
Abstract
Many primates produce one type of alarm call to a broad range of events, usually terrestrial predators and non-predatory situations, which raises questions about whether primate alarm calls should be considered ‘functionally referential’. A recent example is black-fronted titi monkeys, Callicebus nigrifrons, which emit sequences of B-calls to terrestrial predators or when moving towards or near the ground. In this study, we reassess the context specificity of these utterances, focussing both on their acoustic and sequential structure. We found that B-calls could be differentiated into context-specific acoustic variants (terrestrial predators vs. ground-related movements) and that call sequences to predators had a more regular sequential structure than ground-related sequences. Overall, these findings suggest that the acoustic and temporal structure of titi monkey call sequences discriminate between predator and non-predatory events, fulfilling the production criterion of functional reference.
Significance statement
Primate terrestrial alarm calls are at the centre of an ongoing debate about meaning in animal signals. Primates regularly emit one alarm call type to ground predators but often also to various non-predatory events, raising questions about the referential nature of these signals. In this study, we report observational and experimental data from wild titi monkeys and show that terrestrial alarm calls are usually given in sequences of acoustically distinct variants composed in structurally distinct ways depending on the external event. These differences are salient and could help recipients to distinguish the nature of the call eliciting event. Since most previous studies on animal alarm calls have not checked for acoustic variants within different call classes, it may be premature to conclude that primate terrestrial calls do not meet the criteria of functional reference.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Animal alarm calls can potentially convey a rich set of information, used by receivers to make adaptive behavioural decisions. Alarm calls have been shown to convey information about predator species (Randall et al. 2005; Suzuki 2014), predator size (Templeton et al. 2005), predator behaviour (Griesser 2008; Cunningham and Magrath 2017) or threat level (Blumstein and Armitage 1997; Manser 2001). Such information is encoded in a wide range of vocal features, including spectral properties (Manser 2001), temporal structure (Templeton et al. 2005), call rate (Warkentin et al. 2001) or call combinations (Ouattara et al. 2009a; Suzuki 2014).
The fact that some animal signals are structurally linked to distinct external events has created a debate about the cognitive nature driving signalling behaviour. Humans use a range of communication strategies, from simple index finger pointing to complex linguistic utterances, to refer an audience to an external event. In animals, signals that provide reliable information to the recipients about external events are often termed ‘functionally referential’ because the underlying mental processes of call production are usually unclear. The criteria for functional reference have been that the signal has to be stimulus-specific (production criterion) and sufficient for receivers to display an appropriate response (perception criterion), even in the absence of the eliciting stimulus or any correlated contextual cues (Macedonia and Evans 1993). Various examples of animal communication qualify as functionally referential (Townsend and Manser 2013) because they are elicited by a feature of the environment (e.g. predator type). Importantly, this chain of events can be the result of different underlying mechanisms. For example, an event-specific alarm call can be ‘affective’ if its production is mediated by a specific arousal level, without impacting the referential properties of the signal. In other words, although signals can be linked to external events, they may be simple reflections of undetermined emotional states without carrying any semantic properties (Seyfarth and Cheney 2003; Price et al. 2015). The current debate is less about the psychological mechanism driving call production, but about the referential specificity of the calls (Wheeler and Fischer 2012).
Many animal species possess two alarm call types: one for aerial and one for terrestrial predators (see Kiriazis and Slobodchikoff 2006). A consistent finding in primates is that aerial alarms are typically highly predator-specific while terrestrial alarms tend to be more general and can be used in many contexts (Fichtel and Kappeler 2002; Fichtel et al. 2005; Kirchhof and Hammerschmidt 2006; Wheeler 2010; Wheeler and Fischer 2012; Zuberbühler and Neumann 2017). For example, red-fronted lemurs (Eulemur fulvus rufus) give ‘woof’ calls to fossas and dogs, but also in non-predatory situations of seemingly high arousal, while ‘chutter’ calls are exclusively given to hawks (Fichtel and Kappeler 2002). Similarly, tufted capuchins (Cebus apella nigritus) give ‘bark’ calls to aerial threats and ‘hiccup’ calls to terrestrial predators, but also in non-predatory, seemingly stressful situations (Wheeler 2010).
Strictly speaking, the terrestrial alarm calls of these species do not fulfil the production criterion by Macedonia and Evans (1993) and hence cannot be classified as functionally referential. Instead, they are more similar to human pointing insofar as they attract the attention of other group members, who then either consider pragmatic cues, such as other recent events (Arnold and Zuberbühler 2013) or simply follow the caller’s gaze direction to the cause of his or her calling (Crockford et al. 2015).
However, there are additional complexities regarding the hypothesis that primate terrestrial alarms are referentially unspecific. In particular, recent progress in acoustic and statistical analyses continues to highlight the richness of information encoded in animal signals (e.g. Griesser 2008). Moreover, the recent introduction of automated feature extraction technology and unsupervised learning algorithms can highlight fine-grained contextual variation related to external events that may not be readily perceivable by human observers (e.g. Fedurek et al. 2016). Since most of the studies reporting unspecific terrestrial alarm calls lack the necessary detailed acoustic analyses (e.g. Fichtel and Kappeler 2002; Kirchhof and Hammerschmidt 2006; Wheeler 2010; but see Wheeler and Hammerschmidt 2013; Price et al. 2015), a sensible hypothesis is that terrestrial alarm calls in primates differ acoustically depending on whether they are given to predators or in non-predatory situations. Without such detailed acoustic analyses, it may be premature to conclude whether a contextually unspecific terrestrial alarm call is in fact a collection of contextually specific terrestrial call variants (e.g. Fischer et al. 1995).
