
Abstract
Fruit growth patterns are often exploited in predictions of final fruit size and to inform planting and harvesting decisions. Ten local apricot (Prunus armeniaca) varieties with superior genotypes (two early-ripening, five mid-ripening and three late-ripening varieties) were assessed using 20 nonlinear regression models (NRMs) and a radial basis function (RBF) neural network model. Fruit diameter and weight measurements for each genotype were collected at four-day intervals from fruit set to commercial harvest. Patterns based on diameter and weights were attributed to each genotype. Among the NRM tested, only four were able to flawlessly predict apricot diameter and weight during the growing season. In addition, comparison of nonlinear regression methods with the neural network indicated than the RBF model displayed fewer prediction errors than the NRMs. The RBF model predicted fruit size with a coefficient of determination (R2 value) greater than 0.95. Therefore, predictions of growth patterns in fruit trees can be accomplished with neural network modeling.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Fruit growth patterns have always interested fruit growers and researchers. These patterns are mostly used to determine the best time for different horticultural operations such as fruit thinning, optimal irrigation, application of nutrient and growth regulators, and pest and disease control management (Pérez-Pastor et al. 2014; Westwood 2009). Patterns can be based on fruit weight, volume, or diameter from fruit-set to harvesting time (Westwood 2009). Fruit size is primarily controlled genetically but several factors such as crop load, nutrition and fertilizers, irrigation, and weather conditions also influence fruit size (Jackson and Coombe 1966; Pérez-Pastor et al. 2014; Westwood 2009). Predictions of fruit size and weight have been successfully tested with soft computing models previously (Godoy et al. 2008; Zadravec et al. 2014). Soft models lack precision and are tolerant of approximations, uncertainties, and partial truths. The basis for these models lies in techniques such as expert systems which use fuzzy rather than Boolean logic. These models, which include artificial neural networks, genetic algorithms, and machine learning, are best used to solve highly variable problems involving a greater degree of uncertainty (Ibrahim 2016). The potential exists for fruit size to be affected by cell number and size. Cell division is initiated after flowering and fruit set, though the final fruit size is further determined by cell expansion (Westwood 2009). It is imperative to determine a timeline for optimal fruit quality and size in the early stages of development as these characteristics are considered before products are permitted to be offered and sold in most markets (Lötze and Bergh 2004).
Linear and nonlinear models of fruit growth curves have been fitted based on fruit weight or diameter (Lötze and Bergh 2004; Torkashvand et al. 2017; Zadravec et al. 2014). These models can anticipate final fruit size or weight based on initial growth information. Apricot is one of the most important stone fruits (Westwood 2009). Growth curves in apricot based on weight or fruit volume have been previously described as a double sigmoid (Baldicchi et al. 2015; Nigam and Sharma 1986). This double-sigmoid pattern is found in most stone fruits and typically consists of three steps. Cell division features prominently in the first stage followed by a lagging second stage where the physiological process of pit hardening takes place. The third stage is dedicated to cell enlargement and increasing intercellular space (Westwood 2009).
Growth patterns in early- and late-ripening stone fruits are not entirely consistent with the double sigmoid patterns. The lag phase is loosely defined and unclear in some early-ripening cultivars. Hence, growth patterns for each stone fruit cultivar should be considered independently. Several studies of growth patterns in stone fruit such as peach have been reported (DeJong and Goudriaan, 1989; Farinati et al. 2021). Scant information has been published on apricots, especially Iranian varieties, despite an obvious interest in stone fruit growth and developmental patterns.
