
Abstract
Action and object are deeply linked to each other. Not only can viewing an object influence an ongoing action, but motor representations of action can also influence visual categorization of objects. It is tempting to assume that this influence is effector-specific. However, there is indirect evidence suggesting that this influence may be related to the action goal and not just to the effector involved in achieving it. This paper aimed, for the first time, to tackle this issue directly. Participants were asked to categorize different objects in terms of the effector (e.g. hand or foot) typically used to act upon them. The task was delivered before and after a training session in which participants were instructed either just to press a pedal with their foot or to perform the same foot action with the goal of guiding an avatar’s hand to grasp a small ball. Results showed that pressing a pedal to grasp a ball influenced how participants correctly identified graspable objects as hand-related ones, making their responses more uncertain than before the training. Just pressing a pedal did not have any similar effect. This is evidence that the influence of action on object categorization can be goal-related rather than effector-specific.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Action and object are deeply linked to each other. A number of studies indicate that viewing an object (e.g. a hammer) can influence an ongoing action (e.g. grasping) and can do so even when the agent has no intention of acting on the object (Craighero et al. 1996, 1999). A leading account of this influence suggests that viewing objects might automatically trigger motor representations similar to those typically involved in action execution (Jeannerod et al. 1995; Murata et al. 1997; Raos et al. 2006; Rizzolatti et al. 1988). Because of this similarity, the visual features of objects can be converted into action even in the absence of an intention to act (Cardellicchio et al. 2011).
An analogous account has also been provided for the influence of motor representations of action on the visual categorization of objects. In a seminal study, Tucker and Ellis (1998) presented pictures of an everyday handled object such as a teapot or a frying pan. Participants were asked to decide whether the objects were upright or inverted by, for example, pressing a right or a left key. The results showed a significant compatibility effect: participants were faster in judging the orientation of the viewed objects when their handles were spatially aligned with the responding hand than when they were spatially aligned with the contralateral hand. Compatibility effects have also been reported in visual categorization tasks, where participants were asked to decide whether graspable objects of different sizes were living or man-made by performing a precision or a whole hand grasp (Tucker and Ellis 2001, 2004). This suggests that viewed objects might automatically trigger motor representations of action, thus speeding the response to the visual stimuli, even though the action-related object properties (e.g. having an handle or a given size) were not relevant to the visual categorization task (e.g. spatial orientation or object categorization).
It is tempting to assume that the link between action and object categorization is effector-specific. This seems to be corroborated, albeit indirectly, by several pieces of evidence. For instance, there is evidence that the affording features of a graspable object are motorically processed just when the object is literally ready-to-hand to a real or virtual actor (Ambrosini and Costantini 2013; Cardellicchio et al. 2011, 2013; Costantini et al. 2010, 2011a, b; De Stefani et al. 2014). Further evidence comes from action observation as well as from language processing. Several studies indicate that observing other people performing a given action can facilitate the execution of the action when the same effector is involved (Bach et al. 2007; Brass et al. 2000; Gillmeister et al. 2008; Wiggett et al. 2011, 2013). Similarly, behavioural (Ambrosini et al. 2012; Buccino et al. 2005; Dalla Volta et al. 2009; Ferri et al. 2011; Repetto et al. 2013; Sato et al. 2008) and neuroimaging (Hauk et al. 2004; Pulvermüller et al. 2001; Pulvermüller and Shtyrov 2006; Tettamanti et al. 2005) studies show that action-related words and sentences are motorically processed in a somatotopic manner.
Despite this evidence, there seems to be more to the story. Indeed, many studies demonstrate that even at the motor level, action processing can be goal-related rather than just effector-specific. Single-cell recordings from the ventral premotor cortex of the monkey brain show that when both executing and observing action, a number of neurons selectively discharge according to which goal the action is directed to (e.g. the grasping of a piece of food), irrespective of which of several effectors is used to achieve the goal (Jeannerod et al. 1995; Rizzolatti et al. 1988, 2001) and irrespective of which of several tools is used to achieve the goal (e.g. pliers or reverse pliers) even where achieving the goal using different tools requires opposite sequences of movements (e.g. closing or opening the fingers (Rochat et al. 2010; Umiltà et al. 2008). Analogous results have been found in humans (for a review, see Rizzolatti and Sinigaglia 2010). A TMS adaptation study (Cattaneo et al. 2010) clearly indicates that when processing an observed action, the human premotor cortex selectively encodes the goal (e.g. the grasping) to which the action is directed, regardless of the effector involved (e.g. hand or foot).
