
Abstract
The surroundings of the former Kremikovtzi steel mill near Sofia (Bulgaria) are influenced by various emissions from the factory. In addition to steel and alloys, they produce different products based on inorganic compounds in different smelters. Soil in this region is multiply contaminated. We collected 65 soil samples and analyzed 15 elements by different methods of atomic spectroscopy for a survey of this field site. Here we present a novel hybrid approach for environmental risk assessment of polluted soil combining geostatistical methods and source apportionment modeling. We could distinguish areas with heavily and slightly polluted soils in the vicinity of the iron smelter by applying unsupervised pattern recognition methods. This result was supported by geostatistical methods such as semivariogram analysis and kriging. The modes of action of the metals examined differ significantly in such a way that iron and lead account for the main pollutants of the iron smelter, whereas, e.g., arsenic shows a haphazard distribution. The application of factor analysis and source-apportionment modeling on absolute principal component scores revealed novel information about the composition of the emissions from the different stacks. It is possible to estimate the impact of every element examined on the pollution due to their emission source. This investigation allows an objective assessment of the different spatial distributions of the elements examined in the soil of the Kremikovtzi region. The geostatistical analysis illustrates this distribution and is supported by multivariate statistical analysis revealing relations between the elements.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Many case studies of diverse metal pollution due to atmospheric deposition have been reported [1–3]. Mostly, quantitative analyses of the soil properties were performed. Furthermore, studies focusing on the interactions between soil and the biosphere (e.g., fungi, mosses, plants) have been done [4, 5]. However, investigations on iron smelters are rare. Currently, the volatile organic compounds in the ambient air of steel mills [6] are being investigated. As in most soil pollution studies, we carried out a quantitative analysis of the soil properties. However, in the present study we also applied various statistical approaches to prove the significance of our observations.
In the last decades of the twentieth century the annual production of the Kremikovtzi steel mill in Bulgaria was about one million tons of steel. In addition, the steel mill produced alloys and inorganic compounds, such as lime, barite, and dolomite. The 2007 investigation by Schulin et al. [7] considered only the vertical distribution of 19 elements in two different soil types in the southern region of the metallurgical complex of Kremikovtzi. The authors suggested that the soil types investigated (chromic luvisols and alluvial fluvisols) contain different metal concentrations due to their parent materials rather than due to the emission from the steel mill. Furthermore, they found no variation of the element concentrations dependent on the depth. It was concluded that the distributions of As, Cr, and Ni were caused by geogenic processes and the distributions of Pb, Zn, and Cu were caused by atmospheric deposition. In contrast, the present study also includes the analysis for other pollutants such as tracers for steel, iron alloys, and the main inorganic products. We collected 65 samples in an area of about 64 km2 in the Kremikovtzi steel mill region. After determination of 15 elements, we used geostatistical methods, cluster analysis, factor analysis, and source apportionment modeling to analyze the complex data set.
Source apportionment modeling originates from investigations in air quality studies [8] and is not well known in soil science. Recent reports have pointed out that it is difficult to distinguish between contributions from different sources to the pedosphere [9]. Davis et al. [10] used the combination of principal component analysis and geostatistics to find different sources but did not calculate a receptor model. Furthermore, traditional monitoring data interpretation methods such as cluster analysis, principal component analysis, and source apportionment modeling were used to identify and apportion sources of soil pollution around an iron smelting facility but were not combined with geostatistics [11]. The present research closes this gap by showing the possibility of combining source apportionment modeling and geostatistics. The only previous study dealing with the combination of these two methods did not have a preliminary step able to select the appropriate pollution tracers [12]. In the present investigation, geostatistical analysis as a preliminary step for selection of tracers is introduced.