Several linear and nonlinear models have been used to construct growth curves for fruit (Torkashvand et al. 2017; Zadravec et al. 2014). Most of these models described a sigmoid growth pattern in apple. Welte (1990) proposed a complex differential dynamic simulation model for predicting final harvest size in Jonagold (Malus domestica ‘Jonagold’), a semi-dwarf apple variety. Lakso et al. (1995), developed an expo-linear model of the apple (Malus domestica Borkh.) growth pattern. Goudriaan and Monteith (1990) proposed an expolinear model of apple growth patterns. The logistic equation, a classical function that works well in describing sigmoid development, is widely used to simulate or predict plant organ growth (Fujikawa et al. 2004). In addition, with the piecewise fitting method, the logistic equation can fit complex curves consisting of several consecutive sigmoid increases (Tseng and Yu 2014). Linear two-part models and exponential-linear models have also been used to model the fruit growth curve of temperate trees (Goudriaan and Monteith 1990; Lakso et al. 1995). The initial apple growth stage, cell division, is exponential while the second stage continues in a linear fashion until harvesting time (Faust 1989). In addition to an applied mathematical model, it is also important to determine an appropriate fruit parameter that effectively describes fruit growth dynamics (White et al. 2000). Fruit growth patterns differ depending on the trait evaluated (diameter or weight) (Pinzón-Sandoval et al. 2021). Pinzón-Sandoval et al. (2021), also noted the logistic model was most appropriate for describing fruit growth curves based on fresh or dry weight in peach (Prunus persica ‘Dorado’) while the Gompertz curve model was the most suitable for descriptions based on fruit diameter. Exponential-linear models were able to describe apple fruit growth patterns based on fresh weight (Zadravec et al. 2014). Three growth models (Gompertz, Logistic, and Winter) describe apple growth based on fruit diameter (Orlandini et al. 1998). Compound equations for double sigmoid functions are considered for stone fruit analyses. In these compound equations, interpretation of each sigmoid cycle or phase may be misleading because estimated asymptotes are occasionally substantially different from the observed values (Orlandini et al. 1998). Generalized exponential models such as Gompertz, logistic, and monomolecular have successfully been used to represent double sigmoid curves in stone fruit (Hau et al. 1993).
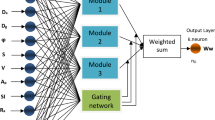
Nonlinear models based on neural networks are gaining popularity and have been used for various practices. Artificial neural networks (ANN) are well known for their desirable learning, adaptation, parallelization, generalization, and fault and noise tolerance capabilities (Gurjar and Patel 2021). In recent years, ANN models have been frequently used to assess fruit quality, (Heidari et al. 2020; Huang et al. 2021), yield prediction (Ashtiani et al. 2020; Khairunniza-Bejo et al. 2014; Torkashvand et al. 2020), and fruit biomass estimation (Ashtiani et al. 2020; Castro et al. 2017). These models generate highly accurate predictions based on a series of input data (Gurjar and Patel 2021). Different ANN model types (e.g. KNN, SVM, SOM, ANFIS and RBF) exist for appraising biological phenomena. Prior exploration into fruit trees aided by biological models have reported that RBF (radial basis function) network models have an efficiency superior to other models (Heidari et al. 2020; Amini et al. 2020; Ashtiani et al. 2020). Therefore, the RBF method was selected for use in the present study. An RBF network model usually has three layers: an input layer, a hidden layer with a nonlinear RBF activation function, and a linear output layer. RBF uses radial basis functions as activation functions. An ideal solution for weight adjustment to the mean least squares error (MLSE), generalized approximation, and regularization capabilities are all obtained using the linear optimization method (Wu et al. 2012).
Considerable effort has been expended by researchers to explore patterns of fruit growth and development. Yet, no research thus far has merged the various models available into a single effort. ANN models have yet to be discussed in these investigations. In this study, approximately twenty NRMs deemed suitable for further study were subjected to comprehensive inspection. An RBF model was considered as an alternative to the NRMs for accurately fitting apricot growth data. Fruit growth parameters and sampling type were used to derive inputs while each individual model was assessed. Predicted model performances were summarized and the best model was selected for future study. The objectives of this study were to: (1) evaluate the fit of various fruit growth models of early-, mid-, and late-ripening apricot varieties under presumed optimal conditions with low crop competition, and (2) assess efficiency of the RBF ANN model for estimations of apricot fruit growth patterns for later comparison to results from various conventional models.
