
Abstract
Simulation mechanisms are thought to play an important role in action recognition. On this view, actions are represented through the re-enactment of the observed action. Mirror neurons are thought to be the neuronal counterpart of such a process, and code actions at a rather abstract level, often generalizing across sensory modalities and effectors. In humans, attention has been focussed on the somatotopic, effector dependent representation of observed actions in the mirror system. In this series of behavioural studies, we used incidental repetition priming to determine to which degree the cognitive representation of observed actions relies on effector- and target-dependent representations. Participants were presented with images depicting meaningless or meaningful actions and pressed a button only when presented with a meaningful action. Images were classified as depicting a repeated or new action, relative to the previous image in the trial series. In the first experiment, we demonstrate a priming effect based on the repetition of an action, performed by the same effector over the same target object. In the second experiment, we demonstrate that this facilitation holds even when the same action is performed over a different target object. Finally, in the third experiment we show that the action priming effect holds even when the same action is accomplished with different effectors. These results suggest the existence of a cognitive representation of actions, automatically activated during observation, which is abstract enough to generalize across different targets for that action and different effectors performing that action.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Recognizing actions made by others is a fundamental cognitive function on which the survival of individuals and social life in general depends. Everyday human behaviour is generally perceived as a continuous sequence of actions with a few pauses to mark transitions between component events. Though the transitions between one event and the next may be fuzzy and unclear, actions can be divided into discrete events (Hanson and Hirst 1989; Newtson 1973). What is still unclear is the way in which our brain represents these events.
According to the perceptual symbols theory (Barsalou 1999), knowledge, for both events/actions and objects, is not amodal but instead grounded in physical experiences. Relative to objects, Borghi (2004), using a feature generation task, which is assumed to assess the way concepts are represented (Tversky and Hemenway 1984), has shown that sensory-motor simulation underlies conceptualization of affordable objects and that the related concepts are action based.
In relation to actions, it has been postulated that action recognition requires sensory-motor simulation (for an extended overview of simulation see Gallagher 2007) carried out by the brain sensory-motor cortex (Gallese and Lakoff 2005). Indeed, recently researchers have argued the existence of a vocabulary of actions stored in the sensory-motor systems. According to this idea actions are represented by running a simulation or re-enacting the actual motor experience (Gallese and Lakoff 2005). A large amount of studies have, indeed, demonstrated the involvement of sensory-motor cortex while observing, listening or imagining motor acts (e.g., Binkofski et al. 2000; Buccino et al. 2001; Cross et al. 2006; Fadiga et al. 1995; Grezes et al. 2003; Koski et al. 2002; Iacoboni et al. 1999). The existence of such a re-enacting process is further supported by behavioural studies showing that execution of a given action is positively or negatively modulated by observation of the same or a different action (Brass et al. 2001; Craighero et al. 2002).
The neuronal underpinnings of such a simulation mechanism are supposed to be the mirror neurons, discovered in the macaque ventral premotor cortex (Di Pellegrino et al. 1992; Gallese et al. 1996), and more recently in the inferior parietal lobule (Fogassi et al. 1998, 2005). Mirror neurons indeed fire not only when the monkey performs a particular action, but also when it observes a conspecific or a human, carrying out the same action. The effective motor action and the effective observed action usually coincide in conceptual terms (for example, grasping), but may differ in terms of how the action is accomplished (for example, power vs. precision grip) and which effector is used. For example, a mirror neuron may respond when the monkey observes another individual breaking a peanut with the hand and also when the same action is performed with the mouth, thus suggesting the ability to generalize, across effectors, the meaning of an observed action, and giving strength to the idea that premotor neurons hold a “vocabulary” of actions in the motor repertoire (Gallese et al. 1996). Converging evidence for an abstract representation of actions in the motor system comes from experiments showing that the activation of mirror neurons is independent from the sensory modality of the perceived action (Kohler et al. 2002) and from the actual perceptual availability of the known action target (Umiltà et al. 2001). Moreover, some parietal mirror neurons are modulated by the final goal of the action (e.g., grasping for eating vs. grasping for placing: Fogassi et al. 2005).
In agreement with monkey studies, the mirror neuron system in humans is independent from the sensory modality of the perceived action (Gazzola et al. 2006) and is modulated by the final goal of the action (Iacoboni et al. 2005). Interestingly, it is more active in a context of joint actions than when simply observing or imitating an action (Newman-Norlund et al. 2007). However, most of the studies carried out so far, with the aim of investigating links between action representations and other domains, have used actions eliciting strong effector-specific representations, such as sewing, turning a key, writing, marching (Buccino et al. 2005), thus emphasizing the effector-specific organization of the cognitive representation of observed actions.
Thus, it is still unclear to which degree representations, thought to be automatically activated by the “simulation” or “re-enactment” process, are selective for the specific motor implementation of the observed action (as suggested by the somatotopic activation of the premotor cortex during action observation, e.g., Buccino et al. 2001; Hauk et al. 2004; Tettamanti et al. 2005; Aziz-Zadeh et al. 2006), or generalize across a variety of different presentations of the action (as suggested by the features of mirror neurons reviewed above). Here we present a series of behavioural studies aimed at understanding whether cognitive representations of observed actions are selective for (or generalize across) different effectors performing the same action, and different target objects for the same action. To this aim, we searched for incidental repetition priming effects in a go-no go task requiring action/non-action recognition.