Material and methods
Study area, soil sampling, preparation, and analysis
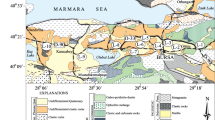
The Kremikovtzi steel mill is located about 20 km northeast of the Bulgarian capital, Sofia. We collected 65 samples in an area of about 64 km2, of which 16 sampling points were located within the boundaries of the steel mill (Fig. 1). Owing to the anthropogenic interventions in this region, we chose an irregular grid fitted to the local conditions as the sampling design. Taking the samples on a regular sampling grid was impossible since buildings, streets, mounds, plants, or cultivated fields shape this area. Furthermore, the complete coverage of the region investigated was requested. To ensure the comparability of the samples, we took the samples on grassland from soil not treated by fertilizers and with comparable orographic conditions.

Study area with the 65 sampling points in the Kremikovtzi steel mill region, Sofia, Bulgaria
We took component soil samples, consisting of five subsamples, from the upper 0–20-cm layer. The soil samples were dried, homogenized, and passed through a 2-mm sieve. We performed a microwave (power 1,200 W) aqua regia digestion with a mixture of 21 mL HCl (12 M) and 7 mL HNO3 (15.8 M) according to the German standard [13] with 0.5 g of the soil twice for each sampling site. After cooling, we made up the solutions to 100 mL with dilute HNO3 (0.5 M). We determined the concentrations of 15 elements using a 5100 PC instrument from PerkinElmer for flow injection hydride generation atomic absorption spectroscopy, an AAS-3110 instrument from PerkinElmer for flame atomic absorption spectroscopy, and an Elan 6000 instrument from PerkinElmer for inductively coupled plasma mass spectrometry.
All metals examined could be detected in concentrations higher than the detection limits (Table 1) calculated according to the indirect method of the German standard [14]. Analyzing the certified reference material IAEA/Soil-7 (International Atomic Energy Agency, Vienna) verified the trueness (P = 95%) of the analytical methods.
Overview of the theoretical fundamentals
Geostatistical methods
Geostatistical methods were used to analyze the spatial dependence of data and their correlation, and finally to estimate the concentration of the element of interest at an unsampled location. The statistical theory behind this analysis is the theory of regionalized variables, which means that the variance between two realizations of the random function Z(X) depends only on the step width h between those locations and not on the absolute location in space [15]. Currently, geostatistical methods are used in different environmental analyses [16, 17], especially soil sciences [18, 19], or even human health studies [20]. There are two important parts of geostatistical analysis: first, the semivariogram analysis and, second, the estimation by means of kriging.
For semivariogram analysis the semivariance γ(h) is calculated as
where h is the step width, γ(h) the semivariance, n(h) the number of sample pairs at each step width h, z(x i ) the realization of the random function at location i, and z(x i + h ) the realization of the random function at location (i + h).
The semivariogram is the graphical representation of the semivariance γ(h) as a function of the step width h. After the experimental semivariogram has been calculated, a theoretical semivariogram is modeled by fitting a function to the data points. We used exponential, Gaussian, linear, power, and spherical models in this investigation. The nugget effect, representing the microinhomogeneity of the data, the sill, which represents the variance of the data, and the range, up to which the data set is spatially correlated, are characterizing parameters of those functions. Linear models are defined by a slope and may have a nugget effect. They are not characterized by a range or a sill, which means that they never reach a certain variance at a given distance. The parameters can be used to detect spatial structures within the data.
Kriging estimation can be used to describe the spatial distribution of the elements within a map. The results are usually represented as isoline plots. This technique uses a weighted moving average interpolation method, which means that closer points have more influence on the estimated value than more distant ones. The kriging estimation is calculated as follows:
where z*(x 0) is the estimate of the unknown value z(x 0), λ i are the weights of known neighboring points z(x i ), and z(x i ) are the known neighboring points.
The weights λ i are calculated on the basis of the semivariogram function, so that the kriging variance is minimized:
where \( \sigma_k^2 \) is the kriging variance, z(x i )−z(x 0) is the distance between two known values z(x) at sample location i and 0, μ is the Lagrange multiplier, and \( \sum\limits_{1 = 1}^n {{\lambda_i} = 1} \).
More detailed mathematical information can be found in [21, 22].
