
Abstract
Respiration modelling is the fundamental of the packaging and storage of fresh fruit and vegetables. Previous model of respiration rate accounted for external forcing from temperature and modified atmosphere but did not attempt to predict internally generated natural variability such as maturity. We present two types of respiration models here that predict the respiration rate of fresh papaya in response to changes of temperature, CO2/O2 concentrations and maturity as well. These two models were separately developed using a quadratic polynomial with four parameters and fifteen coefficients and using an artificial neural network (ANN) model with 4-15-2 architecture trained by Levenberg–Marquardt algorithm, in which the maturity of papaya covers skin yellowing from 10 to 90% and the temperatures vary over 10–30 °C. Comparison between the two types of respiration models shows a predictive superiority of the ANN-based model over the regressive one, demonstrating that the use of ANN technique can provide a reliable and effective approach to describe papaya’s respiration rate as a function of multivariate influencing factors.
Similar content being viewed by others
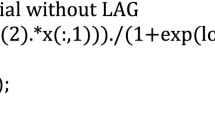

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
There have been a number of mathematical models in relation to the description of the respiration rate of fresh fruit and vegetables [1]. Quite often, these models are created to only predict the influence of external factors, such as modified atmosphere and temperature, but internal factors like maturity is either out of consideration or specified at one given level. However, the rate of respiration is subject to both external and internal influences and can change as a horticultural commodity goes through its natural process of ripening, maturity and senescence [2]. Therefore, using a respiration model that ignores the effect of maturity degree will lead to low prediction accuracy. As a matter of fact, to develop a physical respiration model that comprehensively takes account of maturity, temperature and concentrations of CO2/O2 seems quite difficult, because of the highly complex and nonlinear interactions of these variables with respiration metabolism.
Statistical equations such as second-order polynomial are a type of mathematical model most frequently applied to define the correlation between dependent and independent variables. The second-order-type polynomial has been reported successful in the respiration modelling for some horticultural commodities [3–6]. This type of equation should enable the construction of multivariate respiration model, since it allows models to be established through fitting a given formula to experimental data with almost no needs of knowing mechanism underlying the variables.
Artificial neural network (ANN) has emerged as a powerful tool for modelling complex systems in the recent 20 years. One of the advantages of using ANN is that there is no requirement for pre-selecting a model formula beforehand. Another benefit is that it allows specification of multiple input dimensions and generation of multiple output recommendations. In our previous paper, ANN model has proved effective in modelling the respiration rate of guava fruit as a function of three external factors, namely, temperature, CO2 and O2 concentrations [7]. But its capacity for addressing four factors with an added variable of maturity still remains unknown.
Papaya (Carica papaya L.) is a subtropical fruit recognised as typical respiratory climacteric [8]. This fruit is an excellent resource of vitamin A, lycopene, polysaccharides and proteins. It can be eaten as delicious fruit, soup material or used as medicine for its strong resistance to lymphatic leukaemia cells. Papaya fruit can be harvested and marketed at mature-green, colour break, quarter, half, and three-quarter colour stages, depending on the final consumption and distance to be transported. The necessity of shipping, storing and marketing papayas of different maturities impels the development of multivariate respiration models, so that accurate predictions of respiration rate can be available for the rigorous design of preservation systems for this fruit.
So, the objectives of this paper are to (1) develop multivariate models for the respiration rate of papaya using regressive model and ANN approach, respectively: in which four factors, namely, CO2 and O2 concentrations, temperature and maturity degree, act as independent (input) variables; respiration rates of CO2 production and O2 uptake as dependent (output) variables; (2) evaluate and compare the developed models to define a better one for future practical application; (3) carry out input importance analysis to examine the contribution of each factor to the respiratory metabolism.