Another complexity arises from findings that some alarm calls are organised sequentially, often in context-specific ways. An example is the alarm roaring of Guereza colobus monkeys Colobus guereza. One finding has been that vocal utterances elicited by leopards contain fewer roars per phrase but a higher number of phrases compared to those elicited by crowned eagles, which show the opposite pattern (Schel et al. 2009). In this case, there is also evidence that receivers respond to these structural differences as if they perceived the corresponding predators themselves (Schel et al. 2010).
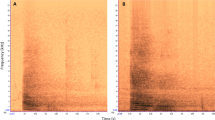
In this study, we reassess the context specificity of alarm utterances of wild black-fronted titi monkeys, Callicebus nigrifrons, focussing both on the acoustic and sequential levels. The species has been subject to a series of previous studies that have reported soft, structurally simple B-call sequences to terrestrial predators, such as oncillas Leopardus tigrinus, puma Puma concolor and tayra Eira barbara (Cäsar et al. 2012a, 2013) but also when moving or foraging near the ground (Cäsar 2011; Cäsar et al. 2012b) (Fig. 1). Sequences to predators can last up to 2 h, although B-calls are then gradually replaced by other call types (Cäsar 2011). B-call sequences during foraging appear to be much shorter, lasting only a few seconds, with multiple sequences uttered during the same movement events, usually in synchronisation with the movements (MB, personal observation).

Spectrograms of B-calls from a the terrestrial predator context and b the ground context, and spectrograms of B-call sequences from c the terrestrial predator context and d the ground context, all from the same individual
The small size of these primates (0.8–1.3 kg; Norconk 2011) exposes them to high predation pressure (Ferrari 2009). Since titi monkeys live in dense forests with low visibility, natural selection may have favoured the evolution of context-specific signalling. We were therefore puzzled by the fact that monkeys emitted B-calls to both terrestrial predators and while descending to the ground to forage, despite the two situations carrying different degrees of risk. If calls given in these two situations cannot be discriminated, then receivers have to consider additional information to determine whether a predator is present or not. Establishing visual contact with the caller and determining its gaze direction is one possible strategy, but this can be costly as it requires more time to react adaptively. On the other hand, maintaining visual contact with the caller is generally adaptive for the latter because it facilitates the location of a hidden predator (Wheeler 2010). This strategy only works, however, if alarm signals occur at low rate in the absence of predators.
Pilot observations suggested that titi monkey B-calls are emitted in a more regular fashion in predatory situations than when descending near the ground in non-predatory situations. Moreover, B-call sequences emitted in alarm situations appear to elicit vigilance (Cäsar et al. 2012b) while B-call sequences emitted during foraging do not (MB, personal observations). We therefore hypothesised that B-sequences to predators and during descents are different at two different levels: in the acoustic structure and in the sequential structure.
Methods
Study subjects and site
Our study took place at the Reserva Particular do Patrimônio Natural Santuário do Caraça, a private reserve of 11,000 ha in the Espinhaço Mountain range, Minas Gerais, Brazil (20° 05′ S, 43° 29′ W). Our study took part in the central part of the reserve, in the two forests of Tanque Grande and Cascatinha. The two forests are located 1 km apart from each other and are composed of transition zones between native Atlantic forest, ‘cerrado’ (savannah), ‘campo rupestre’ (rocky grassland) and ‘capoeira’ (deforested areas), ranging from 1200 to 1300 m of altitude (Brandt and Motta 2002). The climate is characterised by a rainy season (from October to March) and a dry season (from April to September).
We studied six groups of Callicebus nigrifrons that have been habituated to human presence since 2003 (Cäsar 2011) (Table 1). Four groups reside in the forest of Tanque Grande and two groups in the forest of Cascatinha. Titi monkeys typically live in family groups comprising an adult heterosexual pair, monogamous for life, and up to four offspring (Bicca-Marques and Heymann 2013). Both sexes disperse after reaching sexual maturity, at around 3–4 years of age (Bossuyt 2002). We considered an individual as adult from the age of 30 months, as sub-adult between 18 and 30 months, as juvenile between 6 and 18 months and as infant if less than 6 months old (Cäsar 2011). Recognition of individuals was based on morphological cues, such as size, fur pattern and facial or corporal characteristics.
The research reported in this article was conducted in compliance with all relevant local and international laws and has the approval of the ethical committee CEUA/UNIFAL, number 665/2015.
Data collection
We monitored groups on a daily basis during two field seasons (April to June 2015 and October 2015 to August 2016). We followed each group and collected data on at least 4 days per month. It was not possible to record data blindly because our study involved focal animals in the field. In order to assess acoustic and sequential differences in B-call utterances, we recorded natural B-call sequences and conducted predator presentations. We used two stuffed terrestrial predators as stimuli: one tayra, Eira barbara, and one oncilla, Leopardus tigrinus. Each model was presented twice to each group, once in the canopy (between 3 and 10 m high, depending on the structure of the arboreal strata) and once on the ground. The context of emission was categorised as (a) ‘terrestrial predator’ (natural or experimental terrestrial predator encounters) and (b) ‘ground’ (caller descends or moves horizontally near the ground, at 2–3 m high maximum, usually to forage, no predator presence). Spectrograms of calls and sequences associated with each context are in Fig. 1 and example sound files are presented in the supplementary material. We recorded vocalisations in WAV format with a Marantz solid-state recorder PMD661 (44.1 kHz sampling rate, 16 bits accuracy) and a directional microphone Sennheiser K6/ME66 or K6/ME67 (frequency response, 40–20,000 Hz ± 2.5 dB).
