doi.org/10.1007/s11053-019-09577-3
Amiri B, Hossain L, Crawford JW, Wigand RT (2013) Community detection in complex networks: multiobjective enhanced firefly algorithm. Knowl Based Syst 46:1–11
Mohammadi S, Mozafari B, Solimani S, Niknam T (2013) An adaptive modified firefly optimization algorithm based on Hong’s point estimate method to optimal operation management in a microgrid with consideration of uncertainties. Energy 51:339–348
Mohammadi K, Shamshirband S, Seyed Danesh A, Zamani M, Sudheer C (2015) Horizontal global solar radiation estimation using hybrid SVM-firefly and SVM-wavelet algorithms: a case study. Nat Hazards. https://doi.org/10.1007/s11069-015-2047-5
Khandelwal M, Singh TN (2006) Prediction of blast induced ground vibrations and frequency in opencast mine-a neural network approach. J Sound Vib 289:711–725
Singh TN, Singh V (2005) An intelligent approach to prediction and control ground vibration in mines. Geotech Geolog Eng 23:249–262
Breiman L (1996) Bagging predictors. Mach Learn 24:123–140
Khiari J, Moreira-Matias L, Shaker A, Ženko B, Džeroski S (2018) Metabags: Bagged meta-decision trees for regression. In: Joint European conference on machine learning and knowledge discovery in databases. Springer, Cham, pp 637–652. arXiv:1804.06207
Pham BT, Bui DT, Prakash I (2018) Bagging based support vector machines for spatial prediction of landslides. Environ Earth Sci 77(4):146
Yang XS (2009) Firefly algorithms for multimodal optimization. In: Stochastic algorithms: foundations and applications SAGA 2009, Lecture Notes in Computer Science, vol 5792, pp 169–178
Chen W, Hasanipanah M, Nikafshan Rad H, Jahed Armaghani D, Tahir MM (2019) A new design of evolutionary hybrid optimization of SVR model in predicting the blast-induced ground vibration. Eng Comput. https://doi.org/10.1007/s00366-019-00895-x
Yang H, Nikafshan Rad H, Hasanipanah M, Bakhshandeh Amnieh H, Nekouie A (2019) Prediction of vibration velocity generated in mine blasting using support vector regression improved by optimization algorithms. Nat Resour Res. https://doi.org/10.1007/s11053-019-09597-z
Qi C, Fourie A, Ma G, Tang X, Du X (2017) Comparative study of hybrid artificial intelligence approaches for predicting hangingwall stability. J Comput Civil Eng 32(2):04017086
Qi C, Fourie A, Zhao X (2018) Back-analysis method for stope displacements using gradient-boosted regression tree and firefly algorithm. J Comput Civil Eng 32(5):04018031
Qi C, Tang X (2018) Slope stability prediction using integrated metaheuristic and machine learning approaches: a comparative study. Comput Ind Eng 118:112–122
Yang L, Dong W, Yang O, Zhao J, Liu L, Feng S (2018) An automatic impedance matching method based on the feedforward-backpropagation neural network for a WPT system. IEEE Trans Ind Electron 66:3963–3972
Ibrahim A, Faris H, Mirjalili S, Al-Madi N (2018) Training radial basis function networks using biogeography-based optimizer. Neural Comput Appl 29:529–553
Shirani Faradonbeh R, Jahed Armaghani D, Bakhshandeh Amnieh H, Tonnizam Mohamad E (2016) Prediction and minimization of blast-induced flyrock using gene expression programming and firefly algorithm. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2537-8
Shang Y, Nguyen H, Bui XN, Tran QH, Moayedi H (2019) A novel artificial intelligence approach to predict blast-induced ground vibration in open-pit mines based on the firefly algorithm and artificial neural network. Nat Resour Res. https://doi.org/10.1007/s11053-019-09503-7
Liu KY, Qiao CS, Tian SF (2004) Design of tunnel shotcrete bolting support based on a support vector machine approach. Int J Rock Mech Min Sci 41(3):510–511
Khandelwal M (2011) Blast-induced ground vibration prediction using support vector machine. Eng Comput 27:193–200
Hasanipanah M, Monjezi M, Shahnazar A, Armaghani DJ, Farazmand A (2015) Feasibility of indirect determination of blast induced ground vibration based on support vector machine. Measurement 75:289–297
Armaghani DJ, Hasanipanah M, Mohamad ET (2016) A combination of the ICA-ANN model to predict air-overpressure resulting from blasting. Eng Comput 32(1):155–171
Hasanipanah M, Noorian-Bidgoli M, Armaghani DJ, Khamesi H (2016) Feasibility of PSO–ANN model for predicting surface settlement caused by tunneling. Eng Comput 32(4):705–715
Hasanipanah M, Faradonbeh RS, Armaghani DJ, Amnieh HB, Khandelwal M (2017) Development of a precise model for prediction of blast-induced flyrock using regression tree technique. Environ Earth Sci 76(1):27
Hasanipanah M, Shahnazar A, Arab H, Golzar SB, Amiri M (2017) Developing a new hybrid-AI model to predict blast induced backbreak. Eng Comput 33(3):349–359