Materials and methods
Fruit samples
Papaya used was local popular cultivar ‘Tainung No. 2’, carefully harvested from a commercial orchard at Zhuhai (22° 14′ N; 113° 23′ E), Guangdong, China, during May to October in 2008. For experimental purpose, attention was paid to ensure papayas were harvested at different ripening stages but with similar size. Fruit were delivered to the laboratory within 1 h after detachment. On arrival, papayas were selected for similar shape and freedom from blemishes by visual detection. Each sample was measured for volume using water replacement method.
Experimental design and data acquisition
Skin colour is a good indicator of the maturity degree of papaya fruit [9]. Therefore, maturity grading by means of judging the percentage of skin yellowing with eyes was frequently used in literature [8, 10–13]. This method is suitable for this study since it is non-destructive and easy to use. Nevertheless, maturity determination by naked eyes usually produces rough results because of the observer’s subjectivity and ocular limitations. To absorb the merit but overcome the shortcomings of this method, we developed a software pack to assist visual detection in implementing the maturity classification. This software was programmed on the principle of digital image processing and chromatology. It imitates human eyes scanning the pixels of papaya’s digital image to calculate the proportion of the skin area that had turned yellow to the whole skin area of the fruit and gives a decimal fraction as identifying result. Information about this software has been published elsewhere [14], and the details will not be repeated here in view of the limitation of paper length. Five maturity degrees were examined in the present research, which were 0.1, 0.3, 0.5, 0.7 and 0.9, referring to corresponding percentage of yellow skin of 10, 30, 50, 70 and 90%, respectively.
Papaya samples at each experimental maturity stage were measured for respiration rates at five temperatures, 10, 15, 20, 25 and 30 °C, using the closed system method, a respiration-measuring method broadly used in the literature [1, 5, 6, 15–19]. For each experiment, one fruit was hermetically sealed in a container of 1850 mL after temperature had equilibrated. The respiration container was then stored in dark in a temperature-controlled cabinet with an accuracy of 0.5 °C. Headspace gas of 1 mL was sampled at regular intervals of 2 h through a pore in container lid covered with a silicon septum. The gas sample was immediately analysed for its CO2 and O2 concentrations with a portable oxygen/carbon dioxide analyser (Model 325, MOCON, Minnesota, USA). All gas measurements were over after 10 h in order to obviate the instigation of anaerobic respiration and to alleviate the negative effect of storage duration.
Respiration rates at a given temperature were calculated using the following equations [6, 17, 18].
where \( R_{{{\text{CO}}_{2} }} \) and \( R_{{{\text{O}}_{ 2} }} \) are respiration rates in terms of CO2 and O2, respectively, ml/(kg h); \( V_{\text{f}} \) denotes the void volume of respiration chamber, ml; [CO2] and [O2] are gas concentrations of CO2 and O2, respectively, %; t denotes measurement point; \( \Updelta t \) is the time interval between two gas measurements, h; W is the weight of papaya, kg.
Regressive model
A second-order polynomial that was successfully used by Yang et al. for tomatoes and followed by Zhu et al. for rutabaga is of the following form [4, 5]
where \( a_{0} \) is a constant term; \( k_{i} \), i = 1–9, are equational coefficients; T, temperature in °C.
The above equation describes respiration rate as a function of temperature and concentrations of CO2 and O2, in which the quadratic terms represent the interplay of two variables. By referring to Eq. 3, a quadratic equation taking account of four variables could be written as:
where, x i and x j , i, j = 1–4, stand for the ith and jth element of the variable vector \( \left( {[{\text{CO}}_{2} ],[{\text{O}}_{2} ],T,M} \right) \), respectively, where M signifies maturity degree.
A similar equation of Eq. 4 has been applied by Ravindra et al. to model mango’s respiration rate but with containing storage time rather than the maturity [6]. Coefficients in Eq. 4 were estimated with the help of experimental data by nonlinear regression analysis using the commercial software DataFit 7.1 (Oakdale Engineering, Pennsylvania, USA).