Acoustic structure
Call selection and data sets
We extracted single calls from the original recordings of sequences given in the two contexts using Praat 5.3.84 (Boersma and Weenink 2009). We removed calls from the data set for the following reasons: if recorded from more than about 7 m away, if given by immature (infant or juvenile) or unidentified individuals, or if the context could not be determined. Alarm calling typically involved all group members joining in a chorus. Therefore, the selected calls generally were taken from the beginning and end of calling sequences to ensure reliable identification of callers. We created two data sets, one for females and one for males to remove the confounding effects of sex in the subsequent statistical analyses. Each individual (seven males and seven females) provided at least six calls in each context (ground: N = 14 individuals, N = 3 sequences/individual; terrestrial predator: N = 14 individuals; N = 1 sequence/individual). We considered a total of 271 calls from 68 sequences (Table 2).
Acoustic analysis
We visually inspected spectrograms (FFT size 512, Hanning window, time resolution 3.54 ms, frequency resolution 86.1 Hz) to exclude recording sections disturbed by other sounds or with low signal-to-noise ratio. We adapted acoustic parameters used in Podos (2001). For each call, we first measured directly on the spectrogram (1) the duration and (2) the number of harmonics. We then measured frequency parameters from the power spectra: (3) the peak frequency, (4) the minimum and (5) the maximum frequency at which the amplitude exceeds − 20 dB relative to peak frequency, (6) the frequency range (maximum-minimum frequency), the peak frequency at the (7) first 10 ms of the call (referred later as ‘first peak’) and (8) last 10 ms of the call (referred later as ‘last peak’) (Fig. 2). The measurement of the minimum and maximum frequency relative to the peak frequency allows to maximise the proportion of signal measured, by not including background noise nor excluding signal energy (Podos 2001; Zollinger et al. 2012). All measurements were conducted using Raven Pro 1.5 Beta Version. Raw data are provided in the supplementary materials.

Measure of acoustics parameters on a B-call from the ground context, on the spectrogram (top panel) and the power spectrum (bottom panel) with 1: duration, 2: number of harmonics, 3: peak frequency, 4: minimum frequency, 5: maximum frequency, 6: frequency range, 7: first peak, 8: last peak. Figures were drawn using the ‘seewave’ package (Sueur et al. 2008)
Acoustic analyses were done by two raters (MB, GM). To assess between-rater reliability, we used a subset of 51 randomly selected calls (19% of the total dataset). We calculated the interclass correlation coefficient (ICC) for each of the acoustic parameters, and the level of between-rater agreement reached the required reliability level for all acoustic parameters (r ≥ 0.8, Cicchetti 1994).
Statistical analysis
For each acoustic parameter, we visually inspected histograms and transformed data to approach symmetric distributions (log, square root or fourth root) if necessary. We excluded strongly correlated parameters (r ≥ 0.7) (Quinn and Keough 2002). Thus, we excluded maximum frequency (both sexes) because it was strongly correlated with the minimum frequency.
We used discriminant function analysis (DFA) to test for acoustic differences between contexts. The aim of this analysis is to determine whether certain objects (here the calls) can be discriminated into classes (caller identity, context) by parameters measured from each object (acoustic parameters). However, a DFA requires independence of data (i.e. it only allows the consideration of a single factor at a time, for example ‘individual’ or ‘context’), and violating this assumption leads to increased probability of type I errors (Mundry and Sommer 2007). We therefore used permuted discriminant function analysis (pDFA; Mundry and Sommer 2007), which combines a permutation approach with a DFA. We conducted a crossed pDFA for each sex separately to assess whether the B-calls could be differentiated among contexts based on their acoustic structure. We set ‘context’ as the test factor and ‘individual’ as the control factor to test for contextual differences while controlling for multiple calls of each individual (Mundry and Sommer 2007).
In order to extract the key variables, i.e. the variables that enable discrimination of context in the pDFA, we re-ran 1000 permuted DFA and recorded those variables that had the highest coefficient of linear discriminant in at least 800 DFAs out of 1000, i.e. the variables allowing for discrimination in more than 80% of the discrimination tests.
The ICC was conducted with the rptR package (Stoffel et al. 2017) in R version 2.14.0 (R Development Core Team 2011). All other tests were conducted in R version 3.4.1 (R Development Core Team 2017). The pDFA was generated using a function kindly provided by R. Mundry, based on the function ‘lda’ of the R package MASS (Venables and Ripley 2002). The R script is provided in the supplementary materials.
Sequential structure
Sequence selection
Responses to predator presence must be rapid, suggesting that alarm signals should convey any potential predator information as early as possible, i.e., once the caller has identified the disturbance. For this reason, we only focused on the first 11 calls of each sequence to measure 10 call intervals (mean = 6.69 s, SD = 3.38). Hence, what we refer to as ‘sequence’ in the following are the first 11 calls of a sequence.
For the predation context, we only considered sequences of pure B-calls, i.e. with no other alarm call type interspersed (e.g. A-call, Cäsar et al. 2012a). Since B-call sequences can be emitted in synchronisation with movements during foraging bouts, we only considered as a new sequence an utterance preceded by at least 30 s of silence. As for call selection, we did not consider sequences if given by several individuals at the same time, by immature (infant or juvenile) or unidentified individuals, or if the context could not be determined.
Dataset and analysis
A total of 36 sequences from 12 individuals were considered for this analysis (Table 3).
For each sequence, we extracted two features. First, we measured the time interval between two subsequent calls for each of the 11 first calls (i.e. a total of 10 duration per sequence). Second, we quantified the level of variability of the call interval for each sequence by calculating the coefficient of variation of the call intervals (CV = standard deviation/mean). A low CV indicates that calls are regularly emitted in the sequence, while a high CV indicates that calls intervals are variable in the sequence, with a mix of longer and shorter intervals. Raw data are provided in the supplementary materials.