Repetition priming is the effect, in terms of behavioural facilitation, of previous exposure to an item when responding to the same item or to an item sharing a given feature. Repetition priming paradigms are largely used in experimental psychology as a way to shed light on the nature of the involved cognitive representations. For instance, people typically have lower perceptual identification thresholds for repeated stimuli and are faster and more accurate in a semantic classification task for repeated compared to new stimuli (Henson and Rugg 2003; Schacter and Buckner 1998). Incidental priming refers to situations where the shared item or feature, or the fact that it has been previously presented, is not explicitly acknowledged by the subject or is completely task irrelevant. We chose incidental repetition priming because of the advantage that the facilitation due to repetition cannot be attributed to explicit cognitive strategies. Importantly, it has been shown (Coles et al. 1985; Dehaene et al. 1998; De Jong et al. 1994) that relevant and irrelevant informations such as prime-target congruency have a significant influence not only on behaviour, but also on electrical and haemodynamic activity of those brain regions where the shared item is processed.
In Experiment 1, we demonstrate an incidental priming effect based on the repetition of an action, performed by the same effector over the same target object, in a sequence of static images representing simple actions. In Experiment 2, we demonstrate that this facilitation is due to the repetition of the same action and not the same target, and that the priming effect generalizes across different targets of the same action. Finally, in Experiment 3 we show that the facilitation is not due to the repetition of the effector and the priming effect holds even when the same action is accomplished with a different effector, thus demonstrating an effector- and target-independent representation of observed actions.
Experiment 1
Experiment 1 was designed to establish the existence of behavioural facilitation due to repetition of an action through the mere observation of static images depicting the action itself. This experiment was designed as 2 by 2 factorial. The two factors were: action (repeated vs. new) and effector used to perform the action (hand vs. foot).
Participants
Twenty undergraduate right-handed students (5 males, mean age 21.8 years; range 18–24 years) gave informed consent, but were naive as to the purpose of the experiment. The study was approved by the Ethics Committee of the “G. d’Annunzio” University, Chieti and was conducted in accordance with the ethical standards of the 1964 Declaration of Helsinki.
Stimuli and task
Stimuli were coloured pictures depicting the end state of actions. We used five meaningful actions. Each of them was performed with both the left hand and left foot (e.g., to stub out a cigarette; see supplementary Fig 1) and depicted twice with different visual features (e.g., a different point of view), for a total of 20 meaningful experimental pictures (height 10°, width 13° of visual angle). Moreover, we used six meaningless actions (see supplementary Fig 2). Those were defined as meaningless when the interaction between the effector (hand or foot) and the object was not proper with the function of the object (e.g., to press a coffee pot). All the experimental pictures were selected from a set of 50 pictures, on the basis of meaning ratings from 30 independent subjects. Only pictures reported as clearly meaningful or meaningless by at least 80% of the subjects were used in the experiment.
Participants were instructed to press the response button, with the right index finger, only when presented with meaningful actions. To avoid possible interference between the responding hand and the observed effector, all the actions were performed with either the left foot or hand, while subjects responded with the right hand.
Procedure
Participants were seated in a dimly lit room with the response button under their right hand. A computer screen was placed in front of the participant’s eyes and positioned so that the screen centre was in the centre of the participant’s horizontal straight-ahead line of sight. All the stimuli were presented in colour in front of a black background. Each action was presented individually at the centre of the screen for 150 ms. A 1,850 ms white fixation cross followed each image. The experiment consisted of 184 pictures, 56 of which (30%) depicting meaningless actions. The presentation of the stimuli and the recording of the participants’ responses were controlled by a PC-compatible computer running Cogent 2000 (developed by the Cogent 2000 team at the FIL and the ICN, University College London, UK) and Cogent Graphics (developed by John Romaya at the LON at the Wellcome Department of Imaging Neuroscience, University College London, UK) under Matlab (The Mathworks Company, Natick, MA, USA).
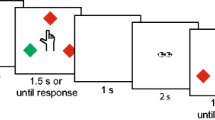
The order of the pictures was pseudo-randomized so to have two experimental conditions (repeated vs. new) for each effector (hand or foot). The action depicted in any given image was considered as repeated or new with respect to the previous image. We had the following trials (Fig. 1, top panel): (1) Repeated hand action: in these trials a hand action was preceded by the same hand action, but the visual features of the pictures and the point of view were varied; (2) New hand action: in these trials a hand action was preceded by a different hand action; (3) Repeated foot action: a foot action was preceded by the same foot action with different visual features; (4) New foot action: a foot action was preceded by a different foot action. Only actions preceded by meaningful actions were considered. Each subject provided 20 observations per condition.
Meaningless actions, in which response was not required, were used to separate hand trials from foot trials. All the responses (RTs, omissions and false alarms) were recorded and analysed off-line.
Results
Trials in which subjects failed to respond (20.4%) were discarded from the analysis. Error rates did not differ across conditions: repeated hand action = 18.5%; new hand action = 21.3%; repeated foot action = 20%; new foot action = 21.8%. The mean RT of the correct responses was calculated for each condition; responses longer than two standard deviations from the individual mean were treated as outliers and not considered (5.1% of the data set). Repeated measure analysis of variance (ANOVA) was carried out. The main factors were: action (repeated vs. new) and effector (hand vs. foot).