The results can be verified with the help of full cross-validation. In succession, all sampling points are eliminated and newly estimated according to Eqs. 2 and 3. To evaluate the cross-validation, two parameters were used. First, Pearson’s correlation coefficient (r) calculated according to Eq. 4 should be 1 for a perfect estimation:
where z(x i ) is the observed known value, \( z\left( {{{\overline x }_i}} \right) \) is the mean of the observed known values, z*(x i ) is the estimated known value, \( z * \left( {{{\overline x }_i}} \right) \)is the mean of the estimated known values, and n is the number of observations.
Furthermore, as a measure of uncertainty, the root mean square error of prediction (RMSEP) can be calculated for the cross-validation:
For geostatistical analysis we used the software package R version 2.9.0 with the package gstat and Surfer 9.0.
Source apportionment modeling on absolute principal component scores
Source apportionment modeling can be used to quantify the contribution of different sources to the soil in the study area [8]. This technique is widely used for describing air pollution [23, 24] and aquatic systems [25, 26]. A multiple linear regression of the total concentrations on the absolute principal component scores (APCS) is done to use this method. First, a factor analysis is necessary to calculate the APCS. Factor analysis is used to reduce the dimensionality of a data set and to find hidden correlations or structures. Therefore, the matrix of all measured values X is divided into the product of a matrix of factor loadings A and a matrix of factor scores F, and a matrix of residuals Q:
where m is the number of features, n is the number of objects, and t is the number of factors.
The covariance matrix of all features is computed, and then an eigenvalue analysis is performed to extract the factors. In this work we used varimax rotation to enable an easier interpretation of the factors [27].
The resulting factor scores are used to compute APCS for each sampling point. Z-scores have to be created, because the factor analysis is based on normalized data (Eq. 7). These Z-scores represent the absolute zero concentration at a so-called “zero day,” on which none of the sources have yet influenced the samples.
where s is the standard derivation, \( \overline x \) is the mean, and (z 0) i is the concentration on the “zero day.”
Absolute zero principal component scores and furthermore APCS are calculated with these resulting (z 0) i and the factor score coefficients. This step is followed by multiple linear regression of the total mass as a function of APCS as
where M k is the particle mass record during observation k, ζ is the particle mass contribution, APCS jk is the rotated APCS for component j at observation k, and j...p is the number of pollution sources.
Furthermore, the element source profiles of the estimated source impact can be calculated. A detailed mathematical description can be found in [28]. We used the software package STATISTICA 6.1 for source apportionment modeling.
Results and discussion
Chemical analysis
The mean values and distribution measures of the elements examined are listed in Table 2. We found the range of the element concentration to be different. The values for Cd, Co, Cr, Cu, Fe, K, Na, Ni, and V were within 1 order of magnitude. The concentration of Ca ranged from 0.07 to 153 mg/g (4 orders of magnitudes) owing to the geogenic origin of this metal. In contrast, Cd, Mn, Pb, and Zn had 25–41 times as high concentrations in polluted samples as in unpolluted ones owing to their anthropogenic origin.
To evaluate these results considering the impact of the pollution, the optimum and action values of the new Dutchlist are presented for As, Cd, Co, Cr, Cu, Ni, Pb, and Zn in Table 3 [29]. The Dutchlist is seen as the unofficial guideline for risk assessment.
Over 90% of the sampling sites have higher contents of Cu and Pb than the optimum threshold (Table 3). Half of the sampling points exceed the optimum threshold for As, Cd, or Zn. For Co, Cr, and Ni the optimum threshold is exceeded for a couple of sampling sites. The situation for the action threshold is completely different. About 40% of the sampling points are highly contaminated with As and only 5–12% are contaminated with Cu, Pb, and Zn. The comparison of the results with another investigated iron-smelting facility in the UK shows a different kind of pollution from that found in the Kremikovtzi region. Whereas the area polluted with Cd, Cr, Cu, Ni, and Zn is smaller for the Kremikovtzi region, the area polluted with As is almost the same [30]. Furthermore, the maximum concentration of Pb is of about the same magnitude. The comparison with a German iron smelter shows comparable maximum concentrations for Pb and Zn, whereas the maximum concentrations for Cd, Cr, and Ni are lower for the Kremikovtzi region as well [31]. These comparisons suggest that Cr and Ni are not used for steel alloys in the Kremikovtzi region.