Statistical analysis
We fitted two generalised linear mixed models (GLMM). The first one was on the relationship between duration of the call interval and the context of emission with a gamma error structure. The second one was on the relationship between the CV of the sequence and the context of emission, again with a gamma error structure (Payton 1996). For both, we entered context (terrestrial predator vs. ground) and sex of the caller as fixed factors. Identity of the caller was controlled for by including it as a random factor nested within the group identity. We obtained p values with likelihood ratio tests (LRT) of the full models against the null models, i.e. models without the fixed factor context. The fit of the models was evaluated by the proportion of variance explained (the marginal coefficient of determination R 2 m, i.e. the variance accounted for by fixed factors, and the conditional coefficient of determination R 2 c, i.e. the variance accounted for by both fixed and random factors) estimated with the delta method for variance estimation described in Nakagawa et al. (2017).
Both GLMM were fitted using the lme4 package (Bates et al. 2015) in R version 3.4.1 (R Development Core Team 2017). The R script is provided in the supplementary materials.
Data availability statement
The datasets generated and the Rscripts used for the current study as well as audio examples of B-sequences are available in the following Figshare repository: https://figshare.com/projects/Contextual_encoding_in_titi_monkey_alarm_call_sequences/23248
Results
Acoustic structure
In females, B-calls could be distinguished on the basis of emission context with 82% of calls correctly classified, significantly higher than the 63% expected by chance (p = 0.001) (Fig. 3). The key parameter allowing for discrimination was the minimum frequency in 937 DFAs out of the 1000 permutations: minimum frequency was about 0.5 kHz higher in the terrestrial predator context than in the ground context (Fig. 4).

Distribution of the discriminant scores of female B-calls given to terrestrial predators and in the ground context. Note that the pDFA does not allow for graphic representation. Hence, this figure is drawn from the results of a DFA, and only serves to illustrate discrimination, but does not represent the results of the actual pDFA

Minimum frequencies in ground and predator context, in females (a) and in males (b). Shown are the median, first and third quartiles, whiskers (defined as 1.5x the interquartile range) and outliers
In males, classification of B-calls to the correct emission context was 69%, which was not significantly higher than the 60% expected by chance (p = 0.153).
Sequential structure
Context did not affect significantly the duration of inter-call intervals (LRT χ 2(1) = 0.63, p = 0.4252; R 2 m = 0.019, R 2 c = 0.133) (Table 4, Fig. 5), but it affected the coefficient of variation of the inter-call intervals (LRT: χ 2(1) = 6.57, p = 0.010, R 2 m = 0.303, R 2 c = 0.334). Variation of inter-call intervals was greater during descent sequences than in sequences in response to terrestrial predators (Table 4, Fig. 6): in the predator context, calls were given with a more regular rhythm than in the ground context calls.

Call interval duration in the ground and predator context. Shown are the median, first and third quartiles, whiskers (defined as 1.5x the interquartile range) and outliers

Coefficient of variation of the call intervals in the ground and predator context. Shown are the median, first and third quartiles, whiskers (defined as 1.5x the interquartile range) and outliers
Discussion
We tested whether B-call sequences to predators and during descent differed in terms of call acoustic structure and/or on the sequential structure level. In female titi monkeys, B-calls could be differentiated probabilistically, mostly based on their minimum frequencies, with the terrestrial predator context being higher-pitched than the ground context (Figs. 3 and 4). B-calls were also typically emitted in more regularly structured sequences during the terrestrial predator compared to the ground context (Fig. 6). These results suggest that B-call sequences can convey information about the emission context on at least two levels: the acoustic structure of individual calls and the structure of the entire call sequences.
Context-specific acoustic variants within one alarm call type have also been reported in other primate species, notably Barbary macaques, Macaca sylvanus, that produce acoustically different variants depending on the predator type (Fischer et al. 1995), and these variants are perceived by receivers (Fischer and Hammerschmidt 2001). This is also the case in chimpanzees Pan troglodytes, whose barks are emitted in two different contexts (hunt and snake presence) correlated with two acoustic variants (Crockford and Boesch 2003).
We found acoustic variants in B-calls, but one might consider the classification results as weak. Indeed, the difference between the number of correctly classified calls and the ones expected by chance was only moderately significant in females and not significant in males. These levels of correct classification to the emission context are low compared to other studies (e.g. Price et al. 2015) and thus raise the question of whether the differences are biologically relevant and sufficient to allow discrimination by receivers. In the end, playback experiments are needed, but in the meantime it is worth pointing out that the sample sizes were small, the statistical tests were performed on only one call type and B-calls are structurally very simple calls (Fig. 1), especially if compared to other primate alarm calls (e.g. Crockford and Boesch 2003; Ouattara et al. 2009b; Price et al. 2015). In this view, it was noteworthy that the classification rate was significant. Moreover, it is possible that sequences emitted in the predator context represent a mix of predatory and ground B-calls because of movements of callers towards the ground to check on the threat. As such, it seems likely that the classification results underestimate the true differences between the two contexts. Therefore, our results suggest the existence of at least two context-specific variants of B-calls, but only future playback experiments will show whether these subtle differences can actually be perceived by receivers.
The minimum frequency was the main parameter allowing for discrimination between the B-call acoustic variants, with the B-calls given to terrestrial predators being higher-pitched than those given in the ground context. Similar increases of minimum frequency with higher arousal have been frequently observed in mammals and birds (Perez et al. 2012; Briefer 2012), in line with Morton’s (1977) motivation-structural rules. The presence of a predator may be a more stressful situation for the caller and should result in a higher minimum frequency compared to the arguably less stressful situation of moving towards or near the forest floor.