RT analysis (Fig. 1, bottom panel) revealed a significant main effect of action (F 1,19 = 19.43, P < 0.001). Indeed, RTs to actions preceded by the same action [mean (SD) = 499 (107) ms] were faster than those preceded by a different action [mean (SD) = 549 (145) ms].
Neither the effector factor nor the interaction turned out to be significant.

Experiment 1: within-effector action repetition priming. Top panel exemplar of experimental conditions. Bottom panel mean reaction times in the four experimental conditions. Error bars indicate standard errors
Discussion
This first experiment shows the existence of an incidental repetition priming effect driven by the repetition of the same action performed by the same effector.
Behavioural facilitation has been shown to work at both the perceptual and conceptual level of information processing (for a review Buckner and Koutstaal 1998). The former level is associated with the sensory features of the stimulus, such as colour and shape, while the latter is associated with the meaning of the stimulus. Here, the repetition effect is unlikely to occur at the perceptual level, because the visual features of the pictures were different, even when the action was repeated. However, this experiment cannot rule out the possibility that behavioural facilitation was either due to the vision of the object which is target of the action (which might produce facilitation itself Kourtzi and Kanwisher 2000) or to its affordance (Di Pellegrino et al. 2005; Gibson 1979). There is now accumulating behavioural (Borghi 2004; Phillips and Ward 2002; Tucker and Ellis 1998) and physiological (Grafton et al. 1997; Grezes and Decety 2002) evidence that simply viewing an object can partially activate possible action plans towards it, even in the absence of explicit intentions to act. Thus, observing a handle automatically primes the motor programs for reaching and grasping (Di Pellegrino et al. 2005). Given that, we ran a second experiment to rule out the possibility that the target of the action, rather than the action itself, might have produced the behavioural facilitation.
Experiment 2
Experiment 2 was aimed at verifying whether the action priming effect observed in Experiment 1 was truly due to the repetition of an action, and not to the repetition of its target object. Experiment 2 was based again on repetition priming, where in any trial both the target of the observed action and the action itself could be either the same or different relative to the previous trial. As the main aim of this experiment was to dissociate between action and target repetition, we ran it using only hand actions. This experiment was designed as 2 by 2 factorial. The two factors were: action (repeated vs. new) and action target (repeated vs. new).
Participants
Twenty different undergraduate students (7 males, mean age 27.2 years; range 20–34 years) gave informed consent, but were naive as to the purpose of the experiment. All the subjects but one were right-handed. As stated above, the study was conducted in accordance with ethical standards.
Stimuli and task
To run this experiment, we created a new set of pictures showing the end state of meaningful actions. We used six different target objects and six meaningful actions. Two different actions were performed on each target object, and each action was performed on two different target objects (see supplementary Fig 3). Meaningless actions were instead one per target (see supplementary Fig 2). Actions were selected as for Experiment 1. The experiment consisted of 184 pictures, 56 of which (30%) depicting meaningless actions. Task was the same as in the previous experiment.
Procedure
In this experiment the order of the images was pseudo-randomized to have four experimental conditions (Fig. 2, top panel): (1) Repeated action, repeated target: in these trials a hand action was preceded by the same hand action, but the visual features of the pictures and the point of view were varied (as in the repeated hand action condition of Experiment 1); (2) Repeated action, New target: in these trials the same action was performed on a different target (i.e., grasping a dish vs. grasping a mug); (3) New action, repeated target: in these trials the target action was preceded by a different action but performed on the same target object; (4) New action, new target: in these trials neither the action nor the object was repeated (as in the new hand action condition of Experiment 1).
Results
Trials in which subjects failed to respond (7% of the data set) were discarded from the analysis. Error rates did not differ across conditions: repeated action–repeated target = 5.5%; repeated action–new target = 8.0%; new action–repeated target = 6.7%; new action–new target = 7.7%.
The mean RT of the correct responses was calculated for each condition, and responses longer than two standard deviations from the individual mean were treated as outliers and not considered (1% of the data set). Repeated measure analysis of variance (ANOVA) was carried out. The main factors were: action (repeated vs. new) and action target (repeated vs. new).
RT analysis (Fig. 2, bottom panel) revealed a significant main effect of action (F 1,19 = 5.8, P < 0.05). Indeed, RTs to actions preceded by the same action [mean (SD) = 645 (54.3) ms] were faster than those preceded by a different action [mean (SD) = 661 (54.9) ms]. The effect of action target and the interaction were not significant.

Experiment 2: action and target repetition priming. Top panel exemplar of experimental conditions. Bottom panel mean reaction times in the four experimental conditions. Error bars indicate standard errors
Discussion
As in Experiment 1, we found a repetition priming effect when the observed action was repeated. On the other hand, the repetition of the target object did not have any effect on reaction times. As we stated above, behavioural and neurophysiological experiments have shown that objects can be primed (Kourtzi and Kanwisher 2000) and can trigger actions (Di Pellegrino et al. 2005), but this experiment clearly showed that the facilitation in Experiment 1 (observed for both the hand and the foot) was due neither to the simple object repetition nor to the possible effect of affordance, but was instead truly based on the repetition of the action.