Does this hold also for action and object? Is the link between action and object categorization goal-related? Or is it just effector-specific, as people are usually tempted to assume? The aim of this paper is to provide, for the first time, a direct answer to this question. A way of doing this is to contrast two actions performed with the same effector and differing from each other just in which goal they are directed to. Consider an action such as pressing a pedal with your foot. The goal of this action may be simply to press the pedal. But imagine you are playing a video game. You can still press the pedal with your foot, but now the goal of your action is, say, to guide a virtual actor to grasp a small ball with her hand. Does the motor representation of the action change with the change of the goal (guiding the actor’s hand rather than just pressing the pedal), even if the effector (i.e. the foot) to be used is the same? Or does it concern the foot’s movements required to press the pedal, irrespective of the change of the goal of the action?
To assess whether the action influence on object categorization is mainly goal- or effector-specific, we presented participants with objects and asked them to identify which body effectors are typically used to act upon them. For instance, when presented with a graspable object such as a hammer they had to provide the response: hand, whereas when presented with a kickable object such a soccer ball they were expected to respond: foot. Participants’ responses were measured by a mouse tracker, which allowed us to detect the real-time dynamics of object categorization. The object categorization task was delivered before and immediately after a training session in which participants were instructed either just to press a pedal with their foot or to perform the same foot action with the goal of guiding an avatar’s hand to grasp a small ball. According to the view that the influence of action on object representation is effector-specific, the training sessions should not have any differential effect on the dynamics of object categorization. In more detail, one should expect that the two training sessions have a similar facilitation effect on the categorization of foot-related objects only. But if the influence of action on object representation is goal-specific, then performing the same movements directed to different goals could have a differential impact on the dynamics of object categorization. According to this alternative view, one should expect that performing a foot-related action with a hand-related goal might also influence the categorization of hand-related objects. And this is actually what we found.
Methods
Participants
Forty volunteers (22 females, 18 males; age range 20–30, m = 24.82, SD = 3.29) were recruited among the students of the Università Cattolica Sacro Cuore, thanks to public advertisements. They all were right-handed (Briggs and Nebes 1975) and had normal or corrected to normal vision. None of them was aware of the specific purposes of the study. All of them were required to sign an informed consent form in order to join the experiment. The experimental procedure and the specific consent form describing it had been previously approved by the university ethics committee.
Procedure
The experiment consisted of three sessions, namely: a pre-training mouse tracking session, a training session and a post-training mouse tracking session.
Pre-training mouse tracking session
Participants were welcomed in a quiet room by an experienced researcher. The experimental equipment included a PC connected to a mouse. The computer screen was arranged in front of the participants at a distance of approximately 50 cm. Participants were instructed to identify visual stimuli according to the effector, hand or foot, typically used to act upon them. Ten visual stimuli depicting common objects on a white background were selected. Five of them represented graspable objects (a hammer, a baseball bat, a shaving brush, a cup and a glass) typically targeted by hand actions, and five represented kickable or pressable objects (a soccer ball, a floor button, a bike pedal, a car pedal and a doorstop) typically targeted by foot actions. Participants’ responses were recorded by means of a mouse tracker (Freeman and Ambady 2010; Freeman et al. 2011). They saw the start button in the lower part of the screen, horizontally centred: they were asked to click it with the mouse to start the session. At this point, the visual stimuli appeared, one at time, in the centre of the screen, together with two response options, located in the upper part of the screen, one on the right, and one on the left. The two response options were the strings “hand” and “foot”. Each stimulus was repeated 15 times. After each trial, 1 s of blank was set up, before the starting of the following one. The pre-training session consisted in two blocks of 75 stimuli each presented in randomized order (the position of the response options on the screen was inverted in the second block). See Fig. 1a for a visual description of the individual trial phases.

a and c Represent an example of a single trial from the mouse tracking session. b Represents a scene from the training session: participants in the experimental group press a pedal to guide a virtual actor to grasp a ball with her hand, while participants in the control group press the pedal to initiate the next trial
Training session
After the pre-training mouse tracking session just described, a training session with a virtual environment started. The virtual environment was specifically designed for this experiment with the software “Unity 3d”. It showed an avatar representing a young man standing in front of a table facing the participant. No other structural or social cues were included in the environment. The avatar gazed at a virtual small ball located on a table at different locations. The avatar continuously moved its arm/hand above the table (also over the ball) to the left and right. The movement was always biomechanically plausible. Participants were seated at the same computer used in the pre-training session and interacted with the virtual environment shown on screen via a USB foot-pedal connected to the computer. The foot-pedal device was located on the floor, beside the participant’s right foot (see Fig. 1b).