We found acoustic differences between the alarm and descending contexts in females but not in males. In general, the hypothesis is that pair-living primates, such as titi monkeys, do not show sex differences in vocal repertoires and use their calls in similar ways (Snowdon 2017) in contrast to species with other breeding systems (e.g. Gautier and Gautier-Hion 1982; Stephan and Zuberbühler 2016). Male titi monkeys may indeed produce two acoustic variants but our study failed to show it. In many animal species, males are more engaged in anti-predator behaviour (e.g. van Schaik and van Noordwijk 1989; Brunton 1990), suggesting that male alarm call sequences to terrestrial predators consisted of a mix of predator and ground B-calls, likely emitted while descending near the predator to check on it, more so than in females. This hypothesis needs to be tested in the future with systematic data.
Our study also went beyond more traditional analyses insofar as we also analysed differences at the level of the sequential structure. Here, we found that B-calls were emitted more regularly in the predator than in the ground context. Similar effects have been reported in black-capped chickadees (Poecile atricapilla), which produce ‘chick-a-dee’ calls with a shorter time interval between the ‘chick’ and ‘dee’ syllables and more ‘dee’ syllable when encountering small, manoeuvrable raptors than large ones (Templeton et al. 2005).
Snowdon et al. (1997) suggested that non-social calls (e.g. alarm calls) show less variability than calls used in intragroup social interactions (e.g. contact calls) because alarm calls require quick responses from recipients. This has been shown at the spectral level for primates and birds (Charrier et al. 2001; Lemasson and Hausberger 2011; Bouchet et al. 2012) but to the best of our knowledge has not been tested on call sequence structure. Our results can be interpreted such that temporal variability in call sequences is also linked to the degree of social significance of the signal. B-sequences emitted in response to predators may be less socially relevant and thus more regular than B-sequences when the caller is signalling its movement towards the ground to other members of the group.
Since the coefficient of variation of the call interval is a sequence feature, it may be too costly for receivers to wait until the emission of (at least) three calls to perceive this feature. Thus, differences in acoustic structure may be more important for early decisions about the call-eliciting event, which does not prevent variation in the call interval to convey further information about the context later on. Moreover, although B-call sequences are redundant, call intervals will reassure recipients and enhance discriminability after a few repetitions. However, whether titi monkeys rely on acoustic and/or sequential parameters to attribute meaning about the eliciting context needs to be tested with playback experiments.
Alarm calls to predators can have various functions, such as signalling detection to a predator or warning members of the group (see review in Zuberbühler 2009), but the function of the ground B-call sequences are less evident. We can think of several possibilities. First, ground B-calls may signal the caller’s own perception of enhanced risk. Foraging in lower strata may be more dangerous, due to higher predation risk (Mourthé et al. 2007). B-calls sequences thus provide relatively specific information about the caller’s whereabouts, which may be relevant to other group members, as also documented in pied babblers Turdoides bicolor or Diana monkeys Cercopithecus diana (Uster and Zuberbühler 2001; Radford and Ridley 2007). Callers, for example, may elicit higher levels of vigilance from other group members, which increases their own safety. Second, ground B-calls sequences could indicate that no predator is around and that it is safe to forage near the ground, like the ‘guarding’ close calls in meerkats Suricata suricatta (Townsend et al. 2011). However, we regard this as a less plausible scenario, simply because the two B-call variants are very similar, with a corresponding high risk of misunderstanding, which is also indicated by the less than 100% classification results. Further playbacks are needed to understand the main function of the ground B-call sequences, but it is likely that titi monkeys categorise both event types, going near the ground and terrestrial predator, in similar ways, e.g. as threats (real or feared) related to the ground (Zuberbühler and Neumann 2017). Going down may be perceived as dangerous, simply because terrestrial predators are likely to be encountered (Mourthé et al. 2007).
It is a common finding, across many nonhuman primate species, that calls associated with terrestrial disturbances are also given in other contexts (e.g. Fichtel and Kappeler 2002; Wheeler 2010), which has questioned the notion of functionally referential alarm calls (Macedonia and Evans 1993; Fischer and Price 2016). Our current study adds an additional layer of complexity to this debate, because of context-dependent acoustic and sequential structures in titi monkey ‘terrestrial alarm’ calls. Also relevant is that the production criterion of functional reference is generally difficult to operationalize, since context is always defined by the observer, and this may be different from how animals categorise the world (Zuberbühler and Neumann 2017). Moreover, calls can exhibit different degrees of context specificity, varying from a classification success of 100% to a statistically significant classification success, like the B-calls of titi monkeys. As such, it appears important that future work explores the concept of context specificity to get a better understanding of what constitutes context-specific and context-unspecific, or better even, to develop a continuous measure of how context-specific call types are (Zuberbühler and Neumann 2017; see also Scarantino and Clay 2015). Such research seems essential to understand better the ‘potentially more complex processes underlying responses to more unspecific calls’ (Wheeler and Fischer 2012, p. 195).
To conclude, titi monkey B-calls seem to have the potential to provide listeners with information about external events, which encourages careful analyses of terrestrial alarm calls and other vocalisations to check for the presence of acoustic and sequential variants. From the recipient’s perspective, further experiments are needed to determine whether call variants are discriminated and whether additional contextual cues are taken into account (Scarantino and Clay 2015). Future work on the evolution of referential signalling and its potential roots in primate signalling will need to address these points, notably if callers direct their calls to specific recipients and, in doing so, take their mental states into account.