The second main result of this experiment is that cognitive representations of actions can be generalized also across action targets. It is currently unknown whether mirror neurons which are specifically activated during the observation of a given action, respond equally well independent of the action target. However, it is known that F5 neurons respond regardless of the action target during action execution, if the targets involved in the action share the same type of grasping (precision grip vs. whole hand prehension Murata et al. 1997). Our results show that, even when observing others’ action, the evoked cognitive representation may be independent of the action target object.
Hamilton and Grafton (2006, 2007) have performed a series of functional neuroimaging experiments using a repetition priming paradigm, where they have tested the effect of the repetition of the target object (the immediate goal, in their terminology) of an observed action. Unlike in the current study, the observed action was kept constant (hand grasping), although the hand trajectories and grasping kinematics were systematically changed. The main result was an effect of target object priming in the anterior intraparietal sulcus but not in F5 itself. In the current study, we do not find a behavioural advantage of target object repetition. However, the absence of a behavioural effect is in itself a negative finding and does not imply that the brain does not code the identity of the target object—a conclusion that would be obviously untenable. The point here is not the absence of a behavioural effect of target repetition, but rather the presence of a behavioural effect of action repetition which is the same within and across targets. Such an effect was not tested by Hamilton and Grafton (2006, 2007), since they used only one action (to grasp).
Experiment 3
Experiment 2 demonstrated the existence of a repetition effect based on the action independently of the action target. However, in both Experiment 1 and 2, we always tested situations where the effector performing the action was repeated across trials. In Experiment 3, we changed the experimental setup so that the effector performing the action was never repeated, and looked for a cross-effector action repetition effect. If such an effect occurs, it will suggest that the cognitive representation of observed actions is not limited to the effector performing the action but instead generalizes to the same action performed by different body parts.
Participants
Twenty different undergraduate right-handed students (8 males, mean age 21 years; range 19–28 years) gave informed consent, but were naive as to the purpose of the experiment. As above, the study was conducted in accordance with ethical standards.
Stimuli, task and procedure
Experimental stimuli, task and procedure were the same as in Experiment 1. Importantly, however, in this experiment the effector was never repeated. The order of the images was pseudo-randomized in order to have four experimental conditions (Fig. 3, top panel): (1) Repeated hand action: differently from the first experiment, in these trials the hand action was preceded by the same action, but achieved with the other effector (the foot); (2) New hand action: in these hand action trials, the previous action was different and was achieved with the other effector (the foot); (3) Repeated foot action: in these trials the foot action was preceded by the same action but achieved with the other effector (the hand); (4) New foot action: in these foot action trials, the previous action was different and was achieved with the other effector (the hand). A pictorial example of the stimuli used is provided in the supplementary Fig 1.
Results
Trials in which subjects failed to respond (18.9%) were discarded from the analysis. Error rates did not differ across conditions: repeated hand action = 20.8%; new hand action = 17.5%; repeated foot action = 17.5%; new foot action = 19.7%.
The mean RT of correct responses was calculated for each condition, with responses longer than two standard deviations from the individual mean treated as outliers and not considered (1% of the data set). Repeated measure analysis of variance (ANOVA) was carried out. The main factors were: action (repeated vs. new) and effector (hand vs. foot).
RT analysis (Fig. 3, bottom panel) revealed a significant main effect of Action (F 1,19 = 29.29, P < 0.001). Indeed, RTs to actions preceded by the same action, even though performed with a different effector [mean (SD) = 478 (127) ms] were faster than those preceded by a different action [mean (SD) = 517 (141) ms]. Neither a significant effect of the factor effector was observed, nor an interaction between the two factors.

Experiment 3: cross-effector action repetition priming. Top panel exemplar of experimental conditions. Bottom panel mean reaction times in the four experimental conditions. Error bars indicate standard errors
Comparison between within-effector and cross-effector experiments
In Experiment 1, we demonstrated a within-effector action priming effect, using a 2 by 2 (action by effector) experimental design. In Experiment 3, we used the same design and demonstrated a cross-effector action priming effect. Note that we did not directly compare, in the same experiment, the within- and the cross-effector action priming effects. Thus, it remains the possibility that cross-effector priming, although significant, be smaller than within-effector priming. To further investigate this issue, we re-analyzed the data from Experiment 1 and Experiment 3 together, by running a mixed-model ANOVA with action (repeated vs. new) and effector (hand vs. foot) as within-subjects factors, and experiment (within-effector vs. cross-effector) as a between-subjects factor. RT analysis confirmed the significant main effect of action (F 1,38 = 43.7, P < 0.001), with RTs to actions preceded by the same action faster than those preceded by a different action. Moreover, the experiment by effector interaction was significant (F 1,38 = 5.3, P < 0.05). Post hoc analysis (Newman–Keuls) of this interaction revealed that RTs to foot actions were slower in the within-effector (mean 530 ms) than in the cross-effector experiment (mean 488 ms: P < 0.01). Importantly, however, the action factor did not significantly interact with other factors. Although negative findings must be interpreted with caution, this suggests that the action priming effect depends neither on the observed effector (hand or foot) nor on the fact that the observed effector is the same as in the previous trial or not. In other words, the within-effector action priming is as large as the cross-effector one.
Discussion
This experiment shows an incidental repetition priming effect when the same action is achieved with a different effector. This result suggests that the representation of observed actions may be abstracted relative to the effects produced on the physical world regardless of the means used to achieve it.