Participants were divided into two different groups (experimental group and control group, respectively). Participants assigned to the experimental group were instructed to guide the avatar’s hand, which was moving over the small ball, in grasping it. As soon as they pressed the pedal with their foot, the avatar’s reach-to-grasp movements were triggered. The next trial started automatically immediately after the avatar’s action had unfolded completely. Participants assigned to the control group were instructed to watch the avatar, which not only moved its hand over the ball but also autonomously reached for and grasped it. Participants in this group had to press the pedal with a foot as soon as the avatar concluded its own grasping movement; doing so allowed them to pass to the next scene in the virtual representation. In 30 % of trials, the avatar failed to grasp the ball, which was the error rate estimated in a pilot experiment involving different but comparable participants. Participants of both groups were exposed to the virtual environment for 10 min, performing approximately 80 trials (according to their dexterity in guiding avatar’s actions).
Post-training mouse tracking session
Finally, participants performed a post-training mouse tracking session, which was identical to the pre-training one (see Fig. 1c).
Data analysis
Trials in which participants did not respond were discarded (40 out of 12,000 recorded trials, corresponding to 0.33 %). Dependent variables calculated on remaining trials included: mouse trajectory data, accuracy (ACC) and reaction times (RTs), all recorded by a mouse tracker.
Regarding the mouse tracking data, we first transformed mouse trajectories according to standard procedures (Freeman and Ambady 2010). In particular, all trajectories were rescaled into a standard coordinate space (top left = [−1, 1.5]; bottom right = [1, 0]) and flipped along the x-axis such that they were directed to the top-right corner. Moreover, all trajectories were time-normalized into 101 time steps using linear interpolation to permit averaging of their full length across multiple trials. In order to obtain a trial-by-trial index of the trajectory’s attraction towards the non-selected response label (indexing how much that response was simultaneously active), we computed one commonly used measure of response competition, namely maximum deviation (MD). MD represents the largest perpendicular deviation between the actual trajectory performed by the subject and the idealized linear trajectory estimated by the system (Freeman and Ambady 2010). To obtain a measure of hesitation during the selection of the correct response, we computed the x-flips and y-flips (Roche et al. 2015). This measure captures the hesitation in the hand’s movement along the horizontal and vertical axes and can be conceived as indices of subjects’ uncertainty in the response.
Accuracy was measured by recording whether participants provided a correct response in a given trial. The latency measure quantified the time elapsed in milliseconds between the click on the start button (triggering the presentation of the stimulus) and the click on the response button (RTs). Accuracy was almost at ceiling (Accuracy >99 %); thus, it will not be considered further.
The three remaining dependent variables were entered in three separate ANOVAs with effector (foot vs. hand) as within subject factor and group (experimental vs. control) as between-subject factor. For follow-up analyses, we used paired-samples (or independent samples, when necessary) two-tailed T tests.
Results
First, we tested whether the distributions of the obtained data were normal using the Shapiro–Wilk test. Some of the distributions were non-normal (ps < 0.05). Thus, we performed a logarithmic transformation on the data. Two participants from the experimental group and two from the control group were discarded from the analyses because at least one of the dependent variables was two standard deviations higher than the group mean. Visual inspection of the data suggests an important difference at baseline between groups. Nonetheless, our dependent variables, namely y-flips, MD and reaction times, did not significantly differ between groups (all ps > 0.08).
Mouse tracking data
The ANOVA on y-flips revealed the main effects of both effector (F(1,34) = 11.1; p = 0.002; η 2p = 0.25) and session (F(1,37) = 8.87; p = 0.005; η 2p = 0.19) and the two-way interaction effector by session (F(1,37) = 5.18; p = 0.029; η 2p = 0.13). The main effect of effector was explained by larger y-flips to foot-related objects (6.399 log-transformed y-flip) as compared to y-flips to hand-related objects (6.383 log-transformed y-flip). The main effect of session was explained by larger y-flips during the pre-training session (6.403 log-transformed y-flip) as compared to y-flips recorded during the post-training session (6.379 log-transformed y-flip). Importantly, the three-way interaction effector by session by group was also significant (F(1,34) = 6.99; p = 0.01; η 2p = 0.17). Follow-up analyses revealed that in both groups, y-flips were higher to foot-related objects as compared to hand-related objects. In the experimental group, we also found smaller y-flips during the post-training session as compared to the pre-training session to foot-related objects (pre-training = 6.401, post-training = 6.311, p = 0.001). Further, we found larger y-flips to hand-related objects during the post-training session as compared to the pre-training session (pre-training = 6.321, post-training = 6.364, p = 0.04). That is, only in the experimental group was it the case that as an effect of the training session, hand responses tended to be grabbed by the alternative response (see Fig. 2).