References
Arnold K, Zuberbühler K (2013) Female putty-nosed monkeys use experimentally altered contextual information to disambiguate the cause of male alarm calls. PLoS One 8(6):e65660. https://doi.org/10.1371/journal.pone.0065660
Bates D, Maechler M, Bolker B, Walker S (2015) Fitting linear mixed-effects models using lme4. J Stat Softw 67:1–48
Bicca-Marques JC, Heymann EW (2013) Ecology and behavior of titi monkeys (genus Callicebus). In: Veiga LM, Barnett AA, Ferrari SF, Norconk MA (eds) Evolutionary biology and conservation of Titis, Sakis and Uacaris. Cambridge University Press, New York, pp 196–207. https://doi.org/10.1017/CBO9781139034210.023
Blumstein DT, Armitage KB (1997) Alarm calling in yellow-bellied marmots: I. The meaning of situationally variable alarm calls. Anim Behav 53(1):143–171. https://doi.org/10.1006/anbe.1996.0285
Boersma P, Weenink D (2009) Praat: doing phonetics by computer, www.praat.org/
Bossuyt F (2002) Natal dispersal of titi monkeys (Callicebus moloch) at Cocha Cashu, Manu National Park, Peru. Am J Phys Anthropol 117:35–59
Bouchet H, Blois-Heulin C, Pellier A-S, Zuberbühler K, Lemasson A (2012) Acoustic variability and individual distinctiveness in the vocal repertoire of red-capped mangabeys (Cercocebus torquatus). J Comp Psychol 126(1):45–56. https://doi.org/10.1037/a0025018
Brandt A, Motta L (2002) Mapa de cobertura vegetal e uso do solo [map] 1:50,000. Brandt Meio Ambiente, Nova Lima
Briefer EF (2012) Vocal expression of emotions in mammals: mechanisms of production and evidence. J Zool 288(1):1–20. https://doi.org/10.1111/j.1469-7998.2012.00920.x
Brunton DH (1990) The effects of nesting stage, sex, and type of predator on parental defense by killdeer (Charadrius vociferous): testing models of avian parental defense. Behav Ecol Sociobiol 26:181–190
Cäsar C (2011) Anti-predator behaviour of black-fronted titi monkeys (Callicebus nigrifrons). University of St Andrew, PhD dissertation
Cäsar C, Byrne R, Young RJ, Zuberbühler K (2012a) The alarm call system of wild black-fronted titi monkeys, Callicebus nigrifrons. Behav Ecol Sociobiol 66(5):653–667. https://doi.org/10.1007/s00265-011-1313-0
Cäsar C, Byrne RW, Hoppitt W, Young RW, Zuberbühler K (2012b) Evidence for semantic communication in titi monkey alarm calls. Anim Behav 84(2):405–411. https://doi.org/10.1016/j.anbehav.2012.05.010
Cäsar C, Zuberbühler K, Young RW, Byrne RW (2013) Titi monkey call sequences vary with predator location and type. Biol Lett 9(5):20130535. https://doi.org/10.1098/rsbl.2013.0535
Charrier I, Jouventin P, Mathevon N, Aubin T (2001) Individual identity coding depends on call type in the South Polar skua Catharacta maccormicki. Polar Biol 24(5):378–382. https://doi.org/10.1007/s003000100231
Cicchetti DV (1994) Guidelines, criteria, and rules of thumb for evaluating normed and standardized assessment instruments in psychology. Psychol Assess 6(4):284–290. https://doi.org/10.1037/1040-3590.6.4.284
Crockford C, Boesch C (2003) Context-specific calls in wild chimpanzees, Pan troglodytes verus: analysis of barks. Anim Behav 66(1):115–125. https://doi.org/10.1006/anbe.2003.2166
Crockford C, Wittig RM, Zuberbühler K (2015) An intentional vocalization draws others’ attention: a playback experiment with wild chimpanzees. Anim Cogn 18(3):581–591. https://doi.org/10.1007/s10071-014-0827-z
Cunningham S, Magrath RD (2017) Functionally referential alarm calls in noisy miners communicate about predator behaviour. Anim Behav 129:171–179. https://doi.org/10.1016/j.anbehav.2017.05.021
Fedurek P, Zuberbühler K, Dahl CD (2016) Sequential information in a great ape utterance. Sci Rep 6(1):38226. https://doi.org/10.1038/srep38226
Ferrari SF (2009) Predation risk and antipredator strategie. In: Garber PA, Estrada A, Bicca-Marques JC, Heymann EW, Strier KB (eds) South American Primates. Springer, New York, pp 251–277. https://doi.org/10.1007/978-0-387-78705-3_10
Fichtel C, Kappeler PM (2002) Anti-predator behavior of group-living Malagasy primates: mixed evidence for a referential alarm call system. Behav Ecol Sociobiol 51:262–275
Fichtel C, Perry S, Gros-Louis J (2005) Alarm calls of white-faced capuchin monkeys: an acoustic analysis. Anim Behav 70(1):165–176. https://doi.org/10.1016/j.anbehav.2004.09.020
Fischer J, Hammerschmidt K (2001) Functional referents and acoustic similarity revisited: the case of Barbary macaque alarm calls. Anim Cogn 4(1):29–35. https://doi.org/10.1007/s100710100093
Fischer J, Hammerschmidt K, Todt D (1995) Factors affecting acoustic variation in Barbary-macaque (Macaca sylvanus) disturbance calls. Ethology 101:51–66
Fischer J, Price T (2016) Meaning, intention, and inference in primate vocal communication. Neurosci Biobehav Rev 82:22–31. https://doi.org/10.1016/j.neubiorev.2016.10.014
Gautier J-P, Gautier-Hion A (1982) Vocal communication within a group of monkeys: an analysis by biotelemetry. In: Snowdon CT, Brown CH, Peterson MR (eds) Primate communication. Cambridge University Press, New York, pp 5–29
Griesser M (2008) Referential calls signal predator behavior in a group-living bird species. Curr Biol 18(1):69–73. https://doi.org/10.1016/j.cub.2007.11.069