2 Materials and methods
2.1 Plant material and orchard management
Ten apricot types (seven local varieties (Var) and three superior genotypes (PG)) were selected from the apricot collection maintained on the grounds of the Agricultural Jihad Centre of Semnan Province, Iran (Table 1). All varieties and superior genotypes were grafted on apricot seedling rootstocks and pruned to maintain an open-centre (vase) form to support optimal fruit numbers. The trees were planted at a 3 × 4 m distance and were 12 yr old at the time of sampling with all maintenance (i.e. irrigation and fertilization) completed regularly. In addition, trees were free of pests and nutritional deficiencies. Ideally, it is best to observe fruit growth patterns in authentic environmental conditions. Current field conditions expose apricot trees to competition for resources and space. All necessary precautions were taken to mimic realistic growth conditions and eliminate potentially confounding data points.
2.2 Measured traits
Eight to ten fruit samples for each cultivar and genotype were considered for evaluation. Sampling was performed at intervals of three to four days from fruit set to commercial harvest for each tree. To prevent fruit thinning and development of a strong sink, approximately 5 to 12 fruit from random and varied locations on each tree were collected for trait measurement. Sampling was performed in each of the four directions (north, south, east, west) to ensure adequate selection dispersal. Fruit were weighed to a precision of ± 0.001 on a scale (Ohaus SP602 AM, Fotronic Corporation, MA, USA). Diameter, length, and width were obtained with a digital calliper. Fruit data were used individually in the respective models.
2.3 Nonlinear regression models (NRMs)
Twenty nonlinear regression models (NRMs) were used to portray the apricot growth pattern (Table 2). Other research efforts have included only one or two models. This study includes 14 NRMs in addition to six conventional models (Chapman-Richard (CRM), Double-Sigmoid (DSM), Exponential-linear (ELM), LinBiExp (LBE), Monomolecular-logistic (MLM), Richard (RCD)) constructs (Buchwald 2007; Buchwald and Sveiczer 2006; Khamis 2005; Wang et al. 2011) to allow for adequate comparison of individual research capabilities (Table 2). Nonlinear parameters (β = a, b, c…), plus fruit growth time (t) as a variable predictor, form the NRM structure used to capture growth data throughout the growth period (Y) (Eq. 1)
where ε is the random error term. The ε variable for error is independent and identically distributed.
The Statistical Toolbox fm MATLAB software vR2020b (The Matworks, Inc, Natick, MA) was used to obtain the NRM parameters. The MATLAB function fit nonlinear regression model (fitnlm) was used to calculate the model coefficients (Fig. 1). Optimal β values are based on prediction error minimization by the Levenberg–Marquardt nonlinear least squares algorithm. However, initial model coefficient (β0) values must be determined first. Beginning parameter values were obtained from previous research on other fruit and by continuous trial and error until the desired results were attained regarding the expected fruit growth process.

Basic MATLAB code for implementing the fitnlm function
2.4 Radial basis function (RBF) neural network
The RBF neural network model is a soft computing model able to predict apricot development patterns during the growing season. Although growth over time can be explained by NRMs, our results indicate these models are limited to explanations of overall variation. An alternative ANN method was identified to provide additional detail regarding pattern variation during growth. Additional merits of a neural network over regression methods include direct learning from laboratory data, and statistical assumptions such as the normal distribution of error are unnecessary (Amini et al. 2020; Taki et al. 2018). The straightforward neural structure and expedited training processes of RBF with a neural network of linearly arranged radial basis functions make it a better candidate than the Multilayer Perceptron (MLP) neural network. Suppose a data set with N pattern (xP, yP), so that xP is an independent variable and yP is a dependent variable. Each neuron in the hidden layer operates nonlinearly based on the radial basis function. The network output of “i” in the activation function \({\mathrm{\varnothing }}_{\mathrm{i}}\) from the hidden layer of RBF neural network can be calculated using Eq. 2 where the distance between the input pattern x and the center c are defined as:
where \(\| \cdot \|\) is the Euclidean distance, and \({c}_{i}\) and \({\sigma }_{j}\) are center and spread parameters for the j neuron, respectively. Network output can be calculated using Eq. 3
where x is the neural network input (DAFB, day after full bloom), y corresponds to fruit growth parameters (e.g. weight, diameter) and \({w}_{jk}\) defines weights between the neurons.