Geostatistical analysis
We used kriging estimation to interpolate the concentrations of the elements examined in the areas between sampling points. First, a semivariogram analysis for all elements was necessary. The elements were not transformed because the results should be compared with the source apportionment modeling. We used a visual fit of the possible theoretical semivariogram to the experimental semivariogram to select an adequate model. To confirm those results we performed a cross-validation for ordinary kriging. The correlation coefficients and the relative RMSEP values were estimated for each model chosen (see Table 4). The semivariograms showed a typical behavior for elements in heavily polluted areas [32, 33].
For most of the elements, a Gaussian model was found to be the most appropriate. In addition to the Gaussian model, we used three spherical models, three exponential models, one linear model, and one power model. The range for all elements except Cu and V was around 1 km or less. So, there was no high spatial correlation of the elements over the complete region.
To evaluate the results of the semivariogram analysis, we used the correlation coefficients and the RMSEP values. For a perfect estimation the correlation coefficient would be 1. For eight elements the correlation coefficients are above 0.6, which is acceptable in environmental analysis. For some elements the correlation coefficients are around 0.4 owing to the random, rather than normal distribution of these elements. The estimated RMSEP values are small for elements with a small concentration range and the RMSEP values were unsatisfactory for elements with a high range. For Ca, with a RMSEP of 179%, we found concentrations from 0.07 to 153 mg/g and for Co, with a RMSEP of 24%, we found concentrations from 9.39 to 28.5 μg/g (see Table 2). To avoid these problems, the calculations could be carried out with the lognormal transformed data. However, a calculation with the lognormal transformed data was not possible in this work because we wanted to apply the results of geostatistics to the source apportionment modeling. In summary, it can be said that the semivariogram analysis showed satisfactory results for the elements As, Cd, Cu, Fe, Mn, Na, Pb, and Zn.
In Fig. 2 the kriging estimation for all elements based on the semivariogram models listed in Table 4 are displayed as isoline plots to visualize the results.

Isoline plots for all elements after kriging estimation
The distributions of the elements differ a lot. Whereas Cd, Cu, Fe, Pb, and Zn have the highest concentration in the center of the factory, As, Co, K, Ni, and V show a rather haphazard distribution. K and V, for example, have their lowest concentration in the center of the steel mill. The region is not polluted by Co and Ni even though these elements are used for steel coating. High concentrations of Ca, Cr, Mg, and Na were detected in the southeastern part of the factory. The emission of the elements Ca, Mg, and Na is connected with lime production. Furthermore, the concentrations of Ca and Mg are high in the northern part of this area owing to their geogenic origin. For these two elements there are two different factors responsible for their distribution: the lime production and their geogenic origin. Elements usually connected with steel production—such as Cd, Cu, Fe, Pb, and Zn—have high concentrations in the area of the stacks of the iron smelter. The isoline plots of Fe and Pb almost look alike, which indicates that those elements are highly correlated. One of the main reasons is that the ore is rich in Pb. It is notable that Mn shows high concentrations in the center and as well in the southeastern part of the factory. Despite the lime production—indicated by Ca, Mg, and Na—the alloy production is located in this area. This explains the high concentrations of Cr and Mn in this southeastern part of the factory.
Cluster analysis
Cluster analysis is an unsupervised learning technique. In this study we used the agglomerative hierarchical cluster analysis according to Ward [34]. Applying cluster analysis for the elements examined shows a separation between elements emitted by the steel mill, which can also be distinguished into iron production (cluster 3), lime production (cluster 2), and elements originating from diffuse sources (cluster 1) (Fig. 3).