The fact that the sensory-motor cortex is activated even when reading words (Hauk et al. 2004), listening or reading sentences denoting actions (Aziz-Zadeh et al. 2006; Tettamanti et al. 2005), supports the existence of a representation of actions that is quite abstract relative to the actual motor implementation. Recent neuroimaging data (Galati et al. 2008) show that the inferior frontal cortex, probably corresponding to the monkey F5, selectively encodes actions at an abstract, semantic level, and for multiple effectors. This study reported a selective enhancement in the activation of the inferior frontal cortex when the sound produced by a human action (e.g., whistling) was preceded by a written description of the same action, i.e., when semantic priming of actions occurred. Notably, such an enhancement was selective for human actions and was not present for sounds produced by events not related with human actions (e.g., rain). Furthermore, the activation and the selective enhancement of the inferior frontal cortex occurred both for mouth and for hand actions. However, Galati et al. (2008) did not test the same actions across effectors. Our current results expand upon these data by providing true evidence for a cross-effector representation of actions.
A completely different kind of evidence in favour of the idea that what is mirrored by the sensory-motor system is not simply the motor program of the observed action, comes from studies showing the effect of the experience with the action the subject is looking at (Lahav et al. 2007; Catmur et al. 2007). Catmur et al. (2007) have indeed shown that it is possible to manipulate the selectivity of the human mirror system by giving participants a training to perform on one action while observing a different action. They measured motor evoked potentials (MEPs) by means of transcranial magnetic stimulation (TMS) before and after incompatible sensory-motor training, which consisted in performing index-finger movements while observing little-finger movements and vice versa. Before training, they found the well known muscle-specific response to TMS, that is, MEPs in the abductor digiti minimi (ADM) were greater during observation of little finger movement than during observation of index-finger movement, and vice versa for MEPs in the first dorsal interosseous (FDI). What is relevant is that after training the muscle-specific response to TMS was reversed, that is MEPs in the ADM were greater during observation of index than of little finger movement and vice versa. Other evidence come from a recent study (Gazzola et al. 2007), showing that aplasics born without hands activate the cortical representation of the foot when observing goal-directed hand actions, thus suggesting that what is mirrored by the sensory-motor system is not only the motor program of the observed action but also the goal.
General discussion
Action recognition is crucial for our social interactions. Especially in joint actions we do not have only to coordinate each other at the level of motor control (Burstedt et al. 1997), but we also need to incorporate the actions of others in the planning of our own actions. To do this, the others’ actions must first be recognized and read in terms of their goals. There is accumulating evidence showing that the sensory-motor cortex not only executes movements, but also houses more abstract representations of one’s own and others’ actions. The premotor cortex has been proposed to store a vocabulary of actions in the animal’s motor repertoire, which allows both to plan goal-driven actions and to understand others’ actions and their goals, by running a simulation or re-enacting the actual motor experience.
Classical multidimensional accounts of action representation in psychology (e.g., Miller et al. 1960; Lashley 1951; Vallacher and Wegner 1987) are based on the idea that action representation is hierarchically organized. The lowest level of this hierarchy conveys the details or specifics of the action and so indicates how the action is done. It also contains information about the means (effector: leg, arm, mouth) by which the action is performed. The highest level conveys a more general understanding of the action, indicating why the action is done or what its effects and implications are. It also contains an abstract description of the purpose or goal of the action. Relative to low-level identities, higher level identities tend to be less movement-defined and more abstract, providing a more comprehensive understanding of the action. Understanding an action by inferring the goal can overcome large differences in bodily measures and abilities (Calinon et al. 2005), so that, for example, if I have to imitate you grasping an apple on a tree and I am much taller than you, I cannot simply imitate your movement but I can imitate your goal (taking a ladder or using a tool). Interestingly, then, preschool children asked to imitate a model touching a left or right ear with the left or right hand, reach correctly for the object (i.e., ears) but prefer ipsilateral movements, thus achieving the goal rather than imitating the actual motor implementation (Bekkering et al. 2000).
The existence of a goal-based representation of action is largely accepted in the monkey literature (Fogassi et al. 2005; Gallese et al. 1996; Umiltà et al. 2001). Direct evidence that premotor neurons code actions by their goals rather than as simple sequences of muscular events, comes from an elegant study by Umiltà et al. (2008), who showed that some neurons in F5 are activated both when the monkey grasps a piece of food with its hand and when it grasps a piece of food by means of a tool, even if the tool requires a hand movement which is antithetic relative to the one required to directly grasp the food.
Evidence for a similar, explicit representation of action goals during the observation, rather than the execution, of actions, is more indirect. For example, for some mirror neurons the preferred “motor” and “visual” actions correspond in terms of the general goal, but not in terms of the actual motor implementation (“broadly congruent” mirror neurons Gallese et al. 1996). Again, this is not necessarily a rule, because other mirror neurons require a stricter congruency at the motor implementation level (Gallese et al. 1996). Also, some mirror neurons become active during action presentation when the final part of the action is hidden and can therefore only be inferred (Umiltà et al. 2001). In humans, premotor activation is independent from the sensory modality of the perceived action (Gazzola et al. 2006), is modulated by the final goal of the action (Iacoboni et al. 2005), and is sensitive to semantic priming of actions (Galati et al. 2008).