Gao W, Karbasi M, Hasanipanah M, Zhang X, Guo J (2018) Developing GPR model for forecasting the rock fragmentation in surface mines. Eng Comput 34(2):339–345
Hasanipanah M, Amnieh HB, Arab H, Zamzam MS (2018) Feasibility of PSO–ANFIS model to estimate rock fragmentation produced by mine blasting. Neural Comput Appl 30(4):1015–1024
Rezapour Tabari MM, Zarif Sanayei HR (2018) Prediction of the intermediate block displacement of the dam crest using artificial neural network and support vector regression models. Soft Comput. https://doi.org/10.1007/s00500-018-3528-8
Hasanipanah M, Armaghani DJ, Amnieh HB, Koopialipoor M, Arab H (2018) A risk-based technique to analyze flyrock results through rock engineering system. Geotech Geol Eng 36(4):2247–2260
Qi C, Chen Q, Fourie A, Zhang Q (2018) An intelligent modelling framework for mechanical properties of cemented paste backfill. Miner Eng 123:16–27
Faradonbeh RS, Hasanipanah M, Amnieh HB et al (2018) Development of GP and GEP models to estimate an environmental issue induced by blasting operation. Environ Monit Assess 190:351
Qi C, Fourie A, Ma G, Tang X (2018) A hybrid method for improved stability prediction in construction projects: a case study of stope hangingwall stability. Appl Soft Comput 71:649–658
Yakubu I, Ziggah YY, Peprah MS (2018) Adjustment of DGPS data using artificial intelligence and classical least square techniques. J Geomat 12(1):13–20
Qi C, Chen Q, Dong X, Zhang Q, Yaseen ZM (2019) Pressure drops of fresh cemented paste backfills through coupled test loop experiments and machine learning techniques. Powder Technol. https://doi.org/10.1016/j.powtec.2019.11.046
Asante-Okyere S, Shen C, Ziggah YY, Rulegeya MM, Zhu X (2019) A novel hybrid technique of integrating gradient-boosted machine and clustering algorithms for lithology classification. Nat Resour Res. https://doi.org/10.1007/s11053-019-09576-4
Ziggah YY, Hu Y, Issaka Y, Laari PB (2019) Least squares support vector machine model for coordinate transformation. Geodesy Cartogr 45(1):16–27
Lu X, Hasanipanah M, Brindhadevi K, Amnieh HB, Khalafi S (2019) ORELM: A novel machine learning approach for prediction of flyrock in mine blasting. Nat Resour Res. https://doi.org/10.1007/s11053-019-09532-2
Brantson ET, Ju B, Ziggah YY, Akwensi PH, Sun Y, Wu D, Addo BJ (2019) Forecasting of horizontal gas well production decline in unconventional reservoirs using productivity, soft computing and swarm intelligence models. Nat Resour Res. https://doi.org/10.1007/s11053-018-9415-2
Mojtahedi SFF, Ebtehaj I, Hasanipanah M, Bonakdari H, Amnieh HB (2019) Proposing a novel hybrid intelligent model for the simulation of particle size distribution resulting from blasting. Eng Comput 35(1):47–56
Qi C, Chen Q, Fourie A, Tang X, Zhang Q, Dong X, Feng Y (2019) Constitutive modelling of cemented paste backfill: a data-mining approach. Constr Build Mater 197:262–270
Zhou J, Li C, Arslan CA, Hasanipanah M, Amnieh HB (2019) Performance evaluation of hybrid FFA–ANFIS and GA–ANFIS models to predict particle size distribution of a muck-pile after blasting. Eng Comput. https://doi.org/10.1007/s00366-019-00822-0
Qi C, Fourie A (2019) Cemented paste backfill for mineral tailings management: review and future perspectives. Miner Eng 144:106025
Armaghani J et al (2019) Development of a novel hybrid intelligent model for solving engineering problems using GS-GMDH algorithm. Eng Comput. https://doi.org/10.1007/s00366-019-00769-2
Arthur CK, Temeng VA, Ziggah YY (2020) Novel approach to predicting blast-induced ground vibration using Gaussian process regression. Eng Comput 36:29–42. https://doi.org/10.1007/s00366-018-0686-3
Lu X, Zhou W, Ding X, Shi X, Luan B, Li M (2019) Ensemble learning regression for estimating unconfined compressive strength of cemented paste backfill. IEEE Access. https://doi.org/10.1109/ACCESS.2019.2918177
Yang Y, Zang O (1997) A hierarchical analysis for rock engineering using artificial neural networks. Rock Mech Rock Eng 30:207–222
Chen Y, Tan H (2017) Short-term prediction of electric demand in building sector via hybrid support vector regression. Appl Energy 204:1363–1374
Acknowledgements
This paper is supported by the National Natural Science Foundation of China (Grant No. 51804299) and the Natural Science Foundation of Jiangsu Province, China (Grant No. BK20180646).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ding, X., Hasanipanah, M., Nikafshan Rad, H. et al. Predicting the blast-induced vibration velocity using a bagged support vector regression optimized with firefly algorithm. Engineering with Computers 37, 2273–2284 (2021). https://doi.org/10.1007/s00366-020-00937-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-020-00937-9