Kirchhof J, Hammerschmidt K (2006) Functionally referential alarm calls in tamarins (Saguinus fuscicollis and Saguinus mystax)—evidence from playback experiments. Ethology 112(4):346–354. https://doi.org/10.1111/j.1439-0310.2006.01165.x
Kiriazis J, Slobodchikoff CN (2006) Perceptual specificity in the alarm calls of Gunnison’s prairie dogs. Behav Process 73(1):29–35. https://doi.org/10.1016/j.beproc.2006.01.015
Lemasson A, Hausberger M (2011) Acoustic variability and social significance of calls in female Campbell’s monkeys (Cercopithecus campbelli campbelli). J Acoust Soc Am 129(5):3341–3352. https://doi.org/10.1121/1.3569704
Macedonia JM, Evans CS (1993) Essay on contemporary issues in ethology: variation among mammalian alarm call systems and the problem of meaning in animal signals. Ethology 93:177–197
Manser MB (2001) The acoustic structure of suricates’ alarm calls varies with predator type and the level of response urgency. Proc R Soc Lond B 268(1483):2315–2324. https://doi.org/10.1098/rspb.2001.1773
Morton ES (1977) On the occurrence and significance of motivation-structural rules in some bird and mammal sounds. Am Nat 111(981):855–869. https://doi.org/10.1086/283219
Mourthé IMC, Guedes D, Fidelis J, Boubli JP, Mendes SL, Strier KB (2007) Ground use by northern muriquis (Brachyteles hypoxanthus). Am J Primatol 69(6):706–712. https://doi.org/10.1002/ajp.20405
Mundry R, Sommer C (2007) Discriminant function analysis with nonindependent data: consequences and an alternative. Anim Behav 74(4):965–976. https://doi.org/10.1016/j.anbehav.2006.12.028
Nakagawa S, Johnson PCD, Schielzeth H (2017) The coefficient of determination R 2 and intra-class correlation coefficient from generalized linear mixed-effects models revisited and expanded. J R Soc Interface 14(134):20170213. https://doi.org/10.1098/rsif.2017.0213
Norconk MA (2011) Sakis, Uacaris and Titi monkeys; behavioural diversity in a radiation of primate seed predators. In: Campbell CJ, Fuentes A, MacKinnon KC, Bearder Sk, Stumpf RM (eds) Primates in perspective, 2nd edn. Oxford University Press, Oxford, pp 122–138
Ouattara K, Lemasson A, Zuberbühler K (2009a) Campbell’s monkeys concatenate vocalizations into context-specific call sequences. P Natl Acad Sci USA 106(51):22026–22031. https://doi.org/10.1073/pnas.0908118106
Ouattara K, Zuberbühler K, N’goran EK et al (2009b) The alarm call system of female Campbell’s monkeys. Anim Behav 78(1):35–44. https://doi.org/10.1016/j.anbehav.2009.03.014
Payton ME (1996) Confidence interval for the coefficient of variation. 8th Annual Conference of Applied Statistics in Agriculture. http://newprairiepress.org/agstatconference/1996/proceedings/8
Perez EC, Elie JE, Soulage CO, Gombert J-E, Lemasson A (2012) The acoustic expression of stress in a songbird: does corticosterone drive isolation-induced modifications of zebra finch calls? Horm Behav 61(4):573–581. https://doi.org/10.1016/j.yhbeh.2012.02.004
Podos J (2001) Correlated evolution of morphology and vocal signal structure in Darwin’s finches. Nature 409(6817):185–188. https://doi.org/10.1038/35051570
Price T, Wadewitz P, Cheney D, Seyfarth R, Hammerschmidt K, Fischer J (2015) Vervets revisited: a quantitative analysis of alarm call structure and context specificity. Sci Rep 5(1):13220. https://doi.org/10.1038/srep13220
Quinn GP, Keough MJ (2002) Multivariate analysis of variance and discriminant analysis. In: Experimental design and data analysis for biologists. Cambridge University Press, Cambridge, pp 425–442. https://doi.org/10.1017/CBO9780511806384.017
R Development Core Team (2011) R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org
R Development Core Team (2017) R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org
Radford AN, Ridley AR (2007) Individuals in foraging groups may use vocal cues when assessing their need for anti-predator vigilance. Biol Lett 3(3):249–252. https://doi.org/10.1098/rsbl.2007.0110
Randall JA, McCowan B, Collins KC, Hooper SL, Rogovin K (2005) Alarm signals of the great gerbil: acoustic variation by predator context, sex, age, individual, and family group. J Acoust Soc Am 118(4):2706–2714. https://doi.org/10.1121/1.2031973
Scarantino A, Clay Z (2015) Contextually variable signals can be functionally referential. Anim Behav 100:e1–e8. https://doi.org/10.1016/j.anbehav.2014.08.017
Schel AM, Candiotti A, Zuberbühler K (2010) Predator-deterring alarm call sequences in Guereza colobus monkeys are meaningful to conspecifics. Anim Behav 80(5):799–808. https://doi.org/10.1016/j.anbehav.2010.07.012
Schel AM, Tranquilli S, Zuberbühler K (2009) The alarm call system of two species of black-and-white colobus monkeys (Colobus polykomos and Colobus guereza). J Comp Psychol 123(2):136–150. https://doi.org/10.1037/a0014280
Seyfarth RM, Cheney DL (2003) Signalers and receivers in animal communication. Annu Rev Psychol 54(1):145–173. https://doi.org/10.1146/annurev.psych.54.101601.145121
Snowdon CT (2017) Vocal communication in family-living and pair-bonded primates. In: Quam RM, Ramsier MA, Fay RR, Popper AN (eds) Primate hearing and communication. Springer International Publishing, Cham, pp 141–174. https://doi.org/10.1007/978-3-319-59478-1_6