In the series of behavioural experiments presented in the current paper, the existence of an action-based incidental priming effect provides direct evidence for the idea that the mere observation of an action automatically activates a cognitive representation, which is abstract enough to generalize across different effectors performing that action (Experiment 3) and different targets for that action (Experiment 2). This not necessarily implies that the action recognition system does not “mirror” more specific properties of observed actions, including its specific motor implementation, but strongly argues for a prevalently abstract representation of observed actions. It remains to be discussed at which exact level the action is represented in such an abstract way.
Keele et al. (1990) propose four levels of action representations, which constitute a further specification of hierarchical models: movements (e.g., extending the arm), actions (e.g., grasping), immediate goals (e.g., taking a cookie), and task goals (e.g., preparing a snack). In particular, the action level would include non-specific instructions that broadly code for a class of motor tasks (such as “walk” or “grasp”), and whose higher-order specifications would allow effector independence and motor equivalence (Hughes and Abbs 1976). For example, we can define the action of “grasping” as an attempt to take hold of something: this abstract specification generalizes (1) across a variety of motor implementations, which are defined at the movement level (e.g., using the hand vs. the mouth vs. a tool); (2) across a variety of immediate goals, which in this case can be defined, following Hamilton and Grafton (2006, 2007), as the specific targets of the action (e.g., grasping an apple vs. a cup of tea); and (3) across a variety of task goals (e.g., eating vs. drinking).
While most monkey and human studies reviewed above carefully distinguish between the movement level and the three higher levels, very few studies help disentangling between the three. In monkeys, Fogassi et al. (2005) provided evidence for coding of task goals in the inferior parietal lobule. In humans, Hamilton and Grafton (2006, 2007) proposed that the inferior parietal lobule codes immediate goals, since it discriminates between different target goals in the context of the same grasping action. On the other side, the inferior frontal cortex generalizes across different immediate goals of the same action (not discriminating novel from repeated grasping targets Hamilton and Grafton 2006), and between different presentation modalities of the same action (Galati et al. 2008), but not across different actions (Galati et al. 2008). This makes it a likely candidate for encoding the “action” level in the hierarchy.
Importantly, in the present study, the behavioural action priming effect does not occur at the “movement” level, because it can be observed even when the same action is performed by a different effector (Experiment 3). At the same time, it does not occur at the “immediate goal” level, because it can be observed even when the same action is performed on a different target object, which implies a different immediate goal (Experiment 2). We thus propose that the automatic representation of observed actions which is shown in the present study occurs at the “action” level, and that, at such a level, general features of each action class are defined in a way that is relatively independent of the involved effector.
As said in the “Introduction”, repetition has a significant influence not only on behaviour, but also on electrical and haemodynamic activity of those brain regions involved in the process of the repeated item. Looking at neurophysiological and neuroimaging studies carried out so far, both on monkeys and humans, it is clear that action recognition involves an extended network encompassing the inferior parietal lobule (Buccino et al. 2001; Costantini et al. 2005; Fogassi et al. 2005), the superior temporal sulcus (Kable and Chatterjee 2006; Kable et al. 2002, 2005; Majdandzic et al. 2007; Pizzamiglio et al. 2005), and the premotor/inferior frontal cortex (Pobric and Hamilton 2006; Urgesi et al. 2007), where mirror neurons were first described (Di Pellegrino et al. 1992). Further neuroimaging studies are needed to disentangle the contribution of the single nodes of this network and to specify the level at which each of them encodes observed actions.
References
Aziz-Zadeh L, Wilson SM, Rizzolatti G, Iacoboni M (2006) Congruent embodied representations for visually presented actions and linguistic phrases describing actions. Curr Biol 16:1818–1823
Barsalou LW (1999) Perceptual symbol systems. Behav Brain Sci 22:577–609
Binkofski F, Amunts K, Stephan K, Posse S, Schormann T, Freund H, Zilles K, Seitz R (2000) Broca’s region subserves imagery of motion: a combined cytoarchitectonic and fMRI study. Hum Brain Mapp 11:273–285
Bekkering H, Wohlschlager A, Gattis M (2000) Imitation of gestures in children is goal-directed. Q J Exp Psychol A 53:153–164
Borghi AM (2004) Object concepts and action: extracting affordances from objects parts. Acta Psychol 115:69–96