y-flips recorded during the mouse tracking sessions (asterisk represents p < 0.05)
The ANOVA on MD revealed the main effects of both effector (F(1,37) = 30.91; p < 0.001; η 2p = 0.45) and session (F(1,37) = 10.31; p = 0.003; η 2p = 0.22). The main effect of effector was explained by a larger MD to foot-related objects (7.070 log-transformed MD) as compared to MD to hand-related objects (6.995 log-transformed MD). The main effect of session was explained by a larger MD during the pre-training session (7.043 log-transformed MD) as compared to the post-training session (7.023 log-transformed MD). The interaction Effector × Session was also significant (F(1,37) = 8.87; p = 0.002; η 2p = 0.24). Follow-up analyses revealed smaller MD to foot-related objects in the post-training session (7.051 log-transformed MD) as compared to the pre-training session (7.089 log-transformed MD; t(19) = 4.8, p < 0.001, two-tailed). No other main effects or interactions were significant. No effects were found on the x-flip.
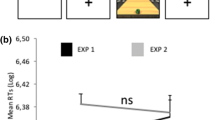
RTs
The ANOVA on the log-transformed RTs revealed the main effects of both sessions (F(1,34) = 6.07; p = 0.02; η 2p = 0.15). The main effect was explained by faster RTs during the post-training session (5.72 log-RT) as compared to the pre-training session (5.79 log-RT). No other main effects or interactions turned out to be significant. Also the interaction between effector, session and group was far from significance (p > 0.30, see Fig. 2).
Discussion
The present study aimed to assess whether the influence of action on object categorization is always effector-specific or whether it can be related to action goals that are achievable by more than one effector. To this end, we asked participants to categorize different objects in terms of the body effector (hand or foot) typically used to act upon them, before and immediately after a training session in which they were instructed to press a pedal to guide an avatar’s hand to grasp a small ball. In a control group, the pressing of the pedal did not impact on the avatar’s action, but was used just to initiate the next trial. There were two main findings.
First, performing a foot action (such as pressing a pedal) made the categorization of foot-related objects more straightforward and robust. Participants showed smaller y-flips and MD when correctly identifying the objects related to foot actions during the post-training than during the pre-training mouse tracking session. No similar effects were found in the categorization of hand-related objects.
This finding is in line with several studies showing an action priming effect when congruent body effectors are involved (Brass et al. 2000; Gillmeister et al. 2008; Wiggett et al. 2011, 2013). For instance, it has been shown that people are typically faster to provide foot responses (e.g. pressing a pedal) when viewing foot-related actions (kicking a ball) than when viewing hand-related actions (typing on a keyboard), and vice versa (Bach et al. 2007; Bach and Tipper 2007). Similar effects have also been demonstrated in the domain of language processing. Buccino et al. (2005) asked participants to respond with the hand or the foot while listening to hand- or foot-related action sentences, as compared to abstract sentences. Results showed a modulation of hand reaction times while listening to hand-related sentences. Conversely, a modulation of foot reaction time was observed while listening to foot-related sentences.
One might be tempted to construe all these findings as evidence that the influence of action on object categorization is just effector-specific. However, the second finding of the present study seems to suggest that this cannot be the whole story. Indeed, participants showed larger y-flips in correctly identifying the graspable objects as related hand-related objects during the post-training as compared to the pre-training mouse tracking session when the training session consisted in pressing a pedal with a foot in order to guide an avatar’s hand to grasp a small ball. Pressing a pedal with a foot after the avatar autonomously grasped the small ball did not have any similar effect. This indicates that when participants could use their foot to perform an action that is typically hand-related, such as grasping a small ball, it was not straightforward for them to categorize the presented graspable objects (e.g. a hammer, a baseball bat, a shaving brush, a cup, a glass) as just hand-related (rather than foot-related) objects.