Dendrogram of cluster analysis for all variables (Ward’s method)
The elements in cluster 1 are those with a haphazard distribution according to the kriging estimation. The fact that As, Cr, and Ni originate from geogenic sources [7] was confirmed independently by cluster analysis. Usually Cr and Ni would be expected to be grouped with Fe because they are essential constituents in steel alloys. There are two specific production-related reasons as to why this is not the case in the Kremikovtzi region. Firstly, the Ni content is very low in the ore [35]. Secondly, the amount of low-alloy steel production is small and the electric arc furnaces are better equipped with dust-removing filters than the other production facilities. The elements in clusters 2 and 3 are the ones with high concentrations in the areas of the factory used for iron production (Cd, Cu, Fe, Mn, Pb, and Zn) and for lime production (Ca, Mg, and Na).
Source apportionment modeling
Factor analysis
We performed a factor analysis to conduct source apportionment modeling on principal components. The results of the geostatistical and cluster analysis showed that a reduction of variables for the source apportionment modeling was necessary. The factor analysis was performed with the elements Cd, Cu, Fe, Mg, Mn, Na, Pb, and Zn because those elements were not haphazardly distributed. Ca was removed because of its high RMSEP. The factor loadings after varimax standard rotation are listed in Table 5.
It is possible to distinguish between two factors explaining about 82% of the variance together. Factor 1 represents the elements that are emitted by the steel factory and factor 2 represents the elements emitted by the lime production. The communalities are high except for Mg.
Absolute principal component scores
We performed source apportionment modeling for the two main factors detected using factor analysis. The two factors represent the source iron production (factor 1) and lime–alloy production (factor 2). The resulting model has a correlation coefficient of 0.94 and an RMSEP of 26%. Source 1 explains 65% of the computed model, source 2 explains 12%, and about 23% cannot be connected to either source. After identifying the two sources, we considered the impact of them for each metal. Therefore, we calculated the contribution of each polluting source to the metal concentration. The correlation coefficients and the RMSEP values for each metal are presented in Table 6. The impact of each source on the metals examined is illustrated in Fig. 4.

Contribution of each source for the elements included in the source-apportionment modeling (blue source 1, red source 2, yellow unexplained)
Except for Zn, the RMSEP values are below 40%. The correlation coefficients are above 0.8 for all elements except Mn and Zn.
Only the concentrations of Cu, Fe, and Mg are influenced by sources outside the Kremikovtzi steel mill. Fe and Pb are mainly emitted by source 1 (more than 70%) and just slightly by source 2. Na and Mg are mainly emitted in the southeastern part (source 2) of the factory. The other elements—Cd, Cu, Mn, and Zn—are emitted by both sources but with different intensities. Whereas Cd and Mn are emitted by both sources almost equally, Cu and Zn are emitted threefold more by source 1 than by source 2. Those results prove as well that source 1 is the iron production and source 2 is a combination of lime and alloy production.
Conclusion
The combination of the geostatistical analysis and the source apportionment modeling is very beneficial. The kriging plots allow a graphical description of the area, which helps one interpret the emission sources. Furthermore an objective variable reduction can be accomplished. As source apportionment modeling with all elements was unsatisfactory, finding an objective tool which allows an element reduction was very important. We pointed out two main emission sources with the help of source apportionment modeling. One is the iron smelter and the other one comes from the southeastern part of the factory, which is a combination of lime and manganese–iron–alloy production. To separate those two in more detail, a study including more sampling points inside the territory of the steel mill should be done.