Hidden layer neuron numbers and spread parameter designations were determined by trial and error. The Bayesian regularization training algorithm with the trainbr function in MATLAB was used to train the RBF neural network (Fig. 2). Of the dataset, 80% was used randomly for the training phase and the remaining 20% for the testing phase (Ashtiani et al. 2020).

Basic MATLAB code for constructing the RBF neural network
2.5 Evaluation index and model comparison
The coefficient of determination (R2) and root mean square error (RMSE) were used to evaluate each model for fit and error. The ideal candidate model will have an R2 near one indicating close alignment (fit) between predicted and actual data and the lowest possible prediction error (RMSE value). An issue to overcome is the origin of time coordinates as no fruit is formed at flower initiation. Thus, model prediction (MP) of fruit growth parameters at the zero timepoint must equal zero in the perfected model
where \({y}_{o}\) and \({\mathrm{y}}_{p}\) represent the real and predicted dependent variables, respectively.
3 Results and discussion
3.1 Fruit weight and diameter
The mean comparisons for fully ripened fruit weights and diameter in each of the 10 apricot varieties are presented in Fig. 3. The maximum and minimum fruit weight and diameter were observed in ‘Jafari’ and Sh42, respectively. Fruit from the ‘Jafari’ variety were red-skinned, large, oblong, and averaged 73.4 g with a range of 51.64 to 90 g when fully ripe. In contrast, the Sh42 genotype highly proliferative and produced ovate, symmetrical fruit that averaged 10.18 g (Table 1). Rezaei et al. (2020), reported fruit weights for 94 apricot genotypes in north-eastern Iran varied between 7.30 and 69.60 g. The 128 Turkish apricots in the eco-geographic group of Iran and Caucasus showed consistently low fruit weights (Asma and Ozturk, 2005). Of the 128 genotypes, only seven produced fruit weighing more than 50 g. Despite having larger sizes, ‘Jahangiri’ and ‘Shams’ fruit averaged 42.88 and 47 g and were significantly different from ‘Jafari’. Fruit weight in the Sh48 genotype and ‘Shahroudi’ and ‘Nasiri’ varieties ranged from 34.58 to 38.77 g and all generated medium-sized fruit. The smallest fruit sizes were reported for the Sh42 genotype; however, the Sh52 genotype, and the ‘Norri-Dirras’, and ‘Nakhjavan’ varieties produced only slightly larger fruit weighing between 27.16 and 30.94 g (Fig. 3). In a study of 98 apricot genotypes, Rezaei et al. (2020) sorted each by fruit size into five classes: very small (1), small (31), intermediate (44), large (18), and very large (4). Their results indicated 45% or 44 of 98 genotypes generated medium-size fruit in the 50-g weight class. Fruit diameters ranged from 24.31 to 46.10 mm (Fig. 3). The fruit diameters reported in the study of 98 Iranian apricot genotypes varied from 16 to 49 mm (Rezaei et al. 2020). The ‘Jafari’ variety had the largest fruit diameter while Sh42 had the smallest diameter, consistent with fruit weight results. Category separation for varieties and genotypes based on fruit diameter nearly mirror those for weight excepting ‘Norri-Dirras’. However, as the diameter of ‘Jafari’ was considerably larger than any others in the group, categorization is less certain than fruit weight (Fig. 3).

Mean comparisons of fresh fruit weights (FFW) and diameters (FD) of 10 apricot varieties based on least significant differences (LSD) with 6–10 replicates. p ≤ 0.05
Correlations between fresh fruit weights (FFW) and diameters (FD) during the growing period and other measured fruit characteristics are given in Table 2. FFW was significantly correlated (p < 0.01) with fruit length, width, and dry fruit weight in all apricot varieties and genotypes. Correlation coefficients were greater than 0.86 for all comparisons. Growth curves based on FFW data are reliable representations of all investigated traits. FD is also an effective characteristic to study as correlations between diameter and the remaining traits were all significant and greater than 0.72. As surveys of FD are non-destructive and easier to conduct, FD is best for tree management decisions.