ANN model
The ANN used is a multilayered perceptron (MLP) network with back-propagation (BP) algorithm to determine the weight and bias matrixes. The network was designed containing only one hidden layer, since it has proved that a three-layer MLP network with moderate number of hidden neurons is capable of approximating any continuous function [20]. The ANN respiration model was built and trained using the Neural Network Toolbox embedded in MATLAB 7.8 software (MathWorks, Massachusetts, USA).
A thorough description of terminology, usage and methodology on ANN technology is beyond the scope of the present work. Based on an extensive understanding of the ANN theory and principle, some technical points related to the ANN model development are clarified as below. The Levenberg–Marquardt (TRAINLM) algorithm was chosen as training function, for that it was proposed as the fastest method for training moderate-sized feedforward neural networks (up to several hundred weights) (please refer to ‘Product Help’ of MATLAB 7.8). Moreover, this algorithm has shown high performance in function approximation problems [21]. Transfer functions used in the ANN model were log-sigmoid transfer function (LOGSIG) in the hidden layer and linear transfer function (PURELIN) in the output layer. The number of neurons in hidden layer has an important role in the effectiveness of networks, since too many or too less hidden neurons are all unsuitable and will harm the network capability. Because generally conceded method for determining optimal number of hidden neurons is currently absent, the number of hidden neurons here was determined through exhaustive search by varying hidden neuron number from 1 to 20 with increasing step of 1. During exhaustive search, the Akaike information criterion (AIC) was adopted as a measure of the performance of ANN candidates [22]. Each network was appraised by the average of AIC of ten separate runs. Finally, the number of neurons that gave the highest AIC was chosen. Figure 1 shows the result of exhaustive search, which manifests that the optimal number of neurons in the hidden layer should be 15. Therefore, the ANN model used was of 4-15-2 topological structure, four neurons in the input layer standing for CO2 concentration, O2 concentration, temperature and maturity, respectively; two neurons in the output layer denoting respiration rates in terms of CO2 and O2, respectively. Other parameters used in the ANN model were set as the defaults.

The result of exhaustive search for the determination of hidden neurons (data point represents the average of ten runs)
Model verification
The bias in the total difference between model simulations and experimental measurements was determined by calculating the mean absolute percentage error (MAPE,%) [6, 18]
To assess whether simulated values follow the same pattern as measured values, the Pearson product–moment correlation coefficient (r) was used, which can be calculated by [7]
In the above two equations, x i are the observed (measured) data; y i are the predicted (simulated) values; N is the number of observation–prediction pairs. A model is thought of as excellent when the MAPE is the minimum and r is high.
Input importance analysis
Implementation of input importance analysis allows identifying sensitive parameters associated with the respiratory activity. This task was accomplished via a method described by Gevrey, Dimopoulos and Lek [23], which assesses the changes in the mean squared error of the network by sequentially removing input neurons from the neural network and rebuilding the neural network at each step. Each of the rebuilt neural networks was technically optimised as same as original ANN models. The resulting change in the mean squared error for every variable removal determines the relative importance of the predictor variable.
Results and discussion
Experimental database and its partitioning
During the whole experimental period, changing trends of O2 and CO2 concentrations in the respiring container headspaces were observed as a typical closed measurement system: O2 concentrations were diminished accompanying with enhancement in CO2 concentration as storage time lapsed, while changing rates of both gases were temporally slowing (data not shown). Moreover, the scene of gas concentration changing was also observed maturity dependent. Table 1 shows statistical characteristics of these gas concentration data as well as their corresponding respiration rates, which characterise a total of 125 data combinations collected from the present experiment. It can be seen from Table 1 that both gas concentrations and respiration rates cover a wide range of data distribution with good skewness and kurtosis, implying that the experimental data is applicable to the development of respiration models. When used, these data combinations were randomly divided into two groups: one comprising 110 sets used for developments of the regressive and ANN models (named α-dataset, for later citation), one containing 15 sets used for model verification purpose (β-dataset). During the training course of ANN model, the α-dataset was again randomly separated into three subgroups automatically by the MATLAB 7.8. Of which, one was assigned as training data group containing 78 datasets to set the weight and bias matrixes of the network; one was validation data group of 16 datasets to measure network generalisation and to halt training when generalisation stops improving; the last was testing data group also of 16 datasets used to provide an independent measure of network performance during and after training.