How can this effect be explained? One hypothesis may refer to some attentional biases due to an associative coupling between (performed) foot and (observed) hand movements. This hypothesis may sound attractive, especially because it is in line with previous evidence on the critical role of associative coupling in action processing (Catmur et al. 2007, 2009; Gillmeister et al. 2008). In particular, Gillmeister et al. (2008) showed that performing a foot action when viewing a hand action (e.g. lifting a food after seeing a hand lift) might impact on the motor processing of action-related features by significantly reducing the standard action priming effect. More interestingly, Wiggett et al. (2011) demonstrated that this effect occurs even in the case of implicit associative learning. In their study, participants chose whether to perform a foot or hand action, and were then presented with visual feedback of a compatible or incompatible body effectors. The results showed that the action priming effects were selectively modulated as a function of the compatibility of performed and observed actions, being significantly smaller in the case of incompatible associations, such as seeing a foot lift immediately after lifting a hand or seeing a hand lift immediately after lifting a food.
Despite the attractiveness of this hypothesis, it does not seem to fully account for the main finding of our study, namely the differential impact of the training sessions on the object categorization task in the experimental and control groups. Indeed, both the experimental and the control groups always performed a foot action (i.e. pressing a pedal) while observing a hand action (grasping a small ball). But while performing the foot action impacted on the categorization of compatible (i.e. foot-related) objects in both the experimental and control groups, performing the same foot action affected the categorization of incompatible (hand-related) objects in the experimental group only.
An alternative hypothesis may suggest that the influence of the action training on the categorization task occurs at the decision stage in terms of response competition. In other terms, performing a foot-related action with a hand-related goal influenced the categorization of hand-related objects because interfered with the identification of the body effector typically involved in acting upon them, thus increasing the uncertainty of the participants’ responses.
A further (and at least in part complementary) hypothesis may emphasize that action influence might affect not only the decision but also (and maybe primarily) the object representation. If you can achieve an action goal such as the grasping of an object by using not only your hand but also your foot, this indicates that the goal of this action can be represented in you without being identified just with a given body effector. This has consequences for both action and object representations. The sight of a graspable object may trigger in you a motor representation of the grasping action you can perform on the object, but this action can be represented not just as a hand action where the goal of grasping is achievable for you also by using a foot. This could explain why participants in the experimental group showed some uncertainty in categorizing the presented graspable objects as hand- rather than foot-related objects, making the choice between hand and foot less straightforward after the training session than it was for the participants belonging to the control group.
Although further research is needed, the latter hypothesis seems to be, albeit indirectly, supported by previous studies showing that action processing can be action- rather than effector-specific (Jeannerod et al. 1995; Rizzolatti et al. 1988, 2001; Rochat et al. 2010; Umiltà et al. 2008). More specifically, Helbig et al. (2006) investigated whether action representations facilitate object recognition. They presented participants with two objects affording either congruent or incongruent motor interactions. Results showed superior naming accuracy for object pairs with congruent as compared to incongruent motor interactions. In another study, Kiefer et al. (2011) presented participants with two objects (e.g. tools), which had to be named. The two objects could afford either congruent or incongruent actions. Action congruency between the object pairs affected event-related potentials (ERPs) as early as 100 ms after stimulus onset at fronto-central electrodes. Using source analysis, this ERP effect could be referred to early activation of the motor system.
In the same vein, Costantini et al. (2008) used incidental repetition priming to determine whether observed actions are represented in terms of the effector used to achieve them or in terms of the goal they pursue. Participants were presented with images depicting meaningless or meaningful actions and should press a button only when presented with a meaningful action. Images were classified as depicting a repeated or new action, relative to the previous image in the trial series. Results showed a facilitation effect based on the goal of the observed action (i.e. the grasping) rather than the effector used to achieve it or even the specific object the actor acted upon.
At the neuronal level, Cattaneo et al. (2010) showed, using a transcranial magnetic stimulation (TMS) adaptation paradigm, the recruitment of a fronto-parietal network in the goal-specific action representation. They showed participants with adapting movies of either a hand or foot acting upon an object. Subsequently, they were presented with a test picture representing either the same or a different action performed by either the same effector or a different effector. The task was to judge whether the adapting movie and the test picture were the same. Results showed that performance was deeply impacted by TMS only when the TMS pulses were delivered over the ventral premotor cortex and the inferior parietal lobule. TMS pulses delivered over the superior temporal cortex were ineffective in changing the goal-specific action representation.