There was a positive relationship between FD and FFW (Fig. 4) with little variation appearing before the final growth stages where size and weight become quickly distinguishable. In addition, the rate of FFW gain was greater than the increase in FD (Fig. 4) for all studied varieties and genotypes; an example of which is indicated at the 25-mm diameter timepoint. In elongated fruits, oblong-shaped fruit (Table 1), such as the ‘Jafari’ and ‘Norri-Dirras’ varieties, had larger diameters early in growth resulting in accelerated weight gain while round fruit remained more gradual (Fig. 4). Descriptions of fruit growth patterns and curves are trait dependent. Pérez-Pastor et al. (2004), described apricot growth patterns in a Mediterranean climate to be double sigmoidal with a clear lag phase based on the diameter of ‘Búlida’ apricot fruit, while a lag phase stage based on fruit weight was less apparent. Rate of FFW gain during the third growth stage was noted to be superior to the rate of increase in FD, a result consistent with work reported in this study.

Correlation between fresh fruit weight (FFW) and fruit diameter (FD) in various apricot varieties and genotypes. Each circle shows the correlation between the diameter and weight of the fruit in each sample (The number of samples and other information are given in Table 1)
3.2 NRM assessment
Twenty regression models were surveyed for accuracy in estimating apricot FFW and FD from the point of flowering during the growth period. A model must be able to estimate a zero value at the start of growth to place an origin point at coordinate (0, 0). Of the 20 models, only seven, (LE0, EXP0, MM, MMM, LOG2, MLM, and LBE) were initially acceptable for use in estimations of fruit growth. RMSE and R2 data for each model as well as the minimum value predicted by the model (MP) for predicting FFW and FD are given in Tables 3 and 4, respectively. Increasing cutoff stringency for RMSE and R2 narrowed model choices to five (LE0, MM, MMM, MLM, and LBE). Checking model reliability based on FFW showed that MLM was best suited to Var1, LBE for Var2, Var3, Var4, and Var7, MM for PG1, and finally LE0 for PG2, Var5, Var6, and PG3 (Table 3). Incorporation of FD led to selection of MLM for Var3 and the MMM model for all other varieties for modeling fruit growth patterns. The results revealed that the best model with the least prediction error is dependent on fruit growth parameter and genotype; a vital consideration for NRMs. The coefficients of the selected nonlinear regression models are also given in Table 5.
3.3 RBF neural network model assessment
A first in the field, a neural network was employed to predict fruit growth. The training and test phase data for RMSE, R2, and MP values for FFW and FD are reported in Table 6. The number of hidden network neurons was determined to be 10 and the ideal spread parameter values spanned values from 0.05 to 0.9. The Bayesian regularization backpropagation was selected for the training algorithm after careful consideration and numerous tests with all varieties and genotypes. The RBF neural network model was able to use a 0, 0 point of origin, resulting in a predicted value of MP = 0. The RMSE and R2 values resulting from the RBF model confirmed its ability to outperform NRMs (Tables 3 and 4) in predictions of FFW and FD. Resultant R2 values were higher and the RMSE was lower (Table 6). In addition, to compare the RBF neural network prediction results with nonlinear regression models, neural network training phase data were used to find the optimal values of the NRM parameters. As the results of Table 6 show, the segmentation of data in regression analysis increased the prediction error compared to the results of Tables 3 and 4 as well as the neural network prediction results. Therefore, it is expected that the prediction trend of the neural network compared to nonlinear regression models is very similar to the normal trend of fruit growth Table 7.