Regressive model
In order to render Eq. 4 qualified, fifteen coefficients have to be estimated for each of the two respiration rates, \( R_{{{\text{CO}}_{ 2} }} \) and \( R_{{{\text{O}}_{ 2} }} \). Estimated values of the equational coefficients are summarised in Table 2. These estimations were the result of nonlinear fitting of Eq. 4 to the α-dataset according to \( R_{{{\text{CO}}_{2} }} \) and \( R_{{{\text{O}}_{2} }} \), respectively. Figure 2 illustrates the affinity between the observed respiration data in the α-dataset and the model curves characterised by the estimated coefficients in Table 2. From Fig. 2, it is apparent that the model curves representing for both \( R_{{{\text{CO}}_{2} }} \) and \( R_{{{\text{O}}_{2} }} \) did take through most of the data markers, but not completely. This incomplete mulch indicates the imperfection of the second-order equation linked to the multivariate respiration modelling, presumably due to the highly complex relations between respiratory activities and the influencing factors, which exceeds the calculating ability of the regressive model employed.

Scattered plots of α-dataset versus fitted model curves by regression method
Another finding by referring to Fig. 2 is that the curve of \( R_{{{\text{CO}}_{ 2} }} \) is analogous in shape to that of \( R_{{{\text{O}}_{ 2} }} \). This situation implies a similarity between the two terms, in other words, the respiratory quotients (RQs) of the papayas studied are close to unity with insignificant variations when environmental conditions are changing. It has been reported that for respiratory substrates as carbohydrate, long-chain fatty acids and short-chain organic acids, their respective RQ is usually to be 1.0, 0.7 and 1.3 [24]. Accordingly, substrates involved in the papaya respiration should be mainly carbohydrate materials. This speculation is reasonable when relating to the fact that papaya flesh typically has high sugar contents and low titratable acidity, the sugar/acid ratio reported larger than 130 [25, 26].
ANN model
A best ANN model was picked out from about twenty times of independent training. Its dynamic performance during training process is graphically shown in Fig. 3. The whole training course was stopped after 28 iterations within less than one second. During training, gradual increases were seen in model performance demonstrated by the mean squared errors sharply dropping from 5.49 × 104 to 0.504 in the text of the training data group. Prior to 22 iterations, the model performance in terms of both testing and validation data group was also enhanced as training progressed; thereafter, it stopped increasing, although the model performance regulated by the training dataset was continued to improve. This phenomenon suggests that the happening of over-fit in model training subsequent to epoch 22 and that the weight and bias matrixes of the ANN model should be fixed at the 22nd iteration, as marked with an open circle in Fig. 3, where the best model was generated.

The dynamic performance of ANN model during training
Figure 4 represents the correlativity between the target data (α-dataset) and the corresponding outputs produced by the selected model. It is evident that the trained ANN model is of very good quality, denoted by the high value of correlation coefficient (r) up to 0.99 more. However, the ANN model has to be verified with new data that has not taken part in the model-developmental period to confirm its prediction capacity.