In conclusion, the findings of the present paper suggest that action and object representations are so deeply linked to each other that their link cannot be construed just in terms of the effector typically associated with both the action and the object. Acting upon an object is not just a matter of which part of your body you are actually using but also—and perhaps mainly—of which goal your action is directed to. The possibility of achieving this goal using any of several body effectors may affect your representation of the targeted object when you are engaged in categorizing it.
References
Ambrosini E, Costantini M (2013) Handles lost in non-reachable space. Exp Brain Res 229:197–202
Ambrosini E, Scorolli C, Borghi AM, Costantini M (2012) Which body for embodied cognition? Affordance and language within actual and perceived reaching space. Conscious Cogn 21:1551–1557
Bach P, Tipper SP (2007) Implicit action encoding influences personal-trait judgments. Cognition 102:151–178
Bach P, Peatfield NA, Tipper SP (2007) Focusing on body sites: the role of spatial attention in action perception. Exp Brain Res 178:509–517
Brass M, Bekkering H, Wohlschläger A, Prinz W (2000) Compatibility between observed and executed finger movements: comparing symbolic, spatial, and imitative cues. Brain Cogn 44:124–143
Briggs GG, Nebes RD (1975) Patterns of hand preference in a student population. Cortex 11:230–238
Buccino G, Riggio L, Melli G, Binkofski F, Gallese V, Rizzolatti G (2005) Listening to action-related sentences modulates the activity of the motor system: a combined TMS and behavioral study. Brain Res Cogn Brain Res 24:355–363
Cardellicchio P, Sinigaglia C, Costantini M (2011) The space of affordances: a TMS study. Neuropsychologia 49:1369
Cardellicchio P, Sinigaglia C, Costantini M (2013) Grasping affordances with the other’s hand: a TMS study. Soc Cogn Affect Neurosci 8:455–459
Catmur C, Walsh V, Heyes C (2007) Sensorimotor learning configures the human mirror system. Curr Biol 17:1527–1531
Catmur C, Walsh V, Heyes C (2009) Associative sequence learning: the role of experience in the development of imitation and the mirror system. Philos Trans R Soc Lond B Biol Sci 364:2369–2380
Cattaneo L, Sandrini M, Schwarzbach J (2010) State-dependent TMS reveals a hierarchical representation of observed acts in the temporal, parietal, and premotor cortices. Cereb Cortex 20:2252–2258
Costantini M, Committeri G, Galati G (2008) Effector- and target-independent representation of observed actions: evidence from incidental repetition priming. Exp Brain Res 188:341–351
Costantini M, Ambrosini E, Tieri G, Sinigaglia C, Committeri G (2010) Where does an object trigger an action? An investigation about affordances in space. Exp Brain Res 207:95
Costantini M, Ambrosini E, Scorolli C, Borghi A (2011a) When objects are close to me: affordances in the peripersonal space. Psychon Bull Rev 18:302–308
Costantini M, Committeri G, Sinigaglia C (2011b) Ready both to your and to my hands: mapping the action space of others. PLoS one 6:e17923
Craighero L, Fadiga L, Umiltà CA, Rizzolatti G (1996) Evidence for visuomotor priming effect. NeuroReport 8:347–349
Craighero L, Fadiga L, Rizzolatti G, Umiltà C (1999) Action for perception: a motor-visual attentional effect. J Exp Psychol Hum Percept Perform 25:1673–1692
Dalla Volta R, Gianelli C, Campione GC, Gentilucci M (2009) Action word understanding and overt motor behavior. Exp Brain Res 196:403–412
De Stefani E, Innocenti A, De Marco D, Busiello M, Ferri F, Costantini M, Gentilucci M (2014) The spatial alignment effect in near and far space: a kinematic study. Exp Brain Res 232:2431–2438
Ferri F, Riggio L, Gallese V, Costantini M (2011) Objects and their nouns in peripersonal space. Neuropsychologia 49:3519–3524
Freeman JB, Ambady N (2010) MouseTracker: software for studying real-time mental processing using a computer mouse-tracking method. Behav Res Methods 42:226–241
Freeman JB, Dale R, Farmer TA (2011) Hand in motion reveals mind in motion. Front Psychol 2:59