3.4 Nonlinear regression model and RBF neural network performance
Predictions of FFW and FD for apricot after fruit set during the growing season after fruit set using NRM and the RBF neural network are shown in Figs. 5 and 6. NRMs displayed a relationship between the measured points that was uniform and continuously ascending. The RBF neural network, as expected, predicted apricot FFW and FD according to natural changes and biological growth behavior during the growing season. Incremental growth of FFW and FD during the growing season was better justified by the RBF neural network and captured local changes not recorded with NRMs. The RBF neural network, like other types of neural networks, basically provides a non-deterministic mapping between independent and dependent variables. Absence of any preliminary assumed relationship beforehand between input–output quantities, noise resistance capability and learning capability are some advantages of an RBF model over an NRM. However, RBF models have disadvantages, such as their black box nature, a tendency to overfit and the need for sufficient data sets for the training phase. The apricot growth curve, as with other stone fruits, is double sigmoid (Nigam and Sharma 1986; Pérez-Pastor et al. 2004). MLM and LBE regression models were the most precise among nonlinear models for anticipating fruit growth patterns. Unfortunately, when fit with actual field data, FFW failed to show the second growth stage or a lag phase (Fig. 5).

Comparison of fruit growth patterns from nonlinear regression models (NRMs) and an RBF model based on fresh fruit weight (FFW) and number of days after first bloom (DAFB)

Comparison of fruit growth patterns from nonlinear regression models (NRMs) and an RBF model based on fruit diameter (FD) and number of days after first bloom (DAFB)
3.5 Fruit growth pattern and Fruit ripening
FFW and FD growth curves for three groups of apricots (two early-ripening, five mid-ripening and three late-ripening) are presented in Fig. 7. Slopes were highest in early-ripening varieties with mid- and late-ripening following behind, a pattern also visible in the third growth stage. The ‘Jahangiri’ variety, the heaviest apricot in the study, is the earliest ripening cultivar and can be harvested about 61 days after full bloom (DAFB). Fruit weight in this cultivar accelerates quickly from 25 g to more than 56 g in fewer than five days (56 to 61 DAFB). This sudden weight increase is also observed in ‘Shahroodi’ as this variety increased nearly 30% (~ 1.67 g/d) from 12.55 to 44.27 g from 52 to 70 DAFB. Although FD in these varieties increased during this period as well, the speed was markedly slower than FFW. The third stage is when between 45 and 55% of fruit total weight is amassed for all varieties but the increase in FD is limited to 22 to 25% (Fig. 7).

Growth curves for two early-ripening (60–70 DAFB), five mid-ripening (70–80 DAFB), and three-late ripening (80–90 DAFB) apricot groups based on fresh fruit weight (FFW), fruit diameter (FD), and number of days after first bloom (DAFB)
Fruit maturity in mid-ripening varieties occurs between 70 and 80 DAFB. The FFW-based lag phase and double sigmoid pattern were clear for all varieties and genotypes except Sh42. Additionally, the elongated lag phase in ‘Nakhjavan’ is not seen in other varieties. In mid-ripening fruits, the third stage of FD development is difficult to decipher (Fig. 7). Harvest occurs 85 to 90 DAFBin the late ripening apricot group and the lag phase is nearly indistinguishable in both FFW and FD. After a surge in growth nearing 25 DAFB, similar growth patterns are observed in late ripening varieties though they are not as blatant or as high as in ‘Jafari’ (Fig. 7).
4 Conclusion
Recognition of fruit growth patterns based on FFW or FD is used to determine when standard horticulture operations are needed. In this study, fruit growth patterns of 10 apricot varieties and superior genotypes were investigated. The apricots varied in ripening time and fruit size and shape. Twenty NRMs were tailored to fit apricot growth patterns for comparison in determining the model best suited to display actual field data. Seven of the 20 NRMs (LE0, EXP0, MM, MMM, LOG2, MLM, and LBE) were suitable and selected for further evaluation. An alternative to NRMs, the RBF artificial neural network model was also considered and was able to predict highly accurate apricot FFW and FD (R2 > 0.95) during the growing season that mimicked the actual process of fruit growth. These data suggest that neural networks such as RBF, rather than NRMs, be used as alternative models for fruit growth pattern research.