Correlativity between the target dataset and the ANN outputs
Verification result
Figure 5 delineates the observed \( R_{{{\text{CO}}_{2} }} \) and \( R_{{{\text{O}}_{2} }} \) in the β-dataset comparing with their corresponding simulations yielded individually by the regressive models and the ANN model built here. The model fitness reflected by statistical indexes of MAPE and r was shown in Table 3. Lower MAPE values and higher correlations (r) are all pointed to the ANN model, be it \( R_{{{\text{CO}}_{2} }} \) or \( R_{{{\text{O}}_{2} }} \), demonstrating that the ANN-based model has better performance than the models built through use of regressive method. Values of MAPE below 10% are indicative of reasonable good fit, 10–20% fairly good fit and more than 20% are not satisfactory fit for all practical purposes [18]. Under this criterion, it can say that the ANN model performs prediction very well, inasmuch as its MAPE values are all less than 10%. By contrast, the regression models were considered of bad quality because their MAPE are greatly out of the acceptable limit. The ANN model also has r values less than that of the regression models. The statistic, r, can be useful in assessing how well the shape of the simulation series matches that of the measured data. This is well documented by the pictures of scattered data plots in Fig. 5, in which larger deviation of several simulated points of the regression models was seen. The verification result demonstrates that the ANN model is excellent in respiratory prediction subject to four influencing variables, but the second-order regressive model is unacceptable for practical application.

Relationship between the respiration values predicted by developed models and the experimental data from β-dataset
Input importance analysis
The result of input importance analysis is shown in Fig. 6. Temperature was found to be the most decisive factor surpassing three other factors under investigation, contributing a relative importance up to 43.28% to the respiratory activity. Fruit maturity occupies the second place with the relative importance of 32.24%. The fact that the two factors share more than 75% relative importance in papaya respirations predicates that temperature management and ripeness classification have to be seriously considered when planning technical strategies for papaya storage. Although CO2 and O2 concentrations affect the respiration rate not as dramatically as the two former parameters, their impacts are crucial likewise, because once storing temperature is well regulated, modified atmospheres become the most important external impetus that can vary respirations of papaya that are at a given maturity stage.

The result of input importance analysis
Discussion
Either regressive model or ANN model has its own strong points and shortcomings in solving the problem of respiration modelling. On the one hand, modelling using regressive equations is a traditional approach that is familiar to many of the researchers. However, ANN modelling is a computer-aided technique that requires the user of more or less special knowledge so as to be competent for reining this modelling technology. On the other hand, regressive models usually render complex form with less accurate predictions when used for addressing multivariate issues, just as the second-order polynomial models presented in this research. Another similar example was reported by Ravindra et al. [6], in which a second-order equation with four parameters, CO2 and O2 concentrations, temperature and storage time, was developed for mango fruit, but proved impracticable for the prediction of CO2 respiration rate, with MAPE up to 20.33%. For problems with low input dimensions, where only CO2/O2 concentrations and temperature were concerned, good fitness was reported for the use of second-order polynomial for some products [4, 5]. Comparatively, ANN models are computationally robust, to some extent without restriction of the number of dimensions for either inputs or outputs. It can readily integrate more than one output (dependent variable) into one model with high quality, rather than modelling them one-by-one.
For an engineer who designs quality keeping system for respiring products, he should clearly understand the whole thing he does, keep in mind which factors and procedures are the sticking points that will defeat or survive the project. Jacxsens, Devlieghere and Debevere experimentally demonstrated that temperature control was of paramount importance for the successful usage of equilibrium MAP for minimally processed fresh produce [27]. The input importance analysis tells us temperature management also has the first importance to papaya storage. Since the respiration rate of papaya is identified as most sensitive to temperature, slight fluctuation in temperature will rock the respiration significantly, bringing damage to modified or controlled atmosphere and causing disorders in fruit metabolism. Input importance analysis provides a theoretical support for the cognition of the importance of temperature management.
As a climacteric fruit, papaya exhibits respiration intensities varying with ripening evolution [8, 11, 13]. To create good designs of storage systems for papaya, maturity requires more attention prior to designing. However, papaya will continue to ripen during storage even at low temperature and modified atmospheres, which can lead to changes in respiration rates [28, 29]. This unfavourable influence was controlled in this research through reducing experimental duration to about 10 h, with still ensuring sufficient data samplings required by the model establishment (see Table 1). It will be interesting to add a new input variable, storage time, to extend the four-factorial ANN model into a five-factorial one. This problem remains to be examined in the future work.