References
Koptsik S, Koptsik G, Livantsova S, Eruslankina L, Zhmelkova T, Vologdina Zh (2003) J Environ Monit 5:441–450
Yukselen MA (2002) Environ Geol 42:597–603
Vike E (2005) Water Air Soil Pollut 160:145–159
Cabala J, Krupa P, Misz-Kennan M (2009) Water Air Soil Pollut 199:139–149
Frontasyeva MV, Steinnes E (1995) Analyst 120:1437–1440
Ciaparra D, Aries E, Booth MJ, Anderson DR, Almeida SM, Harrad S (2009) Atmos Environ 43:2070–2079
Schulin R, Curchod F, Mondeshka M, Daskalova A, Keller A (2007) Geoderma 140:52–61
Hopke PK (1995) In: Einax J (ed) The handbook of environmental chemistry, vol 2, part H: chemometrics in environmental chemistry - applications. Berlin, Springer
Steinnes E, Frontasyeva MV, Gundorina SF, Pankratova YS (2008) Chem Anal (Warsaw) 53:877–886
Davis HT, Aelion CM, McDermott S, Lawson AB (2009) Environ Pollut 157:2378–2385
Simeonov V, Einax J, Tsakovski S, Kraft J (2004) Cent Eur J Chem 3:1–9
Wang K, Shen Y, Zhang S, Ye Y, Shen Q, Hu J, Wang X (2009) Environ Geol 56:1041–1050
DIN EN 13346:2000 (2001) Characterization of sludges – determination of trace elements and phosphorus – aqua regia extraction methods
DIN 32645 (2008) Chemical analysis – decision limit, detection limit and determination limit under repeatability conditions – terms, methods, evaluation
Matheron G (1965) Les variables régionalisées et leur estimation. Masson, Paris
Carlucci R, Lembo G, Maiorano P, Capezzuto F, Marano CA, Sion L, Spedicato MT, Ungaro N, Tursi A, D’Onghia G (2009) Estuar Coast Shelf Sci 83:529–538
Mohr K, Holy M, Pesch R, Schröder W (2009) Umweltwiss Schadst Forsch 21:454–469
Sigua GC, Hudnall WH (2008) J Soils Sediments 8:193–202
Zhao Y, Xu X, Darilek JA, Huang B, Sun W, Shi X (2009) Environ Geol 57:1089–1102
Goovaerts P (2008) Math Geosci 40:101–128
Journel AG, Huijbregts CH (1978) Mining geostatistics. Academic, New York
Cressie NCA (1991) Statistics for spatial data. Wiley, New York
Tauler R, Viana M, Querol X, Alastuey A, Flight RM, Wentzell PD, Hopke PK (2009) Atmos Environ 43:3989–3997
Olson DA, Hammond DM, Seila RL, Burke JM, Norris GA (2009) Atmos Environ 43:5647–5653
Simeonov V, Sarbu C, Massart DL, Tsakovski S (2001) Mikrochim Acta 137:243–248
Simeonov V, Einax JW, Stanimirova I, Kraft J (2002) Anal Bioanal Chem 374:898–905
Einax JW, Zwanziger HW, Geiss S (1997) Chemometrics in environmental analysis. VCH, Weinheim
Thursten GD, Spengler JD (1985) Atmos Environ 19:9–25
Layla Resources (2001) The new Dutchlist. http://www.contaminatedland.co.uk/std-guid/dutch-l.htm
Harber AJ, Forth RA (2001) Environ Geol 40:324–330
Einax JW, Soldt U (1999) Chemom Intell Lab Syst 46:79–91
Ersoy A, Yunsel TY, Cetin M (2004) Arch Environ Contam Toxicol 46:162–175
Myers JC (1997) Geostatistical error management: quantifying uncertainty for environmental sampling and mapping. Thomson, New York
Ward JH Jr (1963) J Am Stat Assoc 58:236–244
Vassileva M, Ruskov K (2006) Ann Univ Min Geol St Ivan Rilski 49:23–31
Acknowledgements
K.S. acknowledges financial support from the division “Analytical Chemistry” of the German Chemical Society. Special thanks for partial financial support of the Bulgarian coauthors are due to the National Fund of Scientific Research, Bulgarian Ministry of Education and Science (project VUH 206/06). The authors acknowledge the help of Jörg Kraft with the sampling procedure and thank Emily Prince and Thomas Wichard for proofreading the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Schaefer, K., Einax, J.W., Simeonov, V. et al. Geostatistical and multivariate statistical analysis of heavily and manifoldly contaminated soil samples. Anal Bioanal Chem 396, 2675–2683 (2010). https://doi.org/10.1007/s00216-010-3495-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00216-010-3495-0