References
Amini S, Taki M, Rohani A (2020) Applied improved RBF neural network model for predicting the broiler output energies. Appl Soft Comput 87:106006
Ashtiani S-HM, Rohani A, Aghkhani MH (2020) Soft computing-based method for estimation of almond kernel mass from its shell features. Sci Hortic 262:109071
Asma BM, Ozturk K (2005) Analysis of morphological, pomological and yield characteristics of some apricot germplasm in Turkey. Genet Resour Crop Evol 52:305–313
Baldicchi A, Farinelli D, Micheli M, Di Vaio C, Moscatello S, Battistelli A, Walker RP, Famiani F (2015) Analysis of seed growth, fruit growth and composition and phospoenolpyruvate carboxykinase (PEPCK) occurrence in apricot (Prunus armeniaca L.). Sci Hortic 186:38–46
Buchwald P (2007) A general bilinear model to describe growth or decline time profiles. Math Biosci 205:108–136
Buchwald P, Sveiczer A (2006) The time-profile of cell growth in fission yeast: model selection criteria favoring bilinear models over exponential ones. Theor Biol Med Model 3:1–10
Castro CAdO, ResendeKukiCarneiroMarcattiCruzMotoike TRKNVQGECDSY (2017) High-performance prediction of macauba fruit biomass for agricultural and industrial purposes using Artificial Neural Networks. Indust Crops Prod 108:806–813. https://doi.org/10.1016/j.indcrop.2017.07.031
DeJong T, Goudriaan J (1989) Modeling peach fruit growth and carbohydrate requirements: reevaluation of the double-sigmoid growth pattern. J Am Soc Horticultural Sci 114(5):800–804
Farinati S, Forestan C, Canton M, Galla G, Bonghi C, Varotto S (2021) Regulation of fruit growth in a peach slow ripening phenotype. Genes 12:482
Faust M (1989) Physiology of temperate zone fruit trees. Wiley, New Jersey
Fujikawa H, Kai A, Morozumi S (2004) A new logistic model for escherichia coli growth at constant and dynamic temperatures. Food Microbiol 21:501–509. https://doi.org/10.1016/j.fm.2004.01.007
Godoy C, Monterubbianesi G, Tognetti J (2008) Analysis of highbush blueberry (Vaccinium corymbosum L.) fruit growth with exponential mixed models. Sci Hortic 115:368–376
Goudriaan J, Monteith JL (1990) A mathematical function for crop growth based on light interception and leaf area expansion. Ann Bot 66:695–701
Guerriero R, Watkins R (1984) Revised descriptor list for apricot (Prunus armeniaca).In: IBPGR Secretariat, Rome. CEC Secretariat, Brussels. pp. 1–33
Gurjar AP, Patel SB (2021) Fundamental categories of artificial neural networks. Applications of artificial neural networks for nonlinear data. IGI Global, Netherland. pp 30– 64
Hau B, Amorim L, Bergamin Filho A (1993) Mathematical functions to describe disease progress curves of double sigmoid pattern. Phytopathology 83:928–932
Heidari P, Rezaei M, Rohani A (2020) Soft computing-based approach on prediction promising pistachio seedling base on leaf characteristics. Sci Hortic 274:109647
Huang X, Wang H, Qu S, Luo W, Gao Z (2021) Using artificial neural network in predicting the key fruit quality of loquat. Food Sci Nutrit 9(3):1780–1791
Ibrahim D (2016) An overview of soft computing. Proced Comput Sci 102:34–38
Jackson D, Coombe B (1966) The growth of apricot fruit. I. Morphological changes during development and the effects of various tree factors. Aust J Agric Res 17:465–477
Khairunniza-Bejo S, Mustaffha S, Ismail WIW (2014) Application of artificial neural network in predicting crop yield: a review. J Food Sci Eng 4:1
Khamis A (2005) Nonlinear growth models for modeling oil palm yield growth. J of Math Statist 1:225–233
Lakso AN, Corelli Grappadelli L, Barnard J, Goffinet MC (1995) An expolinear model of the growth pattern of the apple fruit. J Hortic Sci 70:389–394
Lötze E, Bergh O (2004) Early prediction of harvest fruit size distribution of an apple and pear cultivar. Sci Hortic 101:281–290