Brass M, Bekkering H, Prinz W (2001) Movement observation affects movement execution in a simple response task. Acta Psychol 106:3–22
Buccino G, Binkofski F, Fink GR, Fadiga L, Fogassi L, Gallese V, Seitz RJ, Zilles K, Rizzolatti G, Freund HJ (2001) Action observation activates premotor and parietal areas in a somatotopic manner: an fMRI study. Eur J Neurosci 13:400–404
Buccino G, Riggio L, Melli G, Binkofski F, Gallese V, Rizzolatti G (2005) Listening to action-related sentences modulates the activity of the motor system: a combined TMS and behavioral study. Cogn Brain Res 24:355–363
Buckner R, Koutstaal W (1998) Functional neuroimaging studies of encoding, priming, and explicit memory retrieval. Proc Natl Acad Sci USA 95:891–898
Burstedt MKO, Benoni BE, Roland SJ (1997) Coordination of fingertip forces during human manipulation can emerge from independent neural networks controlling each engaged digit. Exp Brain Res 117:67–79
Calinon S, Guenter F, Billard A (2005) Goal-directed imitation in a humanoid robot. In: IEEE international conference on robotics and automation, Barcelona, Spain
Catmur C, Walsh V, Heyes C (2007) Sensorimotor learning configures the human mirror system. Curr Biol 17:1527–1531
Coles M, Gratton G, Bashore T, Eriksen C, Donchin E (1985) A psychophysiological investigation of the continuous flow model of human information processing. J Exp Psychol Hum Percept Perform 11:529–553
Costantini M, Galati G, Ferretti A, Caulo M, Tartaro A, Romani GL, Aglioti SM (2005) Neural systems underlying observation of humanly impossible movements: an fMRI study. Cereb Cortex 15:1761–1767
Craighero L, Bello A, Fadiga L, Rizzolatti G (2002) Hand action preparation influences the responses to hand pictures. Neuropsychologia 40:492–502
Cross ES, AFdC Hamilton, Grafton ST (2006) Building a motor simulation de novo: observation of dance by dancers. Neuroimage 31:1257–1267
Dehaene S, Naccache L, Clec’H GL, Koechlin E, Mueller M, Dehaene-Lambertz G, van de Moortele PF, Le Bihan D (1998) Imaging unconscious semantic priming. Nature 395:597–600
De Jong R, Liang C, Lauber E (1994) Conditional and unconditional automaticity: a dual-process model of effects of spatial stimulus–response correspondence. J Exp Psychol Human Percept Perform 20:731–750
Di Pellegrino G, Fadiga L, Fogassi L, Gallese V, Rizzolatti G (1992) Understanding motor events: a neurophysiological study. Exp Brain Res 91:176–180
Di Pellegrino G, Rafal R, Tipper SP (2005) Implicitly evoked actions modulate visual selection: evidence from parietal extinction. Curr Biol 15:1469–1472
Fadiga L, Fogassi L, Pavesi G, Rizzolatti G (1995) Motor facilitation during action observation: a magnetic stimulation study. J Neurophysiol 73:2608–2611
Fogassi L, Gallese V, Fadiga L, Rizzolatti G (1998) Neurons responding to the sight of goal-directed hand/arm actions in the parietal area PF (7b) of the macaque monkey. Soc. Neurosci. Abs. 275.5
Fogassi L, Ferrari PF, Gesierich B, Rozzi S, Chersi F, Rizzolatti G (2005) Parietal lobe: from action organization to intention understanding. Science 308:662–667
Galati G, Committeri G, Aprile T, Spitoni G, Di Russo F, Pitzalis S, Pizzamiglio L (2008) A selective representation of the meaning of actions in the auditory mirror system. Neuroimage 40:1274–1286. doi:doi: 10.1016/j.neuroimage.2007.12.044
Gallagher S (2007) Simulation trouble. Soc Neurosci 2:353–365
Gallese V, Lakoff G (2005) The brain’s concepts: the role of the sensory-motor system in reason and language. Cogn Neuropsychol 22:455–479
Gallese V, Fadiga L, Fogassi L, Rizzolatti G (1996) Action recognition in the premotor cortex. Brain 119:593–609
Gazzola V, Aziz-Zadeh L, Keysers C (2006) Empathy and the somatotopic auditory mirror system in humans. Curr Biol 16:1824–1829
Gazzola V, van der Worp H, Mulder T, Wicker B, Rizzolatti G, Keysers C (2007) Aplasics born without hands mirror the goal of hand actions with their feet. Curr Biol 17:1235–1240
Gibson JJ (1979) The ecological approach to visual perception. Houghton-Mifflin, Boston
Grafton ST, Fadiga L, Arbib MA, Rizzolatti G (1997) Premotor cortex activation during observation and naming of familiar tools. Neuroimage 6:231–236
Grezes J, Decety J (2002) Does visual perception of object afford action? Evidence from a neuroimaging study. Neuropsychologia 40:212–222
Grezes J, Armony JL, Rowe J, Passingham RE (2003) Activations related to “mirror” and “canonical” neurones in the human brain: an fMRI study. Neuroimage 18:928–937
Hamilton AF, Grafton ST (2006) Goal representation in human anterior intraparietal sulcus. J Neurosci 26:1133–1137
Hamilton AF, Grafton ST (2007) The motor hierarchy: from kinematics to goals and intentions. In: Haggard P, Rossetti Y, Kawato M (eds) Sensorimotor foundations of higher cognition. Attention and performance XXII. Oxford University Press, Oxford
Hanson C, Hirst W (1989) On the representation of events: a study of orientation, recall, and recognition. J Exp Psychol Gen 118:136–147
Hauk O, Johnsrude I, Pulvermüller F (2004) Somatotopic representation of action words in human motor and premotor cortex. Neuron 41:301–307