Snowdon CT, Elowson AM, Roush RS (1997) Social influences on vocal development in new world primates. In: Snowdon CT, Hausberger M (eds) Social influences on vocal development. Cambridge University Press, Cambridge, pp 234–248. https://doi.org/10.1017/CBO9780511758843.012
Stephan C, Zuberbühler K (2016) Persistent females and compliant males coordinate alarm calling in Diana monkeys. Curr Biol 26(21):2907–2912. https://doi.org/10.1016/j.cub.2016.08.033
Stoffel MA, Nakagawa S, Schielzeth H (2017) rptR: repeatability estimation and variance decomposition by generalized linear mixed-effects models. Methods Ecol Evol 8(11):1639–1644. https://doi.org/10.1111/2041-210X.12797
Sueur J, Aubin T, Simonis C (2008) Seewave: a free modular tool for sound analysis and synthesis. Bioacoustics 18(2):213–226. https://doi.org/10.1080/09524622.2008.9753600
Suzuki TN (2014) Communication about predator type by a bird using discrete, graded and combinatorial variation in alarm calls. Anim Behav 87:59–65. https://doi.org/10.1016/j.anbehav.2013.10.009
Templeton CN, Greene E, Davis K (2005) Allometry of alarm calls: black-capped chickadees encode information about predator size. Science 308(5730):1934–1937. https://doi.org/10.1126/science.1108841
Townsend SW, Manser MB (2013) Functionally referential communication in mammals: the past, present and the future. Ethology 119(1):1–11. https://doi.org/10.1111/eth.12015
Townsend SW, Zoetti M, Manser MB (2011) All clear? Meerkats attend to contextual information in close calls to cordinate vigilance. Behav Ecol Sociobiol 65(10):1927–1934. https://doi.org/10.1007/s00265-011-1202-6
Uster D, Zuberbühler K (2001) The functional significance of Diana monkey “clear” calls. Behaviour 138(6):741–756. https://doi.org/10.1163/156853901752233389
van Schaik CP, van Noordwijk MA (1989) The special role of male Cebus monkeys in predation avoidance and its effect on group composition. Behav Ecol Sociobiol 24(5):265–276. https://doi.org/10.1007/BF00290902
Venables WN, Ripley BD (2002) Modern applied statistics with S, Fourth edn. Springer, New York. https://doi.org/10.1007/978-0-387-21706-2
Warkentin KJ, Keeley ATH, Hare JF (2001) Repetitive calls of juvenile Richardson’s ground squirrels (Spermophilus richardsonii) communicate response urgency. Can J Zool 79(4):569–573. https://doi.org/10.1139/z01-017
Wheeler BC (2010) Production and perception of situationally variable alarm calls in wild tufted capuchin monkeys (Cebus apella nigritus). Behav Ecol Sociobiol 64(6):989–1000. https://doi.org/10.1007/s00265-010-0914-3
Wheeler BC, Fischer J (2012) Functionally referential signals: a promising paradigm whose time has passed. Evol Anthropol 21(5):195–205. https://doi.org/10.1002/evan.21319
Wheeler BC, Hammerschmidt K (2013) Proximate factors underpinning receiver responses to deceptive false alarm calls in wild tufted capuchin monkeys: is it counterdeception? Am J Primatol 75(7):715–725. https://doi.org/10.1002/ajp.22097
Zollinger SA, Podos J, Nemeth E, Goller F, Brumm H (2012) On the relationship between, and measurement of, amplitude and frequency in birdsong. Anim Behav 84(4):e1–e9. https://doi.org/10.1016/j.anbehav.2012.04.026
Zuberbühler K (2009) Survivor signals: the biology and psychology of animal alarm calling. Adv Stud Behav 40:277–322. https://doi.org/10.1016/S0065-3454(09)40008-1
Zuberbühler K, Neumann C (2017) Referential communication in nonhuman animals. In: Call J (ed) APA handbook of comparative psychology, Basic concepts, methods, neural substrate, and behavior, vol 1. American Psychological Association, Washington, pp 645–661
Acknowledgments
We acknowledge further funding from the University of Neuchâtel and logistic support from the Santuário do Caraça. The Natural Science Museum of the Pontifícia Universidade Católica de Minas Gerais (PUC Minas) kindly lent us the predator models. We wish to thank Rogério Grassetto Teixeira da Cunha (UNIFAL) for helping us to obtain research permits and Roger Mundry for providing us the pDFA function, and we thank N. Buffenoir, A. Colliot, G. Duvot, C. Ludcher, F. Müschenich, C. Rostan, A. Pajot and A. Pessato for their help with data collection. Finally, Brandon Wheeler and an anonymous reviewer provided helpful insights to improve the manuscript, for which we are grateful.
Funding
Our research was funded by the European Research Council under the European Union’s Seventh Framework Programme (FP7/2007–2013)/ERC grant agreement no. 283871.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
The research reported involving animals in this article was conducted in compliance with all relevant local and international laws, and has the approval of the ethical committee CEUA/UNIFAL, number 665/2015.
Additional information
Communicated by E. Huchard
Rights and permissions
About this article

Cite this article
Berthet, M., Neumann, C., Mesbahi, G. et al. Contextual encoding in titi monkey alarm call sequences. Behav Ecol Sociobiol 72, 8 (2018). https://doi.org/10.1007/s00265-017-2424-z
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00265-017-2424-z