Nigam V, Sharma S (1986) Growth pattern of developing fruits of apricot. Indian J Hortic 43:187–190
Orlandini S, Moriondo M, Cappellini P, Ferrari P (1998) Analysis and modelling of apple fruit growth. V Int Sympos Comput Modell Fruit Res Orchard Manag 499:137–146
Orlandini S, Moriondo M, Cappellini P, Ferrari P (1999) Analysis and modelling of apple fruit growth. Acta Hortic 499:137–146
Pérez-Pastor A, Ruiz-Sánchez M, Domingo R, Torrecillas A (2004) Growth and phenological stages of Búlida apricot trees in south-east Spain. Agronomie 24:93–100
Pérez-Pastor A, Ruiz-Sánchez MC, Domingo R (2014) Effects of timing and intensity of deficit irrigation on vegetative and fruit growth of apricot trees. Agric Water Manag 134:110–118
Pinzón-Sandoval HH, Pineda-Ríos W, Serrano-Cely P (2021) Mathematical models for describing growth in peach (Prunus persica [L] Batsch) fruit cv Dorado. Revista Colombiana de Ciencias Hortícolas 15(3):e13259–e1325
Rezaei M, Heidari P, Khadivi A (2020) Identification of superior apricot (Prunus armeniaca L) genotypes among seedling origin trees. Scientia Horticulturae 262:109062
Taki M, Rohani A, Soheili-Fard F, Abdeshahi A (2018) Assessment of energy consumption and modeling of output energy for wheat production by neural network (MLP and RBF) and Gaussian process regression (GPR) models. J Clean Prod 172:3028–3041
Torkashvand AM, Ahmadi A, Nikravesh NL (2017) Prediction of kiwifruit firmness using fruit mineral nutrient concentration by artificial neural network (ANN) and multiple linear regressions (MLR). J Integr Agric 16:1634–1644
Torkashvand AM, Ahmadipour A, Khaneghah AM (2020) Estimation of kiwifruit yield by leaf nutrients concentration and artificial neural network. J Agric Sci 158:185–193
Tseng FM, Yu JR (2014) A two stage fuzzy piecewise logistic model for penetration forecasting. Appl Soft Comput 21:149–158. https://doi.org/10.1016/j.asoc.2014.02.018
Wang M, Tang SX, Tan ZL (2011) Modeling in vitro gas production kinetics: derivation of logistic–exponential (LE) equations and comparison of models. Anim Feed Sci Technol 165:137–150
Welte HF (1990) Forecasting harvest fruit size during the growing season. Acta Hort. https://doi.org/10.17660/ActaHortic.1990.276.32
Westwood MN (2009) Temperate-Zone Pomology: Physiology and Culture, Third Edition. Timber press
White AG, Alspach PA, Weskett RH, Brewer LR (2000) Heritability of fruit shape in pears. Euphytica 112:1–7
Wu Y, Wang H, Zhang B, Du KL (2012) Using radial basis function networks for function approximation and classification. Int Schol Res Notic 324194:1–34. https://doi.org/10.5402/2012/324194
Zadravec P, Veberic R, Stampar F, Schmitzer V, Eler K (2014) Fruit growth patterns of four apple cultivars using nonlinear growth models. Eur J Hortic Sci 79:52–59
Acknowledgements
The authors would like to thank the editor-in-chief and anonymous referees for their valuable suggestions and useful comments that served to considerably improve manuscript content and readability.
Author information
Authors and Affiliations
Contributions
AJ—Experiment execution, data collection, data processing. MR—Idea development, literature search and manuscript writing. AR—statistical analysis, manuscript writing, data processing. SL—overall supervision of the investigation and paper editing. RF—Data collection, idea development.
Corresponding author
Ethics declarations
Conflict of interest
The authors have declared that no competing interest exists.
Additional information
Communicated by Myung-Min Oh.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Jannatizadeh, A., Rezaei, M., Rohani, A. et al. Towards modeling growth of apricot fruit: finding a proper growth model. Hortic. Environ. Biotechnol. 64, 209–222 (2023). https://doi.org/10.1007/s13580-022-00475-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13580-022-00475-x