Henson RNA, Rugg MD (2003) Neural response suppression, haemodynamic repetition effects, and behavioural priming. Neuropsychologia 41:263–270
Hughes O, Abbs JH (1976) Labial–mandibular coordination in the production of speech: Implications for the operation of motor equivalence. Phonetica 44:199–221
Iacoboni M, Woods RP, Brass M, Bekkering H, Mazziotta JC, Rizzolatti G (1999) Cortical mechanisms of human imitation. Science 286:2526–2528
Iacoboni M, Molnar-Szakacs I, Gallese V, Buccino G, Mazziotta J, Rizzolatti G (2005) Grasping the intentions of others with one’s own mirror neuron system. PLoS Biol 3:e79
Kable JW, Chatterjee A (2006) Specificity of action representations in the lateral occipitotemporal cortex. J Cogn Neurosci 18:1498–1517
Kable JW, Lease-Spellmeyer J, Chatterjee A (2002) Neural substrates of action event knowledge. J Cogn Neurosci 14:795–805
Kable JW, Kan IP, Wilson A, Thompson-Schill SL, Chatterjee A (2005) Conceptual representations of action in the lateral temporal cortex. J Cogn Neurosci 17:1855–1870
Keele SW, Cohen A, Ivry R (1990) Motor programs: concepts and issues. In: Jeannerod M (ed) Attention and performance, XIII: motor representation and control. Erlbaum, Hillsdale, NJ, pp 77–107
Kohler E, Keysers C, Umiltà MA, Fogassi L, Gallese V, Rizzolatti G (2002) Hearing sounds, understanding actions: action representation in mirror neurons. Science 297:846–848
Koski L, Wohlschlager A, Bekkering H, Woods RP, Dubeau M-C, Mazziotta JC, Iacoboni M (2002) Modulation of motor and premotor activity during imitation of target-directed actions. Cereb Cortex 12:847–855
Kourtzi Z, Kanwisher N (2000) Cortical regions involved in perceiving object shape. J Neurosci 20:3310–3318
Lahav A, Saltzman E, Schlaug G (2007) Action representation of sound: audiomotor recognition network while listening to newly acquired actions. J Neurosci 27:308–314
Lashley K (1951) The problem of serial order in behavior. Wiley, New York
Majdandzic J, Grol MJ, van Schie HT, Verhagen L, Toni I, Bekkering H (2007) The role of immediate and final goals in action planning: an fMRI study. Neuroimage 37:589
Miller GA, Galanter E, Pribram K (1960) Plans and the structure of behavior. Rinehart and Winston, New York
Murata A, Fadiga L, Fogassi L, Gallese V, Raos V, Rizzolatti G (1997) Object representation in the ventral premotor cortex (area F5) of the monkey. J Neurophysiol 78:2226–2230
Newman-Norlund RD, van Schie HT, van Zuijlen AMJ, Bekkering H (2007) The mirror neuron system is more active during complementary compared with imitative action. Nat Neurosci 10:817–818
Newtson D (1973) Attribution and the unit of perception of ongoing behavior. J Pers Soc Psychol 28:28–38
Phillips JC, Ward R (2002) S-R correspondence effects of irrelevant visual affordance: time course and specificity of response activation. Vis Cogn 9:540–548
Pizzamiglio L, Aprile T, Spitoni G, Pitzalis S, Bates E, D’Amico S, Di Russo F (2005) Separate neural systems for processing action- or non-action-related sounds. Neuroimage 24:852–861
Pobric G, de C Hamilton AF (2006) Action understanding requires the left inferior frontal cortex. Curr Biol 16:524–529
Schacter DL, Buckner RL (1998) Priming and the brain. Neuron 20:185–195
Tettamanti M, Buccino G, Saccuman MC, Gallese V, Danna M, Scifo P, Fazio F, Rizzolatti G, Cappa SF, Perani D (2005) Listening to action-related sentences activates fronto-parietal motor circuits. J Cogn Neurosci 17:273–281
Tucker M, Ellis R (1998) On the relations between seen objects and components of potential actions. J Exp Psychol Hum Percept Perform 24:830–846
Tversky B, Hemenway K (1984) Objects, parts, and categories. J Exp Psychol Gen 113:169–193
Umiltà MA, Kohler E, Gallese V, Fogassi L, Fadiga L, Keysers C, Rizzolatti G (2001) I know what you are doing: a neurophysiological study. Neuron 31:155–165
Umiltà MA, Escola L, Intskirveli I, Grammont F, Rochat M, Caruana F, Jezzini A, Gallese V, Rizzolatti G (2008) When pliers become fingers in the monkey motor system. Proc Natl Acad Sci USA 105:2209–2213. doi:10.1073/pnas.0705985105
Urgesi C, Candidi M, Ionta S, Aglioti SM (2007) Representation of body identity and body actions in extrastriate body area and ventral premotor cortex. Nat Neurosci 10:30–31
Vallacher RR, Wegner DM (1987) What do people think they’re doing? Action identification and human behavior. Psychol Rev 94:3–15
Acknowledgments
We are grateful to Francesca Defeudis and Antonello Baldassarre for their help in collecting and analyzing data, and to Bernhard Hommel for his comments on a previous version of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
This material is unfortunately not in the Publisher's archive anymore:
Meaningful actions used in experiments 1 and 3. (TIFF 1341 kb)
Meaningless actions used in all the experiments. (TIFF 603 kb)
Meaningful actions used in experiment 2. (TIFF 1347 kb)
Rights and permissions
About this article
Cite this article
Costantini, M., Committeri, G. & Galati, G. Effector- and target-independent representation of observed actions: evidence from incidental repetition priming. Exp Brain Res 188, 341–351 (2008). https://doi.org/10.1007/s00221-008-1369-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-008-1369-x