Gillmeister H, Catmur C, Liepelt R, Brass M, Heyes C (2008) Experience-based priming of body parts: a study of action imitation. Brain Res 1217:157–170
Hauk O, Johnsrude I, Pulvermüller F (2004) Somatotopic representation of action words in human motor and premotor cortex. Neuron 41:301–307
Helbig HB, Graf M, Kiefer M (2006) The role of action representations in visual object recognition. Exp Brain Res 174:221–228
Jeannerod M, Arbib MA, Rizzolatti G, Sakata H (1995) Grasping objects: the cortical mechanisms of visuomotor transformation. Trends Neurosci 18:314–320
Kiefer M, Sim EJ, Helbig H, Graf M (2011) Tracking the time course of action priming on object recognition: evidence for fast and slow influences of action on perception. J Cogn Neurosci 23:1864–1874
Murata A, Fadiga L, Fogassi L, Gallese V, Raos V, Rizzolatti G (1997) Object representation in the ventral premotor cortex (area F5) of the monkey. J Neurophysiol 78:2226–2230
Pulvermüller F, Shtyrov Y (2006) Language outside the focus of attention: the mismatch negativity as a tool for studying higher cognitive processes. Prog Neurobiol 79:49–71
Pulvermüller F, Harle M, Hummel F (2001) Walking or talking? Behavioral and neurophysiological correlates of action verb processing. Brain Lang 78:143–168
Raos V, Umiltà MA, Murata A, Fogassi L, Gallese V (2006) Functional properties of grasping-related neurons in the ventral premotor area F5 of the macaque monkey. J Neurophysiol 95:709–729
Repetto C, Colombo B, Cipresso P, Riva G (2013) The effects of rTMS over the primary motor cortex: the link between action and language. Neuropsychologia 51:8–13
Rizzolatti G, Sinigaglia C (2010) The functional role of the parieto-frontal mirror circuit: interpretations and misinterpretations. Nat Rev Neurosci 11:264–274
Rizzolatti G, Camarda R, Fogassi L, Gentilucci M, Luppino G, Matelli M (1988) Functional organization of inferior area 6 in the macaque monkey. II. Area F5 and the control of distal movements. Exp Brain Res 71:491–507
Rizzolatti G, Fogassi L, Gallese V (2001) Neurophysiological mechanisms underlying the understanding and imitation of action. Nat Rev Neurosci 2:661–670
Rochat MJ, Caruana F, Jezzini A, Escola L, Intskirveli I, Grammont F, Gallese V, Rizzolatti G, Umiltà MA (2010) Responses of mirror neurons in area F5 to hand and tool grasping observation. Exp Brain Res 204:605–616
Roche JM, Peters B, Dale R (2015) “Your tone says it all”: the processing and interpretation of affective language. Speech Commun 66:47–64
Sato M, Mengarelli M, Riggio L, Gallese V, Buccino G (2008) Task related modulation of the motor system during language processing. Brain Lang 105:83–90
Tettamanti M, Buccino G, Saccuman MC, Gallese V, Danna M, Scifo P, Fazio F, Rizzolatti G, Cappa SF, Perani D (2005) Listening to action-related sentences activates fronto-parietal motor circuits. J Cogn Neurosci 17:273–281
Tucker M, Ellis R (1998) On the relations between seen objects and components of potential actions. J Exp Psychol Hum Percept Perform 24:830–846
Tucker M, Ellis R (2001) The potentiation of grasp types during visual object categorization. Visual Cognition 8:769–800
Tucker M, Ellis R (2004) Action priming by briefly presented objects. Acta Psychol 116:185–203
Umiltà MA, Escola L, Intskirveli I, Grammont F, Rochat M, Caruana F, Jezzini A, Gallese V, Rizzolatti G (2008) When pliers become fingers in the monkey motor system. Proc Natl Acad Sci USA 105:2209–2213
Wiggett AJ, Hudson M, Tipper SP, Downing PE (2011) Learning associations between action and perception: effects of incompatible training on body part and spatial priming. Brain Cogn 76:87–96
Wiggett AJ, Downing PE, Tipper SP (2013) Facilitation and interference in spatial and body reference frames. Exp Brain Res 225:119–131
Author information
Authors and Affiliations
Corresponding authors
Rights and permissions
About this article

Cite this article
Triberti, S., Repetto, C., Costantini, M. et al. Press to grasp: how action dynamics shape object categorization. Exp Brain Res 234, 799–806 (2016). https://doi.org/10.1007/s00221-015-4446-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-015-4446-y