Conclusion
To effectively design preservation systems for fresh produce, respiration rate of the selected product need to be modelled. Usually, simple models with not more than three parameters are developed and used to the prediction of respiration rate. These models assume a given maturity stage for the studied product and respiratory quotient thereof equalling to unity, which is often not suitable for the commodities of respiring climacteric. In this paper, these assumptions are abandoned. Taking the papaya as a case study, multivariate models were proposed to comprehensively describe effects of four factors (CO2 and O2 concentrations, temperature and maturity) on the rates of CO2 production and O2 uptake using regressive equation and ANN method, respectively.
The conclusion is that the use of second-order polynomial model created on regression method is impracticable because of its low prediction accuracy; the BP-ANN model with a 4-15-2 architecture trained by the Levenberg–Marquardt algorithm is highly effective and can be used to predict the respiration rate of fresh papaya. The result of input importance analysis confirms the importance of rigorous temperature regulation for papaya storage. By introducing the ANN technology into the respiration modelling field, this paper extends the research scope of the respiration modelling from three affecting variables into four and thus is expected to provide more reliable respiration data for the postharvest storage of papaya fruit.
References
Fonseca SC, Oliveira FAR, Brecht JK (2002) Modelling respiration rate of fresh fruits and vegetables for modified atmosphere packages: a review. J Food Eng 52:99–119
Zagory D, Kader AA (1988) Modified atmosphere packaging of fresh produce. Food Technol 42(9):70–74 & 76–77
Herner RC (1987) High carbon dioxide effects on plant organs. In: Weichmann J (ed) Postharvest physiology of vegetables. Marcel Dekker, New York, pp 239–253
Yang CC, Chinnan MS (1988) Modeling the effects of O2 and CO2 on respiration and quality of stored tomatoes. Trans Am Soc Agric Eng 31(3):920–925
Zhu M, Chu CL, Wang SL, Lencki RW (2001) Influence of oxygen, carbon dioxide, and degree of cutting on the respiration rate of rutabaga. J Food Sci 66(1):30–37
Ravindra MR, Goswami TK (2008) Modelling the respiration rate of green mature mango under aerobic condition. Biosyst Eng 99:239–248
Wang Z-W, Duan H-W, Hu C-Y (2009) Modelling the respiration rate of guava (Psidium guajava L.) fruit using enzyme kinetics, chemical kinetics and artificial neural network. Eur Food Res Technol 229(3):495–503
Paull RE, Chen W (1997) Minimal processing of papaya (Carica papaya L.) and the physiology of halved fruit. Postharvest Biol Technol 12:93–99
Kader AA (2009) Papaya: recommendations for maintaining postharvest quality. http://www.postharvest.ucdavis.edu/Produce/ProduceFacts/Fruit/papaya.shtml
Almora K, Pino JA, Hernández M, Duarte C, González F, Roncal E (2004) Evaluation of volatiles from ripening papaya (Carica papaya L., var. Maradol roja). Food Chem 86:127–130
Bron IU, Jacomino AP (2006) Ripening and quality of ‘Golden’ papaya fruit harvested at different maturity stages. Braz J Plant Physiol 18(3):389–396
Karakurt Y, Huber DJ (2007) Characterization of wound-regulated cDNAs and their expression in fresh-cut and intact papaya fruit during low-temperature storage. Postharvest Biol Technol 44:179–183
Manenoi A, Bayogan ERV, Thumdee S, Paull RE (2007) Utility of 1-methylcyclopropene as a papaya postharvest treatment. Postharvest Biol Technol 44:55–62
Duan H-W, Wang Z-W, Hu C-Y (2008) Nondestructive classification of papaya ripeness under modified atmosphere packaging conditions. Packag Eng 29(10): 107–109 &125 (in Chinese with English abstract)
Song Y, Vorsa N, Yam KL (2002) Modeling respiration-transpiration in a modified atmosphere packaging system containing blueberry. J Food Eng 53:103–109
Archbold DD, Pomper KW (2003) Ripening pawpaw fruit exhibit respiratory and ethylene climacterics. Postharvest Biol Technol 30:99–103
Rai DR, Paul S (2007) Transient state in-pack respiration rates of mushroom under modified atmosphere packaging based on enzyme kinetics. Biosyst Eng 98:319–326
Bhande SD, Ravindra MR, Goswami TK (2008) Respiration rate of banana fruit under aerobic conditions at different storage temperature. J Food Eng 87:116–123
Iqbal T, Rodrigues FAS, Mahajan PV, Kerry JP (2009) Mathematical modelling of the influence of temperature and gas composition on the respiration rate of shredded carrots. J Food Eng 91:325–332
Cybenko G (1989) Approximation by superpositions of a sigmoidal function. Math Control Signals Syst 2:303–314
Sohn JH, Smith R, Yoong E, Leis J, Galvin G (2003) Quantification of odours from piggery effluent ponds using an electronic nose and an artificial neural network. Biosyst Eng 86(4):399–410
Burnham KP, Anderson DR (2002) Model selection and multimodel inference: a practical-theoretic approach, 2nd edn. Springer, New York, pp 60–65
Gevrey M, Dimopoulos I, Lek S (2003) Review and comparison of methods to study the contribution of variables in artificial neural network models. Ecol Model 160:249–264
Powrie WD, Skura BJ (1991) Modified atmosphere packaging of fruits and vegetables. In: Ooraikul B, Stiles ME (eds) Modified atmosphere packaging of fruits and vegetables. Ellis Horwood Limited, West Sussex, pp 190–194
Cenci SA, Soares AG, Souza MLM, Balbino JMS (1997) Study of storage sunrise ‘Solo’ papaya fruit under controlled atmosphere. In: Kader AA (ed) Proceedings of the 7th international controlled atmosphere research conference, vol 3. University of California, Davis, pp 205–211
Lobo MG, Cano MP (1998) Preservation of hermaphrodite and female papaya fruits (Carica papaya L., Cv Sunrise, Solo group) by freezing: physical, physico-chemical and sensorial aspects. Z Lebensm Unters Forsch A 206:343–349
Jacxsens L, Devlieghere F, Debevere J (2002) Predictive modelling for packaging design: equilibrium modified atmosphere packages of fresh-cut vegetables subjected to a simulated distribution chain. Int J Food Microbiol 73:331–341
González-Aguilar GA, Buta JG, Wang CY (2003) Methyl jasmonate and modified atmosphere packaging (MAP) reduce decay and maintain postharvest quality of papaya ‘Sunrise’. Postharvest Biol Technol 28:361–370
Karakurt Y, Huber DJ (2003) Activities of several membrane and cell-wall hydrolases, ethylene biosynthetic enzymes, and cell wall polyuronide degradation during low-temperature storage of intact and fresh-cut papaya (Carica papaya) fruit. Postharvest Biol Technol 28:219–229
Acknowledgments
The authors gratefully acknowledge the financial support of this study by Nature Science Foundation of Guangdong Province (07005952) and Science and Technology Project of Zhuhai (PC20061044).
Author information
Authors and Affiliations
Corresponding author
Additional information
Supported by Nature Science Foundation of Guangdong Province (07005952) and Science and Technology Project of Zhuhai (PC20061044).
Rights and permissions
About this article
Cite this article
Wang, ZW., Duan, HW., Hu, CY. et al. Development and comparison of multivariate respiration models for fresh papaya (Carica papaya L.) based on regression method and artificial neural network. Eur Food Res Technol 231, 691–699 (2010). https://doi.org/10.1007/s00217-010-1318-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00217-010-1318-3